
Abstract
In Large-Scale Group Decision-Making (LSGDM), effectively implementing consensus models is pivotal for managing decision complexity. While trust-based LSGDM has garnered attention, there remains a need for deeper insights into the dynamics of interexpert trust and the impact of authority effects on the decision-making process. This study introduces a sophisticated model for large-scale group decision-making, incorporating considerations of expert “trustworthiness-authority.” Initially, the study assesses the trustworthiness of experts based on social network relationships and opinion similarity while using background information and consensus levels to establish their authority. Subsequently, experts are categorized into four distinct regions based on their trustworthiness and authority assessments. Furthermore, tailored consensus adjustment methods are proposed for each region based on social contagion theory to facilitate consensus achievement. Additionally, a case study is conducted to demonstrate the rationality and effectiveness of the proposed LSGDM model, considering expert “trustworthiness-authority.” Finally, the necessity and superiority of the proposed model are further verified through comparison analysis and sensitivity analysis.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
As societal and economic development progresses rapidly, accompanied by the escalating complexity of decision-making environments (Liu and Yang 2022; Xing et al. 2023), the evolution of group decision-making into the domain of Large-Scale Group Decision-Making (LSGDM) has been necessitated (Jin et al. 2023). LSGDM, a burgeoning field, leverages the diverse decision inputs of over 20 individuals to discern the optimal solution from various courses of action (Hochbaum and Levin 2006; Xu et al. 2023; Zhao et al. 2023). Nonetheless, the escalating number of decision-makers may precipitate heightened contradictions and conflicts (Bai et al. 2022b; Xu et al. 2019), potentially diminishing decision efficiency and impeding the formulation of cohesive decision outcomes (Yang et al. 2023b). Addressing the consensus challenge has emerged as a pivotal focus of research, with the Consensus Reaching Process (CRP) gaining prominence in the study of large-scale group decision-making (Liu et al. 2022c).
As research advances, the interconnections within social networks among individuals are becoming increasingly intertwined with the CRP (Liu et al. 2022a; Wu et al. 2017; Xu et al. 2021b). In this context, the role of trust in social networks becomes crucial, with a growing body of research incorporating trust relationships into the CRP. Establishing trust relationships among decision-makers within social networks enhances the reliability of information dissemination. Currently, scholars are predominantly focusing their research efforts on trust relationships in several key areas: clustering experts based on trust relationships (Liu et al. 2022b), setting expert weights based on trust relationships (Zhang et al. 2018; Zhao et al. 2022), and designing adjustment rules based on trust relationships to facilitate consensus among DMs (Li et al. 2022b). However, in actual group decision-making scenarios, experts may lack a comprehensive understanding of each other, making it challenging to establish trust with unfamiliar decision-makers. This can lead to missing values in the initial trust matrix (Gong et al. 2020; Wu et al. 2017). As the decision-making process dynamically evolves, the complexity of the Social Network Group Decision-Making (SNGDM) process also increases (Li et al. 2022a; Sun and Zhu 2023). On one hand, as experts interact and gain a better understanding of one another, trust relationships evolve, thereby completing the trust network. On the other hand, changes in trust relationships at one stage can directly impact the decision-making process in subsequent stages (Li et al. 2023b). Therefore, it is crucial to consider the dynamic evolution of trust relationships among experts.
The traditional CRP involves critical stages, including consensus measurement, consensus adjustment, and prioritization of alternative solutions (Li et al. 2022b). In the consensus measurement phase, consensus levels are primarily assessed based on the distance between decision-makers and group preferences (Gai et al. 2023b). In terms of consensus adjustment, specific guidelines are utilized to offer adjustment suggestions to decision-makers. The integration of social network theory has invigorated consensus methodologies, with researchers advocating for deeper explorations of relationships among DMs (Peng and Chen 2024) and utilizing trust relationships among experts to guide the consensus adjustment process (Zou et al. 2024). Simultaneously, some scholars focus on establishing trust-driven bidirectional interaction and feedback mechanisms among DMs to enhance the consensus achieved (Gai et al. 2023a, b). Additionally, considering DMs trust relationships, researchers have developed methods to reduce information loss and achieve a joint feedback mechanism that minimizes costs while maximizing consensus (Lu et al. 2021; Wang et al. 2024; Zhong et al. 2022). The ultimate goal of group decision-making is to identify the optimal alternative solutions. Hence, some scholars concentrate directly on the ranking of alternative solutions to facilitate consensus. For instance, methods such as Ordinal-cardinal consensus (Meng et al. 2023), multicriteria group sorting (de Morais Bezerra et al. 2017; Li and Zhang 2024), maximum consensus sequences (Ming et al. 2021) can accurately provide solution ranking results without the need for guiding rules during the consensus iteration process. Nevertheless, these consensus models overlook the behavioral characteristics of individual decision-makers and fail to adequately consider psychological traits in experts’ decision-making processes.
The psychological resilience of decision-makers plays a crucial role in facilitating consensus attainment during the decision-making process. Experts are influenced by their peers, not solely relying on relational trust. (Ureña et al. 2019). Traditional theories of group decision-making operate under the assumptions of individual rationality and self-interest maximization (Carneiro et al. 2018). However, the applicability of these premises in real-world settings is challenging, resulting in decision analyses that are not only irrational but also divorced from reality (Wu and Yang 2019). DMs often struggle to access complete information in practical decision-making processes (Wu et al. 2024), and factors such as environmental changes and the opinions of other decision-makers can make achieving full rationality difficult (Sun et al. 2024). For instance, under group pressure, when DMs fear the consequences of their preferences differing from those of others, they are prone to succumbing to the herd effect (Liu and Mao 2022). According to the authority effect (Milgram 1963), when experts exhibit low self-confidence and weak trust relationships, they are highly susceptible to developing a “safety psychology,” wherein they tend to trust the opinions of authoritative experts to mitigate their own risk of error. In decision-making environments characterized by uncertainty, experts’ authoritative backgrounds and psychological behaviors play a crucial role in decision-making. However, traditional decision-making theories overlook experts’ psychological states and their authoritative backgrounds' influence on decisions (Blass 1999).
The primary issues identified in the current research are: (1) Inadequate consideration of trust networks. Most experts tend to focus solely on static social networks, overlooking the dynamic changes in trust relationships among experts during decision-making. (2) Limited consideration of consensus adjustment rules. Most group decision-making models primarily rely on adjustments based on trust relationships among experts, neglecting the individual behavioral and psychological characteristics of DMs. (3) Neglect of the authority effect on the decision-making process. Many studies assume that identified experts are inherently entirely rational without delving into the influence of authority on experts’ decision-making.
To address the aforementioned challenges, this study introduces an innovative approach targeting large-scale group decision problems characterized by trust relationships. The main innovations of the proposed model can be summarized as follows:
-
(1)
Considering the incompleteness and dynamic nature of trust networks, this study integrates expert preferences to investigate the impact on expert trust relationships. We propose a dynamic trust index to more accurately reflect the evolving trust dynamics among experts throughout the decision-making process, thereby providing improved guidance for decision-making.
-
(2)
This study aims to extract data on decision-making experiences and background expertise from online sources. By analyzing this data in conjunction with the consensus level among experts, an authority metric is developed to comprehensively and objectively evaluate the decision-making capabilities and influence of experts.
-
(3)
Integrating considerations of expert trust and authority, this study devises a dual-indicator consensus feedback model to precisely adjust preferences with low consensus levels. The model provides more reliable support for the consensus-reaching process, offering a nuanced perspective on enhancing the reliability of consensus formation.
The remainder of this paper is organized as follows. Section 2 offers a comprehensive review of the relevant literature. Section 3 outlines the preliminary concepts and foundations required for the subsequent discussions. In Sect. 4, the design of the trustworthiness and authority operator is elucidated. A framework for reaching consensus is proposed and detailed in Sect. 5. Section 6 furnishes an exemplary case along with several experimental validations to illustrate the practicality of the proposed concepts. The paper culminates with conclusions and a discussion of managerial implications in Sect. 7.
2 Literature Review
2.1 Consensus Model for LSGDM
In the context of social networks, researchers have proposed various methods for achieving consensus decision-making by integrating different theories. In the literature on LSGDM based on social networks, leverage relationships among experts to facilitate the feedback mechanism of CRP in LSGDM (Tan et al. 2024). Tian et al. (2019) utilize trust propagation to establish social networks and propose a CRP based on conflict detection and resolution to achieve consensus. Gai et al. (2023a) introduced bidirectional interaction/feedback mechanisms among DMs by constructing trust chains. From the perspective of minimizing costs, Zhao et al. (2023) devised a PSO global feedback model that simultaneously considers the adjustment costs of group feedback mechanisms and consensus levels, aiming to minimize the overall adjustment cost. Wang et al. (2024) developed an optimization model focusing on minimizing individual adjustment costs while maximizing group consensus, jointly driving the feedback mechanism. Additionally, scholars concentrate on the ranking of alternative solutions. Zhou et al. (2024) propose a novel sequential consensus measurement method that considers both the consistency of alternative solutions in rankings and the significance of the position of these solutions. Meng et al. (2023) determined the weights of decision-makers and clusters through ordinal and cardinal indices to minimize the number of ranking position adjustments and total cardinal adjustments. Li and Zhang (2024) implemented a threshold-based sorting approach to ensure that the ranking outcomes for each alternative solution remain unaffected by other alternatives. The paper will construct an LSGDM model integrating experts’ trustworthiness and authority to facilitate the achievement of expert consensus.
2.2 Consensus Model Based on Trust Relationships
Trust relationships, as tangible manifestations of social connectivity among decision-makers, embody features such as transitivity, asymmetry, and reciprocal interactivity, thereby exerting a profound influence on the consensus attainment process (Lu et al. 2022; Wu et al. 2021; Yu et al. 2021). In order to complement trust networks and identify optimal transmission paths, some research has established consensus decision models by considering trust relationships among decision-makers (Bai et al. 2022a). Wu et al. (2016) innovatively adopted the Uninorm trust transmission and consolidation algorithm, incorporating four key dimensions–trust, distrust, hesitation, and inconsistency–to architect a group decision-making methodology premised on trust linkages. Gai et al. (2023a) further designed a trust function to express trust and distrust relationships among decision-makers, proposing an algorithm to find the shortest trust chain and achieve consensus bidirectional interaction/feedback among decision-makers. Sun et al. (2023) employed a dynamic programming algorithm to identify the optimal trust propagation path by searching for the path with the highest level of trustworthiness.
During the consensus adjustment phase, some scholars put forth consensus feedback models based on trust relationships, offering targeted adjustment suggestions based on the degree of trust among decision-makers (Li et al. 2020b). Liu et al. (2017) introduced a trust-induced recommendation mechanism, guiding decision-makers to modify their opinions based on the preference information of individuals they trust. Gou et al. (2023) introduced a trust reward and punishment mechanism, incentivizing high-consensus experts and penalizing low-consensus experts to promote consensus among experts. However, few experts have noted that trust relationships during expert interactions are influenced by the similarity of expert preference opinions, overlooking the dynamic nature of trust relationships during the decision-making process. Therefore, this paper will integrate expert opinion similarity and social network trust relationships to construct dynamic trust relationships among experts, accurately quantifying the dynamic evolution of expert trust relationships during the decision-making process.
2.3 Consensus Model Considering Expert Psychological Factors
In the context of uncertain information, individuals engage in mutual communication and interaction within a group, and the influence on decision-making processes is inevitable. The psychological factors and social relationships of decision-makers impact their behavioral choices. With the development of behavioral science, numerous scholars have delved into the psychological factors of DMs (Li and Cao 2019). Wang et al. (2017) proposed a novel emergency group decision-making method based on prospect theory and expert psychological factors. Osório (2020) proposed a practical score aggregation procedure to reduce the impact of subjective judgment bias in the decision-making process of DMs. Yang et al. (2023a) utilized experts’ confidence levels to measure their willingness to adjust, thereby determining the consensus adjustment range of experts. Xu and Xiao (2023), considering people’s tendency to accept similar opinions, designed a decision consensus model based on trust-similarity analysis. By introducing confidence coefficients and retention coefficients, targeted consensus adjustment measures were proposed on the basis of expert social network clustering, thereby enhancing group consensus levels.
Traditional group decision-making theories assume individual complete rationality, but these assumptions are challenging to fulfill in real decision environments, leading to irrational decision outcomes. In the decision-making process, experts often succumb to conformity psychology. To address this issue, Li et al. (2023b) took into account the conformity psychology of experts and developed a model with a two-stage feedback process. Xu et al. (2022), focusing on experts’ bounded rationality in the decision-making process, integrated group pressure with large-scale emergency decision-making issues. Considering the conformity psychology of experts, group pressure was used as a preference coefficient to guide experts in preference adjustment, facilitating consensus among experts. In situations where the trust network is incomplete, experts are susceptible to “security psychology” and tend to trust experts with higher authority to reduce the risk of errors (Blass 1999; Haslam and Reicher 2007). However, current research has seldom explored the influence of expert authority levels on the decision-making process. This paper aims to incorporate the concept of authority levels into LSGDM, comprehensively considering their impact on the decision-making process.
3 Preliminaries
This section provides a concise introduction to the fundamental concepts underpinning the structure in LSGDM and Social Network Analysis. These conceptual frameworks serve as the theoretical bedrock for the current study.
3.1 The Structure in LSGDM
Let \(N=\left\{1,\dots ,n\right\},X=\left\{{x}_{1},\dots ,{x}_{n}\right\} (n\ge 2)\) be a finite set of alternatives, where \({x}_{i}\) denotes program \(i\). \(E=\{{e}_{1},\dots ,{e}_{m}\}(m\ge 2)\) denote a set of experts or DMs participating in the consensus process. When \(m\ge 20\), it is considered as a large-scale group decision-making. Generally speaking, LSGDM problems usually have three stages: expert initial opinion provision, DMs clustering, and consensus reaching process (CRP). All the symbols and their meanings involved in this paper are summarized in Table 12.
3.1.1 Fuzzy Preference Relations
Orlovsky (1978) introduced a decision-making methodology designed to address the inherent ambiguity and uncertainty inherent in decision-making information within DMs. This approach is grounded in fuzzy preference relations, providing a systematic means to effectively tackle decision-making quandaries, particularly when preference relations within the alternative set exhibit a fuzzy nature.
Definition 1
(Li et al. 2023a). A matrix \(P={({p}_{ij})}_{n\times n}\) over a finite set of alternatives \(X\) is a fuzzy set over \(X\times X\).Its affiliation function is \({\mu }_{R}:X\times X\to \left[\text{0,1}\right],{\mu }_{R}\left({x}_{i},{x}_{j}\right)={p}_{ij}\), where \({p}_{ij}\) denotes the degree to which option \({x}_{i}\) is superior to option \({x}_{j}\). If \(\forall i,j\in N\) satisfies,
when \(i=j,{p}_{ii}={p}_{jj}=0.5\).Then \(P={({p}_{ij})}_{n\times n}\) denotes as the fuzzy preference relationships.\({p}_{ij}=0.5\) indicates that option \({x}_{i}\) is as important as option \({x}_{j}\) \(({x}_{i}\sim {x}_{j})\);\({0.5<p}_{ij}\le 1\) indicates that option \({x}_{i}\) is strictly better than option \({x}_{j}({x}_{i}\succ {x}_{j})\), and \({p}_{ij}=1\) indicates that option \({x}_{i}\) is absolutely better than option \({x}_{j}\); \(0<{p}_{ij}\le 0.5\) indicates that option \({x}_{j}\) is strictly better than option \({x}_{i}({x}_{i}\prec {x}_{j})\), \({p}_{ij}=0\) means that option \({x}_{j}\) is absolutely better than option \({x}_{i}\).
3.1.2 DMs Clustering
In the context of social networks, the effective management of information necessitates the application of classical k-means clustering methodology for the classification of DMs contingent upon the similarity of opinions among users. Prior to the application of the k-means clustering algorithm, it is imperative to address two key challenges: (a) the determination of the optimal number of subclusters and (b) the selection of an appropriate similarity measure (Guo et al. 2023). To this end, we now define equations for calculating the Euclidean distance between any two DMs, as well as equations for updating the cluster centers during the clustering process. The specific procedure of the k-means algorithm can be found in the literature (Bai et al. 2022b).
Definition 2
Let \({P}_{k}={({p}_{ij}^{k})}_{n\times n}\) and \({P}_{m}={({p}_{ij}^{m})}_{n\times n}\) be the fuzzy preference matrices of any two DMs \({e}_{k},{e}_{m}\), Then the distance between both DMs is
where \({\Vert \Vert }_{F}\) is the Frobenius paradigm of the matrix.
Definition 3
Let \({c}_{k}\) be the opinion center of any class k, then the Equation for updating the opinion center is as follows:
where \({C}_{k}\) denotes the \(k\)-th class, \(\left|{C}_{k}\right|\) denotes the number of the \(k\)-th cluster. Recall that \({P}_{s}\) denotes the fuzzy preference matrix of the \(s\)-th DM.
Based on the similarity of opinions, the experts are grouped into \(K\) subgroups,with subgroup weights represented by \(\omega =\{{\omega }_{1},{\omega }_{2},\dots ,{\omega }_{K}\}\),also satisfying \(0\le {\omega }_{k}\le 1\) and \(\sum {\omega }_{k}=1\).The weight vector of these decision makers is denoted by \(\theta =\{{\theta }_{1},{\theta }_{2},\dots ,{\theta }_{m}\}\), satisfying \(0\le {\theta }_{k}\le 1\) and \(\sum {\theta }_{k}=1\). The weighted arithmetic averaging (WAA) is one of the most widely used operators in GDM and is the basis for many aggregation operators (Lin and Jiang 2014). Using the WAA operator, subgroup opinions and group opinions can be expressed as follows:
-
(a)
Subgroup fuzzy preference relations \({P}_{{G}_{k}}={({p}_{ij}^{{G}_{k}})}_{n\times n}\):
$$ P_{{G_{K} }} = WAA\left( {P_{1} ,P_{2} , \ldots ,P_{k} } \right) = \mathop \sum \limits_{{e_{k} \in G_{K} }} \theta_{k} \cdot P_{k} = \mathop \sum \limits_{{e_{k} \in G_{K} }} \theta_{k} \cdot \left( {\mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} p_{ij}^{k} } \right) $$(4)where \({\theta }_{k}\) denotes the weights of the experts, and it is assumed that the expert weights are uniformly distributed.
-
(b)
Group fuzzy preference relations \({P}_{G}={({p}_{ij}^{G})}_{n\times n}\):
$$ P_{G} = WAA\left( {P_{{G_{1} }} ,P_{{G_{2} }} , \ldots ,P_{{G_{k} }} } \right) = \mathop \sum \limits_{k = 1}^{K} \omega_{k} \cdot P_{{G_{k} }} = \mathop \sum \limits_{k = 1}^{K} \omega_{k} \cdot \left( {\mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} p_{ij}^{{G_{k} }} } \right) $$(5)where \({\omega }_{k}\) represents the weight assigned to the subgroup \({G}_{k}\), determined by the number of experts within the subgroup.
3.1.3 Consensus Reaching Process
Following the clustering process above, consensus has been achieved among the DMs within each group. Consequently, the focus shifts exclusively to inter-group consensus, denoting the consensus between these distinct groups. Consensus measures quantify disparities between individual and group opinions (Cao et al. 2021; Guo et al. 2023; Li et al. 2020a). This concept is elucidated through the following definition:
Definition 4
Let \({P}_{k}={({p}_{ij}^{k})}_{n\times n},k=1,\dots ,m\) be the fuzzy preference relation of the k-th DM,\({P}_{G}={({p}_{ij}^{G})}_{n\times n}\) is the group fuzzy preference relation obtained through Eq. (5).
-
(a)
The consensus level \({CL(e}_{k})\) of expert \({e}_{k}\) is:
$$ CL(e_{k} ) = 1 - D\left( {P_{k} ,P_{G} } \right) = 1 - \mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} \left| {p_{ij}^{k} - p_{ij}^{G} } \right| $$(6)where \(\text{D}({P}_{k},{P}_{G})\) denotes the distance between individual expert preference and group preference, calculated using the Manhattan distance Equation. The greater the value of the \({CL(e}_{k})\) less the conflict of opinion between \({P}_{k}\) and \({P}_{G}\), and the better their level of common sense.
-
(b)
The inter consensus level of the cluster \({G}_{k}\) is:
$$ ICL(G_{k} ) = 1 - D\left( {P_{{G_{k} }} ,P_{G} } \right) = 1 - \mathop \sum \limits_{i = 1}^{n} \mathop \sum \limits_{j = 1}^{n} \left| {p_{ij}^{{G_{k} }} - p_{ij}^{G} } \right| $$(7)where \(\text{D}({P}_{{G}_{k}},{P}_{G})\) represents the distance between a subgroup’s preference relationship and the overall group preference, calculated using the Manhattan distance Equation.
-
(c)
Further, based on the \(WAA\) operator, the group consensus level \(GCL\) can be obtained as:
$$ GCL = \mathop \sum \limits_{k = 1}^{m} \omega_{k} ICL(G_{k} ) $$(8)where \(GCL\epsilon [0.1]\), and the larger the value of \(GCL\), the better the level of group consensus, \({\omega }_{k}\) is the subgroup weight, which is determined based on the number of experts in the cluster.
Achieving unanimous agreement in real-world group decision-making is generally challenging. Consequently, it may be prudent to establish a predefined threshold for an acceptable degree of group consensus, denoted as \(\overline{GCL }\) or “soft consensus” (Qin et al. 2022; Zhang and Li 2021). Without loss of generality, if the Group Consensus Level \(GCL\) for a given decision-making instance, \(GCL\), exceeds the threshold \(\overline{GCL }\), it signifies that the group has attained an acceptable level of consensus. Subsequently, the decision-selection process can be initiated. Conversely, if \(GCL\) falls below \(\overline{GCL }\), indicating insufficient consensus, the feedback regulation mechanism is triggered to address the divergence and foster a more cohesive decision-making environment. The specific CRP is described in Sect. 5.
3.2 Social Network Analysis
3.2.1 Concepts of Social Network Analysis
A social network constitutes a sophisticated framework that intricately connects individual members of a society through diverse forms of interaction (Ji et al. 2023). In the context of social networks, nodes are conventionally represented by \(V\). At the same time, edges are denoted by \(E\), symbolizing decision-making members and the dynamic relationships among them, respectively. To maintain a refined notation, let \(m\) represent the total number of nodes, reflecting the count of decision-making members as \(\{{e}_{1},{e}_{2},\dots ,{e}_{m}\}\). Let edges be denoted as \(d\), the edge linking node \({e}_{i}\) and node \({e}_{j}\) delineates the social network relationship between decision-making members \({e}_{i}\) and \({e}_{j}\), denoted as \(d({e}_{i},{e}_{j})\) (Chen et al. 2020).
Definition 5
(Wasserman and Faust 1994). The degree centrality \({C}_{B}({e}_{i})\) of node e is the number of all adjacent nodes of node \({e}_{i}\), defined as follows:
Degree centrality is a pivotal metric employed to assess the significance and influence of a node within a network. This metric quantifies the extent of connections a node maintains, with a higher degree centrality indicative of a node’s increased importance within the overall network. In the context of weighted networks, where \({A}_{ij}\) denotes the weight of the edge connecting nodes \({e}_{i}\) and \({e}_{j}\), the presence of an edge is denoted by \({A}_{ij}=1\), while its absence is represented by \({A}_{ij}=0\).
Definition 6
(Wasserman and Faust 1994). The closeness centrality of node \({e}_{i}\), denoted as \({C}_{c}\left({e}_{i}\right)\), quantifies its centrality within a network by considering the closeness or distance between nodes. A node achieves a higher closeness centrality when it is intricately connected to numerous other nodes through relatively shorter paths, defined as follows:
where \(d({e}_{i},{e}_{j})\) denotes the shortest path between nodes \({e}_{i}\) and \({e}_{j}\).
3.2.2 Trust Propagation of SNA
In the realm of social networks, trust relationships among individuals manifest in diverse forms, as illustrated in Fig. 1. Direct Trust is characterized by a direct connection between Nodes A and B, indicative of tangible real-life interaction and accurate assessment (refer to Fig. 1a). Alternatively, Indirect Trust denotes the transmission of trust through intermediaries; if Node A trusts B and B trusts C, it follows that A indirectly trusts C (refer to Fig. 1b). Conversely, an Irrelevant Relationship is denoted by the absence of direct or indirect connections between Nodes A and B, signifying the absence of any trust relationship (refer to Fig. 1c) (Li et al. 2022b; Sun et al. 2023).

Different types of trust relationships
In practical scenarios, the manifestation of complete trust or distrust is a rarity. Social networks exhibit a dynamic interplay of trust levels, influenced by ongoing discussions and opinion exchanges. The degree of similarity in opinions among DMs significantly impacts the nature of trust relationships, giving rise to the concept of Interactive Trust. In this context, Nodes A and B may or may not share a direct connection, but the presence of shared perspectives facilitates the establishment of trust relationships among experts, as depicted in Fig. 1d (Zha et al. 2023).
4 The Determination of Expert Trustworthiness and Authority
In conventional consensus processes, the focus predominantly rests on the trust established among experts, often neglecting the inherent limitations within these trust relationships as they exist in real-world social networks (Gong et al. 2021). It is crucial to acknowledge that experts may be susceptible to the influence wielded by authority figures, a phenomenon intricately tied to the development of “security psychology.” This phenomenon suggests a proclivity among experts to gravitate towards placing trust in those of higher authority, thereby mitigating their own susceptibility to errors (Blass 1999). Consequently, there exists a predisposition among experts to repose trust in individuals possessing both authoritative standing and specialized knowledge. Within this section, our objective is to delineate the constructs of expert trustworthiness and the level of authority they command.
4.1 Trustworthiness Degree
In the realm of practical decision-making, trust relationships among experts are frequently confronted by uncertainties. Firstly, trust relationships within social networks often exhibit incompleteness due to the diverse domains from which experts in decision-making arise (Sun et al. 2023). Given their specialized expertise, it becomes impractical to establish trust relationships with every individual involved. Secondly, the transmission of trust is susceptible to gradual weakening or complete dissipation (Wu et al. 2023; Zhou et al. 2024). Furthermore, the nature of trust relationships is inherently dynamic. Within the context of discussions and the exchange of opinions, individuals initially lacking a pre-existing trust relationship may, over time, attenuate their initial mistrust (Zha et al. 2023). This transformation occurs through processes of mutual understanding and empathy, culminating in the gradual construction of trust. Consequently, trust relationships are shaped by the interplay between social network relationships and the convergence of opinions among experts.
Definition 7
The quantification of the social trust relationship among experts is determined by assessing the interconnection of nodes within the social network and evaluating the shortest path length between these nodes. The strength of expert social network trust relationship \({sr}_{ij}\) is:
where \({A}_{ij}\) represents the weight of the edge between nodes \({e}_{i}\) and \({e}_{j}\). If there is an edge connection between nodes \({e}_{i}\) and \({e}_{j}\), then \({A}_{ij}=1\), otherwise it is 0; where \(d({e}_{i},{e}_{j})\) denotes the shortest path between nodes \({e}_{i}\) and \({e}_{j}\);
Definition 8
The impact of opinion similarity on trust relationships is explored by simultaneously considering the distance and angle between expert preferences to define an opinion similarity function (Cao et al. 2019). The opinion similarity \({sd}_{ij}\) between two preference matrices \({P}_{i}\) and \({P}_{j}\) is formulated as follows:
where \({\Vert \Vert }_{F}\) is the Frobenius paradigm of the matrix, \({\Vert {P}_{i}-{\overline{P} }_{i}\Vert }_{F}=\sqrt{\sum_{i=1}^{n}\sum_{j=1}^{n}{\left|{P}_{ij}^{i}-{\overline{P} }_{i}\right|}^{2}}\); and \({\overline{P} }_{j}=\frac{1}{n\times n}{\sum }_{i=1}^{n}{\sum }_{j=1}^{n}{P}_{ij}^{i},{\overline{P} }_{j}=\frac{1}{n\times n}{\sum }_{i=1}^{n}{\sum }_{j=1}^{n}{P}_{ij}^{j}\).
Definition 9
Trust relationships among experts evolve during the decision-making process. The dynamic trust function, denoted as \({F}_{tr}\), delineates this evolution. In accordance with the state transition equation, the trust relationship is defined as follows:
where \(\alpha \in [\text{0,1}]\) denotes the weight vector.
Building upon the dynamic trust relationships elucidated earlier, it is possible to devise an individual trust index for experts. This index serves as a metric for gauging both the intensity of trust associations among experts and the extent of trust invested.
Definition 10
The expert \({e}_{i}\) individual trustworthiness level is:
where \({\mu }_{ij}\) denotes the i-th trust relationship weight, which is determined based on the magnitude of the \({F}_{tr}\left({e}_{i},{e}_{j}\right)\) values, the higher the trust between experts, the larger \({\mu }_{ij}\), \({\mu }_{ij}=\frac{{F}_{tr}\left({e}_{i},{e}_{j}\right)}{{\sum }_{j=1}^{n}{F}_{tr}\left({e}_{i},{e}_{j}\right)}\).
To facilitate the comprehension of the calculation process described in Definition 4.1, we provide an illustrative example below.
Example 1
Given the fuzzy preference matrices for three experts \({e}_{1},{e}_{2},{e}_{3}\), as presented below, along with the trust relationships (Table 1) and the shortest distances among the experts (Table 2) derived from the social network graph, with \(\alpha =0.6\).
Based on the information from Tables 1 and 2, the relationship intensities between DM1 and DM2 as well as DM3 are computed using Eq. (11) as follows: \({sr}_{12}=0\) and \({sr}_{13}=0.5.\) Subsequently, leveraging the provided fuzzy preference matrices and employing Eq. (12), the similarity of opinions between Expert \({e}_{1}\) and other experts is determined, yielding \({sd}_{12}=0.9447\) and \({sd}_{13}=0.9287\) Hence, utilizing Eq. (13), the trust relationships between Expert \({e}_{1}\) and other experts are calculated: \({F}_{tr}\left({e}_{1},{e}_{2}\right)=0.3779,{F}_{tr}\left({e}_{1},{e}_{3}\right)=0.6715\). Then the corresponding weights \({\mu }_{12}=0.3601,{\mu }_{13}=0.6399\) are computed. Consequently, according to Eq. (14), the individual trustworthiness level of \({e}_{1}\) is ultimately determined as \({F}_{TD}\left({e}_{1}\right)=0.6681\).
4.2 Authority Degree
When the trust network is incomplete, relying solely on trust relationships to guide consensus adjustments is insufficient. In the decision-making process, the level of expertise of an expert within a group also significantly influences the decision outcomes. Therefore, in our research, we not only consider trust relationships among experts but also take into account their background by designing an authority index.
To define an expert’s background, we extract two critical pieces of information: the expert’s decision-making experience and their level of professional knowledge (Xu et al. 2021a). We obtain expert background data through information platforms such as CNKI (China National Knowledge Infrastructure), Baidu Baike, Web of Science, Google Scholar, IEEE, ELSEVIER, Wiley, Expert Database, etc. The expertise background is conceived within the context of evaluating decision-making processes through iterative interactions. Expertise background information pertains to the delineation of certain characteristics/features defining an expert, such as educational attainment, institutional affiliation, and professional rank, among others. At the same time, an expert’s decision-making experience and knowledge level are quantified by using an expert scoring system to assess the background information obtained from the expert.
In the decision-making process, the level of consensus among experts directly reflects the proximity of their viewpoints to the group consensus. Thus, experts with higher consensus levels have relatively greater authority in discussions. Social identity theory (Ashforth and Mael 1989) posits that individuals seek a sense of belonging within a group. If an expert aligns with the group consensus, it may enhance their sense of belonging and consequently strengthen their authority. Conversely, if an expert’s viewpoint diverges from the group consensus, they may face rejection or suspicion, leading to a decrease in their authority.
Building upon these considerations, we introduce an expert authority function, which is defined based on the aforementioned information.
Definition 11
The authority as a comprehensive manifestation derived from expert background (denoted as \(eb\)) and consensus level (denoted as \(cl\)). The authority function is formulated as follows:
where \(de, kl, cl\) represent expert decision-making experience, expert knowledge level, and expert consensus level, respectively. And \(\beta_{1}\), \(\beta_{2}\), \(\beta_{3}\) represent the weight vector, \({\beta }_{1}+{\beta }_{2}+{\beta }_{3}=1\).
Remark 2
In the realm of decision-making, the authority of an expert, intricately tied to their wealth of decision-making experience, can be likened to the curve of \(y=\sqrt{x}\). This smoothly increasing dynamic encapsulates the nuanced relationship between an expert’s background and their authoritative stance. Furthermore, the connection between the level of expert knowledge and authority follows a trend reminiscent of the graph \(y={x}^{2}\), fittingly modeled as a quadratic function. The formulation of expert consensus level (\(cl\)), as per Eq. (6), is confined within the [0, 1] range. Notably, the variable cl demonstrates a positive correlation with authority level, approximated by the sinusoidal function \(\text{sin}(x)\).
Example 2
Assuming the background information obtained from the internet about the expert \({e}_{1}\) is: “Bai Shizhen, male, Han nationality, born in October 1962, is currently a professor and doctoral supervisor at Harbin University of Commerce. His main research areas include digital logistics, smart supply chain management, digital agricultural product markets, and e-commerce. As of November 2022, Bai Shizhen has published over 72 high-quality academic papers independently or as the first author in domestic and international journals. He has also led 11 national-level projects and participated in over 25 research projects. With over 30 years of industry experience, he often takes on the team leader role, responsible for project planning, management, and execution, demonstrating outstanding leadership abilities. Peers highly recognize Bai Shizhen’s professional expertise, and he has been rated as being at the forefront of the industry and enjoying a good professional reputation.”
As assessed by the expert scoring system, the expert’s decision-making experience and level of knowledge are assigned scores: \(de\left({e}_{1}\right)=1,kl\left({e}_{1}\right)=0.8\) respectively. It is also given that the expert’s consensus level is \(cl\left({e}_{1}\right)=0.7450\), with \({\beta }_{1}=0.3,{\beta }_{2}=0.3,{\beta }_{3}=0.4\). The degree of authority of this expert can be calculated according to Eq. (15), FAD(e1) = 0.8603.
5 The CRP Model Based on DM Trustworthiness-Authority Consensus
This section outlines our consensus-reaching process based on the trustworthiness-authority consensus model. Section 5.1 proposes our novel consensus model, integrating decision makers’ trustworthiness and authority dynamics. Additionally, Sect. 5.2 presents alternative ranking methods and comprehensively elaborates on the decision-making process of the LSGDM model proposed in this paper.
5.1 A Trustworthiness-Authority Consensus Model for LSGDM
This section will provide a detailed exploration of the Trustworthiness-Authority Consensus Model. In Sect. 5.1.1, experts are methodically categorized according to their trust levels and authority. Following this, thresholds are determined in Sect. 5.1.2, and exclusive adjustment rules are formulated for experts linked to each specified region in Sect. 5.1.3.
5.1.1 Partitioning of Experts Based on Trustworthiness-Authority Level
By categorizing experts’ trustworthiness and authority levels into two distinct levels each (high and low), we can divide the measurement attributes into four quadrants, forming a Trustworthiness-authority Analysis Chart (refer to Fig. 2). In this chart, the X-axis represents the individual trustworthiness level of experts, while the Y-axis represents authority. The trustworthiness-authority function of experts is mapped onto a two-dimensional coordinate system, with black dots representing their positions. The following is a detailed description of the four quadrants in Fig. 2:
-
Q1: “Optimal Quadrant”.
Experts located in Q1 have high trustworthiness scores and high authority. Such experts are highly trusted within the expert community, enjoying a distinguished reputation and authoritative status. They are widely respected in the community, have a solid foundation of trust, and exhibit consistency in their actions and statements in the public domain. The consensus level is high, and their opinions are reliable and highly influential in the social network.
-
Q2: “Authority Emphasis Quadrant”.
Experts in Q2 have a high reputation in the social network. However, their insights may be less reliable due to several factors. These include a limited understanding of decision-making issues, a tendency to be driven by self-interest, and an over-reliance on theoretical frameworks without adequately considering practical, real-world situations. Consequently, their overall comprehensive trustworthiness is relatively low, and the trust relationships they form are comparatively weak.
-
Q3: “Most Marginal Quadrant”.
Experts in Q3 have low trustworthiness and authority. They lack sufficient knowledge and experience when making decisions, leading to biased opinions. At the same time, they hold a relatively low position in social networks, with weak influence.
-
Q4: “Trust Emphasis Quadrant”.
Compared to the Authority Emphasis Quadrants in Q2, experts in Q4 exhibit higher trustworthiness and a robust foundation of trust. However, they possess lower authority. These experts do not enjoy high social status and lack significant influence within the expert community.

Trustworthiness-authority Analysis plot
5.1.2 Determination of Crosshair Placement
Adopting the 80/20 Principle, inspired by economist Vilfredo Pareto (2014), we recognize that a crucial minority, constituting approximately 20% of experts, holds significant influence, while the majority has a lesser impact. Embracing this mindset, we strategically focus on the 20% of experts with lower consensus, aiming to shape the overall consensus of the entire population. This targeted approach involves segmenting the experts into specific regions, such as the Q3 quadrants, ensuring that the number of experts within this region constitutes 20% of the total number of experts, thus defining the region’s boundaries, namely the authority threshold and trust threshold.
Example 3
Assuming that the number of DMs is 20 and reference to the trustworthiness and authority levels delineated in Table 3, a mapping of this data onto the trustworthiness-authority analysis plot (e.g., Fig. 3) is performed. Subsequently, the division of experts is executed in accordance with the law of two-eighths, categorizing the 16 experts into the distinct regions of Q1, Q2, and Q4. The demarcation lines defining these regions, denoted as thresholds for trust level (\(\phi \)) and authority level (\(\psi \)), can be derived as 0.49 and 0.5, respectively.

Threshold setting based on the Trustworthiness-authority Analysis plot
5.1.3 Consensus Adjustment Rules
Experts are often influenced by their peers in the decision-making process, exemplifying the mechanism highlighted by social contagion theory within social networks where information and behaviors propagate rapidly. Social contagion theory (Barsade 2002) posits that individuals learn new behaviors through observing and imitating their peers, with social identity fostering a tendency to align with the group. Within a collective, experts with high authority and trustworthiness exert significant influence and often initiate “contagion,” while other experts serve as recipients. Building upon social contagion theory, we have devised consensus adjustment rules. In the Q1 region, expert trustworthiness and authority are high, and they are perceived as initiators of social contagion, obviating the need for adjustment.
-
(1)
R1: Adjustment rules for Q2.
Experts in the Q2 region demonstrate significant authority, yet they encounter challenges concerning their trustworthiness. In light of the potential impacts of social contagion, it is advisable for these experts to incorporate the perspectives of their counterparts within the subgroup who possess higher levels of trust. Given the heightened authoritative status of these experts, a prudent approach is necessary when modifying their opinions. Careful consideration should be given to adjusting their views to conform with the proposed fuzzy preference relation \({\overline{P} }_{k}={({\overline{p} }_{ij}^{k})}_{n\times n}\):
where \({P}_{h}\) represents the opinions of expert \({e}_{h}\), characterized by high trustworthiness within the group. The parameter \(\xi \), determined as \(\xi =1-{F}_{AD}\left({e}_{i}\right)\) with \(\xi \in \)[0,1], serves as the modification/merging coefficient. This coefficient is contingent upon the expert’s authority level, with higher authority resulting in lower \(\xi \) values.
-
(2)
R2: Adjustment rules for Q3.
In this particular domain, the diminished trust and authority of experts contribute to their relatively attenuated influence, characterizing them as marginal nodes within the network. In accordance with social contagion theory, individuals occupying nodes of lower connectivity are predisposed to rely upon and emulate behaviors exhibited by more salient nodes, thereby enhancing the reliability of their decision-making. The intermediary role assumed by weakly connected nodes, functioning as bridges across disparate social groups, renders them pivotal in the propagation of information and behavior, consequently shaping decision-making processes. To recalibrate expert opinions within this locale, a stochastic process is employed through a random walk algorithm, thereby ensuring a judicious and effective adjustment of expert preferences.
In the random walk algorithm, nodes undergo random walks with probabilities determined by the trustworthiness and authority of neighboring experts. The probability \(P\left({e}_{i}\right)\) for node \({e}_{i}\) to take a random walk is calculated using the formula:
Based on the calculated probabilities, the expert \({e}_{h}\) with the highest probability is selected for expert opinion fusion. The expert opinions are fused using the formula:
where \(\tau \) is a parameter controlling the adjustment magnitude, adjusted based on the disparity in trustworthiness and authority between experts \({e}_{k}\) and \({e}_{h}\),\(\tau =\frac{{F}_{TD}\left({e}_{k}\right)\times {F}_{AD}({e}_{k})}{{F}_{TD}\left({e}_{h}\right)\times {F}_{AD}({e}_{h})}\).
The detailed algorithm process is as follows:

Random Walk Algorithm
-
(3)
R3: Adjustment rules for Q4.
In the Q4 region, experts demonstrate a notably robust foundation of trust, despite their relatively lower standing and prestige within the broader social network. In accordance with social communication theory, such experts may actively seek to cultivate intimate social connections with prominent counterparts, aiming to elevate their network standing and fortify their group affiliation. Consequently, it is recommended that these experts align their perspectives with those of esteemed authorities, engaging in knowledge exchange and communication with experts who command both high authority and trust within their respective subgroups. The ensuing adjusted fuzzy preference relationships, denoted as \({\overline{P} }_{k}={({\overline{p} }_{ij}^{k})}_{n\times n}\), are proposed as follows:
where \({P}_{h}\) represents the opinions of expert \({e}_{h}\), characterized by high trustworthiness and authority, within the group, the parameter \(\zeta\) falling within the range \([\text{0,1}]\), denotes the modification/merging coefficient.
5.2 Alternative Ranking and Consensus Process
5.2.1 Alternative Ranking
Building upon the aforementioned adjustment rules, continual adjustments are applied to experts with lower consensus levels. Upon reaching the consensus threshold, the alternatives are ranked based on the current \({P}_{G}={({p}_{ij}^{G})}_{n\times n}\). The optimal solution is then selected from these rankings. The scoring Equation for the alternatives is articulated as follows:
The higher the score \(\rho \left({x}_{i}\right)\) for the alternative solution \({x}_{i}\), the more optimal the solution \({x}_{i}\) is deemed.
5.2.2 The Procedure of the Proposed LSGDM Method
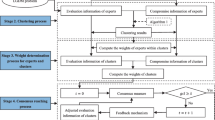
The LSGDM decision-making method proposed in this paper primarily consists of five critical steps. Initially, the method involves acquiring preliminary information from experts. The second step entails clustering these experts and assigning appropriate weights to each. The third step focuses on measuring consensus. In instances where consensus is not achieved, the process advances to the fourth step, which introduces the trustworthiness-authority consensus model. This model aims to adjust the opinions of experts with low consensus levels until a satisfactory consensus is reached. Finally, the fifth step involves selecting the optimal solution. For clarity, the illustrative framework of the proposed method is depicted in Fig. 4. The detailed procedure is as follows:
-
Step 1: Collection of Decision Opinions

Flow chart of the proposed decision-making model
Experts initiate the process by employing the fuzzy preference relation method to articulate their preferences for alternative solutions, thereby generating corresponding preference matrices.
-
Step 2: Expert Categorization and Cluster Weight Determination
Utilizing the k-means clustering algorithm, experts are systematically categorized into distinct clusters, and the weights for individual experts and these clusters are determined. Individual expert weights remain uniform, while cluster weights are contingent upon the number of experts within each cluster.
-
Step 3: Consensus Level Calculation
Expert consensus level \({CL(e}_{k})\), clusters consensus level \({ICL(G}_{k})\), and global consensus level \(GCL\) are computed using Eqs. (6)–(8). If \(GCL>\overline{GCL }\), the process advances to Step 5; otherwise, it proceeds to the subsequent step.
-
Step 4: Perform the CRP with a trustworthiness-authority consensus model.
-
Step 4-1: Obtaining information on experts’ social relationships and mapping initial social networks. In turn, the expert trust relationship \({F}_{tr}\),the expert’s Individual trustworthiness levels \({F}_{TD}\) and authorities \({F}_{AD}\) are calculated through Eqs. (11)–(15).
-
Step 4-2: Subsequently, an expert trustworthiness-authority graph is plotted, and experts are categorized into four quadrants (Q1, Q2, Q3, Q4).
-
Step 4-3: Find the expert with the lowest consensus within Q2, Q3, and Q4, and adjust these three experts simultaneously according to the adjustment rules (R1, R2, and R3).
-
Step 4-4: Updating the trust relationship \({F}_{tr}\), trustworthiness level \({F}_{TD}\), authority \({F}_{AD}\) and preference matrices \({\overline{P} }_{k}\) of the adjusted experts, and the social network graph of the experts and the trustworthiness-authority analysis graph of the experts are redrawn.
-
Step 4-5: The process then reverts to Step 3 for recalculating the group consensus level.
-
-
Step 5: Optimal Alternative Selection
Upon achieving consensus among experts, the optimal alternative is selected based on the aggregated preference information, as calculated by Eq. (20).
6 Case Studies
In this section, we present a real-life case study to validate the effectiveness of our approach. Comparative and sensitivity analyses also test the validity and robustness of the model proposed in this paper. Section 6.1 provides background and outlines the methodology for parameter determination, while Sect. 6.2 details the application of the consensus feedback model, emphasizing Decision Makers’ trustworthiness and authority. Comparative analysis in Sect. 6.3 and sensitivity analysis in Sect. 6.4 showcases the resilience of our method.
6.1 Example Description
The Qingcheng District Government of Tianjin Municipality is proactively answering the global call for environmental stewardship and sustainability, recognizing the potential irreversible harm that conventional agricultural practices can cause to land, water resources, and ecosystems. The Xiqing District has committed to adopting innovative and sustainable agricultural approaches. The primary goal is to find a harmonious equilibrium between agricultural productivity and the preservation of natural resources. To devise the most suitable sustainable agricultural development plan, the Xiqing District has formed an interdisciplinary team for decision-making. This team comprises 20 experts (denoted as \(E=\{{e}_{1},\dots ,{e}_{m}\}(m=20)\) who have been invited to conduct a comprehensive assessment of four alternatives (denoted as \(X=\left\{{x}_{1},\dots ,{x}_{n}\right\},n=4\)). The alternative proposals are as follows:
-
\({x}_{1}\): Precision Agriculture Technologies:
-
Advantages: Achieving intelligent agricultural management through high-tech means enhancing production efficiency and reducing resource wastage. The reduction in the use of fertilizers and pesticides contributes to environmental sustainability.
-
Challenges: Substantial investments are required to introduce new technologies. Farmers need to adapt to new agricultural management methods, potentially creating a technological gap among traditional practitioners.
-
-
\({x}_{2}\): Organic Farming Practices:
-
Advantages: Providing agricultural products free from chemical fertilizers and pesticides meets the growing market demand for health and environmental sustainability. It contributes to improving soil quality and safeguarding water sources.
-
Challenges: High initial costs and relatively longer production cycles may lead to increased agricultural product prices. Comprehensive training is necessary to ensure farmers’ technical proficiency.
-
-
\({x}_{3}\): Agricultural Diversity:
-
Advantages: Diversifying agricultural operations reduces dependence on a single crop, mitigating the economic impact of natural disasters. Promoting diversity in agricultural ecosystems enhances disease resistance.
-
Challenges: Managing and selling different agricultural products may be complex, requiring farmers to possess a broader range of agricultural knowledge. Market risks are relatively high.
-
-
\({x}_{4}\): Community Engagement and Agricultural Education:
-
Advantages: Enhancing awareness and support for sustainable agriculture through community engagement and agricultural education strengthens community foundations and fosters partnerships.
-
Challenges: Significant time and resources are required for community engagement activities and agricultural education. Noticeable economic benefits may take an extended period to materialize.
-
6.2 Resolution by the Proposed Model
To identify the optimal alternative, the proposed LSGDM approach integrates a consensus model that incorporates expert trustworthiness and authority. All facets of information processing and algorithm implementation will be exclusively conducted using MATLAB.
-
Step 1: Collection of Decision Opinions.
20 DMs employed fuzzy preference relations to evaluate four alternative solutions, providing matrices that represent their individual preferences. (To verify the generality and robustness of the proposed method, the data was randomly generated using a MATLAB program.)
-
Step 2: Expert Categorization and Cluster Weight Determination.
Utilizing the k-means clustering algorithm, set subgroup number \(k=4\),experts are systematically categorized into 4 clusters. Expert information is then aggregated, with equal weights assigned to each expert (\({\theta }_{k}=0.05\)). Subgroup weights \({\omega }_{k}\) are determined by the number of experts within each subgroup. The detailed results are presented in Table 4.
-
Step 3: Consensus Level Calculation.
Expert consensus level \({CL(e}_{k})\), clusters consensus level \({ICL(G}_{k})\), and global consensus level \({GCL(G}_{k})\) are computed using Eqs. (6)–(8). Table 5 presents the detailed results.
Since \(GCL=0.7555<\overline{GCL }=0.8\), thus, the CPR should be performed.
-
Step 4: Perform the CRP with a trustworthiness-authority consensus model.
Obtaining information on experts’ social relationships and mapping initial social networks (Fig. 5). The Individual trustworthiness levels and authorities of experts are calculated through Eqs. (11)–(15), with the parameter values \(\alpha =0.6\), \({\beta }_{1}=0.3,{\beta }_{2}=0.3,{\beta }_{3}=0.4\). Subsequently, a graph depicting expert trustworthiness and authority is generated. The trustworthiness threshold (\(\phi \)) is established at 0.48, while the authority threshold (\(\varphi \)) is set to 0.45. The experts are then systematically classified into four quadrants, as illustrated in Fig. 6. Within Quadrants Q2, Q3, and Q4, the expert exhibiting the lowest consensus is identified. Simultaneously, adjustments are made to these three experts based on adjustment rules (R1, R2, and R3), with \(\zeta \) set to 0.8. Updating the trust relationship \({F}_{tr}\), trustworthiness level \({F}_{TD}\), authority \({F}_{AD}\) and preference matrices \({\overline{P} }_{k}\) of the adjusted experts, Furthermore, the social network graph of the experts (Figs. 7, 9, 11) and the trustworthiness-authority analysis graph (Figs. 8, 10, 12) are redrawn. The process then reverts to Step 3 to recalculate the group consensus level. The detailed outcomes of this process are presented comprehensively in Table 6.
-
Step 5: Optimal Alternative Selection.

Initial social network

Initial trustworthiness-authority analysis plot

Updated social network 1

Updated trustworthiness-authority analysis plot 1

Updated social network 2

Updated trustworthiness-authority analysis plot 2

Updated social network 3

Updated trustworthiness-authority analysis plot 3
Upon achieving consensus among experts, the optimal alternative is selected based on the aggregated preference information.
At this moment,\({P}_{G}=\left[\begin{array}{cccc}0.5000& 0.4938& 0.5215& 0.6062\\ 0.5062& 0.5000& 0.4679& 0.4873\\ 0.4785& 0.5321& 0.5000& 0.5073\\ 0.3938& 0.5127& 0.4927& 0.5000\end{array}\right]\),
Calculating the scores of alternative solutions based on Eq. (20) results in \({x}_{1}>{x}_{3}>{x}_{2}>{x}_{4}\). Therefore, the most optimal solution is to implement the precision agriculture technology, specifically the \({x}_{1}\) approach. The execution of this strategy not only significantly enhances production efficiency but also effectively reduces reliance on fertilizers and pesticides, thereby mitigating adverse environmental impacts. Concurrently, the community benefits from introducing this new technology, as it not only holds the potential to elevate the technical proficiency of agricultural practitioners but also contributes to fostering the sustainable development of local agriculture.
Ultimately, the Xiqing District of Tianjin Municipality opted for precision agriculture decision-making, focusing on the local specialty, Xiaozhan rice, to establish an intelligent agricultural platform and promote standardized production. This initiative has significantly propelled the development towards digitization, intelligence, and green practices. In the spring of 2021, Xiaozhan rice was cultivated alongside rapeseed as green manure, resulting in a 20% reduction in nitrogen fertilizer usage for the season. Adopting soil testing-based fertilization led to a 20% decrease in potassium fertilizer application. These measures resulted in an increase of over 10% in yield per acre and an average income rise of 180 yuan per acre.Footnote 1 Moreover, the rice produced at the demonstration farm met the national standards for top-quality rice, earning recognition from the Office of the Ministry of Agriculture and Rural Affairs as a typical case of national agricultural green development in 2021. The success of precision agriculture has strongly driven the advancement of green farming practices, providing compelling evidence for the validity and effectiveness of the decision-making outlined in this article.
6.3 Comparison with Other Consensus Methods
The purpose of this section is to demonstrate the indispensability of the factors of expert trustworthiness and authority in the large-scale group decision consensus model proposed by this study. Therefore, it systematically examines the significance and necessity of the considered variables, namely, expert trustworthiness and authority, within the consensus model. To achieve this, the section proceeds to selectively exclude the factors of expert trustworthiness and authority in the large group decision consensus model, thereby substantiating the rationality and essential nature of the variables under consideration.
6.3.1 Model 1: A Consensus Model for LSGDM Considering Only Expert Trust Relationships
Remove the factors related to authority in the trustworthiness-authority consensus model for LSGDM proposed in this article. Specifically, modify step 4 as follows, keeping the other steps unchanged. The updated step 4 is as follows:
-
Step 4-1 A: Obtaining information on experts’ social relationships and mapping initial social networks. In turn, the expert trust relationship \({F}_{tr}\) is calculated through Eqs. (11)–(14).
-
Step 4-2 A: Identify the expert with the lowest consensus among all experts.
-
Step 4-3 A: Based on the trust relationship \({F}_{tr}\) among experts, find the expert with the strongest trust relationship with a particular expert. This expert will then engage in opinion fusion with the expert with whom they have the optimal trust relationship, using Eq. (19), with \(\zeta \) set to 0.8.
-
Step 4-4 A: Updating the trust relationship \({F}_{tr}\) and preference matrices \({\overline{P} }_{k}\) of the adjusted experts, and the social network graph is redrawn.
-
Step 4-5 A: The process then reverts to Step 3 to recalculate the group consensus level.
.
After modifying the fourth step of the proposed model in this paper, the model now relies solely on trust relationships to achieve consensus. Table 7 provides detailed information about the consensus-reaching process.
At this moment,\({P}_{G}=\left[\begin{array}{cccc}0.5000& 0.4790& 0.5320& 0.6620\\ 0.5210& 0.5000& 0.5650& 0.5310\\ 0.4680& 0.4350& 0.5000& 0.4680\\ 0.3380& 0.4690& 0.5320& 0.5000\end{array}\right]\)
Calculating the scores of alternative solutions based on Eq. (20) results in \({x}_{1}>{x}_{2}>{x}_{3}>{x}_{4}\), and the optimal alternative is \({x}_{1}\).
6.3.2 Model 2: A Consensus Model for LSGDM Considering Only Expert Authority
Remove the factors related to trust relationships in the trustworthiness-authority consensus model for LSGDM proposed in this article. Specifically, modify step 4 as follows, keeping the other steps unchanged. The updated step 4 is as follows:
-
Step 4-1 B: Calculate the expert authority level based on Eq. (15).
-
Step 4-2 B: Identify the expert with the lowest consensus among all experts.
-
Step 4-3 B: Find the most authoritative expert within the subgroup to which this expert belongs and merge opinions with this expert. If this expert is already the most authoritative within the subgroup, then look for the expert with the highest authority to merge opinions. In the process of opinion merging, use Eq. (16) consistently, and the parameter \(\xi \)=0.8.
-
Step 4-4 B: Updating the preference matrices \({\overline{P} }_{k}\) of the adjusted experts.
-
Step 4-5 B: The process then reverts to Step 3 to recalculate the group consensus level.
After modifying the fourth step of the proposed model in this paper, the model now relies solely on the influence of expert authority to achieve consensus. Detailed information about the consensus-reaching process is provided in Table 8.
At this moment, \({P}_{G}=\left[\begin{array}{cccc}0.5000& 0.4830& 0.5320& 0.5940\\ 0.5170& 0.5000& 0.5250& 0.4910\\ 0.4680& 0.4750& 0.5000& 0.4440\\ 0.4060& 0.5090& 0.5560& 0.5000\end{array}\right]\).
Calculating the scores of alternative solutions based on Eq. (20) results in \({x}_{1}>{x}_{2}>{x}_{4}>{x}_{3}\),and the optimal alternative is\({x}_{1}\).
6.3.3 Comparison Analysis
The comparative analysis of three consensus models, denoted as Model 1, emphasizing trust relationships exclusively, Model 2, focused solely on expert authority, and the Trustworthiness-Authority Consensus Model (Model 3) introduced in this manuscript, is meticulously detailed in Table 9. The findings reveal a unanimous selection of solution \({x}_{1}\) by all three models, confirming the viability of the proposed model in this study. Nevertheless, nuanced distinctions in solution rankings among the models arise due to their reliance on distinct adjustment rules. This divergence in adjustment rules results in varied configurations of the preference matrix \({P}_{G}\) for the expert group after consensus adjustments, a phenomenon comprehensible within the given context.
Table 9 indicates that the proposed model (Model 3) exhibits an accelerated convergence toward consensus. The Trustworthiness-Authority Consensus Model (Model 3) manifests more pronounced adjustment effects in each iteration, starkly contrasting to the relatively protracted consensus attainment observed in Models 1 and 2, which hinge exclusively on a singular critical factor for consensus determination. This substantiates the imperative nature of concurrently considering both expert trustworthiness and authority. Furthermore, it underscores the superior performance of the proposed model in offering a more comprehensive representation that aligns closely with the intricacies of real-world expert decision-making scenarios.
6.4 Sensitivity Analysis
In this section, sensitivity analyses that the parameters \(\alpha \) in the trust function (Eq. 13) and the \({\beta }_{1},{\beta }_{2,}{\beta }_{3}\) in the authority function (Eq. 15) of the CRP, respectively, are presented in Sect. 6.4.1 and Sect. 6.4.2.
6.4.1 The Effect of the Parameters \(\boldsymbol{\alpha }\)
In Sect. 6.2, the parameter \(\alpha \) is set to 0.6. In this subsection, a discussion is introduced based on varying values of α to further validate the rationale of the proposed consensus model. In order to ensure that the trust threshold \(\phi \) and authority threshold \(\psi \) adhere to the Pareto principle, where 80% of the effects come from 20% of the causes, both the trust threshold and authority threshold are adjusted with different \(\alpha \) values. The parameter \(\alpha \), trust threshold \(\phi \), authority threshold \(\psi \), final group consensus levels, and alternative rankings are recorded in Table 8 for a sensitivity analysis with varying \(\alpha \) values of \(\{\text{0.5,0.55,0.6,0.65,0.7,0.75,0.8}\}\).
The analysis from Table 10 reveals a notable trend: as the \(\alpha \) parameter increases, the Trustworthiness thresholds (\(\phi \)) consistently decrease. This phenomenon is rooted in the decreasing values of \({F}_{tr}\) associated with higher \(\alpha \), subsequently influencing the decrease of \({F}_{TD}\). To align expert partitioning results with the Pareto principle, it becomes imperative to continually lower the trust threshold, thereby ensuring the precision of the expert partitioning outcomes.
In tandem with variations in \(\alpha \), the consensus adjustment rounds remain consistently within the 1–3 round range. Notably, when α surpasses or equals 0.65, the consensus rounds stabilize at 2 rounds, reflecting a swift attainment of consensus and affirming the efficacy of the proposed methodology in this study.
As \(\alpha \) exceeds or equals 0.55, the ranking results for alternative solutions exhibit a tendency to stabilize, consistently manifesting as \({x}_{1}>{x}_{3}>{x}_{2}>{x}_{4}\). This not only validates the judicious selection of \(\alpha \) = 0.6 but also underscores the stability inherent in the proposed model. In summary, these findings collectively attest to the robustness and effectiveness of the model in achieving reliable and stable consensus in the collaborative decision-making process.
6.4.2 The Effect of the Parameters \({{\varvec{\beta}}}_{1},{{\varvec{\beta}}}_{2},{{\varvec{\beta}}}_{3}\)
In this subsection, we explore the impact of varying values for the key parameters \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\), crucial in calculating the authority function, as they were set to 0.3, 0.3, and 0.4, respectively, in Sect. 6.1. This examination aims to further substantiate the rationale of the proposed consensus model. Changes in \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\) directly influence the authority values assigned to experts. To maintain the stability of expert partitioning, adjustments in the trustworthiness thresholds \((\phi )\) and authority threshold \((\psi )\) are necessary. Detailed information regarding the parameters \({\beta }_{1},{\beta }_{2,}{\beta }_{3}\), trustworthiness thresholds \((\phi )\), authority threshold \((\psi )\), final group consensus levels, and alternative rankings is documented in Table 11.
Table 11 illustrates that alterations in the parameters \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\) result in corresponding adjustments in the Authority thresholds (\(\psi \)). These adjustments are a consequence of tuning \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\), which in turn influence the Authority Degree (\({F}_{AD}\)) for each expert. To ensure adherence to the Pareto Principle within the expert partition, it is imperative to make corresponding adjustments to the Authority thresholds (\(\psi \)).
Under variations in \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\), the primary focus of expert adjustments is observed within the range of 2 to 5 rounds. Remarkably, consensus levels are predominantly attained with a mere 2 or 3 adjustment rounds. This observation underscores the practical efficiency of the proposed model in this study.
For distinct values of \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\),the optimal solution consistently identified by the consensus model is \({x}_{1}\), while the suboptimal solution remains \({x}_{3}.\) Although there might be slight discrepancies in the ranking of alternative solutions, these variations are attributed to changes in expert partition results and subtle alterations in the expert preferences matrix during each adjustment round, arising from variations in \({\beta }_{1},{\beta }_{2}\) and \({\beta }_{3}\). Importantly, these nuances do not compromise the model’s precision in selecting the optimal solution. In a holistic analysis of the outcomes presented in Table 9, it is discerned that the consensus model posited in this study exhibits both efficacy and stability in facilitating the attainment of expert consensus across varied parameter configurations.
7 Conclusion
This paper introduces a novel consensus model tailored for large-scale group decision-making (LSGDM), meticulously incorporating the elements of trustworthiness and authority among experts. The proposed model adeptly integrates the core principles underpinning trustworthiness and authority functions. The primary innovations and theoretical contributions of this study can be summarized as follows:
-
(1)
Anchored in the framework of complex network evolution theory, this study employs a visual representation to elucidate the dynamic evolution process of expert social relationships. It reveals the transformation trajectory from an unordered, chaotic state to a relatively ordered and distinctly patterned state within the complex social network.
-
(2)
Adopting a holistic approach, this research introduces an innovative conceptualization of centrality and authority functions among experts. This approach integrates considerations of experts’ social relationships, personal traits, and opinion preferences, presenting a quantitatively oriented method that significantly reduces subjectivity.
-
(3)
Through meticulous categorization of decision-making experts based on trustworthiness and authority thresholds, and the formulation of distinct consensus improvement rules, this study substantially enhances the efficiency of consensus development. This stratification concurrently ensures a representative range of expert preferences, thereby increasing the scientific rigor and stability of decision-making outcomes.
-
(4)
Drawing on social contagion theory, the study integrates a stochastic random walk algorithm, accounting for the intricacies of expert social networks and the fluctuating nature of opinion attitudes during the decision-making process. By simultaneously considering the individual characteristics of decision-making experts, the research adeptly simulates the authentic decision-making process, thereby propelling the evolution of large-scale group decision-making towards intelligent decision-making at scale.
Although this study contributes significantly, there remains room for refinement in defining trust and authority functions among experts. Firstly, while certain factors have been considered, the computation process for expert trust and authority could benefit from further integration of additional indicators to enhance precision. Secondly, the study’s reliance solely on the Google and CNKI databases introduces limitations in determining expert authority. Future research should consider expanding data sources, potentially incorporating diverse databases, or constructing specialized repositories to bolster the accuracy of authority determination. Lastly, the determination of trust and authority thresholds is inherently subjective. Despite grounding this study in existing trust and authority values and applying the Pareto principle to establish thresholds, future research should acknowledge the asymmetry in expert trust relationships and non-cooperative behaviors during decision-making. This necessitates the design of more scientifically rigorous algorithms to refine expert trust and authority functions, ensuring the scientific and rational underpinning of trust and authority thresholds.
Change history
17 August 2024
A Correction to this paper has been published: https://doi.org/10.1007/s10726-024-09898-6
Notes
Tianjin Development and Reform Commission. Leveraging the wisdom of the agricultural service platform innovation small station rice “five unity” standardized production model[R/OL]. (2022/10/25). Published: National Development and Reform Commission. https://www.ndrc.gov.cn/fggz/nyncjj/zdjs/202210/t20221025_1339101.html.
References
Ashforth BE, Mael F (1989) Social identity theory and the organization. Acad Manag Rev 14:20–39. https://doi.org/10.5465/AMR.1989.4278999
Bai S, He H, Ge M, Yang R, Luo D, Bi X (2022a) Large-scale group decision-making model with cooperative behavior based on social network analysis considering propagation of decision-makers’ preference. J Math. https://doi.org/10.1155/2022/2842601
Bai S, He H, Luo D, Ge M, Yang R, Bi X (2022b) A large-scale group decision-making consensus model considering the experts’ adjustment willingness based on the interactive weights’ determination. Complexity 2022:2691804. https://doi.org/10.1155/2022/2691804
Barsade SG (2002) The ripple effect: Emotional contagion and its influence on group behavior. Adm Sci Q 47:644–675. https://doi.org/10.2307/3094912
Blass T (1999) The milgram paradigm after 35 years: some things we now know about obedience to authority 1. J Appl Soc Psychol 29:955–978. https://doi.org/10.1111/j.1559-1816.1999.tb00134.x
Cao J, Xu X, Chen X (2019) Risk evolution model for large group emergency decision-making influenced byextreme preference. Syst Eng Theory Pract 39:596–614
Cao M, Wu J, Chiclana F, Herrera-Viedma E (2021) A bidirectional feedback mechanism for balancing group consensus and individual harmony in group decision making. Inf Fus 76:133–144. https://doi.org/10.1016/j.inffus.2021.05.012
Carneiro J, Saraiva P, Martinho D, Marreiros G, Novais P (2018) Representing decision-makers using styles of behavior: an approach designed for group decision support systems. Cognit Syst Res 47:109–132. https://doi.org/10.1016/j.cogsys.2017.09.002
Chen X, Zhang W, Xu X (2020) Large group decision-making method based on hesitation and consistency under socianetwork context. Syst Eng Theory Pract 40:1178–1192
de Morais Bezerra F, Melo P, Costa JP (2017) Reaching consensus with VICA-ELECTRE TRI: a case study. Group Decis Negot 26:1145–1171. https://doi.org/10.1007/s10726-017-9539-5
Gai T, Wu J, Cao M, Ji F, Sun Q, Zhou M (2023a) Trust chain driven bidirectional feedback mechanism in social network group decision making and its application in Metaverse virtual community. Expert Syst Appl 228:120369. https://doi.org/10.1016/j.eswa.2023.120369
Gai T, Cao M, Chiclana F, Zhang Z, Dong Y, Herrera-Viedma E, Wu J (2023b) Consensus-trust driven bidirectional feedback mechanism for improving consensus in social network large-group decision making. Group Decis Negot 32:45–74. https://doi.org/10.1007/s10726-022-09798-7
Gong Z, Wang H, Guo W, Gong Z, Wei G (2020) Measuring trust in social networks based on linear uncertainty theory. Inf Sci 508:154–172. https://doi.org/10.1016/j.ins.2019.08.055
Gong Z, Guo W, Słowiński R (2021) Transaction and interaction behavior-based consensus model and its application to optimal carbon emission reduction. Omega 104:102491. https://doi.org/10.1016/j.omega.2021.102491
Gou X, Xu X, Xu Z (2023) Research on multi-attribute group decision-making modeling of energy transition pathevaluation based on dynamic social network. Chinese J Manag Sci. https://doi.org/10.16381/j.cnki.issn1003-207x.2022.1025
Guo L, Zhan J, Xu Z, Alcantud JCR (2023) A consensus measure-based three-way clustering method for fuzzy large group decision making. Inform Sci 632:144–163. https://doi.org/10.1016/j.ins.2023.03.002
Haslam SA, Reicher S (2007) Beyond the banality of evil: Three dynamics of an interactionist social psychology of tyranny. Personal Soc Psychol Bull 33:615–622. https://doi.org/10.1177/0146167206298570
Hochbaum DS, Levin A (2006) Methodologies and algorithms for group-rankings decision. Manage Sci 52:1394–1408. https://doi.org/10.1287/mnsc.1060.0540
Ji F, Wu J, Chiclana F, Wang S, Fujita H, Herrera-Viedma E (2023) The overlapping community driven feedback mechanism to support consensus in social network group decision making. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2023.3241062
Jin F, Cai Y, Zhou L, Ding T (2023) Regret-rejoice two-stage multiplicative DEA models-driven cross-efficiency evaluation with probabilistic linguistic information. Omega 117:102839. https://doi.org/10.1016/j.omega.2023.102839
Li M, Cao P (2019) Extended TODIM method for multi-attribute risk decision making problems in emergency response. Comput Ind Eng 135:1286–1293. https://doi.org/10.1016/j.cie.2018.06.027
Li Z, Zhang Z (2024) Threshold-based value-driven method to support consensus reaching in multicriteria group sorting problems: a minimum adjustment perspective. IEEE Trans Comput Soc Syst 11:1230–1243. https://doi.org/10.1109/TCSS.2023.3251351
Li C, Dong Y, Pedrycz W, Herrera F (2020a) Integrating continual personalized individual semantics learning in consensus reaching in linguistic group decision making. IEEE Trans Syst Man Cybern Syst 52:1525–1536. https://doi.org/10.1109/TSMC.2020.3031086
Li S, Wei C, Song J (2020b) Group decision making method for fuzzy complementary judgement matrices based on trust relationships. Control Decis 35:1240–1246. https://doi.org/10.13195/j.kzyjc.2018.1288
Li G, Kou G, Peng Y (2022a) Heterogeneous large-scale group decision making using fuzzy cluster analysis and its application to emergency response plan selection. IEEE Trans Syst Man Cybern Syst 52:3391–3403. https://doi.org/10.1109/TSMC.2021.3068759
Li Y, Kou G, Li G, Peng Y (2022b) Consensus reaching process in large-scale group decision making based on bounded confidence and social network. Eur J Oper Res 303:790–802. https://doi.org/10.1016/j.ejor.2022.03.040
Li M, Liu G, Xu Y, Liu X, Wang H (2023a) Research on consensus of social network group decision making consideringexperts’ trust risk behaviors mining and dynamic management. Chinese J Manag Sci. https://doi.org/10.16381/j.cnki.issn1003-207x.2022.2549
Li P, Xu Z, Zhang Z, Li Z, Wei C (2023b) Consensus reaching in multi-criteria social network group decision making: a stochastic multicriteria acceptability analysis-based method. Inf Fus 97:101825. https://doi.org/10.1016/j.inffus.2023.101825
Lin J, Jiang Y (2014) Some hybrid weighted averaging operators and their application to decision making. Inf Fus 16:18–28. https://doi.org/10.1016/j.inffus.2011.06.001
Liu Y, Mao Z (2022) An experimental study on the critical state of herd behavior in decision-making of the crowd evacuation. Phys A 595:127087. https://doi.org/10.1016/j.physa.2022.127087
Liu Y, Yang Y (2022) A novel similarity-based consensus model for probabilistic linguistic sets and its application in multi-attribute large-scale group decision making. Comput Appl Math 41:97. https://doi.org/10.1007/s40314-021-01684-3
Liu Y, Liang C, Chiclana F, Wu J (2017) A trust induced recommendation mechanism for reaching consensus in group decision making. Knowl Based Syst 119:221–231. https://doi.org/10.1016/j.knosys.2016.12.014
Liu B, Jiao S, Shen Y, Chen Y, Wu G, Chen S (2022a) A dynamic hybrid trust network-based dual-path feedback consensus model for multi-attribute group decision-making in intuitionistic fuzzy environment. Inf Fus 80:266–281. https://doi.org/10.1016/j.inffus.2021.09.020
Liu P, Zhang K, Wang P, Wang F (2022b) A clustering- and maximum consensus-based model for social network large-scale group decision making with linguistic distribution. Inf Sci 602:269–297. https://doi.org/10.1016/j.ins.2022.04.038
Liu X, Xu Y, Gong Z, Herrera F (2022c) Democratic consensus reaching process for multi-person multi-criteria large scale decision making considering participants’ individual attributes and concerns. Inf Fus 77:220–232. https://doi.org/10.1016/j.inffus.2021.07.023
Lu Y, Xu Y, Herrera-Viedma E, Han Y (2021) Consensus of large-scale group decision making in social network: the minimum cost model based on robust optimization. Inform Sci 547:910–930. https://doi.org/10.1016/j.ins.2020.08.022
Lu Y, Xu Y, Huang J, Wei J, Herrera-Viedma E (2022) Social network clustering and consensus-based distrust behaviors management for large-scale group decision-making with incomplete hesitant fuzzy preference relations. Appl Soft Comput 117:108373. https://doi.org/10.1016/j.asoc.2021.108373
Meng F, Zhao D, Tan C, Li Z (2023) Ordinal-cardinal consensus analysis for large-scale group decision making with uncertain self-confidence. Inf Fus 93:344–362. https://doi.org/10.1016/j.inffus.2023.01.014
Milgram S (1963) Behavioral Study of obedience. J Abnorm Soc Psychol 67:371–378. https://doi.org/10.1037/h0040525
Ming T, Huchang L, Zeshui XU (2021) Large-scale group decision making with interdependent subgroups based on maximum consensus sequences. Syst Eng Theory Pract 41:3043–3054. https://doi.org/10.12011/SETP2020-2429
Orlovsky SA (1978) Decision-making with a fuzzy preference relation. Fuzzy Sets Syst 1:155–167. https://doi.org/10.1016/0165-0114(78)90001-5
Osório A (2020) Performance evaluation: subjectivity, bias and judgment style in sport. Group Decis Negot 29:655–678. https://doi.org/10.1007/s10726-020-09672-4
Pareto V (2014) Manual of political economy: a critical and variorum edition. Oxford University Press
Peng JJ, Chen XG (2024) A large-scale group decision-making approach based on hesitancy degrees and non-cooperative behaviors with picture fuzzy information. Appl Soft Comput 154:111360. https://doi.org/10.1016/j.asoc.2024.111360
Qin J, Li M, Liang Y (2022) Minimum cost consensus model for CRP-driven preference optimization analysis in large-scale group decision making using Louvain algorithm. Inf Fus 80:121–136. https://doi.org/10.1016/j.inffus.2021.11.001
Sun X, Zhu J (2023) Large-scale group classification decision making method and its application with trust–interest dual factors in social network. Appl Soft Comput 133:109890. https://doi.org/10.1016/j.asoc.2022.109890
Sun J, Gong Z, Zhang D, Xu Y, Wei G (2023) A robust ordinal regression feedback consensus model with dynamic trust propagation in social network group decision-making. Inf Fus 100:101952. https://doi.org/10.1016/j.inffus.2023.101952
Sun X, Zhu J, Wang J, Pérez-Gálvez IJ, Cabrerizo FJ (2024) Consensus-reaching process in multi-stage large-scale group decision-making based on social network analysis: exploring the implication of herding behavior. Inf Fus 104:102184. https://doi.org/10.1016/j.inffus.2023.102184
Tan J, Wang Y, Chu J (2024) A consensus method in social network large-scale group decision making with interval information. Expert Syst Appl 237:121560. https://doi.org/10.1016/j.eswa.2023.121560
Tian Z-p, Nie R-x, Wang J-q (2019) Social network analysis-based consensus-supporting framework for large-scale group decision-making with incomplete interval type-2 fuzzy information. Inform Sci 502:446–471. https://doi.org/10.1016/j.ins.2019.06.053
Ureña R, Kou G, Dong Y, Chiclana F, Herrera-Viedma E (2019) A review on trust propagation and opinion dynamics in social networks and group decision making frameworks. Inform Sci 478:461–475. https://doi.org/10.1016/j.ins.2018.11.037
Wang L, Wang Y, Martínez L (2017) A group decision method based on prospect theory for emergency situations. Inform Sci 418:119–135. https://doi.org/10.1016/j.ins.2017.07.037
Wang S, Chiclana F, Chang J, Xing Y, Wu J (2024) A minimum cost-maximum consensus jointly driven feedback mechanism under harmonious structure in social network group decision making. Expert Syst Appl 238:122358. https://doi.org/10.1016/j.eswa.2023.122358
Wasserman S, Faust K (1994) Social network analysis: methods and applications. Cambridge University Press, Cambridge. https://doi.org/10.1017/CBO9780511815478
Wu J, Yang N (2019) A model for emergency decision-making that takes into account the psychological behavior of decision makers. Stat Decis 35:53–56
Wu J, Xiong R, Chiclana F (2016) Uninorm trust propagation and aggregation methods for group decision making in social network with four tuple information. Knowl Based Syst 96:29–39. https://doi.org/10.1016/j.knosys.2016.01.004
Wu J, Chiclana F, Fujita H, Herrera-Viedma E (2017) A visual interaction consensus model for social network group decision making with trust propagation. Knowl Based Syst 122:39–50. https://doi.org/10.1016/j.knosys.2017.01.031
Wu J, Wang S, Chiclana F, Herrera-Viedma E (2021) Two-fold personalized feedback mechanism for social network consensus by uninorm interval trust propagation. IEEE Trans Cybern 52:11081–11092. https://doi.org/10.1109/TCYB.2021.3076420
Wu Y, Gao Y, Zhang B, Pedrycz W (2023) Minimum information-loss transformations to support heterogeneous group decision making in a distributed linguistic context. Inf Fus 89:437–451. https://doi.org/10.1016/j.inffus.2022.07.009
Wu X, Liao H, Zhang C (2024) Preference disaggregation analysis for sorting problems in the context of group decision-making with uncertain and inconsistent preferences. Inf Fus 101:102014. https://doi.org/10.1016/j.inffus.2023.102014
Xing Y, Wu J, Chiclana F, Yu G, Cao M, Herrera-Viedma E (2023) A bargaining game based feedback mechanism to support consensus in dynamic social network group decision making. Inf Fus 93:363–382. https://doi.org/10.1016/j.inffus.2023.01.004
Xu X, Xiao T (2023) Consensus model for large group emergency decision-making driven by social network behavior data. Syst Eng Electron 45:2086–2097
Xu X, Du Z, Chen X, Cai C (2019) Confidence consensus-based model for large-scale group decision making: a novel approach to managing non-cooperative behaviors. Inform Sci 477:410–427. https://doi.org/10.1016/j.inffus.2023.101820
Xu X, Hou Y, He J (2021a) Large group decision making method based on incomplete probabilistic linguistic evaluation information considering authoritative expert and LTS application in site selection of hot dry rock exploration. Oper Res Manag Sci 30:7
Xu Y, Gong Z, Forrest JY-L, Herrera-Viedma E (2021b) Trust propagation and trust network evaluation in social networks based on uncertainty theory. Knowl Based Syst 234:107610. https://doi.org/10.1016/j.knosys.2021.107610
Xu X, Liu Y, Chen X (2022) Large group risk emergency decision-making method based on group pressure. J Syst Eng. https://doi.org/10.13383/j.cnki.jse.2022.04.003
Xu X, Gong Z, Herrera-Viedma E, Kou G, Cabrerizo FJ (2023) Consensus reaching in group decision making with linear uncertain preferences and asymmetric costs. IEEE Trans Syst Man Cybern Syst 53:2887–2899. https://doi.org/10.1109/TSMC.2022.3220837
Yang G, Wang X, Ding R, Lin S, Lou Q, Herrera-Viedma E (2023a) Managing non-cooperative behaviors in large-scale group decision making based on trust relationships and confidence levels of decision makers. Inf Fus 97:101820. https://doi.org/10.1016/j.inffus.2023.101820
Yu S, Du Z, Zhang X, Luo H, Lin X (2021) Trust Cop-Kmeans clustering analysis and minimum-cost consensus model considering voluntary trust loss in social network large-scale decision-making. IEEE Trans Fuzzy Syst 30:2634–2648. https://doi.org/10.1109/TFUZZ.2021.3089745
Zha Q, He X, Zhan M, Lang N (2023) Managing consensus in balanced networks based on opinion and trust/distrust evolutions. Inform Sci 643:119223. https://doi.org/10.1016/j.ins.2023.119223
Zhang Z, Li Z (2021) Personalized individual semantics-based consistency control and consensus reaching in linguistic group decision making. IEEE Trans Syst Man Cybern Syst 52:5623–5635. https://doi.org/10.1109/TSMC.2021.3129510
Zhang H, Palomares I, Dong Y, Wang W (2018) Managing non-cooperative behaviors in consensus-based multiple attribute group decision making: an approach based on social network analysis. Knowl Based Syst 162:29–45. https://doi.org/10.1016/j.eswa.2023.122571
Zhao S, Lei T, Liang C, Na J, Liu Y (2022) A consensus-reaching method for large-scale group decision-making based on integrated trust–opinion similarity relationships. Comput Ind Eng 173:108667. https://doi.org/10.1016/j.cie.2022.108667
Zhao M-K, Guo J, Wu J, Xu Z-S (2023) A global optimization feedback model with PSO for large scale group decision making in hesitant fuzzy linguistic environments. Expert Syst Appl 228:120320. https://doi.org/10.1016/j.eswa.2023.120320
Zhong X, Xu X, Pan B (2022) A non-threshold consensus model based on the minimum cost and maximum consensus-increasing for multi-attribute large group decision-making. Inf Fus 77:90–106. https://doi.org/10.1016/j.inffus.2021.07.006
Zhou X, Li S, Wei C (2024) Consensus reaching process for group decision-making based on trust network and ordinal consensus measure. Inf Fus 101:101969. https://doi.org/10.1016/j.inffus.2023.101969
Zou W, Wan S, Dong J (2024) Trust evolution based minimum adjustment consensus framework with dynamic limited compromise behavior for probabilistic linguistic large scale group decision-making. Inform Sci 652:119724. https://doi.org/10.1016/j.ins.2023.119724
Acknowledgements
All authors appreciate the National Social Science Foundation of China (Grant no. 23BJY191).
Funding
National Social Science Fund of China, 23BJY191, Hong Huo.
Author information
Authors and Affiliations
Contributions
Hong Huo: Conceptualization, Funding acquisition, Supervision. Ruinan Sun: Writing-Original draft preparation, Software MATLAB. Hao He: Methodology, Visualization, Investigation. Zongwei Ren: Writing-Reviewing and Editing.
Corresponding author
Ethics declarations
Conflict of interest
All authors disclosed no relevant relationships.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Huo, H., Sun, R., He, H. et al. A Large-Scale Group Decision-Making Model Considering Expert Authority Degree and Relationship Evolution Under Social Network. Group Decis Negot 33, 839–881 (2024). https://doi.org/10.1007/s10726-024-09892-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10726-024-09892-y