
Abstract
Water resources planning, development, and management need reliable forecasts of river flows. In past few decades, an important dimension has been introduced in the prediction of the hydrologic phenomenon through artificial intelligence-based modeling. In this paper, the performance of three artificial neural network (ANN) and four support vector regression (SVR) models was investigated to predict streamflows in the Upper Indus River. Results from ANN models using three different optimization techniques, namely Broyden-Fletcher-Goldfarb-Shannon, Conjugate Gradient, and Back Propagation algorithms, were compared with one another. A further comparison was made between these ANNs and four types of SVR models which were based on linear, polynomial, radial basis function, and sigmoid kernels. Past 30 years’ monthly data for precipitation, temperature, and streamflow obtained from Pakistan Surface Water Hydrology Department Lahore were used for this purpose. Three types of input combinations with respect to the main input variables (temperature, precipitation, and stream flow) and several types of input combinations with respect to time lag were tested. The best input for ANN and SVR models was identified using correlation coefficient analysis and genetic algorithm. The performance of the ANN and SVR models was evaluated by mean bias error, Nash–Sutcliffe efficiency, root mean square error, and correlation coefficient. The efficiency of the Broyden-Fletcher-Goldfarb-Shannon-ANN model was found to be much better than that of other models, while the SVR model based on radial basis function kernel predicted stream flows with comparatively higher accuracy than the other kernels. Finally, long-term predictions of streamflow have been made by the best ANN model. It was found that stream flow of Upper Indus River has a decreasing trend.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The environmental changes have an impact on water resources that are likely to affect the irrigation system, hydropower, and several other aspects of life in many developed and developing countries (Aalinejad et al. 2016; Kawase et al. 2016; Zhao et al. 2016). These changes are putting stress on management of available water resources to increase the agricultural productivity, boost the economy, and ensure food security (Molden et al. 2016; Sofaer et al. 2016). Proper management of water resources is highly dependent on accurate streamflow prediction, which is a challenging process because of its nonlinear and multidimensional dynamics (Oyerinde et al. 2016; Woldemeskel et al. 2016; Veraart et al. 2017; Ghumman et al. 2017; Rauf and Ghumman 2018). Various modeling techniques have been used for stream flow prediction, e.g., distributed physically based models, lumped conceptual models, stochastic models, and black box models. Although the physically based models use the physical processes involved in the rainfall-runoff modeling, their successful use is limited mainly because of some difficulties in measuring parameters involved and complexity of the governing equations (Yousuf et al. 2017). There are problems in the use of time-series stochastic models due to non-stationary behavior and nonlinearity in the data distributions. Therefore, artificial neural network (ANN), support vector regression (SVR), and adaptive neuro fuzzy inference system (ANFIS) models are gaining importance in the prediction of the hydrologic phenomenon and stream flow forecasting (Kyada and Kumar 2015; Alfarisy and Mahmudy 2016; Kovačević et al. 2018). ANNs are flexible models with respect to the combination of input variables. These models can efficiently treat the nonlinearity of the system and are equally effective in accurate rainfall and streamflow simulations (Goyal et al. 2014; Wang et al. 2017a, b; Adnan et al. 2017a, b; AlOtabi et al. 2018). Shamim et al. 2016, Rauf et al. 2016, and Rauf and Ghumman 2018 have used ANN models to simulate monthly stream flow for high altitude catchments in Pakistan. Flood events have also been predicted using SVR models (Kisi 2015; Ghorbani et al. 2016). However, data-driven models have several types based on the techniques used for input selection, training process, and optimization of various parameters/weights.
Selection of an appropriate type of data-driven models for a given situation is a challenging task (Ali et al. 2017; Zaini et al. 2018; Mishra et al. 2018; Londhe and Gavraskar 2018). This paper has compared the performance of a few of such techniques out of ANN and SVR to facilitate the engineers and scientists in choosing a comparatively accurate streamflow prediction model. Data-driven models are normally trained for a specific data and may have applications limited to a specific site. Hence, there is still a space to work with such models and explore various aspects related to these models. The impact of using various record lengths and data sets need to be studied further, which may definitely be useful for engineers and researchers working in this field of specialization. This is the first time these techniques have been used for streamflow forecasting from the Upper Indus River Basin (UIRB). To predict the monthly stream flow, the measured monthly precipitation (P), temperature (T), and stream flow (Q) with various time (t in months) lags (Pt, Pt-1, Pt-2, Pt-3, Pt-4, Pt-5, Tt, Tt-1, Tt-2, Tt-3, Tt-4, Tt-5, and Qt-1, Qt-2, Qt-3, Qt-4, Qt-5.) were taken as input variable for streamflow (Qt + 1) as output variable. An important step of this modeling was to identify the best input combination. The model has high complexity when there are a large number of inputs (Bray and Han 2004). Hence, an efficient technique is required to choose the best combination of inputs.
In the present paper, the ability of correlation coefficient analysis (CCA) and genetic algorithm (GA) has been investigated to select the best input combination for ANN and SVR models.
In addition to correlation between input and output with respect to time lag, there may be as well a variety of input combination with respect to the main input variables (temperature, precipitation, evaporation, river stage, streamflow, etc.). Some of the past studies in this regards include the research of Dhamge et al. (2012), Jajarmizadeh et al. (2015), Imen et al. (2015), Rauf et al. (2016), Wang et al. (2017a, b), and Adnan et al. (2017a, b). The literature provided by these studies shows that development of input combination with respect to time on the basis of three variables precipitation, temperature, and streamflow has rarely been reported. Researchers commonly used the precipitation and streamflow together and few used streamflow as a single input parameter. Dhamge et al. (2012) for example has used rainfall and runoff depth as input variable. Jajarmizadeh et al. (2015) has used precipitation, temperature, and streamflow as input variables. Aichouri et al. (2015), Rauf et al. (2016), and Wang et al. (2017a, b) have used precipitation and streamflow as input variable. Seyam et al. (2017) has used precipitation and water level as input variable. Tayyab et al. (2016), Mehr and Kahya (2017), Yaseen et al. (2017), and Adnan et al. (2017a, b) have used single variable streamflow as input.
In the present paper, a comparison has been made for the results of stream flow simulation from three input types with respect to the main input variables: (a) temperature, precipitation, and stream flow; (b) temperature and precipitation; and (c) stream flow only. The past data regarding monthly temperature, precipitation, and stream flow for UIRB were used. The total length of data collected is 30 years, i.e., from 1984 to 2014.
Study Area
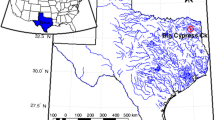
The Indus River Basin comprises a total area of about 970,000 km2. However, the area selected for this study covers only Upper Indus Basin (UIB). It contains the catchment contributing to the upper part of the River Indus up to the Tarbela Reservoir, covering a basin area of about 175, 000 km2. UIB is surrounded by the world mightiest three mountain ranges that are the Karakoram, the Himalayan, and the Hindukush. This is expanded over the north-eastern and north-western part of Pakistan. The climate of the UIB is based on interaction between monsoon and westerlies (Lutz et al. 2016). UIB is a region undergoing a slightly increasing trend of snow cover in the southern (Western Himalayas) and northern (Central Karakoram) parts. Stream flow from the UIB is a combination of snow and glacier melt. The stream flow from rainfall is contributed from southern part, but snow and glacier melt are dominant in the northern part of the catchment (Tahir et al. 2015). The snow-fed sub-catchment of the Astore (sub-basin of UIB) was selected for the stream flow analysis. Astore catchment is located in the region of Gilgit-Baltistan and is about 120 km long having area of 5092 km2. The Astore basin was selected because it has an important geographical location (southern foothills of the Western Himalayas. The Indus River has some tributaries originating from these mountains The Astore River is one of the major tributaries of UIB region and any change in its flow into river Indus will have a considerable impact on the outflow of River Indus at Tarbela Reservoir. Figure 1 shows the location of Tarbela Dam at Indus River in Pakistan. The Astore River contributes an average annual flow of 228.8 m3/s to river Indus at Doyian. The Astore River stream flow is influenced by the winter rainfall at lower elevations which combines with the winter snowfall forced by Westerlies (Tahir et al. 2015). The data for this study were collected from the Astore hydro-climatic station, located at 35° 22′ N, 74° 51′ E with an elevation of 2394 m with respect to mean sea level and the Doyain river gauging station at 35° 45′ N, 74° 30′ E with an elevation of 1460.

Upper Indus Basin (UIB) and Astore catchment
Methodology
The overall methodology is given in Fig. 2. Data regarding temperature, precipitation, and stream flow of upper Indus River was collected from 1984 to 2014. Three types of ANN models based on Broyden-Fletcher-Goldfarb-Shannon (BFGS), conjugate gradient (CG), and back propagation (BP) algorithms were used to simulate stream flow.

Step-wise methodology
Artificial Neural Networks
ANN models are used to execute problems having high complexities. Many investigations have proven that ANN is a proficient technique for modeling nonlinear relationships between inputs and desired outputs in hydrologic time-series analyses (Humphrey et al. 2016; Aziz et al. 2017; Yazdani and Zolfaghari 2017). A general architecture and flow chart of ANN is shown in Fig. 3a, b. ANN consists of several “layers” of neurons, input layer having nodes representing various input variables, the hidden layer with many hidden nodes, and an output layer (Fig. 3a). Application of ANN to stream flow simulation requires selection of best variables, functions and weights, and optimization techniques, which could generate stream flow. Optimization techniques require an objective function based on errors between the simulated and measured stream flows. The values of parameters of model are changed every time in optimization process to find a solution such that the objective function achieves the minimum possible value (usually called global minimum). There are several techniques to change the parameters of model in every iteration and search the minimum value of objective function. Derivatives of objective function and constraints are used in some optimization techniques whereas others do not require derivatives and constraints. In stream flow prediction models, the algorithms that are faster in execution and robust in nature can be used for standard numerical optimization, e.g., conjugate gradient (CG), Quasi-Newton (QN), and Levenberg–Marquardt (Beale 1972; Fletcher 1987). The QN method has shown successful performance in several studies (Martınez 2000; Byrd et al. 2016; Leong et al. 2011). The method was developed by Broyden, Fletcher, Goldfarb, and Shanno (BFGS). The BFGS algorithm needs more computing in each repetition and also requires larger storage than CG method. It is an effective training function for smaller networks. Another method called the back propagation (BP) algorithm is common to train ANN. It is considered one of the simplest and most commonly used methods for optimization in ANN (Ganin et al. 2016; Wang et al. 2017a, b; Pellakuri and Rao 2016). In this study, the results of stream flow prediction for UIB by all the three training algorithms, i.e., the BFGS, CG, and BP have been compared.

a ANN architecture and flow chart. (b) Methodology for predicting the best output using the best input combination for ANN
An efficient technique is required to select the best combination of input with respect to time lag. CCA and GA (Rauf and Ghumman 2018; Ganin et al. 2016; Wang et al. 2017a, b; Pellakuri and Rao 2016) were used to select the best input combination. The input data of the model were taken as the observed monthly rainfall, temperature, and stream flow for UIB. Four possible combinations C1, C2, C3, and C4 were selected by CCA and one by GA regarding time lag of input variables with respect to the corresponding output value of stream flow. The measured stream flow data for the same river were used as the target in the ANN model calibration and validation. Data from1985–2004 was used for the calibration/ training and learning of ANN and 2005 to 2014 for validation.
Support Vector Regression
SVR is an artificial intelligent-based supervised learning model. It is a two-layered network. The weights are nonlinear in the first layer and linear in the second (Bray and Han 2004). SVR can be applied to regression problems (Smola 1996; Kecman 2001). A general structure and flow chart of SVR model is shown in Fig. 4a, b. The basic mathematical function used in SVR is given by Eq. (1) (Lafdani et al. 2013)

a Structure of SVR model. b The methodology of selecting the best output from the best input combination for SVR modeling
In Eq. (1), K is the kernel function, N is the number of training data points, xi represents vectors used in the training process, x is an independent vector, and αi and b are the parameters derived by the objective function maximization. There are four types of commonly used kernels, namely linear kernel, polynomial kernel, RBF kernel, and sigmoid kernel. Additional details may be seen from (Schölkopf and Smola 2002).
Several codes for SVR are available. The one used in this study is known as LIBSVM (Chang and Lin 2011), supported by the National Science Council of Taiwan. The modeling of SVR was done using MATLAB R2013a.
Genetic Algorithm
GA follows genetic principals by creating various combinations of inputs. The best one with respect to reducing the error in output and complexity of ANN and SVR models is obtained. GA can perform a global search. It consists of an iterative process for a constant-size population of individuals (inputs and weights). The GA is capable of effectively exploring large search spaces, which can be used with ANN for determining the number of hidden nodes and hidden layers, select relevant feature subsets and the learning rate. It initializes and optimizes the network connection weights of ANN. Further details can be seen from (Arena et al. 1992; Blanco et al. 2000). The Win Gamma Software was used in this study to run GA. From the available options in the Winn Gamma Software, GA was used for the identification of better input combination. The default values given in the software for various variables were considered for this study. The GA simulations developed 100 possible input combinations of which 10 best combinations were selected on the basis of least gamma (Ʈ) and standard error (SE) values. One best combination was selected out of these combinations for analysis with lowest Gamma value.
Gamma value (Ʈ)
The gamma Ʈ is the estimate of that part of the variance of the output which cannot be accounted for by a smooth data model. The gamma is actually the vertical intercept of the regression line (Evans and Jones 2002).
Standard Error
This is the usual goodness of fit applied to the regression line. If this number is close to zero, one has more confidence in the value of the gamma as an estimate of the noise variance on the given output. The standard error (SE) is defined as (Krause et al. 2005; Lafdani et al. 2013).
where σ is the standard deviation of the population and n is the size (number of observations) of the sample.
The comparatively lower values of Ʈ and SE indicate that the given combination will produce lower complexity in modeling with better predicted results of stream flow.
Correlation Coefficient Analysis
A correlation coefficient is a number that quantifies the statistical relationships between two or more variables. Here, this relationship has been determined between the 17 input parameters (PPT, temp, and streamflow) and one output streamflow. The correlation coefficient analysis was performed using statistical tool available in MS Excel for the purpose. The correlated values classified as most effective correlation values (> 50% correlation) and least effective correlation values (< 50% correlation). Positive correlation indicates that for any two variables say Pt-1 and Qt + 1, both the variables increase and decrease together, whereas a negative correlation coefficient means that, an increase in Pt-1 is associated with a decrease in Qt + 1. Correlation coefficients have values always between − 1 and 1. The value − 1 shows a perfect, linear negative correlation, and 1 shows a perfect, linear positive correlation. The most effective parameters were found to be Pt-3, Tt, Tt-1, Tt-5, and Qt-1 while Pt-2, Pt-4, Pt-5, Tt-4, Qt-2, and Qt-4 comes out as the least effective parameters. The input parameters having most effective correlation with the output were considered for the development of the input combinations. Four different input combinations were developed on this criterion. Similarly, the input combinations were developed for other two input types having two variables as precipitation and temperature and single variable streamflow only.
Model Performance Evaluation
There are a number of statistical parameters to measure the performance of the models (Burnham 2002). The most widely used parameters were adopted in this study (Krause et al. 2005; Lafdani et al. 2013; Shamim et al. 2016; Rauf et al. 2016).
-
1.
Root mean square errors (RSME)
$$ \mathrm{RMSE}=\sqrt{\sum_{i=1}^n\frac{{\left({Q}_i^p-{Q}_i^o\right)}^2}{n}} $$(3) -
2.
Mean bias error (MBE)
$$ \mathrm{MBE}={\sum}_{i=1}^n\frac{\left({Q}_i^p-{Q}_i^o\right)}{n} $$(4) -
3.
The correlation between actual and predicted values (R2):
$$ {R}^2=1-\frac{\left({Q}_i^o-{Q}_i^p\right)}{\left({Q}_i^o-{Q}_{avg}\right)} $$(5) -
4.
Nash–Sutcliffe model efficiency coefficient (NSE)
$$ \mathrm{NSE}=1-\frac{\sum_{\mathrm{i}=1}^{\mathrm{n}}{\left({Q}_i^o-{Q}_i^p\right)}^2}{\sum_{\mathrm{i}=1}^{\mathrm{n}}{\left({Q}_i^o-{Q}_{avg}\right)}^2} $$(6)
In the above equations, \( {Q}_i^p \) represents the predicted value of streamflow, \( {Q}_{\mathrm{i}}^{\mathrm{o}} \) represents the observed values of stream flow, Qavg is the average of observed stream flow, and n represents the total number of input samples.
Results and discussion
Input Combinations
Various input combinations assessed by GA for the input type having all three parameters are shown in Table 1. Figure 5 illustrates Ʈ and SE variations. It is observed that the 10101110100110100 (nine inputs as Pt, Pt-2, Pt-4, Pt-5, Tt, Tt-2, Tt-5, Qt-1, Qt-3 for single output Qt + 1) was the best combination of given input variables and was selected for analysis on basis of least gamma and SE value. It shows that precipitation and temperature within a time lag of running month (t) and five previous months(t−5) have an impact on stream flow Qt + 1, whereas only two previous values of stream flow (Qt-1, Qt-3) are linked to Qt + 1. According to Slater and Villarini (2017), the variability of precipitation is key parameter for high stream flows. The temperature is driving factor for streamflow predictions in seasons and catchment areas having notable snowmelt. The stream flow of UIB contains glacier melt components, flow from rain, and a groundwater component. So the selected input combination is logical and understandable. The correlation values among various input variables and output in case of CCA are shown in Fig. 6. Here, the negative (−ve) values of correlation show that such an input values will give decreasing values of output Q. Hence, the input variables, Pt-3, Tt, Tt-1, Tt-5, and Qt-1, correlate highly to the output parameter (Qt + 1). Considering the most correlating input parameters predicted by CCA, four input combinations (given in Table 2) were used in ANN and SVR modeling. It is worth mentioning that some percentage of subjectivity is involved in selecting the input combinations on the basis of CCA.

Gamma and SE of the data corresponding to input combinations

Correlation between different input variables and streamflow (Qt + 1)
Results of Stream Flows Modeling
ANN models
The R2, RMSE, NSE, and MBE for various-ANN models from different input combinations for all the three parameters (P, T, and Q) developed by GA and CCA are given in Figs. 7, 8, and 9 and Table 3. Comparison of observed and predicted stream flow for the testing phase of various ANN models is represented by Figs. 10 and 11. Italic values in Table 3 represent the best values of indices. It is observed that hardly any model has best values of all the four indices. One model has the best R2 value whereas the other has lowest RMSE. One has the highest NSE and other has the best value of MBE. For example, BFGS-ANN model based on input combination of CCA-C3 has highest R2 (Fig. 7) whereas the same model based on GA has the lowest value of RMSE. A similar situation can be seen from other figures. Hence, selection/rejection of the best possible model should not be based on a single evaluating index. However, the indices in these figures show that all input combinations produced acceptable accuracy which demonstrates the high-efficiency selecting algorithms CCA and GA and the ANN models. However, the input combination determined through CCA can be marked as comparatively better than that of GA because its performance both in training and testing phase is better. The best ANN model with respect to overall performance is the BFGS algorithm. The accuracy depends upon the choice of input and the optimization method used in ANN. As the efficiency of optimization method increases, it brings higher accuracy in the simulated stream flow. It is proven that the combination of CCA/GA and efficient optimization technique BFGS improves the performance of ANN model significant. Similarly, the ANN models were developed using input combinations for two variables (P and T) and single variable. The results are given in Tables 4 and 5.

Errors and correlation coefficient (BFGS-ANN model)

Errors and correlation coefficient (CG-ANN model)

Errors and correlation coefficient (BP-ANN model)

Scatter plot of observed and predicted stream flow by best ANN models for testing data sets

Comparison of the observed Vs predicted stream flow by ANN models using GA and CCA
SVR Models
Results obtained by using four selected kernels in SVR model based on the input combination selected by GA are compared to that of CCA in Figs. 12, 13, 14, and 15. The best combinations determined for the different selected SVR kernel models are given in Table 6. The SVR with RBF kernel shows the best results with minimum RMSE = 1.0 and maximum R2 = 0.811 in case of combination of nine inputs for single output. The performance of the SVR-RBF kernel with input combination C2 from CCA was good in the training phase, while in the testing phase, the input combination C4 showed the best results with the lowest RMSE. The curves of predicted stream flows (Qt + 1) versus observed stream flows from Epsilon-SVR models for the testing phase are shown in Figs. 16 and 17. Similarly, the SVR models were developed using input combinations for two variables (P and T) and single variable (only Q). The results are given in Tables 7 and 8.

Errors and correlation coefficient (SVR–linear kernel model)

Errors and correlation coefficient (SVR–polynomial kernel model)

Errors and correlation coefficient (Epsilon–SVR–RBF kernel model)

Errors and correlation coefficient (SVR—Sigmoid kernel model)

Scatter plot of observed and predicted discharge by Epsilon-SVR models

Comparison of the observed and predicted stream flow by SVR models using GA and CCA
Comparison of SVR and ANN Models
The performance of the SVR and ANN models is compared in Table 9 and Figs. 18 and 19. The performance of BFGS-based ANN model is better than SVR (RBF kernel) model. The R2 is 0.846, 0.811 and RMSE is 0.616 and 1.0 respectively for the two models. Furthermore, BFGS-ANN and SVR (RBF kernel) models have the best NSE values, 0.846 and 0.800 respectively.

Comparison between SVR and ANN models for prediction of future discharge

ANN and SVR models with the best input (simulated and observed stream flow)
Future Stream Flow Predictions
Figures 20 and 21 show the future precipitation and stream flow predicted by the ANN model. It is evident from the figures that the precipitation and stream flow are almost of the same pattern, indicating that the stream flow is depending on the precipitation in the region and any change in precipitation due to climatic variability will have an effect on stream flow of river Indus The figures show that precipitation is decreasing from 2015 to 2045, while in the same period, the stream flow is being increased. This might be due to high snowmelt caused by the rising temperature during the said period. In the mid-twenty-first century, the precipitation is seen to be increasing, which is causing an increase in the stream flow during the period. The figures show the alarming picture at the end of the century that both precipitation and stream flow are decreasing till the start of the twenty-second century.

Future precipitation predicted by the ANN model

Future stream flows predicted by the ANN method
Summary, Conclusion, and Recommendations
In this study, two types of data-driven techniques, ANN and SVR were applied to develop models for predicting stream flow in the UIB. The GA and CCA were used to predict the best input combination for stream flow forecasting. The performance of three different ANN and four SVR models was compared using four statistical parameters (R2, RMSE, MBE, and NSE). Determination of the best input combination for nonlinear systems like streamflow is a complex and challenging process. Hence, the aim of this study was to determine the most effective combination of input variables to be used for data-driven modeling, like ANN and SVR, for short-term streamflow forecasting.
The SVR-RBF kernel with input combination identified by CCA had better performance than the other three SVR models (linear, polynomial, and Sigmoid kernel) both in the training and testing phase. The results also showed that BPNN models had better performance than BFGS-ANN and CG-ANN that of in the training phase while in the testing phase, BFGS-ANN and CG-ANN models showed the better results than BPNN models for input combination identified by CCA. In brief, the BFGS-ANN model and SVR model (RBF kernel) produced the best performance in streamflow forecasting. The performance of input combination identified by the CCA is better than that of GA. The input combination, “Pt-3, Tt, Tt-1 Tt-2, Tt-5, Qt-1, Qt-5,” showed the best results for BFGS-ANN model.
The input combinations developed for three variables (P, T, and Q) show comparatively better results than that from the input combinations developed using two variables (P and T) and single variable (Q only).
To improve the study further, we recommend that the results obtained from GA test be compared against other input selection methods, e.g., principal component analysis and fuzzy system, to predict streamflow through ANN and SVR models with higher reliability. The results obtained in this study are for the monthly data inputs and can be improved if daily data are used for the purpose.
References
Aalinejad, M. H., Dinpashoh, Y., & Jahanbakhsh, A. S. L. (2016). Impact of climate change on runoff from snowmelt by taking into account the uncertainty of GCM models (case study: Shahrchay Basin in Urmia). European Online Journal of Natural and Social Sciences, 5(1), 200.
Adnan, R. M., Yuan, X., Kisi, O., & Anam, R. (2017a). Improving accuracy of river flow forecasting using LSSVR with gravitational search algorithm. Advances in Meteorology, 3, 1–23.
Adnan, R. M., Yuan, X., Kisi, O., & Yuan, Y. (2017b). Streamflow forecasting using artificial neural network and support vector machine models. American Scientific Research Journal for Engineering, Technology, and Sciences (ASRJETS), 29(1), 286–294.
Aichouri, I., Hani, A., Bougherira, N., Djabri, L., Chaffai, H., & Lallahem, S. (2015). River flow model using artificial neural networks. Energy Procedia, 74, 1007–1014.
Alfarisy, G. A. F., & Mahmudy, W. F. (2016). Rainfall forecasting in Banyuwangi using adaptive neuro fuzzy inference system. Journal of Information Technology and Computer Science, 1, 65–71.
Ali, Z., Hussain, I., Faisal, M., Nazir, M. H., Hussain, T., Shad, M. Y., Shoukry, M. A., & Gani, S. H. (2017). Forecasting drought using multilayer perceptron artificial neural network model. Advances in Meteorology, 2017, 1–9. https://doi.org/10.1155/2017/5681308.
AlOtabi, K., Ghumman, A. R., Haider, H., Ghazaw, Y., & Shafiquzzan, M. D. (2018). Future predictions of rainfall and temperature using GCM and ANN for arid regions: a case study for the Qassim region. Saudi Arabia, Water, 10, 1–25.
Arena, P., Caponetto, R., Fortuna, L., & Xibilia, M. G. (1992). Genetic algorithms to select optimal neural network topology. In Circuits and Systems, 1992, Proceedings of the 35th Midwest Symposium on (pp. 1381–1383). IEEE.
Aziz, K., Haque, M. M., Rahman, A., Shamseldin, A. Y., & Shoaib, M. (2017). Flood estimation in ungauged catchments: application of artificial intelligence based methods for Eastern Australia. Stochastic Environmental Research and Risk Assessment, 31(6), 1499–1514.
Beale E. M. L. (1972). A derivation of conjugate gradients. In: F. A. Lootsma (Ed.), Numerical methods for non-linear optimization pp. 39–43. London: Academic Press.
Blanco, A., Delgado, M., & Pegalajar, M. C. (2000). A genetic algorithm to obtain the optimal recurrent neural network. International Journal of Approximate Reasoning, 23(1), 67–83.
Bray, M., & Han, D. (2004). Identification of support vector machines for runoff modelling. Journal of Hydroinformatics, 6(4), 265–280.
Burnham, K. P. (2002). Information and likelihood theory: a basis for model selection and inference. In Model selection and multi model inference: a practical information-theoretic approach (2nd ed., pp. 49–97). New York Berlin Heidelberg Barcelona Hong Kong London Milan Paris Singapore Tokyo: Springer.
Byrd, R. H., Hansen, S. L., Nocedal, J., & Singer, Y. (2016). A stochastic quasi-Newton method for large-scale optimization. SIAM Journal on Optimization, 26(2), 1008–1031.
Chang, C. C., & Lin, C. J. (2011). LIBSVM: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST), 2(3), 27.
Dhamge, N. R., Atmapoojya, S. L., & Kadu, M. S. (2012). Genetic algorithm driven ANN model for runoff estimation. Procedia Technology, 6, 501–508.
Evans, D., & Jones, A. J. (2002). A proof of the Gamma test. Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, 458(2027), 2759–2799 The Royal Society.
Fletcher R. (1987). Practical methods of optimization, 2nd ed. New York: Wiley.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., & Lempitsky, V. (2016). Domain-adversarial training of neural networks. Journal of Machine Learning Research, 17(1), 2096–2030.
Ghorbani, M. A., Zadeh, H. A., Isazadeh, M., & Terzi, O. (2016). A comparative study of artificial neural network (MLP, RBF) and support vector machine models for river flow prediction. Environmental Earth Sciences, 75(6), 476.
Ghumman, A. R., Al-Salamah, I. S., AlSaleem, S. S., & Haider, H. (2017). Evaluating the impact of lower resolutions of digital elevation model on rainfall-runoff modeling for ungauged catchments. Environmental Monitoring and Assessment, 189(2), 54.
Goyal, M. K., Bharti, B., Quilty, J., Adamowski, J., & Pandey, A. (2014). Modelling of daily pan evaporation in sub- tropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS. Expert Systems with Applications, 41(11), 5267–5276.
Humphrey, G. B., Gibbs, M. S., Dandy, G. C., & Maier, H. R. (2016). A hybrid approach to monthly streamflow forecasting: integrating hydrological model outputs into a Bayesian artificial neural network. Journal of Hydrology, 540, 623–640.
Imen, A., Azzedine, H., Nabil, B., Larbi, D., Hicham C., & Sami, L. (2015). River flow model using artificial neural networks. Energy Procedia, 74, 1007–1014.
Jajarmizadeh, M., Lafdani, E. K., Harun, S., & Ahmadi, A. (2015). Application of SVM and SWAT models for monthly streamflow prediction, a case study in South of Iran. KSCE Journal of Civil Engineering, 19(1), 345–357.
Kawase, H., Murata, A., Mizuta, R., Sasaki, H., Nosaka, M., Ishii, M., & Takayabu, I. (2016). Enhancement of heavy daily snowfall in central Japan due to global warming as projected by large ensemble of regional climate simulations. Climatic Change, 139(2), 265–278.
Kecman, V. (2001). Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models (1st ed.). Cambridge, Massachusetts London, England: MIT Press ISBN: 9780262112550.
Kisi, O. (2015). Streamflow forecasting and estimation using least square support vector regression and adaptive neuro-fuzzy embedded fuzzy c-means clustering. Water Resources Management, 29(14), 5109–5127.
Kovačević, M., Ivanišević, N., Dašić, T., & Marković, L. (2018). Application of artificial neural networks for hydrological modelling in karst. Građevinar, 70(1), 1–10. https://doi.org/10.14256/JCE.1594.2016.
Krause, P., Boyle, D. P., & Bäse, F. (2005). Comparison of different efficiency criteria for hydrological model assessment. Advances in Geosciences, 5, 89–97.
Kyada, P. M., & Kumar, P. (2015). Daily rainfall forecasting using adaptive neurofuzzy inference system (ANFIS) models. International Journal of Science and Nature, 6, 382–388.
Lafdani, E. K., Nia, A. M., & Ahmadi, A. (2013). Daily suspended sediment load prediction using artificial neural networks and support vector machines. Journal of Hydrology, 478, 50–62.
Leong, W. J., Hassan, M. A., & Yusuf, M. W. (2011). A matrix-free quasi-Newton method for solving large-scale nonlinear systems. Computers & Mathematics with Applications, 62(5), 2354–2363.
Londhe, S. N., & Gavraskar, S. (2018). Stream flow forecasting using least square support vector regression. Journal of Soft Computing in Civil Engineering, 2, 56–88.
Lutz, A. F., Immerzeel, W. W., Kraaijenbrink, P. D. A., Shrestha, A. B., & Bierkens, M. F. (2016). Climate change impacts on the upper Indus hydrology: sources, shifts and extremes. PLoS One, 11(11), e0165630.
Martınez, J. M. (2000). Practical quasi-Newton methods for solving nonlinear systems. Journal of Computational and Applied Mathematics, 124(1–2), 97–121.
Mehr, A. D., & Kahya, E. (2017). A Pareto-optimal moving average multigene genetic programming model for daily streamflow prediction. Journal of Hydrology, 549, 603–615.
Mishra, N., Soni, H. K., Sharma, S., & Upadhyay, A. K. (2018). Development and analysis of artificial neural network models for rainfall prediction by using time-series data. International Journal of Intelligent Systems and Applications, 10(1), 16–23. https://doi.org/10.5815/ijisa.2018.01.03.
Molden, D. J., Shrestha, A. B., Nepal, S., & Immerzeel, W. W. (2016). Downstream implications of climate change in the Himalayas. In Water security, climate change and sustainable development (pp. 65–82). Singapore: Springer.
Oyerinde, G. T., Wisser, D., Hountondji, F. C., Odofin, A. J., Lawin, A. E., Afouda, A., & Diekkrüger, B. (2016). Quantifying uncertainties in modeling climate change impacts on hydropower production. Climate, 4(3), 34.
Pellakuri, V., & Rao, D. R. (2016). Training and development of artificial neural network models: single layer feedforward and multi-layer feedforward neural network. Journal of Theoretical and Applied Information Technology, 84(2), 150.
Rauf, A., & Ghumman, A. R. (2018). Impact assessment of rainfall-runoff simulations on the flow duration curve of the Upper Indus River—a comparison of data-driven and hydrologic models. Water, 10, 876. https://doi.org/10.3390/w10070876.
Rauf, A., et al. (2016). Data-driven modelling for real-time flood forecasting. 2nd International Multi-Disciplinary Conference, Gujrat, Pakistan, December 19–20, Vol. 2, no 90.
Schölkopf, B., & Smola, A. J. (2002). Learning with kernels: support vector machines, regularization, optimization, and beyond (1st ed.). Cambridge, Massachusetts London, England: MIT press ISBN: 9780262194754.
Seyam, M., Othman, F., & El-Shafie, A. (2017). Prediction of stream flow in humid tropical rivers by support vector machines. In MATEC Web of Conferences (vol. 111, p. 01007). EDP Sciences.
Shamim, M. A., Hassan, M., Ahmad, S., & Zeeshan, M. (2016). A comparison of artificial neural networks (ANN) and local linear regression (LLR) techniques for predicting monthly reservoir levels. KSCE Journal of Civil Engineering, 20(2), 971–977.
Slater, L. J., & Villarini, G. (2017). Evaluating the drivers of seasonal stream flow in the U.S. Midwest. Water, 9, 695. https://doi.org/10.3390/w9090695.
Smola, A. J. (1996). Regression estimation with support vector learning machines. Doctoral dissertation, Master’s thesis, Technische Universität München.
Sofaer, H. R., Skagen, S. K., Barsugli, J. J., Rashford, B. S., Reese, G. C., Hoeting, J. A., … & Noon, B. R. (2016). Projected wetland densities under climate change: habitat loss but little geographic shift in conservation strategy. Ecological Applications, 26(6), 1677–1692.
Tahir, A. A., Chevallier, P., Arnaud, Y., Ashraf, M., & Bhatti, M. T. (2015). Snow cover trend and hydrological characteristics of the Astore River basin (Western Himalayas) and its comparison to the Hunza basin (Karakoram region). Science of the Total Environment, 505, 748–761.
Tayyab, M., Zhou, J., Zeng, X., & Adnan, R. (2016). Discharge forecasting by applying artificial neural networks at The Jinsha River Basin, China. European Scientific Journal, ESJ, 12(9).
Veraart, J. A., van Duinen, R., & Vreke, J. (2017). Evaluation of socio-economic factors that determine adoption of climate compatible freshwater supply measures at farm level: a case study in the southwest Netherlands. Water Resources Management, 31(2), 587–608.
Wang, D., Luo, H., Grunder, O., Lin, Y., & Guo, H. (2017a). Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Applied Energy, 190, 390–407.
Wang, J., Shi, P., Jiang, P., Hu, J., Qu, S., Chen, X., … & Xiao, Z. (2017b). Application of BP neural network algorithm in traditional hydrological model for flood forecasting. Water, 9(1), 48.
Woldemeskel, F. M., Sharma, A., Sivakumar, B., & Mehrotra, R. (2016). Quantification of precipitation and temperature uncertainties simulated by CMIP3 and CMIP5 models. Journal of Geophysical Research-Atmospheres, 121(1), 3–17.
Yaseen, Z. M., Ebtehaj, I., Bonakdari, H., Deo, R. C., Mehr, A. D., Mohtar, W. H. M. W., & Singh, V. P. (2017). Novel approach for streamflow forecasting using a hybrid ANFIS-FFA model. Journal of Hydrology, 554, 263–276.
Yazdani, M. R., & Zolfaghari, A. A. (2017). Monthly River forecasting using instance-based learning methods and climatic parameters. Journal of Hydrologic Engineering, 22(6), 04017002.
Yousuf, I., Ghumman, A. R., & Hashmi, H. N. (2017). Optimally sizing small hydropower project under future projected flows. KSCE Journal of Civil Engineering, 21(5), 1964–1978.
Zaini, N., Malek, M. A., Yusoff, M., Mardi, N. H., & Norhisham, S. (2018). Daily River flow forecasting with hybrid support vector machine—particle swarm optimization. IOP Conference Series: Earth and Environmental Science, 140, 012035. https://doi.org/10.1088/1755-1315/140/1/012035.
Zhao, M., Golaz, J. C., Held, I. M., Ramaswamy, V., Lin, S. J., Ming, Y., & Guo, H. (2016). Uncertainty in model climate sensitivity traced to representations of cumulus precipitation microphysics. Journal of Climate, 29(2), 543–560.
Acknowledgments
The authors would like to thank Almighty Allah, the source of all knowledge and wisdom within and beyond our comprehension. We wish to express our sincere thanks to all the contributing authors and review editors. Without their expertise, commitment, integrity, and vast investments of time, a paper of this quality would never have been completed. We are much obliged to Dr. Asim Rauf, Director and Engr. Mian Waqar Ali Shah, a research associate at Pakistan Glacier Management and Research Centre, whose expertise and guidance were pivotal to carry out this study. We would also like to thank the staff of the Pakistan Surface Water Hydrology Department, especially Director Abdul Majid and Data keeper Mr. Tariq Khan for their assistance and providing the necessary data. We are deeply indebted to them.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claimsin published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ateeq-ur-Rauf, Ghumman, A.R., Ahmad, S. et al. Performance assessment of artificial neural networks and support vector regression models for stream flow predictions. Environ Monit Assess 190, 704 (2018). https://doi.org/10.1007/s10661-018-7012-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-018-7012-9