
Abstract
Universities, research institutes, and firms are the main entities in the national innovation system. Owing to the heterogeneity of their outputs, prior studies have focused on their independent efficiency evaluation. This study adopts the nonhomogeneous data envelopment analysis model to assess the efficiency of three innovation entities in 30 provinces in China on a common platform. Results show that firms have the highest efficiency, and research institutes have the lowest efficiency. Innovation entities perform poorly due to the inefficiency of their subunits. Additionally, the 30 provinces are divided into three clusters by using the hierarchical clustering method. Moreover, Tobit regressions are used to estimate the impact of five environmental factors on the innovation efficiency of the three entities. The regression results show that the more open the region, the stronger the positive impact on the innovation efficiency of research institutes and firms. The regional economic environment has different degrees of negative impact on the three innovation entities. The direction and intensity of the impact of education input, government support, and information infrastructure on the three entities exhibit a large dispersion. The results provide important information for improving the efficiency of innovation entities.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Universities, research institutes, and firms are direct innovation entities, but they play different functions and roles in the national innovation system [1, 2]. Specifically, universities need to cultivate talent and conduct basic research, research institutes are committed to cutting-edge science and technology research and attending to social needs, and firms focus on producing new products by technological innovation [3]. Cutting-edge technology, often known as technology at the cutting edge of knowledge, is defined as technical tools, methods, or results that make use of the most recent and advanced IT breakthroughs. Cutting-edge refers to organizations that are at the forefront of innovation in the IT sector.
Based on the three innovation entities’ important roles in the national innovation system, managers and scholars have always been concerned about measuring their performance to effectively guide decision-making. Innovation efficiency is a key indicator of innovation performance [4]. Efficiency here refers to the technical efficiency of the innovation entity, which is the ability to transform innovation inputs into outputs [5]. As innovation activity is a multi-input and multi-output process, most existing literature employs data envelopment analysis (DEA) to evaluate their efficiency, which reflects the complexity of innovation activities [6,7,8]. DEA (data envelopment analysis) is a benchmarking technique that rates the efficiency with which a population of DMUs and PMUs transform input into output. These analysis's aim is to determine the countries that convert their inputs into outputs in the most efficient manner. Further, Multiple input, multiple output (MIMO) systems describe processes that require multiple control loops because they have more than one input and more than one output. These systems are susceptible to complexity due to loop interactions that cause variables to have unanticipated consequences. Nevertheless, few studies examine the efficiency of universities, research institutes, and firms on a common platform, making it impossible to compare their innovation efficiency. As might be expected, if we want to compare their innovation efficiency on a common platform, the issue that should be considered is that the three innovation entities have different outputs as a result of their different operational goals. For example, universities and research institutes do not produce new products, and research institutes and firms do not train students.
As the classic DEA model is based on the assumption of homogeneity, it does not apply to our case. In this study, we attempt to use a nonhomogeneous DEA model to measure three innovation entities on a common platform. Using datasets of 30 provinces in mainland China from 2011–2019, the results illustrate that the efficiency of innovation entities is low, especially research institutes. Additionally, we use the hierarchical clustering method to divide provinces with the same innovative advantages into three clusters. The classification results reveal the characteristics presented by the innovation entities in China's provinces.
Furthermore, we adopt Tobit regressions to analyze the five typical factors that affect the efficiency of innovation entities. Regressions using the Tobit method are appropriate in situations when the dependent variable is unbounded except at one of the extremes, where it exhibits a positive mass of data. It is impossible for a variable to take values larger than one or lower than zero if its range is constrained to between 0 and 1 inclusive. Regression results show that the five environmental factors have different effects on the three innovation entities in terms of orientation and intensity.
The main contributions of this paper are as follows. First, to our knowledge, this study is the first to give the three innovation entities a common platform to fairly evaluate their performance. Second, our research results reveal the sources of inefficiency from the country-level and province-level to each decision-making unit (DMU), and provide rich information for managers’ decision-making. Third, we explore the influence factors that affect the three innovation entities by using Tobit regressions.
The rest of this paper is organized as follows. Section 2 lays out the related literature. Section 3 introduces the nonhomogeneous DEA model. Section 4 uses the model to evaluate the efficiency of three innovation entities in China. Section 5 analyzes the influencing factors for three innovation entities using Tobit regressions. Section 6 presents the conclusions and implications of this study.
2 Literature review
2.1 Efficiency assessment of innovation entities with DEA
Universities, research institutes, and firms have always received significant attention in the field of innovation. As their level of performance determines the national innovation level, policymakers are deeply concerned about measuring their innovation efficiency to improve them, which is also scholars’ interest.
Many studies have adopted the DEA method to measure the efficiency of the three innovation entities [8,9,10,11,12]. In addition, from the perspective of measurement indicators, almost all input indicators consider personnel and funds, and output indicators are inconsistent owing to the different operating structures of the entities. For example, Fukuyama et al. (2016) used research and development (R&D) expenditure and knowledge reserves as input indicators and journal publications, patents, and Ph.D. graduates as output indicators to evaluate the efficiency of nanobiotechnology research in 25 universities in the United States [6]. Coccia, Falavigna, and Manello (2015) suggested that the inputs of public research institutions in Italy are government and market funds, researchers, and administrative staff, and the outputs are divided into high-visibility outputs (e.g., papers, books and patents) and low-visibility outputs (e.g., reports and other editorial activities) [13]. Cruz-Cázares, Bayona-Sáez, and García-Marco (2013) employed Spanish manufacturing companies’ R&D capital stock and high-skill staff (as inputs) and patents and new products (as outputs) to evaluate the efficiency of technological innovation [14].
Although informative for the particular innovation entity, these studies do not tell us about measuring the innovation efficiency of the three entities under a common platform.
Zuo and Guan (2017) proposed that each province in mainland China includes three R&D sub-processes of universities, research institutes, and companies, and used a DEA game cross-efficiency model to measure their efficiency [15]. Unfortunately, the study did not take into account the heterogeneity of the outputs of the three innovative entities, and some information was omitted during the evaluation. Thus, it is necessary to construct an efficiency evaluation model that considers the heterogeneity of innovation entities.
2.2 Nonhomogeneous DEA
As a non-parametric method that can handle multi-inputs and multi-outputs, DEA is widely used in efficiency evaluation of many fields [16, 17]. However, classical DEA is applied based on the assumption that all DMUs are homogeneous. This assumption does not always conform with all situations [18]. For example, hospitals that provide different medical services have different outputs [19], and regions with the same economic and environmental outputs have different inputs because of their different natural resource endowments [20]. As a remedy, Cook, Harrison, Imanirad, Rouse, and Zhu (2012), and Cook, Harrison, Rouse, and Zhu (2013) examined how to fairly evaluate the efficiency of nonhomogeneous DMUs [21, 22]. Subsequently, some scholars have further expanded and applied research on this basis. Du, Chen, and Huo (2015), and Barat, Tohidi, Sanei, and Razavyan (2019) considered that there is also a nonhomogeneous situation under the network structure [23, 24]. Li et al. (2019) used the nonhomogeneous DEA model to evaluate the efficiency of Hong Kong hospitals [19]. The above studies were based on the heterogeneous output side. On the input side, Li et al. (2016) observed that there are three different forms of natural resources in the provinces of China, and investigated a nonhomogeneous DEA model on the input side [20]. Zhu, Yu, and Sun (2018) proposed the cross-like efficiency nonhomogeneous model to measure the low-carbon investment performance of 39 companies in the US [25]. In addition, several studies have considered the nonhomogeneous nature of both inputs and outputs [26, 27].
Prior studies have provided us with valuable insights in dealing with nonhomogeneous issues. Combining the backdrop of the innovation entities, we propose a nonhomogeneous DEA model to measure the efficiency of the three entities.
2.3 Tobit regression analysis
As a statistical methodology, the Tobit model was introduced in a pioneering work by Tobin (1958) and has superiority in dealing with discrete and limited dependent variables [28]. The Tobit model, also known as a censored regression model, is made to determine linear correlations between variables when the dependent variable either has left- or right-censoring. The efficiency score calculated by DEA is between zero and one and is not continuous, which is suitable for the premise of the application of the Tobit model. The Tobit model is the preferred model for discussing the factors affecting the efficiency value. More importantly, the two-stage method has become popular; that is, DEA is used to measure the efficiency of DMUs in the first stage, and the influence of variables on the efficiency is estimated in the second stage [29, 30].
Furthermore, the use of Tobit regression is a common practice in innovation literature [31]. For example, after examining the R&D efficiency of universities in China, Qin, and Du (2018) showed how environmental factors are related to the efficiency by the Tobit model [32]. Kekezi and Klaesson (2020) analyzed the factors that affect the innovation performance of knowledge intensive business service firms in Sweden [33]. Amara, Rhaiem, and Halilem (2020) adopted the Tobit panel data model to describe how seniority, public sources of research funding, and the business school’s reputation can improve the research efficiency of Canadian scholars in the management field [34].
We adopt the Tobit regression model to estimate the impact of external environmental factors on the efficiency of the three innovation entities after measuring their innovation efficiency.
3 Nonhomogeneous DEA model
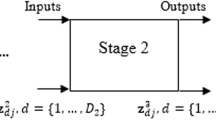
Nonhomogeneous models, which refer to a group of institutions where not all of the departments are the same, include DMUs. The non-homogeneous DMU problem might be solved by grouping the collection of DMUs into several groups, each of which would provide the identical outputs, and doing a separate DEA analysis for each group. The three innovation entities (Universities, research institutes, and firms) with the same outputs are grouped together into P DMU groups, \({G}_{p} (p=1,\dots ,P)\), where in this study, P = 3. DMUs in \({\mathrm{G}}_{1}\) can produce outputs \({\mathrm{y}}_{1}, {\mathrm{y}}_{2}, and {\mathrm{y}}_{3}\). DMUs in \({\mathrm{G}}_{2}\) have outputs \({\mathrm{y}}_{1} and {\mathrm{y}}_{2}\). DMUs in \({\mathrm{G}}_{3}\) produce outputs \({\mathrm{y}}_{1} and {\mathrm{y}}_{4}\) (see Table 1).
When evaluating the DMUs of\({\mathrm{G}}_{1}\), previous studies usually gave an average value or made a zero value artificially \({\mathrm{y}}_{4}\) because they lacked this output. This method is suitable for DMUs that intend to produce certain products but cannot do so. However, the method is unreasonable for the DMUs that choose not to produce or cannot produce for some reason [19,20,21]. To solve the issues, our model supposes that each DMU has \(\mathrm{k }\left(k=1,\dots , K\right)\) subunits. Each subunit consists of two inputs and one output. For example, when\(\mathrm{k}=1\), the inputs are\({x}_{1}\mathrm{ and }{x}_{2}\), the output is\({y}_{1}\). When\(\mathrm{k}=2\), the inputs are also\({x}_{1}\mathrm{ and }{x}_{2}\), and the output is\({y}_{2}\). In our case,\(\mathrm{K}=4\). Assume that \({L}_{p}\) represents the set of subunits of the DMUs in\({G}_{p}\), where \({L}_{1}=\left\{k=1, 2, 3 \right\}, {L}_{2}=\left\{k=1, 2\right\}, {L}_{3}=\left\{k=1, 4\right\}.\)
Unlike the efficiency assessment of homogeneous DMUs, the key point of the nonhomogeneous DEA model is to evaluate different subunits separately. Specifically, each DMU containing the same subunit should be evaluated together. Accordingly, the efficiency of nonhomogeneous DMUs is evaluated through the following three steps.
Step 1 Obtain the allocation proportion of the DMU inputs among each subunit. Let \({\alpha }_{ikp}\) denote the proportion of the ith input assigned to the kth subunit by \({L}_{p}\). Suppose \({e}_{d}\) represents the overall efficiency of \({DMU}_{d}\), \({\omega }_{kd}\) is the weight of the kth subunit of \({DMU}_{d}\), and \({u}_{k}\) and \({v}_{i}\) are the weights of output \({y}_{kd}\) and input \({x}_{id}\), respectively. Moreover, to keep the variable returns to scale, there is no restriction on \({u}_{k}^{0}\) here, and model (1) is established.
where the objective function of model (1) indicates that the weighted sum of the subunits’ efficiency is the total efficiency. The first constraint expresses that the efficiency of each subunit is less than or equal to 1. The second constraint states that the sum of the subunit weights of \({DMU}_{d}\) is 1. The third constraint suggests that the sum of the input proportion allocated to its subunits by each DMU is also 1. The fourth constraint stresses that \({\alpha }_{ikp}\) is within a reasonable interval to avoid extreme outliers. Furthermore, as \({\omega }_{kd}\) is an unknown weight, and following Cook et al. (2012, 2013), \({\omega }_{kd}\) is determined according to the proportion of inputs in the subunits [21, 22]. As shown in formula (2):
Then, model (1) can be transformed into model (3):
We need to convert it into a linear form to facilitate the solution in model (3), which is nonlinear. Let \({z}_{ikp}={\nu }_{i}{\alpha }_{ikp}\), and note that \(\mathop \sum \limits_{{k \in L_{p} }} \alpha_{ikp} = 1 \Rightarrow \mathop \sum \limits_{{k \in L_{p} }} \nu_{i} \alpha_{ikp} = \nu_{i} \Rightarrow \mathop \sum \limits_{{k \in L_{p} }} z_{ikp} = \nu_{i}\). Additionally, the model uses the Charnes–Cooper (C–C) transformation \(\mathrm{t}=1/{\sum }_{i}{\nu }_{i}{x}_{id},\) and defines \({\mu }_{k}=t{u}_{k}, {\phi }_{i}=t{\upsilon }_{i}, {\gamma }_{ikp}=t{z}_{ikp}, {\mu }_{k}^{0}=t{u}_{k}^{0}\). The Charnes-Cooper transformation is a variable modification that allows us to construct additional variables by converting a linear-fractional program into a linear program. It is also used to resolve linear-fractional programs by first resolving a linear program. In doing so, model (3) is equivalent to model (4), as follows:
where we obtain the optimal solutions \({\phi }_{i}^{*},{\mu }_{k}^{*},{\gamma }_{ikp}^{*}, and {\mu }_{k}^{0*}\). Then, we can calculate the optimal proportions \({\alpha }_{{ikp}^{d}}^{*}\), inputs of \({DMU}_{d}\) allocated to its subunit \(\mathrm{k}\) is \({x}_{id}^{k*}\), and the weight of each subunit, \({\omega }_{kd}^{*}\).
Step 2 Calculate the efficiency of the kth subunit of \({DMU}_{d}\). Note that the reference set is the all DMUs groups that include subunits k. Specifically, we define \({M}_{k}\) as the set of all DMU groups that have k as a member, namely \({M}_{k}=\left\{p if k\in {L}_{p}\right\}.\) Here, \({M}_{1}=\left\{p=\mathrm{1,2},3\right\}, {M}_{2}=\left\{p=\mathrm{1,2}\right\}, {M}_{3}=\left\{p=1\right\}, {M}_{4}=\left\{p=3\right\}\). We use model (5) to measure the efficiency of subunit k of \({DMU}_{d}:\)
Step 3 Obtain the whole efficiency of \({DMU}_{d}\) by formula (6).
where \({\omega }_{kd}^{*}\) is derived from model (4), and \({e}_{kd}^{*}\) is derived from model (5).
4 Efficiency measurement of Chinese provincial nonhomogeneous innovation entities
Next, we employ the nonhomogeneous models proposed in Sect. 3 to measure the efficiency of innovation entities with collected data. We first introduce the selected indicators and data. Then, we analyze and compare the innovation efficiency scores.
4.1 Indicators and data
Universities, research institutes, and firms in 30 provincial-level regions in mainland China (excluding Tibet because of incomplete data) are regarded as independent DMUs, and then we obtain 90 DMUs. As mentioned in Sect. 3, these DMUs have the same inputs but are divided into three groups because of their different outputs. Table 2 shows the indicators and data sources. The descriptive statistics are shown in Table 3.
The production of any innovation entity cannot be separated from labor and funds; thus, the full-time equivalent of R&D personnel (RDP) and intramural expenditures on R&D (RDE) are typically regarded as innovation inputs [11, 14]. The ratio of working hours actually spent on research and development during a certain reference period to the total number of hours typically worked by a person or a group during the same period is known as the full-time equivalent (FTE) of R&D employees. For R&D carried out within a statistical unit within a specified reference period, regardless of the source of funding, all current expenses plus gross fixed capital expenditures are considered intramural R&D expenditures. R&D spending within a statistical unit is identical with R&D performance. However, although universities, research institutes, and firms are all innovation entities, there are some differences in their outputs as a result of their operational goals. Therefore, our choice of output indicators is determined based on the three different operation objectives mentioned above and the existing literature. Specifically, the number of patent applications (NPA) is the output of all innovation entities, and although subject to question, it is still a clear and widely recognized innovation output [11]. The non-provisional patent application and the foreign application submitted in accordance with the terms of the Patent Cooperation Treaty are the two types of patent applications that are submitted to the USPTO most frequently. These two patents are frequently referred to as NPAs and PCTs. Patent applications are granted when the likelihood of the patent office failing is lesser than the likelihood of receiving a patent. The sales revenue of new products (SRN) is the innovative result of the firms’ technological transformation and the unique output of firms [35]. Sales revenue of products is the particular type of income. This might involve the selling of a product or a service. Additionally, it could include both goods and services, also covers the overall revenue generated by all financial records. The sales revenue is computed by multiplying the service or product price by the number of services or items sold. For the universities and research institutes, they focus on scientific research rather than on maximizing profit [13]. Therefore, we use scientific papers issued (SPI) as their output indicator. In addition, for universities, the process of technological innovation is also the main platform for cultivating graduate students; consequently, we select the number of postgraduate graduates as one of the innovation outputs for universities [6]. The graduate students here include master students and PhD students. Relevant data are derived from the Educational Statistics Yearbook of China (ESYC) and the China Statistical Yearbook on Science and Technology (CSYS). We deflated all of the currency data to the year 2010 using China’s consumer price index (CPI). The consumer price index (CPI) evaluates changes in the cost of household consumption of goods and services. These modifications have an impact on customers' wellbeing and real buying power. In reality, China's official CPI measures changes in the cost of a predetermined basket of products and services that are often used by both urban and rural consumers.
Moreover, it takes a certain amount of time for each innovation entity to transform inputs into outputs; for this reason, scholars mostly consider time lag when evaluating innovation efficiency [36]. However, there is no consensus about time lags owing to a lack of theoretical basis [37]. Based on the existing literature and a simple linear regression analysis of the data in this study, we allowed for a one-year lag in the measurement; namely, the inputs are the data of 2011–2018, and the outputs comprise the data of 2012–2019.
4.2 Analysis of the efficiency of the three innovation entities
The overall efficiency results of all DMUs from 2012–2019 are shown in Appendix, Tables 9, 10, 11. None of the innovation entities are effective in our sample period, except for DMU26 in 2017. Zuo and Guan (2017) found that universities are the most efficient in China, followed by research institutes and firms [15]. Their results are different from proposed method because the studies used different DEA models, datasets, and measures of relative efficiency.
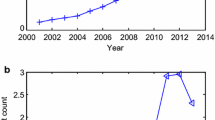
To analyze the dynamic changes in the efficiency of three innovation entities, we compare the national average efficiency of each innovation entity by year (see Fig. 1 and Table 4). Compared with research institutes, the efficiency of universities and firms fluctuates more. In most years, the efficiency of firms is higher than that of universities. In 2019, the efficiency of firms suddenly drops sharply, while the efficiency of universities increases significantly.

Comparison of the average efficiency of innovation entities
However, the efficiency of research institutes is far lower than that of the other two innovation entities. According to nonhomogeneous model in this Sect. 3.1, the efficiency scores of research institutes depend on the performance level of the two subunits \({k}_{1}\) and \({k}_{2}\). The reference set of \({k}_{1}\) includes universities, research institutes, and firms in 30 provinces, and there are in total 90 DMUs. Similarly, the reference set of \({k}_{2}\) includes 60 DMUs in universities and research institutes in 30 provinces. Research institutes consume more RDP and RDE than universities while producing less NPA and SPI (see Table 3). The central government began to implement the transformation of the Chinese Academy of Sciences system in 2014. Although the reform has made a series of achievements, it still faces complex challenges.
To avoid some extreme allocation situations, according to the actual situation of the survey, we assume that the proportion of inputs allocated to each subunit of each DMU is \({\alpha }_{ikp}\in \left[0.2, 0.8\right]\). DMU1, DMU31, and DMU61 are the first DMUs in the group. We use the 2018–2019 data of these three DMUs as an example to describe the proportion of each input allocated to their subunits (see Table 5 and Fig. 2).
Figure 2 shows that the allocation ratio of two inputs in the three subunits of DMU1 is the same, indicating that the two inputs have equivalent importance in the three subunits. In addition, about half of the distribution ratio is close to the given upper or lower limits owing to the optimization algorithm [19, 23]. A distribution ratio is a measurement of the percentage of net profit that a business distributes to shareholders as compared to making an investment in the company. The distribution ratio precisely indicates dividends as a proportion of net profit after tax and interest.

\({\alpha }_{1k}\) and \({\alpha }_{2k}\) of three DMUs in 2018
A DMU is efficient only when each of its subunits is efficient, according to the models in Sect. 3. Obviously, the three DMUs are not effective because all of their subunits are ineffective (see Fig. 3 and Table 6). Figure 3 clearly shows which subunit's efficiency should be improved. Specifically, DMU1 and DMU61 should focus on improving the efficiency of patent application. Both of the subunits of DMU31 perform poorly; nevertheless, DMU31 should prioritize the efficiency of scientific papers issued.

The overall and subunits efficiency of three DMUs in 2019
4.3 Cluster analysis
To further explore the characteristics of innovative entities in China’s provinces, we use a clustering method to classify 30 provinces according to average annual efficiency of innovation entities. In addition to being a kind of unsupervised machine learning, clustering may also be used to produce clusters as features to enhance classification models. The findings demonstrate that they are insufficient for categorization on their own. However, it increases the model frequency when it is employed as feature. The ratio of the output sub-index to the input sub-index is known as the innovation efficiency ratio. It demonstrates how much innovation is produced for each country's input. This method has been widely used to classify various DMUs [26, 37].
Broadly speaking, clustering methods can be divided into hierarchical clustering and non-hierarchical clustering methods. A hierarchical clustering is a tree-like arrangement of nested clusters. The hyper spherical structure of the clusters is discovered to make K-Means clustering effective. When the clusters are hyper spherical, then the hierarchical clustering is less effective than k-means. The k-means method is regarded as a representative of non-hierarchical clustering, which has a fast calculation speed and can handle large datasets, but the number of clusters needs to be specified in advance. By contrast, hierarchical clustering regards each observation as the initial cluster and does not need a priori specification of the number of clusters [38]. We determine the final category by repeatedly calculating the distance of clusters and combining them. When the sample size is too large, or there are too many variables, the hierarchical clustering calculation speed is slow. The link between groups cannot be established with non-hierarchical clustering, such the k-means method. Hierarchical clustering connects pairs of clusters repeatedly until every data object is included in hierarchy. However, the datasets in this study are not large and do not affect the calculation speed. Therefore, we adopt the hierarchical clustering method (using SPSS software). In SPSS, hierarchical clustering is a process that uses an algorithm to locate generally homogenous groupings of instances or variables based on chosen features, starting with each example or variable in a distinct cluster and combining clusters until only one is left. Three clusters are identified in Fig. 4.

Average clustering efficiency of the three innovation entities
There are 12 provinces grouped together in cluster 1, and nine provinces in clusters 2 and 3 (Fig. 4). A common characteristic of all provinces belonging to cluster 1 is that the efficiency of firms is higher than that of universities. In contrast, the efficiency of universities in cluster 2 provinces is higher than that of firms. The efficiency of firms in the provinces in cluster 3 is similar to that of universities. In China, firms in more provinces perform better in innovation than that of the other two innovation entities. The results indicate that since China proposed the establishment of firm-based innovation development system in the outline of the national medium and the long-term science and technology development program (2006–2020), firms have achieved development and growth.
Furthermore, the clustering results show the relative advantages and disadvantages of provinces. Particularly, compared with the provinces of cluster 1, the provinces of cluster 2 have comparative advantages in university innovation, and provinces of cluster 2 should strengthen their advantages in this respect. Meanwhile, the efficiency of firms in provinces belonging to cluster 2 is low, so the clustering results can provide a suitable benchmark for each province. For example, Heilongjiang in cluster 2 has the lowest firm efficiency among all provinces. Therefore, it is difficult to take Anhui, which has the highest firm’s efficiency, as Heilongjiang’s improvement target. It is more realistic and suitable to use Yunnan, which has the best performance of firm in the same cluster, as a benchmark.
5 Impact of environmental factors on innovation entities’ efficiency
This section first introduces the selected environmental factors and then presents the results of the Tobit regressions.
5.1 Variable description
Extracting factors that affect innovation performance from the external environment is a difficult task. Broadly speaking, almost all external environmental factors may have an impact on innovation efficiency. Based on the existing literature, we select five factors.
-
(1)
Regional economic environment
The economic environment impacts the innovation activities of entities, which has long been discussed in innovation studies [39]. The level of economic development not only provides market demand for innovative activities, but also guarantees the source of funding. In this study, the economic environment indicator is expressed by regional gross domestic product (GDP).
-
(2)
Education input
Innovation activities need quality labor. A region with more investment in education will have a greater likelihood of obtaining high-quality labor [40]. Therefore, we use per capita expenditure for education to measure the level of education in the region.
-
(3)
Government support
As a public product, innovation has external characteristics, which determines that the government plays an important role in innovation activities and gives innovation entities support through various ways [41, 42]. In this study, the per capita expenditure for science and technology is selected as the indicator to measure the support from government; a higher value indicates stronger support.
-
(4)
Information infrastructure
Phenomenal advances in information technology have made the transfer of knowledge faster and more convenient [43]. Good information infrastructure plays an important role in the assimilation of internal and external knowledge and technology by innovative entities. With this in mind, many scholars have considered information infrastructure when studying the influencing factors of innovation performance [44, 45]. To account for information infrastructure, we use the number of internet ports owned by 10,000 people as a proxy.
-
(5)
Regional openness
Innovation needs to be actively integrated into the global innovation network to make the best use of global innovation resources. This is the basic principle of the “National innovation driven development strategy program.” National innovation-driven development plan, emphasizing that technical innovation is a strategic support for enhancing social productivity and total national strength, and that it must be positioned at the center of the nation's overall growth. The National Innovation System, is the movement of technology and information among individuals, businesses, and organizations. As a number of researchers have argued, enhancing regional openness can reduce trade barriers, promote resource circulation, avoid knowledge spillovers, and affect innovation production efficiency [1, 46, 47]. Considering its impact, the measure of regional openness is the proportion of import and export goods trade in the region’s GDP.
The above independent variables are the typical variables of the external environment that innovation entities face when carrying out innovation activities. These external factors are beyond the control of the innovation entities, yet it will be of great interest to administrators and policymakers to consider these factors, which may be helpful in improving them.
We draw data from China Statistical Yearbook 2011–2018 to construct a dataset of independent variables. Additionally, to eliminate heteroscedasticity and volatility, we follow prior literature and generate a natural log transformation for the three indicators: lngdp lnpee, and lnpest [48, 49]. Applying the natural log to data transformation in statistics is justified by the need to achieve constant variance or make somewhat skewed data more evenly distributed. To enable the use of a straight line to represent data that has a curved pattern. Table 7 summarizes the definitions and source of independent variables. Table 8 shows the descriptive statistics of all variables used in the Tobit regressions.
5.2 Regression results
As described in Sect. 2.3, because the dependent variable is the efficiency score calculated by the DEA model, which ranges from 0 to 1, the Tobit model is applied for regression. To consider the heterogeneity of the research entity, the fixed- or random-effects Tobit model is more appropriate [31]. We choose the random-effects Tobit model based on a likelihood-ratio test result (see Appendix, Table 12).
Furthermore, the impact of external environmental factors on the innovation entities may not be immediate. Thus, there are two situations to consider, t and t + 1. Specifically, we run the Tobit model as follows:
\(y_{it}^{*} = X_{it}^{^{\prime}} \beta + \varepsilon_{it}\),
\(y_{it} = \left\{ {\begin{array}{*{20}c} {y_{it}^{*} , y_{it}^{*} > 0} \\ {0,y_{it}^{*} \le 0} \\ \end{array} } \right.\).
Table 12 reports the Tobit regression results. Columns (1) and (2) show the regression results for the efficiency of universities (unieff) in years t to t + 1. Similarly, columns (3) and (4) present the results for the efficiency of research institutes (reseff), and columns (5) and (6) report the results for the efficiency of firms (fireff). Environmental factors have obvious differences in the impact of the three innovation entities, which again confirms their heterogeneity. To be specific:
-
(1)
In columns (1), (3), and (5), estimated coefficients of lngdp are all not statistically significant. Compared to those given in columns (2), (4), and (6), there are negative correlations at the levels of 10%, 1%, and 10%, respectively. These results indicate a negative effect of the regional economic environment on the innovation entities’ future efficiency. Moreover, similar results are obtained by Wolszczak–Derlacz and Parteka (2011) and Wu et al. (2020) [48, 49]. The higher the level of economic development in a region, the more funds that can be raised, which easily leads to input redundancy, especially for research institutes supported by public and market-oriented financing [8].
-
(2)
In columns (1), (2), and (3), the coefficient estimates on lnpee have mixed signs, and all of them are insignificant. In the subsequent year, the coefficient estimates on lnpee are positive and significant at the 5% level in columns (2) and (4), and negative at the 1% level in column (6). The results indicate that education input has a significant promotion effect on the technological innovation of universities and research institutes, but it impedes the efficiency of technological innovation of firms. It is possible that the increase in education input will augment the number of people who are willing to continue their studies and reduce the supply of human capital for firms. Chen and Kou (2014) also pointed out that there is a long time lag on the impact of education-related investment on innovation activities [50].
-
(3)
The impact of government funding measured by lnpest on universities and research institutes is not significant. Clearly, the government’s support has not been transformed into a driving force to promote the innovation efficiency of the two entities. Additionally, the promotion effect on the research institutes is obvious in the current period, but after one year, this effect has dropped to an insignificant level.
-
(4)
The influence of infor on the universities seems to be trivial, and the coefficient estimates are positive but insignificant. The coefficients on infor are negative in columns (3) and (4), and the former is statistically significant, while the latter insignificant. Moreover, the coefficients of infor are positive both in column (5) and (6), and the former is statistically insignificant, while the latter significant. These results suggest that after one year, the impact of information infrastructure on research institutes and firms changes significantly.
-
(5)
For the research institutes and firms, the coefficient estimates on open are all significant, suggesting that increasing the level of trade openness can greatly promote the innovation efficiency of research institutes and firms. Compared with research institutes and firms, the impact of open on universities is not significant, but it is also positive. One possible explanation for this result is that the external communications of universities are mainly concentrated in the fields of education and research.
6 Conclusions and implications
We combined the DEA and Tobit model not only to evaluate the innovation efficiency of Chinese universities, research institutes, and firms, but also to estimate the external environmental factors that may increase or hinder their efficiency.
At the national level, the efficiency of the three innovation entities is inefficient, especially research institutes. At the provincial level, the efficiency of firms in cluster 1 provinces have comparative advantages, and the efficiency of universities in cluster 2 provinces have comparative advantages. At the individual level, almost none of the DMUs are effective during the period 2012–2019, because their subunits are inefficient. Tobit regression results show that the regional economic environment has a negative impact on the future efficiency of innovation entities.
Several policy recommendations can be formulated from findings in our study.
-
First, the central (national) government can design a general framework for innovation policies and aim to supporting basic frontier research, and market-related applied research can encourage financial institutions and market funds to support the framework. Local governments can formulate policies based on the actual conditions of the region combined with the innovation level of innovation entities.
-
Second, although universities stress basic research and cultivating innovative talents, they are far away from the market, and it is difficult to transform research results. Universities should be aware of their responsibilities, transform technological achievements into innovative productive forces, and integrate them into the overall environment of economic development.
-
Third, the research institutes are supported by public and market-oriented financing, indicating they are necessary to improve the ability of resource integration management, which may improve their efficiency.
-
Fourth, firms should continue to optimize internal R&D institutions, strengthen cooperation with universities and research institutes, and improve their innovation performance.
In this study, we focused on the innovation efficiency of firms, universities, and research institutes. However, their nonhomogeneous nature means that they require interaction to complement each other. This will be the direction of our future research. Moreover, a better understanding of the mechanism whereby the external environment affects innovation entities is needed as well.
Change history
15 April 2024
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s10660-024-09844-3
Abbreviations
- DEA:
-
Data envelopment analysis
- IT:
-
Information technology
- MIMO:
-
Multiple input, multiple output
- DMU:
-
Decision-making unit
- R&D:
-
Research and development
- RDP:
-
R&D personnel
- RDE:
-
R&D expenditures
- NPA:
-
Number of patent applications
- CSYS:
-
China Statistical Yearbook on Science and Technology
- SPI:
-
Scientific papers issued
- NPG:
-
Number of Postgraduates
- SRN:
-
Sales revenue of new products
- FTE:
-
Full-time equivalent
- USPTO:
-
United States patent and trademark office
- ESYC:
-
Educational Statistics Yearbook of China
- CPI:
-
Consumer price index
- SPSS:
-
Statistical package for social sciences
- GDP:
-
Gross domestic product
- CSY:
-
China Statistical Yearbook
References
Li, X. (2009). China’s regional innovation capacity in transition: An empirical approach[J]. Research policy, 38(2), 338–357.
Han, U., Asmild, M., & Kunc, M. (2016). Regional R&D efficiency in Korea from static and dynamic perspectives[J]. Regional Studies, 50(7), 1170–1184.
Han, U., Asmild, M., & Kunc, M. (2020). Do research institutes benefit from their network positions in research collaboration networks with industries or/and universities?[J]. Technovation, 94, 102002.
Min, S., Kim, J., & Sawng, Y. W. (2020). The effect of innovation network size and public R&D investment on regional innovation efficiency[J]. Technological Forecasting and Social Change, 155, 119998.
Guan, J., & Chen, K. (2012). Modeling the relative efficiency of national innovation systems[J]. Research Policy, 41(1), 102–115.
Fukuyama, H., Weber, W. L., & Xia, Y. (2016). Time substitution and network effects with an application to nanobiotechnology policy for US universities[J]. Omega, 60, 34–44.
Lee, J., Kim, C., & Choi, G. (2019). Exploring data envelopment analysis for measuring collaborated innovation efficiency of small and medium-sized enterprises in Korea[J]. European Journal of Operational Research, 278(2), 533–545.
Yue, W., Gao, J., & Suo, W. (2020). Efficiency evaluation of S&T resource allocation using an accurate quantification of the time-lag effect and relation effect: A case study of Chinese research institutes[J]. Research Evaluation, 29(1), 77–86.
Shamohammadi, M., & Oh, D. (2019). Measuring the efficiency changes of private universities of Korea: A two-stage network data envelopment analysis[J]. Technological Forecasting and Social Change, 148, 119730.
Ghasemi, N., Najafi, E., Lotfi, F. H., & Sobhani, F. M. (2020). Assessing the performance of organizations with the hierarchical structure using data envelopment analysis: An efficiency analysis of Farhangian University. Measurement, 156, 107609.
Chen, X., Liu, Z., & Zhu, Q. (2018). Performance evaluation of China’s high-tech innovation process: Analysis based on the innovation value chain[J]. Technovation, 74, 42–53.
Anyu, Y., Shi, Y., You, J., & Zhu, J. (2021). Innovation performance evaluation for high-tech companies using a dynamic network data envelopment analysis approach[J]. European Journal of Operational Research, 292(1), 199–212.
Coccia, M., Falavigna, G., & Manello, A. (2015). The impact of hybrid public and market-oriented financing mechanisms on the scientific portfolio and performances of public research labs: A scientometric analysis[J]. Scientometrics, 102(1), 151–168.
Cruz-Cázares, C., Bayona-Sáez, C., & García-Marco, T. (2013). You can’t manage right what you can’t measure well: Technological innovation efficiency[J]. Research policy, 42(6–7), 1239–1250.
Zuo, K., & Guan, J. (2017). Measuring the R&D efficiency of regions by a parallel DEA game model[J]. Scientometrics, 112(1), 175–194.
Zhu, Y., Yang, F., & Yang, M. (2021). Measuring the performance of international trade using a DEA-based approach with trade imbalances consideration. Annals of Operations Research, 1–22.
Zhu, Y., Yang, F., Wei, F., & Wang, D. (2022). Measuring environmental efficiency of the EU based on a DEA approach with fixed cost allocation under different decision goals. Expert Systems with Applications, 118183.
Jiang, R., Yang, Y., Chen, Y., & Liang, L. (2021). Corporate diversification, firm productivity and resource allocation decisions: The data envelopment analysis approach[J]. Journal of the Operational Research Society, 72(5), 1002–1014.
Li, Y., Lei, X., & Morton, A. (2019). Performance evaluation of nonhomogeneous hospitals: The case of Hong Kong hospitals[J]. Health Care Management Science, 22(2), 215–228.
Li, W. H., Liang, L., Cook, W. D., & Zhu, J. (2016). DEA models for non-homogeneous DMUs with different input configurations[J]. European Journal of Operational Research, 254(3), 946–956.
Cook, W. D., Harrison, J., Imanirad, R., Rouse, P., & Zhu, J. (2013). Data envelopment analysis with nonhomogeneous DMUs[J]. Operations Research, 61(3), 666–676.
Cook, W. D., Harrison, J., Rouse, P., & Zhu, J. (2012). Relative efficiency measurement: The problem of a missing output in a subset of decision making units[J]. European Journal of Operational Research, 220(1), 79–84.
Du, J., Chen, Y., & Huo, J. (2015). DEA for non-homogenous parallel networks[J]. Omega, 56, 122–132.
Barat, M., Tohidi, G., Sanei, M., & Razavyan, S. (2019). Data envelopment analysis for decision making unit with nonhomogeneous internal structures: An application to the banking industry[J]. Journal of the Operational Research Society, 70(5), 760–769.
Zhu, W., Yu, Y., & Sun, P. (2018). Data envelopment analysis cross-like efficiency model for non-homogeneous decision-making units: The case of United States companies’ low-carbon investment to attain corporate sustainability[J]. European Journal of Operational Research, 269(1), 99–110.
Jie, W., Li, M., Zhu, Q., Zhou, Z., & Liang, L. (2019). Energy and environmental efficiency measurement of China’s industrial sectors: A DEA model with non-homogeneous inputs and outputs[J]. Energy Economics, 78, 468–480.
Yang, M., Wei, Y., Liang, L., Ding, J., & Wang, X. (2021). Performance evaluation of NBA teams: A non-homogeneous DEA approach[J]. Journal of the Operational Research Society, 72(6), 1403–1414.
Tobin, J. (1958). Estimation of relationships for limited dependent variables[J]. Econometrica: Journal of the Econometric Society, 26, 24–36.
Adam, A., & Tsarsitalidou, S. (2019). Environmental policy efficiency: Measurement and determinants[J]. Economics of Governance, 20(1), 1–22.
Wang, L., Zhou, Z., Yang, Y., & Wu, J. (2020). Green efficiency evaluation and improvement of Chinese ports: A cross-efficiency model. Transportation Research Part D: Transport and Environment, 88, 102590.
Kafouros, M., Wang, C., Piperopoulos, P., & Zhang, M. (2015). Academic collaborations and firm innovation performance in China: The role of region-specific institutions[J]. Research Policy, 44(3), 803–817.
Qin, X., & Du, D. (2018). Measuring universities’ R&D performance in China’s provinces: A multistage efficiency and effectiveness perspective[J]. Technology Analysis & Strategic Management, 30(12), 1392–1408.
Kekezi, O., & Klaesson, J. (2020). Agglomeration and innovation of knowledge intensive business services[J]. Industry and Innovation, 27(5), 538–561.
Amara, N., Rhaiem, M., & Halilem, N. (2020). Assessing the research efficiency of Canadian scholars in the management field: Evidence from the DEA and fsQCA[J]. Journal of Business Research, 115, 296–306.
Liu, C., Gao, X., Ma, W., & Chen, X. (2020). Research on regional differences and influencing factors of green technology innovation efficiency of China’s high-tech industry. Journal of computational and applied mathematics, 369, 112597.
Chen, K., Kou, M., & Fu, X. (2018). Evaluation of multi-period regional R&D efficiency: An application of dynamic DEA to China’s regional R&D systems[J]. Omega, 74, 103–114.
Liu, X., Serger, S. S., Tagscherer, U., & Chang, A. Y. (2017). Beyond catch-up—can a new innovation policy help China overcome the middle income trap? Science and Public Policy, 44(5), 656–669. https://doi.org/10.1093/scipol/scw092
Govender, P., & Sivakumar, V. (2020). Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019)[J]. Atmospheric Pollution Research, 11(1), 40–56.
Wang, S., Fan, J., Zhao, D., & Wang, S. (2016). Regional innovation environment and innovation efficiency: the Chinese case[J]. Technology Analysis & Strategic Management, 28(4), 396–410.
Varis, M., & Littunen, H. (2012). SMEs and their peripheral innovation environment: Reflections from a Finnish case[J]. European Planning Studies, 20(4), 547–582.
Hong, J., Feng, B., Wu, Y., & Wang, L. (2016). Do government grants promote innovation efficiency in China’s high-tech industries? Technovation, 57, 4–13.
Liang, X., & Liu, A. M. M. (2018). The evolution of government sponsored collaboration network and its impact on innovation: A bibliometric analysis in the Chinese solar PV sector[J]. Research Policy, 47(7), 1295–1308.
Cui, T., Ye, H. J., Teo, H. H., & Li, J. (2015). Information technology and open innovation: A strategic alignment perspective. Information & Management, 52(3), 348–358.
Paunov, C., & Rollo, V. (2016). Has the internet fostered inclusive innovation in the developing world?[J]. World Development, 78, 587–609.
Schweikl, S., & Obermaier, R. (2020). Lessons from three decades of IT productivity research: Towards a better understanding of IT-induced productivity effects[J]. Management Review Quarterly, 70(4), 461–507.
Tziogkidis, P., Philippas, D., Leontitsis, A., & Sickles, R. C. (2020). A data envelopment analysis and local partial least squares approach for identifying the optimal innovation policy direction. European Journal of Operational Research, 285(3), 1011–1024. https://doi.org/10.1016/j.ejor.2020.02.023
Potter, A., & Paulraj, A. (2021). Unravelling supplier-laboratory knowledge spillovers: Evidence from Toyota’s central R&D laboratory and subsidiary R&D centers[J]. Research Policy, 50(4), 104200.
Wolszczak-Derlacz, J., & Parteka, A. (2011). Efficiency of European public higher education institutions: A two-stage multicountry approach[J]. Scientometrics, 89(3), 887–917.
Jie, W., Zhang, G., Zhu, Q., & Zhou, Z. (2020). An efficiency analysis of higher education institutions in China from a regional perspective considering the external environmental impact. Scientometrics, 122(1), 57–70. https://doi.org/10.1007/s11192-019-03296-5
Kaihua, C., & Mingting, K. (2014). Staged efficiency and its determinants of regional innovation systems: A two-step analytical procedure[J]. The Annals of Regional Science, 52(2), 627–657.
Acknowledgements
This research was supported by the National Natural Science Foundation of China (71991464, 71921001, and 71671001), and Department of Education of Zhejiang Province (Y202147829).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author(s) declared no potential conflicts of interest with respect to the research, author-ship, and/or publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article has been retracted. Please see the retraction notice for more detail:https://doi.org/10.1007/s10660-024-09844-3
Appendix
Appendix
See Tables 9,
10,
11,
12.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, Y., Yang, F., Gong, B. et al. RETRACTED ARTICLE: Assessing the efficiency of innovation entities in China: evidence from a nonhomogeneous data envelopment analysis and Tobit. Electron Commer Res 23, 175–205 (2023). https://doi.org/10.1007/s10660-022-09599-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10660-022-09599-9