
Abstract
The procedures to discover proper new models in probability theory for different data collections are highly prevalent these days among the researchers of this area whenever existing literature models are not appropriate. Before delivering a product, manufacturers of raw materials or finished materials must follow some compliance standards in various engineering disciplines to avoid severe losses. Materials of high strength are necessary to ensure the safety of human lives along with infrastructures to elude the significant obligations linked with the provisions of non-compliant products. Using probability theory, we introduce the weighted version of inverted Kumaraswamy Distribution, which could be considered a better model than some other sub-models used to model Carbon fiber’s strength data. We derive various statistical properties of this distribution such as cumulative distribution, moments, mean residual life, reversed residual life functions, moment generating function, characteristic function, harmonic mean, and geometric mean. Parameters are estimated through the maximum likelihood method and ordinary moments. Simulation studies are carried out to illustrate the theoretical results of these two approaches. Furthermore, two real data sets of Carbon fibers strength are utilized to contrast the proposed model and its sub-models like inverted Kumaraswamy distribution and Kumaraswamy Sushila distribution through different goodness of fit criteria such as Akaike Information Criterion (AIC), corrected Akaike information criterion, and the Bayesian Information Criterion (BIC). Results reveal the outperformance of the proposed model compared to other models, which render it a proper interchange of the current sub-models.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the present time, a special consideration is given to find new probability models in probability theory to facilitate the practitioners and applied researchers for model specification and investigation of the real-life data sets. This urge implies that there is a powerful desire for presenting suitable probability models for better data exploration. Due to high-level computational facilities’ availability, the methods in defining probability models are different from the previous models depicted before 1997 (see Tahir and Cordeiro 2016; Hussain et al. 2018). The main focus in developing probability models is to fulfill various requirements arising from diverse fields such as environmental sciences, medical sciences, engineering sciences, and many more.
In order to circumvent the inadaptability and inadequacy for some of the very well-known probability models such as Rayleigh, Weibull, exponential gamma, Lindley, among others, several authors have investigated the problem of finding new distributions. For instance, we cite the distribution of Kumaraswamy introduced by Kumaraswamy and Krishnamurthy (1980) as an alternative to the Beta distribution with more important advantages. The latter is usually used to model several phenomena such as atmospheric temperature or daily rainfall, daily streamflow in hydrological data. In theory as well as in practice, this distribution has received a lot of attention; see, for instance, Sundar and Subbiah (1989), Fletcher and Ponnambalam (1996), Seifi et al. (2000), Ponnambalam et al. (2001)), and Ganji et al. (2006) for previous works and Jones (2009), Golizadeh et al. (2011), Sindhu et al. (2013) and Sharaf EL-Deen et al. (2014) for recent advances and references. We refer to Lemonte et al. (2013) for the exponentiated Kumaraswamy (EK) distribution and its log-transform. They proved some mathematical properties of both distributions as well as the maximum likelihood estimators of theirs parameters. More recently, Shawki and Elgarhy (2017) presented a new class of distribution called Kumaraswamy Sushila distribution, and they stated the theoretical properties, but they have not applied it to any real data. Although these distributions have some interest in dealing with real data applications, authors have been focused more on the notion of weighted distribution introduced by Fisher (1934). Since this pioneering work, the weighted distribution has been the subject of many works in the probability and statistical literature. For instance, Rao (1965) gave a general formula for this concept of weighted distribution, which can be used to analyze statistical data when the standard distributions are failed. We cite Zelen (1974) for the length-biased sample’s modelization using weighted distributions ideas. From a practical perspective, weighted distributions are usually used to model data from the reliability domain (materials strength data), bio-medicine, or ecology and branching processes. We refer to Patil and Rao (1978), Gupta and Keating (1986), Gupta and Kirmani (1990), Oluyede (1999), among others) for some real data examples. Castillo and Pérez-Casany (1998) defined new exponential families based on the notion of the weighted distribution, and Priyadarshani (2011) introduced the weighted distribution of the generalized gamma distribution. In contrast, Abd El-Monsef and Ghoneim (2015) studied the weighted Kumaraswamy distribution. Later, Abd AL-Fattah et al. (2017) introduced the inverted Kumaraswamy distribution (IKD), studied some of its properties, and showed its performance on real data.
In this paper, we use the weighted technique to develop a new model to measure the strength of materials strength data, mainly modeling the strength of Carbon fiber data. The newly developed probability model constitutes the weighted version of the inverted Kumaraswamy distribution obtained by Abd AL-Fattah et al. (2017). We will use WIKD as an abbreviation for this new distribution, i.e., Weighted Inverted Kumaraswamy Distribution. The constructed distribution plays a vital role to fit the fiber strength, which is very important in the industries allowing to guarantee the safety of material used in the aero industry and construction of bridges. To the best of our knowledge, our proposed model has not been studied theoretically or dealt with it in a practice way. On the other hand, the statistical analysis of the variability in the strength of the composite is promoter subject in the micromechanical area. At this stage, the WIKD model is significantly more efficient than the classical probability models. The superiority of the WIKD model was confirmed by the different measures of goodness of fit, including AIC, CAIC, BIC rules.
The current paper is organized as follows. We devote Sect. 2 to the methodology. Section 3 derives in detail the statistical properties of the WIKD such as the probability density function, the cumulative distribution function, reliability measures including survival, hazard, the reverse hazard, Mills ratio rate functions, and mean residual. For completeness, we also present some further properties, include the moments and related measures (such as harmonic mean, moment generating function and characteristic function), stochastic ordering, order statistics, measures of skewness and kurtosis and information-theoretic measures. Section 4 gives statistical inferences and deals with the parameter estimation methods of the WIKD. Simulation studies and applications of the WIKD and discussions are given in Sect. 5. This section contains two parts. The first part considers the simulation studies to investigate the efficiency of both the maximum likelihood and the moment estimators of the WIKD. Then, we present the performance and comparison of the WIKD model with the existing models. Second, a strength of carbon fiber data is shown and modeled by the proposed model. Also, the performance and comparison of the WIKD model with the existing sub-models are discussed based on the given real data sets. Finally, we conclude our study in Sect. 6.
2 Method
As discussed in the first section, our main purpose is to study the WIKD distribution and its statistical properties. From a theoretical point of view, the present contribution completes previous studies in Kumaraswamy distribution. Motivated by its flexibility to fit some natural phenomena whose outcomes are bounded from both sides, namely, the climatological data and daily hydrological data of rainfall, the family of Kumaraswamy distribution has received growing interest. For example, Abd AL-Fattah et al. (2017) have studied by inverted Kumaraswamy distribution. The latter is built as the transformation of the Kumaraswamy distribution using the function \(\displaystyle \frac{1}{x}-1\). This transformation is defined analogously to the inverted beta distribution. It allows to explicit the probability density of the Inverted Kumaraswamy Distribution (IKD) by
Unlike the classical Kumaraswamy distribution, the (IKD) has a large domain that is in \((0, +\infty )\). For the statistical properties of the IKD distribution, we may refer the readers to Mansour et al. (2018), who estimated the unknown parameters of IKD. In particular, they studied the maximum likelihood and Bayesian estimators. The applicability of the constructed estimators under censoring is illustrated in simulated data. We return to Zafar et al. (2017) for the Generalized IKD distribution (GIKD). The latter is constructed by using the power transformation \(x^\gamma \). Therefore, the probability density function of the GIKD is
where \(x>0,\alpha ,\beta>,\gamma >0\).
The novelty of this paper is to study another version of the IKD distribution that is the weighted version. We focus on its statistical properties such as cumulative distribution, moments, mean residual life, reversed residual life functions, moment generating function, characteristic function, harmonic mean, and geometric mean. The maximum likelihood and the moment estimators of the parameters are determined. Numerical studies are carried out to investigate and illustrate the theoretical results of both estimators. From a practical point of view, we also applied this distribution to Carbon fiber data. The material scientist constantly searches for the most suitable model that could fit the sample data better and can be mathematically improved and recognized.
3 Results
We study and derive the mathematical and statistical properties of WIKD.
3.1 The density function of WIKD
In the following, we suppose that X is a random variable (r.v.) and takes non-negative values, follows IKD (Abd AL-Fattah et al. 2017). The weighted probability density function (pdf) of (1) is determined by
In (2), assume that \(W(X)=x^k\), \(k>0\) is the weight of the distribution. Then use (2) to get
Using the variable change
We obtain
Here, the B(., .) represents Beta-function. Hence, the pdf of WIKD is explicitly given by
with
It is clear that
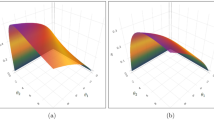
The latter is obtained as the ratio of two polynomial functions. It appears clearly that this limits and the integrability of \(f_{WIKD}\) require \(\alpha>k>0\). Graphically, the shapes of this density are varied with respect to the values of \((\alpha , k,\beta )\); see plots in Fig. 1. Note that if \(k=1\), we get size-biased WIKD. if \(k=2\), we get area biased WIKD.

Some examples of WIKD densities
3.2 Cumulative distribution function of WIKD
Now, consider a random variable X which follows WIKD with parameters \(\alpha \), \(\beta \) and k. The cumulative distribution function is derived as follows.
Then, use the same previous variables change to write that

where \(\nu =(1+x)^{-\alpha }\). It follows that, the corresponding cumulative distribution function (cdf) is defined by:
where \({\mathbb {B}} (x,a,b)\) is the incomplete beta function. Fig. 2 shows various plots for the cdf.

Some examples of the cumulative function of WIKD
3.3 Reliability measures
In the current section, we study the reliability characteristics of the WIKD, including the functions of reliability, hazard, and reversed hazard. Also, we derive the central tendency, dispersion measures, graphical and order statistics for such distribution.
3.3.1 Reliability function
Suppose that X is an r.v. follows WIKD with parameters \(\alpha \), \(\beta \) and k. The distribution survival function is determined by
Thus, from (5) we get
3.3.2 Hazard, reversed hazard and mills ratio rate functions
Recall that the hazard function is expressed by
Therefore, having that the X follows WIKD, the hazard function is deduced by combining (4) and (6) to get the expression
The reversed hazard function is defined by

Both functions \(H_1(x)\) and \(H_2(x)\) are graphically shown in Fig. 3.

Some examples of WIKD Hazard functions
On the other hand, we express the Mills ratio function, which is denoted by m(t) where
It suffices to replace \(H_1(t)\) by its expression to prove that the WIKD has a Mills ratio function defined by
3.3.3 Mean residual life (MRL)
The MRL function is defined by
Now, having that the X follows WIKD, we obtain by some analytical arguments, used on the determination of \(f_{WIKD}\), G and S, the MRL of WIKD. Thus, the MRL can be expressed by
3.4 Stochastic ordering
Assume that the corresponding distributions to the random variables X and Y are \(F_X(x)\) and \(F_Y(y)\) respectively. Then, if \(F_Y(x)\le F_X(x)\), we say that X is stochastically larger than Y. We use st to represent the stochastic relationship between variables. In our case, we write that \(X\ge _{st} Y\) if \(F_X(x) \ge F_Y(x)\). This stochastic property can also be held if we compare the two random variables in terms of hazard rate order and mean residual life order. In terms of likelihood ratio order, we can say that \((Y\le _{lr} X)\) if \(\frac{f_X(x)}{f_Y(x)}\) is an increasing function of X.
Theorem 1
If X and Y are independent r.v.s and follow WIKD where their distributions parameters are \((\alpha _1, \beta _1, k_1)\) and \((\alpha _2, \beta _2, k_2)\), respectively, then, \(Y\le _{lr}X\) if \(k_1>k_2\), \(\alpha _2>\alpha _1\), \(\beta _1>\beta _2\) and \(\alpha _1\, \alpha _2,\, \beta _1, \beta _2>1\).
Proof
Let \(X\sim WIKD(k_1,\alpha _1,\beta _1)\) and \(Y\sim WIKD(k_2,\alpha _2,\beta _2)\). Denote by \(\phi (x)\) the likelihood ratio where
The \(f_X(x)\) and \(f_Y(x)\) are:
Rewrite (7) as
where
Take the logarithm to get
Now, \((Y\le _{lr} X)\) if \(\frac{d}{dx}\log \phi (x)>0\). Then, differentiate \(\log \phi (x)\) to get
It is clearly that \( \frac{d}{dx}\log \phi (x)>0\) if \(k_1<k_2\), \(\alpha _2>\alpha _1\), \(\beta _1>\beta _2\) and \(\alpha _1\, \alpha _2,\, \beta _1, \beta _2>1\). Hence, for \(k_1<k_2\), \(\alpha _2>\alpha _1\), \(\beta _1>\beta _2\) and \(\alpha _1\, \alpha _2,\, \beta _1, \beta _2>1\), Shaked and Shanthikumar (1994) showed stochastic ordering implications of a distribution as: \(Y\le _{lr}X \rightarrow Y\le _{hr}X \rightarrow Y\le _{mrl}X\) or \(Y\le _{lr}X \rightarrow Y\le _{st}X \rightarrow Y\le _{mrl}X\).
3.5 Order statistics
Consider the sample \(X_1, X_2,\ldots X_n\) of a random variable X which follows the WIKD. It is well known that the cumulative function of the \(l^{th}\) order statistics, denoted by \(X_{(l)}\) (such that \((X_{(1)}< X_{(2)}<X_{(l)}<X_{(l+1)}\ldots < X_{(n)}) \)), is determined by
It follows that the density of \(X_{(l)}\) is expressed by
Thus, the expression for the pdf of \(X_{(l)}\) is
3.5.1 Shannon entropy
Assume that X is a non-negative continuous r.v. with the f(x) as a pdf. The uncertainty classical measure for the r.v. X is the derivative of entropy; this also gives the well known Shannon entropy (see Shannon 1948) and is determined by
Hence, the \(H_{Shan}\) is derived as follows.
Now, we treat
by using the same variable change, as in the determination of \(f_{WIKD}\), as follows.
Thus,
3.6 Renyi entropy
The Renyi Entropy is defined by
Firstly, we calculate
Use the same variables changes, as in the prove of (2), to prove that
Finally,

4 Statistical inferences
We devote this section to the estimation of the parameters of WIKD. We construct two estimators in which the maximum likelihood obtains the first one and the second one is constructed by the moment methods. All estimators can be obtained by a numerical procedure.
4.1 Maximum likelihood estimators
Consider a size n, \(X_1,\ldots X_n\), a random sample drawn from a r.v. X with the pdf
Based on the above pdf, the function of the likelihood is determined by
and the corresponding log-likelihood is determined by
It follows that the estimates \({\hat{\alpha }}\), \({\hat{\beta }}\) and \({{\hat{k}}}\) are the maximum likelihood estimators (MLE) which are the solutions of the following set equations:
The estimators are computed by using the code-routine goodness.fit of the R-package AdequacyMode. The latter is based on the Particle Swarm Optimization (PSO) algorithm, which provides greater control of the optimization process, allowing to overcome the effects of the presence of flat regions or the independence to the choice of the initial values. The initial values are automatically chosen. Of course, the solution of these equations require the positive-definite of the Hussein matrix on the solution \(({\hat{\alpha }}, {\hat{\beta }},{{\hat{k}}})\). The Hussein matrix is defined by
where

The matrix \(\sum \) is used to evaluate the asymptotic variance-covariance matrix of maximum likelihood estimators (MLE). The latter is the inverse of the observed Fisher information matrix. Empirically, by the maximum likelihood method and the fisher information given by \(\sum \) , it suffices to replace \((\alpha ,\beta , k)\) by \({\hat{\alpha }}, {\hat{\beta }},{{\hat{k}}}\) to get the variance asymptotic of the maximum likelihood estimator.
4.2 Estimation by the moments’ method
Now, we construct the Moment Method Estimator (MME) of the parameters \((\alpha ,\beta , k)\). To do that, we consider a size n, \(X_1,\ldots X_n\), of a random sample drawn from a r.v. X with the pdf
Then, the estimates \({\tilde{\alpha }}, {\tilde{\beta }},{\tilde{k}}\) are the solutions of the below set of equations:
The solution is obtained by using the R-code nleqslv with the initial values (10, 5, 6).
5 Performance and discussion
In this section, we test the performance of our introduced model using simulation studies and real data and discuss its superiority by comparing it to the comparative models.
5.1 Simulation studies
In the first illustration, a comparative study between both estimation methods is developed to show both estimators’ applicability (MLE and MME). For this purpose, we generate n random variables from the weighted inverted Kumaraswamy distribution by inverting the cumulative distribution function over the uniform distribution, using the R-code inverse. The simulation experiment is performed over two cases \((\alpha , k,\beta ) =(2,1,3)\) and \((\alpha , k,\beta ) =(10,9,10)\). The bias and the mean square errors (MSE) are summarized in Table 1. The bias for an estimator is calculated as the difference between the expected and the true values. The MSE is non-negative and is used to measure the estimator quality; a better estimator is that with an MSE value closer to zero.
Comparing the results of MLE and MME of the first case to the second case of the experiment, based on the bias values, we see that the precision for the MLE is very high for a very small sample size. But, when the sample size is increased, there are some differences between both methods. In addition, and based on the MSE values, we see that for each n, the MSE values for the MLE method are smaller than those for the MME method. In what follows, we will carry our analysis and investigation based on the MLE method.
In the second illustration, we use Monte Carlo data to test the efficiency of the proposed probability model compared to the known model that is the Kumaraswamy Sushila distribution (KSD) (Shawki and Elgarhy 2017). To do that, we consider two simulated models that are very close to realistic situations. Precisely, we use some observations drawn by the absolute variable of the Laplace Distribution (\(Laplace(\mu ,b)\)) which cover the nonhomogeneous data, and the second one is constructed from the absolute variable of the mixture model \(\rho N(0,.1)+(1-\rho )N(0,1)\). Recall that our main aim in this second illustration is to test the quality of WIKD over these usual models. In fact, there are many measures for the model selection and the goodness of fit in probability theory. The AIC and BIC are two of the most used measures. These criteria permit the quantification of the information loss in this simulated data. Indeed, the best model is the model with smaller values of the AIC and BIC. The Monte Carlo study is carried out over several values of the parameters \(\mu \), b, \(\rho \), m, and p. Table 2 displays the results.
It apparats clearly that the WIKD is significantly better than the IKD and KSD. Of course, this gain is varied with respect to the generated data and the choice of the parameters. In particular, the best result of the WIKD corresponds to the Laplace distribution with \(\mu =0\) and \(b=0.5\). Meanwhile, for the IKD and KSD, there is a significant loss of information, mainly when using the BIC measure. The border range for IKD (respectively for KSD) is between 175.61 and 507.42 (respectively, 504.98 and 618.78) versus 91.82 and 450.93 for the WIKD.
5.2 A real life application
Two real data sets of Carbon fiber data are used to compare the efficiency and flexibility of the WIKD with existing sub-models. Carbon fibers distinct lightness and strength make it a viable, versatile, and useful commercial product for a wide variety of markets. Carbon fiber is commonly used to reinforce composite materials to make them strong and reliable. It is typically two times stronger, six times harder, and half time heavier than fiberglass. Accurate and reliable modeling of this important material is of great importance in a variety of fields. Noting that, in survival analysis, practitioners are usually interested in choosing the distribution providing the best fit for the underlying data. This is the principal motivation to build new distributions. For this purpose, we highlight the feasibility of the WIKD using the two data sets evaluating the strength of carbon fiber. The first one contains \((n = 63)\) observations. Such data is frequently used in this kind of study. It was initially reported and studied by Badar and Priest (1982) and then by Mead et al. (2017) as an application for the beta exponential Frechet distribution. The data is measured in GPA and represents the strength of single carbon fibers and impregnated 1000-carbon fiber tows. More examples of this kind of data are available in the R-package AdequacyMode. In the first part of this computational study, we use the following observations:
1.901, 2.132, 2.203, 2.228, 2.257, 2.350, 2.361, 2.396, 2.397, 2.445, 2.454, 2.474, 2.518, 2.522, 2.525, 2.532, 2.575, 2.614, 2.616, 2.618, 2.624, 2.659, 2.675, 2.738, 2.740, 2.856, 2.917, 2.928, 2.937, 2.937, 2.977, 2.996, 3.030, 3.125, 3.139, 3.145, 3.220, 3.223, 3.235, 3.243, 3.264, 3.272, 3.294, 3.332, 3.346, 3.377, 3.408, 3.435, 3.493, 3.501, 3.537, 3.554, 3.562, 3.628, 3.852, 3.871, 3.886, 3.971, 4.024, 4.027, 4.225, 4.395, 5.020.
This data is fitted using three models; WIKD and its sub-models, i.e., IKD and KSD. Recall that the fit of this data is performed by R-code goodness.fit based on the PSO algorithm. As we mentioned before, this algorithm provides greater control of the optimization process and overcomes the effects of flat regions or the independence to the choice of the initial values.
For comparing the WIKD with its sub-models, criteria such as the AIC, BIC, and the corrected Akaike information criterion (AICC) are used. A distribution with smaller AIC, AICC, and BIC values is judged to be the best fit compared with its existing models. The estimation of the parameters of the WIKD and its sub-models are achieved with the help of R-code goodness.fit; Table 3 displays the results.
It is evident from Table 3 that the WIKD gives a superior fit when contrasted with other sub-models since it has the most minimal estimations of AIC, AICC, and BIC.
The second illustration also concerns another example of carbon fiber data. Recall that this data’s popularity is motivated by the fact that carbon fiber is essential to measure the benefit of a material in strength and stiffness. In particular, obtaining carbon fiber materials with high stiffness and strength is possible through specialized heat treatment processes with very expansive and costs much higher values. In this sense, the devolvement of new distributions allowing to fit these characteristics is extremely important. To confirm the superiority of the WIKD over its competitive models, we evaluate its performance over other celebrated data that represent the tensile strength of carbon fibers. The considered data was initially reported and studied by Badar and Priest (1982) and then by Shanker et al. (2016) as an application for weighted Lindley distribution. It contains \((n = 69)\) observations. It gives the GPA measures of the tensile strength of carbon fibers. The data observations are:
1.312, 1.314, 1.479, 1.552, 1.700, 1.803, 1.861, 1.865, 1.944, 1.958, 1.966, 1.997, 2.006, 2.021, 2.027, 2.055, 2.063, 2.098, 2.14, 2.179, 2.224, 2.240, 2.253,2.270, 2.272, 2.274, 2.301, 2.301, 2.359, 2.382, 2.382, 2.426, 2.434, 2.435, 2.478, 2.490, 2.511,2.514, 2.535, 2.554, 2.566, 2.57, 2.586, 2.629, 2.633, 2.642, 2.648, 2.684, 2.697, 2.726, 2.770,2.773, 2.800, 2.809, 2.818, 2.821, 2.848, 2.88, 2.954, 3.012, 3.067, 3.084, 3.090, 3.096, 3.128,3.233, 3.433, 3.585, 3.585.
The WIKD estimates and its sub-models parameters, AIC, AICC and BIC for dataset II, are also obtained with the help of R-code goodness.fit; Table 4 displays the results.
From Table 4, it is again apparent that the WIKD gives a superior fit when contrasted with other sub-models since it has the lowest estimations of AIC, AICC, and BIC.
6 Conclusion
Materials of high strength are always necessary to ensure the safety of human lives and infrastructures to elude the significant obligations linked with the provisions of non-compliant products. In this paper, we introduced the weighted inverted Kumaraswamy distribution. We provide explicit expressions for the model properties: the moments, mgf, hazard rate function, mean residual function, stochastic ordering, and measure of uncertainty for WIKD. Parameters of the proposed model are achieved using the maximum likelihood and moments method. Also, comparative studies of both methods based on simulation studies are conducted to show the applicability of both estimators and test the performance of WIKD over that KSD. The results show that the WIKD performance better than KSD. Finally, we present an illustration that endorses the applicability of the WIKD for modeling real-life data over their existing sub-models. Two real carbon fiber data are used, and again the results show the superiority of the WIKD in fitting the data better than IKD and KSD.
References
Abd AL-Fattah AM, EL-Helbawy AA, AL-Dayian GR (2017) Inverted Kumaraswamy distribution: properties and estimation. Pak J Stat 33(1):37–61
Abd El-Monsef MME, Ghoneim SAE (2015) The weighted Kumaraswamy distribution. Information 18(8):3289–3300
Badar MG, Priest AM (1982) Statistical aspects of fiber and bundle strength in hybrid composites. In: Hayashi T, Kawata K, Umekawa S (eds) Progress in science and engineering composite. ICCM-IV, Tokyo, pp 1129–1136
Castillo JD, Pérez-Casany M (1998) Weighted Poisson distributions for overdispersion and underdispersion situations. Ann Inst Stat Math 50(3):567–585
Fisher RA (1934) The effects of methods of Ascertainment upon the estimation of frequencies. Ann Eugen 6:13–25
Fletcher SG, Ponnambalam K (1996) Estimation of reservoir yield and storage distribution using moments analysis. J Hydrol 182(1–4):259–275
Ganji A, Ponnambalam K, Khalili D (2006) Grain yield reliability analysis with crop water demand uncertainty. Stoch Environ Res Risk Assess 20(4):259–277
Golizadeh A, Sherazi MA, Moslamanzadeh S (2011) Classical and Bayesian estimation on Kumaraswamy distribution using grouped and ungrouped data under difference of loss functions. J Appl Sci 11(12):2154–2162
Gupta RC, Keating LP (1986) Relations for reliability measures under length-biased sampling. Scand J Stat 13:49–56
Gupta RC, Kirmani SNVA (1990) The role of weighted distributions in stochastic modelling. Commun Stat Theory Methods 19(9):3147–3162
Hussian MA (2013) A weighted inverted exponential distribution. Int J Adv Stat Probab 1(3):142–150
Hussain T, Bakouch HS, Iqbal Z (2018) A new probability model for hydrologic events: properties and applications. J Agric Biol Environ Stat 23(1):63–82
Jing XK (2010) Weighted inverse Weibull and Beta-inverse Weibull distributions. Ph.D. thesis, Statesboro, Georgia
Jones MC (2009) Kumaraswamy’s distribution: a beta-type distribution with some tractability advantages. Stat Methodol 6(1):70–81
Kumaraswamy K, Krishnamurthy N (1980) The acoustic gyrotropic tensor in crystals. Acta Cryst Sect A 36(5):760–762
Lemonte A, Barreto-Souza W, Cordeiro G (2013) The exponentiated Kumaraswamy distribution and its log-transform. Braz J Probab Stat 27:31–53
Mead ME, Afify AZ, Hamedani GG, Ghosh I (2017) The Beta exponential Frechet distribution with applications: properties and applications. Austrain J Stat 46:41–63
Mansour M, Aryal G, Afify, Ahmed Z Ahmad M (2018) The Kumaraswamy exponentiated Frechet distribution. Pak J Stat 3:177–193
Oluyede BO (1999) On inequalities and selection of experiments for length biased distributions. Probab Eng Inf Sci 13:169–185
Patil GP, Rao CR (1978) Weighted distributions and size biased sampling with applications to wildlife populations and human families. Biometrics 34:179–189
Ponnambalam K, Seifi A, Vlach J (2001) Probabilistic design of systems with general distributions of parameters. Int J Circuit Theory Appl 29(6):527–536
Priyadarshani HA (2011) Statistical properties of weighted generalized Gamma distribution. Math Subj Classif 62N05:62B10
Rao CR (1965) On discrete distributions arising out of methods of ascertainment. In: Patil GP (ed) Classical and contagious discrete distributions. Pergamon Press and Statistical Publishing Society, Calcutta, pp 320–332
Renyi A (1961) On measure of entropy and information. In Proceedings of the fourth Berkeley symposium on mathematical statistics and probability, University of California Press, Berkely, vol 1, pp 547–561
Seifi A, Ponnambalam K, Vlach J (2000) Maximization of manufacturing yield of systems with arbitrary distributions of component values. Ann Oper Res 99(1–4):373–383
Shaked M, Shanthikumar JG (1994) Stochastic orders and their applications. Academic Press, San Diego
Shanker R, Hagos F, Shukla KK (2016) On weighted Lindley distribution and its applications to model lifetime data. Jacobs J Biostat 1(1):002
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J (27): 379-423, 623-656
Sharaf EL-Deen MM, AL-Dayian GR, EL-Helbawy AA (2014) Statistical inference for Kumaraswamy distribution based on generalized order statistics with applications. Br J Math Comput Sci 4(12):1710–1743
Shawki AW, Elgarhy M (2017) Kumaraswamy Sushila distribution. Int J Sci Eng Sci 1(7):29–32
Sindhu TN, Feroze N, Aslam M (2013) Bayesian analysis of the Kumaraswamy distribution under failure censoring sampling scheme. Int J Adv Sci Technol 51:39–58
Sundar V, Subbiah K (1989) Application of double bounded probability density function for analysis of ocean waves. Ocean Eng 16(2):193–200
Tahir MA, Cordeiro GM (2016) Compounding of distributions: a survey and new generalized classes. J Stat Distrib Appl 3(13):1–35
Zelen M (1974) Problems in cell kinetics and the early detection of disease. Reliab Biometry 56:701–726
Zafar I, Maqsood TM, Riaz N, Azeem A, Munir A (2017) Generalized inverted Kumaraswamy distribution: properties and application. Open J Stat 2017(7):645–662
Acknowledgements
The authors thank and extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through the research groups program under grant number R.G.P. 2/82/42.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Communicated by Luiz Duczmal.
A Moments and related measures
A Moments and related measures
It is well known that the moments of a r.v. are fundamental characteristics. They allow studying skewness and kurtosis of a variable following a certain distribution and permits to construct an estimator of the parameters. Here, we focus on the different moments of the WIKD.
1.1 A.0.1 The central and non-central moments
1.2 A.1 The central and non-central moments
Let X be a random variable has WIK distribution with parameters \(\alpha \), \(\beta \) and k . The non central moment of order r,
Finally, the non-central moment, of order r, \(E[X^r] \) is defined by
Hence, the variance is
Similarly, for the central moments \(E[X-\mu ]^r\), we have
Then,
Using the moment definition of WIKD, the harmonic mean of the r.v. X is defined by
1.3 A.1.1 Moment generating function and characteristic function
Assume that the X follows WIKD. Then, The moment generating function and characteristic function are respectively defined by
and
We conclude that
and
1.4 A.2 Measures of skewness and kurtosis
The skewness and kurtosis coefficients are usually used to judge, respectively, the asymmetry and flatness of a distribution. The skewness coefficient is determined by
Using (9)and (10), it follows, for the WIKD, that
Also, the Kurtosis coefficient is
Thus, for WIKD and using (9)and (10), it is
Rights and permissions
About this article

Cite this article
Almanjahie, I.M., Dar, J.G., Laksaci, A. et al. A new probability model for modeling of strength of carbon fiber data: properties and applications. Environ Ecol Stat 28, 523–547 (2021). https://doi.org/10.1007/s10651-021-00503-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10651-021-00503-6