
Abstract
An e-learning recommender system (RS) aims to generate personalized recommendations based on learner preferences and goals. The existing RSs in the e-learning domain still exhibit drawbacks due to its inability to consider the learner characteristics in the recommendation process. In this paper, we are dealing with the new user cold-start problem, which is a major drawback in e-learning content RSs. This problem can be mitigated by incorporating additional learner data in the recommendation process. This paper proposes an ontology-based (OB) content recommender system for addressing the new user cold-start problem. In the proposed recommendation model, ontology is used to model the learner and learning objects with their characteristics. Collaborative and content-based filtering techniques are used in the recommendation model to generate the top N recommendations based on learner ratings. Experiments were conducted to evaluate the performance and prediction accuracy of the proposed model in cold-start conditions using the evaluation metrics mean absolute error, precision and recall. The proposed model provides more reliable and personalized recommendations by making use of ontological domain knowledge.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
E-learning systems have undergone rapid growth in the current decade. A tremendous amount of e-learning resources that are highly heterogeneous and in various media formats have been created and included in the online learning platforms (Chen et al., 2014). This information-overload has led to the need for personalization in e-learning environments (Khanal et al., 2019; Mobasher, 2007). Researchers utilized various recommendation techniques to overcome the information overload problem by filtering out irrelevant learning resources and providing more personalized content.
Learners have different individual needs, objectives, and preferences that affect their learning processes (Buder & Schwind, 2012; Kamal & Radhakrishnan, 2019). Similarly, different learners have different characteristics in terms of learner's background knowledge, learners' history, competency level, learning style and learning activities, making the recommendation of learning resources to a particular learner more difficult (Aeiad & Meziane, 2019; Kolekar et al., 2019). One of the main challenges in such systems is that user interests, preferences and needs are not fixed but changes over time. Therefore, the focus of RSs in e-learning environments should be the learner's specific requirements and characteristics (Deschênes, 2020; Essalmi et al., 2010). Other than this, RSs support instructors in the learning design process by considering learner needs and preferences (Karga & Satratzemi, 2018).
One of the most known problems associated with RSs in the e-learning environment is the cold-start problem (Lam et al., 2008; Natarajan et al., 2020). Typically, two classifications exist for this problem: new item cold-start problem and new user cold-start problem (Lika et al., 2014; Safoury & Salah, 2013). The former problem occurs when a new item is introduced to the RS. The ratings available for this newly added item may be zero or significantly less. The new user cold-start problem occurs when a new user has been registered in the system (Son, 2016). When a new user becomes part of the system, the system has no information about the users' prior choices. But it is the responsibility of the system to start suggesting items for the new user also. Otherwise, it will negatively affect the RS's performance, and users may stop using the system due to its inability to provide meaningful recommendations. In the new user cold-start condition, the challenge is to recommend items to the new user without knowing their prior choices.
The typical recommendation techniques used for predicting user preference in PLEs are collaborative filtering (CF), content-based filtering (CB), or a hybrid approach (Schafer et al., 2007; Najafabadi & Mahrin, 2016; Yao et al., 2014). These conventional techniques require users' historical ratings for finding similar users' groups and making appropriate recommendations. However, previous studies have shown that traditional recommenders such as CF and CB suffer from the cold-start problem (Barjasteh et al., 2016; Son, 2016) and rating sparsity problem (Ranjbar et al., 2015; Zhao et al., 2015a, b), which in turn limit their performance. Furthermore, these techniques are not suitable for the e-learning domain since they do not consider the differences in learner features such as learning style, qualification, knowledge level in the recommendation process. These challenges are potent motivators to experiment with different recommendation strategies to suggest a new method that can better recommend appropriate learning resources.
In response to the above-mentioned problems, we propose a knowledge-based recommendation model capable of addressing the new user cold-start problem in e-learning recommender systems. In the proposed recommendation model, ontological knowledge is combined with conventional recommendation techniques such as collaborative and content-based filtering techniques. The ontology provides the initial knowledge about the learner. This mainly includes the prominent learner characteristics such as learning style and knowledge level. Ontologies are capable of giving dynamicity in learner profiling. In addition to learner characteristics, historical ratings of similar learners and LO characteristics are utilized in the proposed recommendation approach to fine-tune the quality of recommendations. Therefore, collaborative and content-based filtering techniques are part of the proposed model to address the pure and partial cold-start problem based on the learner and the learning object similarities.
2 Literature review
This section provides a brief background on four topics: different recommendation techniques, related systematic reviews on e-learning content recommenders, ontology-based recommender systems for e-learning, and various studies conducted to address the cold-start problem in e-learning content recommenders and PLEs.
2.1 Recommendation techniques
Recommender systems are classified according to the technique used in the recommendation process. This sub-section presents a brief overview of the different recommendation techniques widely used in e-learning environments and are particular for this study.
2.1.1 Collaborative filtering
The most popular technique for RS design is the CF approach, which uses the feedback (rating history) of the learner to group similar learners and to make relevant future recommendations (Kim et al., 2016; Sarwar et al., 2001). The underlying assumption is that if users had similar tastes in the past, they would have similar tastes in the future also (Jannach et al., 2010). The rating history is the key attribute to measure the similarity between two users. Therefore the theory behind CF is the computation of similarity between users based on the rating history. The CF technique's major drawback is the new user cold-start problem and the rating sparsity problem (Ricci et al., 2011).
2.1.2 Content-based filtering
In the content-based approach, the RS recommends items similar in terms of content features to the ones that the target user liked in the past (Pazzani & Billsus, 2007). This approach's underlying principle is based on the similarity computation of the item features associated with the compared items.
2.1.3 Hybrid systems
Hybrid systems combine two or more recommendation techniques (Barragáns-Martínez et al., 2010; Burke, 2007; Harrathi et al., 2017). These systems were evolved to overcome the limitations of individual approaches and thereby to improve the recommender performance.
2.1.4 Ontology-based recommender systems
These are knowledge-based recommender systems that use ontology for knowledge representation (Romero et al., 2019; Tarus et al., 2017). Ontology is an explicit formal specification of a shared conceptualization (Gruber, 1993). In the context of e-learning recommender systems, ontology is used to model the knowledge about the learner and the learning resources (Bajenaru et al., 2015; Shishehchi et al., 2012). OB recommenders do not experience cold-start and rating sparsity problems when compared with other conventional recommender systems (Zhao et al., 2015a, b). This is because the OB recommenders rely more on domain knowledge while the conventional recommender systems rely more on user ratings (Yang, 2010). These merits make OB recommenders more appropriate for the e-learning domain. On the other hand, the disadvantage is that the construction of ontologies is challenging, expensive, and time-consuming (Tarus et al., 2018). The following section explains OB systems in an e-learning context.
2.2 Existing systematic reviews on e-learning recommender systems
The researchers focusing on the e-learning domain have published many review papers in e-learning content recommender systems in the last few years. Some of the existing systematic reviews are described in this section. Klašnja-Milićević et al. (2015) have conducted a comprehensive review of recommender systems in e-learning environments with a focus to identify the major requirements and challenges in designing recommender systems in e-learning environments. According to the authors, more exhaustive experiments are required to obtain founded conclusions about the existing recommendation models' benefits. Tarus et al. (2018) conducted a detailed review of ontology-based recommender systems in the e-learning domain. They have performed an in-depth analysis of different recommendation techniques, ontology types and ontology representation languages used in various studies. The authors conclude that the performance and quality of recommendations and the recommendation problems such as cold-start and sparsity can be further improved by hybridizing recommendation techniques using ontologies. In another study conducted by George and Lal (2019), a detailed analysis on how personalization can be achieved in e-learning RSs using ontologies has been done. Their review also discusses several techniques to calculate learner similarity based on learner interests. In their study, the authors also point out the need for extensive work in this domain to find the right combinations of recommendation techniques to improve performance.
Zhong et al. (2019) published a review paper based on five assessment aspects of e-learning recommender systems. They are the metrics for the e-learning system, the recommendation algorithms' evaluation metrics, the recommendation filtering technology, the phases of the recommendation process, and the system's learning outcomes. Their analysis indicates that most e-learning systems will adopt the adaptive mechanism as a primary metric, and accuracy is a vital evaluation indicator for recommendation algorithms. After an in-depth analysis of the research studies, the authors made the following conclusions to enhance RS performance. It is critical to maintain the system's performance and stability with feedback and self-adjustment mechanisms. Also, only 38 percentages of the articles apply hybrid filtering technology with collaborative and content-based techniques, and both are equally important to improve the quality of e-learning content RS. Khanal et al. (2019) presented a systematic literature review on different recommendation approaches and machine learning algorithms used in e-learning RSs. Their study focused on generating classifications of recommendation techniques, machine learning techniques and algorithms used in RS, methods applied, application areas, datasets, and validation/evaluation approaches. According to the authors, the major issues that still required being resolved are RS's scalability and the interaction aspects of the learners with the learning management systems. Kilani et al. (2018) conducted a detailed review of different studies that utilized artificial intelligence techniques to build the collaborative filtering RSs. Their research includes RSs using various artificial intelligence techniques such as fuzzy algorithms, genetic algorithms, neural network algorithms, and optimization algorithms. The authors conclude that artificial intelligent techniques can be combined with existing recommendation models to improve the results.
The reviews mentioned above mainly analyzing different recommendation models that use traditional recommendation techniques, ontology-based strategies, machine-learning algorithms, deep learning-based methods, and comparisons between different recommendation strategies in e-learning systems. The significant gaps for improving the recommendation performance identified by the existing reviews are (1) the enhancement of e-learning RS by hybridization techniques and finding out the right combination of methods (2) need of exhaustive experiments to obtain founded conclusions (3) the importance of feedback and self-adjustment mechanisms (4) addressing the unresolved issues such as scalability, cold-start, and sparsity. In this study, we are trying to solve the cold-start problem using a hybridization technique that involves ontology, collaborative and content-based filtering techniques. The proposed model uses learner feedback, and learner profiles are adjusted using this data.
2.3 Ontology-based e-learning content recommenders
In e-learning content recommendation, ontology is a way to model the learners and the learning resources. Many existing studies have utilized ontology for knowledge representation in e-learning content recommenders, and their results have shown improvement in the quality of recommendations. The personalization framework developed by Ouf et al. (2017) for content recommendation used four ontologies to represent the learner, the learning object (LO), the learning activities, and the teaching method. They tried to enhance the personalization dimension by using rules over these ontologies. Their LO repository contains heterogeneous LO types such as interactive media, audio, video, text etc., corresponding to different learning properties such as difficulty level, media type and learning time. The LO repository is created by the teachers focusing on students of homogeneous students. Pukkhem (2013) has designed a LO recommendation system with multiple agents, in which ontologies are used for creating the agents. Their recommendation model also used a LO repository consisting of different resource types to match the learner preferences and styles. Bouihi and Bahaj (2017) have designed a semantic layer integrated into the current e-learning platforms and pointed out the benefits of semantic layer integration. The semantic layer contains three ontologies to incorporate the learner's learning context, the learning object, and the learning content. Different organizations and authors developed the semantically heterogeneous learning content of huge volumes.
Klašnja-Milićević et al. (2011) have proposed a personalized e-learning system that can automatically adapt to the learners' interests, habits, and knowledge levels using domain ontology. In their model, learners were clustered based on FSLSM learning style, and behavioral patterns are extracted from learner logs using the AprioriAll algorithm. LOs are collected to match various FSLSM dimensions and other learner preferences. The experiments with the proposed system are conducted with 340 first-year Information Technology students undergoing introductory computer literacy courses. The experimental results show that the learners of the experimental group completed more lessons successfully than the control group. Saleena and Srivatsa (2015) have designed an adaptive learning system by utilizing fuzzy domain ontology and domain expert's ontology. Fuzzy domain ontology is constructed by accumulating the documents specific to a learning topic, while the experts built a domain expert ontology for a particular domain. The cross ontology similarities between learning concepts are calculated and based on the similarity score, the learning document is retrieved. For conducting the experiments, e-learning documents are collected from the web for the single topic 'Database Management System'. Target recommendations are generated for learners of varying skillsets (student, professional, work experiences etc.). The document-type resources alone are considered for this study.
The notion of combining recommendation techniques to improve performance is a flourishing trend in the e-learning domain (Bahmani et al., 2012). Many such studies have been conducted with the e-learning content recommenders also. Pukkhem (2014) used a hybrid RS with ontology to interpret and process learning objects in his learning object recommender (LORecommendNet). In this system, the learner is mapped with LOs using Semantic Web Rule Mapping (SWRL) in the domain ontology. The LOs are collected and annotated by experts based on the five LOM properties format, interactivity type, interactivity level, semantic density and learning resource type. Fraihat and Shambour (2015) have presented a hybrid semantic OB recommender system framework to assist learners with personalized recommendations. Their approach also relies on ontology and user ratings to recommend learning activities. In their domain ontology model, different methods of automatic content extraction are applied to the LO types text, audio, image and video. Zhuhadar and Nasraoui (2010) have proposed a hybrid recommender system that uses multi-ontology models to recommend educational content in the e-learning repository. Their hybrid approach is implemented on a search engine to an online learning repository named HyperManyMedia. This repository contains educational content of courses, lectures, and multimedia resources. The content documents are displayed on the recommendations page considering the degree of matching between a learner's query and the document's reverse indexing (Webpage). Ruiz-Iniesta et al. (2014) introduced a hybrid knowledge-based recommender for recommending learning resources of a computer science course. The recommendation approach's objective was to provide personalized access to the vast learning resources available in open educational repositories. The participants of the experiments were students of CS1 and CS2 (C + +) introductory programming courses. Experimental results show the improvement in faster and the personalized material retrievals from the LO repository. Most of the hybrid recommendation techniques with ontologies have shown improvement in the quality of recommendations and performance. Therefore, domain ontologies were developed to store learner and LO characteristics in the current study to enhance the recommendation process.
2.4 Cold-start problem in e-learning recommenders
An important issue for RSs that has significantly captured researchers' attention is the new user cold-start problem. It has two variants; pure cold-start and partial cold-start conditions. In the literature, the pure cold-start issue is mentioned as a subtype of the cold-start problem. Despite being closely analyzed, both the problems should be addressed separately. The cold-start problem is related to generating meaningful recommendations with minimal historical data. The pure cold-start problem is related to creating appropriate recommendations without any historical data about the users (Bobadilla et al., 2013). There are different strategies for addressing the cold-start problem with minimum historical data, but in the case of the pure cold-start condition, there are only a few approaches to satisfy first-time users (Barjasteh et al., 2016; Wongchokprasitti et al., 2015). Most of the techniques described in the literature are not capable of dealing with the pure cold-start problem (Park et al., 2006; Schein et al., 2002; Shaw et al., 2010; Victor et al., 2008; Zhang et al., 2010). The two categories of RSs designed to deal with the pure cold-start problem are (1) Knowledge-based RSs; (2) Social filtering RSs (Silva et al., 2019). Knowledge-based RSs use the domain knowledge about the users, which is usually collected from the user during their first interaction with the RS. The social filtering RSs exploit external information about the users, such as social, demographic and personal data. In the subsections, we briefly summarize the relevant works related to the new user cold-start problem.
2.4.1 Using ontology
There are several research works conducted to solve the cold-start issue in RSs using ontologies. Klašnja-Milićević et al. (2011) proposed a personalized e-learning system that can automatically adapt to learners' interests, habits, and knowledge levels using domain ontology. Their methodology adopts the data mining technique (Aprioriall algorithm) to identify learners' sequential patterns and the CF technique to LO recommendation. Their model is not suitable in pure cold-start conditions since it relies mainly on historical ratings of learners. Harrathi et al. (2017) attempted to solve the cold-start problem using a hybridized approach using ontologies. Their approach also relies on the learning activities modeled in the proposed ontology and user ratings. Tarus et al. (2017) developed a recommender system that uses ontological domain knowledge to overcome the cold-start issue in e-learning RS. When the initial data is not available in their system, the ontology can create hidden knowledge about the learner. They have integrated a sequential pattern mining (SPM) technique with the ontology model to identify the learner's historical sequential pattern from weblogs. The ontological domain knowledge and learning patterns are utilized to mitigate the cold-start problem in their model. The experiments were conducted with 240 learning resources (created and uploaded by the instructors) under 12 computer science subjects. The experiments were conducted with 50 third-year computer science undergraduate students who use an LMS to support their learning. Most of the existing studies to solve the cold-start problem using ontologies handle partial cold-start conditions only. The accuracy and completeness of knowledge acquired in the domain ontology affect the effectiveness of ontology-based recommender systems.
2.4.2 Using data mining techniques
Many of the existing e-learning RSs have used data mining techniques to improve personalization and recommendation problems. Murad et al. (2020) presented a personalized RS based on contextual information and learning outcome scores. The authors used K Nearest Neighbor (KNN) algorithm to predict the target learner's learning outcome. In the recommendation engine, a set of decision rules is combined with the above-predicted learning outcome to suggest relevant learning materials for the target learner. The experiments of the proposed model are conducted with the learner data collected from a single subject Information System Analysis and Design. In a study conducted by Dwivedi et al. (2018), the authors proposed a personalized RS to recommend a sequence of learning materials called learning path. The learning sequences recommended are matched with learner preferences such as learning style and knowledge level. Their model also used the KNN algorithm to identify similar learners and train the input dataset. Similarly, different data mining techniques such as clustering (K-means) and pattern mining (GSP, AprioriAll) are widely used in different phases of the recommendation process (Bourkoukou et al., 2017; Klašnja-Milićević et al., 2018; Senthilnayaki et al., 2015; Bhaskaran & Santhi, 2019; Vanitha & Krishnan, 2019). In many RSs, data mining techniques are adopted to address the recommendation problems.
Nafea et al. (2019) developed an e-learning RS to recommend course learning objects based on Felder Silverman Learning Style Model (FSLSM) (Felder & Silverman, 1988). In their recommendation framework, the k-means clustering algorithm improves the recommendation accuracy and computational efficiency in cold-start conditions by efficient learner grouping. The experiments were conducted using LOs come under 20 learning topics of the single subject 'networks and e-commerce' and found to be effective in cold-start conditions. Bourkoukou and El Bachari (2016) presented a LO recommender system using the CF filtering technique that focuses on explicit and implicit ratings given to the LOs by the learners. In their recommendation model, K-Means and KNN algorithms were implemented to improve the cold-start recommendations using the FSLSM learning style.
2.4.3 Other techniques
Even if there are many research works conducted to address the cold-start problem in different domains, there are minimal works to address the cold-start problem in e-learning content recommenders using conventional methods. In the existing works, ontologies are widely used to address this problem. However, some of the studies use techniques other than ontologies for addressing this problem. For instance, Benhamdi et al. (2017) developed a recommendation model NPR_eL (New multi-Personalized Recommender for e-Learning) to suggest the best learning materials to students using collaborative and content-based filtering techniques. The authors implemented a multi-dimensional similarity between learners based on their interest, prior knowledge, time spends on different tests, and memory capacity. The teachers created the learning materials (URLs or Item location) required for the study. The experiments were conducted with ten postgraduate students of the computer science department using the university's (Badji Mokhtarusing University, Algeria) dataset and achieved better results in the cold-start condition. Salehi et al. (2013) proposed a hybrid recommender system for recommending learning materials based on genetic algorithms and a multi-dimensional information model. The new user cold-start problem is tested with 500 random samples taken from a MACE dataset consisting of 1148 learners and 12,000 learning resources (MACE, a pan-European initiative to interconnect and distribute digital information architecture). The model performed better in cold-start conditions. Dwivedi and Bharadwaj (2013) proposed a weighted hybrid trust-aware RS to recommend the learner the right learning resources. They have experimented with a collaborative filtering technique with primary learner characteristics learning styles and knowledge level to overcome the cold-start problem and achieve better recommendation accuracy. The experiments of the proposed model are tested with the public datasets MovieLens and Jester.
Though several research studies have been carried out in e-learning content recommendation, a more accurate recommendation approach handling drawbacks like cold-start issues yet to be realized. The significant gaps identified in the existing literature are:
-
1.
Minimal research works to address the cold-start problem (especially pure cold-start problem) in PLEs using ontologies.
-
2.
Most of the existing studies in the e-learning domain have experimented with datasets MovieLens, GroupLens, Netflix etc. Experimentations with real learners lack in this area.
This study aims to analyze whether the recommendation accuracy in cold-start conditions can be enhanced by combining collaborative and content-based filtering techniques with ontologies. The proposed approach is different from previous works in the following means.
-
1.
Aggregation of learner and learning object ontology for knowledge representation as well as the integration of ontology domain knowledge with conventional recommendation techniques.
-
2.
Handling pure and partial cold-start conditions using different recommendation logic.
-
3.
Usage of LO data repository annotated by experts (IEEE LOM Standard) for the learner- learning object mapping.
-
4.
Evaluation based on real learner data.
3 The recommendation model
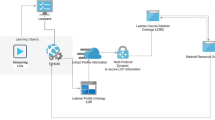
The primary goal of the proposed ontology-based recommender system is to mitigate the new user cold-start problem in e-learning content recommender systems. The architecture of the proposed recommendation model is shown in Fig. 1.

Ontology-based recommendation framework for addressing cold-start problem
The main components of the proposed model are learner interfaces, ontologies (learner, learner Log, Learner Material), learner and learning object similarity measurement unit and an OB recommendation engine. The steps involved in generating the recommendations are:
-
1.
Creating the domain ontology for storing learner, learning material and learner log data.
-
2.
Learner and learning object modeling using ontologies.
-
3.
Computing the learner similarities (in pure cold-start) and the LO similarities (in partial cold-start).
-
4.
Generating the top N recommendation list of learning objects by the ontology-based recommendation engine using collaborative and content-based filtering techniques.
3.1 Learner interfaces
The learner interfaces play a vital role in the RS because the learner interacts with the Learning Management System (LMS) through the learner interfaces only. The initial learner attributes have to be collected directly from the learner when the learner starts using the LMS initially. The learner interfaces were developed to aid this purpose. All the prominent learner attributes such as demographic data, learning style (through a questionnaire), knowledge level, and background knowledge are collected through these interfaces. When the learner selects a topic for learning, the system will list the top N recommendations in the learner interface. The learner can start his/her learning from this point. The interfaces also provide provisions to change the learner profile information and rate the learning material. Other than this, additional interfaces were developed to be used by the instructors to add annotated learning materials to the LMS.
3.2 Building ontologies
The ontology is built entirely in Python, and RDF tools are used to describe the data. OWL representation language was employed in creating the ontology. The detailed design considerations for the developed ontology are presented in our previous work (Joy et al., 2019). The developed ontology contains three sub-ontologies and is briefly explained in the subsections. The layout of the developed ontology is shown in Fig. 2.

Learner, learning material and learner log ontology layout
3.2.1 Learner
The individual differences and preferences of learners should be considered to achieve personalization in learning environments. Here, we focused on both the static and dynamic characteristics of the learners for modeling them. The center of the developed ontology is a Learner class. When the learner starts using the LMS initially, the personal information is recorded using forms, and this information is fed into the Learner class of the ontology. The components of the Learner class include personal information about the learner (student identification number, name, age, gender, branch, qualification and background knowledge) as well as the learning style (Felder Silverman Learning Style Model-FSLSM (1988)) of each learner. The personal information, together with the learning style constitutes the initial static profile for each learner.
3.2.2 Learner Log
When a learner starts learning through the LMS, the learning path should be tracked, and this information is vital for making suitable recommendations. The LearnersLog class is included in the ontology to follow the learning path of each learner. The data type values of this class are materials_visited, material_visited_time and material_ratings. These attribute values help to calculate the time spent by the learners on each learning material and their preferences. The LearnersLog class contributes to the dynamic part of the learner profile.
3.2.3 Learning material
Knowledge representation is vital in understanding the concepts in digital learning environments (Buitrago & Chiappe, 2019). Resources metadata are fundamental for searching and recommending content in e-learning systems. Resources can be described in several ways. For instance, they can be described through standardized structured metadata or unstructured metadata such as tags. Standardized metadata, such as IEEE LOM (IEEE-LTSC, 2010), specifies the metadata syntax and semantics of LOs. Due to its relatively wide acceptance in the academic environment and its extensive usage by institutional repositories, we opted for IEEE LOM. The standard proposes 80 data elements grouped into 9 categories: general, lifecycle, meta-meta data, technical, educational, rights, relation, annotation and classification. It is essential to highlight that only the educational category of IEEE LOM is considered for modeling the LOs in our work. The educational category of LOM is enough to recommend suitable learning material to a learner based on different learner characteristics. The instructor found out the appropriate learning resources and annotated them based on the IEEE LOM specification for this work. The annotated LO characteristics are loaded into the LearningMaterial class of the ontology.
In this work, ontologies are mainly utilized for knowledge representation and tracking learning paths. The domain ontology has been built with the necessary learner and LO attributes required for the content recommendation in PLEs. The ontology learns how a learner progresses through the LMS, and this information is utilized to generate recommendations to the target learner in cold-start conditions. Appropriate learner groups have to be extracted from the ontologies and inputted to the OB recommender system to make relevant recommendations in the cold-start conditions. Once the similar learners are identified, the learning paths (includes ratings) of existing learners are utilized in the recommendation engine to generate the cold-start recommendations. This paper addresses both the pure and partial cold-start problems by applying the collaborative and content-based filtering techniques against the constructed domain ontology.
3.3 Learner and learning object modeling
An effective learner and learning object model is essential in any e-learning content RS. In this study, ontologies are used for modeling both learner and learning objects.
3.3.1 Learner modeling
The learner profile is practically the standard representation of learner's data that can be gathered in two ways: directly from the learner or by analyzing his/her behavior through an LMS. If the details are gathered directly from the learner, the profile made is called explicit or static. Whereas if this information is collected by observing the learner's behavior in an LMS, then the profile created is known as the implicit or dynamic profile. A good learner profile can be effortlessly adjusted for every learner according to his/her preferences. Sheeba and Krishnan (2016) proposed an approach to construct an ontology-based learner profile for achieving effective information retrieval. The sophisticated representation of static and dynamic learner characteristics is an advantage of their learner model. Their methodology includes a decision tree classifier to classify the learning styles automatically. The experimental evaluation reveals enhanced performance with an ontological representation of the learner profile. Nafea et al. (2016) proposed an adaptive learner profile based on learning styles by analyzing the learning patterns through an LMS. The theoretical base for building their learner profile is the Felder-Silverman Learning Style Model (FSLSM) and Myers-Briggs Type Indicator (MBTI) theory. Chen et al. (2014) considered background knowledge and learner history along with learning style for learner modeling. The limitation of their learner profile is its static nature. The learner model proposed by Klašnja-Milićević et al. (2011) in a personalized e-learning system considered the learner interests, habits and knowledge levels. Their strategy is capable of recognizing different patterns of learners' habits through mining server logs. Tarus et al. (2017) included the learners' learning style with knowledge level in their learner model. Since the required data for building the learner profile is collected through questionnaires alone, the dynamicity of learner modeling is lacking in their recommendation model.
For building our learner model, we have considered the learner parameters learning style and knowledge level. Along with these learner parameters, each learner's learning path is stored in the ontology to provide dynamicity in the learner profile. FSLSM learning style model is opted for this work due to its probabilistic nature and wide acceptance in the e-learning domain. Most other learning style models classify learners into a few groups, whereas FSLSM distinguishes between the preferences on four learning dimensions and describes more about the learning style (Graf et al., 2007).
3.3.2 Learning object modeling
The terms learning content, learning resource and learning objects are interchangeably used in e-learning scenarios. LOs are small, self-contained and reusable units that represent learning materials. The IEEE Learning Technology Standards Committee (LTSC) describes LOs as "any entity, digital or non-digital, which can be used, reused or referenced during technology supported learning". The concept of learning objects came about from the need to create highly structured e-learning content with pedagogical aspects that can be reused in different learning scenarios (Atif et al., 2003). Learning contents presented according to learner preferences are effective in enhancing the learning experience and outcomes in adaptive e-learning systems (Premlatha & Geetha, 2015). Wiley (2000) classifies the LOs into five groups as follows:
-
1.
Fundamental LO: Content included either as an image (JPEG, GIF or other), a document (DOC, PPT, PDF, etc.), a movie (MPEG, AVI etc.); or any other file.
-
2.
Combined-closed LO: Example- a video with accompanying audio.
-
3.
Combined-open LO: Example- an (external) link to a web page, dynamically combining JPEG with textual material.
-
4.
Generative-presentation LO: Example- a JAVA applet;
-
5.
Generative-instructional LO: Example, an EXECUTE instructional transaction shell, which instructs and provides practice for any procedure type.
The characteristics to be considered to create qualitative LOs are(Holzinger et al., 2006; Wiley, 2000):
-
1.
Must be much shorter than traditional learning units, typically ranging from 2 to 15 min;
-
2.
Must be self-containing: each learning object can be used independently;
-
3.
Must be tagged with metadata, which contains descriptive information allowing it to be easily found;
-
4.
Can be aggregated: learning objects can be grouped into larger content collections, including traditional course structures13.
Ontologies are widely used for metadata modeling of LOs (especially with the IEEE LOM standard) in e-learning applications (Ciloglugil & Inceoglu, 2016). Al-Yahya et al. (2015) discussed how ontologies help to extract relevant information when the information is retrieved based on the learning objects' semantics. Raju and Ahmed (2012) describe a model for representing a learning object repository using ontologies. The developed domain ontology stores annotated LOs, resulting in a discoverable and reusable learning object. Sosnovsky et al. (2012) used ontology in their personalized recommender system for storing adaptively annotated learning material. The annotation level for the recommended learning material is computed as a weighted aggregate of knowledge levels for all concepts mapped into the topic. Cakula and Sedleniece (2013) tried to identify the overlapping points between e-learning phases and knowledge management to improve the delivery of personalized learning materials. In most OB content recommenders, the learning materials are also stored in ontologies to efficiently map with it with the learner characteristics (Pukkhem, 2014; Fraihat & Shambour, 2015; Tarus et al., 2017). By using effective methods of ontology and metadata, the e-learning resources can be easily customized, and personalization can be achieved.
For building our LO model, we have considered all the attributes that come under the educational category of IEEE LOM standard (structure, format, interactivity type, interactivity level, learning resource type and difficulty). An LO can have more than one data value corresponding to the six LO properties. For example, the format of an LO can be 'video', interactivity type can be 'mixed' and learning resource type can be 'lecture'. For the current study, a wide range of LOs (Audio, Video, PDF, PPT, Web links) having different properties are collected and annotated in IEEE LOM format.
3.4 Computing similarities
The learner and LO similarity computation are vital in collaborative and content-based filtering techniques. Two similarity measures are considered for this study; (1) similarity between the learners and (2) similarity between the learning objects. In the pure cold-start condition (zero ratings), only the learner similarity is considered, while in the case of partial cold-start condition (very few ratings available) both learner and learning object similarity computations are utilized in the recommendation algorithm.
In computing the learner's similarities, only the ontology domain knowledge is considered. The learner parameters considered for the similarity computation are learning style and background knowledge. The parameters considered for computing LO similarity are structure, format, interactivity type, interactivity level, learning resource type and difficulty. Each of these attributes can hold different values, as shown in Table 1.
In this study, the similarity between the learners and learning objects are calculated using cosine similarity. The existing studies have proven that cosine similarity gives better recommender performance in the e-learning domain (Tarus et al., 2018). Also, there is no chance of occurring missing values in the input dataset, and therefore cosine similarity can produce accurate results during parameter comparison (Adomavicius & Kwon, 2007). The cosine similarity between two vectors is calculated using Eq. 1.
The next step is to compute the nearest neighbours' predictions and generate the top N recommendation list for the target learner.
3.5 Generating top N recommendation list of LOs
The proposed recommendation model generates the top N recommendation list of learning objects for the target learner based on:
-
Ontological domain knowledge about the learner and learning objects
-
Rating given to a learning object by the target learner
-
Rating given to a learning object by other similar learners
The new recommendation problem can be formulated in two different ways in pure cold-start and partial cold-start conditions as follows.
3.5.1 In pure cold-start condition
In the pure-cold start condition, the inputs to the recommendation engine are ontological domain knowledge and ratings given to a learning object by other similar learners.
Let 'L' denote the set of all learners L = {\({\mathrm{l}}_{1}\),\({\mathrm{l}}_{2}\dots\),\({\mathrm{l}}_{\mathrm{m}}\)}, let 'LO' denotes the possible subset of learning objects LO = {\({\mathrm{lo}}_{1},{\mathrm{lo}}_{2}\dots , {\mathrm{lo}}_{\mathrm{n}}\)} that can be recommended (LO contains only the learning objects included for a particular topic requested by learner l). Let 'O' be the set of all ontological domain knowledge O = {\({\mathrm{o}}_{1},{\mathrm{o}}_{2}\dots , {\mathrm{o}}_{\mathrm{p}}\)} about the learner and learning objects. The ratings given to a learning object by the learners are indicated as 'r'. The possible rating values are measured on a numerical scale from 1 to 5 (1- poor, 2-average, 3- good, 4- very good, 5-excellent). Let f be the recommendation function of L, LO and O. The top N refers to the sets of learning objects recommended by the recommendation engine. The recommendation function can thus be expressed as:
The top N list of learning objects for the target learner is generated based on the ratings given to the learning objects (in the subset LO) by the most similar learners. Algorithm 1 indicates how the top N recommendation list is generated for the target learner in pure cold-start condition. A collaborative filtering technique that uses the historical ratings (historical ratings of similar learners) is adopted in this algorithm.
Algorithm 1 Generating top N recommendation list in pure cold-start condition

3.5.2 In partial cold-start condition
In the partial cold start condition, historical ratings are available for the target learner, but the number of ratings available is less. For this study, all the learners who have rated 20 or less learning objects are considered as cold-start learners. Here, the ratings given to the LOs by the target learner are additional inputs to the recommendation algorithm. A content-based filtering technique is applied in the recommendation engine by computing the similarity between LOs and choosing the most similar LOs from the LO subset that matches the target learner's LO preference. The recommendation list based on LO similarity can be generated by Algorithm 2.
Algorithm 2 Generating recommendation list in partial cold-start condition

For example, let LO1 is the subset of learning objects rated (3 and above) by the target learner, and LO2 is the subset that contains all the LOs of the requested topic.
Recommendation list = {most similar LO from LO2 with \({\mathrm{lo}}_{21}\), most similar LO of LO2 with \({\mathrm{lo}}_{26}\), most similar LO of LO2 with \({\mathrm{lo}}_{17}\)}. The most similar learning object with the highest-rated learning object by the target learner will come in the first position of the recommendation list. The final top N recommendations are generated by combining the recommendation list (obtained by Algorithm 2) with the top N list obtained using Algorithm 1 (pure cold-start condition). The details of the experiments conducted and the analysis of the results are presented in the subsequent section.
4 Experiments and results
To evaluate the proposed recommendation model's effectiveness in cold-start conditions, experiments were carried out in different input conditions. The primary goal of the experiments was to measure the performance, enhancement in quality of recommendations in pure and partial cold-start conditions.
4.1 Experimental setup
The initial learner dataset consists of 300 students' data with 8200 LO ratings. The learner data is collected from two state universities in India- Cochin University of Science and Technology (CUSAT) and APJ Abdul Kalam Technological University (KTU). The initial learner dataset contains data collected from undergraduate and postgraduate students undergoing Computer Science and Information Technology courses in the two universities. Initially, the learner attributes that include background knowledge and FSLSM learning styles are collected and uploaded into the Learner ontology. The learner's FSLSM learning style is identified using the Learning Styles Index (ILS), developed by Soloman and Felder (Soloman & Felder, 2005). The ILS includes 44 questions to determine the four learning dimensions corresponding to the FSLSM learning style. The four learning dimensions' probabilistic values are calculated by evaluating the ILS questionnaire, as explained in the literature (Graf & Kinshuk, 2007). The next step was to collect the required LOs for the study. Four hundred and sixty-eight learning objects are collected on two core Computer Science subjects, Data Structures and Data Mining. The collected LOs were annotated in the IEEE LOM standard by the experts and uploaded into the LearningMaterial ontology through the instructor interface of the developed LMS. Later, when the learner logs in to the LMS, recommendations were generated for each learner for the selected learning topic. The learners were asked to go through the recommended learning topics and rate them on a 5 point rating scale (1- poor, 2-average, 3-good, 4- very good, 5-excellent) based on their satisfaction level and relevance of the recommended LO. Over a period of 4 months, the initial dataset consists of 8200 ratings from 300 learners are collected.
For conducting the experiments in cold-start conditions, 45 new learners of the third-year undergraduate students of Computer Science branch are selected. The initial learner attributes are collected from the new learners at the time of registration in the LMS portal. When a new learner logs into the LMS, the learner has to choose a subject for studying. Depending on the subject selected, all the learning topics come under the selected subject are listed on the learner interface page. When the learner chooses a particular topic, the cold-start recommendations are generated for the new learner by running the recommendation algorithms against the domain ontology that consist of 300 learner profiles and 8200 LO ratings. It was mandatory to rate all the LOs that the learners had undergone. The recommendations suggested to the learners for the very first learning topic are considered as the pure cold-start recommendation. For this study, the first 25 recommendations given to the learner are considered as cold-start recommendations. The number of recommendations generated for each learning topic varies depending on the matching LOs available in the LearningMaterial Ontology. For most cases, the cold-start threshold (25) is achieved within recommendations created for the first five learning topics.
4.2 Description of dataset
Our dataset is a real-world dataset that contains 300 students' data. The dataset was collected within four months. Table 2 illustrates the detailed description of the dataset used for the experimentations.
4.3 Results and discussion
In this sub-section, the experimental results of the proposed ontology-based recommendation algorithms (CF + Ontology, CF + CB + Ontology) are discussed and compared with those of the traditional CF algorithm. For conducting experiments of e-learning recommender systems, the availability of public datasets is very rare (Manouselis et al., 2011). Therefore, it is difficult to compare different studies' performance results in e-learning recommender systems with the required accuracy. The main focus of experiments in e-learning RSs is to evaluate the accuracy of predictions and performance of the RS. In this study, the following evaluations were done.
-
Prediction accuracy with neighbourhood size
-
Prediction accuracy with different thresholds of rating values
-
Performance of algorithms in terms of Precision and Recall
-
Learner satisfaction in terms of ratings.
4.3.1 Prediction accuracy with neighbourhood size
The size of the neighbourhood plays a vital role in determining the quality of predictions in RSs (Chen et al., 2016). Mean Absolute Error (MAE) and Normalized Mean Absolute Error (NMAE) are two standard and well-established methods for measuring the quality of predictions. In this study, we have used MAE to compare the prediction accuracy with different neighbourhood sizes. MAE measures the average deviation between the predicted and the actual ratings (Shani & Gunawardana, 2011). The lower value of MAE indicates a more accurate prediction. Equation 2 is used to compute the MAE.
where,
- PRi:
-
Predicted rating for the learning object i
- ARi:
-
Actual rating for the learning object i
- N:
-
Total number of cases
In this work, experiments were carried out with neighbourhood size varying from 5 to 30. Figure 3 shows how prediction accuracy varies with the size of the neighbourhood. The figure shows a marginal difference in the prediction accuracy for the proposed algorithms compared with the CF technique. In the case of proposed algorithms, the prediction accuracy is highest when the neighbourhood size is 20. But when the CF technique is used, the accuracy is highest when the neighbourhood size is 25. When the neighbourhood size further increases, the prediction accuracy decreases for all three algorithms. For the proposed algorithms, as the number of neighbours increases from 5 to 20, the MAE decreases gradually (CF + Ontology-0.80 to 0.61, CF + CB + Ontology- 0.79 to 0.58).

Prediction accuracy with neighbourhood size
4.3.2 Prediction accuracy with different thresholds of rating values
In the partial cold-start condition, the learning object similarity is computed and applied in the CB recommendation logic. We have considered the LOs (rated by the target learner) with ratings three and above (good to excellent) for calculating the object similarity. In this sub-section, the experiments conducted to find how recommendation accuracy varies with the number of rated learning materials with different thresholds (r = 3, 4, 5) are presented. Figure 4 shows how recommendation accuracy varies for different thresholds of rating values. From the plot, it is understood that when the threshold value is 3, the predicted accuracy gradually increases as the number of learning objects (N) increases. But in the case of threshold values 4 and 5, the accuracy increases progressively and becomes stable when the number of learning materials reaches 15. Therefore, if highly-rated learning objects are available, reliable predictions can be obtained with a small number of LOs. The MAE values obtained for different threshold values are also consolidated in Table 3.

Prediction accuracy with number of learning objects
The MAE values obtained for different neighbourhood sizes (N = 5, optimum value and 30) and LOs with varying values of threshold are consolidated in the Table 3. The MAE values indicate that the proposed algorithms outperform the conventional CF technique in cold-start conditions for all sizes of neighbourhoods.
4.3.3 Performance of algorithms in terms of precision and recall
The commonly used evaluation matrices in RSs for information retrieval are precision, recall and f-measure (Shani & Gunawardana, 2011). Precision is calculated as the ratio of relevant recommendations to total recommendations made by the RS. A recommendation is considered to be relevant if the recommended LO is liked by the learner. The recall is a measure to calculate RS's ability to recommend irrelevant learning objects as few as possible. It is the ratio of relevant recommendations made to the user to total relevant recommendations. The precision and recall calculation is easily understood by the \(2\times 2\) contingency table as shown in Table 4. Precision and recall can be calculated using Eqs. 3 and 4 respectively.
In this study, learning objects rated 1 and 2 are considered as irrelevant while LOs rated 3 and above are considered as relevant. Figures 5 and 6 show how the performance of the proposed algorithms in terms of precision and recall varies with the number of recommendations. The experiment was conducted many times with a varying number of recommendations in both cases. The figure shows that the proposed algorithms outperform the conventional collaborative technique with both measures.

Performance in terms of precision

Performance in terms of recall
4.3.4 Learner satisfaction based on ratings
The learner satisfaction is measured by using the ratings given to the learning objects by the 45 participants of the experiments. To evaluate learner satisfaction, we have considered 100 ratings given to the LOs by 45 learners with the three recommendation approaches. Figure 7 illustrates the satisfaction level of learners with the recommendations given by the three methods. The survey tells that 89% of learners are satisfied with the LO recommendations generated by the proposed CF + CB + ontology model and 77% are satisfied with the recommendations made by CF + Ontology approach. The percentage of learners satisfied with the LO recommendations created by CF technique is 61%. The number of individual ratings obtained for each model is consolidated in Table 5.

User satisfaction based on LO ratings
Different experimental calculations are made to evaluate the accuracy and performance of the proposed ontology-based algorithms. The computed data show that the proposed algorithms provide better performance in both pure and partial cold start conditions. The proposed approach overcomes the cold-start problem by integrating ontological domain knowledge while initializing the learner profile in the recommendation process. The recommendation engine will use this domain knowledge in computing learner and learning object similarities and predict learner preferences. The proposed model incorporates the learner characteristics learning style, knowledge level and qualification along with the learner ratings in the recommendation process and thereby generating more personalized recommendations. Furthermore, the learner satisfaction achieved by the proposed model is commendable.
5 Conclusion and future works
In this paper, we propose an ontology-based e-learning content recommender system to address the cold-start problem. The proposed approach incorporates collaborative and content-based filtering techniques in the recommendation process. Ontology is used to store the domain knowledge about the learner and learning objects and the learning history of each learner. The experimental results show that the performance and accuracy of proposed algorithms are better in the cold-start conditions. Furthermore, the proposed algorithm generates more reliable and personalized recommendations by using ontological domain knowledge and historical ratings of learners in the RS.
Our future work will emphasize more on learners' behavioral analysis in the LMS and integrating the new technologies such as machine learning and deep learning in the recommendation process to achieve better performance and more personalized recommendations.
Data availability
The datasets used and/or analyzed during the current study are available from the authors on reasonable request.
References
Adomavicius, G., & Kwon, Y. (2007). New recommendation techniques for multicriteria rating systems. IEEE Intelligent Systems, 22(3), 48–55.
Aeiad, E., & Meziane, F. (2019). An adaptable and personalised E-learning system applied to computer science programmes design. Education and Information Technologies, 24(2), 1485–1509.
Al-Yahya, M., George, R., & Alfaries, A. (2015). Ontologies in e-learning: Review of the literature. International Journal of Software Engineering and its Applications, 9(2), 67–84.
Atif, Y., Benlamri, R., & Berri, J. (2003). Learning objects based framework for self-adaptive learning. Education and Information Technologies, 8(4), 345–368.
Bahmani, A., Sedigh, S., & Hurson, A. (2012). Ontology-based recommendation algorithms for personalized education. In International Conference on Database and Expert Systems Applications (pp. 111–120). Springer.
Bajenaru, L., Borozan, A. M., & Smeureanu, I. (2015). Using ontologies for the e-learning system in healthcare human resources management. InformaticaEconomica, 19(2), 15.
Barjasteh, I., Forsati, R., Ross, D., Esfahanian, A. H., & Radha, H. (2016). Cold-start recommendation with provable guarantees: A decoupled approach. IEEE Transactions on Knowledge and Data Engineering, 28(6), 1462–1474.
Barragáns-Martínez, A. B., Costa-Montenegro, E., Burguillo, J. C., Rey-López, M., Mikic-Fonte, F. A., & Peleteiro, A. (2010). A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition. Information Sciences, 180(22), 4290–4311.
Benhamdi, S., Babouri, A., & Chiky, R. (2017). Personalized recommender system for e-learning environment. Education and Information Technologies, 22(4), 1455–1477.
Bhaskaran, S., & Santhi, B. (2019). An efficient personalized trust based hybrid recommendation (tbhr) strategy for e-learning system in cloud computing. Cluster Computing, 22(1), 1137–1149.
Bobadilla, J., Ortega, F., Hernando, A., & Gutiérrez, A. (2013). Recommender systems survey. Knowledge-Based Systems, 46, 109–132.
Bouihi, B., & Bahaj, M. (2017). An ontology-based architecture for context recommendation system in E-learning and mobile-learning applications. In 2017 International Conference on Electrical and Information Technologies (ICEIT) (pp. 1–6). IEEE.
Bourkoukou, O., & El Bachari, E. (2016). E-learning personalization based on collaborative filtering and learner’s preference. Journal of Engineering Science and Technology, 11(11), 1565–1581.
Bourkoukou, O., El Bachari, E., & El Adnani, M. (2017). A recommender model in e-learning environment. Arabian Journal for Science and Engineering, 42(2), 607–617.
Buder, J., & Schwind, C. (2012). Learning with personalized recommender systems: A psychological view. Computers in Human Behavior, 28(1), 207–216.
Buitrago, M., & Chiappe, A. (2019). Representation of knowledge in digital educational environments: A systematic review of literature. Australasian Journal of Educational Technology, 35(4).
Burke, R. (2007). Hybrid web recommender systems. In The adaptive web (pp. 377–408). Springer.
Cakula, S., & Sedleniece, M. (2013). Development of a personalized e-learning model using methods of ontology. Procedia Computer Science, 26, 113–120.
Chen, H., Cui, X., & Jin, H. (2016). Top-k followee recommendation over microblogging systems by exploiting diverse information sources. Future Generation Computer Systems, 55, 534–543.
Chen, W., Niu, Z., Zhao, X., & Li, Y. (2014). A hybrid recommendation algorithm adapted in e-learning environments. World Wide Web, 17(2), 271–284.
Ciloglugil, B., & Inceoglu, M. M. (2016). Ontology usage in e-learning systems focusing on metadata modeling of learning objects. In International Conference on New Trends in Education, ICNTE, pp. 80–96.
Deschênes, M. (2020). Recommender systems to support learners' agency in a learning context: A systematic review. International Journal of Educational Technology in Higher Education, 17(1), 1–23.
Dwivedi, P., & Bharadwaj, K. K. (2013). Effective trust-aware e-learning recommender system based on learning styles and knowledge levels. Journal of Educational Technology & Society, 16(4), 201–216.
Dwivedi, P., Kant, V., & Bharadwaj, K. K. (2018). Learning path recommendation based on modified variable length genetic algorithm. Education and Information Technologies, 23(2), 819–836.
Essalmi, F., Ayed, L. J. B., Jemni, M., & Graf, S. (2010). A fully personalization strategy of e-learning scenarios. Computers in Human Behavior, 26(4), 581–591.
Felder, R. M., & Silverman, L. K. (1988). Learning and teaching styles in engineering education. Engineering Education, 78(7), 674–681.
Fraihat, S., & Shambour, Q. (2015). A framework of semantic recommender system for e-learning. Journal of Software, 10(3), 317–330.
George, G., & Lal, A. M. (2019). Review of ontology-based recommender systems in e-learning. Computers & Education, 142, 103642.
Graf, S., & Kinshuk, K. (2007). Providing adaptive courses in learning management systems with respect to learning styles. In E-Learn: World Conference on E-Learning in Corporate, Government, Healthcare, and Higher Education (pp. 2576–2583). Association for the Advancement of Computing in Education.
Graf, S., Viola, S. R., Leo, T., & Kinshuk. (2007). In-depth analysis of the felder-silverman learning style dimensions. Journal of Research on Technology in Education, 40(1), 79–93.
Gruber, T. R. (1993). A translation approach to portable ontology specifications. Knowledge Acquisition, 5(2), 199–221.
Harrathi, M., Touzani, N., & Braham, R. (2017). A hybrid knowlegde-based approach for recommending massive learning activities. In 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA) (pp. 49–54). IEEE.
Holzinger, A., Smolle, J., & Reibnegger, G. (2006). An object-oriented approach to manage e-learning content using learning objects. In Handbook of research on informatics in healthcare and biomedicine (pp. 89–98).
IEEE-LTSC. (2010). IEEE P1484.12.1–2002/Cor 1/D14. Draft standard for learning object metadata — corrigendum 1: corrigenda for 1484.12.1 LOM (learning object metadata), IEEE Learning Technology Standards Committee.
Jannach, D., Zanker, M., Felfernig, A., & Friedrich, G. (2010). Recommender systems: An introduction. Cambridge University Press.
Joy, J., Raj, N. S. & Renumol V.G. (2019). An ontology model for content recommendation in personalized learning environment. In Proceedings of the Second International Conference on Data Science, E-Learning and Information Systems (pp. 1–6). ACM.
Kamal, A., & Radhakrishnan, S. (2019). Individual learning preferences based on personality traits in an e-learning scenario. Education and Information Technologies, 24(1), 407–435.
Karga, S., & Satratzemi, M. (2018). A hybrid recommender system integrated into LAMS for learning designers. Education and Information Technologies, 23(3), 1297–1329.
Khanal, S. S., Prasad, P. W. C., Alsadoon, A., & Maag, A. (2019). A systematic review: Machine learning based recommendation systems for e-learning. Education and Information Technologies, 25(4), 2635–2664.
Kilani, Y., Alhijawi, B., & Alsarhan, A. (2018). Using artificial intelligence techniques in collaborative filtering recommender systems: Survey. International Journal of Advanced Intelligence Paradigms, 11(3–4), 378–396.
Kim, S. C., Sung, K. J., Park, C. S., & Kim, S. K. (2016). Improvement of collaborative filtering using rating normalization. Multimedia Tools and Applications, 75(9), 4957–4968.
Klašnja-Milićević, A., Vesin, B., Ivanović, M., & Budimac, Z. (2011). E-learning personalization based on hybrid recommendation strategy and learning style identification. Computers & Education, 56(3), 885–899.
Klašnja-Milićević, A., Ivanović, M., & Nanopoulos, A. (2015). Recommender systems in e-learning environments: A survey of the state-of-the-art and possible extensions. Artificial Intelligence Review, 44(4), 571–604.
Klašnja-Milićević, A., Ivanović, M., Vesin, B., & Budimac, Z. (2018). Enhancing e-learning systems with personalized recommendation based on collaborative tagging techniques. Applied Intelligence, 48(6), 1519–1535.
Kolekar, S. V., Pai, R. M., & ManoharaPai, M. M. (2019). Rule based adaptive user interface for adaptive e-learning system. Education and Information Technologies, 24(1), 613–641.
Lam, X. N., Vu, T., Le, T. D., & Duong, A. D. (2008). Addressing cold-start problem in recommendation systems. In Proceedings of the 2nd international conference on Ubiquitous information management and communication (pp. 208–211).
Lika, B., Kolomvatsos, K., & Hadjiefthymiades, S. (2014). Facing the cold start problem in recommender systems. Expert Systems with Applications, 41(4), 2065–2073.
Manouselis, N., Drachsler, H., Vuorikari, R., Hummel, H., & Koper, R. (2011). Recommender systems in technology enhanced learning. In Recommender systems handbook (pp. 387–415). Springer.
Mobasher, B. (2007). Data mining for web personalization. In The adaptive web (pp. 90–135). Springer.
Murad, D. F., Heryadi, Y., Isa, S. M., & Budiharto, W. (2020). Personalization of study material based on predicted final grades using multi-criteria user-collaborative filtering recommender system. Education and Information Technologies, 25, 5655–5668.
Nafea, S., Maglaras, L. A., Iewe, F., Smith, R., & Janicke, H. (2016). Personalized students’ profile based on ontology and rule-based reasoning. EAI Endorsed Transactions on E-Learning, 3(12), 151720.
Nafea, S. M., Siewe, F., & He, Y. (2019). On recommendation of learning objects using felder-silverman learning style model. IEEE Access, 7, 163034–163048.
Najafabadi, M. K., & Mahrin, M. N. R. (2016). A systematic literature review on the state of research and practice of collaborative filtering technique and implicit feedback. Artificial intelligence review, 45(2), 167–201.
Natarajan, S., Vairavasundaram, S., Natarajan, S., & Gandomi, A. H. (2020). Resolving data sparsity and cold start problem in collaborative filtering recommender system using linked open data. Expert Systems with Applications, 149, 113248.
Ouf, S., Ellatif, M. A., Salama, S. E., & Helmy, Y. (2017). A proposed paradigm for smart learning environment based on semantic web. Computers in Human Behavior, 72, 796–818.
Park, S. T., Pennock, D., Madani, O., Good, N., & DeCoste, D. (2006). Naïve filterbots for robust cold-start recommendations. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 699–705).
Pazzani, M. J., & Billsus, D. (2007). Content-based recommendation systems. In The adaptive web (pp. 325–341). Springer.
Premlatha, K. R., & Geetha, T. V. (2015). Learning content design and learner adaptation for adaptive e-learning environment: a survey. Artificial Intelligence Review, 44(4), 443–465.
Pukkhem, N. (2013). Ontology-based semantic approach for learning object recommendation. International Journal on Information Technology, 3(4), 12.
Pukkhem, N. (2014). LORecommendNet: an ontology-based representation of learning object recommendation. In Recent Advances in Information and Communication Technology (pp. 293–303). Springer.
Raju, P., & Ahmed, V. (2012). Enabling technologies for developing next-generation learning object repository for construction. Automation in Construction, 22, 247–257.
Ranjbar, M., Moradi, P., Azami, M., & Jalili, M. (2015). An imputation-based matrix factorization method for improving accuracy of collaborative filtering systems. Engineering Applications of Artificial Intelligence, 46, 58–66.
Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to recommender systems handbook. In Recommender systems handbook (pp. 1–35). Springer.
Romero, L., Saucedo, C., Caliusco, M. L., & Gutiérrez, M. (2019). Supporting self-regulated learning and personalization using ePortfolios: a semantic approach based on learning paths. International Journal of Educational Technology in Higher Education, 16(1), 16.
Ruiz-Iniesta, A., Jimenez-Diaz, G., & Gomez-Albarran, M. (2014). A semantically enriched context-aware OER recommendation strategy and its application to a computer science OER repository. IEEE Transactions on Education, 57(4), 255–260.
Safoury, L., & Salah, A. (2013). Exploiting user demographic attributes for solving cold-start problem in recommender system. Lecture Notes on Software Engineering, 1(3), 303–307.
Saleena, B., & Srivatsa, S. K. (2015). Using concept similarity in cross ontology for adaptive e-learning systems. Journal of King Saud University-Computer and Information Sciences, 27(1), 1–12.
Salehi, M., Kamalabadi, I. N., & Ghoushchi, M. B. G. (2013). An effective recommendation framework for personal learning environments using a learner preference tree and a GA. IEEE Transactions on Learning Technologies, 6(4), 350–363.
Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2001). Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web (pp. 285–295).
Schafer, J. B., Frankowski, D., Herlocker, J., & Sen, S. (2007). Collaborative filtering recommender systems. In The adaptive web (pp. 291–324). Springer.
Schein, A. I., Popescul, A., Ungar, L. H., & Pennock, D. M. (2002). Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual international ACM SIGIR conference on research and development in information retrievaz (pp. 253–260).
Senthilnayaki, B., Venkatalakshmi, K., & Kannan, A. (2015). An ontology based framework for intelligent web based e-learning. International Journal of Intelligent Information Technologies (IJIIT), 11(2), 23–39.
Shani, G., & Gunawardana, A. (2011). Evaluating recommendation systems. In Recommender systems handbook (pp. 257–297). Springer.
Shaw, G., Xu, Y., & Geva, S. (2010). Using association rules to solve the cold-start problem in recommender systems. In Pacific-Asia conference on knowledge discovery and data mining (pp. 340–347). Springer.
Sheeba, T., & Krishnan, R. (2016). An ontological framework of semantic learner profile in an e-learning system. International Conference on Brain Inspired Cognitive Systems. (pp. 284–297). Springer.
Shishehchi, S., Banihashem, S. Y., Zin, N. A. M., Noah, S. A. M., & Malaysia, K. (2012). Ontological approach in knowledge based recommender system to develop the quality of e-learning system. Australian Journal of Basic and Applied Sciences, 6(2), 115–123.
Silva, N., Carvalho, D., Pereira, A. C., Mourão, F., & Rocha, L. (2019). The pure cold-start problem: A deep study about how to conquer first-time users in recommendations domains. Information Systems, 80, 1–12.
Soloman, B. A., & Felder, R. M. (2005). Index of learning styles questionnaire. NC State University. Available online at: http://www.engr.ncsu.edu/learningstyles/ilsweb.html. Accessed 14 May 2010, 70.
Son, L. H. (2016). Dealing with the new user cold-start problem in recommender systems: A comparative review. Information Systems, 58, 87–104.
Sosnovsky, S., Hsiao, I. H., & Brusilovsky, P. (2012). Adaptation “in the Wild”: ontology-based personalization of open-corpus learning material. European Conference on Technology Enhanced Learning. (pp. 425–431). Springer.
Tarus, J. K., Niu, Z., & Yousif, A. (2017). A hybrid knowledge-based recommender system for e-learning based on ontology and sequential pattern mining. Future Generation Computer Systems, 72, 37–48.
Tarus, J. K., Niu, Z., & Mustafa, G. (2018). Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artificial intelligence review, 50(1), 21–48.
Vanitha, V., & Krishnan, P. (2019). A modified ant colony algorithm for personalized learning path construction. Journal of Intelligent & Fuzzy Systems, 37(5), 6785–6800.
Victor, P., De Cock, M., Cornelis, C., & Teredesai, A. M. (2008). Getting cold start users connected in a recommender system's trust network. In Computational Intelligence in Decision and Control (pp. 877–882).
Wiley, D. A. (2000). Connecting learning objects to instructional design theory: A definition, a metaphor, and a taxonomy. The instructional use of learning objects, 2830(435), 1–35.
Wongchokprasitti, C., Peltonen, J., Ruotsalo, T., Bandyopadhyay, P., Jacucci, G., & Brusilovsky, P. (2015). User model in a box: Cross-system user model transfer for resolving cold start problems. In International Conference on User Modeling, Adaptation, and Personalization (pp. 289–301). Springer.
Yang, S. Y. (2010). Developing an ontology-supported information integration and recommendation system for scholars. Expert Systems with Applications, 37(10), 7065–7079.
Yao, L., Sheng, Q. Z., Ngu, A. H., Yu, J., & Segev, A. (2014). Unified collaborative and content-based web service recommendation. IEEE Transactions on Services Computing, 8(3), 453–466.
Zhang, Z. K., Liu, C., Zhang, Y. C., & Zhou, T. (2010). Solving the cold-start problem in recommender systems with social tags. EPL (Europhysics Letters), 92(2), 28002.
Zhao, X., Niu, Z., Chen, W., Shi, C., Niu, K., & Liu, D. (2015a). A hybrid approach of topic model and matrix factorization based on two-step recommendation framework. Journal of Intelligent Information Systems, 44(3), 335–353.
Zhao, X., Niu, Z., Wang, K., Niu, K., & Liu, Z. (2015b). Improving top-N recommendation performance using missing data. Mathematical Problems in Engineering, 2015.
Zhong, J., Xie, H. & Wang, F.L. (2019). The research trends in recommender systems for e-learning: A systematic review of SSCI journal articles from 2014 to 2018. Asian Association of Open Universities Journal, 14(1), 12–27.
Zhuhadar, L., & Nasraoui, O. (2010). A hybrid recommender system guided by semantic user profiles for search in the e-learning domain. Journal of Emerging Technologies in Web Intelligence, 2(4), 272–281.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jeevamol, J., Renumol, V.G. An ontology-based hybrid e-learning content recommender system for alleviating the cold-start problem. Educ Inf Technol 26, 4993–5022 (2021). https://doi.org/10.1007/s10639-021-10508-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10639-021-10508-0