
Abstract
The augmented Lagrangian method (ALM) provides a benchmark for solving the canonical convex optimization problem with linear constraints. The direct extension of ALM for solving the multiple-block separable convex minimization problem, however, is proved to be not necessarily convergent in the literature. It has thus inspired a number of ALM-variant algorithms with provable convergence. This paper presents a novel parallel splitting method for the multiple-block separable convex optimization problem with linear equality constraints, which enjoys a larger step size compared with the existing parallel splitting methods. We first show that a fully Jacobian decomposition of the regularized ALM can contribute a descent direction yielding the contraction of proximity to the solution set; then, the new iterate is generated via a simple correction step with an ignorable computational cost. We establish the convergence analysis for the proposed method, and then demonstrate its numerical efficiency by solving an application problem arising in statistical learning.
Similar content being viewed by others


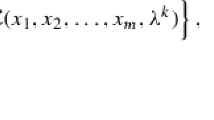
Avoid common mistakes on your manuscript.
1 Introduction
Our discussion starts with the following canonical convex minimization problem with linear equality constraints:
where \(\theta : \mathfrak {R}^{n}\rightarrow \mathfrak {R}\cup \{+\infty \}\) is a closed proper convex but not necessarily smooth function; \({{{\mathcal {X}}}}\subseteq \mathfrak {R}^{n}\) is a closed convex set; \({\mathcal {A}}\in \mathfrak {R}^{l\times n} \;\hbox {and} \; b\in \mathfrak {R}^{l}\). Among algorithms for solving (1.1), the augmented Lagrangian method (ALM) introduced in [24, 29] turns out to be a fundamental tool in both theoretical and algorithmic aspects, and its associated iterative scheme reads as
where
denotes the augmented Lagrangian function of (1.1); \(\lambda \in \mathfrak {R}^l\) is the Lagrange multiplier and \(\beta >0\) is a penalty parameter for the linear constraints. As analyzed in [30], the classic ALM is indeed an application of the proximal point algorithm (PPA) in [26] to the dual of (1.1). Throughout our discussion, the penalty parameter \(\beta\) is assumed to be fixed for simplification.
In this paper, we focus on a special case of (1.1), where its objective function is the sum of m subfunctions without coupled variables:
Here, \(\theta _i: \mathfrak {R}^{n_i}\rightarrow \mathfrak {R}\cup \{+\infty \} \;(i=1,\ldots ,m)\) are closed proper convex functions and they are not necessarily smooth; \({{{\mathcal {X}}}}_i\subseteq \mathfrak {R}^{n_i} \;(i=1,\ldots ,m)\) are closed convex sets; \(\sum _{i=1}^mn_i=n\); \(A_i\in \mathfrak {R}^{l\times n_i} \;(i=1,\ldots ,m)\;\hbox {and} \; b\in \mathfrak {R}^{l}\). Obviously, the model (1.3) corresponds to (1.1) with \(x=(x_1;\ldots ;x_m)\), \({\mathcal {A}}=(A_1,\ldots ,A_m)\) and \(\theta (x)=\sum _{i=1}^m\theta _i(x_i)\). In practice, the generic model (1.3) finds a multitude of applications in, e.g., [4, 31] for some image reconstruction problems, [32, 35] for the matrix recovery model and the Potts based image segmentation problem, and [5, 6, 33] for a number of problems arising in distributed optimization and statistical learning. We also refer to, e.g., [25, 34], for more applications in other communities. Throughout our discussion, the solution set of (1.3) is assumed to be nonempty and the matrices \(A_i\;(i=1,\ldots ,m)\) are assumed to be full column-rank. In addition, we assume each \(x_i\)-subproblem
with any given \(q_i\in \mathfrak {R}^l\) and \(\beta >0\), has a closed-form solution or can be easily solved with a high precision (see, e.g., [27], for specific supported examples).
Applying the classical ALM (1.2) straightforwardly to (1.3), the resulting scheme then reads as
where
However, note there are coupled terms in the quadratic term \(\Vert \sum _{i=1}^mA_ix_i-b\Vert _2^2\). The \(x_i\)-subproblems (\(i=1,\ldots ,m\)) generally can not be tackled simultaneously. Exploiting the separable structure of the objective function \(\theta\), a common-used separable strategy for x-subproblem is the following Gaussian decomposition iterative scheme:
Clearly, each \(x_i\)-subproblem in (1.6) possesses the favorable composition (1.4) and can be treated individually. In particular, for the case \(m=2\), the method (1.6) corresponds to the classical alternating direction method of multipliers (ADMM) proposed in [9, 10], which is indeed an application of the Douglas-Rachford splitting method (see [8]). The generic scheme (1.6) is thus named the direct extension of ADMM (D-ADMM) in [7, 10]. For the case \(m\ge 3\), the D-ADMM has been shown to be empirically efficient for various applications, see, e.g., [28, 32] and references cited therein. However, a counterexample in [7] reveals that the D-ADMM (1.6) is not necessarily convergent. It has immediately inspired a number of works such as [11, 13, 17,18,19, 23, 25, 31,32,33]. Especially, the ADMM with Gaussian back substitution in [12, 17, 19], which needs only an additional back substitution step based on the D-ADMM, turns out to be a convergent yet numerically well-preforming method.
We now turn our attention to another common-used splitting strategy for the x-subproblem in the generic ALM scheme (1.2). Applying the full Jacobian-decomposition of x-subproblem to (1.2), it immediately leads to the following so-named direct extension of ALM (abbreviated as D-ALM):
It is obvious that each \(x_i\)-subproblem in the above D-ALM can be solved in a parallel way. In practice, there are many applications (see [36]) in the medical image processing field such as the Potts-model based image segmentation problem and its variants, can be solved efficiently by using the D-ALM. However, as analyzed in [14], the D-ALM is proved to be not necessarily convergent in theory. Let \(w:=(x_1;\ldots ;x_m;\lambda )\). To ensure the convergence, in [14], the authors regard first the output of the D-ALM as a predictor \({\tilde{w}}^k\) (i.e., \(({\tilde{x}}_1^k;\ldots ;{\tilde{x}}_m^k;{\tilde{\lambda }}^k):=(x_1^{k+1};\ldots ;x_m^{k+1};\lambda ^{k+1})\)), then the new iterate \(w^{k+1}\) is updated via
Since the modification is simple, the variant is also named the parallel splitting ALM (denoted by P-ALM) in [14]. It is easy to verify that, as the increase of m, the step size \(\alpha\) would be tiny (for example, if \(m=3\), then \(\alpha \in (0,0.268)\)), which would adversely affect the convergence efficiency in the real computations. In [18], by adding extra regularization terms to the D-ALM, it directly leads to the following parallel splitting ADMM-like scheme (denoted by PS-ADMM):
in which \(\tau >m-2\). Clearly, it would correspond to a huge regularization term (or equivalently, a tiny step size) as the increase of m. Recent works such as [15, 16, 20] have demonstrated that relaxation of regularization term allows a bigger step size to potentially accelerate the convergence. Hence, it is necessary to reduce such a regularization factor \(\tau\).
The primary purpose of the paper is to present a novel parallel splitting ALM-based algorithm for the multiple-block separable convex programming problem (1.3). More concretely, our new method begins with the following fully parallel regularized ALM-based scheme:
where \(\tau >(m-4)/4\). As can be seen easily, the scheme (1.7) possesses a fully parallel splitting structure for both \(x_i\)-subproblems (\(i=1,\ldots ,m\)) and \(\lambda\)-subproblem. It thus belongs to the category of parallel operator splitting schemes. Furthermore, as will be shown in Sect. 3.1, the scheme (1.7) can provide a descent direction yielding the contraction of proximity to the solution set of (1.3). It is thus inspired to generate the new iterate \(w^{k+1}\) via
where \(\alpha \in (0,1)\) and the correction matrix M will be defined in (2.11). Note that the step size \(\alpha\) is a constant. The correction step (1.8), as the initialization of next iteration, could be handled easily. Moreover, we give a more practical and succinct scheme (3.7) to replace the method (1.7)–(1.8) in Sect. 3.3.
The novel algorithm (1.7)–(1.8) enjoys great advantages in mainly two folds: first, compared with the P-ALM, the constant step size \(\alpha \in (0,1)\) can be taken more broadly; second, it reduces the regularization factor \(\tau\) from \((m-2)\) to \((m-4)/4\) compared with the PS-ADMM, so it provides a wider choice of the regularization term to potentially accelerate the convergence. Also, we show the global convergence of the proposed method, and then illustrate its efficiency by extensive numerical experiments.
The rest of the paper is organized as follows. In Sect. 2, we summarize some preliminaries and fundamental matrices, which will be useful for further analysis. Then, we propose the novel method in Sect. 3 and establish its convergence analysis in Sect. 4. The numerical efficiency of the proposed method is further demonstrated in Sect. 5. Some conclusions are drawn in Sect. 6.
2 Preliminaries
In this section, we summarize some preliminary results that will be used frequently throughout our discussion. The analysis of the paper is based on the following elementary lemma (its proof can be found in, e.g., [2]).
Lemma 1
Let \({{{\mathcal {X}}}} \subseteq \mathfrak {R}^n\) be a closed convex set, \(\theta (x)\) and \(\varphi (x)\) be convex functions. If \(\varphi (x)\) is differentiable on an open set which contains \({{{\mathcal {X}}}}\), and the solution set of the convex minimization problem \(\min \{\theta (x)+\varphi (x) \; | \; x\in {\mathcal {X}} \}\) is nonempty, then we have
if and only if
2.1 A variational characterization of (1.3)
To begin with, using the similar techniques in, e.g., [22], we show first how to stand for the optimality condition of (1.3) in the variational inequality context. By attaching the Lagrange multiplier \(\lambda \in \mathfrak {R}^l\) to the linear constraints, the Lagrange function of (1.3) reads as
and it is defined on the set \(\Omega :={\mathcal {X}}_1\times {\mathcal {X}}_2\times \cdots \times {\mathcal {X}}_m\times \mathfrak {R}^l\). Suppose the pair \((x_1^*,x_2^*,\ldots ,x_m^*,\lambda ^*)\in \Omega\) is a saddle point of (2.1). Then, for any \(\lambda \in \mathfrak {R}^l\) and \(x_i\in {\mathcal {X}}_i\,(i=1,\ldots ,m)\), we have
In view of Lemma 1, it is equivalent to finding \((x_1^*,\ldots ,x_m^*,\lambda ^*)\) such that
Furthermore, if we set
the inequalities (2.2) can be compactly rewritten as
In the later sections, we denote by \(\Omega ^*\) the solution set of (2.4), which is assumed to be nonempty. On the one hand, since the operator F(w) in (2.3) is affine with a skew-symmetric matrix, we obtain
which means F is monotone. On the other hand, the objective function \(\theta (x)\) is not necessarily differentiable. With this regard, we also name (2.4) the mixed monotone variational inequality. In the following, we say (2.4) the variational inequality (VI) for short.
2.2 A variational characterization of (1.7)
The associated VI-structure of the introduced parallel splitting scheme (1.7) can be deduced by the following fundamental lemma.
Lemma 2
Let \(\{{\tilde{w}}^{k}\}\) be the sequence generated by (1.7) for solving (1.3). Then, we have
where
Proof
To begin with, for each \(x_i\)-subproblem in (1.7), it follows from the fundamental Lemma 1 that \({\tilde{x}}_i^k\in {\mathcal {X}}_i\), and \({\tilde{x}}_i^k\) satisfies
Since \({\tilde{\lambda }}^{k} = \lambda ^k - \beta ({\mathcal {A}}x^{k} -b)\) in (1.7), we obtain
Therefore, the \(x_i\)-subproblem in (1.7) satisfies
For the \(\lambda\)-subproblem in (1.7), it is easy to see that \({\mathcal {A}}x^k-b+\frac{1}{\beta }({\tilde{\lambda }}^k-\lambda ^k)=0\), which is also equivalent to
Using the notations in (2.3), the assertion of the lemma follows immediately by adding (2.8) and (2.9). \(\square\)
2.3 Some basic matrices
We list some fundamental matrices which will be useful for further discussion. Recall the matrix Q defined in (2.7). Setting \(S=Q^T+Q\), we get
Note that the matrices \(A_i\;(i=1,\ldots ,m)\) are assumed to be full column-rank. Clearly, the matrix S is symmetric, and \(S\succ 0\) provided \(\tau >(m-4)/4\). Throughout, \(\tau >(m-4)/4\) is required to guarantee the positive definiteness of the matrix S. Furthermore, we define \(M=Q^{-T}S\), and thus
Note that these inverses \((A_i^TA_i)^{-1}\;(i=1,\ldots ,m)\) are just for algebraically showing the correction step explicitly, and they can be completely avoided (see Sect. 3.3). We also set
and
3 Algorithm
Based on the framework of contraction method (see, e.g., [3]), we present the novel parallel algorithm (1.7)–(1.8) in this section.
3.1 A descent direction of the distance function induced by (1.7)
Recall the VI-structure of (1.7). The predictor \({\tilde{w}}^{k}\) generated by (1.7) satisfies
Without loss of generality, we assume \(w^k\ne {\tilde{w}}^k\) throughout our discussion. Otherwise, it follows from (2.4) that \({\tilde{w}}^k\) would be an optimal solution. Let \(w^*\) be an arbitrary solution of (2.4). Setting \(w=w^*\) in (3.1), we have
Using \({\tilde{w}}^k-w^*=({\tilde{w}}^k-w^k)+(w^k-w^*)\) and \(w^TQw=\frac{1}{2}w^T(Q^T+Q)w\), the above inequality can be rewritten as
Taking the nonsingularity of the matrices Q and H (see (2.7) and (2.12)) into consideration, the inequality (3.2) can be further reformulated as
Therefore, for any fixed \(w^*\in \Omega ^*\),
is a descent direction of the unknown distance function \(\Vert w-w^*\Vert _H^2\) at the point \(w^k\). According to the same analysis in [21], such a direction is able to yield the contraction of proximity to the solution set of (1.3) if an appropriate step size is taken. Hence, we generate the new iterate \(w^{k+1}\) via
It remains to find a step size \(\alpha _k\) to make the update \(w^{k+1}\) closer to \(\Omega ^*\).
3.2 A befitting step size \(\alpha _k\) in the correction step (3.3)
We now turn to choose an appropriate step size \(\alpha _k\) in the correction step (3.3). Since
we have
Maximizing the quadratic term \(q(\alpha )\), it follows that
Meanwhile, note that \(q(\alpha )\) is a lower bounded quadratic contraction function. Refer to the similar technique in [14], we can introduce a relaxation factor \(\gamma \in (0,2)\) and thus \(\alpha _k:=\gamma \alpha _k^*\in (0,1)\), which means a fixed step size \(\alpha _k\in (0,1)\) can be taken in (3.3). Consequently, the correction step (3.3), as an update process, can be tackled easily.
3.3 The practical computing scheme for the new method (1.7)–(1.8)
Since the matrix M defined in (2.11) contains some inverses \((A_i^TA_i)^{-1}\;(i=1,\ldots ,m)\), the corrector (3.3) is relatively complicated. Refer to the similar analysis in [23], these inverses are just for algebraically showing the correction step explicitly, and they can be completely avoided in computation empirically. More concretely, note that the variables \((A_1x_1^{k},\ldots ,A_mx_m^{k},\lambda ^{k})\) is essentially required in each iteration of (1.7). Using the same technique in, e.g., [19, 23], the correction step (3.3) can be replaced with
where the matrix \({\bar{M}}\) is defined in (2.13), and it can be concretely written as
We now give a succinct representation of (3.5) for easy-implementation. Recall \({\tilde{\lambda }}^{k} = \lambda ^k - \beta ({\mathcal {A}}x^{k} -b)\) in (1.7). By substituting it into (3.5), it follows that
and
Therefore, the practical correction step (3.5) can be reformulated concisely as

An ideal parallel implementation mechanism of the proposed algorithm (3.7)
It further leads to the following more practical and succinct scheme to replace the proposed algorithm (1.7)–(1.8):
in which \(\alpha \in (0,1)\) and \(\tau >(m-4)/4\). Figure 1 shows an ideal parallel implementation mechanism of the proposed algorithm (3.7) for the case where each \(x_i\)-subproblem needs a high computational cost. In such a case, every \(x_i\)-subproblem can be solved in an independent CPU platform.
4 Convergence
We establish the convergence analysis of the proposed method (1.7)–(1.8) in this section. The technique of analysis is motivated by the work in [19, 23]. As we have mentioned, \(\tau >(m-4)/4\) is required to guarantee the positive definiteness of the matrices S and H. To show the global convergence of the novel algorithm (1.7)–(1.8), we first prove a lemma, followed by a theorem.
Lemma 3
Let \(\{{\tilde{w}}^k\}\) and \(\{w^k\}\) be the sequences generated by the algorithm (1.7)–(1.8) for (1.3). Then, for any constant \(\alpha \in (0,1),\) we have
Proof
It follows from (3.3) that
and the proof is complete. \(\square\)
Theorem 1
Let \(\{{\tilde{w}}^k\}\) and \(\{w^k\}\) be the sequences generated by the method (1.7)–(1.8) for solving (1.3). Then, for any \(\alpha \in (0,1),\) we obtain \(\lim _{k\rightarrow \infty }w^k=w^\infty\) where \(w^\infty\) belongs to \(\Omega ^*.\)
Proof
First of all, it follows from (4.1) that the generated sequence \(\{w^k\}\) satisfies
which means the sequence \(\{w^k\}\) is bounded. Furthermore, summing (4.1) over \(k=0,1,\ldots ,\infty\), we obtain
and thus
This indicates the sequence \(\{{\tilde{w}}^k\}\) is also bounded. Let \(w^\infty\) be a cluster point of \(\{{\tilde{w}}^k\}\), where \(\{{\tilde{w}}^{k_j}\}\) is a subsequence which converges to \(w^\infty\). Then, it follows from (2.6) that
Note the matrix Q is nonsingular. It follows from the continuity of \(\theta (x)\) and F(w) that
which means \(w^\infty\) is a solution of the VI(\(\Omega ,F,\theta\)) (2.4). On the one hand, according to (4.2), we have \(\lim _{k\rightarrow \infty }w^{k_j}=w^\infty\). On the other hand, it follows from (4.1) that
which means it is impossible that the sequence \(\{w^k\}\) has more than one cluster point. Therefore, we have \(\lim _{k\rightarrow \infty }w^k=w^\infty\) and the proof is complete. \(\square\)
Remark 1
Refer to the same techniques in, e.g., [19, 23], we can easily show a worst-case \({\mathcal {O}}(1/N)\) convergence rate measured by iteration complexity for the novel method (1.7)–(1.8) by using the essential Lemma 2. Since the techniques are completely similar, the analysis of the convergence rate is omitted here.
5 Numerical experiments
We report the numerical results of the proposed algorithm (1.7)–(1.8) (practical scheme is indeed (3.7)) in this section. All codes are written in a Python 3.9 and implemented in a laptop with Intel Core CPU 2.20 GHz (i7-8750H) and 16 GB memory. The preliminary numerical results affirmatively demonstrate that the proposed method can perform more efficiently than some known parallel spitting algorithms.
5.1 The test model
The latent variable Gaussian graphical model selection (LVGGMS) problem in [6] is a typical three-block separable convex minimization model arising in statistical learning. As stated in [1], the mathematical form of the LVGGMS model reads as
where \(C\in \mathfrak {R}^{n\times n}\) is the covariance matrix obtained from the observation, \(\nu\) and \(\mu\) stand for two given positive weight parameters, \(\Vert Y\Vert _1=\sum _{i,j}|Y_{i,j}|\) and \(\hbox {tr}(\cdot )\) represents the trace of a matrix.
We first show the implementation of the proposed scheme (3.7) for tackling the LVGGMS model (5.1). Since the update (3.6) is simple, we only focus on the detail of the resulting \(x_i\)-subproblems (\(i=1,2,3\)). Let
be the augmented Lagrangian function of (5.1). The corresponding scheme of the x-subproblem in (3.7) then reads as
For the X-subproblem in (5.2), according to the first-order optimal condition, it is equivalent to solving the nonlinear equation system
Multiplying X to both sides, it follows that
Let \(UDU^T=C-\tau \beta X^k-\beta Y^k+\beta Z^k-\Lambda ^k\) be an eigenvalue decomposition. Plugging it back into (5.3) and setting \(P=U^TXU\), we have
and thus obtain
Therefore, we can derive that \({\tilde{X}}^k=U\,\hbox {diag}(P)\, U^T\) is a solution of (5.3). For the Y-subproblem in (5.2), since
the Y-subproblem can be solved via the soft shrinkage operator (see [32]) immediately. Finally, for the Z-subproblem in (5.2), note that
Let \(VD_1V^T=\frac{1}{1+\tau }(-X^k+Y^k+\tau Z^k+\frac{1}{\beta }\Lambda ^k-\frac{\mu }{\beta }I)\) be an eigenvalue decomposition. Then, we can easily verify that \({\tilde{Z}}^k=V\max (D_1,0)\, V^T\) is a solution of the Z-subproblem (where \(\max (D_1,0)\) is taken component-wisely).
5.2 Numerical results
We evaluate the numerical performance of the proposed method (3.7) in this subsection. Some parallel splitting algorithms including the parallel augmented Lagrangian method (denoted by P-ALM) proposed in [14] and the parallel splitting ADMM-like method (denoted by PS-ADMM) proposed in [18] are compared. In addition, as a reference, the numerical results of the direct extension of ADMM (denoted by D-ADMM) is also listed.
In our experiments, we take \(\nu =0.005\) and \(\mu =0.05\) (refer to [1]), and the covariance matrix C is randomly generated according to S. Boyd’s Homepage (see http://web.stanford.edu/~boyd/papers/admm/covsel/covsel_example.html). Moreover, refer to [1], the following two stopping conditions are taken:
Clearly, the feasibility errors IER and CER can be regarded as the primal and dual errors of the mentioned algorithms, respectively. When the proposed method (3.7) is applied for solving (5.1), it is convergent provided \(\tau >(3-4)/4\), and we consider three special cases: \(\tau =0\), \(\tau =1/3\) and \(\tau =1\). Moreover, the initial values are chosen as \((X_0,Y_0,Z_0,\Lambda _0)=(I_{n},2I_{n},I_{n},\mathbf {0}_{n\times n})\) in our experiments. Meanwhile, taking the high communication cost between different CPU platforms into consideration, what we emphasize here is that the tested algorithms are implemented by a serial way, rather than a parallel way. In the following tables and figures, the numerical performance of the tested methods is evaluated by the following parameters:
-
Iter: the required iteration number;
-
Time: the total computing time in seconds;
-
CPU: the maximum total running time of subproblems in seconds.
Note that the D-ADMM enjoys a Gaussian decomposition structure. The CPU time is indeed the total computing time for the D-ADMM.
In Table 1, we report the numerical results of the proposed method (3.7) for solving the LVGGMS model (5.1) with \(n=100\) when various stop stopping conditions are adopted. As can be seen easily, both the feasibility errors IER and CER have a similar changing pattern with the change of \(\beta\) for the various regularization parameters \(\tau\). In particular, the cases where \(\tau =1/3\) and \(\beta \in (0,12,0.14)\) perform more stably and efficiently, and they need only a reduced iterations and computational time (both Time and CPU) in terms of the feasibility errors IER and CER.
To show the comparisons between the novel method (3.7) and other operator spitting methods, we list first some efficient parameters for the above mentioned splitting algorithms. Using the same parameter adjustment strategy (trial-and-error) as the novel method (3.7), the toned parameters of the mentioned methods for solving the LVGGMS problem are given in Table 2.
In Table 3, we report the numerical results of the above tested algorithms for the LVGGMS problem (5.1) with various settings of n. As shown in Table 3, it is clear that the D-ADMM needs less required iterations and the proposed method (3.7) needs less CPU time than other algorithms. Compared with P-ALM and PS-ADMM, the novel method needs also fewer required iterations to reach different stopping criteria, which verifies empirically our theoretical motivation of this study (our purpose is to present a more efficient parallel spitting method). In addition, it can be seen easily from Table 3 that the D-ALM is divergent for the LVGGMS model (5.1), which can be further numerically illustrated that the direct extension of ALM is not necessarily convergent.

First column: convergence curves of the IER and CER with iteration numbers; second column: convergence curves of the IER and CER with CPU time (\(n=100\))
To further visualize the numerical comparison between the new method and the other splitting algorithms, in Fig. 2, we plot their respective feasibility errors with respect to iterations and CPU time for the case \(n=100\). Computational results in Fig. 2 demonstrate that the proposed method has steeper convergence curves than PS-ADMM and P-ALM both in iterations and CPU time. In particular, it can bee seen from Fig. 2 that the new method is faster than D-ADMM, even though the latter needs a less required iterations. For other settings of n, since their convergence curves are similar as the case \(n=100\), we opt to skip them for succinctness.
6 Conclusions
We propose a novel parallel splitting ALM-based algorithm for solving the multiple-block separable convex programming problem with linear equality constraints, where the objective function can be expressed as the sum of some individual subfunctions without coupled variables. By adding a simple update (1.8) to the fully parallel regularized ALM (1.7), convergence of the novel method can be guaranteed provided a reduced parameter of the regularization terms, which allows bigger step sizes and thus potentially results in fewer required iterations in the real computations. The numerical results on the LVGGMS problem affirmatively illustrates that the proposed method has an acceleration effect compared with some known parallel splitting algorithms.
References
Bai, J., Li, J., Xu, F., Zhang, H.: Generalized symmetric ADMM for separable convex optimization. Comput. Optim. Appl. 70(1), 129–170 (2018). https://doi.org/10.1007/s10589-017-9971-0
Beck, A.: First-Order Methods in Optimization, vol. 25. SIAM, Philadelphia (2017)
Blum, E., Oettli, W.: Mathematische Optimierung. Grundlagen und Verfahren. Ökonometrie und Unternehmensforschung. Springer, Berlin (1975)
Bose, N., Boo, K.: High-resolution image reconstruction with multisensors. Int. J. Imaging Syst. Technol. 9(4), 294–304 (1998) https://doi.org/10.1002/(SICI)1098-1098(1998)9:4%3c294::AID-IMA11%3e3.0.CO;2-X
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2010). https://doi.org/10.1561/2200000016
Chandrasekaran, V., Parrilo, P.A., Willsky, A.S.: Latent variable graphical model selection via convex optimization. Ann. Stat. 40(4), 1935–1967 (2012). https://doi.org/10.1214/11-AOS949
Chen, C., He, B., Ye, Y., Yuan, X.: The direct extension of ADMM for multi-block convex minimization problems is not necessarily convergent. Math. Program. 155(1–2), 57–79 (2016). https://doi.org/10.1007/s10107-014-0826-5
Facchinei, F., Pang, J.S.: Finite-Dimensional Variational Inequalities and Complementarity Problems. Springer Series in Operations Research, vol. I. Springer, New York (2003)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2(1), 17–40 (1976). https://doi.org/10.1016/0898-1221(76)90003-1
Glowinski, R.: Numerical Methods for Nonlinear Variational Problems. Springer, Berlin (1984)
Hager, W.W., Zhang, H.: Convergence rates for an inexact ADMM applied to separable convex optimization. Comput. Optim. Appl. 77(3), 729–754 (2020). https://doi.org/10.1007/s10589-017-9971-0
He, B.: My 20 years research on alternating directions method of multipliers. Oper. Res. Trans. 22, 1–31 (2018)
He, B.: Study on the splitting methods for separable convex optimization in a unified algorithmic framework. Anal. Theory Appl. 36, 262–282 (2020). https://doi.org/10.4208/ata.OA-SU13
He, B., Hou, L., Yuan, X.: On full Jacobian decomposition of the augmented Lagrangian method for separable convex programming. SIAM J. Optim. 25(4), 2274–2312 (2015). https://doi.org/10.1137/130922793
He, B., Ma, F., Yuan, X.: Optimal proximal augmented Lagrangian method and its application to full Jacobian splitting for multi-block separable convex minimization problems. IMA J. Numer. Anal. 40(2), 1188–1216 (2020). https://doi.org/10.1093/imanum/dry092
He, B., Ma, F., Yuan, X.: Optimally linearizing the alternating direction method of multipliers for convex programming. Comput. Optim. Appl. 75(2), 361–388 (2020). https://doi.org/10.1007/s10589-019-00152-3
He, B., Tao, M., Yuan, X.: Alternating direction method with Gaussian back substitution for separable convex programming. SIAM J. Optim. 22(2), 313–340 (2012). https://doi.org/10.1137/110822347
He, B., Tao, M., Yuan, X.: A splitting method for separable convex programming. IMA J. Numer. Anal. 35(1), 394–426 (2015). https://doi.org/10.1093/imanum/drt060
He, B., Tao, M., Yuan, X.: Convergence rate analysis for the alternating direction method of multipliers with a substitution procedure for separable convex programming. Math. Oper. Res. 42(3), 662–691 (2017). https://doi.org/10.1287/moor.2016.0822
He, B., Xu, S., Yuan, J.: Indefinite linearized augmented Lagrangian method for convex optimization with linear inequality constraints. arXiv preprint arXiv:2105.02425 (2021)
He, B., Yuan, X.: Convergence analysis of primal-dual algorithms for a saddle-point problem: from contraction perspective. SIAM J. Imaging Sci. 5(1), 119–149 (2012). https://doi.org/10.1137/100814494
He, B., Yuan, X.: On the \(O(1/n)\) convergence rate of the Douglas–Rachford alternating direction method. SIAM J. Numer. Anal. 50(2), 700–709 (2012). https://doi.org/10.1137/110836936
He, B., Yuan, X.: A class of ADMM-based algorithms for three-block separable convex programming. Comput. Optim. Appl. 70(3), 791–826 (2018). https://doi.org/10.1007/s10589-018-9994-1
Hestenes, M.R.: Multiplier and gradient methods. J. Optim. Theory Appl. 4(5), 303–320 (1969). https://doi.org/10.1007/BF00927673
Kiwiel, K.C., Rosa, C.H., Ruszczynski, A.: Proximal decomposition via alternating linearization. SIAM J. Optim. 9(3), 668–689 (1999). https://doi.org/10.1137/S1052623495288064
Martinet, B.: Régularisation d'inéquations variationnelles par approximations successives. Rev. Fr. Inform. Rech. Oper. 4(R3), 154–158 (1970)
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 1(3), 127–239 (2014). https://doi.org/10.1561/2400000003
Peng, Y., Ganesh, A., Wright, J., Xu, W., Ma, Y.: RASL: robust alignment by sparse and low-rank decomposition for linearly correlated images. IEEE Trans. Pattern Anal. Mach. Intell. 34(11), 2233–2246 (2012)
Powell, M.J.: A Method for Nonlinear Constraints in Minimization Problems. In: Fletcher, R. (ed.) Optimization, pp. 283–298. Academic Press, New York (1969)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14(5), 877–898 (1976). https://doi.org/10.1137/0314056
Setzer, S., Steidl, G., Teuber, T.: Deblurring Poissonian images by split Bregman techniques. J. Visual Commun. Image Represent. 21(3), 193–199 (2010). https://doi.org/10.1016/j.jvcir.2009.10.006
Tao, M., Yuan, X.: Recovering low-rank and sparse components of matrices from incomplete and noisy observations. SIAM J. Optim. 21(1), 57–81 (2011). https://doi.org/10.1137/100781894
Tibshirani, R., Saunders, M., Rosset, S., Zhu, J., Knight, K.: Sparsity and smoothness via the fused lasso. J. R. Stat. Soc. 67(1), 91–108 (2005). https://doi.org/10.1111/j.1467-9868.2005.00490.x
Yuan, J., Bae, E., Tai, X.C.: A study on continuous max-flow and min-cut approaches. In: 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2217–2224. IEEE (2010)
Yuan, J., Bae, E., Tai, X.C., Boykov, Y.: A continuous max-flow approach to Potts model. In: Computer Vision-ECCV 2010, pp. 379–392. Springer (2010)
Yuan, J., Fenster, A.: Modern convex optimization to medical image analysis. arXiv preprint arXiv:1809.08734 (2018)
Acknowledgements
Funding was provided by National Natural Science Foundation of China (Grant No.11871029).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Xu, S., He, B. A parallel splitting ALM-based algorithm for separable convex programming. Comput Optim Appl 80, 831–851 (2021). https://doi.org/10.1007/s10589-021-00321-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00321-3
Keywords
- Convex programming
- Augmented Lagrangian method
- Jacobian decomposition
- Parallel computing
- Operator splitting methods