
Abstract
In this paper, we study a class of fractional semi-infinite polynomial programming (FSIPP) problems, in which the objective is a fraction of a convex polynomial and a concave polynomial, and the constraints consist of infinitely many convex polynomial inequalities. To solve such a problem, we first reformulate it to a pair of primal and dual conic optimization problems, which reduce to semidefinite programming (SDP) problems if we can bring sum-of-squares structures into the conic constraints. To this end, we provide a characteristic cone constraint qualification for convex semi-infinite programming problems to guarantee strong duality and also the attainment of the solution in the dual problem, which is of its own interest. In this framework, we first present a hierarchy of SDP relaxations with asymptotic convergence for the FSIPP problem whose index set is defined by finitely many polynomial inequalities. Next, we study four cases of the FSIPP problems which can be reduced to either a single SDP problem or a finite sequence of SDP problems, where at least one minimizer can be extracted. Then, we apply this approach to the four corresponding multi-objective cases to find efficient solutions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we consider the fractional semi-infinite polynomial programming (FSIPP) problem in the following form:
where f, g, \(\psi _1,\ldots ,\psi _s\in {{\mathbb {R}}}[x]\) and \(p\in {{\mathbb {R}}}[x,y]\). Here, \({{\mathbb {R}}}[x]\) (resp. \({{\mathbb {R}}}[x,y]\)) denotes the ring of real polynomials in \(x=(x_1,\ldots ,x_m)\) (resp., \(x=(x_1,\ldots ,x_m)\) and \(y=(y_1,\ldots ,y_n)\)). Denote by \({\mathbf {K}}\) and \({\mathbf {S}}\) the feasible set and the optimal solution set of (1), respectively. In this paper, we assume that \({\mathbf {S}}\ne \emptyset\) and make the following assumptions on (1):
(A1): \({\mathbf {Y}}\) is compact; f, \(-g\), each \(\psi _i\) and \(p(\cdot , y)\) for each \(y\in {\mathbf {Y}}\) are all convex in x;
(A2): Either \(f(x)\ge 0\) and \(g(x)>0\) for all \(x\in {\mathbf {K}}\); or g(x) is affine and \(g(x)>0\) for all \(x\in {\mathbf {K}}.\)
The feasible set \({\mathbf {K}}\) is convex by (A1), while the objective of (1) is generally not convex. The assumption (A2) ensures that the objective of (1) is well-defined. It is commonly adopted in the literature about fractional optimization problems [24, 36, 44], and can be satisfied by many practical optimization models [4, 36, 49]. If \({\mathbf {Y}}\) is noncompact, the technique of homogenization can be applied (c.f. [53]).
Over the last several decades, due to a great number of applications in many fields, semi-infinite programming (SIP) has attracted a great interest and has been a very active research area [14, 15, 22, 35]. Numerically, SIP problems can be solved by different approaches including, for instance, discretization methods, local reduction methods, exchange methods, simplex-like methods, feasible point methods etc; see [14, 22, 35] and the references therein for details. A main difficulty in solving general SIP problems is that the feasibility test of a given point is equivalent to globally solving a lower level subproblem which is generally nonlinear and nonconvex.
To the best of our knowledge, there are only limited research results devoted to semi-infinite polynomial optimization by exploiting features of polynomial optimization problems. For instance, Parpas and Rustem [40] proposed a discretization-like method to solve minimax polynomial optimization problems, which can be reformulated as semi-infinite polynomial programming (SIPP) problems. Using polynomial approximation and an appropriate hierarchy of semidefinite programming (SDP) relaxations, Lasserre [29] presented an algorithm to solve the generalized SIPP problems. Based on an exchange scheme, an SDP relaxation method for solving SIPP problems was proposed in [53]. By using representations of nonnegative polynomials in the univariate case, an SDP method was given in [54] for linear SIPP problems with the index set being closed intervals. For convex SIPP problems, Guo and Sun [16] proposed an SDP relaxation method by combining the sum-of-squares representation of the Lagrangian function with high degree perturbations [30] and Putinar’s representation [42] of the constraint polynomial on the index set.
In this paper, in a way similar to [16], we will derive an SDP relaxation method for the FSIPP problem (1). Different from [16], we treat the problem in a more systematical manner. We first reformulate the FSIPP problem to a conic optimization problem and its Lagrangian dual, which involve two convex cones of polynomials in the variables and the parameters, respectively (Sect. 3). Under suitable assumptions on these cones, approximate minimum and minimizers of the FSIPP problem can be obtained by solving the conic reformulations. If we can bring sum-of-squares structures into these cones, the conic reformulations reduce to a pair of SDP problems and become tractable. To this end, inspired by Jeyakumar and Li [23], we provide a characteristic cone constraint qualification for convex semi-infinite programming problems to guarantee the strong duality and the attachment of the solution in the dual problem, which is of its own interest. We remark that this constraint qualification, which is crucial for some applications (see Sect. 5.2), is weaker than the Slater condition used in [16].
In what follows, we first present a hierarchy of SDP relaxations for the FSIPP problem whose index set is defined by finitely many polynomial inequalities (Sect. 4). This is done by introducing appropriate quadratic modules to the conic reformulations. The asymptotic convergence of the optimal values of the SDP relaxations to the minimum of the FSIPP problem can be established by Putinar’s Positivstellensatz [42]. Moreover, when the FSIPP problem has a unique minimizer, this minimizer can be approximated from the optimal solutions to the SDP relaxations. By means of existing complexity results of Putinar’s Positivstellensatz, we can derive some convergence rate analysis of the SDP relaxations. We also present some discussions on the stop criterion for such SDP relaxations. Next, we restrict our focus on four cases of FSIPP problems for which the SDP relaxation method is exact or has finite convergence and at least one minimizer can be extracted (Sect. 5). The reason for this restriction is due to some applications of the FSIPP problem where exact minimum and minimizers are required. In particular, we study the application of our SDP method to the corresponding multi-objective FSIPP problems, where the objective function is a vector valued function with each component being a fractional function. We aim to find efficient solutions (see Definition 5.1) to such problems. Some sufficient efficiency conditions and duality results for such problems can be found in [8, 52, 55, 56]. However, as far as we know, very few algorithmic developments are available for such problems in the literature because of the difficulty of checking feasibility of a given point.
This paper is organized as follows. Some notation and preliminaries are given in Sect. 2. The FSIPP problem is reformulated as a conic optimization problem in Sect. 3. We present a hierarchy of SDP relaxations for FSIPP problems in Sect. 4. In Sect. 5, we consider four specified cases of the FSIPP problems and the application of the SDP method to the multi-objective cases. Some conclusions are given in Sect. 6.
2 Notation and preliminaries
In this section, we collect some notation and preliminary results which will be used in this paper. The symbol \({\mathbb {N}}\) (resp., \({\mathbb {R}}\), \({{\mathbb {R}}}_+\)) denotes the set of nonnegative integers (resp., real numbers, nonnegative real numbers). For any \(t\in {\mathbb {R}}\), \(\lceil t\rceil\) denotes the smallest integer that is not smaller than t. For \(u\in {\mathbb {R}}^m\), \(\Vert u\Vert\) denotes the standard Euclidean norm of u. For \(\alpha =(\alpha _1,\ldots ,\alpha _n)\in {\mathbb {N}}^n\), \(|\alpha |=\alpha _1+\cdots +\alpha _n\). For \(k\in {\mathbb {N}}\), denote \({\mathbb {N}}^n_k=\{\alpha \in {\mathbb {N}}^n\mid |\alpha |\le k\}\) and \(\vert {\mathbb {N}}^n_k\vert\) its cardinality. For variables \(x \in {\mathbb {R}}^m\), \(y \in {\mathbb {R}}^n\) and \(\beta \in {\mathbb {N}}^m, \alpha \in {\mathbb {N}}^n\), \(x^\beta\), \(y^\alpha\) denote \(x_1^{\beta _1}\cdots x_m^{\beta _m}\), \(y_1^{\alpha _1}\cdots y_n^{\alpha _n}\), respectively. For \(h \in {{\mathbb {R}}}[x]\), we denote by \(\deg (h)\) its (total) degree. For \(k\in {\mathbb {N}}\), denote by \({{\mathbb {R}}}[x]_k\) (resp., \({{\mathbb {R}}}[y]_k\)) the set of polynomials in \({{\mathbb {R}}}[x]\) (resp., \({{\mathbb {R}}}[y]\)) of degree up to k. For \(A={{\mathbb {R}}}[x],\ {{\mathbb {R}}}[y],\ {{\mathbb {R}}}[x]_k,\ {{\mathbb {R}}}[y]_k\), denote by \(A^*\) the dual space of linear functionals from A to \({{\mathbb {R}}}\).
A polynomial \(h\in {{\mathbb {R}}}[x]\) is said to be a sum-of-squares (s.o.s) of polynomials if it can be written as \(h=\sum _{i=1}^l h_i^2\) for some \(h_1,\ldots ,h_l \in {{\mathbb {R}}}[x]\). The symbols \(\Sigma ^2[x]\) and \(\Sigma ^2[y]\) denote the sets of polynomials that are s.o.s in \({{\mathbb {R}}}[x]\) and \({{\mathbb {R}}}[y]\), respectively. Notice that not every nonnegative polynomial can be written as s.o.s, see [43]. We recall the following properties about polynomials nonnegative on certain sets, which will be used in this paper.
Theorem 2.1
(Hilbert’s theorem) Every nonnegative polynomial \(h\in {{\mathbb {R}}}[x]\) can be written as s.o.s in the following cases: (i) \(m=1\); (ii) \(\deg (h)=2\); (iii) \(m=2\) and \(\deg (h)=4\).
Theorem 2.2
(The S-lemma) Let h, \(q\in {{\mathbb {R}}}[x]\) be two quadratic polynomials and assume that there exists \(u^0\in {{\mathbb {R}}}^m\) with \(q(u^0)>0\). The following assertions are equivalent: (i) \(q(x)\ge 0\) \(\Rightarrow\) \(h(x)\ge 0\); (ii) there exists \(\lambda \ge 0\) such that \(h(x)\ge \lambda q(x)\) for all \(x\in {{\mathbb {R}}}^m\).
Proposition 2.1
[45, Example 3.18] Let \(q\in {{\mathbb {R}}}[x]\) and the set \({\mathcal {K}}=\{x\in {{\mathbb {R}}}^m\mid q(x)\ge 0\}\) be compact. If \(h \in {{\mathbb {R}}}[x]\) is nonnegative on \({\mathcal {K}}\) and the following conditions hold
-
(i)
h has only finitely many zeros on \({\mathcal {K}},\) each lying in the interior of \({\mathcal {K}};\)
-
(ii)
the Hessian \(\nabla ^2 h\) is positive definite on each of these zeros,
then \(h=\sigma _0+\sigma _1q\) for some \(\sigma _0, \sigma _1\in \Sigma ^2[x]\).
For \(h, h_1, \ldots , h_\kappa \in {{\mathbb {R}}}[x]\), let us recall some background about Lasserre’s hierarchy [27] for the polynomial optimization problem
Let \(H:=\{h_1,\ldots ,h_{\kappa }\}\) and \(h_0=1\) for convenience. We denote by
the quadratic module generated by H and denote by
its k-th quadratic module. It is clear that if \(h\in \mathbf {qmodule}(H)\), then \(h(x)\ge 0\) for any \(x\in S\). However, the converse is not necessarily true.
Definition 2.1
We say that \(\mathbf {qmodule}(H)\) is Archimedean if there exists \(\phi \in \mathbf {qmodule}(H)\) such that the inequality \(\phi (x)\ge 0\) defines a compact set in \({{\mathbb {R}}}^m;\) or equivalently, if for all \(\phi \in {{\mathbb {R}}}[x],\) there is some \(N\in {\mathbb {N}}\) such that \(N\pm \phi \in \mathbf {qmodule}(H)\) (c.f., [46]).
Note that for any compact set S we can always force the associated quadratic module to be Archimedean by adding a redundant constraint \(M-\Vert x\Vert ^2_2\ge 0\) in the description of S for a sufficiently large M.
Theorem 2.3
[42, Putinar’s Positivstellensatz] Suppose that \(\mathbf {qmodule}(H)\) is Archimedean. If a polynomial \(\psi \in {{\mathbb {R}}}[x]\) is positive on S, then \(\psi \in \mathbf {qmodule}_k(H)\) for some \(k\in {\mathbb {N}}\).
For a polynomial \(\psi (x)=\sum _{\alpha \in {\mathbb {N}}^m} \psi _\alpha x^\alpha \in {{\mathbb {R}}}[x]\) where \(\psi _\alpha\) denotes the coefficient of the monomial \(x^\alpha\) in \(\psi\), define the norm
We have the following result for an estimation of the order k in Theorem 2.3.
Theorem 2.4
[39, Theorem 6] Suppose that \(\mathbf {qmodule}(H)\) is Archimedean and \(S\subseteq (-\tau _S,\tau _S)^m\) for some \(\tau _S>0\). Then there is some positive \(c\in {{\mathbb {R}}}\) (depending only on \(h_j\)’s) such that for all \(\psi \in {{\mathbb {R}}}[x]\) of degree d with \(\min _{x\in S}\psi (x)>0,\) we have \(\psi \in \mathbf {qmodule}_k(H)\) whenever
For an integer \(k\ge \max \{\lceil \deg (h)/2\rceil , k_0\}\) where \(k_0:=\max \{\lceil \deg (h_i)/2\rceil , i=1,\ldots ,\kappa \}\), the k-th Lasserre’s relaxation for (2) is
and its dual problem is
For each \(k\ge k_0\), (4) and (5) can be reduced to a pair of primal and dual SDP problems, and we always have \(h_k^{\text {{\tiny primal}}}\le h_k^{\text {{\tiny dual}}}\le h^{\star }\) (c.f. [27]). The convergence of \(h_k^{\text {{\tiny dual}}}\) and \(h_k^{\text {{\tiny primal}}}\) to \(h^{\star }\) as \(k\rightarrow \infty\) can be established by Putinar’s Positivstellensatz [27, 42] under the Archimedean condition. If there exists an integer \(k^{\star }\) such that \(h_k^{\text {{\tiny primal}}}=h_k^{\text {{\tiny dual}}}=h^{\star }\) for each \(k\ge k^{\star }\), we say that Lasserre’s hierarchy for (2) has finite convergence. To certify \(h_k^{\text {{\tiny dual}}}=h^{\star }\) when it occurs, a sufficient condition on a minimizer of (4) called flat extension condition [9] is available. A weaker condition called flat truncation condition was proposed by Nie in [37]. Precisely, for a linear functional \({\mathscr {L}}\in ({{\mathbb {R}}}[x]_{2k})^*\), denote by \({\mathbf {M}}_k({\mathscr {L}})\) the associated k-th moment matrix which is indexed by \({\mathbb {N}}^m_{k}\), with \((\alpha ,\beta )\)-th entry being \({\mathscr {L}}(x^{\alpha +\beta })\) for \(\alpha , \beta \in {\mathbb {N}}^m_{k}\).
Condition 2.1
[37, flat truncation condition] A minimizer \({\mathscr {L}}^{\star }\in ({{\mathbb {R}}}[x]_{2k})^*\) of (4) satisfies the following rank condition : there exists an integer \(k'\) with \(\max \{\lceil \deg (h)/2\rceil , k_0\}\le k'\le k\) such that
Nie [37, Theorem 2.2] proved that Lasserre’s hierarchy has finite convergence if and only if the flat truncation holds, under some generic assumptions. In particular, we have the following proposition.
Proposition 2.2
[37, c.f. Theorem 2.2] Suppose that the set \(\{x\in {{\mathbb {R}}}^m\mid h(x)=h^{\star }\}\) is finite, the set of global minimizers of (2) is nonempty, and for k big enough the optimal value of (5) is achievable and there is no duality gap between (4) and (5). Then, for k sufficiently large, \(h_k^{\text {{\tiny primal}}}=h_k^{\text {{\tiny dual}}}=h^{\star }\) if and only if every minimizer of (4) satisfies the flat truncation condition.
Moreover, if a minimizer \({\mathscr {L}}^{\star }\in ({{\mathbb {R}}}[x]_{2k})^*\) of (2) satisfies the flat extension condition or the flat truncation condition, we can extract finitely many global minimizers of (2) from the moment matrix \({\mathbf {M}}_k({\mathscr {L}}^{\star })\) by solving a linear algebra problem (c.f. [9, 20]). Such procedure has been implemented in the software GloptiPoly [21] developed by Henrion, Lasserre and Löfberg.
We say that a linear functional \({\mathscr {L}}\in ({{\mathbb {R}}}[x])^*\) has a representing measure \(\mu\) if there exists a Borel measure \(\mu\) on \({{\mathbb {R}}}^m\) such that
For \(k\in {\mathbb {N}}\), we say that \({\mathscr {L}}\in ({{\mathbb {R}}}[x]_k)^*\) has a representing measure \(\mu\) if the above holds for all \(\alpha \in {\mathbb {N}}^m_{k}\). By [9, Theorem 1.1], Condition 2.1 implies that \({\mathscr {L}}^{\star }\) has an atomic representing measure. Each atom of the measure is a global minimizer of (2) and can be extracted by the procedure presented in [20].
We end this section by introducing some important properties on convex polynomials.
Definition 2.2
A polynomial \(h\in {{\mathbb {R}}}[x]\) is coercive whenever the lower level set \(\{x\in {{\mathbb {R}}}^m\mid h(x)\le \alpha \}\) is a (possibly empty) compact set, for all \(\alpha \in {{\mathbb {R}}}\).
Proposition 2.3
[25, Lemma 3.1] Let \(h\in {{\mathbb {R}}}[x]\) be a convex polynomial. If \(\nabla ^2h(u')\succ 0\) at some point \(u'\in {{\mathbb {R}}}^m,\) then h is coercive and strictly convex on \({{\mathbb {R}}}^m.\)
Recall also a subclass of convex polynomials in \({{\mathbb {R}}}[x]\) introduced by Helton and Nie [19].
Definition 2.3
[19] A polynomial \(h\in {{\mathbb {R}}}[x]\) is s.o.s-convex if its Hessian \(\nabla ^2 h\) is an s.o.s-matrix, i.e., there is some integer r and some matrix polynomial \(H\in {{\mathbb {R}}}[x]^{r\times m}\) such that \(\nabla ^2 h(x)=H(x)^TH(x)\).
In fact, Ahmadi and Parrilo [2] has proved that a convex polynomial \(h\in {{\mathbb {R}}}[x]\) is s.o.s-convex if and only if \(m=1\) or \(\deg (h)=2\) or \((m,\deg (h))=(2,4)\). In particular, the class of s.o.s-convex polynomials contains the classes of separable convex polynomials and convex quadratic functions.
The significance of s.o.s-convexity is that it can be checked numerically by solving an SDP problem (see [19]), while checking the convexity of a polynomial is generally NP-hard (c.f. [1]). Interestingly, an extended Jensen’s inequality holds for s.o.s-convex polynomials.
Proposition 2.4
[28, Theorem 2.6] Let \(h\in {{\mathbb {R}}}[x]_{2d}\) be s.o.s-convex, and let \({\mathscr {L}}\in ({{\mathbb {R}}}[x]_{2d})^*\) satisfy \({\mathscr {L}}(1)=1\) and \({\mathscr {L}}(\sigma )\ge 0\) for every \(\sigma \in \Sigma ^2[x]\cap {{\mathbb {R}}}[x]_{2d}\). Then,
The following result plays a significant role for the SDP relaxations of (1) in Sect. 5.
Lemma 2.1
[19, Lemma 8] Let \(h\in {{\mathbb {R}}}[x]\) be s.o.s-convex. If \(h(u)=0\) and \(\nabla h(u)=0\) for some \(u\in {{\mathbb {R}}}^m,\) then h is an s.o.s polynonmial.
3 Conic reformulation of FSIPP
In this section, we first reformulate the FSIPP problem (1) to a conic optimization problem and its Lagrangian dual, which involve two convex subcones of \({{\mathbb {R}}}[x]\) and \({{\mathbb {R}}}[y]\), respectively. Under suitable assumptions on these cones, we show that approximate minimum and minimizers of (1) can be obtained by solving the conic reformulations.
3.1 Problem reformulation
Consider the problem
Note that, under (A1-2), (6) is clearly a convex semi-infinite programming problem and its optimal value is 0.
Now we consider the Lagrangian dual of (6). In particular, the constraints \(p(x,y)\le 0\) for all \(y\in {\mathbf {Y}}\) means that for each \(u\in {\mathbf {K}}\), \(p(u,y)\in {{\mathbb {R}}}[y]\) belongs to the cone of nonpositive polynomials on \({\mathbf {Y}}\). The polar of this cone is taken as the cone of finite nonnegative measures supported on \({\mathbf {Y}}\), which we denote by \({\mathcal {M}}({\mathbf {Y}})\). Therefore, we can define the Lagrangian function \(L_{f,g}(x,\mu ,\eta ): {{\mathbb {R}}}^m\times {\mathcal {M}}({\mathbf {Y}})\times {{\mathbb {R}}}_+^s \rightarrow {{\mathbb {R}}}\) by
Then, the Lagrangian dual of (6) reads
See [7, 22, 35, 47] for more details.
Consider the strong duality and dual attainment for the dual pair (6) and (8):
(A3): \(\exists \mu ^{\star }\in {\mathcal {M}}({\mathbf {Y}})\) and \(\eta ^{\star }\in {{\mathbb {R}}}_+^s\) such that \(\inf _{x\in {{\mathbb {R}}}^m} L_{f,g}(x,\mu ^{\star },\eta ^{\star })=0\).
The following straightforward result is essential for the SDP relaxations of (1) in Section 5.
Proposition 3.1
Under (A1-3), \(L_{f,g}(u^{\star },\mu ^{\star },\eta ^{\star })=0\) and \(\nabla _x L_{f,g}(u^{\star },\mu ^{\star },\eta ^{\star })=0\) for any \(u^{\star }\in {\mathbf {S}}\).
Under (A1-3), we first reformulate (1) to a conic optimization problem with the same optimal value \(r^{\star }\). We need the following notation. For a subset \({\mathcal {X}}\subset {{\mathbb {R}}}^m\) (resp., the index set \({\mathbf {Y}}\)), denote by \({\mathscr {P}}({\mathcal {X}})\subset {{\mathbb {R}}}[x]\) (resp. \({\mathscr {P}}({\mathbf {Y}})\subset {{\mathbb {R}}}[y]\)) the cone of nonnegative polynomials on \({\mathcal {X}}\) (resp., \({\mathbf {Y}}\)). For \({\mathscr {L}}\in ({{\mathbb {R}}}[x])^*\) (resp., \({\mathscr {H}}\in ({{\mathbb {R}}}[y])^*\)), denote by \({\mathscr {L}}(p(x,y))\) (resp., \({\mathscr {H}}(p(x,y))\)) the image of \({\mathscr {L}}\) (resp., \({\mathscr {H}}\)) on p(x, y) regarded as an element in \({{\mathbb {R}}}[x]\) (resp., \({{\mathbb {R}}}[y]\)) with coefficients in \({{\mathbb {R}}}[y]\) (resp., \({{\mathbb {R}}}[x]\)), i.e., \({\mathscr {L}}(p(x,y))\in {{\mathbb {R}}}[y]\) (resp., \({\mathscr {H}}(p(x,y)))\in {{\mathbb {R}}}[x]\)). For a subset \({\mathcal {X}}\subset {{\mathbb {R}}}^m\), consider the conic optimization problem
Proposition 3.2
Under (A1-3), suppose that \({\mathcal {X}}\cap {\mathbf {S}}\ne \emptyset\), then \(\tilde{r}=r^{\star }\).
Proof
Under (A3), define \({\mathscr {H}}^{\star }\in ({{\mathbb {R}}}[y])^*\) by letting \({\mathscr {H}}^{\star }(y^\beta )=\int _{{\mathbf {Y}}} y^\beta d\mu ^{\star }(y)\) for any \(\beta \in {\mathbb {N}}^n\). Then, \({\mathscr {H}}^{\star }\in ({\mathscr {P}}({\mathbf {Y}}))^*\) and \((r^{\star },{\mathscr {H}}^{\star },\eta ^{\star })\) is feasible to (9). Hence, \(\tilde{r}\ge r^{\star }\). As \({\mathcal {X}}\cap {\mathbf {S}}\ne \emptyset\), for any \(u^{\star }\in {\mathcal {X}}\cap {\mathbf {S}}\) and any \((\rho ,{\mathscr {H}},\eta )\) feasible to (9), it holds that
Then, the feasibility of \(u^{\star }\) to (1) implies that \(r^{\star }=\frac{f(u^{\star })}{g(u^{\star })}\ge \rho\) and thus \(r^{\star }\ge \tilde{r}\). \(\square\)
Remark 3.1
Before moving forward, let us give a brief overview on the strategies we adopted in this paper to construct SDP relaxations of (1) from the reformulation (9). The difficulty of (9) is that the exact representions of the convex cones \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\) are usually not available in general case, which makes (9) still intractable. However, the Positivstellensatz from real algebraic geometry, which provides algebraic certificates for positivity (nonnegative) of polynomials on semialgebraic sets, can give us approximations of \({\mathscr {P}}({\mathcal {X}})\) (with a carefully chosen \({\mathcal {X}}\)) and \({\mathscr {P}}({\mathbf {Y}})\) with sum-of-squares structures. Replacing \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\) by these approximations, we can convert (9) into SDP relaxations of (1). In order to obtain (approximate) optimum and optimizers of (1) from the resulting SDP relaxations, we need establish some conditions which should be satisfied by these approximations of \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\). Then according to these conditions, we can choose suitable subset \({\mathcal {X}}\) and construct appropriate approximations \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\). Remark that different subsets \({\mathcal {X}}\) and versions of Positivstellensatz can lead to different approximations of \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\) satisfying the established conditions. Therefore, to present our approach in a unified way, we next use the symbols \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) to denote approximations of \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\), respectively, and derive the conditions they should satisfy (Theorem 3.1). Then, we specify suitable \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) in different situations to construct concrete SDP relaxations of (1) in Sects. 4 and 5. \(\square\)
Let \({\mathcal {C}}[x]\) (resp., \({\mathcal {C}}[y]\)) be a convex cone in \({{\mathbb {R}}}[x]\) (resp., \({{\mathbb {R}}}[y]\)). Replacing \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\) by \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) in (9), respectively, we get the conic optimization problem
and its Lagrangian dual
For simplicity, in what follows, we adopt the notation
for any \({\mathscr {L}}\in ({{\mathbb {R}}}[x])^*\). Let
For any \(\varepsilon \ge 0\), denote the set of \(\varepsilon\)-optimal solutions of (1)
The following results show that if the cones \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) satisfy certain conditions, we can approximate \(r^{\star }\) and extract an \(\varepsilon\)-optimal solution by solving (10) and (11).
Theorem 3.1
Suppose that (A1-2) hold and \({\mathcal {C}}[y]\subseteq {\mathscr {P}}({\mathbf {Y}})\). For some \(\varepsilon \ge 0,\) suppose that there exists some \(u^{(\varepsilon )}\in {\mathbf {S}}_\varepsilon\) such that \(-p(u^{(\varepsilon )},y)\in {\mathcal {C}}[y]\) and \(h(u^{(\varepsilon )})\ge 0\) for any \(h(x)\in {\mathcal {C}}[x]\).
-
(i)
If (A3) holds and \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\in {\mathcal {C}}[x]\), then \(r^{\star }-\varepsilon \le r^{\mathrm{{\tiny primal}}}\le r^{\mathrm{{\tiny dual}}}\le r^{\star }+\varepsilon\).
-
(ii)
If \({\mathscr {L}}^{\star }\) is a minimizer of (11) such that the restriction \({\mathscr {L}}^{\star }|_{{{\mathbb {R}}}[x]_{{\mathbf {d}}}}\) admits a representing nonnegative measure \(\nu ,\) then \(r^{\star }\le r^{\mathrm{{\tiny dual}}}\le r^{\star }+\varepsilon\) and
$$\begin{aligned} \frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}= \frac{1}{\int d\nu }\left( \int x_1 d\nu ,\ldots ,\int x_m d\nu \right) \in {\mathbf {S}}_{\varepsilon }. \end{aligned}$$
Proof
Define a linear functional \({\mathscr {L}}'\in ({{\mathbb {R}}}[x])^*\) such that \({\mathscr {L}}'(x^\alpha )=\frac{(u^{\varepsilon })^\alpha }{g(u^{\varepsilon })}\) for each \(\alpha \in {\mathbb {N}}^m\). By the assumption, it is clear that \({\mathscr {L}}'\) is feasible to (11). Then, \(r^{\mathrm{{\tiny dual}}}\le {\mathscr {L}}'(f)=\frac{f(u^{\varepsilon })}{g(u^{\varepsilon })}\le r^{\star }+\varepsilon\).
-
(i)
Define \({\mathscr {H}}^{\star }\in ({{\mathbb {R}}}[y])^*\) by letting \({\mathscr {H}}^{\star }(y^\beta )=\int _{{\mathbf {Y}}} y^\beta d\mu ^{\star }(y)\) for any \(\beta \in {\mathbb {N}}^n\). By the assumption, \({\mathscr {H}}^{\star }\in ({\mathcal {C}}[y])^*\). Since \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\in {\mathcal {C}}[x]\), \((r^{\star }-\varepsilon ,{\mathscr {H}}^{\star },\eta ^{\star })\) is feasible to (10). Hence, \(r^{\mathrm{{\tiny primal}}}\ge r^{\star }-\varepsilon\). Then, the weak duality implies the conclusion.
-
(ii)
As \({\mathscr {L}}^{\star }|_{{{\mathbb {R}}}[x]_{{\mathbf {d}}}}\) admits a representing nonnegative measure \(\nu\), we have \({\mathscr {L}}^{\star }(1)=\int d\nu >0\); otherwise \({\mathscr {L}}^{\star }(g)=0\), a contradiction. For every \(y\in {\mathbf {Y}}\), as \(p(x,y)\) is convex in \(x\) and \(\frac{\nu }{\int d\nu }\) is a probability measure, by Jensen’s inequality, we have
$$\begin{aligned} p\left( \frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)},y\right) \le \frac{1}{\int d\nu }\int p(x,y)d\nu (x) =\frac{1}{{\mathscr {L}}^{\star }(1)}{\mathscr {L}}^{\star }(p(x,y))\le 0, \end{aligned}$$(14)where the last inequality follows from the constraint of the Lagrangian dual problem (11). For the same reason,
$$\begin{aligned} \psi _{j}\left( \frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}\right) \le 0,\ \ j=1,\ldots ,s, \end{aligned}$$(15)which implies that \({\mathscr {L}}^{\star }(x)/{\mathscr {L}}^{\star }(1)\) is feasible to (1). Therefore, it holds that
$$\begin{aligned} \begin{aligned} r^{\star }+\varepsilon&\ge {\mathscr {L}}^{\star }(f)=\frac{{\mathscr {L}}^{\star }(f)}{{\mathscr {L}}^{\star }(g)} =\frac{\int f(x)d\nu }{\int g(x)d\nu } =\frac{\frac{1}{\int d\nu }\int f(x)d\nu }{\frac{1}{\int d\nu }\int g(x)d\nu }\\&\ge \frac{f\left( {\mathscr {L}}^{\star }(x)/{\mathscr {L}}^{\star }(1)\right) }{g({\mathscr {L}}^{\star }(x)/{\mathscr {L}}^{\star }(1))}\ge r^{\star }. \end{aligned} \end{aligned}$$In particular, the second inequality above can be easily verified under (A2). Therefore, we have \(r^{\star }\le r^{\mathrm{{\tiny dual}}}\le r^{\star }+\varepsilon\) and \({\mathscr {L}}^{\star }(x)/{\mathscr {L}}^{\star }(1)\in {\mathbf {S}}_{\varepsilon }\).
\(\square\)
Theorem 3.1 opens the possibilities of constructing SDP relaxations of (1). In fact, if we can find suitable cones \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) with sum-of-squares structures and satisfy the conditions in Theorem 5.1, then (10) and (11) can be reduced to SDP problems and become tractable; see Sections 4 and 5 for details.
Remark 3.2
We would like to emphasize that the Slater condition used in [16] to guarantee (A3) and the convergence of the SDP relaxations proposed therein might fail for some applications (see Remark 5.1 (i)). Thus, we need a weaker constraint qualification for (A3). \(\square\)
3.2 A constraint qualification for (A3)
Inspired by Jeyakumar and Li [23], we consider the following semi-infinite characteristic cone constraint qualification (SCCCQ).
For a function \(h : {{\mathbb {R}}}^m \rightarrow {{\mathbb {R}}}\cup \{-\infty , +\infty \}\), denote by \(h^*\) the conjugate function of h, i.e.,
and by \(\text {epi}\ h^*\) the epigraph of \(h^*\). Let
Definition 3.1
SCCCQ is said to be held for \({\mathbf {K}}\) if \({\mathcal {C}}_1+{\mathcal {C}}_2\) is closed.
Remark 3.3
Along with Proposition A.2, the following example shows that the SCCCQ condition is weaker than the Slater condition. Recall that the Slater condition holds for \({\mathbf {K}}\) if there exists \(u\in {{\mathbb {R}}}^m\) such that \(p(u,y)<0\) for all \(y\in {\mathbf {Y}}\) and \(\psi _j(u)<0\) for all \(j=1,\ldots ,s.\) Consider the set \({\mathbf {K}}=\{x\in {{\mathbb {R}}}\mid yx\le 0,\ \forall y\in [-1,1]\}\). Clearly, \({\mathbf {K}}=\{0\}\) and the Slater condition fails. As \(s=0\), we only need verify that \({\mathcal {C}}_1\) is closed. It suffices to show that \({\mathcal {C}}_1=\{(w,v)\in {{\mathbb {R}}}^2\mid v\ge 0\}\). Indeed, fix a \(\mu \in {\mathcal {M}}([-1,1])\) and a point \((w,v)\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\mu (y)\right) ^*\in {\mathcal {C}}_1\). Then,
Conversely, for any \((w,v)\in {{\mathbb {R}}}^2\) with \(v\ge 0\), let
where \(\delta _{\{-1\}}\) and \(\delta _{\{1\}}\) are the Dirac measures at \(-1\) and 1, respectively. Then, \(\tilde{\mu }\in {\mathcal {M}}([-1,1])\) and \(w=\int _{[-1,1]} yd\tilde{\mu }(y)\) holds. By (17), we have \((w,v)\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\tilde{\mu }(y)\right) ^*\). \(\square\)
For convex semi-infinite programming problems, we claim that the SCCCQ guarantees the strong duality and the attachment of the solution in the dual problem, see the next theorem. Due to its own interest, we give a proof in a general setting in the Appendix 1.
Theorem 3.2
Under (A1-2), SCCCQ implies (A3).
Proof
See Theorem A.2. \(\square\)
4 SDP relaxations with asymptotic convergence
In this section, based on Theorem 3.1, we present an SDP relaxation method for the FSIPP problem (1) with the index set \({\mathbf {Y}}\) being of the form
The asymptotic convergence and convergence rate of the SDP relaxations will be studied. We also present some discussions on the stop criterion for such SDP relaxations.
By Theorem 3.1, if we can choose a suitable subset \({\mathcal {X}}\subset {{\mathbb {R}}}^m\) and construct appropriate approximations \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) of \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\), respectively, which satisfy the conditions in Theorem 3.1 for some \(\varepsilon > 0\), then we can compute the \(\varepsilon\)-optimal value of (1) by solving (10) and (11). Consequently, to construct an asymptotically convergent hierarchy of SDP relaxations of (1), we need find two sequences \(\{{{\mathcal {C}}_{k}}[x]\}\subset {{\mathbb {R}}}[x]\) and \(\{{\mathcal {C}}_{k}[y]\}\subset {{\mathbb {R}}}[y]\), which are approximations of \({\mathscr {P}}({\mathcal {X}})\) and \({\mathscr {P}}({\mathbf {Y}})\), respectively, and have sum-of-squares structures. These sequences of approximations should meet the requirement that for any \(\varepsilon >0\), there exists some \(k_{\varepsilon }\in {\mathbb {N}}\) such that for any \(k\ge k_{\varepsilon }\), the conditions in Theorem 3.1 will hold if we replace the notation \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) by \({{\mathcal {C}}_{k}}[x]\) and \({\mathcal {C}}_{k}[y]\), respectively. We may construct such sequences of approximations by the Positivstellensatz from real algebraic geometry (recall Putinar’s Positivstellensatz introduced in Section 2) where the subscript k indicates the degree of polynomials in the approximations and the containment relationship \({{\mathcal {C}}_{k}}[x]\subset {{\mathcal {C}}_{k+1}}[x]\), \({\mathcal {C}}_{k}[y]\subset {\mathcal {C}}_{k+1}[y]\) is satisfied. In (10) and (11), replace the notation \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) by \({{\mathcal {C}}_{k}}[x]\) and \({\mathcal {C}}_{k}[y]\), respectively, and denote the resulting problems by (10k) and (11k). Then, as k increases, a hierarchy of SDP relaxations of (1) can be constructed. Denote by \(r^{\mathrm{{\tiny primal}}}_k\) and \(r^{\mathrm{{\tiny dual}}}_k\) the optimal values of (10k) and (11k), respectively. The argument above is formally stated in the following theorem.
Theorem 4.1
Suppose that (A1-3) hold and \({\mathcal {C}}_{k}[y]\subseteq {\mathscr {P}}({\mathbf {Y}})\) for all \(k\in {\mathbb {N}}, k\ge \lceil {\mathbf {d}}/2\rceil\). For any small \(\varepsilon >0,\) suppose that there exist \(k_{\varepsilon }\in {\mathbb {N}}, k_{\varepsilon }\ge \lceil {\mathbf {d}}/2\rceil\) and some \(u^{(\varepsilon )}\in {\mathbf {S}}_\varepsilon\) such that for all \(k\ge k_{\varepsilon }\), \(-p(u^{(\varepsilon )},y)\in {\mathcal {C}}_{k}[y]\), \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\in {{\mathcal {C}}_{k}}[x]\), and \(h(u^{(\varepsilon )})\ge 0\) holds for any \(h(x)\in {{\mathcal {C}}_{k}}[x]\). Then, \(\lim _{k\rightarrow \infty }r_k^{\mathrm{{\tiny primal}}}=\lim _{k\rightarrow \infty } r_k^{\mathrm{{\tiny dual}}}=r^{\star }\).
Proof
For any small \(\varepsilon >0\), by Theorem 3.1 (i), we have \(r^{\star }-\varepsilon \le r^{\mathrm{{\tiny primal}}}_k\le r^{\mathrm{{\tiny dual}}}_k\le r^{\star }+\varepsilon\) for any \(k\ge k_{\varepsilon }\) and hence the convergence follows. \(\square\)
4.1 SDP relaxations with asymptotic convergence
In what follows, we will construct appropriate cones \(\{{{\mathcal {C}}_{k}}[x]\}\) and \(\{{\mathcal {C}}_{k}[y]\}\), which can satisfy conditions in Theorem 4.1 and reduce (10k) and (11k) to SDP problems.
Fix two numbers \(R>0\) and \(g^{\star }>0\) such that
Remark 4.1
Since \({\mathbf {S}}\ne \emptyset\) and (A2) holds, the above R and \(g^{\star }\) always exist. Let us discuss how to choose R and \(g^{\star }\) in some circumstances. If \({\mathbf {K}}\) or \({\mathbf {S}}\) is bounded, then we can choose sufficiently large R such that \({\mathbf {K}}\subset [-R, R]^m\) or \({\mathbf {S}}\subset [-R, R]^m\). Now let us consider that how to choose a sufficiently small \(g^{\star }>0\) such that \(g(u^{\star })>g^{\star }\) for some \(u^{\star }\in {\mathbf {S}}\), which may be not easy to certify in practice. If \(g(x)\equiv 1\), then clearly, we can let \(g^{\star }=1/2\). If g(x) is affine, then we can set \(g^{\star }\) by solving \(\min _{x\in {\mathbf {K}}} g(x)\), which is an FSIPP problem in which the denominator in the objective is one. Suppose that g(x) is not affine and a feasible point \(u'\in {\mathbf {K}}\) is known. We first solve the FSIPP problem \(f^{\star }:=\min _{x\in {\mathbf {K}}} f(x)\). If \(f(u')=0\) or \(f^{\star }=0\), then by (A2), \(r^{\star }=0\); otherwise, we have \(f^{\star }>0\) and
for any \(u^{\star }\in {\mathbf {S}}\). Thus, we can set \(g^{\star }\) to be a positive number less than \(\frac{g(u')}{f(u')}f^{\star }\). \(\square\)
We choose the subset
which clearly satisfies the condition \({\mathcal {X}}\cap {\mathbf {S}}\ne \emptyset\) in Proposition 3.2 and let
For any \(k\in {\mathbb {N}}, k\ge \lceil {\mathbf {d}}/2\rceil\), let
i.e., the k-th quadratic modules generated by G and Q in \({{\mathbb {R}}}[x]\) and \({{\mathbb {R}}}[y]\), respectively. Then, for each \(k\ge \lceil {\mathbf {d}}/2\rceil\), computing \(r^{\mathrm{{\tiny primal}}}_k\) and \(r^{\mathrm{{\tiny dual}}}_k\) is reduced to solving a pair of primal and dual SDP problems. We omit the detail for simplicity.
Consider the assumption:
(A4): \(\mathbf {qmodule}(Q)\) is Archimedean and there exists a point \({\bar{u}}\in {\mathbf {K}}\) such that \(p({\bar{u}},y)<0\) for all \(y\in {\mathbf {Y}}\).
Theorem 4.2
Under (A1-4) and the settings (18) and (20), the following holds.
-
(i)
\(\lim _{k\rightarrow \infty }r_k^{\mathrm{{\tiny primal}}}=\lim _{k\rightarrow \infty } r_k^{\mathrm{{\tiny dual}}}=r^{\star }\).
-
(ii)
If \(r_k^{\mathrm{{\tiny dual}}}<+\infty\) which holds for k large enough, then \(r_k^{\mathrm{{\tiny primal}}}=r_k^{\mathrm{{\tiny dual}}}\) and \(r_k^{\mathrm{{\tiny dual}}}\) is attainable.
-
(iii)
For any convergent subsequence \(\{{\mathscr {L}}^{\star }_{k_i}(x)/{\mathscr {L}}^{\star }_{k_i}(1)\}_i\) (always exists) of \(\{{\mathscr {L}}^{\star }_k(x)/{\mathscr {L}}^{\star }_k(1)\}_k\) where \({\mathscr {L}}_k^{\star }\) is a minimizer of (11k), we have \(\lim _{i\rightarrow \infty }{\mathscr {L}}^{\star }_{k_i}(x)/{\mathscr {L}}^{\star }_{k_i}(1)\in {\mathbf {S}}\). Consequently, if \({\mathbf {S}}\) is singleton, then \(\lim _{k\rightarrow \infty }{\mathscr {L}}^{\star }_k(x)/{\mathscr {L}}^{\star }_k(1)\) is the unique minimizer of (1).
Proof
-
(i)
Clearly, \({\mathcal {C}}_{k}[y]\subset {\mathscr {P}}({\mathbf {Y}})\) for any \(k\in {\mathbb {N}}, k\ge \lceil {\mathbf {d}}/2\rceil\). Let \(\varepsilon >0\) be fixed. Let \(u^{\star }\in {\mathbf {S}}\) be as in (18) and \(u^{(\lambda )}:=\lambda u^{\star }+(1-\lambda ){\bar{u}}\). As \({\mathbf {K}}\) is convex, \(u^{(\lambda )}\in {\mathbf {K}}\) for any \(0\le \lambda \le 1\). By the continuity of g and \(\frac{f}{g}\) on \({\mathbf {K}}\), there exists a \(\lambda '\in (0,1)\) such that
$$\begin{aligned} \Vert u^{(\lambda ')}\Vert <R,\quad g(u^{(\lambda ')})>g^{\star }\quad \text {and}\quad u^{(\lambda ')}\in {\mathbf {S}}_{\varepsilon }. \end{aligned}$$(21)For any \(y\in {\mathbf {Y}}\), by the convexity of p(x, y) in x,
$$\begin{aligned} p(u^{(\lambda ')},y)\le \lambda ' p(u^{\star },y) + (1-\lambda ') p({\bar{u}},y)<0. \end{aligned}$$By Theorem 2.3, there exists a \(k_1\in {\mathbb {N}}\) such that \(-p(u^{(\lambda ')},y)\in {\mathcal {C}}_{k}[y]\) for any \(k\ge k_1\). Since \(g^{\star }>0\), (A3) implies that \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\) is positive on the set \({\mathcal {X}}\). As \(\mathbf {qmodule}(G)\) is Archimedean, by Theorem 2.3 again, there exists a \(k_2\in {\mathbb {N}}\) such that \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\in {{\mathcal {C}}_{k}}[x]\) for any \(k\ge k_2\). It is obvious from (21) that \(h(u^{(\lambda ')})\ge 0\) for any \(h\in {{\mathcal {C}}_{k}}[x]\), \(k\ge k_2\). Let \(k_{\varepsilon }=\max \{k_1, k_2, \lceil {\mathbf {d}}/2\rceil \}\), then the sequences \(\{{{\mathcal {C}}_{k}}[x]\}\) and \(\{{\mathcal {C}}_{k}[y]\}\) satisfies the conditions in Theorem 4.1 which implies the conclusion.
-
(ii)
From the above, the linear functional \({\mathscr {L}}'\in ({{\mathbb {R}}}[x])^*\) such that \({\mathscr {L}}'(x^\alpha )=\frac{(u^{\lambda '})^\alpha }{g(u^{\lambda '})}\) for each \(\alpha \in {\mathbb {N}}^m\) is feasible for (11k) whenever \(k\ge \max \{k_1,\lceil {\mathbf {d}}/2\rceil \}\) and hence \(r^{\mathrm{{\tiny dual}}}_k< +\infty\). For any \(k\ge \max \{k_1,\lceil {\mathbf {d}}/2\rceil \}\) and any feasible point \({\mathscr {L}}_k\) of (11k), because \({\mathscr {L}}_k\in ({{\mathcal {C}}_{k}}[x])^*\), we have \({\mathscr {L}}_k(g-g^{\star })\ge 0\) and \({\mathscr {L}}_k(1)\ge 0\). Hence, along with \({\mathscr {L}}_k(g)=1\), we have \(0\le {\mathscr {L}}_k(1)\le 1/g^{\star }\) for all \(k\ge \lceil {\mathbf {d}}/2\rceil\). Since there is a ball constraint in (19), by [26, Lemma 3] and its proof, we have
$$\begin{aligned} \sqrt{\sum _{\alpha \in {\mathbb {N}}^m_{2k}}\left( {\mathscr {L}}_k(x^{\alpha })\right) ^2} \le {\mathscr {L}}_k(1) \sqrt{\left( {\begin{array}{c}m+k\\ m\end{array}}\right) }\sum _{i=0}^k R^{2i} \le \frac{1}{g^{\star }} \sqrt{\left( {\begin{array}{c}m+k\\ m\end{array}}\right) }\sum _{i=0}^k R^{2i} \end{aligned}$$for all \(k\in {\mathbb {N}}\), \(k\ge \lceil {\mathbf {d}}/2\rceil\) and all \({\mathscr {L}}_k\in ({{\mathcal {C}}_{k}}[x])^*\). In other words, for any \(k\ge \max \{k_1,\lceil {\mathbf {d}}/2\rceil \}\), the feasible set of the (11k) is nonempty, bounded and closed. Then, the solution set of the (11k) is nonempty and bounded, which implies that (10k) is strictly feasible (c.f. [48, Sect. 4.1.2]). Consequently, the strong duality \(r_k^{\mathrm{{\tiny primal}}}=r_k^{\mathrm{{\tiny dual}}}\) holds by [48, Theorem 4.1.3].
-
(iii)
As \(\mathbf {qmodule}(G)\) is Archimedean, by the definition,
$$\begin{aligned} \forall t\in {\mathbb {N}},\ \exists N_t,\ l(t)\in {\mathbb {N}},\ \forall \alpha \in {\mathbb {N}}_t^m,\ N_t\pm x^{\alpha }\in \mathbf {qmodule}_{l(t)}(G)={{\mathcal {C}}_{l(t)}}[x]. \end{aligned}$$For any \(k\ge l(t)\), since \({\mathscr {L}}^{\star }_k\in ({{\mathcal {C}}_{k}}[x])^*\), for all \(\alpha \in {\mathbb {N}}_t^m\),
$$\begin{aligned} |{\mathscr {L}}^{\star }_k(x^{\alpha })|\le {\mathscr {L}}^{\star }_k(N_t)=N_t\cdot {\mathscr {L}}^{\star }_k(1)\le N_t/g^{\star }. \end{aligned}$$(22)Then, for any \(k\ge \lceil {\mathbf {d}}/2\rceil\), we have \(|{\mathscr {L}}^{\star }_k(x^{\alpha })|\le N_t'\) for any \(\alpha \in {\mathbb {N}}_t^m\) where
$$\begin{aligned} N_t':=\max \{N_t/g^{\star }, M_t\}\quad \text {and}\quad M_t:=\max \{|{\mathscr {L}}^{\star }_k(x^{\alpha })| \mid \alpha \in {\mathbb {N}}_t^m, \lceil {\mathbf {d}}/2\rceil \le k\le l(t)\}. \end{aligned}$$Moreover, from (22) and the equality \({\mathscr {L}}^{\star }_k(g)=1\), we can see that \({\mathscr {L}}^{\star }_k(1)>0\) for all \(k\ge \lceil {\mathbf {d}}/2\rceil\). For any \(k\ge \lceil {\mathbf {d}}/2\rceil\), extend \({\mathscr {L}}^{\star }_k\in ({{\mathbb {R}}}_{2k}[x])^*\) to \(({{\mathbb {R}}}[x])^*\) by letting \({\mathscr {L}}^{\star }_k(x^{\alpha })=0\) for all \(|\alpha |>2k\) and denote it by \(\widetilde{{\mathscr {L}}}^{\star }_k\). Then, for any \(k\ge \lceil {\mathbf {d}}/2\rceil\) and any \(\alpha \in {\mathbb {N}}^m\), it holds that \(|\widetilde{{\mathscr {L}}}^{\star }_k(x^{\alpha })|\le N_{|\alpha |}'\). That is,
$$\begin{aligned} \left\{ \left( \widetilde{{\mathscr {L}}}^{\star }_k(x^{\alpha })\right) _{\alpha \in {\mathbb {N}}^m} \right\} _{k\ge \lceil {\mathbf {d}}/2\rceil }\subset \prod _{\alpha \in {\mathbb {N}}^m}\left[ -N_{|\alpha |}', N_{|\alpha |}'\right] . \end{aligned}$$(23)By Tychonoff’s theorem, the product space on the right side of (23) is compact in the product topology. Therefore, there exists a subsequence \(\{\widetilde{{\mathscr {L}}}^{\star }_{k_i}\}_{i\in {\mathbb {N}}}\) of \(\{\widetilde{{\mathscr {L}}}^{\star }_k\}_k\) and a \(\widetilde{{\mathscr {L}}}^{\star }\in ({{\mathbb {R}}}[x])^*\) such that \(\lim _{i\rightarrow \infty }\widetilde{{\mathscr {L}}}^{\star }_{k_i}(x^{\alpha })=\widetilde{{\mathscr {L}}}^{\star }(x^{\alpha })\) for all \(\alpha \in {\mathbb {N}}^m\). From the pointwise convergence, we get the following: (a) \(\widetilde{{\mathscr {L}}}^{\star }\in (\mathbf {qmodule}(G))^*\); (b) \(\widetilde{{\mathscr {L}}}^{\star }(g)=1\); (c) \(\widetilde{{\mathscr {L}}}^{\star }(p(x,y))\le 0\) for any \(y\in {\mathbf {Y}}\) since \(\widetilde{{\mathscr {L}}}^{\star }_k(p(x,y))\le 0\) for any \(k\ge \lceil {\mathbf {d}}/2\rceil\); (d) \(\widetilde{{\mathscr {L}}}^{\star }(\psi _j)\le 0\) for \(j=1,\ldots ,s\). By (a) and Putinar’s Positivstellensatz, along with Haviland’s theorem [18], \(\widetilde{{\mathscr {L}}}^{\star }\) admits a representing nonnegative measure \(\nu\), i.e., \(\widetilde{{\mathscr {L}}}^{\star }(x^{\alpha })=\int x^{\alpha } d\nu\) for all \(\alpha \in {\mathbb {N}}^m\). From (b) and (22), \(\widetilde{{\mathscr {L}}}^{\star }(1)>0\). Then, like in (14) and (15), by (c) and (d), we can see that
$$\begin{aligned} \lim _{i\rightarrow \infty }\frac{{\mathscr {L}}^{\star }_{k_i}(x)}{{\mathscr {L}}^{\star }_{k_i}(1)} =\frac{\widetilde{{\mathscr {L}}}^{\star }(x)}{\widetilde{{\mathscr {L}}}^{\star }(1)}\in {\mathbf {K}}. \end{aligned}$$From (i),
$$\begin{aligned} \begin{aligned} r^{\star }=\lim _{i\rightarrow \infty }\widetilde{{\mathscr {L}}}^{\star }_{k_i}(f)&= \widetilde{{\mathscr {L}}}^{\star }(f)=\frac{\widetilde{{\mathscr {L}}}^{\star }(f)}{\widetilde{{\mathscr {L}}}^{\star }(g)} =\frac{\int f(x)d\nu }{\int g(x)d\nu } =\frac{\frac{1}{\int d\nu }\int f(x)d\nu }{\frac{1}{\int d\nu }\int g(x)d\nu }\\&\ge \frac{f\left( \widetilde{{\mathscr {L}}}^{\star }(x)/\widetilde{{\mathscr {L}}}^{\star }(1)\right) }{g(\widetilde{{\mathscr {L}}}^{\star }(x)/\widetilde{{\mathscr {L}}}^{\star }(1))}\ge r^{\star },\\ \end{aligned} \end{aligned}$$which implies that \(\lim _{i\rightarrow \infty }{\mathscr {L}}^{\star }_{k_i}(x)/{\mathscr {L}}^{\star }_{k_i}(1)\in {\mathbf {S}}\).As \({\mathbf {S}}\) is singleton, \({\mathbf {S}}=\{u^{\star }\}\). The above arguments show that \(\lim _{i\rightarrow \infty } {\mathscr {L}}^{\star }_{k_i}(x)/{\mathscr {L}}^{\star }_{k_i}(1)=u^{\star }\) for any convergent subsequence of \(\{{\mathscr {L}}^{\star }_k(x)/{\mathscr {L}}^{\star }_k(1)\}_k\). By (23), \(\{{\mathscr {L}}^{\star }_k(x)/{\mathscr {L}}^{\star }_k(1)\}_k\subset [-N'_1, N'_1]^m\) which is bounded. Thus, the whole sequence \(\{{\mathscr {L}}^{\star }_k(x)/{\mathscr {L}}^{\star }_k(1)\}_k\) converges to \(u^{\star }\) as k tends to \(\infty\). \(\square\)
4.2 Convergence rate analysis
Next, we give some convergence rate analysis of \(r_k^{\mathrm{{\tiny primal}}}\) and \(r_k^{\mathrm{{\tiny dual}}}\) based on Theorem 2.4.
Let us fix \(R, g^{\star }\in {{\mathbb {R}}}\), \(u^{\star }\in {\mathbf {K}}\) satisfying (18), \(\mu ^{\star }\in {\mathcal {M}}({\mathbf {Y}}), \eta ^{\star }\in {{\mathbb {R}}}^s_+\) satisfying (A3), \({\bar{u}}\in {\mathbf {K}}\) satisfying (A4), a number \(R_{{\mathcal {X}}}>R\) and a number \(R_{{\mathbf {Y}}}>0\) such that \({\mathbf {Y}}\subset (-R_{{\mathbf {Y}}}, R_{{\mathbf {Y}}})^n\).
For any \(\varepsilon >0\), define the following constants.
It is easy to see that \(N_{\varepsilon }\in [0, 1)\). Let
Lemma 4.1
The point \(u^{(\lambda ')}\) in (24) satisfies the conditions in (21).
Proof
If \(\Vert {\bar{u}}\Vert <R\), then clearly \(\Vert u^{(\lambda ')}\Vert <R\); otherwise, \(\Vert {\bar{u}}\Vert \ge R>\Vert u^{\star }\Vert\) and
Since g(x) is concave, we have
If \(g({\bar{u}})>g^{\star }\), it is clear that \(g(u^{(\lambda ')})>g^{\star }\). Suppose that \(g({\bar{u}})\le g^{\star }\), then \(g({\bar{u}})<g(u^{\star })\) and
If \(f({\bar{u}})<(r^{\star }+\varepsilon )g({\bar{u}})\), by the convexity of f(x) and \(-g(x)\), it holds that
which implies that \(u^{(\lambda ')}\in {\mathbf {S}}_{\varepsilon }\). If \(f({\bar{u}})\ge (r^{\star }+\varepsilon )g({\bar{u}})\), we have
Then, the second inequality of (25) still holds and hence \(u^{(\lambda ')}\in {\mathbf {S}}_{\varepsilon }\). Therefore, all conditions in (21) are satisfied by \(u^{(\lambda ')}\). \(\square\)
Recall the norm defined in (3). Write \(p(x,y)=\sum _{\beta \in {\mathbb {N}}^n}p_{y,\beta }(x) y^{\beta }\) and let
Then, \(p_{\max }\) is well-defined and \(\Vert p(u^{(\lambda ')},y)\Vert \le p_{\max }\) by Lemma 4.1. Denote \(p^{\star }_{{\bar{u}}}:=\max _{y\in {\mathbf {Y}}} p({\bar{u}},y)\). As \({\mathbf {Y}}\) is compact, \(p^{\star }_{{\bar{u}}}<0\). Denote \(d_y=\deg _y p(x,y)\) and \(L_{\max }:= \Vert L_{f,g}(x,\mu ^{\star },\eta ^{\star })\Vert\) for simplicity. The convergence rate analysis of \(r_k^{\mathrm{{\tiny primal}}}\) and \(r_k^{\mathrm{{\tiny dual}}}\) is presented in Proposition 4.1, where the only constant depending on \(\varepsilon\) is \(N_\varepsilon\), and all others depend on the problem data in (1) and the fixed \(R, g^{\star }, u^{\star }, {\bar{u}}, \mu ^{\star }\), \(\eta ^{\star }\), \(R_{{\mathcal {X}}}\) and \(R_{{\mathbf {Y}}}\) in the assumptions.
Proposition 4.1
Under (A1-4) and the settings (18) and (20), there exist constants \(c_1,\ c_2\in {{\mathbb {R}}}\) (depending on \(q_i\)’s, g, R and \(g^{\star }\) \()\) such that for any \(\varepsilon >0,\) we have \(r^{\star }-\varepsilon \le r_k^{\mathrm{{\tiny primal}}}\le r^{\mathrm{{\tiny dual}}}_k\le r^{\star }+\varepsilon\) whenever
Proof
Recall the proof of Theorem 4.2 (i). By Lemma 4.1, \(u^{(\lambda ')}\) in (24) satisfies the conditions in (21). Then, by Theorem 2.4, there is a constant \(c_1\in {{\mathbb {R}}}\) depending only on \(q_i\)’s such that \(-p(u^{(\lambda ')},y)\in {\mathcal {C}}_{k}[y]\) for all \(k\ge k_1\) where
and there exists a constant \(c_2\in {{\mathbb {R}}}\) depending only on g(x), R and \(g^{\star }\) such that \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\in {{\mathcal {C}}_{k}}[x]\) for all \(k\ge k_2\) where
For any \(y\in {\mathbf {Y}}\), by the convexity of p(x, y) in x,
Moreover, \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })+\varepsilon g(x)\ge \varepsilon g^{\star }\) on the set \({\mathcal {X}}\) in (19). Therefore,
Then, the conclusion follows. \(\square\)
4.3 Discussions on the stop criterion
Recall the asymptotic convergence of the hierarchy of SDP relaxations (10k) and (11k) for the FSIPP problem (1) established in Theorem 4.2. Before we give an example to show the efficiency of this method, let us discuss how to check whether or not \({\mathscr {L}}_k^{\star }(x)/{\mathscr {L}}_k^{\star }(1)\) where \({\mathscr {L}}^{\star }_k\) is a minimizer of (11k) for some k is a satisfying solution to (1).
Under (A1-2), it is clear that a feasible point \(u^{\star }\in {\mathbf {K}}\) is a minimizer of (1) if and only if \(u^{\star }\) is a minimizer of the convex semi-infinite programming problem
For (26), it is well-known [35] that if the KKT condition holds at \(u^{\star }\in {\mathbf {K}}\), i.e. there are finite subsets \(\Lambda (u^{\star })\subset {\mathbf {Y}}\), \(J(u^{\star })\subset \{1,\ldots ,s\}\) and multipliers \(\gamma _y\ge 0\), \(y\in \Lambda (u^{\star })\), \(\eta _j\ge 0\), \(j\in J(u^{\star })\) such that
then \(u^{\star }\) is a minimizer of (26). The converse holds if \({\mathbf {K}}\) satisfies the Slater condition. Next, we use this fact to give a stop criterion of the hierarchy of SDP relaxations (11k) for (1).
Recall Lasserre’s SDP relaxation method for polynomial optimization problems introduced in Sect. 2. Fix a \(k\in {\mathbb {N}}\) and let \(u^{\star }={\mathscr {L}}_k^{\star }(x)/{\mathscr {L}}_k^{\star }(1)\). Denote by \(\tau\) a small positive number as a given tolerance. Now, we proceed with the following steps:
- Step 1.:
-
Solve the polynomial minimization problem
$$\begin{aligned} p^{\star }:=\min _{y\in {\mathbf {Y}}} -p(u^{\star }, y) \end{aligned}$$(28)by Lasserre’s SDP relaxation method (4) using the software GloptiPoly. If
$$\begin{aligned} \max \{-p^{\star }, \psi _1(u^{\star }),\ldots , \psi _s(u^{\star })\}\le \tau , \end{aligned}$$then \(u^{\star }\) is a feasible point of (1) within the tolerance \(\tau\). In the case when Condition 2.1 holds in Lasserre’s relaxations, we can extract the set of global minimizers of (28) which is a finite set in this case (c.f. [9, 20]) and we denote it by \(\Lambda (u^{\star })\). Let \(J(u^{\star }):=\{j\mid |\psi _j(u^{\star })|\le \tau \}\), then \(\Lambda (u^{\star })\cup J(u^{\star })\) indexes the active constraints at \(u^{\star }\) within the tolerance \(\tau\).
- Step 2.:
-
Solve the non-negative least-squares problem
$$\begin{aligned} \qquad \omega:= & {} \min _{\gamma _y\ge 0, \eta _j\ge 0} \Big \Vert \nabla f(u^{\star })-\frac{f(u^{\star })}{g(u^{\star })} \nabla g(u^{\star }) \nonumber \\&+ \sum _{y\in \Lambda (u^{\star })} \gamma _{y} \nabla _x p(u^{\star },y) + \sum _{j\in J(u^{\star })} \eta _j \psi _j(u^{\star })\Big \Vert ^2, \end{aligned}$$(29)which can be done by the command lsqnonneg in Matlab. If \(\omega \le \tau\), then the KKT condition in (27) holds at \({\mathscr {L}}_k^{\star }(x)/{\mathscr {L}}_k^{\star }(1)\) within the tolerance \(\tau\). Then we may terminate the SDP relaxations (11k) at the order k and output \({\mathscr {L}}_k^{\star }(x)/{\mathscr {L}}_k^{\star }(1)\) as a numerical minimizer of (1).
The key of the above procedure is Condition 2.1 which can certify the finite convergence of Lasserre’s relaxations for (28) and be used to extract the set \(\Lambda (u^{\star })\). For a polynomial minimization problem with generic coefficients data, Nie proved that Condition 2.1 holds in its Lasserre’s SDP relaxations (c.f. [38, Theorem 1.2] and [37, Theorem 2.2]). Hence, an interesting problem is that if the coefficients data in (1) is generic, does Condition 2.1 always hold in Lasserre’s SDP relaxations of (28)? It is not clear to us yet because the coefficients of \(p(u^{\star },y)\) also depend on the solutions \({\mathscr {L}}^{\star }_k\) to (11k) and thus we leave it for future research.
Several numerical examples will be presented in the rest of this paper to show the efficiency of the corresponding SDP relaxations. We use the software Yalmip [34] and call the SDP solver SeDuMi [51] to implement and solve the resulting SDP problems (10) and (11). To show the advantage of our SDP relaxation method for solving FSIPP problems, we compare it with the numerical method called adaptive convexification algorithmFootnote 1 (ACA for short) [12, 50] for the following reasons. On the one hand, if g(x) is not a constant function, then the FSIPP problem (1) is usually not convex. Hence, numerical methods in the literature for convex SIP problems [14, 22, 35] are not appropriate for (1). On the other hand, most of the existing numerical methods for SIP require the index set to be box-shaped, while the ACA method can solve SIP problems with arbitrary, not necessarily box-shaped, index sets (as \({\mathbf {Y}}\) in (1) is). The ACA method can deal with general SIP problems (the involved functions are not necessarily polynomials) by two procedures. The first phase is to find a consistent initial approximation of the SIP problem with a reduced outer approximation of the index set. The second phase is to compute an \(\varepsilon\)-stationary point of the SIP problem by adaptively constructing convex relaxations of the lower level problems. All numerical experiments in the sequel were carried out on a PC with two 64-bit Intel Core i5 1.3 GHz CPUs and 8G RAM.
Example 4.1
In order to construct an illustrating example which is not in the special cases studied in the next section, we consider the following two convex but not s.o.s-convex polynomials where \(h_1\) is given in [2, (4)] and \(h_2\) is given in [3, (5.2)]
It can be verified by Yalmip that both \(h_1\) and \(h_2\) are s.o.s polynomials. Let
and \(f(x_1,x_2):=h_2(x_1-1,x_2-1)/10000\). Clearly, f(x) and p(x, y) for all \(y\in {{\mathbb {R}}}^2\) are convex but not s.o.s-convex in x. Let \(g(x_1,x_2):=-x_1^2-x_2^2+4\) and \(\psi (x_1,x_2):=x_1^2/2+2x_2^2-1\).
Consider the FSIPP problem
where
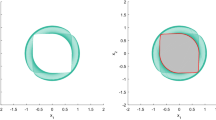
Geometrically, the feasible region \({\mathbf {K}}\) is constructed in the following way: first rotate the shape in the \((x_1,x_2)\)-plane defined by \(-1+h_1(x_1,x_2,1)/100-x_1+x_2\le 0\) continuously around the origin by \(90^\circ\) clockwise; then intersect the common area of these shapes in this process with the ellipse defined by \(\psi (x)\le 0\) (see Fig. 1). It is easy to see that (A1-4) hold for this problem. Let \(R=2\) and \(g^{\star }=1\). For the first order \(k=4\), we get \(r_4^{\mathrm{{\tiny dual}}}=0.0274\) and \({\mathscr {L}}_4^{\star }(x)/{\mathscr {L}}_4^{\star }(1)=(0.7377, 0.6033)\).
As we have discussed before this example, now let us check that if \(u^{\star }:=(0.7377, 0.6033)\) is a satisfying solution to (31) within the tolerance \(\tau =10^{-3}\). We first solve the problem (28) by Lasserre’s SDP relaxations in GloptiPoly. It turns out that Condition 2.1 is satisfied in Lasserre’s relaxations of the first order. We obtain that \(p^{\star }=6.7654\times 10^{-5}\) and \(\Lambda (u^{\star })=\{(0.775, 0.6315)\}\). Since \(\psi (u^{\star })=4.2425\times 10^{-5}\), within the tolerance \(10^{-3}\), we can see that \(u^{\star }\) is a feasible point of (31) and the constraints
are active at \(u^{\star }\). Then, we solve the non-negative least-squares problem (29) by the command lsqnonneg in Matlab. The result is \(\omega =0.0000\), which shows that the KKT condition (27) holds at \(u^{\star }\). Thus, \(u^{\star }\) is a numerical minimizer of (26) and hence of (31) within the tolerance \(10^{-3}\). The total CPU time for the whole process is about 25 seconds.
To show the accuracy of the solution, we draw some contour curves of f/g, including the one where f/g is the constant value \(f(u^{\star })/g(u^{\star })=0.0274\) (the blue curve), and mark the point \(u^{\star }\) by a red dot in Fig. 1. As we can see, the blue curve is almost tangent to \({\mathbf {K}}\) at the point \(u^{\star }\), which illustrates the accuracy of \(u^{\star }\).
Next, we apply the ACA method to (31). It turns out that the first phase of ACA to find a consistent initial approximation of (31) with a reduced outer approximation of \({\mathbf {Y}}\) always failed. That is possibly because \({\mathbf {Y}}\) in (31) has no interior point and the upper level problem is not convex (c.f. [12, 50]). Then, we reformulate (31) to the following equivalent fractional semi-infinite programming problem involving trigonometric functions and a single parameter t
Then we solve (32) by the ACA method again. After a successful phase I, the first 10 iterations of phase II to compute an \(\varepsilon\)-stationary point of (32) run for about 22 minutes and produced a feasible point (0.6530, 0.6272). The 15th iteration of phase II produced a feasible point (0.7374, 0.6034) and the accumulated CPU time is about 40 minutes. The algorithm did not reach its default termination criterion within an hour. \(\square\)

The feasible set \({\mathbf {K}}\) and contour curves of f/g in Example 4.1
5 Special cases with exact or finitely convergent SDP relaxations
In this section, we study some cases of the FSIPP problem (1), for which we can derive SDP relaxation which is exact or has finite convergence and can extract at least one minimizer of (1). The reason for this concern is due to some applications of the FSIPP problem where exact optimal values and minimizers are required, see Sect. 5.2.
Recall the reformulations (10) and (11). Letting \(\varepsilon =0\) in Theorem 3.1 implies that
Theorem 5.1
Suppose that (A1-3) hold and the cones \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) satisfy the following conditions : \({\mathcal {C}}[y]\subseteq {\mathscr {P}}({\mathbf {Y}})\), \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\in {\mathcal {C}}[x],\) there exists some \(u^{\star }\in {\mathbf {S}}\) such that \(-p(u^{\star },y)\in {\mathcal {C}}[y]\) and \(h(u^{\star })\ge 0\) for any \(h(x)\in {\mathcal {C}}[x]\).
-
(i)
We have \(r^{\mathrm{{\tiny primal}}}=r^{\mathrm{{\tiny dual}}}=r^{\star }\).
-
(ii)
If \({\mathscr {L}}^{\star }\) is a minimizer of (11) such that the restriction \({\mathscr {L}}^{\star }|_{{{\mathbb {R}}}[x]_{{\mathbf {d}}}}\) admits a representing nonnegative measure \(\nu ,\) then
$$\begin{aligned} \frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}= \frac{1}{\int d\nu }\left( \int x_1 d\nu ,\ldots ,\int x_m d\nu \right) \in {\mathbf {S}}. \end{aligned}$$
Next, we specify four cases of the FSIPP problem, for which we can choose suitable cones \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) with sum-of-squares structures and satisfy conditions in Theorem 5.1.
5.1 Four cases
Recall the s.o.s-convexity introduced in Sect. 2 and consider
Case 1. (i) \(n=1\) and \({\mathbf {Y}}=[-1,1]\); (ii) \(f(x)\), \(-g(x)\), \(\psi _i(x), i=1,\ldots ,s\), and \(p(x,y)\in {{\mathbb {R}}}[x]\) for every \(y\in {\mathbf {Y}}\) are all s.o.s-convex in \(x\).
Case 2.
-
(i)
\(n>1\), \({\mathbf {Y}}=\{y\in {{\mathbb {R}}}^n\mid \phi (y)\ge 0\}\) where \(\deg (\phi (y))=2\), \(\phi ({\bar{y}})>0\) for some \({\bar{y}}\in {{\mathbb {R}}}^n\);
-
(ii)
\(\deg _y(p(x,y))=2\); (iii) \(f(x)\), \(-g(x)\), \(\psi _i(x), i=1,\ldots ,s\), and \(p(x,y)\in {{\mathbb {R}}}[x]\) for every \(y\in {\mathbf {Y}}\) are all s.o.s-convex in \(x\).
Let \(d_{x}=\deg _{x}(p(x,y))\) and \(d_{y}=\deg _{y}(p(x,y))\). For Case 1 and Case 2, we make the following choices of \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) in the reformulations (10) and (11):
In Case 1: Let
and
In Case 2: Let \({\mathcal {C}}[x]\) be defined as in (33) and
Recall Proposition 3.2 and Remark 3.1. In Cases 1 and 2, we in fact choose \({\mathcal {X}}={{\mathbb {R}}}^m\) and \(\Sigma ^2[x]\cap {{\mathbb {R}}}[x]_{2{\mathbf {d}}}\) as the approximation of \({\mathscr {P}}({\mathcal {X}})\). In each case, we can reduce (10) and (11) to a pair of primal and dual SDP problems.
Lemma 5.1
Under (A1-2), if \(f(x)\), \(-g(x),\) \(\psi _i(x),\ i=1,\ldots ,s,\) and \(p(x,y)\in {{\mathbb {R}}}[x]\) for every \(y\in {\mathbf {Y}}\) are all s.o.s-convex in \(x,\) then the Lagrangian \(L_{f,g}(x,\mu ,\eta )\) is s.o.s-convex for any \(\mu \in {\mathcal {M}}({\mathbf {Y}})\) and \(\eta \in {{\mathbb {R}}}_+^s.\)
Proof
Obviously, we only need to prove that \(\int _{{\mathbf {Y}}} p(x,y)d\mu (y)\) is s.o.s-convex under (A1-2). Note that there is a sequence of atomic measures \(\{\mu _k\}\subseteq {\mathcal {M}}({\mathbf {Y}})\) which is weakly convergent to \(\mu\), i.e., \(\lim _{k\rightarrow \infty } \int _{{\mathbf {Y}}} h(y)d\mu _k(y)=\int _{{\mathbf {Y}}} h(y)d\mu (y)\) holds for every bounded continuous real function h(y) on \({\mathbf {Y}}\) (c.f. [5, Example 8.1.6 (i)]). It is obvious that \(\int _{{\mathbf {Y}}} p(x,y)d\mu _k(y)\in {{\mathbb {R}}}[x]_{d_x}\) is s.o.s-convex for each k. Since the convex cone of s.o.s-convex polynomials in \({{\mathbb {R}}}[x]_{d_x}\) is closed (c.f. [2]), the conclusion follows. \(\square\)
Theorem 5.2
In Cases 1-2 : under (A2), the following holds.
-
(i)
\(r^{\mathrm{{\tiny dual}}}=r^{\star }\) and \(\frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}\in {\mathbf {S}}\) where \({\mathscr {L}}^{\star }\) be a minimizer of (11) which always exists.
-
(ii)
If (A3) holds, then \(r^{\mathrm{{\tiny primal}}}=r^{\star }\) and it is attainable.
Proof
In Case 1, by the representations of univariate polynomials nonnegative on an interval (c.f. [31, 41]), we have \(-p(x,y)\in {\mathcal {C}}[y]\) for each \(x\in {\mathbf {K}}\). In Case 2, by the S-lemma and Hilbert’s theorem, we also have \(-p(x,y)\in {\mathcal {C}}[y]\) for each \(x\in {\mathbf {K}}\). For any \(u^{\star }\in {\mathbf {S}}\), the linear functional \({\mathscr {L}}'\in ({{\mathbb {R}}}[x])^*\) such that \({\mathscr {L}}'(x^\alpha )=\frac{(u^{\star })^\alpha }{g(u^{\star })}\) for each \(\alpha \in {\mathbb {N}}^m\), is feasible to (11). Hence, \(r^{\mathrm{{\tiny primal}}}\le r^{\mathrm{{\tiny dual}}}\le r^{\star }\) by the weak duality.
(i) Let \({\mathscr {L}}^{\star }\) be a minimizer of (11), then \({\mathscr {L}}^{\star }(1)>0\). In fact, \({\mathscr {L}}^{\star }(1)\ge 0\) since \({\mathscr {L}}^{\star }\in (\Sigma ^2[x]\cap {{\mathbb {R}}}[x]_{2{\mathbf {d}}})^*\). If \({\mathscr {L}}^{\star }(1)=0\), then by the positive semidefiniteness of the associated moment matrix of \({\mathscr {L}}^{\star }\), we have \({\mathscr {L}}^{\star }(x^{\alpha })=0\) for all \(\alpha \in {\mathbb {N}}^m_{{\mathbf {d}}}\), which contradicts the equality \({\mathscr {L}}^{\star }(g)=1\). As \(\psi _1(x),\ldots ,\psi _s(x)\), \(p(x,y)\in {{\mathbb {R}}}[x]\) for every \(y\in {\mathbf {Y}}\) are all s.o.s-convex in \(x\), similar to the proof of Theorem 3.1 (ii), it is easy to see that \(\frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}\in {\mathbf {K}}\) due to Proposition 2.4. Since \(f(x)\) and \(-g(x)\) are also s.o.s-convex, under (A2), we have
It means that \(r^{\mathrm{{\tiny dual}}}=r^{\star }\) and \(\frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}\) is minimizer of (1). Clearly, for any \(u^{\star }\in {\mathbf {S}}\), the linear functional \({\mathscr {L}}'\in ({{\mathbb {R}}}[x]_{2{\mathbf {d}}})^*\) such that \({\mathscr {L}}'(x^\alpha )=\frac{(u^{\star })^\alpha }{g(u^{\star })}\) for each \(\alpha \in {\mathbb {N}}^m_{2{\mathbf {d}}}\) is a minimizer of (11).
(ii) By Lemma 5.1, Proposition 3.1 and Lemma 2.1, \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\in {\mathcal {C}}[x]\) in both cases. Thus, \(r^{\mathrm{{\tiny primal}}}=r^{\star }\) due to Theorem 5.1 (i) and is attainable at \((r^{\star }, {\mathscr {H}}, \eta ^{\star })\) where \({\mathscr {H}}\in ({{\mathbb {R}}}[y])^*\) satisfies that \({\mathscr {H}}(y^\beta )=\int _{{\mathbf {Y}}} y^\beta d\mu ^{\star }(y)\) for any \(\beta \in {\mathbb {N}}^n\). \(\square\)
Now we consider another two cases of the FSIPP problem (1):
Case 3.
-
(i)
\(n=1\) and \({\mathbf {Y}}=[-1,1]\);
-
(ii)
The Hessian \(\nabla ^2 f(u^{\star })\succ 0\) at some \(u^{\star }\in {\mathbf {S}}.\)
Case 4.
-
(i)
\(n>1\), \({\mathbf {Y}}=\{y\in {{\mathbb {R}}}^n\mid \phi (y)\ge 0\}\) where \(\deg (\phi (y))=2\), \(\phi ({\bar{y}})>0\) for some \({\bar{y}}\in {{\mathbb {R}}}^n\);
-
(ii)
\(\deg _y(p(x,y))=2\);
-
(iii)
The Hessian \(\nabla ^2 f(u^{\star })\succ 0\) at some \(u^{\star }\in {\mathbf {S}}\).
Let \(R>0\) be a real number satisfying (18) and \(q(x):=R^2-(x_1^2+\cdots +x_m^2)\). For an integer \(k\ge \lceil {\mathbf {d}}/2\rceil\), we make the following choices of \({\mathcal {C}}[x]\) and \({\mathcal {C}}[y]\) in the reformulations (10) and (11) in Case 3 and Case 4:
In Case 3: Replace \({\mathcal {C}}[x]\) by \({{\mathcal {C}}_{k}}[x]=\mathbf {qmodule}_k(\{q\})\) and let \({\mathcal {C}}[y]\) be defined as in (34).
In Case 4: Replace \({\mathcal {C}}[x]\) by \({{\mathcal {C}}_{k}}[x]=\mathbf {qmodule}_k(\{q\})\) and let \({\mathcal {C}}[y]\) be defined as in (35).
Recall Proposition 3.2 and Remark 3.1. In Cases 3 and 4, we in fact choose \({\mathcal {X}}=\{x\in {{\mathbb {R}}}^m\mid q(x)\ge 0\}\) and quadratic modules generated by \(\{q\}\) as the approximation of \({\mathscr {P}}({\mathcal {X}})\). For a fixed k, in each case, denote the resulting problems of (10) and (11) by (10k) and (11k), respectively. Denote by \(r^{\mathrm{{\tiny primal}}}_k\) and \(r^{\mathrm{{\tiny dual}}}_k\) the optimal values of (10k) and (11k). We can reduce (10k) and (11k) to a pair of primal and dual SDP problems.
Theorem 5.3
In Cases 3-4 : under (A1-2), the following holds.
-
(i)
For each \(k\ge \lceil {\mathbf {d}}/2\rceil ,\) \(r^{\mathrm{{\tiny primal}}}_k\le r^{\mathrm{{\tiny dual}}}_k\le r^{\star }\) and \(r^{\mathrm{{\tiny dual}}}_k\) is attainale.
-
(ii)
For a minimizer \({\mathscr {L}}_k^{\star }\) of (11k), if there exists an integer \(k'\in [\lceil {\mathbf {d}}/2\rceil , k]\) such that
$$\begin{aligned} \mathrm{rank}\ {\mathbf {M}}_{k'-1}({\mathscr {L}}_k^{\star })=\mathrm{rank}\ {\mathbf {M}}_{k'}({\mathscr {L}}_k^{\star }), \end{aligned}$$(36)then, \(r^{\mathrm{{\tiny dual}}}_k=r^{\star }\) and \(\frac{{\mathscr {L}}_k^{\star }(x)}{{\mathscr {L}}_k^{\star }(1)}\) is minimizer of (1);
-
(iii)
If (A3) holds, then for k large enough, \(r_{k}^{\mathrm{{\tiny primal}}}=r_{k}^{\mathrm{{\tiny dual}}}=r^{\star }\) and every minimizer \({\mathscr {L}}_k^{\star }\) of (11k) satisfies the rank condition (36) which certifies that \(\frac{{\mathscr {L}}_k^{\star }(x)}{{\mathscr {L}}_k^{\star }(1)}\) is a minimizer of (1).
Proof
(i) As proved in Theorem 5.2, we have \(-p(u^{\star },y)\in {\mathcal {C}}[y]\) for every \(u^{\star }\in {\mathbf {S}}\subset {\mathbf {K}}\) in both cases and hence \(r^{\mathrm{{\tiny primal}}}_k\le r^{\mathrm{{\tiny dual}}}_k\le r^{\star }\). Due to the form of q(x), the attainment of \(r^{\mathrm{{\tiny dual}}}_k\) follows from [26, Lemma 3] as proved in Theorem 4.2 (ii).
(ii) From the proof of Theorem 4.2 (iii), we can see that \({\mathscr {L}}_k^{\star }(1)>0\). By [9, Theorem 1.1], (36) implies that the restriction \({\mathscr {L}}_k^{\star }|_{{{\mathbb {R}}}[x]_{2k'}}\) has an atomic representing measure supported on the set \({\mathbf {K}}':=\{x\in {{\mathbb {R}}}^m\mid q(x)\ge 0\}\). Then, the conclusion follows by Theorem 5.1 (ii).
(iii) Under (A1-3), consider the nonnegative Lagrangian \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\). By Proposition 2.3, \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\) is coercive and strictly convex on \({{\mathbb {R}}}^m\). Hence, by Proposition 3.1, \({\mathbf {S}}\) is a singleton set, say \({\mathbf {S}}=\{u^{\star }\}\), and \(u^{\star }\) is the unique minimizer of \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\) on \({{\mathbb {R}}}^m\). Clearly, \(u^{\star }\) is an interior point of \({\mathbf {K}}'\). Then, by Proposition 2.1, there exists \(k^{\star }\in {\mathbb {N}}\) such that \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\in \mathbf {qmodule}_{k^{\star }}(\{q\})\). Thus, in both Case 3 and Case 4, \(L_{f,g}(x,\mu ^{\star },\eta ^{\star })\in {{\mathcal {C}}_{k}}[x]\) for every \(k\ge k^{\star }\). Then, \(r^{\mathrm{{\tiny primal}}}_{k}=r^{\mathrm{{\tiny dual}}}_{k}=r^{\star }\) for each \(k\ge k^{\star }\) by Theorem 5.1 (i).
Consider the polynomial optimization problem
Then, \(l^{\star }=0\) and is attained at \(u^{\star }\). The k-th Lasserre’s relaxation (see Sect. 2) for (37) is
and its dual problem is
We have shown that \(l_{k^{\star }}^{\mathrm{{\tiny primal}}}\ge 0\). As the linear functional \({\mathscr {L}}'\in ({{\mathbb {R}}}[x]_{2k})^*\) with \({\mathscr {L}}'(x^{\alpha })=(u^{\star })^{\alpha }\) for each \(\alpha \in {\mathbb {N}}^m_{2k}\) is feasible to (38), along with the weak duality, we have \(l_k^{\mathrm{{\tiny primal}}}\le l_k^{\mathrm{{\tiny dual}}}\le l^{\star }=0\), which means \(l_{k^{\star }}^{\mathrm{{\tiny primal}}}=l_{k^{\star }}^{\mathrm{{\tiny dual}}}=0\). Hence, Lasserre’s hierarchy (38) and (39) have finite convergence at the order \(k^{\star }\) without dual gap and the optimal value of (39) is attainable. Moreover, recall that \(u^{\star }\) is the unique point in \({{\mathbb {R}}}^m\) such that \(L_{f,g}(u^{\star },\mu ^{\star },\eta ^{\star })=0=l^{\star }\). Then by Proposition 2.2, the rank condition (36) holds for every minimizer of (38) for sufficiently large k. Let \({\mathscr {L}}_k^{\star }\) be a minimizer of (11k) with \(k\ge k^{\star }\). Now we show that \(\frac{{\mathscr {L}}_k^{\star }}{{\mathscr {L}}_k^{\star }(1)}\) is a minimizer of (38). Clearly, \(\frac{{\mathscr {L}}_k^{\star }}{{\mathscr {L}}_k^{\star }(1)}\) is feasible to (38). Because
\(\frac{{\mathscr {L}}_k^{\star }}{{\mathscr {L}}_k^{\star }(1)}\) is indeed a minimizer of (38). Therefore, for k sufficiently large, the rank condition (36) holds for \(\frac{{\mathscr {L}}_k^{\star }}{{\mathscr {L}}_k^{\star }(1)}\) and hence for \({\mathscr {L}}_k^{\star }\). \(\square\)
Example 5.1
Now we consider four FSIPP problems corresponding to the four cases studied above.
Case 1: Consider the FSIPP problem
For any \(y\in [-1,1]\), since p(x, y) is of degree 2 and convex in x, it is s.o.s-convex in x. Hence, the problem (40) is in Case 1. For any \(x\in {{\mathbb {R}}}^2\) and \(y\in [-1, 1]\), it is clear that
Then we can see that the feasible set \({\mathbf {K}}\) can be defined only by two constraints
That is, \({\mathbf {K}}\) is the area in \({{\mathbb {R}}}^2\) enclosed by the ellipse \(p(x,-1)=0\) and the two lines \(p(x,1)=0\). Then, it is not hard to check that the only global minimizer of (40) is \(u^{\star }=(-0.5,-0.5)\) and the minimum is 0.25. Obviously, (A2) holds for (40). Solving the single SDP problem (11) with the setting (33) and (34), we get \(\frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}=(-0.5000, -0.5000)\) where \({\mathscr {L}}^{\star }\) is the minimizer of (11). The CPU time is 0.80 seconds. Then we solve (40) with ACA method. The algorithm terminated successfully and returned the solution \((-0.5000, -0.5000)\). The over CPU time is 4.25 seconds.
Case 2: Consider the FSIPP problem
It is easy to see that (41) is in Case 2. For any \(y\in {\mathbf {Y}}\), it holds that
Hence, \({\mathbf {K}}\) is the part of the unit disc around the origin between the two lines defined by \(\psi (x)=0\) and the only global minimizer is \(u^{\star }=(0.5, 0.5)\). Obviously, (A2) holds for (41). Solving the single SDP problem (11) with the setting (33) and (35), we get \(\frac{{\mathscr {L}}^{\star }(x)}{{\mathscr {L}}^{\star }(1)}=(0.4999, 0.5000)\) where \({\mathscr {L}}^{\star }\) is the minimizer of (11). The CPU time is 1.20 seconds. Then we solve (41) with ACA method. The algorithm terminated successfully and returned the solution (0.5000, 0.5000). The overall CPU time is 52.75 seconds.
Case 3: Recall the convex but not s.o.s-convex polynomial \(h_2(x)\) in (30). Consider the FSIPP problem
Clearly, this problem is in Case 3 and satisfies (A1-2). We solve the SDP relaxation (11k) with the setting \({{\mathcal {C}}_{k}}[x]\) and \({\mathcal {C}}[y]\) aforementioned. We set the first order \(k=4\) and check if the rank condition (36) holds. If not, check the next order. We have \(\mathrm{rank}{\mathbf {M}}_{3}({\mathscr {L}}_4^{\star })=\mathrm{rank}{\mathbf {M}}_{4}({\mathscr {L}}_4^{\star })=1\) (within a tolerance \(<10^{-8}\)) for a minimizer \({\mathscr {L}}_4^{\star }\) of of \(r^{\mathrm{{\tiny dual}}}_4\), i.e., the rank condition (36) holds for \(k'=4\). By Theorem 5.3 (ii), the point \(u^{\star }:=\frac{{\mathscr {L}}_4^{\star }(x)}{{\mathscr {L}}_4^{\star }(1)}=(0.9044, 0.8460)\) is a minimizer and \(r^{\mathrm{{\tiny dual}}}_4=-0.8745\) is the minimum of (42). The CPU time is about 16.50 seconds. To show the accuracy of the solution , we draw some contour curves of f/g, including the one where f/g is the constant value \(f(u^{\star })/g(u^{\star })=-0.8745\) (the blue curve), and mark the point \(u^{\star }\) by a red dot in Figure 2 (left). Then we solve (42) with the ACA method. The algorithm terminated successfully and returned the solution (0.9040, 0.8463). The overall CPU time is 21.57 seconds.
Case 4: Consider the FSIPP problem
Clearly, this problem is in Case 4 and satisfies (A1-2). We solve the SDP relaxation (11k) with the setting \({{\mathcal {C}}_{k}}[x]\) and \({\mathcal {C}}[y]\) aforementioned. For the first order \(k=4\), we have \(\mathrm{rank}{\mathbf {M}}_{3}({\mathscr {L}}_4^{\star })=\mathrm{rank}{\mathbf {M}}_{4}({\mathscr {L}}_4^{\star })=1\) (within a tolerance \(<10^{-8}\)) for a minimizer \({\mathscr {L}}_4^{\star }\) of of \(r^{\mathrm{{\tiny dual}}}_4\). By Theorem 5.3 (ii), the point \(u^{\star }:=\frac{{\mathscr {L}}_4^{\star }(x)}{{\mathscr {L}}_4^{\star }(1)}=(0.7211, 0.6912)\) is a minimizer of (43). The CPU time is about 14.60 seconds. See Figure 2 (right) for the accuracy of the solution. Then we solve (43) with the ACA method. The algorithm terminated successfully and returned the solution (0.7039, 0.6823). The overall CPU time is 768.02 seconds.
For the above four FSIPP problems, we remark that the optimality of the solution obtained by our SDP method can be guaranteed by Theorem 5.2 (i) and Theorem 5.3 (ii), while the solution concept of the ACA method is that of stationary points and all iterates are feasible points for the original SIP. \(\square\)

The feasible set \({\mathbf {K}}\) and contour curves of f/g in Example 5.1Case 3 (left) and Case 4 (right)
5.2 Application to multi-objective FSIPP
In this part, we apply the above approach for the special four cases of FSIPP problems to the following multi-objective fractional semi-infinite polynomial programming (MFSIPP) problem
where \(f_i(x), g_i(x)\in {{\mathbb {R}}}[x],\) \(i = 1, \ldots , t,\) \(p(x,y) \in {{\mathbb {R}}}[x,y]\). Note that “\({\text{Min}}_{{\mathbb{R}_{{\text{ + }}}^{{\text{t}}} }}\)” in the above problem (44) is understood in the vectorial sense, where a partial ordering is induced in the image space \({{\mathbb {R}}}^t,\) by the non-negative cone \({{\mathbb {R}}}^t_+.\) Let \(a, b \in {{\mathbb {R}}}^t,\) the partial ordering says that \(a \ge b\) (or \(a - b \in {{\mathbb {R}}}^t_+\)), which can equivalently be written as \(a_i \ge b_i,\) for all \(i = 1, \ldots , t,\) where \(a_i\) and \(b_i\) stands for the ith component of the vectors a and b, respectively. Denote by \({\mathbf {F}}\) the feasible set of (44). We make the following assumptions on the MFSIPP problem (44):
(A5): \({\mathbf {Y}}\) is compact; \(f_i(x)\), \(-g_i(x)\), \(i = 1, \ldots , t,\) and \(p(x,y)\in {{\mathbb {R}}}[x]\) for every \(y\in {\mathbf {Y}}\) are all convex in \(x\);
(A6): For each \(i=1,\ldots ,t\), either \(f_i(x)\ge 0\) and \(g_i(x)>0\) for all \(x\in {\mathbf {F}}\); or \(g_i(x)\) is affine and \(g_i(x)>0\) for all \(x\in {\mathbf {F}}\).
Definition 5.1
A point \(u^{\star }\in {\mathbf {F}}\) is said to be an efficient solution to (44) if
Efficient solutions to (44) are also known as Pareto-optimal solutions. The aim of this part is to find efficient solutions to (44). As far as we know, very few algorithmic developments are available for such a case in the literature because of the difficulty of checking feasibility of a given point.
The \(\epsilon\)-constraint method [6, 17] may be the best known technique to solve a nonconvex multi-objective optimization problem. The basic idea for this method is to minimize one of the original objectives while the others are transformed to constraints by setting an upper bound to each of them. Based on the criteria for the \(\epsilon\)-constraint method given in [11], an algorithm to obtain an efficient solution to (44) follows.

Theorem 5.4
The output \(u^{\star }\) in Algorithm 5.1 is indeed an efficient solution to (1).
Proof
We refer to [11, Propositions 4.4 and 4.5]; see also [32, Theorem 3.4]. \(\square\)
Remark 5.1
-
(i)
Clearly, (\(\hbox {P}_i\)) is an FSIPP problem of the form (1). It is easy to see that for each \(i=2,\ldots ,t\), the constraints
$$\begin{aligned} g_j(u^{(i-1)})f_j(x)-f_j(u^{(i-1)})g_j(x)\le 0,\ j=1,\ldots ,i-1, \end{aligned}$$are all active in (\(\hbox {P}_i\)). Therefore, the Slater condition fails for ((\(\hbox {P}_i\)) with \(i=2,\ldots ,t.\)
-
(ii)
According to Algorithm 5.1, the problem of finding an efficient solution of the MFSIPP problem (44) reduces to solving every scalarized problem (\(\hbox {P}_i\)) and extracting a (common) minimizer, which is the key for the success of Algorithm 5.1. Generally, approximate solutions to (\(\hbox {P}_i\)) can be obtained by some numerical methods for semi-infinite programming problems. However, note that the errors introduced by any approximate solutions can accumulate in the process of the \(\epsilon\)-constraint method. This can potentially make the output solution unreliable.
\(\square\)
We have studied four cases of the FSIPP problem, for which at least one minimizer can be extracted by the proposed SDP approach. Now we apply this approach to the four corresponding cases of MFSIPP problem:
Case I (resp., II): (\(\hbox {P}_i\)) is in Case 1 (resp., 2) for each \(i=1,\ldots ,t\);
Case III (resp., IV): (\(\text {P}_{i'}\)) is in Case 3 (resp., 4) for some \(i'\in \{1,\ldots ,t\}\).
For Case I and II, if the assumptions in Theorem 5.2 hold for each (\(\hbox {P}_i\)), then an efficient solution to the MFSIPP problem (44) can obtained by solving t SDP problems.
For Case III and IV, we only need solve (\(\text {P}_{i'}\)) to get an efficient solution to (44). In fact, we have the following result.
Proposition 5.1
In Cases III-IV : under (A5-6), the scalarized problem \((\text {P}_{i'})\) has a unique minimizer \(u^{(i')}\) which is an efficient solution to the MFSIPP problem (44).
Proof
By assumption, \(f_{i'}(x)-r_{i'}g_{i'}(x)\) is convex and its minimum on the feasible set of (\(\text {P}_{i'}\)) is 0 attained at any optimal solution of (\(\text {P}_{i'}\)). By Proposition 2.3, \(f_{i'}(x)-r_{i'}g_{i'}(x)\) is coercive and strictly convex on \({{\mathbb {R}}}^m\). Then, \(f_{i'}(x)-r_{i'}g_{i'}(x)\) has a unique minimizer on the feasible set of (\(\text {P}_{i'}\)). Consequently, (\(\text {P}_{i'}\)) has a unique minimizer \(u^{(i')}\). By Theorem 5.4, \(u^{(i')}\) is an efficient solution to (44). \(\square\)
As a result, in Case III and Case IV, if the assumptions in Theorem 5.3 hold for (\(\text {P}_{i'}\)), an efficient solution to the MFSIPP problem (44) can be obtained by solving finitely many SDP problems.
Example 5.2
To show the efficiency of the SDP method for the four cases of the MFSIPP problem discussed above, now we present an example for each case. In each of the following examples, \(m=2\) and \(t=2\). We pick some points y on a uniform discrete grid inside \({\mathbf {Y}}\) and draw the corresponding curves \(p(x,y)=0\). Hence, the feasible set \({\mathbf {F}}\) is illustrated by the area enclosed by these curves. The initial point \(u^{(0)}\) and the output \(u^{\star }\) of Algorithm 5.1 are marked in \({\mathbf {F}}\) by ‘\(*\)’ in blue and red, respectively. To show the accuracy of the output, we first illustrate the image of \({\mathbf {F}}\) under the map \(\left( \frac{f_1}{g_1},\frac{f_2}{g_2}\right)\). To this end, we choose a square containing \({\mathbf {F}}\). For each point u on a uniform discrete grid inside the square, we check if \(u\in {\mathbf {F}}\) (as we will see it is easy for our examples). If so, we plot the point \(\left( \frac{f_1(u)}{g_1(u)},\frac{f_2(u)}{g_2(u)}\right)\) in the image plane. The points \(\left( \frac{f_1(u^{(0)})}{g_1(u^{(0)})},\frac{f_2(u^{(0)})}{g_2(u^{(0)})}\right)\) and \(\left( \frac{f_1(u^{\star })}{g_1(u^{\star })},\frac{f_2(u^{\star })}{g_2(u^{\star })}\right)\) are then marked in the image by ‘\(*\)’ in blue and red, respectively. We will see from the figures that the output of Algorithm 5.1 in each example is indeed as we expect.
Case I: Consider the ellipse
which can be represented by
where
and \({\mathbf {Y}}=[-1,1]\) (See [13]). The feasible set \({\mathbf {F}}\) is illustrated in Fig. 3 (left).
Consider the problem
Clearly, this problem is in Case I. By checking if a given point is in the ellipse \({\mathbf {F}}\), it is easy to depict the image of \({\mathbf {F}}\) in the way aforementioned, which is shown in Fig. 3 (right). Let the initial point be \(u^{(0)}=(-1,1)\) in Algorithm 5.1. The output is \(u^{\star }=u^{(2)}=(-0.2138,0.8319)\). These points and their images are marked in Fig. 3.
Case II: Consider the set
where \(p(x_1,x_2,y_1,y_2)=-1+x_1^2+x_2^2+(y_1-y_2)^2x_1x_2\) and
The set \({\mathbf {F}}\) is illustrated in Fig. 4 (left). The Hessian matrix of p with respect to \(x_1\) and \(x_2\) is
It is easy to see that \(p(x_1,x_2,y_1,y_2)\) is s.o.s-convex in \((x_1,x_2)\) for every \(y\in {\mathbf {Y}}\).
Consider the problem
Clearly, this problem is in Case II. To depict the image of \({\mathbf {F}}\) in the aforementioned way, we remark that \({\mathbf {F}}\) is in fact the area enclosed by the lines \(x_1+x_2=\pm 1\) and the unit circle. Hence, it is easy to check whether a given point is in \({\mathbf {F}}\). The image of \({\mathbf {F}}\) is shown in Fig. 4 (right). Let the initial point be \(u^{(0)}=(0,1)\) in Algorithm 5.1. The output is \(u^{\star }=u^{(2)}=(0.6822,-0.1476)\). These points and their images are marked in Fig. 4.
Case III: Consider the polynomial \(h_1(x_1,x_2,x_3)\) in (30) and let
where \(p(x_1,x_2,y_1)=-1+h_1(x_1,x_2,1)/100-y_1x_1-y_1^2x_2\) and \({\mathbf {Y}}=[-1,1]\). Clearly, \(p(x,y_1)\) is convex but not s.o.s-convex for every \(y_1\in {\mathbf {Y}}\). We illustrate \({\mathbf {F}}\) in Fig. 5 (left).
Consider the problem
For a given point \(u\in {{\mathbb {R}}}^2\), as \(p(u_1,u_2,y_1)\) is a univariate quadratic function, it is easy to check whether \(-p(u_1,u_2,y_1)\) is nonnegative on \([-1,1]\) (i.e., whether \(u\in {\mathbf {F}}\)). Hence, The image of \({\mathbf {F}}\) can be easily depicted in Fig. 5 (right). Clearly, (\(\text {P}_1\)) is in Case 3. Hence, we only need to solve (\(\text {P}_1\)) to get an efficient solution by Proposition 5.1 and Theorem 5.4. We let the initial point be \(u^{(0)}=(-0.6,0.5)\) in Algorithm 5.1 and solve (\(\text {P}_1\)) by the SDP relaxations for Case 3. We set the first order \(k=4\) and check if the rank condition (36) holds. If not, check the next order. We have \(\text {rank}{\mathbf {M}}_{3}({\mathscr {L}}_4^{\star })=\text {rank}{\mathbf {M}}_{4}({\mathscr {L}}_4^{\star })=1\) (within a tolerance \(<10^{-8}\)) for a minimizer \({\mathscr {L}}_4^{\star }\) of of \(r^{\text {{\tiny dual}}}_4\), i.e., the rank condition (36) holds for \(k'=4\). By Theorem 5.3 (ii), the point \(u^{\star }:=\frac{{\mathscr {L}}_4^{\star }(x)}{{\mathscr {L}}_4^{\star }(1)}=(0.000,-0.1623)\) is an efficient solution to (46). These points \(u^{(0)}, u^{\star }\) and their images are marked in Fig. 5.
Case IV: Let \(h_1(x_1,x_2,x_3)\) be the polynomial in (30) and
where \(p(x_1,x_2,y_1,y_2)=(h_1(x_1,x_2,1)/100-1)-y_1y_2(x_1+x_2)\) and
Clearly, p(x, y) is convex but not s.o.s-convex for every \(y\in {\mathbf {Y}}\). We illustrate \({\mathbf {F}}\) in Fig. 6 (left).
Consider the problem
To depict the image of \({\mathbf {F}}\) in the aforementioned way, we remark that \({\mathbf {F}}\) is in fact the area enclosed by the two curves \(p\left( x_1,x_2,\pm \frac{\sqrt{2}}{2},\pm \frac{\sqrt{2}}{2}\right) =0\). Hence, it is easy to check whether a given point is in \({\mathbf {F}}\). Then the image of \({\mathbf {F}}\) can be easily depicted in Fig. 6 (right). Clearly, (\(\text {P}_1\)) is in Case 4. Again, we only need to solve (\(\text {P}_1\)). We let the initial point be \(u^{(0)}=(-0.5,0.5)\) in Algorithm 5.1 and solve (\(\text {P}_1\)) by the SDP relaxations for Case 4. We check if the rank condition (36) holds for the order initialized from 4. Similarly to Case III, when \(k=4\) and \(k'=4\), the rank condition (36) holds for a minimizer \({\mathscr {L}}_4^{\star }\) of \(r^{\text {{\tiny dual}}}_4\). By Theorem 5.3 (ii), the point \(u^{\star }:=\frac{{\mathscr {L}}_4^{\star }(x)}{{\mathscr {L}}_4^{\star }(1)}=(0.1231,0.000)\) is an efficient solution to (47). These points \(u^{(0)}, u^{\star }\) and their images are marked in Fig. 6. \(\square\)

The feasible set \({\mathbf {F}}\) (left) and its image (right) in the example of Case I

The feasible set \({\mathbf {F}}\) (left) and its image (right) in the example of Case II

The feasible set \({\mathbf {F}}\) (left) and its image (right) in the example of Case III

The feasible set \({\mathbf {F}}\) (left) and its image (right) in the example of Case IV
6 Conclusions
We focus on solving a class of FSIPP problems with some convexity/concavity assumption on the function data. We reformulate the problem to a conic optimization problem and provide a characteristic cone constraint qualification for convex SIP problems to bring sum-of-squares structures in the reformulation. In this framework, we first present a hierarchy of SDP relaxations with asymptotic convergence for the FSIPP problem whose index set is defined by finitely many polynomial inequalities. Next, we study four cases of the FSIPP problems for which the SDP relaxation is exact or has finite convergence and at least one minimizer can be extracted. This approach is then applied to the four corresponding multi-objective cases to find efficient solutions.
Notes
Its code named SIPSOLVER is available at https://kop.ior.kit.edu/791.php.
References
Ahmadi, A.A., Olshevsky, A., Parrilo, P.A., Tsitsiklis, J.N.: NP-hardness of deciding convexity of quartic polynomials and related problems. Math. Program. 137(1), 453–476 (2013)
Ahmadi, A.A., Parrilo, P.A.: A convex polynomial that is not sos-convex. Math. Program. 135(1), 275–292 (2012)
Ahmadi, A.A., Parrilo, P.A.: A complete characterization of the gap between convexity and sos-convexity. SIAM J. Optim. 23(2), 811–833 (2013)
Bajalinov, E.B.: Linear-Fractional Programming: Theory, Methods, Applications and Software. Springer, Berlin (2003)
Bogachev, V.I.: Measure Theory, vol. II. Springer, Berlin (2007)
Chankong, V., Haimes, Y.Y.: Multiobjective Decision Making: Theory and Methodology. North-Holland, Amsterdam (1983)
Charnes, A., Cooper, W.W., Kortanek, K.: Duality in semi-infinite programs and some works of Haar and Carathéodory. Manage. Sci. 9(2), 209–228 (1963)
Chuong, T.D.: Nondifferentiable fractional semi-infinite multiobjective optimization problems. Oper. Res. Lett. 44(2), 260–266 (2016)
Curto, R.E., Fialkow, L.A.: Truncated \(K\)-moment problems in several variables. J. Op. Theory 54(1), 189–226 (2005)
Dhara, A., Dutta, J.: Optimality Conditions in Convex Optimization: A Finite-Dimensional View. CRC Press, Boca Raton (2012)
Ehrgott, M.: Multicriteria Optimization, 2nd edn. Springer, Berlin (2005)
Floudas, C.A., Stein, O.: The adaptive convexification algorithm: a feasible point method for semi-infinite programming. SIAM J. Optim. 18(4), 1187–1208 (2007)
Goberna, M.Á., López, M.A.: Linear Semi-infinite Optimization. John Wiley & Sons, Chichester (1998)
Goberna, M.A., López, M.A.: Recent contributions to linear semi-infinite optimization. 4OR 15(3), 221–264 (2017)
Goberna, M.A., López, M.A.: Recent contributions to linear semi-infinite optimization: an update. Ann. Oper. Res. 271(1), 237–278 (2018)
Guo, F., Sun, X.: On semi-infinite systems of convex polynomial inequalities and polynomial optimization problems. Comput. Optim. Appl. 75(3), 669–699 (2020)
Haimes, Y., Lasdon, L., Wismer, D.: On a bicriterion formulation of the problems of integrated system identification and system optimization. IEEE Trans. Syst. Man Cybern. 1(3), 296–297 (1971)
Haviland, E.K.: On the momentum problem for distribution functions in more than one dimension. II. Am. J. Math. 58(1), 164–168 (1936)
Helton, J., Nie, J.: Semidefinite representation of convex sets. Math. Program. 122(1), 21–64 (2010)
Henrion, D., Lasserre, J.B.: Detecting global optimality and extracting solutions in GloptiPoly. In: Henrion, D., Garulli, A. (eds.) Positive Polynomials in Control, pp. 293–310. Springer, Berlin, Heidelberg (2005)
Henrion, D., Lasserre, J.B., Löfberg, J.: GloptiPoly 3: moments, optimization and semidefinite programming. Opt. Methods Softw. 24(4–5), 761–779 (2009)
Hettich, R., Kortanek, K.O.: Semi-infinite programming: theory, methods, and applications. SIAM Rev. 35(3), 380–429 (1993)
Jeyakumar, V., Li, G.Y.: Strong duality in robust convex programming: complete characterizations. SIAM J. Optim. 20(6), 3384–3407 (2010)
Jeyakumar, V., Li, G.Y.: Exact SDP relaxations for classes of nonlinear semidefinite programming problems. Oper. Res. Lett. 40(6), 529–536 (2012)
Jeyakumar, V., Pham, T.S., Li, G.Y.: Convergence of the Lasserre hierarchy of SDP relaxations for convex polynomial programs without compactness. Oper. Res. Lett. 42(1), 34–40 (2014)
Josz, C., Henrion, D.: Strong duality in Lasserre’s hierarchy for polynomial optimization. Opt. Lett. 10(1), 3–10 (2016)
Lasserre, J.B.: Global optimization with polynomials and the problem of moments. SIAM J. Optim. 11(3), 796–817 (2001)
Lasserre, J.B.: Convexity in semialgebraic geometry and polynomial optimization. SIAM J. Optim. 19(4), 1995–2014 (2009)
Lasserre, J.B.: An algorithm for semi-infinite polynomial optimization. TOP 20(1), 119–129 (2012)
Lasserre, J.B., Netzer, T.: SOS approximations of nonnegative polynomials via simple high degree perturbations. Math. Z. 256(1), 99–112 (2007)
Laurent, M.: Sums of squares, moment matrices and optimization over polynomials. In: Putinar, M., Sullivant, S. (eds.) Emerging Applications of Algebraic Geometry, pp. 157–270. Springer, New York, NY (2009)
Lee, J.H., Jiao, L.G.: Solving fractional multicriteria optimization problems with sum of squares convex polynomial data. J. Optim. Theory Appl. 176(2), 428–455 (2018)
Li, G.Y., Ng, K.F.: On extension of Fenchel duality and its application. SIAM J. Optim. 19(3), 1489–1509 (2008)
Löfberg, J.: YALMIP : a toolbox for modeling and optimization in MATLAB. In 2004 IEEE International Conference on Robotics and Automation (IEEE Cat. No.04CH37508), pages 284–289, (2004)
López, M., Still, G.: Semi-infinite programming. Eur. J. Oper. Res. 180(2), 491–518 (2007)
Nguyen, V.-B., Sheu, R.-L., Xia, Y.: An SDP approach for quadratic fractional problems with a two-sided quadratic constraint. Opt. Methods Softw. 31(4), 701–719 (2016)
Nie, J.: Certifying convergence of Lasserre’s hierarchy via flat truncation. Math. Program. Ser. A 142(1–2), 485–510 (2013)
Nie, J.: Optimality conditions and finite convergence of Lasserre’s hierarchy. Math. Program. Ser. A 146(1–2), 97–121 (2014)
Nie, J., Schweighofer, M.: On the complexity of Putinar’s positivstellensatz. J. Complex. 23(1), 135–150 (2007)
Parpas, P., Rustem, B.: An algorithm for the global optimization of a class of continuous minimax problems. J. Optim. Theory Appl. 141(2), 461–473 (2009)
Powers, V., Reznick, B.: Polynomials that are positive on an interval. Trans. Am. Math. Soc. 352(10), 4677–4692 (2000)
Putinar, M.: Positive polynomials on compact semi-algebraic sets. Indiana Univ. Math. J. 42(3), 969–984 (1993)
Reznick, B.: Some concrete aspects of Hilbert’s 17th problem. In Contemporary Mathematics, volume 253, pages 251–272. American Mathematical Society, (2000)
Schaible, S., Shi, J.M.: Fractional programming: the sum-of-ratios case. Opt. Methods Softw. 18(2), 219–229 (2003)
Scheiderer, C.: Sums of squares on real algebraic curves. Math. Z. 245(4), 725–760 (2003)
Schmüdgen, K.: The k-moment problem for compact semi-algebraic sets. Math. Ann. 289(1), 203–206 (1991)
Shapiro, A.: Semi-infinite programming, duality, discretization and optimality conditions. Optimzation 58(2), 133–161 (2009)
Shapiro, A., Scheinber, K.: Duality, optimality conditions and perturbation analysis. In: Wolkowicz, H., Saigal, R., Vandenberghe, L. (eds.) Handbook of Semidefinite Programming - Theory. Algorithms, and Applications, pp. 67–110. Kluwer Academic Publisher, Boston (2000)
Stancu-Minasian, I.M.: Fractional Programming: Theory. Methods and Applications. Springer, Netherlands (1997)
Stein, O., Steuermann, P.: The adaptive convexification algorithm for semi-infinite programming with arbitrary index sets. Math. Program. 136(1), 183–207 (2012)
Sturm, J.F.: Using SeDuMi 1.02, a Matlab toolbox for optimization over symmetric cones. Opt. Methods Softw. 11(1–4), 625–653 (1999)
Verma, R.U.: Semi-Infinite Fractional Programming. Infosys Science Foundation Series, Springer Singapore (2017)
Wang, L., Guo, F.: Semidefinite relaxations for semi-infinite polynomial programming. Comput. Optim. Appl. 58(1), 133–159 (2013)
Xu, Y., Sun, W., Qi, L.: On solving a class of linear semi-infinite programming by SDP method. Optimization 64(3), 603–616 (2015)
Zalmai, G., Zhang, Q.: Semiinfinite multiobjective fractional programming, Part I: sufficient efficiency conditions. J. Appl. Anal. 16(2), 199–224 (2010)
Zalmai, G., Zhang, Q.: Semiinfinite multiobjective fractional programming, Part II: duality models. J. Appl. Anal. 17(1), 1–35 (2011)
Acknowledgements
The authors are very grateful for the comments of two anonymous referees which helped to improve the presentation. The authors wish to thank Guoyin Li for many helpful comments. Feng Guo is supported by the Chinese National Natural Science Foundation under grant 11571350, the Fundamental Research Funds for the Central Universities. Liguo Jiao is supported by Jiangsu Planned Projects for Postdoctoral Research Funds 2019 (no. 2019K151).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
Consider the general convex semi-infinite programming problem
where \(h(\cdot )\), \(\psi _1(\cdot ),\ldots ,\psi _s(\cdot )\), \(p(\cdot ,y):{{\mathbb {R}}}^m\rightarrow {{\mathbb {R}}}\) for any \(y\in {\mathbf {Y}}\), are continuous and convex functions (not necessarily polynomials), \(p(x,y):{{\mathbb {R}}}^m\times {{\mathbb {R}}}^n \rightarrow {{\mathbb {R}}}\) is a lower semicontinuous function such that \(p(x,\cdot ): {{\mathbb {R}}}^n\rightarrow {{\mathbb {R}}}\) is continuous for all \(x \in {{\mathbb {R}}}^m\), the index set \({\mathbf {Y}}\) is an arbitrary compact subset in \({{\mathbb {R}}}^n\). We denote by \({\mathbf {K}}\) the feasible region of (48) and assume that \({\mathbf {K}}\ne \emptyset\). Inspired by Jeyakumar and Li [23], we next provide a constraint qualification weaker than the Slater condition for (48) to guarantee the strong duality and the attachment of the solution in the dual problem.
Denote by \({\mathcal {M}}({\mathbf {Y}})\) the set of nonnegative measures supported on \({\mathbf {Y}}\). We first show that for all \(\mu \in {\mathcal {M}}({\mathbf {Y}}),\)
is a continuous and convex function. Indeed, it is clear that this function always takes finite value due to the continuity assumption of \(p(x,\cdot )\) for all \(x \in {{\mathbb {R}}}^m\). Now, by Fatou’s lemma, for any \(x^{(k)} \rightarrow x,\)
This shows that \(\Phi _{\mu }\) is a lower semicontinuous function. Also, as \(p(\cdot ,y)\) is convex and \(\mu \in {\mathcal {M}}({\mathbf {Y}})\), it is easy to see that \(\Phi _{\mu }\) is also convex for all \(\mu \in {\mathcal {M}}({\mathbf {Y}})\). Thus, \(\Phi _{\mu }\) is a proper lower semicontinuous convex function which always takes finite value, and so, is continuous.
The Lagrangian dual of (48) reads
Recall the notation in (16),
We say that the semi-infinite characteristic cone constraint qualification (SCCCQ) holds for \({\mathbf {K}}\) if \({\mathcal {C}}_1+{\mathcal {C}}_2\) is closed.
Proposition A.1
The set \({\mathcal {C}}_1+{\mathcal {C}}_2\) is a convex cone.
Proof
As \({\mathcal {C}}_2\) is a convex cone due to [10, Theorem 2.123], we only need to prove that \({\mathcal {C}}_1\) is a convex cone.
We first prove that \({\mathcal {C}}_1\) is a cone. It is clear that \((0,0)\in {\mathcal {C}}_1\). Let \(\lambda >0\) and \((\xi ,\alpha )\in {\mathcal {C}}_1\) Then, there exists \(\mu '\in {\mathcal {M}}({\mathbf {Y}})\) such that \((\xi ,\alpha )\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\mu '(y)\right) ^*\). Let \(\tilde{\mu }=\lambda \mu '\in {\mathcal {M}}({\mathbf {Y}})\). As \(\Phi _{\mu '}\) is continuous and convex, by [10, Theorem 2.123 (iv)],
Hence, \(\lambda (\xi ,\alpha )\in {\mathcal {C}}_1\).
Now it suffices to prove that \(\text {co}({\mathcal {C}}_1)\subseteq {\mathcal {C}}_1\). Let \((\xi ,\alpha )\in \text {co}({\mathcal {C}}_1\)). As \({\mathcal {C}}_1\) is a cone in \({{\mathbb {R}}}^{m+1}\), from the Carathedory theorem, there exist \((\xi _{\ell },\alpha _{\ell })\in {\mathcal {C}}_1\), \({\ell }=1,\ldots ,m+1\), such that \((\xi ,\alpha )=\sum _{{\ell }=1}^{m+1}(\xi _{\ell },\alpha _{\ell })\). For each \({\ell }=1,\ldots ,m+1\), there exists \(\mu _{\ell }\in {\mathcal {M}}({\mathbf {Y}})\) such that \((\xi _{\ell },\alpha _{\ell })\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\mu _{\ell }(y)\right) ^*\). Note that \(\Phi _{\mu _{\ell }}\) is continuous for each \({\ell }=1,\ldots ,m+1\). Let \({\hat{\mu }}=\sum _{{\ell }=1}^{m+1}\mu _{\ell }\in {\mathcal {M}}({\mathbf {Y}})\), then by [10, Theorem 2.123 (i) and Proposition 2.124],
The proof is completed. \(\square\)
Theorem A.1
Exactly one of the following two statements holds :
-
(i)
\((\exists x\in {{\mathbb {R}}}^m)\ h(x)<0,\ \psi _j(x) \le 0,\ j=1,\ldots ,s, \ p(x,y)\le 0, \forall \ y\in {\mathbf {Y}};\)
-
(ii)
\((0,0)\in \text {epi}\ h^*+\text {cl}({\mathcal {C}}_1+{\mathcal {C}}_2).\)
Proof
Let
and
It is easy to see that \({\mathbf {K}}={\mathbf {K}}_1\cap {\mathbf {K}}_2\) and the indicator functions of \({\mathbf {K}}_1\) and \({\mathbf {K}}_2\) are
By Proposition A.1 and [33, Lemma 2.2], it holds that
Now, we show that [not (i)] is equivalent to [(ii)]. In fact,
By the continuity of h and [10, Theorem 2.123 (i)], we have
Hence, the conclusion follows. \(\square\)
Theorem A.2
Suppose that the SCCCQ holds for (48), then there exist \(\mu ^{\star }\in {\mathcal {M}}({\mathbf {Y}})\) and \(\eta ^{\star }\in {{\mathbb {R}}}_+^s\) such that
where \(r^{\star }\) is the optimal value of (48).
Proof
From the weak duality, we have
As we assume that \({\mathbf {K}}\ne \emptyset\), \(r^{\star }>-\infty\). Applying Theorem A.1 with h replaced by \(\overline{h}\) where \(\overline{h}(x)=h(x)-r^{\star }\) for all \(x \in {{\mathbb {R}}}^m\), and making use of the SCCCQ, one has
Then, there exist \((\xi ,\alpha )\in \text {epi}\ h^*\), \(\mu ^{\star }\in {\mathcal {M}}({\mathbf {Y}})\), \((\tau ,\beta )\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\mu ^{\star }(y)\right) ^*\), \(\eta ^{\star }\in {{\mathbb {R}}}_+^s\), \((\zeta ,\gamma )\in \text {epi}\left( \sum _{j=1}^s\eta _j^{\star }\psi _j\right) ^*\) such that \((\xi ,\alpha )+(\tau ,\beta )+(\zeta ,\gamma )=(0,-r^{\star })\). Then, for every \(x\in {{\mathbb {R}}}^m\),
Then the conclusion follows by the weak duality. \(\square\)
Recall that the Slater condition holds for (48) if there exists \(u\in {{\mathbb {R}}}^m\) such that \(p(u,y)<0\) for all \(y\in {\mathbf {Y}}\) and \(\psi _j(u)<0\) for all \(j=1,\ldots ,s.\) We show that the Slater condition can guarantee the SCCCQ condition.
Proposition A.2
If the Slater condition holds for (48), then \({\mathcal {C}}_1+{\mathcal {C}}_2\) is closed.
Proof
Let \(\left( w^{(k)},v^{(k)}\right) \in {\mathcal {C}}_1+{\mathcal {C}}_2\) such that \(\left( w^{(k)},v^{(k)}\right) \rightarrow (w,v)\) and we show that \((w,v)\in {\mathcal {C}}_1+{\mathcal {C}}_2\). For each \(k\in {\mathbb {N}}\), there exist \(\left( w^{(k,1)},v^{(k,1)}\right) \in {\mathcal {C}}_1\) and \(\left( w^{(k,2)},v^{(k,2)}\right) \in {\mathcal {C}}_2\) such that
Then, for each \(k\in {\mathbb {N}}\), there exists a measure \(\mu ^{(k)}\in {\mathcal {M}}({\mathbf {Y}})\) and \(\eta ^{(k)}\in {{\mathbb {R}}}_+^s\) such that for any \(x\in {{\mathbb {R}}}^m\),
and
Therefore, for any \(x\in {{\mathbb {R}}}^m\),
Without loss of generality, we may assume that \((w,v)\not \in \{0\}\times {{\mathbb {R}}}_+\) since \(\{0\}\times {{\mathbb {R}}}_+\subset {\mathcal {C}}_1+{\mathcal {C}}_2\). Hence, for each \(k\in {\mathbb {N}}\), without loss of generality, we may assume that \(\int _{{\mathbf {Y}}} d\mu ^{(k)}(y)+\sum _{j=1}^s\eta _j^{(k)}>0\) and let
Then, passing to subsequences if necessary, we may assume that there are a measure \(\nu \in {\mathcal {M}}({\mathbf {Y}})\) and a point \(\xi \in {{\mathbb {R}}}_+^s\) such that the sequence \(\{\tilde{\mu }^{(k)}\}\) is weakly convergent to \(\nu\) by Prohorov’s theorem (c.f. [5, Theorem 8.6.2]) and the sequence \(\{\tilde{\eta }^{(k)}\}\) is convergent to \(\xi\). We claim that both \(\int _{{\mathbf {Y}}} d\mu ^{(k)}(y)\) and \(\sum _{j=1}^s\eta _j^{(k)}\) are bounded as \(k\rightarrow \infty\). If it is not the case, then dividing both sides of (52) by \(\int _{{\mathbf {Y}}} d\mu ^{(k)}(y)+\sum _{j=1}^s\eta _j^{(k)}\) and letting k tend to \(\infty\) yealds
Recall that \(p(x,\cdot ): {{\mathbb {R}}}^n\rightarrow {{\mathbb {R}}}\) is continuous for all \(x \in {{\mathbb {R}}}^m\). As the Slater condition holds and \({\mathbf {Y}}\) is compact, there exist a point \(u\in {{\mathbb {R}}}^m\) and a constant \(c<0\) such that
a contradiction. Then, passing to subsequences if necessary, we may assume that there is a measure \(\tau \in {\mathcal {M}}({\mathbf {Y}})\) and a point \(\chi \in {{\mathbb {R}}}_+^s\) such that the sequence \(\{\mu ^{(k)}\}\) is weakly convergent to \(\tau\) by Prohorov’s theorem again and the sequence \(\{\eta ^{(k)}\}\) is convergent to \(\chi\). Letting k tend to \(\infty\) in (52) yealds that for any \(x\in {{\mathbb {R}}}^m\)
i.e., \((w,v)\in \text {epi}\left( \int _{{\mathbf {Y}}} p(\cdot ,y)d\tau (y)+\sum _{j=1}^s\chi _j\psi _j\right) ^*\). As both \(\int _{{\mathbf {Y}}} p(\cdot ,y)d\tau (y)\) and \(\sum _{j=1}^s\chi _j\psi _j\) are continuous on \({{\mathbb {R}}}^m\), we have
Therefore, the conclusion follows. \(\square\)
Rights and permissions
About this article

Cite this article
Guo, F., Jiao, L. On solving a class of fractional semi-infinite polynomial programming problems. Comput Optim Appl 80, 439–481 (2021). https://doi.org/10.1007/s10589-021-00311-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00311-5
Keywords
- Fractional optimization
- Convex semi-infinite systems
- Semidefinite programming relaxations
- Sum-of-squares
- Polynomial optimization