
Abstract
String matching algorithm is widely used in many application areas such as bio-informatics, network intrusion detection, computer virus scan, among many others. Knuth–Morris–Pratt (KMP) algorithm is commonly used for its fast execution time compared with many other string matching algorithms when applied to large input texts. However, the performance of the KMP algorithm is limited when the input text size increases significantly beyond a certain limit. In this paper, we propose a high performance parallel KMP algorithm on the Heterogeneous High Performance Computing (HPC) architecture based on the general-purpose multicore microprocessor and the manycore graphic processing unit (GPU) using OpenCL as the General Purpose computing using Graphic Processing Unit (GPGPU) platform. The proposed parallel KMP algorithm mainly focuses on optimizing the CPU–GPU memory hierarchy by overlapping the data transfer between the CPU memory and the GPU memory with the string matching operations on the GPU. It also optimizes the allocation of the work-groups and the work-items, and places the pattern data and the failure table in the on-chip local memory of the GPU. Exploiting multiple GPUs further the performance improvements. The experimental results show that the optimized parallel KMP algorithm leads up to 15.25 times speedup compared with the version before our optimization techniques were applied.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
String matching algorithms are commonly used in various applications such as the keyword matching for the given input text, the intrusion detection in the network system [1, 2], the human genome sequence matching for the bio-informatics [3], among many others [4, 5]. The Knuth–Morris–Pratt (KMP) algorithm is superior to other similar pattern matching algorithms for its fast execution time when it is applied to large sized input texts and reference patterns. However, when the input text size increases significantly beyond a certain limit such as in the genome sequence matching, the execution time also increases accordingly [6]. Therefore, it is crucial to minimize the execution time by efficiently parallelizing the KMP algorithm [7].
Recently, a heterogeneous high performance computing (HPC) architectures based on general-purpose multicore microprocessors and the manycore graphic processing units (GPUs) are becoming increasingly popular for a wide range of applications. Its influence has been steadily growing in the Top 500 list, in particular, and in other various applications. The architecture of the GPU has gone through a number of innovative design changes in the last 1.5 decades by integrating a large number of fine-grained uniform cores with the multithreading capability, levels of the cache hierarchies, enhanced bandwidths with the memory and other CPU or GPU chips, and the large amount of the on-board memory. These architectural innovations have led to a drastic performance improvement to surpass several Teraflops for the double precision arithmetic per chip. In addition, user friendly programming environments such as CUDA [8, 9] from Nvidia, OpenCL [10, 11] from Khronos Group, OpenACC [12] from a subgroup of OpenMP Architecture Review Board (ARB) have been developed for the general-purpose computing using GPUs (GPGPU).
There has been some previous research to speed-up the KMP algorithm using the GPU or the field programmable gate array (FPGA) [13,14,15,16,17,18]. In this paper, we aim to optimize the performance of the KMP algorithm on the heterogeneous architecture by optimizing the CPU–GPU memory hierarchy and the efficient parallelization using the OpenCL. In order to minimize the memory access latencies, we place the pattern data and the failure table used for the string matching in the local memory in OpenCL (shared-memory on Nvidia GPU). We then optimize the allocation of the work-groups and the work-items on the GPU to maximize the benefit of the multithreading. For further performance improvement, the input/output data transfers between the CPU memory and the GPU memory are overlapped with the string matching operations on the GPU. We also exploit multiple GPUs for the parallel KMP algorithms. The resulting optimized parallel implementation leads up to 15.25 times performance improvement compared with the previous parallel KMP on GPU version before our optimization techniques were applied.
The rest of the paper is organized as follows: Section 2 introduces the KMP algorithm. Section 3 explains our techniques for parallelizing and optimizing the KMP algorithm. Section 4 shows the experimental results with analyses. Section 5 concludes the paper with future research directions.
2 KMP algorithm
KMP algorithm was developed by Knuth et al. [19]. This algorithm uses the prefix and the suffix of the reference pattern string in the process of the pattern matching. First, a preprocessing step is conducted for the reference pattern string to generate a failure table. The pattern string and its failure fable have the same length. Starting with the beginning of the pattern string, we count the number of occurrences of the pattern matching with the prefix and the suffix at the current index of the string until we reach the end of the pattern string. We store these count values at the corresponding indices of the failure table. Next, we conduct the pattern matching of the reference string with the input text using the failure table. When a character in the pattern string matches with the character in the input text, the pattern match continues for the next character. When a mismatch occurs, then we skip by the number of characters stored at the corresponding index of the failure table. Then the whole window of the pattern string is shifted by the number to the forward direction of the input text string.
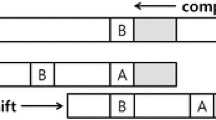
Figure 1 illustrates the KMP algorithm. In Fig. 1a, the pattern string and the input text string matches from index 0 to 4. When Input Text[5] is compared with Pattern String[5], a mismatch occurs. We check the Failure Table[4] = 2, since Failure Table[i-1] is the re-starting index when the Pattern String[i] is mismatched. For the subsequent string matching operations, we slide the pattern string window by 3 (= Table[5]) characters to the right and then continue to match from the Pattern String[2] as shown in Fig. 1b.

Illustration of KMP algorithm
Assume that the input text length is L and the pattern string length is P. The time complexity of the KMP algorithm is O(L + P). Previous algorithms without the failure table result in O(LP) time complexity. Therefore, the KMP algorithm is superior to the previous algorithms [19].
The execution time of the KMP algorithm grows linearly as the input text size increases, as shown in Fig. 2. For an application dealing with a huge input size such as in the human genome sequence matching, it is crucial to minimize the execution time by parallelizing and optimizing the KMP algorithm.

Execution time of KMP algorithm for various input sizes
3 Parallelization of KMP algorithm
3.1 Preliminaries
In this section, we explain our parallelization and optimization strategies for the KMP algorithm on the heterogeneous architecture based on the multicore CPU and the manycore GPU using OpenCL as the GPGPU platform. In order to minimize the memory access latencies, we place the pattern data and the failure table in the local memory (shared-memory on the Nvidia GPU) because their sizes are rather limited and can be accommodated in the small-sized local memory. We then optimize the allocation of the work-groups and the work-items on the GPU to maximize the benefit of the multithreading capability of the GPU. For further performance improvement, we optimize the CPU–GPU memory hierarchy by overlapping the input/output data transfers between the CPU memory and the GPU memory with the string matching operations on the GPU. We also exploit multiple GPUs in the heterogeneous architecture for the parallel KMP algorithm. In the following subsections, we explain the work-item and the work-group allocation, the overlapping of pattern matching computation with the input/output data transfers, and the exploiting of the multiple GPUs.
3.2 Optimizing work-item and work-group allocation
Assuming we place the pattern string and the failure table in the on-chip local memory of the GPU, the input text string is loaded from the global memory to the registers of the GPU. The input text is divided into small sub-texts. We let each sub-text to be allocated to a work-item to be mapped to each processing element (PE) of the GPU. Then the pattern matching is conducted between the pattern string and the work-items. A possible matching sub-text might be separated into two consecutive sub-texts. To avoid this, we redundantly copy (P − 1) characters of the subsequent sub-text. Multiple work-items are allocated to each work-group. Figure 3 illustrates the work-groups and work-items allocation to the whole input text.

Work-item and work-group allocation
In order to optimize the SIMD and multithreaded execution of the KMP algorithm on the GPU, we need to carefully decide the input sub-text size for the work-item. We also need to carefully decide the number of work-items to be allocated to each work-group which will be mapped to a computing unit (CU) of the GPU. The conditions of work-items and work-groups are allocated as follows:
where Wgroup is the total number of work-groups, Witem/CU is the number of work-items allocated to each CU called as the local work items, Wlitem is the number of work-items allocated to each CU called as the local work items, PECU is the number of PE’s in each CU, and CUgpu is the number of CU’s on GPU.
To optimize the performance, we need to explore the parameters for the work-item and the work-group by considering the proposed conditions. To reduce the space for the exploration, the local and the global work-item are allocated as follows:
where Wgitem is the total number of work-items called as the global work item, \(k\) and \(\alpha\) are multipliers to select the work-items. The size of the sub-text allocated to each work-item (Lpart) is.
where L is the input text length, P is the pattern string length and Lsub is the length of subtext to be assigned to each work-item.
The total number of characters in the input text string that needs to be scanned for the string matching is L-P+1. Thus we need to evenly divide them amongst all work-items. For each work-item, we need to allocate extra P-1 characters in order to avoid the missing pattern string matching. The range of the input text that each work-item processes is
where Wid is the id-th work-item. The overall time complexity based on OpenCL is
where \(PE_{gpu} = CU_{gpu} \times PE_{CU}\).
3.3 Optimizations considering CPU–GPU memory hierarchy
Parallel computing on the heterogeneous architectures based on the multicore CPU and the manycore GPU involves the data transfers between the host DRAM and the device memory. Thus we extend the memory hierarchy to include the host side DRAM from the GPU perspective (see Fig. 4). Our optimization for the KMP algorithm considers such a memory hierarchy. At the top of the memory hierarchy is the local memory (or shared-memory on Nvidia GPU), followed by the global memory (a region in the device memory), and the host side main memory. There is an order of magnitude memory latency differences as we go down the hierarchy [9].

Performance optimization considering CPU–GPU memory hierarchy
As explained in Sect. 3.1, the frequently referenced pattern string and the failure table are stored in the local memory. However, since the input data has low reuses, we load the input data to the registers from the global memory. The input data is usually large, and it may not fit in the global memory of the GPU. Thus, we assume that it is initially placed in the host main memory. Then we divide the input data into multiple chunks each of which can fit in the global memory of the GPU. Then we copy each chunk to the global memory in turn. For each input data chunk, string matching operations are conducted on the GPU. For each computation of the input data chunk, the number of matching occurrences is counted and copied back to the host side main memory.
The total execution time of the KMP algorithm is
where L is the input text length, \(\tau_{d}\) is the data transfer rate between CPU and GPU over the PCI-Express, Tgpu is the string matching computation time on GPU and R is the length of the result data for each input chunk.
The data transfer from the host main memory to the global memory takes a long time. In order to reduce or hide the high overhead of the data transfer, we overlap the computation (string matching operation) of the current chunk with the data transfer of the next chunk so that all the subsequent input data chunk is transferred while the current chunk is computed. Then the result data for the current chunk is transferred back to the host main memory. This data transfer is also overlapped with the string matching computation.
Figure 5 illustrates our optimization strategy of dividing the input data into 4 chunks, overlapping the computations and the data transfers for both the input and the output data. This scenario is contrasted to the non-overlapping case and shows that the execution time gets improved. The execution time using the overlapping is
where Ns is the number of data chunks or streams and \(T_{stage}\) is the execution time of each overlapped stages.

Overlapping data transfers with string matching computations
The amount of data copied from the CPU host to the GPU device at each stream is \(L/N_{s}\). The amount of data copied from the GPU device to the CPU host at each stream is \(R/N_{s}\). The optimization of work-group and work-item allocation discussed in Sect. 3.2 is applied to each stream computation.
\(T_{stage}\) is the longest time among H2D (CPU Host-to-GPU Device) transfer time, GPU execution time, and D2H (GPU Device-to-CPU Host) transfer time for each stream data. Most of the execution time savings stems from the hidden data transfer time with the computation time.
3.4 Exploiting multiple GPUs
In order to further the performance improvements, we exploit multiple GPUs in our heterogeneous architecture. Figure 6 illustrates the execution scenario of KMP algorithm using two GPUs while overlapping the string matching computations with the data transfers. Given the input data, as the number of GPU used increases, the data chunk size for each data stream decreases. Thus the times for the computation and the data transfer are reduced accordingly. However, as we increase the number of GPUs and the resulting number of data streams, the burden on the communication medium between the host memory and the device memory increases. Also, the data transfer time does not decrease linearly in accordance with the decrease of the data chunk size, because the start-up time for the data transfer which is a major overhead does not decrease linearly with the data size decrease. Therefore, the expected speedup using the multiple GPUs is lower than the linear speedup.

Multi-streams overlapping on two GPUs
4 Experimental results
For evaluating the performance improvement of our proposed parallelization and optimization approach, we implemented our approach using the OpenCL on two different platforms as shown in the following Table 1.
For the experiments, we used a pattern string of length 8, 16, 24, 30, 60, and 96. The length of an input text was varied from 1 MB to 1 GB (1 MB, 10 MB, 100 MB, 250 MB, 500 MB, and 1 GB). We measured the whole execution time which includes sending the input data from the host main memory to the device memory, performing the pattern matching operations, and returning the result data from the device memory to the host memory. The reported execution time is the average of five execution times for each experimental set. For the performance comparisons, we measured the time without optimization and the time with various optimizations including work-item and work-group allocations, local memory copy, the computation and the data transfer overlapping, and exploiting multiple GPUs.
Figure 7 shows the execution times when the number of global work items was varied in OpenCL. As shown in the figure, even though the number of work-items increases, the performance did not improve. Therefore, it is crucial to carefully select the computation parameters considering work-groups and work-items in order to optimize the performance. However, the search space to explore all the possibilities or combinations is too huge to apply an exhaustive search. In this paper, we consider the proposed work-items selection strategy described in Sect. 3.2.

Execution times without any optimization on Nvidia GeForce GTX 1080 Ti
Figure 8 shows the execution time on the GTX 1080 Ti platform using the proposed work-items/work-group optimizations for pattern length = 8 and 6 different text sizes. The work-group (Wgroup) is set to the number of CUs as shown in Table 1. The work-item (\(W_{litem}\)) is considered as the multiple (\(\alpha\)) of the number of PEs in Table 1 as discussed in Sect. 3.2. We conducted experiments varying work-item (\(W_{litem}\)) and \(\alpha\) from 1 to 1024 in order to find the best performance combination. As shown in Fig. 8, the best performance for large strings was shown in the global work-item (\(W_{gitem}\)) = 14,336 when work-group = 28, work-item (\(W_{litem}\)) = 256 or 512, and \(\alpha =\) 2 or 1. Figure 9 presents the execution time on the Tesla P100 platform for pattern length=16 and text size = 100 MB, 500 MB and 1 GB cases. Tesla P100 consists of 56 CUs. The best performance for large strings was achieved when the work-group (Wgroup) = 56, the work-item (\(W_{litem}\)) = 256 or 512, and \(\alpha = 512\) or 1024. Unlike GTX 1080 Ti, the best performance on the Tesla P100 was found around a large \(\alpha\) in experimental results. Even though \(\alpha\) is large, the experimental results showed that work-item and work-group allocation conditions for the best performance still hold. The best performance is found in the following condition: \(W_{gitem} = \alpha \cdot W_{litem} \cdot W_{litem}\).

Comparison of work group and work item optimization on GTX 1080Ti: pattern length = 8

Comparison of work group and work item optimization on Tesla P100: pattern length = 16
Figure 10 shows the effect of the local memory copy of the pattern string and the failure table on a GTX 1080 Ti platform. The best performance was found in the global work-items = 14,336 when work-group = 28, (work-items, \(\alpha\)) = (128, 4), (256, 2), and (512, 1) pairs, similar to the combination of the work-items/work-group parameters. In the small strings, the local copy was one of the overheads for the pattern matching computation. As the string size increases, the performance improves up to 1.45 times compared with work-group/work-item only optimization. Figure 11 shows the effect of the local memory copy of the pattern string and the failure table on a Tesla P100 platform, also.

Comparison of execution times using local-memory copy optimization on GTX 1080Ti: pattern length = 8

Comparison of execution times using local-memory copy optimization on Tesla P100: pattern length = 16
Figure 12 shows the effect of overlapping the computation and the data transfer of the multi-stream on the single GTX 1080 Ti. The work-group and work-item on a stream was allocated according to the condition for the single stream considered in Figs. 8 and 10. The number of work-items was allocated as 64, 128, 256, 512, or 1024. For 250 MB, 500 MB, and 1 GB cases, the best performance was achieved on the 8 streams with the work-items and work-groups allocated for Fig. 12. The best performance in 100 MB case was found by overlapping the computation and the data transfer of 4 streams. In 1 MB and 10 MB case, the best performance was achieved when 2 streams are overlapped, since the stream computation overhead nullified the performance gain from the stream overlapping computation in the small string. Figure 13 shows the effect of overlapping the computation and the data transfer of multi-stream on the Tesla P100 platform. For the input text size 500 MB and 1 GB cases, the best performance was achieved on the 8 streams with the work-items and work-groups allocation parameters shown in Fig. 8. Since the input text is divided and distributed into each stream, the input text size in each GPU computation stream is reduced. Therefore, \(\alpha\) became smaller than the \(\alpha\) in Fig. 8.

Comparison of multi-stream executions on a GTX 1080Ti: pattern length = 8

Comparison of multi-stream executions on a Tesla P100: pattern length = 16
Figure 14 shows the execution times using various optimizations on the single GTX 1080 Ti platform: non-optimization (Non-Opt), work-group and work-item (WGWI), work-group/work-item + local memory copy (WGWI+LC), the computation and data transfer overlap of multi-streams on the single GPU (MS1G). The best performance was achieved when the number of streams is 16 for 1 GB and 8 for 500 MB. For 1 GB and 500 MB case, MS1G achieves up to 2.16 times speedup compared with WGWI + LC and 6 times speedup compared with Non-Opt. Figure 15 shows the execution times using various optimizations on the Tesla P100 platform. The best performance was achieved when the number of streams is 8 for the input text sizes 1 GB and 500 MB. For 1 GB and 500 MB cases, MS1G achieves up to 3.39 times speedup compared with WGWI + LC and 6 times speedup compared with Non-Opt.

Execution time for various optimizations on a GTX 1080Ti: pattern length = 8

Execution time for various optimizations on a Tesla P100: pattern length = 16
Figure 16 presents the effect of multi-stream overlapping executions on multi-GPUs (4 × GTX 1080 Ti) through the comparisons of multi-stream on the single GPU (MS1G), single-stream on 2 GPUs (SS2G), multi-stream on 2 GPUs (MS2G), single-stream on 4 GPUs (SS4G), and multi-stream on 4 GPUs (MS4G). The best performance of the string matching computation using the input text 1 GB was achieved on the MS4G optimization in the case of 4 streams, the global work-items = 14,336 with work-group = 28, and (work-items, \(\alpha\)) = (256, 2) pair. The streaming allocation for the best performance was 16 streams on the single GPU and 4 streams per GPU on 4 × GPU platforms. It verified that the multi-streams overlapping on multi-GPUs as shown in Fig. 6 improved the overall performance. The MS4G achieves up to 2.51 times speedup compared with MS1G in 1 GB case.

Effect of multi-stream overlapping executions on 4 x GTX 1080Ti: pattern length = 8
In Fig. 17, the execution times for the pattern length 16, 24, 30, 60, and 96 are compared with various optimizations. The complexity of the proposed parallel KMP algorithm is \(O\left( {L/PE_{gpu} + P} \right)\). Since the input text size L is large enough compared with \(PE_{gpu}\) and the pattern length (P), the overall performance increased as the input text size increased. The performance variation caused by different pattern lengths was small. In the overall performance evaluation, our MS4G approach achieves up to 15.25 times speedup over the non-optimized parallel implementation (Non-Opt).

Execution time comparison for various pattern length on 4 × Nvidia GTX 1080ti
5 Conclusion and future research direction
In this paper, we introduced a parallelization and optimization approach for the KMP algorithm on a heterogeneous architecture based on a multicore CPU and manycore multi-GPUs. In order to optimize the KMP algorithm from the input data transfer from the host main memory to the device memory and to the result data transfer from the device memory to the host memory after the pattern matching operations are performed on the GPU, we divide the input data into multiple chunks, transfer the data from the host memory to the device memory while the pattern matching operations are performed for the previous chunk of the input data. The output data is also transferred while the computations are being performed on the GPU. Through the computation and the data transfer overlapping, most of the data transfers are hidden by the computations. Our approach also optimizes the work-item and work-group allocations, and also places the pattern data and the failure table in the local memory. Furthermore, by exploiting multiple GPUs in the heterogeneous architecture, we further improve the performance. Our approach results in up to 15.25 times speedup over the parallel implementation before applying our optimizations.
For further performance improvements, we are working on copying the input data chunk to the local memory instead of loading from the global memory directly while the pattern matching computations are performed on the GPU in a multithreaded fashion. A naïve implementation resulted in the performance loss. For an optimal implementation, we are working on coalescing the multiple global memory accesses. We also work on avoiding the shared memory bank conflicts. These optimizations will lead to further improvement in the computation time. Together with more aggressive input data partitioning to increase the degree of the computation and the communication overlapping, we expect to boost the overall performance.
References
Bellekens, X., Atkinson, R.C., Renfrew, C., Kirkham, T.: Investigation of GPU-based pattern matching. In: Proceeedings of the 14th Annual Post Graduate Symposium on the Convergence of Telecommunications, Networking and Broadcasting (PGNet2013) (2013)
Jiang, W., Yang, Y.H.E., Prasanna, V.K.: Scalable multi-pipeline architecture for high performance multi-pattern string matching. In: Proceedings of the 2010 IEEE International Symposium on Parallel and Distributed Processing (IPDPS 2010) (2010)
Rajesh, S., Prathima, S., Reddy, D.L.S.S.: Unusual pattern detection in DNA database using KMP algorithm. Int. J. Comput. Appl. 1(22), 1–7 (2010)
Kalubandi, V.K.P., Varalakshmi, M.: Accelerated spam filtering with enhanced KMP algorithm on GPU. In: 2017 National Conference on Parallel Computing Technologies (PARCOMPTECH) (2017)
Al-Ssulami, A.M.: Hybrid string matching algorithm with a pivot. J. Inf. Sci. 41(1), 82–88 (2014)
Kim, J.W., Kim, E., Park, K.: Fast Matching method for DNA sequences. In: Combinatorics, Algorithms, Probabilistic and Experimental Methodologies (2007)
Sitaridi, E.A., Ross, K.A.: GPU-accelerated string matching for database applications. In: VLDB J (2016)
NVIDIA: Cuda C Programming Guide. https://developer.download.nvidia.com/compute/DevZone/docs/html/C/doc/CUDA_C_Programming_Guide.pdf (2012)
Manavski, S.A.: Cuda compatible GPU as an efficient hardware. No. November, pp. 24–27 (2007)
AMD: AMD accelerated parallel processing OpenCL programming guide. AMD Document. http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/07/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide-rev-2.7.pdf (2013)
Nvidia: OpenCL Programming Guide for the CUDA Architecture. Nvidia. https://www.nvidia.com/content/cudazone/download/opencl/nvidia_opencl_programmingguide.pdf (2009)
OpenACCstandard.org: The OpenACC Application Programming Interface 2.5. Openacc.Org Doc., pp. 1–118 (2015)
Sidhu, R.P.S., Mei, A., Prasanna, V.K.: String matching on multicontext FPGAs using self-reconfiguration. In: Proceedings of 1999 ACM/SIGDA Seventh International Symposium on Field Programmable Gate Arrays, pp. 217–226 (1999)
Rasool, A., Khare, N.: Parallelization of KMP string matching algorithm on different SIMD architectures: multi-core and GPGPU’s. Int. J. Comput. Appl. 49(11), 26–28 (2012)
Aygun, S., Gunes, E.O., Kouhalvandi, L.: Python based parallel application of Knuth-Morris-Pratt algorithm. In: Proceedings of 2016 IEEE 4th Workshop on Advances in Information, Electronic and Electrical Engineering (AIEEE 2016) (2017)
Alzoabi, U.S., Alosaimi, N.M., Bedaiwi, A.S., Alabdullatif, A.M.: Parallelization of KMP string matching algorithm. In: Proceeedings of 2013 World Congress on Computer and Information Technology (WCCIT 2013) (2013)
Lei, S., Wang, C., Fang, H., Li, X., Zhou, X.: SCADIS: a scalable accelerator for data-intensive string set matching on FPGAs. In: Proceeedings of 2016 IEEE Trustcom/BigDataSE/ISPA, pp. 1190–1197 (2016)
Kouzinopoulos, C.S., Margaritis, K.G.: String matching on a multicore GPU using CUDA. In: Proceeedings of 2009 13th Panhellenic Conference on Informatics (PCI 2009), pp. 14–18 (2009)
Knuth, D.E., Morris Jr., J.H., Pratt, V.R.: Fast pattern matching in strings. SIAM J. Comput. 6(2), 323–350 (1977)
Acknowledgements
This research was supported in part by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. 2017R1D1A1B03033128). This research was supported in part by Next-Generation Information Computing Development Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science, and Technology (NRF-2015M3C4A7065662).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Park, N., Park, S. & Lee, M. High performance parallel KMP algorithm on a heterogeneous architecture. Cluster Comput 23, 2205–2217 (2020). https://doi.org/10.1007/s10586-019-02975-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-019-02975-5