
Abstract
The process of current urban and accelerating the number of motor vehicles increased rapidly resulting in road traffic pressure is increasing, we need to analyze large data traffic in the city, to guide urban road planning and improve the level of city management, and city operation rules found from traffic data in complex. However, traffic data are characterized by large amount and high dimension, which makes the analysis process difficult. In this paper, the composition, characteristics and application of large data in traffic field are introduced. Mining multi-source heterogeneous data traffic generated by the depth of the traffic data to establish a comprehensive analysis platform and project evaluation subsystem, the formation of integrated traffic system model for multi field, multi-level application requirements. In this paper, we propose a visualization model based on self-organizing feature map neural networks with graph theory. This paper analyzes the traffic data of the whole life cycle, combing the traffic data collection, analysis, discovery, the level of application, and uses big data techniques to guide the city traffic planning, construction, management, operation and decision support.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the continuous development of city traffic and location, traffic flow, traffic continues to increase the number of track data caused by the explosive growth, how these data concludes with perplexing information and rules supporting the significance to the development of city traffic, to the city road traffic planning has important significance. The focus of this paper reflects on the visualization of massive trajectory data and multidimensional data is to find a balance, that is how to within a limited space as much as possible to show the various dimensions of the track data, to help users to see the data in the whole data exploration and analysis. To a large extent, when we discover the implicit knowledge of data, we have a comprehensive analysis of the data, so that people can sum up the correct rules and knowledge in visual analysis [1].
In this context, the traditional methods such as investigation and classification of data, the establishment of the four stage macro model cannot meet the requirements of comprehensive evaluation of urban traffic in the new period. Traditional technology is facing change. In recent years, big data as a new hot spot in the research and development of the international, the data related the traditional areas of large volume, the lower the value of the data link, to provide new research ideas, method and path for the comprehensive assessment of city traffic and technology upgrading reconstruction [2, 3] (Figs. 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18).

Big data in the field of transportation
In the process of the construction of intelligent transportation now, traffic system and intelligent vehicle road test and sensor information, will produce a large number of vehicle information, road information, traveler information and information management services, including city Road, highway, rail, bus, taxi, inter provincial passenger transport, public security traffic management and civil aviation, railway, and even the weather and other traffic data content. These traffic data have large capacity, fast growth, diversified structure, low value of many data, so they need to be further processed and excavated [4].
The operation of urban traffic network is a dynamic process, and its status changes with time and place. Analysis of traffic state science can describe the evolution of traffic congestion, reasonable evaluation can provide the spatial distribution information of the road network to the congested city traffic management department, to provide guidance for transportation, lay the foundation for the scientific management of city traffic system and effective control. The deduction of traffic condition is the basis of traffic system analysis and evaluation.
With the gradual progress of China’s intelligent transportation construction process, traffic data has been greatly enriched from scarcity, and has brought severe challenges to big traffic data. First of all, the data did not establish an effective association, was isolated in the category, industry, and local authorities, road video as the biggest source of traffic information is not fully utilized, so the public cannot get accurate coherent travel information services.
Many data sources, storage modes, complex data types, which contains a large number of video and image semi-structured and unstructured data, and the data without uniform standards, in the organization, integration, cleaning and transformation of these data is difficult. Dig into the potential value of traffic data. First of all, we need a management platform that can handle various types and sizes of data. The management platform also needs to be able to process structured data, semi-structured data and unstructured data at the same time. According to the traffic data of high growth, increasingly large scale, we need a high efficient data processing technology, analysis of traffic data mining effectively, extract the high value information from, and flexible support for various traffic service application demand increasing [5, 6].

The growth of big traffic data
The basic technology of ITS includes: integrated information processing technology, communication technology, sensing and positioning technology, computer technology, intelligent control technology, the technology can only cooperate with each other, used for traffic management system. While each technology plays a different role in the ITS system, we first briefly introduce the following three technologies.
Integrated information processing technology. Information technology is the basic technology of ITS, mainly based on the analysis of the collected information, and the use of communication technology and information transmission are specific to a particular user, information acquisition and processing technology of ITS is the foundation, is the key to realize information transfer. And then use advanced communication technology to send the relevant information processing results to the user’s port for users to use.
Communications technology. Communication technology is the core technology of the ITS operation, role of communication technology in the ITS system is an information transmission function, information acquisition device to collect information through the communication sent to the information processing system, information processing system to various terminal equipment processed information through the communication system is sent to the user, to meet user the use of demand. Communication technology is the nervous system of ITS.
GIS and GPS technology. GIS is the geographic information system, is a kind of spatial processing technology with graphics, mainly according to the user’s request, GPS technology combined with the geographic data information obtained by 3D, or other more directly transmitted to the user. The main purpose of GPS technology in ITS is to give users precise positioning and combine GIS to provide efficient navigation for users. The use of GPS technology in urban traffic can provide appropriate scheduling for urban public transport, and can reduce the urban traffic pressure and improve the efficiency of urban traffic.
The system structure of ITS has different standards all over the world, which is determined by the development of the region. The developed ITS standards developed by the United States are relatively perfect and mature, and belong to international standards. The structure design of IST is mainly based on the user’s needs. The internal structure is mainly modular and modular. The four subsystems use the same information communicator, so the structure of the general ITS is mainly composed of four subsystems and convenient information communication methods. The operation of these four subsystems is to transfer the collected information through the appropriate port to the user who sends the request.

Different means of transportation will lead to larger amounts of data

The structure of self-organizing feature map

Distribution of cluster vectors

Class of clustering vectors

Clustering results of SOFM networks (topological structure: 3 \(\times \) 4)

Clustering results of SOFM networks (topological structure: 5 \(\times \) 5)

Clustering results of SOFM networks (topological structure: 15 \(\times \) 15)

Weight distribution of the network (epochs = 10)

Weight distribution of the network (epochs = 50)

Weight distribution of the network (epochs = 100)

Weight distribution of the network (epochs = 200)

Clustering hit ratio of SOFM neural network

Undirected graphs and directed graphs

Geometry based visualization

The ratio of the distance between the evaluation point and the congestion source to the domain bandwidth. a Single source congestion. b Multi source congestion

Evaluating principle of congestion region in 2D coordinated system
2 Large data theory in intelligent transportation
2.1 Integration of information resources
Information acquisition and data processing analysis are the basis of intelligent transportation system, they can be shared between ITS and other related data information of the system which can improve the system to obtain information, speed and efficiency of data processing. Information collection and data analysis subsystem according to the user request data, the type of service, call the appropriate data processing port for data processing and analysis, and then the processed data is transmitted to the information subsystem, and then sent to the hands of users, so as to provide accurate data for ITS. In the integration of information resources, the need for information reception, web information access, data information import and other technical means of support. In ITS, the system can share and exchange data with other systems. In addition to the use of information acquisition system for data acquisition and analysis of ITS, when a special emergency occurs, still needs the original form of artificial data acquisition.
The information issued by the system belongs to the information which is filtered and processed according to the needs of the user, and is transmitted to the user in various forms. Depending on the terminal setting of the received information, the manner in which the information is transmitted is different. The main equipments in daily life are TV, Internet, mobile equipment, newspaper and so on. No matter what kind of equipment users use, ITS should meet the needs of users and provide maximum convenience for traffic.
2.2 Big data application analysis
The main form of big data in life is the Internet of things, and the Internet of things mainly includes: perception, network, applications and other parts. The perception layer is the basic layer of Internet of things technology, which can enhance the perception ability of ITS through various sensors and obtain more accurate and reliable data. For example: by road, car, sensor and information transmission device and meteorological center can stop the information back to the master server and server for data analysis and processing of information, to provide users with the need of traffic, traffic jam, transfer, weather conditions, the surrounding accommodation information, catering information and so on, so that not only to improve the efficiency of travellers, but also to ensure traffic safety, enhancing traffic system perception.
Cloud computing processing of large data broke through the temporal and spatial constraints of data processing, and achieved data sharing. It provides convenience for traffic management at all levels of the city. Big data using integrated way, users can use many kinds of data, the need for integrated processing of these data, in order to meet user requirements, to ease traffic pressure, improve the efficiency of traffic management purposes. Through the use of big data technology, all existing public resources can be allocated properly, and the most excellent traffic plan cases can be worked out. The application of big data in traffic can not only reduce the degree of dependence on the traffic environment, but also reduce the pressure of traffic operation and improve the utilization ratio of traffic information.
To completely solve traffic problems, we need big data to merge with ITS. ITS in large data can provide users with the necessary road traffic information, vehicle information, and information sharing. According to their own needs, users can obtain multiple travel plans provided by the intelligent system, and decide the most appropriate routes and tools. Between the user and the traffic control system data exchange, information transmission, not only improves the user experience, but also improve the efficiency and speed data processing data in public transportation, and greatly saves the cost of operation.
2.3 Characteristics of big traffic data
Traffic big data has five characteristics. Objectivity. Most data do not have to be accessed by investigators, but are actively acquired by sensors to ensure objectivity of data. Silent persons can be found, including elderly, children, or less active person [7,8,9].
Pluralism. The data from different channels reflect the traffic characteristics in different ways, and the data can be checked with each other.
Stability. You can repeatedly verify the survey target over multiple periods of time to reduce the interference of extreme data.
Accuracy. Reduce sampling, access, fill in, input and other manual operations to improve data accuracy.
Cheapness. The cost of data acquisition is lower than that of traditional investigation. The input of test equipment can be used repeatedly, and a large amount of data is originally used for other purposes. After data transformation, it can become the data source of traffic analysis.
Although the application of big data in the field of traffic has just arisen, some large city traffic research institutions, High German, Baidu and other map companies, Jingdong, Alibaba and other e-commerce companies have been carried out practical applications. In particular, major transportation research institutions have gradually begun to use large traffic data to change traditional survey methods, so that traffic analysis begins from sampling data analysis to full sample data analysis.
Multiple use of big data generated by a running City, including floating car GPS, IC card, fixed detection coil, vehicle identification system, mobile phone data, instead of the original large-scale traffic survey to a certain extent, effectively save the city traffic analysis cost and improve work efficiency. At the same time, traditional methods cannot be achieved, such as long time continuous survey, bus IC card and mobile terminal tracking, etc., but it can using large data mining to achieve the purpose.
Overall, big data in the traffic analysis field has made a breakthrough, but has yet to grasp the overall requirements of comprehensive assessment of city traffic technology trends, to grasp the development direction of evaluation in the integrity, direction and user demand point. Therefore, it is of great significance to systematically sort out the actual demand of traffic planning decision, and construct a new comprehensive evaluation system of urban traffic.
3 Self-organizing feature map based neural network
Because artificial neural network can handle that are difficult to describe with traditional mathematical model of the system, can approximate any nonlinear, strong adaptive, self-learning, associative memory, highly fault-tolerant and parallel processing ability. In recent years, artificial neural networks for pattern classification have become a hot research topic. The self-organizing feature map(SOFM) neural network can determine the reasonable decision of complex problems according to the learned knowledge and experience, it uses unsupervised one calculation method in clustering the sample data at the same time, can keep the topological ordering of performance and feature extraction, especially suitable for solving the clustering problem [10, 11].
3.1 The structure of SOFM neural network
Self-organization is the process of learning the results always makes the weight vector of the clustering region to maintain neurons close to the input vector of the trend, so that the input vectors of similar properties together. SOFM neural network is composed of input layer and competition layer, the input layer receives samples, competitive layer to classify the samples, the two layers of neurons were completely connected, the competition layer neurons arranged in a matrix of nodes according to the two-dimensional form of general input nodes is equal to the number of dimensions can represent the pattern classification problem, the output node the number depends on the specific issues. Feature mapping can be viewed as a nonlinear projection of information from two-dimensional input pattern space to two-dimensional output feature plane.
3.2 SOFM neural network algorithm
The self-organizing feature map algorithm is a unsupervised clustering method. Compared with the traditional pattern clustering method, the clustering center formed by it can be mapped to a surface or plane, and the topology remains unchanged. SOFM neural network algorithm iteration process is as follows [12].
Initialization. The link weights of N input neurons to output neurons is given a smaller weight, and select the set of output neurons adjacent to neurons, denoted as \(S_j \).
Provide a new input mode, denoted as X.
The Euclidean distance is calculated as follows, and a neuron with the minimum distance is calculated, which is denoted as \(j^*\) and satisfies the following equation.
Give a neighborhood around, denoted as \(S_k (t)\). The weights of the modified adjacent neuron of the output neuron are as follows:
where \(\eta (t)\) is a gain term, which satisfies:
Calculate the output, denoted as \(O_k \).
Finally, new learning samples are provided to repeat the above learning process.
Corresponding program is as follows:

3.3 Learning vector quantization (LVQ)
Learning vector quantization is an extended form of tutor learning in SOFM network learning, which allows the input to be assigned to which class. Except that each neuron in the output layer is assigned to one of several classes, the LVQ network structure is exactly the same as the SOFM network. Since the problem to be solved in this paper belongs to the study of tutors, in the unsupervised learning phase, SOFM networks are used to extract features and form clustering centers. In the tutorial learning phase, we use the LVQ learning algorithm to determine the classification results of each neuron in the clustering center, and then adjust accordingly.
LVQ algorithm and its improved algorithms are mainly LVQ 1, LVQ2, LVQ3 and so on. According to the needs of the problem, this paper uses LVQ2 algorithm. The algorithm is characterized in that the weight vector is adjusted differently when the first winner is wrong and the second winner is correct and when the first winner is correct when the second winner is wrong.
SOFM neural network with different topologies can get different clustering results, the number of neurons in the output layer. The more the actual distribution of clustering classification more detailed and more close to the sample vector, the clustering result is more accurate, shown as follows.
3.4 Neighborhood distance matrix
The competition layer of SOFM neurons in the network can be arranged in any way, this arrangement can be represented by the competition between neurons in layer Manhattan distance neighborhood distance matrix to describe, and two neurons in the Manhattan range is the vector of two neurons after subtracting the coordinates, and calculate the absolute value of the sum of the elements.
Neighborhood distance matrix is as follows:
Manhattan distance is calculated as follows:
The connection weights between the competition layer neuron j and the input layer neuron i is denoted as \(w_{ji} \), therefore:
where \(W_{M\times N} \) is network weight matrix. Because network input data is likely to appear in the middle value region of the input data. Therefore, the initial weights of the network are set in the middle value region of the input data space, and the learning effect of the network will be better.
Let SOFM network have P input patterns, each input mode contains N variables, and the input mode matrix is as follows:
Calculates the maximum, minimum, and intermediate values of each of the variables in the P input modes:
Thus forming an intermediate value vector of the Nvariables of the input mode:
Then the network initial weight matrix is constructed as:
3.5 The influence of training steps on the clustering results of SOFM neural networks
In order to study the influence of training steps on the clustering results of SOFM neural networks, taking into account the influence of the different topological structures mentioned above on the clustering results of SOFM neural networks, the output layer neurons are taken as 225, and the output node topology is set as 15 \(\times \) 15. The learning of the SOFM neural network is to adjust the direction of the weight vector toward the direction of the input pattern vector, so that each weight vector moves closer to the central position of each cluster model group. At the same time, the arrangement of the geometric points of the network weight vector is basically consistent with the natural arrangement of the neurons in the competition layer, that is, the topological structure is basically the same.
When epochs is greater than 200, the distribution of network weights will no longer change obviously. If the training steps are increased, then there will be no practical significance.
The SOFM network model, in the process of clustering analysis, only need to provide some samples for the network, and does not need to provide the ideal output, network can be self-organized learning according to the input sample, and divides the sample into the corresponding model class. Since it is not necessary to provide ideal output samples, the establishment process of SOFM network clustering model is greatly simplified. The simulation results show that the neurons in the output layer is six edge under the condition of different topologies produced great influence on the clustering results using SOFM neural network, the number of neurons in the output layer. The more clustering classification more detailed, more accurate clustering results. In the same neurons in the output layer topology conditions, generally speaking, the larger the number of training steps, the SOFM network clustering result is more accurate, but have little effect on the number of training steps for the clustering results, resulting in lengthy training time. Therefore, we should take into account the number of samples and the number of pre clustering in the SOFM clustering model.
4 Graph theory
The generation of graph theory can be extended to the 1736, and its development until the last century, 40s has been the attention of people. Graph theory has a very intuitive and simple characteristics, especially when applying graph theory to solve some practical problems, it can better transform the problem into an equivalent graph theory problem. These characteristics make graph theory widely used in modern science. For example: computer, systems engineering, network engineering, applied mathematics and many other fields have been applied and developed. In simple terms, graph theory is a relatively old discipline, and its tenacious vitality, like the human neural network, has made many contributions to the development of people’s science and technology [13,14,15,16].
Artificial neural networks refer to the study of an analog organism based on modern neurobiology. It can calculate some characteristics in the human brain, and then form a new information feedback and processing system through simplification and simulation. With the development of artificial neural networks, more and more features of human brain have been presented, and its technology has possessed the function of human brain. With the continuous development of its technology, artificial neural networks have been integrated with information storage, information processing, self-learning and other characteristics. The salience of these features has enabled their technology to be used in systems identification, information processing, troubleshooting, and prediction of various types, and provides strong data support for the corresponding technologies [17].
4.1 Efficient fusion of graph theory and artificial neural networks
In the 80 s of last century, two scholars from Hopfield and Tank worked together to realize the application of graph theory to the Hopfield network model in neural networks. The study sets a city of \(P=30\) and uses a Hopfield network of 900 neurons to find an optimal solution in less than 0.2 seconds. This study caused a stir in the academic circles, and in the study of stimulus, people began to carry out more research on the neural network, so the technology can get a rapid development in the related academic circles. In such a developing situation, graph theory and neural network form an effective fusion pattern. It also makes people realize that the artificial neural network and graph theory have certain relations, and can also promote the research and development of neural networks under the function of graph theory. For example, the structure algorithm of neural network, the model design of neural network, the stability theory of neural network and the classification problem of forward artificial neural network model. In addition, the artificial neural network and graph theory are integrated, it can better solve the difficult problems, especially for some difficult problems, in the integration of the two, to get the optimal solution, realize the application of neural network to deal with some problems of graph theory in fracture conjecture.
It is worth mentioning that when applying artificial neural networks to graph theory problems, the following principles of application should be followed. With the help of graph theory, the problem can be solved by mapping it to the neural network model. Therefore, in the selection of neurons and neural networks, it is necessary to consider and analyze the key point of constructing the energy function. Because of the effective fusion of graph theory and neural networks, many problems have been solved, such as coloring of graphs, covering of graphs and so on.
Graph theory is an important modern mathematical tool for the study of natural science, engineering technology, economic management and social problems, and has attracted more and more attention in the world of mathematics and other scientific circles.
4.2 Basic algorithm of graph theory
Graph theory plays an important role in computer science. It provides a simple and systematic modeling method for many problems. It can also be understood as a basic operation and constitute provisions of operations in order to complete the steps, or as designed in accordance with the requirements of the limited the exact sequence of calculation, in the real world, many problems can be transformed into the problem of graph theory, then using graph theory to solve the basic algorithm.
An algorithm should have the following five important features.
Poverty: an algorithm must guarantee that the execution has finite steps to ends.
Accuracy: each step of the algorithm must have a precise definition.
Input: an algorithm has 0 or more inputs to describe the initial condition of an object. The 0 input refers to the initial condition set by the algorithm itself.
Output: an algorithm having one or more outputs to reflect the result of processing of the input data.
Feasibility: the algorithm works in a precise way, and can be done with a limited number of calculations with a pen and paper.
4.3 Parallel graph theory algorithm
The study of parallel graph theory began in the middle of 70s of last century, and has been basically mature till the middle of last century of 80s. The early work in this area mainly focuses on the research of algorithms for basic graph theory problems. Later, with the deepening of the research, people began to study complex graph problems, typical examples such as the maximum matching of the graph.
Parallel graph algorithm basically can be divided into two categories: one focuses on some basic problems such as graph, undirected graph connectedness, directed graph reachability, strongly connected components, minimum spanning tree, the depth and breadth first search. The other is to study complex graph problems, such as maximum cardinality, weighted matching, graph coloring, maximum flow, minimum cut, etc..
4.4 Threshold segmentation algorithm
Threshold segmentation algorithm is a widely used region based image segmentation technologies, it uses the image to extract the difference between the target and the background in gray characteristics, the image is regarded as a combination of two kinds of regions with different gray levels, select an appropriate threshold to determine each pixel in the image is the target or belong to the background. The threshold method is first to determine a gray threshold in the gray range of the image, denoted as T. Then, the gray values of each pixel in the image are compared with this threshold, and the pixel is classified into a class of the two class according to whether it exceeds the threshold value. These two kinds of pixels generally belong to two kinds of regions in the image, so the pixels can be segmented according to the threshold to achieve the purpose of region segmentation.
It can be seen from the method that determining an optimal threshold is the key to segmentation, and it is also a difficult problem of threshold segmentation.
4.5 Minimum spanning tree clustering algorithm
Minimum spanning tree clustering algorithm was first proposed by Zahn, which is to each pixel as a node, according to gray and spatial relation weights, because of the noise and the fuzzy boundary sensitive lead cut set, thus affecting the segmentation effect, after the transformation to achieve fuzzy clustering analysis, the improved algorithm is as follows.
When initializing the gray pixels divided the same as a class, instead of each pixel as a class, according to the different pixel and the original image is divided into several sub images, each pixel requires sub graphs of the same, and most can be divided into 255 sub images. Each subgraph contains a number of regions that are not connected but have the same gray levels.
Each sub graph is connected with a domain mark, so that the original image is divided into several connected domains, and the gray levels in the connected domain are the same. Each connected domain is considered as a class. Calculation weight. Construct the minimum spanning tree, clustering, and realize image segmentation.
4.6 Minimum spanning tree clustering algorithm
Solving graph theory problems generally needs to be modeled by graph theory. Graph theory modeling refers to the process of abstracting and simplifying some objective things, and describing the characteristics and internal relations of objects with graphs. The establishment of graph theory model is to simplify the problem and highlight the main points in order to study the essence of the problem more deeply. The goal of graph theory can be either an optimization or a problem of existence or construction.
Generally, before the model is built, the research object should be investigated comprehensively, and the prototype will be idealized and simplified. Then a preliminary analysis of the prototype is made to distinguish the elements and the goals, and to find out the relationship between them. In the model to describe the research object using graph theory, in order to highlight the factors and solution is closely related to the target, reducing the complexity of thinking, inevitably give some elements. In the modeling process, ignoring the elements in the prototype which have little relationship with the target, can simplify the problem properly.
According to the nature of the three aspects of the midpoint, edge and weight of the graph, there are different graph theoretic models. Different theories and algorithms form different theoretical systems, and they also lead to the diversification of graph theory model, which can make the graph model adapt to all kinds of problems. But these rich choices also add to the difficulty of graph modeling. For some problems, it is natural to think of some kind of graph model, for example, to see the expression will be reminiscent of expression tree; but for other questions, analysis of different angles, then different models have different effects.
Generally speaking, the graph theory models of different theoretical systems are likely to produce completely different effects, which highlights the importance of choosing the appropriate theoretical system. When there are multiple models to choose from, the models that are suitable for solving can only be selected by careful identification of the subtle and crucial differences between them.
5 Establishment of visual model
5.1 The process of visualizing information
In the information visualization model proposed by Card, information visualization process can be divided into 3 processes: data conversion to original data conversion, data table, data table to convert the visual structure visualization structure to the view. The process of data visualization is divided into the following 3 stages.
The data pretreatment can preprocess and process the collected information so that it is easy to understand and easy to be input and display. The contents of preprocessing include data format and standardization, data transformation technology, data compression and decompression, etc.. Some data also need to do outlier detection, clustering, dimensionality reduction and so on.
The function of drawing is to complete the conversion from data to geometric image. A complete graphical description needs to be applied to various visualization rendering techniques on the basis of considering user requirements.
Display and interaction. The function of the display is to output the image data generated by the drawing module according to the user specified requirements. In addition to the output function of image information, the user’s feedback information should be transmitted to the software layer to realize human-computer interaction.
6 Geometry based visualization
In 1980, parallel coordinate system proposed by Inselberg is one of the classic multidimensional data visualization technologies. Parallel coordinates using a vertical axis parallel to represent dimensions, through numerical characterization of multidimensional data on the shaft and shaft line connecting all the coordinates of points to display multidimensional data in two-dimensional space.
Parallel coordinate system can display multidimensional data succinctly and quickly. Because of its classical and extensive application, many scholars have applied parallel coordinate method to visualization, data mining, process control, decision support, approximate computation and some other fields. When the size of the data set becomes very large, the dense fold lines make parallel coordinate systems difficult to interpret. Therefore, visual aliasing reduction is also noticed by many experts. The parallel vision based obfuscation methods include dimensional rearrangement, interactive method, clustering, filtering, animation, etc..
6.1 Regional traffic state analysis and evaluation method
Operation time of road congestion accumulation can reflect the road in statistical interval, the average travel speed calculation section is lower than the speed of road congestion identification threshold to determine whether the average speed of road congestion, the use of map matched floating car GPS data transfer calculation, congestion threshold is determined by the grade of road sections and historical traffic data. The congestion discriminant function is as follows.
where \(v_{tr1} \) and \(v_{tr2} \) respectively represent average travel speed and congestion speed threshold. The cumulative spatiotemporal congestion is calculated by accumulating the length of congestion in the target section and the length of the congested section, as follows:
In order to analyze regional traffic congestion reasonably, we need to describe the traffic congestion degree of each point in the study area to describe the traffic status in the study area. The more the congestion source in the neighborhood, the closer the distance from the evaluation point to the location of the congestion point, the higher the congestion level of the evaluation point. We use congestion intensity C to evaluate the degree of congestion at a certain point in the region:
The congestion intensity increases with the increase and accumulation of the congestion sources in the local area, which can reflect the spatial distribution of congestion. When the number of congestion sources in the whole study area is certain, the average value of the congestion intensity remains the same regardless of the distribution of the congestion sources. In order to realize the regional traffic congestion evaluation, we must first determine the congestion, in order to describe the distribution of congestion on the road, which is separated into scatter distribution along the road, each point represents the congestion intensity certain units of the unit, decided by the statistical average of the congestion intensity interval J.
Assuming that the points are uniformly distributed along the road, in fact, the traffic condition is uneven, and the point source distribution along the road is not uniform. However, when we evaluate the whole area, we can ignore the heterogeneity.
In order to describe the relationship between the evaluation point and the congestion source and introduce Gauss kernel function as the attenuation function, we consider that the influence of the congestion source on the evaluation point decreases exponentially with the square of the distance between the congestion source and the evaluation point.
When the coordinates of the evaluation points are two-dimensional, the neighborhood bandwidth is a diagonal matrix of 2 \(\times \) 2, where the congestion intensity of a point in the region can be expressed as follows:
In the evaluation of regional traffic congestion, the rationality of the selection of neighborhood bandwidth of the evaluation point is concerned. When the bandwidth selection is too large, the region evaluation scale will be too large, and the local features of the region will be smoothed out, so it is difficult to reflect the uneven distribution of regional congestion intensity. When the bandwidth selection is too small, will be limited to road congestion, cannot reflect the relative relationship between the road network scale on the significance of regional distribution and correlation and congestion.
7 Conclusion
Through the life cycle analysis of large traffic data, this paper makes a preliminary study of the role of the data at all stages. The traffic engineering technology and big data combination is introduced in this paper, in order to help eliminate traffic fuzzy decision, and provide a quantitative analysis method and decision support data, traffic data for later in-depth application of the foundation.
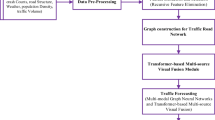
In this paper, the road congestion intensity is used to describe the congestion degree of each road network. We construct a visual model describing the overall distribution characteristics of urban network congestion, and describe the spatial distribution and agglomeration degree of each area in different periods of the city road network of different congestion level. This paper presents an analytical framework for pattern recognition and classification of urban traffic congestion. We combine self-organizing feature map neural network and graph theory, and construct visualization model in order to better analyze the big traffic data. The experimental results show that our proposed algorithm realizes the feature extraction and clustering of high-dimensional congestion visualization data, and achieves the effective identification and classification of traffic congestion model.[18]
Change history
05 December 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s10586-022-03907-6
References
Wang, Z., Yuan, X.: Visual analysis of trajectory data. J. Comput. Aided Des. Comput. Graph. 1, 9–30 (2015)
Tobler, W.: Experiments in migration mapping by computer. Cartogr. Geogr. Inf. Sci. 14(2), 140–163 (1987)
Kapler, T., Wright, W.: GeoTime information visualization. Inf. Vis. 4(2), 135–146 (2005)
Lee, J.G., Jiawei, H.: Trajectory Clustering: A Partition and Group Framework. In: Proceedings of ACM’s Special Interest Group on Management of Data. Beijing, China (2007)
Chetverikov, D., Szabo, Z.: A Simple and Efficient Algorithm for Detection of High Curvature Points in Planar Curves. In: Proceedings of the 10th International Conference on Computer Analysis of Images and Patterns. Goningen, The Netherlands (2003)
Scheepens, R., Willems, N., Van de Wetering, H.: Composite density maps for multivariate trajectories. IEEE Trans. Vis. Comput. Graph. 17(12), 2511–2532 (2011)
Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., ... Chen, J.: Deep speech 2: end-to-end speech recognition in english and mandarin. In: International Conference on Machine Learning, pp. 173–182 (2006)
Chen, Y., Luo, Y., Huang, W., Hu, D., Zheng, R.Q., Cong, S.Z.,. & Wang, X.Y., : Machine-learning-based classification of real-time tissue elastography for hepatic fibrosis in patients with chronic hepatitis B. Comput. Biol. Med. 89, 18–23 (2017)
Zhu, L.Q., Ma, M.Y., Zhang, Z., Zhang, P.Y., Wu, W., Wang, D.D.,. & Wang, H. Y.: Hybrid deep learning for automated lepidopteran insect image classification. Oriental Insects 51(2), 79–91 (2017)
Shuo, D., Xiao-Heng, C., Qinghui, W.: Approximation performance of BP neural networks improved by heuristic approach. Appl. Mech. Mater. 411–414, 1952–1955 (2013)
Shuo, D., Xiao-Heng, C., Qinghui, W.: Pattern classification based on self-organizing feature mapping neural network. Appl. Mech. Mater. 448–453, 3645–3649 (2014)
Cao, J., Shridhar, M.: A hierarchical neural network architecture for hand written numeral recognition. Pattern Recognit. 30(2), 280–294 (1997)
Pierre, P.: An Introduction to the Modeling of Neural Networks. Cambridge University Press, London (1992)
Defanti, T.A., Brown, M.D., Mccormick, B.H.: Visualization: expanding scientific and engineering researchopportunities. Computer 22(8), 10–21 (1989)
Chen, J., Zhiqiang, Y., Zhu, J.: Data visualization technology and its application. Infrared Laser Eng. 30(5), 330–342 (2001)
Liu, D.: The Research of Large-Scale Data Visualization. Tianjin University, Tianjin (2009)
Sun, Y., Feng, X.: Survey on research of multidimensional and multivariate data visualization. Comput. Sci. 35(11), 1–17 (2008)
Heer, J., Robertson, G.G.: Animated transitions in statistical data graphics. IEEE Trans. Vis. Comput. Graph. 13(6), 1240–1247 (2007)
Acknowledgements
This study was supported by GoPerception Open Project Funding.
Author information
Authors and Affiliations
Corresponding author
Additional information
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s10586-022-03907-6
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chen, X., Wang, H.H. & Tian, B. RETRACTED ARTICLE: Visualization model of big data based on self-organizing feature map neural network and graphic theory for smart cities. Cluster Comput 22 (Suppl 6), 13293–13305 (2019). https://doi.org/10.1007/s10586-018-1848-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-018-1848-1