
Abstract
This paper is concerned with the least squares inverse eigenvalue problem of reconstructing a linear parameterized real symmetric matrix from the prescribed partial eigenvalues in the sense of least squares, which was originally proposed by Chen and Chu (SIAM J Numer Anal 33:2417–2430, 1996). We provide a geometric Gauss–Newton method for solving the least squares inverse eigenvalue problem. The global and local convergence analysis of the proposed method is established under some assumptions. Also, a preconditioned conjugate gradient method with an efficient preconditioner is proposed for solving the geometric Gauss–Newton equation. Finally, some numerical tests, including an application in the inverse Sturm–Liouville problem, are reported to illustrate the efficiency of the proposed method.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
An inverse eigenvalue problem (IEP) aims to reconstruct a structured matrix from the prescribed spectral data. Inverse eigenvalue problems (IEPs) arise in various applications such as structural dynamics, vibration, inverse Sturm–Liouville problem, control design, geophysics, nuclear spectroscopy and molecular spectroscopy, etc. For the existence theory, numerical methods and applications of general IEPs, one may refer to [11, 13, 14, 20, 24, 25, 43] and references therein.
Recently, one may find some new applications and numerical methods of IEPs including the experiments for beaded strings [17], the inverse eigenvalue problem for graphs [5, 6, 31], the solvability condition and numerical algorithm for the parameterized generalized IEP [18], the weight optimization in a geodetic network [19], the IEP in wireless communications [40], the transcendental inverse eigenvalue problem in damage parameter estimation [36, 37], the IEP for quantum channels [42], and the IEP in microelectromechanical systems [38], etc. In many applications, the number of distributed parameters in the required structured matrix is often smaller than the number of measured eigenvalues (see for instance [9, 22, 39]). Thus it is desirable that one can find a least square solution to a structured IEP. Sparked by this, in this paper, we consider the following parameterized least squares inverse eigenvalue problem, which was originally given by Chen and Chu [10].
PLSIEP I
Given \(l+1\) real symmetric matrices \(A_0,A_1,\ldots ,A_l \in {\mathbb {R}}^{n\times n}\) and m real numbers \(\lambda ^*_1 \le \lambda ^*_2 \le \cdots \le \lambda ^*_m\ (m\le n)\), find a vector \(\mathbf {c}=(c_1,c_2,\ldots ,c_l)^T\in \mathbb {R}^{l}\) and a permutation \(\sigma =\{\sigma _1,\sigma _2,\ldots ,\sigma _m\}\) with \(1 \le \sigma _1< \sigma _2< \cdots < \sigma _m \le n\) to minimize the function
where the real numbers \(\lambda _1(\mathbf {c})\le \lambda _2(\mathbf {c}) \le \cdots \le \lambda _n(\mathbf {c})\) are the eigenvalues of the matrix \(A(\mathbf {c})\) defined by
This is a nonlinear least-squares problem, where \(l\le m\le n\) and the cost function \(f(\mathbf {c},\sigma )\) is a function of a continuous variable \(\mathbf{c}\) and a discrete variable \(\sigma \). This is a special kind of mixed optimization problem, where the function \(f(\mathbf {c},\sigma )\) is nondifferentiable when the permutation \(\sigma \) is changed. For the PLSIEP I, there exists an equivalent least-squares problem defined on a product manifold. Let \(\mathscr {D}(m)\) and \(\mathscr {O}(n)\) denote the set of all real diagonal matrices of order m and the set of all real \(n\times n\) orthogonal matrices, respectively. Define \(\varLambda ^*_m := \mathrm{diag} (\lambda ^*_1, \lambda ^*_2, \ldots , \lambda ^*_m)\), where \(\mathrm{diag}(\mathbf{a})\) denotes a diagonal matrix with \(\mathbf{a}\) on its diagonal. Given a matrix \(\varLambda \in \mathscr {D}(n-m)\), \(\mathrm{blkdiag}\left( \varLambda ^*_m ,\; \varLambda \right) \) denotes the block diagonal matrix obtained from \(\varLambda ^*_m\) and \(\varLambda \). Based on Theorem 3.2 in [10], the PLSIEP I is equivalent to the following problem.
PLSIEP II
Given \(l+1\) real symmetric matrices \(A_0,A_1,\ldots ,A_l \in {\mathbb {R}}^{n\times n}\) and m real numbers \(\lambda ^*_1 \le \lambda ^*_2 \le \cdots \le \lambda ^*_m\ (m\le n)\), find a vector \(\mathbf {c}\in \mathbb {R}^{l}\), an orthogonal matrix \(Q\in \mathscr {O}(n)\), and a diagonal matrix \(\varLambda \in \mathscr {D}(n-m)\) to minimize the function
where \(\Vert \cdot \Vert _F\) denotes the Frobenius norm.
The PLSIEP II is a nonlinear least-squares problem defined on the product manifold \(\mathbb {R}^{l} \times \mathscr {O}(n) \times \mathscr {D}(n-m)\). To solve the PLSIEP II, Chen and Chu [10] proposed a lift and projection (LP) method. This method is a modification of the alternating projection method to an affine space and a Riemannian manifold. To solve the PLSIEP I, Chen and Chu [10] proposed a hybrid method called the LP-Newton method. The idea is that an initial guess of \((\mathbf{c}, \sigma )\) is obtained by using the LP method to the PLSIEP II, then the Newton method is applied to the PLSIEP I by fixing the value of \(\sigma \). As noted in [10], in spite of non-smoothness of f in \(\sigma \), one may still adopt the Newton method for solving the PLSIEP I, where the Hessian matrix of f can be explicitly derived. However, as the separation of eigenvalues decreases, the Hessian matrix becomes increasingly ill-conditioned. Also, as noted in [23], when \(l<m\), it is natural to consider the well-known techniques in [21, Chap. 10] (e.g., the Gauss–Newton method). Wang and Vong [41] proposed a Gauss–Newton-like method for a special case of \(m=n\).
Optimization methods on smooth manifolds have been widely studied and applied to various kinds of areas such as numerical linear algebra and dynamical systems (see for instance [1,2,3,4, 12, 15, 30, 35] and references therein). Recently, some Riemannian optimization methods were proposed for solving nonlinear eigenvalue problems and inverse eigenvalue problems [44,45,46,47]. In this paper, we propose a geometric inexact Gauss–Newton method for solving the PLSIEP II. Absil et al. [2] proposed a Riemannian Gauss–Newton method for solving nonlinear least squares problems defined between Riemannian manifold and Euclidean space, where the convergence analysis was not discussed. Gratton et al. [27] gave some approximate Gauss–Newton methods for solving nonlinear least squares problems defined on Euclidean space. Sparked by [2, 27], we present an efficient geometric inexact Gauss–Newton method for solving the PLSIEP II. The global convergence and local convergence rate are also derived under some assumptions. An effective preconditioner is proposed for solving the Riemannian Gauss–Newton equation via the conjugate gradient (CG) method [26]. Finally, some numerical experiments, including an application in the inverse Sturm–Liouville problem, are reported to show the efficiency of the proposed method for solving the PLSIEP II.
Throughout this paper, we use the following notation. The symbol \(A^T\) denotes the transpose of a matrix A. The symbol \(\mathrm{Diag}(M):= \mathrm{diag}(m_{11}, m_{22}, \ldots , m_{nn})\) denotes a diagonal matrix containing the diagonal elements of an \(n \times n\) matrix \(M = [ m_{ij} ]\). Let \(\mathbf {0}_{m\times n}\) be the \(m\times n\) zero matrix and \(\mathbf{e}_k\) be the kth column of the identity matrix \(I_n\) of order n. Let \({\mathbb {R}}^{n\times n}\) and \(\mathbb {SR}^{n\times n}\) be the set of all n-by-n real matrices and the set of all n-by-n real symmetric matrices, respectively. Denote by \(\mathrm{tr}(A)\) the trace of a square matrix A. For two matrices \(A,B\in {\mathbb {R}}^{n\times n}\), the Lie Bracket [A, B] of A and B is defined as the difference of the matrix products AB and BA, i.e., \([A,B]:=AB-BA\) [32, p. 512]. Let \(\mathrm{vec}(A)\) be the vectorization of a matrix A, i.e., a column vector obtained by stacking the columns of A on top of one another. For two finite-dimensional vector spaces \(\mathscr {X}\) and \(\mathscr {Y}\) equipped with a scalar inner product \(\langle \cdot ,\cdot \rangle \) and its induced norm \(\Vert \cdot \Vert \), let \(\mathscr {A}:\mathscr {X}\rightarrow \mathscr {Y}\) be a linear operator and the adjoint of \(\mathscr {A}\) be denoted by \(\mathscr {A}^*\). The operator norm of \(\mathscr {A}\) is defined by  .
.
The remainder of this paper is organized as follows. In Sect. 2 we propose a geometric inexact Gauss–Newton method for solving the PLSIEP II. In Sect. 3 we establish the global convergence and local convergence rate of the proposed approach under some assumptions. A preconditioner is also proposed for solving the geometric Gauss–Newton equation. Finally, we report some numerical tests in Sect. 4 and give some concluding remarks in Sect. 5.
2 Geometric inexact Gauss–Newton method
In this section, we present a geometric inexact Gauss–Newton method for solving the PLSIEP II. Define an affine subspace and an isospectral manifold by
We see that \(\mathscr {M}(\varLambda ^*_m)\) is the set of all real \(n\times n\) symmetric matrices whose spectrum contains the m real numbers \(\lambda ^*_1, \lambda ^*_2, \ldots , \lambda ^*_m\). Thus, the PLSIEP II has a solution such that \(h(\mathbf {c},Q,\varLambda ) =0\) if and only if \(\mathscr {L}\cap \mathscr {M}(\varLambda ^*_m) \ne \emptyset \).
Denote
Let H be a nonlinear mapping between \(\mathscr {Z}\) and \(\mathbb {SR}^{n\times n}\) defined by
for all \((\mathbf {c}, Q, \varLambda )\in \mathscr {Z}\). Then, the PLSIEP II can be written as the following minimization problem:
Sparked by the ideas in [2, 27], we propose a geometric inexact Gauss–Newton method for solving Problem (2.3). We note that the dimension of the product manifold \(\mathscr {Z}\) is given by
If \(l<m\), then
Therefore, the nonlinear equation \(H(\mathbf {c}, Q, \varLambda ) =\mathbf{0}_{n\times n}\) is an over-determined matrix equation defined on the product manifold \(\mathscr {Z}\).
Notice that \(\mathscr {Z}\) is an embedded submanifold of the Euclidean space \(\mathbb {R}^{l} \times {\mathbb {R}}^{n\times n}\times \mathscr {D}(n-m)\). One may equip \(\mathscr {Z}\) with the induced Riemannian metric:
for \((\mathbf {c},Q,\varLambda ) \in \mathscr {Z}\), and \((\xi _1, \eta _1, \tau _1), (\xi _2, \eta _2, \tau _2)\in T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\), and its induced norm \(\Vert \cdot \Vert \). The tangent space \(T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\) of \(\mathscr {Z}\) at \((\mathbf {c},Q,\varLambda )\) is given by [2, p. 42]
Hence, \((\mathscr {Z},g)\) is a Riemannian product manifold.
For simplification, we use the following notation:
A Riemannian Gauss–Newton method for solving Problem (2.3) can be stated as follows. Given the current iterate \(X_k\in \mathscr {Z}\), solve the normal equation
for \(\varDelta X_k \in T_{X_k}\mathscr {Z}\). Here,
is the Riemannian differential of H at the point \(X_k\), which is given by
where
With respect to the Riemannian metric g, the adjoint
of \(\mathrm {D}H(X_k)\) is given by
where
For explicit derivation of (2.4) and (2.6), one may refer to Appendix A. Based on (2.6), the Riemannian gradient of h at a point \(X:=(\mathbf {c},Q,\varLambda )\in \mathscr {Z}\) is determined by [2, p. 185]:
Let \(\nabla \) denote the Riemannian connection of \(\mathscr {Z}\). By using (8.31) in [2, p. 185] we obtain
for all \(X:= (\mathbf {c},Q,\varLambda ) \in \mathscr {Z}\) and \(\xi _X, \eta _X \in T_{X}\mathscr {Z}\), where \(\nabla ^2 h\) is a (0, 2)-tensor field and \(\nabla ^2 H(X)[\cdot ,\cdot ]=\big [\nabla ^2 H_{ij}(X)[\cdot ,\cdot ] \big ]\in \mathbb {SR}^{n\times n}\) [2, p. 109]. The Riemannian Hessian \(\mathrm{Hess}\; h(X)\) at a point \(X\in \mathscr {Z}\) is determined by
for all \(\xi _X, \eta _X \in T_{X}\mathscr {Z}\). In particular, if \(X_{*}\) is a solution of the equation \(H(X)=\mathbf {0}_{n\times n}\), then we can obtain
Based on the above discussion, a geometric inexact Gauss–Newton method for solving Problem (2.3) can be described as follows.
Algorithm 1
A geometric inexact Gauss–Newton method
- Step 0:
-
Choose an initial point \(X_0 \in \mathscr {Z}\), \(\beta , \eta _{\max }\in (0,1)\), \(\sigma \in (0,\frac{1}{2})\). Let \(k:=0\).
- Step 1:
-
Apply the CG method to finding an approximate solution \(\varDelta X_k \in T_{X_k} \mathscr {Z}\) of
$$\begin{aligned} (\mathrm {D}H(X_k))^*\circ \mathrm {D}H(X_k)[\varDelta X_k] = - \, \mathrm{grad}\,h(X_k) \end{aligned}$$(2.11)such that
$$\begin{aligned} \Vert (\mathrm {D}H(X_k))^*\circ \mathrm {D}H(X_k)[\varDelta X_k] +(\mathrm {D}H(X_k))^*[H(X_k)]\Vert \le \eta _k\Vert \mathrm{grad}\,h(X_k)\Vert \end{aligned}$$(2.12)and
$$\begin{aligned} \langle \mathrm{grad}\,h(X_k) ,\varDelta X_k \rangle \le -\,\eta _k\langle \varDelta X_k ,\varDelta X_k\rangle , \end{aligned}$$(2.13)where \(\eta _k:=\min \{\eta _{\max }, \Vert \mathrm{grad}\,h(X_k)\Vert \}\). If (2.12) and (2.13) are not attainable, then let
$$\begin{aligned} \varDelta X_k:=-\,\mathrm{grad\,}h(X_k). \end{aligned}$$ - Step 2:
-
Let \(l_k\) be the smallest nonnegative integer l such that
$$\begin{aligned} h\big (R_{X_k}(\beta ^{l} \varDelta X_k)\big )- h( X_k) \le \sigma \beta ^l\langle \mathrm{grad}\,h(X_k),\varDelta X_k\rangle . \end{aligned}$$(2.14)Set
$$\begin{aligned} X_{k+1}:= R_{X_k}(\beta ^{l_k} \varDelta X_k). \end{aligned}$$ - Step 3:
-
Replace k by \(k+1\) and go to Step 1.
We point out that, in Step 2 of Algorithm 1, (2.14) is the Armijo condition (see [2, Definition 4.2.2]) and R is a retraction on \(\mathscr {Z}\), which takes the form of
where \(R^o\) is a retraction on \(\mathscr {O}(n)\), which may be chosen as [2, p. 58]:
Here, \(\mathrm{qf}(A)\) denotes the Q factor of the QR decomposition of an invertible matrix \(A\in \mathbb {R}^{n\times n}\) as \(A=Q\widehat{R}\), where Q belongs to \(\mathscr {O}(n)\) and \(\widehat{R}\) is an upper triangular matrix with strictly positive diagonal elements. For the retraction R defined by (2.15), there exist two scalars \(\nu >0\) and \(\mu _{\nu } >0\) such that [2, p. 149]
for all \(X\in \mathscr {Z}\) and
where “\(\mathrm{dist}\)” means the Riemannian distance on the Riemannian product manifold \(( \mathscr {Z},g)\) [2, p. 46]. Of course, one may choose other retractions on \(\mathscr {O}(n)\) via the polar decomposition, Givens rotation, Cayley transform, exponential mapping, or singular value decomposition (see for instance [2, p. 58] and [45]).
3 Convergence analysis
In this section, we establish the global convergence and local convergence rate of Algorithm 1.
3.1 Global convergence
For the global convergence of Algorithm 1, we have the following result. The proof follows from Theorem 4.1 in [45]. Thus we omit it here.
Theorem 1
Any accumulation point \(X_*\) of the sequence \(\{X_k\}\) (if exists) generated by Algorithm 1 is a stationary point of the cost function h defined in Problem (2.3).
Remark 1
In Step 2 of Algorithm 1, the Armijo condition (2.14) guarantees that the objective function h is monotone decreasing. As in [2, Corollary 4.3.2], the sequence \(\{X_k\}\) generated by Algorithm 1 must have an accumulation point if the level set \(\mathscr {L}:=\{X\in \mathscr {Z}\ | \ h(X) \le h(X_0) \}\) is bounded. In particular, if \(m=n\) and the matrices \(A_1, A_2, \ldots , A_l\) are linearly independent, then it is easy to check that the level set \(\mathscr {L}\) is bounded for any initial point \(X_0\in \mathscr {Z}\) (see for instance [47, Lemma 3.1]).
The search directions \(\{\varDelta X_k\}\) generated by Algorithm 1 have the following property. The proof is similar to that of Lemma 4.3 in [45]. Thus we omit it here.
Lemma 1
Let \(X_*\) be an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. If \(\mathrm{D}H(X_{*}): T_{X_*}\mathscr {Z}\rightarrow T_{H(X_*)}\mathbb {SR}^{n\times n}\) is injective, then there exist five positive constants \(\bar{\rho }, \kappa _0,\kappa _1, d_1, d_2 > 0\) such that for all \(X_k\in B_{\bar{\rho }}(X_{*})\), the linear operator \((\mathrm{D}H(X_k))^*\circ \mathrm{D}H(X_k):T_{H(X_*)}\mathbb {SR}^{n\times n}\rightarrow T_{H(X_*)}\mathbb {SR}^{n\times n}\) is nonsingular,

and
where \(B_{\bar{\rho }}(X_{*}):=\{X\in \mathscr {Z}\ | \ \mathrm{dist}(X,X_*)<\bar{\rho }\}\).
Next, we discuss the global convergence of Algorithm 1. We need the following assumption.
Assumption 1
Suppose the differential \(\mathrm{D}H(X_{*}): T_{X_*}\mathscr {Z}\rightarrow T_{H(X_*)}\mathbb {SR}^{n\times n}\) is injective and \(X_{*}\) is an isolated local minimizer of h defined in Problem (2.3), where \(X_{*}\) is an accumulation point of the sequence \(\{X_{k}\}\) generated by Algorithm 1.
For the global convergence of Algorithm 1 related to an isolated local minima of h, we have the following result. The proof follows from [8, Proposition 1.2.5].
Theorem 2
Let \(X_{*}\) be an accumulation point of the sequence \(\{X_{k}\}\) generated by Algorithm 1. Suppose that Assumption 1 holds, then \(\{X_{k}\}\) converges to \(X_{*}\).
Proof
By assumption, \(X_*\) is an isolated local minimizer of h. Thus there exists a parameter \(\hat{\rho }>0\) such that \(X_{*}\) is the only stationary point of h in the neighborhood \(B_{\hat{\rho }}(X_{*})\) and
Since h is continuously differentiable and \(X_*\) is a stationary point of h, i.e., \(\mathrm{grad}\; h(X_{*}) = 0_{X_*}\), we obtain
By using (3.3), the norm \(\Vert \mathrm{grad\,}h(X)\Vert \) can be as small as possible if X is sufficiently close to \(X_*\). Thus there exists a scalar \(0<\rho < \min \{\hat{\rho },\bar{\rho }\}\) such that
where \(\mu _{\nu }\) is defined in (2.17). By assumption, the differential \(\mathrm{D}H(X_{*})\) is injective. Thus, by Lemma 1 we know that (3.2) holds for \(X_k\in B_{\rho }(X_{*})\) since \(\rho \le \bar{\rho }\).
Let
We note that \(\phi \) is a monotonically nondecreasing function of t and thus \(\phi (t) >0\) for all \(t\in (0,\rho ]\). Using (3.3), for any \( \varepsilon \in (0,\rho ]\), there exists a constant \(r \in (0,\varepsilon ]\) such that
for all \(X\in B_{r}(X_{*})\), where \(\nu \) is defined in (2.16). Define the open set
It is easy to see that \(S\subset B_{\rho }(X_{*})\) since \(\varepsilon \in (0,\rho ]\).
We claim that if \(X_k \in S\) for some k, then \(X_{k+1} \in S\). Indeed, by using the definitions of \(\phi \) and S, if \(X_k \in S\), then
Since \(\phi \) is monotonically nondecreasing we have \(\mathrm{dist}(X_k,X_{*}) < r\). This, together with (3.5), yields
Thus, (3.2) holds for \(X_k\) since \(X_k\in S\subset B_{\rho }(X_{*})\). Using (2.16), (3.2), and (3.4) we have
Since \(h(X_{k+1}) \le h(X_k)\), it follows from (3.6), (3.7), and (3.8) that
By the above inequalities and the definition of the set S we have \(X_{k+1} \in S\). This completes the proof of the claim. Also, By using induction to the claim we have \(X_i \in S\) for all \(i \ge k\) if \(X_{k} \in S\) for some k.
Since \(X_*\) is an accumulation point of the sequence \(\{X_k\}\), there exists a subsequence \(\{X_{k_j}\}\) such that \(\lim \nolimits _{j\rightarrow \infty }X_{k_j}=X_*\). Thus there exists an integer \(k_{\bar{l}}\) such that \(X_{k_{\bar{l}}}\in S\). By using the claim we have \(X_k\in S\) for all \(k \ge k_{\bar{l}}\). Since \(h(X_{k+1})<h(X_k)\) for all \(k \ge k_{\bar{l}}\) and \(\lim \nolimits _{k_j\rightarrow \infty }h(X_{k_j}) = h(X_*)\), it follows that
Using (3.6), \(X_k\in S\) for all \(k \ge k_{\bar{l}}\), and (3.9) we have \(\lim \nolimits _{k\rightarrow \infty }\phi \big ( \mathrm{dist} (X_k,X_{*}) \big )=0\). Since \(\phi \) is monotone nondecreasing, it follows that \(\lim \nolimits _{k\rightarrow \infty } \mathrm{dist} (X_k,X_{*}) =0\) and thus \(X_k \rightarrow X_{*}\). The proof is complete. \(\square \)
3.2 Convergence rate
We discuss the local convergence rate of Algorithm 1. The pullbacks of H and h are defined as \(\widehat{H} := H\circ R\) and \(\widehat{h} := h\circ R\), where R is the retraction defined in (2.15). In addition, we use \(\widehat{H}_X := H\circ R_X\) and \(\widehat{h}_X := h\circ R_X\) to denote the restrictions of \(\widehat{H}\) and \(\widehat{h}\) to the tangent space \(T_X\mathscr {Z}\).
Since \(R_X(0_X) = X\) [2, Definition 4.1.1], the value of H at X is equal to the value of its pullback \(\widehat{H}_X\) at \(0_X\), i.e.,
It follows from (2.3) and (3.10) that
Let \(\mathrm{Id}_{T_X\mathscr {Z}}\) denote the identity mapping on \(T_X\mathscr {Z}\). Then one has \(\mathrm{D}R_X(0_X) = \mathrm{Id}_{T_X\mathscr {Z}}\) [2, (4.2)]. Thus the differential of H at X is equal to the differential of its pull back \(\widehat{H}_X\) at \(0_X\), i.e.,
for all \(X \in \mathscr {Z}\). Using (3.12) we have
for all \(X \in \mathscr {Z}\). For the Riemannian gradient of h and the gradient of its pull back \(\widehat{h}\), we have [2, p. 56]
for all \(X \in \mathscr {Z}\).
Here, we need the following result on mean value inequality for differentiable mapping defined between normed vector spaces.
Lemma 2
[16, Corollary 3.3] Let V and W be normed vector spaces, U an open subset of V and \(F:U\rightarrow W\) differentiable on U. Given two vectors \(\mathbf{a},\mathbf{b}\in U\), if the segment between \(\mathbf{a}\) and \(\mathbf{b}\) is contained in U, then we have

where \(\Vert \cdot \Vert _V\) and \(\Vert \cdot \Vert _W\) denote the norms of V and W, respectively.
For the stepsize \(\beta ^{l_k}\) in (2.14), we have the following result [33].
Lemma 3
Let \(X_*\) be an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. Suppose that Assumption 1 holds and \(\Vert H(X_*)\Vert _F\) is sufficiently small, then for k sufficiently large, \(l_k = 0\) satisfies (2.14).
Proof
By hypothesis, Theorem 1, and Lemma 2 we have
By the definition of \(\eta _k\) in Algorithm 1 and (3.15) we have
Since \(\mathrm{D}H(X_{*})\) is injective, it follows from (3.1) and (3.16) that the conditions (2.12) and (2.13) are satisfied for all k sufficiently large. Thus \(\varDelta X_k\) is an approximate solution to (2.11) for all k sufficiently large. Let \(\varDelta X_k^{GN}\) denote the exact solution to (2.11). Then we have
From (2.11), (3.10), (3.12), and (3.13), it follows that
Using the definition of least-squares solution, (3.10), and (3.12) we find
This implies that
By hypothesis, \(\mathrm{D}H(X_{*})\) is injective. Thus, by using Lemma 1, (2.12), (3.1), and (3.17), we have for all k sufficiently large,

In addition, the adjoint \((\mathrm{D}\widehat{H}_{X})^*\) of \(\mathrm{D}H_X\) is Lipschitz-continuous at \(0_X\) uniformly in a neighborhood of \(X_*\). That is, there exist three scalars \(\kappa _2, \delta _1, \delta _2 > 0\) such that

for all \(X\in B_{\delta _1}(X_*)\) and \(\xi _X \in B_{\delta _2}(0_X)\). Let
By using Lemma 2, (3.21), and (3.22), we have

for all k sufficiently large.
In the rest of the proof, for simplification, we drop the subindex k. Based on (3.11), (3.14), and (3.22), we have
Using (3.1), (3.10), (3.18), (3.19), (3.20), (3.23), and the above equality, we have for all k sufficiently large,

Based on (3.15), if \(\Vert H(X_*)\Vert _F\) is sufficiently small, then \(\Vert H(X_k)\Vert _F\) is small enough for all k sufficiently large. By using the above inequality, (2.14) holds with \(l_k=0\) for all k sufficiently large. This completes the proof. \(\square \)
We now establish the local convergence rate of Algorithm 1.
Theorem 3
Let \(X_*\) be an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. Suppose that Assumption 1 holds and \(\Vert H(X_*)\Vert _F\) is sufficiently small, then the sequence \(\{X_k\}\) converges to \(X_*\) linearly. Furthermore, if \(H(X_*)=\mathbf {0}_{n\times n}\), then the sequence \(\{X_k\}\) converges to \(X_*\) quadratically.
Proof
By hypothesis and using Lemma 3 we have \(X_k\rightarrow X_*\) and \(X_{k+1} = R_{X_k}(\varDelta X_k)\) for all k sufficiently large. Using Lemma 7.4.8 and Lemma 7.4.9 in [2], there exist three scalars \(\tau _0,\tau _1,\tau _2>0\) such that for all k sufficiently large,
By using Taylor’s formula we have for all k sufficiently large,
Since H is twice continuously differentiable, it follows from (2.9) and (2.10) that there exist two scalars \(\kappa _3>0\) and \(\delta _3>0\) such that for all \(X\in B_{\delta _3}(X_*)\),

Furthermore, the Hessian operator \(\mathrm{Hess}\; \widehat{h}_{X}\) is Lipschitz-continuous at \(0_X\) uniformly in a neighborhood of \(X_*\), i.e., there exist three scalars \(\kappa _4>0\), \(\delta _4 >0\), and \(\delta _5 > 0\), such that for all \(X\in B_{\delta _4}(X_*)\) and \(\xi _X \in B_{\delta _5}(0_X)\), it holds that

In addition, H is Lipschitz-continuous in a neighborhood of \(X_*\), i.e., there exist two constants \(L>0\) and \(\delta _6 > 0\) such that for all \(X,Y\in B_{\delta _6}(X_*)\),
From Lemma 1, (2.12), (3.24), (3.25), (3.26), and (3.27), we have for k sufficiently large,
Thus,
where \(c_1:=\tfrac{\tau _1\tau _2}{\tau _0}\kappa _3d_2\) and \(c_2 :=\tfrac{\tau _1^2\tau _2}{\tau _0}( 1 + \kappa _4 d_2^2)\). If \(\Vert H(X_*)\Vert _F\) is sufficiently small, then \(\Vert H(X_k)\Vert _F\) is small enough such that \(c_1\Vert H(X_k)\Vert _F <1\) for all k sufficiently large. Thus if \(\Vert H(X_*)\Vert \) is sufficiently small, then\(\{X_k\}\) converges to \(X_*\) linearly.
If \(H(X_*)=\mathbf {0}_{n\times n}\), then we have from (3.28) for all k sufficiently large,
Using (3.29) and (3.30), we have
Therefore, if \(H(X_*)=\mathbf {0}_{n\times n}\), then \(\{X_k\}\) converges to \(X_*\) quadratically. This completes the proof. \(\square \)
As a direct consequence of (3.24) and (3.29), we have the following result.
Corollary 1
Let \(X_*\) be an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. Suppose the assumptions in Theorem 3 are satisfied. Then there exist two constants \(\mu _1, \mu _2>0\) such that for all k sufficiently large,
Furthermore, if \(H(X_*)=\mathbf {0}_{n\times n}\), then there exists a scalar \(\bar{\nu }>0\) such that for all k sufficiently large,
3.3 Injectivity condition
We provide the injectivity condition of \(\mathrm {D} H(X_{*})\), where \(X_*=(\mathbf{c}_*,Q_*,\varLambda _*)\) is an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. Based on (2.4), \(\mathrm {D} H(X_*)\) is injective if and only if the following matrix equation
has a unique solution \((\varDelta \mathbf {c}, \varDelta Q, \varDelta \varLambda )=(\mathbf {0}_{l},\mathbf {0}_{n\times n}, \mathbf {0}_{(n-m)\times (n-m)})\in T_{X_*}\mathscr {Z}\), where \(\overline{\varLambda }_*:=\mathrm{blkdiag}\left( \varLambda ^*_m ,\varLambda _* \right) \) and P is defined in (2.5).
For \(W\in \mathbb {R}^{n\times n}\) define \(\widehat{\mathrm {vec}}(W) \in \mathbb {R}^{\frac{n(n-1)}{2}}\) by
This shows that \(\widehat{\mathrm {vec}}(W)\) is a column vector obtained by stacking the strictly upper triangular part of W. For \(\mathbf {w}\in \mathbb {R}^{\frac{n(n-1)}{2}}\) define \(\widehat{\mathrm {skew}}(\mathbf {w}) \in \mathbb {R}^{n\times n}\) by
and
We observe that \(\widehat{\mathrm {skew}}(\mathbf {w})\) is a skew-symmetric matrix constructed from \(\mathbf {w}\). Therefore, \(\widehat{\mathrm {vec}}\) and \(\widehat{\mathrm {skew}}\) are a pair of inverse operators. In addition, there exists a matrix \(\widehat{P}\in \mathbb {R}^{n^2\times \frac{n(n-1)}{2}}\) such that
for all \(\mathbf {w}\in \mathbb {R}^{\frac{n(n-1)}{2}}\). Since \(\varDelta Q\in T_{Q_*} \mathscr {O}(n)\), there exists a skew-symmetric matrix \(\varDelta \varOmega \in \mathbb {R}^{n\times n}\) such that \(\varDelta Q = Q_*\varDelta \varOmega \). For \(\varDelta \varOmega \in \mathbb {R}^{n\times n}\), it follows from (3.32) that there exists a vector \(\varDelta \mathbf {v}\in \mathbb {R}^{\frac{n(n-1)}{2}}\) such that \(\mathrm {vec}\big (\varDelta \varOmega \big ) = \widehat{P}\varDelta \mathbf {v}\). Thus, we have
where “\(\otimes \)” means the Kronecker product [7, Definition 7.1.2]. Let \(\widehat{A}\) be an \(n^2\times l\) matrix defined by
Since \(\varDelta \varLambda \in \mathscr {D}(n-m)\), there exists a matrix \(G\in {\mathbb {R}}^{(n-m)^2\times (n-m)}\) and a vector \(\varDelta \mathbf{w}\in {\mathbb {R}}^{n-m}\) such that
Based on (3.33), (3.34), and (3.35), the vectorization of the matrix equation (3.31) is given by
Based on the above analysis, we have the following injectivity condition of \(\mathrm {D} H(X_{*})\).
Theorem 4
Let \(X_*=(\mathbf{c}_*,Q_*,\varLambda _*)\) be an accumulation point of the sequence \(\{X_k\}\) generated by Algorithm 1. Then \(\mathrm{D}H(X_*)\) is injective if and only if the following matrix
is of full rank.
3.4 Preconditioning technique
We propose a preconditioner for solving (2.11). Here we adapt a centered preconditioner [34, p. 279]. For the CG method, instead of solving (2.11), we solve the following preconditioned linear system
where \(M_k:T_{H(X_k)}\mathbb {SR}^{n\times n}\rightarrow T_{H(X_k)}\mathbb {SR}^{n\times n}\) is a self-adjoint and positive definite linear operator.
According to (2.4) and (2.6), for \(\varDelta Z_k\in T_{H(X_k)}\mathbb {SR}^{n\times n}\), we have
where \(\hat{t}>0\) is a given constant, and \(\mathrm {Id}_{T_{H(X_k)} \mathbb {SR}^{n\times n}}\) means the identity mapping on \(T_{H(X_k)} \mathbb {SR}^{n\times n}\). Replacing the matrix \(\mathrm{Diag}\big (P^TQ_k^T \varDelta Z_k Q_kP\big )\) in (3.36) by \(P^TQ_k^T \varDelta Z_k Q_kP\), we can construct a centered preconditioner \(M_k\) in the following form:
for all \( \varDelta Z_k\in T_{H(X_k)}\mathbb {SR}^{n\times n}\). Based on (3.36) and (3.37), the constructed preconditioner \(M_k\) is an approximation of \(\mathrm {D}H(X_k)\circ (\mathrm {D}H(X_k))^*+ \hat{t}\mathrm {Id}_{T_{H(X_k)} \mathbb {SR}^{n\times n}}\).
Given four matrices \(A,B,C,D\in {\mathbb {R}}^{n\times n}\), we have the following properties of the Kronecker product [7, pp. 400–401]:
Using (3.34) we find
From (2.7), (3.37), (3.38), (3.39) we have for any \( \varDelta Z_k\in T_{H(X_k)}\mathbb {SR}^{n\times n}\),
where the equality \(I_n = Q_kI_nQ_k^T\) is used. Let
and
From (3.40) and (3.42) we have for \(\varDelta Z_k\in T_{H(X_k)}\mathbb {SR}^{n\times n}\),
Given two nonsingular matrices \(C_1\in {\mathbb {R}}^{n\times n}\) and \(C_2\in {\mathbb {R}}^{m\times m}\), we have
By using the definition of the matrix P in (2.4) we have
Thus the matrix \((I_{n}\otimes \overline{\varLambda }_k -\overline{\varLambda }_k \otimes I_{n})^2 + (PP^T)\otimes (PP^T) +\widehat{t}I_{n^2}\) is a diagonal matrix with positive diagonal entries. Then it follows that the matrix \(\widehat{B}_k\) is invertible. Using (3.41), and (3.44) we have
Thus \(\widehat{B}_k^{-1}\) can be easily computed.
By (3.39), the matrix \(\widehat{A}\widehat{A}^T\) is a low rank matrix, i.e., \(\mathrm {rank}(\widehat{A}\widehat{A}^T) \le l\). By assumption, \(l<m\le n<n^2\), thus \(\widehat{M}_k\) is a low rank perturbation of \(\widehat{B}_k\). By using the Sherman–Morrison–Woodbury formula [28] we find
We conclude from (3.45) that, for any vector \(\mathbf {x}\in \mathbb {R}^{n^2}\), the matrix-vector product \(\widehat{M}_k^{-1}\mathbf {x}\) can be computed efficiently, where the main computational cost is to calculate the inverse of \((I_l + \widehat{A}^T\widehat{B}_k^{-1}\widehat{A} )\in {\mathbb {R}}^{l\times l}\).
4 Numerical experiments
In this section we report the numerical performance of Algorithm 1 for solving the PLSIEP II. All the numerical tests are carried out by using MATLAB 7.1 running on a workstation with a Intel Xeon CPU E5-2687W at 3.10 GHz and 32 GB of RAM. To illustrate the efficiency of our algorithm, we compare Algorithm 1 with the LP method in [10].
In our numerical tests, we set \(\beta =0.5\), \(\eta _{\max }=0.01\), \(\sigma =10^{-4}\), and \(\hat{t}=10^{-5}\). The largest number of iterations in Algorithm 1 and the LP method is set to be 30000, and the largest number of iterations in the CG method is set to be \(n^3\). Let ‘CT.’, ‘IT.’, ‘NF.’, ‘NCG.’, ‘Res.’, ‘grad.’ , and ‘err-c.’ denote the averaged total computing time in seconds, the averaged number of outer Gauss–Newton iterations or LP iterations, the averaged number of function evaluations, the averaged total number of inner CG iterations, the averaged residual \(\Vert H(X_k)\Vert _F\), the averaged residual \(\Vert \mathrm{grad\,}h(X_k)\Vert \), and the averaged relative error \(\Vert \mathbf{c}_k-\widehat{\mathbf{c}}\Vert _\infty /\Vert \widehat{\mathbf{c}}\Vert _\infty \) at the final iterates of the corresponding algorithms, accordingly. Here, \(\Vert \cdot \Vert _\infty \) means the vector \(\infty \)-norm.
The stopping criterion for Algorithm 1 and the LP method is set to be
where \(\zeta >0\) is the prescribed tolerance.
We consider the following two examples.
Example 1
We consider the Sturm–Liouville problem of the form:
where q is a real, square-integrable function and the following Dirichlet boundary conditions are imposed
By using the Rayleigh–Ritz method in [29], the Rayleigh quotient of (4.1) is given by
Suppose that \(y(x) = \sum \nolimits _{j=1}^n w_j \sin (jx)\). By simple calculation, we have
i.e.,
where \(\mathbf{w}:= (w_1, w_2, \ldots , w_n)^T\) and the entries of the symmetric matrix \(A=[a_{ij}]\in {\mathbb {R}}^{n\times n}\) are given by
for \(i,j=1,2,\ldots ,n\). If \(q(x)=2\sum \nolimits _{k=1}^l c_k \cos (2kx)\), then one has
Let \(T_k\ (k=1,2,\ldots , n-1)\) and \(H_k\ (k=1,2, \ldots , 2n-1)\) be \(n\times n\) real matrices generated by the MATLAB built-in functions toeplitz and hankel:
and
Define
Then
To estimate the first l Fourier coefficients of the potential q(x) defined by [29]
we consider the PLSIEP with above \(\{A_k\}\) and the n eigenvalues of \(A(\widehat{\mathbf{c}})\) as the prescribed spectrum for varying \(n=m\) and l, where the entries of \(\widehat{\mathbf{c}}\) are given by
Example 2
We consider the PLSIEP with varying n, l, and m. Let \(\widehat{\mathbf {c}}\in \mathbb {R}^{l}\) be a random vector and \(A_0,A_1,\ldots ,A_l \) be \(n\times n\) random symmetric matrices, which are generated by the MATLAB built-in function randn:
We choose the m smallest eigenvalues of \(A(\widehat{\mathbf{c}})\) as the prescribed partial spectrum.
For Algorithm 1 and the LP method in [10], the starting points are generated by the MATLAB built-in function eig:
For Example 1, \(\mathbf{c}_0\) is set to be a zero vector. For Example 2, \(\mathbf{c}_0\) is formed by chopping the components of \(\widehat{\mathbf{c}}\) to two decimal places for \(n<100\) and to three decimal places for \(n\ge 100\).
We first apply the LP method and Algorithm 1 to Example 1 with \(\zeta =10^{-6}\). Table 1 displays numerical results for Example 1, where the symbol “*” means the largest number of iterations is reached. We observe that Algorithm 1 with PCG works much better than the LP method in terms of computing time.
Next, we apply the LP method and Algorithm 1 to Example 2 with \(\zeta =10^{-8}\). For comparison purposes, we repeat our experiments over 10 different problems. Table 2 shows numerical results for Example 2. We observe from Table 2 that Algorithm 1 is more effective than the LP method in terms of computing time. We also see that the proposed preconditioner can reduce the number of inner CG iterations effectively.
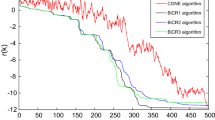
To further illustrate the efficiency of Algorithm 1, we apply Algorithm 1 with the proposed preconditioner to Examples 1 and 2 for varying n, l, m with \(\zeta =10^{-8}\). The corresponding numerical results are displayed in Tables 3 and 4. In Fig. 1, we give the convergence history of Algorithm 1 for two tests. Figure 1 depicts the logarithm of the residual versus the number of outer iterations. We see from Tables 3 and 4 that Algorithm 1 with the proposed preconditioner works very efficient for different values of n, l, m. Finally, the linear or quadratic convergence of Algorithm 1 is observed from Fig. 1, which agrees with our prediction.

Convergence history of two tests
5 Conclusions
In this paper, we focus on the parameterized least squares inverse eigenvalue problem where the number of parameters is smaller than the number of given eigenvalues. We have proposed a geometric Gauss–Newton method for solving the problem. We have established the global and linear or quadratic convergence of the proposed method under the assumption that the Riemannian differential \(\mathrm{D}H(\cdot )\) is injective and the residual \(\Vert H(\cdot )\Vert _F\) is sufficiently small or equal to zero at an accumulation point \(X_*\) of the sequence \(\{X_k\}\) generated by our method.
In each outer iteration of the proposed method, the Riemannian Gauss–Newton equation is solved approximately by the CG method. However, the Riemannian Gauss–Newton equation is often ill-conditioned. To improve the efficiency of our method, we have constructed a preconditioner by investigating the special structure of the Riemannian Gauss–Newton equation. Numerical results show that the proposed preconditioner can reduce the number of inner CG iterations and the computational time very effectively. Thus our method can be applied to solve large-scale problems.
Finally, we should point out that the proposed method may not be effective as expected if the differential \(\mathrm{D}H(X_*)\) is not injective or the residual \(\Vert H(X_*)\Vert _F\) is not small enough. This needs further study.
References
Absil, P.-A., Baker, C.G., Gallivan, K.A.: Trust-region methods on Riemannian manifolds. Found. Comput. Math. 7, 303–330 (2007)
Absil, P.-A., Mahony, R., Sepulchre, R.: Optimization Algorithms on Matrix Manifolds. Princeton University Press, Princeton (2008)
Absil, P.-A., Malick, J.: Projection-like retractions on matrix manifolds. SIAM J. Optim. 22, 135–158 (2012)
Adler, R.L., Dedieu, J.-P., Margulies, J.Y., Martens, M., Shub, M.: Newton’s method on Riemannian manifolds and a geometric model for the human spine. IMA J. Numer. Anal. 22, 359–390 (2002)
Barrett, W., Butler, S., Fallat, S.M., Hall, H.T., Hogben, L., Lin, J.C.-H., Shader, B.L., Young, M.: The inverse eigenvalue problem of a graph: multiplicities and minors. arXiv:1708.00064 (2017)
Barrett, W., Nelson, C.G., Sinkovic, J.H., Yang, T.: The combinatorial inverse eigenvalue problem II: all cases for small graphs. Electron. J. Linear Algebra 27, 742–778 (2014)
Bernstein, D.S.: Matrix Mathematics-Theory, Facts, and Formulas, 2nd edn. Princeton University Press, Princeton (2009)
Bertsekas, D.P.: Nonlinear Programming, 2nd edn. Athena Scientific, Belmont (1999)
Brussaard, P.J., Glaudemans, P.W.M.: Shell Model Applications in Nuclear Spectroscopy. North-Holland Publishing Company, Amsterdam (1977)
Chen, X.Z., Chu, M.T.: On the least-squares solution of inverse eigenvalue problems. SIAM J. Numer. Anal. 33, 2417–2430 (1996)
Chu, M.T.: Inverse eigenvalue problems. SIAM Rev. 40, 1–39 (1998)
Chu, M.T., Driessel, K.R.: Constructing symmetric nonnegative matrices with prescribed eigenvalues by differential equations. SIAM J. Math. Anal. 22, 1372–1387 (1991)
Chu, M.T., Golub, G.H.: Structured inverse eigenvalue problems. Acta Numer. 11, 1–71 (2002)
Chu, M.T., Golub, G.H.: Inverse Eigenvalue Problems: Theory, Algorithms, and Applications. Oxford University Press, Oxford (2005)
Chu, M.T., Guo, Q.: A numerical method for the inverse stochastic spectrum problem. SIAM J. Matrix Anal. Appl. 19, 1027–1039 (1998)
Coleman, R.: Calculus on Normed Vector Spaces. Springer, New York (2012)
Cox, S.J., Embree, M., Hokanson, J.M.: One can hear the composition of a string: experiments with an inverse eigenvalue problem. SIAM Rev. 54, 157–178 (2012)
Dai, H., Bai, Z.Z., Wei, Y.: On the solvability condition and numerical algorithm for the parameterized generalized inverse eigenvalue problem. SIAM J. Matrix Anal. Appl. 36, 707–726 (2015)
Dalmolin, Q., Oliveira, R.: Inverse eigenvalue problem applied to weight optimisation in a geodetic network. Surv. Rev. 43, 187–198 (2011)
Datta, B.N.: Numerical Methods for Linear Control Systems: Design and Analysis. Elsevier Academic Press, London (2003)
Dennis, J.E., Schnabel, R.B.: Numerical Methods for Unconstrained Optimization and Nonlinear Equations. Prentice-Hall, Englewood Cliffs (1983)
Friedland, S.: The reconstruction of a symmetric matrix from the spectral data. J. Math. Anal. Appl. 71, 412–422 (1979)
Friedland, S., Nocedal, J., Overton, M.L.: The formulation and analysis of numerical methods for inverse eigenvalue problems. SIAM J. Numer. Anal. 24, 634–667 (1987)
Friswell, M.I., Mottershead, J.E.: Finite Element Model Updating in Structural Dynamics. Kluwer Academic Publishers, Dordrecht (1995)
Gladwell, G.M.L.: Inverse Problems in Vibration. Kluwer Academic Publishers, Dordrecht (2004)
Golub, G.H., Van Loan, C.F.: Matrix Computations, 4th edn. Johns Hopkins University Press, Baltimore (2013)
Gratton, S., Lawless, A.S., Nichols, N.K.: Approximate Gauss–Newton methods for nonlinear least squares problems. SIAM J. Optim. 18, 106–132 (2007)
Hager, W.W.: Updating the inverse of a matrix. SIAM Rev. 31, 221–239 (1989)
Hald, O.H.: The inverse Sturm–Liouville problem and the Rayleigh–Ritz method. Math. Comput. 32, 687–705 (1978)
Helmke, U., Moore, J.B.: Optimization and Dynamical Systems. Springer, London (1994)
Hogben, L.: Spectral graph theory and the inverse eigenvalue problem of a graph. Electron. J. Linear Algebra 14, 12–31 (2005)
Horn, R.A., Johnson, C.R.: Topics in Matrix Analysis. Cambridge University Press, Cambridge (1994)
Ring, W., Wirth, B.: Optimization methods on Riemannian manifolds and their application to shape space. SIAM J. Optim. 22, 596–627 (2012)
Saad, Y.: Iterative Methods for Sparse Linear Systems, 2nd edn. SIAM, Philadelphia (2003)
Smith, S.T.: Optimization techniques on Riemannian manifolds. In: Bloch, A. (ed.) Hamiltonian and Gradient Flows, Algorithms and Control. Fields Institute Communications, vol. 3, pp. 113–136. AMS, Providence (1994)
Singh, K.V.: Transcendental inverse eigenvalue problems in damage parameter estimation. Mech. Syst. Signal Process. 23, 1870–1883 (2009)
Singh, K.V., Ram, Y.M.: A transcendental inverse eigenvalue problem associated with longitudinal vibrations in rods. AIAA J. 44, 317–332 (2006)
Tao, G.W., Zhang, H.M., Chang, H.L., Choubey, B.: Inverse eigenvalue sensing in coupled micro/nano system. J. Microelectromech. Syst. 27, 886–895 (2018)
Toman, S., Pliva, J.: Multiplicity of solutions of the inverse secular problem. J. Mol. Spectrosc. 21, 362–371 (1966)
Tropp, J.A., Dhillon, I.S., Heath, R.W.: Finite-step algorithms for constructing optimal CDMA signature sequences. IEEE Trans. Inf. Theory 50, 2916–2921 (2004)
Wang, Z.B., Vong, S.W.: A Gauss-Newton-like method for inverse eigenvalue problems. Int. J. Comput. Math. 90, 1435–1447 (2013)
Wolf, M.M., Perez-Garcia, D.: The inverse eigenvalue problem for quantum channels. arXiv:1005.4545 (2010)
Xu, S.F.: An Introduction to Inverse Algebraic Eigenvalue Problems. Peking University Press, Beijing (1998)
Yao, T.T., Bai, Z.J., Zhao, Z., Ching, W.K.: A Riemannian Fletcher–Reeves conjugate gradient method for doubly stochastic inverse eigenvalue problems. SIAM J. Matrix Anal. Appl. 37, 215–234 (2016)
Zhao, Z., Bai, Z.J., Jin, X.Q.: A Riemannian Newton algorithm for nonlinear eigenvalue problems. SIAM J. Matrix Anal. Appl. 36, 752–774 (2015)
Zhao, Z., Bai, Z.J., Jin, X.Q.: A Riemannian inexact Newton-CG method for constructing a nonnegative matrix with prescribed realizable spectrum. Numer. Math. 140, 827–855 (2018)
Zhao, Z., Jin, X.Q., Bai, Z.J.: A geometric nonlinear conjugate gradient method for stochastic inverse eigenvalue problems. SIAM J. Numer. Anal. 54, 2015–2035 (2016)
Acknowledgements
We are very grateful to the editor and the referees for their valuable comments and suggestions, which have considerably improved this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Michiel E. Hochstenbach.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by NSFC Nos. 11701514, 11671337, 11601112. The research of Z. J. Bai was partially supported by the Fundamental Research Funds for the Central Universities (No. 20720180008). The research of X. Q. Jin was supported by the research grant MYRG2016-00077-FST from University of Macau.
Appendix A
Appendix A
In this appendix, we deduce (2.4) and (2.6). To derive the Riemannian differential of \(H:\mathscr {Z}\rightarrow \mathbb {SR}^{n\times n}\) defined by (2.2), we consider the following extended mapping
which is defined by
for all \((\mathbf {c}, Q, \varLambda )\in \mathbb {R}^{l} \times \mathbb {R}^{n\times n} \times \mathscr {D}(n-m)\), where \(\overline{\varLambda }\) is defined as in (2.1). Thus the map H is the restriction of \(\widetilde{H}\) from the Euclidean space \(\mathbb {R}^{l} \times \mathbb {R}^{n\times n} \times \mathscr {D}(n-m)\) to the Riemannian product manifold \(\mathscr {Z}\), i.e., \(H =\widetilde{H}|_{\mathscr {Z}}\).
Similar to [2, (3.17)], for any \((\varDelta \mathbf {c},\varDelta Q, \varDelta \varLambda ) \in T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\), one has
For a tangent vector \((\varDelta \mathbf {c},\varDelta Q, \varDelta \varLambda ) \in T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\), the matrix \(\varDelta QQ^T\) is skew-symmetric [2, (3.26)], i.e.,
By the definition of P in (2.5) we have
Using (2.1), (2.5), (A.1), (A.3), and (A.4) we have
where \(t\in {\mathbb {R}}\). Based on Proposition 2.5 in [16] and the above equality, we have
This, together with (A.2), yields
for all \((\mathbf {c}, Q, \varLambda )\in \mathscr {Z}\) and \((\varDelta \mathbf {c},\varDelta Q, \varDelta \varLambda ) \in T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\), and thus (2.4) holds.
Let \((\mathbf {c}, Q, \varLambda )\in \mathscr {Z}\). For the Riemannian differential \(\mathrm {D}H(\mathbf {c},Q,\varLambda )\) and its adjoint \((\mathrm {D}H(\mathbf {c},Q,\varLambda ))^*\) with respect to the Riemannian metric g, one has [2, p. 185],
for any \((\varDelta \mathbf {c},\varDelta Q, \varDelta \varLambda ) \in T_{(\mathbf {c},Q,\varLambda )}\mathscr {Z}\) and \(\varDelta Z \in T_{H(\mathbf {c},Q,\varLambda )}\mathbb {SR}^{n\times n}\). Using (3.36) in [2], the definition of the linear operator \(\mathbf {v}\) in (2.7), (A.5), and (A.6) we have
where \(\mathrm{skew}(A):=\frac{1}{2}(A-A^T)\). Thus,
for all \(\varDelta Z \in T_{H(\mathbf {c},Q,\varLambda )}\mathbb {SR}^{n\times n}\). This proves (2.6).
Rights and permissions
About this article

Cite this article
Yao, TT., Bai, ZJ., Jin, XQ. et al. A geometric Gauss–Newton method for least squares inverse eigenvalue problems. Bit Numer Math 60, 825–852 (2020). https://doi.org/10.1007/s10543-019-00798-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-019-00798-9