
Abstract
Behavioral disinhibition (BD) is a quantitative measure designed to capture the heritable variation encompassing risky and impulsive behaviors. As a result, BD represents an ideal target for discovering genetic loci that predispose individuals to a wide range of antisocial behaviors and substance misuse that together represent a large cost to society as a whole. Published genome-wide association studies (GWAS) have examined specific phenotypes that fall under the umbrella of BD (e.g. alcohol dependence, conduct disorder); however no GWAS has specifically examined the overall BD construct. We conducted a GWAS of BD using a sample of 1,901 adolescents over-selected for characteristics that define high BD, such as substance and antisocial behavior problems, finding no individual locus that surpassed genome-wide significance. Although no single SNP was significantly associated with BD, restricted maximum likelihood analysis estimated that 49.3 % of the variance in BD within the Caucasian sub-sample was accounted for by the genotyped SNPs (p = 0.06). Gene-based tests identified seven genes associated with BD (p ≤ 2.0 × 10−6). Although the current study was unable to identify specific SNPs or pathways with replicable effects on BD, the substantial sample variance that could be explained by all genotyped SNPs suggests that larger studies could successfully identify common variants associated with BD.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Behavioral disinhibition (BD) is a latent quantitative measure designed to capture common variation shared across many harmful or dangerous behaviors including substance problems, antisocial or criminal behavior, and novelty seeking (Young et al. 2000). In addition, 60–80 % of variation in BD is attributed to additive genetic effects, making BD more heritable than many of the individual component behaviors used to formulate the latent BD construct (Young et al. 2000; Krueger et al. 2002; Hicks et al. 2013). To date, genome-wide association studies (GWAS) have been restricted to such individual component behaviors of BD (McGue et al. 2013), including use or abuse of various substances (e.g. alcohol (Bierut et al. 2010; Edenberg et al. 2010; Frank et al. 2012; Gelernter et al. 2014a; Kapoor et al. 2013; Schumann et al. 2011; Treutlein et al. 2009; Wang et al. 2012), tobacco (Bierut et al. 2007; Tobacco and Genetics Consortium 2010; Liu et al. 2010a, b; Thorgeirsson et al. 2010), cannabis (Agrawal et al. 2011; Verweij et al. 2013), methamphetamine (Uhl et al. 2008), opioids (Gelernter et al. 2014b; Nielsen et al. 2010), and cocaine (Gelernter et al. 2014c)), conduct disorder (Dick et al. 2011), adult antisocial behavior (Tielbeek et al. 2012), and related personality constructs such as excitement seeking (Terracciano et al. 2011). Although certain behaviors, most notably tobacco use (Bierut et al. 2007; Tobacco and Genetics Consortium 2010; Liu et al. 2010a, b; Thorgeirsson et al. 2010), have identified robust associations with specific variants, many GWAS fail to identify individual loci with genome-wide significant effects. This suggests that much of the heritability underlying each trait is unlikely the result of a small number of variants with large effects, and will require larger sample sizes in order to identify variants with small effects (Lee et al. 2011). GWAS of other phenotypes have identified significant replicated effects when large enough samples sizes have been amassed to provide adequate statistical power to identify variants despite very small effect sizes (e.g., accounting for 0.1 % of the total variance, or less; Sullivan 2011; Rietveld et al. 2013).
Increasing sample sizes is only one of a number of ways to increase statistical power. Improved phenotypic assessment and modeling could also provide increased statistical power for studies conducted in more moderately sized samples, and particularly for phenotypes that are presumed to be continuously distributed in the population (van der Sluis et al. 2013). BD is a prime example in this context, as relevant quantitative differences in phenotypic severity are maintained between individuals, whereas a case–control approach is fairly insensitive to these differences. However, one issue with searching for specific genetic influences on many continuous phenotypes, such as BD, is that the most severe, clinically significant levels are relatively rare in the general population, as they are located on the extreme ends of the distribution. Ascertaining samples specifically for individuals with extreme phenotypes may improve our ability to detect small genetic effects by increasing the sample variance. Therefore, an ideal sample might be considered one that is enriched (and well-measured) for extreme BD characteristics.
We report here results and characterization of the initial GWAS from the Center on Antisocial Drug Dependence (CADD), an adolescent sample over-selected for severe BD characteristics. Any genetic effects on BD are potentially attributable to many (i.e., thousands of) variants, each with a very, very small effect. Incorporating methods for aggregating effects across multiple variants, such as gene- and pathway-based analyses, can identify promising causal biological systems beyond the significance of any single variant. In addition to SNP level association, the current study applied gene-based, pathway-based, and genome-wide approaches to characterize genetic influences on BD in a diverse, clinically-oversampled, thoroughly phenotyped sample. By supplementing a GWAS with several methods of aggregating genetic evidence across many potentially associated variants, we sought to generate novel insights into the potential genetic etiology of BD and identify promising candidates, either old or new, for future study.
Methods
Participants
Participants with genetic and relevant phenotypic data were ascertained from the CADD projects; full details of participant selection for inclusion in the GWAS sample are provided in the Supplemental materials. GWAS participants were drawn from several primary studies described elsewhere (Hartman et al. 2008, Petrill et al. 2003, Rhea et al. 2006; Stallings et al. 2005). The current sample of 1,901 unrelated adolescents was over-selected for adolescent BD, with half of the participants ascertained specifically from high-risk populations (i.e. recruited through substance abuse treatment, special schools, or involvement with the criminal justice system; see Supplement for additional criteria for clinical probands). CADD GWAS participants had an average age of 16.5 (SD = 1.4, range = 13.0–19.9), 28.9 % were female, and 37.3 % of participants reported non-Caucasian ancestry (primarily Hispanic or African; see Supplemental Table S1 for complete demographic statistics).
Phenotype
BD was defined as a composite measure of substance dependence vulnerability (assessed across 10 substances), novelty seeking, and conduct disorder symptoms. The BD phenotype has been previously examined within the CADD samples, including Young et al. (2000) demonstrating that the component measures have loadings ≥0.4 on a common, highly heritable BD latent factor, and linkage analyses by Stallings et al. (2003, 2005). A full description of construction of the BD phenotype is provided in the Supplement; Supplemental Fig. S1 shows the distribution of BD in the CADD GWAS sample. Briefly, principal component scores were normed to community-representative samples in CADD and applied to all CADD GWAS participants from both the community-representative (48.2 %) and high-risk samples (51.8 %). Average scores on the BD composite measure were 0.19 (SD = 1.2, range = −1.9 to 5.0) for the community-representative participants and 2.76 (SD = 1.2, range = −0.3 to 6.7) for the high-risk participants.
Genotyping
All participants were genotyped on the Affymetrix 6.0 platform (Affymetrix, Inc., Santa Clara CA), with a total of 696,388 autosomal SNPs available for analysis after quality control. Full details on processing and cleaning genotypes for the CADD GWAS sample is provided in the Supplement. Population stratification was examined by performing multidimensional scaling in PLINK (Purcell et al. 2007), in which ten ancestry dimensions were estimated. The first three dimensions notably captured genetic variation among individuals of self-reported African, Hispanic, and Asian ancestry, compared to a central (majority) node of individuals of self-reported European ancestry. Supplemental Fig. S2 illustrates the first three ancestry dimensions within the CADD GWAS sample (along with individuals’ self-reported ancestry).
Analyses
Genome-wide analysis was conducted as a linear regression of the additive effect of each SNP on BD in PLINK (Purcell et al. 2007). All autosomal SNPs that passed basic quality controls were tested for association with BD, and 10 ancestry dimensions were included as covariates. Age and sex were accounted for in the estimation of the BD phenotype. The criterion for individual SNP significance was set at p < 5 × 10−8.
Genome-wide data from the CADD GWAS sample were further characterized using genome-wide complex trait analysis (GCTA; Yang et al. 2011). GCTA allows us to estimate the proportion of variance in the phenotype that may be explained using all of the genotyped SNPs using restricted maximum likelihood (REML) analysis. While this method does not specifically identify any causal variants, it does estimate the total proportion of sample variance that may be explained by all of the genotyped SNPs.
Gene-based tests were conducted using VEGAS (Liu et al. 2010a, b), which aggregates evidence of association across all SNPs within a gene. A total of 16,094 autosomal genes were tested for association with BD in CADD, based on the primary GWAS results, with a multiple-testing-corrected significance threshold set at p < 3.1 × 10−6.
INRICH (Lee et al. 2012) was selected to conduct our pathway analyses as it is well-suited for testing both large (i.e., exploratory) and small (i.e., candidate) pathway sets. We took two, complementary approaches to pathway analysis: first, we sought to confirm previously proposed candidate gene pathways (Hodgkinson et al. 2008); second, we conducted an exploratory analysis aimed at identifying novel pathways involved in BD (The Gene Ontology Consortium 2000). Additional details of the pathway analysis methods are discussed in the Supplemental Materials.
Promising results from the pathway analysis of the CADD sample were followed up in two additional samples: the Minnesota Center for Twin and Family Research (MCTFR; N = 3,378), a community-based adolescent sample (McGue et al. 2013; Miller et al. 2012), and the Study of Addiction: Genes and Environment (SAGE; N = 3,988), a clinically over-selected study of addiction (Bierut et al. 2010; dbGaP study accession: phs000092.v1.p1). A phenotype similar to BD as defined in the CADD sample was available in the MCTFR sample (Hicks et al. 2011; McGue et al. 2013). The phenotype analysed in the SAGE sample was the average number of dependence symptoms for substances that each participant used. Full description of the MCTFR and SAGE samples is provided in the Supplement.
Results
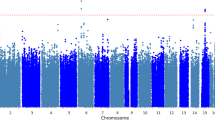
Figure 1 summarizes the GWAS results for BD in the over-selected CADD sample. No individual SNP reached genome-wide significance (p < 5 × 10−8), nor did any SNP reach genome-wide significance in the MCFTR or SAGE samples (see Supplemental Fig. S3 for QQ plots of the GWAS results from each study). Results from loci reaching p < 5.0 × 10−5 in CADD are summarized in Table 1 (full GWAS results are available from the first author on request). The most significant SNP in the CADD GWAS was rs7104461 (p = 5.8 × 10−6), an intergenic SNP on chromosome 11 for which there are no previously reported associated phenotypes. While this SNP was not genotyped in either the MCTFR or SAGE samples, it is in linkage disequilibium with rs341058 (r 2 = 1.0 in 1,000 Genomes Pilot 1 CEU sample, distance = 8,721 bp; Johnson et al. 2008), which was genotyped on both MCTFR and SAGE platforms and may serve as a proxy to compare results across samples. This proxy SNP was not associated with either adolescent BD in MCTFR (p = 0.30) or adult substance dependence symptoms in SAGE (p = 0.87).

Plot of −log10(p) from the CADD GWAS, arranged by chromosomal location. The top (dashed) horizontal line indicates genome-wide significance at p = 5 × 10−8; the lower (solid) line marks p = 5 × 10−5 (loci described in Table 1)
Whole-genome SNP-heritability was estimated with GCTA in the CADD sample. SNPs genotyped in the current study explained 27.8 % of the CADD sample variance in BD (SE = 0.15, p = 0.03). The point estimate of heritability remained fairly stable when the sample was restricted to individuals estimated to be <2.5 % identical-by-state (N = 1148, V(G)/Vp = 30.9 %, SE = 0.28, p = 0.10) or those individuals with only Caucasian ancestry (as determined by an examination of ancestry component plots, N = 1031, V(G)/Vp = 49.3 %, SE = 0.31, p = 0.06).
Gene-based association tests identified seven genes as significant after Bonferroni correction for testing >16,000 genes: MAGI2 (p < 1.0 × 10−6), NAV2 (p < 1.0 × 10−6), CACNA1C (p = 1.0 × 10−6), PCDH9 (p = 1.0 × 10−6), MYO16 (p = 1.0 × 10−6), IQCH (p = 2.0 × 10−6), DLGAP1 (p < 1.0 × 10−6). We examined overlap of these novel “candidate” genes derived from the CADD GWAS with results from MCTFR and SAGE as a single “pathway” (i.e., gene set) in INRICH (Lee et al. 2012). This allowed us to estimate whether specific genes identified in the CADD results overlapped with the low p value genomic regions (i.e., loci tagged at r 2 > 0.5 by a SNP reaching GWAS p < 5 × 10−3) in the MCTFR and SAGE results more than expected by chance. The CADD-identified gene set was not significant in analysis of either the MCTFR (0 regions overlapped genes identified in CADD, p = 1.0) or SAGE samples (6 regions overlapped genes identified in CADD, p = 0.14).
Supplemental Table S2 presents gene-based association test results for previously identified addiction candidate genes (Hodgkinson et al. 2008), none of which were significant after adjustment for multiple testing (minimum p = 1.4 × 10−3). Supplemental Table S3 gives results for each of the addiction candidate gene sets tested in CADD. None of the addiction candidate gene sets showed evidence of greater-than-chance overlap with low p value genomic regions in the CADD GWAS (minimum p = 5.0 × 10−1).
Promising pathways emerging from our exploratory pathway analysis were defined as those meeting nominal significance before correcting for multiple testing in CADD and either MCTFR or SAGE samples (Empirical p < 0.05). Two pathways met these criteria: visual perception (Empirical p CADD = 0.038, p MCTFR = 0.012, p SAGE = 0.22) and phosphatidylcholine biosynthetic process (Empirical p CADD = 0.039, p MCTFR = 1.0, p SAGE = 0.026). Neither pathway achieved marginal significance in any sample after correction for multiple testing (i.e., Corrected p < 0.10). Supplemental Table S4 provides results from all 72 pathways meeting Empirical p < 0.05 in CADD (from a total of 3,440 pathways tested) that were subsequently tested in the MCTFR and SAGE samples.
Discussion
No SNP was significantly associated with BD in the CADD GWAS. This is not surprising, given the relatively small sample. GWAS of psychiatric and behavioral phenotypes that have successfully identified and replicated individual effects of common SNPs have relied on very large samples (Rietveld et al. 2013; Ripke et al. 2013). Despite the lack of significance of any individual SNP, GCTA REML analysis estimated that 49.3 % (SE = 0.31, p = 0.06) of the Caucasian ancestry sub-sample variation in BD could be accounted for by all of the genotyped SNPs. Conversely, a similar study found no evidence of variance in early adolescent (12-year-old) non-substance behavioral problems being attributable to common variants (Trzaskowski et al. 2013). This may suggest qualitative differences between genetic effects on BD at different ages, an effect that has been reported from twin models of comorbidity between dependence on different substances (Vrieze et al. 2012), which is a marker of BD.
Gene-based tests identified seven genes associated with BD in the CADD sample. However, neither the genes nor pathways identified as marginally overrepresented in the CADD GWAS results showed evidence of replicable low-p values in either the MCTFR or SAGE samples. Taken together, these findings suggest that discoverable effects of common SNPs underlie the genetic architecture of BD, although better-powered studies are required to identify the associated loci.
The comparisons made between datasets must be considered in light of several limitations of the current study. There are substantial differences among the examined samples in terms of age (CADD and MCTFR represent adolescent data, while SAGE was comprised of adults), sex composition (MCTFR and SAGE are split evenly by sex, while CADD has an overrepresentation of males due to the sampling scheme), and diversity of ancestry (MCTFR is less diverse than either CADD or SAGE, which each have different representations of non-Caucasian ancestry groups). The sampling schemes of CADD and SAGE aimed to increase power to detect effects by oversampling extreme phenotype individuals, whereas the MCTFR study is closer to community-representative.
We sought to identify genetic influences on adolescent BD through a multifaceted approach. We initially characterized results from a standard GWAS by estimating the variance explained by common SNPs, and used gene- and pathway-based tests to identify potential novel candidate genes and pathways. Results from the estimation of sample variance explained by all genotyped SNPs and significant gene-based tests suggest there is a real genetic signal to be detected within the noise. However, the current sample is likely underpowered to detect realistic effect sizes of individual SNPs. Further, the lack of correspondence between pathway analyses in the CADD and replication samples may be due to limited power, or qualitative differences in the genetic effects on BD across different ages (adolescent versus adult) or sampling distributions (over-sampled for BD versus community-representative). Key to the search for causal genetic pathways underlying BD will be the availability of increasingly large, thoroughly phenotyped samples. Although the current analyses did not identify specific loci associated with BD, we demonstrate substantial heritability due to effects of common SNPs. Larger studies with appropriate phenotypes could well allow successful identification of common variants associated with BD.
References
Agrawal A, Lynskey MT, Hinrichs A et al (2011) A genome-wide association study of DSM-IV cannabis dependence. Addict Biol 16(3):514–518
Bierut LJ, Madden PA, Breslau N et al (2007) Novel genes identified in a high-density genome wide association study for nicotine dependence. Hum Mol Genet 16(1):24–35
Bierut LJ, Agrawal A, Bucholz KK et al (2010) A genome-wide association study of alcohol dependence. Proc Natl Acad Sci 107(11):5082–5087
Dick DM, Aliev F, Krueger RF et al (2011) Genome-wide association study of conduct disorder symptomatology. Mol Psychiatry 16(8):800–808
Edenberg HJ, Koller DL, Xuei X et al (2010) Genome-wide association study of alcohol dependence implicates a region on chromosome 11. Alcohol Clin Exp Res 34(5):840–852
Frank J, Cichon S, Treutlein J et al (2012) Genome-wide significant association between alcohol dependence and a variant in the ADH gene cluster. Addict Biol 17(1):171–180
Gelernter J, Kranzler HR, Sherva R et al (2014a) Genome-wide association study of alcohol dependence: significant findings in African-and European-Americans including novel risk loci. Mol Psychiatry 19:41–49
Gelernter J, Kranzler HR, Sherva R et al (2014b) Genome-wide association study of opioid dependence: multiple associations mapped to calcium and potassium pathways. Biol Psychiatry 76(1):66–74
Gelernter J, Sherva R, Koesterer R et al (2014c) Genome-wide association study of cocaine dependence and related traits: FAM53B identified as a risk gene. Mol Psychiatry 19(6):717–723
Hartman CA, Gelhorn H, Crowley TJ et al (2008) Item response theory analysis of DSM-IV cannabis abuse and dependence criteria in adolescents. J Am Acad Child Adolesc Psychiatry 47(2):165–173
Hicks BM, Schalet BD, Malone SM et al (2011) Psychometric and genetic architecture of substance use disorder and behavioral disinhibition measures for gene association studies. Behav Genet 41(4):459–475
Hicks BM, Foster KT, Iacono WG et al (2013) Genetic and environmental influences on the familial transmission of externalizing disorders in adoptive and twin offspring. JAMA Psychiatry 70(10):1076–1083
Hodgkinson CA, Yuan Q, Xu K et al (2008) Addictions biology: haplotype-based analysis for 130 candidate genes on a single array. Alcohol Alcohol 43(5):505–515
Johnson AD, Handsaker RE, Pulit SL et al (2008) SNAP: a web-based tool for identification and annotation of proxy SNPs using HapMap. Bioinformatics 24(24):2938–2939
Kapoor M, Wang JC, Wetherill L et al (2013) A meta-analysis of two genome-wide association studies to identify novel loci for maximum number of alcoholic drinks. Hum Genet 132(10):1141–1151
Krueger RF, Hicks BM, Patrick CJ et al (2002) Etiologic connections among substance dependence, antisocial behavior and personality: modeling the externalizing spectrum. J Abnorm Psychol 111(3):411
Lee SH, Wray NR, Goddard ME et al (2011) Estimating missing heritability for disease from genome-wide association studies. Am J Hum Genet 88(3):294–305
Lee PH, O’Dushlaine C, Thomas B et al (2012) INRICH: interval-based enrichment analysis for genome-wide association studies. Bioinformatics 28(13):1797–1799
Liu JZ, Mcrae AF, Nyholt DR et al (2010a) A versatile gene-based test for genome-wide association studies. Am J Hum Genet 87(1):139–145
Liu JZ, Tozzi F, Waterworth DM et al (2010b) Meta-analysis and imputation refines the association of 15q25 with smoking quantity. Nat Genet 42(5):436–440
McGue M, Zhang Y, Miller MB et al (2013) A genome-wide association study of behavioral disinhibition. Behav Genet 43(5):363–373 Behavioral disinhibition GWAS 17
Miller MB, Basu S, Cunningham J et al (2012) The Minnesota Center for Twin and Family Research genome-wide association study. Twin Res Hum Genet 15(6):767–774
Nielsen DA, Ji F, Yuferov V et al (2010) Genome-wide association study identifies genes that may contribute to risk for developing heroin addiction. Psychiatr Genet 20(5):207–214
Petrill S, Plomin R, DeFries JC, Hewitt JK (eds) (2003) Nature, nurture, and the transition to adolescence. Oxford University Press, New York
Purcell S, Neale B, Todd-Brown K et al (2007) PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet 81(3):559–575
Rhea SA, Gross AA, Haberstick BC et al (2006) Colorado twin registry. Twin Res Human Genet 9(06):941–949
Rietveld CA, Medland SE, Derringer J, Yang J, Esko T, Martin NW,… McMahon G (2013) GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science 340(6139): 1467–1471
Ripke S, O’Dushlaine C, Chambert K et al (2013) Genome-wide association analysis identifies 13 new risk loci for schizophrenia. Nat Genet 45(10):1150–1159
Schumann G, Coin LJ, Lourdusamy A et al (2011) Genome-wide association and genetic functional studies identify autism susceptibility candidate 2 gene (AUTS2) in the regulation of alcohol consumption. Proc Natl Acad Sci 108(17):7119–7124
Stallings MC, Corley RP, Dennehey B et al (2005) A genome-wide search for quantitative trait loci that influence antisocial drug dependence in adolescence. Arch Gen Psychiatry 62(9):1042–1051
Stallings MC, Corley RP, Hewitt JK et al (2003) A genome-wide search for quantitative trait loci influencing substance dependence vulnerability in adolescence. Drug Alcohol Depen 70(3):295–307
Sullivan P (2011) Don’t give up on GWAS. Mol Psychiatry 17(1):2–3
Terracciano A, Esko T, Sutin AR et al (2011) Meta-analysis of genome-wide association studies identifies common variants in CTNNA2 associated with excitement-seeking. Transl Psychiatry 1(10):e49
The Gene Ontology Consortium (2000) Gene ontology: tool for the unification of biology. Nat Genet 25(1):25–29
Thorgeirsson TE, Gudbjartsson DF, Surakka I et al (2010) Sequence variants at CHRNB3-CHRNA6 and CYP2A6 affect smoking behavior. Nat Genet 42(5):448–453
Tielbeek JJ, Medland SE, Benyamin B et al (2012) Unraveling the genetic etiology of adult antisocial behavior: a genome-wide association study. PLoS One 7(10):e45086
Tobacco and Genetics Consortium (2010) Genome-wide meta-analyses identify multiple loci associated with smoking behavior. Nat Genet 42(5):441–447
Treutlein J, Cichon S, Ridinger M et al (2009) Genome-wide association study of alcohol dependence. Arch Gen Psychiatry 66(7):773–784
Trzaskowski M, Dale PS, Plomin R (2013) No genetic influence for childhood behavior problems from DNA analysis. J Am Acad Child Adolesc Psychiatry 52(10):1048–1056
Uhl GR, Drgon T, Liu QR et al (2008) Genome-wide association for methamphetamine dependence: convergent results from 2 samples. Arch Gen Psychiatry 65(3):345–355
Van der Sluis S, Posthuma D, Nivard MG et al (2013) Power in GWAS: lifting the curse of the clinical cut-off. Mol Psychiatry 18:2–3
Verweij KJ, Vinkhuyzen AA, Benyamin B et al (2013) The genetic aetiology of cannabis use initiation: a meta-analysis of genome-wide association studies and a SNP-based heritability estimation. Addict Biol 18(5):846–850
Vrieze SI, Hicks BM, Iacono WG et al (2012) Decline in genetic influence on the co-occurrence of alcohol, marijuana, and nicotine dependence symptoms from age 14 to 29. Am J Psychiatry 169(10):1073–1081
Wang JC, Foroud T, Hinrichs AL et al (2012) A genome-wide association study of alcohol-dependence symptom counts in extended pedigrees identifies C15orf53. Mol Psychiatry 18(11):1218–1224
Yang J, Lee SH, Goddard ME et al (2011) GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet 88(1):76–82
Young SE, Stallings MC, Corley RP et al (2000) Genetic and environmental influences on behavioral disinhibition. Am J Med Genet 96(5):684–695
Acknowledgments
The Center on Antisocial Drug Dependence (CADD) data reported here were funded by grants from the National Institute on Drug Abuse (P60 DA011015, R01 DA012845, R01 DA021913, R01 DA021905). The Minnesota Center for Twin and Family Research (MCTFR) was supported in part by USPHS Grants from the National Institute on Alcohol Abuse and Alcoholism (AA09367 and AA11886), the National Institute on Drug Abuse (DA05147, DA13240, and DA024417), and the National Institute of Mental Health (MH066140). Funding support for the Study of Addiction: Genetics and Environment (SAGE) was provided through the NIH Genes, Environment and Health Initiative [GEI] (U01 HG004422). SAGE is one of the genome-wide association studies funded as part of the Gene Environment Association Studies (GENEVA) under GEI. Assistance with phenotype harmonization and genotype cleaning, as well as with general study coordination, was provided by the GENEVA Coordinating Center (U01 HG004446). Assistance with data cleaning was provided by the National Center for Biotechnology Information. Support for collection of datasets and samples was provided by the Collaborative Study on the Genetics of Alcoholism (COGA; U10 AA008401), the Collaborative Genetic Study of Nicotine Dependence (COGEND; P01 CA089392), and the Family Study of Cocaine Dependence (FSCD; R01 DA013423). Funding support for genotyping, which was performed at the Johns Hopkins University Center for Inherited Disease Research, was provided by the NIH GEI (U01HG004438), the National Institute on Alcohol Abuse and Alcoholism, the National Institute on Drug Abuse, and the NIH contract “High throughput genotyping for studying the genetic contributions to human disease” (HHSN268200782096C). The datasets used for the analyses described in this manuscript were obtained from dbGaP at http://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000092.v1.p1 through dbGaP accession number phs000092.v1.p. Jaime Derringer was supported by the National Institute of Mental Health (T32 MH016880).
Conflict of Interest
Jaime Derringer, Robin P. Corley, Brett C. Haberstick, Susan E. Young, Brittany A. Demmitt, Daniel P. Howrigan, Robert M. Kirkpatrick, William G. Iacono, Matt McGue, Matthew C. Keller, Sandra Brown, Susan Tapert, Christian J. Hopfer, Michael C. Stallings, Thomas J. Crowley, Soo Hyun Rhee, Ken Krauter, John K. Hewitt, and Matthew B. McQueen declare that they have no conflict of interest.
Human and Animal Rights and Informed Consent
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. Informed consent was obtained from all individual participants included in the study.
Author information
Authors and Affiliations
Corresponding author
Additional information
Edited by Sarah Medland.
Electronic Supplementary Material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Derringer, J., Corley, R.P., Haberstick, B.C. et al. Genome-Wide Association Study of Behavioral Disinhibition in a Selected Adolescent Sample. Behav Genet 45, 375–381 (2015). https://doi.org/10.1007/s10519-015-9705-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-015-9705-y