
Abstract
Structural damage detection is of very importance to improve reliability and safety of civil structures. A novel sensor data-driven structural damage detection method is proposed in this paper by combining continuous wavelet transform (CWT) with deep convolutional neural network (DCNN). In this method, time-frequency images are obtained by CWT from original one-dimensional sensor signals. And, DCNN is designed to mine structural damage features from the time-frequency images and distinguish different structural damage condition. The proposed method is carried out on three-story building structure dataset and steel frame dataset. The experimental results show that the proposed method has the high accuracy and robustness of the damage detection compared with other existing machine learning methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Civil structures have been subjected to various kinds of damage such as corrosion, fatigue, cracking, degradation, etc. It might accelerate the deterioration of their service functions and cause a major threat to public safety [1, 2]. Thus, health monitoring and regular assessment are essential for the civil structures. However, the effectiveness of traditional structural condition assessment is limited by regular personnel inspections, which cause the delay in damage detection and increase maintenance time and cost. It is urgently required for automatically estimating health conditions of the civil structures by using sensor networks and computer application systems. For this purpose, many researchers have focused on structural health monitoring (SHM) and structural damage detection (SDD) systems to periodically perform data acquisition, feature extraction, damage identification, and maintenance decision-making [3,4,5].
With the rapid improvement in computing power, machine learning (ML) algorithms have been widely used in the SDD systems. The ML algorithms are adopted to interpret available history data and gain knowledge from those, then make decisions or prediction on new data. In recent years, it has been proved that the ML methods are superior to traditional rule-based learning methods, especially in dealing with small sample data. For examples, support vector machine [6,7,8], ensemble algorithm [9] and Bayesian algorithm [10] are used for extracting sensitive features from vibration signals and evaluating the structural health condition. In addition, Rogers [11] and Wu [12] used unsupervised ML methods to monitor and evaluate the health status of civil structures. However, these classical ML algorithms have an obvious limitation that they are not good at dealing with massive and polluted data.
With the continuous increase of big data and the revolution of deep learning, deep learning methods have attracted wide attention and applied in many fields such as image classification [13,14,15], and natural language processing [16]. It is because the deep learning methods have the ability to perform automatic feature extraction from raw data [17, 18]. By adopting the deep learning methods, vision-based SSD methods are widely used in the engineering field. Recent investigations show that crack and corrosion detection methods based on image processing techniques with CNN are meticulous and superior than the ML methods [19,20,21]. Xue [22] and Gao [23] proposed the vision-based SSD methods localize and display the cracks and corrosions with very high accuracy. However, vision-based SDD methods have an obvious limitation that they cannot detect invisible structural damage. In actual civil structures, the joints of the structure and many other components are not easy inspected. Sensor-based SDD methods can potentially identify invisible structural damages [24, 25]. Sensor-based deep Bayesian belief network was proposed by Pan [26] to extract structural information and probabilistically determine structural conditions, which achieves good results. Abdel [27] and Zhang [28] proposed the structural damage identification method based on sensor data processing techniques with one-dimensional CNN, which can detect the small local structural rigidity and mass changes. However, the damage identification method based on one-dimensional CNN has poor performance for contaminated data, because it directly processes one-dimensional sensor signal, which may regard the contaminated information as fault information. Hence, many scholars have studied pre-processing methods for contaminated data to improve the accuracy of damage identification in noisy environments. For example,
Raich [29] adopted implicit redundant representation (IRR) genetic algorithm to solve the problems of damage detection in noise environment. Zhao [30] combined variational mode decomposition (VMD) and probabilistic principal component analysis (PPCA) to denoise the collected vibration signals from a test rig and then achieve signal feature extraction and fault classification with convolutional artificial neural network (CNN). However, the pre-processing methods for one-dimensional sensor signal with contaminated may eliminate the damage information, resulting in unsatisfactory damage detection results. Thus, it is highly demanded that an SDD method is converted sensor data into image data and used to identify invisible structural damages. Mousavi [31] and Zhao [32] designed SDD method based on Hilbert-Huang transform and artificial neural network to analyze the nonlinear structural response and identify structural damage condition. Tehrani [33] proposed SDD method based on short time fourier transform (STFT) to identify structural damage condition,which achieves good results. However, these methods mentioned above have some shortcomings. For instance, the STFT method is not suitable for analyzing non-stationary signals whose statistic characteristics vary with time, and HHT method has mode aliasing, end effects and stop conditions. Time frequency analysis method based on CWT can effectively solve the above shortcomings, owing that it is very suitable for non-stationary and noisy vibration signals. Fault diagnosis methods based on CWT-CNN [34, 35] are used for accurately diagnosing machinery fault in noisy environments. However, it is unclear whether this method can be widely used in civil structures and achieve high-precision identification of structural damage in noisy environments.
In this paper, a high precision and robust SSD method is proposed based on CWT-DCNN. In this method, CWT is introduced to convert one-dimensional sensor signal into time-frequency images, and the built DCNN model is trained to detect and locate damages. Noted that raw signal is directly transformed into time-frequency images without any pre-processing. Such a transformation provides highly redundant information and helps DCNN to analyze information hidden in the signals. Since DCNN has a strong capability of extracting hidden features from time-frequency images, the proposed method might achieve a high accuracy damage detection and positioning, despite the signals having noise and unrelated patterns. Finally, the proposed method is evaluated by a three-story building structure from LOS ALAMOS national laboratory [36] and a steel frame from Qatar University Grandstand Simulator (QUGS) [37]. The three-story building structure and steel frame are commonly used to evaluate machine learning-based SHM and SSD.
The main contributions of this paper are summarized as follows. (1) A novel sensor data-driven structural damage detection method is proposed by combining CWT with DCNN, which can directly process the sensor signal and accurately identify the structural damage condition. (2) The comprehensive experiments based on two structure equipment are conducted on explore the effectiveness of the proposed method. The results demonstrate that the proposed method might achieve a high accuracy damage detection and positioning, despite the signals having noise and unrelated patterns. Meanwhile, several existing SSD approaches built on ML algorithms and deep neural networks are selected for comprehensive analysis, and the results demonstrate the effectiveness and superiority of the proposed method.
The rest of the paper is organized as follows. Section 2 describes the proposed CWT-DCNN architecture in detail. Section 3 introduces structural damage detection method based on CWT-DCNN. Section 4 presents the evaluation of the proposed method using the three-story building structure dataset and steel frame dataset. Finally, Section 5 summarizes the proposed methods and potential topics for future research.
2 Proposed CWT-DCNN architecture
The architecture of the designed CWT-DCNN is shown in Fig. 1. It consists of thirteen layers, i.e., input layer, CWT layer, convolutional layers (Conv1, Conv2, Conv3, Conv4, Conv5), max pooling layers (MP1, MP2, MP3), fully connected (FC) layers, and classification layer (SFM). In this frame, raw sensor data are processed in the CWT layer. Representative features are extracted in the convolutional layers and the max pooling layers from the output of the CWT layer. The Batch normalization (BN) and Dropout are used to prevent model overfitting in the convolutional layers and the max pooling layers. Non-linear functions are adopted in the FC layers to fit the extracted features. The structural damage conditions are identified in the SFM layer.

Architecture of the CWT-DCNN
2.1 Continuous wavelet transform layer
The CWT is introduced to transform time-domain data into time-frequency image. Extraction steps of wavelet time-frequency images are shown in the Fig. 2. First of all, n consecutive time-domain data points are randomly sampled from the original signal with sliding window. Then, the CWT of the consecutive time-domain data \(s\left(t\right)\) is defined as:
where \(a\) and \(b\) represent control scaling and wavelet translation factor of the \(s\left(t\right)\), respectively. \(\psi \left(t\right)\) is wavelet basis function. The frequency distribution corresponding to the signal scale is obtained as:
where \({F}_{c}\) is the center frequency of the wavelet and describes the general characteristics of the wavelet. The \({f}_{s}\) is the sampling frequency of the raw signal, and \({F}_{a}\) is the actual frequency corresponding to the scale a. The coefficient matrix converted by CWT is transformed into time-frequency image. Finally, the unified time-frequency images with the size of 224*224 are inputted into DCNN.

Flowchart of time-frequency image extraction
2.2 Convolutional layer
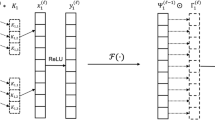
Convolutional operation is used to extract feature images by sliding on the image with convolution kernel. In this paper, time-frequency images inputted into the convolutional layer are defined as \({x}_{l}({r}_{l},{c}_{l})\), where \({r}_{l}\) and \({c}_{l}\) represents the length and width of the time-frequency images respectively. Output \({C}_{ln}\) of the convolutional layer is formulated as:
where \({W}^{\left(1\right)}\) and \({B}^{\left(1\right)}\) represent weight and bias, respectively. \(f(\cdot)\) represents activation function of nonlinear mapping. Actual size of feature image \({C}_{ln}\) is described as:
where \({K}_{C}\) is the number of convolution kernel, the \({r}_{s}\) and \({c}_{s}\) respectively represents the length and width of the convolution kernel. The \(p\) represents the edge extension parameter, and the\(s\) is the step size of the convolution kernel.
2.3 Pooling layer
After pooling layer, the dimension of output features and the number of parameters will increase, which makes the model easy to over fit and has low fault tolerance. Based on this, the pooling layer is used to reduce the dimensionality of output feature maps. Pooling operation is used to replace the output of a certain position in the network with the overall statistical characteristics of its neighboring outputs, which reduce parameters of the network structure and amount of calculation. In this paper, maximum pooling kernel is defined as \(P({r}_{p}\times {c}_{p})\), where \({r}_{p}\) and \({c}_{p}\) respectively represents the length and width of the maximum pooling kernel. The \(Cl(r\times c)\) is output of the convolutional layer. \({P}_{i}\) (\(i=\text{1,2},3\dots {K}_{p})\) are multiple feature images. The maximum pooling process is expressed as:
The output size of max pool layer is derived as:
where \({K}_{p}\) is the number of pooling kernel and p represents the edge extension parameter. s is the step size of the convolution kernel.
2.4 Fully-connected layer
The multiple neurons in the Fc layer are used to non-linearly fit its input from the MP3 layer. The connected operation is described as:
where u is the outputs of the MP3 layer, Y represents the outputs of FC layer such as FC1. The w and b denotes the weight and additive bias term respectively, and \(f(\cdot)\) is activation function. In this paper, the activation function of the FC layers is rectified linear unit function. In addition, dropout between FC layers is added to improve the generalization ability of the network and avoid overfitting of the network.
2.5 Classification layer
The structural damage degrees are identified in the SFM layer. Softmax is adopted in the SFM layer, which is used to solve the multi-classification problem. The calculation is given by
where \({Y}_{i}\) is the structural-state identification result, \({u}_{i}\) represents the outputs of FC2 layer. The Eq. (8) describes that probabilities of all predictive candidates are evaluated, and the candidate with the highest possibility is output as the final result.
3 Proposed CWT-DCNN based on structural damage detection method
A CWT-DCNN based SSD method is proposed by adopting CWT to convert one-dimensional sensor signal into time-frequency image, DCNN to mine structural damage features from the time-frequency images and distinguish different structural damage condition. Figure 3 shows the specific steps of structural damage detection. Firstly, the datasets are obtained from slicing with raw vibration sensor signal. The datasets are randomly divided into training datasets, verification datasets and testing datasets according to a certain proportion. Then, time-frequency images are obtained by CWT on training datasets, which are inputted into the DCNN model to continuously iterate and update the model parameters by the loss function and optimizer. The purpose of verification datasets is to prevent the DCNN model from overfitting and evaluate the quality of each training mode. Finally, identification performance and robustness of the CWT-DCNN model are evaluated on the testing datasets.

Flowchart of the proposed CWT-DCNN base on structural damage detection
In the training process of CWT-DCNN model, the one-dimensional vibration time domain signal is directly inputted into CWT layer, and time-frequency images are automatically extracted. The unified time-frequency images with the size of 224*224 are inputted into the convolution layers for convolution operation to extract the feature images (\({C}_{ln}\)). The Max pool layers selects representative features from the feature image (\({C}_{ln}\)) to reduce the dimension of the feature images. In order to prevent the model from overfitting, (BN) and dropout are added after the convolution layers and the max pooling layers. After five convolutions and three max pooling operations, all the neurons from the MP3 layer are connected in FC layers, and initial structural damage degree are identified in the SFM layer. Then, the model is iterated and updated by optimizer and loss function. The optimizer is used to continuously optimize the DCNN model parameters. Adam optimization used in the paper is configured as: learning rate = 0.0001, \({\beta }_{1}\)=0.9,\({\beta }_{2}\)=0.999, ϵ=10−8, and decay=0.001. The loss function is used to evaluate the training result and decide whether the training process stops. The CrossEntropyLoss function is used in the paper, which is expressed as:
where \({P}_{K}\) represents the true value, \({q}_{k}\) is the predicted value.
Finally, the completion of the model training process depends on whether the CWT-DCNN model achieve high identification accuracy and the loss error is the lowest. After the model training process, the testing datasets is used to evaluate the trained model. If the testing accuracy meets the requirements, the trained CWT-DCNN model can be applied to actual structural damage detection.
4 Experiment studies
The section uses two case to evaluate the effectiveness of the proposed method.
4.1 Case one: damage detection of building structure
4.1.1 Experimental setup and data description
The proposed CWT-DCNN model is validate by using a three-story building structure dataset from LOS ALAMOS national laboratory [36]. As shown in Fig. 4, the three-story building model is made of aluminum columns and plates connected by bolts, and the structure can move along the track in the x direction. Each layer of the structure passes through 4 aluminum columns (17.7 cm × 2.5 cm × 0.6 cm), and the upper and lower ends are connected to an aluminum plate (30.5 cm × 30.5 cm × 2.5 cm) to form a four-degree-of-freedom system. The change of the structural stiffness is added additional mass. Furthermore, the degree of nonlinear damage is adjusted by regulating the gap between the cantilever column and the buffer under the top layer of the structure.

Experiment setup of case one
Table 1 shows 17 different scenarios of three-story building structure. Each scenario is repeated ten times, and the four sensors recorded the response data of each testing. Due to the damage of the structure mainly caused by nonlinearity, the degree of structural damage is related to the gap between the cantilever column and the buffer [20]. Therefore, the 17 scenarios can be divided into six scenarios depending on the degree of structural damage, as listed in Table 2. In this experiment, in order to expand the number of data sets, four sensor data are used, and training samples is enhanced during the training process. Datasets are sliced with the window of 1024 points. 2280 samples are obtained from each scenario datasets. Then, the datasets are divided for training datasets, verification datasets and testing datasets according to the ratio of 80%:10%:10%, as listed in Table 2.
4.1.2 CWT-DCNN testing result
Raw one-dimensional signal that is set to a scale factor of 1024, is analyzed by CWT in the time-frequency domain. The 1024 × 1024 coefficient matrix is extracted by wavelet function from each acquired signal. Then, the coefficient matrix is converted to time-frequency image, and the time-frequency images are set as image size of 224 × 224. Figure 5 shows the process of extracting time-frequency images for six different structural damage condition, which are 10% damage, 20% damage, 30% damage, 40% damage and 50% damage. It can be seen from Fig. 5 that the time-frequency images of different structural damage condition are different, and the frequency fluctuation of the time-frequency image increases with the increase of damage degree. In this way, DCNN model can better identify different structural damage degree.

Time-frequency image transformation of six structural damage states
The detailed configuration of the applied DCNN model for structural damage degree detection is shown in Table 3. The five-fold cross-validation results of the three-story building structure dataset are shown in Table 4. In each iteration, the training accuracy is close to 100%, the verification accuracy is 99.802% on average and the testing accuracy is 99.795% on average. This result shows that the CWT-DCNN model is suitable for structural damage detection. The training history of Fold 1 is presented as an example in Fig. 6. Plotted are the accuracies of the training, testing and validation datasets in each epoch. The accuracies of validation and testing reached 90% after Epoch7. It is seen that CWT-DCNN model is trained at faster convergence speed and balance.

Training procedure of the CWT-DCNN in case one
Figure 7 presents the confusion matrix of the best of five trials. Seen from Fig. 7, the overall identification accuracy of six structural damage condition is 99.92%, error rate is 0.08%, and undamaged, 20% damage and 50% damage are 100%. While the 10% damage and 30% damage had wrong identification, but its accuracy are still over 99%. In addition, it can also be seen that there is no misidentification between undamage and damage, which is an important assessment standard for actual SSD.

State identification confusion matrix of the fold 1 in case one
4.1.3 Compared with other methods
The classical ML methods could extract sensitive features from sensor data to assess the structural damage degree. Table 5 shows the comparison of the identification accuracy between the proposed methods and existing ML methods and other deep neural networks. It should be seen that the proposed method achieves the higher identification performance than the existing methods including support vector machine (SVM), CWT-SVM, random forest, back propagation (BP), k-nearest neighbor (KNN), gaussian naive bayes (GaussianNB) and deep Bayesian Belief Network Learning proposed by Pan [27]. Therefore, this result also shows that the proposed method has high identification ability in civil structural damage degree.
In this case study, all experiment methods are performed on the same hardware and software environment and the same dataset. Table 6 shows the proposed method consumes more time than other ML methods in training time of 10 epochs and the testing time of one testing sample. This is mainly because time consuming mainly depends on the computer performance. If there are good computing resources, the consumption of time can be further shortened. On the contrary, more attention should be paid to the accuracy of structural damage identification, because this is related to the safety and reliability of the structure.
4.1.4 Effectiveness of the CWT-DCNN for structural uncertainties due to noise interferences
In practice, vibration signal contains inevitable noise by device instability or human errors. Therefore, it is very important to quantify the robustness of SDD applications in processing noisy data. For this purpose, varying degrees of Gaussian noise are added to the testing datasets. The proposed CWT-DCNN method is evaluated using noisy datasets. Figure 8 depicts how the structural damage identification accuracy evolves with respect to the noise amplitude. It can be seen that the proposed method maintains highly accurate results at low level of noise. The identification accuracy decreases with the increasing noise level. However, the identification ability between structural damage and structural undamage is more valued in practical SHM applications, while proposed method remain a high identification ability between structural damage and structural undamage with the increasing noise level. These results confirm that the proposed method has strong robustness and can be applied for data contaminated by actual environmental noise.

Evolution of identification accuracy on testing versus added-nosie level
4.2 Case two: damage detection of steel frame
4.2.1 Experimental setup and data description
In this case, the proposed CWT-DCNN model is validate by using a steel frame with 5 × 6 bolted joints from QUGS [37]. As shown in Fig. 9, the steel frame consists of 8 girders and 25 filler beams supported by 4 columns. The length of the 8 girders are 4.6 m, while the length of the 5 filler beams in the cantilevered portion is about 1 m and the length of the remaining 20 beams is 77 cm. In each experiment, acceleration signals were collected in the environment of white noise shaker excitation at a sampling frequency of 1024 Hz. The signals were recorded for 256 s, so that each signal contains 262,144 samples. The QUGS experiment consists of 31 structural scenarios, one of which is undamaged scenarios, and damage was introduced to joints 1 to 30 in the scenarios 2–31, respectively. The joint numbers are shown in the Fig. 9. In this experiment, 2000 samples are obtained by slicing with the window of 1024 points. Then, the datasets are divided into training datasets, verification datasets and testing datasets according to the ratio of 80%:10%:10%. The training datasets, verification datasets and testing datasets of each structural scenarios are 1600, 200, 200 samples respectively.

Experiment setup of case two
4.2.2 CWT-DCNN testing result
Five-fold cross-validation results in the QUGS dataset are shown in Table 7. In each iteration, the training accuracy is 100%, the verification accuracy is 99.794% on average and the testing accuracy is 99.610% on average. This result shows that the CWT-DCNN model is suitable for structural damage detection. In the Fig. 10, the label H represents undamage, and the labels D1 to D30 represent the damage joints 1 to 30 respectively. Seen from Fig. 10, the overall identification accuracy of 31 structural scenarios is 99.61%. It is also seen that there is no misidentification between undamage and damage, which is an important assessment standard for actual SSD.

Damage joints identification confusion matrix of the fold 1 in case two
4.2.3 Comparative analysis
Classical ML methods could extract sensitive features from sensor data to detect the structural damage joints. Table 8 shows the comparison of the identification accuracy between the proposed methods and existing ML methods. It is seen that the proposed method achieves the higher performance than the existing ML methods including (SVM), CWT-SVM, random forest, BP, KNN, GaussianNB. This result also indicates that the proposed method has high identification ability in civil structural joints damage.
4.2.4 Effectiveness of the CWT-DCNN for structural uncertainties due to noise interferences
Figure 11 depicts how the structural damage identification accuracy evolves with respect to the noise amplitude. It can be seen that the proposed method maintains highly accurate results at low level of noise. The identification accuracy decreases with the increasing noise level, but the identification accuracy has remained above 80%. These results confirm that the proposed method has strong robustness and can be applied for data contaminated by actual environmental noise.

Evolution of identification accuracy on testing versus added-nosie level
5 Conclusions and future work
This paper proposes a sensor data-driven structural damage detection method based on CWT-DCNN. The proposed method has been proved to have strong identification performance and robustness by the three-story building structure dataset from LOS ALAMOS national laboratory and the steel frame from QUGS. The two conclusions are drawn from the results. One is that the proposed CWT-DCNN method is suitable for structural damage level identification and structural joints damage identification. The other is that the proposed method has strong robustness and can be applied to actual structural damage detection.
This method also has some limitations. For example, this method needs to rely on a large number of lost damage data.
In future work, we will study a deep transfer learning method to promote the successful applications of damage identification of civil structures with unlabeled data.
References
Pedro P, Steiger R (2020) Structural health monitoring of timber structures – Review of available methods and case studies. Constr Build Mater 248:118528
Kralovec C, Schagerl M (2020) Review of structural ealth monitoring methods regarding a multi-Sensor approach for damage assessment of metal and composite structures. Sensors 20(3):826
Glisic B, Inaudi D (2007) Fibre optic methods for structural health monitoring. Wiley, Hoboken
Farrar C R, Worden K (2007) An introduction to structural health monitoring. Philos Trans R Soc A 365(1851):303–315
Santos A, Figueiredo E, Silva MFM, Salesa CS, Costa JCWA (2016) Machine learning algorithms for damage detection: kernel-based approaches. J Sound Vib 363:584–599
Hazarika B B, Gupta D (2020) Density-weighted support vector machines for binary class imbalance learning. Neural Comput Applic. https://doi.org/10.1007/s00521-020-05240-8
Li X, Yu W, Villegas S (2016) Structural health monitoring of building structures with online data mining methods. IEEE Syst J, 10(3):1–10
Hazarika B B, Gupta D, Berlin M (2020) Modeling suspended sediment load in a river using extreme learning machine and twin support vector regression with wavelet conjunction. Environ Earth Sci 79(10):234
Wu J, Guo P F, Cheng Y W, Zhu H P, Wang X B, Shao X Y (2020) Ensemble generalized multiclass support-vector-machine-based health evaluation of complex degradation systems. IEEE/ASME Trans Mechatron 25(5):2230–2240
Oh C K (2007) Bayesian learning for earthquake engineering applications and structural health monitoring. https://authors.library.caltech.edu/26563/
Rogers TJ, Worden K, Fuentes R, Dervilis N, Tygesen UT, Cross EJ (2018) A Bayesian non-parametric clustering approach for semi-supervised Structural Health Monitoring. Mech Syst Signal Process 119(MAR.15):100–119
Wu J, Hua K, Cheng Y, Zhu H, Wang Y (2019) Data-driven remaining useful life prediction via multiple sensor signals and deep long short-term memory neural network. ISA Trans 97:241–250
Srinivas U, Mousavi HS, Monga V, Hattel A, Jayarao B (2014) Simultaneous sparsity model for histopathological image representation and classification. IEEE Trans Med Imaging 33(5):1163–1179
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. IEEE, Las Vegas, pp 770–778
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. IEEE, Boston, pp 1–9
Luong M T, Pham H, Manning C D (2015) Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025
Wu J, Su Y, Cheng Y, Shao X, Deng C, Liu C (2018) Multi-sensor information fusion for remaining useful life prediction of machining tools by adaptive network based fuzzy inference system. Appl Soft Comput 68:13–23
Cheng Y, Zhu H, Wu J, Shao X (2018) Machine health monitoring using adaptive kernel spectral clustering and deep long short-term memory recurrent neural networks. IEEE Trans Industr Inf 15(2):987–997
LeCun Y, Bengio Y (2003) Convolutional networks for images, speech, and time series. In: The handbook of brain theory and neural networks, pp 276–79
Fan Z, Li C, Chen Y, Di Mascio P, Chen X, Zhu G, Loprencipe G (2020) Ensemble of deep convolutional neural networks for automatic pavement crack detection and measurement. Coatings 10(2):152
Cawley P, Adams RD (1979) The location of defects in structures from measurements of natural frequencies. J Strain Anal 14(2):49–57
Xue Y, Li Y (2018) A Fast Detection Method via Region-Based Fully Convolutional Neural Networks for Shield Tunnel Lining Defects. Computer‐Aided Civil and Infrastructure Engineering 33(4).
Gao Y, Mosalam KM (2018) Deep transfer learning for image-based structural damage recognition. Comput Aided Civ Inf Eng 33(9):748–768
Matarazzo TJ, Santi P, Pakzad SN, Carter K, Ratti C, Moaveni B, Osgood C, Jacob N (2018) Crowdsensing framework for monitoring bridge vibrations using moving smartphones. Proc IEEE 106(4):577–593
Adeli H, Jiang X (2008) Intelligent infrastructure: Neural networks, wavelets, and chaos theory for intelligent transportation systems and smart structures. CRC Press, Boca Raton
Pan H, Gui G, Lin Z, Yan C (2018) Deep BBN learning for health assessment toward decision-making on structures under uncertainties. KSCE J Civ Eng 22(3):928–940
Abdel JO, Avci O, Kiranyaz S, Gabbouj M, Inman DJ (2017) Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J Sound Vib 388:154–170
Zhang Y, Miyamori Y, Mikami S, Saito T (2019) Vibration-based structural state identification by a 1‐dimensional convolutional neural network. Comput Aided Civ Inf Eng 34(9):822–839
Raich AM, Liszkai T (2003) Benefits of implicit redundant genetic algorithms for structural damage detection in noisy environments. Genetic and evolutionary computation - GECCO 2003, genetic and evolutionary computation conference, Chicago, IL, USA, July 12–16, 2003. Proceedings, Part II. DBLP
Zhao W, Hua C, Dong D, Ouyang H (2019) A novel method for identifying crack and shaft misalignment faults in rotor systems under noisy environments based on CNN. Sensors 19(23):5158
Mousavi AA, Zhang C, Masri SF, Gholipour G (2020) Structural damage localization and quantification based on a CEEMDAN hilbert transform neural network approach: a model steel truss bridge case study. Sensors 20(5):1271
Zhao Z, Liu C, Li Y, Li Y, Wang J, Lin B-S, Li J (2019) Noise rejection for wearable ECGs using modified frequency slice wavelet transform and convolutional neural networks. IEEE Access 7:34060–34067
Tehrani HA, Bakhshi A, Akhavat M (2019) An effective approach to structural damage localization in flexural members based on generalized S-transform. Sci Iran 26(6):3125–3139
Gou L, Li H, Zheng H, Li H, Pei X (2020) Aeroengine control system sensor fault diagnosis based on CWT and CNN. Math Probl Eng 2020. https://doi.org/10.1155/2020/5357146
Liu Q, Huang C (2019) A fault diagnosis method based on transfer convolutional neural networks. IEEE Access 7:171423–171430
Figueiredo E, Park G, Figueiras J, Farrar C, Worden K (2009) Structural health monitoring algorithm comparisons using standard data sets. Technical report, Los Alamos National Laboratory (LANL), Los Alamos
Abdel JO, Avci O, Kiranyaz MS, Boashash B, Sodano H, Inman DJ (2018) 1-D CNNs for structural damage detection: Verification on a structural health monitoring benchmark data. Neurocomputing 275:1308–1317
Acknowledgements
The work was supported by the National Natural Science Foundation of China under the Grant No.51875225 and the 18th batch of graduate student innovation fund of Huazhong University of Science and Technology No. 2020yjsCXCY059.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chen, Z., Wang, Y., Wu, J. et al. Sensor data-driven structural damage detection based on deep convolutional neural networks and continuous wavelet transform. Appl Intell 51, 5598–5609 (2021). https://doi.org/10.1007/s10489-020-02092-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-020-02092-6