
Abstract
In this paper, we discuss the index tracking strategy using mathematical programming. First, we use a non-linear programming formulation for the index tracking problem, considering a limited number of assets. Since the problem is difficult to be solved in reasonable time by commercial mathematical packages, we apply a hybrid solution approach, combining mathematical programming and genetic algorithm. We show the efficiency of the proposed approach comparing the results with optimal solutions, with previous developed methods, and from real-world market indexes. The computational experiments focus on Ibovespa (the most important Brazilian market index), but we also present results for consolidated markets such as S&P 100 (USA), FTSE 100 (UK) and DAX (Germany). The proposed framework shows its ability to obtain very good results (gaps from the optimal solution smaller than 5 % in 8 min of CPU time) even for a highly volatile index from a developing country.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Index tracking (index fund) is a passive investment strategy that seeks to replicate the performance of a market index. This strategy can be used, for example, to form an ETF (Exchange-Traded Fund—a security that represents an index fund, and which, in recent years, has become popular in Brazil) or to reproduce a market indicator such as inflation (rather than following a stock index). The decision of an investor in choosing a passive investment fund is based on the efficient markets hypothesis proposed by Fama (1970) which was also discussed, for example, by Frino and Gallagher (2001) and Fama and French (2010). When forming an index fund, the first choice would be to produce an exact replica of the index. However, the disadvantage of this strategy is that it leads to portfolios with large quantities of stocks, thereby generating a larger number of transactions and higher costs (Barro and Canestrelli 2009; Canakgoz and Beasley 2009). Thus, to reduce transaction and management costs, index tracking funds commonly limit the amount of assets in the portfolio as discussed by Maringer and Oyewumi (2007), Murray and Shek (2012) and Scozzari et al. (2013)—just to cite a few.
In the contemporary literature, various methods were adopted in attempting to solve the index tracking (IT) problem, such as optimization (Konno and Wijayanayake 2001), simulation and optimization (Consiglio and Zenios 2001), heuristics (Beasley et al. 2003; Oh et al. 2005; Maringer and Oyewumi 2007; Jeurissen and van den Berg 2008; Guastaroba and Speranza 2012; Scozzari et al. 2013), cointegration (Alexander and Dimitriu 2005; Dunis and Ho 2005) and quadratic programming combined with fundamental analysis for asset selection (Jansen and van Dijk 2002; Coleman et al. 2006). Although these models present interesting ideas, they were developed and tested oriented to mature markets, such as in the US, Japan, and in some countries of Europe, where the volatility is relatively lower compared to developing markets. This paper introduces an attempt to understand the performance of these index tracking methods in a developing country, specifically, the Brazilian stock market.
In general, index funds limit the number of assets in the portfolio, increasing the concentration risks. Adding higher concentration risks to markets that are not mature might demand new features of the index tracking model. For instance, in the year 2013, a company called OGX weighted more than 4 % of the most important Brazilian stock index,Footnote 1 the Ibovespa. This same company filed for Chapter 11 in the year 2014. This simple example shows the risks of concentration in a developing country. Furthermore, during periods of increased market volatility, it would be appropriate to conduct several tests to support decision-making in relation to rebalancing the portfolio, towards establishing whether it is better for the new portfolio to have fewer, or slightly more stocks based on tracking forecasts. Again, this demands a rapid analysis to update the index tracking portfolio. Thus, a method that can process information in a short period of time gives flexibility in a high volatile environment in which rebalancing might be more frequent. Moreover, faster computational methods have an increasing importance in the era of higher frequency trading (Gencay et al. 2001; Aldridge 2009). There is no reason to doubt the use of index tracking for higher frequency trading in the near future. In summary, although there is a vast literature on the application of mathematical programming to the index tracking problem, the requirements and difficulties involved in developing country markets were neglected by the current methods and techniques.
We apply a mathematical model aiming at minimizing the mean squared difference between return of a portfolio and an index (tracking error minimization) with a limited number of assets in the portfolio. As the objective is to solve this problem in a short processing time and for markets with different levels of volatility, we developed a hybrid approach, combining mathematical programming and genetic algorithm (GA) methods. Since the choice of the initial generation directly affects the performance and the convergence process of the GA, fundamental aspects when dealing with highly volatile markets, we designed a simple, but effective initial solution generator for both speeding up and enhance the solution process of our hybrid method.
We demonstrate the effectiveness and efficiency of the developed approach by adopting the Brazilian Ibovespa index as central reference, with a sample of 67 assets for the period January 2009 to July 2012. Our central goal is to form portfolios containing up to 5 and 10 assets with a CPU time of less than 10 min and solutions with a maximum gap from the optimal solution of around 10 %—in line with the results presented in Beasley et al. (2003). Thus, this study is an extension of Sant’Anna et al. (2014), in which it was demonstrated the impossibility of forming portfolios containing 20 assets (for this exactly same data sample) with optimization times shorter than 1 h and gaps smaller than 10 %. We also apply the method to the S&P 100 (USA), FTSE 100 (UK) and DAX (Germany) to verify the method performance when applied to less volatile markets. Tests were performed with out-of-sample intervals of 20, 60, 120 and 240 business days (basically monthly, quarterly, semi-annual and annual rebalancing). Finally, to provide evidence of the flexibility of the method, we discuss an exercise in which the S&P 100 and FTSE 100 are tracked using just assets traded in the Brazilian market. Based on the results obtained (gaps from the optimal solution under 5 % in 8 min of CPU time) even for highly volatile indexes, we can conclude that our developed method suits both markets with lower volatility (which is the case of the S&P 100, FTSE 100 and DAX) and with higher volatility (which happens specially in stock markets of emerging countries, such as the Brazilian), being a very competitive method to solve the index tracking problem.
The contribution of this paper is twofold. On the one hand, we contribute to the solution of the index tracking problem, offering a hybrid method that solves this problem with efficiency and efficacy, without requiring prior knowledge from the index being tracked. On the other hand, the empirical testing also presents innovations. The method was tested and applied in an uncommon market and tracking exercises. Overall, we developed a framework that is able to efficiently generate portfolios that closely follow the behavior of market indexes with different volatility patterns.
This paper is organized as follows. Section 2 presents a brief literature review on index tracking, emphasizing the contributions of our developed method to the current literature. In Sect. 3, we introduce the mathematical formulation of the developed model. Section 4 describes with details the developed solution approach. Section 5 presents the experiments carried out and the computational analysis of the hybrid solution approach. Finally, Sect. 6 concludes the paper and points out further research on the topic.
2 Literature review
Index tracking optimization has attracted the attention of several researchers in the area of operations research and computational finance. The initial research works were mainly directed to formal mathematical formulations of the problem. Konno and Wijayanayake (2001) developed a non-linear programming model for the problem. Consiglio and Zenios (2001) were the first authors to develop a hybrid model, employing simulation and optimization, to follow a composite index of the international bond market. Gaivoronski et al. (2005) discussed different approaches for index tracking with transaction costs constraints and control of the amount of assets in the portfolios. These authors demonstrated that the tracking error is strongly influenced by the amount of assets used and the length of the out-of-sample intervals. Alexander and Dimitriu (2005) and Dunis and Ho (2005) applied a statistical cointegration index tracking method, arguing that it tends to form more stable portfolios over time, with quarterly rebalancing periods providing the best results. Jansen and van Dijk (2002) and Coleman et al. (2006) applied initially fundamental analysis methods to select the assets that will compose each portfolio (i.e. portfolio composition is exogenous to the optimization), then, a quadratic programming modeling is performed.
The importance of using heuristic approaches for portfolio optimization problems with larger samples and cardinality constraints can be noticed in a number of heuristics’ studies. Derigs and Nickel (2004) used a heuristic method defined as 2-phase Simulated Annealing approach for the index tracking problem. Maringer and Oyewumi (2007), Krink et al. (2009), and Scozzari et al. (2013) focused on a heuristic approach, the so-called Differential Evolution. These authors employed quadratic integer optimization models with constraint on the amount of assets in the portfolios. Also, Krink et al. (2009) and Scozzari et al. (2013) centered their efforts on dealing with specific trading constraints for European markets (UCITS constraints). Gilli and Schumann (2012) described the use of several heuristics with emphasis on Threshold Accepting.
Angelelli et al. (2012) and Guastaroba and Speranza (2012) combined linear integer programming and a heuristic framework, the so-called Kernel Search, for index tracking. These articles used databases with a total of eight indexes, some of them were employed by Beasley et al. (2003), and samples comprising up to 2151 assets to compose portfolios with a maximum of 90 assets.
In a very relevant contribution to the index tracking problem, Beasley et al. (2003) developed a general formulation for the problem and used GA to solve it. An index tracking formulation is presented using constraints on the portfolio maximum number of assets, transaction costs, and rebalancing control. Their solution method is based on “population heuristic” which takes into account the complexity of the problem and the need for rapid responses. Tests were carried out using five benchmarks, namely Hang Seng Index (Hong Kong), DAX (Germany), FTSE (UK), S&P 100 (USA), and Nikkei (Japan), all from developed countries. Since then, evolutionary heuristics and GA have been applied by several authors (Oh et al. 2005; Maringer and Oyewumi 2007; Jeurissen and van den Berg 2008; Ruiz-Torrubiano and Suárez 2009).
Oh et al. (2005) developed a two-phase index tracking algorithm based on GA. The algorithm’s first step is to select, based on the firms’ indicators, the assets that will be part of the chosen portfolio. Then, the selected assets are used to minimize the objective function. A limitation of this study is that it requires extra information such as trading volume, market capitalization and weight of the industries in the portfolio, not only assets and index returns. Jeurissen and van den Berg (2008) and Ruiz-Torrubiano and Suárez (2009) developed hybrid methods, combining non-linear programming and GA. Ruiz-Torrubiano and Suárez (2009) assessed the performance of the hybrid method on the benchmark problems described in Beasley et al. (2003). Although good results were obtained for real world problems, the method presented some convergence problems when the number of assets in the universe was high.
In terms of contributions, we can start pointing out our developed method additions to the literature. We designed a hybrid solution method, combining genetic algorithm and non-linear programming modeling, in the same direction as proposed by Jeurissen and van den Berg (2008) and Ruiz-Torrubiano and Suárez (2009). However, our study presents a different way of measuring the index tracking in comparison with the former research, without the need of estimating the covariance matrix of the portfolio, a quite complex task (Filomena and Lejeune 2012). Our study is also, regarding some aspects, more ambitious than the model studied by Ruiz-Torrubiano and Suárez (2009), because it considers a much wider experimental setting, including comparisons with optimal solutions, which is not the case in the aforementioned paper. An extra contribution to the literature is the inclusion of Kernel Search ideas to our method. The initial candidate solution is obtained by a special designed procedure, as discussed by Angelelli et al. (2012) and Guastaroba and Speranza (2012), in opposite to the randomly generated method (Beasley et al. 2003; Ruiz-Torrubiano and Suárez 2009), and the fundamental variables based method (Oh et al. 2005) applied in the literature on index tracking. Furthermore, we contribute by finding near optimal solutions requiring very short CPU times. As we have discussed, this might be important not only in a high-frequency trading environment (Gencay et al. 2001; Aldridge 2009) but also in developing markets in which volatility may present high variations during a short period of time. The quality of the heuristic solutions are compared to optimal solutions obtained from CPLEX, a well-known commercial mathematical package.
Another set of contributions is related to the empirical tests. We targeted our efforts on an index tracking environment barely explored by the operations research community: the Brazilian market. To show that our method is not market specific, we also experimented our model on the S&P 100, FTSE 100 and DAX. Given that our method does not need the tracking assets to be in the benchmark portfolio, we examined the tracking of the S&P 100 and FTSE 100 with just Brazilian stocks and the US dollar. This exercise is quite relevant, since it is common for a country to forbid the buying of assets from other countries, due to strict legislation. This tracking exercise across different markets was discussed but not presented by Beasley et al. (2003). Furthermore, acknowledging the differences not only on the models, but also on the data, we provided a rough comparison with the results presented by Beasley et al. (2003) and Guastaroba and Speranza (2012) for the S&P 100, FTSE 100 and DAX. This should not be taken as a strict comparison, but rather a validation process, in which results from previous studies are used to give an idea of our model tracking error performance. The data used in our experiments is available on-line for future comparisons.Footnote 2
3 Model
In this section, we present the optimization model. Before describing the model, we need to present the following notation:
-
\(r_{it}=\) daily return of asset i at time t;
-
\(R_{t}=\) daily return of the index at time t;
-
\(t=\) time (each trading day);
-
\(T=\) total of trading in-sample days;
-
\(N=\) set of assets in the sample;
-
\(K=\) threshold amount of assets in the portfolio;
-
\(\vartheta =\) minimum error between the portfolio and index at each t;
-
\(\theta =\) maximum error between the portfolio and index at each t.
Equations (1) and (2) show, respectively, how the values of \(R_t\) and \(r_{it}\) are computed based on the market database (in general, comprised of the index and assets’ average daily returns), as follows:
Considering this set of parameters, we developed a model based on the objective function described in Gaivoronski et al. (2005), a well-known reference for the index tracking problem. The central goal is to minimize the average tracking error (TE) of the portfolio over all considered in-sample periods, defined in the objective function as the variance of the difference between the returns from the portfolio relative to the index. There are two decision variables. Let \(x_i\) be a continuous variable, indicating the weight of asset \(i \in N\) in the portfolio (that is, x represents the composition of the portfolio). Let \(z_i\) be a binary decision variable, with \(z_i =1\) if the asset i is included in portfolio, and \(z_i =0\) otherwise. The index tracking problem can be formulated as a non-linear mixed-integer programming model as follows:
Model NLMIP(N, K):
The objective function (3) seeks to minimize the difference between the variance of the portfolio’s and the index’s returns. Constraints (4) and (5) restrict the difference in return between the portfolio and the index to a minimum value and a maximum value at each time/moment t (parameters \(\vartheta \) and \(\theta \)); the purpose of both constraints is to avoid tracking error peaks over the in-sample period. Constraint (6) states that 100 % of the wealth available should be allocated. Together, constraints (7) and (8) define the maximum number of assets in the portfolio (parameter K). Constraints (9) and (10) define the range of the decision variables.
Coleman et al. (2006) showed that the tracking error minimization problem, with a restriction on the total number of assets, is NP-hard. Since for high volatility markets this problem should not be solved quickly, we developed an heuristic method to solve the problem.
4 Heuristic method
As the proposed non-linear mixed-integer program is not likely to be solvable in a reasonable time for instances of real-world size, we propose a heuristic solution method. The heuristic decomposes the problem into two intertwined subproblems as follows: (1) To define a subset \(Z = \{z \in N| \, |Z| = K\}\) of assets that will compose the portfolio; and (2) To define the weight of each asset \(x_i, i \in Z\) to form a valid portfolio. The first problem is solved using a GA. The second one is solved using a non-linear programming model with only continuous variables, embedded into the GA. The next sections described with details the developed heuristic.
4.1 The genetic algorithm
The genetic algorithm in our heuristic approach has the objective of selecting K assets of the set N of total assets. We use a natural, compact and efficient encoding. Each chromosome corresponds to a binary vector I with N positions. Each gene position \(I[i] =1\) represents that the asset i is in the portfolio, e.g., asset \(i \in Z\), otherwise \(I[i]=0\). Given the encoding technique, the genetic algorithm typically consists of an initial population, genetic operations and fitness evaluation. These elements are presented below.
4.1.1 Initial population
The choice of the initial generation directly affects the performance and the convergence process of the GA. Algorithm 1 presents the specially designed routine to provide an initial population for the GA, considering the specificities (objectives and constraints) of the index tracking problem.

This routine is quite fast, since model NLP is a relaxed version of model NLMIP, without the constraints related to the amount of assets—i.e. without constraints (7), (8) and (10)—therefore containing only continuous variables. The routine is dependent on a new parameter, counter L, that specifies the number of additional assets to be considered in a portfolio of size K to introduce diversity in the initial population, avoiding an initial population that would lead the GA to a local optimum, and resulting in the algorithm stagnation. The value of this parameter is determined based on experimentation. High values would improve the initial population, but it will require extra CPU time. Initial experiments suggest values in the interval [2, 4], depending on the number of assets in the set.
4.1.2 Genetic operators
Two genetic operators were applied in our heuristic, namely crossover and mutation. These operators are responsible for introducing diversity in the space of solutions, creating a new generation at each iteration of the GA.
The main genetic operator in our implementation is crossover. In this operator, two individuals (parents) are reproduced based on the parameter crossover rate, that defines the probability that these individuals can be selected to mate. Offspring are produced following the 1-point order crossover procedure (Jeurissen and van den Berg 2008). For this, one cut-off point is randomly set, defining a boundary for a series of copying operations. The crossover operator creates offspring that preserve the order and position of symbols in a subsequence of one parent, delimited by the cut-off point, while preserving the remaining symbols from the second parent. Figure 1 illustrates how this operator works. From two individuals, 1 and 2, individual 3 is formed with an initial piece of individual 1 and an end piece of individual 2 (dashed line), and individual 4 is formed with the initial part of individual 2 and the end part of individual 1.

Crossover illustration
The resulting individuals generated by the crossover operator can have a number of assets \(\sum _{i} I[i] \ne K\), that make this specific individual unacceptable. A feasibility routine was developed to avoid such situation. In case of an incorrect total amount, some positions are randomly changed. For instance, in portfolios consisting of 5 assets: if the individual has six positions equal to 1, one of them will be randomly selected and changed to 0, so that the portfolio has 5 assets. Analogue operations are carried out for individuals with smaller number of assets. The feasibility routine also takes care of repetitive individuals, keeping the population as diverse as possible.
The other GA operator implemented was mutation. Since all individuals suffering mutations are validated, the procedure is quite simple. Each individual has a set of positions altered from 0 to 1, and another set altered from 1 to 0, keeping the individual with \(\sum _{i} I[i] = K\). The changed positions are randomly set. Single and double mutations were implemented. In double mutations, four genes are changed, not just two. Parameter \(\textit{Num}\_\textit{Mut}\) defines the option for single (\(\textit{Num}\_\textit{Mut}= 1\)) or double mutation (\(\textit{Num}\_\textit{Mut} = 2\)).
4.1.3 Fitness evaluation
Given a population of individuals, we need to determine a fitness value for each individual, defining its potential to remains in the population into the generation. The tracking error \(TE = \frac{1}{T} \sum _{t=1}^{T^{}}[\sum _{i \in N}x_{i}r_{it}-R_{t}]^2\) (Eq. 3) would be the natural fitness value of each solution. However, each individual has only the information of which assets may compose a portfolio, not the required weights (\(x_{i}\)), necessary to compute \(\textit{TE}\). To define the assets’ weights, for each portfolio, model NLP (3)–(6) and (9) is used. Next section describes how this model is connected with the GA.
4.2 Algorithm summary
Algorithm 2 presents an overview of the hybrid heuristic for the index tracking problem.

In order to completely define a portfolio, the heuristic combines GA and non-linear mathematical programming. As stated before, the GA is responsible for finding the assets in the future portfolio, applying genetic operator, while the non-linear programming defines the weight of each asset (defined by the GA) in the portfolio. For each individual k at the current population (initial individuals plus the new individual generated through crossover and mutation), the fitness k is determined by solving a relaxed version of model NLMIP(K, N), in which all binary variables are considered implicitly as parameters rather than decision variables. This relaxed version solves the problem NLP (3)–(6) and (9) over set Z(k), that contains only the assets of individual k, obtaining the assets’ weights for each portfolio (\(x_i, i \in Z\)) and its correspondent fitness value (the result of the objective function). Although model NLP(Z) is non-linear, the current commercial mathematical packages are able to solve this model using very low CPU times due to the reduced number of continuous decision variables and the absence of an integer constraint. As we are using a minimization problem, the smaller the fitness value, the better the individual. It should be noticed that, even though we set K assets to compose each individual, the optimal portfolio might have less than K assets, since the optimization requires \(x_i \ge 0\).
After a single iteration of the algorithm finishes, the population in the next generation suffers the elite strategy in order to keep the fixed number of the population. This strategy selects the P individuals with the smallest fitness.
5 Computational experiments
The tests were performed using an Intel Core i7-3770 @ 3.40GHz computer with 8GB RAM. The solution approach was coded with C++ programming language using IBM ILOG CPLEX version 12.6 as the commercial solver. As noted above, this paper proposes to extend the results obtained in Sant’Anna et al. (2014), in which portfolios to track the Ibovespa index were formed with 40, 30 and 20 assets from the same sample of 67 assets that composed the Ibovespa and that was used in this paper. The results obtained on that occasion demonstrated not only the quality of the optimization in terms of tracking but also the possibility of using it in a commercial environment by comparing the results with a Brazilian ETF market asset (BOVA11). The main idea in this study was to form smaller portfolios, generating benefits in terms of operating costs without diminishing the quality of solutions.
Section 5.1 describes the experimental settings. In Sect. 5.2, we perform a validation process, through rough comparison, due to different data set, with results reported in the literature. In Sect. 5.3, we present the main results obtained with the heuristic for the Ibovespa, verifying the quality of the solutions in terms of their gap responses. Finally, in Sect. 5.4, we perform additional tests aiming to emulate foreign indexes using only Brazilian assets, in such a way to explore the flexibility of our method.
5.1 Database and the description of the tests
For the Ibovespa, the sample consisted of 67 assets out of 69 that were quoted on the Ibovespa index from May to August 2012. For the S&P 100, the sample consisted of 97 assets. For the DAX index, we used 30 assets, and for the FTSE 100, we used 96 assets. Historical prices for Ibovespa and S&P 100 were obtained using Economatica database; historical prices for DAX and FTSE 100 were obtained from Bloomberg database. Each set of assets contains 871 daily stock price observations, adjusted for dividends, stock splits, etc.—therefore, we have 870 observations of daily returns. For the Ibovespa, price range goes from Jan 2009 to July 2012; for the remainder three indexes, price range is from Jan 2009 to June 2012.
For the tests, we adopted \(T=150\) (in-sample period), which corresponds to the use of historical prices of 150 trading days for the optimization (range of 7–8 months), to form a portfolio that will be further employed to estimate the behavior of the market index in the following days. This is in accordance with Gaivoronski et al. (2005) who recommended longer in-sample intervals in order to form more stable portfolios. Each formed portfolio had its return projected on the n subsequent trading days. In these projections, n is equal to 20, 60, 120 and 240 (i.e. monthly, quarterly, semi-annual and annual rebalancing). Thus, to form the first portfolio with \(n=60\), for instance, we used the data in the interval \(1\le t\le 150\), and the portfolio was projected on the interval \(151\le t\le 210\). The second portfolio will be formed with data from \(61\le t\le 210\), and the portfolio was projected in the interval \(211\le t\le 270\), and so on. Overall, 36 portfolios were formed for \(n=20\); 12 for \(n=60\); 6 for \(n=120\); and 3 for \(n=240\). Considering \(T=150\), the projection of the portfolios in rolling horizon started in Aug/2009 for all tested indexes, while the full projections finished in July/2012 for Ibovespa and in June/2012 for S&P 100, FTSE 100 and DAX.
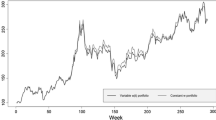
As an illustration, Fig. 2 presents the cumulative returns for the Ibovespa and the S&P 100 from Jan 2009 to July 2012. It should be noticed the difference in the volatility between Ibovespa and S&P 100, which emphasizes our goal of using the proposed solution method to solve the index tracking problem in several markets, with different volatility patterns.

Cumulated returns of S&P 100 and Ibovespa, from January 2009 to July 2012
The objective of the heuristic was to form portfolios containing 5 and 10 assets for the Ibovespa, and portfolios with 10 assets for the S&P 100, FTSE 100 and DAX indexes. Based on Beasley et al. (2003) and Oh et al. (2005), the runtime of the algorithm was defined at around 5 min (specifically between 4.5 and 5.5 min), while we expect to get answers with an average gap of below 10 %—this is the runtime for Initial_Test and Tests 1 and 2 described in Table 1. Subsequently, the time was increased to around 8 min (specifically between 7.5 and 8.5 min)—runtime for Test 3 also described in Table 1—in order to obtain solutions with a gap of less than 5 % (which is a standard gap used in other portfolio optimization studies, such as Filomena and Lejeune 2014).
Table 1 describes the four different tests that were performed (Initial_Test and Tests 1, 2 and 3) and their respective parameters. Initial_Test is the base scenario with a computational time of around 5 min (runtime strictly between 4.5 and 5.5 min, as mentioned above). In Tests 1 and 2, parameters P and \(\textit{Num}\_\textit{Iteration}\) were jointly changed and the computational time remained within 5 min. For Test 3, parameter P was maintained within the same value as in Initial_Test and the parameter \(\textit{Num}\_\textit{Iteration}\) was increased, therefore the computational time was increased and set to around 8 min (strictly between 7.5 and 8.5 min). The Mutation Rate and \(\textit{Num}\_\textit{Mut}\) parameters were randomly set in Initial_Test and then changed, being increased in Test 2 as an attempt to form portfolios with greater diversity among individuals.
For the optimization model, \(\vartheta \) and \(\theta \) were defined to be equal in magnitude, only changing their sign. The values were maintained at \(\vartheta =-0.01\) and \(\theta =0.01\) (i.e., 1 % in module). This was the smaller interval we could find. For smaller intervals between these parameters, no solution was found for some portfolios. For the tests across different markets that involved Ibovespa, S&P 100 and FTSE 100 (which will be further explained), \(\vartheta \) and \(\theta \) were altered to 5 % in module, since the model could not be solved with smaller values. We have adopted crossover rate of 100 % in all experiments, so ensuring the generation of a larger amount of new individuals at each iteration, seeking to avoid local minimum points. For all tests carried out, counter L (required for generating the initial population) was set to 2. The use of higher values did not have a significant impact in the results for the market indexes involved in the experiments.
5.2 Validation
The performance of the developed heuristic was evaluated comparing the results with previous methods described in the literature. In order to evaluate these performances, we use the same tracking error definition from Beasley et al. (2003) and Guastaroba and Speranza (2012) as follows:
where \(r_{t}^{p} = \sum _{i \in N} x_{i}r_{it}\) is the return of portfolio p at period t.
Since we formed six portfolios for semiannual rebalancing interval, and three portfolios for annual rebalancing, the tracking errors for our tests, presented in Tables 2, 3, 5 and 6, correspond to the average \({\textit{TE}}^{B}\) of the six (or three) portfolios.
Initially, we ran the developed heuristic towards obtaining the projection of the selected portfolios considering semiannual and annual rebalancing using the S&P 100, FTSE 100 and DAX indexes. As an illustration, Fig. 3 compares the performance of the selected portfolios using the S&P 100 index and annual rebalancing interval. The tracking error was, in general, good, with the model emulating quite closely the market index during the whole out-of-sample period. We can only notice small tracking errors in two periods, in which the difference between the cumulative returns from the portfolio and the index reached \(-6.5\) percentage points (Oct 10, 2010) and 5.3 percentage points (March 14, 2012).

S&P 100—Test 3: forecast for annual rebalancing
Next, we performed a predictive validation (Borenstein 1998) with previous reported results in the literature. We selected the research works of Beasley et al. (2003) and Guastaroba and Speranza (2012) as references. They used the S&P 100, FTSE 100 and DAX indexes, forming portfolios with 10 assets. While in Beasley et al. (2003) and Guastaroba and Speranza (2012), the DAX sample was composed by 85 stocks, our sample contained only 30 assets, due to structural changes in the index over time. For these validation experiments, we employed the parametrization defined in Test 3 (see Table 1), situation in which the heuristic obtained the best results in previous tests (as described in Sect. 5.3). It is important to highlight that, since we do not employ the same databases from the aforementioned studies, this is just a rough comparison presented as a validation of our algorithm. Table 2 succinctly presents the experimental settings and average \({\textit{TE}}^{B}\) values computed by the three research works using DAX, FTSE 100 and S&P 100 indexes.
From the obtained results in Table 2, we can notice that the \({\textit{TE}}^{B}\) values slightly decrease as the rebalancing intervals become larger for DAX, FTSE 100 and S&P 100. Comparing our results with Beasley et al. (2003) and Guastaroba and Speranza (2012), we obtained smaller \({\textit{TE}}^{B}\) values for all analyzed indexes. Using semiannual rebalancing, we reduced the average \({\textit{TE}}^{B}\) for the DAX, FTSE 100 and S&P 100 indexes by factors of 9.40, 4.48, and 4.35, respectively. Using annual rebalancing, the reduction factors were 12.57, 5.88, and 6.14, respectively. Particularly for the DAX index, these were expected results, since our sample size for this index was smaller as presented in Table 2. Based on the obtained results, our heuristic was considered a valid and competitive method for the index tracking problem, considering market indexes from developed countries.
5.3 Case study 1: Ibovespa market index
Table 3 shows the results of the application of Initial_Test parametrization (see Table 1) in the Ibovespa market index, in terms of the \({\textit{TE}}^{B}\) and the monthly turnover of the portfolios. The average error decreases as the rebalancing interval is extended, a counterintuitive result. Nevertheless, average monthly turnover decreases with larger rebalancing intervals, as expected.
Figure 4 shows the forecast for the Ibovespa tracking with the portfolios with 5 and 10 assets (results for the Initial_Test parametrization) for an out-of-the-sample interval of 120 business days (semi-annual rebalancing). We can observe that the portfolios’ curves are relatively close to the index’s curve, with the portfolio with 10 assets being the closest (in accordance with what is seen in Table 3) for the 120-period interval: average tracking error and standard deviation are lower for portfolios with 10 rather than 5 assets.
In order to analyze the quality of the solutions of the heuristic for Ibovespa, we opted to check the gap of the solutions obtained, considering optimal solutions obtained by CPLEX, a well-known commercial mathematical package. For this purpose, we adopted a 20-period rebalancing interval, in which we formed a total of 36 portfolios with 5 assets and 36 ones with 10 assets. To check the gap, we randomly selected one third of the 36 portfolios obtained (for each type of portfolio). Gaps from the optimal solutions were calculated using gap \(=\) \((\textit{OF}_{H}/\textit{OF}_{O})-1\), where \(\textit{OF}_{H}\) is the heuristic solution, and \(\textit{OF}_{O}\) is the optimal solution offered by CPLEX (Guastaroba and Speranza 2012).
Table 4 shows the average gap for each of the parametrizations described in Table 1. As already mentioned, runtimes for Initial_Test and Tests 1 and 2 are around 5 min, while the runtime for Test 3 is around 8 min. In order to obtain the optimal solutions for each of the 24 portfolios randomly selected (12 portfolios with 5 assets, and another 12 with 10 assets), CPLEX required on average 7 h of CPU time for each portfolio, reaching more than 10 hours in some cases. Surprisingly, better results were found with a smaller number of assets in the portfolio, using our method. This fact might be consequence of the Ibovespa volatility or the in-sample chosen periods. Since GA is a stochastic experimental method, the solution found is highly dependent on experiments and the set of random variables generated in our heuristic approach. Therefore, further experimentation may be required towards a conclusive explanation for this counter-intuitive behavior. Nevertheless, it is possible to point out some interesting aspects captured by the conducted experiments as follows.

Ibovespa—Initial_Test: forecast for semi-annual rebalancing
In the case of 10 assets, the gaps were larger in the Initial_Test; however, the average value remained at 7.68 %, with a minimum gap of only 3 %. The gap was above 10 % for only 2 of the 12 tested portfolios (maximum gap 17.58 %). In the case of portfolios with 5 assets, we obtained an average gap of only 2.44 %. Furthermore, the algorithm provided optimal solutions in 7 of the 12 test cases. Although the maximum gap found was 15.1 %, there was only one portfolio with a gap bigger than 10 %.
For portfolios with 5 assets, using settings defined in Tests 1 and 2, changes in the parameters did not significantly influenced the solutions provided by the algorithm. The average, maximum and standard deviation values of the gaps increased in Tests 1 and 2, which tends to imply larger tracking errors. Thus, we observed an advantage in the Initial_Test results, which suggests that the use of a larger population tends to produce better results. Test 3 outperformed all other parametrization settings. This result was expected, since a higher CPU time was offered to this situation. The average gap decreased to only 1.05 %, with a maximum gap below 5 %, and the optimal solution was obtained in 8 out of the 12 test cases.
For 10-asset portfolios, in relation to the Initial_Test parametrization, the average gap varied in contrasting directions in Tests 1 and 2. In Test 1, the average gap increased; while in Test 2, the average gap decreased. However, there was an increase in the standard deviation of the errors. Thus, we concluded that these altered parameters did not significantly influence the heuristic results. Test 3 also obtained the best results for 10-asset portfolios. The average gap was only 3.77 %, with a maximum gap below 10 %; that is, all the 12 generated portfolios had a gap below 10 %, and the heuristic provided optimal solution for 1 of the 12 test cases. We observed again that a small increase in processing time is able to have a significant impact on the solutions.
Table 5 presents the results applying the developed heuristic for the Ibovespa index, considering analogue experimental conditions described in Sect. 5.2 and semiannual and annual rebalancing intervals. The main difference is in the higher relation \(\frac{C}{N}\), since Ibovespa has a smaller number of assets in its portfolio relative to FTSE 100 and S&P 100. Analyzing the results for our heuristic method, we can see a rather higher tracking error for the Ibovespa index than for the S&P 100. These are expected results given that the former presents a higher volatility than the latter.
However, considering that the gaps of the solutions of the algorithm indicate that these solutions are at least close to the optimal responses, we can conclude that it is rarely possible to conduct tracking of the Ibovespa index specially using portfolios of only 5 assets (at least considering longer rebalancing intervals). Intuitively, tracking an index with only 5 assets generates higher concentration risks. Any abnormal behavior in one of this 5 assets should create great impact in the portfolio. Also, we can see that the error for the Ibovespa index increases considerably from 10 to 5 assets. For 10 assets, we can compare the Ibovespa results with those obtained for markets with lower volatility, such as the S&P, and the FTSE 100 (see Table 2). This is a significant result, considering the volatility of the Ibovespa index.
5.4 Case study 2: emulating other indexes using stocks in the Brazilian market
Finally, we formalized two tests for index tracking across different markets. To do so, we opted to use Brazilian assets (that compose the Ibovespa sample) to follow FTSE 100 and S&P 100 indexes. From an economic viewpoint, the possibility of following a foreign index (from a mature market) using Brazilian assets (an example of emerging and more unstable market) should be considered important not only as a possibility to emulate assets not locally available but also as a hedge operation. Through the use of a portfolio capable of tracking a mature market, the investor is able to diversify the risks of the market in which he/she is inserted.
Computational tests were performed using the 67 assets that compose the Brazilian sample plus the US Dollar currency exchange quotation. The US Dollar price series was extracted from Economatica (the same database in which we obtained stock prices series for the assets that compose the Ibovespa). The inclusion of the US Dollar in our sample is relevant since we are now attempting to track foreign indexes. We could have used another currency, like the Sterling Pound, specially to help with the FTSE tracking. However, differently from the US Dollar, there is no structured and liquid market for the Sterling Pound in Brazil. Thus, the US Dollar was selected not only by being the currency in which the S&P 100 is quoted, but also as a way of connecting Brazil and its risks (country and currency risks) to the rest of the world.
In order to perform this experiment, we need to introduce the following small changes in model NLMIP(N,K), to allow not only long, but also short positions in the portfolio: (1) we eliminated constraints (9), towards accepting short positions in our portfolio; and (2) we must consider the absolute value of \(x_i\) in constraint (8), replacing this constraint by \(|x_{i}|\le z_{i}, \forall i \in N\). The latter alteration was a relevant practical adjustment, allowing our model to achieve better tracking results specially in periods in which Ibovespa and FTSE 100/S&P 100 are moving in opposite directions. The new formulation of model NLMIP(N,K) was then used in Algorithms 1 and 2.
Table 6 presents the results for the tests performed using assets in Ibovespa to track S&P 100 (“Ibovespa-S&P 100”) and FTSE 100 (“Ibovespa-FTSE 100”), considering semiannual and annual rebalancing. The results for both indexes were very similar, with a slight better average \({\textit{TE}}^{B}\) for the FTSE 100. As in previous sections, longer rebalancing intervals resulted in smaller TE values.
Analyzing the results for both indexes, larger average \({\textit{TE}}^{B}\) values for both semiannual and annual rebalancing periods were obtained in comparison with the results presented in Table 2. This was an expected result, given the high volatility discrepancy between Ibovespa and S&P 100/FTSE 100 indexes (see Fig. 2 for an illustration). In addition, it seems reasonable to accept that a practical ETF composed by Brazilian stocks aiming to track a foreign index should necessarily accept larger tracking error values over time. Therefore, we consider the results obtained in both tests quite promising.
6 Conclusions
In this study, we applied an index tracking model with controlled number of assets to several market indexes, with different volatility patterns. Considering the tight constraint on the amount of assets to constitute the portfolios, this problem has already been proved to be an NP-hard problem. As a consequence, we presented a hybrid heuristic approach to solve the problem, combining genetic algorithm and non-linear mathematical programming method.
Initially, we validated our method, using results from benchmark methods described in Beasley et al. (2003) and Guastaroba and Speranza (2012) with respect to S&P 100, FTSE 100, and DAX indexes. The obtained results demonstrated that our method is competitive with these aforementioned studies, giving the different computational settings of the performed experiments. Next, we applied the heuristic approach for the Ibovespa. The central objectives of forming portfolios containing 5 and 10 assets with solutions gaps below 10 %, and processing times of about 5 min were achieved. Also, by increasing the time to about 8 min, it was possible to obtain responses with an average gap below 5 % for both 5 and 10-asset portfolios, thus providing strong evidence to suggest that the heuristic provides good quality solutions. With the heuristic, it was possible to form portfolios combining a small number of assets, short-length processing times, and average gap values below 10 %, comparing with optimal solutions obtained by CPLEX. Also, with a slightly longer processing time, about 8 min, the average gap obtained was below 5 %.
In practice, the set of financial analysts would run the heuristic several times in one day, with different parametrizations and data scenarios, towards setting up the position of the new portfolio, especially in situations involving abrupt market movements. We consider that 8 min is still an appropriate time for real-world environments. Obviously, processing times above 8 min should lead to higher quality answers in terms of gap. However, new tests (with higher computational time) were not performed since 8 min were enough to obtain solutions with average gap below 5 %, as initially expected.
Furthermore, we performed tests in an attempt to employ index tracking across different markets. The obtained results were quite promising, emphasizing the flexibility of our method. The developed solution approach was able to make it possible to emulate FTSE 100 and S&P 100 indexes using Brazilian stocks.
Summarizing the experimental results, we can consider the results of the heuristic quite satisfactory. We got near-optimal responses with a computational time of about 5 min for problems that would require several processing hours to generate optimal solutions. The results of the experiments also confirmed that the heuristic has fulfilled the proposed objectives both for high and low volatile market indexes. Actually, the developed method is quite competitive with previous related methods for mature market indexes, considering simultaneously efficiency and efficacy, with the advantage of being tested and validated for less stable, and therefore, more volatile market indexes. As a consequence, we believe that our method can be applied with success to other developing markets in Latin America, Africa, and Asia.
Future research proceeds to expand the range of the application of the method to other market indexes, including multi-market ones, and to improve the effectiveness of the heuristic, introducing more sophisticated techniques in the GA, such as the use of specifically designed penalty functions to cope with the index tracking problem constraints, increasing the efficiency of the search algorithm used for optimization.
Notes
Newspaper: Valor Economico, August 2013: http://www.valor.com.br/financas/3235752/ogx-e-acao-que-mais-ganha-peso-na-nova-carteira-do-ibovespa.
References
Aldridge, I. (2009). High-frequency trading: A practical guide to algorithmic strategies and trading systems (Vol. 459). Hoboken: Wiley.
Alexander, C., & Dimitriu, A. (2005). Indexing and statistical arbitrage: Tracking error or cointegration? The Journal of Portfolio Management, 31(2), 50–63.
Angelelli, E., Mansini, R., & Speranza, M. G. (2012). Kernel search: A new heuristic framework for portfolio selection. Computational Optimization and Applications, 51(1), 345–361.
Barro, D., & Canestrelli, E. (2009). Tracking error: A multistage portfolio model. Annals of Operations Research, 165(1), 47–66.
Beasley, J. E., Meade, N., & Chang, T. J. (2003). An evolutionary heuristic for the index tracking problem. European Journal of Operational Research, 148(3), 621–643.
Borenstein, D. (1998). Towards a practical method to validate decision support systems. Decision Support Systems, 23(3), 227–239.
Canakgoz, N. A., & Beasley, J. E. (2009). Mixed-integer programming approaches for index tracking and enhanced indexation. European Journal of Operational Research, 196, 384–399.
Coleman, T. F., Li, Y., & Henniger, J. (2006). Minimizing tracking error while restricting the number of assets. Journal of Risk, 8(4), 33–56.
Consiglio, A., & Zenios, S. A. (2001). Integrated simulation and optimization models for tracking international fixed income indices. Mathematical Programming, 89, 311–339.
Derigs, U., & Nickel, N. H. (2004). On a local-search heuristic for a class of tracking error minimization problems in portfolio management. Annals of Operations Research, 131(1–4), 45–77.
Dunis, C. L., & Ho, R. (2005). Cointegration portfolios of european equities for index tracking and market neutral strategies. Journal of Asset Management, 6(1), 33–52.
Fama, E. (1970). Efficient capital markets: A review of theory and empirical work. The Journal of Finance, 25, 383–417.
Fama, E., & French, K. (2010). Luck versus skill in the cross-section of mutual fund returns. The Journal of Finance, 65(5), 1915–1947.
Filomena, T. P., & Lejeune, M. A. (2012). Stochastic portfolio optimization with proportional transaction costs: Convex reformulations and computational experiments. Operations Research Letters, 40, 212–217.
Filomena, T. P., & Lejeune, M. A. (2014). Warm-start heuristic for stochastic portfolio optimization with fixed and proportional transaction costs. Journal of Optimization Theory and Applications, 161, 308–329.
Frino, A., & Gallagher, D. R. (2001). Tracking s&p 500 index funds. The Journal of Portfolio Management, 28, 44–55.
Gaivoronski, A. A., Krylov, S., & van der Wijst, N. (2005). Optimal portfolio selection and dynamic benchmark tracking. European Journal of Operational Research, 163, 115–131.
Gencay, R., Dacorogna, M., Muller, U. A., Pictet, O., & Olsen, R. (2001). An introduction to high-frequency finance. New York: Academic Press.
Gilli, M., & Schumann, E. (2012). Heuristic optimisation in financial modelling. Annals of Operations Research, 193(1), 129–158.
Guastaroba, G., & Speranza, M. G. (2012). Kernel search: An application to the index tracking problem. European Journal of Operational Research, 217, 54–68.
Jansen, R., & van Dijk, R. (2002). Optimal benchmark tracking with small portfolios. The Journal of Portfolio Management, 28(2), 33–39.
Jeurissen, R., & van den Berg, J. (2008). Optimized index tracking using a hybrid genetic algorithm. In IEEE congress on evolutionary computation, 2008 (CEC 2008, IEEE world congress on computational intelligence) (pp. 2327–2334).
Konno, H., & Wijayanayake, A. (2001). Minimal cost index tracking under nonlinear transactions costs and minimal transactions unit constraints. International Journal of Theoretical and Applied Finance, 4, 939–958.
Krink, T., Mittnik, S., & Paterlini, S. (2009). Differential evolution and combinatorial search for constrained index-tracking. Annals of Operations Research, 172(1), 153–176.
Maringer, D., & Oyewumi, O. (2007). Index tracking with constrained portfolios. Intelligent Systems in Accounting, Finance and Management, 15, 57–71.
Murray, W., & Shek, H. (2012). A local relaxation method for the cardinality constrained portfolio optimization problem. Computational Optimization and Applications, 53(3), 681–709.
Oh, K. J., Kim, T. Y., & Min, S. (2005). Using genetic algorithm to support portfolio optimization for index fund management. Expert Systems with Applications, 28, 371–379.
Ruiz-Torrubiano, R., & Suárez, A. (2009). A hybrid optimization approach to index tracking. Annals of Operations Research, 166(1), 57–71.
Sant’Anna, L. R., Filomena, T. P., & Borenstein, D. (2014). Index tracking with control on the number of assets. Brazilian Review of Finance (in Portuguese), 12(1), 89–119.
Scozzari, A., Tardella, F., Paterlini, S., & Krink, T. (2013). Exact and heuristic approaches for the index tracking problem with UCITS constraints. Annals of Operations Research, 205, 235–250.
Acknowledgments
The authors thank the two anonymous referees and the associate editor for their valuable comments and suggestions that greatly improved the quality of the paper. This research was funded by the following Brazilian Research Agencies: CAPES, CNPq, and FAPERGS; and Senescyt, Ecuador.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sant’Anna, L.R., Filomena, T.P., Guedes, P.C. et al. Index tracking with controlled number of assets using a hybrid heuristic combining genetic algorithm and non-linear programming. Ann Oper Res 258, 849–867 (2017). https://doi.org/10.1007/s10479-016-2111-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-016-2111-x