
Abstract
Magnetic Tunnel Junction (MTJ) is an important device to store the non-volatile. This MTJ device overcomes the disadvantages of CMOS technology by reducing the leakage power. Also, it stores the data in magnet domain. Non Volatile combinational circuits are nonvolatile memory elements, which distributes over a logic-circuit plane and expected to realize both the ultra-low-power and reduced interconnection delay. The existing Spin Orbit Torque- Magnetic Tunnel Junction method is used to store data with higher density, cost benefits, endurance and Non-Volatility. But it has some limitations, such as high current density needed for writing can infrequently damage the MTJ barrier, achieving reliable reading without making a difference remains a challenge. More constraints limit the designer to attain higher speed with reliable MRAM architectures, because the operations of writing and reading share the same path (via the junction). To overcome these limitations, an innovative nonvolatile combinational circuit depending on Spin Transfer Torque (STT) with perpendicular Magnetic Tunnel Junction (STT-PMTJ) is proposed in this manuscript for fast data storage in real time applications. Here, the nonvolatile combinational circuits are Spin Transfer Torque and Spin Orbit Torque. The proposed method gives higher reliability and the lower resistive writing path acts high-speed with energy-efficient WRITE operation with the help of Read and Write Parallel Switching (RWPS). The RWPS circuit is designed using Spin Orbit Torque (SOT) logic. The RWPS-PMTJ device used to maximize the robustness of entire structure and the noise is apparently reduced. The performance of the proposed method is compared with other existing methods, such as STT-MTJ, SOT-MRAM. The experimental results shows that the proposed RWPS-PMTJ method is efficiently reduced write delay by 64% compared to the STT switching, it also exhibits 61% faster read access with full swing eventually eliminating the setup time requirement. It enables the design of a new era of In-memory computing circuits to meet the challenges in the design of memory-based computation logic circuits. The AND logic gate and Full Adder (FA) circuits are implemented using Cadence virtuoso 45 nm technology.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
MTJ is a vital device to store non-volatile, where it overcomes the disadvantages of CMOS technology by reducing leakage power. It stores data in magnet domain [1]. The important application of MTJ is Magnetic Random Access Memory (MRAM), Hard Disk Drive read heads and memory mapping [2,3,4,5]. The perpendicular MTJ has high Tunnel Magneto Resistance (TMR), high thermal stability, energy-efficient and low switching current compared to the In-plane MTJ (IMTJ) and Tilted MTJ [6,7,8].
Different switching mechanisms have been developed to the write operation. They are Spin Transfer Torque [9, 10], Field-Induced, Thermally Assisted, Voltage Assisted and Spin–Orbit Torque switching techniques. Spin–orbit PMTJs is the most suitable device, due to its faster switching time, higher energy efficiency compared with the spin–orbit IMTJ. Three terminal MTJ devices have higher reliability than two-terminal devices [11, 12].
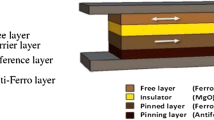
The three terminals PMTJ is chosen for analysis and design. In this model, the initial SOT torque is very strong and the incubation delay is negligible [12,13,14]. It supports rail-to-rail swing and eliminates the need of Pre-charge Sense Amplifier to read/write access. An external magnetic field is applied initially in the Y direction as shown in Fig. 1. It is designed with four primary layers, two ferromagnetic layers (CoFeB) namely pinned layer (PL) and free layer (FL), separated by Tunneling barrier (MgO) or Insulating layer (IL). Three layers are placed on top of the strong spin–orbit coupling, called the channel (Pt) [15,16,17,18,19]. Channel is the additional layer integrated with the free layer.

The architecture of PMT
The presence of an external magnetic field collinear with the current flow is required to break the symmetry in a spin–orbit PMTJ. The power consumption of memories is predominantly occupied by the writing circuit [20].
The schematic view of the Perpendicular MTJ model with the terminals is shown in Fig. 2. It has six terminals; three terminals are used for interfacing. Terminals \({\mathrm{W}}_{1}\) and \({\mathrm{W}}_{2}\) are used to write into the free layer and fixed/pinned layer respectively. ‘R’ terminal is used for a read operation. \({\mathrm{M}}_{\mathrm{X}}\),\({\mathrm{M}}_{\mathrm{y}}\),\({\mathrm{M}}_{\mathrm{z}}\) terminals indicate the magnetization direction of the free layer during write operations. The external magnetic and electric field are applied; the magnetization direction of non-volatile data is always in the Z-direction in the fixed layer. All are perpendicular to each other.

Perpendicular Magnetic Tunnel Junction in Parallel and Anti-parallel state
Contribution of the Work:
The major contributions in this work are
-
To improve the read and write speed of non-volatile data by STT switching with PMTJ compare to the other STT–MTJ,
-
To reduce the energy consumption of STT–PMTJ based combinational logic,
-
Novel RWPS circuit is designed for write operation using SOT logic,
-
To analyse the speed, power and energy parameter in STT and RWPS circuit,
-
Noise analysis in the III stage inverter in RWPS circuit,
-
To implement the combinational circuit in STT and RWPS based switching logic.
1.1 STT based switching technique
This section describes the Spin Transfer Torque switching mechanism with the PMTJ-CMOS device model described using PMTJ is represented in Fig. 1. Circuit operation is verified for lower supply voltages. Sizing of switching transistors is designed to increase the switching current.
Electrons cross the barrier layer during each writes operation and read operation in STT switching. The spin electrons are crossing through the barrier layer from one ferromagnetic layer into other. In this case, tunnelling barrier thickness decides the critical current. Tunnel Magneto Resistance (TMR) is a magneto resistive effect that occurs in MTJ. It defines as the ratio of the difference in the anti-parallel resistance and the parallel resistance. Parallel state resistance is less than the anti-parallel state resistance. It prevents Boron atoms from segregating into the interface. TMR ratio increases with the spin polarization.
Critical switching current is proportional to the MTJ device area depends on other parameters shown in Eq. (1).
Also, the parameters are analyzed to get the desired output.
2 Literature survey
Among the research works on expeditious switching circuit design for non-volatile combinational circuit, some of the recent works are revised here,
Fakhari et al. [21] have presented CNTFET switching logic base lesser power with area-efficient quaternary adder. The presented design substantially decreases the count of transistors, area, power consume, when managing output driving ability along full swing mode. The presented model was simulated utilizing HSPICE and Stanford CNTFET. To CNTFET-base circuits, the presented circuit was drawn by physical design tool. The outcomes show the effectiveness with respect to area, average power consume, PDP likened to its state-of -art counterparts.
Bastani et al. [22] have presented energy with area-efficient approximate ternary adder depending on CNTFET switching logic for decreasing area with energy consume. By utilizing the Synopsys HSPICE simulator along Stanford 32 nm CNTFET technology, the presented design was lesser than other CNTFET-base ternary circuits. Moreover, the presented ternary full adder was utilized to lessen the ternary multiplier structure steps with certain metrics, viz energy-error tradeoff, normalized error distance were computed to estimate the presented circuit performance.
Hussain and Chaudhury [23] have presented fast and high-performing 1-bit full adder circuit depending on input switching activity patterns and gate diffusion input (GDI) technique. The adder was structured in 2 states: (i) XOR–XNOR module, (ii) required outputs. The switching activities of the transistors were lessened by utilizing the switching activity pattern of inputs with GDI in each stage. The presented method lessens delay, power consumption, computational complexity.
Mandal et al. [24] have presented an optical quaternary adder and subtractor model utilizing polarization switching. The frequency encoding approach was employed to data representation due to its inherent feature of constancy during reflection, refraction, transmission. Various bits were processed without any error instead of any fluctuation in intensity, thus, the bit error rate was lessened. Polarization switching properties of semiconductor optical amplifier were adopted to develop these basic units.
Amirany and Rajaei [25] have presented spin-base fully nonvolatile full-adder circuit for scaling in memory. A nonvolatile with lower cost radiation hardened magnetic full adder (MFA) was presented. When compared with other designs, the presented MFA was able to tolerate particle strikes not considering the quantity of charge induced to a single and multiple nodes. The presented magnetic full adder gives lesser power, lesser area and higher performance. The full non volatility was presented by the magnetic full adder. Nonvolatile logic circuits eliminate the cost of higher volume data transactions amid the memory and logic, also make possible power gating in logic-in-memory structures.
Alghare et al. [26] have presented a Non-volatile spintronic flip-flop design for energy-efficient Single-Event Upset and Double Node Upset resilience. Where, latching circuits depending on soft error resilient CMOS was structured to be leveraged as master and slave latches in NV-FF structure. The presented design use feedback loops and clock-gating Muller C-elements, also maximizing the charging ability of vulnerable nodes. The simulations show that the presented Single-Event Upset and Double Node Upset resilient latching circuits attains 81% and 24% power-delay-product improvement compared to other designs. The presented latching circuit was combined to develop four radiation hardened NV-FF designs. In this area was increased.
Razi et al. [27] have presented an energy-efficient radiation-hardened non-volatile magnetic latch. The presented model was deemed to design a reliable non-volatile magnetic latch utilizing MTJs. The presented latch was utilized to create a rad-hard magnetic master–slave flip-flop. Simulations show that the presented design present advantageous figures of merit over the prior works. The presented design attains 52% and 82% enhancement in power and delay over other designs.
Rajaei and Amirany [28] have presented a Nonvolatile low-cost approximate spintronic full adders for computing in memory architectures. The presented magnetic FAs provide full non-volatility, lower area, lower energy consume. The presented magnetic FAs have the benefit of single event upset (SEU) tolerance. The outcomes show that the presented design provides 50% energy efficiency than other fully nonvolatile magnetic FAs. In the approximate Gaussian filter, the filtered noisy images have almost the same results as the accurate Gaussian filter. The presented magnetic FAs have an accurate carry-out output and an approximate sum output with an error distance of 2. The delay was increased.
3 Proposed RWPS based switching technique
Previous research shows read and write ‘0’ accesses by applying opposite direction current pulses through PMTJ. Transfer of data to the cell and from the cell is not illustrated so far. Therefore, this paper proposes a novel switching circuit to write and read data. Instantaneous changes in the input data are immediately transferred to the contents of the memory without hold operation.
3.1 SOT write and read circuit
Spin–Orbit Torque Switching—In this case, read and write paths are decoupled, so they can be independently optimized.
WRITE: External electric current is applied to the channel due to Spin Hall Effect, the non-volatile data is written in the Z direction of PMTJ. Digital data ‘0’ or ‘1’ is stored, according to the direction of the spin polarization.
NMOS transistors MN1–MN4 generate a positive current pulse for volatile input data’1’, the free layer is aligning Antiparallel to the fixed layer of PMTJ. The MTJ write output is ‘1’. Input data 0 is applied as negative current pulse to PMOS transistors MP1–MP4. It leads to the parallel connections of fixed and free layers. The write operation is based on the input data and does not depend on the “Enable” control signal. A basic current mirror circuit is used to read and write the data. \({\mathrm{I}}_{\mathrm{D}2}\)(Drain Current) is equal to W1 terminal current, MN4, MN3 transistor sizes are chosen equal and half of MN1. Similarly, PMOS transistor sizes are also chosen using the same design technique. The volatile data at the input is transferred to non-volatile data and written in the MZ pin. It has been read out from the point ‘B’ as shown in Fig. 3.

Read Write Parallel switching Circuit
Mn3, Mn4 width are high because 200 µA current is passed, it act as a switch (triode region).
Mn1, Mn2–length should be high, due to Mn1 current should mirror of Mn2 and operated in saturation region [29].
The following conditions are satisfied to mirror the current in Mn1 and Mn2 transistor.
Similarly the Mn3 and Mn4 transistors are follow the given equation
READ: The read path is from a fixed layer to the free layer through a barrier layer. The read and write accesses can be activated simultaneously. Transistors MN0, MN5, MP0 and MP5 are used for a read operation. The volatile data ‘0’ is applied, MP1 – MP4 transistors are work up for write ‘0’ and MN5,MN0 are turned ON to create a path for read operation. The complement data are processed similarly as shown in Fig. 3.
3.2 SOT based combinational circuit design
The combinational circuit AND and Full Adder circuits are implemented with PMTJ-CMOS. The resistance value of 100 Ω is chosen for the readout terminal, to transfer the data with reduced output swing to the NMOS pass transistor logic. PCSA is used to derive rail-to-rain swing for design the combinational circuit and buffer is used at the inputs of NMOS logic to increase the speed.
AND: Inputs 'B' and 'B bar' of the combinational logic is applied through PMTJ. Inputs 'A' and 'Abar' are applied through buffers. Buffers are designed to equalize the delay of volatile and non-volatile inputs of combinational logic. Transistors MN5, MN6 and MN7 are used to implement AND and NAND logic as shown in Fig. 4. The transistor's states are explained in Table 1.

RWPS based AND and NAND logic gate
Full Adder: During the read operation, MN0 and MP0 transistors discharge fast and improve the access speed. The combinational circuit of a Full Adder is shown in Fig. 5. Two MTJ devices are used in the writing circuit and configured for FA sum and carry operation. The logic operation is performed in the evaluation mode. Similar to AND logic, buffers are included in the path of inputs 'A' and 'C' to make propagation delay of all signals the same. It reduces the set-up requirement of the PCSA logic circuit. The transistor's states are explained in Table 2. Table 2 tabulates the true table along resistance configuration of \(C_{0}\) logic. \(R_{OFF}\) and \(R_{ON}\) represents MOS transistors close with open resistances. \(R_{L}\),\(R_{R}\) represent entire resistance of PCSA left, right branch. To determine \(A\) and \(C_{i}\), the \(AC_{i}\), \(\overline{{AC_{i} }}\) sub branches have no impact in output. The 2 sub branches resistance are same if \(A\) and \(C_{i}\) are varied. If it is same, their comparison associated with \(R_{L}\) and \(R_{R}\) in \(R_{OFF} > R_{AP}\) condition, which is always true. It allows \(AC_{i}\) to be deleted from Eq. (4) and get \(C_{0}\) logic circuit. The output of \(Sum\) is represented in Eq. (9), the output of \(\overline{Sum}\) is expressed in Eq. (10) and the output of \(C_{0}\) and \(\overline{{C_{0} }}\) are represented in Eqs. (11) and (12) respectively.

RWPS based Full Adder
4 Simulation result and analysis
The proposed RWPS switching circuit is implemented using cadence virtuoso 45 nm standard CMOS technology with a perpendicular MTJ model. Table 3 tabulates the MTJ parameters. The read and write circuits are analyzed for STT and RWPS switching techniques. Logic gates and Full Adder are implemented. A supply voltage of 1 V is used. The threshold value is calculated from the transfer characteristics of the inverter and its value is 0.5 V. The proposed RWPS novel method result is analyzed, the simulation of STT model is analyzed the parameters required for novel method to compare the results of STT model as well as RWPS model.
4.1 Write and read circuit transient response for STT
The read and write operations are analyzed for input output and control signals in order to represent the volatile data. Compose access is enacted with Enable signal at a significant level and read admittance at zero levels. In Pre charge mode, the yields get charged to VDD, when 'CLK' is lower. In the Assessment stage, the put away worth has been perused with the CLK at a significant level. The positive edge CLK is applied at the time of Enable signal is low. Table 4 shows 86% percentage of improvement with respect to proposed work.
In this segment, life RWPS– PMTJ combinational circuits for AND logic and Full adder using Spintronics are analyzed. Input, output data and control signals of STT for read and write operations are depicted in Fig. 6. The 100 MHz volatile data input is applied to the writing circuit of STT–PMTJ. Write access is activated with Enable signal at a high level and read access at zero levels. In Precharge mode, the outputs get charged to VDD, when ‘CLK’ is low. In the Evaluation phase, the stored value has been read with the CLK at a high level. The positive edge CLK is applied at the time of Enable signal is low.

Write and read access for STT
Figure 7 shows the Read and write access with degraded output and without set up time violation in STT AND logic. In this the out waveform of the AND switching circuit provides Input data ‘B’ (MTJ Data Output) is applied through PMTJ and input ‘A’ is applied directly in NMOS logic, AND and NAND outputs have taken from the PCSA. The setup time requirement of STT AND logic is 0.06 ns. The operating frequency is 17GHZ. The drawback of this method is that read write operations cannot be done parallel. Therefore, the proposed RWPS method does not require any setup time for RWPS based AND gate.

Read and write access with degraded output and without set up time violation in STT AND logic
Similarly, the input set-up time requirement is not satisfied and it affects the output. The setup time is not violated in 20 ns, the output response for the previous input value of ‘A’.
Figure 8 shows the output waveform of STT based Full Adder circuit simulation result. The operation of full adder shows the Full Adder: Clock of frequency 50 MHz is chosen for the full adder. The setup time requirement of STT FA is 0.09 ns. The sum path read delay is 15% higher than the carry path and programming frequency is 11GHZ.

STT based Full Adder circuit simulation result
Figure 9 shows the output wave form of the Write and read access for RWPS. In the case of RWPS, the 100 MHz volatile data is applied to the current mirror circuit; the data is stored and read from the PMTJ devices without any control signal. The data has written into the PMTJ devices, parallelly read out from the terminal ‘R’ with full rail to rail. For example logic ‘0’ is written ‘B’ and complement MTJ output ‘B bar’. At the same time, it is readout. The writing a circuit (Fig. 3) is used to read and writes access. Read and write access delays are reduced by 65% and 38%, but the energy is increased. Half of the transistors are turned ON permanently and data missing (No hold state) is eliminated.

Write data in STT VS RWPS
Figure 9 shows the Write data in STT VS RWPS. In the RWPS method, the energy is high as 80% since switching is also 80% then the previous methods.
Figure 10 shows the AND and NAND logic simulation using RWPS. The AND and NAND outputs are evaluated according to the input A and MTJ data with ‘CLK’ at a high level. In A = 1, \({\mathrm{R}}_{\overline{{\mathrm{Q} }_{\mathrm{m}}}}\)<\({\mathrm{R}}_{{\mathrm{Q}}_{\mathrm{m}}}\) and B = 1. So, the AND output is logic ‘1’ value and complement output of NAND is logic ‘0’. The other input combination of A = 0, B = 1, \({\mathrm{R}}_{\overline{{\mathrm{Q} }_{\mathrm{m}}}}\)>\({\mathrm{R}}_{{\mathrm{Q}}_{\mathrm{m}}}\) then \(\mathrm{AND}\) = 0. The clock frequency is fixed at 66.6 MHZ. The outputs are very fast (82% and 80%) compared with the STT–PMTJ. The read access time is increased by adding a buffer with ‘Input A’. The delay between the outputs is reduced by 79% in RWPS. Its write access is faster compared with the STT.

AND and NAND logic simulation using RWPS
Table 4 shows the Noise analysis in the III stage inverters. In this the input noise voltage is applied in the first stage inverter and the input, output and noise gain also calculated. Here, 3 inverters are implemented instead of one as it is the concept of pipelining which is used and eventually analyzed for power of background noise. In this, the margins of the write operation, which need to be improved, so introduced a pipelining concept, it is beneficial as write margin is available without any noise.
Table 5 shows the performance analysis of proposed switching circuit design compared with various existing methods. The proposed RWPS-PMTJ-NVCC design uses 45 transistors and the number of used transistors for AND gate is 33 and the Full adder is 48. For write delay analysis the proposed method provides 21.44%, 28.04%, 27.37% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For read delay analysis the proposed method provides 32.86%, 33.05%, 20.73% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For total delay analysis the proposed method provides 31.65%, 34.03%, 26.97% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For PDP analysis the proposed method provides 25.96%, 35.87%, 16.76% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For Write Energy analysis the proposed method provides 25.43%, 38.96%, 25.87% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For Read Energy analysis the proposed method provides 35.87%, 27.97%, 39.43% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For Write voltage analysis the proposed method provides 28.97%, 36.32%, 25.86% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For read voltage analysis the proposed method provides 25.86%, 20.85%, 29.22% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For Read Time analysis the proposed method provides 31.83%, 22.34%, 37.93% lower than the existing method such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, SHE-STT-MTJ-NVLCASF respectively. For write Time analysis the proposed method provides 24.02%, 31.83%, 27.94% lower than the existing methods, such as STT-PMTJ-NVSFF, SHE-STT-MTJ-NVML, and SHE-STT-MTJ-NVLCASF respectively.
5 Conclusion
This paper proposes the RWPS–PMTJ combinational circuits for AND logic and Full adder using Spintronics devices. This design uses a minimum number of transistors with an increase in access speed. Timing issues and the conditions on signal transitions for valid outputs are analyzed in detail. The propagation delay of the proposed design is likened with the existing designs. The read and write access time is lower for RWPS switching. The critical path of logic gates lies in the complement output and the delay is reduced by introducing a buffer. The RWPS based full adder is more preferable than STT based full adder. The total propagation delay is less than 70% by introducing a buffer for applied volatile input. The RWPS-FA carry delay is 80% lower than STT-FA. The adder efficiency is improved in this paper. Especially CARRY output delay is significantly less and highly suitable for carry dependent adders. Set up time requirement of the STT based device is 67% higher than the RWPS FA. It is preferable to use RWPS based logic for high speed and STT logic for energy-efficient applications.
Data availability
Data sharing does not apply to this article as no new data was created or examined here.
References
Lakys, Y., Zhao, W., Klein, J., & Chappert, C. (2010). Low power, high reliability magnetic flip-flop. Electronics Letters, 46, 1493.
Wang, M., Cai, W., Cao, K., Zhou, J., Wrona, J., Peng, S., Yang, H., Wei, J., Kang, W., Zhang, Y., Langer, J., Ocker, B., Fert, A., & Zhao, W. (2018). Current-induced magnetization switching in atom-thick tungsten engineered perpendicular magnetic tunnel junctions with large tunnel magnetoresistance. Nature Communications. 9.
Prenat, G., Garello, K., Langer, J., Ocker, B., Cyrille, M., Gambardella, P., Tahoori, M., Gaudin, G., Jabeur, K., Vanhauwaert, P., Pendina, G., Oboril, F., Bishnoi, R., Ebrahimi, M., Lamard, N., & Boulle, O. (2016). Ultra-fast and high-reliability SOT-MRAM: From cache replacement to normally-off computing. IEEE Transactions on Multi-Scale Computing Systems, 2, 49–60.
Zabihi, M., Chowdhury, Z., Zhao, Z., Karpuzcu, U., Wang, J., & Sapatnekar, S. (2019). In-memory processing on the SpintronicCRAM: From hardware design to application mapping. IEEE Transactions on Computers, 68, 1159–1173.
Oboril, F., Bishnoi, R., Ebrahimi, M., & Tahoori, M. (2015). Evaluation of hybrid memory technologies using SOT-MRAM for on-chip cache hierarchy. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 34, 367–380.
Das, J., Alam, S., & Bhanja, S. (2012). Ultra-low power hybrid CMOS-magnetic logic architecture. IEEE Transactions on Circuits and Systems I: Regular Papers, 59, 2008–2016.
Ikeda, S., Miura, K., Yamamoto, H., Mizunuma, K., Gan, H., Endo, M., Kanai, S., Hayakawa, J., Matsukura, F., & Ohno, H. (2010). A perpendicular-anisotropy CoFeB–MgO magnetic tunnel junction. Nature Materials, 9, 721–724.
Kishi, T., Yoda, H., Kai, T., Nagase, T., Kitagawa, E., Yoshikawa, M., & Takahashi, S. (2008). Lower-current and fast switching of a perpendicular TMR for high speed and high density spin-transfer-torque MRAM. In 2008 IEEE International Electron Devices Meeting, 1–4. IEEE.
Monga, K., Chaturvedi, N., & Gurunarayanan, S. (2020). Energy-efficient data retention in D flip-flops using STT-MTJ. Circuit World, 46, 229–241.
Nasri, A., Fathy, M., & Broumandnia, A. (2017). An energy-efficient 3D-stacked STT-RAM cache architecture for cloud processors: The effect on emerging scale-out workloads. The Journal of Supercomputing, 74, 1547–1561.
Jabeur, K., Pendina, G., Prenat, G., Buda-Prejbeanu, L., & Dieny, B. (2014). Compact modeling of a magnetic tunnel junction based on spin orbit torque. IEEE Transactions on Magnetics, 50, 1–8.
Kazemi, M., Rowlands, G., Ipek, E., Buhrman, R., & Friedman, E. (2016). Compact model for spin-orbit magnetic tunnel junctions. IEEE Transactions on Electron Devices, 63, 848–855.
Zhang, Y., Zhao, W., Lakys, Y., Klein, J., Kim, J., Ravelosona, D., & Chappert, C. (2012). Compact Modeling of Perpendicular-Anisotropy CoFeB/MgO Magnetic Tunnel Junctions. IEEE Transactions on Electron Devices, 59, 819–826.
Deng, E., Zhang, Y., Klein, J., Ravelsona, D., Chappert, C., & Zhao, W. (2013). Low Power Magnetic Full-Adder Based on Spin Transfer Torque MRAM. IEEE Transactions on Magnetics, 49, 4982–4987.
Sivaraman, E., & Manickachezian, R. (2019). Intelligent decision making service framework based on analytic hierarchy process in cloud environment. International Journal of Networking and Virtual Organisations, 21(2), 221–236.
Mythili, S., Thiyagarajah, K., Rajesh, P., & Shajin, F. H. (2020). Ideal position and size selection of unified power flow controllers (UPFCs) to upgrade the dynamic stability of systems: An antlion optimiser and invasive weed optimisation algorithm. HKIE Trans, 27(1), 25–37.
Rajesh, P., & Shajin, F. (2020). A multi-objective hybrid algorithm for planning electrical distribution system. European Journal of Electrical Engineering, 22(4–5), 224–509.
Shajin, F. H., & Rajesh, P. (2020). Trusted secure geographic routing protocol: Outsider attack detection in mobile ad hoc networks by adopting trusted secure geographic routing protocol. International Journal of Pervasive Computing and Communications.
Thota, M. K., Shajin, F. H., & Rajesh, P. (2020). Survey on software defect prediction techniques. International Journal of Applied Science and Engineering, 17(4), 331–344.
Endoh, T., & Honjo, H. (2018). A recent progress of spintronics devices for integrated circuit applications. Journal of Low Power Electronics and Applications, 8, 44.
Fakhari, S., Bastani, N. H., & Moaiyeri, M. H. (2019). A low-power and area-efficient quaternary adder based on CNTFET switching logic. Analog Integrated Circuits and Signal Processing, 98(1), 221–232.
Bastani, N. H., Moaiyeri, M. H., & Navi, K. (2018). An energy-and area-efficient approximate ternary adder based on CNTFET switching logic. Circuits, Systems, and Signal Processing, 37(5), 1863–1883.
Hussain, I., & Chaudhury, S. (2021). Fast and high-performing 1-bit full adder circuit based on input switching activity patterns and gate diffusion input technique. Circuits, Systems, and Signal Processing, 40(4), 1762–1787.
Mandal, S., Mandal, D., Mandal, M. K., & Garai, S. K. (2018). Design of optical quaternary adder and subtractor using polarization switching. Journal of Optics, 47(3), 332–350.
Amirany, A. & Rajaei, R. (2019). Spin-based fully nonvolatile full-adder circuit for computing in memory. In Spin, 9(0), 1950007. World Scientific Publishing Company.
Alghareb, F. S., Zand, R., & DeMara, R. F. (2019). Non-volatile spintronic flip-flop design for energy-efficient SEU and DNU resilience. IEEE Transactions on Magnetics, 55(3), 1–11.
Razi, F., Moaiyeri, M. H., & Rajaei, R. (2020). Design of an energy-efficient radiation-hardened non-volatile magnetic latch. IEEE Transactions on Magnetics, 57(1), 1–10.
Rajaei, R., & Amirany, A. (2020). Nonvolatile low-cost approximate spintronic full adders for computing in memory architectures. IEEE Transactions on Magnetics, 56(4), 1–8.
Ibrahim, S., & Razavi, B. (2011). Low-power CMOS equalizer design for 20-Gb/s systems. IEEE Journal of Solid-State Circuits, 46, 1321–1336.
Funding
No funding has been received.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors state that they have unknown competing financial interests or personal relationships that could have appeared to influence the work reported here.
Ethical approval
This article does not have any studies with human participants performed by any authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Aruna, A.R., Kamala, J. & Hanuman, C.R.S. A novel expeditious switching circuit design for non volatile combinational circuit. Analog Integr Circ Sig Process 113, 331–342 (2022). https://doi.org/10.1007/s10470-022-02086-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10470-022-02086-z