
Abstract
The Index is a data structure which stores data in a suitably abstracted and compressed form to facilitate rapid processing by an application. Multidimensional databases may have a lot of redundant data also. The indexed data, therefore need to be aggregated to decrease the size of the index which further eliminates unnecessary comparisons. Feature-based indexing is found to be quite useful to speed up retrieval, and much has been proposed in this regard in the current era. Hence, there is growing research efforts for developing new indexing techniques for data analysis. In this article, we propose a comprehensive survey of indexing techniques with application and evaluation framework. First, we present a review of articles by categorizing into a hash and non-hash based indexing techniques. A total of 45 techniques has been examined. We discuss advantages and disadvantages of each method that are listed in a tabular form. Then we study evaluation results of hash based indexing techniques on different image datasets followed by evaluation campaigns in multimedia retrieval. In this paper, in all 36 datasets and three evaluation campaigns have been reviewed. The primary aim of this study is to apprise the reader of the significance of different techniques, the dataset used and their respective pros and cons.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the explosive growth of multimedia data technologies, it becomes challenging to fulfill diverse user needs related to textual, visual and audio data retrieval. The advances in the integration of computer vision, machine learning, database systems, and information retrieval have enabled the development of advanced information retrieval systems (Gani et al. 2016). As multidimensional databases are gigantic, it has become important to develop data accessing and querying techniques that could facilitate fast similarity search. The issues of feature extraction and high-dimensional indexing mechanism are crucial in visual information retrieval (VIR) due to the massive amount of data collections. A typical VIR system (Wang et al. 2016) operates in three phases namely feature extraction phase, high-dimensional indexing phase, and retrieval system design phase. Potential applications (Datta et al. 2005, 2008) include digital libraries, commerce, medical, biodiversity, copyright, law enforcement and architectural design. Figure 1, below, displays the block diagram of the query by visual example.

Overview of visual information retrieval processes
The most important aspect of any indexing technique is to make a quick comparison between the query and object in the multidimensional database (Bohm et al. 2001). Multidimensional databases may have a lot of redundant data also. The indexed data, therefore, need to be aggregated to decrease the size of the index which further eliminates unnecessary comparisons.
1.1 Basic concepts
Feature and feature extraction Feature corresponds to the overall description of the image contents. ‘Local’ and ‘global’ are the terms used in the context of image features. Shape, color, and texture individually describe contents of an image, but that information is not descriptive enough. In this regard Histograms, SIFT, and CNN based computer vision techniques are developed to extract more informative contents. Feature aggregation techniques like Bag-of-visual-words (BoVW), VLAD, and Fisher vector produces fixed length vector which helps to approximate the performance of similarity metrics.
Index The image index is a data structure which stores data in a suitably abstracted and compressed form to facilitate rapid processing by an application. Feature-based indexing is found to be quite useful to speed up retrieval and is currently needed in this generation. Typically, any information retrieval system demands the following principle requirements (Téllez et al. 2014): size of the index, parallelism, the speed of index generation and speed of search.
Query processing The retrieval process starts with feature extraction for a query image. The primary aim is to extract and match the corresponding query features with pre-computed image dataset features under issue such as scalability of image descriptors and user intent to search. A query can be processed in a number of ways, depending on the type of indexing and extracted features.
Query formation Query formation is an attempt to define user’s precise needs and subjectivity. It is very difficult to capture the human perception and intention into a query. There is different query formation schemes proposed in literature such as query by text, query by image example, query by sketch, query by color layout etc. In Fig. 2 different query formation techniques are presented.

Illustration of different query schemes
Relevance feedback The different user intent may contain image clarity, quality, and associated meta-data. With the use of earlier user logs and semantic feedback; query refinement and iterative feedback techniques are highly recommended to satisfy the user. The ultimate goal is to optimize the interaction between system and user during a session. Feedback methods may range from short-term techniques, that directly modify the queries to long-term methods, that make the use of query logs.
1.2 Indexing techniques
Indexing phase is one of the most important aspects of any VIR system. Indexing techniques are a powerful means to make a quick comparison between the query and object in the multidimensional database (Bohm et al. 2001). Multidimensional databases may have a lot of redundant data also. The indexed data, therefore, need to be aggregated to decrease the size of the index which further eliminates unnecessary comparisons. Most of the VIR systems are designed for specific types of image such as sports, species, architecture design, art galleries, fashion, etc. Generally, in VIR four kinds of techniques are adopted for indexing: inverted files, hashing based, space partitioning and neighborhood graph construction. To facilitate the indexing and image similarity there is need to pack the visual features. The different techniques of image similarity and indexing are highly affected by the feature extraction/aggregation and query formation as discussed above. For hashing techniques we refer readers to previous survey (Gani et al. 2016; Wang et al. 2016, 2018). In Gani et al. 2016 surveyed indexing techniques in the past 15 years from the perspective of big data. They categorize the indexing techniques in three different categories viz. Artificial Intelligence, Non-artificial Intelligence and Collaborative Artificial Intelligence on the basis of time and space consumption. The main intent of the paper is to identify indexing techniques in cloud computing. Other recent surveys on hashing are reported in Wang et al. (2016, 2018). The concept of learning to hash are delineated there. The survey in Wang et al. (2016) only categorizes and emphasizes on the methodology of data sensitive hashing techniques with big data perspective without any performance analysis. Wang et al. (2018) analyze and compare a comprehensive list of learning to hash algorithms in brief. In this work, they consider similarity preserving and quantization to group the hashing techniques exists in the literature. In addition, they have analyzed the query performance of pair-wise, multi-wise and quantization techniques for limited datasets. The recently conducted survey has been focused only on hash based indexing techniques for which there are only a limited support for experimental analysis and applications.
Therefore, we found that there is a need of survey article which has to cover detail of applications, datasets, performance analysis, evaluation challenges and non-hash based indexing techniques as well. In this regard, we analyze and compare a comprehensive list of indexing techniques. Here, we are focusing on overview of hash and non-hash based indexing techniques of the recent years. We provide more categorical detail of indexing techniques in Sect. 4. In comparison to earlier surveys (Gani et al. 2016; Wang et al. 2016, 2018), the contributions of our article are as follows:
-
1.
It provides splendid image retrieval application areas.
-
2.
It provides an immense description and categorization of hash and non-hash based indexing techniques.
-
3.
It extensively discussed and listed 36 different datasets in detail.
-
4.
It presents a separate evaluation section to examine the performance of different hashing techniques for different datasets.
-
5.
It presents details of multimedia evaluation programs covering top conferences related to indexing techniques.
1.3 Organization of the article
The rest of the article has been organized as follows: Sect. 2 describes the significant challenges in VIR system; Sect. 3, presents promising application areas followed by Sect. 4, which categorizes the indexing techniques. Section 5 provides an evaluation framework for different hash based indexing techniques followed by Sect. 6, that presents some evaluation campaign organized for multimedia indexing. Section 7 addresses the future work, and in the last section, we draw a conclusion.
2 Major challenges in VIR systems
2.1 Similarity search
Content-based search extends our capability to explore/search the visual data in different domains. This operation relies on the notion of similarity for search e.g. to search for images with content similar to a query image (Kurasawa et al. 2010). Translating the similarity search into the nearest neighbor (NN) (Uysal et al. 2015), search problem finds many applications for information retrieval, machine learning, and data mining. The context of large-scale unstructured data envisages finding approximate solutions. Approximate similarity (Pedreira and Brisaboa 2007; Hjaltason and Samet 2003) search relaxes the search constraints to get acceptable results at a lower cost (e.g. computation, memory, time).
2.2 Curse of dimensionality
All the research works have a common concern of scaling up indexing from low dimensional feature space to high dimensional feature space in getting good results, and it is a significant problem due to the phenomenon so called “the curse of dimensionality” (Wang et al. 1998). Recent studies show that most of the indexing schemes even become less efficient than sequential indexing for high dimensions. Such degradations and shortcomings prevent a widespread usage of such indexing structures, especially on multimedia collections.
2.3 Semantic gap
The field of semantic based image retrieval first received active research interest in the late 2000s (Zhang and Rui 2013). Both the single feature and the combination of multiple features are lacking in capturing the high-level concept of images. It is essential to understand the discrepancy between low-level image features and high-level concept to design good applications for VIR. The disparity leads to the so-called semantic gap (Sharif et al. 2018) in the VIR context. Describing images in semantic terms is the highest level of visual information retrieval, and it is a challenging task (Wang et al. 2016).
3 Applications
Indexing is widely used in visual information retrieval systems to make fast offline and online comparisons among data items. With the increase of storage devices as well as progress on the internet, image retrieval is growing with diverse application domains. In the literature a very few fully operational VIR systems are available but the importance of image retrieval has been highlighted in many fields. Though these certainly represent only the tip of the mountain, some potentially productive areas at the end of 2017 are as follows:
-
a.
Medical applications A rapid evolution in diagnostic techniques results in a large archives of medical images. At present this area is largely publicized as the prime users of VIR systems. This area has great potentials to be developed as huge markets for VIR system as it has unique ingredients (feature set viz. shape, texture etc.) for feature selection and indexing. The use of VIR can result in valuable services that can benefit biomedical information systems. The retrieval, monitoring, and decision-making should be integrated seamlessly to design an efficient medical information system for radiologist, cardiologist, and others.
-
b.
Biodiversity information systems Researchers in the life sciences are becoming increasingly concerned about to detect various diseases related to agricultural plants and to understand habitats of species. The in-time gathering and monitoring of visual data consistently achieve objectives as well as minimize the effect of diseases in plants/animals and monitors the lack of nutrients in plants.
-
c.
Remote sensing applications VIR system can be used to retrieve images related to fire detection, flood detection, land sliding, rainfall observation in agriculture, etc. For the query “show all forest area having less rainfall in last ten years” system replies with images having a region of interest. From military applications point of view probably this area is well developed and less publicized.
-
d.
Trademarks and copyrights This is one of the mature areas and on the advanced stage of development. In recent years, illegal use of logos and trademarks of noted brands has been emerged for business benefits. VIR is used as a counter mechanism in the identification of duplicate/similar trademark symbols which further helps in law enforcement and copyright violation investigation.
-
e.
Criminal investigation As an application this is not a truly VIR system as it purely supports identity matching rather than similarity matching. The VIR systems have a big significance in the criminal investigation. The identification of mugshot images, tattoos, fingerprint and shoeprint can be supported by these systems. Practically a large number of systems are used throughout the world for criminal investigation.
-
f.
Architectural and interior design Images that visually model the inner and outer structure of a building are containing more diagrammatic information. The use of VIR can result in important services that can benefit interior design or decorating and floor plan of a building.
-
g.
Fashion and fabric design The fashion and fabric industry have a predominant position among other industries all over world. For the product development purpose, designer of cloths has to refer previous designs. For the online shopping purpose, the user has to retrieve similar product options. As an application the aim of VIR system is to search the similar fabrics and products for designers and buyers respectively.
-
h.
Cultural heritage In comparison to other areas, image retrieval in art galleries and museum highly depends upon the creativity of user as images have heterogeneous specifics. In digitized art gallery and museum, the feature set is of high dimensionality which in turn requires advanced VIR systems.
-
i.
Education and manufacturing The main paradigm for performing 3D model retrieval has been using query-by example and query-by-sketch approach. The 3D image retrieval can be seen, as a toolbox for computer aided design, video game industry, teaching material and different manufacturing industries.
Other examples of database applications where visual information retrieval and indexing is useful: Personal Archives, Scientific Databases, Journalism and advertising, Storage of fragile documents, Biometric identification and Sketch-based Information Retrieval.
4 Categorization of indexing techniques
This section provides a background on indexing techniques and how they facilitate visual information retrieval and visual query by example. Many of the existing indexing techniques may range from the simple tree based (Robinson 1981; Lazaridis and Mehrotra 2001; Uhlmann 1991; Baeza-Yates et al. 1994) approaches to complex approaches that include deep learning (Babenko et al. 2014; Donahue et al. 2014; Dosovitskiy et al. 2014; Fischer et al. 2014) and hashing based (Andoni and Indyk 2008; Baluja and Covell 2008; He et al. 2011; Zhuang et al. 2011; Mu and Yan 2010; Liu et al. 2012). By approximate nearest neighbor search there exist hash and non-hash based indexing techniques and methodology of both turns around various concepts in the literature. But our finding says it is limited to some quality concepts. The hash based techniques are basically turnaround these concepts: Graph based, Matrix Factorization, Column Sampling, Weight Ranking, Rank Preserving, List-wise Ranking, Quantization, Semantic similarity (Text/image), Bit Scalability, Variable bit etc. whereas the non hash based techniques contains concepts namely Pivot Selection, Ball Partitioning, Pruning Rules, Semantic Similarity, Queue based Clustering, Manifold Ranking, Hybrid Segmentation, Approximation etc. Out of these significant concepts related methods have been detailed in this section. The categorization of these indexing techniques is presented in Fig. 3.

Categorization of Indexing Techniques
4.1 Hash based indexing
The Hashing has its origins in different fields including computer vision, graphics, and computational geometry. It was first introduced as locality sensitive hashing (Datar et al. 2004) in an approximate nearest neighbor (ANN) (Muja and Lowe 2009) search context. Any hash based ANN search works in three basic steps: figuring out the hash function, indexing the database objects and querying with hashing. Most ordinary hash functions are of the form
here f() is nonlinear function. The projection vector w and the corresponding bias b are estimated during the training procedure. sgn() is the element wise function which returns 1 if element is positive number and return − 1 otherwise. In addition, the choice of f() varies with type of hashing under consideration. Further, the choice of Hashing technique is highly dependent and mostly effected by the following factors: type of hash function, hash code balancing, similarity measurement and code optimization. The hash functions are of following forms: Linear, Non-linear, Kernelized, Deep CNN. The concept of code balancing is transfigured to bit balance and bit uncorrelation. Bit bi is balanced iff it is set to 1 in one half of all hash codes. Bit uncorrelation means that all pair of bits of hash code B is uncorrelated. Hash codes similarity is measured by hamming distance and its variants. Further, in optimization process sign function keeping, dropping and other relaxation methods are available. All these factors are denoted by legend in Fig. 3. To improve the search performance by fast hash function learning, researchers come up with new hashing methods of different flavors:
4.1.1 Data-dependent hashing (unsupervised)
The design of hash functions subject to analysis of available data and to integrate different properties of data. The main aim is to learn features from the particular dataset and to preserve similarity among the various spaces viz. data space and Hamming space. The unsupervised data dependent method uses unlabeled data to learn hash codes and committed to maintaining Euclidean similarity between the samples of training data. A representative method includes Kernelized LSH (Kulis and Grauman 2012), Spectral Hashing (Weiss et al. 2008), Spherical Hashing (Heo et al. 2012) and much more. Some of these techniques are discussed below.
4.1.1.1 Discrete graph hashing
Liu et al. (2014) proposed a mechanism for nearest neighbor search. To introduce a graph- based hashing approach, the author uses anchor graph to capture neighborhood structure in a dataset. The anchor graph provides nonlinear data-to-anchor mapping, and they are easy to build in linear time which is directly proportional to a number of data points. The proposed discrete graph hashing is an asymmetric hashing approach as it has different ways to deal with queries and in and out of sample data points (Table 1). The objective function written in matrix form is:
Define graph Laplacian L as anchor graph Laplacian \( L = I_{n} - S \), then the objective function is rewritten as:
By softening the constraints and ignoring error prone relaxation the objective function can be transformed as
4.1.1.2 Asymmetric inner product hashing
Fumin Shen et al. (Shen et al. 2017) address the asymmetric inner product hashing to learn binary code efficiently. In another context, it maintains inner product similarity of feature vectors. With the help of asymmetric hash function the Maximum Inner Product Search (MIPS) problem is formulated as
Here \( h\left( \cdot \right) \) and \( z\left( \cdot \right) \) are the hash functions, \( \cdot \) is the Frobenius norm and S is the similarity matrix computed as \( S = A^{T} X \). Further with linear form of hash functions the proposed Asymmetric Inner-product Binary Coding problem is formulated as (in matrix form):
The author incorporates the discrete variable as a substitute for sign function to optimize the bit generation approach.
4.1.1.3 Scalable graph hashing
Jiang and Li (2015) get inspiration from asymmetric LSH (Datar et al. 2004) to propose an unsupervised graph hashing. The proposed scheme formulates the approximation of the whole graph through feature transformation. Here approximation of graph is made without computing pair-wise similarity graph matrix. It learns hash functions bit by bit. The objective function is:
In particular, it uses concept of kernel bases to learn hash function and the objective function is defined as (in matrix form):
Subject to: \( K\left( X \right) \in {\mathbb{R}}^{n \times m} \) is the kernel feature matrix.
4.1.1.4 Locally linear hashing to capture non-linear manifolds
Irie et al. (2014) suggest a locally linear hashing to obtain the manifolds structure concealed in visual data. To identify the nearest neighbor in the same manifold related to the query, a local structure preserving scheme is proposed. In particular, it uses Locally Linear Sparse Reconstruction to capture locally linear structure:
The proposed model maintains the linear structure in a Hamming space by simultaneously minimizing the errors and losses due to reconstruction weights and quantization respectively. Therefore, the optimization problem is defined as:
4.1.1.5 Non-linear manifold hashing to learn compact binary embeddings
Shen et al. (2015) address the embedding to learn Nonlinear Manoifolds efficiently. The proposed method is entirely unsupervised which is used to uncover the multiple structures obscured in image data via Linear embedding and t-SNE (t-distributed stochastic neighbor embedding). For the construction of embedding a prototype algorithm has been proposed. For a given data point \( x_{q} \), the embedding \( y_{q} \) can be generated as
4.1.2 Data-dependent hashing (supervised)
Another category of learning to hash technique is supervised hashing. The supervised data dependent method uses labeled data to learn hash codes and committed to maintaining semantic similarity constructed from semantic labels of training samples. In comparison to unsupervised methods, supervised methods are slower during learning of large hash codes and labeled data. Further, it is limited to applications as it is not possible to get semantic labels always. The level of supervision further categorizes supervised methods in point-wise, triplets and list-wise approaches. Representative method includes Supervised Discrete hashing (Shen 2015), Minimal loss hashing (Norouzi and Fleet 2011) and many more (Lin et al. 2013; Ding et al. 2015; Ge et al. 2014; Neyshabur et al. 2013). Some of these techniques are listed and discussed below.
4.1.2.1 Discrete hashing
Shen et al. (2015) proposed a new learning-based data dependent hashing framework. The main aim is to optimize the binary codes for linear classification. This method jointly learns bit embedding and linear classifier under the optimization. For the optimization of hash bits, the discrete cyclic coordinate descent (DCC) algorithm is proposed. The objective function is defined as (in matrix form):
here \( \uplambda\;{\text{and}}\; v \) are the regularization parameter and penalty term respectively. They use hinge loss and \( l_{2 } \) loss for linear classifier. The proposed method showed improvement in results when it is compared with state-of-the-art supervised hashing methods (Zhang et al. 2014; Lin et al. 2014; Deng et al. 2015; Wang et al. 2013) and addressed their limitations. Further, in (Shen et al. 2016) they presented fast optimization of binary codes for linear classification and retrieval. Supervised and Unsupervised losses are considered for the development of scalable and computationally efficient method.
4.1.2.2 Discrete hashing by applying column sampling approach
Kang et al. (2016) presented discrete supervised hashing method based on column sampling for learning hash codes generated from semantic data. The proposed scheme is an iterative scheme where sampling of similarity matrix columns has been done through a column sampling technique (Li et al. 2013) i.e. the technique sample current available training data point into a single iteration. A randomized approach is used to sample data points i.e. few of the possible data points are selected for random sampling. Further, it partitions the sample space into two unequal halves and objective function is formulated as:
\( s.t. \)\( \tilde{S} \in \left\{ { - 1,1} \right\}^{\varGamma \times \varOmega } \), \( \varOmega \) and \( \varGamma \) are two halves of sample space, \( \varGamma = \)N – \( \varOmega \) with N = {1, 2,… n}.
It is a multi-iterative approach where the sample spaces updated with each iteration on an alternate basis.
4.1.2.3 Adaptive relevance based multi-task visual labeling
Deng et al. (2015) developed an image classification approach to overcome issues like data scarcity and scalability of learning technique. A use of hashing based feature dimension reduction reported much better image classification and stepped down required storage. The proposed method is a two-pronged multi-task hashing learning. Firstly, in learning step, each task suggests learning the defined model for a particular label. Further, this learning step executed in two levels viz. tasks and features simultaneously. The idea suggests that the complicated structure of processed features efficiently handle by task relevance scheme. Secondly, in the prediction step test datasets and trained model simultaneously classify and predicts the multiple labels. Outcomes reveal the algorithm potential of enhancing the quality of classification across multiple modalities.
4.1.3 Ranking-based hashing
With the advent of supervised, unsupervised and semi-supervised learning algorithms it is easy to generate optimized compact hash codes. Nearest neighbor search in large dataset under data-dependent methods produces suboptimal results. By exploring the ranking order and accuracy, it is easy to evaluate the quality of hash codes. Associated relevant values of hash codes help to maintain the ranking order of search results. A representative method includes Ranking-based Supervised Hashing, Column Generation Hashing and Rank Preserving Hashing and much more. Some of these methods are listed and discussed below.
4.1.3.1 Weighting scheme for hash code ranking
Ji et al. (2014) presented a ranking method involving weighting system. They aim to make an improved hamming distance ranking. However hamming distance ranking loses some valuable information during quantization of hash functions. To get highly efficient hamming distance measurement the proposed scheme learns weights [Qsrank (Zhang et al. 2012) and Whrank (Zhang et al. 2013)] during similarity search. To cope with expensive computing of higher order independence among hash function, this method uses mutual information of hash bit to propose mutual independence among hash bits. The neighbour preservation weighting scheme is defined as:
Here p and q are two weight vectors to capture the shared structure among task parameters, and variations specific to each task respectively. The objective function is maximized as follows:
s.t. \( 1^{T} \pi = 1, \pi \ge 0, \gamma \ge 0, \)\( a_{ij} \) is mutual independence between bit variables and \( w_{i}^{*} \) = \( w_{k} \pi_{k} \).
The anchor graph is used to represent sample to make similarity measurement useful for various datasets.
4.1.3.2 Ranking preserving hashing
Wang et al. (2015) proposed ranking preserving hashing to improve the ranking accuracy named Normalized Discounted Cumulative Gain (NDCG) which is the quality measure for hashing codes. The main aim is to learn new devised hashing codes that can maintain the ranking order and relevance values both for data examples. The ranking accuracy is calculated as follows:
here ranking position is defined as \( , \pi \left( {x_{i} } \right) = 1 + \mathop \sum \limits_{k = 1}^{n} I(b_{q}^{T} \left( {b_{k} - b_{i} } \right) > 0) \), Z is the normalization factor and \( r \) is the relevance value of data item \( x \). It’s hard to optimize NDCG directly due to its dependency on the ranking of data standards. Optimization of NDCG is done through linear hashing function which evaluates the expectation of NDCG.
4.1.3.3 Use of list-wise supervision for hash codes learning
Wang et al. (2013) presented an interesting variant for learning hash function. To this end, ranking order is used for learning procedure. The proposed approach implemented in three steps: (a) Firstly, transforms Ranking lists of queries into triplet matrix. (b) Secondly, the inner product has been used to compute the hash codes similarity which further derives the rank triplet matrix in Hamming space. (c) Finally, triplets are set to minimize inconsistency. The formulation of Listwise supervision is based on ranking triplet defines as:
The objective is to measure the quality of ranking list, which is formally calculated through loss function written in matrix form:
s.t. \( C \in {\mathbb{R}}^{\text{dxk}} \) is the coefficient matrix, \( p_{m} = \mathop \sum \limits_{i,j} \left[ {x_{i} - x_{j} } \right]S_{mij} \) and G = \( \mathop \sum \limits_{m} p_{m} q_{m}^{T} \).
The measurement of Loss function differentiates two ranking lists. They used Augmented Lagrange Multipliers (ALM) for optimization to reduce the computation time.
4.1.4 Multi-modal hashing
Developing a new retrieval model that is focusing on different types of multimedia data is a challenging task. Cross view or multimodal hashing techniques map different high dimensional data modalities into a small dimensional Hamming space. The main issue in performing joint modality hashing is preserving of similarity among inter and intra modalities. Utilization of information further categorize these methods in real-valued (Rasiwasia et al. 2010) and binary representation learning (Song et al. 2013) approaches. Some of the representative techniques are listed and discussed below.
4.1.4.1 Semantic-preserving hashing
Lin et al. (2015) proposed semantic preserving hashing named SPH for multimodal retrieval. The proposed scheme formulate the procedure in two steps: Firstly, it transforms semantic labels of data into a probability distribution. Secondly, it approximates data in Hamming space by minimizing its Kullback-Leiber divergence. The objective function is written as follow:
s.t. \( \alpha \) is the parameter for balancing the KL divergence and \( No \) is the normalizing factor
here the probabilities \( p_{i,j} \) and \( q_{i,j} \) are the probability of observing the similarity among training data and similarity among data items in hamming space respectively. I is the matrix having all entries 1. Quantization loss is measured as \( \left| {\widehat{H}} \right| - I^{2} \). They used kernel logistic regression boosted by sampling technique to introduce projection, the regression is done through k-mean and random sampling similarly.
4.1.4.2 Semantic topic hashing via latent semantic information
Wang et al. (2015) addresses the issues with graph-based and matrix decomposition based multimodal hashing methods. The long training time, decrease in mapping quality, and large quantization errors are the generic drawbacks of above-mentioned techniques. In the proposed work, the discrete nature of hash code has been considered. The overall objective function for text and image concept (\( L_{T} , L_{I} , L_{C} \)) is defined as:
Here, F is a set of latent semantic topic, P is the correlation matrix between text and image, U and V are the set of semantic concepts, \( \uplambda, \mu , \gamma \) are the tradeoff parameters and \( {\text{R}}\left( \cdot \right) \) is the regularization term to avoid over fitting.
4.1.4.3 Multiple complementary hash tables learning
Liu et al. (2015) switches research direction from compact hash codes to multiple additional hash tables. The author claims that this is the first approach which takes into account the multi-view complementary hash tables. In this method, additional hash tables are considered as clusters that use exemplars-based feature fusion. They extend exemplar based approximation techniques by adopting a new feature representation \( \left[ {z_{i} } \right]_{k} = \frac{{\delta_{k} K\left( {x_{i } , u_{k} } \right)}}{{\mathop \sum \nolimits_{{k^{\prime} = 1}}^{M} \delta_{k} K\left( {x_{i } , u_{{k^{\prime}}} } \right)}} \) here \( \delta_{k} \in \left\{ {0,1} \right\}, u_{k} \) are exemplar points \( \in \)\( \{ {\mathbb{R}}^{\text{d}} \} _{k = 1}^{M} \) and \( \kappa \left( { \cdot , \cdot } \right) \) is kernel function. The overall objective is to minimize:
Here μ is the weight vector. The strength of presented scheme is that they assume a few cluster centers to measure the similarity in between entire data points. They defend linear weighting and bundling of multiple features in one vector using nonlinear transformation.
4.1.4.4 Alternating co-quantization based hashing
Irie et al. (2015) proposed an improved multimodal retrieval which is based on the binary hash codes. The primary goal is to minimize the binary quantization error. To reduce the errors, the proposed model learns hash functions that provide a uniform mapping to one standard hash space with minimum distance among projected data points. The overall objective function (similarity preserving + quantization error) is formulated as:
Here λ, η are the balancing parameter, A and D are parameters of the binary quantizer, C is used to define inter and intra modal correlation matrix between X and Y and \( U,V \in \left\{ { \pm 1} \right\} \) are binary codes for X and Y. Later in quantization phase, two different quantizers are generated for two separate modalities viz. image and data which leads to end-to-end binary optimizers.
4.1.5 Deep hashing
In all hashing methods, the quality of extracted image features will affect the quality of generated hash codes. To ensure good quality and error free compact hash codes a joint learning model is needed to incorporate feature learning and hash value learning simultaneously. The model consists of different stages of learning and training deep neural networks. Deep hashing model has three simple steps to generate individual hash codes: (a) Image input (b) generation of intermediate features using convolution layer (c) a divide and encode module to distribute intermediate features into different channels further each channel is encoded into the hash bit. Representative methods (Abbas et al. 2018) are based on Recurrent Neural Networks (RNN) and Convolutional Networks (CNN). Some of these methods are listed and discussed below.
4.1.5.1 Point-wise deep learning
Lin et al. (2015) suggested a deep learning framework for fast ANN search. The main aim is to generate compact binary codes driven by CNN. Instead of applying learning separately on image representation and binary codes, simultaneous learning has been adopted with the assumption of labeled data. The proposed approach implemented in three steps: (a) supervised pre-training on the dataset (b) fine tuning the network (c) image retrieval. For computationally cheap large scale learning with compact binary codes, multiple visual signatures are converted to binary codes. Following the data independence approach, the proposed approach is highly scalable which lead to very efficient and practical large scale learning algorithms.
4.1.5.2 Pair-wise labels based supervised hashing
Li et al. (2016) addresses the issue of optimal compatibility among handcrafted features and hashing function used in various hashing methods. Simultaneous learning has been adopted, instead of applying learning separately on feature and hash code. The proposed end-to-end learning framework contains three main elements: (a) deep neural network for learning (b) hash function, which takes care of mapping between two spaces (c) loss function that is used to grade the hash code led by the pairwise label. The overall problem (feature learning + objective function) is formulated as:
Here θ represents the all parameters of the 7 layers, \( \emptyset \left( {{\text{x}}_{\text{i}} ;\uptheta} \right) \) denotes the output of the last Full layer, v is the bias vector and \( \eta \) is the hyper-parameter. Following the principles, deep architecture integrates all three components which further permit the cyclic chain of feedback among different parts.
4.1.5.3 Regularized learning based bit scalable hashing
Zhang et al. (2015) incorporate the concept of bit scalability to compute similarity among the images. For rapid and efficient image retrieval the author group training images into a pack of triplet sample. The author assumes that each sample consists of two images with a similar label and one with the dissimilar label. In particular, the learning algorithm has been implemented in a batch-process fashion that makes use of stochastic gradient descent (SGD) for minimizing the objective function in large-scale learning. The objective function is formally written as follows:
Here \( D_{{\mathbf{w}}} \left( {r_{i} ,r_{i}^{ + } ,r_{i}^{ - } } \right) = {\text{M}}\left( {r_{i} ,r_{i}^{ + } } \right) - {\text{M}}\left( {r_{i} ,r_{i}^{ - } } \right) \) with \( r_{i} ,r_{i}^{ + } ,r_{i}^{ - } \) are the approximated hash codes,\( {\text{M}} \) is weighted Euclidean distance, \( C = - \frac{\text{q}}{2} \) for q bit hashing code, \( R = \left[ {r_{1} \widehat{\text{w}}^{{\frac{1}{2}}} ,r_{2} \widehat{\text{w}}^{{\frac{1}{2}}} , \ldots ,r_{T} \widehat{\text{w}}^{{\frac{1}{2}}} } \right] \) for T number of images and \( \omega \) and \( \uplambda \) are the parameter of hashing function and hyper-parameter for balancing respectively.
4.1.5.4 Similarity-adaptive deep hashing
For learning similarity-preserving binary codes Shen et al. (2018) proposed an unsupervised deep hashing method. To introduce similarity preserving binary codes, the author uses anchor graph to propose pair-wise similarity graph. The anchor graph provides nonlinear data-to-anchor mapping, and they are easy to build in linear time which is directly proportional to a total number of data points. The proposed approach implemented in three steps: (a) Firstly, Euclidean loss layer has been introduced to train the deep model for error control (b) Secondly, the pair-wise similarity graph has been updated to make deep hash model and binary codes more compatible. (c) Finally, alternating direction method of multipliers (Boyd et al. 2010) is used for optimization. The updating of similarity graph is highly dependent on the output representations of deep hash model which subsequently improves the code optimization.
4.1.6 Online hashing
Existing data dependent and independent hashing schemes follows batch mode learning algorithms. That is learning based hashing methods demands massive labeled data set in advance for training and learning. Providing gigantic data in advance is infeasible. A new hashing technique that is focusing on updating of a hash function with a continuous stream of data has been developed known as online hashing. Some of the representative methods are listed and discussed below.
4.1.6.1 Kernel-based hashing
Huang et al. (2013) proposed a real-time online kernel based hashing which has its origins in the problem of large data handling in existing batch-based learning schemes. In other contexts, the online learning is known as the passive aggressive learning. It is first introduced by Crammer et al. (2006). The objective function for updating projection matrix is inspired by structured prediction and given as below:
Here C is the aggressiveness parameter and \( \upxi \) ≥ 0.
4.1.6.2 Adaptive hashing
Cakir and Sclaroff (2015) presented adaptive hashing, a new hashing approach that makes use of SGD for minimizing the objective function in large-scale learning. The objective function is defined as:
An update strategy is utilized for deciding in what amount any hash function need to update and which of the hash function need to be corrected. W is updated as follows: \( W^{t + 1} = W^{t} - \eta^{t} \nabla_{\text{W}} l\left( {f\left( {x_{i} } \right),f\left( {x_{j} } \right);W^{t} } \right) \). Here \( \eta^{t} \) is the constant value, \( \nabla_{\text{W}} \) is obtained approximating the sgn() function with sigmoid. During online learning orthogonality regularization is required to break the correlation among decision boundaries. Adaptive hashing is highly flexible and iterative as it updated the hash function with the speed of streaming data.
4.1.7 Quantization for hashing
Every approximate nearest neighbor searching techniques comprise two stages: projection and quantization. Initially, the data points are mapped into low dimensional space. Next, each assigned value quantized into binary code. During quantization information loss is instinctive, but in any bit selection approach for quantization, similarity preservation of Hamming and Euclidean distance and independence between bits are other major issues. A representative method includes single bit quantization (Indyk and Motwani 1998), double bit quantization (Kong and Li 2012), multiple bit quantizations (Moran et al. 2013) and much more. Some of these methods are listed and discussed below.
4.1.7.1 Variable bit quantization
Moran et al. (2013) proposed a data driven variable bit allocation per locality sensitive hyperplane hashing for quantization stage of hashing based ANN search. In previous widely popular approaches SBQ (Indyk and Motwani 1998), DBQ (Kong and Li 2012), NPQ (Moran et al. 2013) and MQ (Kong et al. 2012) it is taken for granted that each hyperplane has been assigned with 1 or 2 bit respectively and in case of any method violate the defined assignment principle then either bits are discarded or other hyperplanes serves with lesser bits accordingly. Initially, in order to allocate a variable number of bits to each hyperplane, the F-measure has been computed for each hyperplane. The principle idea behind F-measure calculation is that large informative hyper-planes results in higher F-measure.
4.1.7.2 Most informative hash bit selection
Liu et al. (2013) proposed a bit selection method named NDomSet which unify different selection problem into a single framework. The author presents a new family of hash bit selection from a pool of hashed bits which further grows into the discovery of standard dominant set in the bit graph. In this approach, firstly an edge-weighted graph is made, representing the bit pool. The proposed approach consisted of bit selection as quadratic programming to deal with similarity preservation and non-redundancy properties of bits. The experimental results show that the proposed non-uniform bit selection strategy perform well while using hash bits generated by different hashing methods viz. ITQ (Gong et al. 2013), SPH (Weiss et al. 2008), RMMH (Joly and Buisson 2011).
4.1.7.3 Exploring code space through multi bit quantization
Wang et al. (2015) address the issue of quantization error and neighborhood structure of raw data. The author introduced an innovative multi-bit quantization scheme to use available code space at its maximum. To depict the similarity preservation among Hamming and Euclidean distance space, a distance error function has been introduced. They also proposed an O(n3) algorithm for optimization to reduce the computation time. Results obtained by experiments demonstrate a possible improvement in search accuracy due to proposed quantization method. They also demonstrate the effectiveness of Hamming, Quadra and Manhattan distance on multi-bit quantization approach.
Table 2 compares various hash based indexing techniques regarding their pros, cons, dataset, feature used, evaluation measure and experimental results. Table 3 lists a brief introduction to different datasets used in hash based indexing techniques.
4.2 Non-hash based indexing
Non-hash based methods are classified in various categories viz. tree, bitmap, machine learning, deep learning and soft computing based. To maximize the scope of non-hash based methods here, we consider every technique one by one in order.
4.2.1 Tree based techniques
Earlier nearest neighbor searching methods are tree-based, and there is a need for indexing structure to partition the data space. Further different similarity measurement metrics, space partitioning, and pivot selection techniques are adopted to compute the nearest neighbor among image features. Due to these joint efforts, a large class of tree-based indexing techniques is available in literature such as R-Tree (Guttman 1984), KD-Tree (Friedman et al. 1977), VP-Tree (Markov 2004) and M-tree (Ciaccia et al. 1997). Studies below stressed on some essential techniques in large image datasets.
4.2.1.1 Pivot selection based
Indexing schemes based on reference (pivot) objects results in minor distance computation and disk accesses. The different pivot selection algorithms compete for selection of right pivots, the number of pivots, pre-computed distances, and distribution of pivots. Pivot selection techniques are classified into two categories: Pivot partitioning and Pivot filtering. Further partitioning can be done in two different ways ball partitioning and hyperplane partitioning. Some of these techniques are listed and discussed below.
-
(i)
Use of Spacing-Correlation Objects Selection for Vantage Indexing
Van Leuken et al. (2011) propose an algorithm to select a set of pivots carefully. The proposed vantage indexing makes use of a randomized incremental algorithm for the selection of a set of pivots. The two-pronged scheme firstly proposes criteria to measure the quality of pivots and secondly provides a pivot selection scheme with the condition of no random pre-selection. They have proposed two new quality criteria for variance of spacing and correlation, defined as:
Here \( \mu \) is the average spacing \( \sigma \) be the variance of spacing, A and V are objects and vantage objects respectively, \( d\left( {\cdot,\cdot} \right) \) be the distance function and C be the linear correlation coefficient.
-
(ii)
Cost-Based Approach for Optimizing Query Evaluation
Erik and Hetland (2012) proposed a cost-based approach to evaluating pivot selection dynamically. The main aim is to find selective pivots and an exact number of pivots required to assess a query. Initially, to perform a sequential search by skipping the searching in indexes, the cost model has been used. Quadratic Form Distance is used to compare histograms, and Euclidean distance has been used for experimental measurements. This approach believes in the static use of pivots (Traina et al. 2007) and the principle of maximizing the distance between pivots strengthen the approach.
-
(iii)
Improving Node Split Strategy for Ball-Partitioning
De Souza et al. (2013) described ball-partitioning-based metric access methods that able to reduce the number of distance calculation and fast execution of distance-based queries. Node split strategies of M-tree and slim tree are too complex. The main aim is to propose the modified node split strategies. For better pivot selection, to avoid unbalanced splits and to categorize the nodes in different sets, three different algorithms viz. maximum dissimilarity, path distance sum based on prim’s algorithm and reference element have been proposed. The proposed methods are shown to be efficient in the number of distance calculations and the time spent to build the structures.
-
(iv)
Efficient k-closest pair queries by considering Effective Pruning Rules
Gao et al. (2015) proposed several algorithms for closest pair query processing by developing more effective pruning rule. The contribution of this paper is twofold: minimizes the number of distance computations as well as the number of node accesses. The proposed approach consisted of depth-first and best-first traversals to deal with duplicate accesses. Query efficiency is achieved by the employment of new pruning rules based on metric space. Experimental results on different data sets proved that the proposed scheme reached minimum distance computation and minimized I/O overhead.
-
(v)
Metric all-kNN search by Considering Grouping, Reuse and Progressive Pruning Techniques
Chen et al. (2016) proposed a novel method for All-k-Nearest-Neighbor Search named Count M-tree (COM). The contribution of this paper is twofold: minimizes the number of distance computations as well as some node accesses. The indexing method relies on dynamic disk-based metric indexes which use different pruning rules, grouping, recycle and pruning methods. The strength of presented scheme is that the query set and the object set share the same dataset as no different dataset required to train them separately.
-
(vi)
Radius-Sensitive Objective Function for Pivot Selection
Mao et al. (2016) proposed an improved metric space indexing which is based on the selection of several pivots. The system performs following functions: Firstly, they present importance of pivot selection. Their criterion for pivot selection is based on relevance and distance among pivot objects. An extended pruning mechanism has been presented with a framework to fix and select some relevant pivots. Radius-sensitive objective function for pivot selection is to maximize:
Here S is the dataset in metric space, \( L_{\infty } \) is the distance.
4.2.1.2 Clustering based
The grouping of semantically similar images into clusters suggests a novel framework for nearest neighbor search in image retrieval. Instead of matching large part of image data set with query image it is meaningful to match a representative image(s) from a cluster. Following the principles, clustering based techniques work for a particular dataset. Varieties of clustering methods are available in the literature. Some of these methods are listed and discussed below.
-
(i)
Priority Queues and Binary Feature based Scalable Nearest Neighbor Search
Muja and Lowe (2014) proposed a priority queue based algorithms for approximate nearest neighbor matching and proposed an algorithm for matching binary features also. The focus of this algorithm is to extend in finding a large number of closest neighbors. They have developed an extended version using a well-known best-bin-first strategy. A small number of iterations considerably cut down the tree build time which further maintains the search performance. The author also comes up with an open source library called the fast library for approximate nearest neighbors (FLANN) for the use of research community.
-
(ii)
Indexing and Packaging of Semantically Similar Images into Super-Images
Luo et al. (2014) work on the packaging of semantically similar images into super-images. The fact behind this proposal is the strong relevance of the images into a dataset. The concept of super-image effectively bundle the multiple images into a single unit of same relevance and significantly decreases the size of the index. Semantic attribute extraction is the main issue in index construction. The attributes are extracted during packaging of one super-image i.e. during off-line indexing to make fast index structure. Visual compactness of a superimage candidate is calculated as:
Here TF is the normalized term frequency vector and dist() is the cosine distance.
-
(iii)
Image Discovery through Clustering Similar Images
Zhang and Qiu (2015) proposed a scheme to discover landmark images in large image datasets. For rapid and efficient image retrieval the author group semantically similar images into clusters. One landmark image with different viewpoints adequately packed into a sub-cluster. Clusters can be partially overlapped. Each sub-cluster contains a center called as bundling center. Further, the bundling center of sub-cluster acts as a representative of the sub-cluster, to avoid exact image matching the scheme performs image matching by placing the bundling center.
4.2.1.3 Other techniques
This half contains the approximation, relevance feedback and some other techniques for VIR. Retrieval of images by approximation, relevance feedback or by some other means viz. online techniques and query as video demands extra efforts but results in fine-grained results. Some of the representative methods are listed and discussed below.
-
(i)
Indexing via Sparse Approximation
Borges et al. (2015) propose a high-dimensional indexing scheme based on sparse approximation techniques. The focus of this scheme is to improve the retrieval efficiency and to reduce the data dimensionality by designing a dictionary for mapping the feature vectors onto sparse feature vectors. The proposed scheme switches its direction to compute the high-dimensional sparse representations based on regression with the condition of preserved maximum locality. They showed that traversal of the data structure would be independent of metric function, low storage space required for efficient encoding of sparse representation and search space pruned efficiently.
-
(ii)
Use of Hybrid Segmentation and Relevance Feedback for Colored Image Retrieval
Bose et al. (2015) proposed a new Relevance Feedback (RF) based VIR. The first advantage of the proposed scheme is feature-reweighting for relevance feedback i.e. to compute relevance score and weights of features the combination of feature-reweighting and instance based cluster density approach are used. The second advantage is a good utilization of image and shape contents. This scheme extracts the color and shape information through the color co-occurrence matrix (CCM) and segmentation of the image respectively. Here, unrestricted segmentation (k-mean) is used to segment the images. The relevance feedback scheme is initialized with three different approaches: intersection approach, union approach, and a combination approach. They have proposed two new measures retrieval efficiency, false discovery respectively to address the accuracy of retrieval.
-
(iii)
Parallelism based Online Image Classification
Xie et al. (2015) propose a united algorithm for classification and retrieval named ONE (Online Nearest-neighbor Estimation). They observed that image classification and retrieval fundamentals are same and similarity measurement function could launch both of them. Its overall aim is to utilize the GPU parallelization to make the fast computation fully. The dimension reduction scheme is initiated with the help of both PCA and PQ. The scheme relies on feature extraction, training, quantization and an inverted index structure.
-
(iv)
Query by Video Search
Yang et al. (2013) proposed a priority queue based algorithms for feature description and proposed a cache based bi-quantization algorithm also for information retrieval concept implementation. This method considers a short video clip as a query. Further, to find stable and representative good points among SIFT features, scheme perform feature tracking (Ramezani and Yaghmaee 2016) within video frames. The calculation of good point is formulated as:
Here \( S\left( {p_{i}^{j} } \right) \) denotes stableness of the point, Len() represents number of frames being tracked, and Framecount denotes the total number of frames in video query. Query representation is initiated by combining good points into a histogram.
Table 4 compares various tree-based indexing techniques regarding their pros, cons, dataset, feature used, evaluation measure and experimental results. Table 5 lists a brief introduction to different datasets used in tree-based indexing techniques.
4.2.2 Ranking based
Another category of tree-based indexing technique exists in literature to rectify the distance computation cost and index building cost by the use of different ranking strategies. In comparison to other methods, most of the ranking based methods are independent of distance measures. By exploring the ranking order and post processing, it is easy to the accurate and fast construction of index. The ranking scheme can be further extended to graph based, manifold ranking, supervised and unsupervised techniques.
4.2.3 Deep learning based
The need for full utilization of feature extraction, processing, and indexing in VIR shifted the research direction towards deep learning. The recently proposed models map low-level features into a high level with the help of nonlinear mapping techniques. Different feature extraction networks are available in literature viz. Alexnet (Krizhevsky et al. 2012), Goognet (Szegedy et al. 2015) and VGG (Simonyan and Zisserman 2014). Issues like number of layers in a network, distance metric, indexing techniques and much more are still unanswered and need to be benchmarked. Representative methods are based on RNN and CNN.
4.2.4 Machine learning based
It is essential to understand the discrepancy between low-level image features and high-level concept to design good applications for VIR. This leads to the so-called semantic gap in the VIR context. To reduce the semantic gap different classification and clustering techniques under machine learning are available. The support vector machine (SVM) and manifold learning are used to identify the category of the images in the dataset. Relevance feedback is also a good alternative. The level of learning and feedback further categorize learning methods in ‘active’ and ‘passive’ learning and ‘long’ and ‘short’ term learning approaches.
4.2.5 Soft computing based
Soft computing is combined effort of reasoning and deduction that employ development of membership and classification. The key to any productive soft computing based CBIR technique is to choose the best feature extraction scheme. Some of the soft computing techniques are Artificial Neural Network, Fuzzy Logic, and Evolutionary Computation. Above listed methods are discussed in Table 6.
In the previous half we present a detailed review of hash and non-hash based indexing techniques and we found that hash and non hash (tree) based techniques are totally different in nature. Generally speaking, in comparison to hash based techniques, the tree based techniques have following serious issues:
-
(1)
Tree based methods are in need of large storage requirement in comparison to hashing based methods (sometimes more than the size of dataset itself) and the situation becomes worse when managing high dimensional datasets.
-
(2)
For high dimensional datasets, in comparison to hashing based methods the retrieval accuracy of tree based methods approaches to linear search as backtracking takes long search time.
-
(3)
The use of branch and bound criteria in tree based method makes them computationally more expensive as they are unable to stop after finding the optimal point and continuing in search of other points whereas in hashing based methods the criteria is to stop the search once they find a good enough points.
-
(4)
On behalf of partitioning the entire dataset the hashing based methods repeatedly partition the dataset to generate a one ‘bit’ hash from each partitioning whereas tree based methods uses the recursive one.
On the application side tree based methods are applicable and useful when we have low dimensional datasets and user wanting exact nearest neighbor search. In the era of big data and deep learning, hashing based techniques are more suitable for high dimensional datasets and nearest neighbor search with low online computational overheads. Further, different intents and needs of users bring up unheard challenges as discussed in Sect. 7 later, all these challenges are in the scope of hash based methods. So we surely handle all of these issues by employing advanced hashing techniques. Therefore, to ensure fair comparisons a summary of their potential is presented in Table 7.
5 Evaluation framework
In this section, we evaluate hashing techniques by careful analysis of results in the literature and approaches surveyed in this paper. By focusing on experimental works, we make an analysis of large number of notable hash based indexing techniques whose codes are available online. The experiments are run on an Intel Core i7 (4.20 GHz) with 32 GB of RAM, and Windows 10 OS. All the strategies are implemented in Matlab R2017b using the same framework to allow a fair comparison (Table 8).
5.1 Description of data
For the experiments regarding large scale similarity search and image retrieval we resorted to the five data sets: NUS-WIDE, CIFAR, SUN397, LabelMe, Wiki. The five datasets are chosen for their qualities viz. diverse, accessible, large size, and a rich set of descriptor considering different properties of the image. A large number of datasets are available in the literature as listed in Table 3 with their license, content, and accessibility issues. We have only opted general image datasets as they are largely opted by state-of the-art.
5.2 Evaluation metrices
The majority of datasets and techniques use Mean Average Precision (MAP) as the central evaluation metric for experiments. Along with MAP, they consider Mean Precision, Mean Classification Accuracy (MCA), Precision and Recall of Hamming distance 2. They also use two different metrics for evaluating retrieval: (i) Normalized Discounted Cumulative Gain (NDCG) using Hamming Ranking (ii) Average Cumulative Gain (ACG) using Hamming Ranking.
5.3 Evaluation mechanisms
The evaluation of system decides how far the system accomplish user’s needs and technically which methodology is best for feature selection feature weighting, and hash function generation to make efficient and accurate retrieval process. Accordingly, researchers have explored a variety of ways to assessing user satisfaction and general evaluation of Image Retrieval system. It has always been a challenging and difficult matter for image retrieval importantly due to semantic gap (Wang et al. 2016) and further it is more problematic to pick out relevant set in the image database. There exist different ways of evaluating Image Retrieval systems in the literature are described below.
-
(1)
Precision It is a measure of exactness which pertains to the fraction of the retrieved images that is relevant to the query.
-
(2)
Recall It is the measure of completeness which refers to the fraction of relevant images that is responded to the query.
-
(3)
Average precision This is the ratio of relevant images to irrelevant images in a specific number of retrieved images.
-
(4)
Mean average precision This is the average of the average precision value for a set of queries.
-
(5)
Normalized discounted cumulative gain (NDCG): It is the measure of uniformity between ground-truth relevance list to a query and estimated ranking positions.
-
(6)
F-measure It is combined measure that assesses precision/recall tradeoff.
Besides these evaluation measures there exist some measures which can strengthen the evaluation procedure despite semantic gap type of challenges.
-
(1)
The size of index It determines the storage utilization of generated Index. Practically the size of the index must be a fraction of dataset size.
-
(2)
Index compression Some indexing techniques generate short hash codes or other similar codes for image data thereby reducing the storage requirement of Index.
-
(3)
Multimodal indexing This refers to the ability of the index to support cross-media retrieval. As per current scenario the user intent to search via query by keywords, query by image or combination of both. Practically being multimodal, a system must support text to text, text to image and image to image search.
The metrics and measures mentioned above do not quantify user requirements. Other than image semantic, the different user intent may contain image clarity, quality, and associated meta-data. The satisfaction of user highly depends on the following factors:
-
(1)
User effort This factor decides the role of the user and their efforts in devising queries, conducting the search, and viewing the output.
-
(2)
Visualization This refers to the different ways to display the results to the users either in linear list format or 2-D grid format. Further, it influences the user’s ability to employ the retrieved results.
-
(3)
Outcome coverage This factor decides to which level the relevant images (by agreed relevant score) are included in the output.
5.4 Evaluated techniques and results
To evaluate the large-scale similarity search accuracy and effectiveness, we compare some hashing methods. To allow the comparison the most important aspects to evaluate is the algorithm performance metric as discussed in Sect. 5.2. Figure 4 below shows the comparison of various unsupervised data dependent techniques on CIFAR (GIST features) and SUN397 (CNN features) datasets.

Comparison of Data-Dependent Hashing (Unsupervised) methods
It is evident from the Fig. 4a that AIBC (Shen et al. 2017) performed better than other unsupervised techniques. The AIBC improved Mean Average Precision nearly 2%, 4% and 9% for code length 32, 64 and 128 bits. The MAP results for various unsupervised data dependent are examined on the SUN397 dataset. Best score of MAP are obtained by AIBC because the correlation among inner products in this approach is maximum, the key to generating high-quality codes. Figure 4b displays the comparison of various techniques with AIBC regarding MAP values. The AIBC improved the MAP nearly 8% for code length 64 and 128 bits.
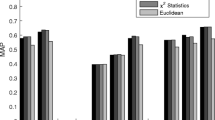
In Fig. 5 we compare the performance of Column Sampling based Discrete Supervised Hashing (Kang et al. 2016) with state-of-the-art. Figure 5a presents the MAP obtained with values of code length ranging from 32, 64 and 128 bits. It can be seen that the column sampling based discrete hashing improved the MAP nearly 16%, 12% and 12% for code length 32, 64 and 128 bits respectively on CIFAR (GIST features) dataset. Figure 5b displays the comparison regarding MAP value for NUSWIDE (GIST features) dataset. The COSDISH improved MAP nearly 6% for code length 32, 64 and 128 bits with the use of column sampling technique to sample similarity matrix columns iteratively.

Comparison of Data-Dependent Hashing (Supervised) methods
The ranking quality of retrieved results for Ranking based Hashing on the NUS-WIDE (GIST features) dataset is displayed in Fig. 6. NDCG@K is used to evaluate the ranking quality. Here K represents the value of retrieved instance. The figure presents the value of NDCG obtained with values of K ranging from 5 to 20 for 64 hashing bits. The Ranking preserving hashing improved NDCG nearly 1% under NDCG@5, 10 and 20 measures.

Comparison of Ranking Based Hashing methods on NUS-WIDE
Next, the comparison of various Multi-Modal techniques on WiKi (CNN features for image data and skipgrams for text data) and NUS-WIDE (SIFT features for image data and binary tagging vector for text data) datasets has been represented. Figure 7a depicts the MAP values results on Wiki dataset for the image to image search. The MAP value results are observed for 32, 48 and 64-bit code length. The ACQ (Irie et al. 2015) improved the values approximately 1.5%, for three different code lengths respectively. Figure 7b also displays the comparison regarding MAP values among various techniques on Wiki dataset for the text to image search. Here we show the comparison of ACQ (Irie et al. 2015) with state-of-the-art multi-modal techniques. The ACQ improved the values nearly 4, 3 and 2% for 32, 48 and 64-bit code length respectively. Figure 7c depicts the MAP values results on NUS-WIDE dataset for the text to image search. Here we show the comparison of Semantics-Preserving Hashing (Lin et al. 2015) with state-of-the-art multi-modal techniques. The probability based SPH showed an average maximum improvement of 19% for 32, 48 and 64-bit code length respectively.

Comparison of MultiModal Hashing methods
The image retrieval results for Deep Hashing on CIFAR and NUSWIDE dataset are displayed in Fig. 8. The figure presents the value of MAP obtained for different values of hash code length viz. 32, 48 and 64 bits. Figure 8a depicts the MAP values results on CIFAR dataset. The Pair-wise Labels based Supervised Hashing (Li et al. 2016) improved MAP by 13, 12 and 12% respectively. Figure 8b also displays the comparison regarding MAP values among various techniques on NUS-WIDE dataset. The DPSH (Li et al. 2016) improved the values nearly 2, 3 and 3% respectively.

Comparison of Deep Hashing methods
Figure 9 list the retrieval results of Adaptive Hashing, Online hashing and other Batch Hashing techniques are examined on LabelMe (GIST features) dataset. The MAP values for different hash code length generated by Adaptive hashing are not very promising. BRE (Kulis and Darrell 2009) showed an average maximum improvement of 6% in MAP on other batch techniques and 4% as compared to online methods. Further, it is observed that the concept of adaptive hashing (Cakir and Sclaroff 2015) does not put much impact on MAP values of kernel-based online hashing (Huang et al. 2013).

Comparison of Adaptive Hashing, Online hashing, and other Batch Hashing techniques on LabelMe
From the above evaluations, we draw the following conclusions:
-
(1)
Supervised learning methods mostly attain good performance in comparison to unsupervised learning methods. As, the supervised method uses labeled data to learn hash codes and committed to maintaining semantic similarity constructed from semantic labels. In comparison to unsupervised methods, supervised methods are slower during learning of large hash codes due to labeled data. This slowness can be overcome by incorporating deep learning concept.
-
(2)
The performance of multimodal retrieval methods is totally guided by the quality of feature set. The results of text to image search are better than image to image search for multimodal datasets. The direct extension of two- modality algorithm into three or more modality is not possible.
-
(3)
The methods like adaptive hashing and online hashing does not provide promising results. Even, the concept of adaptive hashing does not put much impact on performance of kernel-based online hashing.
-
(4)
Nearest neighbor search on optimized compact hash codes of large dataset induces suboptimal results. By exploring the ranking order and accuracy, it is easy to evaluate the quality of hash codes. Associated relevant values of hash codes help to maintain the ranking order of search results.
6 Multimedia indexing evaluation programs
There are several well-instituted evaluation campaigns and meetings which provide test-bed and metric based environment to compare different proposed solutions in image retrieval domain. In this section, we describe various evaluation campaigns in image retrieval organized by the University of Sheffield, Stanford University, Princeton University and various research groups.
6.1 MediaEval
MediaEvalFootnote 1 Benchmarking Initiative is a benchmarking activity organized by various research groups devoted to evaluating a new algorithm for multilingual multimedia content access and retrieval. It set out initially to benchmark some tasks related to the image, video, and music viz. Tagging Task for videos including Social Event Detection, Subject Classification, affect task, later from 2013 it sets to benchmark Diverse Images task.
The goal of Diverse Images task is to retrieve images from tourist images dataset that is participants has to refine (reorder) provided a ranked list of photos by maintaining diversity and representativeness. As a novelty in 2015, the diverse image task has been extended to multi-concept, ad-hoc, queries scenario. The dataset used for campaign is of small size having general-purpose visual/textual descriptors. It contains 95,000 images, splits into 50% for designing/training and 50% for evaluating. Different metric are considered to evaluate the system: Cluster Recall, Precision and F-measure. The evaluation of ranking (F-measure score) has been done by visiting the first page of the displayed outcome only. Other popular evaluation metrics are intent-aware expected reciprocal rank and the Normalized discounted cumulative gain (NDCG). Table 9 shows the evolution of MediaEval tasks over the year.
6.2 ImageCLEF
This evaluation forumFootnote 2 was initiated by University of Sheffield in 2003 nowadays it is run by individual different research groups. Initially, it is launched as a part of CLEF.Footnote 3 As mentioned on the website: It is a series of challenges to promote concept based annotation of images and multimodal and multilingual retrieval both. The first image retrieval track was included in 2003, where the objective was to perform similarity search and to find relevant images related to a topic in the cross-language environment. In 2004, Visual features were included the first time in any image CLEF track. The task was to perform image (tagged by English captions) search with text queries and visual features based medical image retrieval and classification. Over the year, it considers a broad range of topics related to multimedia retrieval and analysis. Different tracks under imageCLEF challenge are listed in Table 10.
6.3 ILSVRC
ILSVRC is in its 8th year in 2017 and is governed by a research team from Stanford and Princeton University respectively. The ImageNetFootnote 4 large scale task organized (since 2010) some object category classification and category detection task to promote the evaluation of proposed retrieval and annotation methods. Over the year ILSVRC consists of following tasks: Image classification (2010–2014), Single-object localization (2011–2014) and Object detection (2013–2014) and different dataset for testing and training and evolution tasks are listed in Tables 11 and 12 respectively.
7 Open issues and future challenges
Over the years, image retrieval has come a long way from simple linear scan techniques to more traditional learning and hashing techniques such as rank-based, deep learning, multimodal and online hashing techniques. Interest in topics such as quantization, supervised and unsupervised hashing is also increasing. The field of multimedia retrieval has witnessed different indexing techniques for data analysis. Further, different intents and needs of users bring up unheard challenges. We discuss some open and unresolved issues as follows:
7.1 A collection of big multimodal dataset
Instead of the uni-modal retrieval system, multiple unimodal systems can be combined to obtain multimodal retrieval system. To study and retrieve information across various modalities have been widely adopted by different research communities. There is an urgent need of large, annotated, easily available, and benchmarked multimodal dataset to train, test and evaluate multimodal algorithms.
7.2 Utilization of labeled and unlabeled data samples to learn
Earlier VIR systems were simple, and were answerable to small datasets only i.e. they were independent or partially dependent on side (extra/labeled information. Simultaneous learning of labeled and unlabeled data samples put more complications in modern labeled information based systems. The ignorance of unlabelled database samples and a limited selection of these samples are the generic drawbacks of current approaches. Hence, need to utilize labeled and unlabeled data samples jointly for a better active learning.
7.3 Unsupervised deep learning
The need for full utilization of feature extraction, processing and indexing in VIR shifted the research direction towards deep learning. The recently proposed models map low-level features into a high level with the help of nonlinear mapping techniques. Researchers adopt the idea of supervised deep learning because it is a mature field and is in its middle stages of development. Human and animal learning is largely unsupervised which opens the door for researchers to develop future VIR system.
7.4 Multi feature fusion
To fulfil diverse user needs it becomes more challenging to develop fast and efficient multimodal VIR system as the traditional single feature or uni-modal based VIR system are lopsided. Better mechanism for fusing the multiple features for hash generation and learning are to be determined as assimilation of feature fusion concept can lessen the effect of well known Semantic gap.
7.5 Open evaluation program
Differences in technical capacities and data availability enlarge the VIR research gap between academics and industry based real application. A large number of researchers in academics bound to available resources and it is difficult to achieve industry based real application solution for them. It is necessary to organize open evaluation program to bridge this gap. The most felicitous part of organizing the open program is that they provide a common platform to industry and academic researchers to exchange more practical solutions. Further they jointly look into the key difficulties in different real time scenarios to develop application-independent methods.
The complete report of datasets, evaluation results, and the list of participants can be reviewed from the annual evaluation reports and websites of the challenges discussed above.
8 Conclusion
In this paper, we restrict ourselves to images and leave text and video indexing as a distinct topic. We propose to review two categories of indexing techniques developed for nearest neighbor search: (1) Hash based Indexing, and (2) Non-Hash based Indexing. These two categories contribute in many nearest neighbor search and similarity search techniques to provide efficient search capabilities. Further, the different methods of hash based and non-hash based indexing are categorized with brief details of the methodology employed including their pros and cons. Evaluation results are presented on various datasets for Hash-based techniques. A large number of potentially productive application areas and some relevant research domains, such as soft computing, clustering, ranking and deep learning have also been overviewed. We have summarized the open issues and future challenges. Our survey paper offers a number of practical guidelines to the readers:
-
1.
It demonstrates the way to handle and process different types of queries.
-
2.
The paper examines factors viz. query formation, image descriptors, type of hash function, code balancing, similarity measurement and code optimization can demonstrate the performance of hash based indexing techniques. The affect of above mentioned factors has been measured among standard 34 hash based approaches to derive the MAP and NDCG value.
-
3.
Different types of low-level image representation and feature extraction criteria can coexist and be compared. (Multimodal hashing/Deep hashing methods).
-
4.
There is an urgent need of large, annotated, easily available, and benchmarked multimodal dataset to train, test and evaluate multimodal algorithms.
-
5.
There is a need.
-
i.
to utilize labeled and unlabeled data samples jointly for a better active learning.
-
ii.
of better mechanism for fusing the multiple features for hash generation and learning as assimilation of feature fusion concept can lessen the effect of well known Semantic gap.
-
i.
References
Abbas Q, Ibrahim MEA, Jaffar MA (2018) A comprehensive review of recent advances on deep vision systems. Int J Artif Intell Rev. https://doi.org/10.1007/s10462-018-9633-3
Andoni A, Indyk P (2008) Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Int Mag Commun ACM 51(1):117–122
Arulmozhi P, Abirami S (2016) An analysis of BoVW and cBoVW based image retrieval. In: Proceedings of international symposium on big data and cloud computing challenges, pp 237–247
Babenko A, Slesarev A, Chigorin A, Lempitsky V (2014) Neural codes for image retrieval. In: Proceedings of European conference on computer vision, pp 584–599
Baeza-Yates R, Cunto W, Manber U, Wu S (1994) Proximity matching using fixed queries trees. Proceedings of Combinatorial pattern matching. Lecture notes in computer science 807:198–212
Baluja S, Covell M (2008) Learning to hash: forgiving hash functions and applications. Int J Data Min Knowl Discov 17(3):402–430
Bohm C, Berchtold S, Keim DA (2001) Searching in high-dimensional spaces: index structures for improving the performance of multimedia databases. Int J ACM Comput Surv 33(3):322–373
Boiman O, Shechtman E, Irani M (2008) In Defense of nearest-neighbor based image classification. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1–8
Bolettieri P, Esuli A, Falchi F, Lucchese C, Perego R, Piccioli T, Rabitti F (2009) CoPhIR: a test collection for content-based image retrieval. arXiv preprint arXiv: 0905.4627
Borges P, Mourão A, Magalhães J (2015) High-Dimensional indexing by sparse approximation. In: Proceedings of ACM international conference multimedia retrieval, pp 163–170
Bose S, Pal A, Mallick J, Kumar S, Rudra P (2015) A hybrid approach for improved content-based image retrieval using segmentation. arXiv preprint arXiv:1502.03215
Boyd S, Parikh N, Chu E, Peleato B, Eckstein J (2010) Distributed optimization and statistical learning via the lternating direction method of multipliers. Found Trends Mach Learn 3(1):1–122
Bronstein MM, Bronstein AM, Michel F, Paragios N (2010) Data fusion through cross-modality metric learning using similarity-sensitive hashing. In: Proceedings of computer vision and pattern recognition, pp 3594–3601
Cakir F, Sclaroff S (2015) Adaptive hashing for fast similarity search. In: Proceedings of IEEE international conference on computer vision, pp 1044–1052
Chen L, Gao Y, Chen G, Zhang H (2016) Metric all-k-nearest-neighbor search. Proc IEEE Int Conf Data Eng ICDE 28(1):1514–1515
Chua TS, Tang J, Hong R, Li H, Luo Z, Zheng Y (2009) NUS-WIDE: a real- world web image database from national university of Singapore. In: Proceedings of ACM international conference on image and video retrieval, pp 48–56
Ciaccia P, Patella M, Zezula P (1997) M-tree: an efficient access method for similarity search in metric spaces In: Proceedings of international conference on very large data bases, pp 426–435
Crammer K, Dekel O, Keshet J, Shalev-Shwartz S, Singer Y (2006) Online passive aggressive algorithms. J Mach Learn Res 7:511–585
Datar M, Immorlica N, Indyk P, Mirrokni VS (2004) Locality-sensitive hashing scheme based on p-stable distributions. In: Proceedings of annual symposium on computational geometry, pp 253–262
Datta R, Li J, Wang JZ (2005) Content-based image retrieval: approaches and trends of the new age. In: Proceedings of SIGMM international workshop on multimedia information retrieval, ACM, pp 253–262
Datta R, Joshi D, Li J, Wang JZ (2008) Image retrieval: ideas, Influences, and Trends of the New Age. Comput Surv ACM 40(2):1–60
De Souza J, Razente H, Barioni M (2013) Faster construction of ball-partitioning-based metric access methods. In: Proceedings of ACM annual symposium on applied computing, pp 8–12
Delalleau O, Bengio Y, Le Roux N (2005) Efficient non-parametric function induction in semi-supervised learning. In: Proceedings of international workshop Artif. Intelli. Stat., pp 96–103
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: a large-scale hierarchical image database. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 248–255
Deng C, Liu X, Mu Y, Li J (2015) Large-scale multi-task image labeling with adaptive relevance discovery and feature hashing. Int J Signal Process ACM 112:137–145
Ding G, Guo Y, Zhou J (2014) Collective matrix factorization hashing for multimodal data. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2083–2090
Ding K, Huo C, Fan B, Pan C (2015) kNN hashing with factorized neighborhood representation. In: Proceedings of IEEE international conference on computer vision, pp 1098–1106
Donahue J, Jia Y, Vinyals O, Hoffman J, Zhang N, Tzeng E, Darrell T (2014) Decaf: a deep convolutional activation feature for generic visual recognition. In: Proceedings of international conference on international conference on machine learning, pp 647–655
Dosovitskiy A, Springenberg JT, Riedmiller M, Brox T (2014) Discriminative unsupervised feature learning with convolutional neural networks. In: Proceedings of international conference on neural information processing systems, pp 766–774
Duda RO, Hart PE, Stork DG (2000) Pattern classification, 2nd edn. Wiley, Hoboken
Erik S, Hetland L (2012) Dynamic optimization of queries in pivot-based indexing. Int J Multi Tools Apps 60(2):261–275
Farhadi A, Endres I, Hoiem D, Forsyth DA (2009) Describing objects by their attributes. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1778–1785
Fischer P, Dosovitskiy A, Brox T (2014) Descriptor matching with convolutional neural networks: a comparison to SIFT. arXiv Preprint arXiv: 1405.5769v2
Friedman JH, Bentley JL, Finkel RA (1977) An algorithm for finding best matches in logarithmic expected time. ACM Trans Math Softw 3(3):209–226
Gani A, Siddiqa A, Shamshirband S, Hanum F (2016) A survey on indexing techniques for big data: taxonomy and performance evaluation. Int J Knowl Inf Syst 46(2):241–284
Gao S, Tsang IW, Chia L (2013) Laplacian sparse coding, hypergraph laplacian sparse coding, and applications. IEEE Trans Pattern Anal Mach Intell 35(1):92–104
Gao Y, Chen L, Li X, Yao B, Chen G (2015) Efficient k-closest pair queries in general metric spaces. Int J Very Large Data Bases ACM 24(3):415–439
Ge T, He K, Sun J (2014) Graph cuts for supervised binary coding. In: Proceedings of international european conference on computer vision, pp 250–264
Geusebroek J-M, Burghouts GJ, Smeulders AWM (2005) The amsterdam library of object images. Int J Computer Vision 61(1):103–112
Gong Y, Lazebnik S, Gordo A, Perronnin F (2013) Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans Pattern Anal Mach Intell 35(12):2916–2929
Guttman A (1984) R-trees: a dynamic index structure for spatial searching. In: Proceedings of ACM SIGMOD international conference on management of data, pp 47–57
He X, Cai D, Yan S, Zhang HJ (2005) Neighborhood preserving embedding. In: Proceedings of IEEE international conference on computer vision, pp 1208–1213
He X, Cai D, Han J (2008) Learning a maximum margin subspace for image retrieval. IEEE Trans Knowl Data Eng 20(2):189–201
He J, Radhakrishnan R, Chang SF, Bauer C (2011) Compact hashing with joint optimization of search accuracy and time. In Proceedings of computer vision and pattern recognition, pp 753–760
Heo J, Lee Y, He J, Chang SF, Yoon S (2012) Spherical hashing. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2957–2964
Hjaltason GR, Samet H (2003) Index-driven similarity search in metric spaces. ACM Trans Database Syst 28(4):517–580
Huang LK, Yang Q, Zheng W-S (2013) Online hashing. In: Proceedings of ACM international joint conference on artificial intelligence, pp 1422–1428
Huiskes MJ, Thomee B, Lew MS (2010) New trends and ideas in visual concept detection: The MIR-FLICKR retrieval evaluation initiative. In: Proceedings of ACM international conference on multimedia information retrieval, pp 527–536
Indyk P, Motwani R (1998) Approximate nearest neighbors: towards removing the curse of dimensionality. In Proceedings of ACM symposium on Theory of computing, pp 604–613
Ionescu RT, Ionescu AL, Mothe J, Popescu D (2018) Patch autocorrelation features: a translation and rotation invariant approach for image classification. Int J Artif Intell Rev 49:549–580
Irie G, Li Z, Wu X-M, Chang S-F (2014) Locally linear hashing for extracting non-linear manifolds. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2123–2130
Irie G, Arai H, Taniguchi Y (2015) Alternating co-quantization for cross-modal hashing. In: Proceedings of IEEE international conference on computer vision, pp 1886–1894
Jegou H, Douze M, Schmid C (2008) Hamming Embedding and weak geometry consistency for large scale image search. In: Proceedings of european conference on computer vision, pp 304–317
Jegou H, Douze M, Schmid C (2011) Product quantization for nearest neighbor search. IEEE Trans Pattern Anal Mach Intell 33(1):117–128
Ji T (2014) Query-adaptive hash code ranking for fast nearest neighbor search. In: Proceedings of ACM international conference on multimedia, pp 1005–1008
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093
Jiang Q, Li W (2015) Scalable graph hashing with feature transformation. In: Proceedings of international joint conference on artificial intelligence, pp 2248–2254
Joly A, Buisson O (2011) Random maximum margin hashing. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 873–880
Kang WC, Li WJ, Zhou ZH (2016) Column sampling based discrete supervised hashing. In: Proceedings of ACM AAAI conference on artificial intelligence, pp 1230–1236
Kong W, Li WJ (2012) Isotropic hashing. In: Proceedings of international conference advances in neural information processing systems, pp 1655–1663
Kong W, Li WJ (2012) Double-bit quantization for hashing. In: Proceedings of ACM AAAI conference on artificial intelligence, pp 634–640
Kong W, Li WJ, Guo M (2012) Manhattan hashing for large-scale image retrieval. In: Proceedings of the international ACM conference on research and development in information retrieval, pp 45–54
Korytkowski M, Rutkowski L, Scherer R (2016) Fast image classification by boosting fuzzy classifiers. Int J Info Sci 327(C):175–182
Krizhevsky A (2009) Learning multiple layers of features from tiny images. Technical report, University of Toronto
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In: Proceeding of international conference on neural information processing systems. pp 1097–1105
Kulis B, Darrell T (2009) Learning to hash with binary reconstructive embeddings. In: Proceedings of international conference advances in neural information processing systems, pp 1042–1050
Kulis B, Grauman K (2012) Kernelized locality-sensitive hashing for scalable image search. IEEE Trans Pattern Anal Mach Intell 34(6):1092–1104
Kumar S, Udupa R (2011) Learning hash functions for cross-view similarity search. In: Proceedings of international joint conference on artificial intelligence, pp 1360–1365
Kurasawa H, Fukagawa D, Takasu A, Adachi J (2010) Margin-based pivot selection for similarity search indexes. IEICE Trans Inf Syst E93(D6):1422–1432
Lai H, Pan Y, Liu Y, Yan S (2013) Simultaneous feature learning and hash coding with deep neural networks. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 3270–3278
Latecki LJ, Lakmper R, Eckhardt U (2000) Shape descriptors for non-rigid shapes with a single closed contour. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 424–429
Lazaridis I, Mehrotra S (2001) Progressive approximate aggregate queries with a multi-resolution tree structure. In: Proceedings of ACM SIGMOD international conference on management of data, pp 401–412
Le Cun Y, Boser B, Denker JS, Howard RE, HabbardW, Jackel LD, Henderson D (1990) Handwritten digit recognition with a back-propagation network. Advances in neural information processing systems 2, Morgan Kaufmann Publishers Inc., pp 396–404
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Li H (2011) A short introduction to learning to rank. IEICE Trans Inf Syst 94(10):1854–1862
Li X, Lin G, Shen C, van den Hengel A, Dick A (2013) Learning hash functions using column generation. In: Proceedings of international conference on international conference on machine learning, pp 142–150
Li W, Zhao R, Xiao T, Wang X (2014) Deepreid: deep filter pairing neural network for person re-identification. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 152–159
Li W, Wang S, Kang W (2016) Feature learning based deep supervised hashing with pairwise labels. In: Proceedings of ACM international joint conference on artificial intelligence, pp 1711–1717
Lin G, Shen C, Suter D, van den Hengel A (2013) A general two-step approach to learning-based hashing. In: Proceedings of IEEE international conference on computer vision, pp 2552–2559
Lin G, Shen C, Shi Q, van den Hengel A, Suter D (2014) Fast supervised hashing with decision trees for high dimensional data. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1971–1978
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollar P, Zitnick L (2014) Microsoft coco: common objects in context. In: Proceedings of European conference on computer vision, pp 740–755
Lin Z, Hu M, Wang J (2015) Semantics-preserving hashing for cross-view retrieval. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 3864–3872
Lin K, Yang H, Hsiao J, Chen C (2015) Deep learning of binary hash codes for fast image retrieval. In: Proceedings of IEEE conference on computer vision and pattern recognition workshops, pp 27–35
Liu W, Wang J, Kumar S, Chang SF (2011) Hashing with graphs. In: Proceedings of international conference machine learning, pp 1–8
Liu W, Wang J, Mu Y, Kumar S, Chang SF (2012) Compact hyperplane hashing with bilinear functions. In: Proceedings of international conference on machine learning, pp 467–474
Liu W, Wang J, Ji R, Jiang YG, Chang SF (2012) Supervised hashing with kernels. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2074–2081
Liu X, He J, Lang B, Chang SF (2013) Hash bit selection: a unified solution for selection problems in hashing. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1570–1577
Liu W, Mu C, Kumar S (2014) Discrete graph hashing. In: Proceedings of ACM international conference on neural information processing systems, pp 3419–3427
Liu X, Deng C, Lu J, Lang B (2015) Multi-view complementary hash tables for nearest neighbor search. In: Proceedings of IEEE international conference on computer vision, pp 1107–1115
Liu R, Zhao Y, Wei S, Zhu Z, Liao L, Qiu S (2015) Indexing of CNN features for large scale image search. arXiv preprint arXiv:1508.00217
Luo Q, Zhang S, Huang T, Gao W, Tian Q (2014) Indexing heterogeneous features with superimages. Int J Multimed Inf Retr 3(4):245–257
Mao R, Zhang P, Li X, Liu X, Lu M (2016) Pivot selection for metric-space indexing. Int J Mach Learn Cybern 7(2):311–323
Markov I (2004) VP-tree: content-based image indexing. In: Proceedings of IEEE international joint conference on neural networks, pp 45–50
Micó ML, Oncina J, Vidal E (1994) A new version of the nearest-neighbour approximating and eliminating search algorithm (AESA) with linear preprocessing time and memory requirements. Int J Pattern Recogn 15(1):9–17
Moran S, Lavrenko V, Osborne M (2013) Variable bit quantisation for LSH. In: Proceedings of annual meeting of the association for computational linguistics, pp 753–758
Moran S, Lavrenko V, Osborne M (2013) Neighbourhood preserving quantisation for LSH. In: Proceedings of ACM international conference on research and development in information retrieval, pp 1009–1012
Mu Y, Yan S (2010) Non-metric locality-sensitive hashing. In: Proceedings of AAAI conference on artificial intelligence, pp 539–544
Muja M, Lowe DG (2009) Fast approximate nearest neighbours with automatic algorithm configuration. In: Proceedings of international conference on computer vision theory and applications, pp 331–340
Muja M, Lowe DG (2014) Scalable nearest neighbor algorithms for high dimensional data. IEEE Trans Pattern Anal Mach Intell 36(11):2227–2240
Mukane Shailendrakumar M, Gengaje Sachin R, Bormane Dattatraya S (2014) A novel scale and rotation invariant texture image retrieval method using fuzzy logic classifier. Int J Comput Electr Eng 40(8):154–162
Murthy VSVS, Vamsidhar E, Swarup Kumar INVR, Sankara Rao P (2010) Content based image retrieval using hierarchical and k-means clustering techniques. Int J Eng Sci Technol 2(3):209–212
Neyshabur B, Srebro N, Salakhutdinov R, Makarychev Y, Yadollahpour P (2013) The power of asymmetry in binary hashing. In: Proceedings of international conference advances in neural information processing systems, pp 2823–2831
Nilsback M, Zisserman A (2008) Automated flower classification over a large number of classes. In: Proceedings of Indian conference on computer vision, graphics and image processing, pp 722–729
Nistér D, Stewénius H (2006) Scalable recognition with a vocabulary tree. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2161–2168
Norouzi M, Fleet DJ (2011) Minimal loss hashing for compact binary codes. In: Proceedings of international conference machine learning, pp 353–360
Norouzi M, Punjani A, Fleet DJ (2012) Fast search in hamming space with multi-index hashing. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 3108–3115
Okada CY, Carlos D, Pedronette G, Torres RS (2015) Unsupervised distance learning by rank correlation measures for image retrieval. In: Proceedings of ACM international conference on multimedia retrieval, pp 331–338
Online. http://www.ux.uis.no/~tranden/brodatz.html. Accessed 22 May 2017
Online. http://phototour.cs.washington.edu/patches/default.htm. Accessed 27 May 2017
Online. http://vision.ucsd.edu/datasets/yale_face_dataset_original/yalefaces.zip Accessed 27 May 2017
Parkhi O, Vedaldi A, Zisserman A, Jawahar C (2012) Cats and dogs. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 3498–3505
Pedreira O, Brisaboa NR (2007) Spatial selection of sparse pivots for similarity. In: Proceedings of Springer international conference on current trends in theory and practice of computer science. Lecture notes in computer science, pp 434–445
Pereira J, Coviello E, Doyle G, Rasiwasia N, Lanckriet G, Levy R, Vasconcelos N (2014) On the role of correlation and abstraction in cross-modal multimedia retrieval. IEEE Trans Pattern Anal Mach Intell 36(3):521–535
Philbin J, Chum O, Isard M, Sivic J, Zisserman A (2007) Object retrieval with large vocabularies and fast spatial matching. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1–8
Philbin J, Chum O, Isard M, Sivic J, Zisserman A (2008) Lost in quantization: improving particular object retrieval in large scale image databases. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1–8
Qin Tao, Liu Tie-Yan, Li Hang (2010) A general approximation framework for direct optimization of information retrieval measures. Int J Inf Retr 13(4):375–397
Quattoni A, Torralba A (2009) Recognizing indoor scenes In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 413–420
Ramezani M, Yaghmaee F (2016) A review on human action analysis in videos for retrieval Applications. Int J Artif Intell Rev 4:485–514
Rasiwasia N, Costa Pereira J, Coviello E, Doyle G, Lanckriet GR, Levy R, Vasconcelos N (2010) A new approach to cross-modal multimedia retrieval. In: Proceedings of ACM international conference on multimedia, pp 251–260
Rastegari M, Choi J, Fakhraei S, Hal D, Davis LS (2013) Predictable dual-view hashing. In: Proceedings of international conference on machine learning, pp 1328–1336
Robinson JT (1981) The K–D–B–tree: a search structure for large multidimensional dynamic indexes. In: Proceedings of ACM SIGMOD international conference on management of data, pp 10–18
Saul L, Roweis S (2003) Think globally, fit locally: unsupervised learning of low dimensional manifolds. Int J Mach Learn Res 4:119–155
Schaefer G, Stich M (2003) UCID: an uncompressed color image database. In: Proceedings of international society for optical engineering, pp 472–480
Sharif U, Mehmood Z, Mahmood T, Javid MA, Rehman A, Saba T (2018) Scene analysis and search using local features and support vector machine for effective content-based image retrieval. Int J Artif Intell Rev. https://doi.org/10.1007/s10462-018-9636-0
Shen F (2015) Supervised discrete hashing. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 37–45
Shen F, Shen C, Shi Q, van den Hengel A, Tang Z, Shen HT (2015) Hashing on Nonlinear Manifolds. IEEE Trans Image Process 24(6):1839–1851
Shen F, Zhou X, Yang Y, Song J, Shen HT, Tao D (2016) A Fast Optimization Method for General Binary Code Learning. IEEE Trans Image Process 25(12):5610–5621
Shen F, Liu W, Zhang S, Yang Y, Shen HT (2017) Asymmetric binary coding for image search. IEEE Trans Multimed 19(9):2022–2032
Shen F, Xu Y, Liu L, Yang Y, Huang Z, Shen HT (2018) Unsupervised deep hashing with similarity-adaptive and discrete optimization. IEEE Trans Pattern Anal Mach Intell. https://doi.org/10.1109/tpami.2018.2789887
Shrivastava A, Li P (2014) Asymmetric LSH (ALSH) for sublinear time maximum inner product search. In: Proceedings of international conference advances in neural information processing systems, pp 2321–2329
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556
Snavely N, Seitz S, Szeliski R (2006) Photo tourism: exploring photo collections in 3D. ACM Trans Gr 25(3):835–846
Song J, Yang Y, Yang Y, Huang Z, Shen H (2013) Inter-media hashing for large-scale retrieval from heterogeneous data sources. In: Proceedings of ACM SIGMOD international conference on management of data, pp 785–796
Swets DL, Weng J (1996) Using discriminant eigen features for image retrieval. IEEE Trans Pattern Anal Mach Intell 18(8):831–836
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1–9
Téllez ES, Chávez E, Bejar JO (2014) Scalable proximity indexing with the list of clusters. In: Proceedings of international IEEE autumn meeting on power, electronics and computing, pp 1–6
Tomita E, Tanaka A, Takahashi H (2006) The worst-case time complexity for generating all maximal cliques and computational experiments. Int J Theor Comput Sci 363(1):28–42
Torralba A, Fergu R, Weiss Y (2008) Small codes and large image databases for recognition. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1–8
Torralba A, Fergus R, Freeman W (2008b) 80 million tiny images: a large data set for nonparametric object and scene recognition. IEEE Trans Pattern Anal Mach Intell 30(11):1958–1970
Traina CJ, Filho RF, Traina AJ, Vieira MR, Faloutsos C (2007) The omni-family of all-purpose access methods: a simple and effective way to make similarity search more efficient. Int J Very Large Data Bases 16(4):483–505
Uhlmann JK (1991) Satisfying general proximity/similarity queries with metric trees. Int J Inf Proc Lett 40(4):175–179
Uysal MS, Beecks C, Schmücking J, Seidl T (2015) Efficient similarity search in scientific databases with feature signatures. In: Proceedings of international conference on scientific and statistical database management, pp 1–12
Valem LP, Pedronette DCG, Torres RS, Borin E, Almeida J (2015) Effective, efficient, and scalable unsupervised distance learning in image retrieval tasks. In: Proceedings of ACM international conference multimedia retrieval, pp 51–58
van de Weijer J, Schmid C (2006) Coloring local feature extraction. In: Proceedings of European conference on Computer vision, pp 334–348
Van Leuken RH, Veltkamp RC, Typke R (2011) Selecting vantage objects for similarity indexing. ACM Trans Multimed Comput Commun Appl 7(3):453–456
Vedaldi A, Lenc K (2015) Mat-ConvNet—convolutional neural networks for MATLAB. In: Proceedings of ACM international conference on multimedia, pp 689–692
Vleugels J, Veltkamp RC (2002) Efficient image retrieval through vantage objects. Int J Pattern Recogn 35(1):69–80
Wah C, Branson S, Welinder P, Perona P, Belongie S (2011) The Caltech-UCSD birds-200-2011 dataset, computation & neural systems technical report, California Institute of Technology
Wang JZ, Wiederhold G, Firschein O, Wei SX (1998) Content-based image indexing and searching using Daubechies’ wavelets. Int J Digit Libr 1(4):311–328
Wang James Z, Li Jia, Wiederhold G (2001) SIMPLIcity: semantics-sensitive integrated matching for picture libraries. IEEE Trans Pattern Anal Mach Intell 23(9):947–963
Wang J, Kumar S, Chang SF (2010) Sequential projection learning for hashing with compact codes. In: Proceedings of international conference on machine learning, pp 1127–1134
Wang J, Kumar S, Chang SF (2012) Semi-supervised hashing for large scale search. IEEE Trans Pattern Anal Mach Intell 34(12):2393–2406
Wang J, Liu W, Sun AX, Jiang YG (2013) Learning hash codes with list-wise supervision. In: Proceedings of IEEE international conference on computer vision, pp 3032–3039
Wang Q, Zhang Z, Si L, Lafayette W (2015) Ranking preserving hashing for fast similarity search. In: Proceedings of ACM international joint conference on artificial intelligence, pp 3911–3917
Wang D, Gao X, Wang X, He L (2015) Semantic topic multimodal hashing for cross-media retrieval. In: Proceedings of ACM international joint conference on artificial intelligence, pp 3890–3896
Wang Z, Duan L, Lin J, Wang X, Huang T, Gao W (2015) Hamming compatible quantization for hashing. In: Proceedings of ACM international joint conference on artificial intelligence, pp 2298–2304
Wang J, Liu W, Kumar S, Chang SF (2016a) Learning to hash for indexing big data: a survey. Proc IEEE 104(1):34–57
Wang W, Yang X, Ooi BC, Zhang D, Zhuang Y (2016b) Effective deep learning based multi-modal retrieval. Int J Very Large Data Bases 25(1):79–101
Wang J, Zhang T, Sebe N, Shen HT (2018) A survey on learning to hash. IEEE Trans Pattern Anal Mach Intell 40(4):769–790
Weber R, Schek HJ, Blott S (1998) A quantitative analysis and performance study for similarity-search methods in high-dimensional spaces. In: Proceedings of international conference on very large data bases, pp 194–205
Weiss Y, Torralba A, Fergus R (2008) Spectral hashing. In: Proceedings of neural information processing systems conference, pp 1753–1760
Wolf L, Hassner T, Maoz I (2011) Face recognition in unconstrained videos with matched background similarity. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 529–534
Wu B, GhanemB (2016) lp-box admm: a versatile framework for integer programming. arXiv preprint arXiv: 1604.07666
Xia R, Pan Y, Lai H, Liu C, Yan S (2014) Supervised hashing for image retrieval via image representation learning. In: Proceedings of ACM AAAI conference on artificial intelligence, pp 2156–2162
Xiao J, Hays J, Ehinger KA, Oliva A, Torralba A (2010) Sun database: large-scale scene recognition from abbey to zoo. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 3485–3495
Xie L, Hong R, Zhang B, Tian Q (2015) Image classification and retrieval are onE. In: Proceedings of ACM international conference multimedia retrieval, pp 3–10
Xu B, Bu J, Chen C, Cai D, He X, Liu W Luo J (2011) Efficient manifold ranking for image retrieval. In: Proceedings of ACM international conference on research and development in information retrieval, pp 525–534
Yang Y, Newsam S (2010) Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of international conference on advances in geographic information systems, pp 270–279
Yang L, Hua X, Cai Y (2013) Searching for Images by Video. Int J Multimed Inf Retr 2(3):213–225
Yu F, Ji R, Tsai M-H, Ye G, Chang SF (2012) Weak attributes for large-scale image retrieval. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2949–2956
Zhang D, Li W (2014) Large-scale supervised multimodal hashing with semantic correlation maximization. In: Proceedings of AAAI conference on artificial intelligence, pp 2177–2183
Zhang Q, Qiu G (2015) Bundling centre for landmark image discovery. In: Proceedings of ACM international conference multimedia retrieval, pp 179–186
Zhang L, Rui Y (2013) Image search—from thousands to billions in 20 year. ACM Trans Multimed Comput Commun Appl 9(1):36–55
Zhang X, Zhang L, Shum HY (2012) Qsrank: query-sensitive hash code ranking for efficient neighbor search. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 2058–2065
Zhang L, Zhang Y, Tang J, Lu K, Tian Q (2013) Binary code ranking with weighted hamming distance. In: Proceedings of IEEE conference on computer vision and pattern recognition, pp 1586–159
Zhang Q, Fu H, Qiu G (2013) Tree partition voting min-hash for partial duplicate image discovery. In: Proceedings of IEEE international conference on multimedia and expo, pp 1–6
Zhang P, Zhang W, Li WJ, Guo M (2014) Supervised hashing with latent factor models. In: Proceedings of the international ACM SIGIR conference on research and development in information retrieval, pp 173–182
Zhang R, Lin L, Zhang R, Zuo W, Zhang L (2015a) Bit-scalable deep hashing with regularized similarity learning for image retrieval and person re-identification. IEEE Trans Image Process 24(12):4766–4779
Zhang S, Yang M, Wang X, Lin Y, Tian Q (2015b) Sematnic-aware co-indexing for image retrieval. IEEE Trans Pattern Anal Mach Intell 37(12):2573–2587
Zhang L, Shum HPH, Shao L (2017) Manifold regularized experimental design for active learning. IEEE Trans Image Process 26(2):969–981
Zhong LW, Kwok JT (2012) Convex multi task learning with flexible task clusters. In: Proceedings of international conference on machine learning, pp 41–48
Zhou J, Ding G, Guo Y (2014) Latent semantic sparse hashing for cross-modal similarity search. In: Proceedings of ACM international SIGIR conference on research and development in information retrieval, pp 415–424
Zhuang Y, Liu Y, Wu F, Zhang Y, Shao J (2011) Hypergraph spectral hashing for similarity search of social image. In: Proceedings of ACM international conference on multimedia, pp 1457–1460
Acknowledgements
The authors thank the reviewers for their helpful comments. First author would like to thank Ministry of Electronics and IT, Government of INDIA, for providing fellowship under Grant number: PhD-MLA/4(61)/2015-16 (Visvesvaraya PhD Scheme for Electronics and IT) to pursue his Ph.D. work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sharma, S., Gupta, V. & Juneja, M. A survey of image data indexing techniques. Artif Intell Rev 52, 1189–1266 (2019). https://doi.org/10.1007/s10462-018-9673-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-018-9673-8