
Abstract
Character recognition is one of the challenging tasks of pattern recognition and machine learning arena. Though a level of saturation has been obtained in machine printed character recognition, there still remains a void while recognizing handwritten scripts. We, in this paper, have summarized all the existing research efforts on the recognition of printed as well as handwritten Odia alphanumeric characters. Odia is a classical and popular language in the Indian subcontinent used by more than 50 million people. In spite of its rich history, popularity and usefulness, not much research efforts have been made to achieve human level accuracy in case of Odia OCR. This review is expected to serve a benchmark reference for research on Odia character recognition and inspire OCR research communities to make tangible impact on its growth. Here several preprocessing methodologies, segmentation approaches, feature extraction techniques and classifier models with their respective accuracies so far reported are critically reviewed, evaluated and compared. The shortcomings and deficiencies in the current state-of-the-art are discussed in detail for each stage of character recognition. A new handwritten alphanumeric character database for Odia is created and reported in this paper in order to address the paucity of benchmark Odia database. From the existing research work, future research paradigms on Odia character recognition are suggested. We hope that such a comprehensive survey on Odia character recognition will serve its purpose of being a solid reference and help creating high accuracy Odia character recognition systems.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The future is not just about machines, but about man-machine interaction as effective as human interactions. This requires an effective communication or exchange of information. A computer being able to see the world the same way as humans do or read a book the way we could is one of the current research interests among the artificial intelligence community (Plamondon and Srihari 2000). Handwritten document recognition, otherwise known as optical character recognition and popularly abbreviated as OCR is a subtask of this bigger research challenge. A significant amount of effort have been devoted for the last couple of decades for recognition of handwritten characters in scripts such as Latin, Chinese, Arabic and many other Indian languages (Devanagari, Bangla, etc.) (Plamondon and Srihari 2000; Park et al. 2013; Lorigo and Govindaraju 2006; Arica and Yarman-Vural 2001; Jayadevan et al. 2011; Parvez and Mahmoud 2013; Bag and Harit 2013). However, there is limited research attention given to some other important and popular scripts, and Odia is one such language.
Odia is one of the popular and widely used languages of India. Spoken by more than 50 million people, it is the primary regional language of the Indian state of Odisha. Parts of the neighborhood states such as West Bengal, Jharkhand, Chhattisgarh and Andhra Pradesh also use Odia language. It is among the six Classical languages of India, having its indigenous history of evolution over 3000 years till present days. Therefore hundreds of thousands of ancient documents is found in Odia literature, many of them written on palm leaves. These needs restoration and digitization and the ability to automate the interpretation of written Odia script would have widespread benefits, both commercial and cultural. In this review paper, we have intended to bring together all the research efforts reported so far on Odia handwritten character recognition and the current state-of-the-art.
2 Characteristics and challenges of Odia
2.1 Odia script
In modern Odia script, there are 12 vowels and 40 consonants. These 52 characters are called basic characters, as shown in Fig. 1. Writing style in Odia, similar to other Indo-Aryan language descended from Magadhi Prakrit, is from left to right. Unlike English, there is no concept of upper or lower case in Odia.

Basic Characters of Odia Script
Like some of the other Indian languages, Odia script contains modified characters and compound characters. When a vowel follows a consonant, the resulting character takes a different shape, where a symbol, known as ‘kaara’ or allograph is placed at the left, right, or both sides, bottom or top of the consonant depending on the vowel (Fig. 2a). Similarly, when a consonant or a vowel is followed by a consonant, the resulting character is called a compound character (Fig. 2b). A sample of handwritten Odia basic characters is shown in Fig. 3a. A set of Odia printed as well as handwritten numerals is shown in Fig. 3b.

a Odia modified characters, b Odia compound characters

a Sample of a handwritten Odia basic characters, b writing variations in characters because of different handwritings
Though the old Odia literature contains many compound characters, recently linguists and researchers in Odia have followed a trend of omitting several redundant compound characters and instead, recommended to use modifiers to represent the same phonetics. Table 1 summarizes the complete list of numeral, basic and compound characters of Odia used nowadays with few modified characters to give a holistic idea about ‘kaara’s.
2.2 Challenges of Odia OCR
Peculiar challenges in regards to Odia characters that a recognition system faces are described as follows:
-
(a)
Presence of many roundish, similar, and often confusing characters to making it difficult to distinguish character classes even for human eyes.
-
(b)
No presence of any reference line(s) as in cases of other popular Indian languages such as Hindi and Bangla.
-
(c)
Almost all modifiers are non-touching to the parent character which they modify. This creates serious challenge in word to character segmentation for Odia scripts.
-
(d)
Another specific shortcoming in case of Odia handwritten character recognition is the limited availability of benchmarking databases. There was only one public database created at Indian Statistical Institute Kolkata until another has recently been prepared at Indian Institute of Technology Bhubaneswar (Dash et al. 2015c) and its extended one is reported in this paper. It was not possible to attract more researchers to experiment and validate new algorithms addressing the before-mentioned peculiarities of Odia handwritten characters without standard public databases.
Because of the unique nature of Odia script it is difficult to borrow successful methods existing in other languages and apply to Odia directly. As Odia script has many curvy characters, methods such as curvature based features (Majhi et al. 2011; Pal et al. 2007a), directional features (Roy et al. 2005; Tripathy and Pal 2006; Wakabayashi et al. 2009), and image transforms (Nigam and Khare 2011; Dash et al. 2014a) those capture this property of Odia script are proposed which are discussed subsequently in this paper. Similarly topologies that takes into account the concavity of Odia script are discussed in detail for feature extraction as well as reservoir based segmentation. An adaptive zone based image transformation proposed in Dash et al. (2015c) which updates, during training phase, the non-rectangular image Voronoi zones to selectively choose features is reported. This technique treats the classification error at every training epoch as feedback to the feature selection module and learns the best feature suited for Odia script.
3 State-of-the-art in Odia OCR
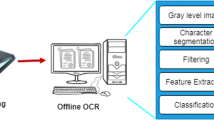
Irrespective of the type of script and language, any character recognition system comprises of the modules shown as Fig. 4 (Park et al. 2013; Arica and Yarman-Vural 2001).

A standards work flow of a character recognition system
3.1 Handwritten Odia OCR
We review each of the modules for the existing Odia handwritten character recognition systems reported in literature. However, before describing the modules we present the databases in Odia script.
3.1.1 Databases
The available research work, in Odia handwritten as well as printed character recognition, have only focused on offline data acquisition using a scanner. Offline character recognition could also be performed by capturing document images by a camera. The database at ISI Kolkata has been prepared using a HP flatbed scanner with 300dpi resolution with a total of 18,190 samples of basic characters and 5970 samples of handwritten numerals (Bhattacharya and Chaudhuri 2005; Pal et al. 2007a). There are few other datasets on which researchers have evaluated the performance of their algorithms and have reported in literature, but they are not publicly available and no clear mention of acquisition method or sample size.
We therefore put effort to create a new database of Odia handwritten numerals and characters. The handwritten numerals as well as characters are collected from a diverse group of individuals: from children of age group 12–15, individuals of age groups 16–25, mid-age adults and up to sexagenarians. These include contributors from rural to urban demography, pan-gender and from different literacy levels. The samples are collected from different geographic regions and under different climatic conditions. The individuals were asked to write in an unconstrained environment so that different font sizes, shape irregularities can be captured. The collected documents were scanned at 300 and 600 dpi. Though we intend to further increase the size of the database, at present there are 5000 samples of handwritten Odia numerals and 35,000 samples of handwritten Odia characters in IITBBS database collected from 500 individuals. The number of classes in IITBBS handwritten Odia numeral database is 10 whereas the number of classes in IITBBS handwritten Odia character database is 70. These databases are freely available on request to the authors. A sample of IITBBS Odia handwritten numerals and characters is shown in Fig. 5.
In the database creation drive, two modalities are adopted to capture the handwritings. Individuals are asked to write isolated numbers and characters on a plain datasheet (70 GSM paper thickness) without any grid pattern or constraints. Extraction of these isolated characters were done by connected component analysis on a binarized version of the datasheet image. Then minimum bounding boxes are located and extracted to get the coordinates of the isolated handwritings. Finally the original grayscale and/or color images are saved as individual images from the coordinates obtained from the binary datasheet image.

Sample handwritten Odia numerals and characters of IITBBS database
The second approach involves writing on a specially designed datasheet form developed at IIT Bhubaneswar. It has horizontal and vertical grids separated by a specific pixel distance. Individuals are asked to write isolated numerals and characters inside the boxes created by the grids. Extracting these isolated images are fairly straight-forward as the grid coordinates are known apriori and a simple program captured and saved individual handwritten images to our storage disk. Though one presumed disadvantage of this approach could be the constraint posed by box size of the database form, we kept the sizes fairly bigger so that natural writing style of an individual is not tampered with.
However, in both these approaches of data collection we intentionally kept size or intensity normalization processes at bay. As these are method-specific preprocessing steps, it may be desirable to some researchers working with this database not to do any kind of normalization and still find a recognition system well suited to classify handwritings. The same philosophy holds true for other preprocessing steps such as binarization, skew or slant adjustments etc. which, we believe, are better left to the database users to have discretion over. The participation statistics of individuals based on their age groups is presented in Fig. 6. It was noticed that education level does play a role in writing patterns of users. The rural population with statistically lower level of literacy had enormous writing variation than educated urban population. Climatic conditions also affect the handwritings as it was observed that individuals in cold winter tend to introduce unwanted indentations at character boundaries. The same case was observed with older contributors because of age factor.

Participation statistics of the individuals in IITBBS Odia database creation according to their age
3.1.2 Preprocessing
The digital image, captured in the previous acquisition module, is to be converted to a more concise representation prior to recognition. Therefore, after a document is scanned using an optical scanner, it is subjected to a number of preliminary processing steps, known as preprocessing. The process of scanning introduces noise to the character document and a small degree of skew is also unavoidable. The scanner output is often in the form of grayscale image. The primary objectives of preprocessing are (1) Noise reduction, (2) Intensity and size normalization, (3) Skew or slant adjustment and (4) Segmentation. For Odia scripts, the preprocessing tasks undertaken by researchers in order to achieve the above objectives are outlined in sequel.
3.1.2 (a) Noise reduction
Filtering
The idea of filtering is to convolve a predefined mask or kernel with the character image to modify the pixel intensity value as a function of its neighborhood pixels. The aim is to reduce noise and eliminate spurious points introduced by uneven writing surface or poor sampling rate of the scanner. The noise is introduced by the optical scanning device or the writing instrument which causes gaps in character pixels, disconnected lines, filled loops etc. Filtering can be performed both in spatial and frequency domains.
Bhowmik et al. (2006) have used median filtering at two stages of preprocessing. First, the scanned image is smoothened with a median filter followed by binarization by Otsu’s thresholding method. The binary image is again median filtered for noise reduction. Meher and Basa (2011) report three aspects of preprocessing. The primary aspect deals with performing a binarization based on selecting a proper gray intensity level from histogram of the image and assigning intensity values ‘1’ or ‘0’ depending on that threshold. The second aspect uses filtering operation to eliminate three types of noises, namely, background noise, shadow noise, and salt and pepper noise.
In Wakabayashi et al. (2009), the authors have applied a mean filter of size  five times to the grayscale image for achieving noise reduction. In a similar approach (Majhi et al. 2011), the size normalized grayscale image is filtered with a mean filter of mask size \(3\times 3\) repeatedly followed by intensity normalization. Recently, Obaidullah et al. (2014) have proposed a two stage binarization method, where the first stage is called a pre-binarization, based on local window algorithm to know the region of interest (ROI). Then to overcome the limitations of the first stage, a Run Length Smoothing Approach (RLSA) has been applied on the pre-binarized image. A component labeling is used to select and map each component in the original gray image to get respective zones and the final binary image is obtained using histogram based global binarization algorithm on these regional zones.
five times to the grayscale image for achieving noise reduction. In a similar approach (Majhi et al. 2011), the size normalized grayscale image is filtered with a mean filter of mask size \(3\times 3\) repeatedly followed by intensity normalization. Recently, Obaidullah et al. (2014) have proposed a two stage binarization method, where the first stage is called a pre-binarization, based on local window algorithm to know the region of interest (ROI). Then to overcome the limitations of the first stage, a Run Length Smoothing Approach (RLSA) has been applied on the pre-binarized image. A component labeling is used to select and map each component in the original gray image to get respective zones and the final binary image is obtained using histogram based global binarization algorithm on these regional zones.
Morphological operation
Noise in the scanned character image can also be reduced using different morphological techniques. The fundamental idea behind such operations is to filter the scanned image replacing the convolution operation with the logical operations. Thus, any morphological operations are performed after binarizing the character image. Morphological operations are successfully used to connect the broken strokes, smooth the contours, prune wild points, thin the characters, extract the boundaries so that irregularities introduced in the images due to low quality of paper and ink, erratic hand movement of individuals as well as due to scanning process can be removed.
Mishra et al. (2013) have applied three morphological operations using branch points and thickening after size normalizing and binarization of the character images. The thickening is followed by thinning operation and finally dilation is performed. (Nigam and Khare 2011) have used a 2-level thinning and 2-level thickening operation one by one on the binary image. First a thinning operation is performed followed by thickening. Again a thinning and a thickening are performed respectively. The idea behind such morphological operation is to encode the changes in position of curves after such transformation which helps in the next stage of feature extraction using the concepts of Curvelets.
3.1.2 (b) Normalization
Normalization process removes the variations of the writing and obtains standardized data. Depending on the approach of normalization, it may be divided into two types as follows.
Intensity normalization
Document images, after scanning, are in the form of grayscale or RGB. In order to facilitate a uniform feature extraction module as well as a less computational one, intensity normalization is performed. Though logically, binarization is one kind of intensity normalization, several authors in Odia character recognition have normalized the character image in grayscale itself. For grayscale intensity normalization, the mean gray intensity of all the image pixels is computed. The mean intensity value is subtracted from each pixel intensity values. Finally, the maximum pixel intensity divides all mean subtracted intensities so that the gray normalized images have maximum intensity value of 1 and mean intensity level of zero (Wakabayashi et al. 2009; Majhi et al. 2011; Pal et al. 2007a, b; Dash et al. 2014b).
Size Normalization
This is used to adjust the character size to a uniform standard. Several papers have reported to have normalized the character image size to various dimensions, such as \(64\times 64\) (Majhi et al. 2011), \(72\times 72\) (Pal et al. 2007b), \(21\times 21\) (Dash et al. 2014a, 2015c). Size normalization can also be performed as a sub-module of feature training stage with the size parameters being estimated separately for each particular training data. No one, to the best of our knowledge, has employed such methods for Odia characters.
In case of word recognition, the interesting aspect of size normalization is that the length of word is one of the distinguishing factors of differentiating interclass word segments. The desire to preserve large interclass differences in the length of words so as to assist in word level classification tends to involve only vertical height normalization or bases the horizontal width normalization on the scale factor calculated for the vertical normalization (Lorigo and Govindaraju 2006).
3.1.2 (c) Skew or slant adjustment
The intrinsic inaccuracies in the scanning process and due to writing styles, the writing is slightly tilted or skewed within the document image. Again, many individuals seem to write in such a way that there is an angular deformity, known as slant angle, introduced between longest stroke in a word and the vertical direction. These skew and slant errors hurt the effectiveness of feature extraction algorithms and therefore, should be detected and adjusted. Most common techniques of skew detection are baseline extraction using projection profile of image, cross-correlation method between lines, using methods based on the Hough transform, and nearest neighborhood clustering. Once the skew is detected, the character, word or line is translated to the origin, rotated or stretched till the baseline is horizontal (Tripathy and Pal 2006). Similarly, different methods of slant normalization include extracting chaincode components of near vertical lines and computing the slant angle from the extreme coordinate points of each line, projection profile, Hough transform, estimating center of gravity for upper and lower half of vertical and horizontal windows the image is divided of Tripathy and Pal (2004).
3.1.2 (d) Segmentation
The last stage of preprocessing is the stage of segmentation. It is important, because the extent of separation of lines, words or characters affects the recognition accuracy. It is intuitive to say that segmentation is fairly easy if the document is printed with a standard font size and with lack of irregularities or cursiveness as found in handwritten documents. However, segmentation is always a challenge. Depending on the type of approach, segmentation can be external segmentation or internal segmentation. External segmentation is the process of isolating different writing units, such as paragraphs, sentences, or words. Internal segmentation is the isolation of individual characters from words.
Though some researchers rightly indicate external segmentation as a sub-domain of document analysis with its own methodologies and techniques, segmenting the document image into blocks of words or separating text and non-text regions is an integral part of OCR. In Tripathy and Pal (2006), horizontal and vertical projection profiles are used for segmenting lines and words respectively. Tripathy and Pal propose a piece-wise projection method for line and word segmentation (Tripathy and Pal 2006). Global horizontal projection works well for line segmenting printed documents, but fails to work in case of unconstrained handwritten documents because the characters of two consecutive text lines may touch or overlap (Fig. 7).
Assuming the document to be in portrait mode, the document is divided into small vertical stripes called piece-wise separating line (PSL) (Fig. 8). For a text width of Z, vertical stripe width of W and N be the number of stripes, the width of the last stripe is \([Z-W\times (N-1)]\). The row-wise sum of all black pixels of a stripe is computed and the row where this sum is zero is a PSL. The normal distance between two consecutive PSLs is computed. The statistical mode of such distances for all stripes is calculated. If the distance between any two consecutive PSLs of a stripe is less than the mode value, the upper PSL of these two PSLs is removed. PSLs obtained after this removal are the potential PSLs. By proper joining of these potential PSLs, the authors have found out the segmented text line. This line-segmented method is independent of size and style of handwriting.
In case of internal segmentation, there are mainly two strategies, namely, explicit segmentation and implicit segmentation. In explicit segmentation, the segments are identified based on ‘character-like’ properties. This strategy attempts to segment words into letters or other units without use of feature-based dissection algorithms. Instead, the word image is divided systematically into many overlapping pieces without regard to content. The basic principle applied is to use a mobile window of variable width to provide sequences of tentative segmentations that are confirmed by the recognition system. This method works fine with machine printed characters. Implicit segmentation, on the other hand, segments the image implicitly by classification of subsets of spatial features collected from the image as a whole, which means the recognition process is performed taking the whole word itself without further segmenting into individual characters.
For Odia handwritten character segmentation, Tripathy and Pal (2004) proposes a technique based on water reservoir philosophy. Because most of the Odia characters are roundish in nature, often there is tendency of characters touching at the upper portion creating cavities facing either upward or downward depending on the character. This property of cavity formation lays the foundation for this segmentation principle. When two Odia characters touch each other (Fig. 9), they create a large space which represents the bottom reservoir which is very useful for touching character detection and segmentation. Owing to the shape of Odia characters a small top reservoir is also generated due to touching. This small top reservoir also helps in touching character detection and segmentation. The base line is detected for each such reservoir. Depending on the height of reservoir and direction of water flow, individual characters are segmented.

Touching lines in a handwritten Odia document where projection profile fails

a Vertical stripes for calculating PSLs, b line segmentation after joining potential PSLs (Tripathy and Pal 2006)
From a statistical analysis, the authors in Tripathy and Pal (2004) have found out that there are mainly three positions where Odia characters touch. They are at top, middle or bottom zones. It has been observed that 72 % of the touching happens in top portion, 17 % of touching occurs at the lower end of the middle zone above the base line; whereas only 11% of touching lies below the base line, i.e. the bottom zone. Using this technique, the reported segmentation accuracy is close to 96.7 %. However, the error occurs when there is multiple touching of characters. The reported rejection rate is 4.7 % which is mainly because of presence of multi-touching patterns.

Formation of top and bottom reservoir when two Odia characters touch (Tripathy and Pal 2004)
3.1.3 Feature extraction
Feature extraction is one of the most important stages of any recognition system. The crudest form of feature is directly feeding the grayscale or binary character image to the recognizer. However, in most of the recognition system, a more compact and characteristic representation is required in order to avoid extra complexity and to increase the accuracy of the recognition. For that purpose, a feature or a set of features is extracted for each class of images such that the intra-class variance is minimized while the interclass separation is maximized. There are several feature extraction methods adopted by different researchers for Odia printed and handwritten alphanumeric characters. These methods can be broadly categorized into three groups: (1) Statistical features, (2) Structural and Topological features, and (3) Image transformations
3.1.3 (a) Statistical features
Though the representation of a document image by statistical distribution of points does not allow the reconstruction of the original image, it takes care of writing style variations to some extent as well as reduces the dimension of the feature set providing high speed and low complexity. Major statistical features used for feature extraction are point density of zoning, number of crossing of a contour by a line segment in a particular direction, distance of a segment from image boundaries, projections of image to form 1-D representation (Meher and Basa 2011; Majhi et al. 2011; Mishra et al. 2013; Wang et al. 1994).
3.1.3 (b) Structural and topological features
Many geometrical and topological properties can provide a solid set of features for character images with high tolerance to distortions and style variations. These representations encode the structure of the object and provide knowledge as to what sort of components make up that object. Most popular structural features include primitive structures such as lines, arcs, splines, maxima and minima points, cusps above and below a threshold, opening to the right, left, up, and down, direction of a stroke from a special points, cross and branch points, measure of curvature and change in the curvature, ratio between width and height of the bounding box of a character etc. There are various feature extraction techniques reported for Odia printed and handwritten characters.
Obaidullah et al. (2014) measure different structural properties of characters such as circularity, rectangularity, Freeman chaincode and component based features. The minimum circle that consumes the character is computed and its radius stored. Similarly the circle that completely fits inside the same character is evaluated and its radius stored. The difference between these two radii indicates the circularity of the character. The rectangularity of a character is measured by measuring the ratio of the width and height of the minimum bounding box. Freeman’s chaincode is essentially obtained by mapping the strokes of a character into a 2-D parameter space, characterized by eight directions and designated by numbers 0 to 7. Finally, the number of pixel counts of a connected component is categorized as large, medium or small component.
Dash et al. (2015b) proposed a novel approach to handwritten Odia numeral recognition based on Gestalt configural superiority effect. A set of model images are selected by analyzing different writing styles of individuals. For an unknown numeral image, all such model images are affine transformed by a point set correspondence for matching cost minimization. A composite image is created by binary AND operation of each of the transformed model image and the unknown image which results in more perceptual complexity. The unknown image is detected by finding the class which corresponds to minimum complexity of composite images (Fig. 10).

Formation of more complex composite images from model and unknown images (Dash et al. 2015b)
Pal et al. (2007b) compute two sets of features for recognition purpose. A 64 dimension feature vector is computed for high speed recognition and a 400 dimension feature vector is computed for high accuracy recognition. From experimentation, the optimal size for isolated numeral images is set at \(72\times 72\) pixels. After normalization, the image is segmented into \(9\times 9\) blocks. Using Robert’s cross operator, the gradient image is obtained (Fig. 10). The direction of gradient is quantized into 16 levels and the gradient strength is accumulated in each of these directions. The histogram values of all such 16 directions are computed for 81 blocks. Finally the \(9\times 9\) blocks are downsampled to \(5\times 5\) blocks using a Gaussian filter resulting in a \(5\times 5\times 16=400\) dimension feature vector. For the 64 dimension feature vector, the image is divided into \(7\times 7\) blocks and histogram of chaincode in 4 directions is calculated followed by downsampling by Gaussian filter. This reduces the number of blocks to \(4\times 4\) blocks which results in a feature vector of dimension \(4\times 4\times 4=64\).
The authors in Wakabayashi et al. (2009) improved upon this feature extraction technique suggesting that there is not much difference between feature vectors extracted from the patterns of similar classes and it is difficult to classify the similar shaped patterns occurring frequently in Odia characters based on these feature vectors. They propose a feature weighting method based on F-ratio which is calculated statistically from feature vectors of similar looking character images. Dash et al. (2014b) have used a Kirsch operator based gradient map for extracting features for Odia handwritten numerals. Kirsch operator is reported to provide better gradient features as compared to Robert’s cross operator, Prewitt’s or Sobel’s gradient operator because of its ability to calculate gradient in all the 8 neighborhood of an image pixel (Fig. 11).

Directional edge operators used to compute gradient feature
Feature extraction based on calculation of curvature is explored by Majhi et al. (2011) and Dash et al. (2014b) for Odia handwritten numerals and Pal et al. (2007a) for Odia character images. The curvature of the image is calculated using a bi-quadratic interpolation method and quantized to 3 levels using a threshold, viz. concave, linear and convex. Gradient of the image is also calculated and the directions are quantized to 32 levels. The strength of the gradient is accumulated in each of the 32 directions as well as in each of the 3 curvature levels to get local joint spectra of directions and curvatures.
3.1.3 (c) Image transformations
Another way of representation of images is by a linear combination of a series of basis functions. The coefficients of the linear combination provide a compact encoding known as a transformation or a series expansion (Arica and Yarman-Vural 2001). Popular transforms used to represent the feature vector of a character recognition system are Fourier transform (Zhu et al. 1999), wavelets (Mishra et al. 2013; Lee et al. 1996; Shioyama et al. 2001), curvelet transform (Nigam and Khare 2011), Stockwell transform (Dash et al. 2014a) and Slantlet transform (Dash et al. 2015a).
Mishra et al. (2013) compare the performance of Odia numeral recognition system by incorporating features using discrete wavelet transform (DWT) and discrete cosine transform (DCT). After computing the DCT of the preprocessed image, the authors have considered highest 75 DCT coefficients as the feature vector. Similarly, a third level decomposition is performed using Haar wavelets to obtain DWT coefficients which are fed to the subsequent classifier as feature vector.
Nigam and Khare (2011) uses curvelet transform to extract feature from multi-font Odia characters. The idea behind using such a transform is that wavelets, though popularly being used for character feature extraction, cannot well describe curve discontinuities. Curvelet transform is based on parabolic scaling law and is capable to handle curve discontinuities better, as compared to wavelet and ridgelet transform. The authors propose a four step feature extraction method based on curvelet transform: sub-band decomposition, smooth partitioning, renormalization of each sub-band, and ridgelet analysis. Morphological preprocessing enables to obtain curve positions in character images before and after applying thinning and thickening. The change in positions of curves, thus introduced, is encoded by curvelet transform to provide an effective feature set.
Dash et al. propose to use a non-redundant version of Stockwell transform for handwritten Odia numeral recognition in Dash et al. (2014a, (2015c). In a similar fashion, Slantlet transform is proposed in Dash et al. (2015a) by extracting transform coefficients in a zone-wise manner from numeral images to train the classifier. It is, however, to be noted that the major goal of feature extraction is to select a set of attributes which maximizes the recognition rate with the least amount of elements. This selection should be carried out in such a way that minimizes the within class pattern variability while enhancing the between class pattern variability. Though feature extraction problem can be formulated as a dynamic programming problem or by using principal component analysis or a neural network trainer, these approaches of feature selection require expensive computational power and most of the time yields a suboptimal solution (Patra et al. 2002). Therefore, Odia, like any other language, depends mostly on heuristics or intuition based feature extraction techniques pertaining to its specific nature of script.
3.1.4 Training and recognition
The recognition of an unknown sample of character image or a word refers to a pattern recognition problem, which can be based on (1) template matching, (2) statistical techniques, (3) neural networks. The recognition engine can be rule-based, probabilistic, or a combination of both. Any character recognition approach uses either holistic or analytic strategies for the training and recognition. Holistic strategy is a top-down approach for recognizing the full word, thus eliminating internal segmentation. This has an inherent advantage of saving computational complexity due to further segmentation to individual characters, but this method is constrained to a limited vocabulary. The recognition accuracy is affected by the size of dictionary from which the words are trained. For cursive script such as Odia, the net complexity introduced because of a whole word is more than the complexity of a single character or stroke. This again reduces the recognition accuracy. On the other hand, the analytic strategy is a bottom-up approach, starting with the recognition of strokes or individual characters, and going up towards formation of word, and producing a meaningful text.
3.1.4 (a) Template matching
Template matching is the crudest form of training and recognition. The simplest idea is to match the stored prototypes against the unknown character or word to be recognized. This works relatively well for machine printed or constrained handwritten character recognition. However, it completely fails for handwritten characters which are free from any writing constraints. Direct matching of similarity measures based on Euclidean, Mahalanobis, Jaccard and Hausdorff distance are available in many literatures. The matching techniques can be one-to-one comparison or as a rule based decision tree analysis where only selected pixels are compared.
A rule-based decision tree classifier is adopted in Chaudhuri et al. (2002). Here the recognition of Odia characters is divided into two parts, one part for recognition of modified characters and the other for basic characters. Again the recognition of basic characters follows a decision tree searching for presence of loops, vertical strokes and finally a template matching is performed. The template matching corresponds to run number (number of continuous black pixels) based matching approach.
3.1.4 (b) Statistical techniques
Classification based on statistical techniques finds popularity in Odia character recognition. The idea is to formulate the recognition problem as a statistical decision function and a set of optimality criteria that maximizes the probability of the observed pattern, given the model of a certain class features assuming the feature set distribution is Gaussian or uniform. A simple linear logistic regression model is proposed for classification of printed Odia characters in Obaidullah et al. (2014). For cursive script and unconstrained handwritings in Odia characters, a higher order statistical decision function performs better than such a linear model.
Pal et al. (2007a) have used a quadratic function for classification. The discriminant function is defined based on a Bayesian estimate of maximum likelihood. The classification technique is known as a modified quadratic discriminant function (MQDF) classifier as proposed by Kimura et al. (1987). In a conventional quadratic discriminant function based on eigenvalues evaluation of feature covariance matrix, the estimation error for non-dominant eigenvectors are more than the dominant eigenvectors and are much more sensitive to the estimation error in the feature covariance matrix. This issue is addressed by employing a pseudo-Bayesian estimate of covariance matrix. Similar techniques have been adopted by researchers in Wakabayashi et al. (2009), Pal et al. (2007b) and Roy et al. (2005) for handwritten Odia numeral recognition. In Dash et al. (2014b), the authors have adopted a discriminative learning based quadratic discriminant classifier (DLQDF), proposed by Liu et al. (2004) which optimizes the parameters of the MQDF classifier under a minimum classification error (MCE) criterion.
Bhowmik et al. (2006) propose a non-homogeneous Hidden Markov model (HMM) for training of features and recognition of handwritten Odia numerals. Given an observation sequence \(O=O_1 ,O_2 ,\ldots ,O_T \), and a model \(\gamma =(\pi ,A,B)\), the problem is to compute the conditional probability of the observation sequence given the model. A and B are the state transition probability distribution and observation sequence probability distribution respectively. For m number of model classes, the conditional probability is evaluated for all models and the unknown image is assigned a class corresponding to the model that gives maximum probability. Biswas et al. (2009) have proposed a hybrid system for recognition of Odia name entities in document images combining a maximum entropy model along with HMM. First, the name entities in an Odia corpus are identified using maximum entropy model and tagged temporarily. The tagged corpus is regarded as training process and the final tagging is done using the HMM.
3.1.4 (c) Neural network techniques
Neural networks are massively parallel interconnections of adaptive neuron processors. Because of its parallel architecture, it performs computations at a higher rate compared to classical techniques Kotsiantis et al. (2006). Due to its adaptive nature, it adapts to the changes in data and learns the characteristics of input. Neural network architectures are classified into two categories, such as, feed-forward and feedback or recurrent networks.
The feed-forward neural network (FFNN) uses back propagation learning algorithm for training of its network parameters. In Mishra et al. (2013), the DCT and DWT coefficients computed from the feature extraction stage are fed separately as inputs to a back propagation neural network (BPNN). In Majhi et al. (2011), authors have proposed a nonlinear neural network classifier which is nothing but an analogy of functional link artificial neural network (FLANN) classifier where the inputs are mapped in a trigonometric expansion function before being fed to the network. The learning rule adopted in this paper to update the network weights is epoch based delta learning rule (Hopfield 1982).
Some research work has been carried out in the area of computational forensics where Odia characters are recognized. Chanda et al. (2012) propose a method for writer identification from Odia handwritings which uses the SVM for classification. The SVM is a binary classifier that looks for the optimal hyper-plane so as to maximize the distance or the margin between the nearest examples of two classes. These nearest examples or margin vectors are called support vectors (Cortes and Vapnik 1995).
Though machine printed documents are much easier to recognize and most research initiatives have been focusing on handwritten Odia documents, we, for the sake of a holistic review, present the recent literature on printed Odia OCR before moving on to the state-of-the-art and difficult research challenges of handwritten OCR.
3.2 Printed Odia OCR
Research work on printed Odia character recognition can be found in Chaudhuri et al. (2002), Senapati et al. (2012), Mohanty et al. (2009) and Mohapatra et al. (2016). There are no standard database for printed Odia. Authors in Chaudhuri et al. (2002) have collected printed Odia texts from pages of an Odia novel for good quality images and from cheap paper quality children’s alphabet books for inferior printed images. Similarly the authors in Mohapatra et al. (2016) have collected Odia printed digits from various printed sources and have named the private database as Odia Digit Database (ODDB). The focus of Senapati et al. (2012) is on text line and word segmentation only whereas (Mohanty et al. 2009) deals with identification of printed Odia script.
3.2.1 Preprocessing
Commonly adopted preprocessing modules such as binarization, noise removal, normalization have been reported in printed Odia OCR. Chaudhuri et al. (2002) have employed histogram based thresholding to binarize the scanned image. The protrusions and dents created with the binarized characters as well as the isolated black pixels over the background are cleaned by a logical smoothing approach. Hough transform is used for skew correction in printed Odia texts. They have identified three basic regions or zones in a typical Odia text document, namely, upper zone, middle zone and lower zone. The virtual line between upper and middle zone is assigned the name Mean line and that of between middle and lower zone is called Base line. The uppermost and lowermost points of most of the characters in an Odia text line lie on the mean line and base line respectively. The authors have first calculated the connected components of characters and its bounding box. Keeping a threshold width of such bounded images, they have filtered out dots, punctuation marks or small modifiers so that the skew angle calculation is not affected. Finally the skew is detected using Hough transform and image is rotated accordingly to adjust the skew angle. Similarly, baseline angle estimation based skew correction technique is proposed in Senapati et al. (2012).
Authors in Mohanty et al. (2009) have segmented printed Odia lines by using both foreground and background pixel intensity information. After grayscale conversion, the consecutive horizontal white pixel lines are identified between two text lines. The pixel intensity values between 200 and 255 are considered as white pixels. The threshold number of lines is set at two, i.e. if three or more white horizontal lines are found consecutively, the middle of the lines is replaced by a dark line of zero intensity which demarks a separating line segment. Similarly, the word segmentation is performed by scanning the document image horizontally. Here the threshold for number of consecutive white pixels is set as four. If five or more number of white pixels is found, a vertical line is drawn at the middle of white pixels to demark segmented words. Similarly in Chaudhuri et al. (2002), horizontal and vertical projection profile based segmentation methods are proposed for printed texts.
The preprocessing steps used in Mohapatra et al. (2016) include binarization, skeletonization and size normalization. The authors have adopted conventional image processing and morphology operations to perform the preprocessing.
3.2.2 Feature extraction
Topological features, stroke-based features and features derived from water reservoir modelling are used in Chaudhuri et al. (2002) for recognizing printed Odia characters. The topological features include existence of holes and their numeracy, position of holes with respect to character bounding box and ratio of hole height to character height. Stroke-based features include the position and number of straight lines. These features are linear in structure, simple to detect and robust to noise and font variation. The authors have normalized the stroke lengths with respect to the character middle zone height to handle characters of differing font and size.
In Mohapatra et al. (2016), a Freeman’s encoding is performed on the skeletonized binary image. From the chaincode sequence, the authors propose to generate a string of length four which represents the number of end points, T-joints, X-joints and loops in this order from left to right. Other feature extraction techniques available in printed Odia character recognition is the percentage of foreground black pixels in a zone based partitioned printed image (Mohanty et al. 2009), presence of loop, line or kink in upper, middle or lower zone of Odia characters, etc. (Senapati et al. 2012; Mohanty et al. 2009).
3.2.3 Training and recognition
The features extracted in Chaudhuri et al. (2002) are used to train a decision tree based classifier where the decision at each node of the tree is taken on the basis of the presence or absence of a particular feature. This decision tree is a binary tree having two number of descendants from a non-terminal node. Only one feature, chosen from the occurrence statistics of the characters, is tested at a time while traversing the tree. If there is no feature available at a non-terminal node which can divide the set of patterns into two sub-groups, a semi-optimal tree is generated out of the available features. This ensures that the sum of occurrence probabilities of one group is roughly equal to the other group.
Authors in Mohapatra et al. (2016) propose a recognition module using finite automaton. The feature strings obtained from concatenation of the number of end points, T-joints, X-joints and loops are fed to the finite automaton with output for classification. They argue that if the number of end points is one, then the image is passed to a correlation function for classification in order to remove ambiguity in similar looking Odia numeral classes such as numeral two, six and seven.
4 Experiments
We have overviewed all the existing literature so far reported on Odia handwritten alphanumeric recognition. The recognition results are verified by simulation on the publicly available ISI Kolkata database. Though the database on handwritten Odia numeral developed by ISI Kolkata is openly available on request, the same was not the case for handwritten Odia characters. Because of the private nature of the database, it was not possible to perform evaluation on it. Therefore we simulated each of the reported algorithms summarized in Table 4 and validated their performances on the IITBBS database. We encoded the algorithms described in each of the tabulated papers (for both numerals and characters) in MATLAB environment and simulated for ISI Kolkata numeral database, IITBBS numeral database and IITBBS character database.
The idea behind writing executable codes for each of the simulated papers by ourselves was, (1) to have a hands-on experience on recreating an OCR package as mentioned in the literature and (2) to validate the performances of the algorithms in first person before reporting the same for our readership. The experimental results on handwritten Odia numerals are presented as Tables 2 and 3 for ISI Kolkata and IITBBS database respectively. Similarly the experimental validation of existing methods on the recognition of handwritten Odia characters on IITBBS database is summarized in Table 4. An overall picture of preprocessing, feature extraction and classification modules applied to printed and handwritten Odia OCR is presented as Table 5.
The highest recognition accuracy for handwritten Odia numerals on ISI Kolkata database is reported to be 98.80 % by Dash et al. (2014a) which uses Stockwell transform coefficients as features and k-Nearest Neighbor classifier. An accuracy of 99.0 % is achieved on IITBBS database by the same method. The classification accuracy for Odia handwritten characters is obtained to be 95.14 % by Wakabayashi et al. (2009). All the simulations are run on an intel-i7 64-bit processor with 8GB RAM.
5 Discussion
5.1 Analysis of current scenario
A critical review of the existing Odia character recognition system reveals a number of deficiencies and weaknesses, which can be summarized as follows:
-
1.
There is no standard database for the whole set of Odia characters, both basic and compound. The existing methods are validated on the only publicly available numeral database of ISI Kolkata. We have made a sincere effort to create a complete database of Odia handwritten numerals and characters (basic, compound and modified) and have reported in this paper. However the state-of-the art methods are yet to be validated on this complete database. The lack of benchmarking database is a vital reason for limited research attention to Odia handwritten OCR.
-
2.
Another major deficiency lies in the fact that there is no provision for noise modeling in any reported literature. Due to lack of noise modeling at all stages of recognition system, many assumptions and parameters of the algorithms are set by trial and error at the initial phase. In the presence of an outlier due to error in handwriting (striking off any character or unintentional garbage script being written by an individual), the initial phase error propagates through the system. Unless constraints are assumed about the writing environment, these noises can adequately degrade the overall accuracy of recognition system.
-
3.
In most of the methods available in Odia OCR, the recognition is isolated from training. The large amount of data in the form of features is collected prior to the classification stage. Hence, it is not possible to adaptively improve the recognition rate using the knowledge obtained from the error analysis.
-
4.
A large volume of Odia documents are in the form of palm leaf documents which are more than thousand years old. These documents carry important information regarding history, scientific developments, literature etc. which must be digitized and preserved. The problem with such documents is that they require intensive and time consuming preprocessing. For example, the script written on palm leaves using metal markers has gray levels very close to the background because of ageing of the leaves. A global thresholding to binarize such documents is a non-productive approach. More specific attention is needed for OCR in palm leaf manuscripts.
-
5.
In many feature extraction techniques, authors have proposed a zoning based algorithm where a character image is divided into a predefined fixed size and fixed number of zones. Although by experimentation an optimal zone arrangement is set, it is not entirely scientific to select what number and size of zones to be selected for a particular problem at hand. No researchers have experimented on taking non-rectangular or flexible zone arrangements for feature extraction.
-
6.
The segmentation techniques, so far proposed, are basically adopted the principles of projection profiles of texts in a document. Only a few other approaches have shown promising results such as the one based on water reservoir technique. There is no research initiatives so far, on segmentations based on active shape models or active contour models which have recently shown great promises in other languages.
-
7.
The advancement in smartphone technology and cheaper touch-screen tablet computers has enabled us to write on a touch sensitive screen using a stylus. However, there is no attempt in the recognition of online Odia handwriting recognition. Till date no patent or commercial software package on online Odia OCR is available to the best of our knowledge. One reason for the absence of commercial Odia OCR is because of large class pattern recognition problem that Odia language poses, due to many compound and modified characters (close to 150 class). An OCR package which can have such huge memory capacity for apriori stored feature matrix and computational efficiency to train a multiclass classifier on a large dataset is a tough challenge. Open sources such as Tesseract have been showing promising results in English and some Indian languages such as Devanagari and Bangla, but the accuracy highly deteriorates due to lack of extensive training and necessary feature extraction algorithm addressing the peculiarity of Odia.
-
8.
Majority of the papers have focused on spatial domain feature extraction techniques and conventional back propagation neural networks. The vast knowledge base on spectral domain features has not been explored fully in Odia character recognition. More robust classifier models have also not been experimented so as to increase the recognition accuracy. Similarly, the use of deformable templates for matching cursive handwritten characters is yet to be explored.
5.2 Suggestions on future direction
The following are some suggestions on future research directions in Odia character recognition:
-
1.
There must be multiple standard handwritten character databases for facilitating more research on Odia language. The database should be adequately large in size and it should be created keeping in view of noisy data modeling as well as images captured under different resolutions and lighting conditions. We have presented IITBBS database which is openly available to use for complete Odia dataset of handwritten numerals and characters.
-
2.
All the character recognition methods in Odia language have ignored the semantic information considering only the shape information. It is true that neither the structural nor the statistical information can represent a pattern as complex as cursive Odia characters. Therefore, a combination of statistical and structural features supported by the semantic information should be considered for representation.
-
3.
Adaptive image thresholding for binarization and use of active shape and active contour models for segmentation should be given more attention in the preprocessing stages, particularly for digitizing old degraded Odia documents.
-
4.
One approach to character recognition is by modeling linguistic information as well as shape information. An integration of top-down linguistic model and bottom-up character recognition model by intelligent sequential techniques may be effective for achieving higher recognition accuracy. Hidden markov models and high-level neural network architectures can be cascaded to design such a tool.
-
5.
More research should focus on the image transformation based representations. Localized techniques such as Stockwell transform and Gabor wavelet transforms can provide essential features which might not be available in spatial domain. However, efficient zoning techniques can supplement such approaches by defining character recognition as an optimization problem.
-
6.
Given a good selection of feature and classifier, more research can be carried out on the next stage of character recognition system, i.e. postprocessing. This stage, not necessarily a compulsory one in OCR, is mainly application specific and interface with natural language processing.
6 Conclusion
There have been objective research efforts being carried out in many regional languages for the last couple of years (Bag and Harit 2013; Bhattacharya and Chaudhuri 2009). Shrinking the globe in terms of communication and understanding cutting across all language barriers is today’s agenda. Therefore, it is important to make serious efforts to enhance the current state-of-the-art of Odia handwritten character recognition. A moderate amount of effort has been given to printed and handwritten Odia character recognition so far. But achieving efficiency and fluency similar to human beings require much more endeavor. Only when a commercial OCR package can be developed which attains close to human-like accuracy, many real life challenges can be addressed. Developing such a recognition system can be used for text-to-speech processing, automatic paper evaluation in examination, digitizing bulk amount of precious historical documents, assisting visually challenged individuals to read and enhancing e-Learning programmes in rural regions with the help of communication technology.
We have made an effort to create an open access benchmark database for Odia handwriting alphanumeric characters and have reported in this paper. From the extensive review of the existing literature, it is observed that a combination of spatial domain features preserving the structural peculiarity and a spatio-spectral image transformation preserving local variations in the handwriting is the best feature for Odia OCR. Similarly statistical classifiers and modern machine learning techniques can be suitably re-engineered to achieve high level of recognition accuracy. In this continuous research effort, the researchers on Odia script recognition are yet to reach such high accuracy level and a comprehensive review such as this can provide impetus to go ahead.
References
Arica N, Yarman-Vural FT (2001) An overview of character recognition focused on off-line handwriting. IEEE Trans Syst Man Cybern Part C Appl Rev 31(2):216–233
Bag S, Harit G (2013) A survey on optical character recognition for Bangla and Devanagari scripts. Sadhana 38(1):133–168
Bag S, Harit G (2013) A survey on optical character recognition for Bangla and Devanagari scripts. Sadhana 38(1):133–168
Bhattacharya U, Chaudhuri B B (2005) Databases for research on recognition of handwritten characters of Indian scripts. In: Proceedings of IEEE 8th international conference on document analysis and recognition ICDAR, pp 789–793
Bhattacharya U, Chaudhuri BB (2009) Handwritten numeral databases of Indian scripts and multistage recognition of mixed numerals. IEEE Trans Pattern Anal Mach Intell 31(3):444–457
Bhowmik TK, Parui SK, Bhattacharya U, Shaw B (2006) An HMM based recognition scheme for handwritten Oriya numerals. In: Proceedings of IEEE 9th international conference on information technology, pp 105–110
Biswas S, Mohanty S, Mishra SP (2009) A hybrid Oriya named entity recognition system: integrating HMM with MaxEnt. In: Proceedings of IEEE 2nd international conference on emerging trends in engineering and technology (ICETET), pp 639–643
Chanda S, Franke K, Pal U (2012) Text independent writer identification for Oriya script. In: IEEE 10th IAPR international workshop on document analysis systems, pp 369–373
Chaudhuri BB, Pal U, Mitra M (2002) Automatic recognition of printed Oriya script. Sadhana 27(1):23–34
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Dash KS, Puhan NB, Panda G (2014) A hybrid feature and discriminant classifier for high accuracy Odia handwritten numeral recognition. In: Proceedings of IEEE region 10 technical symposium (TENSYMP’14) Kuala Lumpur, pp 531–535
Dash KS, Puhan NB, Panda G (2014) Non-redundant Stockwell transform based feature extraction for handwritten digit recognition. In: Proceedings of IEEE signal processing and communication, SPCOM’14, pp 1-4
Dash KS, Puhan NB, Panda G (2015) Gestalt configural superiority effect: a complexity paradigm for handwritten numeral recognition. In: Proceedings of IEEE 8th international conference on advances in pattern recognition, ICAPR’15, pp 1–6
Dash KS, Puhan NB, Panda G (2015) On extraction of features for handwritten Odia numeral recognition in transformed domain. In: Proceedings of IEEE 8th international conference on advances in pattern recognition, ICAPR’15, pp 1–6
Dash KS, Puhan NB, Panda G (2015) Handwritten numeral recognition using non-redundant Stockwell transform and bio-inspired optimal zoning. IET Image Process. doi:10.1049/iet-ipr.2015.0146
Hopfield JJ (1982) Neural networks and physical systems with emergent collective computational abilities. Proc Natl Acad Sci 79(8):2554–2558
Jayadevan R, Kolhe SR, Patil PM, Pal U (2011) Offline recognition of Devanagari script: a survey. IEEE Trans Syst Man Cybern Part C Appl Rev 41(6):782–796
Kimura F, Takashina K, Tsuruoka S, Miyake Y (1987) Modified quadratic discriminant functions and the application to Chinese character recognition. IEEE Trans Pattern Anal Mach Intell 1:149–153
Kotsiantis SB, Zaharakis ID, Pintelas PE (2006) Machine learning: a review of classification and combining techniques. Artif Intell Rev 26(3):159–190
Lee SW, Kim CH, Ma H, Tang YY (1996) Multiresolution recognition of unconstrained handwritten numerals with wavelet transform and multilayer cluster neural network. Pattern Recognit 29(12):1953–1961
Liu CL, Sako H, Fujisawa H (2004) Discriminative learning quadratic discriminant function for handwriting recognition. IEEE Trans Neural Netw 25(2):430–444
Lorigo LM, Govindaraju V (2006) Offline arabic handwriting recognition: a survey. IEEE Trans Pattern Anal Mach Intell 28(5):712–724
Majhi B, Mallick J, Rout M (2011) Efficient recognition of Odiya numerals using low complexity neural classifier. In: Proceedings of IEEE international conference on energy, automation, and signal (ICEAS), pp 1–4
Meher S, Basa D (2011) An intelligent scanner with handwritten odia character recognition capability. In: Proceedings of IEEE fifth international conference on sensing technology, pp 53–59
Mishra TK, Panda S, Majhi B (2013) A comparative analysis of image transformations for handwritten Odia numeral recognition. In: Proceedings of IEEE international conference on advances in computing, communications and informatics, pp 790–793
Mohanty S, Dasbebartta HN, Behera TK (2009) An efficient bilingual optical character recognition (English-Oriya) system for printed documents. In: Proceedings of IEEE 7th international conference on advances in pattern recognition, ICAPR’09, pp 398–401
Mohapatra RK, Majhi B, Jena SK (2016) Printed Odia digit recognition using finite automaton. In: Proceedings of 3rd international conference on advanced computing, networking and informatics, pp 643–650
Nigam S, Khare A (2011) Multifont Oriya character recognition using curvelet transform. In: Information systems for indian languages. Springer, Berlin Heidelberg, pp 150–156
Obaidullah M, Mondal A, Roy K (2014) Structural feature based approach or script identification from printed Indian document. In: Proceedings of IEEE international conference on signal processing and integrated networks (SPIN), pp 120–124
Pal U, Sharma N, Wakabayashi T, Kimura F (2007) Handwritten numeral recognition of six popular Indian scripts. In: Proceedings of IEEE 9th international conference on document analysis and recognition, ICDAR 2007, vol 2, pp 749–753
Pal U, Wakabayashi T, Kimura F (2007) A system for off-line Oriya handwritten character recognition using curvature feature. In: Proceedings of IEEE 10th international conference on information technology (ICIT 2007), pp 227–229
Park G-R, Kim I-J, Liu C-L (2013) An evaluation of statistical methods in handwritten Hangul recognition. Int J Doc Anal Recognit 16(3):273–283
Parvez MT, Mahmoud SA (2013) Offline Arabic handwritten text recognition: a survey. ACM Comput Surv (CSUR) 45(2):23
Patra PK, Nayak M, Nayak SK, Gobbak NK (2002) Probabilistic neural network for pattern classification. In: Proceeding of IEEE international joint conference on neural networks, IJCNN’02.2, pp 1200–1205
Plamondon R, Srihari SN (2000) Online and off-line handwriting recognition: a comprehensive survey. IEEE Trans Pattern Anal Mach Intell 22(1):63–84
Roy K, Pal T, Pal U, Kimura F (2005) Oriya handwritten numeral recognition system. In: Proceedings of IEEE 8th international conference on document analysis and recognition, pp 770–774
Senapati D, Rout S, Nayak M (2012) A novel approach to text line and word segmentation on odia printed documents. In: Proceedings of IEEE 3rd international conference on computing communication and networking technologies (ICCCNT), pp 1–6
Shioyama T, Wu HY, Nojima T (2001) Recognition algorithm based on wavelet transform for handprinted Chinese characters. In: Proceedings of 14th international conference on pattern recognition, vol 1, pp 229–232
Tripathy N, Pal U (2004) Handwriting segmentation of unconstrained Oriya text. In: Proceedings of IEEE 9th international workshop on Frontiers in handwriting recognition, IWFHR-9, pp 306–311
Tripathy N, Pal U (2006) Handwriting segmentation of unconstrained Oriya text. Sadhana 31(6):755–769
Wakabayashi T, Pal U, Kimura F, Miyake Y (2009) F-ratio based weighted feature extraction for similar shape character recognition. In: Proceedings of 10th international conference on document analysis and recognition, ICDAR’09, pp 196–200
Wang SS, Chen PC, Lin WG (1994) Invariant pattern recognition by moment Fourier descriptor. Pattern Recognit. 27:1735–1742
Zhu X, Shi Y, Wang S (1999) A new algorithm of connected character image based on Fourier transform. In: Proceedings of 5th international conference on document analysis and recognition, Bangalore, India, pp 788–791
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Dash, K.S., Puhan, N.B. & Panda, G. Odia character recognition: a directional review. Artif Intell Rev 48, 473–497 (2017). https://doi.org/10.1007/s10462-016-9507-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-016-9507-5