
Abstract
During the last decades the Mediterranean zone in Europe has experienced an increment in the incidence of forest wildfires. This increase is partly explained by higher mean temperature and lower relative humidity, while socioeconomic change has lead to the abandonment of farms, resulting in an increase in an unusual accumulation of forest fuels, increasing the risk of wildfires. Mapping wildfire risk is highly important because wildfires are known to potentially lead to landscape changes and to modify fire regime by inducing potential changes in vegetation composition. Also, they pose a hazard to human property and life. Maps of wildfire risk based on statistical models provide a measure of uncertainty for the inferences derived from such risk maps, leaving a quantitative error margin for managers and decision takers. Further, some of the model parameters often have a physical or a biological interpretation which can give ecologists and forest engineers answers about scientific questions of interest. In this paper, we analyze the incidence of wildfires in the province of Castellón in Spain in order to identify risk factors associated with wildfire incidences during the years 2001–2006. We used the discrete nature of wildfire events to build such models using point process theory and methods and included information about elevation, slope, aspect, land use and distance to nearest road as covariates in our modeling process. Our results show that wildfire risk in Castellón is associated with all the covariates considered and that three land-use categories have the highest risk of wildfire incidence. Also, wildfire incidences are not independent and some degree of interaction exists, which indicates that the commonly used Poisson point process models are not applicable in this case, but instead area-interaction models should be considered.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
During the last decades, Spain and all the Mediterranean zone in Europe have experienced an increment in the incidence of forest fires and consequently an increase in the risk of forest fire ignition (Moreira et al. 2011; Wittenberg and Malkinson 2009). It is worth noting here that we will mean by forest fire risk the probability that a fire ignites at a given location within a study area (Hardy 2005) and by forest fire incidence the number of fires per unit area. Thus, fire incidence refers to the observed spatial pattern (number and location) of wildfires occurring in a given study area, while fire risk refers to a probability measure obtained from a mathematical model. In Spain, the increase in forest fires incidence is partly explained by climate change as well as socioeconomic transformation in rural areas. Climate change has resulted in higher mean temperature and lower relative humidity, while socioeconomic change has lead to the abandonment of farms, resulting in an increase and an unusual accumulation of forest fuels (Vilar del Hoyo et al. 2011). The accumulation of forest fuels and the higher temperature can potentially lead to the outbreak of wildfires. Yet, however, the risk of wildfires is not expected to be uniform since it is not only the quantity but also the vegetation type which is directly related to the probability of ignition of a wildfire. Other factors associated with the risk of wildfire ignitions are related to variables such as vegetation types, human activities, land use, among others (Moreira et al. 2011; Carmo et al. 2011).
The spatial variation shown by climate and by vegetation composition and coverage and by socioeconomic factors suggests strongly that wildfire risk is not evenly distributed over medium- to large-sized areas. It is known, for example, that quantity and quality of forest fuels are related to topography and geomorphology, which also affect relative humidity and rainfall (Caballero et al. 2007) .
Wildfire incidence is high in the Mediterranean region of Spain due to the high temperatures and low humidity during summer months, a climatic trend with high seasonality that extends to the last months of spring and the beginning of autumn. In the province of Castellón (northeast of Spain), the process of afforestation in different agricultural areas and the increasing abandonment of rural activities have led to a situation of high vulnerability to fires, particularly in Mediterranean mountainous areas, where the aforementioned factors have led to forests being abandoned and their subsequent expansion, proliferation and fuel continuity (Bastarrika Izagirre and Chuvieco Salinero 2006). The four major natural causes of wildfire ignitions are lightning, volcanic eruption, sparks from rock falls and spontaneous combustion (National Interagency Fire Center 2011). In Spain, a significant proportion of the wildfires is provoked by arsonists (Ministerio de Medio Ambiente 2006), making this kind of fires difficult to predict using only the weather risk index.
Predicting where a wildfire will occur is not possible due to the many factors involved in the process of wildfire incidence. However, one may construct maps showing the probability of wildfire ignition or risk maps, using data of wildfire incidence aggregated by non-overlapping geographic regions with known area or by the use of the coordinates of the starting location of past wildfire events, assuming an adequate statistical model. Risk maps are needed in the process of risk management by government agencies managing natural resources, by fire fighting agencies and by the general public.
Methods to construct maps of wildfire ignition risk should be based on easily measurable variables (covariates) to be useful for forest and risk managers. An approach that has been followed to construct wildfire risk maps is based on logistic regression. For example, Vilar del Hoyo et al. (2011) used logistic regression to model human-caused wildfire risk in central Spain. Díaz-Avalos et al. (2001) used a spatial autologistic model with covariates to construct forest fire risk maps in Oregon, using a Bayesian approach. Other approaches have used spatial point process models, in which the so-called intensity function is proportional to wildfire risk (Juan et al. 2012; Mateu et al. 1998; Møller and Díaz-Avalos 2010; Turner 2009; Serra et al. 2014). The inclusion of covariates in the modeling helps to account for the spatial variation associated with the association between the expected mean number of fires per unit area and the covariates, thus reducing the variance of the model parameter estimates (Martínez-Fernández et al. 2013).
Statistical models are usually preferred because they provide a measure of uncertainty for the inferences derived from the risk maps, leaving a quantitative error margin for managers and decision takers. Further, some of the model parameters often have a physical or a biological interpretation which can give ecologists and forest engineers answers about scientific questions of interest.
In this paper, we analyze the incidence of wildfires in the province of Castellón in Spain in order to identify risk factors associated with wildfire incidences during the years 2001–2006 using the locations of the wildfires centroids. Our goals are to construct wildfire risk maps for the province, to identify which factors are relevant to explain the spatial variation of wildfire incidence and to analyze the interaction among wildfires. To attain our goals, we need to find and fit statistical models to the observed spatial pattern of wildfire incidence. The resulting models and risk maps can provide aid in tasks such as planing wildfire fighting campaigns, to assess the hazard for the human populations and can also be helpful to plan fire prevention and presuppression activities. We use the discrete nature of wildfire events to build such models using point process theory and methods.
The rest of the paper is organized as follows: In “Study area and data” section, we describe the study area and the data sets. Section “Statistical analysis” gives all the details needed to clarify why and how we fit the models as well as some diagnostics to assess model fit. Section “Results” describes and discusses the results and the interpretation and implication of such results. Also, in “Results” section we discuss how the maps constructed can be used in planning fire fighting strategies, controlled burns and other related tasks. We finish with conclusions and description of future open research lines in “Discussion” section.

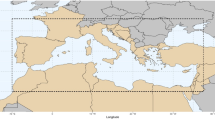
Geographic location of the province of Castellón, Spain.
Study area and data
The province of Castellón is located in the northeast of the Iberian Peninsula (Fig. 1). It is delimited by the mountain range called Sistema Iberico to the west and the Mediterranean sea to the east. It also has borders with the provinces of Catalonia in the north and Valencia in the south. Castellón has a surface area of 6632 km\(^2\), which represent 1.3 % of the Spanish national territory. The topography and geology of Castellón allows the existence of a wide variety of vegetation types, which include coniferous forests, oak forests, mixed forests, shrubs and grasslands, among others. According to the Coordination for the Information on the Environment (CORINE), there are forty-four vegetation types in the province of Castellón. Some of the tree species that compose these vegetation types produce litter that is highly flammable, as is the case of the Mediterranean pine (Pinus halepensis).
The database considered in this paper includes information about all the wildfires recorded in the study area during the period 2001–2006 . The information includes the geographic coordinates of the centroid of the fire at its final size, the year, elevation, slope, aspect, land use, distance to nearest road to the wildfire’s centroid, isothermality and soil permeability. This last covariate may be taken as a proxy for fuel moisture, as less permeable soils tend to retain water and moisture. However, soil permeability may well relate with fuel moisture of the deeper horizon in the forest floor (humus) for some point after rain. Thus, moisture should not be expected to exert an influence over longer time periods, because the moisture of slow-drying fuels depends essentially of time since rain. Note also that slow-drying fuels contribute very weakly to fire ignition and fire spread. Although other authors such as Koutsias et al. (2013) have acknowledged the association between fire incidence and precipitation, we did not have those data available for our study area during the time scope of this study. Except for the geographic coordinates and the year, the rest of the information was obtained from the corresponding digital maps for the province of Castellón. Figure 2 shows the distribution of the wildfires occurring in Castellón by year for the time period considered in our analysis. Except for time, all the other variables were also used as spatial covariates. In particular, four continuous covariates: slope, aspect, distance to nearest road and elevation, and one categorical covariate (land use) were included in the modeling process.

Spatial location of wildfires occurring in Castellón from 2001 to 2006. 2001 (top left) and 2006 (down right)
Slope is the steepness or degree of incline of a surface. As slope cannot be directly computed from elevation points, one must first create either a raster or TIN surface. In this paper, the slope for a particular location was computed as the maximum rate of change of elevation between that location and its surrounding pixels. Slope was expressed in degrees.
Regarding land use, we used the CORINE database (Coordination of Information on the Environment). In particular, we used the CORINE land-cover map for the year 2006 (European Environment Agency 2007; Heymann et al. 1994), on a 1:100.000 scale with a minimum mapping unit (MMU) of 25 ha; the linear elements listed are those with a width of at least 100 m.
In this paper, we reclassified land use into nine categories (Table 1). We arbitrarily assigned a probability of zero to wildfire risk in category 9, so from now on we will refer exclusively to categories 1 through 8. All the covariates were defined on a grid of 360,000 points covering Castellón. The digital images for some of the covariates are shown in Fig. 3. The main causes of wildfires in Castellón during 2001–2006 were lightning strikes, followed by negligence and arsonism. It is expected that fires due to those causes be associated with different risk factors. For this reason, we made separate statistical models for wildfires caused by lightning strike (natural cause) and for negligence, arsonism and other human-related causes.

Spatial variation of the covariates available for this study. Continuous: slope (left), elevation (center), permeability (right)
Statistical analysis
The statistical analysis of the wildfire patterns for the years 2001–2006 in Castellón was done using the theory and methodology of spatial point processes (Cressie 1993; Diggle 2003; Møller and Waagepetersen 2007). Although we could have followed the most common logistic and autologistic approaches, those methods cannot be extended easily to different spatial scales. On the other hand, as spatial point process modeling is based on the first- and second-order properties, The spatial continuity of such properties allows models fitted at a given scale to be adapted to a coarser or thinner resolution scale without much difficulty. A full description of such theory is beyond the scope of this paper, and the interested reader is referred to the previously mentioned authors. Here we will only describe the theoretical parts that are relevant to explain our analytical methods.
First- and second-order properties
We will denote the points of a spatial point process by x = (long, lat), and we will make a distinction of the theoretical spatial point process and the spatial point pattern observed whenever the context of the text does not make clear to which one of the two we are referring. Point process models can be characterized by their first- and second-order properties, which are analogous to first and second moments of ordinary random variables. We will denote by \({\mathcal {A}}\) the study area, also known as the observation window.
The (first-order) intensity function of a spatial point process is defined as
where \(\hbox {d}x\) denotes a small region containing the point x. and \(E[\cdot ]\) denotes the expected value of the random variable inside the brackets.
\(\lambda (x)\) may be interpreted as the expected number of events occurring in an infinitesimal set of area \(\hbox {d}x\) and is known as the intensity function of the point process. The intensity function is unknown and has to be estimated from the data \(\{x_{1},\ldots ,x_{n}\}\) from the observed spatial point pattern. Estimation may be done by posting a parametric model \(\lambda _{\theta }(x)\) for the intensity function or nonparametrically, using kernel density estimators (Cressie 1993; Diggle 2003)
where h is know as the bandwidth and controls the amount of smoothing in the estimation of \(\lambda\). Nonparametric estimates of \(\lambda (s)\) are commonly used as exploratory tools to gain insight about the type of parametric model that should be fitted to the data and have been used in fire incidence mapping by Koutsias et al. (2004), de la Riva et al. (2004) and Amatulli et al. (2007).
We fitted nonparametric kernel estimators to the observed wildfire patterns for each year considered in our study. The resulting estimates are shown in Fig. 4. The maps for \(\hat{\lambda }\) for each year show that wildfires in Castellón tend to occur in some fixed areas forming clusters of different sizes. Part of such clustering may be related to factors such as elevation, land use, or others. Nevertheless, the plots suggest that the class of point process models that should be fitted to the observed patterns needs to consider clustering and the possible effect of covariates. Possible choices are the non-homogeneous Poisson point process or an interaction model that can allow clustering, such as the area interaction (Fig. 5).

Nonparametric intensity function estimates for wildfires occurring in Castellón region in the different years considered in this study using kernel density estimator
The second-order intensity is a measure of the dependency structure of the events in \({\mathcal {A}}\) and is given by
The second-order intensity does not have a biological interpretation as it relates to data. An alternative very useful statistic is the reduced second moment function (Ripley 1976, 1981)
where \(N_{o}(h)\) is the number of extra events at a distance h from an arbitrary event \(x\in {\mathcal {A}}\). When the points of the process distribute independently at random within \(\mathcal {A}\) we speak of complete spatial randomness (CSR), which can be modeled with an homogeneous Poisson process (Cressie 1993; Diggle 2003). In this case, the intensity function (3.1) is a constant \(\lambda\), and a nonparametric estimator of K(h)is given by
where \(|{\mathcal {A}|}\) is the area or volume of the study area, x and y are arbitrary data points and \(w_{{\mathcal {A}}}(x,y)\) is a border effect correction.
The reduced second moment function is also known as Ripley’s K-function or simply as the K-function.
The intensity function provides information related to the homogeneity of the process within \({\mathcal {A}}\), while second-order properties provide information related to the interaction between points in a spatial point pattern and can be used to test the null hypothesis of CSR (Illian et al. 2008). For a point pattern with n points, nonparametric tests for CSR are constructed by simulating s spatial patterns of size n from an homogeneous spatial Poisson process, under CSR, and using such simulated patterns, compute confidence bands for the K-function
The hypothesis of CSR is rejected if the empirical K-function obtained from the observed point pattern fall outside the confidence bands for some set of distances h. Nonparametric tests based on second-order moments allow to conclude whether or not an observed spatial point pattern follows a random, clustered or dispersed distribution pattern. Non-homogeneity of \(\lambda (s)\) may often be explained through spatial varying covariates such as temperature, litter depth and elevation above sea level, among others. When information on spatial covariates is available, a common choice for the form of the intensity function is
where \(\mathbf{z}\) is a vector whose entries are the values of the covariates at the point x, and \(\beta\) is a vector of coefficients. For model identifiability, we used sum contrasts for the categorical variables, i.e., the coefficients associated with the satisfy the restriction \(\sum _{j}\beta _{j}=0\).
Tests of CSR which are constructed from functional summary statistics of an observed pattern such as the \(K-function\) are useful for two reasons: When CSR is conclusively rejected, the behavior of such summary statistics provide clues about the kind of model which might provide a reasonable fit to the data. They also suggest preliminary estimates of model parameters. In our case, we tested first the null hypothesis of complete spatial randomness (CSR) using the K-function in order to gain further insight about weather clustering or repulsion was evident in the observed wildfire patterns.
For those years for which the CSR hypothesis was rejected and the evidence was for clustering, we fitted first non-homogeneous Poisson point process (NHPP) models, with intensity function of the form 3.6. NHPP models are a natural alternative to CSR, since they preserve the assumption of independence between events of Poisson point processes. Although the NHPP models may not be good to capture strong clustering in the observed patterns, they are useful as a first step to check whether the spatial variability in the observed spatial pattern may be explained by the spatial variation of the covariates. Also, in case the NHPP gives a good fit to the data, the significance of the covariate effect may be done using the fact that the coefficient estimators are asymptotically normal if the number of data is large enough (Waagepetersen 2007), as is our case. Because the intensity function is not constant on \({\mathcal {A}}\), we used the corrected version for the \(K-function\) (Møller and Waagepetersen 2007) to test goodness of fit, namely
For an inhomogeneous random Poisson process with intensity function \(\lambda (u)\), the inhomogeneous K-function is \(K_\mathrm{inhom}(r) = \pi r^2\), exactly as for the homogeneous case. We can then define the \(L_\mathrm{inhom}\)-function as
Note that the inhomogeneous K-function depends on the first-order properties of the point process.
Wildfires burn areas that occupy a wide surface. Although the shape of the burned area is highly irregular, it is expected that the incidence of a wildfire in a given zone affects the probability of another wildfire starting within the burned area. This results in negative interaction between wildfires at least for some short term. Therefore, we also explored the goodness of fit of area-interaction models (Baddeley and van Lieshout 1995). For a bounded number of events \(s_{1},\ldots , s_{n}\), the area-interaction model has a density of the form
where \(\alpha\) is a proportionality constant, \(\beta\) is the intensity function of the process, \(\gamma\) is the interaction parameter, n(s) is the number of points of the process, and A(s) is the area of the region formed by the intersection of balls of radius r centered at the points of the process. For the intensity \(\beta\) we choose a log-linear form as in (3.6). The interaction parameter \(\gamma\) can be any positive number. If \(\gamma = 1\) then the model reduces to a Poisson process with intensity \(\kappa\). If \(\gamma < 1\) then the process is regular, while if \(\gamma > 1\) the process is clustered. Thus, an area-interaction process can be used to model either clustered or regular point patterns. Two points interact if the distance between them is less than 2r. If \(\gamma = 0\), then a hardcore process is encountered in which there are no points within the hardcore distance (r) of any point in the point process; that is, there is total inhibition.
Goodness of fit for the NHPP and for the area-interaction models was done by simulating patterns under the fitted models with the same number of wildfires for each year. Each of the simulated patterns was used to compute the empirical non-homogeneous K-function to obtain the envelopes. We used the rank test ( Grabarnik et al. 2011) to compute the 95 % envelopes to get a better approximation to the true p value for the test. To fit the models, we used the R free software (R Development Core Team 2010), and the contributed package spatstat (Baddeley and Turner 2000, 2005), which can be obtained from the R project Web site www.r-project.org.
In all cases, the intensity function was standardized to integrate to 1.0 in the study area, thus becoming a probability density function. Therefore, the intensity function \(\lambda (x)\) is proportional to the probability of ignition of a wildfire in x and thus to the risk of wildfire at x.
Results
The number of wildfires occurring on each year considered in this study is shown in Table 2. The number of fires per year showed high variability during the time span of this study, with an average of 110.5 fires per year. Years 2002, 2003 and 2005 were those that deviated more from the average, due to high precipitation in both years during the summer months, resulting in an increase in fuel moisture.
The spatial distribution of the wildfires (Fig. 2) and the kernel estimators of the intensity function (Fig. 4) indicated the presence of multiple hot spots, where wildfires tend to occur at a significant higher rate than in the rest of the province. The majority of the wildfires observed in Castellón between 2001 and 2006 occurred at distances closer than 400 m from the nearest road. This last covariate is a proxy of human-caused wildfires, as most of the human activities tend to occur near roads. The empirical odds of wildfire for the different vegetation classes is shown in Fig. 6, where one can see that the risk of wildfires standardized by the area covered by each land-use category was higher for classes one, six and seven, which correspond to coniferous forests, scrub and natural grasslands. Areas covered by that kind of vegetation have been recognized as fire prone (González et al. 2006).

Histograms of wildfire incidences by covariate (cause, distance and slope) in Castellón, for the years 2001–2006
The multiplicative structure of the area-interaction model permits to analyze the results of the spatial and the temporal components of the model separately. The intensity parameter was given a log-linear structure dependent on the covariates, as in (3.6), where Z is a matrix whose entries are the values covariates. The parameter estimates of the significant covariates for each year are shown in Table 3. The absolute value of the coefficient estimates related to elevation, slope and distance to nearest road is small due to the variation range of those continuous covariates. When multiplied by the values of the corresponding covariate and exponentiating the result gives either the increase or the decrease in the intensity function associated with the covariate. Comparing the values of \(\exp {\beta _{j}(Z_{jk}-Z_{jl}) }\) provides a measure of the relative change in the probability of wildfire caused by a change \(Z_{jk}-Z_{jl}\) in the covariate. Thus, for example, in 2001, a change of 100 m in elevation resulted in a decrease of 10 % in the probability of wildfire, keeping the rest of the covariates at fixed values. Analogous results are obtained for slope and distance to nearest road.

Odds of wildfire incidence for different land-use classes
Table 3 shows the coefficient estimates for the logarithm of the intensity function (Eq. 3.6) for naturally caused wildfires. The sign and value for the different coefficients for the years considered are not constant and indicate that the importance and association of the covariates to wildfire risk are not constant over time. The coefficients for the log intensity function for human-caused wildfires are shown in Table 4. Unlike the coefficients for the naturally caused wildfires, the sign of the coefficients for most of the covariates remains constant for the years considered in this study.
Distance to nearest road has a negative or neutral effect on the probability of wildfire. This covariate has been considered a proxy of human activity, which is another important cause of wildfires in the study area as well as in other parts of the Mediterranean basin (Wittenberg and Malkinson 2009; Vilar del Hoyo et al. 2011). The negative coefficients for this covariate indicate that human-caused wildfires are more likely to occur near the roads, where arsonists and other human activities are often observed.
The parameter \(\beta _{0}\) can be thought as the basal risk for each year if the other \(\beta\) coefficients are kept equal to zero and the interaction parameter \(\gamma\) is equal to unity. Under this consideration, we see that the variation of \(\beta _{0}\) along the years followed the same trend as the yearly number of wildfires shown in Table 2. Thus, we may think of \(\beta _{0}\) as a parameter related to the average annual risk in the whole province and in consequence of the number of wildfires per year \(\{n_{t}, t=2001,\ldots , 2006\}\) and that the remaining \(\beta\) coefficients increase or decrease the wildfire risk according to the spatial variation shown by the linear combination of the covariates. The table also shows that for areas covered with coniferous forests the risk of wildfire was high, in particular during 2001 and 2002. Except for areas with land use 2, 4 and 7, the fire risk associated with land use followed a similar trend along the years considered in our study, with higher wildfire risk during 2001 and 2002 and moderate risk the rest of the years (Fig. 7).

Inhomogeneous L-function for area-interaction models fitted to the wildfire incidence data in Castellón including all the covariates for the years 2001–2004

Estimated intensity function obtained from the area-interaction models for the years 2001–2006 in Castellón, natural causes
The estimates of the interaction parameter \(\gamma\) for naturally caused wildfires took values below 1.0 for the years 2002 and 2005 (Table 4) and for the years 2001 and 2002 for human-caused wildfires (Table 4) indicating the presence of repulsion among the wildfires for those years and causes. This results in a more regular pattern of wildfire spatial distribution than under complete spatial randomness. For the rest of the years in this study, the positive value of \(\gamma\) indicates the presence of clustering of wildfire incidences. The fact that the parameter \(\gamma\) is not closer to 1.0 provides evidence that the incidences of wildfires in Castellón are not independent events, but the result of a complex process where the incidence of a wildfire in a given location somehow affects the probability of ignition of other wildfires.
Figure 8 shows the intensity function estimates for the naturally caused wildfires. The areas of high intensity show different location for the different years. This is a result of the variability of the covariate effects described in previous paragraphs where we described the results of the models fitted to the intensity function for the observed wildfire patterns. The map for the intensity function of human-caused wildfires (Fig. 9) shows that the higher-risk values occurred in a centered band going from southwest to northeast, where the elevation ranges between 0 and 500 m, where the highest risk was located in the southeast part of the province, not in high elevation areas where the Iberian Range is located in Castellón. Note that the maps do not resemble the spatial pattern of the covariates (Fig. 3), as what we show in the maps in Fig. 9 is the combination of all the components in model 3.8.

Estimated intensity function obtained from the area-interaction models for the years 2001–2006 in Castellón, human causes
The risk maps also provide insight about the spatial variation of wildfire risk, and for non-overlapping areas A and B within the study area, the ratio (q).
may be evaluated to get a measure of the relative risk of wildfire in those areas or to compare the estimated annual changes in wildfire risk in the same area if we take \(A=A_{t}\) and \(B=A_{t+k}\) with \(k=1,2,\ldots\). This information is useful for risk managers in the process of risk evaluation and as an input for risk management (Caballero et al. 2007; Hanewinkel et al. 2006). Government agencies and forest managers can also use relative risks to decide where to put the resources for fire control and fighting and provide a more efficient response in case of wildfire occurrence.
Discussion
The leading cause of wildfires in Castellón during 2001–2006 was lightning strikes, followed by negligence and arsonism (Fig. 5, upper). These three causes accounted for over 75% of the wildfires during the time span of our study. This supports the assertion that climate change and changes in land use are among the main factors associated with wildfire incidence (Pausas 2004). For the particular case of Castellón, land-use changes are the consequence of rural abandonment. Terrains with slopes lower than 30 degrees and closer than 400 m to the nearest road are relatively easy to access for humans. Our results show that most of the wildfires occurred in hill sides facing south or east, in slopes with less than 30 degrees. Hills sides facing east and south receive a higher amount of solar energy along the year, and thus, the moisture content in the fuel in those hillsides is expected to be lower than in hillsides facing north or west, resulting in different risk of wildfire ignition. This was confirmed through formal statistical analysis, although factors such as relative humidity and wind speed are likely to influence the risk of fires, particularly for west-facing slopes. Note, however, that our analysis is on an annual basis and that variables such as relative humidity and wind speed vary at an hourly basis, and that the average annual variability due to those and other non-observed covariates is included in the residual point process (Baddeley et al. 2005) in an analogous way to generalized linear models. Higher temperatures are perhaps associated with the highest number of wildfires per year during 2005. Wildfires tend to be less selective as their size increase, so factors such as vegetation type are less significant for bigger wildfires (Barros and Pereira 2014). This explains in part why land use was not a significant covariate in the models.
For 2004 all the covariates showed a positive association to wildfire incidence in Castellón. For year 2001, on the other hand, the elevation, slope and isothermality were associated with increase in the wildfire incidence while distance to the nearest road and soil permeability were associated with lower incidence. For the rest of the years, there was also variation of the signs of the coefficients, indicating that the effect of most of the covariates on the wildfire incidence is not constant along time. Slope was the only covariate that showed positive association for the whole study period for naturally caused wildfires. This variability in the effects of the covariates is indicative that naturally caused wildfires may occur in the whole province of Castellón but show a slight association to physical and climatic factors, which show variation along time.
Elevation and permeability showed negative coefficients, something that could be expected because the higher the elevation the lesser human presence in the province. Because soil permeability can be considered a proxy of fuel moisture, the negative coefficients for this covariate suggest that human-caused wildfires tend to occur in areas where fuel moisture is lower. On the other hand, slope and isothermality showed positive coefficients for the six years. The positive coefficients for isothermality indicate that human-caused wildfires are more likely to occur in areas where temporal variation of temperature is low, perhaps due to the higher population density in those areas. In Castellón such areas are found mostly in coastal areas, where dry and hot weather conditions prevail most of the year. Regarding slope, the coefficients have the same sign as for naturally caused wildfires, which suggests that the effect of slope is the same regardless of the cause, and the positive values may be due to the fact that fire propagates easier in steep terrains, facilitating a small fire to become a wildfire. The relative risks between the different land-use categories were not constant across time. This may be because in a given year wildfires may occur at a slightly higher rate in areas with a particular land use or have larger wildfires, suggesting that for the next year the fuel loads are lower and therefore the expected number of wildfires will be smaller. This is in fact the idea behind the use of controlled fires to reduce wildfire incidence (Hutchinson et al. 2005).
The presence of interaction between the wildfires is probably a consequence of the burned area in previous years, which left a patchy arrangement of unburned areas where wildfires can occur. It is not the clear reason for the change from repulsion to clustering in the observed wildfire pattern, although a possible explanation is that the repulsion during years 2001 and 2002 for human-related causes and 2002 and 2005 for natural causes left wide unburned areas that became fire prone the last two years. Another possible explanation is that the number of wildfires and the burned area is not too high and therefore the change from a regular distribution pattern to a clustered one is due to the variation in the number of wildfires along the years under study. The area-interaction model covers a wide range of possible scenarios, going from regular patterns with strong repulsion to point processes with moderate clustering. The fit to the wildfire data of Castellón was acceptable, as no empirical L-function lies outside the confidence bands obtained by simulating point patterns using the parameter estimates for each year.
For human-caused wildfires the high intensity areas are located near coastal areas, in particular in the southern part of the province, where the capital city Castellón is located (Fig. 9). This figure shows a well-defined pattern, associated with the areas where most of the human population (about 80 %) lives, making those areas more likely to have a human-caused ignition, which combined to the dry weather prevailing in the coastal areas makes the presence of a wildfire to have a higher probability of ignition. The expansion of the low-risk zone is in part because of the increased amount of rain, which has a direct association to elevation and to the reduced human presence due to farm abandonment. Overall, we see from Figs. 8, 9 that in terms of wildfire risk the province of Castellón may be roughly divided into three zones: A high-risk zone comprising the coastal plains where most of the human activities take place, a medium-risk zone is distributed in a central strip in the NE–SW direction, which contains areas where farms and agricultural activities used to take place and where field abandonment has increased fuel loads in the recent years, and a low-risk area, located in the NW part of the province, where most of the forest of the province are located.
Other authors have approached the problem of producing forest fire risk maps using methods such as GIS (Vázquez and Moreno 1998), logistic regression (Preisler and Westerling 2007), autologistic regression (Koutsias 2003) and empirical generalized linear models (Barbero et al. 2014), among others. Some of such approaches either are based on pure descriptive methods or ignore the presence of spatial dependence observed in the data. The use of inferences based on pure descriptive methods may be misleading because the variability of empirical data sets, and therefore posing a model for the observed data as we have done, has the advantage of providing external validation to the inferences obtained from such models. Our approach also acknowledges the presence of spatial dependence through the incorporation of spatially varying covariates and through the inherent spatial association of non-Poisson point process models like the ones we have fitted to the wildfire data in Castellón, allowing the assessment of the effect of changes in the covariate values on the risk of wildfires for different locations within the study area. Although posting and fitting models may be difficult in some cases, it is a clear improvement as compared to pure descriptive or non-spatial methods of analysis of fire risk.
Conclusions
The first step in risk assessment is the estimation of the probability of wildfire. The standard tool to model the probability of fires in forest ecosystems has been logistic regression as in Wittenberg and Malkinson (2009) or in Vilar del Hoyo et al. (2011). Here we have proposed the use of spatial point process models with interactions, a well-known methodology that acknowledges the non-independence between wildfire events. The general form of the model we used allows its application in wider areas as long as information about wildfire incidence and covariate information are available. It is worth pointing that the significance of the covariates used for modeling wildfire risk in a given area is likely to change when the model is applied in a different area, or if the study area becomes broader than the original. This, however, is not a disadvantage of the model used here, as the general form allows to adapt the model in case drastic spatial changes in vegetation composition or in topography may occur. Our results show that the spatial variation of forest wildfire risk is associated with the environmental covariates and to human factors considered in our analysis. Distance to nearest road was used as a proxy for human activity in the study area, but the model fit may improve if information about population density, socioeconomic activities and other related information becomes available. Castellón’s province is a mountainous area and forest is restricted to the interior part of the province. Unlike what happens in other provinces of Spain, such as Catalonia, where forest wildfire risk is associated with abandonment of agricultural land (Serra et al. 2014), wildfire presence in Castellón is higher in forest-covered areas. However, for the last two years analyzed the higher-risk zone occurred in the flat area close to the sea. This change in the spatial distribution of wildfire risk is likely associated with non-observed human-related covariates, as the vegetation cover and geographic features of the province did not change during the time span of this study.
We have compared the incidence of wildfires separated in two wide classes, which has showed that both classes have a different association with the climatic and physical factors included as covariates. Naturally caused wildfires do not show a specific spatial pattern for the different years but are nevertheless slightly associated with the covariates we have included in our study. On the other hand, human-caused wildfires show a well-defined pattern with higher incidence associated with the covariate values observed in coastal areas.
Although kernel estimates have been used previously to study the spatial distribution of forest fires incidence (Díaz-Avalos and Alvarado 1998; Koutsias et al. 2004; de la Riva et al. 2004; Amatulli et al. 2007), those are only nonparametric estimators and are not useful for spatial prediction nor to asses the existence of association between wildfire incidence and suspected risk factors. Parametric models such as the ones fitted in our study besides providing predictive estimators for the association between the intensity function of wildfire incidence are also useful to asses the effect of changes of those factors on such intensity function.
The statistical modeling approach to forest wildfire risk mapping provides to forest fire managers a valuable tool for planning forest wildfire prevention task and surveillance. These maps show not only areas with high wildfire risk but also may be used to distinguish between those forest areas with high risk of wildfire by natural causes and those with high risk of wildfire because of human activities. Point process methods are a sensible approach to model the probability of wildfire ignition. However, this approach works better if reliable databases including historical records of forest fire locations as well as digitalized maps of spatial varying variables are available to the modeler. Such databases are becoming available due to the increasing quantity of data acquired with remote sensing technologies and the increasing accessibility to such information. Thus, it is reasonable to expect that the number of applications of spatial point process models to forest fires data will increase in the near future and that improved models and fire risk maps will become available to risk managers and to the general public. Predictive models for the final size of wildfires and the factors influencing such size are yet to be developed. Better management of wildfire risk is therefore a goal that is being attained as research continues.
References
Amatulli G, Peréz-Cabello F, De la Riva J (2007) Mapping lightning/human-caused wildfires occurrence under ignition point location uncertainty. Ecol Model 200(3–4):321–333
Baddeley A, van Lieshout MNM (1995) Area-interaction point processes. Ann. Inst. Statist. Math. 47:601–619
Baddeley A, Turner R (2005) Spatstat: an R package for analyzing spatial point patterns. J Stat Softw 12:1–42
Baddeley A, Turner R, Moller J, Hazelton M (2005) Residual analysis for spatial point processes. J R Stat Soc B 67(5):617–666
Baddeley A, Turner R (2000) Practical maximum pseudolikelihood for spatial point processes. N Z J Stat 42:283–322
Barbero R, Abatzoglou JT, Steel EA, Larkin NK (2014) Modeling very large-fire occurrences over the continental United States from weather and climate forcing. Environ Res Lett 9:1–11
Barros AMG, Pereira JMC (2014) Wildfire selectivity for land cover type : does size matter? PLoS One 9(1):e84760. doi:10.1371/journal.pone.0084760
Bastarrika Izagirre A, Chuvieco Salinero E (2006) Cartografía del área quemada mediante crecimiento de regiones: aplicación en entornos mediterráneos con imágenes tm y etm+. GeoFocus 6:182–204
Caballero D, Beltran I, Velasco A (2007) Forest fires and wildland-urban interface in Spain: types and risk distribution. In: Proceedings of the IV international wildfire conference, Seville, Spain
Carmo M, Moreira F, Casimiro P, Vaz P (2011) Land use and topography influences on wildfire occurrence in northern Portugal. Landsc Urban Plan 100:169–176
Cressie NAC (1993) Statistics for spatial data, Revised edn. Wiley, New York
de la Riva J, Pérez-Cabello F, Lana-Renault N, Koutsias N (2004) Mapping forest fire occurrence at a regional scale. Remote Sens Environ 92(3):363–369
Díaz-Avalos C, Alvarado CE (1998) Space-time analysis of fire pattern in the Blue Mountains, Oregon. In: En Weber R (ed) 13th Fire and forest meteorology conference. Lorne Australia October 27–31, 1996. International Association of Wildland Fire, pp 413–420
Díaz-Avalos C, Peterson DL, Alvarado E, Ferguson SA, Besag JE (2001) Space-time modelling of lightning-caused ignitions in the Blue Mountains, Oregon. Can J For Res 31(9):1579–1593
Diggle PJ (2003) Statistical analysis of spatial point patterns, 2nd edn. Arnold, London
European Environment Agency (2007) Technical report No 17/2007. CLC2006 technical guidelines. Office for Official Publications of the European Communities, Luxembourg
González JR, Palahi M, Trasobares A, Pukkala T (2006) A fire probability model for forest stands in Catalonia (north-east Spain). Ann For Sci 63:169–176
Grabarnik P, Myllymäki M, Stoyan D (2011) Correct testing of mark independence for marked point patterns. Ecol Model 222:3888–3894
Hanewinkel M, Hummel S, Albretch A (2006) Assessing natural hazards in forestry for risk management: a review. Eur J For Res 130:329–351
Hardy CC (2005) Wildland fire hazard and risk: problems, definitions, and context. For Ecol Manag 211:73–82
Heymann Y, Steenmans CH, Croissille G, Bossard M (1994) CORINE land cover. Technical guide. Office for Official Publications of the European Communities, Luxembourg
Hutchinson TF, Sutherland EK, Yaussy DA (2005) Effects of repeated prescribed fires on the structure, composition, and regeneration of mixed-oak forests in Ohio. For Ecol Manag 218(1–3):210–228
Illian J, Penttinen A, Stoyan H, Stoyan D (2008) Statistical analysis and modelling of spatial point patterns. Wiley, West Sussex
Juan P, Mateu J, Saez M (2012) Pinpointing spatio-temporal interactions in wildfire patterns. Stoch Environ Res Risk Assess. doi:10.1007/S00477-012-0568-y
Koutsias N (2003) An autologistic regression model for increasing the accuracy of burned surface mapping using Landsat Thematic Mapper data. Int J Remote Sens 24(10):2199–2204
Koutsias N, Kalabokidis KD, Allgöwer B (2004) Fire occurrence patterns at landscape level: beyond positional accuracy of ignition points with kernel density estimation methods. Nat Resour Model 17(4):359–375
Koutsias N, Xanthopoulos G, Founda D, Xystrakis F, Nioti F, Pleniou M, Mallinis G, Arianoutsou M (2013) On the relationships between forest fires and weather conditions in Greece from long-term national observations (1894–2010). Int J Wildland Fire 22(4):493–507
Martínez-Fernández J, Chuvieco E, Koutsias N (2013) Modelling long-term fire occurrence factors in Spain by accounting for local variations with geographically weighted regression. Nat Hazards Earth Syst Sci 13(2):311–327
Mateu J, Uso JL, Montes F (1998) The spatial pattern of a forest ecosystem. Ecol Model 108:163–174
Ministerio de Medio Ambiente (2006) Los incendios forestales en España. Decenio 1996–2005
Møller J, Waagepetersen RP (2007) Modern statistics for spatial point processes (with discussion). Scand J Stat 34:643–711
Møller J, Díaz-Avalos C (2010) Structured spatio-temporal shot-noise Cox point process models, with a view to modelling forest fires. Scand J Stat 37:2–15
Moreira F, Viedma O, Arianoutsou M, Curt T, Koutsias N, Rigolot E, Barbati A, Corona P, Vaz P, Xanthopoulos G, Mouillot F, Bilgili E (2011) Landscape–wildfire interactions in southern Europe: implications for landscape management. J Environ Manag 92:2389–2402
National Interagency Fire Center (2011) The science of wildland fire. http://www.nifc.gov/)
Pausas JG (2004) Changes in fire and climate in the eastern Iberian Peninsula (Mediterranean basin). Clim Change 63:337–350
Preisler HK, Westerling AL (2007) Statistical model for forecasting monthly large wildfire events in western United States. J Appl Meteorol Climatol 46:1020–1030
R Development Core Team (2010) R: a language and environment for statistical computing. R Foundation for Statistical Computing. http://www.r-project.org/
Ripley BD (1976) The second-order analysis of stationary point processes. J Appl Probab 13:256–266
Ripley BD (1981) Spatial statistics. Wiley, New York
Serra L, Varga D, Juan P, Saez M, Mateu J (2014) Spatio-temporal log-Gaussian Cox processes for modelling wildfire occurrence: the case of Catalonia, 1994–2008. Environ Ecol Stat 21(3):531–563
Turner R (2009) Point patterns of forest fire locations. Environ Ecol Stat 16:197–223
Vázquez A, Moreno JM (1998) Patterns of lightning-, and people-caused fires in peninsular Spain. Int J Wildland Fire 8(2):103–115
Vilar del Hoyo L, Martin Isabel MP, Matinez Vega FJ (2011) Logistic regression models for human-caused wildfire risk estimation: analyzing the effect of the spatial accuracy in fire occurrence data. Eur J For Res 130:983–996
Waagepetersen RP (2007) An estimating function approach to inference for inhomogeneous Neyman–Scott processes with appendix. Biometrics 63:252–258
Wittenberg L, Malkinson D (2009) Spatio-temporal perspectives of forest fires regimes in a maturing Mediterranean mixed pine landscape. Eur J For Res 128:297–304
Acknowledgments
We would like to thank the Department of Infrastructure Territory and Environment of the Generalitat Valenciana, Section of Forest Fire Prevention, for the assignment of geographic data.
Author information
Authors and Affiliations
Corresponding author
Additional information
Handling Editor: Dr. Hans Pretzsch.
Rights and permissions
About this article

Cite this article
Aragó, P., Juan, P., Díaz-Avalos, C. et al. Spatial point process modeling applied to the assessment of risk factors associated with forest wildfires incidence in Castellón, Spain. Eur J Forest Res 135, 451–464 (2016). https://doi.org/10.1007/s10342-016-0945-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-016-0945-z