
Abstract
There is a growing concern about health hazards linked to nitrate (NO3) toxicity in groundwater due to overuse of nitrogen fertilizers in rice production systems of northern Iran. Simple-cost-effective methods for quick and reliable prediction of NO3 contamination in groundwater of such agricultural systems can ensure sustainable rural development. Using 10-year time series data, the capability of adaptive neuro-fuzzy inference system (ANFIS) and support vector machine (SVM) models as well as six geostatistical models was assessed for predicting NO3 concentration in groundwater and its noncarcinogenic health risk. The dataset comprised 9360 water samples representing 26 different wells monitored for 10 years. The best predictions were found by SVM models which decreased prediction errors by 42–73 % compared with other models. However, using well locations and sampling date as input parameters led to the best performance of SVM model for predicting NO3 with RMSE = 4.75–8.19 mg l−1 and MBE = 3.3–5.2 mg l−1. ANFIS models ranked next with RMSE = 8.19–25.1 mg l−1 and MBE = 5.2–13.2 mg l−1 while geostatistical models led to the worst results. The created raster maps with SVM models showed that NO3 concentration in 38–97 % of the study area usually exceeded the human-affected limit of 13 mg l−1 during different seasons. Generally, risk probability went beyond 90 % except for winter when groundwater quality was safe from nitrate viewpoint. Noncarcinogenic risk exceeded the unity in about 1.13 and 6.82 % of the study area in spring and summer, respectively, indicating that long-term use of groundwater poses a significant health risk to local resident. Based on the results, SVM models were suitable tools to identify nitrate-polluted regions in the study area. Also, paddy fields were the principal source of nitrate contamination of groundwater mainly due to unmanaged agricultural activities emphasizing the importance of proper management of paddy fields since a considerable land in the world is devoted to rice cultivation.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In many parts of the world, agriculture mostly relies on groundwater resources which are generally exposed to higher risk of contamination due to excessive depletion of low water stocks and rapidly enhanced human activities such as excessively unmanaged application of fertilizers and pesticides, producing urban sewage and industrial wastes. These contamination might render groundwater unsuitable for consumption and put human and animal life as well as the whole environment at great risk (Babiker et al. 2004).
Having high solubility and weak adsorption to soil particles, nitrate is the most frequently introduced pollutant into groundwater systems (Spalding and Exner 1993) since it accompanies the largest life/death cycle in the biosphere. Intensive agriculture is usually the main source of nitrate contamination due to unmanaged and excessive application of chemical fertilizers which alter the balance of nitrogen compounds in soil and introduce the excessive nitrogen to the soil and consequently to the groundwater. High levels of nitrate in groundwater originating mainly from agricultural activities were encountered in almost all regions of the world (e.g., Spalding and Exner 1993; Dudley et al. 2008; Burow et al. 2010; Melo et al. 2012; Dahan et al. 2014). The adverse health effects of high nitrate levels in drinking water are well documented (Mousavifazl et al. 2013; Sundaraiah and Sudarshan 2014). Groundwater with nitrate concentration exceeding the threshold of 3 mg l−1 NO3 −–N or 13 mg l−1 NO3 − is considered due to human activities (the so-called human-affected value; Burkart and Kolpin 1993; Eckhardt and Stackelberg 1995). However, the maximum acceptable concentration of nitrate for potable water according to the World Health Organization (WHO) is 11.3 mg l−1 NO3 −–N or 50 mg l−1 NO3 −. Thus, exploring the contaminated area and proposing suitable solution for sustaining the groundwater resources are essential.
The first step in planning and management of groundwater resources is assessing and predicting water quality. Such assessment requires reliable quantitative models which led to developing a lot of physical and mathematical models. Conceptual or physical models have been widely used to simulate water and solute transport in subsurface environment during past decades. Nevertheless, the lack of precise data diminishes the reliability of these models (Almasri and Kaluarachchi 2005). Machine-learning models such as adaptive neuro-fuzzy interference (ANFIS) and support vector machines (SVM) might be better alternatives since these models acquire implicit knowledge among dataset without requiring the knowledge of mathematical relationship between the inputs and the corresponded outputs as well as explicit characterization and quantification of physical properties and conditions (Almasir et al. 2005). Even under limited data, machine-learning models provide methods for quick and flexible estimation aimed at achieving high level of generalization and prediction accuracy (Khalil et al. 2005). Among machine-learning models, SVM are a new structure which were introduced as robust and significant learning tool for classification and regression problems. It is a novel inductive rule for learning from a finite dataset and has shown good performance with small samples (Liu et al. 2010). Although machine-learning models have been widely used for simulating hydrological process of surface water resources during past decades (Jiang and Cotton 2004; Ahmad and Simonovic 2005; Elshorbagy and Parasuraman 2008; Zou et al. 2010; Dai et al. 2011; Asefa et al. 2006; Yu and Liong 2007; Lin et al. 2009; Liu et al. 2010; Deng et al. 2011), they have rarely been used for assessing groundwater quality (Khalil et al. 2005).
Geostatistical modeling is another method for assessing ground water quality. This method is based on the theory of regionalized variables (Goovaerts 1997), and is generally preferred for such assessment, because it allows to take into account spatial correlation between neighboring observations to predict attribute values at un-sampled locations. Since the pioneering work of Delhomme (1976), geostatistics has been widely employed in hydrogeology to obtain maps of peizometric surface, to estimate transmissivity or hydraulic conductivity, to create iso-concentration maps of groundwater contaminations, to produce iso-probability maps that the concentration of a specific contaminant exceeds a threshold and as tool for inverse problem solutions (Assaf and Saadeh 2006). Kriging method has been reported as a suitable method for creating the spatial distribution of nitrate concentration in contaminated groundwater (Babiker et al. 2004; Castrignano et al. 2008; Assaf and Saadeh 2006). However, the other geostatistical interpolation methods such as weighting moving average and cokriging methods have less been considered.
Literature review indicates a lack of a comprehensive study dealing with the evaluation of different fast-cost-effective methods for assessing nitrate toxicity in shallow aquifers under point- and non-point-sources of pollution. Therefore, the present research was designed to clarify the performance of both machine-learning and geostatistical modeling for predicting seasonal variations of nitrate toxicity and its associated noncancerous health risk in shallow aquifers under both point- and non-point-sources pollution. Based on long-term time series data, ANFIS and SVM models as well as six geostatistical models including ordinary Kriging (OK), Ordinary Cokriging with the covariates of Ca2+ concentration (OCK1) and total hardness (OCK2) and weighting moving average with powers of 2 (WMA2), 4 (WMA4) and 6 (WMA6) were employed for diagnosing the negative impacts of human activities on polluting groundwater resources.
Materials and methods
Site description and sampling
The experimental site located within 653794–679951 m longitudes and 4030314–4064326 m latitudes in Mazandaran province, Northern Iran (Fig. 1a, b). In this part of the province, the long-term average annual rainfall is 700 mm about 70 % of which occurs over the October–March period (Karandish 2016). Long-term annual minimum, maximum, and average temperatures of the study area are about 12.5, 21.5, and 17 °C, respectively. Paddy fields are dominant in crop sown area in the study area (Fig. 1c).

The location of the study area in Iran (a), in Mazandaran province (b), land use classes and location of monitoring wells (w01–w 26) (c)
Groundwater in 26 monitoring wells distributed across the study area (Fig. 1c) were sampled three times a month during 10 years. Water samples were analyzed at the Water Quality Laboratory of Mazandaran Regional Water Company for Nitrate concentration (NO3) and the 11 physical and chemical properties of water were also analyzed. Pearson correlation analysis was performed between the measured chemical parameters to identify possible relationships and to define covariates for predicting methods. The log normalized data were subjected to six geostatistical methods including: weighting moving average (WMA) with powers of two (WMA-2), four (WMA-4) and six (WMA-6), ordinary kriging (OK) and Co-kriging with two covariates of Ca2+ concentration (OCK1) and TH (OCK2). In addition, the capability of two machine-learning methods including adaptive neuro-fuzzy inference systems (ANFIS) and SVM for simulating NO3 concentration in groundwater was assessed. The simulated and observed data were analyzed by considering the cropping season of major crop (rice) grown in the study area so that a year was divided into four periods including preplanting period (winter), cropping season (spring and summer), and the postharvest period (autumn). Based on the national standards of Iran, seasons were defined as spring (April, May, and June), summer (July, August, and September), autumn (October, November, and December), and winter (January, February, and March).
Geostatistical analysis approach
In classic statistical analysis, samples are treated as if they are stripped of spatial dimension. In geostatistics, however, the location of a data point is considered in conjunction to its value. Semivariogram is a measure of spatial correlation of a given variable. The experimental semi variogram (γ) is calculated by (Issaks and Srivastava 1989):
where n (h) is the number of sample pairs separated by distance h, Z(x i ) is the measured value at locationx i , and Z(x i + h) is the measured value at distance h from x i . Range (R) is the distance where γ reaches a constant value. The value of semivariogram at R is defined as sill. In theory, sill value is equal to the sample variance under the assumption of second-order stationary. The value of γ at h = 0 in the semivariogram is called the nugget effect (C 0). γ is used in kriging methods for estimating the weight parameters and deriving the spatial distribution of estimation variance. A detailed presentation of geostatistical theories can be found in Goovaerts (1997), Chiles and Delfiner (1999), and Webster and Oliver (2006).
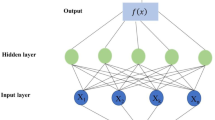
ANFIS
In 1993, Jung introduced ANFIS considering the capabilities of the fuzzy theory and the neural nets (Tang et al. 2005). A popular teaching method in neuro-fuzzy systems is the fuzzy inference system, which uses the hybrid learning algorithms to identify the fuzzy system parameters and teach the model as well (Rehman and Mohandes 2008). ANFIS model is a five-layer structure, which is the result of adding the fuzzy logical models to the artificial neural net:
In the layer 1 or input layer, the membership degree of the nodes entering different fuzzy periods is determined by using the membership functions (MFs). The shape of the membership function and the amount of their overlapping are optional, and are determined by Eq. (2):
where x is input, and a, b, and c are the comparative parameters and the nonlinear coefficients of this equation, which determine the shape of the membership function. The set of the fuzzy variable coefficients is called S1 set or the left-handed set (LHS). The output amounts of the first layer show the membership amount for each input regarding the different membership functions of the inputs.
Layer 2 is the result of multiplying the input amounts by the nodes, and finally the firing strength. For example, for the first node, we have
Nodes of layer 3 normalize the firing strength as follows:
where n is the number of nodes in each layer.
Layer 4 is the terms layer in which terms are achieved. These terms are the results of operation on the input signals into this layer:
where r 1, q 1, and p 1 are the consequent parameters.
Layer 5 is the last layer of the net which includes only one node and is calculated via adding all input amounts into its total output as Eq. (6):
Detailed description of the structure of a ANFIS model and the calculation procedures were discussed in Dastirani et al. (2010). One of the features of every ANFIS model is the type of function considered for the model inputs. In this research, different membership functions were employed. In addition, different numbers of MFs were tried in each application, and the best one giving the minimum errors was selected.
SVM
Being introduced by Vapnik (1995), SVM are a classifier derived from statistical learning theory. The SVM can be used both for classification and regression problems and can be represented as two-layer networks where the weights are nonlinear in the first layer and linear in the second layer (Bray and Han 2004). Support vector regression (SVR) is used to describe regression with SVM in the literature. The regression estimation with SVR is to estimate a function according to a given dataset {(xi, yi)}n, where xi denotes the input vector; yi denotes the output value; and n is the total number of datasets (Tabari et al. 2012). Herein, the input vectors (xi) refer independent variables whereas the target values (yi) refer to nitrate concentration. The linear regression function uses the following function:
where \(\phi \left( x \right)\) is a nonlinear function by which x is mapped into a feature space, b and \(\omega\) are a weight vector and a coefficient that should be estimated from the data. Linear regression is performed in a high dimensional feature space via a nonlinear mapping. The coefficients b and x are estimated by minimizing the sum of the empirical risk and a complexity term.
where c is a positive constant (implied as additional capacity control parameter) that determines the trade-off between the model complexity and the amount up to which error larger than \(\varepsilon\) are tolerated, \(\left\| \omega \right\|^{2}\) is the regularization term which denotes the Euclidean norm, and Le is called e-insensitive loss function that measuring the empirical risk and has the advantage that we will not need all the input data for describing the regression vector x.
As shown in Eq. (12), the loss function is equal to 0 if the difference between the predicted \(f\left( x \right)\) and the measured value \(y_{i}\) is less than \(\varepsilon\). The choice of \(\varepsilon\) is easier than the choice of c and it is often given as a desired percentage of the output values \(y_{i}\). So, a nonlinear regression function is given by a function that minimizes Eq. (11) subject to Eq. (12), as in the following expression:
With \(\alpha_{i} \alpha^{*} = 0,\;\alpha_{i} \alpha^{*} \ge 0,i = 1, \ldots ,N\) and the kernel function \(k(x_{i} ,x)\) describes the inner products in the D-dimensional feature space.
It should be mentioned that the features \(\phi_{j}\) need not be computed; rather what is needed is the kernel function that is very simple and has a known analytical form. In this study, linear, polynomial, radial basis function, and sigmoid kernels were used. The best kernel was determined by a trial and error process. The coefficients \(\alpha_{i} \alpha^{*}\) are obtained by maximizing the following form:
Only a number of coefficients \(\alpha_{i} \alpha^{*}\) will be different from zero, and the data points associated to them are called support vectors (Mohandes et al. 2004; Kisi and Cimen 2009; Zhou et al. 2009).
Criteria indices
Prediction performances were assessed by cross-validation. Also, mean bias error (MBE) and root mean square error (RMSE) were calculated for comparing different interpolation models as follows:
where Z(x i ) and Z *(x i ) are the observed and estimated values of NO3 concentration, respectively, and n is the number of data points.
Health risk assessment
Risk assessment is defined as the process of estimating the probability of occurrence of an event and the probable magnitude of adverse health effects over a specified time period (Gao et al. 2012). This research used the HRA model suggested by the United States Environmental Protection Agency (EPA, 1989), including mathematical models of noncarcinogenic risks caused by a single factor (Ni et al. 2010), to calculate the health risk of groundwater for drinking water supply with respect to nitrate concentration. The noncarcinogenic chronic toxic property of chemical pollutants in the human body takes the reference dose as a yardstick: people whose exposure level is higher than the reference dose are probably at risk; those whose exposure level is equal to or lower than the reference dose are less likely to be at risk. Potential noncarcinogenic risk for exposure to contaminant was evaluated as follows (EPA, 1989):
where HQ is hazard quotient (unitless), Rfd is the reference does (mg kg−1 day−1) and CDI is the exposure dose rate (mg kg−1 day−1) representing the daily intake of assessed pollutant per kg weight of a person. Rfd for nitrate was 1.6 mg kg−1 day−1. CDI was calculated as follows:
where C is the nitrate concentration in groundwater (mg l−1); RI is the drinking rate (L day−1), representing a person’s daily amount of drinking water; EF is the exposure frequency, representing the days of assessed pollutants intake per year in the evaluation period (day year−1); ED is the exposure duration (year, the value recommended by the U.S. EPA is 30 years), representing the years of lifelong intake of assessed pollutants; BW is the average weight of human bodies (kg); and AT is the average time (d, the average noncarcinogenic time is ED × 365 days). According to Gao et al. (2012), IR = 2 L day−1, ED = 30 years, EF = 365 day year−1, BW = 70 kg
Results and discussion
Data quality check and exploration
The descriptive statistics of NO3, total hardness (TH), and calcium concentrations (Ca2+) data are presented in Table 1. Nitrate concentration in 9360 samples ranged from 0.1 to 120.05 mg l−1. On average, the concentration of NO3 in groundwater was generally below the permissible limit of 50 mg l−1 as drinking health standard while it was exceeded the human-affected value of 13 mg l−1 NO3 most of the study period. Average of NO3 concentrations of groundwater samples collected during winter seasons was 17.5 mg l−1, consistently lower than their for the other seasons (23.7, 36.8, and 29.6 mg l−1 related to spring, summer, and autumn seasons, respectively). Nutrient and water management and cultural practices, timing and amount of precipitation, water table depth, and differences in soil types and nitrate uptakes by plants are major factors affecting nitrate concentration in groundwater. The maximum and minimum sample variances belonged to summer (736.85) and spring (422.9) period, respectively.
All datasets exhibit non-normal distribution; particularly in the spring (Skewness = 2.36, Kurtosis = 6.63) and winter (Skewness = 2.88, Kurtosis = 9.09) datasets. Previous researches indicate that nitrate concentrations follow a log-normal distribution. So, the data were log-transformed prior to the calculation of semivariogram in the geostatistical modeling to make the data normally distributed and satisfy assumptions of constant variability. The minimum and maximum SD corresponded to spring and autumn, respectively, after normalization.
Geostatistical modeling
Structural analysis
By superimposing trials of various models with different combinations of model parameters including nugget, sill and range of influence, the best approximation of the semivariogram was selected based on root sum square (RSS) index. A spherical model was selected for summer and autumn dataset while the spring and winter semivariogram was fitted with an exponential model (Fig. 2). Spherical model was advised in the results of other investigation for groundwater nitrate concentrations (Babiker et al. 2004; Castrignano et al. 2008; Assaf and Saadeh 2006).

Semivariograms (a) and Cross-Variograms for NO3-Ca2+ (b) and NO3-TH (c) for different periods
The selected semivariogram for different periods and their components are presented in Table 2. The semivariogram for autumn had the highest sill which could be attributed to the highest sample variance after normalization and relatively large amount of maximum NO3 concentration (Table 1). On the contrary, the sill of the semivariogram model for spring was the smallest which is in consistent with lower sample variance and lower amount of maximum nitrate concentration for spring. Spatial dependence of groundwater nitrate concentration can be classified according to nugget to sill ratio, known as Cambardella Index (CI) (1994) with a ratio of CI < 0.25, CI 0.25–0.75 and CI > 0.75 indicating a strong, moderate, and weak spatial dependence, respectively. Nitrate concentration in groundwater had a moderate spatial structure according to CI index (CI 0.26 for spring; 0.54 for Autumn and 0.5 for winter) with R ranging from 2310 m (spring) to 43470 m (winter). Exception was for summer when NO3 had strong spatial dependency with R of 12540 m (Table 2). The relatively well spatial continuity is a reflection of the high stability and mobility of nitrates in groundwater, which facilitate the migration of nitrates untransformed well beyond their source of input given the presence of highly permeable subsurface materials with adequate dissolved oxygen (Canter 1997).
Pearson-correlation analysis was carried out between NO3 concentration and different effective parameters including water table depth (WD), total amount of precipitation (Rain), water temperature (T), and the soil chemical properties including electrical conductivity (EC), total dissolved solids (TDS), acidity (pH), CO3 concentration, HCO3 concentration, Cl concentration, SO4 concentration, Ca2+ concentration, Mg concentration, Na concentration, and K concentration. These parameters well represent the nutrient and water management and cultural practices in the study area which affect the NO3 concentration in groundwater. Figure 3 shows that, amongst all parameters, TH and Ca2+ had the highest correlation coefficient with NO3 − concentration, and therefore, they were incorporated for NO3 − estimation using cokriging method as secondary variables (covariates). Structural analysis showed that Except for cross-variogram on NO3 − and Ca2+ in summer for which an exponential model had the least RSS, a spherical model was the best fitted to the dataset for the other periods (Table 2; Fig. 2). According to CI, for OCK1 and OCK2 semi-variograms, groundwater nitrate concentration had generally a weak spatial structure with some exceptions (Table 2). No significant improvement was observed in R with respect to Ca2+ or TH.

Pearson correlation coefficients of the different groundwater parameters with NO3 − concentration
Evaluating the geostatistical models
Different geostatistical techniques were used to estimate NO3 − concentration in groundwater for all sampling periods. Produced maps by OK were smoother and were substantially different with WMA since OK considers the pattern of spatial dependence of observed data, while the WMA method considers only the distance between estimated and observed locations (data not shown). Also, the locations of wells are more obviously shown in WMA maps since WMA generally produces spikes around the sample points (Lloyd 2005). Unlike WMA, produced maps by OCK represented more similarities with the OK map especially when incorporating Ca2+ as covariate.
Having the least RMSE, MAE, and MBE (Table 3), OK provided the best results for all datasets among different geostatistical methods, which is in consistent with other studies (Babiker et al. 2004; Assaf and Saadeh 2006). Less accurate results under OCK could be attributed to insignificant correlation between the primary and secondary variables and weak spatial correlation (Goovaerts 1997, 2000). Despite a higher correlation between NO3 − and Ca2+ compared with that between NO3 − and TH, Ca2+ may not still improve the prediction accuracy through OCK1 if the spatial continuity of Ca2+ is weaker than of NO3 −, as was observed here (Tables 3). However, the better performance of OCK than WMA shows that OCK may increase the estimation accuracy by using the secondary data available at un-sampled locations even in the presence of a moderate cross-correlation between the primary and secondary variables (Table 2).
Positive MBE index for all interpolation techniques revealed an overall underestimation for all methods (Table 3). Higher bias was observed in summer and autumn which could be attributed to higher variation of NO3 − concentration due to both agricultural activities and intensive precipitation. Overall, OK provided more acceptable bias for all observed wells than the other methods. Also, created error maps for OK showed that the average values of standard error of the estimations were 1.11, 1.79, 1.63, and 1.34 mg/l for spring, summer, autumn, and winter, respectively, which were less than sample variance on the corresponded sampling dates (data not shown). This result indicates that OK interpolation is a reliable method for estimating NO3 − concentration. However, the visual inspection of the observed NO3 and the NO3 values estimated by the OK model by means of scatter plots in Fig. 4 demonstrates that even applying Ok method did not led to a high agreement between observed and simulated NO3 in the study area.

Scatter plot of observed and simulated NO3 − for OK models
Evaluating ANFIS and SVM models
For both ANFIS and SVM models, NO3 concentration was defined as a dependent output variable in ANFIS and SVM models while the Julian day number (DOY) of the sampling date, well locations as X- and Y-coordinates, Ca2+ and TH concentrations were defined as independent input variables in these models. DOY was defined based on the sampling dates. For example, if sampling is carried out on February 5, 15, and 25, the DOY will be set to 36, 46, and 56, respectively, and so on for the other months. Three input combinations evaluated in this research were as follows: (i) DOY, X-coordinate, and Y-coordinate (ANFIS1 and SVM1); (ii) DOY, X-coordinate, Y-coordinate, and Ca2+ (ANFIS2 and SVM2); and (iii) DOY, X-coordinate, Y-coordinate, and TH (ANFIS3 and SVM3). Out of the total 10-year data, 70 % of data which (data for 7 years) were incorporated in the train phase while the other 30 % of data related to the other 3 years were incorporated in the test phase.
Different ANFIS architectures were tried using a written code in MATLAB language including fuzzy logic. The efficient models were determined for each input combinations. Then, ANFIS models were tested and given results were compared using criteria indices. Table 4 represents the final architectures of ANFIS models for the test phase where the performance statistics are included. Two MFs were found to be sufficient for simulating NO3 − with ANFIS models. The increase in the number MFs not only does not provide any significant improvement in the results, but also increases the number of parameters to be optimized. Because of that, the number of MFs should be kept in the minimum number (Ozger and Yildrim 2008). Gaussian combination (Gus2) membership functions were the best MFs for all ANFIS models. With respect to RMSE, ANFIS1 model with inputs of DOY, X- and Y-coordinates had the best performance (RMSE = 8.19–17.3 mg l−1 and MBE = 5.2–9.7 mg l−1) for all seasons followed by ANFIS2 with inputs of DOY, X- and Y-coordinates and Ca2+ concentration (RMSE = 9.73–25.1 mg l−1 and MBE = 6–13.2 mg l−1). Generally, better results were obtained for spring periods while the worst one was obtained for autumn period.
As shown in Table 4, all ANFIS models underestimated NO3 concentrations. However, a visual inspection of the observed NO3 and the NO3 values estimated by the ANIFS models by means of scatter plots in Fig. 5 clearly indicate the high potential of ANFIS modeling. Despite high values of R 2 in Fig. 5, it should be noted that the R 2 term provides information for the linear dependence between observed and simulated NO −;3 and R 2 values equal to 1 does not guarantee that a model captures the behavior of the investigated parameters (Tabari et al. 2012).

Scatter plot of observed and simulated NO3 − for ANFIS models
SVM models were implemented by a written program code in MATLAB language by which different SVM architectures were tried. Finally, the appropriate model structures were determined for each input combination. Then, SVM models were tested and the results were compared with performance statistics. The results of SVM models are presented in Table 5. When SVM models are applied, an appropriate choice of kernels allows the data became separable in feature space although being non-separable in the original space. This allows one to obtain nonlinear algorithms from algorithm previously restricted to handling linearity separable datasets (Bray and Han 2004). Here, radial basis function was the best kernel for all SVM models. SVM1 with RMSE = 4.75–8.19 mg l−1 and MBE = 3.3–5.2 mg l−1 had the best performance for simulating NO3 − concentration. SVM2 and SVM3 models had nearly the same performance, and the selection of one of these models over the other should be dependent upon the available data. Scatterplots of observed and simulated NO3 concentrations with SVM models demonstrate the high potential of SVM modeling with high R 2 index (Fig. 6).

Scatter plot of observed and simulated NO3 − for SVM models
Comparison of the models
The global evaluation ranking of the approaches used was done based on RMSE and MBE indices and the results are summarized in Table 6. For all periods, SVM1 ranked first (RMSE = 4.75–8.19 mg l−1) followed by SVM2 (RMSE = 6.34–12.1 mg l−1) and SVM3 (RMSE = 5.1–11.5 mg l−1). ANFIS models could be considered as 4th to 6th best models (RMSE = 8.19–25.1 mg l−1) while geostatistical methods occupied that the last places for estimating NO3 − concentration with RMSE = 22.1–44.6 mg l−1.
ANFIS models combine the transparent, linguistic representation of fuzzy system with the learning ability of ANN. Therefore, they can be trained to perform an input/output mapping just as with an ANN, but with the additional benefit of being able to provide the set of rules on which the model is based. This given further insight into the process being modeled (Sayed et al. 2003). The main advantage of using SVM is their flexibility and ability to model nonlinear relationship. Furthermore, the SVM training process always seeks a global optimized solution and avoid over-fitting that eventually leads to better generalization performance than ANN models. SVM is able to select the key vectors in the training process as it supports vectors and remove the nonsupport vectors automatically from the model. This makes the model to cope well with the noisy condition. The main disadvantage of the SVR technique is that it has no physical basis and belongs to a class of data-box approaches. In addition, the SVR can only be used when the training data are available (Bray and Han 2004; Zhou et al. 2009; Kisi and Cimen 2009).
NO3 spatial variability pattern and quality assessment
Spatial variability of nitrate concentration was prepared by SVM1 model in five thematic classes indicating “safe” class (NO3 < 13 mg l−1), “moderately human affected” class (13 < NO3 < 20 mg l−1), “extremely human affected” class (20 < NO3 < 50 mg l−1, i.e., 50 is the maximum acceptable level for drinking), “unacceptable for drinking” class (50 < NO3 < 75 mg l−1) and “extremely unacceptable for drinking” class (NO3 > 75 mg l−1) (Fig. 7). The pattern of spatial distribution was nearly erratic while it was more spatially structured in autumn when NO3 concentration gradually decreased southward and westward. This pattern has been suggested to result from the disappearances of nitrate by natural de-nitrification in the direction of groundwater flow (Babiker et al. 2004).

Classified spatial variability maps of groundwater nitrate level combined with related histograms for spring (a), summer (b), autumn (c), and winter (d)
Nearly, most parts of the study area displayed a relatively weak association with maximum acceptable concentration of nitrate for potable water (50 mg l−1) according to the World Health Organization (WHO). Exception was for a few spots in spring and summer, especially centered around W01 observation well, indicating a possible pollution by point sources. Nevertheless, a large part of the study area was found to be suffering from nitrate concentration exceeding the human-affected threshold of 13 mg l−1 (Fig. 7). Of all the period tested, winter had the smallest area affected by excessive nitrate pollution (40.3 % of the study area) whereas just about 9.8–23 % of the area felt in the range of 0–13 mg l−1 for the other periods. Nitrate concentration commonly ranged from 20 to 50 mg l−1 during spring, summer, and autumn period, indicating an ongoing potential risk from groundwater pollution. Thus, recognizing the most vulnerable area could help with a better understanding of the pollution source in the study area.
The probability maps of NO3 > 13 mg l−1 (P N13) were generated for all periods (Fig. 8) which were classified with 5 equal classes of PN13 including 0–0.2, 0.2–0.4, 0.4–0.6, 0.6–0.8, and 0.8–1. Despite a decreasing trend of NO3 from summer to winter, about 56–97 % of the area showed the highest probability (0.8 < P N13 < 1) of NO3 > 13 mg l−1 with the minimum and maximum PN13 for spring and autumn, respectively. Exception was for winter when less than 10 % of the study area was at high risk of groundwater contamination (0.8 < P N13 < 1). Also, a considerable parts of the study area (0.6–20.1 %) showed a strong probability (0.6 < P N13 < 0.8) of groundwater pollution induced by human activities. From nitrate contamination viewpoint, water of acceptable quality (P N13 < 10 %) may be found in a few part of the study area. Overall, having P N13 > 50 %, a large part of the study area is at high risk of nitrate contamination, quite likely due to human-related pollution, accounted for 78.5, 97.7, 97.8 and 42.7 % in spring, summer, autumn, and winter, respectively. Thus, groundwater is more vulnerable to nitrate contamination in summer and autumn than the other periods.

Spatial distribution of excessive groundwater nitrate probabilities in the study area combined with related histograms for spring (a), summer (b), autumn (c), and winter (d)
Results revealed a considerable difference in groundwater NO3 concentration attributed to land use (Fig. 1b) which is well documented in previous researches (Burow et al. 2010; Melo et al. 2012; Dahan et al. 2014). Commonly, monitoring wells located in “paddy fields” class had highest average of nitrate concentration followed by those located in “urban” class. The least NO3 concentration was attributed to “dense forest” class with an average of 7.97–19.49 mg l−1 during the study period. Non-point-source pollution is evidence in paddy fields, where more than 90 % of it was associated with NO3 − > 13 mg/lit. Being an essential for productive agriculture, fertilizer application is one of the most important factors affecting groundwater contamination under paddy fields as is documented in the previous researches (Spalding and Exner 1993; Dudley et al. 2008; Burow et al. 2010; Melo et al. 2012; Dahan et al. 2014). Since 80 % of the study area devoted to rice cultivation, temporal variations in NO3 concentration could be explained based on three periods of preplanting (winter), transplanting (spring and summer), and postharvest (autumn). In paddy fields, fertilizers are commonly applied in spring. Thus, higher nitrate concentration in summer well reflects the lag time between the applications of fertilizers during the rainless season to the time required to nitrates leach into the groundwater. During postharvest period (autumn), nitrate concentration in groundwater was higher than that of preplanting (winter) period mainly related to solute transport to the groundwater due to heavy rainfall in autumn as what does heavy irrigation followed by fertilization for the summer crops sown in the spring. However, higher nitrate concentration in planting and postharvest periods indicates the considerably negative effect of agricultural activities in the study area. Irrigation practice and management may also influence nutrient transport to groundwater in the paddy fields (Gao et al. 2012). Flooding irrigation, especially after fertilizer application, increases nitrate losses into groundwater compared with dry farming. Also, irrigation water quality can have a profound impact on groundwater quality especially under flooding irrigation due to having dissolved mineral salts (Grattan 2002). A considerable depletion in groundwater level in summer (data not shown) due to irrigation may deteriorate groundwater quality during rice growing season due to a strong relationship between the increase of salt contamination and the lowering of piezometric levels (Lashkaripour and Ghafoori 2011; Chaudhuri and Ale 2014). In addition, the shallow aquifer in paddy fields which is relatively close to the surface may receive direct input of NO3-rich leachate from the agricultural soils (Gao et al. 2012).
Figures 1b, 7, and 8 show that regions surrounded by both paddy fields and urban classes had the highest NO3 concentration which reflects the additive negative effect of both classes for contaminating groundwater. Point source pollution could be found around W01 borehole with consistent NO3 > 50 mg/lit, presumably due to releases of untreated wastewater to open areas, ditches, and septic tanks and the common practice of dumping solid waste.
Health risk assessment
The spatial distribution of HQ of nitrate is illustrated in Fig. 9. The HQ assumes that there is a level of exposure (i.e., Rdf) below which it is unlikely for even sensitive pollutions to experience adverse health effects; there may be a concern arising for the potential noncarcinogenic effect of the HQ exceeds the unity. HQ due to nitrate showed seasonal changes of 0.09–1.71 in spring, 0.14–2.02 in summer, 0.14–0.83 in autumn, and 0.07–0.78 in winter. HQ exceeded the unity in about 1.13 and 6.82 % of the study area in spring and summer, respectively, which indicates that long-term drinking of groundwater or irrigation using groundwater poses a significant health risk to local resident (Gao et al. 2010).

Spatial distribution of HQ due to nitrate in spring (a), summer (b), autumn (c), and winter (d)
Figure 10 shows that paddy fields were commonly associated with the highest risk value. Totally, noncarcinogenic risk values of nitrate decreased in the following order: paddy fields > urban > dense forest > dry farming. Exception was for spring when it had higher HQ compared with urban land use. Relatively higher risk value under agricultural lands has been reported by other researchers (Gao et al. 2010). Higher values of HQ under paddy fields could be attributed to unmanaged use of fertilizers during the growing season.

HQ due to nitrate for different land uses in spring (a), summer (b), autumn (c), and winter (d)
Conclusion
In this research, the spatial and temporal variation of nitrate concentration in groundwater of Northern Iran’s coastal areas as well as its noncarcinogenic health risk was assessed using different machine-learning and geostatistical models. The comparative analysis demonstrated the high capability of simple SVM models for predicting nitrate concentration in groundwater. Created raster maps with SVM models revealed a high risk of nitrate pollution in a large part of the study area which is mainly under rice production. However, nitrate contamination from urban sources is also possible. Higher risk of groundwater contamination during the rice cultivation as well as postharvest periods compared with preplanting period well reflects the negative effect of unmanaged use of chemical fertilizers for contaminating the groundwater. In addition, over-abstraction of groundwater resources for irrigation in rice growing season and leaching of nitrate through heavy precipitation during postharvest periods causes further contamination of shallow groundwater aquifers. Health risk analysis revealed a necessity of devising policy guidelines for using groundwater due to high levels of HQ which poses a significant health risk for Mazandaran’s residents. Overall, sustaining the environment and protecting the human health requires a serious attention to manage the agricultural activities in paddy fields since a considerable part of the agricultural land in Mazandaran province is allotted to rice cultivation in which more than 40 % of the total Iran’s rice production is produced. Controlled use of fertilizers, optimal irrigation based on the plant water demand, preventing overexploitation of the shallow groundwater, and removing point source pollution would help with providing sustainable agriculture in the study area.
References
Ahmad S, Simonovic SP (2005) An artificial neural network model for generating hydrograph from hydro-meteorological parameters. J Hydrol 315:236–251
Almasri MN, Kaluarachchi JJ (2005) Modular neural networks to predict the nitrate distribution in ground water using the on ground nitrogen loading and recharge data. Environ Model Softw 20:851–871
Assaf H, Saadeh M (2006) Development of an integrated decision support system for water quality control in the Upper Litani Basin, Lebanon. In: Voinov A, Jakeman AJ, Rizzoli AE (eds) Proceedings of the iEMSs third Biennial meeting: “summit on environmental modelling and software”, international environmental modelling and software society. Burlington, USA
Asefa T, Kemblowski M, McKee M, Khalil AF (2006) Multi-time scale stream flow predictions: the support vector machines approach. J Hydrol 318:7–16
Babiker IS, Mohamed AAM, Terao H, Kato K, Ohta K (2004) Assessment of groundwater contamination by nitrate leaching from intensive vegetable cultivation using geographical information system. Environ Int 29(8):1009–1017
Bray M, Han D (2004) Identification of support vector machines for runoff modeling. J Hydroinf 6(4):265–280
Burkart MR, Kolpin DW (1993) Hydrologic and land use factors associated with herbicides and nitrates in near-surface aquifers. J Environ Qual 22:646–656
Burow KR, Nolan BT, Rupert MG, Dubrovsky NM (2010) Nitrate in groundwater of the United States, 1991–2003. Environ Sci Technol 44:4988–4997
Cambardella CA, Moorman TB, Novak JM, Parkin TB, Karlen DL, Turco RF, Konopka AE (1994) Field-scale variability of soil properties in central Iowa soils. Soil Sci Soc Am J 58:1501–1511
Canter LW (1997) Nitrates in groundwater. Lewis, Boca Raton
Castrignano A, Buttafuoco G, Troccoli A, Colecchia SA, Di Bitetto V, Pisante M, Basso F, Cafiero G, Cammarano D, Basso B (2008) Multivariate geostatistical analysis for delineation of management zones using crop index. In: Proceedings of the international conference on agricultural engineering, Hersonissos (Ageng2008), Crete Isle, Greece, 23–25 June 2008
Chaudhuri S, Ale S (2014) Long term (1960–2010) trends in groundwater contamination and salinization in the Ogallala aquifer in Texas. J Hydrol 513:376–390
Chiles JP, Delfiner P (1999) Geostatistics: modelling spatial uncertainty. Wiley, New York 695 p
Dahan O, Babad A, Lazarovitch N, Russak EE, Kurtzman D (2014) Nitrate leaching from intensive organic farms to groundwater. Hydrol Earth Syst Sci 18:333–341
Dai X, Huo Z, Wang H (2011) Simulation for response of crop yield to soil moisture and salinity with artificial neural network. Field Crops Res 121:441–449
Dastirani MT, Moghadamnia A, Piri J, Rico-Ramirez M (2010) Application of ANN and ANFIS models for reconstructing missing flow data. Environ Monit Assess 166:421–434
Delhomme JP (1976) Kriging in the hydrosciences. Adv Water Resour 1:251–266
Deng J, Chen X, Du Z, Zhang Y (2011) Soil water simulation and predication using stochastic models based on LS-SVM for red soil region of China. Water Resour Manage 25:2823–2836
Dudley LM, Ben-Gal A, Lazarovitch N (2008) Drainage water reuse: biological, physical, and technological considerations for system management. J Environ Qual 37:25–35
Eckhardt DAV, Stackelberg PE (1995) Relation of ground-water quality to land use on Long Island, New York. Groundwater 33:1019–1033
Elshorbagy A, Parasuraman K (2008) On the relevance of using artificial neural networks for estimating soil moisture content. J Hydrol 362:1–18
Gao Y, Mao L, Miao C, Zhou P, Gao J, Zhi Y, Shi W (2010) Spatial characteristics of soil enzyme and microbial community structure under different land suse in Chongming Islan, China: Geostatistical modeling and PCR-RAPD method. Sci Total Environ 408:3251–3260
Gao Y, Yu G, Luo C, Zhou P (2012) Groundwater nitrogen pollution and assessment of its health risk: a case study of a typical village in rural-urban continuum, china. PLoS One 7(4):1–8
Goovaerts P (1997) Geostatistics for natural resources evaluation. Oxford University Press, New York, p 483
Goovaerts P (2000) Geostatistical approaches for incorporating elevation into the spatial interpolation of rainfall. J Hydrol 228:113–129
Grattan SR (2002) Irrigation water salinity and crop production. University of California, Division of Agriculture and National Resources. Publication 8066
Issaks E, Srivastava RM (1989) Applied geostatistics. Oxford University Press, New York
Jiang H, Cotton WR (2004) Soil moisture estimation using an artificial neural network: a feasibility study. Can J Rem Sens 30:827–839
Karandish F (2016) Improved soil-plant water dynamics and economic water use efficiency in a maize field under locally water stress. Arch Agron Soil Sci. doi:10.1080/03650340.2015.1135326
Khalil AF, McKee M, Kemblowski M, Asefa T (2005) Basin scale water management and forecasting using artificial neural network. J Am Water Resour Assoc 41:195–208
Kisi O, Cimen M (2009) Evapotranspiration modelling using support vector machines. Hydrol Sci J 54(5):918–928
Lashkaripour GR, Ghafoori M (2011) The effects of water table decline on the groundwater quality in aquifer of torbat jam plain, Northeast Iran. Int J Emerg Sci 1(2):153–163
Lin GF, Chen GR, Wu MC, Chou YC (2009) Effective forecasting of hourly typhoon rainfall using support vector machines. Water Resour Res 45:W08440
Liu D, Yu Z, Lü H (2010) Data assimilation using support vector machines and ensemble Kalman filter for multi-layer soil moisture prediction. Water Sci Eng 3:361–377
Lloyd CD (2005) Assessing the effect of integrating elevation data into the estimation of monthly precipitation in Great Britain. J Hydrol 308:128–150
Melo A, Pinto E, Aguiar A, Mansilha C, Pinho O, Ferreira I (2012) Impact of intensive horticulture practices on groundwater content of nitrates, sodium, potassium, and pesticides. Environ Monit Assess 184:4539–4551
Mohandes MA, Halawani TO, Rehman S, Hussain AA (2004) Support vector machines for wind speed prediction. Renew Energy 29:939–947
Mousavifazl H, Alizadeh A, Ghahraman B (2013) Application of geostatistical methods for determining nitrate concentration in groundwater (Case study of Mashhad plain, Iran). IJACS 5(4):318–324
Ni F, Liu G, Tan Y, Deng Y (2010) Spatial variation of health risk of groundwater for drinking water supply in Mingshan County, Ya’an City, China. Water Sci Engin 3(4):454–466
Ozger M, Yildriım G (2008) Determining turbulent flow friction coefficient using adaptive neuro-fuzzy computing technique. Adv Eng Soft. doi:10.1016/j.advengsoft.2008.04.006
Rehman S, Mohandes M (2008) Artificial neural network estimation of global solar radiation using air temperature and relative humidity. J Energy Policy 63(2):571–576
Sayed T, Tavakolie A, Razavi A (2003) Comparison of adaptive network based fuzzy inference systems and B-spline neuro-fuzzy mode choice models. Water Resour Res 17(2):123–130
Spalding RF, Exner ME (1993) Occurrence of nitrate in groundwater—a review. J Environ Qual 22:392–402
Sundaraiah R, Sudarshan V (2014) Nitrate contamination in groundwater of Kalwakurthy area, Mahabubnagar District, Andhra Pradesh, India. Indian J Appl Res 4(9):240–243
Tabari H, Kisi O, Ezani A, Talaee PH (2012) SVM, ANFIS, regression and climate based models for reference evapotranspiration modeling using limited climate data in a semi-arid highland environment. J Hydrol 444–445:78–89
Tang LS, Li Y, Zhang J (2005) Physiological and yield responses of cotton under partial root-zone irrigation. Field Crop Res 94:214–223
U.S. Epa (United States Environmental Protection Agency) (1989) Supplement risk assessment (Part 1). U.S. EPA, Washington, D.C.
Vapnik V (1995) The nature of statistical learning theory. Springer, New York
Webster R, Oliver MA (2006) Optimal interpolation and isarithmic mapping of soil properties. VI. Disjunctive kriging and mapping the conditional probability. Eur J Soil Sci 40:497–512
Yu X, Liong SY (2007) Forecasting of hydrologic time series with ridge regression in feature space. J Hydrol 332:290–302
Zhou H, Li W, Zhang C, Liu J (2009) Ice breakup forecast in the reach of the Yellow River: the support vector machines approach. Hydrol Earth Syst Sci Discuss 6:3175–3198
Zou P, Yang J, Fu J, Liu G, Li D (2010) Artificial neural network and time series models for predicting soil salt and water content. Agric Water Manag 97:2009–2019
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Karandish, F., Darzi-Naftchali, A. & Asgari, A. Application of machine-learning models for diagnosing health hazard of nitrate toxicity in shallow aquifers. Paddy Water Environ 15, 201–215 (2017). https://doi.org/10.1007/s10333-016-0542-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10333-016-0542-2