
Abstract
Ruffed lemurs (Varecia spp.) exhibit a unique suite of behavioral traits compared to other lemur species, which includes their fluid fission–fusion social dynamics, communal rearing of parked litters, and pronounced frugivory in their humid rainforest habitats. Given these traits, and the dense rainforests they inhabit, vocal communication may be key to maintaining social cohesion, coordinating infant care, and/or defending their high-quality food resources. Indeed, they are known for their raucous ‘roar-shriek’ calls. However, there has been surprisingly little research on vocal communication in Varecia species and only two previously published repertoires, both of which were qualitative descriptions of their calls. In this study, we quantitatively examined the vocal repertoire of wild black-and-white ruffed lemurs (Varecia variegata) at Mangevo, Ranomafana National Park, Madagascar. We characterized 11 call types using 33 bioacoustic parameters related to frequency, duration, tonality, and composition. We also used discriminant function analysis and hierarchical clustering to quantitatively and objectively classify call types within the black-and-white ruffed lemur vocal repertoire. The repertoire consists of both monosyllabic and multisyllabic calls that are individually given or emitted in contagious choruses. Eight of the 11 calls were also used in combination or in larger multi-call sequences. The discriminant function analysis correctly assigned call types with 87% success, though this varied greatly by call type (1–65%). Hierarchical clustering identified 3–4 robust clusters, indicating low clustering structure in the data and suggesting that V. variegata exhibits a graded vocal repertoire. Future work should consider the environmental and behavioral contexts in which calls are used to better understand the function of these call types and combinations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Vocal repertoires, including descriptions of calls’ bioacoustic structures, provide important insights into the behavior of a species. Quantitative descriptions of the bioacoustic properties of different call types within a primates’ repertoire are therefore essential to understanding the behavioral ecology of the species (Cheney and Seyfarth 2018; Hammerschmidt and Fischer 2019). The bioacoustic properties of a primate’s vocal repertoire can be influenced by a myriad of factors including (but not limited to) its body size (negative size-frequency allometry, Bowling et al. 2017), habitat density (acoustic adaptation hypothesis, Marten and Marler 1977; Wiley and Richards 1978; Ey and Fischer 2009), arousal level (Morton’s law, Morton 1977), perceived predation pressure (Zuberbühler et al. 1999; Stephan and Zuberbühler 2008), and social structure (McComb and Semple 2005). However, to test the relative importance of each of these factors to shaping a species’ vocal repertoire first requires a thorough description and understanding of the vocal repertoire’s bioacoustic properties.
Primate vocal repertoires can exhibit great flexibility due to variable combinations of call types or syllable types within a call sequence (Kershenbaum et al. 2016; Fischer et al. 2017; Engesser and Townsend 2019). Animal vocal repertoires tend to be organized hierarchically; different call types contain syllable types that differ in duration and number which can be combined in variable ways to form call sequences (Kershenbaum et al. 2016; Seyfarth and Cheney 2018). The acoustic structure of primate calls is thought to be fairly constrained and call combinations may be one way of creating variation and flexible usage in spite of these constraints (Cheney and Seyfarth 2018). Structuring at the different scales of a vocal repertoire can result in call combinations and sequences that may contain meaningful information about context or caller (Arnold and Zuberbühler 2008; Bouchet et al. 2012; Keenan et al. 2013; Inoue et al. 2017; Keenan et al. 2020). Within these call combinations, it is also common for one call type to transition (i.e., grade) into another type, thereby complicating the process of classifying calls within a vocal repertoire (Kershenbaum et al. 2016; Fischer et al. 2017).
Statistical methods such as supervised or unsupervised clustering analyses are commonly used to quantitatively distinguish call types based off of bioacoustic measurements extracted from spectrograms. These methods are advantageous compared to manual classification or enumeration because they are thought to be more objective and reduce human/observer bias (Fischer et al. 2017). For instance, primatologists have commonly used principal component analysis (PCA; Microcebus murinus, Leliveld et al 2011; Lepilemur sahamalazensis, Mandl et al 2019a; Mirza zaza, Hending et al. 2020), discriminant function analysis (DFA; Cercocebus atys, Range and Fischer 2004; Cebus capucinus, Gros-Louis et al. 2008; Cacajao melanocephalus, Bezerra et al. 2010; L. sahamalazensis, Seiler et al. 2015; Gorilla gorilla, Salmi et al. 2018) and clustering (Macaca sylvanus, Hammerschmidt and Fischer 1998; Papio spp., Hammerschmidt and Fischer 2019) to classify vocal repertoires.
Like most primates, vocalizations are a critical communicative modality for Malagasy strepsirrhines. Knowledge of lemur vocal repertoires has been key to determining habitat preference (Microcebus sambiranensis; Hending et al. 2017), assessing behavioral contexts of calling behavior (V. variegata, Batist et al. 2022), discriminating between species (Braune et al. 2008; Méndez‐Cárdenas et al. 2008) and understanding mother–infant relationships (M. murinus, Scheumann et al. 2017), anti-predator strategies (Lemur catta, Bolt et al. 2015; Propithecus spp., Fichtel and Kappeler 2011), social cohesion (L. catta, Kulahci et al. 2015), establishment and maintenance of dominance hierarchies (L. catta, Bolt 2013a), mating (M. zaza, Seiler et al. 2019; L. catta, Bolt 2013b), and coordination of group movements (Eulemur rufifrons, Sperber et al. 2017; L. catta, Bolt 2020).
Ruffed lemurs (genus Varecia) are well known for their vocalizations, particularly their raucous roar-shriek chorus, and yet are understudied in the primate vocal communication literature. Ruffed lemurs are large-bodied, highly frugivorous lemurs that inhabit the eastern rainforests of Madagascar (Louis et al. 2020). They live in relatively large social groups with unusually strong fission–fusion dynamics (FFD), meaning that individuals in a community move fluidly between subgroups with variable duration, composition, and cohesion (Baden et al. 2016; Holmes et al. 2016). Moreover, ruffed lemurs have unusual and highly specialized infant care. Unlike most other diurnal primates, females synchronously give birth to litters of 1–3 altricial infants that are parked in nests and communally raised (Morland 1993; Vasey 2007; Baden et al. 2013; Baden 2019). This suite of traits is unique among strepsirrhines, and among primates more generally. These traits appear to emphasize the importance of vocal communication, particularly since their dispersed social system within Madagascar’s dense rainforests can often preclude the use of visual and/or olfactory signals. In these contexts, vocalizations have been described as ‘grooming-at-a-distance’ (Arlet et al 2015; Kulahci et al 2015).
The first of two reported ruffed lemur vocal repertoires, which was generated from captive research more than three decades ago, was initially qualitatively characterized as comprising 13 calls that included both individual calls and contagious choruses (Pereira et al. 1989). The vocal repertoire was part of a larger summary of the Varecia behavioral repertoire and as such, was largely descriptive. More recently, we investigated call usage in a wild population of black-and-white ruffed lemurs, wherein we identified 11 calls that can be readily distinguished by experienced human observers (Batist et al. 2021). However, this again was a largely qualitative description as the paper focused more on the behavioral context and demographics of calling behavior. There has therefore not yet been a quantitative characterization of the acoustic structure of call types, nor a statistical classification of the vocal repertoire as a whole.
Moreover, most previous studies have only focused on a subset of the V. variegata vocal repertoire, such as predator alarm calls (the bark; Macedonia 1990) or the roar-shriek loud call (Turner and Harrenstien 1985; Macedonia and Taylor 1985). While all studies have noted that there are loud calls which are contagious choruses as well as individually given, quieter calls (Petter and Charles-Dominique 1979; Turner and Harrenstien 1985; Pereira et al 1988; Alessandra et al. 2002), only two have examined their acoustic features: one quantified acoustic properties of the roar-shriek loud call (Macedonia and Taylor 1985), while the second used vocal tract modelling to analyze formant patterns in four call types (Gamba and Giacoma 2006). Though the form and function of their calls remains poorly understood, the few studies that have previously examined Varecia vocalizations have suggested that some of their loud calls (bark, roar-shriek) exist on what has been described as a “response urgency continuum” that is affected by context and an individual’s arousal state; this could contribute to variation within and between call types (Petter and Charles-Dominique 1979; Pereira et al. 1988; Macedonia 1990). Batist et al. (2021) provide a full description of the behavioral contexts related each call type.
While it is often easier to record calls in captivity, because of the more controlled environment, captive groups may exhibit different vocal repertoires than their wild counterparts due to lack of predation pressure, smaller social groups, and limited space (Turner and Harenstein 1985; Zimmerman 1995). It is therefore important to have a complete picture of the vocal repertoire, including data from captive and wild groups, to facilitate research including explicit hypothesis testing and conservation efforts moving forward.
Here, we aim to quantitatively describe the bioacoustic properties of the ruffed lemur vocal repertoire in a wild population and validate our qualitative vocal descriptions with statistical classification and clustering methods. The present study has three main objectives: (1) to comprehensively characterize the acoustic structure of V. variegata call types using a suite of variables related to duration, frequency and tonality; (2) to describe the sequences derived from combinations of the different call types within the V. variegata vocal repertoire; and, recognizing that qualitative classifications can still be subjective and difficult to interpret, (3) conduct statistical classification methods to compare their performance to our qualitative classifications and to more objectively determine the clustering structure of the repertoire.
Methods
We collected data for this study from May through August 2019 at Mangevo, a site within Ranomafana National Park (Figure S1). The park is a 435 km2, mid-elevation (600–1200 m) sub-humid forest in southeastern Madagascar (Wright et al. 2011). Mangevo is home to the long-term Ranomafana Ruffed Lemur Project, which began in 2005. There are two habituated black-and-white ruffed lemur communities at Mangevo, which had 31 radio-collared individuals at the time of the study (see Glander 1993 and Baden et al. 2016 for collaring protocol). The research herein adheres to the American Society of Primatologists’ Principles for the Ethical Treatment of Primates and was approved by Hunger College’s Institutional Animal Care and Use Committee (IACUC; protocol: AB-RuffedLemur-2.22). Research permits for this project were issued by Madagascar National Parks (permit #109).
We conducted 50 dawn-to-dusk focal follows of targeted individuals, located daily via radio-telemetry (resulting in ~ 375 observation hours). We targeted each individual as a focal animal at least once, and no more than twice, to ensure comprehensive sampling and avoid bias. The same individual was never the focal on consecutive days (there were often weeks between sampling), nor were members of the same subgroup. We continuously recorded vocalizations from all individuals within auditory range (not just the subject of focal sampling) using an AudioTechnica shotgun microphone (with windscreen) and a Tascam DR-07 recorder, at a sampling rate of 44.1 kHz with 16-bit accuracy in mono format (WAV file format). Calls were recorded semi-continuously when the focal individual was in an active behavioral state (e.g., not asleep). For each acoustic recording we also noted the call type, calling individual, subgroup ID, date, and time. It was not possible to identify individual contributions to choruses because of the dense vegetation, dispersion of calling individuals, and difficulty in individually identifying animals (radio-collars were sometimes blocked and some individuals did not have a collar). After annotating our Varecia calls within the recordings, we were left with 940 call clips.
Data analysis
Only call clips with a high signal-to-noise ratio (i.e., callers close to observers/the microphone, no background interference of other animals, rain, etc.) were used for analyses (Table S1). We determined this through detailed visual and aural inspection by two people. This resulted in a final dataset of 688 call clips. Audio recordings were stored as WAV files in the recorder’s SD card and then uploaded into RavenPro (Cornell Lab of Ornithology) to be digitized into spectrograms and waveforms. Spectrograms were created using 512-point fast Fourier transformations (FFT) with a Hanning window function, resulting in a temporal resolution of 0.01 s, and a frequency resolution of 86.1 Hz. Prior to statistical analysis, we qualitatively classified each recording as one of 11 call types based on visual inspection of the spectrogram and listening to the call (Fig. 1; see Batist et al. 2021 for details). Call types were named and identified based on our own and previous repertoires (Pereira et al. 1988; Batist et al. 2021). While there were 688 call clips used in total, the sample size varied widely between call types (mean 63, range, 10–244; Table 2). We conducted all statistical analyses in R.


Sample spectrograms for each of the 11 V. variegata call types classified in this study: A bark, B chatter, C growl, D hum, E mu, F pulsed rah, G quack, H roar, I roar-shriek, J squeal, K wail. X-axes (time) and Y-axes (frequency/pitch) are varied for each spectrogram to best exemplify the acoustic structure of each call type
To characterize the acoustic properties of calls (Obj. 1), we annotated and labeled calls within recordings by drawing bounding boxes around them (using Raven). We set a minimum of half a second duration between calls for us to consider them as separate. We then extracted 33 acoustic measurements from each annotation (call) using the warbleR package (Table S2; Araya-Salas and Smith-Vidaurre, 2017). These measurements included those related to temporal, spectral, tonal, and power properties and provided a comprehensive quantitative characterization of call types (Table 1). Calls were split into two call categories: individual calls (a single individual emitting the call) or choruses (multiple individuals calling simultaneously; Table 1). Calls were also split into two syllabic categories: monosyllabic or multisyllabic (Table 1). Monosyllabic calls are those with one held note, whereas multisyllabic calls contain serially repeated elements in a sequence. We scaled the dataset of acoustic variables due to the different units and scales used for each; this scaled dataset was then used for subsequent statistical analyses. We conducted a PCA to reduce dimensionality and collinearity across the acoustic measurements. We also extracted the loadings of each variable onto the principal components to assess which variables were most explanatory for conducting the PCA (Table S3).
To analyze call combinations and sequences (Obj. 2), we used recordings that contained multiple call types and noted which call types were present in combinations and the number of times a call was repeated in sequences. We focused on two call types that consistently comprised call sequences: roar-shriek and bark. Sample size for these call types was larger than it was in other analyses because signal-to-noise ratio did not need to be accounted for in marking whether a different call type was given before or after the call of interest. We were not extracting bioacoustics measurements, just qualitatively noting call types within a sequence. We then calculated the proportion of barks and roar-shrieks, respectively, that were preceded or followed by a different call type within three minutes.
Finally, we used classification (DFA) and clustering (hierarchical) methods to compare their performance to our qualitative classifications (the 11 call types) and to more objectively determine the clustering structure of the repertoire (Obj. 3). First, we conducted a DFA (MASS R package) to determine how well call types could be distinguished statistically (Ripley et al 2013). We ran separate DFAs using the raw dataset of bioacoustic variables and the principal components (PC) dataset to compare how these inputs affected the DFA results.
Further, we used Ward’s hierarchical clustering from the ‘stats’ package (hclust function; Kaushik and Mathur 2014). Hierarchical clustering algorithms aim to build a hierarchy of clusters without necessarily having a fixed number of clusters (Kaushik and Mathur 2014). Agglomerative hierarchical methods sequentially combine similar clusters until there is one cluster containing all data points (Kaushik and Mathur 2014). This method results in a dendrogram of nested clusters that resembles a taxonomic phylogeny. In the dendrogram, branch length corresponds to the Euclidean distance between any two clusters (Kaushik and Mathur 2014). To assess the optimal number of clusters we used the comprehensive NbClust function (NbClust R package), which simultaneously tests a dataset against > 20 different methods and indices (including gap statistic, silhouette values, etc.; Charrad et al. 2014). The function outputs a table showing how many of the methods supported certain numbers of clusters. We then ran the clustering analysis on the top two optimal numbers of clusters. We again conducted this analysis on both the raw and the principal components datasets, to determine how these inputs affected the cluster outcomes.
Results
Acoustic structure of vocal repertoire
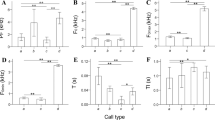
For our first objective (Obj. 1), we qualitatively classified each recording as one of the 11 call types distinguished by experienced observers (Fig. 1). Summary statistics for the 33 bioacoustic measurements related to duration, frequency and tonality used for each call type can be found in Table 1 (see supplementary materials for audio clips of each call type). We ran a PCA to reduce dimensionality and collinearity and provided a preliminary visualization of the vocal repertoire based off spectrographic measurements. We calculated the Kaiser-Meyer Olkin criterion to assess the quality of the PCA, which yielded a value of 0.82, indicating that PCA is appropriate for the dataset. We found that n = 6 PCs cumulatively explained 90% of the variance (PC1 = 40.3%, PC2 = 24.4%, PC3 = 11.9%, PC4 = 5.6%, PC5 = 5.0%, PC6 = 3.2%). Frequency-related variables loaded highly onto PC1 while time-related variables loaded highly onto PC2 and entropy-related variables loaded highly onto PC3 (Table S3). PC4 had high values from skew and kurtosis, and PC5 had a very high value for dominant frequency slope (Table S3). When plotting the PCs, call types did not seem to occupy distinct spaces (Fig. 2).

Results of a principal components analysis on the Varecia call types, with the first principal component (that explains the most variation) represented on the x-axis, against PC2 ( A) and PC3 (B) on the y-axis. The bottom panel is a biplot that visualizes which bioacoustic parameters contributed to the call type differentiation. The closer a call type is to a variable, the more important that variable was in the PCA
Call combinations and sequences
Of the 11 call types we identified (above), three were only ever given in isolation (hum, mu, roar). The remaining eight call types were given both on their own and as part of larger sequences of call types. For example, the roar call type consisted of a single roar syllable given on its own, but also given repeatedly in roar-shrieks. Pulsed rahs consisted of a rah syllable repeated in a series, but also singly and serially in roar-shrieks. Further, pulsed rahs were given both by a single individual and in choruses (i.e., the level of contagion was variable). Wails were given as standalone calls, but were also found in roar-shrieks and quacks. Stand-alone wails were often emitted before or after barks. Quacks were similar to roar-shrieks, but were given individually whereas roar-shrieks were given as choruses.
Ruffed lemurs used many of their call types in combination. For example, roar-shrieks were often preceded (76%) or followed (49%) by other calls (Figs. 3a, b, 4). Barks, chatters, and squeals typically preceded roar-shrieks, while wails only ever followed. Roar-shrieks typically comprised two syllables, roar and shriek, but occasionally included rahs and wails (discussed below). The shriek syllable resembled chatter syllables, such that a chattering individual would sometimes add a roar suffix and stimulate the rest of the subgroup to transition into a roar-shriek chorus (Fig. 3a). Barks were also often used in sequences, with 31% preceded by another call type and 21% followed by another call (Fig. 4).

Spectrograms illustrating examples of V. variegata call combinations and sequences. Arrows indicate start of each call type. A chatter to roar-shriek to pulsed rah; B growl to bark to roar-shriek to growl; C squeal to chatter to roar-shriek

The percentage of roar-shrieks (a) and barks (b) beginning with (before) or ending with (after) a different call type
In addition to classifying whole calls, we also classified syllable types within four multi-syllabic calls: growl, roar-shriek, bark, and quack (Table 1). The growl always consisted of two consecutive syllables: a hum-like growl syllable followed by a huff syllable (Fig. 1c). The bark always comprised two syllable types (bark and wail), but their sequence order and repetition patterns varied. Roar-shrieks contained up to four syllable types: roar, shriek, wail and rah. Because roar-shrieks were contagious calls, roars and shrieks were sometimes emitted simultaneously within a single syllable (‘roar + shriek’ syllable). Among recorded roar-shriek syllables, 24% were roars, 31% were shrieks, 21% were simultaneous roars and shrieks, 17% were rahs and 8% were wails. Syllables within a roar-shriek chorus were a composite of multiple individuals' calls, making it impossible to differentiate between callers. Finally, the quack comprised six syllable types: quack, breath, rah, roar, shriek and wail (the four roar-shriek syllables plus two unique to quacks: quack and breath). Rahs (35%), shrieks (19%) and breaths (18%) were the most used syllable types, with wail being the least used (5%).
Classification and clustering analyses
The DFA on the raw dataset correctly classified call types 87.8% of the time, while DFA using the PC dataset had a classification accuracy of 86.2%. As such, for clarity and concision, we only present results from the raw dataset (but see Figure S2). The call types that were most often mis-classified were the roar (60% missed), wail (64%) and quack (50%), while the DFA was most accurate with chatters and barks, (1 and 2% missed, respectively; Table 2). The classification accuracy seems to be related to the sample size of each call type, as wails, roars and quacks had the lowest sample sizes and also the highest percentage of mis-classifications; barks and chatters had the highest sample sizes and the lowest percentage of mis-classifications (Table 2). The top two linear discriminants (LDs) combined for 81% proportion of trace. The DFA and PCA plots showed some general clusters consisting of 1) mu + growl + hum, 2) pulsed rah + roar, 3) bark + wail + squeal, 4) roar-shriek + quack, and 5) chatter (Fig. 5, S3). The variables that loaded highest on the LDs were similar to those that loaded highly onto the PCs; frequency-related variables were prominent in the first few LDs while time-related variables were high in the subsequent LDs (Table S3, S4).

Results of a discriminant function analysis on the Varecia call types, with the first linear discriminant (LD) represented on the x-axis, against LD2 (A) and LD3 (B) on the y-axis
Results from the NbClust analysis using raw data showed nine methods proposing three clusters as best; the next best consensus was a four-cluster solution (proposed by five methods). When using the PCs as input, eight methods proposed four clusters as best and four methods proposed three clusters. The agglomerative coefficient, a measure of clustering structure in a dataset (range, 0–1), was 0.97 for the raw data and 0.96 for the PC data. Our very high coefficient confirms the conclusions of the other clustering analyses in describing the dataset as difficult to cleanly partition. We conducted the clustering algorithm and then extracted the cluster assignments for a three- and four-cluster solution (as supported by the NbClust analysis) to identify which call types were predominantly assigned to which clusters (Table 3, Figure S3). Cluster assignments were very similar using raw data and PCs, so we only present assignments for the raw data for concision (Table 3). Like in the DFA, growls, mus and hums consistently clustered together, but were consistently grouped with roars in hierarchical clustering (Table 3). Chatters and barks were each roughly in their own cluster, with squeals split between those clusters (Table 3). Pulsed rahs, quacks, and roar-shrieks clustered together as well, similar to the DFA, though this was more apparent in the three-cluster solution (Table 3).
Discussion
In this study, we characterized the acoustic structure of the V. variegata vocal repertoire using a suite of parameters related to time, frequency, tonality, and composition (Obj. 1 and 2) and used statistical clustering methods to validate both these and our earlier qualitative call type classifications (Obj. 3). We identified 11 call types that differed in both caller context (four individually given calls, seven contagious choruses) and syllabic structure (four mono-syllabic calls, seven multi-syllabic calls). Within the multi-syllabic calls, we further differentiated between call types comprising a single repeated syllable (chatter, pulsed rah) versus those comprising multiple syllable types (bark, growl, quack, roar-shriek, squeal). Pereira et al. (1988) described 13 call types (huff and bray call types were not found during our study), but did not discuss other “levels” within the repertoire hierarchy such as syllables or call combinations. It is important to note that Pereira et al. (1988) was a captive study while ours was conducted in the wild, and these discrepancies could be a result of this.
Results from the DFA somewhat corroborated our manual call assignments; overall accuracy was ~ 90%, but this varied greatly among calls and seemed highly dependent on the sample size of each call type. Our subsequent naïve (without assigning a priori call type labels) hierarchical clustering analysis indicated a low cluster structure within our dataset, with the optimal number of clusters somewhere in the range of 3–4. The clusters identified in the vocal repertoire contained multiple call types, and multiple call types were assigned into more than one cluster, illustrating that calls can be considered quantifiably variable and the vocal repertoire exhibits gradation. In datasets with considerable gradation within and between clusters, an optimal number of clusters (call types) may not exist, no matter which clustering algorithm is applied. Varecia variegata appears to exhibit gradation within its vocal repertoire, particularly between calls that are close in acoustic structure and/or may be given frequently in combination. Such graded continuums (e.g., bark and wail; roar-shriek, roar and pulsed rah) are consistent with previous studies of ruffed lemurs (Petter and Charles-Dominique 1979; Pereira et al. 1988; Macedonia 1990), as well as several other lemur species (E. macaco, Gosset et al. 2000; multiple species-Scheumann et al. 2007; Indri indri, Baker-Médard et al. 2013; L. sahamalaza, Mandl et al. 2019a, 2029b). These call types were coincident with stressful contexts such as subgroup fission or fusion, presence of a predator, or inter-individual aggression (Batist et al. 2021); we therefore hypothesize that the gradation of V. variegata calls and sequences may be the result of varying arousal levels based on such contexts.
The 11 call types we qualitatively discerned were based off of previous literature, and in large part from local guides and research technicians from the Ranomafana area who have decades of observational experience. Nevertheless, three call types (roar, quack, wail) were consistently misidentified by DFA, calling their validity as distinct call types into question. We attribute this to small sample size, as calls with the lowest sample sizes (quack: n = 10, wail: n = 14, roar: n = 20) also had the highest percentage of mis-classifications, whereas those with the highest sample sizes (chatter: n = 244, bark: n = 146) had the lowest percentage of mis-classifications. Increased sampling in the future would allow this hypothesis to be tested. However, some calls are simply not given frequently, so it can be difficult to increase sample sizes in these cases without extended periods of monitoring. For example, the quack is given rarely, usually during the short mating season (Batist et al. 2021). It is of course also possible that humans are detecting acoustic similarities or differences across call types that are meaningless to lemurs.
Nevertheless, there was a fair amount of consistency in which call types clustered together or were frequently mis-assigned (e.g., pulsed rah and roar; growl, mu and hum; chatter on its own, etc.). Observer classification is still important, as evidenced by the poor performance of naïve/unsupervised clustering methods, but has now been supported by statistical classification analyses. New classification methods, such as neural networks, are emerging rapidly, which present opportunities for more complex and nuanced analyses moving forward, with larger sample sizes (Gamba et al. 2015, Valente et al. 2020, Pozzi et al. 2013; Turesson et al. 2016; Valente et al. 2019; Romero-Mujalli et al. 2021; Ravaglia et al. 2023).
There were also call combinations separate from these spectra (e.g., growl and bark; squeal and roar-shriek). In addition to being used in isolation, the vast majority of calls identified were frequently combined or used in sequences. Many primate species use call combinations or sequences, which is thought to be a reflection of vocal production and developmental constraints; primates can overcome these highly conserved (bioacoustically speaking) call types by flexibly combining a smaller number of call types into sequences and combinations that expand their vocal repertoire (Hammerschmidt and Fischer 2008; Fischer 2017; Cheney and Seyfarth 2018). Modifications to a call's temporal characteristics are assumed to be less constrained than changes in frequency-related features, so variability is thought to come from gradual changes in syllable repetition, inter-syllable duration, and so on (Engesser and Townsend 2019). Call rate and duration can also correlate with caller arousal, with high-arousal callers producing calls at a faster rate and with a longer duration (Schamberg et al. 2018). We were not able to operationalize a measure of arousal in this study, but this is an intriguing idea for future study (as in Fichtel et al. 2001).
Ours was only a 3-month study, so we cannot claim to have recorded all V. variegata call types, nor captured the full seasonal variation in calling behavior. This study period covered only the mating and early gestational phases within their reproductive cycle; the presence of infants during other times of the year may alter the vocal repertoire characterized herein. Future work should investigate how acoustic structure changes developmentally given what we know about the relationship between body size and bioacoustics (negative size-frequency allometry; Bowling et al. 2017). Further, the eastern Malagasy rainforests exhibit extreme seasonality which may also affect call structure. This seasonality drives fruit abundance and distribution, and acoustic structure has been shown to vary according to food type in some other primates (Clay and Zuberbühler 2009; Kalan et al. 2015).
It is also important to note that what humans perceive as a different sound or an important acoustic distinction may not be perceived the same by ruffed lemurs. Our auditory morphology, neurobiology, and perception systems are, obviously, very different. Humans may not detect subtle differences that could be informative in classifying calls. Future experimental work will be necessary to better understand vocal perception in ruffed lemurs. Individually given calls may show more variation if they encode information on individual identity in the call. We also do not know whether call variation actually encodes meaningful information. Future studies should focus on examining if call combinations or sequences are related to context or caller identity (i.e., evidence for semantic communication, as in Arnold and Zuberbühler 2006 [putty-nosed monkeys], Coye et al. 2018 [Campbell’s monkeys]; Candiotti et al. 2012 [Diana monkeys]; Schamberg et al. 2016 [bonobos]; Berthet et al. 2019 [titi monkeys]).
The active acoustic monitoring (AAM) described here differs from the more recently developed passive acoustic monitoring (PAM), in which specialized recorders are deployed in an ecosystem to record sound autonomously using a user-specified configuration of sampling parameters. Despite providing complementary information, these two approaches – active and passive acoustic monitoring – are typically used independently. For instance, data produced by AAM provides details of a species’ vocal repertoire that are crucial for optimizing PAM settings, determining recorder configurations and schedules, and strategically identifying deployment sites. Additionally, AAM recordings can be utilized to train machine learning models for automated processing of larger PAM datasets. Nevertheless, there have been comparatively few studies using PAM with primates and even fewer which have done so with lemurs (but see Markolf et al. 2022; Ravaglia et al. 2023). The combination of acoustic monitoring methods is an exciting and promising avenue for future research and we encourage primatologists to consider these methods to further both basic and applied research.
Data availability
All data generated or analyzed during this study are included in this published article [and its supplementary information files].
References
Alessandra C, Gamba M, Giacoma C (2002) Ontogeny and variability in the vocal repertoire of Varecia variegata variegata. Bioacoustics 13:188–189
Arlet M, Jubin R, Masataka N, Lemasson A (2015) Grooming-at-a-distance by exchanging calls in non-human primates. Biol Let 11(10):20150711
Arnold K, Zuberbühler K (2008) Meaningful call combinations in a non-human primate. Curr Biol 18(5):R202–R203
Baden AL (2019) A description of nesting behaviors, including factors impacting nest site selection, in black-and-white ruffed lemurs (Varecia variegata). Ecol Evol 9(3):1010–1028
Baden AL, Wright PC, Louis EE, Bradley BJ (2013) Communal nesting, kinship, and maternal success in a social primate. Behav Ecol Sociobiol 67(12):1939–1950
Baden AL, Webster TH, Kamilar JM (2016) Resource seasonality and reproduction predict fission–fusion dynamics in black-and-white ruffed lemurs (Varecia variegata). Am J Primatol 78(2):256–279
Batist CH, Razafindraibe MN, Randriamanantena F, Baden AL (2022) Factors affecting call usage in wild black-and-white ruffed lemurs (Varecia variegata) at Mangevo. Ranomafana National Park Primates 63(1):79–91
Bezerra BM, Souto AS, Jones G (2010) Vocal repertoire of golden-backed uakaris (Cacajao melanocephalus): Call structure and context. Int J Primatol 31(5):759–778
Bolt LM (2013a) The relationship between dominance and vocal communication in the male ring-tailed lemur (Lemur catta). Doctoral Dissertation, University Toronto. https://doi.org/10.1007/s10764-012-9654-8
Bolt LM (2013b) The function of howling in the ring-tailed lemur (Lemur catta). Int J Primatol 34:157–169
Bolt LM (2020) Affiliative contact calls during group travel: chirp and wail vocalization use in the male ring-tailed lemur (Lemur catta). Folia Primatol 91(6):575–594
Bolt LM, Sauther ML, Cuozzo FP, Youssouf Jacky IA (2015) Antipredator vocalization usage in the male ring-tailed lemur (Lemur catta). Folia Primatol 86(1–2):124–133
Bouchet H, Blois-Heulin C, Pellier AS, Zuberbühler K, Lemasson A (2012) Acoustic variability and individual distinctiveness in the vocal repertoire of red-capped mangabeys (Cercocebus torquatus). J Comp Psychol 126(1):45–56
Bowling DL, Garcia M, Dunn JC, Ruprecht R, Stewart A, Frommolt KH, Fitch WT (2017) Body size and vocalization in primates and carnivores. Sci Rep 7(1):1–11
Braune P, Schmidt S, Zimmermann E (2008) Acoustic divergence in the communication of cryptic species of nocturnal primates (Microcebus ssp). BMC Biol 6(1):1–10
Charrad M, Ghazzali N, Boiteau V, Niknafs A (2014) NbClust: An R package for determining the relevant number of clusters in a data set. J Stat Softw 61(6):1–36
Cheney DL, Seyfarth RM (2018) Flexible usage and social function in primate vocalizations. Proc Natl Acad Sci 115(9):1974–1979
Clay Z, Zuberbühler K (2009) Food-associated calling sequences in bonobos. Anim Behav 77(6):1387–1396
Engesser S, Townsend SW (2019) Combinatoriality in the vocal systems of nonhuman animals. Wiley Interdiscip Rev Cogn Sci 10(4):e1493
Ey E, Fischer J (2009) The “acoustic adaptation hypothesis”—a review of the evidence from birds, anurans and mammals. Bioacoust 19(1–2):21–48
Fichtel C, Kappeler PM (2011) Variation in the meaning of alarm calls in Verreaux’s and Coquerel’s sifakas (Propithecus verreauxi, P. coquereli). Int J Primatol 32:346–361
Fichtel, C., Hammerschmidt, K., Jürgens, U. (2001). On the vocal expression of emotion. A multi-parametric analysis of different states of aversion in the squirrel monkey. Behaviour, 97–116.
Fischer J (2017) Primate vocal production and the riddle of language evolution. Psychon Bull Rev 24(1):72–78
Gamba M, Giacoma C (2006) Vocal tract modeling in a prosimian primate: the black and white ruffed lemur. Act Acust 92(5):749–755
Gamba M, Friard O, Riondato I, Righini R, Colombo C, Miaretsoa L, Torti V, Nadhurou B, Giacoma C (2015) Comparative analysis of the vocal repertoire of Eulemur: A dynamic time warping approach. Int J Primatol 36(5):894–910
Gros-Louis JJ, Perry SE, Fichtel C, Wikberg E, Gilkenson H, Wofsy S, Fuentes A (2008) Vocal repertoire of Cebus capucinus: acoustic structure, context, and usage. Int J Primatol 29(3):641–670
Hammerschmidt K, Fischer J (1998) The vocal repertoire of Barbary macaques: a quantitative analysis of a graded signal system. Ethology 104(3):203–216
Hammerschmidt K, Fischer J (2008) Constraints in primate vocal production. In: Oller K, Griebel U (eds) The Evolution of Communicative Creativity: From fixed signals to contextual flexibility. MIT Press, Cambridge, MA, USA, pp 93–119
Hammerschmidt K, Fischer J (2019) Baboon vocal repertoires and the evolution of primate vocal diversity. J Hum Evol 126:1–13
Hending D, Holderied M, McCabe G (2017) The use of vocalizations of the Sambirano mouse lemur (Microcebus sambiranensis) in an acoustic survey of habitat preference. Int J Primatol 38:732–750
Hending D, Seiler M, Stanger-Hall KF (2020) The vocal repertoire of the northern giant mouse lemur (Mirza zaza) in captivity. Int J Primatol 41:732–763
Inoue Y, Sinun W, Yosida S, Okanoya K (2017) Combinatory rules and chunk structure in male Mueller’s gibbon songs. Interact Stud 18(1):1–25
Kalan AK, Mundry R, Boesch C (2015) Wild chimpanzees modify food call structure with respect to tree size for a particular fruit species. Anim Behav 101:1–9
Kaushik M, Mathur B (2014) Comparative study of K-means and hierarchical clustering techniques. Int J Softw Hardw Research Eng 2(6):93–98
Kershenbaum A, Blumstein DT, Roch MA, Akçay Ç, Backus G, Bee MA, Coen M (2016) Acoustic sequences in non-human animals: a tutorial review and prospectus. Biol Rev 91(1):13–52
Kulahci IG, Rubenstein DI, Ghazanfar AA (2015) Lemurs groom-at-a-distance through vocal networks. Anim Behav 110:179–186
Leliveld L, Scheumann M, Zimmermann E (2011) Acoustic correlates of individuality in the vocal repertoire of a nocturnal primate (Microcebus murinus). J Acoustical Society Am 129(4):2278–2288
Louis EE, Sefczek TM, Raharivololona B, King T, Morelli TL, Baden A (2020) Varecia variegata. The IUCN Red List of Threatened Species. https://doi.org/10.2305/IUCN.UK.2020-2.RLTS.T22918A115574178.en
Macedonia JM (1990) What is communicated in the antipredator calls of lemurs: Evidence from playback experiments with ring tailed and ruffed lemurs. Ethol 86(3):177–190
Macedonia JM (1993) The vocal repertoire of the ringtailed lemur (Lemur catta). Folia Primatol 61(4):186–217
Macedonia JM, Taylor LL (1985) Subspecific divergence in a loud call of the ruffed lemur (Varecia variegata). Amer J Primatol 9(4):295–304
Mandl I, Schwitzer C, Holderied M (2019a) Sahamalaza sportive lemur, Lepilemur sahamalaza, vocal communication: call use, context and gradation. Folia Primatol 90(5):336–360
Markolf M, Zinowsky M, Keller JK, Borys J, Cillov A, Schülke O (2022) Toward passive acoustic monitoring of lemurs: using an affordable open-source system to monitor phaner vocal activity and density. Int J Primatol 43(3):409–433
Marten K, Marler P (1977) Sound transmission and its significance for animal vocalization. Behav Ecol Sociobiol 2(3):271–290
McComb K, Semple S (2005) Coevolution of vocal communication and sociality in primates. Biol Lett 1(4):381–385
Méndez-Cárdenas M, Randrianambinina B, Rabesandratana A, Rasoloharijaona S, Zimmermann E (2008) Geographic variation in loud calls of sportive lemurs (Lepilemur ssp) and their implications for conservation. Am J Primatol 70(9):828–838
Morland HS (1993) Reproductive activity of ruffed lemurs (Varecia variegata variegata) in a Madagascar rain forest. Am J Phys Anthropol 91(1):71–82
Morton ES (1977) On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. Am Nat 111(981):855–869
Pereira ME, Seeligson ML, Macedonia JM (1988) The behavioral repertoire of the black-and-white ruffed lemur, Varecia variegata variegata (Primates: Lemuridae). Folia Primatol 51(1):1–32
Petter JJ, Charles-Dominique P (1979) Vocal communication in prosimians. In: Doyle G, Martin R (eds) The Study of Prosimian Behavior. Academic Press, Cambridge, MA, pp 247–305
Pozzi L, Gamba M, Giacoma C (2013) Artificial neural networks: A new tool for studying lemur vocal communication. Advances in Prosimian Biology, Leaping Ahead, pp 305–313
Range F, Fischer J (2004) Vocal repertoire of sooty mangabeys (Cercocebus torquatus atys) in the Taï National Park. Ethol 110(4):301–321
Ravaglia D, Ferrario V, De Gregorio C, Carugati F, Raimondi T, Cristiano W, Gamba M (2023) There you are! automated detection of indris’ songs on features extracted from passive acoustic recordings. Animals 13(2):241
Ripley B, Venables B, Bates DM, Hornik K, Gebhardt A, Firth D, Ripley MB (2013) Package ‘mass.’ CRAN 538:113–120
Romero-Mujalli D, Bergmann T, Zimmermann A, Scheumann M (2021) Utilizing DeepSqueak for automatic detection and classification of mammalian vocalizations: a case study on primate vocalizations. Sci Rep 11(1):24463
Schamberg I, Wittig RM, Crockford C (2018) Call type signals caller goal: a new take on ultimate and proximate influences in vocal production. Biol Rev 93(4):2071–2082
Scheumann M, Rabesandratana A, Zimmermann E (2007) Predation, communication, and cognition in lemurs. In: Gursky SL, Nekaris KAI (eds) Primate Anti-Predator Strategies. Springer, New York, pp 100–126
Scheumann M, Linn S, Zimmermann E (2017) Vocal greeting during mother–infant reunions in a nocturnal primate, the gray mouse lemur (Microcebus murinus). Sci Rep 7(1):10321
Seiler M, Schwitzer C, Holderied M (2015) Call repertoire of the Sahamalaza sportive lemur. Lepilemur Sahamalazensis Int J Primatol 36(3):647–665
Sperber AL, Werner LM, Kappeler PM, Fichtel C (2017) Grunt to go—vocal coordination of group movements in red-fronted lemurs. Ethology 123(12):894–905
Stephan C, Zuberbühler K (2008) Predation increases acoustic complexity in primate alarm calls. Biol Lett 4(6):641–644
Turesson HK, Ribeiro S, Pereira DR, Papa JP, de Albuquerque VHC (2016) Machine learning algorithms for automatic classification of marmoset vocalizations. PLoS ONE 11(9):e0163041
Turner ME, Harrenstien L (1985) Loud calls of the ruffed lemur, Varecia variegata. J the Elisha Mitchell Sci Soc 101(1):1–8
Valente D, De Gregorio C, Torti V, Miaretsoa L, Friard O, Randrianarison RM, Gamba M (2019) Finding meanings in LOW dimensional structures: stochastic neighbor embedding applied to the analysis of Indri indri vocal repertoire. Animals 9(5):243
Vasey N (2007) The breeding system of wild red ruffed lemurs (Varecia rubra): a preliminary report. Primates 48:41–54
Wiley RH, Richards DG (1978) Physical constraints on acoustic communication in the atmosphere: implications for the evolution of animal vocalizations. Behav Ecol Sociobiol 3(1):69–94
Zimmermann E (1995) Acoustic communication in nocturnal prosimians. In: Alterman L, Doyle GA, Izard MK (eds) Creatures of the Dark. Springer, Boston, MA, pp 311–330
Zuberbühler K, Jenny D, Bshary R (1999) The predator deterrence function of primate alarm calls. Ethol 105(6):477–490
Acknowledgements
We thank our local guide, Ezafy, and cook, Tolotra, without whom this project could not have been completed. We thank the Centre ValBio staff for their extensive logistical support. Ford, Noro, and the Mangevo field teams were great campmates and helpful with trouble-shooting. MICET provided vital documentation facilitation. CB thanks undergraduate interns/trainees Phoebe Halper, Eunice Ng, Aeja Rosette, Gabriela Galindo, and Charlene Lopez for their incredible work processing and annotating spectrograms.
Funding
This study was generously funded by the CUNY Graduate Center Provost’s Office through its Digital Innovations Grant and Predoctoral Research Fellowship.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Ethical approval
The research herein adheres to the American Society of Primatologists’ Principles for the Ethical Treatment of Primates and was approved by Hunger College’s Institutional Animal Care and Use Committee (IACUC; protocol: AB-RuffedLemur-2.22). CB had a scientific research visa from the US-Malagasy Embassy. Madagascar National Parks provided research permits (#109).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
About this article

Cite this article
Batist, C.H., Razafindraibe, M.N., Randriamanantena, F. et al. Bioacoustic characterization of the black-and-white ruffed lemur (Varecia variegata) vocal repertoire. Primates 64, 621–635 (2023). https://doi.org/10.1007/s10329-023-01083-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10329-023-01083-8