
Abstract
Data envelopment analysis (DEA) is a non-parametric technique to assess the performance of a set of homogeneous decision making units (DMUs) with common crisp inputs and outputs. Regarding the problems that are modelled out of the real world, the data cannot constantly be precise and sometimes they are vague or fluctuating. So in the modelling of such data, one of the best approaches is using the fuzzy numbers. Substituting the fuzzy numbers for the crisp numbers in DEA, the traditional DEA problem transforms into a fuzzy data envelopment analysis (FDEA) problem. Different methods have been suggested to compute the efficiency of DMUs in FDEA models so far but the most of them have limitations such as complexity in calculation, non-contribution of decision maker in decision making process, utilizable for a specific model of FDEA and using specific group of fuzzy numbers. In the present paper, to overcome the mentioned limitations, a new approach is proposed. In this approach, the generalized FDEA problem is transformed into a parametric programming, in which, parameter selection depends on the decision maker’s ideas. Two numerical examples are used to illustrate the approach and to compare it with some other approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Data envelopment analysis (DEA) is a non-parametric technique for evaluating the relative efficiency of homogeneous decision making units (DMUs) on the basis of multiple inputs and multiple outputs. DEA, first introduced by Charnes et al. (1978), is in fact the generalization of Farrell’s (1957) single-input single-output ratio. The advantage of the DEA approach over other approaches is the possibility of examining the complex and often unknown relations among multiple inputs and multiple outputs. The huge number of published papers and books in DEA field and the extensive applications of it demonstrate the superiority of this approach.
The prerequisite of using traditional DEA approaches is to measure the inputs and outputs precisely. In practice, however, the data occasionally are imprecise or vague. In order to address this problem, we can use fuzzy numbers to model such data and in this case, we have a fuzzy data envelopment analysis (FDEA) problem. By introducing the fuzzy logic into DEA, it has been used more extensively. For instance, FDEA has been applied in preprinting and packaging (Triantis and Girod 1998), in information technology industry (Kuo and Wang 2007), in determining fuzzy efficiency scores of machinery companies (Kao and Liu 2005), in investment programs (Zhou et al. 2008), and banks (Hatami et al. 2009; Puri and Yadav 2013), in ranking libraries (Kao and Liu 2000), and in addressing NATO enlargement problem (Hatami-Marbini et al. 2013).
The aforementioned examples demonstrate the extensive usage of FDEA. They also emphasize the importance and necessity of working more and more on this field and eventually presenting more efficient approaches. From the first study by Sengupta (1992), great amount of papers have been published in FDEA. Emrouznejad et al. (2014) have presented a taxonomy and review of the published papers in the field of FDEA up to 2013. They have classified the FDEA papers in seven different categories:
-
A.
The tolerance approach
-
B.
The \(\upalpha \)-level based approach
-
C.
The fuzzy ranking approach
-
D.
The possibility approach
-
E.
The fuzzy arithmetic approach
-
F.
The fuzzy random/type-2 fuzzy set approach
-
G.
Other developments in FDEA.
Among them, the most popular approach is the \(\upalpha \)-level based approach. This is evident by the number of \(\upalpha \)-level based papers published in the fuzzy DEA literature (Emrouznejad et al. 2014). In this approach, the fuzzy DEA model is solved by parametric programming using \(\upalpha \)-cuts (Lertworasirikul et al. 2003b).
However, most of the FDEA methods have limitations such as: utilizable for a specific model of FDEA, using specific group of fuzzy numbers, complexity in calculation and non-contribution of decision maker in decision making process.
To overcome the mentioned limitations, the present paper proposes a new method for solving FDEA problems. This method transforms the generalized FDEA problem into a parametric programming problem by using a transformation function. This function was first proposed by Shureshjani and Darehmiraki (2013). It was defined and used to rank fuzzy numbers. The approach is explained through two examples and is compared with some other approaches.
The present paper is organized as follows: the fuzzy numbers ranking method introduced by Shureshjani and Darehmiraki (2013) is briefly explained in the second section. In the third section, the generalized DEA model is introduced in the crisp and fuzzy environments and the details of our proposed approach in FDEA are mentioned. In the fourth section, two examples will be given to illustrate the new approach and the results will be compared with some other approaches. The materials will be concluded in the last section.
2 The ranking fuzzy numbers approach (Shureshjani and Darehmiraki 2013)
In the next section, we will use a transformation function that is first proposed by Shureshjani and Darehmiraki (2013). They applied it to rank fuzzy numbers. Their method is briefly explained in this section.
Dealing with fuzzy numbers, we often need an appropriate ranking method in order to compare these numbers with each other and rank them. Different ranking methods, with specific advantages and limitations, have been presented so far. A new and logical approach in this field is the one presented by Shureshjani and Darehmiraki (2013). This approach has the following advantages that distinguishes it from other approaches in this field:
-
A.
The fuzzy numbers can be shown by the arbitrary membership functions.
-
B.
The fuzzy numbers can be normal or abnormal.
-
C.
The fuzzy numbers can be intersected.
-
D.
The fuzzy numbers ranking depends on the decision maker’s (DM) ideas and on the basis of \(\upalpha \)-cuts.
-
E.
The approach is easily computable.
We will also introduce the approach in the following paragraphs:
Definition 2.1
A fuzzy number \(\tilde{A}\) in parametric form is an ordered pair \((\underline{A} \left( r \right) ,\bar{A} \left( r \right) )\) of functions \(\underline{A} \left( r \right) \) and \(\bar{A}\left( r \right) \), \(0\le r\le \omega \), which satisfy the following requirements:
-
1.
\(\underline{A} \left( r \right) \) is a bounded monotonic increasing left continuous function over \(\left[ {0,\omega } \right] \),
-
2.
\(\bar{A} \left( r \right) \) is a bounded monotonic decreasing left continuous function over \(\left[ {0,\omega } \right] \),
-
3.
\(\underline{A} \left( r \right) \le \bar{A} \left( r \right) ,\, 0\le r\le \omega \).
\(\upomega \) is an arbitrary constant such that \(0<\omega \le 1\).
If, we set \(\omega =1\) in the above mentioned definition, then \(\tilde{A}\) is a normal fuzzy number. A crisp (non-fuzzy) number K is simply represented by \(\underline{A} \left( r \right) =\bar{A} \left( r \right) = K,\,0\le r\le 1\).
Definition 2.2
If \(\tilde{A}\) is an arbitrary fuzzy number then the \(\upalpha \)-cut of \(\tilde{A}\) is defined as \([{\tilde{A}}]_\alpha =[ {\underline{A} (\alpha ),\bar{A} (\alpha )}],\,0\le \alpha \le \omega \).
Here \(\tilde{A}_\omega \) represents a fuzzy number in which ‘\(\omega \)’ is the maximum membership value that a fuzzy number takes on.

\(\tilde{A}_\omega =\left( \underline{A} \left( r \right) ,\bar{A} \left( r \right) \right) \)
Let \(\tilde{A}_\omega =( {\underline{A} ( r ),\bar{A} ( r )} ),0\le r\le \omega \) be a fuzzy number. The following transformation function \(Q_\alpha ( {\tilde{A}_\omega })\) is assigned to \(\tilde{A}_\omega \) which is calculated as follows:
and, it is supposed that if \(\alpha \ge \omega \), then \(Q_\upalpha ({\tilde{A}_\omega } )=0\).
This function will be used as a basis for comparing fuzzy numbers.
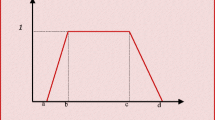
It has been graphically shown in Fig. 1 that the quantity of \(Q_\alpha ( {\tilde{A}} )\) is the summation of the cross-hatched area and the dotted area from \(\upalpha \) to \(\upomega \). Hence, in identifying the quantity of \(Q_\alpha ( {\tilde{A}} )\), only those elements of the fuzzy number \(\tilde{A}\) are computed which have the membership quantities that are equal with or higher than \(\upalpha \). The selection of the quantity of \(\upalpha \) depends on the decision maker’s ideas. If the quantity of \(\upalpha \) is chosen close to 1, that is, while comparing the fuzzy numbers, the elements with high membership quantities are only of importance and the decision maker looks for a low risk decision. In contrary, if the decision maker chooses the quantity of \(\upalpha \) close to zero, it means that the elements with low membership quantities are important as well and the decision maker compares the fuzzy numbers with high risk. Therefore, if the decision maker chooses a quantity for \(\upalpha \) close to 1, then the decision made is called “high level decision” and if \(\upalpha \) is given a quantity close to zero, then the decision made is called “low level decision”.
Definition 2.3
If \(\tilde{A}_{\upomega }\) and \(\tilde{B}_{\upomega '}\) are two arbitrary fuzzy numbers and \(\omega ,{\omega '} \in (0,1]\), then we have:
Definition 2.4
If we compare two arbitrary fuzzy numbers including \(\tilde{\hbox {A}}_{\upomega } \) and \(\tilde{\hbox {B}}_{\upomega '}\) at decision levels higher than “\(\upalpha \)” and \(\upalpha , \omega ,{\omega }'\in (0,1]\), then we have:
where \(\tilde{\hbox {A}}_{\upomega }\preccurlyeq _{\upalpha } \tilde{\hbox {B}}_{\upomega '} \), i.e., at decision levels higher than \(\upalpha ,\tilde{\hbox {B}}_{\upomega '}\) is greater than or equal to \(\tilde{\hbox {A}}_{\upomega }\).

A triangular fuzzy number

A trapezoidal fuzzy number
Two well-known kinds of fuzzy numbers are the triangular fuzzy numbers and the trapezoidal fuzzy numbers. In Figs. 2 and 3, \({\tilde{A}_\omega } = \left( \underline{A}\left( r \right) , \bar{A}\left( r \right) \right) = \left( {x_0} - \delta + \frac{\delta }{\omega }r, {x_0} + \beta - \frac{\beta }{\omega }r \right) \) and \({\tilde{B}_\omega } \!= \!\left( {\underline{B}\left( r \right) , \bar{B}\left( r \right) } \right) \!=\! \left( {{x_0} \!-\! \delta \!+\! \frac{\delta }{\omega }r, {y_0} + \beta - \frac{\beta }{\omega }r} \right) \) are triangular and trapezoidal fuzzy numbers, respectively, and by computing the quantity of \(Q_\alpha \), we have:
It has been obviously observed that if the triangular fuzzy numbers and trapezoidal fuzzy numbers are symmetric \(\left( {\delta =\beta } \right) \), then the above mentioned formulas will be simpler. Besides, for the crisp numbers like K, we have:
3 The generalized FDEA model and the proposed approach
Lots of various models have been presented in DEA. The most popular and useful models in DEA are the CCR model (Charnes et al. 1978), the BCC model (Banker et al. 1984), the FG model (Färe and Grosskopf 1985) and the ST model (Seiford and Thrall 1990). In these models, the DMU is allowed to evaluate its efficiency in the most favorable way. The significant difference between above models are: the CCR model is constant returns to scale, the BCC model is variable returns to scale, the FG model is non-increasing returns to scale, and the ST model is non-decreasing returns to scale.
We consider the following generalized DEA model (GDEA) (Yu et al. 1996a, b; Hadi-Vencheh et al. 2008).

where

and \(\delta _1,\delta _2,\,\delta _3\) are binary parameters and we can see that
-
(i)
If \(\delta _1 = 0\) then the GDEA model is reduced to CCR model.
-
(ii)
If \(\delta _1=1\) and \(\delta _2=0\) then the GDEA model is reduced to BCC model.
-
(iii)
If \(\delta _1 =\delta _2 =1\) and \(\delta _3=0\) then the GDEA model is reduced to FG model.
-
(iv)
If \(\delta _1 =\delta _2 =\delta _3 =1\) then the GDEA model is reduced to ST model.
Regarding the fact that the data are not always precise or deterministic in the real world, using the conventional DEA models can cause some problems. In order to overcome these problems, the crisp inputs and outputs can be replaced by the fuzzy numbers. In this case, the GDEA model is converted into the following form:

where

\(\delta _1,\delta _2,\,\delta _3\) are binary parameters and \(\left( {\tilde{x}_{ij}:i=1,\ldots , m} \right) \) and \(\left( {\tilde{y}_{rj}:r=1,\ldots , s} \right) \) are fuzzy input and fuzzy output vectors of \(\hbox {DMU}_{\mathrm{j}}, \hbox {j}=1,\ldots , \hbox {n}\), respectively.
Different methods have been presented to solve the FDEA models, which in fact are a fuzzy linear programming. Herein, we use the \(Q_\alpha \) function proposed by Shureshjani and Darehmiraki (2013) and present a new approach to solve the FDEA models.
As can be seen from Sect. 2, the \(Q_\alpha \) transformation function is dependent on \(\upalpha \)-cuts, considers both left and right parts of the fuzzy numbers, and is sensitive to any change in the left and right part of fuzzy numbers. So, it is a good representative of the fuzzy inputs and outputs in fuzzy DEA models. By substituting the fuzzy inputs and outputs with their assigned \(Q_\alpha \) functions, the generalized fuzzy DEA model is transformed into the following parametric programming which is dependent on \(\upalpha \)-cuts.

where

Herein, \(\upalpha \) relies on the decision maker’s opinions. If \(\upalpha \) is considered close to 1, then the achieved result will be a result which is obtained from a risk-averse decision making and if the decision maker adopts an amount close to zero for \(\upalpha \), then the result is a risk-prone result.
By proper selection of \(\delta _1, \delta _2, \,\delta _3 \) in GFDEA model, we define:
Definition 3.1
\(DMU_o \) is FCCR-efficient \(\leftrightarrow \forall \alpha \in \left[ {0,1} \right) , DMU_o \) is efficient in transformed FCCR model.
Definition 3.2
\(DMU_o \) is FCCR \(\upalpha \)-efficient \(\leftrightarrow \exists \alpha \in \left[ {0,1} \right) , DMU_o \) is efficient in transformed FCCR model.
Similarity, we have above definitions for fuzzy BCC, FG and ST models.
For conventional BCC model, Cooper et al. (2007) proved that if \(DMU_o \) has a minimum input value for any input item, or a maximum output value for any output item then \(DMU_o \) is BCC-efficient.
The following two theorems generalize the above mentioned theorem to provide a tool to check the accuracy of the obtained results from our proposed method for the fuzzy BCC model.
Theorem 3.1
By substituting the fuzzy inputs and outputs with the \(Q_\alpha \) function, if for all \(\upalpha \),\(\alpha \in \left[ {0,1} \right) \), \(DMU_o \) has a minimum input value for any input item or a maximum output value for any output item then \(DMU_o \) is FBCC-efficient.
Proof
Choosing an arbitrary \(\upalpha \), \(\alpha \in \left[ {0,1} \right) ,\) the transformed FBCC model is converted to a traditional BCC model. Now, if \(DMU_o\) has a minimum input value for any input item or a maximum output value for any output item, then \(DMU_o\) is efficient (Cooper et al. 2007, p. 93). As \(\upalpha \) was arbitrary, so according to the Definition 3.2, \(DMU_o \) is FBCC-efficient. \(\square \)
Theorem 3.2
By substituting the fuzzy inputs and outputs with the \(Q_\alpha \) function, if for one \(\upalpha \),\(\alpha \in \left[ {0,1} \right) \), \(DMU_o \) has a minimum input value for any input item or a maximum output value for any output item then \(DMU_o \) is FBCC \(\upalpha \)-efficient.
Proof
The proof of this theorem is the same as the former. \(\square \)
Although a variety of techniques are available to solve fuzzy DEA models, each method has its own limitations. Some of the techniques are only developed for using triangular or trapezoidal fuzzy inputs and outputs; however they either do not work for general forms of fuzzy inputs and outputs with arbitrary membership functions or need to solve a nonlinear programing with complex calculations. For example, Guo and Tanaka (2001) method is applicable only for symmetric triangular fuzzy numbers. Moreover, proposed models by Lertworasirikul et al. (2003a, (2003b), Wen and Li (2009) and Hatami-Marbini et al. (2013) are nonlinear programs which can be converted to linear programs only for trapezoidal fuzzy numbers.
However, in real-world problems, numerous fuzzy inputs and outputs with arbitrary membership functions are involved. So, simple yet effective methods need to be developed to solve these problems.
As mentioned earlier, in our proposed method fuzzy inputs and outputs have arbitrary membership functions (not necessarily triangular or trapezoidal form). In this method after determining the amount of alpha, which depends on the decision maker’s opinion, a simple linear program needs to be solved to compute the efficiency of DMUs. So, it is easily possible to obtain the efficiency measures of DMUs for different amounts of alpha and plot their efficiency functions.
In addition to normal fuzzy numbers, non-normal ones are also defined in fuzzy logic (Cheng 1998; Wang et al. 2006; Shureshjani and Darehmiraki 2013; Hatami-Marbini et al. 2013). Almost all available methods for solving fuzzy DEA models are applicable just for normal fuzzy numbers but according to the structure of \(Q_\alpha \) transformation function, our proposed method is applicable for both normal and non-normal fuzzy numbers.
4 Numerical examples
In this section, two numerical examples are provided to illustrate the proposed approach in fuzzy DEA. First, we will explain the proposed approach through a simple numerical example, with a fuzzy input and a fuzzy output. Then, in another example, we will compare the obtained results of our approach with the results of some other approaches in this field.
Example 1
Consider 3 DMUs with a fuzzy input and a fuzzy output. All the data are normal and triangular except \(\tilde{B}\) (Table 1).
\(\tilde{B}= \left( \underline{B} \left( r \right) ,\bar{B}\left( r \right) \right) = \left( {2 - \sqrt{1 -{r^2}},2 + 2\sqrt{1 - {r^2}} } \right) ,~0 \le r \le 1\) is a general fuzzy number (Fig. 4).
By using the \(Q_\alpha \) function for fuzzy numbers in Table 1, we will have Table 2.
By computing the fuzzy efficiency of DMUs in four models of transformed GFDEA, for different decision levels made by decision maker, for example \(\alpha =0.1, 0.3, 0.5, 0.7, 0.9,\) we will have: Tables 3, 4, 5 and 6
As it was shown in Fig. 4, the inputs of first and second DMUs are two intersected fuzzy numbers. From their \(Q_\alpha \) function, different rankings are achieved for them in different amounts of \(\upalpha \). For example, if \(\alpha =0.1\), \(\tilde{A}\succ \tilde{B}\) and when \(\alpha =0.7\), \(\tilde{A}\prec \tilde{B}\). As it is shown in the FCCR efficiency results (Table 3), DMUs 1 and 2 are FCCR \(\upalpha \)-efficient but they are not FCCR-efficient (Definitions 3.1 and 3.2).
Also, by using \(Q_\alpha \) function, the output data of the first and second DMUs are equal. From Table 2 we can see that for all amounts of \(\upalpha \), DMU3 has the biggest output among all DMUs, so according to the Theorem 3.1 DMU3 should be FBCC-efficient. Inputs of DMUs 1 and 2 are two intersected fuzzy numbers and from Table 2 we can see that for \(\alpha \le 0.3\) DMU2 has the smallest input among all DMUs. So, from Theorem 3.2 for \(\alpha \le 0.3\) DMU2 should be FBCC \(\upalpha \)-efficient. Similarly we can see that for \(\alpha \ge 0.5\) DMU1 should be FBCC \(\upalpha \)-efficient. Table 4 shows that the obtained results are coincident with Theorems 3.1 and 3.2.
The obtained results for FFG and FST models are shown in Tables 5 and 6.
The efficiency diagram of DMUs for FCCR, FBCC, FFG, and FST models are presented in Figs. 5, 6, 7, and 8.
Example 2
In this example, we use the numerical example proposed by Guo and Tanaka (2001) which is also used by Saati et al. (2002), Lertworasirikul et al. (2003a, (2003b), Wen and Li (2009), and Hatami-Marbini et al. (2013).
Consider five DMUs with two fuzzy inputs and two fuzzy outputs presented in Table 7.

The inputs of DMUs 1 and 2 (two intersected fuzzy numbers)

FCCR efficiency diagram

FBCC efficiency diagram

FFG efficiency diagram

FST efficiency diagram
All the applied fuzzy numbers in inputs and outputs are normal fuzzy numbers which are triangular and symmetric.
According to many approaches in ranking fuzzy numbers, for example, Cheng (1998), Yao and Wu (2000), Detyniecki and Yager (2001), Chu and Tsao (2002), Wang and Lee (2008), Abbasbandy and Hajjari (2009), Chen and Sanguansat (2011), and Shureshjani and Darehmiraki (2013), when two normal triangular fuzzy numbers \(\,\tilde{A}\) and \(\tilde{B}\) have the same modes and symmetric spreads, \(\tilde{A}\) is equal to \(\tilde{B}\) and is equal with the crisp number which is in the mode of \(\tilde{A} \) and \(\tilde{B}\). So, using the presented approach, when we use the data of Table 7 in the GFDEA model, the efficiency quantities don’t change for different amounts of \(\upalpha \), \({\alpha }\in \left[ {0,1} \right) \).
For FCCR model, regarding the achieved results from approaches compared in this example (Table 8), it can be seen that:
DMU A is always inefficient, in Guo and Tanaka (2001), Wen and Li (2009), and the proposed approach in this paper. Also, in Saati et al. (2002) DMU A is always inefficient except for \(\upalpha =0\) but in Lertworasirikul et al. (2003a) different \(\upalpha \) leads to different results.
For DMU B, all the approaches agree on its efficiency except for Wen and Li (2009) at credibility level 0.1 (Table 9).
For DMU C, different approaches leads to different results, of which some are in contrary to the others. But, in the proposed approach, DMU C is always inefficient.
For DMU D, all the approaches agree on its efficiency.
DMU E is also efficient in all the approaches except for Guo and Tanaka (2001).
As mentioned above, in this example, the efficiency results obtained from our proposed approach in FCCR model are coincident with the efficiency results of most of the other approaches.
Lertworasirikul et al. (2003b) and Hatami-Marbini et al. (2013) have presented new models in order to compute the efficiency in FBCC model. For this example, their results are shown in Table 10, besides, their results have been compared with our presented approach.
According to the Theorem 1, it can be seen that DMU B has a minimum input value for any input item and DMU E has a maximum output value for any output item in the transformed FBCC model. So, the DMUs B and E are efficient. This result has been achieved in all three presented approaches. In addition to this, DMU D is also efficient in all the three approaches. According to the proposed approach, DMUs A and C are always inefficient but in the other approaches, the results of efficiency in different amounts of \(\upalpha \) are various.
5 Conclusion
As the data are sometimes imprecise or vague in real world, using the fuzzy numbers to show the inputs and outputs in DEA facilitates the computation of practical problems in DEA field. After modeling the problem in FDEA, next step is finding a proper approach to solve it. In the present paper, a new parametric method is proposed to solve the FDEA problems and specifically applied for a generalized FDEA model including FCCR, FBCC, FFG and FST models. Some important characteristics of this approach are, the possibility of using fuzzy numbers with arbitrary membership functions in inputs and outputs, contribution of decision maker in the process of decision making, and simplicity of calculation.
The presented approach in this paper can be easily generalized to other FDEA models.
References
Abbasbandy S, Hajjari T (2009) A new approach for ranking of trapezoidal fuzzy numbers. Comput Math Appl 57:413–419
Banker RD, Charnes A, Cooper WW (1984) Some models for estimating technical and scale inefficiencies in DEA. Manag Sci 30(9):1078–1092
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 6:429–444
Cheng CH (1998) A new approach for ranking fuzzy numbers by distance method. Fuzzy Sets Syst 95:307–317
Chen S-M, Sanguansat K (2011) Analyzing fuzzy risk based on a new fuzzy ranking method between generalized fuzzy numbers. Expert Syst Appl 38(3):2163–2171
Chu TC, Tsao CT (2002) Ranking fuzzy numbers with an area between the centroid point and the original point. Comput Math Appl 43:111–117
Cooper WW, Seiford LM, Tone K (2007) Data envelopment analysis: a comprehensive text with models, applications, references and DEA-solver software, 2nd edn. Springer, New York
Detyniecki M, Yager RR (2001) Ranking fuzzy numbers using \(\alpha \)-weighted valuations. Int J Uncertain Fuzziness Knowl-Based Syst 8(5):573–592
Emrouznejad A, Tavana M, Hatami-Marbini A (2014) The state of the art in fuzzy data envelopment analysis. In: Emrouznejad A, Tavana M (eds) Performance measurement with fuzzy data envelopment analysis (Studies in Fuzziness and Soft Computing), vol. 309. Springer, Berlin, pp 1–45
Färe R, Grosskopf S (1985) A nonparametric cost approach to scale efficiency. Scand J Econ 87(4):594–604
Farrell MJ (1957) The measurement of productive efficiency. J R Stat Soc A 120(3):253–281
Guo P, Tanaka H (2001) Fuzzy DEA: a perceptual evaluation method. Fuzzy Sets Syst 119(1):149–160
Hadi-Vencheh A, Foroughi AA, Soleimani-Damaneh M (2008) A DEA model for resource allocation. Econ Model 25:983–993
Hatami-Marbini A, Saati S, Makui A (2009) An application of fuzzy numbers ranking in performance analysis. J Appl Sci 9(9):1770–1775
Hatami-Marbini A, Tavana M, Saati S, Agrell PJ (2013) Positive and normative use of fuzzy DEA-BCC models: a critical view on NATO enlargement. Int Trans Oper Res 20:411–433
Kao C, Liu ST (2000) Data envelopment analysis with missing data: an application to University libraries in Taiwan. J Oper Res Soc 51(8):897–905
Kao C, Liu ST (2005) Data envelopment analysis with imprecise data: an application of Taiwan machinery firms. Int J Uncertain Fuzziness Knowl-Based Syst 13(2):225–240
Kuo HC, Wang LH (2007) Operating performance by the development of efficiency measurement based on fuzzy DEA. In: Second international conference on innovative computing, information and control, p 196
Lertworasirikul S, Shu-Cherng F, Joines JA, Nuttle HLW (2003a) Fuzzy data envelopment analysis (DEA): a possibility approach. Fuzzy Sets Syst 139(2):379–394
Lertworasirikul S, Fang SC, Nuttle HLW, Joines JA (2003b) Fuzzy BCC model for data envelopment analysis. Fuzzy Optim Decis Mak 2(4):337–358
Puri J, Yadav SP (2013) A concept of fuzzy input mix-efficiency in fuzzy DEA and its application in banking sector. Expert Syst Appl 40:1437–1450
Saati S, Memariani A, Jahanshahloo GR (2002) Efficiency analysis and ranking of DMUs with fuzzy data. Fuzzy Optim Decis Mak 1:255–267
Seiford LM, Thrall RM (1990) The mathematical programming approach to frontier analysis. J Econom 46:7–38
Sengupta JK (1992) A fuzzy systems approach in data envelopment analysis. Comput Math Appl 24(9):259–266
Shureshjani RA, Darehmiraki M (2013) A new parametric method for ranking fuzzy numbers. Indag Math 24:518–529
Triantis KP, Girod O (1998) A mathematical programming approach for measuring technical efficiency in a fuzzy environment. J Product Anal 10(1):85–102
Wang YM, Yang JB, Xu DL, Chin KS (2006) On the centroids of fuzzy numbers. Fuzzy Sets Syst 157:919–926
Wang YJ, Lee HS (2008) The revised method of ranking fuzzy numbers with an area between the centroid and original points. Comput Math Appl 55:2033–2042
Wen M, Li H (2009) Fuzzy data envelopment analysis (DEA): model and ranking method. J Comput Appl Math 223:872–878
Yao J, Wu K (2000) Ranking fuzzy numbers based on decomposition principle and signed distance. Fuzzy Sets Syst 116:275–288
Yu G, Wei QL, Brockett P (1996a) A generalized data envelopment analysis model: a unification and extension of existing methods for efficiency analysis of decision making units. Ann Oper Res 66:47–89
Yu G, Wei QL, Brockett P, Zhou L (1996b) Construction of all DEA efficient surfaces of the production possibility set under the generalized data envelopment analysis model. Eur J Oper Res 95:491–510
Zhou SJ, Zhang ZD, Li YC (2008) Research of real estate investment risk evaluation based on fuzzy data envelopment analysis method. In: Proceedings of the international conference on risk management and engineering management, pp 444–448
Acknowledgments
The authors are grateful for the comments and suggestions made by two anonymous reviewers, which helped to improve this paper. By the agreement between EURO and IFORS, second author could be sponsored by IFORS from a non-EURO member society to participate in ESI XXXII and this paper was first presented there. Also, his travel report is published in IFORS newsletter, September 2015. Thanks to IFORS and ESI organizing committee.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Foroughi, A.A., Shureshjani, R.A. Solving generalized fuzzy data envelopment analysis model: a parametric approach. Cent Eur J Oper Res 25, 889–905 (2017). https://doi.org/10.1007/s10100-016-0448-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10100-016-0448-5