
Abstract
The problem of completion of low-rank matrices is considered in a special setting, where each element of the matrix may be erroneous with a limited probability. Although such a perturbation is extremely sparse on a given mask of known elements, it is not incoherent and may cause instabilities in the commonly used projected gradient method. A new iterative method is proposed that is insensitive to rare observation errors and is more stable for ill-conditioned solutions. The method can also be used for finding a matrix approximation in the format of a sum of a low-rank and a sparse matrix.
Similar content being viewed by others

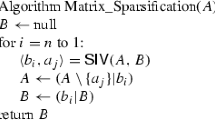
Avoid common mistakes on your manuscript.
1 Introduction
The problem of matrix completion generally refers to the problem of finding a low-rank matrix under a condition that only a small fraction of its elements is known.
The ‘textbook’ application of this problem lies in the field of recommender systems [1]; however, matrix completion algorithms recently found many other applications, including machine learning [2, 3], signal processing [4, 5] and genomic data integration [6].
Mathematically, such a problem can be formulated in different ways, resulting in problems and algorithms with different properties.
Consider an operator \(\mathcal{A}_{\Omega }: {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) of the form
where \(\Omega \in {\mathbb {N}}_n \times {\mathbb {N}}_n\) is a subset of indices that define the mask of matrix elements given as input, and \(\rho \) is the fraction of known elements \(\rho = \frac{\# \Omega }{n^2}\).
Using this definition, one of the possible mathematical formulation of the matrix completion problem as an optimization problem looks as follows:
This problem is NP-hard in general [7], and it is a common technique to replace the functional to be minimized by its convex envelope, which is the nuclear norm. The functional then can be optimized in polynomial time, and furthermore, this approach allows to bound the number of matrix elements sufficient for completion [8]. This number depends on the matrix size n as \(O(n \log ^2 n)\), and certain assumptions on the rank and the non-sparsity of the unknown matrix are required for the bound.
However, the computational complexity of such an approach remains high, as convex optimization is applied with the whole matrix unknown, resulting in \(O(n^2)\) variables to be optimized. In order to cope with that problem, alternative ‘fixed-rank’ approaches have also been studied, which consider the following optimization problem:
The fixed-rank approach allows to either search for the unknown matrix in a factorized form using gradient-based optimization [9, 10], or to use techniques based on optimization on algebraic manifolds [11,12,13,14]. The latter approach allows to use optimization methods with faster than linear (e.g. second order) convergence, but has initial point restrictions and commonly does not have a direct estimate on the required matrix element count; the former approach allows to build geometrically-convergent methods that do not have strong initial point requirements, and keeps the same estimate of \(O(n \log ^2 n)\) matrix elements being sufficient for successful completion. Furthermore, recent results [15, 16] have shown that it is possible to substantially reduce the computational complexity of such methods while maintaining provable geometric convergence.
In this paper, one of the factorized-form iterative gradient-based optimization algorithms called ‘Singular Value Projection’ (SVP) [9] will be considered under a special setting with erroneous input data: it will be assumed that a small fraction of given element values may be subject to errors. The theoretical bounds developed for the original SVP method have a certain requirement of the non-sparsity of the unknown matrix and the residual on each iteration. Thus, the original SVP method, if applied directly to the mask with erroneous elements, will generally not converge to the unaffected matrix.
The main result of this paper is an algorithm that is able to solve the completion problem with sparse errors. An alternative procedure, that introduces two independent completion ‘masks’ and searches for the most ‘aligned’ parts of the resulting matrices, is proposed and analyzed theoretically. The proposed procedure can also be formulated as a ‘low-rank plus sparse’ approximation algorithm with provable theoretical bounds under the assumptions commonly used in the analysis of the matrix completion algorithms.
The organization of the paper is as follows. The second section contains brief discussion of the concepts of ‘Restricted Isometry Property (RIP)’, canonical angles between supspaces, and SVD perturbations, that are widely used throughout the paper. In the third section, the matrix completion SVP method is discussed. Theoretical convergence results, which are close to those from [9, 15], but provide a direct dependence on the problem condition number, are provided in order to form a base for the new algorithm. These results guarantee geometric convergence of the method in the case when \(\mathcal{A}\) is a general operator that satisfies the so-called ‘Restricted Isometry Property’ (RIP). In the fourth section, a novel ‘Twin Completion’ approach, that is able to solve the matrix completion problem in the setting of sparse measurement errors, is proposed and analyzed. In the fifth section, numerical results are provided that show the effectiveness of the proposed method.
2 Required concepts
In this section, some linear algebra and matrix completion concepts will be discussed, that will be used throughout the rest of the paper.
2.1 Restricted isometry property
As the matrix completion problems, if posed directly, are commonly NP-hard [7], it is common to impose additional constraints on the functional (1) and/or its solutions. One way to do so is to suppose that the linear operator \(\mathcal{A}\) fulfills the so-called RIP property, which means that it approximately preserves the norm of the input.
Definition 2.1
(‘Restricted isometry property’, RIP)
The approximate relative norm preservation necessarily means absolute scalar product preservation, which is shown in the following Lemma using the common scalar product expression in terms of corresponding norm:
Lemma 2.1
If a linear operator \(\mathcal{A} \in {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) satisfies restricted isometry property (2) for all matrices \(Z: rank(Z) \le 2r\), then
Proof
As the Frobenius scalar product is induced by the Frobenius norm, by the parallelogram identity
Now, if \(\Vert X\Vert _F = \Vert Y\Vert _F = 1\), then
In general case with arbitrary values of \(\Vert X\Vert _F, \Vert Y\Vert _F\), the proof follows from applying the considerations above to \(\frac{X}{\Vert X \Vert _F}, \frac{Y}{\Vert Y \Vert _F}\), and scaling the result (3) by \(\Vert X \Vert _F \Vert Y \Vert _F\). \(\square \)
While it is possible to provide an example of such an operator \(\mathcal{A} \in {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) with an image dimensionality of \(O(n^2)\), it is unclear if such operators with smaller image dimensionalities \(m \ll n^2\) even do exist. However, certain additional limitations on the set of low-rank matrices on which the RIP constraint must hold allow one to build some examples of such operators \(\mathcal{A}\) with low image dimensionality [9, 15]. An important example is the so-called ‘matrix completion’ operator.
Consider \(\mathcal{A}_{\Omega } \in L({\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n})\) to be called a random ‘matrix completion’ operator, if it has the form
where \(\Omega \) is a set of indices corresponding to the known elements of a matrix, and \(\rho = \frac{|\Omega |}{n^2}\) is the sparsity parameter. Such an operator, with a minimal sparsity requirement is known to satisfy RIP property on a subset of matrices of low rank.
This subset is defined using the so-called matrix \(\mu \)-incoherence condition, or essentially ‘non-sparsity’ condition of the following form:
Definition 2.2
(\(\mu \)-incoherent matrix) A matrix \(X, \; rank(X) = r\) is called \(\mu \)-incoherent, if the SVD factors of this matrix satisfy
Theorem 2.1
(Theorem 4.2, [9]) There exists a constant \(C_{RIP} \ge 0\) such that for any \(0< \delta _r < 1,\) any \(\mu \ge 1, n \ge 3,\) and a sparsity parameter
a matrix completion operator \(\mathcal{A}_{\Omega }\) with \(\Omega \) selected randomly using uniform index distribution
with a probability not less than \(1 - \exp (-n \log (n))\) satisfies RIP with parameter \(\delta _r\) on all \(\mu \)-incoherent matrices of rank not larger than r.
Here and throughout the paper the logarithm is assumed to be natural (with base e), but it is mostly insignificant for asymptotic analysis. It is notable that the incoherence property can be translated to an elementwise bound of a matrix using a following Lemma.
Lemma 2.2
If X is a rank-r matrix, that satisfies incoherence properties (4) with constant \(\mu \), then
Proof
The proof is given in [9], Lemma 4.7. \(\square \)
2.2 Angles between subspaces
In this paper, we are going to analyze the convergence of matrix completion methods using the idea of singular vector subspace stability to almost orthogonal perturbations. The analysis will require the following common linear algebra concept of canonical angles and vectors between linear subspaces. Consider two linear subspaces \(\mathcal{L} \in {\mathbb {R}}^n\) and \(\mathcal{M}\in {\mathbb {R}}^n\) such that \(\dim (\mathcal{L}) = \dim (\mathcal{M}) = r\). Let \(P_\mathcal{L}, P_\mathcal{M}\) denote the corresponding orthogonal projectors. Then [17, 18],
-
The singular values \(\sigma _k\) of the product \(P_\mathcal{L} P_\mathcal{M}\) belong to the interval [0, 1]. The left and right sorted singular vector pairs of \(P_\mathcal{L} P_\mathcal{M}\) are called the ‘canonical vectors’ between subspaces \(\mathcal{L}, \mathcal{M}\). The sorted values \(\phi _k \in [0, \frac{\pi }{2}]\), such that \(\cos \phi _k = \sigma _k(P_\mathcal{L} P_\mathcal{M})\), are known as the canonical angles between subspaces \(\mathcal{L}, \mathcal{M}\).
-
The first canonical vector pair between subspaces has the meaning of the pair of most correlated unit vectors of these subspaces:
$$\begin{aligned} \{\vec {x}_1, \vec {y}_1\} = \arg \max _{\vec {x} \in \mathcal{L}, \vec {y} \in \mathcal{M}} (\vec {x}, \vec {y})_2. \end{aligned}$$All the other canonical vector pairs can be expressed iteratively with
$$\begin{aligned} \{\vec {x}_k, \vec {y}_k\} = \arg \max _{\vec {x} \in \mathcal{L}, x \perp x_1 \dots x_{k-1}; \vec {y} \in \mathcal{M}, y \perp y_1 \dots y_{k - 1}} (\vec {x}, \vec {y})_2, k \le r. \end{aligned}$$.
-
The eigenvalues of a symmetric matrix \(P_\mathcal{L} - P_\mathcal{M}\) are equal to \(\pm \sin \phi _k\) (maximum total of 2r nonzero values), where \(\phi _k\) denotes the canonical angles between \(P_\mathcal{L}, P_\mathcal{M}\).
2.3 SVD perturbations
Now, let us recall a singular base additive perturbation bound proved by Wedin, which is close to the well-known Davis– bound. The theorem essentially guarantees that if the perturbation is almost orthogonal to both left and right singular subspaces of the original matrix, these subspaces are not changed much after the perturbation.
Throughout the paper, it will be commonly assumed that \(P_U := UU^*\) denotes an orthogonal projection onto a subspace spanned by orthogonal columns of U, and \(P_r(X) \in {\mathbb {R}}^{n \times n}\) denotes the optimal SVD-projection of a matrix \(X \in {\mathbb {R}}^{n \times n}\) onto the set of matrices with a rank not larger than r.
Lemma 2.3
(Wedin, [19, 20]) Let \(X \in {\mathbb {R}}^{n \times n}\) be a rank-r matrix, and \(X = U \Sigma _r V^*\) be its short SVD with \(U, V \in {\mathbb {R}}^{n \times r}\). Let \(E \in {\mathbb {R}}^{n \times n}\) be an additive error matrix that fulfills \(\max \{\Vert P_U E \Vert _F, \Vert E P_V \Vert _F \} \le \eta \). Let \(\gamma \in {\mathbb {R}}\) be a positive constant.
-
If \(\gamma \le \sigma _r(X) - \Vert E \Vert _2\), and \(P_r(X + E) = {\hat{U}}_r \hat{\Sigma }_r {\hat{V}}_r^*\), then
$$\begin{aligned} \max \{\Vert P_U - P_{{\hat{U}}_r} \Vert _F, \Vert P_V - P_{{\hat{V}}_r} \Vert _F \} \le 2 \frac{\eta }{\gamma }. \end{aligned}$$ -
More generally, if there exist size-r singular vector bases \({\hat{U}}, {\hat{V}}\) of \(X + E\) (which do not necessarily correspond to the top-r singular values), and \(\gamma \le \min _{i \le r,j} |\sigma _i(X) - \sigma _j((I - P_{{\hat{U}}}) (X + E) (I - P_{{\hat{V}}})) |\), then
$$\begin{aligned} \max \{\Vert P_U - P_{{\hat{U}}_r} \Vert _F, \Vert P_V - P_{{\hat{V}}_r} \Vert _F \} \le 2 \frac{\eta }{\gamma }. \end{aligned}$$
Proof
The statements are proved in [20] and also discussed in [19]. The claims are obtained by plugging into Theorem 4, [19] the notations \(\Sigma _r \leftrightarrow \tilde{\Sigma }_1\), \(\sigma ((I - P_{{\hat{U}}}) (X + E) (I - P_{{\hat{V}}})) \leftrightarrow \sigma (\Sigma _2)\), \(U_r^* E \leftrightarrow S, E V_r \leftrightarrow R\). \(\square \)
Now, let us prove an additional Lemma that uses the above theorem for the particular case of a low-rank matrix perturbation.
Lemma 2.4
Let \(X \in {\mathbb {R}}^{n \times n}\) be a rank-r matrix, and \(U \Sigma V^*\) be its short SVD such that \(U, V \in {\mathbb {R}}^{n \times r}\). Let \(E \in {\mathbb {R}}^{n \times n}\) be an additive error matrix that fulfills \(\max \{\Vert P_U E \Vert _F, \Vert E P_V \Vert _F \} \le \eta \), \(\Vert E \Vert _2 \le \frac{\sigma _r(X)}{2}\).
Let \(\kappa := \frac{\sigma _1(X)}{\sigma _r(X)}\) be the ‘problem condition number’. Then,
Proof
Defining \(P_r(X + E) := {\tilde{U}} \tilde{\Sigma }{\tilde{V}}^*\), \(\Delta P_U := P_{{\tilde{U}}} - P_{U}\), \(\Delta P_{V} := P_{{\tilde{V}}} - P_{V}\), where \({\tilde{U}}, {\tilde{V}} \in {\mathbb {R}}^{n \times r}\), we can use the previous Lemma to open the brackets as
Let us define \(\gamma := \sigma _r(X) - \Vert E \Vert _2\); as \(\Vert E \Vert _2 < \frac{\sigma _r(X)}{2}\), \(\gamma > \frac{\sigma _r(X)}{2}\). Then, Lemma 2.3 gives the bound \(\Vert \Delta P_U \Vert _F \le \frac{2 \eta }{\gamma }, \Vert \Delta P_V \Vert _F \le \frac{2 \eta }{\gamma }\), and we can bound the two additive terms of (5), (6) by
and
where we used \(\Vert AB \Vert _F \le \Vert A \Vert _F \Vert B \Vert _2\) multiple times, and the last inequality follows from \(\gamma > \frac{\sigma _r(X)}{2} \ge \Vert E \Vert _2\). Summing the two additive terms finishes the proof. \(\square \)
3 Exact restricted isometry SVP
The so-called ‘Singular Value Projection’ [9] method is essentially an iterative projected gradient method applied to the functional of the form
One iteration of the method can be described with equations
where k is the iteration number, \(X_k\) denotes the current approximation of the desired unknown matrix X, \(W_k\) denotes current error, \(\alpha > 0\) is the step parameter, and \(\mathcal{I} \in {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) denotes the identity operator defined in the space of matrices.
In [9], it is proven that if the operator \(\mathcal{A}: {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) satisfies the RIP property (2) with a constant \(0< \delta _{2r} < 1\) for all matrices up to rank 2r, then the SVP method with \(\alpha = \frac{1}{1 + \delta _{2r}} \approx 1\) attains geometric convergence in terms of the optimization functional (7), regardless of the initial point \(X_0\). Here, we will provide alternative convergence theorems and proofs that are based on the analysis of a low-rank SVD perturbation. In our paper, we will consider a fixed step size of \(\alpha = 1\). Our arguments are based on the following Lemma.
Lemma 3.1
(Projected \(\mathcal{A}^* \mathcal{A} - \mathcal{I}\) residual) Let \(U, V \in {\mathbb {R}}^{n \times r}\) be arbitrary bases with orthogonal columns, and \(Y \in {\mathbb {R}}^{n \times n}\), \(rank(Y) \le r\). Let \(\mathcal{A}\) be an operator that satisfies RIP with a constant \(\delta _{2r}\) on all matrices of rank up to 2r. Then
where \(P_U, P_V\) denote orthogonal projectors \(UU^*, VV^*\) respectively.
Proof
Using that \(rank(P_U (\mathcal{A}^* \mathcal{A} - \mathcal{I})Y) \le r\), and rewriting the Frobenius norm with a scalar product maximization, we have
where the inequality follows from a scalar product isometry Lemma 2.1. \(\square \)
Lemma 3.1 brings the following idea: although the SVP iteration additive term \(E_k = (\mathcal{A}^* \mathcal{A} - \mathcal{I}) W_k\) itself may have a relatively ‘large’ norm compared to current error \(W_k\), it is almost orthogonal to the bases of the solution X. Thus, by Lemma 2.3, addition of \(E_k\) should have a limited impact on the top singular bases of X, and \(\Vert P_r(X + E_k) - X \Vert \ll \Vert W_k \Vert \).
Recent studies [15, 16] have shown that the most numerically-complex operation of the SVP algorithm, which is the SVD decomposition (that costs \(O(n^3)\) operations in general), can be reduced by using approximate partial SVP decomposition. Such an approximate decomposition can be obtained using any algorithm \({\hat{P}}_r\) that satisfies the approximation condition: for any matrix Y, \({\hat{P}}_r(Y)\) should be a rank-r matrix that in some sense approximates the actual projection \(P_r(Y)\). In [15], the following definition of approximation is introduced:
Definition 3.1
(Approximate projector, [15]) The operator \({\hat{P}}_r\) is called an \(\epsilon \)-approximate SVD projection operator if
Same condition in expectation form is used in [16]. In this paper, we are going to use a stronger version of such a condition compared to [15, 16]:
Definition 3.2
(Approximate projector) The operator \({\hat{P}}_r\) is called an \(\epsilon \)-approximate SVD projection operator if
The Definitions 3.1, 3.2 are non-equivalent: if (9) holds, then
and (8) is fulfilled with \(1 + \tilde{\epsilon }= \sqrt{1 + \epsilon }\). If (8) holds instead, the Definition 3.2 may not be fulfilled in general, which can be seen on the following example. Let
Then, taking \(\epsilon = 0.001\) we have
In the context of this paper, however, the matrices Y of interest are bounded by some limitations. Lemma 2.4, for example, requires a gap in the singular values of \(Y = X + E\) of the form \(\sigma _r(Y) - \sigma _{r + 1}(Y) > const\). We will now show that imposing additional constraints on the singular value decay of the considered matrix Y make the Definitions 3.1, 3.2 close-to-equivalent.
First, consider that if the rank-r matrix has an orthogonal column basis \({\hat{U}} \in {\mathbb {R}}^{n \times r}, {\hat{P}}_r(Y) = {\hat{U}} Z\), then \(\Vert {\hat{P}}_r(Y) - Y \Vert _F \ge \Vert P_{{\hat{U}}} Y - Y \Vert _F\), where \(P_{{\hat{U}}} = {{\hat{U}}} {{\hat{U}}}^*\) is the orthogonal projector. Since computing \({{\hat{U}}}^* Y\) is a (relatively to the common SVD) low-complexity operation, it can be assumed that the approximate projector \({\hat{P}}_r(Y)\) always has the form \(P_{{\hat{U}}(Y)} Y\), where \({\hat{U}}(Y)\) is some approximation to the top-r singular columns of Y.
Lemma 3.2
(Approximate projector equivalence) Let \(Y \in {\mathbb {R}}^{n \times n}\), and let \(P_r(Y) = P_U Y = U \Sigma V^*, U, V \in {\mathbb {R}}^{n \times r}\) - be its optimal SVD-projection onto the set of rank-r matrices. Let \(P_{{\hat{U}}} Y\) be an approximate projection, which satisfies
Let the singular values of Y satisfy
Then,
Proof
By the approximation property 10, it can be seen that
where the last inequality follows from the bound on the optimal Frobenius-norm residual between the matrix \((I - P_U) Y\) and a rank-r matrix. By subtraction, we have
On the other hand, by the orthogonal projection properties and optimality of singular subspace U, we have
By rearranging the terms, we can bound
Now, we need to bound the value \(\Vert P_{U} Y \Vert _F^2 - \Vert P_U P_{{\hat{U}}} Y \Vert _F^2\) using the previously obtained \(\Vert P_U Y - P_U P_{{\hat{U}}} Y \Vert _F^2 \le \beta ^2 (Y) \Vert P_U Y \Vert _F^2\). The bound would be straightforward in the absence of squares; in order to handle the squares, let us make an arithmetic substitution \(a \leftrightarrow \Vert P_U P_{{\hat{U}}} Y \Vert _F, b \leftrightarrow \Vert P_U Y \Vert _F, b \ge a \ge 0, (b-a)^2 \le \beta ^2 b^2\). Then,
Now we can use the obtained bounds to obtain
In order to finalize the proof, we need to use conditions (11), (12) to bound \(\beta (Y)\). Inequality (12) gives
thus by (11) \(\beta (Y) > 1\). Then,
\(\square \)
Now, we will sum up the SVP convergence theory results, similar to those in [9, 15], with a theorem. The theorem uses the Definition 3.2 and requires the RIP property (2) to hold for all matrices of rank up to 4r, compared to 2r in [9, 15]. With these more strict conditions it is possible to establish a short and understandable proof of convergence using the concept of SVD perturbation analysis.
Theorem 3.1
(SVP convergence) Let X be a rank-r matrix and \(\kappa = \frac{\sigma _1(X)}{\sigma _r(X)}\). Let \(\mathcal{A}\) be an operator that satisfies RIP with a constant \(\delta _{4r}\) on all matrices of rank up to 4r. Then the SVP algorithm attains local linear(geometric) convergence with constant \(\delta _{4r} (8 \kappa + 3)\).
Let \(\Vert \mathcal{A}^*\Vert _F = \max _{X \ne 0}\frac{\Vert \mathcal{A}^*(X)\Vert _F}{\Vert X\Vert _F}\). Additionally, let \({\hat{P}}_r\) be an \(\epsilon \)-approximate SVD projection operator in the sense of Definition 3.2, and let \(\epsilon \Vert \mathcal{A}^* \Vert _{F} (1 + \delta _{4r}) < 1 - \delta _{4r} (8 \kappa + 3)\). Then, approximate SVP with \(P_r\) replaced by \({\hat{P}}_r\) attains local linear(geometric) convergence.
Proof
In the case of exact SVP projection, taking into account that \(rank(W_k) \le 2r\), and assuming \(\Vert E_k \Vert _2 \le \frac{\sigma _r(X)}{2}\), Lemmas 2.4, 3.1 give estimates
The assumption \(\Vert E_k \Vert _2 \le \frac{\sigma _r(X)}{2}\) holds true locally when the error value of the current iterate is small enough: as
it is sufficient to assume
In the case of inexact SVP projection, it can be seen that
and it suffices to bound \(\Vert P_r(X + E_k) - {\hat{P}}_r(X + E_k) \Vert _F\) with
where we replaced an optimal approximation with a suboptimal approximation \(X_k\) of rank r in order to obtain an upper bound. \(\square \)
Compared to the results of [9], Theorem 3.1 gives a convergence bound that depends on the optimization condition number \(\kappa \), which is seen in numerical experiments. For the purposes of this paper, let us generalize this theorem for the case of nonzero additive error occurring on each gradient step. This would result in the following Lemma.
Lemma 3.3
(SVP with errors) Consider the same conditions as in the previous theorem, but assume each SVP iteration is done with an additive error matrices \({\hat{S}}_k\) present:
Let the additive error matrices suffice the following bounds:
Then,
-
If \(2 \delta _{4r} (8 \kappa + 3) < 1\), the SVP algorithm with additive errors and exact SVD projection attains local geometric convergence with constant \(2 \delta _{4r} (8 \kappa + 3)\).
-
If \(\epsilon \Vert \mathcal{A}^* \Vert _F (2 + \delta _{4r}) < 1 - 2 \delta _{4r} (8 \kappa + 3)\), then the SVP algorithm with additive errors and \(\epsilon \)-approximate SVD projection attains local geometric convergence.
Proof
Again, in the case of exact SVP projection, Lemma 2.4 gives an estimate
By Lemma 3.1 and the theorem assumptions we can then bound
These bounds are true under locality assumption \(\Vert E_k + S_k \Vert _2 \le \sigma _r(X)\), for which, taking into account the condition (13), it is sufficient to assume that the current error is bounded by
In the case of approximate SVD projection and gradient additive error,
and it suffices to bound \(\Vert P_r(X + E_k + S_k) - {\hat{P}}_r(X + E_k + S_k)\Vert _F\) using the \(\epsilon \)-approximation property (9)
\(\square \)
4 Twin completion
4.1 Low-rank plus sparse problem setting
Assume a matrix \(Y \in {\mathbb {R}}^{n \times n}\) can be represented as a sum
where the first term is a low-rank matrix, \(rank(X) = r \ll n\), and the second term \({\hat{S}}\) is sparse. The problem that will be considered in this section is finding both X and \({\hat{S}}\) by knowing Y. In other terms, a two-part representation is computed for the input matrix, where the two parts are known to have different structure types (‘low-rank’ and ‘sparse’). If one of these parts is known and the model decomposition (15) is exact, the second part can be obtained by subtraction.
An algorithm that is based on the matrix completion concept will be proposed as a solution. For the convergence analysis of the algorithm, it will be assumed that nonzero elements of \({\hat{S}}\) are distributed uniformly among the set of all possible indices, with a constant probability of order \(\frac{\beta }{n}, \beta = const\), which results in an average of \(\beta n\) nonzero elements in \({\hat{S}}\).
Referring to the Sect. 2 and Theorem 2.1, assume that the low-rank part X is \(\mu \)-incoherent. Algorithms for finding both the exact low-rank part X and the sparse part \({\hat{S}}\) for a given Y based on convex relaxations are available under certain tangent-space conditions for X [21], but involve numerically complex procedures because X is handled as a vector of \(O(n^2)\) unknowns. In our work, we will provide an algorithm that maintains the low-parametric structure of approximations for both X (factorized low-rank) and \({\hat{S}}\) iteratively. In order to achieve that, we will consider a problem in the following form:
Here, \(\Lambda \subset \{1 \dots n\} \times \{1 \dots n\}\), and \(\mathcal{P}_{\Lambda } \in {\mathbb {R}}^{n \times n} \rightarrow {\mathbb {R}}^{n \times n}\) denotes an operator that sets to zero all matrix elements with indices that do not belong to \(\Lambda \). The functional (16) suggests that an approximation for \(Y = X + {\hat{S}}\) is searched in a form of a low-rank and sparse matrix again, but the sparse part may have a constant times more elements than the original \({\hat{S}}\), thus we are looking for a possibly suboptimal approximation in the original low-rank plus sparse format.
Then, consider the following iterative algorithm, starting with \(k = 0, X_0 = 0, W_0 = X\), empty set \(\Lambda \) and a random mask \(\Omega _0\) selected uniformly with sparsity \(\rho \ge {C_{RIP}} \frac{\mu ^2 r^2}{\delta _{4r}^2} \frac{\log (n)}{n}\), as in Theorem 2.1. Algorithm iterations are then is described by:

The value \(\varepsilon \) is a predefined threshold which the low-rank part of the approximation should meet along matrix entries that do not belong to the sparse part of the approximation. The logic behind this algorithm is essentially that by construction, additive error matrices \(S_k := \mathcal{A}_{\Omega _k}^* \mathcal{A}_{\Omega _k} ({\hat{S}})\), that arise in the iterative process, should fall under the assumptions of Lemma 3.3, making the algorithm convergent. In order to prove that, we need the following Lemmas characterizing \(S_k\). Firstly, \(S_k\) lies in an intersection of two random sparse subsets, defined by \({\hat{S}}\) and by \(\Omega _k\); that means, that \(S_k\) must be a very sparse matrix with high probability:
Lemma 4.1
(Sparse mask intersections) If \(C \in [e^2, \frac{n}{\beta })\) be a constant, and let each index (i, j) have the same probability \(\frac{\beta }{n}\) to belong to the set \(supp({\hat{S}})\) of nonzero elements of \({\hat{S}}\), then:
-
With probability not less than \(1 - e^{-(C + 1)\beta n}\), \(|supp({\hat{S}}) |\le C \beta n\).
-
With probability not less than \(1 - e^{-(C + 1)\beta \rho n}\), \(|supp(S_k) |\le C \rho \beta n, \rho \in (0,1)\).
Proof
Note that \(|supp(S_k) |\le |supp(S_0) |\), and both \(|supp({\hat{S}}) |\) and \(|supp(S_0) |\) can be considered random Binomial-distributed variables that correspond to \(n^2\) experiments with ‘success’ chances \(\frac{\beta }{n}\) and \(\frac{\rho \beta }{n}\), respectively. The Lemma then requires a bound on two Binomial distributions
where \(F(s; m, p) = {\mathbb {P}}(X_{m,p} \le s)\) denotes a cumulative distribution function of a Binomial random variable \(X_{m,p}\) with m experiments and ‘success’ chance p. Thus, we need a bound for the CDF of a Binomial distribution: such bound can be taken, for example, from [22], where it is established that
where the notation \(D(q \Vert p)\) denotes the so-called Kullback–Leibler divergence, expressed directly for the particular case of two binary coins with probabilities q, p. Then, the bound we need follows from
where we used \(\log (1 + x) \le x\) and \(\log C \ge 2\). The second bound is obtained in the same way by replacing \(\beta \leftrightarrow \beta \rho \) in the derivation. The condition \(\log C \ge 2\) here can be relaxed; it is used in order to obtain simpler probability bound formulas. \(\square \)
4.2 Sparse error bounds
Now, we are going to establish a bound on \(\Vert S_k\Vert _F, \Vert P_U S_k\Vert _F, \Vert S_k P_V\Vert _F\), where \(U, V \in {\mathbb {R}}^{n \times r}\) are the singular bases of the \(\mu \)-incoherent bases of the low-rank part of the solution X. The bound is based on the idea that the \(\Upsilon _k\) exclusion step should remove all ‘sharp’ sparse part elements except those that are not above the current residual in absolute values. This is done in the following Lemma:
Lemma 4.2
(Sparse error exclusion) Let \(C \in [e^2, \frac{n}{\beta })\). Assume \(W_{k - 1}\) is \(\mu \)-incoherent. Then, with probability no less than \(1 - e^{-C \beta \rho n}\),
Proof
Assume \(|supp({\hat{S}}) |\le C \beta n\) and \(|supp(S_k) |\le C \beta \rho n\); by previous Lemma, the probability that both events hold is no less than \(1 - e^{-C \beta \rho n}\). Then, recalling \(S_k = \mathcal{A}_{\Omega _k}^* \mathcal{A}_{\Omega _k} ({\hat{S}})\), we have
where the last inequality follows from the set \(\Upsilon _k\) having more elements than the support of \({\hat{S}}\), thus at least for one \((i,j) \in \Upsilon _k\) it holds that \((W_{k-1} + {\hat{S}})_{i,j} = (W_{k-1})_{i,j}\). Using the incoherence assumption and Lemma 2.2, the bound then continues as
Now, let us use \(|supp(S_k) |\le C \beta \rho n\) and the obtained elementwise bound on \(S_k\) in order to establish Frobenius norm bounds on \(S_k, P_U S_k, S_k P_V\):
The derivation of the bound on \(\Vert S_k P_V \Vert _F\) is based on the same considerations as those for \(\Vert P_U S_k\Vert _F\). \(\square \)
The Lemma 4.2 combined with the proof of Lemma 3.3 now gives the following insight: the proposed Algorithm 1 converges geometrically in terms of \(\Vert (\mathcal{I} - \mathcal{P}_{\Lambda })(Y - X) \Vert _F\) if the following conditions keep true for each iteration k:
-
Both the current iterate \(X_k\) and residual \(W_k\) are \(\mu \)-incoherent.
-
The operator \(\mathcal{A}_{\Omega _k}\) satisfies the ‘Restricted Isometry Property’ (2) on all \(\mu \)-incoherent matrices with high probability.
The former condition is a complicated issue to prove: while \(X_k\) is guaranteed to be incoherent when \(\Vert W_k \Vert _2 \ll \sigma _r(X)\), the residual \(W_k\) is known to lose incoherence properties in practice even for the common SVP algorithm (without additive errors) applied to completion operator in some cases [15] (this can, however, be resolved in practice using heuristic rank-increasing techniques [15]). The latter statement though can be proved using the following idea: despite \(\Omega _k\) losing its randomness/uniformity (because the excluded sets \(\Upsilon _j\) are not random and depend on \(X, {\hat{S}}\)), \(\Omega _k\) is obtained from the initial set \(\Omega _0\) by excluding a relatively small number of elements from the mask, and the operator \(\mathcal{A}_{\Omega _0}\) does satisfy RIP w.h.p. based on Theorem 2.1. We fill finalize the analysis of the Algorithm 1 with the following Lemma.
Lemma 4.3
(Restricted isometry preservation) Let the initial set \(\Omega _0\) of Algorithm 1 be selected randomly using uniform index distribution
and let \(\rho \ge {C_{RIP}} \frac{\mu ^2 r^2}{{\delta _r}^2} \frac{\log (n)}{n}\). Then, with probability not less than \(1 - exp(-n \log (n))\), the operator \(\mathcal{A}_{\Omega _k}\) (with the same scaling parameter \(\rho \)) that appears on iteration k of the Algorithm 1—satisfies the RIP-property with a constant \({\delta _{r,k}}\) on all \(\mu \)-incoherent matrices with rank not larger than r, and
Proof
By Theorem 2.1, the operator \(\mathcal{A}_{\Omega _0}\) with probability not less than \(1 - exp(-n \log (n))\) satisfies RIP-property on all \(\mu \)-incoherent matrices with rank at most k. Now consider an arbitrary \(\mu \)-incoherent matrix \(Y \in {\mathbb {R}}^{n \times n}, rank(Y) \le r\). Note that \(\Vert \mathcal{A}_{\Omega _0}(Y)\Vert _F^2 = \Vert \mathcal{A}_{\Omega _k}(Y)\Vert _F^2 + \frac{\Vert P_{\Omega _0 / \Omega _k}(Y) \Vert _F^2}{\rho } \), and \(|\Omega _0 / \Omega _k |\le C k \beta n\). Then,
\(\square \)
As we are assuming geometric convergence, \(k = O(\log \varepsilon )\), where \(\varepsilon \) is the desired solution residual threshold, and thus is not large. Better RIP constant \(\delta _{r,k}\) can be obtained via increasing \(\rho \) above theoretical minimum, as seen from the proof.
4.3 Twin completion
The proposed Algorithm 1 has the following notable drawbacks:
-
1.
The number of elements in the sparse part of an approximation returned by the Algorithm 1 is not smaller than the true number of erroneous elements multiplied by the number of iterations. Both the convergence analysis (Lemma 3.3) and practical results (see next section) suggest that although the convergence is geometric, large values of the condition number \(\kappa := \frac{\sigma _1(X)}{\sigma _r(X)}\), where X is the unknown low-rank matrix, can greatly increase the required number of iterations, making the sparse part of approximation have more elements.
-
2.
In practice, if \(\kappa \gg 1\), on an early (e.g. first) iteration k of the Algorithm 1 it is possible that \(\Vert S_k\Vert _2\) is below \(\sigma _1(X)\) but is above \(\sigma _r(X)\) (which contradicts locality assumption of convergence Lemma 3.3). In that case, the matrix \(X + E_k + S_k\) could have a set of singular vectors similar to those of X, but not all of them would occupy positions among the top-r singular values. The matrix \(W_{k + 1} = P_r(X + E_k + S_k) - X\) then commonly loses it’s incoherence properties, because one of the singular vectors \(P_r(X + E_k + S_k)\) is largely affected by \(S_k\), and the Algorithm 1 diverges. The same problem arises in practice for ill-conditioned matrices X even for the common SVP algorithm [15].
To deal with the discussed problems, a novel ‘Twin Completion’ approach is proposed. The approach is based on the following ideas:
-
If a random sparse mask \(\Omega \) projection \(P_{\Omega }\) is applied to an already sparse matrix \({\hat{S}}\), the result \(P_{\Omega } ({\hat{S}})\) can be considered a low-rank matrix, because it is very sparse.
-
If two random mask projections \(P_{\Omega _1}, P_{\Omega _2}\) are applied to an already sparse matrix, both results \(P_{\Omega _1} ({\hat{S}}), P_{\Omega _2} ({\hat{S}})\) will be very sparse low-rank matrices, and they are likely to have orthogonal column and row subspaces.
-
Sparse subspaces are almost orthogonal to incoherent subspaces. A sum of an incoherent matrix and a sparse matrix should have a set of (almost) incoherent singular vectors and a set of (almost) sparse singular vectors.
-
If two SVP steps, corresponding to two random masks, are carried out, the two results should have a pair of close rank-r subspaces (close to the solution X subspaces), and two sets of mutually orthogonal singular vectors.
Based on these considerations, it is proposed to generalize the Algorithm 1 so that it can use two masks. On each iteration, two gradient steps along two masks are carried out and SVP-projected onto the set of matrices with rank not larger than \(r + p\), where p is a parameter that should be an estimate to the number of elements in the two assumingly orthogonal very sparse matrices.
The algorithm is initialized with \(k = 0, X_0 = 0, W_0 = X\), an empty set \(\Lambda \) and two random masks \(\Omega _{a,0}, \Omega _{b,0}\), both selected randomly and uniformly with equal sparsity \(\rho \ge {C_{RIP}} \frac{\mu ^2 r^2}{\delta _r^2} \frac{\log (n)}{n}\), as in Theorem 2.1. The iterations are then described in Algorithm 2.

The proposed algorithm no longer relies on the construct \(P_r(X + E_k + S_k)\), which considers only the top-r singular vectors, directly, thus making it more stable in the case of ill-conditioned solutions. Furthermore, in practice, it is possible to relax the requirements on the norm of \(\Vert S_k\Vert _C\), which is controlled by the \(\Upsilon _k\) exclusion. That means, exclusions can be carried out more rarely (or less elements can be excluded on each iteration), resulting in smaller set \(\Lambda \) at the end of the algorithm, which corresponds to smaller number of elements in the sparse part of the final approximation. In the remainder of the paper, we will provide theoretical convergence background for the Algorithm 2 .
Firstly, let us prove the following technical Lemma: if two column bases \(span(U_a), span(U_b)\) have a pair of close and known rank-r subspaces \(span(U_{a,r}), span(U_{b,r})\), and the ‘remainders’ are almost orthogonal, then the canonical subspaces between \(span(U_a), span(U_b)\) cannot be much different from \(span(U_{a,r}), span(U_{b,r})\), respectively.
Lemma 4.4
(Canonical base distance bound) Let \(U_a, U_a \in {\mathbb {R}}^{r + p \times n}\) be matrices with orthogonal columns, that are decomposable into the following blocks:
where \(U_{a,r}, U_{b,r} \in {\mathbb {R}}^{n \times r}\). Let \(\Vert P_{U_{a,r}} - P_{U_{b,r}}\Vert _F \le \alpha , \Vert U_{a,p-r}^* U_{b,p-r} \Vert _F \le \beta \). Then, if the matrices \({\bar{U}}_{a}, \bar{U}_{b} \in {\mathbb {R}}^{n \times r}\) correspond to the top-r canonical vector pairs between the subspaces \(span(U_a), span(U_b)\),
Proof
Consider the following block-product:
Under the assumptions of the theorem, and considering the values of \(\alpha , \beta \) to be small, this block-product only has one large-norm block. The top-left element norm has a lower bound of
while the remaining block norms can be estimated with
The structure of the matrix \(U_b^* U_a\) then implies that its top left block defines a close-to-optimal rank-r approximation of the whole matrix. It can be seen that
Now, assuming that the optimal SVD-projection \(P_r(U_b^* U_a)\) can be expressed as \(U_{col} \Sigma _{col} V^*_{col}, U_{col}, V_{col} \in {\mathbb {R}}^{p \times r}\), then canonical vector column matrices \({\bar{U}}_{a}, {\bar{U}}_{b}\) can be expressed as
Using that, we can bound
Furthermore, \(\Sigma _{col}\) is a diagonal matrix with values corresponding to the cosines of the r smallest canonical angles between \(U_a\), \(U_b\). By the structure of \(U_a, U_b\), these canonical angles cannot be larger than those between \(U_{a,r}, U_{b,r}\). Considering the expression, which uses \(\cos \phi \in [0,1]\)
and taking into account that
where \(\phi _k\) denote the canonical angles between \(U_{a}, U_{b}\), we have \(\Vert \Sigma _{col} - I\Vert _F \le \alpha \), and thus
Using that \(\Vert P_{U_{a,r}} - P_{U_{b,r}}\Vert _F \le \alpha \), again we have
Then, it suffices to bound
Bounding the square root difference, along with \(\Vert P_{{\bar{U}}_{a}} - P_{U_{a,r}}\Vert _F \le \sqrt{r} - \sqrt{r - (6 \alpha + 2 \beta )^2}\) obtained in a similar way, finalizes the proof. \(\square \)
Now we are going to introduce two assumptions, under which we are going to analyse the Algorithm 2 convergence.
Assumption 4.1
By Lemmas 3.1, 2.3, matrices \(X + E_{a,k}\), \(X + E_{b,k}\) should both have singular subspaces (not necessarily top-r) close to those of the rank-r solution matrix X. Let us define the corresponding column base pairs by \(\{ U_{a,r}, U_{b,r} \}, \{ V_{a,r}, V_{b,r} \}\). Then, with high probability, top \(p-r\) singular vectors of the remainder matrices
are almost orthogonal to each other.
The assumption is motivated by the observation that
and, by definition \(E_{a(b),k} = (\mathcal{I} - \mathcal{A}_{\Omega _{a(b),k}}^* \mathcal{A}_{\Omega _{a(b),k}}) W_k\). Now assume that \(W_k\) is a residual of the common-SVP algorithm. Then, looking at Lemma 2.4 proof (opening the brackets), we can write
The top \(p-r\) singular vectors of \(P_{U^{\perp }} E_{a(b),k} P_{V^{\perp }}\) can be expressed with an optimization functional
where \({\mathbb {H}} = \{ B \in {\mathbb {R}}^{n \times n}, \; rank(B) \le p - r, \; \Vert B\Vert _2 = 1 \}\). Taking into account \((E_{a(b),k}, ZY^*)_F = (\mathcal{A}_{\Omega _{a(b),k}} W_k, \mathcal{A}_{\Omega _{a(b),k}} ZY^*)_F - (W_k, ZY^*)_F\), singular vectors of the matrix \(P_{U^{\perp }} E_{a(b),k} P_{V^{\perp }}\) are then expressed as vectors that result in largest discrepancy between a \(\mathcal{A}\)-projected and non-projected versions of a scalar product of two matrices almost orthogonal to each other. The assumption is based on intuition that as the scalar product \((W_k, ZY^*)_F\) is relatively small, then the corresponding vectors are functions of the operator \(\mathcal{A}\), and are thus random among all vectors orthogonal to U, V respectively.
Assumption 4.2
The addition of random sparse matrices \(S_{a,k}, S_{b,k}\) with not more than \(p-r\) nonzero elements, do not damage the properties of Assumption 4.1. It is supposed that, with high probability, top \(p-r\) singular vectors of the remainder matrices
are also almost orthogonal to each other.
The matrices \(S_{a,k}, S_{b,k}\) are assumed to be very sparse: if \(\rho = O(\frac{\log n}{n})\), then by Lemma 4.2 they both have \(O(\log n)\) elements. Thus, \(S_{a,k}, S_{b,k}\) can be viewed as low-rank matrices singular vectors close to one-element unit vectors with random positions of the nonzero element. The probability that left (right) singular vectors of \(S_{a,k}, S_{b,k}\) then have a matching index can be roughly estimated with
As the singular vectors of \(S_{a(b),k}\) are sparse, and the bases U, V are incoherent, then each singular vector of \(X + E_{a(b),k} + S_{a(b),k}\) should be either close to a singular vector of X, or to a singular vector of \(S_{a(b),k}\), or be random (if \(\Vert E_{a(b),k}\Vert \gg \Vert S_{a(b),k}\Vert \)), which explains the assumption.
Now let us finalize the analysis of the ‘Twin Completion’ Algorithm 2 with the following theorem.
Theorem 4.1
(Twin completion convergence) Let \(X_{k-1}\) be a current iterate of the proposed ‘twin completion’ algorithm, and X be the unknown matrix. Using the notation introduced in Algorithm 2, assume that both \(X_{k-1}, W_{k-1}\) are \(\mu \)-incoherent. Assume the Lemma 2.1 holds for all scalar products of \(\mu \)-incoherent matrices with operators \(\mathcal{A}_{\Omega _a}, \mathcal{A}_{\Omega _b}\), and assume Lemma 3.1 holds for \(\mu \)-incoherent U, V. Let Assumptions 1,2 made above hold with an upper bound of \(\frac{\epsilon }{\Vert X\Vert _2}\) on the scalar products. Let the second assumption variant of Lemma 2.3 hold for matrix X and two perturbations \((E_{a,k} + S_{a,k}), (E_{b,k} + S_{b,k})\) with \(\gamma \ge C_{\gamma } \Vert X\Vert _2\). Then,
where \({\hat{f}}, {\hat{g}}\) are polynomial functions.
Proof
By Lemma 2.3, the two projected gradient steps of the proposed ‘twin completion’ algorithm can be expressed as
where \(\Vert P_{U_{a(b),r}} - P_U\Vert _F \le \frac{2 \eta }{\gamma }\), and
Using Lemmas 2.2, 3.1, it is seen that
As by Theorem 2.1 it can be assumed that \(1 \ge \frac{C_{RIP} \mu ^2 r^2 \log n}{\delta _{4r}^2 n}\), thus
Now, we can apply Lemma 4.4 with
and obtain
where f, g denote some polynomial functions. The theorem then follows by observing
\(\square \)
5 Numerical experiments
5.1 Artificial experiments
In order to numerically check the convergence theory and compare the proposed one-mask based and two-mask based procedures, both the proposed one-mask and two-mask Algorithms 1, 2 were tested on artificial data matrices that fit the required low-rank plus sparse structure exactly. The test matrices were constructed in the following way:
-
Two matrices with orthogonal columns \(U, V \in {\mathbb {R}}^{n \times r}\) were generated as the top-r singular bases of a random matrix filled with normal variables with zero mean. Such orthogonal columns empirically have logarithmic incoherence, thus are eligible to original SVP completion algorithm.
-
The solutions X were built as products of the form \(U \Sigma V^*\), where \(\Sigma \) is a diagonal real matrix with positive entries such that the singular values of X are controlled and decay with one of the following relations:
-
\(\sigma _k = \frac{1}{k}\), which models a well-conditioned problem;
-
\(\sigma _k = \frac{1}{3^k}\), which models an ill-conditioned problem.
-
-
The sparse part \({\hat{S}}\) was built randomly using uniform distribution with probability \(\frac{\beta }{n}\) for each element of the matrix to be nonzero; the corresponding nonzero values of the matrix were also selected randomly using independent normal Gaussian distribution scaled in such a way that \(\frac{\Vert {\hat{S}} \Vert _F}{\Vert X \Vert _F} \approx 0.3\).
For improved stability, heuristic sequential rank-increasing techniques as well as step size control techniques were implemented in both one-mask and two-mask algorithms, similar to those discussed in [15]; that means that the approximation starts with a rank-one iterate \(X_0\), and the iterate \(X_k\) rank is slowly increased up to r with iteration number k.
These heuristic techniques, for example, can include residual tracking [15]: if the residual relative difference \(\frac{\Vert W_k + S_k \Vert _F}{\Vert W_{k - 1} + S_{k - 1} \Vert _F}\) is smaller than a certain threshold \(\lambda = 0.99 < 1\), then the rank is unchanged and the step size slowly increases, else the rank is increased and the step size is reduced.
In our experiments, similar heuristic approaches are used for sparse part handling in order to control the size of the ‘excluded’ set \(\Lambda \); the set \(\Upsilon _k\) is set to an empty set on each iteration that fulfills the steady convergence condition \(\frac{\Vert W_k + S_k \Vert _F}{\Vert W_{k - 1} + S_{k - 1} \Vert _F} \le \lambda \). If the residual relative difference exceeds lambda, a decision should be made whether to increase the rank of the approximation or the size of the sparse exclusion set \(\Lambda \). The two-mask algorithm allows a handy decision-making procedure: if the first ‘tail’ canonical angle \(\phi _{r + 1}\) is smaller than a predefined constant (\(\frac{\pi }{4}\) was used in experiments), then the rank is increased; else the normally computed \(\Upsilon _k\) is added to the sparse exclusion set \(\Lambda \).
With this heuristic sparse part enlargement procedure, the algorithm is quite flexible in terms of the choice of the parameter C, which defines the size of the set \(\Upsilon _k\) of indices that are added to the mask of excluded elements \(\Lambda \) at once. While the theoretical analysis suggests \(C > 1\), it is possible to use smaller values of 0.2–0.5 in practice without any drawbacks (though, by the definition of C, the set \(\Lambda \) should be enlarged in at least \(O(\frac{1}{C})\) iterations, thus exceedingly small C should not be used).
As the one-mask algorithm cannot use canonical angles, the current approximation \(X_k\) incoherence thresholding was used as the criterion for similar decision-making in the one-mask algorithm.
The following paragraph describes the parameters of the carried out numerical experiments in detail.
-
Common scenario. \(n = 1024, r = 10, \sigma _k = \frac{1}{1 + k}, p = 3, \rho = 0.25, \beta = 10.0, C = 1\). The low-rank part is of rank 10, the sparse part consists of 10 nonzero elements per row, and the sparse part enlargement coefficient C is set to one, which means that the true number of elements in the unknown sparse matrix \({\hat{S}}\) corresponds directly to the size of the index set \(\Upsilon _k\) added to the mask of locked matrix elements \(\Lambda \) at a time. The result graphs are provided in Fig. 1. The graphs include the residual and the sines of the column canonical angles: it can be seen that the canonical angles numbered from 1 to r converge at the same rate as the residual, and the next angle \(r + 1\) stays high throughout all the iterations, as supposed by the algorithm idea. The ‘teeth-shaped’ sharp peaks in the \(\sin (\phi _r(U_{a,k}, U_{b, k}))\) graph at early iterations are caused by the heuristic rank increase procedures (the value of r is initialized by 1 and is increased step-by-step up to the true rank r). The convergence properties of the one-mask and two-mask Algorithms 1, 2 are indistinguishable in this scenario. The row canonical angles behave the same way as the column canonical angles do here and in all further experiments.
-
Smoothed scenario. \(n = 1024, r = 10, \sigma _k = \frac{1}{1 + k}, p = 3, \rho = 0.25, \beta = 10.0, C = 0.01\). The previous scenario experiments show that the residual graph is piecewise smooth, with smoothness intervals corresponding to the iteration intervals during which the set \(\Lambda \) is constant—each time a new sparse exclusion is made, the residual falls rapidly for a few iterations and then settles at a lower value again. Such a behavior can be controlled by the parameter C, which defines the number of indices added to the sparse approximation mask \(\Lambda \) of once. On Fig. 2, results are shown for \(C = 0.01\): the residual graph is more smooth, but the overall convergence is slower.
-
Ill-conditioned scenario. \(n = 1024, r = 10, \sigma _k = \frac{1}{3^k}, p = 3, \rho = 0.25, \beta = 10.0, C = 1\). In this scenario, the low-rank unknown matrix is designed to have rapidly decaying singular values, which causes differences in the one-mask and two-mask algorithm performance. In this case, the low-rank column and row factors obtained by the one-mask Algorithm 1 commonly lose incoherence properties, which causes the algorithm to stagnate: new elements are added to the mask of excluded elements until there are not enough elements left for completion. The performance graphs are provided in Fig. 3, the factor incoherence is measured in percents of the maximum value possible by definition. The ‘Matrix locked’ graph shows the size of the set \(\Lambda \) as compared to \(n^2\). The two-mask Algorithm 2 manages to keep the low-rank factor incoherence low and maintain convergence. The corresponding graphs are provided in Fig. 4.
-
High-rank scenario. \(n = 1024, r = 30, \sigma _k = \frac{1}{1 + k}, p = 7, \rho = 0.25, \beta = 10.0, C = 1\). In the case of well-conditioned matrix with high rank, the convergence (both for one-mask and two-mask based algorithms) is stable, yet the sequential rank increase procedure may take a significant number of iterations. The corresponding graph is provided on Fig. 5.

Common scenario algorithm performance

Smoothed scenario algorithm performance

Ill-conditioned scenario one-mask algorithm performance

Ill-conditioned scenario two-mask algorithm performance

High-rank scenario two-mask algorithm performance
5.2 Application to integral equations
The proposed algorithms were applied to the problem of compression of a structured large-scale dense linear system, that stems from a finite element discretization of integral equations arising in scattering problems on metasurfaces. A metasurface consists of conductor and dielectric parts, arranged in the form of blocks of the same shape: an example is shown in Fig. 6.

Metasurface with a finite-element grid
The considered linear system is based on a discretization of Maxwell’s equations using RWG-type basis functions; thus, two potential operators are involved, that correspond to the electric \(({\mathcal {E}}(p))(x)\) and the magnetic \(({\mathcal {M}}(p))(x)\) fields of the metasurface:
where \(G_k(x, y)\) is the Green’s function for the Helmholtz equation with wavenumber k
A notable property of the considered equations is the invariance to a parallel transfer, which, along with the metasurface structure, gives, up to a small number of ‘block edge’ related equations, a block Toeplitz–Toeplitz structure to the considered linear system, where each matrix block characterizes the physical relations between two corresponding metasurface parts. That means, that if the metasurface is based on a \(M_1 \times M_2\) two-dimensional grid of similar blocks, and n is a block size, it is sufficient to store \((2 M_1 - 1) (2 M_2 - 1)\) blocks of size \({\mathbb {C}}^{n \times n}\) that fully define the original matrix of size \({\mathbb {C}}^{M_1 M_2 n \times M_1 M_2 n}\).
During this work, it was attempted to further compress the linear system matrix by constructing the low-rank plus sparse approximations of the underlying \(n \times n\) blocks; notably, those that correspond to the relations between non-neighbor metasurface parts.
The experiments were carried out with a \(4 \times 4\) metasurface discretization, with a block size of \(n = 2542\), which corresponds in a complex dense linear system of size 40672. Table 1 summarizes the compression results as compared to storing the matrix as dense. The first line corresponds to the simple Toeplitz–Toeplitz structured matrix storage, with taking system symmetry into account. The next two lines correspond to using further compression of the underlying dense blocks with low-rank plus sparse structures, using the ‘two-mask’ algorithm proposed in the paper, with rank and sparsity parameters adapted to obtain a predefined Frobenius norm approximation of the full matrix.
6 Discussion
As suggested by theory, the provided numerical results show that the proposed two-mask ‘twin completion’ Algorithm 2 offers a stable performance in ill-conditioned cases where the simpler ‘one-mask’ Algorithm 1 commonly loses the required incoherence properties and thus either diverges or greatly increases the sparse ‘excluded’ part of the output low-rank plus sparse approximation.
It is notable that in all numerical experiments the ‘Twin completion’ algorithm offered ‘exact’ convergence: if an iterate \(X_k\) was taken after a sufficient number of iterations has passed, and the residual \(X - X_k\) was computed, the locations of top \(|X - X_k |_{ij}\) residual elements would fully match the locations of nonzero elements of the true \({\hat{S}}\).
However, in practice, the elements that are nonzero in \({\hat{S}}\) are generally not the first to enter the set of ‘excluded’ elements \(\Lambda \) along with the iterations. This effect is most clearly seen when the norm of \({\hat{S}}\) is much smaller than the norm of X, since the first few iterations of both Algorithm 1, Algorithm 2 would then go as if no sparse errors were present, and set \(\Lambda \) would be initialized with index pairs that are independent of \({\hat{S}}\).
References
Kang, Z., Peng, C., Cheng, Q.: Top-n recommender system via matrix completion. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 30 (2016)
Argyriou, A., Evgeniou, T., Pontil, M.: Convex multi-task feature learning. Mach. Learn. 73(3), 243–272 (2008)
Blei, D., Carin, L., Dunson, D.: Probabilistic topic models. IEEE Signal Process. Mag. 27(6), 55–65 (2010)
Hu, R., Tong, J., Xi, J., Guo, Q., Yu, Y.: Low-complexity and basis-free channel estimation for switch-based mmwave mimo systems via matrix completion. arXiv preprint arXiv:1609.05693 (2016)
Ahmed, A., Romberg, J.: Compressive multiplexing of correlated signals. IEEE Trans. Inf. Theory 61(1), 479–498 (2014)
Cai, T., Cai, T.T., Zhang, A.: Structured matrix completion with applications to genomic data integration. J. Am. Stat. Assoc. 111(514), 621–633 (2016)
Harvey, N.J., Karger, D.R., Yekhanin, S.: The complexity of matrix completion. In: Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm, pp. 1103–1111 (2006)
Recht, B.: A simpler approach to matrix completion. J. Mach. Learn. Res. 12(12) (2011)
Meka, R., Jain, P., Dhillon, I.S.: Guaranteed rank minimization via singular value projection. arXiv preprint arXiv:0909.5457 (2009)
Klopp, O.: Matrix completion by singular value thresholding: sharp bounds. Electron. J. Stat. 9(2), 2348–2369 (2015)
Uschmajew, A., Vandereycken, B.: Geometric methods on low-rank matrix and tensor manifolds. In: Grohs, P., Holler, M., Weinmann, A. (eds.) Handbook of Variational Methods for Nonlinear Geometric Data, pp. 261–313. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-31351-7_9
Vandereycken, B.: Low-rank matrix completion by riemannian optimization. SIAM J. Optim. 23(2), 1214–1236 (2013). https://doi.org/10.1137/110845768
Wei, K., Cai, J.-F., Chan, T.F., Leung, S.: Guarantees of Riemannian optimization for low rank matrix completion. arXiv:1603.06610 [math] (2016)
Wei, K., Cai, J.-F., Chan, T.F., Leung, S.: Guarantees of Riemannian optimization for low rank matrix recovery. SIAM J. Matrix Anal. Appl. 37(3), 1198–1222 (2016). https://doi.org/10.1137/15M1050525
Lebedeva, O., Osinsky, A., Petrov, S.: Low-rank approximation algorithms for matrix completion with random sampling. Comput. Math. Math. Phys. 61(5), 799–815 (2021)
Becker, S., Cevher, V., Kyrillidis, A.: Randomized low-memory singular value projection. arXiv preprint arXiv:1303.0167 (2013)
Davis, C., Kahan, W.M.: Some new bounds on perturbation of subspaces. Bull. Am. Math. Soc. 75(4), 863–868 (1969)
Galántai, A.: Subspaces, angles and pairs of orthogonal projections. Linear Multilinear Algebra 56(3), 227–260 (2008)
Stewart, G.W.: Perturbation theory for the singular value decomposition. Technical report (1998)
Wedin, P.-Å.: Perturbation bounds in connection with singular value decomposition. BIT Numer. Math. 12(1), 99–111 (1972)
Chandrasekaran, V., Sanghavi, S., Parrilo, P.A., Willsky, A.S.: Sparse and low-rank matrix decompositions. IFAC Proc. Vol. 42(10), 1493–1498 (2009)
Arratia, R., Gordon, L.: Tutorial on large deviations for the binomial distribution. Bull. Math. Biol. 51(1), 125–131 (1989)
Acknowledgements
This work was supported by Russian Science Foundation (project 21-71-10072).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Petrov, S., Zamarashkin, N. Matrix completion with sparse measurement errors. Calcolo 60, 9 (2023). https://doi.org/10.1007/s10092-022-00500-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10092-022-00500-6