
Abstract
The paper introduces two new extragradient algorithms for solving a pseudomonotone equilibrium problem with a Lipschitz-type condition recently presented by Mastroeni in auxiliary problem principle. The algorithm uses variable stepsizes which are updated at each iteration and based on some previous iterates. The advantage of the algorithms is that they are done without the prior knowledge of Lipschitz-type constants and also without any linesearch procedure. The convergence of the algorithms is established under mild assumptions. In the case where the equilibrium bifunction is strongly pseudomonotone, the R-linear rate of convergence of the new algorithms is formulated. Several of fundamental experiments are provided to illustrate the numerical behavior of the algorithms and also to compare with others.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The paper considers some methods for approximating solutions of an equilibrium problem in a real Hilbert space H. Let C be a nonempty closed convex subset of H. Recall that an equilibrium problem (shortly, EP) for a bifunction \(f:C\times C\rightarrow \mathfrak {R}\) is stated as follows:
Let us denote by EP(f, C) the solution set of problem (EP). Mathematically, problem (EP) can be considered as a general model in the sense that it unifies in a simple form numerous known models as optimization problems, fixed point problems, variational inequalites as well as Nash equilibrium problems [6,7,8, 10, 20, 26]. This can explain why problem (EP) becomes an attractive field in recent years. Together with theoretical results of solution existence, approximation methods to solutions of problem (EP) are also interesting. The first notable method for solving problem (EP) can be the proximal point method [19, 25]. The main idea of this method is to replace the original problem by a family of regularization equilibrium subproblems which can be solved more easily. The regularized solutions can converge finitely or asymptotically to some solution of the original problem.
In this paper, we are interested in the proximal-like method [9] which is also called the extragradient method [27] due to the early contributions on the saddle point problems in [21]. The convergence of the extragradient method is established in [27] under the assumptions that the bifunction is pseudomonotone and satisties a Lipschitz-type condition presented in [24]. Another method, named the modified extragradient method in [22], can be considered as an improvement of the extragradient method in [9, 27] where the complexity of the algorithm is reduced. Unlike [9, 27], the modified method in [22] only requires to proceed one value of bifunction by iteration. Some other methods for solving problem (EP) can be found, for example, in the works [1,2,3,4, 6, 13,14,15,16,17,18, 23, 28,29,30].
At this stage, it is worth mentioning that the methods in [22, 27] are used under the requirement that the Lipschitz-type constants must be known. This means that those constants must be input parameters of the algorithms. Unfortunately, Lipschitz-type constants in general are unknown or even with complex non-linear problems they are still difficult to approximate. In those cases, methods with a linesearch procedure have been considered. However, a linesearch often requires many computations at each iteration which is inherently time-consuming. Recently, the author in [11, 12] has introduced some extragradient-like algorithms with previously taking suitable stepsizes to avoid the finding of the Lipschitz-type constants of bifunction. The convergence of the methods in [11, 12] is proved under the assumption of strong pseudomonotonicity of bifunction. Without this assumption, those methods cannot converge, see in [11, Remark 2] or [12, Remark 4.6].
In this paper, motivated and inspired by the aforementioned results, we introduce two iterative algorithms with new stepsize rules for solving a pseudomonotone and Lipschitz-type equilibrium problem in a real Hilbert space. The variable stepsizes are generated by the algorithms at each iteration, based on some previous iterates, and without any linesearch procedure. Unlike the results in [22, 27], the proposed algorithms are performed without the prior knowledge of the Lipschitz-type constants. The convergence of the new algorithms is established under some standard conditions. In the case where the bifunction is strongly pseudomonotone, the R-linear rate of convergence of the algorithms has been proved contrary to the algorithms in [11, 12]. Some experiments are performed to show the numerical behavior of the proposed algorithms, and also to compare with others.
This paper is organized as follows: Sect. 2 recalls some definitions and results used in the paper. Sect. 3 presents the new algorithms and proves their convergence while Sect. 4 deals with their rate of convergence. Several fundamental experiments are provided in Sect. 5.
2 Preliminaries
Let H be a real Hilbert space and C be a nonempty closed convex subset of H. We begin with some concepts of monotonicity of a bifunction \(f:C\times C\rightarrow \mathfrak {R}\), see [7, 26] for more details. The bifunction f is called:
(a) \(\gamma \)-strongly monotone on C if there exists \(\gamma >0\) such that
(b) monotone if
(c) \(\gamma \)-strongly pseudomonotone on C if there exists \(\gamma >0\) such that
(d) pseudomonotone on C if
It follows from the definitions that the following implications hold,
A bifunction \(f:C\times C\rightarrow \mathfrak {R}\) satisfies a Lipschitz-type condition [23] if there exist two constants \(c_1,~c_2>0\) such that
Recall that the proximal mapping of a proper, convex and lower semicontinuous function \(g:C\rightarrow \mathfrak {R}\) with a parameter \(\lambda >0\) is defined by
The following is a property of the proximal mapping \({prox}_{\lambda g}\) (see, [5] for more details).
Lemma 1
For all \(x\in H,~y\in C\) and \(\lambda >0\), the following inequality holds,
Remark 1
From Lemma 1, it is easy to show that if \(x=\mathrm{prox}_{\lambda g}(x)\) then
We also need the following lemma (see, [5, Theorem 5.5]).
Lemma 2
Let \(\left\{ x_n\right\} \) be a sequence in H and C be a nonempty subset of H. Suppose that \(\left\{ x_n\right\} \) is Fejér monotone with respect to C, i.e., \(||x_{n+1}-x||\le ||x_n-x||\) for all \(n\ge 0\) and for all \(x\in C\), and that every weak sequential cluster point of \(\left\{ x_n\right\} \) belongs to C. Then, the sequence \(\left\{ x_n\right\} \) converges weakly to a point in C.
3 Explicit extragradient algorithms
In this section, we introduce two extragradient algorithms for solving pseudomontone (EP) with a Lipschitz-type condition. The algorithms are explicit in the sense that they are done without previously knowing the Lipschitz-type constants of bifunction. This is particularly interesting in the case where these constants are unknown or even difficult to approximate. For the sake of simplicity in the presentation, we will use the notation \([t]_+=\max \left\{ 0,t\right\} \) and adopt the conventions \(\frac{0}{0}=+\infty \) and \(\frac{a}{0}=+\infty \) (\(a\ne 0\)). The following is the first algorithm.
Algorithm 1
Initialization Choose \(x_0\in C\) and \(\lambda _0>0\), \(\mu \in (0,1)\).
Iterative steps Assume that \(x_n \in C\) and \(\lambda _n ~(n\ge 0)\) are known. Compute \(x_{n+1}\), \(\lambda _{n+1}\) as follows:
and set
Stopping criterion If \(y_n=x_n\) then stop and \(x_n\) is a solution of EP.
It is seen that the stepsize \(\lambda _{n}\) generated by the algorithm, and updated during the iteration is based on the previous iterate \(x_n\) and the two current ones \(y_n\) and \(x_{n+1}\). This is different from the strategy to choose of diminishing and non-summable stepsizes in [11]. Comparing with linesearch algorithms, for example [27, Algorithm 2a], the stepsize in Algorithm 1 is computed more simply. Indeed, a linesearch procedure needs many computations by iteration with some finite stopping criterion, and is of course more time-consuming. As seen below, the sequence \(\left\{ \lambda _{n}\right\} \) generated by Algorithm 1 is separated from 0. This is more useful than algorithms with diminishing stepsizes.
In order to obtain the convergence of Algorithm 1, we consider the following blanket assumptions imposed on the bifunction f.
(A1) f is pseudomontone on C and \(f(x,x)=0\) for all \(x\in C\).
(A2) f satisfies the Lipschitz-type condition.
(A3) \(\limsup \limits _{n\rightarrow \infty } f(x_n,y)\le f(x,y)\) for each \(y\in C\) and each \(\left\{ x_n\right\} \subset C\) with \(x_n\rightharpoonup x\);
(A4) f(x, .) is convex and subdifferentiable on C for every fixed \(x\in C\).
Remark that under the hypothesis (A2), there exist some contants \(c_1>0\), \(c_2>0\) such that
Thus, from the definition of \(\left\{ \lambda _n\right\} \), we see that this sequence is bounded from below by \(\left\{ \lambda _0,\frac{\mu }{2\max \left\{ c_1,c_2\right\} }\right\} \). Moreover, the sequence \(\left\{ \lambda _n\right\} \) is non-increasing monotone. Thus, there exists a real number \(\lambda >0\) such that \(\lim \limits _{n\rightarrow \infty }\lambda _n=\lambda \). In fact, from the definition of \(\lambda _{n+1}\), if \(f(x_n,x_{n+1}) - f(x_n,y_n) -f(y_n,x_{n+1}) \le 0\) then \(\lambda _{n+1}:=\lambda _n\).
We have the following first result.
Theorem 1
Under the hypotheses (A1)–(A4), the sequence \(\left\{ x_n\right\} \) generated by Algorithm 1 converges weakly to some solution of problem (EP).
Proof
It follows from Lemma 1 and the definition of \(x_{n+1}\) that
From the definition of \(\lambda _{n+1}\), we get
which, after multiplying both sides by \(\lambda _n>0\), implies that
Combining the relations (1) and (2), we obtain
Similarly, from Lemma 1 and the definition of \(y_n\), we also obtain
From the relations (3) and (4), we obtain
Thus, multiplying both sides of the last inequality by 2, we come to the following estimate
We have the following facts:
Combining the relations (5)–(7), we get
For each \(x^*\in EP(f,C)\), we have that \(f(x^*,y_n)\ge 0\) and by (A1) that \(f(y_n,x^*)\le 0\). Then, using \(y=x^* \in C\) in relation (8), we obtain
Let \(\epsilon \in (0,1-\mu )\) be some fixed number. Since \(\lambda _n \rightarrow \lambda >0\),
Thus, there exists \(n_0\ge 1\) such that
From the relations (9) and (10), we obtain
or
where \(a_n=||x_{n}-x^*||^2\) and \(b_n=\epsilon \left( ||x_n-y_n||^2+||x_{n+1}-y_n||^2\right) \). Thus, the limit of \(\left\{ a_n\right\} \) exists and \(\lim \limits _{n\rightarrow \infty }b_n=0\) which imply that \(\left\{ x_n\right\} \) is bounded and
Hence, since \(||x_{n+1}-x_n||\le ||x_{n+1}-y_n||+||x_n-y_n||\), we also get
Now, we prove that each weak cluster point of \(\left\{ x_n\right\} \) is in EP(f, C). Indeed, suppose that \(\bar{x}\) is a weak cluster point of \(\left\{ x_n\right\} \), i.e., there exists a subsequence, denoted by \(\left\{ x_m\right\} \), of \(\left\{ x_n\right\} \) converging weakly to \(\bar{x}\). Since \(||x_n-y_n||\rightarrow \infty \), we also have that \(y_m\rightharpoonup \bar{x}\). Passing to the limit in (8) as \(n=m\rightarrow \infty \) and using hypothesis (A3), the relation (12), and the fact \(\lambda _m\rightarrow \lambda >0\), we obtain
On the other hand, from the triangle inequality, we have
Thus, from the boundedness of \(\left\{ x_n\right\} \) and the relation (13), we get for each \(y\in C\)
Combining the relations (14) and (15), we get \(f(\bar{x},y)\ge 0\) for all \(y\in C\) or \(\bar{x}\in EP(f,C)\). From the relations (9) and (10), we see that the sequence \(\left\{ x_n\right\} _{n\ge n_0}\) is Fejér-monotone. Thus, Lemma 2 ensures that the whole sequence \(\left\{ x_n\right\} \) converges weakly to \(\bar{x}\) as \(n\rightarrow \infty \). This completes the proof. \(\square \)
Algorithm 1 requires to compute at each iteration the values of the bifunction f at \(x_n\) and \(y_n\). Next, we present an algorithm, namely the explicit modified extragradient algorithm, which only needs to compute one value of f at the current approximation.
Algorithm 2
Initialization Choose \(y_{-1},~y_0,~x_0\in C\) and \(\lambda _0>0\), \(\mu \in (0,\frac{1}{3})\).
Iterative steps Assume that \(y_{n-1},~y_n,~x_n\in C\) and \(\lambda _n \ge 0\) (\(n\ge 1\)) are known, calculate \(x_{n+1}\), \(y_{n+1}\) and \(\lambda _{n+1}\) as follows:
Step 1 Compute \(x_{n+1}= \mathrm{prox}_{\lambda _n f(y_n,.)}(x_n)\) and set
Step 2 Compute \(y_{n+1}= \mathrm{prox}_{\lambda _{n+1}f(y_n,.)}(x_{n+1}).\)
Stopping criterion If \(x_{n+1}=y_n=x_n\) then stop and \(x_n\) is a solution of EP.
As for Algorithm 1, the sequence \(\left\{ \lambda _n\right\} \) generated by Algorithm 2 is non-increasing monotone and \(\lim \limits \lambda _n=\lambda >0\). Another point of comparison with Algorithm 1 is that Algorithm 2 uses two different stepsizes \(\lambda _n\) and \(\lambda _{n+1}\) per iteration. Algorithm 2 is also weakly convergent as shown in the next theorem.
Theorem 2
Under the hypotheses (A1)–(A4), the sequence \(\left\{ x_n\right\} \) generated by Algorithm 2 converges weakly to some solution of problem (EP).
Proof
For all \(y\in C\), we have the following equality,
Lemma 1 and the definition of \(x_{n+1}\) ensure that
Similarly, from the definition of \(y_{n}\) and Lemma 1, we get
Combining the relations (16)–(18), we come to the following estimate,
From the definition of \(\lambda _{n+1}\), we see that
which together with relation (19), can be written
Using the triangle inequality and the fact \((a+b)^2\le 2a^2+2b^2\), we obtain
From relations (20) and (21), we have
Adding the term \(\frac{2\lambda _{n+1} \mu }{\lambda _{n+2}} ||y_n-x_{n+1}||^2\) to both sides of the inequality (22), we get
For each \(x^*\in EP(f,C)\), we have \(f(x^*,y_n)\ge 0\). Thus, \(f(y_n,x^*)\le 0\) because of the pseudomonotonicity of f. Now, using the relation (23) for \(y=x^*\), we come to the following inequality,
Let \(\epsilon \in (0,1-3\mu )\) be some fixed number. Since \(\lambda _n\rightarrow \lambda >0\), we obtain
Thus, there exists \(n_0\ge 1\) such that
Thus, from the relations (24)–(26), we obtain
or
where
From the relation (28), we obtain that the limit of \(\left\{ a_n\right\} \) exists, and \(\lim \nolimits _{n\rightarrow \infty }b_n=0\). Thus, from the definition of \(a_n\) and \(b_n\), we obtain that \(\left\{ x_n\right\} \) is bounded and
This together with the triangle inequality implies that
Since \(\lim _{n\rightarrow \infty }a_n \in \mathfrak {R}\), from the definition of \(a_n\) and (29), we also obtain
Next, we prove that every weak cluster point of \(\left\{ x_n\right\} \) is in EP(f, C). Indeed, suppose that \(\bar{x}\) is a weak cluster point of \(\left\{ x_n\right\} \), i.e., there exists a subsequence, denoted by \(\left\{ x_m\right\} \), of \(\left\{ x_n\right\} \) converging weakly to \(\bar{x}\). From the relation (29), we also get that \(y_m\rightharpoonup \bar{x}\). Now, passing to the limit in the relation (23) as \(n=m\rightarrow \infty \), and using the hypothesis (A3), the relation (29), and the fact \(\lambda _n\rightarrow \lambda >0\) we obtain
Arguing as in the proof of Theorem 1, we also obtain for each \(y\in C\)
Combining the relations (32) and (33), we get \(f(\bar{x},y)\ge 0\) for all \(y\in C\) or \(\bar{x}\in EP(f,C)\). To finish the proof, we show that the whole sequence \(\left\{ x_n\right\} \) converges weakly to \(\bar{x}\) as \(n\rightarrow \infty \). Indeed, assume that \(\left\{ x_l\right\} \) is another subsequence of \(\left\{ x_n\right\} \) converging weakly to \(\widetilde{x}\ne \bar{x}\). As aforementioned, we see that \(\widetilde{x}\in EP(f,C)\). The relation (31) ensures that \(\lim \limits _{n\rightarrow \infty }||x_n-\bar{x}||^2\in \mathfrak {R}\) and \(\lim \limits _{n\rightarrow \infty }||x_n-\widetilde{x}||^2\in \mathfrak {R}\) . Using the following identity,
we have immediately that
Passing to the limit in (34) as \(n=m,~l\rightarrow \infty \), we obtain
Thus, \(||\bar{x}-\widetilde{x}||^2=0\) and \(\bar{x}=\widetilde{x}\). This completes the proof. \(\square \)
4 R-linear rate of convergence
Algorithms in [11, 12] have some special advantages that they are done without the prior knowledge of the Lipschitz-type constants of bifunction. However, in the case where the bifunction f is strongly pseudomonotone (SP) and satisfies the Lipschitz-type condition (LC), the linear rate of convergence cannot be obtained for these algorithms. In this section, we will establish the R-linear rate of convergence of Algorithms 1 and 2 under the hypotheses (SP) and (LC). In addition, as in [11, 12], we assume additionally that the function \(f(x,\cdot )\) is convex, lower semicontinuous and the function \(f(\cdot ,y)\) is hemicontinuous on C. Under these assumptions, problem (EP) has the unique solution, denoted by \(x^\dagger \). The rate of convergence of the two proposed algorithms is ensured by the following theorem.
Theorem 3
Under the hypotheses (SP) and (LC), the sequence \(\left\{ x_n\right\} \) generated by Algorithm 1 (or Algorithm 2) converges R-linearly to the unique solution \(x^\dagger \) of problem (EP).
Proof
The proof is divided into two cases following that Algorithms 1 or 2 is considered.
Case 1 The sequence \(\left\{ x_n\right\} \) is generated by Algorithm 1. In this case, using the relation (8) with \(y=x^\dagger \), we obtain
Since \(f(x^\dagger ,y_n)\ge 0\), we get that \(f(y_n,x^\dagger )\le -\gamma ||y_n-x^\dagger ||^2\) by assumption (SP), where \(\gamma \) is some positive real number. Thus, from relation (35), we obtain
Since \(\left\{ \lambda _n\right\} \) is non-increasing monotone and \(\lambda _n\rightarrow \lambda \), we have that \(\lambda _n\ge \lambda _{\infty }=\lambda \) for all \(n\ge 0\). Thus, from (36), we get
Let \(\epsilon \) be some fixed number in the interval \(\left( 0,\frac{1-\mu }{2}\right) \). We find that
Thus, there exists \(n_0\ge 1\) such that
It follows from the relations (37) and (38) that, for all \(n\ge n_0\)
where \(r=1-\min \left\{ \epsilon , \gamma \lambda \right\} \in (0,1)\). From the relation (39), we obtain by induction that
or \(||x_{n+1}-x^\dagger ||^2\le Mr^n\) for all \(n\ge n_0\), where \(M=r^{1-n_0}||x_{n_0}-x^\dagger ||^2\). This implies the desired conclusion.
Case 2 The sequence \(\left\{ x_n\right\} \) is generated by Algorithm 2. Now, using the relation (22) with \(y=x^\dagger \) and noting that \(f(y_n,x^\dagger )\le -\gamma ||y_n-x^\dagger ||^2\), we obtain
Let \(\theta \) and \(\rho \) be two real numbers such that
Adding the term \(\frac{2\lambda _{n+1} \mu \rho }{\lambda _{n+2}} ||y_n-x_{n+1}||^2\) to both sides of (40), we get
Since \(\lambda _n\rightarrow \lambda >0\), we obtain
Thus, there exists \(n_0\ge 1\) such that
From the relations (42)–(43) and the fact \(2\lambda _n \gamma \ge 2\lambda \gamma \), we have
We also have
Combining the relations (45) and (46), we obtain
Set \(a_n=||x_n-x^\dagger ||^2\) and \(b_n=\frac{2\lambda _n \mu \rho }{\lambda _{n+1}}||y_{n-1}-x_n||^2\). From the relation (47), we get
where \(r=\max \left\{ 1-\min \left\{ \theta ,\lambda \gamma \right\} ,\frac{1}{\rho }\right\} \in (0,1)\). Thus, by induction, we obtain that \(a_{n+1}+b_{n+1}\le r^{n-n_0+1}(a_{n_0}+b_{n_0})\) for all \(n\ge n_0\), which can be reduced to \(a_{n+1}=||x_{n+1}-x^\dagger ||^2\le Mr^n\) with \(M=r^{1-n_0}(a_{n_0}+b_{n_0})\). This finishes the proof. \(\square \)
5 Computational experiments
This section presents some fundamental experiments on a model which generalizes the Nash-Cournot oligopolistic equilibrium model [10]. For a readable purpose, we present briefly this model as follows: Suppose that there are m firms producing a common homogeneous commodity. Let \(p_j\) be the price of goods produced by firm j depending on the commodities of all firms j, \(j=1,2,\ldots ,m\), i.e., \(p_j=p_j(x_1,x_2,\ldots ,x_m)\). Denote \(c_j(x_j)\) the cost of firm j which only depends on its produced level \(x_j\). Then the profit made by company j is given by \(f_j(x_1,x_2,\ldots ,x_m)= x_j p_j(x_1,x_2,\ldots ,x_m)-c_j( x_j)\). Let \(C_j\) be the strategy set of firm j. Then \(C=C_1\times C_2\times \ldots \times C_m\) is the strategy of the model. Actually, each firm j seeks to maximize its own profit by choosing the corresponding production level \(x_j\) under the presumption that the production of the other firms is a input parameter. A commonly used approach to the model is based on the famous Nash equilibrium concept.
Let \(x=(x_1,x_2,\ldots ,x_m)\in C\) and recall that a point \(x^* =(x_1^*,x_2^*,\ldots ,x_m^*) \in C\) is called an equilibrium point of the model if
By setting \(\psi (x,y):= -\sum _{j = 1}^m f_j(x_1^*,\ldots , x_{j-1}^*,y_j,x_{j+1}^*\ldots ,x_m^*)\) and \(f(x, y):= \psi (x,y)-\psi (x,x)\), the problem of finding a Nash equilibrium point of the model can be shortly formulated as:
For the purpose of experiment, we assume that the price \(p_j(s)\) is a decreasing affine function of s with \(s= \sum _{j=1}^m x_j\), i.e., \(p_j(s)= a_j - b_j s\), where \(a_j > 0\), \(b_j > 0\), and that the function \(c_j(x_j)\) is increasing and affine for every j. This assumption means that the cost for producing a unit is increasing as the quantity of the production gets larger. In that case, the bifunction f can be formulated in the form \(f(x,y)=\left\langle Px+Qy+q,y-x\right\rangle \), where \(q\in \mathfrak {R}^m\) and P, Q are two matrices of order m such that Q is symmetric positive semidefinite and \(Q-P\) is symmetric negative semidefinite. The bifunction f satisfies the Lipschitz-type condition and is pseudomonotone. The feasible set C has the form \(C=\left\{ x\in \mathfrak {R}^m:Ax\le b\right\} \) where A is a random matrix of size \(l\times m\) (\(l=10\) and \(m=200\) or \(m=300\)) and \(b\in \mathfrak {R}^l\) such that \(x_0=y_{-1}=y_0=(1,1,\ldots ,1)\in C\). The two matrices P, Q are generated randomlyFootnote 1. All the optimization problems can be solved effectively by the function quadprog in Matlab Optimization Toolbox. All the programs are written in Matlab 7.0 and computed on a PC Desktop Intel(R) Core(TM) i5-3210M CPU @ 2.50 GHz, RAM 2.00 GB.
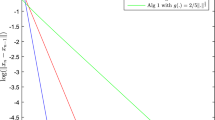
Experiment 1 In this experiment, we study the numerical behavior of Algorithm 1 (shortly, EEGA) and Algorithm 2 (EMEGA). We take \(\mu =0.33\) and \(\lambda _0\in \left\{ 0.2,~0.4,~0.6,~0.8,~1.0\right\} \) and perform the experiments in \(\mathfrak {R}^{200}\) or \(\mathfrak {R}^{300}\). Observe the characteristic of the solutions of problem (EP) that \(x\in EP(f,C)\) if and only if \(x=\mathrm{prox}_{\lambda f(x,.)}(x)\) for some \(\lambda >0\), we use the function \(D(x)=||x-\mathrm{prox}_{\lambda f(x,.)}(x)||^2\) to show the numerical behavior of algorithms EEGA and EMEGA. It is of course that \(D(x)=0\) iff \(x\in EP(f,C)\). The convergence of \(\left\{ D(x_n)\right\} \) generated by each algorithm to 0 can be considered as the sequence \(\left\{ x_n\right\} \) converges to the solution of the problem. The numerical results are shown in Figs. 1, 2, 3 and 4.
In view of these figures, we see that the proposed algorithms work better when \(\lambda _0\) is larger. Moreover, Algorithm 2 (EMEGA) is better than Algorithm 1 (EEGA) in both the execution time and the obtained error after the same number of iterations.

Algorithm 1 (EEGA) in \(\mathfrak {R}^{200}\). The execution time is 5.97, 5.57, 5.71, 5.82, 5.25, respectively

Algorithm 1 (EEGA) in \(\mathfrak {R}^{300}\). The execution time is 23.84, 23.17, 23.66, 23.63, 23.34, respectively

Algorithm 2 (EMEGA) in \(\mathfrak {R}^{200}\). The execution time is 5.19, 5.16, 5.22, 5.12, 5.04, respectively

Algorithm 2 (EMEGA) in \(\mathfrak {R}^{300}\). The execution time is 22.05, 21.87, 22.69, 22.92, 21.93, respectively
Experiment 2 The purpose of this experiment is to present a comparison between the proposed algorithms (EEGA and EMEGA) and two other algorithms, namely the linesearch extragradient algorithm (LEGA) presented in [27, Algorithm 2a] and the ergodic algorithm (ErgA) proposed in [3]. We choose these algorithms to compare because they have a common feature that the Lipschitz-type constants are not the input parameters of the algorithms. The control parameters are \(\mu =0.33\) and \(\lambda _0=1\) (for EEGA and EMEGA); \(\alpha =0.5,~\theta =0.5,~\rho =\gamma =1\) (for LEGA); and \(\lambda _n=\frac{1}{n}\) (for the ErgA). The results are shown in Figs. 5, 6, 7 and 8. In each figure, the x-axis represents either the number of iterations or the execution time elapsed in second while the y-axis gives the value of \(D(x_n)\) generated by each algorithm.

\(D_n\) and # iterations (in \(\mathfrak {R}^{200}\))

\(D_n\) and time (in \(\mathfrak {R}^{200}\))

\(D_n\) and # iterations (in \(\mathfrak {R}^{300}\))

\(D_n\) and time (in \(\mathfrak {R}^{300}\))
The numerical results here have illustrated that the proposed algorithms work better than other ones in both the number of iterations and the execution time. Besides, Algorithm 2 (EMEGA) is also better than Algorithm 1 (EEGA). The advantage of Algorithm 2 over Algorithm 1 is only to compute a value of bifunction at each iteration.
6 Conclusions
The paper has proposed the two explicit extragradient-like algorithms for solving an equilibrium problem involving a pseudomonotone and Lipschitz-type bifunction in a real Hilbert space. A new stepsize rule has been introduced which is not based on the information of the Lipschitz-type constants. The convergence as well as the R-linear rate of convergence of the algorithms have been established. Several experiments are reported to illustrate the numerical behavior of our two algorithms, and to compare them with other ones well known in the literature.
Notes
We randomly choose \(\lambda _{1k}\in [-2,0],~\lambda _{2k}\in [0,2],~ k=1,\ldots ,m\). We set \(\widehat{Q}_1\), \(\widehat{Q}_2\) as two diagonal matrixes with eigenvalues \(\left\{ \lambda _{1k}\right\} _{k=1}^m\) and \(\left\{ \lambda _{2k}\right\} _{k=1}^m\), respectively. Then, we construct a positive semidefinite matrix Q and a negative definite matrix T by using random orthogonal matrixes with \(\widehat{Q}_2\) and \(\widehat{Q}_1\), respectively. Finally, we set \(P=Q-T\)
References
Antipin, A.: Equilibrium programming problems: prox-regularization and prox-methods. In: Gritzmann, P., Horst, R., Sachs, E., Tichatschke, R. (eds.) Recent Advances in Optimization. Lecture Notes in Economics and Mathematical Systems, vol. 452, pp. 1–18. Springer, Heidelberg (1997)
Antipin, A.S.: Extraproximal approach to calculating equilibriums in pure exchange models. Comput. Math. Math. Phys. 46, 1687–1998 (2006)
Anh, P.N., Hai, T.N., Tuan, P.M.: On ergodic algorithms for equilibrium problems. J. Glob. Optim. 64, 179–195 (2016)
Anh, P.N., Hieu, D.V.: Multi-step algorithms for solving EPs. Math. Model. Anal. 23, 453–472 (2018)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer, New York (2011)
Bigi, G., Castellani, M., Pappalardo, M., Passacantando, M.: Nonlinear Programming Techniques for Equilibria. Springer, Basel (2019)
Blum, E., Oettli, W.: From optimization and variational inequalities to equilibrium problems. Math. Program. 63, 123–145 (1994)
Daniele, P., Giannessi, F., Maugeri, A.: Equilibrium Problems and Variational Models. Kluwer, Dordrecht (2003)
Flam, S.D., Antipin, A.S.: Equilibrium programming and proximal-like algorithms. Math. Program. 78, 29–41 (1997)
Facchinei, F., Pang, J.S.: Finite-Dimensional Variational Inequalities and Complementarity Problems. Springer, Berlin (2002)
Hieu, D.V.: New extragradient method for a class of equilibrium problems in Hilbert spaces. Appl. Anal. 97, 811–824 (2018)
Hieu, D.V.: Convergence analysis of a new algorithm for strongly pseudomontone equilibrium problems. Numer. Algor. 77, 983–1001 (2018)
Hieu, D.V., Cho, Y.J., Xiao, Y.B.: Modified extragradient algorithms for solving equilibrium problems. Optimization 67, 2003–2029 (2018)
Hieu, D.V., Strodiot, J.J.: Strong convergence theorems for equilibrium problems and fixed point problems in Banach spaces. J. Fixed Point Theory Appl. 20, 131 (2018)
Hieu, D.V.: An inertial-like proximal algorithm for equilibrium problems. Math. Methods Oper. Res. 88, 399–415 (2018)
Hieu, D.V.: New inertial algorithm for a class of equilibrium problems. Numer. Algor. (2018). https://doi.org/10.1007/s11075-018-0532-0
Hieu, D.V.: Strong convergence of a new hybrid algorithm for fixed point problems and equilibrium problems. Math. Model. Anal. 24, 1–19 (2019)
Iusem, A.N., Sosa, W.: On the proximal point method for equilibrium problems in Hilbert spaces. Optimization 59, 1259–1274 (2010)
Konnov, I.V.: Application of the proximal point method to non-monotone equilibrium problems. J. Optim. Theory Appl. 119, 317–333 (2003)
Konnov, I.V.: Equilibrium Models and Variational Inequalities. Elsevier, Amsterdam (2007)
Korpelevich, G.M.: The extragradient method for finding saddle points and other problems. Ekonomika i Matematicheskie Metody 12, 747–756 (1976)
Lyashko, S.I., Semenov, V.V.: A new two-step proximal algorithm of solving the problem of equilibrium programming. In: Goldengorin, B. (ed.) Optimization and Its Applications in Control and Data Sciences, vol. 115, pp. 315–325. Springer, Cham (2016)
Mastroeni, G.: On auxiliary principle for equilibrium problems. Publicatione del Dipartimento di Mathematica dell, Universita di Pisa. 3, 1244–1258 (2000)
Mastroeni, G.: Gap function for equilibrium problems. J. Glob. Optim. 27, 411–426 (2003)
Moudafi, A.: Proximal point algorithm extended to equilibrum problem. J. Nat. Geometry 15, 91–100 (1999)
Muu, L.D., Oettli, W.: Convergence of an adative penalty scheme for finding constrained equilibria. Nonlinear Anal. TMA 18, 1159–1166 (1992)
Quoc, T.D., Muu, L.D., Hien, N.V.: Extragradient algorithms extended to equilibrium problems. Optimization 57, 749–776 (2008)
Santos, P., Scheimberg, S.: An inexact subgradient algorithm for equilibrium problems. Comput. Appl. Math. 30, 91–107 (2011)
Strodiot, J.J., Nguyen, T.T.V., Nguyen, V.H.: A new class of hybrid extragradient algorithms for solving quasi-equilibrium problems. J. Glob. Optim. 56, 373–397 (2013)
Vuong, P.T., Strodiot, J.J., Nguyen, V.H.: On extragradient-viscosity methods for solving equilibrium and fixed point problems in a Hilbert space. Optimization 64, 429–451 (2015)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Van Hieu, D., Quy, P.K. & Van Vy, L. Explicit iterative algorithms for solving equilibrium problems. Calcolo 56, 11 (2019). https://doi.org/10.1007/s10092-019-0308-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10092-019-0308-5