
Abstract
Offline handwritten signature verification is a challenging pattern recognition task. One of the most significant limitations of the handwritten signature verification problem is inadequate data for training phases. Due to this limitation, deep learning methods that have obtained the state-of-the-art results in many areas achieve quite unsuccessful results when applied to signature verification. In this study, a new use of Cycle-GAN is proposed as a data augmentation method to address the inadequate data problem on signature verification. We also propose a novel signature verification system based on Caps-Net. The proposed data augmentation method is tested on four different convolutional neural network (CNN) methods, VGG16, VGG19, ResNet50, and DenseNet121, which are widely used in the literature. The method has provided a significant contribution to all mentioned CNN methods’ success. The proposed data augmentation method has the best effect on the DenseNet121. We also tested our data augmentation method with the proposed signature verification system on two widely used databases: GPDS and MCYT. Compared to other studies, our verification system achieved the state-of-the-art results on MCYT database, while it reached the second-best verification result on GPDS.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Biometric methods are the most widely used authentication methods. Although there are many biometric authentication methods, the handwritten signature is still the most widely used one even in the modern world. Therefore, it is important to ensure the reliability of the signatures by distinguishing genuine and forged signatures. This makes the signature verification problem one of the extensive research fields.
The most important problem of offline signature verification systems is high intra-personal variability. Even the same writer cannot sign the same signature in the second time using the same method [28]. This obstacle distinguishes handwritten signatures from other biometric methods and makes it a difficult problem to solve. To tackle this challenging problem, signature competitions named as SigComp2011 [33], 4NSigComp2012 [34] and SigWiComp2013 [39] were organized. On the other hand, researches in this field have resulted in numerous verification methods based on support vector machines (SVM) [29], dynamic time wrap (DTW)[7], principle component analysis (PCA) [45], fuzzy systems methods, probabilistic neural network (PNN) [48], and deep multitask metric learning (DMML) [9, 22, 24, 57].
For offline signature recognition, Ribeiro et. al [50] proposed a two-step hybrid classifier system in 2011. The first step identifies the owners of the signatures, while the second step determines its authenticity. Zois et al. [70] proposed a novel grid-based template matching scheme for off-line signature analysis and verification. Another graph-based signature verification system is described by Maergner et al. They proposed a combined model consisting of a combination of keypoint graphs with approximate graph edit distance and inkball models [36, 37]. Aguilar et al. [16] used two different machine expert systems for the signature classification. The first expert takes into account the global features, while the second expert takes into account the local features. Last, they proposed a fixed fusion strategy based on the averaged similarity scores of the global and local experts. Fernandez et al. [3] proposed two automatic measurement approaches to assign how the signature measures affect signature verification system error rates. The measures consist of the area of a signature and the intra-variability of a given set of signatures. Sharif et al. [56] proposed “best feature selection approach” for signature verification. They used the genetic algorithm to select the appropriate features set. Then, they used the SVM for signature classification by using the selected features. Masoudnia et al. [42] proposed a dynamic multi-loss function named Multi-Loss Snapshot Ensemble (MLSE) for CNNs. MLSE consisted of three different loss function subsets: CE, CSD, and hinge losses. Lastly, they used SVM to tackle the signature verification problem for both WI and WD approaches. Ooi et al. [45] proposed a hybrid signature verification method by using discrete Radon transform (DRT), PCA, and PNN. Using PCA, they aimed to compress the features of static 2-D signature images recreated in dynamic subfields with DRT. Lastly, they used PNN to classification.
In the last decades, deep learning (DL) methods such as convolutional neural network (CNN) have achieved state-of-the-art success in many areas. Some of the related studies are object recognition [12], computer vision [49], speech recognition [8], natural language processing (NLP) [69], character recognition [61], augmented reality (AR) [25, 41], etc. Sagayam et al. proposed two different hand gesture recognition systems. The first one [54] was a deep learning-based real-time hand gesture recognition system to control virtual robotic arm. They trained and tested the DBN, CNN, and HOG+SVM. The second one [52] was the probabilistic model based on the SSA in the HMM. The authors reported the both DBN and CNN have greater accuracy than HOG+SVM. In another study, Sagayam et al. [53] proposed a fingerprint recognition model by using Euclidean distance and NN classifier for better accuracy. The success of deep learning approaches has attracted the attention of researchers working on the signature verification problem. So, DL methods have frequently used in signature verification studies in recent years. Soleimani et al. [57] developed a deep multitask metric learning (DMML) method, which consists of the mixed approaches—writer independent (WI) and writer dependent (WD) to obtain the knowledge data. Khalajzadeh [30] used CNNs to detect random forgeries on a dataset of Persian signatures. Eskander et al. [13] proposed a hybrid WI-WD solution, using a development dataset for feature selection. They aimed to use the WI approach with the WD approach to overcome the problem of insufficient signature data. Another WI-WD hybrid approach is described by Hafeman et al. They used CNN as the classifier. To improve classification performance, they also used forged signature samples for training in the WI approach [23]. Maergner et al. [38] proposed a new approach by combining their previously proposed graph-based approach with DL. In their new approach, they used the triple loss function with CNN. They claimed that the proposed method achieved significant improvements in performance on four publicly available benchmark datasets. Shariatmadari et al. [55] proposed an approach based on a hierarchical one-class convolutional neural network (HOCCNN) for learning only genuine signatures with different feature levels. In order to train the classification system, they patched each sample of signature into pieces and implemented data augmentation. Thus, they aimed to overcome limited signature data.
It is clearly seen in these cases another serious problem with handwritten signatures verification is insufficient data. In real life, it is difficult to find genuine and forged (especially skilled forged) offline signature examples. DL methods need substantial amounts of data as training data to obtain the successful results. So, the limited number of signature samples is inadequate to train the classification system. As a result of the insufficient dataset, many methods that obtain good results in other areas have failed in the signature verification systems. This results an inefficient training phase and overfitting. For this reason, the systems are not able to obtain enough success. Many researchers deal with both signature verification and limited data problems [6, 19, 66].
In order to achieve a good result by using DL methods in areas with inadequate data sets data enhancement, additional feature extraction methods, and data augmentation methods are used [31, 62, 67]. In the literature, mirroring, shifting, flipping, and random cropping are widely used standard data augmentation methods [2, 26, 32]. Lv et al. [35] used five different data augmentation methods for face recognition. Costa et al. [11] proposed a data augmentation approach applied to the clinical image dataset to properly train a CNN. Although many data augmentation methods have been studied like those, there are only a few DL-based data augmentation methods. Tustison et al. [58] published an article entitled “Convolutional Neural Networks with Template-Based Data Augmentation for Functional Lung Image Quantification.” They used ANTsRNet for data augmentation. In another study, Frid-Adar et al. [17] presented methods for generating synthetic medical images using recently presented deep learning generative adversarial networks (GANs). These studies’ results reveal data augmentation significantly increases DL model success. Using DL-based data augmentation methods is a promising course to solve problems in the fields with a limited amount of data, as in the field of signature verification. To the best of our knowledge, these few DL-based data augmentation methods in the literature have not been used in signature verification applications.
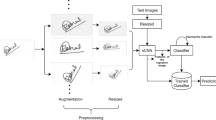
We proposed a CNN-based validation system to tackle the classification problem for offline writer-dependent signatures. In this study, we also aimed to provide a solution to the lack of data by describing a new DL-based data augmentation method. The proposed data augmentation method is based on Cycle-GAN, which is a DL method defined for the image-to-image translation process [68]. Cycle-GAN has not been previously used for data augmentation. Therefore, this study features a novel data augmentation and classification method couple for the signature verification problem. The main goal of the study is to create a hybrid system consisting of data augmentation and classification systems for distinguishing forged and genuine samples better. The proposed system consists of three main steps: (1) preprocessing, (2) data augmentation, and (3) verification. All steps are described in detail below.
The rest of the paper is organized as follows: Sect. 2 introduces the signature verification problem. In Sects. 3 and 4 , we give details of the proposed data augmentation method and signature verification method, respectively. In Sect. 5, we describe the settings of the proposed methods and discuss the experimental results. Lastly, Sect. 6 concludes the paper.
2 Signature verification
As the most commonly used biometric authentication technique, signatures have been signed on paper with pens for hundreds of years. Nowadays, with the development of technology, it can be signed on electronic devices, such as tablets and computers. Signatures that legally impose financial and moral liabilities are still a widely used authentication technique in many areas. Therefore, signature verification/recognition is one of the most important fields for researchers. Signature verification is the process of distinguishing genuine and forged signatures. Signature verification systems compare queried signatures and reference examples to determine whether they are genuine or forged.
Although image processing technology has developed prominently, signature verification is still a very difficult problem to solve. The most challenging feature of signatures is that they are not completely reproducible. Even the most talented people can never do the same signature in the same way. This is called natural diversity. Signatures show high intra-class variability (the individual’s signature can vary widely every day), large temporal change (the signature may change in time), and high-class similarity (by nature, forgery, tries to be indistinguishable from genuine signatures as much as possible) [4]. For all these reasons, signature verification is a NP-Hard problem. Examples of genuine (a, b, c) and forged (d, e, f) signatures of the same person are shown in Fig. 1.
Signature verification systems have two major categories as online and offline according to the data acquirement technique. Online signatures are obtained by signing on touch screen devices such as tablets and mobile phones. Offline signatures are obtained by signing on paper as in traditional methods. The offline signature referred to as a static approach, while the online one referred to as dynamic. In the online signature method, many features such as pen speed, acceleration, coordinates, and pressure are obtained by using a special pen and tablet, along with the scanned signature image [14]. However, offline signature methods have only the scanned signature image. Therefore, the offline signature verification problem is a more challenging problem. Since the signatures are easily affected by factors—such as the psychological condition, health, age, and physical conditions, differences occur in the signature samples of the same person. This makes offline signature verification a much harder problem to solve for researchers [28, 33]. With the proposed hybrid system, composed of data augmentation and signature verification in this study, we are trying to overcome the problems with offline signature verification.
Images are used as input data, in offline signature verification systems. So, the learned features are very few and limited. Therefore, the design of the system to be used is crucial. Signature verification systems are designed according to two main approaches as writer independent (WI) and writer dependent (WD). In WI approaches, the classification system is trained and tested with signature samples of all users at the same time. In the second system, which is WD, classification is performed for each user separately [13, 57]. Since the WI approach is trained with the signatures of all users together, it suffers to learn the specific features of the writers. Therefore, local characteristics of the signatures are missed in the WI approach. In the WD approach, since the signature samples of all authors are trained separately, the personal characteristics can be learned more easily. Hence, the classification performance of the WD approach is higher than the WI approach. In an article published in 2018, we showed that the CNN model has achieved more successful results on the WD approach than on the WI approach [64].

Top row (a, b, c) is genuine signatures and bottom row (d, e, f) is forged signatures
3 Proposed data augmentation method
Basic data augmentation methods are divided into two: geometric augmentation and color augmentation. The former is composed of mirroring, rotation, flipping, etc., and the latter is composed of color spectra [60]. More generic image augmentation method introduced by Xu et al. [63]. In addition, there are also some data augmentation methods integrated into DL frameworks, such as Keras. These methods consist of translation, scaling, adding noise (Gauss, etc.), and random cropping [10].
The method we have proposed for data augmentation has not been used before in the field of signature verification. The basis of the method we propose is the image-to-image translation. The image-to-image translation methods are intended to obtain a new image by using another pair of images’ features (X, Y). They learn features of the pair by relating an image as a given output (Y) and another image as a given input (X). This procedure is formulated as follows \(G:X\rightarrow Y\). Goal of the method is to learn the mapping between an input image and an output image using a training set of aligned image pairs and apply this mapping to another image for translation. Translation can be in different formats, such as grayscale to color, image to semantic labels, and edge-map to photograph [27]. In this study, we aimed to learn the special characteristics of two signatures by matching a pair of signatures from a signature sample. By using these characteristics, it is aimed to create a new signature sample.
One of the best DL methods that can perform this kind of transformation is generative adversarial networks (GANs). GAN was first reported by Goodfellow et al. [20] in 2014. The GANs’ learning process is to train a discriminator D and a generator G simultaneously. The goal of G is to learn the distribution \(P_{x}\) by data x. G starts from Gaussian distribution \(P_{z} (z)\), to sample the input variable z, then maps the input variables z to data space \(G(z;\theta _{g})\) through a differentiable network. At the same time, D is a classifier \(D(x;\theta _{d})\) which is designed to recognize whether an image is from training data or from G [40]. The objective of a GAN can be described as:
where G minimizes the objective function while adversarial D tries to maximize.
In our study, Cycle-GAN [68] method is used for signature augmentation. The method is a GAN approach to reconstruct the adversarial loss to learn the maps of target and input images that are extremely similar to each other. The model uses combination of supervised regression and an adversarial lost. The model is composed of two mapping functions \(G:X\rightarrow Y\) and \(F:Y\rightarrow X\), and associated adversarial discriminators \(D_{y}\) and \(D_{x}\). In this case according to model, if we translate an input image to target, we must get the same image after we translate the reverse images (translated images to input images). Therefore, Cycle-GAN model has the cycle consistency constrain. A reconstruction phase is required for this aim in the Cycle-GAN method after the mapping phase. These steps are repeated after the input image, and the target images are replaced with each other. These two phases are called translation and reconstruction phases. Architecture of Cycle-GAN method is given in Fig. 2. \(D_{y}\) encourages G to translate X into outputs indistinguishable from domain Y, and vice versa for \(D_{X}\) and F. In order to make image translations more accurate, after a translation from one image to another, when a reverse conversion is made, the consistency between the two cycles is provided by the two cycle consistency losses. It is seen in Fig. 2. as: (b) loss of forward loop consistency: x, and (c) loss of loop-consistency: y. Cycle consistency losses are calculated according to Eq. (2).
The full objective is described in Eq. (3).
where \(\lambda \) controls the relative importance of the two objectives.

Architecture of Cycle-GAN [68]
The proposed data augmentation method is shown in Fig. 3. In the proposed data augmentation method, the signature samples belonging to a person obtained from the signature database are used as input data and target data. Among the genuine signatures belonging to the same person, one of the two randomly selected signatures is used as input data and the other one is used as the target data. In this way, the person’s genuine signatures are matched to each other and the Cycle-GAN method is trained. Similarity maps are generated between the genuine signatures by the trained Cycle-GAN network, so that the high-level features between all signatures are sampled. In the Cycle-GAN method, after the translation phase, the method is reworked by reverse operation for the reconstruction phase. After the reconstruction phase, a new augmented genuine signature sample is obtained from two different genuine signatures of the same person. In this reconstruction phase, the obtained signature is filtered by a predetermined threshold value. Therefore, high-level features on the feature map are ensured to be used. The proposed augmentation method is presented in steps in Algorithm 1. Original genuine signatures and augmented genuine signatures which reconstructed by the proposed method are shown in Fig. 4.

Proposed Cycle-GAN model which is applied to the signature verification problem. Two different genuine signatures of the same person are used in the method. By learning the high-level features of each genuine signatures, a new genuine signature is created. Examples of the genuine signatures produced for different epoch are seen in reconstruct phase


Original and reconstructed genuine signatures from GPDSsyntheticSignature (first row) and MCYT75 (second row) databases. Column a is original signatures, and b and c are reconstructed signatures by the proposed augmentation method
In the proposed data augmentation phase, the selection of two different signature in every cycle is guaranteed by a selection algorithm. Since the input and target signature images are different for every epoch, it is infinitesimally small to obtain a duplicated signature. Thus, we aimed to make each reconstructed signature different from the previous ones. However, there is a possibility that a duplicate sample might be created since the two previously matched signature samples can be re-matched and as a result of matching, it is possible to reproduce the same similarity map. We used the augmentation method on only genuine signatures. Since we did not use forged signatures on training phases, the forged signatures were not augmented.
4 Proposed signature verification system
In the last decades, convolutional neural network (CNN) models reached the state-of-the-art results in many fields [8, 12, 49, 59, 69]. Despite their success, CNNs also have some limitations and drawbacks. On every layer, CNNs learn different features, respectively, such as edges, shapes, and finally actual objects. However, they do not learn and take the spatial relationships (perspective, size, orientation) into account between these features. For example, consider a CNN trained with the human face. If we give a modified human face picture by changing the place of eyes, nose, and mouth as input data to this network, it will recognize it as a human face. This is one of the biggest drawbacks of CNNs. So, they can be easily fooled by images that have wrong spatial features. This is called adversarial attacks. For neural networks, these attacks were first introduced by Goodfellow et al. [21]. Many studies have been made to tackle adversarial attacks for neural networks. One of these studies is Capsule Net (CapsNet). Frosst et al. [18] showed that CapsNets are more powerful against adversarial attacks than other architectures.
CapsNet proposed with the paper that is called “Dynamic Routing Between Capsules” by Sabour et al. [51]. CapsNet model considers not only the basic features (lines, curves, and letter), but also the spatial relationships between these features. This is the main advantage of the model. Another important advantage of the model is that it can learn faster and use fewer samples per class. These advantages are vital for signature verification systems that have few data. In the CapsNet model, neurons are grouped into vectors, which are called capsules. Capsules are the activity vectors of these neurons that represent various pose parameters. The length of these vectors shows the probability that a specific entity exists. Thus, it is aimed to model spatial relations more efficiently [1, 43, 44].
In signature verification systems, it is important to evaluate the signatures with all their features together as a whole. It is very important that all the evaluated features (lines, curves, and letters) are in the right place. Therefore, conventional CNN methods have a great risk for signature verification systems. The signature databases have few data. Therefore, the CNN model that can be trained with few data such as CapsNet is being so important for signature verification models. Since CapsNet model has many advantages on the signature verification field, we use CapsNet as a classifier in this study. The proposed system is illustrated in Fig. 5. The architecture of the proposed CapsNet model is described in Table 1.

Structure of the proposed signature verification system
5 Experimental result and settings
In this section, databases are described, information about preprocessing, training and testing phases are given. Then, the experimental results obtained by the proposed methods are listed and discussed. Lastly, obtained results are compared with the state-of-the-art results for GPDS [15] and MCYT [46] databases.
5.1 Databases
We conducted experiments on two well-known datasets for offline signature verification.
The first one is GPDS database, which is one of the most widely used databases for the signature verification field. The GPDS database was obtained from “Instituto Universitario para el Desarrollo Tecnológico y la Innovación en Comunicaciones (IDeTIC).” It contains four different signature datasets: GPDS960signature, 4NSigComp2010 Scenario 2, GPDS960GRAYsignature, and GPDSsyntheticSignature. In the study, GPDSsyntheticSignature [15] dataset was used, because the first three datasets mentioned were no longer available due to the General Data Protection Directive (EU) 2016/679 (“GDP”). GPDSsyntheticSignature dataset consists of signatures of 4000 different individuals. Every individual has 24 genuine signatures together with 30 samples of forged signatures. All the signatures were generated with different modeled pens. The signatures are in “jpg” format and equivalent resolution of 600 dpi.
The second database that we used in experiments is MCYT75 [46]. The MCYT75 signature database consists of signatures of 75 different individuals. Every individual has 15 genuine and 15 forged signatures, and there is a total of 2250 signature samples in the database. All signature samples are digitized with a scanner at the resolution of 600 dpi.
5.2 Preprocessing
We prepare the databases by using some preprocessing methods since the neural networks expect inputs of a fixed size. First, we determine the boundaries of the images (width × height) containing the signature sample. Then, we resized the pictures to 224 × 224 pixels without disturbing the aspect ratio, according to the specified boundaries. We gave the idle pixels 255 value, which is the background color. We cleared the background using OTSU’s algorithm [47]. Then, we set background pixels to white color (intensity 255) and left the foreground pixels in grayscale. We subtracted the each pixels from 255 to set the background colors to 0 for easy calculation. Finally, we normalized all samples by dividing each pixel of the images by 255 that is the value of the maximum pixel. All these preprocessing steps were implemented for both data augmentation method and verification method.
5.3 Train and test phases
As it was mentioned, the proposed data augmentation method is based on Cycle-GAN, and the verification method is based on CapsNet. Training and Testing phases were applied separately in two scenarios for data augmentation and verification systems, respectively. Stochastic gradient descent (SGD) optimizer with a learning rate of 0.0001, accuracy metric, and binary cross entropy was used for both scenarios. In the first scenario where four CNN models were trained, the models were created by using standard functions in the keras framework. In order to adapt the models to two class structures, dense layers with, respectively, 1024, 512, and 2 filters were added at end of the models. The input layer of these four CNN models was set size of 224 × 224 × 3, and transfer learning was implemented for the models by using the weights of imageNet. Routing property was set to 3 for the proposed CapsNet-based classifier in the second scenario.
In the first scenario, we obtained the results for the proposed Cycle-GAN-based data augmentation method. We used both genuine and forged samples on training and testing phases to examine the robustness of the proposed data augmentation method. The reason we used both genuine and forged samples on training and testing phases is that the obtained results are not compared with the results in the literature. We want to show the effects of the proposed data augmentation method, so we compare the obtained results with each other. To do this, we trained and tested the method with four different widely used CNN models. The CNN models are VGG16, VGG19, ResNet50, and DenseNet121. We performed all tests in three different routes to understand the success of the proposed augmentation method. First, the CNN models were trained and tested with only the existing data in the signature dataset without using any data augmentation process (Without Data Augmentation—WODAU). Second, all CNN models were trained and tested by performing only common data augmentation methods (rotation, flipping, mirroring) (Common Data Augmentation—CDAU) on the samples in the signature dataset. Finally, all the models were trained and tested with the signature samples that are increased by performing the proposed data augmentation method (Our Data Augmentation—ODAU). We compared the test results to see the success of our proposed augmentation method according to the validation accuracy, validation loss, and score. In this scenario, we performed all experiments on GPDSsyntheticSignature database. The database contains a total of 54 samples composed of forged and genuine signature for each person. For this reason, 54 signatures were used for each individual in the first experiment. In the second experiment, 54 signatures of each individual were increased five times by using common data augmentation methods (mirroring, flipping, and rotation), and a total of (54 * 5 =) 270 signatures were obtained for each individual. In the last experiment, between 650 and 710 obtained signature samples were used depending on the signature and determined threshold. In order to understand the success of the proposed method, the data augmentation process was applied to all genuine and forged signature samples. Following, genuine and forged signature samples were used together in the training and testing phase in this scenario. In all the experiments, 60 percent of signatures were used for the training phase, 20 percent for the verification phase, and 20 percent for the test phase. The signature data were selected randomly for each phase. For more reliable and accurate results, independent experiments were conducted on multiple writers and the final results were calculated by the average of them.
In the second scenario, we performed the experiments for the proposed signature verification method that is shown in Fig. 5. Since it is not possible to find forged signatures on the real-life scenario, training phases were performed with only genuine signatures. The proposed verification method was trained separately with numbers of five and ten random selected genuine signatures from MCYT75 and GPDSsyntheticSignature databases. But both genuine and forged signatures were used on test phases. To test the verification system with only five genuine augmented signatures, we augmented the dataset by executing the following steps: (1) select five genuine signatures randomly from the database, (2) use the selected signatures to train the proposed data augmentation method, to augment the selected five genuine signatures, (3) select the remaining genuine signatures in the database to train the proposed data augmentation method separately, and (4) augment the remaining signatures. Remaining signatures, after selecting five signatures from a dataset, are ten samples for MCYT75 and 19 samples for GPDSsyntheticSignature. The same steps were executed for experiments with ten genuine signatures. After all data augmentation processes are completed, the proposed signature verification system trained with five and ten genuine augmented signature samples, respectively. And so, the verification results were obtained separately for all samples. As we mentioned before, in this scenario, the performance of the verification system was trained with only genuine samples, but tested with both genuine and forged signature samples separately for databases. We compared the obtained results of the proposed signature verification system with other papers in the literature. We determined that researchers widely used two classical types of error as metrics for evaluation in the literature. The first one is Type I error or false rejection rate (FRR) which means a genuine signature is rejected by the system, and the second one is Type II error or false acceptance rate (FAR) which means a forgery is accepted as a genuine signature by the system. In this case, we use these metrics to enable comparison with other studies in the literature. We also report equal error rates (EER) that is the error obtained when FAR equals FRR.
All experiments are performed with Tensorflow backend on Keras framework by using NVIDIA TITAN XP graphics card. The system has an i7 CPU, 32 GB DDR3 RAM, 500 GB SSD, 12 GB DDR5 GPU memory and UBUNTU operating system.
5.4 Results
In this section, we give the experimental results for both proposed methods separately. First, we list and discuss the results of the proposed data augmentation method. Then, we list and discuss the results for the proposed offline signature verification system, and compare the results with other studies. All experiments were performed on the writer-dependent (WD) scenario and by using skilled forgeries data. In the study, tenfold cross-validation (CV) [5] was used to get more accurate results in both scenarios. The final results were obtained by taking the average of the results of CV.
As we stated in train and test phases section, for examining the robustness of the proposed data augmentation method, the results are obtained separately according to the first scenario by using CNN models: VGG16, VGG19, ResNet50, and DenseNet12. The performance of the proposed data augmentation method is given in Table 2 for comparison of three experiment routes: without data augmentation, with common data augmentation, and with our data augmentation. Moreover, the performances of each CNN methods are visualized with graphs for every training phase to make the performance comparison easier and to contrast the success of our method (ODAU—represented by orange). The accuracy and loss graphs for the four CNN methods are shown in Fig. 6.

Accuracy and loss graphs for the CNN algorithms. Each figure consists of accuracy/loss graphs which contain training, our data augmentation (ODAU), common data augmentation (CDAU), and without data augmentation (WODAU). Figures a and b show the accuracy and loss graphs of the VGG16 method, respectively. It is shown the accuracy and loss graphs, respectively, in figures c and d for VGG19, figures e and f for DenseNet121, figures g and h for ResNet50
It is clearly seen that the proposed data augmentation method increases the accuracy of all models (Fig. 6; Table 2). There are high accuracy differences between the training and verification in the first route, which does not have any data augmentation (WODAU). We think all CNN models are overfitting in this training phase with insufficient signature data. That is why the success of validation is quite low while the success of training is considerably high. In the second route which has a common data augmentation method (CDAU), the accuracy rates of training and verification are closer to each other. This clearly demonstrates the contribution of the number of training data to the success of the methods. With sufficient training data, the success of CNN models in signature verification is increasing significantly. The training and validation accuracy rates obtained in the third route that uses the proposed data augmentation method (ODAU) are very close to each other. It shows the success of the proposed method. In addition, the obtained loss error rates for all CNN models in every training phase support the success of the proposed data augmentation method. According to the experimental results, it is seen that the proposed data augmentation method achieves high success rates in all CNN models, while the method achieved the highest validation accuracy with 0.970 in DenseNet121 model. In another study where we compared the performances of CNN models used in this study, it was seen that DenseNet121 model obtained the most successful results [65]. The results obtained in the two studies show consistency.
In the first scenario, the obtained results show that the proposed data augmentation method positively affects the success of all CNN models. In the second scenario, we tested the proposed signature verification method integrated with data augmentation that is shown in Fig. 5 to examine the robustness of the proposed signature verification system. All experiments performed according to the second scenario stated in the previous section. In addition to these explanations, we want to reiterate that all experimental results are obtained by using skilled forgeries data. Therefore, we compared our results with the results of skilled forgeries in the literature. We used F1 score, AER, FAR, FRR, and EER in performance assessment of the proposed method. AER value is calculated by averaging the FRR and FAR values. FAR takes skilled forgeries into account, and FRR utilizes genuine signatures. We present the obtained results and compare them with other studies for databases of GPDSsyntheticSignature and MCYT75 in Tables 3 and 4, respectively.
The compared results are several published state-of-the-art results. Unfortunately, making a comparison with some studies is difficult, since they use several different evaluation protocols. We notice that some studies report results with FAR, FRR, and AER, while others report results with FAR, FRR, and EER. Some studies do not even have results of FAR and FRR. Thus, it is often difficult to make a full comparison.
The proposed signature verification method showed better performance on MCYT75 than GPDSsyntheticSignature. Although our method does not reach the state-of-the-art results for training with 10 genuine (G) on GPDSsyntheticSignature database, it achieved the second-best result. Our method obtained 12.34% (± 0.2) EER on GPDSsyntheticSignature database. It is better than DMML [57] which is a hybrid method composed of WI and WD. In the literature, there are only a few studies done in the GPDSsyntheticSignature database. We can find only one study for comparison with five genuine on this database. The study that we find uses GA+SVM method [56] and does not publish EER. So, it is quite difficult to compare our results. Their obtained results for 10G on GPDSsyntheticSignature database are FRR = 12.5%. The proposed method achieved FRR = 10.41%, FAR = 8.66%, EER = 12.34% (± 0.2), AER = 9.53%, and F1 score = 88.97% for 10G on GPDSsyntheticSignature. For 5G on GPDSsyntheticSignature, the proposed method achieved FRR = 28.56%, FAR = 7.66%, and EER = 22.93% (± 0.2). Our method obtains the lowest FAR result, while GA+SVM method gets the lowest FRR result.
According to Table 4, in MCYT75 database, the proposed method achieved the state-of-the-art results with 10G, while it is in competition with others for 5G. Our method reached the best EER with 2.58 (± 0.43) for 10G on MCYT75. In addition, the proposed method performed better performance than the hybrid (WI and WD) system [57] for 10G on MCYT75.
6 Conclusion
In this study, we aim to tackle the lack of data problem of offline signature verification systems. So, we present a novel data augmentation method based on Cycle-GAN. Also, we propose a new signature verification system.
We tested the robustness of the proposed data augmentation methods by testing it with widely used CNN methods and the proposed verification system. Experiments were carried out with a writer-dependent (WD) approach on two widely used signature databases: GPDS and MCYT with skilled forgeries data. We divided experiment phases into two as data augmentation and signature verification, respectively. First, we showed the effects of the proposed data augmentation method by testing on four widely used CNN models. Second, we tested our proposed signature verification systems together with our data augmentation method. Finally, we compared the obtained results with the state-of-the-art methods, and the results were compared according to \(\text{FAR}_{(\mathrm{Skilled Forgery})}\), FRR, \(\text{EER}_{(\mathrm{Skilled Forgery})}\).
The experimental results show that the proposed data augmentation method increases the success of all CNN models on the offline signature database. Our experiments also show that the proposed signature verification system obtains the state-of-the-art results with 10G samples on MCYT database. In addition, our verification system achieves the second-best verification results with 5G and 10G samples on both GPDS and MCYT databases. Moreover, it is clearly seen in Table 3 and Table 4 that the proposed signature verification system outperforms many other studies in the literature.
References
Afshar P, Mohammadi A, Plataniotis KN (2018) Brain tumor type classification via capsule networks. In: 2018 25th IEEE international conference on image processing (ICIP). IEEE, pp 3129–3133
Ahmed E, Jones M, Marks TK (2015) An improved deep learning architecture for person re-identification. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3908–3916
Alonso-Fernandez F, Fairhurst MC, Fierrez J, Ortega-Garcia J (2007) Automatic measures for predicting performance in off-line signature. In: 2007 IEEE international conference on image processing, vol 1. IEEE, pp I–369
Alvarez G, Sheffer B, Bryant M (2016) Offline signature verification with convolutional neural networks. Technical report, Stanford University, Stanford
Anguita D, Ridella S, Rivieccio F (2005) K-fold generalization capability assessment for support vector classifiers. In: Proceedings. 2005 IEEE international joint conference on neural networks, 2005, vol 2. IEEE, pp 855–858
Ayan E, Ünver HM (2018) Data augmentation importance for classification of skin lesions via deep learning. In: 2018 Electric electronics, computer science, biomedical engineerings’ meeting (EBBT). IEEE, pp 1–4
Bae YJ, Fairhurst MC (1995) Parallelism in dynamic time warping for automatic signature verification. In: Proceedings of the third international conference on document analysis and recognition, 1995, vol 1. IEEE, pp 426–429
Becerra A, de la Rosa JI, González E, Pedroza AD, Martínez JM, Escalante NI (2017) Speech recognition using deep neural networks trained with non-uniform frame-level cost functions. In: 2017 IEEE international autumn meeting on power, electronics and computing (ROPEC), pp 1–6. https://doi.org/10.1109/ROPEC.2017.8261588
Canuto J, Dorizzi B, Montalvão J, Matos L (2016) On the infinite clipping of handwritten signatures. Pattern Recognit Lett 79:38–43
Chollet F et al (2015) Keras: deep learning library for theano and tensorflow. https://keras io/k7:8
Costa AC, Oliveira HCR, Catani JH, de Barros N, Melo CFE, Vieira MAC (2018) Data augmentation for detection of architectural distortion in digital mammography using deep learning approach
de SanRoman PP, Benois-Pineau J, Domenger JP, Paclet F, Cataert D, de Rugy A (2017) Saliency driven object recognition in egocentric videos with deep CNN: toward application in assistance to Neuroprostheses. Comput Vis Image Underst 164:82–91. https://doi.org/10.1016/j.cviu.2017.03.001
Eskander GS, Sabourin R, Granger E (2013) Hybrid writer-independent-writer-dependent offline signature verification system. IET Biom 2(4):169–181
Fahmy MMM (2010) Online handwritten signature verification system based on DWT features extraction and neural network classification. Ain Shams Eng J 1(1):59–70
Ferrer MA, Diaz-Cabrera M, Morales A (2013) Synthetic off-line signature image generation. In: 2013 International conference on biometrics (ICB). IEEE, pp 1–7
Fierrez-Aguilar J, Alonso-Hermira N, Moreno-Marquez G, Ortega-Garcia J (2004) An off-line signature verification system based on fusion of local and global information. In: International workshop on biometric authentication. Springer, pp 295–306
Frid-Adar M, Diamant I, Klang E, Amitai M, Goldberger J, Greenspan H (2018) GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 321:321–331. https://doi.org/10.1016/j.neucom.2018.09.013
Frosst N, Sabour S, Hinton G (2018) DARCCC: detecting adversaries by reconstruction from class conditional capsules. arXiv preprint arXiv:1811.06969
Ge W, Yu Y (2017) Borrowing treasures from the wealthy: deep transfer learning through selective joint fine-tuning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1086–1095
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems, pp 2672–2680
Goodfellow IJ, Shlens J, Szegedy C (2014) Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572
Hafemann LG, Sabourin R, Oliveira LS (2016) Analyzing features learned for offline signature verification using deep CNNs. In: 2016 23rd international conference on pattern recognition (ICPR), pp 2989–2994. https://doi.org/10.1109/ICPR.2016.7900092
Hafemann LG, Sabourin R, Oliveira LS (2017a) Learning features for offline handwritten signature verification using deep convolutional neural networks. Pattern Recognit 70:163–176. https://doi.org/10.1016/j.patcog.2017.05.012
Hafemann LG, Sabourin R, Oliveira LS (2017b) Offline handwritten signature verification; literature review. In: 2017 Seventh international conference on image processing theory, tools and applications (IPTA), pp 1–8. https://doi.org/10.1109/IPTA.2017.8310112
HaNoi V (2020) Interactive educational content using marker based augmented reality. Inf Technol Intell Transp Syst 323:77
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Isola P, Zhu JY, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. arXiv preprint
Justino EJR, El Yacoubi A, Bortolozzi F, Sabourin R (2000) An off-line signature verification system using HMM and graphometric features. In: Proceedings of the 4th international workshop on document analysis systems, Citeseer, pp 211–222
Justino EJR, Bortolozzi F, Sabourin R (2005) A comparison of SVM and HMM classifiers in the off-line signature verification. Pattern Recognit Lett 26(9):1377–1385
Khalajzadeh H, Mansouri M, Teshnehlab M (2012) Persian signature verification using convolutional neural networks. Int J Eng Res Technol 1(2):7–12
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Advances in neural information processing systems, pp 1097–1105
Larsson G, Maire M, Shakhnarovich G (2016) Fractalnet: ultra-deep neural networks without residuals. arXiv preprint arXiv:1605.07648
Liwicki M, Malik MI, v d Heuvel CE, Chen X, Berger C, Stoel R, Blumenstein M, Found B (2011) Signature verification competition for online and offline skilled forgeries (SigComp2011). In: 2011 International conference on document analysis and recognition, pp 1480–1484, https://doi.org/10.1109/ICDAR.2011.294
Liwicki M, Malik MI, Alewijnse L, v d Heuvel E, Found B (2012) ICFHR 2012 competition on automatic forensic signature verification (4NsigComp 2012). In: 2012 International conference on frontiers in handwriting recognition, pp 823–828. https://doi.org/10.1109/ICFHR.2012.217
Lv JJ, Shao XH, Huang JS, Zhou XD, Zhou X (2017) Data augmentation for face recognition. Neurocomputing 230:184–196
Maergner P, Howe N, Riesen K, Ingold R, Fischer A (2018) Offline signature verification via structural methods: graph edit distance and inkball models. In: 2018 16th international conference on frontiers in handwriting recognition (ICFHR). IEEE, pp 163–168
Maergner P, Howe NR, Riesen K, Ingold R, Fischer A (2019) Graph-based offline signature verification. arXiv preprint arXiv:1906.10401
Maergner P, Pondenkandath V, Alberti M, Liwicki M, Riesen K, Ingold R, Fischer A (2019) Combining graph edit distance and triplet networks for offline signature verification. Pattern Recognit Lett 125:527–533
Malik MI, Liwicki M, Alewijnse L, Ohyama W, Blumenstein M, Found B (2013) ICDAR 2013 competitions on signature verification and writer identification for on- and offline skilled forgeries (SigWiComp 2013). In: 2013 12th international conference on document analysis and recognition, pp 1477–1483. https://doi.org/10.1109/ICDAR.2013.220
Mao X, Li Q, Xie H, Lau RYK, Wang Z, Smolley SP (2017) Least squares generative adversarial networks. In: 2017 IEEE international conference on computer vision (ICCV). IEEE, pp 2813–2821
Martin Sagayam K, Ho CC, Henesey L, Bestak R (2018) 3D scenery learning on solar system by using marker based augmented reality. In: 4th international conference of the virtual and augmented reality in education, VARE 2018; Budapest, Dime University of Genoa, pp 139–143
Masoudnia S, Mersa O, Araabi BN, Vahabie AH, Sadeghi MA, Ahmadabadi MN (2019) Multi-representational learning for offline signature verification using multi-loss snapshot ensemble of CNNs. Expert Syst Appl 133:317–330
Mobiny A, Van Nguyen H (2018) Fast capsnet for lung cancer screening. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 741–749
Mukhometzianov R, Carrillo J (2018) CapsNet comparative performance evaluation for image classification. arXiv preprint arXiv:1805.11195
Ooi SY, Teoh ABJ, Pang YH, Hiew BY (2016) Image-based handwritten signature verification using hybrid methods of discrete Radon transform, principal component analysis and probabilistic neural network. Appl Soft Comput 40:274–282. https://doi.org/10.1016/j.asoc.2015.11.039
Ortega-Garcia J, Fierrez-Aguilar J, Simon D, Gonzalez J, Faundez-Zanuy M, Espinosa V, Satue A, Hernaez I, Igarza JJ, Vivaracho C et al (2003) MCYT baseline corpus: a bimodal biometric database. IEE Proc Vis Image Signal Process 150(6):395–401
Otsu N (1979) A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern 9(1):62–66
Porwik P, Doroz R, Orczyk T (2016) Signatures verification based on PNN classifier optimised by PSO algorithm. Pattern Recognit 60:998–1014
Prabhakar G, Kailath B, Natarajan S, Kumar R (2017) Obstacle detection and classification using deep learning for tracking in high-speed autonomous driving. In: 2017 IEEE region 10 symposium (TENSYMP), pp 1–6. https://doi.org/10.1109/TENCONSpring.2017.8069972
Ribeiro B, Gonçalves I, Santos S, Kovacec A (2011) Deep learning networks for off-line handwritten signature recognition. In: Iberoamerican congress on pattern recognition. Springer, pp 523–532
Sabour S, Frosst N, Hinton GE (2017) Dynamic routing between capsules. In: Advances in neural information processing systems, pp 3856–3866
Sagayam KM, Hemanth DJ (2019) A probabilistic model for state sequence analysis in hidden Markov model for hand gesture recognition. Comput Intell 35(1):59–81
Sagayam KM, Ponraj DN, Winston J, Jeba E, Clara A (2019) Authentication of biometric system using fingerprint recognition with euclidean distance and neural network classifier. Project: hand posture and gesture recognition techniques for virtual reality applications: a survey
Sagayama KM, Viyasb TV, Hoa CC, Heneseyb LE (2017) Virtual robotic arm control with hand gesture recognition and deep learning strategies. Deep Learn Image Process Appl 31:50
Shariatmadari S, Emadi S, Akbari Y (2019) Patch-based offline signature verification using one-class hierarchical deep learning. Int J Doc Anal Recognit 22:375–385. https://doi.org/10.1007/s10032-019-00331-2
Sharif M, Khan MA, Faisal M, Yasmin M, Fernandes SL (2018) A framework for offline signature verification system: best features selection approach. Pattern Recognit Lett. https://doi.org/10.1016/j.patrec.2018.01.021
Soleimani A, Araabi BN, Fouladi K (2016) Deep multitask metric learning for offline signature verification. Pattern Recognit Lett 80:84–90. https://doi.org/10.1016/j.patrec.2016.05.023
Tustison NJ, Avants BB, Lin Z, Feng X, Cullen N, Mata JF, Flors L, Gee JC, Altes TA, Mugler JP III, Qing K (2018) Convolutional neural networks with template-based data augmentation for functional lung image quantification. Acad Radiol. https://doi.org/10.1016/j.acra.2018.08.003
Uçar A, Demir Y, Güzeliş C (2016) Moving towards in object recognition with deep learning for autonomous driving applications. In: 2016 International symposium on INnovations in Intelligent SysTems and Applications (INISTA), pp 1–5. https://doi.org/10.1109/INISTA.2016.7571862
Vasconcelos CN, Vasconcelos BN (2017) Increasing deep learning melanoma classification by classical and expert knowledge based image transforms. CoRR, arXiv:1702.07025
Xiao X, Jin L, Yang Y, Yang W, Sun J, Chang T (2017) Building fast and compact convolutional neural networks for offline handwritten Chinese character recognition. Pattern Recognit 72:72–81. https://doi.org/10.1016/j.patcog.2017.06.032
Xie S, Yang T, Wang X, Lin Y (2015) Hyper-class augmented and regularized deep learning for fine-grained image classification. In: The IEEE conference on computer vision and pattern recognition (CVPR)
Xu Y, Jia R, Mou L, Li G, Chen Y, Lu Y, Jin Z (2016) Improved relation classification by deep recurrent neural networks with data augmentation. arXiv preprint arXiv:1601.03651
Yapıcı MM, Tekerek A, Topaloglu N (2018) Convolutional neural network based offline signature verification application. In: 2018 International congress on big data. Deep learning and fighting cyber terrorism (IBIGDELFT). IEEE, pp 30–34
Yapıcı MM, Tekerek A, Topaloğlu N (2019) Performance comparison of convolutional neural network models on GPU. In: 2019 IEEE 13th international conference on application of information and communication technologies (AICT). IEEE, pp 1–4
Zhang L, Zhang L, Du B (2016) Deep learning for remote sensing data: a technical tutorial on the state of the art. IEEE Geosci Remote Sens Mag 4(2):22–40
Zhang Y, Ling C (2018) A strategy to apply machine learning to small datasets in materials science. NPJ Comput Mater 4(1):25
Zhu JY, Park T, Isola P, Efros AA (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint
Zhuang H, Wang C, Li C, Wang Q, Zhou X (2017) Natural language processing service based on stroke-level convolutional networks for Chinese text classification. In: 2017 IEEE international conference on web services (ICWS), pp 404–411. https://doi.org/10.1109/ICWS.2017.46
Zois EN, Alewijnse L, Economou G (2016) Offline signature verification and quality characterization using poset-oriented grid features. Pattern Recognit 54:162–177
Acknowledgements
This work has been supported by the NVIDIA Corporation. All experimental studies were carried out on the TITAN XP graphics card donated by NVIDIA. We sincerely thank NVIDIA Corporation for their supports.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yapıcı, M.M., Tekerek, A. & Topaloğlu, N. Deep learning-based data augmentation method and signature verification system for offline handwritten signature. Pattern Anal Applic 24, 165–179 (2021). https://doi.org/10.1007/s10044-020-00912-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10044-020-00912-6