
Abstract
Objectives
This study aimed to train deep learning models for recognition of contiguity between the mandibular third molar (M3M) and inferior alveolar canal using panoramic radiographs and to investigate the best effective fold of data augmentation.
Materials and methods
The total of 1800 M3M cropped images were classified evenly into contact and no-contact. The contact group was confirmed with CBCT images. The models were trained from three pretrained models: AlexNet, VGG-16, and GoogLeNet. Each pretrained model was trained with the original cropped panoramic radiographs. Then the training images were increased fivefold, tenfold, 15-fold, and 20-fold using data augmentation to train additional models. The area under the receiver operating characteristic curve (AUC) of the 15 models were evaluated.
Results
All models recognized contiguity with AUC from 0.951 to 0.996. Ten-fold augmentation showed the highest AUC in all pretrained models; however, no significant difference with other folds were found. VGG-16 showed the best performance among pretrained models trained at the same fold of augmentation. Data augmentation provided statistically significant improvement in performance of AlexNet and GoogLeNet models, while VGG-16 remained unchanged.
Conclusions
Based on our images, all models performed efficiently with high AUC, particularly VGG-16. Ten-fold augmentation showed the highest AUC by all pretrained models. VGG-16 showed promising potential when training with only original images.
Clinical relevance
Ten-fold augmentation may help improve deep learning models’ performances. The variety of original data and the accuracy of labels are essential to train a high-performance model.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The removal of the impacted teeth, especially the mandibular third molars (M3Ms), is one of the most common dental surgeries. One important structure near the M3M is the inferior alveolar canal (IAC) which contains the inferior alveolar nerve (IAN). Damaging the IAN during M3M removal process may lead to permanent neurosensory impairments of the innervated areas, including lower anterior teeth, lower lip, and chin, affecting patients’ quality of life [1].
Two-dimensional panoramic radiography is a common pre-operative technique to assess the close proximity between M3M and IAC [2,3]. Darkening of the root [4,5,6,7], narrowing of the root [4], interruption of the white line [5,6,7,8], and diversion of the IAC [4,7] are examples of risk signs spotted in the panoramic radiograph. The risk signs can be subjective among observers and difficult for inexperienced dentists to observe [9]. This could impact the referral decision by the newly graduated dentist who could be the only dentist positioned in the rural hospital of developing countries.
Three-dimensional images obtained from cone beam computed tomography (CBCT) can distinctively show a clear view of the position and proximity of the M3M and the IAC [6,8,10,11,12]. However, this comes at the price of high costs and unavailability in rural hospitals. Recently, machine learning has been widely applied to the assessment of medical images due to its ability to learn and extract image features without being specifically programmed [13,14,15]. One of the most notable machine learning methods is the application of deep learning (DL) models using convolutional neural networks (CNNs), which have shown high diagnostic performance in analyzing radiographic images [16].
DL has been applied in the detection, classification, and segmentation of the M3M and the IAC. The results showed that DL is highly potential to be used in the clinical workflow [17]. The diagnostic performance of three different DL models was studied to classify the relationship between the M3M and the IAC from panoramic radiographs [18]. Four hundred panoramic radiographs have been used to train the models with help of data augmentation [18]. Although all models showed high performance with the highest area under the receiver operating characteristic curve (AUC) values ranging from 0.88 to 0.93, the contact between the M3M and the IAC was not confirmed by CBCT in their study. This may lead to unexpected uncertainty in the model as many case studies showed that signs of contiguity on the panoramic radiograph did not always represent true contact between M3M and IAC [11,19,20]. This study also performed data augmentation, which is a common technique that help improve the generalizability and accuracy of the small dataset [21]. However, the study did not give an idea of how many numbers of the M3Ms should be augmented to achieve the best possible DL model.
To improve the reliability and accuracy of the panoramic radiographs used in model training, confirmation with CBCT images is desirable. In addition, it is commonly considered that DL model needs a large amount of data to train an efficient model. Although data augmentation is found to be beneficial to increase the number of data [21], designing augmented medical images that indeed preserved their labels may be computationally expensive and may take more time for the training process [22]. Therefore, the suitable number of augmented images should be studied. The aims of this study were to train DL models for automated recognition of contiguity between the M3M and the IAC from panoramic radiographs after confirming the proximity between those structures with CBCT images and to investigate the best effective fold of data augmentation to train a DL model.
Materials and methods
All procedures were performed in accordance with the Declaration of Helsinki and the regulations approved by the Institutional Review Board from the Faculty of Dentistry/Faculty of Pharmacy, Mahidol University (CoA no. 2021/079.0109).
Panoramic radiography and cone beam computed tomography (CBCT)
The panoramic radiographs were obtained from 1430 patients who were referred for the radiographic examination of the M3M at the Oral and Maxillofacial Radiology clinic, Faculty of Dentistry, Mahidol University, Thailand, between January 2013 to July 2021. These number of patients included those with only one M3M on the right or the left side of the mandible and those with two M3Ms, one on each side of the mandible. Among 1430 patients, 700 patients contained both panoramic radiographs and CBCT images. The panoramic radiographs were taken with a CS9000C machine (Carestream Health, Inc., New York, USA) with a tube voltage of 68–70 kV, tube current of 8–10 mA, and exposure time of 15.1 s. The CBCT images were taken with a 3D Accuitomo 170 machine (J Morita Mfg. Corp., Kyoto, Japan) with a tube voltage of 90 kV, tube current of 5 mA, and exposure time of 17.5 s. All the CBCT images were used regardless of the voxel sizes (i.e., 0.125 mm., 0.160 mm., and 0.250 mm.). The CBCT images were used to confirm the correlation between the risk signs on panoramic radiographs and direct contact on the CBCT images. The CBCT images must cover the entire root formation of the M3M and reveal its relationship to the IAC and be taken within 6 months of the panoramic radiographs.
Classification of the M3M and IAC on panoramic radiographs
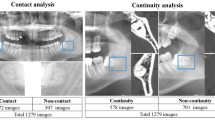
The panoramic radiographs were classified into three groups according to the presence of contiguity between the M3M and the IAC. Group I represented direct contact of the M3M on both panoramic radiographs and CBCT images. This group showed at least one risk sign on panoramic radiographs and no trabecular bone or marrow space between the M3M and the IAC on CBCT images (Fig. 1a, Fig. 1b). Group II clearly presented trabecular bone or marrow space between the M3M and the IAC on panoramic radiographs (Fig. 1c). Thus, it is not necessary to use CBCT images to confirm no contact in Group II. Group III is for false contact, which showed sign of contiguity on panoramic radiographs but no contact on CBCT images (Fig. 1d, Fig. 1e).

Examples of panoramic radiographs and CBCT images of mandibular third molars (M3Ms) used to evaluate the interrater and intrarater reliability. Panels a and b show a panoramic radiograph and a CBCT image in Group I, which illustrates direct contact between the M3M and the inferior alveolar canal (IAC). Panel c is a panoramic radiograph in Group II that clearly shows no contact. Panels d and e are a panoramic radiograph and a CBCT image from Group III, which shows sign of contiguity only on the panoramic radiograph. Arrows in panels b and e indicate the cross-sectional IAC
Reliability test for group labelling
The group classification mentioned in the previous section was performed by D.P., a postgraduate student in oral and maxillofacial radiology. The reliability of data labelling was evaluated by cross-classification between D.P. and W.W., the oral and maxillofacial radiologist with 14-year experience. Ninety radiographs used in cross-classification were selected randomly and equally for each group by S.P., an oral and maxillofacial radiologist with 25-year experience. D.P. and W.W. independently carried out the classification twice in the two-week interval on the identical monitor with a resolution of 2560 × 1600 under dim light. The interrater and intrarater reliability showed perfect agreement with Cohen’s kappa of κ = 1.0 in both cases.
Collection of panoramic radiographs
The inclusion criteria were the panoramic radiographs that presented the complete root formation of the M3M and revealed its relationship to the IAC. The exclusion criteria were the panoramic radiographs showing abnormalities or artefacts in the targeting region, showing an untraceable border of IAC at the area of M3M, and those showing false contact in Group III due to a very limited number of images. We began with studying 700 patients which contained both panoramic radiographs and CBCT images. We were able to include the total of 900 M3Ms in Group I—direct contact on both panoramic radiographs and CBCT images. This was the maximum number of M3Ms that could be collected according to the criteria of Group I. Then, we randomly selected an equal number of 900 M3Ms for Group II—no contact on panoramic radiographs. As a result, we have a final sample of 1800 M3Ms included in Groups I and II.
Preparation of image sets
The radiographs were exported to Joint Photographic Experts Group (JPEG) format and cropped to the region of interest following the methods by Fukuda et al. [18]. The radiographs were exported with the highest quality setting of 1024 × 518 pixels and manually cropped using the Fiji program (Fiji, RRID:SCR_002285) [23]. Figure 2 shows the panoramic radiographs, which were manually cropped, mimicking the area that dentists focus on when they interpret these structures, into 70 × 70 pixels image patches centering at root apices of the M3Ms and IAC [18]. The 900 image patches in each group were randomly separated into three sets of 720, 90, and 90 images for the training, validation, and test sets, respectively [24].

Image preparation. Left (a and c) and right (b and d) panels show the panoramic radiographs and 70 × 70-pixel cropped images centering at root apices between the mandibular third molar and IAC. Top panels (a and b) show an example from Group I, while the bottom panels (c and d) represent Group II
Training deep learning models
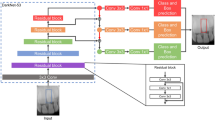
We used a transfer learning technique where pretrained CNNs were used as the starting point for our models [25]. Three highly acknowledged pretrained CNNs, AlexNet, VGG-16, and GoogLeNet, were used for training. AlexNet is a deep CNN that won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012 for its profound ability in natural image classification [26]. VGG-16 is a deep CNN developed in 2014 and well-known for the uniformity of its architecture. VGG-16 was designed based on the same principles as AlexNet but with more layers [27]. In other words, AlexNet contains 8 layers, while there are 16 layers in VGG-16. GoogLeNet, also known as Inception, was the winner model of the ILSVRC in 2014. Although it consisted of 22 layers deeper than previous models, it was designed to reduce a great number of parameters that help reduce the computational cost [28].
The pretrained CNNs were trained by using the FastAi library on Google Colaboratory [29]. FastAi is a high-level DL library built on PyTorch. It provides several sets of codes that practitioners can implement in various fields. Google Colaboratory is an online coding platform that allows writing and executing codes through a web browser. It also provides access to computational resources, including cloud graphic processing units (GPU).
The training processes were divided into 2 rounds with only original images and with a data augmentation technique. We began the first round by training each of the three pretrained models with 1440 original image patches from the training sets; i.e., 720 images each for groups I and II. The learning rate was set at the default value of 0.001 for 1000 epochs. During training, the optimal number of iterations was selected by evaluating the accuracy from the prediction of 180 (90 × 2) image patches in the validation sets. The model was saved when the accuracy reached the optimum value with no improvement in the following twenty training iterations. The second training round was carried out with data augmentation to increase the number of image patches in the training data sets. Image augmentation techniques included horizontal flip, rotation, magnification, warp, brightness, and contrast adjustment (Fig. 3). All mentioned augmentation techniques were applied on every original image patch through FastAi library. We randomly selected image patches from each augmentation technique and created four new training sets: fivefold (7,200 images), tenfold (14,400 images), 15-fold (21,600 images), and 20-fold (28,800 images). The number of training images in parentheses also included the 1440 original images.

Examples of data augmentation techniques. The original image is shown in panel a. Panels b–g demonstrate augmentation techniques using horizontal flip, rotation, magnification, warp, brightness adjustment, and contrast adjustment, respectively
Assessment of the diagnostic performance
The diagnostic performance of each trained model was evaluated by 180 (90 × 2) image patches in the test set. We defined the contact between M3M and IAC as positive, whereas no contact is negative. The receiver operating characteristic (ROC) curves were constructed, and the threshold of the prediction values for each model was determined by the Youden index [30]. Sensitivity, specificity, and accuracy were calculated at these thresholds. The summary of prediction results was presented in confusion matrices consisting of true positive (TP), false negative (FN), false positive (FP), and true negative (TN). The area under the ROC curve (AUC) was used as the main metric to evaluate the overall classifier performances of the models.
The statistical analyses were performed with MedCalc Statistical Software version 20.110 (MedCalc, RRID:SCR_015044). A comparison of the AUC among the models trained with only original images and among the models trained from the same pretrained models was performed by using the method of DeLong et al. (1988) [31].
Results
Figure 4 shows the confusion matrices of all 15 models. As mentioned above, we have trained 3 pretrained models with each set of data, and we have one original data set and 4 sets of augmented data. The number of models is thus 15. The confusion matrix presented four values: TP, FN, FP, and TN. In general, all models correctly classified most of the test images into Group I (positive) or Group II (negative), as shown by the high TP and TN values. It is crucial not to misidentify Group I due to its higher risk of nerve injury; therefore, a low FN value is preferable. Based on the importance in predicting Group I correctly, VGG-16 predicted the least overall wrong images (FN + FP = 11) compared to AlexNet (FN + FP = 16), and GoogLeNet (FN + FP = 20). With data augmentation, the wrong predictions in Group I (FN) decrease significantly in all models, while it is marginal in the case of Group II wrong prediction (FP).

Confusion matrices of all 15 models. The Top, middle, and bottom rows are for AlexNet, VGG-16, and GoogLeNet. Columns from left to right are confusion matrices of the model with the original data set and the models with increasing numbers of trained images, including fivefold (5 ×), tenfold (10 ×), 15-fold (15 ×), and 20-fold (20 ×) increase. True positive, false negative, false positive, and true negative are shown in the top left, top right, bottom left, and bottom right cells of each matrix, respectively
Table 1 shows the sensitivity, specificity, and accuracy. The model with high sensitivity is good at identifying most of the contact cases correctly, which is essential in identifying the patient who potentially has a harmful situation of the M3M and the IAC being contiguous. The high-specificity model is good at avoiding false recognition of no-contact cases. The model with high accuracy correctly classifies most of the cases to the correct group.
Performance comparison among pretrained models with an identical number of data
Among the three models trained with the 1440 original images of M3Ms, VGG-16 showed the best overall performance with the highest AUC of 0.981 followed by AlexNet and GoogLeNet with AUC of 0.956 and 0.951, respectively (Table 1). The statistical analysis with MedCalc showed that the AUC of the VGG-16 model was better than that of GoogLeNet significantly with P < 0.05. However, there was no significant difference in AUC values between VGG-16 and AlexNet (AUCVGG-16: 0.981 versus AUCAlexNet: 0.956, P = 0.0574) and between AlexNet and GoogLeNet (AUCAlexNet: 0.956 versus AUCGoogLeNet: 0.951, P = 0.7832). Similarly, the ROC curves shown in Fig. 5 suggest that the VGG-16 model has the greatest discriminate capacity among the three models, followed by AlexNet and GoogLeNet, respectively.

Receiver operating characteristic (ROC) curves of three different models trained with only original images. Solid, dotted, and dashed lines represent ROC curves of AlexNet, VGG-16, and GoogLeNet, respectively
When comparing AlexNet, VGG-16, and GoogLeNet trained with the same number of augmented images, we found that VGG-16 has the highest AUC values among the three models in all cases but fivefold, where AlexNet has a bit higher AUC (Table 1). However, there are no statistical differences in AUC values among the AlexNet, VGG-16, and GoogLeNet models.
Performance comparison within pretrained models with different folds of data augmentation
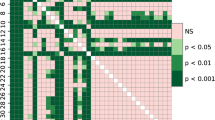
The AUC comparison of the models trained to distinguish between Group I and Group II is shown in Fig. 6. Within a pretrained CNN, the model trained with data set ten times larger than the original one showed the highest AUC, although the AUC values are not significantly different from the models trained with different numbers of augmented data. In contrast, if we compare the performance of models trained with only original images and with augmented images in different folds, the performance of AlexNet and GoogLeNet models improved significantly with P < 0.05 when increasing the number of images with data augmentation (AlexNet; AUCAlexNet: 0.956 versus AUCAlexNet 5x: 0.994, AUCAlexNet: 0.956 versus AUCAlexNet 10x: 0.995, AUCAlexNet: 0.956 versus AUCAlexNet 15x: 0.989, AUCAlexNet: 0.956 versus AUCAlexNet 20x: 0.988 (Fig. 6a, Table 1), and GoogLeNet; AUCGoogLeNet: 0.951 versus AUCGoogLeNet 5x: 0.982, AUCGoogLeNet: 0.951 versus AUCGoogLeNet 10x: 0.990, AUCGoogLeNet: 0.951 versus AUCGoogLeNet 15x: 0.987, AUCGoogLeNet: 0.951 versus AUCGoogLeNet 20x: 0.985 (Fig. 6c, Table 1)). However, increasing the number of images did not affect the performance of VGG-16 models, as shown in Fig. 6b and Table 1.

Bar graphs showing the area under the ROC curves (AUC) of models trained with five different data sets. Panels a, b, and c are the results of AlexNet, VGG-16, and GoogLeNet, respectively. In each panel, the left-to-right bar graph shows the AUC of models trained with the original data set and with the increasing numbers of trained images. Asterisks in panels a and c indicate the statistically significant differences between the AUC of the models trained with the original images and those with augmented images with P < 0.05
Discussion
One aim of this study was to train DL models to recognize contiguity between the M3M and the IAC from panoramic radiographs. We selected not only one specific model but three different pretrained CNNs. All three models that are AlexNet, VGG-16, and GoogLeNet have shown good diagnostic performances as seen by the high sensitivity, specificity, accuracy, and AUC values. This study also supports the promising potential of DL models in evaluating the M3Ms and the IAC, similar to the previous studies [17,18,32,33].
We focused on preparing a highly accurate data. We assessed the relationship between the M3M and the IAC from CBCT images in every case in Group I to confirm our labels. We also collected up to 1800 original cropped images of M3Ms. This represents an excellent variety of M3Ms on panoramic radiographs; for instance, variation of the position or shape of the M3M, the various relationships between the M3M and the IAC, different densities of the surrounding bone, or various brightness or contrast of the radiographs. The accuracy of our labels and the great number and variety of our original images may lead to the higher AUC of the models when compared with the previous study [18]. Thus, to train an efficient DL model for medical image classification, the variety of the original data collected from the patients and the accurate labels annotated by the medical experts are crucial [24].
With only original data, we obtained the highest accuracy with the VGG-16 model, whereas AlexNet and GoogLeNet showed comparable accuracy (Fig. 6). As seen in Fig. 5, the ROC curves of AlexNet and VGG-16 showed a comparable ability to recognize the contiguity between the M3M and IAC. This is probably due to the similar concept of both models. VGG-16 improved the performance by increasing depth with multiple smaller-size (3 × 3) convolutional filters [27]. Meanwhile, GoogLeNet introduced the inception network where different sizes of convolutional filters are placed at the same level [28]. Kernels with different sizes are suitable and very effective for images containing various sizes of features. However, GoogLeNet could not give the best performance among the three pretrained models for our data set (Table 1). GoogLeNet may be more suitable for images with more details, unlike our cropped panoramic radiographs. Our results may suggest that the selection of the pretrained CNN can be determined by the nature of the data [34].
This is one of the first studies to investigate the effect of different folds of data augmentation on the diagnostic performance of the DL model in evaluating the M3Ms. We also compared the diagnostic performance of the models with those trained with the original data set. Although there was no significant difference compared with other fold of data augmentation, all three pretrained models showed the highest AUC values by training with tenfold (10 ×) data augmentation. Therefore, 10 × increase in the number of training data could possibly create an efficient DL model for a classification task involving M3Ms.
Interestingly, using only several original images with accurate labels could train an efficient DL model. Data augmentation obviously enhances the models’ performances since AlexNet and GoogLeNet were significantly improved when increasing the number and variety of images, even with fivefold data augmentation. However, the performance of VGG-16 trained without data augmentation was comparable with those using data augmentation. This suggested that either the number of our original images with accurate labels has already represented a significant variety of data to enhance models’ performances, or the number of original images is already saturated for VGG-16.
We have collected the panoramic radiographs from all patients who were also referred for CBCT to evaluate the M3M region from our database; however, it may not represent the optimum sample size for deep learning models. A recent systemic review emphasized the paucity of studies that determined the appropriate size of the training set for DL models and suggested the need for more studies focusing on the sample sizes [35]. The use of proper techniques for data augmentation showed promising potential in training well−performed models [[[22,36,37]]]. However, from our result, it may not always be necessary. Further investigation of the optimum number of images necessary for training models should be conducted in the future study.
One limitation of this study is that we only used retrospective data from a single institution in both training and testing. Therefore, a prospective study using original images from various sources should be conducted. Moreover, federated learning could promote using multi-institutional data by sharing the model’s parameter trained from individual data instead of sharing the patient data directly [38,39].
Excluding all the radiographs showing abnormalities, artefacts, or those showing an unclear relationship between the M3M and IAC may affect the model’s performance in real-world clinical settings. We also excluded the panoramic radiographs that showed false contact (Group III); however, recognizing these radiographs would benefit clinical settings since it is difficult to notice even by experienced observers. We decided to exclude the panoramic radiographs in Group III, showing false contact, because a very limited number of images (fewer than 100 cases) could be obtained. When training with only original images, including Group III could possibly create bias from a class imbalance that favors the prediction of Group I and II [40,41]. Our further study will certainly focus more on these excluded radiographs, especially those in Group III, to make the clinical application of the model possible.
The validation sets splitting remained constant across the training process of all models. The test set also remained constant for the evaluation of the models’ performances [42]. This eliminated the difference in the performance among models that may be caused by the variability in the validation set and test set. However, the ratio of the number of training images to the validation images was different among five conditions (no augmentation, fivefold, tenfold, 15-fold, and 20-fold). This may have affected the results of our study and can be considered as another limitation of our study [43].
There are many prospects to develop our models. Training the models with only images indicated that the models considered only information from pixel data. However, most practitioners evaluate the radiograph along with considering other clinical information for a better diagnosis. DL models, similar to practitioners, also learn better with more information provided [44,45]. Additional clinical information could be given with the radiographs in the training process.
We also consider developing an end-to-end learning model as a final product that could automatically classify the panoramic radiographs in the DICOM file from the machine. We will further investigate whether cropping panoramic radiographs necessarily improves the model’s performance. Additional data on the bucco-lingual relationship between the M3M and IAC will also be collected to improve the clinical usefulness of the model for surgical planning. We aim to further develop the model as an assistant diagnostic tool to help confirm the dentists’ decision on whether to refer the case for CBCT investigation, particularly the referral of patients from a rural hospital to a provincial hospital. This confirmation can help assure that the referral does not unnecessarily cost the patient time and money.
Conclusion
All 15 models showed good performance in recognizing contiguity between the M3M and IAC on panoramic radiographs with the AUC ranging from 0.951 to 0.996. Within pretrained models, a 10 × of training data augmentation showed the highest AUC values in all three models. However, there were no significant difference when compared with fivefold, 15-fold, and 20-fold data augmentation. Among pretrained models, VGG-16 mainly showed the best performance when training with the same fold of data augmentation. VGG-16 also showed the best performance among models trained only with 1440 (720 × 2) original images and showed comparable results with and without data augmentation. A variety of the original images with accurate labels may be sufficient to train a well-performed model using VGG-16.
References
Valmaseda-Castellón E, Berini-Aytés L, Gay-Escoda C (2001) Inferior alveolar nerve damage after lower third molar surgical extraction: a prospective study of 1117 surgical extractions. Oral Surg Oral Med Oral Pathol Oral Radiol Endod 92:377–383. https://doi.org/10.1067/moe.2001.118284
Blaeser BF, August MA, Donoff RB, Kaban LB, Dodson TB (2003) Panoramic radiographic risk factors for inferior alveolar nerve injury after third molar extraction. J Oral Maxillofac Surg 61:417–421. https://doi.org/10.1053/joms.2003.50088
Flygare L, Ohman A (2008) Preoperative imaging procedures for lower wisdom teeth removal. Clin Oral Investig 12:291–302. https://doi.org/10.1007/s00784-008-0200-1
Uzun C, Sumer AP, Sumer M (2020) Assessment of the reliability of radiographic signs on panoramic radiographs to determine the relationship between mandibular third molars and the inferior alveolar canal. Oral Surg Oral Med Oral Pathol Oral Radiol 129:260–271. https://doi.org/10.1016/j.oooo.2019.09.008
Neves FS, Souza TC, Almeida SM, Haiter-Neto F, Freitas DQ, Bóscolo FN (2012) Correlation of panoramic radiography and cone beam CT findings in the assessment of the relationship between impacted mandibular third molars and the mandibular canal. Dentomaxillofac Radiol 41:553–557. https://doi.org/10.1259/dmfr/22263461
Elkhateeb SM, Awad SS (2018) Accuracy of panoramic radiographic predictor signs in the assessment of proximity of impacted third molars with the mandibular canal. J Taibah Univ Med Sci 13:254–261. https://doi.org/10.1016/j.jtumed.2018.02.006
Ghaeminia H, Meijer GJ, Soehardi A, Borstlap WA, Mulder J, Bergé SJ (2009) Position of the impacted third molar in relation to the mandibular canal. Diagnostic accuracy of cone beam computed tomography compared with panoramic radiography. Int J Oral Maxillofac Surg 38:964–971. https://doi.org/10.1016/j.ijom.2009.06.007
Tantanapornkul W, Mavin D, Prapaiphittayakun J, Phipatboonyarat N, Julphantong W (2016) Accuracy of panoramic radiograph in assessment of the relationship between mandibular canal and impacted third molars. Open Dent J 10:322–329. https://doi.org/10.2174/1874210601610010322
Sedaghatfar M, August MA, Dodson TB (2005) Panoramic radiographic findings as predictors of inferior alveolar nerve exposure following third molar extraction. J Oral Maxillofac Surg 63:3–7. https://doi.org/10.1016/j.joms.2004.05.217
Ohman A, Kivijarvi K, Blombäck U, Flygare L (2006) Pre-operative radiographic evaluation of lower third molars with computed tomography. Dentomaxillofac Radiol 35:30–35. https://doi.org/10.1259/dmfr/58068337
Suomalainen A, Ventä I, Mattila M, Turtola L, Vehmas T, Peltola JS (2010) Reliability of CBCT and other radiographic methods in preoperative evaluation of lower third molars. Oral Surg Oral Med Oral Pathol Oral Radiol Endod 109:276–284. https://doi.org/10.1016/j.tripleo.2009.10.021
Neugebauer J, Shirani R, Mischkowski RA, Ritter L, Scheer M, Keeve E, Zoller JE (2008) Comparison of cone-beam volumetric imaging and combined plain radiographs for localization of the mandibular canal before removal of impacted lower third molars. Oral Surg Oral Med Oral Pathol Oral Radiol Endod 105:633–642. https://doi.org/10.1016/j.tripleo.2007.08.041
Fu GS, Levin-Schwartz Y, Lin QH, Zhang D (2019) Machine learning for medical imaging. J Healthc Eng 2019:9874591. https://doi.org/10.1155/2019/9874591
Lundervold AS, Lundervold A (2019) An overview of deep learning in medical imaging focusing on MRI. Z Med Phys 29:102–127. https://doi.org/10.1016/j.zemedi.2018.11.002
Puttagunta M, Ravi S (2021) Medical image analysis based on deep learning approach. Multimed Tools Appl 80:24365–24398. https://doi.org/10.1007/s11042-021-10707-4
Yasaka K, Akai H, Kunimatsu A, Kiryu S, Abe O (2018) Deep learning with convolutional neural network in radiology. Jpn J Radiol 36:257–272. https://doi.org/10.1007/s11604-018-0726-3
Kwak GH, Kwak EJ, Song JM, Park HR, Jung YH, Cho BH, Hui P, Hwang JJ (2020) Automatic mandibular canal detection using a deep convolutional neural network. Sci Rep 10:5711. https://doi.org/10.1038/s41598-020-62586-8
Fukuda M, Ariji Y, Kise Y, Nozawa M, Kuwada C, Funakoshi T, Muramatsu C, Fujita H, Katsumata A, Ariji E (2020) Comparison of 3 deep learning neural networks for classifying the relationship between the mandibular third molar and the mandibular canal on panoramic radiographs. Oral Surg Oral Med Oral Pathol Oral Radiol 130:336–343. https://doi.org/10.1016/j.oooo.2020.04.005
Rodriguez YBR, Beltrami R, Tagliabo A, Rizzo S, Lupi SM (2017) Differences between panoramic and cone beam-CT in the surgical evaluation of lower third molars. J Clin Exp Dent 9:e259–e265. https://doi.org/10.4317/jced.53234
Ghaeminia H, Meijer GJ, Soehardi A, Borstlap WA, Mulder J, Vlijmen OJ, Bergé SJ, Maal TJ (2011) The use of cone beam CT for the removal of wisdom teeth changes the surgical approach compared with panoramic radiography: a pilot study. Int J Oral Maxillofac Surg 40:834–839. https://doi.org/10.1016/j.ijom.2011.02.032
Moreno-Barea FJ, Jerez JM, Franco L (2020) Improving classification accuracy using data augmentation on small data sets. Expert Syst Appl 161:113696. https://doi.org/10.1016/j.eswa.2020.113696
Shorten C, Khoshgoftaar TM (2019) A survey on image data augmentation for deep learning. J Big Data 6:1–48. https://doi.org/10.1186/s40537-019-0197-0
Schindelin J, Arganda-Carreras I, Frise E, Kaynig V, Longair M, Pietzsch T, Preibisch S, Rueden C, Saalfeld S, Schmid B, Tinevez J-Y, White DJ, Hartenstein V, Eliceiri K, Tomancak P, Cardona A (2012) Fiji: an open-source platform for biological-image analysis. Nat Methods 9:676–682. https://doi.org/10.1038/nmeth.2019
Willemink MJ, Koszek WA, Hardell C, Wu J, Fleischmann D, Harvey H, Folio LR, Summers RM, Rubin DL, Lungren MP (2020) Preparing medical imaging data for machine learning. Radiology 295:4–15. https://doi.org/10.1148/radiol.2020192224
Weiss K, Khoshgoftaar TM, Wang D (2016) A survey of transfer learning. J Big Data 3:9. https://doi.org/10.1186/s40537-016-0043-6
Krizhevsky A, Sutskever I, Hinton GE (2017) ImageNet classification with deep convolutional neural networks. Commun ACM 60:84–90. https://doi.org/10.1145/3065386
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. Proceedings of 3rd International Conference on Learning Representations. ICLR, New York, pp 1–14. https://doi.org/10.48550/arXiv.1409.1556
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2016) Going deeper with convolutions. Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, California, pp 1–9. https://doi.org/10.48550/arXiv.1409.4842
Howard J, Gugger S (2020) Fastai: a layered API for deep learning. Information 11:108. https://doi.org/10.3390/info11020108
Youden WJ (1950) Index for rating diagnostic tests. Cancer 3:32–35. https://doi.org/10.1002/1097-0142(1950)3:1%3c32::AID-CNCR2820030106%3e3.0.CO;2-3
DeLong ER, DeLong DM, Clarke-Pearson DL (1988) Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44:837–845. https://doi.org/10.2307/2531595
Jaskari J, Sahlsten J, Jarnstedt J, Mehtonen H, Karhu K, Sundqvist O, Hietanen A, Varjonen V, Mattila V, Kaski K (2020) Deep learning method for mandibular canal segmentation in dental cone beam computed tomography volumes. Sci Rep 10:5842. https://doi.org/10.1038/s41598-020-62321-3
Vinayahalingam S, Xi T, Berge S, Maal T, de Jong G (2019) Automated detection of third molars and mandibular nerve by deep learning. Sci Rep 9:9007. https://doi.org/10.1038/s41598-019-45487-3
D’souza RN, Huang P-Y, Yeh F-C (2020) Structural analysis and optimization of convolutional neural networks with a small sample size. Sci Rep 10:834. https://doi.org/10.1038/s41598-020-57866-2
Balki I, Amirabadi A, Levman J, Martel AL, Emersic Z, Meden B, Garcia-Pedrero A, Ramirez SC, Kong D, Moody AR, Tyrrell PN (2019) Sample-size determination methodologies for machine learning in medical imaging research: a systematic review. Can Assoc Radiol J 70:344–353. https://doi.org/10.1016/j.carj.2019.06.002
Chlap P, Min H, Vandenberg N, Dowling J, Holloway L, Haworth A (2021) A review of medical image data augmentation techniques for deep learning applications. J Med Imaging Radiat Oncol 65:545–563. https://doi.org/10.1111/1754-9485.13261
Mikołajczyk A, Grochowski M (2018) Data augmentation for improving deep learning in image classification problem. International Interdisciplinary PhD Workshop (IIPhDW 2018). IEEE, New Jersey, pp 117–122. https://doi.org/10.1109/IIPHDW.2018.8388338
Adnan M, Kalra S, Cresswell JC, Taylor GW, Tizhoosh HR (2022) Federated learning and differential privacy for medical image analysis. Sci Rep 12:1953. https://doi.org/10.1038/s41598-022-05539-7
Xu J, Glicksberg BS, Su C, Walker P, Bian J, Wang F (2021) Federated learning for healthcare informatics. J Healthc Inform Res 5:1–19. https://doi.org/10.1007/s41666-020-00082-4
Gianfrancesco MA, Tamang S, Yazdany J, Schmajuk G (2018) Potential biases in machine learning algorithms using electronic health record data. JAMA Intern Med 178:1544–1547. https://doi.org/10.1001/jamainternmed.2018.3763
Tasci E, Zhuge Y, Camphausen K, Krauze AV (2022) Bias and class imbalance in oncologic data-towards inclusive and transferrable AI in large scale oncology data sets. Cancers (Basel) 14. https://doi.org/10.3390/cancers14122897
Schwendicke F, Singh T, Lee JH, Gaudin R, Chaurasia A, Wiegand T, Uribe S, Krois J (2021) Artificial intelligence in dental research: checklist for authors, reviewers, readers. J Dent 107:103610. https://doi.org/10.1016/j.jdent.2021.103610
Singh V, Pencina M, Einstein AJ, Liang JX, Berman DS, Slomka P (2021) Impact of train/test sample regimen on performance estimate stability of machine learning in cardiovascular imaging. Sci Rep 11:14490. https://doi.org/10.1038/s41598-021-93651-5
Kwon YJF, Toussie D, Finkelstein M, Cedillo MA, Maron SZ, Manna S, Voutsinas N, Eber C, Jacobi A, Bernheim A, Gupta YS, Chung MS, Fayad ZA, Glicksberg BS, Oermann EK, Costa AB (2020) Combining initial radiographs and clinical variables improves deep learning prognostication in patients with COVID-19 from the emergency department. Radiol Artif Intell 3:200098. https://doi.org/10.1148/ryai.2020200098
Khan IU, Aslam N, Anwar T, Alsaif HS, Chrouf SMB, Alzahrani NA, Alamoudi FA, Kamaleldin MMA, Awary KB (2022) Using a deep learning model to explore the impact of clinical data on COVID-19 diagnosis using chest x-ray. Sensors (Basel) 22:669. https://doi.org/10.3390/s22020669
Funding
Partial financial support for the graduate student thesis (Dhanaporn Papasratorn) was received from the Faculty of Graduate Studies and Graduate Studies of Mahidol University Alumni Association.
Author information
Authors and Affiliations
Contributions
The conceptualization of the work was performed by Dhanaporn Papasratorn and Suraphong Yuma. The contribution to the design of data acquisition and methodology was performed by Suchaya Pornprasertsuk-Damrongsri and Warangkana Weerawanich. Request for ethical approval was performed by Suchaya Pornprasertsuk-Damrongsri. Data curation and investigation were carried out by Dhanaporn Papasratorn, Suchaya Pornprasertsuk-Damrongsri, and Warangkana Weerawanich. Programming and validation were performed by Dhanaporn Papasratorn and Suraphong Yuma. Suraphong Yuma contributed as an Essential Intellectual Contributor and was responsible for the revision of critical content. The first draft of the manuscript was written by Dhanaporn Papasratorn, and all authors commented and edited on previous versions of the manuscript. The investigation of accuracy in all aspects of the work was performed by Suraphong Yuma and Warangkana Weerawanich. Warangkana Weerawanich contributed as a corresponding author and was responsible for the final approval of the version to be published.
Corresponding author
Ethics declarations
Ethical approval
All procedures were performed in accordance with the Declaration of Helsinki and the regulations approved by the Institutional Review Board from the Faculty of Dentistry/Faculty of Pharmacy, Mahidol University (CoA no. 2021/079.0109).
Informed consent
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Papasratorn, D., Pornprasertsuk-Damrongsri, S., Yuma, S. et al. Investigation of the best effective fold of data augmentation for training deep learning models for recognition of contiguity between mandibular third molar and inferior alveolar canal on panoramic radiographs. Clin Oral Invest 27, 3759–3769 (2023). https://doi.org/10.1007/s00784-023-04992-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00784-023-04992-6