
Abstract
Missing data is a common problem in all scientific research, and the availability of gap-free data is rare in most developing countries. Statistical and empirical methods are the most often used for the approximation of missing data. The performance of eight missing estimation methods was evaluated using PBIAS, RMSE, and NSE for stations located in the rift-bounded lakes system of Katar and Meki subbasins in Ethiopia. The multicriteria decision method of compromise programming was used to identify the best imputation method. Four homogeneity test methods were used to evaluate the homogeneity of the time series data. The Mann–Kendall trend test and Son’s slope were used to locate the change and calculate the magnitude of the trend. Multiple linear regression and multiple imputation by chained equations were well performed at most stations. Alternatively, the modified version of IDWM based on spatial distance and elevation difference (IDWME&D3 for k=3) was ranked third at many stations. The inclusion of elevation differences between stations has improved the capability of the inverse distance weight method. However, the performance of all the missing estimation methods decreased as the percentage of missing data increased. Radius influences have no significant impact on the performance of missing imputation methods. Only Butajera station exhibited nonhomogeneity. Dagaga, Iteya, Bui, and Butajera stations all exhibited decreasing trends. Kulumsa and Ejerese-Lele stations presented an increasing trend in monthly rainfall. However, the rest station has shown no significant increasing or decreasing trends in monthly rainfall.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Missing data is a common problem in all scientific research, project planning, and the development of water resource infrastructure. It (i) reduces the power and precision of statistical analysis results (Piazza 2011; Houari et al. 2014; Schmitt et al. 2015; Gao et al. 2018); (ii) leads to a biased estimate and draws the wrong conclusion about the relationship between two or more variables (Pigott 2001; Gao et al. 2018; Ekeu-wei et al. 2018; Gao et al. 2018; Teegavarapu et al. 2019). It is very common in hydrology and other related fields to estimate the missed values of a target station from the values of neighboring stations. There are various methods available to approximate the missing value of the target station, and they are grouped as empirical, statistical, and function-fitting methods (Xia et al. 1999; Sattari et al. 2016). Unusually, deleting or substituting missing values by the arithmetic mean or median is used as an alternative method (Peugh and Enders 2004). Modern approaches, including spatial interpolation techniques such as inverse distance weighting average (IDWA), normal ratio (NR), simple arithmetic average (AA), kriging, and co-kriging, are the most widely used techniques in different geographic locations (Hartkamp et al. 1999; Ferrari and Ozak 2014; El Kasri et al. 2018; Barrios et al. 2018). The statistical methods, including correlation coefficient weighting (CCW) and multiple linear regression (MLR), are used alternatively to compute the missing values for the target station (Xia et al. 1999; Barrios et al. 2018). Recently, the advance of big data analysis and the computing power of the computer have created an opportunity for the development of multiple imputation by chained equation (MICE) (Peugh and Enders 2004; Schmitt et al. 2015; Gao et al. 2018).
More than 21 missing estimation methods are available in the scientific literature (Armanuos et al. 2020), and it is very difficult to identify which method is the best for specific geographic locations. Choosing any of the methods among the alternatives depends on the characteristics of the observed variables (Gao et al. 2018), the geographic location and spatial distance between the stations (Barrios et al. 2018), the percentage of missing data (Radi et al. 2015), and the characteristics of the missing mechanism (Rubin 1976; El Kasri et al. 2018). It is very common to use any of the imputation methods based on an individual’s preferences, knowledge, or experience (Hasanpour Kashani and Dinpashoh 2012). But the random use of any missing estimation method without evaluating its performance will increase the error value and reduce the reliability of the statistical results (Ismail and Ibrahim 2017; Barrios et al. 2018; El Kasri et al. 2018).
Recently, research has started to evaluate the ability of missing imputation techniques using statistical metrics. For instance, Barrios et al. (2018) assessed the capability of the five missing estimation techniques and the effect of the radius of influence on the complex topography of central South Chile and discovered that the ANN, MLR, and IDW had produced the lowest errors and were the best technique for bridging the gap of missed monthly rainfall. El Kasri et al. (2018) have evaluated the performance of five imputation methods in the southern Atlas of Morocco and have recommended the Theisen polygon, normal ratio, inverse distance weighted, and multiple imputation methods as the best methods for filling the gap of missed rainfall. Similarly, Ismail and Ibrahim (2017) have recommended the inverse distance-weighted and correlation coefficient methods to fill the data gap. The normal ratio (NR) and multiple imputation (MI) methods are considered the most appropriate methods by Radi et al. (2015) at 5%, 10%, and 20% to represent various cases of missing data percentages. A similar study to this was conducted by Addi et al. (2022) in the river basin in Ghana. The authors evaluated the statistical imputation techniques of mean, regression, multiple imputation by chain equation, k-nearest neighbor, missForest, linear interpolation, hot deck, expectation maximization, Gaussian copula, inverse distance weighting, and kriging methods by artificially adding missing record percentages (5%, 10%, 20%, and 30%) to the entire datasets. The performance of the imputation methods was assessed using the root mean square error, mean absolute error, bias, coefficient of determination, similarity index, and Kolmogorov–Smirnov performance statistics (Addi et al. 2022). They have reported that, based on the performance criteria chosen, the findings were variable. However, regression, PPCA, and missForest imputation methods were the top contenders.
It is very difficult to decide which infilling technique is best suited depending on two to more performance statistics without referring to the criteria on the decision-making process (Armanuos et al. 2020). When many criteria (or objectives) must be taken into account at once, multi-criteria decision-making (MCDM) is one of the most exact ways to make decision (Aruldoss 2013). Multi-criteria decision method was developed by Benjamin Franklin when he published his research on the moral algebra concept (Taherdoost and Madanchian 2023). Since then, the method has been widely used in the fields of engineering (Raju and Nagesh 2014), urban transport (Hajduk 2022), computer science (Pramanik et al. 2021), social science (Pomerol and Barba-Romero 2000), agriculture (Romero and Rehman 2003), healthcare and bioengineering (Ozsahin et al. 2021), hydrology and water resources engineering (Yilmaz and Harmancioglu 2010; Osinowo and Arowoogun 2020; Gebre et al. 2021; Vassoney et al. 2021; Abdullah et al. 2021) to solve complex problems by setting different criteria (Taherdoost and Madanchian 2023). The method allows researchers to consider multiple factors simultaneously and analyze effectively, weigh their importance, and make informed decisions based on a comprehensive evaluation of the problem at hand (Beula and Prasad 2012). For example, Raju and Kumar (2014) used multicriteria decision method (MCDM) to rank the global climate model after evaluating their performances to simulate the climate condition in India. Similarly, the authors of this research (Balcha et al. 2023) applied MCDM of compromise programming to select the best regional climate model (RCM) for the same study area.
All the above-mentioned studies have evaluated the ability of different missing imputation methods, and there are no significant studies reported to consider the problem from a multi-objective perspective or provide a clear approach or criteria to select the best method from a wide range of alternatives for missing data management. Furthermore, the choice of infilling technique may also depend on the intended application of the filled data, and the researchers may need to consider any potential biases or limitations associated with each infilling method before making a final decision. This is more of a series in an area of complex topography, sparsely and unevenly located measuring stations, and specific climate conditions like the Central Rift Valley Lakes subbasin of Ethiopia. For example, stations found at high altitudes have received the highest amounts of rainfall compared to stations at lower altitudes in the study region. Even so, stations located at similar altitudes but in opposite directions, such as Leeward or Windward, have exhibited different agroecology and rainfall amounts. Therefore, to overcome with research gaps the present study seeks to (i) identify performance metrics and assess the performance of eight missing imputation methods; (ii) use a compromise programing method to rank and choose the best imputation method; and (iii) evaluate the homogeneity and trend of the monthly precipitation dataset for selected stations in the study region.
2 Materials and methods
2.1 Description of study area
The Great Rift of the Earth runs from Jordan southward through East Africa to Mozambique (Meshesha et al. 2012). The Ethiopian rift extends from the Kenya border up to the Red Sea and is divided into three subsystems: Chew Bahir (Lake Stephanie), the Central Rift Valley Lakes subbasin, “hereafter referred to as the CRV Lakes subbasin,” and the Afar triangle. The CRV is subdivided into four hydrologically interconnected lakes, namely, Ziway, Langano, Shalla, and Abijata. Ziway Lake is the only freshwater lake among the rest of the lakes and flows into Abijata Lake through the Bulbula River. Two river systems flow into Ziway, namely, the Katar and Meki rivers. The Katar and Meki watersheds are located in the CRV Lakes subbasin of Ethiopia’s Rift Valley Lakes Basin. Geographically, the Katar watershed extends between 38.88° and 39.41° E longitudes and 7.36° and 8.18° N latitudes eastward of Lake Ziway. The Meki watershed is extended between 38.22° and 39.00° E longitude and 7.83° and 8.46° N latitude westward of Lake Ziway. The altitude ranges from 1600 m above mean sea level (a.m.s.l.) on the rift floor near Ziway Lake to 4118 a.m.s.l. in the Katar and Meki subbasins (eastern and western highlands, respectively). The subbasins are subdivided into three topographic zones: the eastern highlands (Arsi Mountains, Wonji fault belt) form the eastern escarpment of the rift system; the western highlands (Guraghe Mountains, Silte-Bishoftu fault zone) form the western escarpment; and the rift floor (Ayenew 2001). The average annual precipitation ranges from 749 to 1276 mm and 712 to 1150 mm, respectively, for the Katar and Meki subbasins (Fig. 1). Average monthly minimum and maximum temperatures in the subbasins range between 13.4 and 14.2 °C and 27.5 and 28.7 °C, respectively, and 24 to 27 °C and 27.5 to 30 °C in the high land areas. According to Hulluka et al. (2023), rainfed agriculture accounts for 76.8% of the area, while irrigated agriculture accounts for less than 3%. Approximately 44% of the existing irrigated area is dependent on surface water from streams, 31% on Lake Ziway directly, and 25% on groundwater wells.

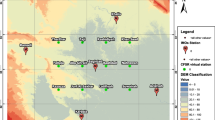
Location of the study area, target station (red star) and neighboring stations (black star). The elevation data extracted from a 30 m resolution of Shuttle Radar Topographic Mission
2.2 Data accusation
2.2.1 Observed data
Monthly observed rainfall data for 22 meteorological stations was collected from the National Meteorology Agency of Ethiopia (ENMA) for the time intervals of January 1997 to December 2017. Exploratory data analysis includes the prescreening of negative values of precipitation, multiple dots between values, and computing the missing percentage and the outlier for each station. Additionally, the spatial distances between stations were calculated to determine the maximum radius of influence. Stations that were more than 40 km away from any other station and had more than 25% missing values been excluded from the analysis. Sixteen meteorological stations were selected in this study for further analysis 1).
2.2.2 Reanalysis data
In Ethiopia, most stations are unevenly located on the main roads of cities and do not provide timely or sufficient data free of missing value. This is causing inhomogeneity, abrupt change, and trends in climate datasets. The reanalysis data has been extensively used as an alternative source of information for the study of climate variability (Dile and Srinivasan 2014; Fuka et al. 2014; Funk et al. 2015; Alhamshry et al. 2020) and to evaluate the ability of regional climate model (RCM) output (Bichet et al. 2020). In this study, the Climate Hazards Group Infrared Precipitation with Station (CHIRPS) was downloaded from http://climateserv.servirglobal.net/site for the time span of 1983–2005 to assess the ability of missing imputation methods. CHIRPS is a quasi-global dataset (covering the area between 50° N and 50° S) available from 1981 to present day at 0.05° spatial resolution (5.3 km), and it is produced using multiple data sources developed to support the US Agency for International Development Famine Early Warning Systems Network (FEWS NET) (Funk et al. 2015).
2.3 Over view of missing data
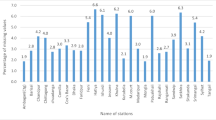
The distribution of missing values in the percentage varies from station to station. The ratio of missing values in percentage for the years considered is displayed in Fig. 2. The percentage of missing observations in the selected stations varies from 0.36 in Kulumsa to 22.1% in Katar G. stations. The study considers different techniques of infilling daily rainfall and compares them to identify the best method for each of the selected stations.

Percentage of missing values (ratio of number of missing observations to total number of observations) of daily rainfall data from 1997 to 2017 for selected station in Katar and Meki subbasins
2.4 Approaches of the evaluation
Four steps are followed to assess the performance of missing imputation methods. Monthly CHIRPS datasets of each grid point were extracted using a python script and interpolated into each meteorological station using four grid points around each observed station using IDWM (Table 1). Then, they deliberately and randomly assigned NA (not available) complete datasets of CHIRPS using R-program to represent different levels of missing percentage of 5%, 10%, 15%, 20%, and 25% of Table 1 using R software. Second, stations within a 20-and 40-km radius of influence from the target station were considered neighboring stations and recalculated the missed values of target stations using eight imputation methods. Third, the ability of the imputation method was evaluated using RMSE, PBIAS, and NSE. Fourth, multicriteria decision methods of compromise programing was applied to identify the best imputation method for each station, and finally, the quality of the data was studied for homogeneity and trend using the selected methods.
2.5 Methods of missing imputation techniques
More than 21 missing estimation methods are available in the scientific literature (Armanuos et al. 2020), and it is very difficult to identify which method is the best for specific locations. Several authors employed different methods, which are already discussed in Sect. 1. There is no clear guideline or criteria to select the best imputation techniques in Ethiopia. Researchers or practitioners used any of the methods, mostly the Invers distance-weighted method, kriging, normal ratio method, or MICE based on personal experience, to fill in missing data, unaware of the impacts of missing data on rainfall-runoff modeling and the quality of the result. Different studies showed the necessity of evaluating the missing imputation techniques while using them for hydrological simulation. For example, Lee and Kang (2015) evaluated five kernel functions for predicting missing values for hydrological simulation using the SWAT model in the Imha watershed. The simulation results showed that the knn-regression exhibits lower SWAT simulation performance for streamflow estimation than other methods. The accuracy of rainfall data is critical for some complex models, like soil–plant-atmosphere models, which are sensitive to variations in precipitation and possibly other environmental inputs (Heinemann et al. 2002). The variability of the simulated outputs is directly correlated to the accuracy of the model inputs. According to Zhang et al. (2023), the annual runoff increases by approximately 10% if the annual precipitation increases by 100 mm. In general, the strength of the selected methods are dependent on the type of the missing data mechanism, the state of neighboring stations, intrinsic features, and consecutive occurrences of rainfall, among other factors (Jahan et al. 2019). Therefore, the present study employed eight methods of missing imputation techniques in Ethiopia by artificially introducing missing data for the complete dataset of monthly CHIRPS rainfall to represent the missing percentage of observed data in Table 1.
2.5.1 Spatial imputation method
A deterministic spatial interpolation technique such as the inverse distance weighting method is modified based on elevation difference, correlation coefficient (CC), and a combination of correlation coefficient and Euclidian distance as weighting factors to estimate missing values for the target station (Vieux 2004; Barrios et al. 2018). According to Hartkamp et al. (1999), the assumption is that values closer to the target station are more representative of the value to be estimated than values further away. Weights change according to the linear distance between target and neighboring stations; in other words, nearby stations have a heavier weight. In this spatial imputation method, missing values of target station were estimated based on the distance, elevation difference, and correlation coefficient between the target station and surrounding stations. The efficiency of this method depends on the strength of the correlation, the close distance, and the lesser elevation difference between the target stations and the surrounding stations (Teegavarapu and Chandramouli 2005; Armanuos et al. 2020). The details of each method are given below.
-
a. Invers distance weighted average (IDWA)
The inverse distance weighting method is commonly used for approximately calculating missing data (Teegavarapu and Chandramouli 2005). The missing value of the target station is determined from the observed values of neighboring stations using Eq. (1) (Vieux 2004; Barrios et al. 2018).
where Pmi is the calculated missing value of the target station, n is the number of neighboring stations, dmi is the Euclidian distance between the target and neighboring station i, and qj(i) is the observed value at station i. k is a coefficient, and its value varies between 1 and 6, but the most commonly suggested value is 2 (Teegavarapu and Chandramouli 2005). The negative sign of k implies that stations closer to the target stations are more important than those farther away (Vieux 2004). The Euclidian distance between the target and neighboring stations is calculated using Eq. (2) (Barrios et al. 2018).
where Xi and Yi are the projected coordinates of the neighboring stations, and Xm and Ym are the projected coordinates of the target station.
-
b. Modified inverse distance weighting (MIDWE&D) based on elevation
Several researchers proposed the needs to modify the IDW (Vasiliev 1996; Teegavarapu and Chandramouli 2005, O’Sullivan and Unwin 2013). According to Vasiliev (1996), the IDW strongly depends on the existence of the strong positive autocorrelation. The normal inverse distance weighted method is mainly modified by taking into account the spatial relationship between the target and neighboring stations, considering both their correlation coefficient weight (CCW) and elevation differences. Elevation is one of the topographic factors that significantly affects the spatiotemporal distribution of precipitation and other climate variables (Golkhatmi et al. 2012). As long as the elevation difference has an effect, the conventional inverse distance-weighted method is modified by the inclusion of the elevation difference between the target and neighboring stations and the correlation coefficient. The values of k ranged from 1 to 3, and the IDWME&D was modified by varying the k values and missing values of the target station calculated using Eq. (3) (Barrios et al. 2018).
where hmi is the elevation difference between the target and the neighboring station, and the exponent “a” is a power parameter and whose value ranges from 1 to 3, with the most commonly used value being 1 (Barrios et al. 2018).
-
c. Modified inverse distance weighted (MIDWMD&C) based on correlation coefficient
For orographic and complex climate regions, the normal inverse distance weighted method is modified based on the spatial distance and correlation coefficient between the target and the neighboring station (R. Romero et al. 1998). The missed value of the target station is estimated from the neighboring station by Eq. (4):
αj(i) is the weighting factor between the target station and the neighboring stations. The weighting factor is calculated by using the Euclidian distance and Pearson correlation target and neighboring stations by Eq. (5):
where Rj(i)2 is the correlation coefficient between the target station and the neighboring stations.
-
d. Coefficient of correlation weighting method (CCWM)
In this version of the inverse distance weighting method, the weighting factors are substituted by the correlation coefficient (Teegavarapu and Chandramouli 2005; Teegavarapu 2009), and the missing value of the target station is given by Eq. (6):
where Rj(i) is the coefficient of correlation, which is the ratio of covariance between the target and neighboring stations to the product of the standard deviation of the datasets. Its values are derived from available historical data.
2.5.2 Multiple linear regression (MLR)
Multiple linear regressions (MLR) are a statistical method used to estimate the relationship between one dependent variable and two or more independent variables. It is used to identify the best weighted combination of independent variables to predict the dependent variable (Sattari et al. 2017). Eisched et al. (1995) emphasized the benefits of the multiple linear regression method for interpolating missed data using Eq. (7):
where aj(i) is the regression coefficient and aj(0) is the intercept.
2.5.3 Multivariate imputation by chained equation (MICE)
Multivariate imputation by chained equations is known as sequential regression imputation, which estimates several missing values systematically and generates distinct sets of complete datasets. In this method, the incomplete dataset can be copied several times, and the missing values are imputed to each copied dataset differently. The imputed missed values are randomly estimated for each copied dataset and combined into the average value of the dataset (Ibrahim et al. 2005). The R package of Bayesian-based MICE functions is available to compute missing values for the target station from the values of neighboring stations. The default setting was used in the MICE function to generate different imputed datasets using the predictive mean matching method (pmm) and five (m = 5) imputations. Finally, the imputed values were averaged to represent the missed value of the target station.
2.6 Accuracy assessment methods
There are several model accuracy assessment metrics described in the literature (Moriasi et al. 2007). Root mean square error (RMSE), Nash-Sutcliff (NSE), and percent of bias (PBIAS) are commonly used to assess the performance and predictive capability of missing estimation methods (Moriasi et al. 2007; Barrios et al. 2018). RMSE can measure the error between the observed and predictive values and give greater weight to any extreme outliers present in the prediction results (Plouffe et al. 2015). The optimal value varies between zeros, which means no residual variation and perfect model simulation, and a greater positive value (Moriasi et al. 2007) and calculated by Eq. (8):
According to Moriasi et al., (2007) and Barrios et al., (2018), "Nash–Sutcliffe efficiency is a normalized statistic that determines the relative magnitude of the residual variance (noise) compared to the measured data variance (information)". It shows the degree of observed versus simulated aligned on the plot of the 1:1 line (Nash and Sutcliffe 1970) and calculated by Eq. 9:
where Yoi is the ith observed value, Ysi is the ith simulated value for Ym is the mean of observed data, and n is the total number of observations. The NSE ranges between − ∞ and 1.0, with NSE = 1 being the ideal value and values between 0 and 1 being the range for acceptable levels of performance, while values < 0.0 indicate unsatisfactory performance and the observed value is better predictor than the simulated (Moriasi et al. 2007).
Percent of bias (PBIAS) measures the average difference between the simulated and observed counterparts (Moriasi et al. 2007; Barrios et al. 2018) and is calculated by Eq. (10):
The optimal values of PBIAS vary between zero for perfect model simulation and a positive or negative value that shows model underestimation or over estimation of bias, respectively (Moriasi et al. 2007).
2.7 Multicriteria decision method (MCDM) of compromise programing
There are several decision-making methods for different problems (Sabaei et al. 2015; Mardani et al. 2015; Majmder 2015; Raju and Kumar 2018). In most multi-criteria decision-making (MCDM) models, assigning weights to criteria is an important step that needs to be reexamined. Though, determining the weights of criteria is one of the key problems that arise in multi-criteria decision making. Over the past few decades, various weighting methods that have been developed for solving different MCDM problems such as goal programming, analytic hierarchy process (AHP), weighted score method, VIKOR, TOPSIS, Elimination EtChoix Traduisant la REalite (ELECTRE), PROMETHEE, and gray theory, compromise programing (CP) (Aruldoss 2013; Odu 2019). The primary distinctions between each weighting methods are the complexity level of the algorithms, weighting method of the criteria, the manner in that preferences are evaluated, the possibility of uncertain data, and, ultimately, the type of data aggregation. For example, analytic hierarchy process (AHP) is easy to use and faces issues due to the interdependence between criteria and alternatives. On the other hand, in fuzzy set theory (FST) using imprecise input is possible; however, this method is not easy to develop (Hajduk 2022; Taherdoost and Madanchian 2023). The advantage and disadvantage of each method were summarized in Aruldoss (2013). The multicriterion decision method of compromise programing (CP) weighting method is used to measure the minimum distance between the ideal value and performance indicators to identify and rank the missed imputation by Eq. (11) (Raju et al. 2016):
where indicators j = 1,2… J, Lp(a) = Lp metric for imputation method a for the chosen value of parameter p, fj(a) = normalized value of indicator j, wj = weight of performance indicator j got from the entropy method, p = parameter (1 for linear, 2 for Euclidean distance measure), and for this study we adopted the p value of 2. Based on the minimum value of the Lp metrics, the imputation methods were ranked accordingly and the best method was proposed for each station. To decide independently of the views of the decision maker, normalizing and weighting of the performance indicators are required. The entropy method is used to normalize and estimate the weight of various criteria from the given payoff matrix (Pomerol and Barba-Romero 2000, Raju and Kumar 2014; Zhu et al. 2020). First, the performance indexes are standardized and the payoff matrix (Pij) is calculated using Eq. (12) (Zhu et al. 2020):
For a given normalized payoff matrix pij, an entropy Ei is calculated using Eq. (13) for a set of alternative criterion (j):
where N is the number of imputation techniques and j is the number of indicators. Degree of diversification of the information provided by the outcomes of criterion j was calculated by Eq. (14):
Then finally, the normalized weights of indicators calculated by Eq. (15):
2.8 Data quality check
2.8.1 Homogeneity test
In order to conduct reliable studies on climate variability, good quality and long-term datasets are required. Actually, many studies have confirmed that climate change analyses are not possible without a clear understanding of the homogeneity of data. There is an assumption that the climate record is considered homogeneous when its variations are caused only by changes in weather and climate (Caloiero et al. 2020; Kocsis et al. 2020; Patakamuri et al. 2020). However, there are non-climatic factors that make the magnitude of climate signals larger than the actual (Caloiero et al. 2020).
The following are the four test techniques that were chosen to assess the time series departure from homogeneity: the standard normal homogeneity test (SNHT), which is sensitive to detecting the breaks near the beginning and end of the data (Alexandersson 1986), Buishand’s range test (BRT) (Buishand 1982), and the Pettit test (Pettitt 1979), are sensitive to locating the breaks in the middle of the series, and the Von Neumann range test (VNRT) do not located the break (Von Neumann 1941). But, if there is a break in the data, the test statistics is less than two, and if not, the test statistics is equal to two. Generally, the first three tests can locate the year of break that is likely to occur. The Pettitt test, unlike the SNHT and the Buishand’s range test, does not assume that Xi values are regularly distributed. Since the Pettitt test is based on the rankings of the elements of a series rather than on the values themselves, such an assumption is not required. All tests are executed under the null hypothesis that annual values Xi of the testing variable X are independent and identically distributed. The alternative (Ha) hypothesis for NSHT, BRT, and PTT is a step-wise shift in the mean of the data. However, the alternative hypothesis for VNRT assumes that the time series data is not randomly distributed. All these tests were conducted using XLSTAT 2020. Then finally, the test results have been summarized by Wijngaard et al. (2003) as useful (when the test has rejected none or one null hypothesis out of four tests), doubtful (when the test has rejected two null hypotheses out of four tests), and suspect (when the test has rejected three or all null hypotheses out of four tests).
2.8.2 Trend analysis of future climate conditions
The Mann–Kendall trend (MK) test is a non-parametric test which is used to determine the presence or absence of mnotonic trends in time series data of a candidate station (Kocsis et al. 2020; Shahfahad et al. 2022). The null hypothesis (Ho) of MK is that there is no trend, and the alternative hypothesis (Ha) is that the time series of a candidate station follows a monotonic trend over time. The Mann–Kendall test statistic is calculated by Eq. (16):
where Xi and Xj are the sequential data in the series and n is the size of the data series.
j > I and i = 1, 2, 3,…, n−1 k = 2, 3, 4,…, n, and n is the number of data sign (Xj − Xi) is calculated by Eq. (17):
The variance S is calculated by Eq. (18):
where
- q :
-
is the number of tied groups in the dataset,
- t p :
-
is the number of data in the pth tied group,
- n :
-
is the total number of data in the time series.
A positive value of S indicates that an increasing and negative value of S is decreasing trend of time series data of the candidate station.
The standardized Mann–Kendall test statistics is calculated by Eq. (19):
3 Results
3.1 Performance of missing estimation methods
In the previous part, various strategies and their comparative methodologies were already covered in order to choose the best imputation technique. Approaches to missing estimations, methods of evaluating their performance, and techniques to identify the best method were discussed in Sect. 2. In this section, the findings of comparative techniques for identifying station-wise suitable methods are discussed. The ability of each missing estimation technique was evaluated using the statistical metrics of RMSE, NSE, and PBIAS. Tables 1 and 2 show the performances of each missing method at a 20- and 40-km radius of influence and at different levels of missing percentage. The MLR and MICE methods gave the best results for all statistical performance measures across all stations. Alternatively, the modified inverse distance method (IDWME&D) presented lower values of RMSE and PBIAS and a higher value of NSE. On the contrary, for all target stations and missing percentage combinations, the CCWM approach performed the worst in terms of percent bias. Stations within a 20-km radius of influence produce less RMSE and PBIAS and a higher NSE than stations within a 40-km radius of influence. However, the radius influences have no significant impact on the performance of missing imputation methods. The CCWM, normal IDWM, and modified versions of IDWM such as IDWMC&D, IDWME&D at k = 1, and IDWME&D2 at k = 2 presented higher biases in RMSE and PBIAS and lower NSE (Fig. 3a–c). The estimation approaches showed an increase in RMSE and PBIAS, as well as a decrease in NSE, when they were applied to the higher missing percentage over all stations considered in this study. Considering the spatial missing estimation techniques such as IDWMC&D, IDWME&D at k = 1, and IDWME&D2 at k = 2, modified based on correlation coefficient, spatial distance and elevation difference are better performed than the normal IDWM and CCWM in terms of RMSR, PBIAS, and NSE with respect to missing value percentages. The inclusion of the correlation coefficient into normal IDWM and modified IDWMC&D significantly decreased the error PBAS increase; however, do not apply for RMSE (Fig. 3b). Comparing the eight methods, the MLR, MICE, and IDWME&D3 performed best over most stations at all levels of missing percentages.

Results of performance measures for the missing value estimation techniques applied to estimate 5, 10, 15, 20, and 25% missing values. RMSE (a), PBAS (b), and NSE (c) for Arata station in Katar subbasin
3.2 Impacts of elevation difference, radius of influence and exponent value “k”
The normal inverse distance weighted method (IDWM) is modified by the inclusion of the elevation difference between the target and neighboring stations and the exponent value of “k,” for distances that range from 1 to 3. As shown in Table 3, the inclusion of an elevation difference and gradually increasing the exponent values for distance significantly lowered the error in terms of RMSE and PBIAS and increased the NSE of the inverse distance weighted method. The inclusion of an elevation difference between the stations significantly increased the performance of normal IDWM. For example, the comparison between IDWM and the modified version IDWME&D for k = 1 has shown that the RMSE is reduced from 1.52 (IDWM) to 0.74 (IDWME&D for k = 1), the PBIAS is reduced from 43.6 (IDWM) to 20.19 (IDWME&D for k = 1), and the NSE is increased from − 1.31 (IDWM) to 0.45 (IDWME&D for k = 1) at 5% of the missing percentage and a 20-km radius of influence for Arata station.
The other value added for IDWM is the value of the exponent for the Euclidian distance between the target and neighboring stations. Gradually increasing the exponent value from 1 to 3 increases the performance of IDWM. For exponent values of k = 1 and k = 3, the performance of the models was significantly improved (see Table 3 as an example for the Arata station and the Appendix B for all stations). For example, at 10% of missing value the RMSE and PBIAS were reduced from 1.79 for (IDWM) to 0.5 (for IDWME&D for k = 3) and 68.53 (IDWM) to 11.62 (for IDWME&D for k = 3), respectively. Even at the maximum missing percentage (25%), the RMSE and PBIAS range from 3.75 to 42.92 and 234.74 to 239.20 for IDWM at 20- and 40-km radius of influence. These errors were reduced for the same condition (25% missing value and radius of influence) from 0.75 and 29.89 to 30.40, respectively, for IDWME&D for k = 3. The modification of IDWM by inclusion elevation difference and k = 3 significantly reduced the errors and increase the goodness of fit. Generally, accounting for the elevation difference and increasing the exponent value “k = 3” can increase the performance of the inverse distance weighted method by lowering the error of RSR and PBIAS and increasing the precision (NSE). However, as the assessment results have been shown in Table 3 and Appendix, both radiuses of influence have no significant difference between the IDWM and its version. Therefore, similar results were obtained for other stations that are considered in this study (the results summarized in Appendix B).
3.3 Impact of missing percentage
As shown in Tables 2 and 4 for the Arata station and in Appendix A for the rest of the stations, the performance of the missing estimation method has decreased as the missing percentage has increased over all stations. The MLR, MICE, and IDWME&D3 at k=3 performed very well for most stations at all levels of missing percentages compared to other missing estimation techniques. For example, the IDWM method presented the poorest performance for Arata station, which resulted in 16.68 RMSE, 239 PBIAS, and 13 NSE. Similarly, for the rest stations, as long as the missing percentages are increasing, the model performance tends to decrease to accurately estimate the missed values of the target station (Appendix A).
3.4 Identifying of the best method
To identify the best infilling technique, the multicriteria decision with compromise programming (CP) method was used. Here, the result for Arata station has been shown for demonstration. Among the three performance indicators, PBIAS (0.498) has a significant weight in the ranking of the missing estimation methods, followed by RMSE (0.421) and NSE (0.08). Equations (11)–(15) were coded in Excel 2016, and the entropy, degree of diversification, normalized weight, payoff matrix (Pij), and LP metrics were calculated subsequently. Then, based on the minimum values of LP metrics, each missing estimation method was ranked. As the results in Tables 5 and 6 showed for Arata station, the MLR, MICE, and IDWME&D3 at k=3 were ranked as the 1st, 2nd, and 3rd best methods, respectively. The normal IDWM and CCWM are ranked 7th and 8th, respectively. Similarly, for the rest stations, the results of the best of three methods are summarized in Appendix A.
3.5 Quality assessment for precipitation data
3.5.1 Statistical characteristics of precipitation
The long-term mean and maximum monthly observed rainfall in the Katar subbasin varied from 58.24 to 87 mm and 230.6 to 581 mm, and for the Meki subbasin, they varied from 60 to 85.63 mm and 292.3 to 489.3 mm, respectively. The standard deviation (SD) varied from 57 to 94.33, and the coefficient of variation (CV) varied from 84.69 to 108.42% for the Katar subbasin. Similarly, for the Meki subbasin, SD and CV varied from 62 to 86.23 and 97.32 to 119.01%, respectively. This demonstrated that there was significant temporal variability in monthly rainfall from 1997 to 2017 in both subbasins. The greatest variability was observed at the Adami, Tulu, and Iteya stations (Table 7).
3.5.2 Homogeneity tests
An absolute homogeneity test was applied using SNHT, Buishand’s, Pettitt, and Von Neumann tests to check whether the long-term climatological data belongs to the same population with no temporal variation. If any change in the time series was only attributed to a natural occurrence. Based on the hypothesis test for homogeneity, the empirically calculated p-value is at 95% of the significant level summarized in Tables 8 and 9 for the Katar and Meki subbasins, respectively. Based on the test results, seven stations were homogeneous in the Katar watershed based on the above four tests. However, one station, Iteya, was nonhomogeneous based only on Buishand’s test. Similarly, for stations in the Meki watershed, homogeneity tests were conducted (Table 8). Except for Butajera station, all stations were homogeneous based on the test results of the SNHT, Buishand’s, Pettit, and Von Neumann tests at 95% of the significant level (Table 9). An extensive examination was carried out on the meta-data and archive information concerning the history of the measurements for both stations. No apparent explanation could be found for the causes of the changes. Based on Wijngaard et al. (2003) classification for homogeneity, 15 stations were classified as useful, and only Butajera stations were suspected.
3.6 Trend analysis
Each chosen station has 17 series (12 months, four seasons, and an annual series), for a total of 255 time series data from 15 meteorological stations. Monthly, seasonal, and annual monotonic upward or downward trends in rainfall were assessed for each station independently using the Mann–Kendall trend test, and the magnitude of the trend was estimated using the Sone’s slope for the time series data of 1997–2017.
3.6.1 Monthly trend analysis
As shown in Table 10, the rainfall had a combination of increasing and decreasing trends at all stations. There was a statistically significant decreasing trend for Dagaga station for the month of January, with a magnitude of 1.52 mm/month. For Iteya station, the rainfall amount shows a decreasing trend for the months of June, August, and October with a magnitude of 2.15, 5.05, and 3.06 mm, respectively. At Kulumsa station, there was a significant increasing trend in rainfall for the months of May and September, with a magnitude of 4.38 and 3.13 mm, respectively. Similarly, Bui station showed a statistically significant decreasing trend with a magnitude of 0.83 mm. At Butajera station for the months of March, April, August, and October, there was a significant decreasing trend with a magnitude of 6.82, 4.54, 5.7, and 4.07 mm, respectively. For Ejerese-lele station, there was a significant increase in monthly rainfall during September, with a magnitude of 2.63 mm. However, the rest station has shown no statistically significant increasing or decreasing trends in monthly rainfall.
3.6.2 Seasonal and annual trend analysis
Seasonal trend analysis was performed and considered the sum of three consecutive months, such as spring (March, April, and May), summer (June, July, and August), autumn (September, October, and November), and winter (December, January, and February). An annual trend analysis was performed for a time series of rainfall data from 1997 to 2017. As a trend, the results of the analysis are stated in Table 11, both increasing (positive) and decreasing (negative) in seasonal and annual rainfall. A decreasing trend in seasonal rainfall was observed for Iteya station during summer (10.65 mm) and autumn (11.48 mm). The Dagaga station had a statistically significant decrease in seasonal rainfall during the autumn (6.41 mm). Similarly, Butajera showed a significant decreasing trend during spring (14.75 mm) and autumn (9.9 mm). The annual trend analysis resulted in increasing and decreasing trends in the annual rainfall series. Iteya and Butajera stations have shown statistically significant decreasing trends with a magnitude of 34.84 mm/year and 40.36 mm/year, respectively. The homogeneity test station at Butajera exhibited suspected result. The non-homogenies of the results may be affecting the trend result and it needs further analysis by considering long data series.
4 Discussion
Accurate and reliable precipitation data helps in assessing the availability and distribution of water resources, which is crucial for managing irrigation systems and ensuring sustainable agricultural practices. It also aids in predicting and preparing for extreme weather events such as droughts or heavy rainfall, allowing for timely emergency response measures to be implemented. Missing data is a problem for all. The most common reasons for missing data are equipment malfunctions, human error, or data transmission issues. The main effects of missing data are to reduce the power and precision of statistical analysis results, lead to a biased estimate, and draw the wrong conclusion about the relationship between two or more variables. Therefore, it is crucial to address and properly handle missing data in order to ensure the accuracy and reliability of hydrometeorological analyses and predictions. To bridge this gap, missing data can be filled using different techniques depending on the characteristics of a particular geographic location, and the missing data mechanism and, finally, the quality of the data should be checked before being used for the intended purposes.
In this study, the outcomes of eight missing estimation methods, such as normal IDWM and its modified versions of IDWMC&D, IDWME&D for k = 1, IDWME&D for k = 2, IDWME&D for k = 3, CCWM, MLR, and MICE, were assessed for infilling missing monthly rainfall records in the Katar and Meki subbasins. Their performances were evaluated using three widely used error metrics, such as RMSE, PBAIS, and goodness of fit tests (NSE) at two radiuses of influence and different levels of missing percentage. The outcome of the study has presented here based on level of missing percentage, radius of influence, and elevation difference between target and neighboring stations.
The percentage of missing values significantly increases the error metrics of RMSE and PBIAS and decreases the fit test at all stations considered in this study. The performance of the missing estimation method has decreased as the missing percentage has increased over all stations. The MLR, MICE, and IDWME&D for k = 3 performed very well for most stations at all levels of missing percentages compared to other missing estimation techniques. The computed values of error for the IDWM method presented the poorest performance for Arata station, which resulted in 16.68% RMSE, 239% PBIAS, and -ve13.61 NSE Table 4. These values indicate that the normal IDWM method was not able to accurately estimate missing data for target (Arata) station compared to the modified IDWM based on the distance and elevation difference between the target and neighboring stations.
The rest station in Appendix A yielded similar findings, indicating consistency in the results. The performance of each missing estimation technique was reduced as the missing percentage increased. These studies also found similar results, indicating a consensus among researchers (Schneider, 2001; El Kasri et al. 2018). This suggests that the missing estimation methods are not robust enough to handle a high percentage of missing values. It is crucial to develop more advanced techniques that can effectively handle missing data in order to improve the performance of these estimation methods. This is because missing data can introduce bias and reduce the representativeness of the sample. Additionally, the larger the percentage of missing data, the greater the potential for imprecise estimates and decreased statistical power, making it more challenging to draw accurate conclusions from the analysis (Pigott 201; Piazza 2011; Houari et al. 2014; Schmitt et al. 2015; Sanusi et al. 2017; Gao et al. 2018). This may result in uncertain flood estimates and imperfect flood management decisions and intervention mechanisms (Ekeu-Wei et al. 2018).
The inverse distance-weighted method was modified by including the elevation difference between the target and neighboring stations and gradually increasing the k exponent for distance. As the studies indicated, topography is one of the factors that affect the characteristics of rainfall (Duckstein et al. 1973). In the study region, topography and direction of the rainfall play a significant role in the rainfall amount and characteristics. Additionally, the direction of rainfall (windward and leeward) and microclimate in the study region significantly affect the rainfall amount and characteristics. For example, Asella and Bui stations are found at altitudes of 2400 and 2000 m in the opposite direction of rainfall (Asella is on the leeward side and Bui station is on the windward side), and the rainfall characteristics are almost similar (Table 1). Therefore, the inclusion of an elevation difference between target and neighboring stations significantly reduces error in terms of RMSE and PBIAS compared to the normal IDWM and modified version of IDWM (IDWME&D for k = 1, IDWME&D for k = 2, and IDWME&D for k = 3). Figure 4 shows that the RMSE reduced as the elevation difference was considered and the exponent (k) for distance gradually increased from 1 to 3. Similarly, Fig. 5 displays that the error term of PBIAS is decreasing, as is the inclusion of elevation difference and the gradual increase in exponent values for distance for the inverse distance-weighted method at all levels of missing percentages.

Performance evaluation based on RMSR and distance and elevation difference between the target and neighboring stations. MD is missing data percentage

Performance evaluation based on PBIAS and distance and elevation difference between the target and neighboring stations. MD is missing data percentage
The CP method allows for the consideration of multiple criteria simultaneously, enabling a comprehensive evaluation of different infilling techniques. By using this method, the study aimed to determine the best infilling technique that would provide the most optimal results of missing value of the target station. Here, the result for Arata station has been shown for demonstration. Among the three performance indicators, PBIAS (0.498) has a significant weight in the ranking of the missing estimation methods, followed by RMSE (0.421) and NSE (0.08). Equations (11)–(15) were coded in Excel 2016, and the entropy, degree of diversification, normalized weight, payoff matrix (Pij), and LP metrics were calculated subsequently. Then, based on the minimum values of LP metrics, each missing estimation method was ranked, and MLR, MICE, and IDWME&D for k = 3 are ranked as 1st to 3rd, respectively, over most stations. The normal IDWM and CCWM are ranked 7th and 8th, respectively; Table 5 for 40-km and Table 6 for 20-k radius of influences, respectively. Similarly, for the rest stations, the results of the best of the three methods are summarized in Appendix B. A similar study has been conducted by Radi et al. (2015) on the performance of missing estimation methods and utilized ANOVA to determine the most effective approach. Similarly, Raju et al. (2016) employed the compromise programing method to assess and choose the optimal global climate models specifically for India’s climate conditions.
Then, after evaluating the missing estimation method and identifying the best for each station, the missing value is filled for each station using their best method. The absolute homogeneity (SNHT), Buishand’s, Pettit’s, and Von Neumann’s tests were used in the quality assessment for rainfall to determine whether the long-term climatological data belong to the same population with no temporal variation. Only one station (Iteya) passed Buishand’s test as being nonhomogeneous, leaving out the other two stations. At the 95% level of significance, the results of the SNHT, Buishand’s, Pettit’s, and Von Neumann’s tests revealed that all stations at one station (Butajera) were homogeneous. The quality assessment for rainfall was applied using absolute homogeneity (SNHT), Buishand’s, Pettit’s, and Von Neumann’s tests to check whether the long-term climatological data belong to the same population with no temporal variation. Except for two stations, Iteya and Butajera stations, all stations were homogeneous based on the test results of SNHT, Buishand’s, Pettit’s, and Von Neumann’s tests at 95% of the significant level (Tables 8 and 9). The meta-data and archive information pertaining to the history of measurements for both stations were thoroughly examined, and no apparent explanation could be found for the causes of the changes. Based on Wijngaard et al.’s (2003) classification for homogeneity, 15 stations were classified as useful, and only one (Butajera) station was classified as suspected. Similar studies were conducted by Schönwiese and Rapp (1997) and Patakamuri et al. (2020) and classified the station using the Winjngaard procedure.
Then, after the homogeneity test, trend analysis was employed for each selected station. The Mann–Kendall trend (MK) test, a popular non-parametric test, was applied to determine the presence or absence of monotonic trends in the time series data of each candidate station (Machiwal and Jha 2012; Kocsis et al. 2020; Shahfahad et al. 2022) and the magnitude of the change is estimated using Son’s slope. The trend analysis results are summarized in Tables 10 and 11 for monthly, seasonal, and annual time series from 1997 to 2017. The trend analysis results show statistically significant decreasing and increasing trends in the monthly rainfall over some stations. The annual trend analysis of Iteya station in Katar subbasin and Butajera station in Meki subbasin shows significant decreasing by 34.84 and 40.4 mm, respectively. The trends in these two stations also reflect seasonality. These two locations are highly productive rainfed agricultural areas on which the Ethiopian economy is primarily dependent (Welteji 2018) and high potential areas for runoff generation and water yield in the subbasins (Balcha et al. 2022). The study agrees with past studies conducted in the subbasin (Kassie et al. 2014) and elsewhere in Ethiopia (Bedane et al. 2022; Ware et al. 2023).
5 Conclusion and recommendation
The missing values can lead to inaccurate calculations and interpretations, as well as hinder the ability to identify patterns or trends in rainfall patterns. This can be overcome through the use of imputation techniques. However, the effectiveness of any imputation technique depends largely on the climatology of the area, the density of the rain gauge network, and the geographical location, among other factors. Thus, it is imperative to assess the performance of various imputation methods to determine the best ones to use for a specific area of interest. By evaluating the performance of different imputation methods, researchers can determine techniques most suitable for a study area. This assessment ensures that the chosen imputation methods effectively compensate for missing rainfall data without distorting patterns or trends, enabling accurate analysis and prediction of rainfall patterns in the area of interest. Instead of applying one fit for all strategy for estimating the missed value of rainfall, we evaluated the performance of 8 missing estimation techniques using RMSE, PBIAS, and NSE and apply a MCDM of compromise programing methods to select the best missing estimation technique. In general, the error statistics (RMSE and PBIAS) were relatively high, with poor goodness of fit (NSE) for IDWM and CCWM. However, MLR, MICE, and IDWME&D for k = 3 performed better for all the percentages of missingness examined. We therefore recommend using MLR, MICE, and IDWME&D for k = 3 to treat missing historical rainfall data in the Katar and Meki subbasins and probably the whole of the Rift Valley Lakes Basin. The methodology we applied in this study may help the researchers working in similar type of study. Nowadays, it is very common to evaluate the performance of missing estimation techniques using different statistical metrics. However, it is not common to use MCDM to select the best methods in climatology. By utilizing the multi-criteria decision method in our study, we have provided a novel approach to selecting the best missing imputation techniques. This methodology can potentially enhance the accuracy and reliability of future research in this field, benefiting other researchers seeking to explore similar areas of study. More than 21 missing estimation techniques are available in the literature. The study’s limitation is that it does not account for all missing estimation techniques, and the evaluation metrics are also not limited to those used in this study. Future studies should also explore the impact of different missing estimation techniques and apply other MCDM to select the best imputation techniques.
Data availability
All datasets, raw or preprocessed, are available upon request from the corresponding author. However, permission is required for observed data collected from National Meteorology Agency of Ethiopia.
References
Abdullah MF, Siraj S, Hodgett RE (2021) An overview of multi-criteria decision analysis (Mcda) application in managing water-related disaster events: analyzing 20 years of literature for flood and drought events. Water 13(10):1358. https://doi.org/10.3390/w13101358
Addi M, Gyasi-Agyei Y, Obuobie E, Amekudzi LK (2022) Evaluation of imputation techniques for infilling missing daily rainfall records on river basins in Ghana. Hydrol Sci J 67(4):613–627. https://doi.org/10.1080/02626667.2022.2030868
Alexandersson H (1986) A homogeneity test applied to precipitation data. J Climatol 6:661–675. https://doi.org/10.1002/joc.3370060607
Alhamshry A, Fenta AA, Yasuda H, Kimura R, Shimizu K (2020) Seasonal rainfall variability in Ethiopia and its long-term link to global sea surface temperatures. J Water 12(55):1–19. https://doi.org/10.3390/w12010055
Armanuos AM, Al-Ansari N, Yaseen ZM (2020) Cross assessment of twenty-one different methods for missing precipitation data estimation. Atmosphere 11(4):389. https://doi.org/10.3390/ATMOS11040389
Aruldoss M (2013) A survey on multi criteria decision making methods and its applications. Am J Inform Syst 1(1):31–43. https://doi.org/10.12691/ajis-1-1-5
Ayenew T (2001) Numerical groundwater flow modeling of the central min Ethiopian rift lakes basin. SINET Ethiopian J Sci 24(2):167–184
Balcha SK, Awass AA, Hulluka TA, Ayele GT, Bantider A (2022) Hydrological simulation in a rift-bounded lake system and implication of water abstraction : central rift valley lakes. Water 14:3929. https://doi.org/10.3390/w14233929
Balcha SK, Hulluka TA, Awass AA, Bantider A (2023) Performance evaluation of multiple regional climate models pdf. Environ Monit Assess 195(7):888. https://doi.org/10.1007/s10661-023-11437-w
Barrios A, Trincado G, Garreaud R (2018) Alternative approaches for estimating missing climate data: application to monthly precipitation records in south-central Chile. Forest Ecosyst 5(1):10. https://doi.org/10.1186/s40663-018-0147-x
Bedane HR, Beketie KT, Fantahun EE, Feyisa GL, & Anose FA (2022) The impact of rainfall variability and crop production on vertisols in the central highlands of Ethiopia. Environmental Systems Research, 11(1). https://doi.org/10.1186/s40068-022-00275-3
Beula TMN, & Prasad GE (2012) Multiple criteria decision making with compromise programming. International Journal of Engineering Science, 4(09), 4083–4086. http://www.doaj.org/doaj?func=fulltext&aId=1155984
Bichet A, Diedhiou A, Hingray B, Evin G, Touré NE, Browne KNA, Kouadio K (2020) Assessing uncertainties in the regional projections of precipitation in CORDEX-AFRICA. Clim Change 162(2):583–601. https://doi.org/10.1007/s10584-020-02833-z
Buishand TA (1982) Some methods for testing the homogeneity of rainfall records. J Hydrol 58(1–2):11–27. https://doi.org/10.1016/0022-1694(82)90066-X
Caloiero T, Filice E, Coscarelli R, Pellicone G (2020) A homogeneous dataset for rainfall trend analysis in the Calabria Region (Southern Italy). Water 12(9):13. https://doi.org/10.3390/w12092541
Dile YT, Srinivasan R (2014) Evaluation of CFSR climate data for hydrologic prediction in data-scarce watersheds: An application in the blue nile river basin. J Am Water Resour Assoc 50(5):1226–1241. https://doi.org/10.1111/jawr.12182
Duckstein L, Fogel MM, Thames JL (1973) Elevation effects on rainfall: a stochastic model. J Hydrol 18:21–35. https://doi.org/10.1016/0022-1694(73)90023-1
Eisched JK, Bruce C, Karl TR, Diaz HF (1995) The quality control of long-term climatological data using objective data anlysis. J Appl Meteorol Climatol 34:2787–2795. https://doi.org/10.1175/1520-0450(1995)034%3c2787:TQCOLT%3e2.0.CO;2
Ekeu-Wei IT, Blackburn GA, Pedruco P (2018) Infilling missing data in hydrology: solutions using satellite radar altimetry and multiple imputation for data-sparse regions. Water (Switzerland) 10(10):1–22. https://doi.org/10.3390/w10101483
El Kasri J, Lahmili A, Latifa O, Bahi L, Soussi H (2018) Comparison of the relevance and the performance of filling in gaps methods in climate datasets. Int J Civil Eng Technol 9(5):992–10000. https://doi.org/10.1007/978-3-030-11881-5_2
Ferrari GT, Ozak EV (2014) Missing data imputation of climate datasets: implications to modeling extreme drought events. Revista Brasileira De Meteorologia 29(1):21–28. https://doi.org/10.1590/s0102-77862014000100003
Fuka DR, Walter MT, Macalister C, Degaetano AT, Steenhuis TS, Easton ZM (2014) Using the climate forecast system reanalysis as weather input data for watershed models. Hydrol Process 28(22):5613–5623. https://doi.org/10.1002/hyp.10073
Funk C, Peterson P, Landsfeld M, Pedreros D, Verdin J, Shukla S, Husak G, Rowland J, Harrison L, Hoell A, Michaelsen J (2015) The climate hazards infrared precipitation with stations — a new environmental record for monitoring extremes. Scientific Data 2:150066. https://doi.org/10.1038/sdata.2015.66
Gao Y, Merz C, Lischeid G, Schneider M (2018) A review on missing hydrological data processing. Environ Earth Sci 77(47):1–12. https://doi.org/10.1007/s12665-018-7228-6
Gebre SL, Cattrysse D, Van Orshoven J (2021) Multi-criteria decision-making methods to address water allocation problems: a systematic review. Water 13(2):1–28. https://doi.org/10.3390/w13020125
Golkhatmi, N. S., Sanaeinejad, S. H., Ghahraman, B., & Pazhand, H. R. (2012). Extended modified inverse distance method for interpolation rainfall. In International Journal of Engineering Inventions (Vol. 1, Issue 3). www.ijeijournal.com
Hajduk S (2022) Multi-criteria analysis in the decision-making approach for the linear ordering of urban transport based on TOPSIS technique. Energies 15(1):274. https://doi.org/10.3390/en15010274
Hartkamp AD, Beurs KD, Stein A, White JW (1999) Interpolation techniques for for climate variables. NRG-GIS Series 99–01:1–35
Hasanpour Kashani M, Dinpashoh Y (2012) Evaluation of efficiency of different estimation methods for missing climatological data. Stoch Env Res Risk Assess 26(1):59–71. https://doi.org/10.1007/s00477-011-0536-y
Heinemann AB, Hoogenboom G, Chojnicki B (2002) The impact of potential errors in rainfall observation on the simulation of crop growth, development and yield. Ecol Model 157(1):1–21. https://doi.org/10.1016/S0304-3800(02)00209-0
Houari R, Bounceu A, Tari A-K, Kechadi M-T (2014) Handling missing data problems with sampling methods. Int Conf Adv Net Distrib Syst Appl 2014:2–7. https://doi.org/10.1109/INDS.2014.25
Hulluka TA, Balcha SK, Yohannes B, Bantider A, Negatu A (2023) Review: groundwater research in the Ethiopian Rift Valley Lakes region. Front Water 5:819568. https://doi.org/10.3389/frwa.2023.819568
Ibrahim JG, Chen M, Lipsitz SR, Herring AH (2005) Missing-data methods for generalized linear model: a comparative review. J Am Stat Assoc 100(469):332–346. https://doi.org/10.1198/016214504000001844
Ismail WNW, Ibrahim WZWZW (2017) Estimation of rainfall and stream flow missing data for Terengganu, Malaysia by using interpolation technique methods. Malay J Fund Appl Sci 13(3):213–217
Jahan F, Sinha NC, Rahman MM, Rahman MM, Mondal MSH, Islam MA (2019) Comparison of missing value estimation techniques in rainfall data of Bangladesh. Theoret Appl Climatol 136(3–4):1115–1131. https://doi.org/10.1007/s00704-018-2537-y
Kassie BT, Rötter RP, Hengsdijk H, Asseng S, Van Ittersum MK, Kahiluoto H, Van Keulen H (2014) Climate variability and change in the Central Rift Valley of Ethiopia: challenges for rainfed crop production. J Agric Sci 152(1):58–74. https://doi.org/10.1017/S0021859612000986
Kocsis T, Kovács-Székely I, Anda A (2020) Homogeneity tests and non-parametric analyses of tendencies in precipitation time series in Keszthely. West Hung Theor Appl Climatol 139(3–4):849–859. https://doi.org/10.1007/s00704-019-03014-4
Lee H, Kang K (2015) Interpolation of missing precipitation data using kernel estimations for hydrologic modeling. Advances in Meteorology 2015:12. https://doi.org/10.1155/2015/935868
Machiwal D, Jha MK (2012) Hydrologic time series analysis: theory and practice. Springer, New Delhi, India
M. Majmder. (2015). Multi criteria decision making. In Impact of urbanization on water shortage in face of climatic aberrations, (35–48). https://doi.org/10.1007/978-981-4560-73-3
Mardani A, Jusoh A, Nor K, Khalifah Z, Zakwan N, Valipour A (2015) Multiple criteria decision-making techniques and their applications – a review of the literature from 2000 to 2014. Econ Res 28(1):516–571. https://doi.org/10.1080/1331677X.2015.1075139
MesheshaAtsushi TT, Mitsuru T, Nigussie H, Meshesha DT, Tsunekawa A, Tsubo M, Haregeweyn N (2012) Dynamics and hotspots of soil erosion and management scenarios of the Central Rift Valley of Ethiopia. Int J Sedim Res 27(1):84–99. https://doi.org/10.1016/S1001-6279(12)60018-3
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidline for systematic quantification of accuracy in wateshed simulations. Ame Soc Agric Biol Eng 50(3):885–900. https://doi.org/10.13031/2013.23153
Nash JE, Sutcliffe JV (1970) River flow forcasting through conceptual models part i a discussion of Principles. J Hydrol 10:282–290
O’Sullivan D, & Unwin DJ (2013) Geographic information analysis. In John Wiley & Sons, INC. https://doi.org/10.1201/b13877-4
Odu GO (2019) Weighting methods for multi-criteria decision making technique. J Appl Sci Environ Manag 23(8):1449. https://doi.org/10.4314/jasem.v23i8.7
Osinowo OO, Arowoogun KI (2020) A multi-criteria decision analysis for groundwater potential evaluation in parts of Ibadan, southwestern Nigeria. Appl Water Sci 10(11):1–19. https://doi.org/10.1007/s13201-020-01311-2
Ozsahin, I., Ozsahin, D. U., & Uzun, B. (2021). Application of multi-criteria decision-making theories in healthcare and biomedical engineering. In Applications of multi-criteria decision-making theories in healthcare and biomedical engineeringhttps://doi.org/10.1016/b978-0-12-824086-1.00021-9
Patakamuri SK, Muthiah K, Sridhar V (2020) Long-term homogeneity, trend, and change-point analysis of rainfall in the arid district of ananthapuramu, Andhra Pradesh State. India. Water 12(1):211. https://doi.org/10.3390/w12010211
Pettitt AN (1979) A non-parametric to the approach problem. Appl Stat 28(2):126–135
Peugh JL, Enders CK (2004) Missing data in educational research: a review of reporting practices and suggestions for improvement. Rev Educ Res 74(4):525–556. https://doi.org/10.3102/00346543074004525
Piazza A Di (2011) The problem of missing data in hydroclimatic time series. Application of spatial interpolation techniques to construct a comprehensive of hydroclimatic data in Sicily, Italy. Kluwer Academic Publishers, Dordrecht, The Netherlands
Pigott TD (2001) A review of methods for missing data. Int J Phytorem 21(1):353–383. https://doi.org/10.1076/edre.7.4.353.8937
Plouffe CCF, Robertson C, Chandrapala L (2015) Environmental modelling & software comparing interpolation techniques for monthly rainfall mapping using multiple evaluation criteria and auxiliary data sources : A case study of Sri Lanka. Environ Model Softw 67:57–71. https://doi.org/10.1016/j.envsoft.2015.01.011
Pomerol J-C, Barba-Romero S (2000) Multicriterion decision in management principles and practice. Kluwer Academic, Netherlands
Pramanik PKD, Biswas S, Pal S, Marinković D, Choudhury P (2021) A comparative analysis of multi-criteria decision-making methods for resource selection in mobile crowd computing. Symmetry 13(9):1–51. https://doi.org/10.3390/sym13091713
Radi NFA, Zakaria R, Azman MAZ (2015) Estimation of missing rainfall data using spatial interpolation and imputation methods. AIP Conf Proc 1643(42):42–48. https://doi.org/10.1063/1.4907423
Raju KS, Kumar DN (2014) Ranking of global climate models for India using multicriterion analysis. Climate Res 60(2):103–117. https://doi.org/10.3354/cr01222
Raju KS, Nagesh DK (2014) Multicriterion Analysis in Engineering and Management. Prentice Hall of India, New Delhi
Raju KS, Sonali P, Kumar DN (2016) Ranking of CMIP5-based global climate models for India using compromise programming. Theor Appl Cimatol 128:563–574. https://doi.org/10.1007/s00704-015-1721-6
Raju KS, & Kumar DN (2018) Impact of climate change on water resources in India. In Journal of Environmental Engineering (United States)https://doi.org/10.1061/(ASCE)EE.1943-7870.0001394
Romero R, Guijarro JA, Ramis C, Alonso S (1998) A 30-year (1964–1993) daily rainfall data base for the Spanish Mediterranean regions: first exploratory study. Int J Climatol 18:541–560. https://doi.org/10.1002/(SICI)1097-0088(199804)18:5%3c541::AID-JOC270%3e3.0.CO;2-N
Romero C, Rehman T (2003) Multi criteria analysis for agricultural decisions (2nd ed). ELSEVER. Amsterdam, The Netherlands
Rubin DB (1976) Inference and missing data. J Biomet 63(3):581–592
Sabaei D, Erkoyuncu J, Roy R (2015) A review of multi-criteria decision making methods for enhanced maintenance delivery. Procedia CIRP 37:30–35. https://doi.org/10.1016/j.procir.2015.08.086
Sanusi W, Zin WZW, Mulbar U, Danial M, Side S (2017) Comparison of the methods to estimate missing values in monthly precipitation data. Int J Adv Sci, Eng Inform Technol 7(6):2168–2174. https://doi.org/10.18517/ijaseit.7.6.2637
Sattari M-T, Rezazadeh-Joudi A, Kusiak A (2016) Assessment of different methods for estimation of missing data in precipitation studies. Hydrol Res 48(4):1–13. https://doi.org/10.2166/nh.2016.364
Sattari M-T, Rezazadeh-Joudi A, Kusiak A (2017) Assessment of different methods for estimation of missing data in precipitation studies Mohammad-Taghi Sattari, Ali Rezazadeh-Joudi and Andrew Kusiak. J Hydrol Res 48(4):1032–1044. https://doi.org/10.2166/nh.2016.364
Schmitt PMJ (2015) A comparison of six methods for missing data imputation. J Biom Biostat 06(01):1–6. https://doi.org/10.4172/2155-6180.1000224
Schneider T (2001) Analysis of incomplete climate data: estimation of mean values and covariance matrices and imputation of missing values. J Clim 14(5):853–871. https://doi.org/10.1175/1520-0442(2001)014%3c0853:AOICDE%3e2.0.CO;2
Schönwiese CD, Rapp J (1997) Clima Te Trend Atlas of Europe Based on Observations 1891-1990 (1st ed). Springer Science and Business Media B.V. Berlin/Heidelberg, Germany
Shahfahad TS, Islam ARMT, Das T, Naikoo MW, Mallick J, & Rahman A (2022) Application of advanced trend analysis techniques with clustering approach for analysing rainfall trend and identification of homogenous rainfall regions in Delhi metropolitan city. Environmental Science and Pollution Research, 19. https://doi.org/10.1007/s11356-022-22235-1
Taherdoost H, Madanchian M (2023) Multi-criteria decision making (MCDM) methods and concepts. Encyclopedia 3(1):77–87. https://doi.org/10.3390/encyclopedia3010006
Teegavarapu RSV (2009) Estimation of missing precipitation records integrating surface interpolation techniques and spatio-temporal association rules. J Hydroinf 11(2):133–146. https://doi.org/10.2166/hydro.2009.009
Teegavarapu RSV, Chandramouli V (2005) Improved weighting methods, deterministic and stochastic data-driven models for estimation of missing precipitation records. J Hydrol 312:191–206. https://doi.org/10.1016/j.jhydrol.2005.02.015
Teegavarapu RSV, Salas JD, & Stedinger JR (2019) Statistical analysis of hydrologic variables: methods and applications. In Published by the American Society of Civil Engineers (1st ed.). American Society of Civil Engineers. https://doi.org/10.1061/9780784415177
Vasiliev IR (1996) Visualization of spatial dependence: an elementary view of spatial autocorrelation. In Practical handbook of spatial statistics (p. 341). CRC Press. https://doi.org/10.2307/2669712
Vassoney E, Mammoliti Mochet A, Desiderio E, Negro G, Pilloni MG, Comoglio C (2021) Comparing multi-criteria decision-making methods for the assessment of flow release scenarios from small hydropower plants in the Alpine area. Front Environ Sci 9:635100. https://doi.org/10.3389/fenvs.2021.635100
Vieux BE (2004) Distributed hydrologic modelling using GIS (second edi). Kluwer Academic Publishers
von Neumann J (1941) Distribution of the ratio of the mean square successive difference to the variance. Ann Math Stat 12(4):367–395. https://doi.org/10.1214/aoms/1177731677
Ware MB, Matewos T, Guye M, Legesse A, & Mohammed Y (2023) Spatiotemporal variability and trend of rainfall and temperature in Sidama Regional State, Ethiopia. Theor Appl Clim, 0123456789. https://doi.org/10.1007/s00704-023-04463-8
Welteji D (2018) A critical review of rural development policy of Ethiopia: access, utilization and coverage. Agric Food Sec 7(1):1–6. https://doi.org/10.1186/s40066-018-0208-y
Wijngaard JB, Tank AMGK, K¨onnen GP (2003) Himogeneity of the 20th cenetury European Daily Temprature and Precipitation Series. Int J Climatol 23:679–692. https://doi.org/10.1002/joc.906
Xia Y, Fabian P, Stohl A, Winterhalter M (1999) Forest climatology: estimation of missing values for Bavaria. Germ Agric Forest Meteorol 96(1–3):131–144. https://doi.org/10.1016/S0168-1923(99)00056-8
Yilmaz B, Harmancioglu NB (2010) Multi-criteria decision making for water resource management: a case study of the Gediz River Basin. Turkey Water SA 36(5):563–576. https://doi.org/10.4314/wsa.v36i5.61990
Zhang J, Wang D, Wang Y, Xiao H, & Zeng M (2023) Runoff prediction under extreme precipitation and corresponding meteorological conditions. Water Resources Managementhttps://doi.org/10.1007/s11269-023-03506-z
Zhu Y, Tian D, Yan F (2020) Effectiveness of entropy weight method in decision-making. Math Probl Eng 20(20):1–5. https://doi.org/10.1155/2020/3564835Research
Funding
This work was supported by the Water Security and Sustainable Development Hub funded by the UK Research and Innovation’s Global Challenges Research Fund (GCRF) [grant number: ES/S008179/1].
Author information
Authors and Affiliations
Contributions
All authors significantly contributed to the development of this manuscript. Sisay Kebede Balcha oversaw the conceptualization, data collection, software, data analysis, investigation, and preparation of the original draft. The manuscript was reviewed, edited, and improved by Taye Alemayehu Hulluka. Gebiaw T. Ayele reviewed and thoroughly checked the scientific methodology and corrected grammar and language the manuscript. Adane Abebe Awass and Amare Bantider overseen and coordinated the overall research work. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Balcha, S.K., Hulluka, T.A., Awass, A.A. et al. Comparison and selection criterion of missing imputation methods and quality assessment of monthly rainfall in the Central Rift Valley Lakes Basin of Ethiopia. Theor Appl Climatol 154, 483–503 (2023). https://doi.org/10.1007/s00704-023-04569-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-023-04569-z