
Abstract
Droughts have far-reaching detrimental impacts on the environment, society, and economy, ranging from regional to national levels. As the drought characteristics are interrelated, multivariate analysis of those is necessary to understand the actual drought situation in a region. However, such studies are limited. Hence, this study aimed to develop a framework to investigate the meteorological and hydrological droughts using a multivariate analysis of drought characteristics in the Pennar River basin (a semi-arid region) of India, dominated by agricultural activity. Long-term observations (1980–2015) of precipitation, temperature, and streamflow were used to calculate the Standardized Precipitation Evapotranspiration Index (SPEI) and Streamflow Drought Index (SDI) at a 3-month timescale. Based on these indices, drought duration, severity, and peak were abstracted using the Run Theory. The best-fit marginal distribution was determined for every drought characteristic to establish the bivariate joint probability distribution (the copula function). Based on the best-fit copula function, the joint probabilities and the joint return periods were estimated. Results revealed that, for meteorological drought, Frank Copula and Survival Clayton copula were the best-fit copula function for the joint risk of drought duration and severity and the combination of drought duration and peak as well as drought severity and peak, respectively. The joint return period of a drought event with characteristics above the 25th percentile of the same varies between 1 and 2 years, whereas it spans between 1 and 45 years for the 50th percentile. This analysis will provide vital information for water management and planning in a region to mitigate droughts.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Hydrological extreme events in today’s world draw the attention of the public and scientific community because of their increase in severity and frequency, human impacts, and catastrophic physical damage. Droughts are one of the most challenging climate hazards which can adversely impact agriculture as well as social and economic sectors (Chandrasekara et al. 2021) (Spinoni et al. 2019). As per the sixth assessment report of the Intergovernmental Panel on Climate Change (IPCC), the temperature has already escalated globally by almost 1.1 °C since the pre-industrial period, and the 1.5 °C threshold is expected to be surpassed before 2040 (Allan et al. 2021). In recent decades, different places in India have witnessed frequent and severe droughts, leading it to become a drought-prone country with high vulnerability (Poonia et al. 2021b). Most Indian states are badly impacted by recurring and long-term droughts, which have a wide range of negative consequences for water supplies, ecosystems, and socioeconomic development (Das et al. 2020) (Swain et al. 2021). Droughts are commonly classified into four: meteorological (Spinoni et al. 2019), hydrological, agricultural (lack of moisture content of soil and growth of plants), and socio-economic (Ayantobo et al. 2017); based on the nature of water shortages and the affected hydrological consequences. Meteorological drought is described as a prolonged lack of rainfall from its normal pattern, sometimes exacerbated by high evapotranspiration rates due to high temperatures. Meteorological droughts must be studied both for their own sake and as precursors to more severe hydrological and agricultural droughts (Ayantobo et al. 2019; Swain et al. 2020; Haied et al. 2017). Water shortages in hydrological storage systems, such as streamflow, groundwater, stored water supplies, power generation, and recreation, are known as hydrological droughts (Hong et al. 2015; Kwak et al. 2016). The most important variable to express the quantity of water available in surface water resources is the streamflow. Thus, hydrological drought is linked to the streamflow shortfall under normal conditions (Hasan et al. 2019; Kwak et al. 2016). In this study, the analysis of meteorological and hydrological drought has been carried out. The study of the relationship between meteorological and hydrological drought is particularly relevant for the management of water resources, early warning, and mitigation of drought for a particular watershed. Droughts caused by meteorological and hydrological factors are essentially linked, although with a temporal lag (Achite et al. 2022). Changes in hydrological patterns, such as a lack of precipitation and increased evaporation and transpiration, signify the onset of a drought. The meteorological drought subsequently becomes a hydrological drought, which leads to agricultural drought. Drought indices are the most effective way to assess the occurrence of droughts because there is no common definition of drought (Poonia et al. 2021a). Drought indices are more appropriate for assessing and monitoring drought than utilizing hydro-meteorological variables directly. Drought indices are calculated numerically utilizing hydro-meteorological inputs and drought indicators (Chandrasekara et al. 2021). Around the world, two types of drought indices are commonly used. One type of mechanism-based indicator considers the laws of hydrological circulation and spatiotemporal water balance. The other type is the index based on statistics, which focuses on the probability distributions of hydrometeorological variables, such as the Standardized Precipitation Index (SPI) (McKee et al. 1993). The latter has gained popularity in recent years due to its simplicity, consideration of geographical and topographical factors, changeable time scale, and cheap data requirements (Hong et al. 2015).
Many researchers used a variety of indices based on their applicability, such as SPI, Standardized Precipitation Evapotranspiration Index, SPEI (Vicente-Serrano et al. 2012), Palmer Drought Severity Index, PDSI (Palmer 1965), Surface Water Supply Index, SWSI (Shafer 1982), Standardized Runoff Index, SRI (Shukla and Wood 2008), Standardized Hydrological Index, SHI (Panu and Sharma 2009), Streamflow Drought Index, SDI (Hong et al. 2015; Pathak and Dodamani 2016; Udayar et al. 2019), Vegetation Condition Index, VCI (Kogan 1995), Standardized Soil Moisture Index, SSI (Hao and AghaKouchak 2013), Multivariate Drought Index, MDI (Rajsekhar et al. 2015), improved Multivariate Standardized Reliability and resilience Index, MSRRI (Guo et al. 2019), Reconnaissance Trivariate Drought Index, RTDI (Dixit and Jayakumar 2021), etc. to define droughts. Still, each drought indices have its unique advantages and disadvantages (Poonia et al. 2021a). The SPEI utilizes the benefits of the PDSI in terms of changes in evaporation demand (induced by temperature swings and trends) along with the SPI’s easiness of operation and applicability of multi-scale analysis (Pandey and Dhama 2000; Rose and Chithra 2020). In this study, the Standardized Precipitation Evapotranspiration Index (SPEI) and Streamflow Drought Index (SDI) were selected for meteorological and hydrological drought characterization, respectively.
Drought characteristics such as drought duration, severity, and peak can easily be extracted using the drought index values. These drought features can be analyzed in a multivariate or univariate manner. Traditional drought frequency analysis methods use the univariate technique (Poonia et al. 2021a). As previously stated, drought characteristics are interdependent and hence have a strong correlation; thus, univariate analysis of drought based on any of these characteristics cannot accurately explain the interdependence structure among them. Due to the multivariate nature of drought characteristics, simultaneous assessment is required, and the outcomes from the multivariate analysis of drought characteristics are important for estimating its potential risks (Mesbahzadeh et al. 2020). Since drought is a multivariate phenomenon, the drought condition can be described more thoroughly using multivariate analysis. Even though numerous probabilistic approaches for examining drought features have been developed in the past, a significant correlation cannot be shown using univariate analysis. Therefore, using a multivariate method and developing the joint dependence structure is preferable to characterize the interconnection between drought characteristics. Most of the multivariate distributions are generated from the univariate distributions of each variable, which have a few drawbacks, including the requirement that the marginal distribution is identical. Furthermore, for parameter estimations, complicated mathematical derivations are required (Poonia et al. 2021a). The Copula function is a great way to figure out the joint probability distribution of multiple variables. The most significant benefit of Copula theory is that it does not require the assumption that a univariate’s marginal distribution is independent. The copula probability distribution function is a very effective correlation analysis and multivariate modelling tool. Hence it is suitable for constructing the joint distribution of the marginal distributions of different variables. It can deal with non-linear and non-symmetrical data and describe the correlation between the variables. Since the beginning of this century, copula functions have been widely used in the sectors of finance, meteorology, hydrology, and risk analysis of natural disasters (Wu et al. 2019; Madadgar and Moradkhani 2016; Evkaya et al. 2019). In the hydrological field, the copula function is now utilized in studying drought, flood, joint change of precipitation and flood, and other phenomena to represent the multivariate joint distribution (Dixit and Jayakumar 2022) (Daneshkhah et al. 2016) (Villarini et al. 2009) (Graler et al. 2013; Qin et al. 2021) (Hou et al. 2021). Archimedean class, elliptical or meta-elliptical class, extreme value class, and miscellaneous class are the four copula classes commonly used for hydrological analysis (Song and Singh 2010a) (Song and Singh 2010b) (Shiau and Modarres 2009) (Xu et al. 2015) (Poonia et al. 2021a) (Poonia et al. 2021b) (Mirabbasi et al. 2012) (Lee et al. 2013).
Copula-based multivariate analysis will aid policymakers in developing better strategies for drought risk management and its mitigation. Several research using the copula function to analyze meteorological drought characteristics have been conducted; however, copula-based hydrological drought analysis in conjunction with meteorological drought is limited. The present study used the multi-variate technique to examine joint dependence structures among three drought characteristics of the meteorological and hydrological droughts for the study area. In this regard, the main objective of this study is thus to investigate both meteorological and hydrological drought in the Pennar River basin by using two standard drought indices, SPEI and SDI, at a 3-month timescale, its characterization using run theory and multivariate analysis of the drought characteristics using Copula function.
The paper starts with a brief introduction about the importance of drought analysis studies along with the objectives of the present study in Section 1, followed by data collection, study area, and methodology details in Section 2. Section 3 deals with results and discussions and in Section 4, a summary and conclusions from the work are presented.
2 Data and method
2.1 Study area
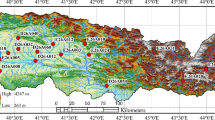
The study region for this work is the Pennar Basin of India. Drought has been a typical occurrence in the Pennar River Basin in recent decades. Between 1982 and 2013, the Pennar River basin in India witnessed 61 continuous droughts out of 107 total droughts in 29 years (Poonia et al. 2021b). The Pennar River is one of India’s major east-flowing rivers, rising in the Thenanahesava peak of the Nandidurg range in Karnataka and draining into the Bay of Bengal near Nellore, Andhra Pradesh. It runs for 597 km and covers a total area of 55,213 sq. km., with 6,937 sq. km. in Karnataka and 48,276 sq. km. in Andhra Pradesh (Fig. 1).

Study area: Pennar River basin
This fan-shaped basin are lying within 13° 16′–15° 52′ N latitude and 77° 04′–80° 10′ E longitude and is bordered on the north by the Erramala range, on the east by the Eastern Ghats’ Nallamala and Velikonda ranges, on the south by the Nandidurg hills, and on the west by the narrow ridge separating it from the Krishna basin’s Vedavati valley. In the basin, there are seven hydrological observation sites, namely Chennur, Singavaram, Tadipatri, Kamallapuram, Alladupalli, Nandipalli, and Pyderu Anicut at Kammapalem. The basin’s elevation ranges from less than 5 to 1250 m. Both the (southwest and northeast) monsoons bring rain to the basin. However, because the basin is in a semi-arid area, it receives little rainfall. The amount of rainfall in the basin varies spatially, with the coastal regions receiving more rainfall than the western parts. The average annual rainfall in the drainage basin ranges from 550 at Anantapur to 900 mm near Nellore. The mean maximum and minimum daily temperature varies from 40.3 to 34.7 °C, and from 20 C to 15.3 °C, according to the temperature data. Rivers in semi-arid environments are characterized by large yearly flow changes and poor water quality. Agriculture occupies much of the basin (approximately 53%), while forest covers the remainder (around 20%). The basin comprises fine to medium-textured clayey soils (Garg et al. 2017).
2.2 Data
Data was collected for this study from Indian Meteorological Department (IMD) and India WRIS (Water Resources Information System). 0.25-degree gridded data of monthly precipitation, 1-degree gridded monthly temperature data, and monthly flow data during the period 1980–2015 were used for the analysis. The flow data are extracted for the following stations as shown in Fig. 1: Alladupalli, Chennur, Kamallapuram, Nandipalli, Pyderu Anicut—Kammapalem, Singavaram, and Tadipatri. The monthly temperature data were regridded to 0.25-degree resolution using Inverse Distance Weighting method. Many researchers (Dixit et al. 2022; Poonia et al. 2021a) successfully used these high-resolution IMD datasets and India WRIS observed streamflow data. The meteorological data (rainfall, temperature) were interpolated to the seven hydrological stations using the bilinear interpolation technique.
2.3 Methodology
The most widely used drought indices, such as the standardized precipitation evapotranspiration index (SPEI) and the streamflow drought index (SDI), were used to define meteorological and hydrological drought. Drought indices used in this study are on a three-month time scale. A drought index with a shorter time scale is more capable of responding to drought events with low intensity and is more discrete. As a result, it can more accurately portray agricultural drought scenarios (if clubbed with the vegetation response) and is also ideal for seasonal drought monitoring (Kulkarni et al. 2020). With the help of obtained drought index value, the drought characteristics values were calculated using Run Theory. The interdependence structure of hydrological and meteorological characteristics is often investigated using multivariate analysis. Drought is a multivariate and complicated phenomenon that necessitates the use of effective tools (e.g., copula) for modelling its dependent characteristics. As a result, to execute bivariate distribution (Mirakbari et al. 2010), a copula-based strategy is used. Several copulas were employed to develop a joint dependence structure across drought characteristics. Then, using the maximum log-likelihood method, the parameters of the copula function were estimated. In addition, maximum log-likelihood (ML), Akaike Information Criteria (AIC), and Bayesian Information Criteria (BIC) values were used to pick the best-fit copula. Finally, bivariate probabilistic approaches, such as exceedance probabilities and joint return periods, were examined based on the optimal copula functions.
2.3.1 Drought indices
Drought events are characterized by an index based on the indicators of the drought. Several meteorological and hydrological parameters, such as precipitation, temperature, evapotranspiration, streamflow, and other water supply indicators, are combined into a single numerical value called an index to provide a complete picture for decision-making. To give planners and policymakers additional decision-making authority, such an index is frequently presented as a numerical value. Using these indices, the government or public and private groups assess and respond to drought (Eslamian et al. 2017). In 1992, the World Meteorological Organization defined the drought index as “an index related to some of the cumulative repercussions of a prolonged and abnormal moisture deficiency.” Indices based solely on precipitation ignore the complexities of processes taking place on the land surface and are unable to justify the effects of evapotranspiration on soil moisture directly. Under warmer circumstances or any other changes in regional hydrology, this could be a major disadvantage. The SPEI (Vicente-Serrano et al. 2012) combines the benefits of both the SPI and the PDSI. Hence, the SPEI is an improvement over the SPI because it considers both precipitation and potential evapotranspiration components (Rose and Chithra 2020). The SPEI was often used to calculate the number of months and days in a drought on a monthly and daily scale. The SPEI index is a well-known drought monitoring index that is used all around the world. A detailed explanation of SPEI calculation is mentioned in (Eslamian et al. 2017). To calculate the SPEI-3 timescale, this study employs the SPEI package in the R language.
According to Nalbantis (Nalbantis and Tsakiris 2009), the cumulative streamflow volume Vi,k can be obtained based on Eq. (1):
where Qi,j is the monthly streamflow volumes for the given time series, i (1, 2, ……….) is the hydrological year, and j (1, 2, ……,12) is the month within that hydrological year. The cumulative streamflow volume is calculated for the ith hydrological year and the kth reference period. In Eq. (1), k = 1, 2, 3, and 4 are for the periods of October-December, January-March, April-June, and July–September, respectively. The Streamflow Drought Index (SDI) is defined based on Vi,k for each reference period k of the ith hydrological year as follows:
where V̅k and sk are the mean and the standard deviation of Vi,k respectively. The truncation level in the definition of SDI is set to Vk; however, other values based on rational criteria could be used as well. (Nalbantis and Tsakiris 2009; Mishra et al. 2009), in their papers, have considered five states (classes) of drought, each designated by an integer value ranging from 0 (non-drought) to 4 (extreme drought) and described by the criteria in Table 1. To calculate the SDI, this study used DrinC software (Tigkas et al. 2015).
2.3.2 Drought characteristics
Several methods are utilized to determine drought features, including the Run Theory, discrete Markov process, percentile method, and so on. In identifying drought processes, the Theory of Runs is a commonly utilized time series analysis tool (Poonia et al. 2021a). The Theory of Runs was presented by Yevjevich (Yevjevich 1967; Wang et al. 2020) as a framework for defining and studying drought. The term “run” refers to a sequence of the same symbol that meets a set of requirements. The foundation of this idea is to select an appropriate threshold. That is, to determine whether a drought is beginning, continuing, or ending based on the relationship between the value of the drought index and the threshold. Some examples of Run Theory events are rainy days, droughts, continuous rain-free days, and alternating natural waters. In this work, drought characteristics such as drought duration, severity, and peak were extracted using the Theory of Runs from the drought index series (SPEI & SDI).
As shown in Fig. 2, each drought event is characterized by drought duration (Dd), drought severity (Ds) (Mishra et al. 2009), and drought peak (Dp) (Song and Singh 2010a). Drought duration (Dd) is defined by the number of consecutive intervals (months) where values remain below the truncation level X0, while Ds and Dp are defined by the cumulative total of values throughout a drought period and the minimum value during a drought period, respectively (Qin et al. 2021; Ayantobo et al. 2017). The inter-arrival time (Ld) is defined as the sum of drought and non-drought duration. The three characteristics can be defined as follows:
-
1.
Drought duration (Dd): the duration for which the drought index value is less than zero.
$${D}_{d}={t}_{e}-{t}_{i}$$(3)
where te = termination time and ti = initiation time

Sketch for the definition of drought characteristics showing three drought events, based on Run Theory (Ayantobo et al. 2019)
-
2.
Drought severity (Ds): the absolute value of the accumulated drought index value over the duration of the drought (Chen et al. 2013);
$${D}_{s}=-\sum_{j=1}^{{D}_{d}}{SPEI}_{j}$$(4)
SPEI will be replaced by other respective drought indices, during its calculation.
-
3.
Drought peak (Dp): the absolute value of the minimum drought index value during the duration of the drought.
2.3.3 Marginal distribution
To investigate the joint distribution of the three variables, the marginal distribution of each drought characteristic should first be obtained using time-series data to establish a binary probability distribution for drought duration, severity, and peak. Different type of distributions was considered for the present analysis, and the best one was selected. The probability distribution functions considered in this study are Normal, Log-normal, Weibull, Exponential, Gamma, Generalized Gamma, Log-gamma, Generalized Extreme Value, and Generalized Pareto distributions. The maximum-likelihood estimation (MLE) method was employed to estimate the distribution parameters for each station. Kolmogorov–Smirnov (K-S) test, chi-squared test, and Anderson–Darling (A-D) test were used for selecting the optimal marginal distribution, with the notion that the threshold value should be as minimal as possible to preserve the largest sample. Eventually, the minimum statistics of Goodness of fit tests are subjected to assess the suitable marginal distribution. The Spearman (ρ) and Kendall (τ) correlation coefficient values were estimated to understand the correlation among different drought characteristics. The closer the correlation coefficients to 1, the stronger the correlation. The copula function can be used to simulate the joint probability distribution between the drought characteristics because of the positive correlation between the drought characteristics and the good fitting effect of each characteristic through different distribution functions.
2.3.4 Copula-based modelling
It is vital to remember that drought characteristics are intertwined; thus, a univariate analysis will only be able to provide a partial picture of the drought situation. Sklar presented copulas to connect univariate distribution functions to multivariate distribution functions. Copulas are functions that join marginal CDFs to generate a multivariate CDF, according to their definition. By isolating the impacts of dependence from the effects of margins, this function makes it easier to characterize the dependence properties. Let F1, 2, …., n (x1, x2, …., xn) be the joint CDF of n associated arbitrary variables of X1, X2,...., Xn with the corresponding marginal CDF F1(x1), F2(x2), …., Fn(xn). The n-dimensional CDF along with the univariate distributions of F1(x1), F2(x2), …., Fn(xn) can be written as shown below in Eq. (5) (Nelsen 2007; Shiau 2006; Vazifehkhah et al. 2019) (Genest and Favre 2007; Tootoonchi et al. 2021):
where C is a d-dimensional copula; Fk(xk) = uk for k = 1,..., n. The copula function is in the form: [0, 1] d → [0, 1], where any pair in the d-dimensional square of the univariate distributions corresponds to the copula function in [0, 1] of joint CDF.
Archimedean copulas and Elliptical copulas are the two most commonly utilized copula classes (Huang et al. 2014; Qin et al. 2021; Ayantobo et al. 2019; Wang et al. 2020; Poonia et al. 2021a) (Tsakiris et al. 2016) (Song and Singh 2010b). In this study, nine copula functions, such as Clayton, Frank, Gumbel, Joe, Student t copula (t-copula), Gaussian, Survival Clayton, Survival Joe, and Survival Gumbel, are considered for the analysis of drought.
Table 2 presents these copula functions, where θ, r, and ϑ represent the parameters of the respective copula functions, and u and v are the variables. In Eq. (6), Ĉ denotes the survival copula function and C represents the respective copula function. The best-fit copula can be selected based on either of K-S test, root mean square error (RMSE) value, ML value, Nash-Sutcliff efficiency (NSE) value, AIC, or BIC values. The parameters of the copula can be estimated using either inversion of scale-free measure of association, MLE, inference from margins (IFM), and canonical maximum likelihood (CFM) methods. In this study, to calculate the copula parameter(s), the IFM approach was applied and for selecting the best copula function ML, AIC, and BIC values were used. The ‘copula’ package in R programming was used to estimate bivariate joint distributions (Yan 2007; Azam et al. 2018; Hofert et al. 2014).
2.3.5 Estimation of parameters of copula
In this study, the inference from margins (IFM) approach has been employed to estimate the copula parameters. In IFM, the log-likelihood function disintegrates the maximum log-likelihood into two segments: one from marginals (LM) and the other from copula dependence (LC), where L, C, and M denote the log-likelihood, copula dependence, and marginals, respectively. The parameters for each marginal distribution function are computed individually in the first stage of IFM. In the second step, using the computed value of the marginal distribution parameter, LC is maximized to get an estimate for the copula parameter (θ) (Maity 2018). Hence, in this method, Eq. (7) was used for getting the estimates of parameters.
2.3.6 Selection of appropriate copula function
It is critical to select the appropriate copula family when developing the joint probability distribution of drought variables. The performance of different copula functions was evaluated using the ML value, AIC, and BIC values in this study. The residuals between model simulations and observations are reduced when a parameter set gives the maximum likelihood. As a result, it provides the best match to the observed data in this sense. Higher model complexity results in better model flexibility, which in turn leads to the best fit to the actual data (Menna et al. 2022; Fang et al. 2014), but can lead to overfitting. AIC is a cost-effective measure of statistical model quality that penalizes overfitting (Pontes Filho et al. 2020). The Kullback–Leibler distance is the basis of the AIC, while the integrated neighborhood is the basis of the BIC in Bayesian theory (Achite et al. 2022). The smaller the value of AIC or BIC, the higher the fitting efficiency. AIC and BIC are calculated (Mesbahzadeh et al. 2020) using the following method:
where k is the number of fitting parameters, MLE is the maximum likelihood of the copula function and n is the number of observations.
2.3.7 Probabilistic analysis
The drought risk probability can be defined as the joint probability of Dd, Ds, and Dp (Zhang et al. 2020). Drought properties have a copula-based joint dependence structure that can be used to obtain some significant information required for the management and mitigation of drought. For instance, it is deemed a crucial situation for a water-supply system if both drought characteristics (severity and duration) surpass specific thresholds at the same time. In this study, the exceedance probability is computed using Eq. (10), which is defined as the probability when all the considered drought variables exceed a specific threshold. Analysis of drought characteristics separately will not determine the exceedance probability; however, copulas can provide this information quickly (Poonia et al. 2021a).
2.3.8 Return period analysis
In drought assessment and water management, analysis of the return periods of drought characteristics renders a vital role. The univariate return period of drought duration (Shiau and Shen 2001) is calculated by Eq. (11):
where E(Ld) is the expected drought interarrival time, and FD(d) is the marginal CDF of drought duration. Similarly, in the case of drought severity and drought peak, FD(d) will be replaced by FS(s) and FP(p) for the expected return period of severity and peak, respectively.
The bivariate return period is calculated in this study using two criteria: (i) AND return period when both the drought variables exceed a particular value, and (ii) OR return period when either of the two drought variables exceeds a specific value. Both are expressed below:
where TDS and TDS’ denote “AND” and “OR” joint return period respectively.
3 Results and discussion
3.1 Drought index
This research estimates SPEI and SDI on a 3-month time scale to replicate the drought characteristics for frequent droughts. As drought events occur more frequently, the drought index with a shorter time scale is better suited to adapt even to smaller drought occurrences. The SPEI of various time scales reflects the cumulative effect of drought. Equation (2) was used to obtain the SDI-3 value for each year. SPEI-3 and SDI-3 series were derived for the period of 1980 to 2015 at each of the seven hydrological stations, allowing the drought events to be recognized easily. SPEI-3 and SDI-3 series at Alladupalli and Tadipatri stations are presented in Figs. 3 and 4, respectively, in which positive values are shown in blue to represent non-drought periods and negative values are shown in red to indicate drought conditions. From the figures, it can be seen that the drought index has reached moderate and extreme drought levels in the range of 69 to 70 times and 6 to 9 times in case of meteorological drought. Whereas, in the case of hydrological drought, moderate drought has exceeded 9 to 180 times, and extreme drought has exceeded about 13 times. The major drought events observed in this study are consistent with the findings of (Kumar et al. 2018), which took into account the GRACE data (available from 2002), and the drought event in 2003–2005 may therefore be compared to this study. Throughout the research period, the Pennar River basin showed a pattern of wetting and drying consecutively. Drought occurrence frequencies and seasonal fluctuations can be estimated at each level to comprehend the pattern of droughts better in the Pennar River basin.

SPEI-3 time series at a Alladupalli station, b Tadipatri station

SDI-3 time series at a Alladupalli station, b Tadipatri station
3.2 Identification of drought characteristics
Before proceeding to the probabilistic analysis, the drought characteristics values (i.e., drought duration, severity, and peak) were computed using Run Theory from observed meteorological and hydrological droughts defined by SPEI-3 and SDI-3, respectively. These three drought characteristic values for each station were obtained using MS Excel and Python programming based on the drought index values. This paper seeks to examine the degree of drought risk based on the computed SPEI-3 and SDI-3; thus, the Run Theory threshold was set to zero. The drought duration, severity, and peak using the SPEI-3 at the Alladupalli and Chennur stations are shown in Fig.5 a and b, respectively. The average drought duration and severity for the study area coincide with the values in Poonia et al. (2021a) and Kumar et al. (2018). Sajeev et al. (2021) studied the bivariate drought characteristics of two contrasting climatic regions of India (Rajasthan and Kerala), and the number of drought events for this study lies between the values obtained for those two regions in their study.

Showing drought characteristics at (a) Alladupalli and (b) Chennur stations for the period of 1980–2015
Figure 6 presents the spatial variation of the total number of drought events and various drought characteristics over the study area. There were 48 meteorological and 28 hydrological drought events on average during the period considered in this study (Fig. 6a and b). But just the spatial plots of the total number of drought events will not give proper judgement to the severity of the drought events, i.e., even if there is a smaller number of drought events, there may be a chance of having drought events with more severity and larger peak. The drought events having a duration greater than 3 months, severity greater than 0.5, and peak greater than 0.25 have been considered for understanding the effects of drought severity over the basin, as droughts with values less than contemplated will not have much impact on the analysis. Results showed that the drought duration is almost equal in all stations. A spatial plot of drought severity (Fig. 6c and e) and peak (Fig. 6d and f) for both the drought types shows that Alladupalli station is having the most severe (Ds = 5.04) meteorological drought event, even if the total number of drought events are not the highest there. This result is in line with Sinha et al. (2018). Similarly, from the spatial plot, it can be inferred that Kamallapuram and Singavaram station, experienced more severe hydrological drought with larger peak, even though its total number of drought events is less than that of other stations.

Spatial plots of a the total number of meteorological drought events, b the total number of hydrological drought events, c Drought severity using SPEI, d Drought peak using SPEI, e Drought severity using SDI, and f Drought peak using SDI
According to preliminary research, analyzing drought duration, severity, and peak separately provides a finite assessment of drought characteristics; thus, it is preferable to use a multivariate approach and build a joint dependence structure to portray the interconnection between the drought characteristics, which is discussed in the next section.
3.3 Marginal distribution
The marginal distribution of each drought variable should be found first before exploring the joint distribution of the three variables. Different types of distributions were investigated in this study, and the best one was selected. The curve for the best-fit probability distribution function at Alladupalli station for the drought characteristics based on SPEI-3 is shown in Fig. 7. Even though streamflow changes could be the result of complicated interactions between climate change and land use land cover change, the variability in hydrological drought characteristics in the Pennar basin is more probably due to the change in meteorological factors such as precipitation and temperature in this study.

PDF of best-fit distribution for various drought characteristics based on SPEI-3 at the Alladupalli station
The curve for the best-fit probability distribution function at Nandipalli station for the drought characteristics based on SDI-3 is shown in Fig. 8. The list of the obtained best-fit marginal distributions and the estimated parameter values of the best-fit distributions for the meteorological and hydrological drought analysis from the drought characteristics are provided in Table 3.

PDF of best-fit distribution for various drought characteristics based on SDI-3 at the Nandipalli station
3.4 Joint distribution of drought characteristics
In order to assess the correlation between drought characteristics, correlation analysis was performed in this study. Tables 4 and 5 show the results of correlation analysis among the three characteristics of meteorological and hydrological drought, respectively. The correlation coefficients between the three sets of variables at each of the seven stations are all near 1, which indicates that the variables in each group are strongly correlated.
Different copula functions have been used in the current work to build the joint distribution of the drought characteristics based on the drought index values. The ML, AIC, and BIC values were used to evaluate the best-fit copula function. For every station, the parameters and the ML, AIC & BIC values for the best-fit copula function for the meteorological and hydrological drought characteristics are tabulated in Tables 6 and 7, respectively. For the overall region of the study area, for meteorological drought, Frank Copula is the best-fit copula function for the joint risk of drought duration and severity, whereas Survival Clayton copula is the best-fit copula for the combination of both drought duration and peak as well as drought severity and peak (Table 6).
The bivariate probability distribution based on SPEI-3 and SDI-3 [including P(D ≤ d, S ≤ s), P(D ≤ d, P ≤ p), and P (S ≤ s, P ≤ p)], is obtained for each station using the best-fit copula function of the drought characteristics chosen. The resulting plot of joint CDF at Alladupalli and Chennur stations for each bivariate analysis (duration vs. severity, duration vs. peak & severity vs. peak) of meteorological and hydrological drought is presented in Figs. 9 and 10, respectively.

Showing joint cdf of DD vs DS, DD vs DP and DS vs DP at (a) Alladupalli and (b) Chennur stations for meteorological drought

Showing joint cdf of DD vs DS, DD vs DP and DS vs DP at (a) Alladupalli and (b) Chennur stations for hydrological drought
From Fig. 5a, the 50th percentile of drought duration, severity, and peak can be seen as 3 months, 1.415, and 0.749, respectively for meteorological drought at Alladupalli station. For example, at the 50th percentile of drought duration, drought severity, and drought peak, at Alladupalli station for meteorological drought, it can be read from Fig. 9a, that the joint probability P(D ≤ 3, S ≤ 1.415) is 0.55, and P(D ≤ 3, P ≤ 0.749) is 0.88, and P (S ≤ 1.415, P ≤ 0.749) value is 0.832. Figure 9 shows that the drought occurrences at Alladupalli and Chennur stations were generally short-term high-severity and long-term moderate-severity events. As the duration and severity of a drought event increase, the value of joint cumulative probability also increases. The joint exceedance probability values at the 25th percentile of drought duration vs severity as obtained in this study align with the results of Poonia et al. (2021a).
Equivalent results can be seen for different combinations, such as drought duration and peak, as well as drought severity and peak. In addition, the results of joint cdf for other stations are similar to the Alladupalli and Chennur stations. The results indicate that a significant percentage of the study area is vulnerable to meteorological drought conditions. Lack of precipitation poses a major risk to the basin, as there is a high probability of meteorological drought. This might be a response to the significant upward trend of mean temperature (Pörtner et al. 2022) and the significant decreasing trend in seasonal and annual rainfall. Kumar et al. (2013) also hypothesize a general rise in moderate meteorological droughts during the past few decades in India. These findings will aid in quantifying the frequency of various levels of drought events.
3.5 Joint return period analysis of drought characteristics
Drought assessment requires a thorough understanding of the return period. In order to compute the joint return period of drought events, the expected value of the drought interarrival time must be calculated first. The drought interarrival time Ld for the stations Alladupalli and Chennur, obtained from the analysis of drought characteristics using the Run Theory, is 13.9 and 13.03 months, corresponding to 1.1 and 1.08 years, respectively, which are almost equal to 1 year. The expected interarrival time for other stations is also remarkably close to 1 year. The return period is calculated using the ‘AND’ and ‘OR’ criteria in this section. The joint return periods were computed using Eqs. (12) and (13) at the 25th and 50th percentile of each drought variable at every station for both meteorological and hydrological droughts. Figures 11 and 12 show the joint return period for the “AND” and “OR” cases of meteorological and hydrological droughts for the 25th and 50th percentiles of the drought events, respectively. For the overall region of the study area, an average joint return period of 1.63 years and 9.3 years is obtained for the AND case of the 25th and 50th percentile, whereas 1.06 years and 1.23 years is obtained for the OR case of the 25th and 50th percentile for the meteorological drought. Similarly, for hydrological drought, an average joint return period of 1.66 years and 8.89 years is obtained for the AND case of the 25th and 50th percentile, whereas 1.16 years and 1.34 years are obtained for the OR case of the 25th and 50th percentile. This shows that the drought events in the study area have a shorter return period. Amrit et al. (2018) found that droughts occur once every 5–6 years in a major section of Southern India, indicating a shorter return period. The joint return period values at the 25th and 50th percentile of drought duration vs severity for both the AND and OR case in this work and the fact that a shorter return period in the drought events prevailing in Southern India is also validated by Poonia et al. (2021a). In previous studies (Brunner et al. 2016; Vandenberghe et al. 2012), working with joint return periods (which is not as straightforward as in the case of univariate analysis) one must choose whether to work with joint (OR / AND) or conditional probabilities, presents an extra challenge in the multivariate case. Hence, in our study, both the AND and OR cases are employed.

Joint return periods for 25th percentile of drought events

Joint return periods for 50th percentile of drought events
The joint return period of the “AND” case is greater than the “OR” case because the computation of the return period of the “AND” event is more restrained than that of the “OR” event. Since the best-fit marginal distribution function of the drought variables and best-fit copula function are determined in the preceding section, and the parameters corresponding to that have been computed, the return period which corresponds to any particular drought duration, severity, or peak can also be calculated according to the requirement.
The return period notion employed in this study is well-known among water resources professionals. As a result of our findings, it is appropriate to raise concerns for drought control, particularly in locations with extremely high joint exceedance probability and low joint return period. If the hydraulic structures are designed based on the results of univariate frequency analysis, then they may under/overestimate drought characteristics, resulting in the failure of the structure or an increase in the structure’s cost. These findings could be helpful in assessing the risk of water resource operations in severe and extreme drought scenarios. In short, the findings of this work can help in providing useful information to predict drought risk, optimize water resource allocation, and lessen the effects of drought on the study area in the future.
4 Summary and conclusion
Drought assessment is essential for water resource management and planning. Drought characteristics such as drought duration, severity, and peak were abstracted for the study area from 1980 to 2015 based on the Run Theory. To summarize, this research uses Copulas to conduct a bivariate frequency analysis of meteorological and hydrological droughts at seven stations in the study area. Compared to prior definitions of bivariate frequency analysis, this method is flexible, thorough, and offers several other benefits. Drought analysis based on copulas considers comprehensive interdependencies between drought characteristics throughout a geographic region. Meteorological and Hydrological drought characteristics in the Pennar River basin were studied from two perspectives: joint cumulative probability and joint return period. The notable outcomes of this study are summarized as follows:
-
1)
In the case of meteorological drought, GEV, Gamma, and Generalized Pareto distributions were found to be the best marginal distributions for drought duration, severity, and peak, respectively in the study area.
-
2)
In the case of hydrological drought, GEV was found to be the best marginal distribution for drought duration, and Generalized Pareto distribution was found to be the best marginal distribution for drought severity and peak in the study area. The selection of a particular marginal distribution for the whole study area is very difficult and hence the analysis has been done for the stations.
-
3)
From the spatial plots, it can be comprehended that Alladupalli station is having the most severe meteorological drought and the whole study area is susceptible to severe meteorological drought. Kamallapuram and Singavaram station have experienced more severe hydrological drought with larger peak, even though the total number of drought events are less than that of other stations. Hence, it should be noted that the total number of drought events does not always justify the severity of the drought for any given area.
-
4)
The ML, AIC, and BIC values were utilized to pick out the optimal copula function. The drought variables showed an excellent correlation among themselves. Out of the nine copula functions, for the overall region of Pennar River basin, for meteorological drought, Frank Copula is found to be the best-fit copula function for the joint risk of drought duration and severity, whereas Survival Clayton copula is found to be the best-fit copula for the combination of both drought duration and peak as well as drought severity and peak.
-
5)
Using joint probability values and joint return periods, the drought risk can be calculated, which provides significant information for the analysis of drought. The joint return period for the study area can vary from as least as 1 year to 2 years or more for the 25th percentile whereas it can vary from 1 to 45 years for the 50th percentile of the combination of drought characteristics considered in the current work.
For instance, using simply the univariate information offered by either of the drought variables may result in under or overestimation of the real drought situation, and thus the corresponding risk. Hence, a multivariate analysis should be adopted.
According to our findings, the whole Pennar River basin is susceptible to frequent droughts. It can be observed that the study area has a high exceedance probability and a smaller joint return period. The research used a zero-threshold value of the drought index to identify the drought events at a three-month timescale. A more thorough analysis will emerge from the modification of the drought index threshold value. Moreover, this can enhance the values for joint return period and be useful in comparing the probabilities of various classes of drought (Poonia et al. 2021a). Additionally, the analysis only for seven selected stations, due to the data unavailability, might not provide a proper understanding of the drought conditions for the whole basin. But with the limited dataset, copula-based methodology produces impressive results.
Lastly, in this article, no account has been made for the impact of climate change and land use land cover change on the analysis, despite the fact that climate change and land use land cover change will affect the calculation of drought return periods. Furthermore, the groundwater level has not been considered in the hydrological analysis, which will have a minor impact on the hydrological drought. In this regard, systematic and rigorous attempts should be made to estimate the expected variations in meteorological and hydrological parameters that affect drought variables and, ultimately, the frequency of drought events.
Data availability
Data is available upon request to the corresponding author.
Code availability
Not applicable.
References
Achite M, Bazrafshan O, Wałęga A, Azhdari Z, Krakauer N, Caloiero T (2022) Meteorological and hydrological drought risk assessment using multi-dimensional copulas in the wadi ouahrane basin in Algeria. Water 14(4):653
Allan RP, Hawkins E, Bellouin N, Collins B (2021) IPCC, 2021: summary for Policymakers
Amrit K, Pandey RP, Mishra SK, Kumre SK (2018) Long-Term meteorological drought characteristics in Southern India. In: World environmental and water resources congress 2018: Groundwater, sustainability, and hydro-climate/climate change. American Society of Civil Engineers, Reston, VA, pp 207–215
Ayantobo OO, Li Y, Song S (2019) Multivariate drought frequency analysis using four-variate symmetric and asymmetric archimedean copula functions. Water Resour Manag 33:103–127
Ayantobo OO, Li Y, Song S, Yao N (2017) Spatial comparability of drought characteristics and related return periods in mainland China over 1961–2013. J Hydrol 550:549–567
Azam M, Maeng SJ, Kim HS, Murtazaev A (2018) Copula-based stochastic simulation for regional drought risk assessment in South Korea. Water 10(4):359
Brunner MI, Seibert J, Favre A-C (2016) Bivariate return periods and their importance for flood peak and volume estimation. Wires Water 3:819–833
Chandrasekara SS, Kwon HH, Vithanage M, Obeysekera J, Kim TW (2021) Drought in South Asia: a review of drought assessment and prediction in South Asian countries. Atmosphere 12(3):369
Chen L, Singh VP, Guo S, Mishra AK, Guo J (2013) Drought analysis using copulas. J Hydrol Eng 18(7):797–808
Daneshkhah A, Remesan R, Chatrabgoun O, Holman IP (2016) Probabilistic modeling of flood characterizations with parametric and minimum information pair-copula model. J Hydrol 540:469–487
Das J, Gayen A, Saha P, Bhattacharya SK (2020) Meteorological drought analysis using standardized precipitation index over Luni River Basin in Rajasthan, India. SN Applied Sciences 2:1–17
Dixit S, Atla BM, Jayakumar KV (2022) Evolution and drought hazard mapping of future meteorological and hydrological droughts using CMIP6 model. Stoch Env Res Risk Assess 36:3857–3874
Dixit S, Jayakumar KV (2021) A study on copula-based bivariate and trivariate drought assessment in Godavari River basin and the teleconnection of drought with large-scale climate indices. Theor Appl Climatal 146:1335–1353
Dixit S, Jayakumar KV (2022) A non-stationary and probabilistic approach for drought characterization using trivariate and pairwise copula construction (PCC) Model. Water Resour Manag 36:1217–1236
Eslamian S et al (2017) A review of drought indices. Int J Constr Res Civil Eng 3:48–66
Evkaya O, Yozgatl Ci, Sevtap S-KA (2019) Drought analysis using copula approach: a case study of Turkey. Communications in Statistics: Case Studies, Data Analysis and Applications, pp 2373–7484
Fang Y, Madsen L, Liu L (2014) Comparison of two methods to check copula fitting. IAENG Int J Appl Math 44(1)
Garg V et al (2017) Assessment of land use land cover change impact on hydrological regime of a basin. Environ Earth Sci 76(18):1–17
Genest C, Favre A-C (2007) Everything you always wanted to know about copula modeling but were afraid to ask. J Hydrol Eng 12(4):347–368
Graler B et al (2013) Multivariate return periods in hydrology: a critical and practical review focusing on synthetic design hydrograph estimation. Hydrol Earth Syst Sci 17(4):1281–1296
Guo Y et al (2019) Assessing socioeconomic drought based on an improved Multivariate Standardized Reliability and Resilience Index. J Hydrol 568:904–918
Haied N, Foufou A, Chaab S, Azlaoui M, Khadri S, Benzahia K, Benzahia I (2017) Drought assessment and monitoring using meteorological indices in a semi-arid region. Energy Procedia 119:518–529
Hao Z, AghaKouchak A (2013) Multivariate standardized drought index: a parametric multi-index model. Adv Water Resour 57:12–18
Hasan HH, Razali SFM, Muhammad NS, Ahmad A (2019) Research trends of hydrological drought: a systematic review. Water 11(11):2252
Hofert M et al (2014) Package ‘copula’. [Online] Available at: http://ie.archive.ubuntu.com/disk1/disk1/cran.r-project.org/web/packages/copula/copula.pdf
Hong X, Guo S, Zhou Y, Xiong L (2015) Uncertainties in assessing hydrological drought using streamflow drought index for the upper Yangtze River basin. Stoch Env Res Risk Assess 29(4):1235–1247
Hou W, Yan P, Feng G, Zuo D (2021) A 3D copula method for the impact and risk assessment of drought disaster and an example application. Front Phys 9:656253
Huang S et al (2014) Copulas-based probabilistic characterization of the combination of dry and wet conditions in the Guanzhong Plain, China. J Hydrol 519:3204–3213
Kwak J, Kim S, Kim D, Kim H (2016) Hydrological drought analysis based on copula theory. River Basin Manag 2016:83–95
Kogan F (1995) Application of vegetation index and brightness temperature for drought detection. Adv Space Res 15(11):91–100
Kulkarni SS et al (2020) Developing a remote sensing-based combined drought indicator approach for agricultural drought monitoring over Marathwada, India. Remote Sensing 12(13):2091
Kumar A, Pandey RP, Mishra SK, Kumre SK (2018) Long-Term meteorological drought characteristics in Southern India. In World Environmental and Water Resources Congress 2018: Groundwater, Sustainability, and Hydro-Climate/Climate Change, p 207–215
Kumar KN et al (2013) On the observed variability of monsoon droughts over India. Weather Clim Extremes 1:42–50
Lee T, Modarres R, Ouarda TB (2013) Data-based analysis of bivariate copula tail dependence for drought duration and severity. Hydrol Process 27(10):1454–1463
Madadgar S, Moradkhani H (2016) Copula function and drought. Taylor & Francis, New York
Maity R (2018) Statistical methods in hydrology and hydroclimatology. Springer, Singapore
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology 17(22):179–183
Menna BY, Mesfin HS, Gebrekidan AG, Siyum ZG, Tegene MT (2022) Meteorological drought analysis using copula theory for the case of upper Tekeze river basin, Northern Ethiopia. Theor Appl Climatol 149(1–2):621–638
Mesbahzadeh T, Mirakbari M, Mohseni Saravi M, Soleimani Sardoo F, Miglietta MM (2020) Meteorological drought analysis using copula theory and drought indicators under climate change scenarios (RCP). Meteorol Appl 27(1):e1856
Mirabbasi R, Fard AF, Dinpashoh Y (2012) Bivariate drought frequency analysis using the copula method. Theoret Appl Climatol 108(1):191–206
Mirakbari M, Ganji A, Fallah SR (2010) Regional bivariate frequency analysis of meteorological droughts. J Hydrol Eng 15(12):985–1000
Mishra AK, Singh VP, Desai VR (2009) Drought characterization: a probabilistic approach. Stoch Environ Res Risk Assess 23(1):41–55
Nalbantis I, Tsakiris G (2009) Assessment of hydrological drought revisited. Water Resour Manag 23(5):881–897
Nelsen RB (2007) An introduction to copulas. Springer Science & Business Media
Palmer W (1965) Meteorological drought. US Department of Commerce, Weather Bureau, Washington, DC
Pandey RP, Dhama YK (2000) Drought characterization in arid and semi arid climatic regions of India. National Institute of Hydrology
Panu U, Sharma T (2009) Analysis of annual hydrological droughts: the case of Northwest Ontario, Canada. Hydrol Sci J 54(1):29–42
Pathak AA, Dodamani BM (2016) Comparison of two hydrological drought indices. Perspect Sci 8:626–628
Pontes Filho JD, Souza Filho FDA, Martins ESPR, Studart TMDC (2020) Copula-based multivariate frequency analysis of the 2012–2018 drought in Northeast Brazil. Water 12(3):834
Poonia V et al (2021a) Drought occurrence in Different River Basins of India and blockchain technology based framework for disaster management. J Clean Prod 312:127737
Poonia V, Jha S, Goyal MK (2021b) Copula based analysis of meteorological, hydrological and agricultural drought characteristics across Indian river basins. Int J Climatol 41(9):4637–4652
Pörtner H-O et al (2022) Climate change 2022: Impacts, adaptation and vulnerability. IPCC, Geneva
Qin F, Ao T, Chen T (2021) Bivariate frequency of meteorological drought in the upper Minjiang River based on copula function. Water 13(15):2056
Rajsekhar D, Singh VP, Mishra AK (2015) Multivariate Drought Index: an information theory based approach for integrated drought assessment. J Hydrol 526:164–182
Rose MAJ, Chithra NR (2020) Evaluation of temporal drought variation and projection in a tropical river basin of Kerala. J Water Clim Chang 11(S1):115–132
Sajeev A, Deb Barma S, Mahesha A, Shiau JT (2021) Bivariate drought characterization of two contrasting climatic regions in India using copula. J Irrig Drain Eng 147(3):05020005
Shafer BA (1982) Developement of a surface water supply index (SWSI) to assess the severity of drought conditions in snowpack runoff areas. In Proceedings of the 50th Annual Western Snow Conference, Colorado State University, Fort Collins, 1982
Shiau J (2006) Fitting drought duration and severity with two-dimensional Copulas. Water Resour Manag 20:795–815
Shiau J-T, Modarres Rb (2009) Copula-based drought severity-duration-frequency analysis in Iran. Meteorol Appl 16(4):481–489
Shiau J-T, Shen HWa (2001) Recurrence analysis of hydrologic droughts of differing severity. J Water Resour Plan Manag 127(1):30–40
Shukla S, Wood AW (2008) Use of a standardized runoff index for characterizing hydrologic drought. Geophys Res Lett 35(2)
Sinha J, Sharma A, Khan M, Goyal MK (2018) Assessment of the impacts of climatic variability and anthropogenic stress on hydrologic resilience to warming shifts in Peninsular India. Sci Rep 8:13833
Song S, Singh VP (2010a) Frequency analysis of droughts using the Plackett copula and parameter estimation by genetic algorithm. Stoch Env Res Risk Assess 24(5):783–805
Song S, Singh VP (2010b) Meta-elliptical copulas for drought frequency analysis of periodic hydrologic data. Stoch Env Res Risk Assess 24(3):425–444
Spinoni J et al (2019) A new global database of meteorological drought events from 1951 to 2016. J Hydrol Reg Stud 22:100593
Swain S, Mishra SK, Pandey A (2020) Assessment of meteorological droughts over Hoshangabad district, India. In IOP conference series: earth and environmental science, vol 491, No 1. IOP Publishing, p 012012
Swain S, Mishra SK, Pandey A (2021) A detailed assessment of meteorological drought characteristics using simplified rainfall index over Narmada River Basin, India. Environ Earth Sci 80:1–15
Tigkas D, Vangelis H, Tsakiris G (2015) DrinC: a software for drought analysis based on drought indices. Earth Sci Inf 8(3):697–709
Tootoonchi F et al (2021) Copulas for hydroclimatic analysis: a practice-oriented overview. Wiley Interdiscip Rev Water 9(2):e1579
Tsakiris G et al (2016) Analysing drought severity and areal extent by 2D Archimedean copulas. Water Resour Manag 30(15):5723–5735
Udayar S et al (2019) Analysis of drought from humid, semi-arid and arid regions of India using DrinC model with different drought indices. Water Resour Manag 33:1521–1540
Vandenberghe S et al (2012) Joint return periods in hydrology: a critical and practical review focusing on synthetic design hydrograph estimation. Hydrol Earth Syst Sci 9(5):6781–6828
Vazifehkhah S, Tosunoglu F, Kahya E (2019) Bivariate risk analysis of droughts using a nonparametric multivariate standardized drought index and copulas. J Hydrol Eng 24(5):05019006
Vicente-Serrano S et al (2012) Accurate computation of a streamflow drought index. J Hydrol Eng 17(2):318–332
Villarini G et al (2009) Flood frequency analysis for nonstationary annual peak records in an urban drainage basin. Adv Water Resour 32(8):1255–1266
Wang L, Zhang X, Wang S, Salahou MK, Fang Y (2020) Analysis and application of drought characteristics based on theory of runs and copulas in Yunnan, Southwest China. Int J Environ Res Public Health 17(13):4654
Wu R, Zhang J, Bao Y, Guo E (2019) Run theory and copula-based drought risk analysis for Songnen grassland in Northeastern China. Sustainability 11(21):6032
Xu K et al (2015) Spatio-temporal variation of drought in China during 1961–2012: a climatic perspective. J Hydrol 526:253–264
Yan J (2007) Enjoy the joy of copulas: with a package copula. J Stat Softw 21(4):1–21
Yevjevich V (1967) An objective approach to definitions and investigations of continental hydrologic droughts. Hydrol Pap Colo State Univ 23:382–391
Zhang L, Wang Y, Chen Y, Bai Y, Zhang Q (2020) Drought risk assessment in Central Asia using a probabilistic copula function approach. Water 12(2):421
Author information
Authors and Affiliations
Contributions
Both authors contributed to the study conception and design. The analysis was done by Balaram Shaw under the supervision of Dr. Chithra NR. The first draft of the manuscript was written by Balaram Shaw, and it was revised by Dr. Chithra NR. Both authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Shaw, B., Chithra N R Copula-based multivariate analysis of hydro-meteorological drought. Theor Appl Climatol 153, 475–493 (2023). https://doi.org/10.1007/s00704-023-04478-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-023-04478-1