
Abstract
Long-term climate memory is ubiquitous in climate systems, but its contribution to climate prediction has not been assessed systematically. We used an integral fractional statistical model (FISM) to quantify climate memories in different variables over China. Their contributions to climate prediction were estimated using explained variances. We found different climate memory effects for different variables in different regions. The contribution of climate memory to climate variability is stronger in temperature than in precipitation records. For temperatures (including both air temperature and land temperature), the average variance explained by climate memory is around 3∼4%. For precipitation, the average explained variance was 0.6%. The low values for explained variances indicate that, on average, the contributions of climate memory to temperature and precipitation predictions are small. But in specific regions, higher climate memory effects may occur. For precipitation, climate memory can contribute 3% of the variance in southeast China. For temperature, climate memory can explain ≥ 10% of the variance in northeast and southwest China, which is not low and should be considered in prediction. Therefore, for more accurate climate prediction, we suggest first determining the contribution of climate memory. For variables or regions with strong climate memory effects, a scheme considering climate memory effects may help improve future climate predictions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Ever since the middle of last century when the well-known Hurst phenomenon was discovered (Hurst 1951), it has been widely recognized that the variability of many climatic variables on different time scales is not arbitrary, but follows a scaling law:
where a represents the time scale and H is the Hurst exponent. This means time series x(t) remains statistically similar if one zooms in or out, and its variability exhibits scale invariance. Calculation of the auto-correlation function C(s) shows that C(s) decays with time scale s as a power-law for variables with the Hurst phenomenon, and the mean correlation time diverges in an infinitely long series. In this case, the present state of a system may have long-lasting influences on its states in the future, and more vividly, the Hurst phenomenon is also known as long-term memory (LTM) (Koscielny-Bunde et al. 1998; Malamud and Turcottr 1999).
Different from short-term memory of weather-systems which only last for several days to weeks, long-term memory indicates persistence of longer time scales (months, years, and decades). LTM is ubiquitous in climate systems and various explanations have been proposed. One physical mechanism to explain LTM is the non-stationary regime behavior. As reported by Franzke et al. (2015), LTM (Hurst effects) can be produced in the deterministic chaotic Lorenz 63 model (Lorenz 1963) due to its regime behavior, which is ubiquitous in the atmosphere. Another origin for LTM may be the coupling of multi-scale processes. For example, weather-scale excitations can store their impacts in slow-change systems (e.g., oceans), which may exhibit the influences slowly on a larger time scale (Yuan et al. 2013).
In recent years, with the development of many methods including spectral analysis (Malamud and Turcottr 1999; Weber and Talkner 2001), structure function method (Lovejoy and Schertzer 2012), wavelet analysis (Arneodo et al. 1995; Abry and Veitch 1998), detrended fluctuation analysis (Peng et al. 1994; Kantelhardt et al. 2001), etc., climatic variables ranging from temperatures (Kurnaz 2004; Pattantyús-Ábrahám et al. 2004; Király et al. 2006; Jiang et al. 2015; Massh and Kantz 2016), relative humidity (Chen et al. 2007) and precipitation (Kantelhardt et al. 2006; Jiang et al. 2017), to wind fields (Feng et al. 2009), atmospheric general circulations (Vyushin and Kushner 2009) and total ozone anomalies (Varotsos and Kirk-Davidoff 2006; Vyushin et al. 2007), are all found to have LTM, even though the memory strength varies among the variables in different regions. In contrast to traditional climatic studies that focus on dynamic interactions among multiple climatic processes over different time scales, LTM represents multi-scale interactions in terms of fractals (Mandelbrot and Van Ness 1968), which allows analysis of the structural properties of the climate system, regardless of the dynamic mechanisms. Therefore, in addition to detecting the existence of LTM in different climate variables, more studies are now concentrating on the application of long-term climate memory, including (i) developing new methods for trend evaluation (Lennartz and Bunde 2009; Yuan et al. 2015; Ludescher et al. 2016); (ii) designing early warning systems for extreme events (Bunde et al. 2005; Bogachev and Bunde 2011); and (iii) quality evaluation of reanalysis datasets/model simulations using long-term climate memory as a test bed (Blender and Fraedrich 2006; Rybski et al. 2008; Monselesan et al. 2015). These studies have greatly increased the understanding of climate memory.
As the name implies, one of the most straightforward application of long-term climate memory is climate prediction, which has not been studied systematically. It has been shown that the stronger the level of memory possessed by the climate variable, the stronger the predictability will be Zhu et al. (2010), Yuan et al. (2013), Yuan et al. (2014), and Anderson et al. (2016). However, most climate prediction models have not properly included the effects of climate memory into their predictions. Do we need to take the long-term climate memory effect into consideration to improve the accuracy of predictions? Also, which variables and regions should be emphasized to determine the effects of climate memory? These important questions need to be addressed to improve climate predictions.
In this work, we analyzed different climatic variables (e.g., 2-m air temperature, land surface temperature, precipitation, etc.) observed over China. We used the fractional integral statistical model (FISM) (Yuan et al. 2013, 2014) to extract the long-term climate memory as a memory signal and quantify the contribution of climate memory to climate variability. By studying different variables over different regions, we were able to report the specific variables and the specific regions where the climate variability is more dependent on the long-term climate memory and also the variables and regions where the climate memory is not useful for climate prediction. Accordingly, the importance of climate memory in climate prediction is assessed quantitatively.
The rest of this paper is organized as follows. In Section 2, we will make a brief introduction of the data and the methods we used for analysis. The effects of climate memory on different variables are estimated in Section 3, and the results are compared with those calculated from artificially generated data. After a detailed discussion of the climate memory effects among different variables and regions, we suggest specific variables/regions where the climate memory effects are non-negligible. In Section 4, we summarize this work and present a future outlook.
2 Data and methods
2.1 Data
Monthly maximum air temperature (MAT), monthly minimum air temperature (MIT), monthly precipitation sums (PRE), and monthly land temperature (LT) from Chinese international exchange stations were analyzed. For the air temperature and precipitation, homogenized daily records were provided by the information center of China Meteorological Administration. For the land temperature, however, daily records downloaded from the China Meteorological Data Sharing Service System (http://data.cma.cn) were only quality controlled, but not homogenized. The monthly data were calculated from the daily records. A total of 177 stations for MAT, MIT, and PRE and 150 stations for LT were selected based on (i) data lengths and (ii) data gaps. Only data covering the period 1961–2010 (50 years) without any missing values were used in this analysis (see Fig. 1). Each time series therefore had a length of 600 months. Before analysis, seasonal trends were removed by subtracting annual cycle from the observed climate data (Koscielny-Bunde et al. 1998), as xi = τi− < τi >, i = 1,...,600, where {τ} is the observed climate data and < τi > is long-time climatological average for each calendar.

Spatial distributions of the meteorological stations where the observed temperatures/precipitation are used in this study. Hollow circles represent the stations, where the maximum air temperature, minimum air temperature, and precipitation records are analyzed. Solid circles represent the stations, where the 0-m average land temperature records are studied. There are 177 hollow circles and 150 solid circles
To verify the results from observational data, we performed the same analysis on artificial data with LTM. Using Fourier filtering technique, artificial datasets with different LTM strengths were generated (Turcotte 1997). For each LTM strength, 3,000 samples were used for adequate statistical accuracy.
2.2 Methods
2.2.1 Detecting long-term climate memory
Long-term climate memory can be detected directly using the auto-correlation function C(s). If C(s) decays with the time scale s as a power-law, C(s) ∼ s−γ (0 < γ < 1), the time series being studied can be considered as long-term correlated and the exponent γ can be used to measure the strength of the long-term climate memory. However, affected by noise and underlying trends, which may exist in the considered time series, C(s) is normally calculated with big uncertainties, and it is difficult to measure the scaling behavior between C(s) and s accurately. Therefore, we employed detrended fluctuation analysis of the second-order (DFA-2) (Kantelhardt et al. 2001). With a time series {xi, i = 1,..., N}, in DFA-2, one considers the cumulated sum \(\{Y_{i},Y_{i}={{\sum }^{i}_{k = 1}x_{k}\}}\) and studies non-overlapping time windows of size s. In each window, the local trend through second-order polynomial fitting is determined, and the square fluctuation Fs(j) is calculated as the variance of {Ys×(j− 1)+ 1,..., Ys×j} around the best quadratic fit, where j is the j th window. By averaging over all windows, we obtained the fluctuation function \(F(s)={\sum }^{[N/s]}_{j = 1}F_{s}(j)\). For time series with long-term memory, F(s) increases with s as F(s) ∼ sα, with the exponent α larger than 0.5. The bigger α is, the stronger the long-term memory will be. For stationary time series, the DFA-2 exponent α equals the Hurst exponent H (see Eq.1) (Talkner and Weber 2000; Kantelhardt et al. 2001). One can also use α to derive the exponent γ in C(s) ∼ s−γ by using γ = 2(1 − α) (Kantelhardt et al. 2001).
2.2.2 Extracting climate memory signals
To extract the long-term climate memory quantitatively as a memory signal, we used the FISM (Yuan et al. 2013, 2014). FISM was developed in analogy to the stochastic climate model proposed by Hasselmann (1976). It is based on fractional integrals and can decompose climate variables at any given time point into two parts: the memory part and the non-memory part, as shown below,
where M(t) represents the memory part and ε(t) stands for the weather-scale dynamical excitation (non-memory part). M(t) and ε(t) are connected via a fractional integral, and the FISM was designed using the Riemann-Lioville fractional integral formula, as shown below:
where Γ denotes the gamma function, q is the integral order, t − u represents the distance between historical time point u and present time t, and δ is the sampling time interval (e.g., monthly). From FISM, the memory part M(t) can be calculated quantitatively when the historical ε(u) = ε(0), ε(δ),..., ε(t − δ) is known, as shown below:
Since the integral order q is connected with the DFA exponent α as q = α − 0.5, using α obtained from DFA, the historical ε(u) can be derived from Eq. (3). After about 100 steps of “spin-up” time, the reverse derived historical ε(u) has been proved reliable with negligible errors (Yuan et al. 2014). Therefore, by fractionally integrating the historical ε(u), the climate memory signal accumulated from the past can be extracted.
It is worth to note that long-term climate memory is essentially a scaling behavior that spans more than one order of magnitude. For some variables, even the climate states from hundred years ago may have influences on the current climate (Fraedrich and Blender 2003). Therefore, the longer the historical ε(u), the better the climate memory signal estimation. However, due to practical limitations on the length of observed data, only a certain length of historical ε(u) is available. For example, the length of the data analyzed in this study is 50 years, which is normal data length for most meteorological stations in the world. With the first 10 years ε(u) sacrificed as the “spin-up” time (∼ 120 months) and the last 10 years serving as the test zone, only the middle 30 years data is available for calculation of M(t). Therefore, in this study, the climate memory signals are extracted using only the past 30 years of ε(u) (see Fig. S1 in the Supporting Information (SI)).
2.2.3 Estimating climate memory effects
After extracting climate memory signals, it is natural to ask how much climate variability was explained by past influences. In this study, the extracted M(t) stands for the influences accumulated from the past 30 years, while the remaining part {x(t) − M(t)} mainly depends on the non-memory part at the current time. Since M(t) and {x(t) − M(t)} are uncorrelated (see Fig. S2 in SI), the contribution of climate memory to climate variability may be approximately estimated as follows:
assuming the terms M(t) and {x(t) − M(t)} are independent from each other. The higher the explained variance (EV) obtained, the greater the amount of climate variability shared by climate memory. We used the last 10 years as test period, to calculate the variance of M(t) and {x(t) − M(t)}.
3 Results
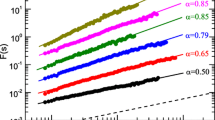
To extract climate memory signals and estimate the climate memory effects, we first needed to determine if long-term climate memory exists in the variable of interest. Using DFA-2, the climate variables observed over China were analyzed. Figure 2 shows the DFA-2 results for the four variables (PRE, MAT, MIT, and LT) at Xingyi (Station ID: 57902; Lat: 25.26N, Lon: 105.11E), as an example. In this log-log plot, straight lines ranging from 9 months to more than one decade were observed, indicating the power-law increase of F(s) with s. The slope of the straight line is the DFA-2 exponent α. For MAT, MIT, and LT, the DFA-2 exponents were 0.65, 0.64, and 0.64, respectively. Since the estimated DFA exponent α has an uncertainty of about ± 0.05 (see SI, DFA-2 was applied to 1,000 shuffled data to estimate the uncertainty of α), these α values indicate the existence of long-term climate memory. For PRE, the DFA-2 exponent α was only 0.52, which may imply the absence of (or very weak) long-term climate memory in precipitation records. For all other stations in China, similar power-law increases of F(s) were obtained. As previously reported (Yuan et al. 2010), the DFA-2 exponent α varied from 0.5 to 0.8 over the whole country. Therefore, it is necessary to identify the different contributions of climate memory to climate variability in different regions. The DFA-2 exponents α in all stations are provided in Table S1 of the Supporting Information (SI).

DFA-2 results of the precipitation, maximum air temperature, minimum air temperature, and 0-m average land temperature (from top to bottom) observed in Xingyi station. From the measured DFA-2 exponent α, one can see that the maximum air temperature, the minimum air temperature and 0-m average land temperature are all characterized by significant long-term memory (\(\alpha \sim 0.65\)), while the precipitation only has very weak long-term memory (α = 0.52)
Normally, a higher DFA exponent α implies a greater contributions of climate memory to climate variability (Zhu et al. 2010). However, α alone does not precisely indicate the level of variance shared by climate memory. Therefore, in addition to the exponent α, we determined the climate memory effects by calculating the explained variance of climate memory signals (Eq. (5)). We used the FISM to extract the climate memory signal M(t) (see Fig. S1) and further decomposed the variable of interest x(t) into two parts: M(t) and {x(t) − M(t)}. After calculating the variances of the two parts, the variance shared by the memory part was determined. Figure 3 shows the explained variances by climate memory for all four different variables (dots). We verified the results by comparing them with those obtained from artificial data of different long-term memory strength (lines). The black solid line represents the mean explained variance estimated from artificial data, while the red and blue-dashed lines are the upper and lower boundaries of the 95% distribution range. The results from the observed records were in good agreement with the results from artificial data, indicating that the explained variances calculated from real records are indeed governed by the strength of long-term memory. With the increased α, the variance explained by climate memory increased rapidly. For PRE, the α mainly ranged from 0.5 to 0.6. Correspondingly, the climate memory normally contributes less than 5% of the variability. For temperature records (MAT, MIT, and LT), the climate memory was stronger and the estimated explained variance was also higher. For most cases, the α values ranged from 0.5 to 0.75. Consequently, the explained variance by climate memory can reach 10%. In some extreme cases (Fig. 3c, d), the explained variances even exceeded 15%.

Explained variance of long-term climate memory in the four variables: a precipitation (PRE), b maximum air temperature (MAT), c minimum air temperature (MIT), and d land temperature (LT). With the increase of DFA exponent α, in general, the contributions of climate memory also increase. To verify the results, the same analysis is also made to artificial data of different long-term memory strengths. The black solid line represents the mean explained variance estimated from artificial data. The red- and blue-dashed lines are the upper and lower bounds of 95% distribution range. There are six stations for MIT and eight stations for LT that fall out of the 95% distribution range (see the solid black points)
To illustrate the different climate memory effects among different variables, we summarized the explained variances for PRE, MAT, MIT, and LT, respectively. By counting the explained variances obtained from all the stations (177 stations for PRE, MAT, and MIT; 150 stations for LT), we found that precipitation has the lowest climate memory effects (Fig. 4). On average, only 0.6% of the variance is shared by climate memory. For MAT, MIT, and LT, the climate memory effects were higher, but the average explained variances were still low, around 3∼4%. The low explained variance in the four variables suggests that the contribution of climate memory to climate prediction may be unimportant, especially for precipitation where the long-term climate memory is very weak (or absent). However, in addition to the low average explained variances shown in Fig. 4, there is large variation for each variable, which suggests different climate memory effects in different regions. For precipitation, the upper boundary of the 95% distribution is around 2–3%, while for temperatures (MAT, MIT, and LT), the upper boundaries are around 10%. Except for precipitation, the climate memory effects on temperatures are thus non-negligible, especially in specific regions.

Summary of the explained variances of the four variables: PRE (black), MAT (red), MIT (blue), and LT (cyan). The solid circle represents the mean explained variance averaged over all the considered stations, while the horizontal line shows the median value. The upper and lower borders represent the 75 and 25 percentage of the explained variances of all the stations, while the vertical line shows the 95 and 5 percentage
To better describe the regions where climate variability is more dependent on the climate memory, geographical distributions of the climate memory effects of different variables are presented in Fig. 5. For precipitation (Fig. 5a), due to the weak long-term climate memory, the variance explained by climate memory is very low (close to 0) in most stations. In southeast of China, there are a few stations with slightly higher climate memory effects (∼ 3%). For air temperatures, similar spatial patterns are found between the maximum air temperatures (Fig. 5b) and the minimum air temperatures (Fig. 5c). The contributions of climate memory to climate variability are smaller than 5% in most regions. Especially in south of the Yangtze River, the explained variances are even lower than 3%. For stations in the northeast and the southwest, however, higher climate memory effects (> 8%) are highlighted. For some stations, the explained variance by climate memory can even exceed 10%, indicating non-negligible climate memory effects. Slightly different from the results of the maximum air temperature, relatively high climate memory effects are also found in southernmost China for the minimum air temperature, where the explained variances by climate memory exceed 6%. For the land temperatures (Fig. 5d), the spatial distribution of climate memory effects is not as clear as those obtained from the air temperatures, but there is a similar pattern. Low climate memory effects were found in most regions, especially in south of the Yangtze River. But for some stations located in the northeast and southwest, higher than 10% explained variance were found. These data characterized these two regions as specific areas, where the temperature variabilities are more dependent on the climate memory.

Geographical distributions of the climate memory effects of different variables, a PRE, b MAT, c MIT, and d LT. For precipitation, slightly higher climate memory effects (\(\sim \) 3%) are found in the southeast of China. While for temperatures, non-negligible climate memory effects (8\(\sim \)10%) are found in the northeast and the southwest of China
4 Discussion and conclusion
In recent years, long-term climate memory has become a well-known concept in the climate community (Koscielny-Bunde et al. 1998; Fraedrich and Blender 2003; Rybski et al. 2008; Yuan and Fu 2014; Yuan et al. 2015; Monselesan et al. 2015; Ludescher et al. 2016; He and Zhao 2018). It can be considered as a kind of “inertia” in climate system, that historical climate conditions may have long-lasting influences on the current climate (Yuan et al. 2013). Therefore, when predicting future climate, it is natural to ask whether the effects of long-term climate memory are important enough for consideration. In this study, we addressed this question by (i) extracting the climate memory signals quantitatively and (ii) calculating the variance explained by climate memory. After analyzing different climate variables over China, we found non-negligible climate memory effects in temperature records (both air and land temperature), but low climate effects in precipitation records. For temperatures, the effects of climate memory can account for more than 10% of the temperature variability in the northeast and southwest of China, while for precipitation, the contributions of climate memory were smaller than 3% in most stations over China. The higher climate memory effects in temperatures suggest stronger predictability from the perspective of climate memory. Therefore, to obtain reliable temperature predictions in the northeast and southwest of China, climate memory effects need to be properly considered. For precipitation, however, predictions made with or without consideration of climate memory effects will have no big differences. It is worth to note that the air temperature and precipitation data used in this study are homogenized, while the land temperature data are not. By comparing the results from homogenized air temperature/precipitation data with those from non-homogenized data, it has been found that the results from only less than 10% stations suffered from the inhomogeneity (Fig. S3 in SI), and the main conclusion remain unchanged (Fig. S4 in SI). Therefore, although the land temperature data are not homogenized, they still can provide approximately reliable estimations of the climate memory effects. But in view of the potential biases due to inhomogeneity, we also emphasize the importance of using homogenized data, in order to further improve the accuracy of the calculations.
In contrast to traditional studies where climate memory is discussed in terms of DFA exponent α (or Hurst exponent H), we translated the exponents α or H into climate memory effects. In previous studies, there are several other methods that can be used to study the effects of climate memory. For example, by calculating the potentially predictable variance fraction (ppvf) (Boer 2000, 2004; Zhu et al. 2010) found that for time series with strong climate memory, the potentially predictable component on longer time scales also accounts for a large fraction of the total variance. As in our data, the inter-annual temperature variability accounts for around 30% of the total variance. By further studying the inter-annual variability from artificial data of the same memory strength, similar to the calculations suggested by Franzke and Woollings (2011), there is on average 46% of the inter-annual temperature variability originated from the climate memory. However, these calculations only estimated the potential predictability of the considered time series on a given time scale. In our study, we quantified the influences from the past and decomposed the considered time series into the memory parts and the remaining part. The explained variance of M(t) describes how large a fraction of the current climate states is determined by past influences. Therefore, the calculations in this study is closer to a real prediction. M(t), which can be extracted quantitatively from FISM, determines the bottom line of the prediction.
We emphasize that for variables with strong climate memory effects, it is necessary to include the influences from the past into future climate predictions. In current prediction models, few have incorporated the effects of climate memory. In statistical models, predictions are usually made from several predictors and linear/nonlinear regression equations without considering past effects. For process-based dynamical models, due to the imperfect representation of physical processes, it is questionable whether the dynamical models can accurately reproduce the long-term climate memory (Govindan et al. 2002; Vyushin et al. 2004; Rybski et al. 2008; Doblas-Reyes et al. 2013). Since the climate memory signals M(t) can be quantitatively extracted using FISM, a potential way to consider the effects of climate memory is that one may first extract M(t), then predict the weather-scale dynamical excitations ε(t). In this way, the ability to estimating ε(t) determines predictive accuracy. To improve climate predictive skills with climate memory effects properly considered, studies on ε(t) are important and deserve more research attentions.
Change history
24 September 2018
The authors note that: “Fig. 5 in the published paper appeared incorrectly. The correct figure and the figure caption are provided below. The main message and the interpretation of our paper remain unaffected by this correction.”
References
Abry P, Veitch D (1998) Wavelet analysis of long-range-dependent traffic. IEEE Trans Inf Theory 44 (1):2–15. https://doi.org/10.1109/18.650984
Anderson BT, Gianotti JS, Guido S, Jason F (2016) Dominant time scales of potentially predictable precipitation variations across the continental United States. J Clim 29(24):8881–8897. https://doi.org/10.1175/JCLI-D-15-0635.1
Arneodo A, Bacry E, Graves PV, Muzy JF (1995) Characterizing long-range correlations in DNA sequences from wavelet analysis. Phys Rev Lett 74(16):3293–3296. https://doi.org/10.1103/PhysRevLett.74.3293
Blender R, Fraedrich K (2006) Long-term memory of the hydrological cycle and river runoffs in China in a high-resolution climate model. Int J Climatol 26(12):1547–1565. https://doi.org/10.1002/joc.1325
Boer GJ (2000) A study of atmosphere-ocean predictability on long time scales. Climate Dyn 16(6):469–477. https://doi.org/10.1007/s003820050340
Boer GJ (2004) Long time-scale potential predictability in an ensemble of coupled climate models. Climate Dyn 23(1):29–44. https://doi.org/10.1007/s00382-004-0419-8
Bogachev MI, Bunde A (2011) On the predictability of extreme events in records with linear and nonlinear long-range memory: Efficiency and noise robustness. Physica A 390(12):2240–2250. https://doi.org/10.1016/j.physa.2011.02.024
Bunde A, Eichner JF, Kantelhardt JW, Havlin S (2005) Long-term memory: a natural mechanism for the clustering of extreme events and anomalous residual times in climate records. Phys Rev Lett 94(4):048701. https://doi.org/10.1103/PhysRevLett.94.048701
Chen X, lin GX, Fu Z (2007) Long-range correlations in daily relative humidity fluctuations: A new index to characterize the climate regions over China. Geophys Res Lett 34(7):L07804. https://doi.org/10.1029/2006GL027755
Doblas-Reyes FJ, García-serrano J, Lienert F, Biescas AP, Rodrigues LRL (2013) Seasonal climate predictability and forecasting: status and prospects. WIREs Clim Change 4(4):245–268. https://doi.org/10.1002/wcc.217
Feng T, Fu Z, Deng X, Mao J (2009) A brief description to different multi-fractal behaviors of daily wind speed records over China. Phys Lett A 373(45):4134–4141. https://doi.org/10.1016/j.physleta.2009.09.032
Fraedrich K, Blender R (2003) Scaling of atmosphere and ocean temperature correlations in observations and climate models. Phys Rev Lett 90(10):108501. https://doi.org/10.1103/PhysRevLett.90.108501
Franzke C, Woollings T (2011) On the persistence and predictability properties of North Atlantic climate variability. J Climate 24(2):466–472. https://doi.org/10.1175/2010JCLI3739.1
Franzke C, Osprey S, Davini P, Watkins N (2015) A dynamical systems explanation of the Hurst effect and atmospheric low-frequency variability. Sci Rep 5:9068. https://doi.org/10.1038/srep09068
Govindan RB, Vyushin D, Bunde A, Brenner S, Havlin S, Schellnhuber HJ (2002) Global climate models violate scaling of the observed atmospheric variability. Phys Rev Lett 89(2):028501. https://doi.org/10.1103/PhysRevLett.89.028501
Hasselmann K (1976) Stochastic climate models Part I Theory. Tellus 28(6):473–485. https://doi.org/10.1111/j.2153-3490.1976.tb00696.x
He W, Zhao S (2018) Assessment of the quality of NCEP-2 and CFSR reanalysis daily temperature in China based on long-range correlation. Climate Dyn 50(1-2):493–505. https://doi.org/10.1007/s00382-017-3622-0
Hurst HE (1951) Long-term storage capacity of reservoirs, trans. Am Soc Civil Eng 116:770–808
Jiang L, Li N, Fu Z, Zhang J (2015) Long-range correlation behaviors for the 0-cm average ground surface temperature and average air temperature over China. Theor Appl Climatol 119(1-2):25–31. https://doi.org/10.1007/s00704-013-1080-0
Jiang L, Li N, Zhao X (2017) Scaling behaviors of precipitation over China. Theor Appl Climatol 128 (1-2):63–70. https://doi.org/10.1007/s00704-015-1689-2
Kantelhardt JW, Koscielny-Bunde E, Rego HHA, Havlin S, Bunde A (2001) Detecting long-range correlations with detrended fluctuation analysis. Physica A 295(3-4):441–454. https://doi.org/10.1016/S0378-4371(01)00144-3
Kantelhardt JW, Koscielny-Bunde E, Rybski D, Braun P, Bunde A, Havlin S (2006) Long-term persistence and multifractality of precipitation and river runoff records. J Geophys Res 111(01):D01106. https://doi.org/10.1029/2005JD005881
Király A, Bartos I, Jánosi IM (2006) Correlation properties of daily temperature anomalies over land. Tellus A 58(5):593–600. https://doi.org/10.1111/j.1600-0870.2006.00195.x
Koscielny-Bunde E, Bunde A, Havlin S, Roman HE, Goldreich Y, Schellnhuber HJ (1998) Indication of a universal persistence law governing atmospheric variability. Phys Rev Lett 81(3):729–732. https://doi.org/10.1103/PhysRevLett.81.729
Kurnaz ML (2004) Application of detrended fluctuation analysis to monthly average of the maximum daily temperatures to resolve different climates. Fractals 12(04):365–373. https://doi.org/10.1142/s0218348x04002665
Lennartz S, Bunde A (2009) Trend evaluation in records with long-term memory: application to global warming. Geophys Res Lett 36(16):L16706. https://doi.org/10.1029/2009GL039516
Lorenz EN (1963) Deterministic nonperiodic flow. J Atmos Sci 20:130–141. https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2
Lovejoy S, Schertzer D (2012). In: Sharma AS, Bunde A, Baker D, Dimri VP (eds) Extreme events and natural hazards: the complexity perspective, low frequency weather and the emergence of the climate. AGU monographs, Washington, pp 231–254. https://doi.org/10.1029/2011GM001087
Ludescher J, Bunde A, Franzke CL, Schellnhuber HJ (2016) Long-term persistence enhances uncertainty about anthropogenic warming of Antarctica. Climate Dyn 46(1-2):263–271. https://doi.org/10.1007/s00382-015-2582-5
Malamud BD, Turcottr DL (1999). In: Dmowska R, Saltzman B (eds) Advances in geophysics: long range persistence in geophysical time series, self-affine time series: I. generation and analyses. Academic Press, San Diego, pp 1–87. https://doi.org/10.1016/S0065-2687(08)60293-9
Mandelbrot BB, Van Ness JW (1968) Fractional Brownian motions, fractional noises and applications. SIAM Review 10(4):422–437. https://doi.org/10.1137/1010093
Massh M, Kantz H (2016) Confidence intervals for time averages in the presence of long-range correlations, a case study on Earth surface temperature anomalies. Geophys Res Lett 43(17):9243–9249. https://doi.org/10.1002/2016GL069555
Monselesan DP, O’Kane TJ, Risbey JS, Church J (2015) Internal climate memory in observations and models. Geophys Res Lett 42(4):1232–1242. https://doi.org/10.1002/2014GL062765
Pattantyús-Ábrahám M, Király A, Jánosi IM (2004) Nonuniversal atmospheric persistence: different scaling of daily minimum and maximum temperatures. Phys Rev E 69(2):021110. https://doi.org/10.1103/physreve.69.021110
Peng C-K, Buldyrev SV, Havlin S, Simon M, Stanley HE, Ary LG (1994) Mosaic organization of DNA nucleotides. Phys Rev E 49(2):1685–1689. https://doi.org/10.1103/PhysRevE.49.1685
Rybski D, Bunde A, von Storch H (2008) Long-term memory in 1000-year simulated temperature records. J Geophys Res 113(2):D02106. https://doi.org/10.1029/2007JD008568
Talkner P, Weber RO (2000) Power spectrum and detrended fluctuation analysis: application to daily temperatures. Phys Rev E 62(1):150–160. https://doi.org/10.1103/PhysRevE.62.150
Turcotte D (1997) Fractals and chaos in geology and geophysics, 2nd edn. Cambridge University Press, Cambridge
Varotsos C, Kirk-Davidoff D (2006) Long-memory processes in ozone and temperature variations at the region 60os-60on. Atmos Chem Phys 6(12):4093–4100. https://doi.org/10.5194/acp-6-4093-2006
Vyushin D, Zhidkov I, Havlin S, Bunde A, Brenner S (2004) Volcanic forcing improves atmosphere-ocean coupled general circulation model scaling performance. Geophys Res Lett 31(10):L10206. https://doi.org/10.1029/2004GL019499
Vyushin DI, Fioletov VE, Shepherd TG (2007) Impact of long-range correlations on trend detection in total ozone. J Geophys Res 112(D14):D14307. https://doi.org/10.1029/2006JD008168
Vyushin DI, Kushner PJ (2009) Power-law and long-memory characteristics of the atmospheric general circulation. J Clim 22(11):2890–2904. https://doi.org/10.1175/2008jcli2528.1
Weber RO, Talkner P (2001) Spectra and correlations of climate data from days to decades. J Geophys Res 106(D17):20131–20144. https://doi.org/10.1029/2001jd000548
Yuan N, Fu Z, Mao J (2010) Different scaling behaviors in daily temperature records over China. Physica A 389(19):4087–4095. https://doi.org/10.1016/j.physa.2010.05.026
Yuan N, Fu Z, Liu S (2013) Long-term memory in climate variability: a new look based on fractional integral techniques. J Geophys Res 118(23):12962–12969. https://doi.org/10.1002/2013JD020776
Yuan N, Fu Z, Liu S (2014) Extracting climate memory using fractional integrated statistical model: a new perspective on climate prediction. Sci Rep 4:6577. https://doi.org/10.1038/srep06577
Yuan N, Fu Z (2014) Century-scale intensity modulation of large-scale variability in long historical temperature records. J Clim 27(4):1742–1750. https://doi.org/10.1175/JCLI-D-13-00349.1
Yuan N, Ding M, Huang Y, Fu Z, Xoplaki E, Luterbacher J (2015) On the Long-term climate memory in the surface air temperature records over Antarctica: a nonnegligible factor for trend evaluation. J Clim 28(15):5922–5934. https://doi.org/10.1175/JCLI-D-14-00733.1
Zhu X, Fraedrich K, Liu Z, Blender R (2010) A demonstration of long-term memory and climate predictability. J Clim 23(18):5021–5029. https://doi.org/10.1175/2010jcli3370.1
Acknowledgements
The homogenized air temperature and precipitation data used in this research are provided by the Information Center of China Meteorological Administration. The land temperature data are obtained from the China Meteorological Data Sharing Service System (http://data.cma.cn). We thank LetPub for its linguistic assistance during the preparation of this manuscript.
Funding
This study is supported by the National Key R&D Program of China (2016YFA0600404 and 2016YFA0601504), the National Natural Science Foundation of China (No. 41675088, No. 41705041, and No. 41675068), and the CAS Pioneer Hundred Talents Program.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Xie, F., Yuan, N., Qi, Y. et al. Is long-term climate memory important in temperature/precipitation predictions over China?. Theor Appl Climatol 137, 459–466 (2019). https://doi.org/10.1007/s00704-018-2608-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00704-018-2608-0