
Abstract
An underwater image enhancement technique based on weighted guided filter image fusion is proposed to address challenges, including optical absorption and scattering, color distortion, and uneven illumination. The method consists of three stages: color correction, local contrast enhancement, and fusion algorithm methods. In terms of color correction, basic correction is achieved through channel compensation and remapping, with saturation adjusted based on histogram distribution to enhance visual richness. For local contrast enhancement, the approach involves box filtering and a variational model to improve image saturation. Finally, the method utilizes weighted guided filter image fusion to achieve high visual quality underwater images. Additionally, our method outperforms eight state-of-the-art algorithms in no-reference metrics, demonstrating its effectiveness and innovation. We also conducted application tests and time comparisons to further validate the practicality of our approach.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The underwater environment differs significantly from the terrestrial environment, presenting complex and hazardous conditions that pose considerable challenges to human exploration of the oceans. To deeply explore and effectively develop marine resources, people often rely on advanced underwater detection technologies, especially the application of underwater robots. These technologies are mainly based on image analysis and processing, enabling the robots to sense their underwater environment and accurately analyze and identify the target objects [1]. Underwater image processing is an indispensable technology for people to explore the ocean and understand the marine environment [2]. The acquisition of underwater images faces many challenges, mainly due to the absorption and scattering of light by suspended particles, which results in lower-quality images acquired by underwater imaging equipment. On the one hand, the different wavelengths of light absorbed by water cause red and yellow wavelengths to be attenuated rapidly, while blue and green wavelengths travel farther, resulting in a blue-green tint in underwater images [3]. In addition, the absorption and scattering of light underwater can lead to degradation of image quality, including blurriness, low contrast, and loss of detail.
There are three main research directions for improving underwater image visualization: enhancement-based, restoration-based, and deep learning-based methods. Enhancement-based methods start from pixel intensity to improve the image and enhance contrast. However, serious artifacts and noise often exist since the specific environment underwater is not considered. Recovery-based methods usually require a large amount of parameter estimation to construct a physical model of the underwater image and accurately estimate the parameters to achieve the effect of recovering the image. This process is too cumbersome and computationally intensive for complex and dynamic underwater environments. Deep learning-based methods usually utilize an "end-to-end" approach to train the network to achieve image enhancement. However, this method requires a large amount of data support and also needs to be tailored to the specific underwater scene to design the network. Otherwise, the features extracted by the network will not be accurate enough.
This study aims to develop an effective underwater image enhancement technique for color distortion, low contrast and detail loss caused by underwater optical conditions. Existing underwater image enhancement methods often struggle to achieve both color correction and contrast enhancement during processing, resulting in unsatisfactory results. Specifically, many existing methods focus on optimizing one aspect, such as color correction or contrast enhancement, without considering overall image quality. In addition, some methods perform inconsistently when processing different types of underwater images, making it difficult to adapt to the variable underwater optical environment. Our method overcomes these limitations through a weighted guided filter image fusion strategy that enables efficient color correction and contrast enhancement while preserving image detail, resulting in higher quality underwater images.
Motivated by the aforementioned challenges, we propose a method based on weighted guided filter image fusion. The process is divided into three steps: color correction, local contrast enhancement, and guided filter image fusion strategy. In the color correction stage, we first obtain the initial color correction results by compensating the three color channels. Secondly, according to the histogram distribution characteristics, we construct the saturation factor for pixel redistribution to achieve the effect of color balance. In the local contrast enhancement stage, we first convert the RGB channels to CIE-LAB channels, use the box filter on the L channel for local contrast enhancement, and then use the variational model to construct the penalty term, which further improves the local contrast as well as the color saturation of the image. Finally, we use the guided filter for multi-scale decomposition to obtain a weighted fusion of the detail and base layers, which results in a high-quality image with rich details and colors.
In the paper, our contributions are as follows:
-
(1)
We propose a color correction method based on attenuated color channel compensation with interval pixel reconstruction(ACPR). The method considers the characteristics of underwater attenuated color channels and histogram distribution characteristics to solve the problem of underwater color distortion.
-
(2)
We propose a local contrast enhancement method based on box filtering with variational modeling(BFVM). The method aims to improve local contrast and saturation by taking into account the spatial information between the color space and the image.
-
(3)
We propose a weighted guided filter image fusion technique(WGIF). The method considers the effect of fusion layer number on metrics and computational efficiency and introduces gradient weights to prevent excessive image smoothing.
The remaining sections of this paper are structured as follows: Sect. 2 summarizes relevant methods for underwater image enhancement. Section 3 offers a detailed overview of the procedures involved in our method. Section 4 discusses the superiority of our method across different datasets. Finally, Section 5 presents the conclusion of this paper and outlines future work.
2 Related work
Current underwater image enhancement techniques can be broadly classified into three categories: Non-physical-based model methods, Physical-based model methods, and deep-learning-based methods. A detailed introduction is given below.
Physical-based model methods: Recovery-based techniques must rely on optical imaging models. Typically based on an understanding of and assumptions about the factors and conditions involved in the underwater imaging process. These methods leverage prior knowledge to estimate and solve for the key parameters that affect the quality of the image. The Dark Channel Prior Algorithm (DCP) [4] is a typical defogging algorithm for dealing with this type of image, leveraging local features and prior knowledge of the image for simplicity and effectiveness. DCP effectively removes fog and improves image clarity. J. Y. Chiang [5] proposed that the WCID method, which analyzes the color information in underwater images, estimates the underwater scattering models, and corrects the color distortion by considering artificial light effects and selective light absorption. Drews [6] proposed the UDCP method to address, introducing an underwater dark channel before analyzing illumination and scattering in underwater images. Adrian Galdran [7] proposed RDCP, leveraging different color channel properties in underwater environments to effectively compensate for underwater image enhancement. Berman [8] proposed a new recovery method that considers spectral profiles in different environments. Zhou [9] utilizes Channel Intensity Prior (CIP) and Adaptive Dark Pixel (ADP) techniques combined with unsupervised learning and, ultimately, color and channel balancing processes to generate high-quality artifact-free images. Although physical-based model methods take into account the underwater imaging model, the inability to control the unknown variables in the underwater environment makes it difficult to accurately estimate the model parameters, resulting in restored results that do not meet people's expectations.
Non-physical-based model methods: By simply changing the gray values of the image in the spatial or transform domain, enhancement-based methods can improve the contrast and color of an image. The main ones are: fusion-based [10, 11] [12], retinex-based [13], histogram-based [14, 15]. Ancuti [16] proposed an image pyramid fusion strategy, which improves exposure and edge sharpening in darker regions. Bai [17] proposed a strategy combining histogram and image fusion to improve the contrast of the image. Mishra [18] proposed a retinex-based method that decomposes the input image into reflective and luminance layers, processing the different layers accordingly, and then fusing these layers to obtain an enhanced image. Nurullah Öztürk [19] by converting RGB to HSI color space, the underexposed areas in low-light environments are refined and enhanced. It avoids excessive contrast enhancement and achieves natural and effective image enhancement. Ghani [20] proposed a histogram-based correction method to correct color distortion in underwater images. The method uses rayleigh distribution to convert the image into HSV space and correct it for saturation and brightness. Zhou [21] proposes a Retinex variational model to address image clarity degradation due to particle scattering and light absorption in seawater. Huang[22] proposed a relative global histogram stretching method to improve underwater visibility, enhance contrast, and correct color in LAB space. Non-physical-based model methods for underwater image enhancement often achieve enhancement by modeling images in specific scenes, resulting in good performance only in those scenes but poor generalizability across different scenarios. Many of these methods rely on histogram stretching in color space to enhance images, which can easily lead to over-enhancement and image distortion.
Deep learning-based model methods: Deep-learning image enhancement methods are a data-driven, end-to-end learning approach designed to capture the distributional characteristics of elements in the input data. Key methods include: Convolutional Neural Networks (CNN): [23,24,25]. Generative Adversarial Networks(GAN) [26, 27]. Li [28] constructed a benchmark dataset of underwater images and constructed Water-Net based on CNN on the dataset yielding promising outcomes. Li [29] proposed a lightweight UWCNN network architecture to advance the field of underwater video enhancement. Fu [30] proposed a new two-branch architecture, which is designed to effectively compensate for the problems of image color loss and contrast degradation, and to optimize the quality of the images generated by the network using histogram equalization techniques. Sun [31] has recently proposed UMGAN, a network that can effectively improve image clarity without needing pairs of samples. Zong [32] improved CycleGAN by fusing the local discriminator with the global discriminator, significantly improving the network's robustness and global discriminative properties. Cai [33] proposed a network called CURE-Net, which progressively improves the problem of low contrast and color deviation due to light absorption and scattering in a coarse-to-fine manner through three cascaded sub-networks. Although the current deep learning-based methods excel in low-illumination image enhancement, they often struggle to achieve optimal results when enhancing non-uniform low-illumination underwater images, they often fail to achieve the ideal enhancement effect and lose more detailed information.
In underwater image enhancement research, the physical model method is based on the physical laws of light propagation underwater, aiming to improve image quality and visual effects. Non-physical model methods utilize statistical and heuristic techniques such as contrast enhancement and color correction to enhance image clarity without requiring in-depth understanding of the physical processes. Deep learning-based approaches, on the other hand, employ deep neural networks to learn complex underwater imaging features, effectively enhancing the visual quality and detail representation of underwater images.
3 Method
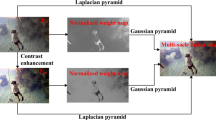
The flow of our proposed method, illustrated in Fig. 1, begins with initial color correction using ACPR to obtain the corrected image \(\text{Im}1\). This step addresses issues such as color distortion caused by underwater optical effects. Following color correction, the next stage focuses on enhancing contrast in the image \(\text{Im}2\). This is achieved through a local integration approach based on a variational model, leveraging the enhanced \(\text{Im}1\). Subsequently, our method employs a weighted guided filtering image fusion technique. Initially, the two source images are mutually guided filtered to derive a base layer, which encapsulates fundamental image characteristics. From the base layer, a detail layer is extracted to preserve intricate details present in the original images. Finally, the high-quality underwater image is synthesized by effectively combining the base and detail layers. This methodology optimally utilizes complementary information from both source images, ensuring that the final enhanced result achieves superior visual quality. The approach is designed to mitigate the inherent challenges of underwater imaging, enhancing color fidelity, contrast, and detail retention for enhanced perceptual clarity. The pseudo-code of the proposed algorithm is presented in Algorithm 1.

Flowchart of the proposed approaches

The pseudo-code of the proposed algorithm
3.1 Color correction
Underwater color distortion is caused by the process of light propagation and absorption in the underwater environment, resulting in color shifts and distortions. Therefore, color correction becomes an essential part of underwater image enhancement. To solve such problems, this paper proposes a color correction method based on attenuated color channel compensation with interval pixel reconstruction, inspired by [34]. Firstly, the attenuation characteristics of color channels in underwater images are analyzed, and a compensation model based on these channel characteristics is constructed to perform channel compensation on the images, achieving preliminary color correction. Secondly, the pixels in the histogram are processed, and color deviation is eliminated by constructing saturation parameters and reconstructing the histogram pixels. As shown in Fig. 2, the main steps of this algorithm are: (1) Perform attenuation color channel compensation. (2) Conduct interval pixel reconstruction. In this method, color correction is performed in the RGB color space. This is because RGB color space directly represents the three primary colors of light (red, green, blue), making the correction process more intuitive, especially when dealing with color distortions. Color distortions primarily manifest as changes in these three basic color channels, thus correcting them in the RGB space is more straightforward and effective.

Based on attenuated color channel compensation with interval pixel reconstruction
Attenuation Color Channel Compensation: In terms of color channel compensation, some methods, such as [35] have been widely applied and shown promising results in color correction for underwater images. Therefore, to achieve a preliminary color correction, we perform channel compensation for underwater images based on the compensation method [36]. The method starts with a color channel whose formula is shown below:
where \({Im}_{c}\) denotes the input image, \(MIm\) denotes the average value of the image channel, \({Im}_{1}\) is the compensated image and \({Im}_{2}\) is the output image. \({x}_{max}\) and \({x}_{min}\) represent the maximum and minimum pixel values of the compensated image. \({x}_{high}\) and \({x}_{low}\) represent the maximum and minimum thresholds for the current channel. Based on the assumption of a grayscale world, we proceed to construct a color channel compensation model. The formula is as follows:
where \({Im}_{gv}\) is the RGB three-channel gray value, \({Im}_{3}\) is the scaled image, and \({Im}_{result}\) is the final color-compensated image.
Figure 3(c) demonstrates the color compensation results of the above method, which we found to be roughly restored in terms of color, but the effect is less satisfactory. Inspired by [34], we use the interval pixel reconstruction method for color matching, which can adapt to the characteristics of different images. This approach ensures that the distribution of pixel values adaptively matches the saturation range, thereby achieving a better display of the image.

Color correction on the UIEB dataset. a Raw image; b CBAF; c Attenuated color channel compensation; d ACPR
Interval Pixel Reconstruction: Firstly, the method calculates the gray level mean of the image using Eq. (3), and then the gray level mean is used to scale the RGB three channels in a reasonable way. Finally, the histogram distribution range is readjusted for pixel reconstruction. The formula is shown below:
Where \({\partial }_{c}\) is the saturation parameter used to dynamically adjust the saturation level of each channel of the image, \(Max( )\) is to take the grayscale value of the largest channel. ϵ is the color balance factor, which is empirically valued up to \(\epsilon =0.02\)(It influences the extent to which color distortions caused by underwater optical effects are compensated. Adjusting \(\epsilon\) fine-tunes color balance, ensuring that the corrected image maintains natural colors without introducing unnatural color shifts). \(\text{\rm P}( )\) is the quantile function, and \({I}_{r}\) is the pixel-reconstructed underwater image. Finally, the pixel-reconstructed image is substituted into Eq. (2):
Where \({I}_{final}\) is the image that gets color corrected.
In order to verify the ability of our algorithm to correct color, three images with different hues were selected on the UIEB dataset. For comparing color methods, we chose white balance [37], ACC [36], and our color correction method (ACPR). As shown in Figs. 3 and 4, comparing these two methods, our method is better in detail and color results (Fig. 4).

Comparison of histograms corresponding to the algorithm in Fig. 3
3.2 Local contrast enhancement
Underwater images are typically characterized by low contrast and loss of detail due to light attenuation and scattering effects, which are used to improve the image's visual quality and enhance the details. Inspired by [38], we propose a local contrast enhancement algorithm based on a box filter with the variational model. The algorithm first converts the image from RGB space to CIE LAB space and operates on the L channel for contrast enhancement. This choice is motivated by the fact that the L channel primarily contains grayscale information, making it ideal for describing differences in image intensity. By focusing contrast enhancement exclusively on the L channel, we avoid unintended shifts in color information present in the AB channels. This approach ensures that the enhancement process targets only the image's grayscale characteristics, preserving its original color integrity.
where \(\sum_{y=m}^{m+W-1}\sum_{x=n}^{n+H-1}{M}_{B}\left(x,y\right)\) represents the local pixel matrix after the box filter and \(\overline{{G }_{B}}\) is denoted as the mean value of the grayscale of the local region. The image contrast can be effectively improved by using the mean value of the local block region applied to the luminance channel. In image processing tasks, the low-frequency component often corresponds to the smooth part of the image, and the high-frequency component corresponds to the edges and related details. Therefore, we assume that \(\overline{{G }_{B}}\) is the low-frequency component, thus separating it to get the high-frequency component. The following formula is used for localized blocks for contrast enhancement:
where \({B}_{C}\) is the local block for contrast enhancement, \(\left({M}_{B}\left(x,y\right)-{G}_{B}\right)\) is the high frequency details of the image, and the coefficient α is the scale factor to avoid over-enhancement, in this paper α = 2.1. As can be seen from Fig. 5(c), the image achieves the contrast enhancement effect, but we use the SLVC method of [39] to further achieve higher saturation. This also introduces subtle artifacts and over-enhancement, which result from the complex characteristics of underwater images. The scattering and attenuation of light underwater can make weak details and color variations more significant, potentially misinterpreting these characteristics as signals of contrast enhancement during the image enhancement process, leading to unnatural artifacts and over-enhancement effects. The algorithm consists of a data term and a canonical term. The data term reduces the difference between the recovered and original colors to ensure that the output image matches the original image. Then, the regular term is used to amplify the difference between the R, G, and B channels to enhance saturation. The formula is shown below:
where \(A\) represents the data term, and \(B\) represents the canonical term. \({u}_{c}\left(k\right)\) represents the enhanced image. It is obtained by gradient descent method with Euler–Lagrange derivative:
where \(0<\Delta t\le 1/(1-2\theta )\), \({{u}_{c}}^{k+1}\) is the image with enhanced saturation. As shown in Fig. 5(d), we can see that the image saturation is further improved to enhance the vividness and richness of the color.

Our proposed contrast enhancement method is tested on the UIEB dataset. a Raw image; b Color correct; c Local contrast enhancement; d BFVM
3.3 Multi-scale weighted guided filter image fusion
The image fusion achieves excellent results. Inspired by [40], we propose a weighted guided filtering image fusion strategy. This is because the traditional image pyramid fusion has some limitations. The traditional image pyramid fusion methods [37] usually lead to the loss of image details, especially when the image scale varies greatly or when there are fine structures such as edges in the image. This is attributed to the simple smoothing operation between images at different scales, which does not effectively preserve fine image details, thus affecting the quality and realism of the fusion result. In contrast, guided filtering, as an image processing technique based on local features, produces better image fusion results. Guided filtering is able to fuse images of different scales according to local features in the image, thus better preserving the details and structural information of the image. With guided filtering, we can maintain the image's clarity and realism more effectively during the fusion process. Therefore, we choose to utilize guided filtering for image fusion to solve the limitations of the traditional image pyramid fusion methods, aiming to obtain a better fusion effect and image quality.
3.3.1 Calculation of detail and foundation layers
Guided filtering is a filtering technique based on local region features, which weights and smoothes the target image by using the guided image. We use guided filtering to compute the base layer to decompose the image at multiple scales so that features at different scales can be analyzed and processed. For the coarse-scale base layer, the global structure and main features can be preserved. And the detail layer, which can capture finer textures and local features. The formula for its guided filtering is shown below:
when the center of the window is located at \(m\), \({p}_{j}\) and \({q}_{j}\) are the coefficients of this linear combination, \({GF}_{m}\) is the output of the guided filter, and \({I}_{m}\) is the input image. Next \({p}_{j}\) and \({q}_{j}\) are calculated as:
where \({p}_{j}\) is the mean value of the unfiltered image \(p\) in window \({n}_{j}\), and \({p}_{m}={I}_{m}\) when the guided image is the input image itself for edge filtering operation. \(\left|n\right|\) is the total number of pixels in the number of windows, \({\zeta }_{j}^{2}\) is the variance of the window, and \(\Theta\) is a control factor that controls the visibility of the filtering effect.
This paper has two input images, one for color correction and the other for contrast enhancement. We get the base layer by using these two input images as guided images for each other (if the base layer is calculated for color correction, then the contrast enhancement is used as a guided image for smoothing and vice versa). The formula for calculating its base layer and detail layer is shown below:
where \(B\) is the base layer, and \(D\) is the detail layer, \(GF\left({im}_{1},{im}_{2}\right)\) means that \({im}_{1}\) is the input image and \({im}_{2}\) is the guiding map for guiding filtering.
3.3.2 Calculation of weights and image fusion
Since this fusion is mainly based on the guided filter for decomposition, we consider the guided filter decomposition image will exist between the two images' smooth transition and denoising problem. Therefore, we add the idea of weighted gradient weighting, which is formulated as shown below:
where \({w}_{x}\) is the gradient value of the Sobel operator in the horizontal direction and \({w}_{y}\) is the gradient value in the vertical direction. Secondly, since the saliency weights can help determine which regions of the image are most salient, it is possible to focus more on these regions. The formula for calculating the saliency weights is as follows:
where \({S}_{i}\) is the computed significance, \(W\) is the significance weight, and \(n\) is the number of layers of guided filtering. The formula for the final fusion is shown below:
where \({B}_{{1}_{end}}\) and \({B}_{{2}_{end}}\) are the final base layers obtained by guided filter decomposition of the two input images, and B is the weighted base layer, and \({D}_{fusion}\) stands for the ith fused detail layer, \({D}_{1i}\) represents the first detail layer of layer \(i\) and \({D}_{2i}\) represents the second detail layer of layer \(i\). \({w}_{Si}\) and \({q}_{Gi}\) are the significance weight and gradient weight, respectively, \(Im\) is the fused final image.
3.3.3 Parameter optimization of layers
Before proceeding to the fusion step, we optimize the number of fused layer parameters to achieve the optimal fusion effect. We selected from the following two perspectives: (1) Qualitative and quantitative evaluation of images. We selected three generalized metrics for evaluating the quality of underwater images, and the impact of the metrics as the number of layers increases. (2) Computational efficiency. As the scale increases, the computation of guided filtering increases. Therefore, when selecting the optimal layer, the factor of computational efficiency needs to be considered, and the layer that can meet the fusion quality requirements while maintaining high computational efficiency is selected. As shown in Table 1, as the number of layers decreases, time also appears to decrease. However, we observe changes in the three metrics with an increase in the number of layers. Interestingly, the metrics for the fourth layer demonstrate relatively favorable results. Consequently, we opted to select the fourth layer for fusion.
4 Experimentation and analysis
In this section, we will further validate the effectiveness of our proposed algorithm. Firstly, we select six current state-of-the-art algorithms for underwater image enhancement and compare them with our proposed method. These six algorithms contain: four methods based on non-physical models and two methods based on physical models. Then, we validate the state-of-the-art of the algorithms in terms of color, contrast, and detail on each of the two datasets. Finally, we performed application and ablation experiments to verify the generalizability of the algorithms and the effectiveness of each component.
Comparison of algorithms: The six algorithms we selected include non-physical model-based methods: ACDC [41], Retinex [42], MW-GF [43], B-Retinex [44] and SPDF [45]. Physical model-based methods: TIP [46], ACCE-D [47]. Deep learning-based model methods: HCLR-Net [48].
Evaluation metrics: In this paper, the following seven evaluation metrics are used: IE(Information entropy) [49], AG(Average Gradient) [49], UCIQE(Underwater color image quality evaluation) [50], UIQM(Underwater image quality metric) [50], PCQI(Patch-based contrast quality index) [51], PSNR(Peak Signal-to-Noise Ratio) [52] and SSIM(Structural Similarity Index)[3]. IE is a kind of index used to evaluate the information richness of an image. The larger the IE, the better the visualization effect and the richer the details. AG is a kind of index used to evaluate the clarity of the fused image. The larger the AG, the more prominent the edges and details of the image, and the better the fusion effect. UCIQE is a comprehensive index based on image color information and contrast. The larger the UCIQE, the better the color quality of the underwater image. UIQM is used to quantify the overall quality of the underwater image. The larger the UIQM, the better the overall quality of the underwater image. PCQI evaluates the distortion of the image. The larger the PCQI, the better the image is in terms of color fidelity and overall quality. PSNR is based on the Mean Squared Error (MSE) between the original image and the distorted image, while SSIM takes into account the structural information and brightness contrast of the image. Higher PSNR and SSIM means less distortion and better brightness and contrast of the image.
Datasets: We use the UCCS [44] and UIEB [25] datasets in this paper. The UCCS dataset contains three shades of blue, green, and blue-green, which is used to verify the color correction ability of different shades, and the UIEB dataset contains 950 underwater degraded images of various scenes, which is used to evaluate the contrast and detail enhancement effect of the UIEB dataset (Fig. 6).

Comparison of histograms corresponding to the algorithm in Fig. 5
4.1 Evaluation on the UIEB Dataset
Qualitative evaluation: To further verify our method's comprehensive capability, we selected seven different types of degraded images from the UIEB dataset, as shown in Figs. 7, 8. ACCE-D achieves color correction on each image, but the effect on details and color saturation is unsatisfactory. MW-GF improves detail but fails to color correct on yellowish-green images when processing yellowish images. Retinex has better texture and details compared to B-Retinex, but the overall appearance of both is locally dark, resulting in a less clear image. ACDC has an overall greyish tint with poor color correction. TIP introduces an additional reddish appearance, resulting in the image undergoing a color bias. SPDF introduces a yellow hue, and the enhanced image deviates from the original hue. HCLR-Net effectively corrects colors, but it does not enhance contrast as much. Our method, on the other hand, has de-blurring and better detail and color saturation compared to the above five methods.

Qualitative evaluation of our method versus comparative methods on the UIEB dataset. a Raw; b ACCE-D; c MW-GF; d B-Retinex; e Retinex; f ACDC; g TIP; h SPDF; i HCLR-Net; j Our

Comparison of histograms corresponding to the algorithm in Fig. 7
Quantitative evaluation: Table 2 shows the evaluation indexes of our method and the comparison method in UIEB. Table 2 shows that our method's AG, IE, PCQI, and UCIQE are better than the other six algorithms, while the UIQM is slightly lower than that of ACDC. Although our PSNR and SSIM metrics are not highest, but our methods have richer color information and detail information. By combining qualitative and quantitative evaluations, it can be concluded that our method is capable of dealing with different degraded images in the UIEB dataset.
4.2 Evaluation on the UCCS Dataset
Qualitative evaluation: In order to verify the color correction capability of our methods, we selected two images, each blue, blue-green, and green, from the UCCS dataset, as shown in Figs. 9 and 10. Color correction is the most important capability of all the methods. ACCE-D introduces red artifacts when processing blue images, which leads to unsatisfactory image results. MW-GF lacks contrast and color saturation when processing green images. B-Retinex and Retinex have similar results when processing blue images, and the overall image shows dark areas. ACDC has better overall image details when processing this dataset, the overall image has better details, but the overall image shows grayish tones. TIP in processing the blue-green region introduces a slight yellow color, localized areas are darker, and details are lost. SPDF and HCLR-Net failed to correct the color. Our method shows better color correction on this dataset and the best saturation of colors.

Qualitative evaluation of our method versus comparative methods on the UCCS dataset. a Raw; b ACCE-D; c MW-GF; d B-Retinex; e Retinex; f ACDC; g TIP; h SPDF; i HCLR-Net; j Our

Comparison of histograms corresponding to the algorithm in Fig. 9
Quantitative evaluation: Table 3 shows the evaluation metrics of our method and the comparison method in UCCS. Our method has the highest quantitative evaluation scores for AG, IE, PCQI, and UCIQE. However, in the SSIM and PSNR full-reference evaluations, our scores are lower than HCLR-Net. This is because HCLR-Net can learn the features of the reference images. On the other hand, most Non-physical-based model methods, including ours, enhance images by adjusting histograms and pixels. Therefore, our scores are higher than HCLR-Net in the no-reference metrics. Combining the quantitative and qualitative evaluations, our method has superior color correction ability in the UCCS dataset.
4.3 Detailed experiments
In many image processing and computer vision tasks, detail-rich images can provide more accurate features and information, thus improving image analysis and processing results. Therefore, to verify the detailed effects of our algorithms, we compare the six algorithms quantitatively and qualitatively on the UIEB dataset.
Qualitative evaluation: As shown in Fig. 11, the red boxes in Fig. 11 represent the observed details. The ACCE-D and MW-GF have better details, but the image is darker in the area of the face of the person in the image, and the details of the face are lost. The B-Retinex, Retinex, and TIP details are blurred and visually unimpressive. The ACCE-D has noticeable details in the gray image, but the visual perception is not good. HCLR-Net and SPDF also suffer from a lack of detail, with much of the detail in the image being over-smoothed, affecting the overall visual effect. Our images have good overall and localized details.

Detail enhancement experiments on the UIEB dataset
Quantitative evaluation: Table 4 shows the scores of our method with the comparative algorithms on the UIEB dataset. The AG and PCQI evaluation metrics measure the clarity and richness of the image, and our method ranks first among both evaluation metrics. In this way, we can prove the superiority of our method in terms of details.
4.4 Ablation experiments
To assess the importance or contribution of each component in a complex system, we gradually remove several algorithmic components through ablation experiments to observe the effect of these changes on overall algorithm performance. Therefore, we perform ablation experiments in UCCS and UIEB datasets, respectively. a) Input image; b)-w/o ACPR is only our color correction method; c)-w/o BFVM is only our contrast enhancement method; d) Our complete method.
Qualitative evaluation: From Fig. 12, we can see the results of each component in both datasets. From the subjective evaluation of the images, we can observe that: b)-w/o ACPR improves the color distortion of the original image and improves the global contrast, but the local details are a bit blurred. c)-w/o BFVM improves the local details of the image. However, it lacks performance in color correction. d) Our complete model can achieve a satisfactory visual result for another one.

Ablation results for each component on the UCCS and UIEB dataset
Quantitative evaluation: As can be seen in Table 5, our complete model has the best score profile. By ablation analysis, and combining qualitative and quantitative evaluation, each of our components is favorable for the complete model.
4.5 Running time comparison
Calculating algorithmic time is critical for evaluating performance and efficiency. By quantifying the execution time, we can objectively evaluate and optimize the algorithms. Therefore, we perform time comparison experiments in this subsection. Our experiments are performed on Matlab and Python respectively (Intel Core i5-12,500 (3.00 GHz), GPU:3050ti). As shown in Table 6 records the average time required to run 100 graphics at each of the 256*256, 512*512, and 1024*1024 resolutions.
4.6 Application experiments
Key-point detection aims to identify unique and stable local features in an image automatically. From Fig. 13, we can see that the key-points of our method grow exponentially. It can be shown that there are more unique and significant local features in the enhanced image with rich information structure.
Saliency detection aims to identify the image's most prominent and important regions, the visually attractive and salient parts. As can be seen from (e) and (f) in Fig. 13, the enhanced image accurately highlights targets and structures, and the general shape of the image can be accurately recognized. Thus, our saliency and keypoint detection have good performance and may be widely used in image processing, computer vision, and so on.

Key-point detection and significance detection on the UIEB dataset. (a) and (b) are the original and enhanced images; (c) and (d) are the key-point detection for the original and enhanced images; (e) and (f) are the significance detection for the original and enhanced images
5 Conclusion and future work
In this paper, we propose an underwater image enhancement technique based on weighted guided filter image fusion. Our approach aims to solve the problems of low contrast, loss of details, and color distortion in underwater images. The proposed includes color correction, local contrast enhancement, and weighted guided filter image fusion. Leveraging information from the source image, both information from color correction and local contrast enhancement guide each other's filters. The decomposed detail layer is weighted and fused with the base layer, resulting in a high-quality underwater image that combines the advantages of the two images. While our method yields favorable output images compared to state-of-the-art techniques, we acknowledge that excessive contrast enhancement may occur. In future work, we aim to mitigate this issue to further enhance the performance of our method.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Raveendran, S., Patil, M.D., Birajdar, G.K.: Underwater image enhancement: a comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 54(7), 5413–5467 (2021). https://doi.org/10.1007/s10462-021-10025-z
Yang, M., Hu, J., Li, C., Rohde, G., Du, Y., Hu, K.: An in-depth survey of underwater image enhancement and restoration. IEEE Access. 7, 123638–123657 (2019). https://doi.org/10.1109/ACCESS.2019.2932611
Guo, P., He, L., Liu, S., Zeng, D., Liu, H.: Underwater image quality assessment: subjective and objective methods. IEEE Trans. Multimed. 24, 1980–1989 (2022). https://doi.org/10.1109/TMM.2021.3074825
He, K., Sun, J., Tang, X.: Single image haze removal using dark channel prior. IEEE Conf. Comp. Vision Pattern Recogn. Miami, FL: IEEE. 33, 2341 (2010)
Chiang, J.Y., Chen, Y.-C.: Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. (2012). https://doi.org/10.1109/TIP.2011.2179666
Drews, P., Jr., Do Nascimento, E., Moraes, F., Botelho, S., Campos, M.: Transmission Estimation in Underwater Single Images”. In: Botelho, S. (ed.) 2013 IEEE International Conference on Computer Vision Workshops. IEEE, Sydney, Australia (2013)
Galdran, A., Pardo, D., Picón, A., Alvarez-Gila, A.: Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 26, 132–145 (2015). https://doi.org/10.1016/j.jvcir.2014.11.006
Berman, D., Levy, D., Avidan, S., Treibitz, T.: Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Anal. Mach. Intell. (2020). https://doi.org/10.1109/TPAMI.2020.2977624
Zhou, J., Liu, Q., Jiang, Q., Ren, W., Lam, K.-M., Zhang, W.: Underwater camera: improving visual perception via adaptive dark pixel prior and color correction. Int. J. Comput. Vis. (2023). https://doi.org/10.1007/s11263-023-01853-3
Marques, T.P., Branzan Albu, A.: L 2 UWE: A Framework for the Efficient Enhancement of Low-Light Underwater Images Using Local Contrast and Multi-Scale Fusion. In: Marques, T.P. (ed.) 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, Seattle, WA, USA (2020)
Zhang, W., Dong, L., Zhang, T., Xu, W.: Enhancing underwater image via color correction and Bi-interval contrast enhancement. Signal Process. Image Commun. 90, 116030 (2021). https://doi.org/10.1016/j.image.2020.116030
Ozturk, N., Ozturk, S.: Efficient and natural image fusion method for low-light images based on active contour model and adaptive gamma correction. Multimed. Tool. Appl. 83(16), 48437–48456 (2023). https://doi.org/10.1007/s11042-023-17141-8
K. R. Joshi and R. S. Kamathe, 2008 “Quantification of retinex in enhancement of weather degraded images,” In: 2008 International Conference on Audio, Language and Image Processing, Shanghai, China IEEE. https://doi.org/10.1109/ICALIP.2008.4590120.
Hummel, R.: Image enhancement by histogram transformation. Comput. Gr. Image Process. 6(2), 184–195 (1977). https://doi.org/10.1016/S0146-664X(77)80011-7
Chang, Y., Jung, C., Ke, P., Song, H., Hwang, J.: Automatic contrast-limited adaptive histogram equalization with dual gamma correction. IEEE Access 6, 11782–11792 (2018). https://doi.org/10.1109/ACCESS.2018.2797872
Ancuti, C., Ancuti, C.O., Haber, T., Bekaert, P.: “Enhancing underwater images and videos by fusion. In: Ancuti, C. (ed.) IEEE Conference on Computer Vision and Pattern Recognition. IEEE, London, Providence, RI (2012)
Bai, L., Zhang, W., Pan, X., Zhao, C.: Underwater Image enhancement based on global and local equalization of histogram and dual-image multi-scale fusion. IEEE Access 8, 128973–128990 (2020). https://doi.org/10.1109/ACCESS.2020.3009161
Mishra, A.K., Choudhry, M.S., Kumar, M.: Underwater image enhancement using multiscale decomposition and gamma correction. Multimed. Tools. Appl. 82(10), 15715–15733 (2023). https://doi.org/10.1007/s11042-022-14008-2
Ozturk, N., Ozturk, S.: A hybrid method for enhancement of both contrast distorted and low-light images. Int. J. Patt. Recogn. Artif. Intell. 37(08), 2354012 (2023). https://doi.org/10.1142/S0218001423540125
Ghani, A.S.A., Isa, N.A.M.: Automatic system for improving underwater image contrast and color through recursive adaptive histogram modification. Comput. Electron. Agric. 141, 181–195 (2017). https://doi.org/10.1016/j.compag.2017.07.021
Zhou, J., Wang, S., Lin, Z., Jiang, Q., Sohel, F.: A pixel distribution remapping and multi-prior retinex variational model for underwater image enhancement. IEEE Trans. Multimedia 26, 7838–7849 (2024). https://doi.org/10.1109/TMM.2024.3372400
Huang, D., Wang, Y., Song, W., Sequeira, J., Mavromatis, S.: Shallow-Water Image Enhancement Using Relative Global Histogram Stretching Based on Adaptive Parameter Acquisition. In: Huang, D. (ed.) MultiMedia Modeling. Springer International Publishing, London (2018)
Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998). https://doi.org/10.1109/5.726791
Wang, Y., Zhang, J., Cao, Y., Wang, Z.: A deep CNN method for underwater image enhancement”. In: Wang, Y. (ed.) 2017 IEEE International Conference on Image Processing (ICIP). IEEE, London, Beijing (2017)
S. Anwar, C. Li, and F. Porikli, Deep Underwater Image Enhancement.” arXiv, Jul. 10, 2018. Accessed: 05 Apr 2024. [Online]. Available: http://arxiv.org/abs/1807.03528
Steffens, C., Lilles Jorge Drews, P., Silva Botelho, S.: Deep Learning Based Exposure Correction for Image Exposure Correction with Application in Computer Vision for Robotics. In: Steffens, C. (ed.) 2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE). IEEE, London, Joao Pessoa (2018)
Xie, Q., Gao, X., Liu, Z., Huang, H.: Underwater image enhancement based on zero-shot learning and level adjustment. Heliyon 9(4), e14442 (2023). https://doi.org/10.1016/j.heliyon.2023.e14442
Li, C., Anwar, S., Porikli, F.: Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recogn. 98, 107038 (2020). https://doi.org/10.1016/j.patcog.2019.107038
Li, C., et al.: An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 29, 4376–4389 (2020). https://doi.org/10.1109/TIP.2019.2955241
Fu, X., Cao, X.: Underwater image enhancement with global–local networks and compressed-histogram equalization. Signal Process. Image Commun. 86, 115892 (2020). https://doi.org/10.1016/j.image.2020.115892
Sun, B., Mei, Y., Yan, N., Chen, Y.: UMGAN: underwater image enhancement network for unpaired image-to-image translation. JMSE 11(2), 447 (2023). https://doi.org/10.3390/jmse11020447
Zong, X., Chen, Z., Wang, D.: Local-CycleGAN: a general end-to-end network for visual enhancement in complex deep-water environment. Appl. Intell. 51(4), 1947–1958 (2021). https://doi.org/10.1007/s10489-020-01931-w
Cai, X., Jiang, N., Chen, W., Hu, J., Zhao, T.: CURE-net: a cascaded deep network for underwater image enhancement. IEEE J. Oceanic Eng. 49(1), 226–236 (2024). https://doi.org/10.1109/JOE.2023.3245760
Lin, S., Li, Z., Zheng, F., Zhao, Q., Li, S.: Underwater image enhancement based on adaptive color correction and improved retinex algorithm. IEEE Access. 11, 27620–27630 (2023). https://doi.org/10.1109/ACCESS.2023.3258698
Lai, Y., et al.: Single underwater image enhancement based on differential attenuation compensation. Front. Mar. Sci. 9, 1047053 (2022). https://doi.org/10.3389/fmars.2022.1047053
Li, X., Hou, G., Tan, L., Liu, W.: A hybrid framework for underwater image enhancement. IEEE Access 8, 197448–197462 (2020). https://doi.org/10.1109/ACCESS.2020.3034275
Ancuti, C.O., Ancuti, C., De Vleeschouwer, C., Bekaert, P.: Color balance and fusion for underwater image enhancement. IEEE Trans.Image Process. 27(1), 379–393 (2018). https://doi.org/10.1109/TIP.2017.2759252
Zhang, W., et al.: Underwater image enhancement via weighted wavelet visual perception fusion. IEEE Trans. Circuits Syst. Video Technol. (2024). https://doi.org/10.1109/TCSVT.2023.3299314
Zhou, J., Pang, L., Zhang, D., Zhang, W.: Underwater image enhancement method via multi-interval subhistogram perspective equalization. IEEE J. Oceanic Eng. 48(2), 474–488 (2023). https://doi.org/10.1109/JOE.2022.3223733
Bavirisetti, D.P., Xiao, G., Zhao, J., Dhuli, R., Liu, G.: Multi-scale guided image and video fusion: a fast and efficient approach. Circuits. Syst. Signal Process. 38(12), 5576–5605 (2019). https://doi.org/10.1007/s00034-019-01131-z
Zhang, W., Wang, Y., Li, C.: Underwater image enhancement by attenuated color channel correction and detail preserved contrast enhancement. IEEE J. Oceanic Eng. 47(3), 718–735 (2022). https://doi.org/10.1109/JOE.2022.3140563
Fu, X., Zhuang, P., Huang, Y., Liao, Y., Zhang, X.P., Ding, X.: A retinex-based enhancing approach for single underwater image. In: Fu, X. (ed.) IEEE International Conference on Image Processing (ICIP). IEEE, London, Paris, France (2014)
Wang, S., Chen, Z., Wang, H.: Multi-weight and multi-granularity fusion of underwater image enhancement. Earth. Sci. Inform. 15(3), 1647–1657 (2022). https://doi.org/10.1007/s12145-022-00804-9
Zhuang, P., Li, C., Wu, J.: Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 101, 104171 (2021). https://doi.org/10.1016/j.engappai.2021.104171
Kang, Y., Jiang, Q., Li, C., Ren, W., Liu, H., Wang, P.: A perception-aware decomposition and fusion framework for underwater image enhancement. IEEE Trans. Circuits Syst. Video Technol. 33(3), 988–1002 (2023). https://doi.org/10.1109/TCSVT.2022.3208100
Li, C.-Y., Guo, J.-C., Cong, R.-M., Pang, Y.-W., Wang, B.: underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. on Image Process. 25(12), 5664–5677 (2016). https://doi.org/10.1109/TIP.2016.2612882
X. Li, G. Hou, K. Li, and Z. Pan, “Enhancing Underwater Image via Adaptive Color and Contrast Enhancement, and Denoising.” arXiv, Aug. 02, 2021. Accessed: 05 Apr 2024. Available: http://arxiv.org/abs/2104.01073
Zhou, J., et al.: HCLR-net: hybrid contrastive learning regularization with locally randomized perturbation for underwater image enhancement. Int. J. Comput. Vis. (2024). https://doi.org/10.1007/s11263-024-01987-y
Zhang, W., Dong, L., Pan, X., Zhou, J., Qin, L., Xu, W.: Single image defogging based on multi-channel convolutional MSRCR. IEEE Access. 7, 72492–72504 (2019). https://doi.org/10.1109/ACCESS.2019.2920403
Yang, M., Sowmya, A.: An underwater color image quality evaluation metric. IEEE Trans. on Image Process. 24(12), 6062–6071 (2015). https://doi.org/10.1109/TIP.2015.2491020
Wang, S., Ma, K., Yeganeh, H., Wang, Z., Lin, W.: A patch-structure representation method for quality assessment of contrast changed images. IEEE Signal Process. Lett. 22(12), 2387–2390 (2015). https://doi.org/10.1109/LSP.2015.2487369
Korhonen, J., You, J.: “Peak signal-to-noise ratio revisited: Is simple beautiful?”, in 2012 Fourth International Workshop on Quality of Multimedia Experience. IEEE, Melbourne, Australia (2012)
Funding
This work was supported by Special projects in universities' key fields of Guangdong Province (2023ZDZX3017), 2022 Tertiary Education Scientific research project of Guangzhou Municipal Education Bureau (202234607), the National Natural Science Foundation of China (52371059) and (52101358). The General Universities' Key Scientific Research Platform Project of Guangdong Province(2023KSYS009).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Dan Xiang, Huihua Wang, Hao Zhao,Zebin Zhou and Pan Gao. The firstdraft of the manuscript was written by Huihua Wang and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that there are no conficts of interest related to this article.
Additional information
Communicated by Qiu Shen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Xiang, D., Wang, H., Zhou, Z. et al. Underwater image enhancement based on weighted guided filter image fusion. Multimedia Systems 30, 240 (2024). https://doi.org/10.1007/s00530-024-01432-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01432-7