
Abstract
Object detection, an important task in computer vision, has achieved a conspicuous improvement. Among the methods for object detection, the one-stage detector is a simple, end-to-end, anchor-free, and straightforward deep learning pipeline. Many one-stage detectors locate the bounding box using regression, and the regression loss is the maximum among all errors. Hence, locating the bounding box accurately is one of the keys for improving the average precision (AP) for a detector. In this paper, we suggest a simple and precise locator named the bounding convolutional network (BoundConvNet) to draw “bounding features” from heatmaps to refine the object locations and apply a category-aware collaborative intersection over union (Co-IoU) loss function to optimize the bounding box regression for dealing with a problem of different class center point overlap. BoundConvNet is a head network for bounding box regression, which contains several depthwise separable dilated convolutional layers to decouple the classification task from the regression task. Extensive experiments demonstrate that BoundConvNet improves the AP of the one-stage detector CenterNet and helps the CenterNet mark the bounding box of objects more accurately. For small object detection, the AP of CenterNet is improved by 13.8% relative on MS COCO dataset with ResNet-18 as backbone.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, with the speedy development of artificial intelligence, research in computer vision has achieved substantial progress. The task of object detection is a task for needing to classify images and needing to precisely predict the category and location of objects in images [1]. Object detection is an elemental and valuable research problem, due to many computer vision tasks that depend on it, such as multiobject tracking and instance segmentation [2]. It also plays a vital role in many lower-stream application technologies, such as, intelligent video surveillance [3] and automatic driving. The combination of innovations in convolutional neural networks and the availability of diverse and large-scale datasets have promoted stable development in the precision of object detectors [4].
Generally, object detection based on deep neural networks can be categorized into two paradigms: “two-stage detector” and “one-stage detector.” The two-stage detector proposes detection as a “coarse-to-fine” process, and the one-stage detector aims to “complete in one step.” Some typical two-stage detectors, such as RCNN [5], SPPNet [6], Fast RCNN [7], and Faster RCNN [8], all localize the bounding box of objects by refining the anchor boxes. However, one-stage detectors, such as YOLO [9], SSD [10], CenterNet [11], and FCOS [12], regress the size of the bounding boxes straightforwardly.

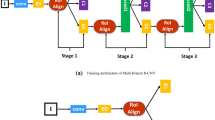
A pipeline of refining object location using BoundConvNet. We apply a convolutional backbone network, such as ResNet-18 [13], ResNet-101, DLA-34 [14], and Hourglass-104 to generate heatmaps of the image. Then, we use depthwise separable convolution as a base of the head network to decouple the regression subnet from classification. Before regressing the width and height of the bounding box, we apply BoundConvNet to pay particular attention to the objects’ location information. Last, we employ classification, bounding box size regression, and offset regression
Therefore, for one-stage detectors, there are two main subtasks of classification and localization for objects. Many detectors use the backbone of the image classification task as the backbone and then add a head network to classify objects and regress its bounding box. The backbones for image classification tasks, such as ResNet [13] and VGG [15], are quite proficient at classification but not proficient in predicting object location. We present a simple and precise head network for object detection named the bounding convolutional network (BoundConvNet) to extract “bounding features” from heatmaps to refine object locations. We regress the size of the bounding boxes in every category to address the matter of different class center point overlap. Furthermore, we apply a new loss function named collaborative intersection over union (Co-IoU) loss to replace the L1 loss for bounding box regression. With the help of BoundConvNet, detectors are able to enhance the representation of bounding boxes to improve bounding box regression accuracy. Moreover, BoundConvNet can be readily combined with many backbones of one-stage detectors. A pipeline with BoundConvNet is displayed in Fig. 1.
In summary, our contributions are as follows:
-
1.
We investigate the training process of the one-stage detector CenterNet and observe that the loss of object size regression is the maximum among all losses.
-
2.
We propose a novel bounding feature extractor called the bounding convolutional network (BoundConvNet) to enhance representation by convoluting heatmaps and perform bounding box size regression in every category. Based on BoundConvNet, we present a simple and accurate object detector architecture.
-
3.
We also present a new loss function named collaborative intersection over union (Co-IoU) loss to replace the L1 loss for bounding box regression (BBR) to optimize the BBR.
-
4.
Extensive experiments show that BoundConvNet can help detectors localize objects more accurately. Our approach achieves a considerable improvement in the MS COCO and PASCAL VOC datasets. Specifically, with the backbones of ResNet-18_DCN and ResNet-101_DCN, the new detector obtains 35.2% AP and 41.6% AP on the MS COCO dataset. For small object detection, the AP is improved by 13.8%.
2 Related work
In this section, we concisely survey relevant studies, including methods of object detection, representations of object features, architecture of one-stage object detectors, and bounding box regression.
2.1 Methods of object detection
Object detection is one of the most important topics in computer vision. Conventional object detectors draw image features using the handcraft method, such as, SIFT, Edge Box, HOG, and Selective Search [16]. DPM [17] and its variants have been dominant in traditional methods for a long time. With the speedy development of convolutional neural networks (CNNs), object detection based on CNNs has achieved fruitful development results and become a hot topic in object detection. For RCNN, Fast RCNN, and Faster RCNN, the main principle of these detectors is to find proposal regions, then classify the object in each region, and regress the bounding box size for localizing objects.
Meanwhile, SSD, YOLO, and FCOS have gradually become the mainstream models of one-stage detectors, which detect objects through a single pipeline and discard the RoI [16] pooling procedure. Generally, one-stage detectors are more computationally efficient than two-stage detectors while retaining competent performance on different challenging benchmarks.
Moreover, the point linking network (PLN) [18] utilizes a single neural network to predict the locations of the center and four corners of the bounding box. It is a one-stage detector without anchor boxes. CornerNet [19] treats an object as a pair of key points, i.e., top-left and bottom-right locations of its bounding box. ExtremeNet [20] predicts the center, top-most, bottom-most, left-most, and right-most points of all objects. CenterNet [11] applies a bounding box and its center point to represent an object. All these methods consider object detection as a key point estimation problem. In this study, we reform the CenterNet and present a novel object detector.
2.2 Representations of object features
Most one-stage object detectors apply point-based features to represent objects. Nevertheless, point-based features hardly preserve adequate feature representation for both classification and location [21]. Cornernet [19] predicts objects using a heatmap of the left-top and right-bottom corners of its bounding box. Recently, some works [22, 23] have attempted to ameliorate the feature representation of object detection. RepPoints [22] utilizes deformable convolution [24] to extract features from a set of representative points presenting object bounding boxes. Cascade-RPN [23] aligns feature maps to their correlated object bounding box by adaptive convolution. ExtremeNet [20] applies a standard keypoint estimation network to detect one center point and four extreme points (left-most, top-most, right-most, and bottom-most) of each object and groups the five keypoints into a bounding box if they are geometrically aligned. CenterNet [11] uses the center point of its bounding box to represent an object. It detects center points by keypoint estimation and regresses other attributes of an object. However, the feature of the center point may not contain sufficient information to represent the full instance with its limited receptive field. Likewise, it cannot regress the bounding box precisely due to the lack of object edge features.
Therefore, in this paper, we add the bounding convolutional network (BoundConvNet) into the head network to enhance its feature present ability. With the support of BoundConvNet, the detector can obtain a higher average precision (AP) and mark bounding boxes more accurately.
2.3 Architecture of a one-stage object detector
Commonly, the architecture of a one-stage object detector consists of two components: the first is a backbone network, and the second is a head network. The backbone network is usually referenced from the ImageNet [25] classification. Therefore, to localize objects, the head network is needed. The backbone of FCOS [12] is ResNet-101-FPN [26], and its head network regresses the top, bottom, left, and right coordinates of the bounding box and classifies it. RetinaNet [27] utilizes a feedforward ResNet attached to a feature pyramid network (FPN) [26] as backbone, and the head network is composed of a classification subnet and a bounding box regression subnet. In [28], the backbone is FPN, and its head network contains a fully connected network and a convolution network. CenterNet [11] employs ResNet attached with a DCN as the backbone for object detection, the head network is in charge of classification, and the bounding box size and offset are regressed. CornerNet [19] applies an hourglass [29] network as the backbone, and its head consists of two prediction modules, one for the top-left corner and the other for the bottom right. SaccadeNet [30] utilizes a CNN as the backbone, and the head network consists of three parts: a center attentive module, a corner attentive module, and an attention transitive module. ssFPN [31] is a new scale sequence (\(S^2\)) feature extraction of FPN to strengthen feature information of small objects. It is basically a scale-invariant feature and built on top of high-resolution pyramid feature maps for small objects. Moreover, the \(S^2\) feature can be extended to most object detectors with FPN backbone.
Inspired by the above detectors, our detector employs ResNet as the backbone and a depthwise separable convolution (DSC) [32] layer following the backbone. The head network is composed of three parts: heatmap classification, bounding box size regression, and offset regression. However, in contrast from the above detectors, we apply the BoundConvNet module to optimize the bounding box regression.
2.4 Bounding box regression (BBR)
Bounding box regression (BBR) can meliorate object localization performance using instance-level annotations in the training phase. Its purpose is to refine the location of a predicted bounding box based on the initial proposal or anchor box. To date, BBR has been applied in most of the latest object detectors [5, 8, 28].
For a two-stage detector or a one-stage detector with anchor boxes, BBR aims to refine the localization of anchor boxes. However, for some of the one-stage detectors without anchor boxes, BBR can determine the size of the objects. For example, CenterNet, by BBR, can obtain the width and height of an object. Thus, reducing the error of BBR is one of the keys to localize objects accurately.
Many studies have been performed on bounding box regression [12, 19,20,21, 28, 33]. In FCOS [12], bounding box regression was achieved by predicting the distance from four edges to the center point, and using the “center-ness” to suppress those low-quality bounding boxes. In CornerNet [19], the authors proposed a new type of pooling layer named corner pooling. Corner pooling determines if a pixel is a top-left corner by looking horizontally to the right for the leftmost boundary of an object and vertically to the bottom for the topmost boundary, and the bottom-right corner is determined in the same way. Therefore, corner pooling can better localize the corners. However, there are a few substantial differences from our method. First, bounding box regression in [33] belongs to two-stage detectors. They performed bounding box regression to refine the locations of anchor boxes. In contrast, we research bounding box regression in a one-stage detector without an anchor box. Second, we improve the accuracy of bounding box regression by convoluting a feature map to obtain a more comprehensive feature representation, not through bounding pooling [21]. Finally, we employ the collaborative intersection over union (Co-IoU) loss function to replace the L1 loss function for BBR.
3 Problem formulation
Let \(I\in R ^{{\left( W\times H\times 3\right) }}\) be an input image of height \(H\) and width \(W\). Through the backbone network and DCN layer, we can generate a keypoint heatmap \(\hat{Y} \in \left[ {0,1} \right]^{{\left( {\frac{W}{R} \times \frac{H}{R} \times C} \right)}}\), where \(R\) is the output stride, and \(C\) is equal to the number of categories, on the MS COCO dataset [34] \(C = 80\) and Pascal VOC07 [35] \(C = 20\). We define \(R = 4\) as the default output stride when the image width \(W = 512\). \({\hat{Y}}_{x,y,c}\) is the point with coordinate \(p(x , y )\) on the heatmap layer \(c\). Let \({\hat{Y}}_{x,y,c}=1\) be a keypoint of category \(c\), while \({\hat{Y}}_{x,y,c}=0\) is the background. The final loss (loss of the detector) is a combination of the three losses, which will be presented in the following subsections (namely, Sect. 3.1 (Loss of Keypoint); Sect. 3.2 (Loss of Bounding Box Size); and Sect. 3.3 (Loss of Offset))
3.1 Loss of keypoint
In the training phase, we apply several different encoder-decoder networks to predict \({\hat{Y}}\). For each ground truth keypoint coordinate \(p \in R^{2}\) of category \(c\), we calculate a low-resolution equivalent \({\tilde{p}}=\left\lfloor \frac{p}{R} \right\rfloor\). We then utilize a Gaussian kernel \(Y_{{xyc}} = \exp \left( { - \frac{{\left( {x - \tilde{p}_{x} } \right)^{2} + \left( {y - \tilde{p}_{y} } \right)^{2} }}{{2\sigma _{p}^{2} }}} \right)\) to transform all ground truth keypoints onto a heatmap \(Y \in \left[ 0,1 \right] ^{\frac{W}{R}\times \frac{H}{R}\times C }\), where \(\sigma _{p}\) is an object size-adaptive standard deviation, and (\({\tilde{p}}_{x}\), \({\tilde{p}}_{y}\)) is an integer coordinate of the keypoint \(p(x , y )\) on the heatmap. With the Gaussian kernel function, the output of the central point of the object on the feature map is close to 1, and the key points further away from the center are closer to 0. If two Gaussians of the same class overlap, we pick up the elementwise maximum. We use the focal loss [27] formula to calculate the loss of keypoint \(\mathrm{\mathcal{L}}_{{{\text{hm}}}}\).
where \(\alpha\) and \(\beta\) are hyperparameters of the focal loss [27], and N indicates the number of keypoints in image \(I\). N is used normalize all positive focal loss instances to 1. In all our experiments, we employ \(\alpha =2\) and \(\beta =4\).
3.2 Loss of bounding box size
We apply the bounding convolutional network (BoundConvNet) to extract bounding features from the heatmap. We adopt a classwise size prediction \({\hat{S}} \in R^{\frac{W}{R}\times \frac{H}{R} \times C \times 2 }\) for all object categories to deal with the different class overlap, and the output \({\hat{S}}\) contains the predicted width \({\hat{W}}\) and the height \({\hat{H}}\) of the objects. We can obtain the coordinates \((x , y )\), width \(W\), and height \(H\) of the objects from instance-level annotations of the dataset, which is the ground truth. Let \((x _{cj}, y _{cj})\) be the coordinate of object \(j\) for category \(c\); the center point of object \(cj\) on the heatmap is \(p\left( {\left\lfloor {\frac{{x_{{cj}} }}{R}} \right\rfloor ,\left\lfloor {\frac{{y_{{cj}} }}{R}} \right\rfloor } \right)\), where \(R\) is the output stride. We utilize a collaborative intersection over union (Co-IoU) loss to optimize the regression of the bounding box size.
Equation (2) is used to compute the intersection between the predicted bounding box and the grand truth. Equation (3) is used to compute the union between the predicted bounding box and the grand truth. Equation (4) is calculating the cosine of the predicted and ground truth diagonal. Where \(C\) is equal to the number of categories, \(n _{c}\) indicates the number of instances for category \(c\), \(\gamma\) is a penalty factor of bounding box size loss, and N indicates the number of keypoints in image \(I\). N is used to normalize all bounding box losses to 1. Equation (5) is the computational formulation of the Co-IoU loss. \({\mathcal {L}}_{wh}\) denotes the loss of bounding boxes.
3.3 Loss of offset
We independently predict a local offset \({\hat{O}} \in R^{\frac{W}{R}\times \frac{H}{R}\times 2}\) for each center point to remedy a discretization error that was caused by output stride \(R\). For ground truth keypoint coordinate (\(p_{x}\), \(p_{y}\)), the ground truth offset is (\(p_{x}-{\tilde{p}}_{x}\), \(p_{y}-{\tilde{p}}_{y}\)). We use the same offset prediction for all categories \(c\) and deal with offset error with an L1 loss.
where \({\tilde{p}}_{x}=\left\lfloor \frac{p_{x}}{R} \right\rfloor\) and \({\tilde{p}}_{y}=\left\lfloor \frac{p_{y}}{R} \right\rfloor\). The coordinates (\(p_{x}\), \(p_{y}\)) of the object centers on the input image have been discretized to the largest integer (\({\tilde{p}}_{x}\), \({\tilde{p}}_{y}\)) on the output feature map. By predicting this offset value, we can better calibrate the central point of the object in the inference. We only supervise the keypoint locations and ignore all other locations.
3.4 Loss of detector
The features of the backbone output are processed by different head networks, and we predict the keypoints \({\hat{Y}}\), bounding box size \({\hat{S}}\), and offset \({\hat{O}}\). The output of the head network is a total of \(C+2C+2\) dimension vectors for each location. The overall training loss of the detector is \(\mathrm{\mathcal{L}}_{{{\text{Total}}}}\).
where \(\lambda _{wh}\) and \(\lambda _{off}\) are hyperparameters and indicate the weights of \({\mathcal {L}}_{wh}\) and \({\mathcal {L}}_{off}\), respectively. We define \(\lambda _{wh}\) = 1 and \(\lambda _{off}\) = 1 in subsequent experiments.
3.5 Inference from points to bounding boxes
The inference of our detector is straightforward. We input an image into the network of our detector, obtain heatmaps, and predict the size of the bounding boxes and the offset of the center points. We employ a \(3 \times 3\) max-pooling operation to extract the peaks in the heatmap for each category independently. We pick out all responses whose values are greater or equal to their 8-connected neighbors and keep the top 100 peaks.
Let \({\hat{P}}_{c}\) be the set of \(n\) predicted center points \({\hat{P}}=\left\{ \left( {\hat{x}}_{j},{\hat{y}}_{j}\right) \right\} _{j=1}^{n}\) of class c. Each keypoint location is defined by an integer coordinate \(\left( x_{cj},y_{cj} \right)\). We utilize keypoint values \({\hat{Y}}_{x_{j}y_{j}c}\) as a measurement of its prediction confidence and generate a bounding box at the location \(\left( {\hat{x}}_{cj}+\delta {\hat{x}}_{j}-{\hat{w}}_{cj}/{2},\quad {\hat{y}}_{cj}+\delta {\hat{y}}_{j}-{{\hat{h}}_{cj}}/{2}, \nonumber \right. \left. {\hat{x}}_{cj}+\delta {\hat{x}}_{j}+ {{\hat{w}}_{cj}}/{2},\quad {\hat{y}}_{cj}+\delta {\hat{y}}_{j}+ {{\hat{h}}_{cj}}/{2}\right)\). where \(\left( \delta {\hat{x}}_{j},\delta {\hat{y}}_{j} \right) ={\hat{O}}_{{\hat{x}}_{j},{\hat{y}}_{j}}\) is the predicted value of the offset and \(\left( {\hat{w}}_{cj},{\hat{h}}_{cj} \right) ={\hat{S}}_{{\hat{x}}_{cj},{\hat{y}}_{cj}}\) is the predicted value of the bounding box size. All outputs are produced directly from the keypoint estimation without IoU-based nonmaxima suppression (NMS) or other postprocessing.
4 Our approach
4.1 Baseline and motivation
In this work, we use CenterNet [11] as our baseline. For object detection, CenterNet produces heatmaps of keypoints and other attributes, and each heatmap represents the location of keypoints for each category. We focus on improving the detectors’ localization ability. One-stage anchor-free detectors usually generate bounding boxes using regression straightforwardly. We use a backbone network for extracting features from images to generate heatmaps and then utilize the feature of each point on the heatmap to predict the object’s category and location. However, this feature representation method based on the center point cannot provide adequate bounding information; consequently, limited information will restrict the detector’s capacity for localizing instances.
Usually, object detectors utilize a pretrained network on the ImageNet classification dataset as the backbone network. As classification is quite different from object detection, the latter needs to recognize the objects’ category and localize objects in space. Therefore, we plan to boost the spatial localization ability of the backbone network. When we trained CenterNet with ResNet-18 [13] as the backbone network, we observed that the regression loss of the bounding box size was the maximum among the three losses. We propose to enhance the spatial information of the feature map and try to add more neural network layers to obtain a more comprehensive feature representation. More details about our detection pipeline are covered in the next section.
4.2 Refining locations with BoundConvNet
The design principles for image classification are unfavorable for localization tasks, as the spatial resolution of feature maps is gradually reduced for standard networks, such as VGG16 [15] and ResNet [13]. Therefore, many researchers have tried to modify the head of the backbone network designed for image classification [21, 22, 28, 33]. We use CenterNet’s object detection architecture as the basis for reconstruction. One of the backbones of CenterNet for object detection is ResNet-18 [13] with pretrained weight. An image of \(512 \times 512\) pixels with three channels is represented as a \(128 \times 128 \times 64\) tensor feature map, then deformable convolutional network (DCN) [24] is used to enhance the features, and finally, the size of the bounding boxes are regressed. By reimplementing CenterNet, we can observe that the loss of bounding box size regression is the max loss during training. Therefore, we present a model to boost the represent ability. After the DCN layer, we add a convolutional layer to decouple classification from regression. Then, we add three convolutional layers, three batch normalizations, and two activation layers. BoundConvNet is used to extract bounding features from the heatmap. Through visualizing the heatmap, we find that the figure of an instance can be identified in the heatmaps. Therefore, before regressing a bounding box, we add depthwise separable [36] dilated convolution layers to enhance the spatial information of instances. With this method, we try to fit an optimal regression function that predicts a more accurate bounding box of instances. The details of BoundConvNet are displayed in Fig. 2.

The architecture of the bounding convolutional network. The WH tensor indicates a \(128 \times 128 \times 2C\) tensor including the width and height of all objects in the image, and \(C\) is equal to the number of categories
During training, the parameters of the base head are adjusted by classification, bounding box regression, and offset regression, and the parameters of BoundConvNet are adjusted by bounding box regression. With the increase in training epochs, the base head network refines the location of the objects’ center point in the heatmap, which is good for reducing the loss of bounding box regression. The above process is operated iteratively until the total loss no longer reduces. In BoundConvNet, we convolute the heatmap for width and height, respectively. The first layer is depthwise separable convolution by the \(3 \times 1\) and \(1 \times 3\) kernel, and then a batch normalization layer and an ReLU activation function are added. The second layer is dilated convolution [37] by the \(3 \times 1\) and \(1 \times 3\) kernel, and the dilation parameter is 3. The last layer is also dilated convolution by the \(3\times 1\) and \(1 \times 3\) kernel, but the dilation parameter is 9. We think this is similar to generating a mask for each point in the heatmap and similar to the local attention [38, 39] mechanism. These operations enhance the position information of each point and perform bounding box regression on every category. The function of bounding box regression can be fitted more reasonably. Therefore, the bounding box of instances can be predicted more accurately.
Figure 3 shows a visualization of the feature maps. An original image was resized to the size of \(512 \times 512\), then input it to the backbone network of ResNet-18, and then process it through the DCN [24] convolution layer to output a feature map of the image. As shown in Fig. 3, the left column represents the original image, and the middle column represents the output feature map with a size of \(128 \times 128\). The bright points in the feature maps represent the central points of the objects to be detected. The right column is a feature map that has undergone BoundConvNet convolution layers, then followed by \(1 \times 1\) convolution to generate vectors for predicting the width and height of objects.

The visualization of feature maps. The Backbone is ResNet-18_DCN, the size of feature map is \(128 \times 128\). It is best viewed on screen
4.3 Co-IoU: loss function of BBR
CenterNet uses the L1 loss for bounding box regression. We look closely into the CenterNet’s training and observe that the convergent bound of bounding box regression is approximately between 10 and 2. L1 loss is an absolute loss that is sensitive to the bounding box scale. This is adverse to detecting small objects because the loss of a small object is smaller than that of a large object.

The diagram of Co-IoU loss. It is best viewed on screen
As shown in Fig. 4a, the green line bounding box is the ground truth. For the L1 loss, the loss of the red line prediction bounding box is the same as the loss of the black line prediction bounding box. And any predicted bounding box between the black line bounding box and the red one, its loss is smaller than that of the black one. The L1 loss does not consider the correlation between the width and height of the bounding box. Therefore, the convergence range of loss is too wide, which slows the convergence speed of the models. Therefore, we apply intersection over union (IoU) loss to replace the L1 loss for bounding box regression. IoU loss ranges from 0 to 1. It is insensitive to the size of objects, which facilitates small object detection [40]. As shown in Fig. 4b, even if we use IoU loss for bounding box regression, the loss of the yellow bounding box is the same as that of the blue bounding box, but neither of them is a good enough prediction bounding box. Thus, with respect to IoU loss, we need to consider the aspect ratio of the predicted bounding box and the ground truth. The angle \(\theta\) is an included angle of the diagonal of the yellow bounding box between the diagonal of the ground truth, and the angle \(\beta\) is an included angle of the diagonal of the brown bounding box between the diagonal of the ground truth. It is known that the smaller the included angle of the diagonal of the bounding boxes, the more similar their aspect ratios. Therefore, we use the cosine of the included angle \(\theta\) as the collaborative coefficient of IoU loss named collaborative intersection over union (Co-IoU) loss (See Sect. 3.3 for details of the Co-IoU loss).
4.4 Decoupled fine-tuning
Object detection is multitask learning (MTL) [41]; normally, it includes classification and regression tasks. Achieving the boost in efficiency and performance of object detectors is not easy, because multitask optimization requires optimizing several (potentially competing) objectives. We configure the weight of losses to balance learning between tasks. In the initial training phase, we optimize the pipeline to obtain the optimal classification loss hm_loss. Then, in the subsequent fine-tuning phase, we freeze the backbone and the DCN (deformable convolutional network) layers to fine-tune the localization subnet only. Decoupling subnets learn better features for their task and boost the localization ability of the detector via BoundConvNet.
5 Experiments
In this section, we first introduce the hyperparameter settings and implementation details of experiments and then employ some comparative experiments to validate our method. After that, we take ablation studies to demonstrate the effectiveness and the efficiency of our BoundConvNet and finally evaluate it on the Pascal VOC dataset.

The training losses of baseline on MS COCO dataset (CenterNet with backbone ResNet-18)
5.1 Implementation details
We conduct experiments on the large-scale object detection datasets, MS COCO [34] and Pascal VOC [35]. There are 118k training images (aka. Train2017), 5k validation images (aka. Val2017), and 20k holdout testing images for object detection in MS COCO. It is one of the most commonly used object detection benchmark datasets. In our experiments, we apply the average precision (AP) value under different intersection over union (IoU) thresholds to evaluate our model and record AP over all IoU thresholds as (AP), AP at IoU threshold 0.5 as (\(AP_{50}\)) and AP at IoU threshold 0.75 as (\(AP_{75}\)). While testing, we use flipping images and multiscale images. In the training phase, the resolution of the input images is fixed to \(512\times 512\). In the testing procedure, we keep the original image resolution and the zero-pad input image to the maximum stride of the network. With ResNet, we yield an output resolution of the \(128 \times 128\) feature map. All our experiments have been developed on JupyterLab using an NVIDIA Tesla V100-SXM3 GPU. For the MS COCO dataset, we train models with an initial learning rate of 1.25e\(-\)4 and a mini-batch size of 48 images. The learning rate decreases by a factor of 10 after 90 epochs and 120 epochs, respectively. The total epochs are 200, and Adam [42] is used to optimize the overall network. Considering the computation and performance trade-off, we define \(\gamma =2\) in the Co-IoU loss function.

The contrast of training losses on MS COCO dataset. It is best viewed on screen
5.2 Contrast experiments
We look closely into the CenterNet training process and analyze the relationship between losses and the average precision (AP) of the model. In general, as the loss decreases, the AP of the model increases gradually until the model converges completely. We reimplement CenterNet and train it with backbone ResNet-18 on the JuypterLab server. The variation curves of losses are depicted in Fig. 5. The value of off_loss is very small and almost unchanged, so we no longer draw the curve of off_loss in other figures.
We reform CenterNet by adding BoundConvNet to optimize bounding box regression and apply Co-IoU loss to replace L1 loss for bounding box regression. Then, we train those modified pipelines. The loss curves are illustrated in Fig. 6. In Fig. 6, we can observe that losses of CenterNet with BoundConvNet are smaller than those of the baseline. When we apply Co-IoU loss to replace L1 loss, pipeline losses decrease further. By analyzing the results of the experiments, it was found that the loss of the bounding box size regression is approximately 0.2, which is the same as the offset loss when we apply the Co-IoU loss for the bounding box regression. After a comprehensive analysis of the model’s performance, it was found that the optimal weights of the bounding box regression loss and offset regression loss are all 1. Therefore, we define \(\lambda _{wh} = 1\) and \(\lambda _{off} = 1\) in subsequent experiments. Meanwhile, in the baseline, \(\lambda _{wh} = 0.1\) and \(\lambda _{off} = 1\).
We evaluate our models’ performances on the MS COCO dataset [34]. In the testing procedure, we use flipping images and multiscale images. The details are shown in Tables 1 and 2. Compared with the baseline, the average precision of our detectors with BoundConvNet are all improved substantially.
As shown in Table 1, the BoundConvNet with ResNet_18 backbone outperforms the baseline CenterNet, improving the performance from 33.1 to 35.2% AP. The improvements are achieved over all IoU thresholds (from AP50 to AP75), with AP50 increasing by 2.8% AP and AP75 increasing by 2.7% AP. It is worth mentioning that AP on small objects has been improved by 13.8% compared with the baseline. Table 2 shows the results of BoundConvNet with the ResNet_101 backbone. The performance of BoundConvNet also outperforms the baseline. BoundConvNet with ResNet_101 achieves an AP of 41.6%, outperforming the baseline by 11.2% in detecting small objects. These notable performance improvements demonstrate the effectiveness of our proposed BoundConvNet, particularly for detecting small objects.
Table 3 displays our results on the MS COCO validation set with different testing options and backbones, where ResNet-18* indicates that the result is reimplemented by the baseline with ResNet-18, N.A. denotes the result without test augmentation [43], F denotes the result of the test with flipping, and MS denotes the result of the test with multiscale augmentation. All results of our method are better than those of the baseline.
Inference Latency. We also assess the inference time of our BoundConvNet on the MS COCO dataset. For a fair comparison, we verify the inference speed of both BoundConvNet and the baseline on a single NVIDIA GeForce GTX 1660 Ti GPU with CUDA 10 on the same machine in the same environment. As shown in Table 4, BoundConvNet with ResNet-18 only increases the 2 ms latency compared with the baseline CenterNet. Likewise, BoundConvNet with ResNet-101 only increases the 1 ms latency compared with the baseline CenterNet. Furthermore, we verify the inference speed on a Tesla V100-SXM3 GPU and CUDA 10 in the same way. The inference times of BoundConvNet with ResNet-18 and ResNet-101 increase to 2 ms and 1 ms compared with CenterNet, respectively. These experiments illustrate that our proposed BoundConvNet increases the computation very little.
Comparison with Other SOTA Detectors. We compare with other state-of-the-art detectors in MS COCO test-dev in Table 5. BoundConvNet is intended to improve the average precision (AP) of the model without increasing the computation. Considering the speed/accuracy trade-off, we only compare with a detector whose backbone is ResNet_101 and whose input image size is approximately \(512 \times 512\). All methods are in the family of anchor-free one-stage detectors. Our BoundConvNet_ResNet-101 achieves the best overall performance.
Comparison with YOLO series detectors. We compare the proposed method with YOLO series detectors in MS COCO test-dev, and the results are shown in Table 6. Frames per Second (FPS) of our method is measured on the machine with a GPU NVIDA GeForce GTX 1660 Ti by resizing input image to make its long side equals to 512. Our FLOPs is calculated by rectangle input resolution like \(512 \times 512\). Other data are copied from the original publications. From the results in Table 6, we know that the proposed approach is suitable for scenarios with small image sizes and limited computational power. If the input resolution is less than 512, our approach achieves a relatively higher AP with less computational power. If the input image size is large, say larger than 640, and the computational power is sufficient, choosing the YOLO model would be a much better solution.
To illustrate the effectiveness of BoundConvNet in locating bounding boxes, we mark the same pictures with BoundConvNet and the baseline. The results are shown in Fig. 7. The first column displays the original pictures, the second column shows pictures marked by the baseline with ResNet-101 backbone, and the third column shows pictures marked by the BoundConvNet with the ResNet-101 backbone. We can observe that the localization ability of the detector with BoundConvNet is preferable to the baseline. Figure 8 presents the results of our method on some images of MS COCO 2017.

Qualitative examples demonstrating that BoundConvNet aids in better localizing bounding boxes. The first column shows the original pictures. The second column shows pictures marked by the baseline with the ResNet-101 backbone, and the third column shows pictures marked by BoundConvNet with the ResNet-101 backbone. In the pictures in the first row, compared with the baseline, we find that our method can generate a more accurate bounding box for the person. In the pictures in the second row, we see that our method can predict higher category confidence for the large boat than the baseline. In the third row, our method can detect the cellphone that is not indicated in the baseline. In the last row, the baseline has marked the elephant incorrectly; however, our detector with BoundConNet can detect the two elephants correctly. In conclusion, our detector with BoundConvNet can localize objects with more precision and accuracy than the baseline

Visualization results of our method on MS COCO 2017, which has the ability to generate precise bounding boxes with the backbone ResNet-101
5.3 Ablation study
We conduct ablation experiments to prove the effectiveness and efficiency of BoundConvNet and Co-IoU loss. Our work proposes two components, a bounding convolutional network (BoundConvNet) and collaborative intersection over union (Co-IoU) loss. To analyze the effectiveness of each individual component, we conduct a series of ablation experiments. The backbone is ResNet-18 with deformation convolution network (DCN) layers. We gradually replace the components in the baseline and follow the parameter settings as described in Sect. 5.1. The results are presented in Table 7.
BoundConvNet. To verify the effect of BoundConvNet, we add the BoundConvNet module to the baseline. As shown in the second row in Table 7, we improve the AP by 1.0% (from 33.1 to 34.1%). The AP and the average recall (AR) increase simultaneously. This proves that our BoundConvNet is effective in regressing the size of objects. Our explanation is that BoundConvNet can extract the bounding feature from the heatmap and enhance the feature represent ability of the model.
Co-IoU Loss. To grasp the importance of the Co-IoU loss, we replace the L1 loss with collaborative intersection over union (Co-IoU) loss to optimize the bounding box regression. The third row in Table 7 presents the results of the baseline with Co-IoU loss. We can observe that the Co-IoU loss improves the AP by 0.9% (from 33.1 to 34.0%). However, we notice that the improvement for small objects (that is, 1.6%) is more remarkable than that for other object scales. This is not surprising because compared with L1 loss, Co-IoU loss is insensitive to the scale of objects. This demonstrates that the Co-IoU loss is effectual in regressing the bounding box size, especially for small objects. Meanwhile, it was found that the average recall (AR) for large objects is decreased by 0.1% (from 69.3 to 69.2%). To evaluate the performance of our detector, we calculate the F1-score [52] using the formula \(F1=\frac{2\times AP \times AR}{AP+AR}\). By comparing the F1-score, we find that the performance of our detector with Co-IoU loss is better than that of the baseline.
Fine-tuning. We add BoundConvNet to the baseline while replacing the L1 loss with the Co-IoU loss. As shown in the fourth row in Table 7, we improve the AP by 1.8% (from 33.1 to 34.9%). The last row shows the results that we train the model in two stages, which improves the AP by 0.3% (from 34.9 to 35.2%). Compared with BoundConvNet and Co-IoU loss, fine-tuning cannot considerable improve the performance of the detector; however, training in multiple stages can save the time of model training.
Efficiency and effectiveness on the Depth of BoundConvNet. We evaluate the effectiveness of our BoundConvNet by controlling the depth (number of convolution layers). As shown in Table 8, we vary the number of used convolution layers (e.g., 1, 2, 3, 4 layers) and compare their performances with the baseline. Our BoundConvNet can benefit from the increase in depth by stacking more convolution layers until 3. When we stack the fourth layer to the network, the detector’s performance is improved very little. By trading off the efficiency and the effectiveness, the network with three layers is the best for our BoundConvNet. This proves the effectiveness of our method.
5.4 Experiments on pascal VOC
On the Pascal VOC dataset, we use the VOC 2012 and VOC 2007 trainval sets for training and the VOC 2007 test set for testing. There are 16551 training images and 4952 testing images for 20 categories. The average precision (AP) at an IoU threshold of 0.5 is used as the evaluation metric.
We conduct experiments on ResNet-18 and ResNet-101 with our BoundConvNet at two input resolutions: \(384\times 384\) and \(512\times 512\). We train our networks in two phases. In the first phase, we train the models for 70 epochs with an initial learning rate of 1.25e−4 that drops 10 times at 45 and 60 epochs. In the subsequent fine-tuning phase, we freeze the backbone and DCN (deformable convolutional network) layers and train the network from the 71st to 140th epoch. In the overall training phase, the batch size is 32. All other hyperparameters are similar to the COCO experiments. In testing, we adopt flip augmentation.
The results are shown in Table 9. Our method can improve the baseline’s performance on the Pascal VOC dataset. This demonstrates that our method can potentially be generalized to other datasets.
5.5 Experiment on FCOS with Co-IoU loss function
We use the FCOS [12] model as the new baseline and apply the Co-IoU loss function for bounding box regression. In FCOS, the final layer predicts an 80D vector \({\varvec{p}}\) of classification labels and a 4D vector \({\varvec{t}}\)=\((l\), \(t\), \(r\), \(b)\) bounding box coordinates. Here \(l\), \(t\), \(r\), and \(b\) are the distances from the location to the four sides of the bounding box, and bounding box regression is implemented by predicting the four values. We train the model on MS COCO train2017 with the backbone network ResNet-50-FPN and all other settings are similar to the FCOS baseline. After 30 epochs of training, the model is tested on MS COCO val2017. Table 10 shows the results of the final model. Since the bounding box regression is based on four values, BoundConvNet cannot be directly used for the FCOS head. The experimental results show that Co-IoU can be utilized for FCOS, with some improvement in average precision (AP).
6 Conclusion and future work
In this paper, we propose the bounding convolutional network (BoundConvNet), a simple yet effective neural network architecture that enhances the position information in the bounding box size regression process to ameliorate the localization ability of the object detector. Meanwhile, we present the Co-IoU loss to replace the L1 loss for BBR. Object detectors with BoundConvNet can produce more accurate bounding boxes for objects. BoundConvNet improves the average precision (AP) of the model almost without increasing the computational burden, especially for detecting small objects.
There are two major limitations of this study that could be addressed in future studies. First, our study focuses on one-stage object detectors, and the proposed BoundConvNet is based on the central points of objects in feature maps, which cannot be directly applied to other two-stage object detectors. Second, the Co-IoU loss function is only suitable for bounding box regression with aspect ratio requirement. The proposed method is suitable for the scenarios with small image sizes and limited computational power, whereas other models such as YOLO v7 or Swin Transformer would be a much better solution if the input image size is large, say larger than 640, and the computational power is sufficient. In the future, we will try to address those limitations and apply BoundConvNet to more object detectors.
Data availability
Some or all data, models or code generated or used during the study are available from the first author and the corresponding author on reasonable request.
References
Szegedy C, Toshev A, Erhan D (2013) Deep neural networks for object detection. l2013 - research. Google
Li Y, Qi H, Dai J, Ji X, Wei Y (2017) Fully convolutional instance-aware semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2359–2367
Kompella A, Kulkarni RV (2021) A semi-supervised recurrent neural network for video salient object detection. Neural Comput Appl 33(6):2065–2083
Chawla A, Yin H, Molchanov P, Alvarez J (2021) Data-free knowledge distillation for object detection. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp 3289–3298
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 580–587
He K, Zhang X, Ren S, Sun J (2015) Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans Pattern Anal Mach Intell 37(9):1904–1916
Girshick R (2015) Fast r-cnn. In: Proceedings of the IEEE international conference on computer vision, pp 1440–1448
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: Towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28:91–99
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 779–788
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C-Y, Berg AC (2016) Ssd: Single shot multibox detector. In: European conference on computer vision, Springer, pp 21–37
Zhou X, Wang D, Krähenbühl P (2019) Objects as points. arXiv preprint arXiv:1904.07850
Tian Z, Shen C, Chen H, He T (2019) Fcos: Fully convolutional one-stage object detection. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 9627–9636
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Yu F, Wang D, Shelhamer E, Darrell T (2018) Deep layer aggregation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2403–2412
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Uijlings JR, Van De Sande KE, Gevers T, Smeulders AW (2013) Selective search for object recognition. Int J Comput Vision 104(2):154–171
Felzenszwalb P, McAllester D, Ramanan D (2008) A discriminatively trained, multiscale, deformable part model. In: 2008 IEEE conference on computer vision and pattern recognition, pp 1–8
Wang X, Chen K, Huang Z, Yao C, Liu W (2017) Point linking network for object detection. arXiv preprint arXiv:1706.03646
Law H, Deng J (2018) Cornernet: Detecting objects as paired keypoints. In: Proceedings of the European conference on computer vision (ECCV), pp 734–750
Zhou X, Zhuo J, Krahenbuhl P (2019) Bottom-up object detection by grouping extreme and center points. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 850–859
Qiu H, Ma Y, Li Z, Liu S, Sun J (2020) Borderdet: Border feature for dense object detection. In: European conference on computer vision, Springer, pp 549–564
Yang Z, Liu S, Hu H, Wang L, Lin S (2019) Reppoints: point set representation for object detection. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 9657–9666
Vu T, Jang H, Pham TX, Yoo CD (2019) Cascade rpn: Delving into high-quality region proposal network with adaptive convolution. arXiv preprint arXiv:1909.06720
Zhu X, Hu H, Lin S, Dai J (2019) Deformable convnets v2: More deformable, better results. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9308–9316
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L (2009) Imagenet: a large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition, pp 248–255
Lin T-Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2117–2125
Lin T-Y, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision, pp 2980–2988
Wu Y, Chen Y, Yuan L, Liu Z, Wang L, Li H, Fu Y (2020) Rethinking classification and localization for object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10186–10195
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. In: European conference on computer vision, Springer, pp 483–499
Lan S, Ren Z, Wu Y, Davis LS, Hua G (2020) Saccadenet: a fast and accurate object detector. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10397–10406
Park H-J, Choi Y-J, Lee Y-W, Kim B-G (2022) ssfpn: Scale sequence (s\(^{\hat{}}{2}\)) feature based-feature pyramid network for object detection. arXiv e-prints, 2208
Chollet F (2017) Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1251–1258
He Y, Zhu C, Wang J, Savvides M, Zhang X (2019) Bounding box regression with uncertainty for accurate object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2888–2897
Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: Common objects in context. In: European conference on computer vision, Springer, pp 740–755
Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vision 88(2):303–338
Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H (2017) Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861
Yu F, Koltun V (2015) Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Zhang W, Fu C, Xie H, Zhu M, Tie M, Chen J (2021) Global context aware rcnn for object detection. Neural Comput Appl 33(18):11627–11639
Nguyen N-D, Do T, Ngo TD, Le D-D (2020) An evaluation of deep learning methods for small object detection. J Electr Comput Eng 2020:1–18
Vandenhende S, Georgoulis S, Van Gansbeke W, Proesmans M, Dai D, Van Gool L (2021) Multi-task learning for dense prediction tasks: A survey. IEEE Trans Pattern Anal Mach Intell 44(7):3614–3633
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980
Wang X, Zhu D, Yan Y (2022) Towards efficient detection for small objects via attention-guided detection network and data augmentation. Sensors 22(19):7663
Farhadi A, Redmon J (2018) Yolov3: an incremental improvement. In: Computer vision and pattern recognition, vol. 1804. Springer Berlin/Heidelberg, Germany, p 1–6
Bochkovskiy A, Wang C-Y, Liao H-YM (2020) Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934
Zhang S, Wen L, Bian X, Lei Z, Li SZ (2018) Single-shot refinement neural network for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4203–4212
Ge Z, Liu S, Wang F, Li Z, Sun J (2021) Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430
Xu S, Wang X, Lv W, Chang Q, Cui C, Deng K, Wang G, Dang Q, Wei S, Du Y, et al (2022) Pp-yoloe: An evolved version of yolo. arXiv preprint arXiv:2203.16250
Glenn J (2022) YOLOv5 release v6.1. https://github.com/ ultralytics/yolov5/releases/tag/v6.1/
Wang C-Y, Yeh I-H, Liao H-YM (2021) You only learn one representation: Unified network for multiple tasks. arXiv preprint arXiv:2105.04206
Wang C-Y, Bochkovskiy A, Liao H-YM (2022) Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696
Chicco D, Jurman G (2020) The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC Genom 21:1–13
Acknowledgements
This work was supported by the Science and Technology Development Fund (FDCT) of Macau under Grant No. 0071/2022/A.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, S., Wang, W., Li, H. et al. Bounding convolutional network for refining object locations. Neural Comput & Applic 35, 19297–19313 (2023). https://doi.org/10.1007/s00521-023-08782-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08782-9