
Abstract
This article investigates the observer-based finite-time adaptive neural network control for the permanent magnet synchronous motor (PMSM) system. The addressed PMSM system includes unknown nonlinear dynamics and constraint immeasurable states. The neural networks are utilized to approximate the unknown nonlinear dynamics and an equivalent control design model is established, by which a neural network state observer is given to estimate the immeasurable states. By constructing barrier Lyapunov functions and under the framework of adaptive backstepping control design technique and finite-time stability theory, a finite-time adaptive neural network control scheme is developed. It is proved that the proposed control scheme ensures the closed-loop system stable and the angular velocity, stator current and other state variables not to exceed their predefined bounds in a finite time. Finally, the computer simulation and a comparison with the existing controller are provided to confirm the effectiveness of the presented controller.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Over the past decades, the demand for PMSMs is growing in numerous industrial equipment fields including vehicles, machine tools, and robots [1,2,3,4]. Nevertheless, PMSM systems are nonlinear, multivariable and strongly coupled objects, which usually face model uncertainties caused by parameter variations and unavoidable external disturbances in industrial applications. Therefore, to solve the above difficulties and achieve the higher requirements of PMSMs in practical application, some effective control methods are proposed for PMSM systems, such as backstepping controllers [5], adaptive controllers [6], sliding mode controllers [7] and disturbance rejection control [8].
In the practical engineering, since the considered PMSM systems are often complex and uncertainties, they are difficult to model accurately. To handle this problem, some intelligent adaptive control methods including neural network controllers and fuzzy controllers have been widely adopted in the control of PMSMs [9,10,11,12,13,14,15,16]. In [9,10,11,12,13], some adaptive fuzzy control methods were presented for position tracking control of PMSMs via backstepping design technique. The authors in [14] proposed a robust adaptive fuzzy controller by dead-zone smooth inverse compensation scheme for PMSMs. In addition, the violations of the state constraints often result in system instability, performance degradation, or even system damage. Thus, the researching state constraint control problem is very significant for PMSM systems [15, 16]. In [15], the authors used the barrier Lyapunov function and proposed an output constraint control method of the PMSM system. Furthermore, the adaptive neural network control scheme [16] was designed for the PMSM system with full state constraints.
It should be mentioned that the aforementioned control strategies are developed by the asymptotic stability theory. Hence, they only guarantee the controller systems are stable in infinite time. In fact, there are many practical systems like the PMSM system addressed in this study, they are more desired that the state trajectories converge to the stable equilibrium point within a finite-time interval rather than an infinite time. For this purpose, the finite-time stability is proposed by [17]. Since the finite-time stability has the properties such as fast transient and better robustness against the uncertainties. Thus, by the finite-time stability theory, many finite-time control methods for PMSMs have been developed during the past few years [18,19,20,21,22]. The literature [18] developed a neural networks finite-time adaptive dynamic surface control method for PMSMs. By combining backstepping control technology with the command filtered technology, [19] studied the fuzzy finite time tracking control problem for PMSMs. [20] considered the finite-time neural network position tracking control scheme considered for the fractional-order chaotic permanent magnet synchronous motor system. In [21, 22], the adaptive finite-time neural network control schemes were proposed for uncertain permanent magnet synchronous motor system. However, to the best of authors’ knowledge, there are few results on finite-time output feedback control for the PMSMs with full state constraints, which prompts us to conduct this study. Note that when the states are not measurable, the state observer becomes an extremely effective technique to solve the state immeasurable problem. In [23,24,25,26], the output feedback controllers were applied to control PMSMs with state immeasurable. However, the state observers were designed in [23,24,25,26] all focus on the PMSM systems whose the nonlinear dynamics are required to be known. Nevertheless, the output-feedback controllers are designed by the asymptotic stability theory and without considering the state constraint control problem.
Based on the above observations, this paper investigates the finite-time neural adaptive output feedback tracking control problem for PMSM system. The considered PMSM system contains unknown nonlinear dynamics and constraint immeasurable states. The neural networks are utilized to approximate the unknown nonlinear dynamics, a neural network state observer is designed to estimate the immeasurable states. By constructing barrier Lyapunov functions and under the framework of adaptive backstepping control design technique and finite-time stability theory, a finite-time adaptive neural network control scheme is developed. The main advantages of the proposed output-feedback control approach are as follows.
-
(i)
This paper proposes an observer-based finite-time adaptive output feedback control method for the PMSM system via a novel neural network state observer. Note that the previous finite-time fuzzy or neural network control schemes [7, 8, 25] all require that the angular velocity, stator current and other state variables of the PMSM system must be measurable. Thus, they can not solve the state immeasurable problem addressed by this study.
-
(ii)
The proposed the observer-based neural network adaptive output feedback controller is designed under the finite-time stability theory. Therefore, it not only can ensure the closed-loop system stable, but also guarantee the angular velocity, stator current and other state variables not exceed their predefined bounds in a finite time. More importantly, it has fast convergence and better robustness to the uncertainties compared with the previous output feedback controllers [15] developed under the asymptotic stability.
2 System description and some preliminaries
2.1 System description
The d–q-axis stator voltage model of PMSMs considered in this paper is shown by Fig. 1. The mathematical equations of PMSMs are expressed by

Structure of the considered PMSM system
In (1), \({u_q}\) and \({u_d}\) express system control inputs, \({i_q}\), \({i_d}\), \(\theta\) and \(\omega\) are the system state variables, they are d–q -axis current, and the rotor position and motor rotor angular velocity. J stands for the rotor moment of inertia, B is the friction coefficient, \({L_d}\) and \({L_q}\) present the d–q -axis stator inductors, \({n_p}\) expresses the number of pole pairs, \({T_L}\) is the load torque, \(\Phi\) is the magnet flux linkage of inertia, \({R_s}\) is the armature resistance.
Introducing variables as follows:
Then, PMSM system (1) is expressed by
where y is the output.
Further, let \({f_2}(\bar{x}) = - \frac{B}{J}{x_2} +\mathrm{{(}}\frac{{{a_1}}}{J} - 1){x_3} + \frac{{{a_2}}}{J}{x_3}{x_4} -\frac{{{T_L}}}{J}\), \({f_3}(\bar{x}) = {b_3}{x_2} + {b_1}{x_3} +{b_2}{x_2}{x_4}\) and \({f_4}(\bar{x})\mathrm{{ = }}{c_1}{x_4} +{c_2}{x_2}{x_3}\), \((\bar{x} = {[{x_1},{x_2},{x_3},{x_4}]^T})\).
Then system (3) becomes as follows
Assumption 1
[16]: Assume that all state variables in (3) are constrained in the compact sets \(|{{x_i}}|< {k_{{c_i}}}\) and \({k_{{c_i}}} > 0\) are constants.
Assumption 2
[16]: There exist constants \({Y_r} > 0\) and \({Y_0} > 0\) such that the desired trajectory \({y_r}\) and \({\dot{y}_r}\) satisfy \(|y_{r} |\le {Y_r} < {k_{{c_1}}}\) and \(|{{{\dot{y}}_r}} |\le {k_r}\).
Lemma 1
(Young’s Inequality): For any vectors x, \(y \in {R^n}\), the following Young’s inequality holds:
where \(\eta > 0\), \(\alpha > 1\), \(\beta > 1\), and \((\alpha - 1)(\beta - 1) = 1\).
The control objectives of this study are to formulate an observer-based output feedback control scheme for PMSMs (4) by finite-time stability and neural networks, which ensure the controlled PMSM system to be stable and make the system output y(t) track the referenced function \({y_r}(t)\) in finite time interval. Especially, all the state variables in the controlled PMSMs do not exceed the prescribed bounds.
2.2 Neural networks
According to [27] and [28], a radial basis function neural network is expressed as
where the input vector \(Z \in {R^p}\), \(W \in {R^q}\) is the weight vector with neurons number q. And \(S(Z) ={[{S_1}(Z),...,{S_q}(Z)]^T}\), where \({S_i}(Z)\) are radial basis functions selected, which are chosen by
In (6), \({\rho _i} = {[{\rho _{i,1}},...,{\rho _{i,p}}]^T}\) are the centers and \({\vartheta _i}\) are the widths of the Gaussian function. The outstanding feature of a neural network \(\hat{f}(Z) ={W^T}S(Z)\) is that it can approximate the smooth continuous function f(Z), which is defined in a bounded closed set.
2.3 Finite-time stability theory
Definition 1
[19, 20]: Suppose \(z = 0\) is the equilibrium point \(\dot{z} = f(z)\). The nonlinear system \(\dot{z} = f(z)\) is called to be semi-global practical finite-time stability (SGPFTS), if for any \(z({t_0}) ={z_0}\), there exist a \(\varepsilon > 0\) and a settling time \(T(\varepsilon ,{z_0}) < \infty\), when \(t \ge {t_0} + T\), then \(\left\| {z(t)} \right\| < \varepsilon\).
Lemma 2
[19, 20]: For the system \(\dot{z} = f(z)\), if there exist a positive-definite function V, and positive constants \(c > 0\), \(0< \beta < 1\) and \(D > 0\), and satisfying the following inequality:
the system \(\dot{z} = f(z)\) is called to be SGPFTS.
3 Finite-time adaptive output-feedback control design
In this section, we first give a neural state observer to estimate the immeasurable states of the PMSM system (4). Then an adaptive neural output feedback controller is developed by using the backstepping control design technique and the finite-time stability theory.
3.1 Neural state observer design
Note that since the friction coefficient B, the rotor moment of inertia J and the load torque \(T_L\) in PMSM system (4) are unknown, the functions \({f_i}(\bar{x})\) \(i = 2,3,4\), are thus also unknown. In this situation, we use neural \({\hat{f}_i}(\bar{x}) =\hat{W}_i^T{S_i}(\bar{x})\) to approximate the unknown functions \({f_i}(\bar{x})\) and obtain an equivalent control design model for PMSM system (4). To begin with, we assume that
where \(i = 2,3,4\), \(W_i^ *\) are ideal parameter vectors, \({\varepsilon _i}\) are approximation errors, and \(|{{\varepsilon _i}} |\le {\bar{\varepsilon } _i}\), \({\bar{\varepsilon } _i}\) are known positive constants.
By (7), then PMSM system (4) is rewritten as
For the convenience of the following analysis, system (8) is rewritten in the following form:
where \(x = {\left[ {\begin{array}{cccc} {{x_1}} & {{x_2}} & {{x_3}} & {{x_4}} \\ \end{array}} \right] ^T}\), \({A_0} = \left[ {\begin{array}{cccc} { - {l_1}} & 1 & 0 & 0 \\ { - {l_2}} & 0 & 1 & 0 \\ { - {l_3}} & 0 & 0 & 0 \\ { - {l_4}} & 0 & 0 & 0 \\ \end{array}} \right]\), \(L = {\left[ {\begin{array}{cccc} {{l_1}} & {{l_2}} & {{l_3}} & {{l_4}} \\ \end{array}} \right] ^T}\), \({B_2} = {\left[ {\begin{array}{cccc} 0 & 1 & 0 & 0 \\ \end{array}} \right] ^T}\),\({B_3} = {\left[ {\begin{array}{cccc} 0 & 0 & 1 & 0 \\ \end{array}} \right] ^T}\),\({B_4} = {\left[ {\begin{array}{cccc} 0 & 0 & 0 & 1 \\ \end{array}} \right] ^T}\), \(\varepsilon = {\left[ {\begin{array}{cccc} 0 & {{\varepsilon _2}} & {{\varepsilon _3}} & {{\varepsilon _4}} \\ \end{array}} \right] ^T}\), \(K = \left[ {\begin{array}{ccc} 0 & \cdots & 0 \\ \vdots & {{b_4}} & \vdots \\ 0 & \cdots & {{c_3}} \\ \end{array}} \right]\), \(u = {\left[ {\begin{array}{cccc} 0 & 0 & {{u_q}} & {{u_d}} \\ \end{array}} \right] ^T}\). To obtain the estimations of immeasurable states, a neural network state observer is designed as
where \(\hat{x} = {\left[ {\begin{array}{cccc} {{{\hat{x}}_1}} & {{{\hat{x}}_2}} & {{{\hat{x}}_3}} & {{{\hat{x}}_4}} \\ \end{array}} \right] ^T}\) and \(\hat{W}_i\) are estimates of \(x = {\left[ {\begin{array}{cccc} {{x_1}} & {{x_2}} & {{x_3}} & {{x_4}} \\ \end{array}} \right] ^T}\) and \(W{_i^{*}}\), respectively.
In state observer (10), observer gains \({l_i}\) \((i = 1,2,3,4)\) are selected such that matrix \({A_0}\) is a Hurwitz. Then there exists a positive definite matrix \(P = {P^T} > 0\) satisfying
where \(Q = {Q^T} > 0\) is a given positive definite matrix.
3.2 Finite-time adaptive neural control design
In this part, we give an adaptive neural controller by the backstepping control design technique and the finite-time theory.
The change of coordinates is first given as.
where \(y_r\) is the desired reference, \({\alpha _1}\) and \({\alpha _2}\) are the virtual controllers.
This specific finite-time output feedback control design process is as follows:
Step 1: The time derivative of \({z_1}\) along with (8) and (12) is
Construct the barrier Lyapunov function as follows:
where \({k_{{b_1}}} > 0\), and the set \({\Omega _{{z_1}}} =\{{z_1}:|{{z_1}} |< {k_{{b_1}}}\}\) is a compact set containing origin.
By the barrier Lyapunov function (14), we design the virtual controller as
where the designed parameters \({k_1}> 0\) and \(0< \beta < 1\).
Step 2: By (8), the time derivative of \({z_2} = {\hat{x}_2} - {\alpha _1}\) is
Construct the following barrier Lyapunov function candidate as:
where \({r_2} > 0\) is the design parameter, \({V_2}\) is continuous in the set \({\Omega _{{z_2}}} = \{ {z_2}:|{{z_2}} |< {k_{{b_2}}}\}\).
By using \({V_2}\) , we design the virtual controller \({\alpha _2}\) and updating law of \({\hat{W}_2}\) as
where \({k_2}> 0\) and \({\sigma _2} > 0\) are designed parameters.
Step 3: By (8) and \({z_3} = {\hat{x}_3} - {\alpha _2}\), we have the time derivative of \({z_3}\),
Select the following barrier Lyapunov function candidate as:
where \({r_3} > 0\) is the design parameter, \({V_3}\) is continuous in the set \({\Omega _{{z_3}}} = \{ {z_3}:|{{z_3}} |< {k_{{b_3}}}\}\).
Similar to step 2, the actual controller \(u_q\) and updating law of \({\hat{W}_3}\) are designed by
where \({k_3}> 0\) and \({\sigma _3} > 0\) are designed parameters.
Step 4: By (8) and define \({z_4} = {\hat{x}_4}\), we have
Select the following barrier Lyapunov function candidate as:
where \({r_4} > 0\) is the design parameter, \({V_4}\) is continuous in the set \({\Omega _{{z_4}}} = \{ {z_4}:|{{z_4}} |< {k_{{b_4}}}\}\). Based on the barrier Lyapunov function (25), we design the actual controller \({u_d}\) and updating law of \({\hat{W}_4}\) as follows
where \({k_4}> 0\) and \({\sigma _4} > 0\) are designed parameters.
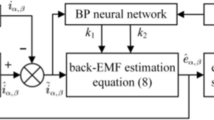
The configuration of the above designed neural adaptive output-feedback controllers is displayed in Fig. 2.

Finite-time neural network adaptive output feedback backstepping control scheme
3.3 Stability analysis
The main merits of the proposed controllers in the above sections are as follows:
Theorem 1
For the PMSM system (1) under the Assumption 1 and Assumption 2, if we adopt adaptive control scheme consisting of the virtual controllers (15), (18), the actual controllers (22), (26), neural network adaptive state observer (9), and parameter updating laws (19), (23) and (27), then the following properties are guaranteed
-
(i)
All the closed-loop system signals are boundedness;
-
(ii)
The observer errors and tracking errors converge in a finite-time interval;
-
(iii)
All the state variables do not exceed their prescribed bounds.
Proof
Define the observer errors as \({e_i} = {x_i} - {\hat{x}_i} (i=1,2,3,4)\), then from (9) and (10), we have the error dynamics equation:
where \(e = {\left[ {\begin{array}{cccc} {{e_1}} & {{e_2}} & {{e_3}} & {{e_4}} \\ \end{array}} \right] ^T}\), \({\tilde{W}_i} = W_i^ * - {\hat{W}_i}\ (i = 2,3,4)\).
Choose the Lyapunov function
By (28), we have \({\dot{V}_0}\) as
By using the Young’s inequality, we obtain
Substituting (31)–(33) into (30), we obtain
where \({\lambda _0} = ({\lambda _{\min }}(Q) - 2) > 0\), \({\lambda _{\min }}(Q)\) denotes the minimum eigenvalue of matrix Q. \({D_0}=\frac{1}{2}{\left\| P \right\| ^2}{\left\| {\bar{\varepsilon } } \right\| ^2} + {\left\| P \right\| ^2}\sum \nolimits _{i = 2}^4 {{{\left\| {W_i^ * } \right\| }^2}}\).
Choose the whole Lyapunov function as follows
From (34) and (35), \(\dot{V}\) is as follows
Substituting (13), (16), (20), (24) into (36) yields
In (37), \({\tau _1} = {z_2} + {\alpha _1} + {e_2} -{\dot{y}_r}\), \({\tau _2} = {z_3} + {\alpha _2} + {\hat{W}_2}^T{S_2} - {\tilde{W}_2}^T{S_2} + {l_2}{e_1} - {\dot{\alpha } _1}\), \({\tau _3} = {\hat{W}_3}^T{S_3} - {\tilde{W}_3}^T{S_3} + {u_q} + {l_3}{e_1} -{\dot{\alpha } _2}\), \({\tau _4} = {\hat{W}_4}^T{S_4} -{\tilde{W}_4}^T{S_4} + {u_d} + {l_4}{e_1}\).
By using the Young’s inequality, we obtain
Substituting (38)–(39) into (37) yields
where \(\lambda = {\lambda _0} + 1\), \({\kappa _1} =\frac{{{z_1}}}{{2(k_{{b_1}}^2 - z_1^2)}} + {z_2} + {\alpha _1} -{\dot{y}_r}\), \({\kappa _2} = \frac{{{z_2}}}{{2(k_{{b_2}}^2 -z_2^2)}} + {z_3} + {\alpha _2} + {\hat{W}_2}^T{S_2} + {l_2}{e_1} -{\dot{\alpha } _1}\), \({\kappa _3} = \frac{{{z_3}}}{{2(k_{{b_3}}^2 -z_3^2)}} + {\hat{W}_3}^T{S_3} + {u_q} + {l_3}{e_1} - {\dot{\alpha } _2}\), \({\kappa _4} =\frac{{{z_4}}}{{2(k_{{b_4}}^2 - z_4^2)}} +{\hat{W}_4}^T{S_4} + {u_d} + {l_4}{e_1}\).
By substituting the controllers (15), (18), (22) and (26) into (40), and using the parameter updating laws (19), (23) and (27), then (40) becomes
Note that the following inequality holds
Thus, from inequality (42), (41) can be rewritten as
where \(\bar{D} = {D_0} + \sum \nolimits _{i = 2}^4 {\frac{{{\sigma _i}}}{{2{r_i}}}{{\left\| {W_i^ * } \right\| }^2}}\).
Let \(\delta = \min \{ {2^\beta }{k_1},{2^\beta }{k_i}, \frac{{{\sigma _i}}}{{{r_i}}} - {\left\| P \right\| ^2} - 1,i =2,3,4\}\), then (43) can be expressed by
By using the following inequality
and selecting \(\varphi = 1\), \(\phi = 1 - \beta\), \(\nu = \beta\) and \(\tau = {\beta ^{({\beta /{1 - \beta }})}}\), then, we can obtain
Note that \(\log ({{k_{{b_i}}^2} /{(k_{{b_i}}^2 - z_i^2)}}) \le ({{z_i^2} /{(k_{{b_i}}^2 - z_i^2)}})\), when \(|{{z_i}}|<{k_{{b_i}}}\). Substituting (45)–(46) into (44) gives
where \(D = \bar{D} + 2\delta \tau (1 - \beta ) + ({{2\lambda } /{{\lambda _{\max }}}}(P))(1 - \beta )\tau\).
Define \(c = \min \left\{ {{{\lambda {2^\beta }} /{{\lambda _{\max }}(P),}}\delta } \right\}\), then we can obtain
By the inequality (48), we follow that the closed-loop system is SGPFS.
Further, based on (48), the following inequality holds
where \({T_0} = \frac{{{V^{1 - \beta }}(0)}}{{c(1 - \beta )(1 - \gamma )}},0< \gamma < 1\).
From (35) and (49), \(\forall t \ge {T_0}\), we have that \(|{y - {y_r}} |\le {k_{b1}}{[1 - {e^{ - 2{{(\frac{D}{{(1 - \gamma )c}})}^{ - \beta }}}}]^{\frac{1}{2}}} < {k_{b1}}\), which means that tracking error is bonded by \({k_{b1}}\). Moreover, it can be made to be smaller after the settling time \({T_0}\) and by adjusting the parameters appropriately.
With the above derivations, we easily derive that \(|{{x_1}} |\le |{{z_1}} |+ |{{y_r}} |< {k_{{b_1}}} + {Y_r}\). By selecting \({k_{{b_1}}} = {k_{{c_1}}} - {Y_r}\), we can obtain \(|{{x_1}} |< {k_{{c_1}}}\). Obviously, \({\alpha _1}\) is bounded and \(|{{\alpha _1}} |< {\bar{\alpha } _1}\). And \({x_2} = {z_2} + {\alpha _1}\). Therefore, \(|{{x_2}} |\le |{{z_2}} |+ |{{\alpha _1}} |< {k_{{c_2}}}\) is true, which means \(|{{x_2}} |< {k_{{c_2}}}\). Similarly, we have proved that \(|{{x_3}} |< {k_{{c_3}}}\) and \(|{{x_4}} |< {k_{{c_4}}}\). \(\square\)
4 Simulation study
In this part, the computer simulation and the comparison with the previous control method are carried out by MATLAB software to demonstrate the effectiveness of the developed control method. The parameters in the considered PMSMs (4) are listed by Table 1 [15].
The referenced function is given as \({y_r} = \sin (t + 0.1)\). As the same in [16], the state variables are restricted by \(|{{x_1}} |< 2.5\), \(|{{x_2}} |< 50\), \(|{{x_3}} |< 25\), \(|{{x_4}} |< 25\).
We design the neural networks \({\hat{f}_i}(\bar{x}) = \hat{W}_i^T{S_i}(\bar{x})\) to approximate the functions \({f_i}(\bar{x})\) in PMSMs (4). Each neural network contains five nodes and radial basis functions are chosen by \({S_i}(x) = \exp ( - \frac{{{{(x - {\rho _i})}^T}(x - {\rho _i})}}{{\vartheta _i^2}})\), where \({\rho _{ij}} = {[j - 2,j - 2]^T}\), \(i = 2,3,4\), \(j = 1,2,3,4,5\), and variance \({\vartheta _i} = 4\).
The neural adaptive state observers are designed as
The observer gain vector L is selected as \(L={[{l_1},{l_2},{l_3},{l_4}]^T} = {[1,50,250,20]^T}\) and A is a Hurwitz matrix. Then, given a definite matrix \(Q = I\), by solving Lyapunov equation \({A_0}^TP + P{A_0} = - 2I\), we obtain
The virtual controllers and the actual controllers are as follows
And also, the parameter updating laws are given as
The design parameters in (51)–(55) are chosen as: \({k_1} = 20\), \({k_2} = 25\), \({k_3} = 30\), \({k_4} = 50\); \({k_{{b_i}}} = 1.5,(i = 1,3,4)\), \({r_i} = 0.01,(i = 2,3,4)\); \({\sigma _i} =20\), \((i = 2,3,4)\); \(\beta = 0.99\). Setting \({x_1}(0) = 0.1\), \({x_2}(0) = 0.01rad/s\), and \({x_3}(0) = 0.01\)A, and other initial values are zeros.
The closed-loop responses are depicted in Figs. 3, 4, 5, 6, 7, 8, 9. Figure. 3 is the responses of rotor position \(\theta\) and reference signal \(y_r\). Figures 4, 5, 6, 7 are the trajectories of rotor position \(\theta\), the angular velocity \(\omega\), the current \(i_q\) and the current \(i_d\) and their estimates \(\hat{\theta }\), \(\hat{\omega }\), \(\hat{i}_q\) and \(\hat{i}_d\), respectively.

The trajectories of the rotor position \(\theta\) with reference signal \(y_r\)

The trajectories of the rotor position \(\theta\) and its estimate \(\hat{\theta }\)

The trajectories of angular velocity \(\omega\) and its estimate \(\hat{\omega }\)

The trajectories of the current \(i_q\) and its estimate \(\hat{i}_q\)

The trajectories of the current \(i_d\) and its estimate \(\hat{i}_d\)

The trajectory of the voltage \(u_q\)

The trajectory of the voltage \(u_d\)
From Figs. 3, 4, 5, 6, 7, 8, 9, it is clearly that the control method of this paper can guarantee that the PMSMs is stable, its stator current and angular velocity do not exceed their predefined bounds. Furthermore, the tracking and observer errors converge in a finite-time.
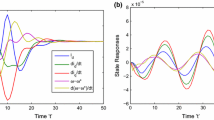
To further demonstrate the effectiveness of the formulated controller in this study, we make a simulation comparison with the adaptive controller method in [15] designed based on asymptotic stability theory. In the simulation, the initial conditions of the variables and the updating parameters are selected as the same as the above simulation. Figures 10, 11, 12, 13, 14 give the trajectories of the tracking error \({z_1}\) and observer errors \({e_i}\).
Figures 10, 11, 12, 13 and 14 indicate that tracking and observer errors in this paper converge in a shorter time than those in [15]. Besides, the control performances are also better than [15].

The tracking errors of \(z_1\)

The observer errors \(e_1\)

The observer errors \(e_2\)

The observer errors \(e_3\)

The observer errors \(e_4\)
5 Conclusion
In this paper, an adaptive neural network finite-time output-feedback control scheme is proposed for the PMSMs with unknown nonlinear functions and unmeasured constraint states. The neural networks are exploited to approximate the unknown nonlinear dynamics. By designing an adaptive neural state observer, the finite-time adaptive neural control method has been developed by constructing barrier Lyapunov functions. The main advantages of the presented finite-time adaptive neural control scheme ensure that the controlled PMSM system is SGPFTS and the tracking error converge to a small neighborhood of zero in a finite time. Furthermore, all the states of the control system do not exceed the given bounds. Computer simulation and comparison results have proved the effectiveness of the proposed control method. The further study direction will focus on the neural network event-triggered output feedback control for PMSMs based on this study.
Data Availability
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
References
Chaoui H, Khayamy M, Okoye O (2018) Adaptive RBF network based direct voltage control for interior PMSM based vehicles. IEEE Trans Veh Technol 67(7):5740–5749
Dai Y, Ni S, Xu D (2021) Disturbance-observer based prescribed-performance fuzzy sliding mode control for PMSM in electric vehicles. Eng Appl Artif Intell 104:104361
Fung RF, Kung YS, Wu GC (2010) Dynamic analysis and system identification of an LCD glass-handling robot driven by a PMSM. Appl Math Model 34(5):1360–1381
Yuan T, Wang D, Wang X (2019) High-precision servo control of industrial robot driven by PMSM-DTC utilizing composite active vectors. IEEE Access 7:7577–7587
Zhou J, Wang Y (2002) Adaptive backstepping speed controller design for a permanent magnet synchronous motor. IEE Pro-Elec Power Appl 149(2):165–172
Morawiec M (2013) The adaptive backstepping control of permanent magnet synchronous motor supplied by current source inverter. IEEE Trans Industr Inf 9(2):1047–1055
Liu J, Li H, Deng Y (2017) Torque ripple minimization of PMSM based on robust ILC via adaptive sliding mode control. IEEE Trans Power Electron 33(4):3655–3671
Chaoui H, Sicard P (2011) Adaptive Lyapunov-based neural network sensorless control of permanent magnet synchronous machines. Neural Comput Appl 20(5):717–727
Deniz E (2017) ANN-based MPPT algorithm for solar PMSM drive system fed by direct-connected PV array. Neural Comput Appl 28(10):3061–3072
Yu J, Ma Y, Chen B (2011) Adaptive fuzzy backstepping position tracking control for a permanent magnet synchronous motor. Int J Innov Comput Inform Control 7(4):1589–1602
Li S, Gu H (2012) Fuzzy adaptive internal model control schemes for PMSM speed-regulation system. IEEE Trans Industr Inf 8(4):767–779
Mao W, Liu G (2019) Development of an adaptive fuzzy sliding mode trajectory control strategy for two-axis PMSM-driven stage application. Int J Fuzzy Syst 21(3):793–808
Gao J, Shi L, Deng L (2017) Finite-time adaptive chaos control for permanent magnet synchronous motor. J Comput Appl 37(2):597–601
Wang XJ, Wang SP (2016) Adaptive fuzzy robust control of PMSM with smooth inverse based dead-zone compensation. Int J Control Autom Syst 14(2):378–388
Chang W, Tong S (2017) Adaptive fuzzy tracking control design for permanent magnet synchronous motors with output constraint. Nonlinear Dyn 87(1):291–302
Liu Y, Yu J, Yu H, Lin C, Zhao L (2017) Barrier Lyapunov functions based adaptive neural control for permanent magnet synchronous motors with full state constraints. IEEE Access 5:10382–10389
Sakthivel R, Santra S, Kaviarasan B (2016) Finite-time sampled-data control of permanent magnet synchronous motor systems. Nonlinear Dyn 86(3):2081–2092
Yu J, Shi P, Dong W, Chen B, Lin C (2014) Neural network-based adaptive dynamic surface control for permanent magnet synchronous motors. IEEE Trans Neural Networks Learn Syst 26(3):640–645
Yang X, Yu J, Wang Q, Zhao L, Yu H, Lin C (2019) Adaptive fuzzy finite-time command filtered tracking control for permanent magnet synchronous motors. Neurocomputing 337(14):110–119
Lu S, Wang X, Wang L (2020) Finite-time adaptive neural network control for fractional-order chaotic PMSM via command filtered backstepping. Adv Difference Equ 1:1–21
Sun Y, Wu X, Bai L, Wei Z, Sun G (2016) Finite-time synchronization control and parameter identification of uncertain permanent magnet synchronous motor. Neurocomputing 207:511–518
Chen Q, Ren X, Na J (2017) Adaptive robust finite-time neural control of uncertain PMSM servo system with nonlinear dead zone. Neural Comput Appl 28(12):3725–3736
Lee H, Lee J (2012) Design of iterative sliding mode observer for sensorless PMSM control. IEEE Trans Control Syst Technol 21(4):1394–1399
Wang H, Li S, Lan Q (2017) Continuous terminal sliding mode control with extended state observer for PMSM speed regulation system. Trans Inst Meas Control 39(8):1195–1204
Zhao Y, Liu X, Zhang Q (2019) Predictive speed-control algorithm based on a novel extended-state observer for PMSM drives. Appl Sci 9(12):2575
Li S, Liu H, Ding S (2010) A speed control for a PMSM using finite-time feedback control and disturbance compensation. Trans Inst Meas Control 32(2):170–187
Wang T, Tong S, Li Y (2013) Adaptive neural network output feedback control of stochastic nonlinear systems with dynamical uncertainties. Neural Comput Appl 23(5):1481–1494
Tang L, Liu Y, Tong S (2014) Adaptive neural control using reinforcement learning for a class of robot manipulator. Neural Comput Appl 25(1):135–141
Acknowledgements
This work is supported in part by the National Natural Science Foundation of China (under Grant Nos. 62173172 and U22A2043) and in part by the Key Laboratory of Intelligent Manufacturing Technology (Shantou University), Ministry of Education (under grant No. 202109244).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no conflicts of interest to this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, S., Sui, S., Li, Y. et al. Observer-based finite-time adaptive neural network control for PMSM with state constraints. Neural Comput & Applic 35, 6635–6645 (2023). https://doi.org/10.1007/s00521-022-08050-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-08050-2