
Abstract
We demonstrate several techniques to encourage practical uses of neural networks for fluid flow estimation. In the present paper, three perspectives which are remaining challenges for applications of machine learning to fluid dynamics are considered: 1. interpretability of machine-learned results, 2. bulking out of training data, and 3. generalizability of neural networks. For the interpretability, we first demonstrate two methods to observe the internal procedure of neural networks, i.e., visualization of hidden layers and application of gradient-weighted class activation mapping (Grad-CAM), applied to canonical fluid flow estimation problems—(1) drag coefficient estimation of a cylinder wake and (2) velocity estimation from particle images. It is exemplified that both approaches can successfully tell us evidences of the great capability of machine learning-based estimations. We then utilize some techniques to bulk out training data for super-resolution analysis and temporal prediction for cylinder wake and NOAA sea surface temperature data to demonstrate that sufficient training of neural networks with limited amount of training data can be achieved for fluid flow problems. The generalizability of machine learning model is also discussed by accounting for the perspectives of inter/extrapolation of training data, considering super-resolution of wakes behind two parallel cylinders. We find that various flow patterns generated by complex interaction between two cylinders can be reconstructed well, even for the test configurations regarding the distance factor. The present paper can be a significant step toward practical uses of neural networks for both laminar and turbulent flow problems.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A modern big wave of machine learning has propagated to fluid dynamics community. In particular, neural networks, which have a great potential as an universal approximator [1,2,3,4], have acquired strong attentions from fluid mechanicians for various extensions [5]. Fundamental studies for closure modeling in large-eddy simulation (LES) and Reynolds Averaged Navier–Stokes (RANS) simulation can be regarded as one of enthusiastic topics in neural networks and fluid dynamics [6]. Gamahara and Hattori [7] applied a multi-layer perceptron (MLP) with only one hidden layer to LES closure and compared its ability to conventional models, considering a turbulent channel flow. An extension of a similar idea was performed by Maulik and San [8] with a deconvolution approach. Following these pieces of seminal work, various studies have tackled to neural network-based LES modeling so as to establish the universal closure that can be applied to a wide range of flows [9,10,11,12]. For RANS modeling, a notable work here is that of Ling et al. [13]. They proposed a tensor-basis neural network (TBNN), which can guarantee a Galilean invariance, and tested the model for flows in a duct and over a wavy-wall. The TBNN have been extended to various flow configurations [14] and more practical issues, e.g., uncertainty quantification [15]. In addition to the aforementioned supervised methods, Novati et al. [16] have recently proposed a reinforcement learning-based closure by considering a homogeneous isotropic turbulent flow, which enables us to expect new methods of machine learning-based turbulence modeling.
One of the outstanding characteristics in the neural network operation is the use of nonlinear activation functions. It is widely known that neural networks can establish efficient reduced order models thanks to the nonlinearity caused herein [17]. Wang et al. [18] proposed a framework to predict the temporal evolution of proper orthogonal decomposition (POD) coefficients using the long short-term memory (LSTM) by considering an ocean gyre and a flow past a cylinder. As an extension to turbulence, Srinivasan et al. [19] used the LSTM to predict the temporal evolution of the coefficients of the nine equation model for a turbulent shear flow and reported its great potential. Focusing on spatial order reduction, neural network-based low dimensionalization, i.e., autoencoder (AE), is also one of the promising candidates [20, 21]. The great role of nonlinear activation functions in neural networks was well summarized in Murata et al. [22], who compared AE-based modes to POD modes considering a laminar cylinder wake and its transient. More recently, the customized AE referred to as a hierarchical AE was proposed by Fukami et al. [23] to handle turbulent flows efficiently.
While information of high-resolution flow fields have allowed us to understand complex flow physics, uses of neural networks which account for nonlinearity into its regression procedure can also be found for data reconstruction and estimation [24]. For instance, Fukami et al. [25] used a combination of convolutional neural network (CNN) and MLP to predict the temporal evolution of a cross-sectional field in a turbulent channel flow and applied the unified model as an inflow turbulence generator. The CNN-based model was also presented by Salehipour and Peltier [26] to predict the small-scale motions in the ocean turbulence referred to as atoms. From the perspective of image processing, super-resolution analysis, in which high-resolution data are recovered from its low-resolution counter part, was applied to turbulent flows by Fukami et al. [27, 28]. The extension of this idea to higher Reynolds number flows [29], experimental data [30], and three-dimensional turbulence [31] can also be found. In addition, a CNN-based velocity estimator for particle image velocimetry (PIV) was proposed by Cai et al. [32]. They examined its ability considering various flows. The applicability of a similar method to deteriorated experimental images was recently investigated by Morimoto et al. [33]. To sum up, various methods for neural network-based fluid data enrichment were proposed for both numerical and experimental studies.
Furthermore, neural networks have played a significant role in the flow control community [34]. The first attempt of supervised machine learning-based flow control was performed in 1997 by Lee et al. [35]. Their model was trained to learn the control input of the opposition control [36] using only the wall-sensor measurement so as to reduce the friction drag. Many of recent efforts have been devoted to reinforcement learning [37]. Rabault et al. [38] applied the reinforcement learning to perform active flow control with two jets on a cylinder surface. The extension of the technique to different Reynolds numbers was assessed by Tang et al. [39], which achieves significant drag reduction in 5.7, 21.6, 32.7, and 38.7%, at \(Re_D = 100, 200, 300,\) and 400, respectively. Although these efforts are still limited to laminar flow cases, the success here motivates us its extension to turbulent flows.
Although a wide range of neural network applications to fluid dynamics problems can be seen as introduced above, we still have some challenges toward more practical steps. In this paper, we focus on three perspectives as follows:
-
1.
Interpretability of machine-learned results. In the practical sense, we should address the interpretability of results collected from machine learning, e.g., ground for estimations and uncertainty quantification. Also, in fluid dynamics fields, some researchers have tackled this issue: Maulik et al. [40] have recently demonstrated the capability of probabilistic neural network (PNN) with a problem setting of POD coefficient prediction over a time of shallow water equation, vortex shedding behind a cylinder or an airfoil, and NOAA sea surface temperature. One of beauties in their work is that the PNN can tell us a confidence interval in estimating target attributes. Otherwise, Jagodinski et al. [41] used a three-dimensional CNN with gradient-weighted class activation mapping (Grad-CAM) [42, 43] to identify the important area for the prediction of ejection events in a turbulent channel flow. In addition, Kim and Lee [44] examined the relationship between the estimation of the wall-normal heat flux and vortical motion of turbulent channel flow by looking inside CNN.
-
2.
Amount of training data. To extract the underlying physics of fluid flow data, massive amount of training data has been utilized for neural networks [45]. For example, Fukami et al. [31] reported that approximately 15 days are required to train their neural network to perform three-dimensional spatio-temporal super-resolution analysis. To reduce the computational cost and storage, a proper method to bulk out the training data while keeping the ability of neural networks is eagerly desired for the fluid dynamics problems.
-
3.
Generalizability of neural networks for fluid flows A generalized model beyond various kinds of flows is also one key factor toward next steps of machine learning and fluid dynamics. Some studies have recently examined this point to consider inter/extrapolation boundary in terms of training data. Hasegawa et al. [46] examined the Reynolds number dependence in performing CNN-LSTM-based reduced order modeling considering a laminar cylinder wake. They also investigated the generalizability of geometric variation using the similar form of reduced order surrogate [47]. Otherwise, Erichson et al. [48] used an MLP referred to as shallow decoder to reconstruct fluid flows from local sensor measurements and discussed for inter/extrapolation of training data by considering two-dimensional forced turbulence.
The aim of the present paper is to demonstrate and introduce the capability of some techniques to clarify the aforementioned challenges in neural networks and fluid dynamics. The main contribution of this paper is to investigate the applicability of various generalization techniques to high-dimensional nonlinear dynamics. We cover various canonical neural network-based applications, i.e., force coefficient estimation, experimental velocity data estimation, spatial super resolution, and temporal prediction, using a wide range of fluid flow data and sea surface temperature data. Although many machine learning studies have been conducted in physical science, the choice of used techniques highly depends on users’ experience and intuition. Hence, providing detailed analyses on the generalization techniques should be highly beneficial in a wide range of science and engineering. The paper is organized as follows: the fundamental information on the fluid flow datasets covered in this study is provided in Sect. 2. The present machine learning models are introduced in Sect. 3. As for the result part, we first introduce the visualization method inside neural networks in Sect. 4 with canonical regression problems. The generalization techniques for the amount of training data and unseen data are then discussed in Sect. 5. Finally, concluding remarks are given in Sect. 6.
2 Flow fields used for training

Flow fields used in the present study. In the table, blue boxes indicate the use of the flow field
We consider various flow fields to cover a wide range of complex fluid flow nature with several canonical problem settings, as summarized in Fig. 1. In what follows, we introduce the setup for the training data used in this study.
2.1 Two-dimensional circular cylinder wake at \(Re_D=100\)
A temporally periodic wake behind a circular cylinder at \({Re}_D=100\) is mainly used for the demonstrations in this study. The datasets are generated with a two-dimensional direct numerical simulation (DNS). The governing equations are the incompressible continuity and Navier–Stokes equations, i.e.,
where \(\varvec{u}\) and p denote the velocity vector and pressure, respectively. All quantities are non-dimensionalized using the fluid density, the free-stream velocity, and the cylinder diameter. The size of the computational domain is (\(L_x, L_y\))=(25.6, 20.0), and the cylinder center is located at \((x, y)=(9,0)\). The Cartesian grid system with the grid spacing of \(\Delta x=\Delta y = 0.025\) is applied to the present simulation. A no-slip boundary condition on the cylinder surface is imposed using an immersed boundary method [49]. Although the number of grid points used for DNS is \((N_x, N_y)=(1024, 800)\), only the flow field around the cylinder is used as the training data whose dimension is \((N_x^*, N_y^*)=(384, 192)\) corresponding to a domain of \(8.2 \le x \le 17.8\) and \(-2.4 \le y \le 2.4\). As for the data attributes, the vorticity field \(\omega\) is considered. The time interval of flow field data is \(\Delta t=0.25\), which corresponds to approximately 23 snapshots per period, with the Strouhal number of 0.172.
2.2 A cross-sectional field of three-dimensional square cylinder wake at \(Re_D=300\) and its particle images
A flow around a square cylinder at the Reynolds number \({Re}_D=300\) is then used for our presentation with the machine learning-based PIV velocity estimator [33] in Sect. 4. The training dataset is prepared by a DNS, which has been verified against Franke et al. [50] and Robichaux et al. [51], with numerically solving the incompressible Navier–Stokes equations with a penalization term [52],
where the penalization term, which represents an object, is expressed with a penalty parameter \(\lambda\), a mask value \(\chi\), and a velocity vector of a flow inside the object \({\varvec{u}}_b\), which is zero for the fixed object. The mask value is \(\chi =0\) in the flow domain and \(\chi =1\) inside the object. The size of the computational domain here is \(\left( L_x, L_y, L_z\right) =\left( 20D,20D,4D\right)\). The computational time step is set to \(\Delta t=5.0\times 10^{-2}\). For the training data of PIV example, we focus on the volume around the square cylinder, i.e., \(\left( 7D\times 6D\times 0.5D\right)\). The number of grid points of the extracted region is \((N_x^*, N_y^*, N_z^*)=(140,120,20)\). To consider the three-dimensionality of the present flow at \({Re}_D=300\) [53], twenty \(x-y\) cross sections at different spanwise locations are used for the training data. The details of preparation for particle images can be found in Morimoto et al. [33].
2.3 NOAA sea surface temperature
The NOAA sea surface temperature dataset [54], obtained from satellite and ship observations, is used to examine the behavior of machine learning models in practical situations which have no modeled governing equations, e.g., geophysical observation. We here use the weekly observation data, which comprise of a spatial resolution of \(360\times 180\) based on a \(1^\circ\) grid. In the present study, we insert zero for the continental portions, which are colored by white in Fig. 1 for clarity of illustration.
2.4 Two-parallel cylinders wake at \(Re_D=100\)

Computational setup for flow over two side-by-side cylinders
A more complicated flow comprising the wake interactions between two side-by-side uneven circular cylinders is also considered to discuss the boundary of inter/extrapolation for training data. A schematic view of the problem setup is shown in Fig. 2. The two circular cylinders with a size ratio of r are separated with a gap of gD, where g is the gap ratio. The Reynolds number is fixed at \(Re_D=U_{\infty }D/\nu =100\). The two cylinders are placed 20D downstream of the inlet where a uniform flow with velocity \(U_{\infty }\) is prescribed, and 40D upstream of the outlet with zero pressure. The side boundaries are specified as slip and are 40D apart. The flows over the two cylinders are solved by the open-source CFD toolbox OpenFOAM [55], using the second-order discretization schemes in both time and space.

Vorticity fields with Lissajous plot for \(C_{L,1}\) and \(C_{L,2}\) of two-parallel cylinders wake
As the size ratio r and gap ratio g are varied, the flow over the two cylinders exhibits various wake patterns, which will be discussed in more detail in our coming paper. For the present study, we fix the size ratio r to 1.15 and vary the gap ratio g from 0.5 to 2.5. The wake patterns and the corresponding Lissajous plots (\(C_{L,1}\)–\(C_{L,2}\)) are shown in Fig. 3. At low gap ratios (\(g=0.5, 0.7,\) and 1.0), the wakes are characterized by irregular interactions of the two vortex streets. The phase spaces spanned by the two lift coefficients feature their chaotic trajectories. As the gap ratio is increased to \(g=1.5\), the two vortex streets in the near wake merge into one in far wake. This is also accompanied by the frequency lock-in among the two nonlinear oscillators. Further increasing the gap ratio to \(g=2.0\) and 2.5, the vortex shedding of the two cylinders takes place independently with their respective natural frequencies, and the wake is featured by complex vortex interactions.
3 Machine learning models
Machine learning models used in the present study are constructed by a multi-layer perceptron (MLP) and/or convolutional neural network (CNN). We consider several combinations of them depending on the problem setting, i.e., the size of dimension of the handled data. Here, let us briefly introduce the fundamental theories of MLP (Sect. 3.1) and CNN (Sect. 3.2), then explain the present models, which are comprised of them in Sect. 3.3.
3.1 Multi-layer perceptron
A multi-layer perceptron (MLP) [56] was inspired by the structure of biological neural circuits. The MLP has successfully been applied to not only computer science field [57], but also fluid dynamics community for turbulence modeling, reduced order modeling, and data estimation [10, 58, 59].

a A perceptron. b Multi-layer perceptron is an aggregate of perceptrons
The MLP illustrated in Fig. 4b is constructed by a lot of perceptrons, which is a minimum unit as shown in Fig. 4a. In the perceptron, the output data at the \((l-1)\mathrm{th}\) layer are fed into the next layer (l) while taking a weight \(\varvec{W}\). Notable characteristics of MLP is that the linear superposition is then passed through a nonlinear activation function \(\varphi\) such that
Weights on all connections \(W_{ij}\) are optimized to minimize a cost function E with a back propagation [60], i.e., \({\varvec{w}}=\mathrm{argmin}_{\varvec{w}}[{E}({\varvec{y}},{\mathcal F}({\varvec{x}};{\varvec{w}}))]\). In the MLP formulation, we use ReLU activation function [61], which works well for weight update issue of deep neural networks.
3.2 Convolutional neural network
Convolutional neural networks (CNN) [62] have mainly been utilized for image recognition tasks since the filter operation inside the CNN enables us to handle high-dimensional data without encountering the curse of dimensionality. The capability of CNN has also encouraged uses of CNN in the field of fluid dynamics [25, 26, 63,64,65].

Two-dimensional convolutional neural network
In this study, we use a two-dimensional CNN illustrated in Fig. 5. An input data \({\varvec{x}}=q^{(0)}\), which has \(L\times L\) pixels, is fed into the layer (l) – and then repeating manner from layer \(q^{(l-1)}\) to layer \(q^{(l)}\), where \(l~(0\le l \le l_\mathrm{max})\), is applied. The procedure of CNN for \(q^{(l)}\) can be mathematically given as
where \(C=\mathrm{floor}(H/2)\), \(b_m^{(l)}\) is the bias, \(q^{(l_\text {max})} = {\mathcal F}({\varvec{x}})\), and K is the number of input data channels. The pink square of \(H\times H\) in Fig. 5 represents the filter h. Similar to the weight update in MLP formulated as Eq. (5), weights in CNNs, i.e., the filtering coefficients, are also obtained through an optimization manner. As the filter of size \(H\times H\) is shared for whole image of \(L\times L\), the filter operation in CNN is generally called weight sharing, which allows us to handle big data with significantly lower computational costs compared to the fully-connected MLP. A max pooling layer is utilized for dimensional reduction. Also, an up-sampling layer, which copies the values in the lower dimensional space into a higher dimension, is applied for dimensional extension.
3.3 Unified models in this study with problem setting

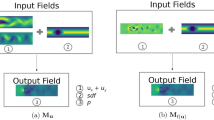
Problem settings with machine learning models in this study. a CNN-MLP model used for scalar output example. b Autoencoder-type CNN used for PIV velocity estimation. c Up-sampling CNN for super-resolution analysis. d Regular CNN for the temporal prediction of cylinder wake. e Multi-scale CNN for the temporal prediction of NOAA sea surface temperature
We use some different structures of neural network suited for each problem setting in this study. Each model is comprised of convolutional neural network (CNN) and/or multi layer perceptron (MLP). Problem settings and illustration of models covered in this study are summarized in Fig. 6.
For the visualization inside machine-learned models (Sect. 4) and the demonstration of data bulking techniques (Sect. 5.2.1), the drag coefficient \(C_D\) estimation for two-dimensional cylinder wake at \(Re_D=100\) is performed [24]. Since the input–output relationship here is a two-dimensional input with a scalar output as can be seen in Fig. 6a, we first capitalize on the CNN with the pooling operations and then the MLP is inserted for low-dimensional vectors.
We also consider an experimental data estimation for PIV images, which is described in our previous work [33], to demonstrate the visualization techniques inside machine learned models. As illustrated in Fig. 6b, an autoencoder (AE)-type CNN is trained to estimate a velocity field from the corresponding particle image. Note in passing that we adopt the AE-like structure, which is robust for noise and spatial sensitivity, to meet the requirement in handling experimental images properly [33].
To examine the possibility of a data augmentation technique, we also consider super-resolution analysis [27]. We here examine two methods of training, global data and local data, as shown in Fig. 6c. We utilize the same network structure for both training processes, which is an up-sampling-based CNN. In the model, the input low-resolution data is extended up to the dimension in which it matches with the data size of high-resolution data, and then the data are convolved to output section.
We also consider the temporal prediction of cylinder wake and NOAA sea surface temperature in this study using CNN without any pooling or up-sampling layers, since dimensions of both input and output are same as each other. The model utilized for temporal prediction of cylinder wake is illustrated in Fig. 6d. We use only the convolutional layers with filter size of \((5\times 5)\). In contrast, for the NOAA SST dataset, we utilize a multi-scale CNN [66] since we can suspect that the flow field contains a wide nature of scales. In our preliminary test, we have checked that the regular CNN does not work for the NOAA SST data, while the multi-scale CNN performs well. As presented in Fig. 6e, the multi-scale CNN used in this study includes four different filter sizes, i.e., \((3\times 3),\ (5\times 5),\ (7\times 7),\) and \((9\times 9)\).
4 Observing internal procedure of machine learning models
Considering the practical uses of neural network for various purposes, the interpretability is one of the significant requirements. Since the internal states of neural networks can be visualized with some techniques, we can expect that we may be able to find some physical insights or evidence of their estimations by observing the internal procedure. Here, let us introduce two methods in observing the inside neural networks, i.e., visualization of hidden layers (Sect. 4.1) and gradient-weighted class activation mapping [41] (Sect. 4.2).
4.1 Output of each hidden layer in convolutional neural networks

Output of each convolutional layer of a machine learning-based \(C_D\) estimation and b PIV velocity estimation
As the first technique for visualizing inside the model, we focus on hidden layers of neural networks. As an example, let us present in Fig. 7 the output of each convolutional layer of drag coefficient estimation [24] and experimental data estimation [33]. These are canonical problem settings in fluid dynamics. Since a force coefficient estimation plays a crucial role in fluid engineering, there is a demand in obtaining the force coefficients in less computational cost, i.e., without numerically solving the flow. For instance, Zhang et al. [67] utilized a CNN to estimate a force coefficient of an airfoil from flow characteristics and geometry information. Similar studies can also be found in Refs. [24, 68]. In contrast, neural network-based experimental velocity data estimation addresses the various experimental constraints, e.g., obtaining denser flow motion [32], and inpainting the data missing region of an experimental image [33].
As presented in Sect. 3.3 and Fig. 6a, the CNN-MLP model is applied to the estimation of drag coefficient \(C_D\). The convolutional part of the model, which comprises of six convolutional layers and five pooling layers, is first utilized and then the MLP part with four hidden layers is combined for the scalar output. As the representative output at each layer, we only extract the hidden output which reports largest average value over all channels per a layer based on the assumption that the outputs with larger weights have a significant contribution for the estimation, as presented in Fig. 7. As explicitly shown in Fig. 7a, the region around the cylinder has the larger intensity at every layer, which is reasonable since the drag coefficient is determined by the variables on the cylinder surface.
For the task of experimental data estimation, the CNN model attempts to output a velocity field from artificial particle image as is detailed in Morimoto et al. [33]. As stated in Sect. 3.3, we use an autoencoder (AE)-like CNN which comprises of 14 convolutional layers and 6 pooling/up-sampling layers. In this case, it is able to estimate the role of each layer by extracting the output value of each hidden layer. For the upper-stream layers, e.g., the 1st and 4th convolutional layers, the region around the square cylinder has larger values. On the other hand, it is obvious that the downstream layers, e.g., the 12th and 13th layers, have relatively large intensities on the region with velocity fluctuation. It implies that the upper-stream layers are responsible for recognizing the alignment of bluff body while the downstream layers attempts to output the velocity fluctuations.
4.2 Gradient-weighted class activation mapping (Grad-CAM)
As we demonstrated in the previous section, we can estimate a role of each layer by observing the outputs at each hidden layer. However, the weakness of the method is that it is unclear whether the large intensity output directly represents the contribution for the estimation and we need to speculate the meaning of each output field. As for more interpretable tool to observe the internal procedure, we here apply a gradient-weighted class activation mapping (Grad-CAM) [42, 43] to our problem settings. A Grad-CAM has been widely used on the field of image recognition, thanks to its capability in telling us the region with higher interest for the estimation of the trained model. Other than the image classification, Jagodinski et al. [41] has recently demonstrated the ability of the Grad-CAM for the probability estimation of ejection events in a turbulent channel flow. In our study, the ability of Grad-CAM is demonstrated with canonical regression problems, i.e., \(C_D\) estimation of a two-dimensional cylinder wake [24] and experimental data estimation [33] as shown in Fig.s 6(a) and (b). For the problem setting of experimental data estimation, we particularly choose the machine learned model trained by artificial particle images with data lacked region. The model is originally trained to estimate the velocity field from lacked artificial particle images of flow around both single and double square cylinders. For more details on this procedure, we refer readers to Morimoto et al. [33].
Basis of the Grad-CAM is a calculation of the gradient of output and designated convolutional layer. For image classification problems, the model is generally consisted with convolutional layers and multi-layer perceptrons [69]. To obtain an intensity map of the interest, the gradient between the output value and last convolutional layer which corresponds to the layer just before the multi-layer perceptron, needs to be calculated. The model used in the \(C_D\) estimation of a cylinder wake has a similar structure to those image classification networks since the output is a scalar value as presented in Fig. 6a. Hence, we use the gradient \(\partial y/\partial A_{ij}^k\) just as the classification problems, where y denotes the estimated \(C_D\) value and \(A_{ij}^k\) explains the output of channel k at the last convolutional layer, respectively. The weight \(\alpha ^k\) for each channel can be then obtained taking the average of the gradients for each value as,
where (i, j) is the index of field \(A_{ij}\) and Z is a number of dimension of output field. We then get the the Grad-CAM map L as a superposition of weighted channels,
Note that the ReLU function is applied here in order to consider only the positive influence. As for the PIV data estimation, whose CNN model has a two-dimensional input–output relationship as shown in Fig. 6b, we examine the gradient calculation on the first and the last convolutional layers to observe the difference of the role of each layer.

Grad-CAM-based visualization.a \(C_D\) estimation of two-dimensional cylinder wake.b PIV velocity estimation for both single and staggered square cylinders
Let us present in Fig. 8 the Grad-CAM maps L of both problem settings. As shown in Fig. 8a, the Grad-CAM map indicates that the region around body is highly responsible for the \(C_D\) estimation — this observation is similar to the result of hidden layer visualization. For the experimental data estimation shown in Fig. 8b, the observable trend is also akin to the layer visualization in Fig. 7, that the upper-stream layer has higher interest on the body alignment and the downstream layer is responsible for the velocity fluctuation—but notable here is its clarity compared to the layer visualization. The Grad-CAM map at the first layer shows that the network is obviously recognizing the alignment of square cylinders to classify the flow type between single and double square cylinder flow. As demonstrated here, the Grad-CAM can be a simple but the powerful tool for observing the grounds of the estimation and it can be applied to not only classification problems but also regression problems, which are common in various demands of fluid dynamics community.
5 Generalization technique for machine learning models
In this section, we apply several well-known methods of training data bulking to canonical fluid flow problems to achieve a low-error level with a small amount of training data. In what follows, the covered methods are briefly introduced with expected benefits for each problem setting.
5.1 Method
5.1.1 Flip in horizontal axis

Original and flipped data of two-dimensional cylinder wake. The dotted line located on center region in the original field is a flipping axis
One of the simplest techniques to increase the amount of training data is to flip the field around proper axis. Hasegawa et al. [47] used the flipping technique for their training data, which is a laminar periodic shedding behind a bluff body. Analogous to this study, we also apply the technique to the cylinder wake as shown in Fig. 9. Since the cylinder wake data is statistically symmetrical with the horizontal axis, we can simply get the snapshot of half-cycle ahead (or ago), meaning that we could double the number of training snapshots such that,
where \(n_\mathrm{DNS}\) is the amount of the reference DNS data and \(n_\mathrm{flip}\) is the number of overall training snapshots obtained through data flipping, respectively. Note that users have to care ergodicity depending on the target dataset and flipping axis [70], i.e., the statistical features of flipped data and original DNS data are common with each other in this particular example.
5.1.2 Noise addition
Another feasible technique is to add noise to the training data. Neural networks can be generalized, i.e., to avoid overfitting, by utilizing non-physical noisy measurement, since the test data can be generally regarded as ‘noisy’ data against the training data [71]. We can increase the training data infinitely such that,
where \(\gamma\) is an increasing rate of data amount and \(n_\mathrm{noise}\) is the number of training snapshots increased by random noise addition. Although several kinds of artificial noises can be considered [72], e.g., Gaussian, speckle, and salt & pepper, for training data, we here use the uniformly distributed random noise among \(-0.1\) to 0.1 for bulking out the training data as an example.
5.1.3 Transfer learning with spatial local data

Zoom-in concept of two-dimensional cylinder wake for spatial super-resolution reconstruction. The original domain is meshed into 64 sub-domains
Another well-known technique to bulk out the training data in image recognition is to zoom-in and/or -out the training image [73]. We here borrow the zoom-in/out concept for the fluid flow estimation. In this study, for the demonstration of super-resolution analysis, we combine the concept of zoom-in augmentation to transfer learning (or fine tuning), which has also been known as a good candidate to ease the training process by setting proper initial weights [70]. To prepare the zoomed-in image, we simply divide the original training data into several sub-domains as shown in Fig. 10.
Supervised transfer learning process utilized in this study can be implemented as follows. We first train the neural network \(\mathcal{F}_\mathrm{pre}\) with local sub-domains \(\varvec{q}_\mathrm{local}\),
where the subscripts Out and In stand for output and input data realizations, respectively. Since we will consider the super-resolution analysis for transfer learning, the local model \(\mathcal{F}_\mathrm{pre}\) learns the relationship between local low-resolution data and local high-resolution counterpart, as shown in Fig. 10. The weights \({\varvec{w}}_\mathrm{pre}\) obtained through a minimization manner, \({\varvec{w}}_\mathrm{pre}=\mathrm{argmin}_{{\varvec{w}}_\mathrm{pre}}||{\varvec{q}}_\mathrm{Out,local}-\mathcal{F_\mathrm{pre}}({\varvec{q}}_\mathrm{In,local};\varvec{w}_\mathrm{pre})||_2\), will be then set as initial weights of posteriori network \(\mathcal{F}_\mathrm{post}\). Hence, the training process can be mathematically written as
where \({\varvec{w}}_\mathrm{post,init}={\varvec{w}}_\mathrm{pre}\). Again, we can expect the improvement of reconstruction accuracy through the learning process for both local and global fields.
5.2 Demonstration
5.2.1 \(C_D\) estimation of a flow around cylinder

\(C_D\) estimation of cylinder wake at \(Re_D=100\). a Dependence of \(L_2\) error norm on number of training DNS snapshots for each data augmentation. b True-predicted plot and c time series of \(C_D\) at \({n_\mathrm{snapshot}}=2\)
Here, let us demonstrate the data bulking techniques by considering the drag coefficient estimation of two-dimensional cylinder wake. We cover two methods for this \(C_D\) estimation: 1. data flipping (Sect. 5.1.1) and 2. noise addition (Sect. 5.1.2). Note that we skip the use of transfer learning since it was clearly observed in the previous section that the region around cylinder is highly responsible for the accuracy of estimation, which indicates that sub-domain meshing is likely not helpful for this problem setting. The numbers of original snapshots used for training \(n_\mathrm{DNS}\) are set to \(n_\mathrm{DNS}=\{2,4,16,64,1000\}\) so as to investigate the dependence of estimation ability on number of training snapshots. Hence, the numbers of bulked out data via data flipping are \(n_\mathrm{flip}=2\times n_\mathrm{DNS}=\{4,8,32,128,2000\}\). In addition, we set the increasing rate \(\gamma\) in Eq. 10 to \(\gamma =8\) for the noise-based data augmentation such that \(n_\mathrm{noise}=8\times n_\mathrm{DNS}=\{16,32,128,512,8000\}\).
The \(L_2\) error norm of estimated \(C_D\) for the covered bulking techniques is shown in Fig. 11a. Note that the horizontal axis is arranged by the number of the original DNS data used for the training process \((n_\mathrm{DNS})\) to check the influence on each bulking technique. Hence, the actual numbers of snapshots used for a training with data flipping \((n_\mathrm{flip})\) and noise addition \((n_\mathrm{noise})\) are 2 and 8 folds more than the present values on the horizontal axis as mentioned above.
The basic trend here is that both mean \(L_2\) error norm and standard deviation (colored surface) decrease as the number of training snapshots increases. Although the cylinder wake data we used is governed by a periodic nature, large amount of training data is required for the sufficient accuracy. Since we do not sample the original DNS data continuously for training data preparation, i.e., randomly extracted from 1000 snapshots with the time interval of 0.25 dimensionless time, the snapshots in various cycles are contained in the training dataset as the number of original snapshots \(n_\mathrm{DNS}\) increases. Fukami et al.[24] had observed in detail that even with the periodic data, the estimation accuracy is improved by feeding larger amount of training data since there may be a slight offset in phase among training data. Especially through out bulking out techniques, the estimation ability is drastically improved at smaller number of snapshots—the training data could be successfully augmented to generalize the neural network, as seen in Figs. 11b and c.
In contrast, for the larger number of training snapshots, it is striking that noise addition causes negative influence on the estimation accuracy. The mean \(L_2\) error norm, averaged among the threefold cross-validation, of the estimation through noise addition (red triangle plots) shows larger value comparing to other cases and also the range of standard deviation (red-colored surface) is getting wider as the \(n_\mathrm{noise}\) increases. The finding here suggests that it is likely inappropriate to add the synthetic noise to sufficient amount of training data since the neural network can already acquire the nature of dataset.
Similar observation can also be found in the use of data flipping. The error of the estimation through data flipping (blue square plots) approximately converges to that of standard training (grey circle plots). This suggests that the amount of original training data for flipping is sufficient to learn the given input–output relationship.
5.2.2 Super-resolution analysis

a \(L_2\) error dependence of super-resolution reconstruction for two-dimensional cylinder wake on the number of used DNS snapshots and data augmentation techniques. Mean vorticity profile of models trained with 4 training snapshots at b \(x=13.2\) and c \(x=15.7\)
To observe the behavior for high-dimensional output regressions, we then consider the super-resolution task \({\varvec{q}}_\mathrm{HR}=\mathcal{F}({\varvec{q}}_\mathrm{LR})\) of two-dimensional cylinder wake. Super-resolution analysis, originally developed in the field of image processing, aims to estimate high-resolution data from its low-resolution counterpart. The idea had been applied to the fluid flow data by Fukami et al. [27] in 2019. The similar idea can also be applied to the universal closure modeling for LES and RANS [74, 75]. Moreover, considering that the low-resolution data corresponds to sparse sensor measurements, it can be applied to a global field reconstruction task from the limited data [48, 76]. These applications also encourage us to obtain detailed information of the weather or ocean data [77], which is crucial for disaster prevention. Here, the low-resolution data \(\varvec{q}_\mathrm{LR}\) are generated by average pooling operation for original DNS data \(\varvec{q}_\mathrm{HR}\) to become 1/8 resolution of the original data.
The \(L_2\) error dependence on the number of training snapshots is presented in Fig. 12a. In this particular example, the data flipping (blue plots) has no clear advantage against the standard training process. In contrast, the estimation can be improved by adding the Gaussian noise to the training data (red plots), especially at the smaller number of training snapshots. The observation for the smaller \(n_\mathrm{snapshot}\) is analogous to the \(C_D\) estimation in Fig. 11. The trend can also be observed from the mean vorticity profile at certain x positions, as shown in Figs. 12b and c. The results of standard process and data flipping slightly disagree with the reference vorticity, shown in black solid line, where the magnitude of vorticity is relatively large. On the other hand, the results with noise addition and fine tuning show great agreement, as can be expected from Fig. 12a.
We also consider the application of transfer learning to this task. The input and output data here are low-resolution (LR) and high-resolution (HR) data. The training process, generally explained in Sect. 5.1.3, for this particular super-resolution task can be expressed as,
where the initial weights for the posteriori model \({\varvec{w}}_\mathrm{post,init}={\varvec{w}}_\mathrm{pre}\), \({\varvec{q}}_\mathrm{HR}\) and \({\varvec{q}}_\mathrm{LR}\) are high-resolution and low-resolution data.

Super-resolved field estimated by the transfer learned model, the regular CNN and the pre-trained model. The values underneath each figure indicate the normalized \(L_2\) error norm to the reference
The super-resolved fields estimated by the transfer learned model \(\mathcal{F}_\mathrm{post}\), the regular CNN, and the pre-trained model \(\mathcal{F}_\mathrm{pre}\) are summarized in Fig. 13. All models are trained at \(n_\mathrm{DNS}=2\). Compared to the regular CNN trained with only global data, the transfer learned model reports approximately \(5\%\) lower error. This result demonstrates the strength of the transfer learning for fluid flow regression. In addition, notable point here is that the pre-trained model \(\mathcal{F}_\mathrm{pre}\) can reconstruct the whole field in reasonable accuracy despite that the model was trained with only local sub-domains. This is because the CNN-based super-resolution reconstruction is scale invariant thanks to filter sharing over a whole domain in images. It implies that the locally trained model \(\mathcal{F}_\mathrm{pre}\) has acquired the generalized function of super-resolution over the spatial domain. This feature of CNN may be utilized for the situation where the local data can only be handled due to users’ CPU limitation.

Application of trained machine learning model to unlearned alignment of bluff body for super-resolution analysis with a two-dimensional cylinder flow. a downstream and b inverse flow
For further investigation, we test the model \(\mathcal{F}_\mathrm{pre}\) to a flow with different alignment of the cylinder as shown in Fig. 14, i.e., cylinder at (a) downstream and (b) inverse flow. Both test data are prepared from the original DNS data. As it can been seen, the model \(\mathcal{F}_\mathrm{pre}\) successfully super resolves the wake region while the error concentrates on region around the body. From these observations, we find that the model trained with local sub-domains had acquired the general function of super-resolution and it is invariant not only to the scale, but also to the different alignment of the cylinder.
5.2.3 Temporal prediction
The applicability of the present data augmentation techniques to machine learning-based temporal prediction is further investigated considering a cylinder wake and the NOAA sea surface temperature data. Neural network-based surrogate modeling for a numerical simulation is one of the promising uses in nonlinear dynamical systems. Thanks to its rapid estimation, a neural network-based method can estimate the future state of the dynamics with significantly shorter computational time compared to the traditional numerical approach. For instance, Fukami et al. [25] proposed an inflow driver for numerical simulation of turbulence using neural networks. Another approaches consisted with long short-term memory [19, 46, 47, 78] and sparse identification of nonlinear dynamics [79, 80] are also promising techniques in estimating the temporal evolution of the flows.
For the cylinder wake example, we train a machine learning model to estimate the field of next time step \(t={(n+1)}\Delta t\) from the current state \(t={n\Delta t}\), where the interval \(\Delta t\) is 0.25 dimensionless time,
As the techniques for training data augmentation, we consider the all three techniques introduced in Sect. 5.1. Note again that the amount of data is twice with the data flipping and it is eight times more with noise addition, similarly to the previous section. For the transfer learning, the training process can be written as,
where \({\varvec{w}}_\mathrm{post,init}={\varvec{w}}_\mathrm{pre}\).

\(L_2\) error dependence of temporal prediction for two-dimensional cylinder wake on the number of used DNS snapshots and data augmentation techniques. Representative fields with time-ensemble averaged root mean squared error at \(n_\mathrm{DNS}=64\) are shown in the right

Results of the temporal prediction model with 64 training snapshots of cylinder wake. a Mean vorticity profile at \(x=10.7\) and 11.5 and b Probability density function of the vorticity field for each method
The error plot of all cases are shown in Fig. 15. Analogous to the previous problem settings, i.e., \(C_D\) estimation in Fig. 11 and super-resolution in Fig. 12, the basic trend shows that mean \(L_2\) error norm and standard deviation, among the threefold cross-validation, decrease as the number of training snapshot increases. As for the data flipping, it is observed that it shows no clear improvement against the standard process except for \(n_\mathrm{DNS}=4\). In contrast, the lower errors are reported on every \(n_\mathrm{DNS}\) by adding the Gaussian noise to the training data. This trend is unique among the other problem settings, i.e., \(C_D\) estimation (Fig. 11), super-resolution task (Fig. 12), and temporal estimation for sea surface temperature data, which will be discussed later. The common trend observed through these other problem settings is that the estimation ability is improved with smaller number of snapshots while no significant difference (or even worse results) would be reported with larger number of snapshots comparing to the standard procedure. This variation of trends among these cases suggests that care should be taken whether noise addition would be suitable for their particular situations or not, by considering target flows, problem settings, number of original snapshots, etc.
Furthermore, the model trained through the transfer learning shows striking results. For the smaller number of snapshots, the transfer learned model shows no significant advantage to the standard process, although the error becomes even lower than the result of noise addition for the larger number of snapshots. Unlike the other techniques, the difference between the standard process and the transfer learning is only the training process. The input/output realization for the posteriori model \(\mathcal{F}_\mathrm{post}\) is the same as that of standard process. In other words, the only difference is whether the initial weight was set randomly or obtained through pre-training with local data. Analogous to the super-resolution task (Sect. 5.2.2), we find that the pre-training using locally divided data can be one of the considerable tools to augment the generalizability of neural networks for fluid flow regression. Moreover, the model trained via transfer learning reports slightly narrower range of standard deviation compared to the result with noise addition, indicating the training process is more stable over the cross-validations. The detailed observations for each method are summarized in Fig. 16. The clear advantage of the transfer learning can also be found from the comparison of estimated mean vorticity at \(x=10.7\) and \(x=11.5\) shown in Fig. 16a. The zoomed-in figures exhibit that the model with transfer learning shows better agreement with the reference data compared to the other cases. The probability density function, shown in Fig. 16b of the vorticity field also shows the great capability of transfer learning. While the distributions estimated with data flipping and noise addition slightly mismatch with the reference data, the model trained via transfer learning shows almost perfect estimations on high probability components.

The dependence of the \(L_2\) error on the number of used snapshots with the covered augmentation techniques of temporal prediction for sea surface temperature. Representative fields at \(n_\mathrm{DNS}=64\) are shown in the right
Similar trends can also been seen with the result of temporal prediction of sea surface temperature data. For the temporal prediction of sea surface temperature data, the model is trained to estimate the state of one week ahead thorough standard process, noise addition, and transfer learning. Note that we do not use the data flipping since the geographical data here are asymmetric in both longitude and latitude axes. Let us present in Fig. 17 the dependence of the \(L_2\) error on the number of used snapshots with the covered augmentation techniques. With the most cases, the error can be successfully decreased utilizing both noise addition and transfer learning. Similar to the temporal prediction of the cylinder wake, the result with noise addition marks lower error for smaller number of snapshots, while the result of transfer learning becomes superior as the training snapshots increases. The result of noise addition shows the similar trend to that of \(C_D\) estimation on cylinder wake (Fig. 11). Among \(n_\mathrm{DNS}=16\) to 64, the error becomes larger despite the increase in training snapshots. As discussed in Sect. 5.2.1, this is likely a demarcation where the influence of synthetic noise turns to be negative as the amount of original training data becomes sufficient.

Local root mean squared error calculated from the results obtained by \(n_\mathrm{ref}=1000\) through a standard process and b transfer learning for the temporal prediction of sea surface temperature

Probability density function (p.d.f.) of the temperature field. The p.d.f. is shown individually in three different latitude band: (1) \(-90^\circ\) to \(-30^\circ\), (2) \(-30^\circ\) to \(30^\circ\), and (3) \(30^\circ\) to \(90^\circ\). The reference data is shown in dark grey for comparison
On the other hand, the model trained through transfer learning shows notably lower error for all \(n_\mathrm{DNS}\) cases. Also, the standard deviation of \(L_2\) error norm becomes significantly narrower comparing to not only the result of noise addition, but also the standard process. What is striking here is that significant improvement can be observed on region around the continents. As shown in Fig. 18, the root mean squared error around the continents are smoothed via transfer learning compared to the standard training process, i.e., trained with global data only. Since the transfer learned model \(\mathcal{F}_\mathrm{post}\) is first trained with local data, the model might be able to acquire the better estimation ability for local manner, e.g., influence of the continents.
The improvement in the estimation with noise addition and fine tuning can also be found from the probability density function, as shown in Fig. 19. We here consider three different latitudinal band, i.e., 1. \(-90^\circ\) to \(-30^\circ\), 2. \(-30^\circ\) to \(30^\circ\), and 3. \(30^\circ\) to \(90^\circ\). While the result of standard training process reports the apparent mismatch on low-probability components for the area between \(-30^\circ\) and \(30^\circ\), the models trained with noisy data and fine tuning show nice agreement with the reference distribution.
5.2.4 Generalization for unlearned data
We demonstrated several data augmentation methods above while considering canonical flows, i.e., two-dimensional cylinder wake and sea surface temperature data. In this section, let us investigate the applicability of machine learned models to unlearned state of the flow utilizing a two-parallel cylinder wake. As presented in Sect. 2.4, the flow over the two-parallel cylinders will change drastically by adjusting the gap ratio g. Utilizing this unique characteristic of the flow, we here examine the generalizability of the neural network via super-resolution task with the up-sampling CNN introduced in Fig. 6c. We consider two input coarseness, i.e., 1/8 and 1/16 resolution of original as shown in the first and the third rows of Fig. 20. The grid number for 1/8 and 1/16 resolution data are \(30\times 56\) and \(15\times 28\), respectively. To observe the applicability of trained model to unlearned states of the flow, we construct three models whose training data include only single case in terms of g for each model, i.e, (i) \(g=1.5\), (ii) \(g=0.5\), and (iii) \(g=2.5\). For instance, the model for case (i) is trained only using the flow regime at \(g=1.5\) and tested covering all cases of g.

Super resolved fields of two-parallel cylinders estimated by the model trained with global data at \(g=1.5\)
We first select the flow at \(g=1.5\) for the training data as shown in Fig. 20. The estimation ability at \(g=1.5\) is significantly better than the other test cases since the model is trained with the same g, although the test time range at \(g=1.5\) is excluding the training process. For the 1/8 resolution data, the trained network is able to successfully reconstruct the low-resolution data of all cases with the \(L_2\) error rate of less than 0.35. The representative super-resolved flow fields are also in excellent agreement with the reference data. On the other hand, although the trained model is able to catch the rough trend of data in all test cases, the \(L_2\) error norms for the 1/16 resolution case are relatively higher than that of 1/8 resolution cases, which implies the influence on the coarser input data.

Super-resolved fields of two-parallel cylinders estimated by the model trained with global data at \(g=0.5\) and \(g=2.5\). Red background indicates flow fields that have similar g to training data, while gray background indicates flow fields that are far from training range in terms of g

\(L_2\) error norm of estimated fields by the model trained with global data at a g=0.5, b g=1.5 c g=2.5. The factor g used for training is colored by blue in the horizontal axes
The aforementioned tren —the performance of the model is affected by the choice of training data—can also be observed with the model trained at \(g=0.5\) and 2.5, as shown in Fig. 21. For both cases, the model can reconstruct the field from 1/8 resolution data with reasonable accuracy even with the flow field at unlearned g. The estimation for the 1/16 resolution data is tougher than that for the 1/8 resolution, especially for the region around cylinders, which is likely because the location of each cylinder differs among fields at different g. The observed sensitivity here for the location of bluff body is analogous to our finding of super-resolution analysis for a single cylinder in Fig. 14.

\(L_2\) error norm calculated with wake region of estimated fields by the model trained with global data at \((a)~g=0.5, (b)~g=1.5\) and \((c)~g=2.5\). The factor used for training is colored by blue in the horizontal axes

a Singular value spectrum of two-parallel cylinders wake at each g. b Amplitude spectrum of the lift coefficients. Here, \(C_L=(C_{l,1}+rC_{l,2})/(1+r)\)
To avoid the influence on the region around cylinders and focus on wake reconstruction, we also check the \(L_2\) error norm on only wake region, i.e., \(4.38 \le x \le 19.0\), as listed in Fig. 23. For the model trained at \(g=1.5\), the \(L_2\) error on flows at unlearned g is relatively high. Even for flows with close gap ratio, i.e., \(g=1.0\) and 2.0, the error rate is approximately same as the other cases, which is a unique trend compared to the performance of the model trained at \(g=0.5\) and 2.5. This is likely because the flow at \(g=1.5\) is governed by synchronized vortex shedding between the two wakes. As demonstrated by the singular value spectrum in Fig. 24a, the energy convergence of the flow at \(g=1.5\) is significantly faster than that of the other cases, meaning the flow can be represented with smaller number of spatial modes. Since the flow at \(g=1.5\) does not contain complex structures as the other cases, the estimation ability on those cases became lower, even with the cases at similar g. In contrast, the models trained at \(g=0.5\) and 2.5 report smaller errors, especially on flows at similar g. The similarity here can be found from the amplitude spectrum of the lift coefficients in Fig. 24b), which shows the chaotic nature of flow for \(g=0.5\), 0.7 and 1, the synchronization at \(g=1.5\), and the quasi-periodicity at \(g=2.0\) and 2.5. Summarizing above, care should be taken for properly choosing the training data considering various factors of target flows.
6 Concluding remarks
We demonstrated several techniques for encouraging the practical use of neural networks on fluid flow problems. We first focused on visualization inside neural networks from the perspective of interpretability, considering two techniques, i.e., layer visualization and use of Grad-CAM. The great ability of them could be appreciated from observing the grounds of the estimation. Especially, the Grad-CAM offered us a clear insight of the crucial region for the estimation. The use of various data augmentation techniques for training dataset, i.e., data flipping, noise addition, and transfer learning, were also considered with canonical fluid flow regressions. Among the covered techniques, we also found that transfer learning through local data can be a great candidate for improving the estimation ability drastically and stably in most of the cases. Lastly, we investigated the generalizability of the neural networks for unlearned data through super-resolution analysis. The trained network was able to catch the rough structure of the flow field even with the flows that are not included in the training data. In particular, the lower error was reported on the flows which has similar characteristics to the training data according to a singular value spectrum. Regarding the variation in data, we investigated the capability of the machine-learned model for unseen data by considering the temporal evolution of a flow around a bluff body with various different shapes in our previous paper [47]. Moreover, the dependence of the model performance on Reynolds number is also investigated in [46]. These observations also tell us that when the test situation is not too far from the training situation, and the training data are sufficiently given, a machine-learning model can hold the generalizability even for unseen data.
Since fluid flow phenomena contain highly nonlinear and chaotic nature, the techniques applied to the fluid flow data in the present study can be generalizable for the applications in a wide range of mechanical engineering. In fact, a machine learning-based temporal prediction technique proposed by our research group [46, 47, 78] has recently been applied to the field of robotics to predict soil deformation in bucket excavation [81]. Such propagation of techniques from fluid mechanics motivates us that our proposed technique for highly nonlinear dynamics can be applied to a wide range of science. Moreover, as demonstrated in the manuscript, the methods can be applied not only to fluid flows, but also for geophysical observation. We can expect the applicability of our techniques to other types of geophysical data, e.g., weather and temperature field, as well. We refer the enthusiastic readers to our previous paper which investigates the various parameter settings of convolutional neural network, which are utilized in all models covered in this study [82].
Although we focused on the processing methods to reduce the amount of training data, other perspectives may also be considered to achieve the same goal. For instance, a physics-informed neural network (PINN) [83] has recently been attracting attention since it can take a constraint based on physical laws as a loss function. Thanks to this characteristic, it is highly expected that models with the concept of PINN can be trained accordingly from a small amount of training data while satisfying the physical laws. Otherwise, the use of other sophisticated neural networks, e.g., graph neural network [84] and reservoir computing [85], may be one of the possible candidates to improve the interpretability and generalizability, although careful choice is required depending on users’ problem settings. Moreover, from the perspective of data reconstruction from limited sensors, an optimal sensor placement derived with the theoretical manner can also drive a practical utilization of neural networks [86,87,88]. We hope that our proposed techniques of internal procedure visualization and data bulking are able to encourage the practical use of neural networks in the fluid dynamics community, by combining with these aforementioned tools.
References
Kreinovich VY (1991) Arbitrary nonlinearity is sufficient to represent all functions by neural networks: a theorem. Neural Netw. 4:381–383
Hornik K (1991) Approximation capabilities of multilayer feedforward networks. Neural Netw. 4:251–257
Cybenko G (1989) Approximation by superpositions of a sigmoidal function. Math. Control Signals Syst. 2:303–314
Baral C, Fuentes O, Kreinovich V (2018) Why deep neural networks: a possible theoretical explanation. In: Ceberio M, Kreinovich V (eds) Constraint programming and decision making: theory and applications. Studies in systems, decision and control, vol 100. Springer, Cham. https://doi.org/10.1007/978-3-319-61753-4_1
Brunton SL, Noack BR, Koumoutsakos P (2020) Machine learning for fluid mechanics. Annu. Rev. Fluid Mech. 52:477–508
Duraisamy K, Iaccarino G, Xiao H (2019) Turbulence modeling in the age of data. Annu. Rev. Fluid. Mech. 51:357–377
Gamahara M, Hattori Y (2017) Searching for turbulence models by artificial neural network. Phys. Rev. Fluids 2(5):054604
Maulik R, San O (2017) A neural network approach for the blind deconvolution of turbulent flows. J. Fluid Mech. 831:151–181
Maulik R, San O, Jacob JD, Crick C (2019) Sub-grid scale model classification and blending through deep learning. J. Fluid Mech. 870:784–812
Maulik R, San O, Rasheed A, Vedula P (2019) Subgrid modelling for two-dimensional turbulence using neural networks. J. Fluid Mech. 858:122–144
Yang XIA, Zafar S, Wang J-X, Xiao H (2019) Predictive large-eddy-simulation wall modeling via physics-informed neural networks. Phys. Rev. Fluids 4(3):034602
Pawar S, San O, Rasheed A, Vedula P (2020) A priori analysis on deep learning of subgrid-scale parameterizations for kraichnan turbulence. Theor. Comput. Fluid Dyn. 34:429–455
Ling J, Kurzawski A, Templeton J (2016) Reynolds averaged turbulence modelling using deep neural networks with embedded invariance. J. Fluid Mech. 807:155–166
Milani PM, Ling J, Eaton JK (2020) Turbulent scalar flux in inclined jets in crossflow: counter gradient transport and deep learning modelling. J Fluid Mech 906:A27
Geneva N, Zabaras N (2019) Quantifying model form uncertainty in Reynolds-averaged turbulence models with bayesian deep neural networks. J. Comput. Phys. 383:125–147
Novati G, de Laroussilhe HL, Koumoutsakos P (2021) Automating turbulence modeling by multi-agent reinforcement learning. Nat. Mach. Intell. 3:87–96
Taira K, Hemati MS, Brunton SL, Sun Y, Duraisamy K, Bagheri S, Dawson S, Yeh CA (2020) Modal analysis of fluid flows: Applications and outlook. AIAA J. 58(3):998–1022
Wang Z, Xiao D, Fang F, Govindan R, Pain CC, Guo Y (2018) Model identification of reduced order fluid dynamics systems using deep learning. Int. J. Numer. Methods Fluids 86(4):255–268
Srinivasan PA, Guastoni L, Azizpour H, Schlatter P, Vinuesa R (2019) Predictions of turbulent shear flows using deep neural networks. Phys. Rev. Fluids 4:054603
Milano M, Koumoutsakos P (2002) Neural network modeling for near wall turbulent flow. J. Comput. Phys. 182:1–26
Fukami K, Hasegawa K, Nakamura T, Morimoto M, Fukagata K (2020) Model order reduction with neural networks: application to laminar and turbulent flows. SN Comput Sci 2:467
Murata T, Fukami K, Fukagata K (2020) Nonlinear mode decomposition with convolutional neural networks for fluid dynamics. J. Fluid Mech. 882:A13
Fukami K, Nakamura T, Fukagata K (2020) Convolutional neural network based hierarchical autoencoder for nonlinear mode decomposition of fluid field data. Phys. Fluids 32:095110
Fukami K, Fukagata K, Taira K (2020) Assessment of supervised machine learning for fluid flows. Theor. Comput. Fluid Dyn. 34(4):497–519
Fukami K, Nabae Y, Kawai K, Fukagata K (2019) Synthetic turbulent inflow generator using machine learning. Phys. Rev. Fluids 4:064603
Salehipour H, Peltier WR (2019) Deep learning of mixing by two ‘atoms’ of stratified turbulence. J. Fluid Mech. 861:R4
Fukami K, Fukagata K, Taira K (2019) Super-resolution reconstruction of turbulent flows with machine learning. J. Fluid Mech. 870:106–120
Fukami K, Fukagata K, Taira K (2019) Super-resolution analysis with machine learning for low-resolution flow data. In: 11th International Symposium on Turbulence and Shear Flow Phenomena (TSFP11), Southampton, UK, number 208,
Liu B, Tang J, Huang H, Lu X-Y (2020) Deep learning methods for super-resolution reconstruction of turbulent flows. Phys. Fluids 32:025105
Deng Z, He C, Liu Y, Kim KC (2019) Super-resolution reconstruction of turbulent velocity fields using a generative adversarial network-based artificial intelligence framework. Phys. Fluids 31:125111
Fukami K, Fukagata K, Taira K (2021) Machine-learning-based spatio-temporal super resolution reconstruction of turbulent flows. J. Fluid Mech., 909(A9),
Cai S, Zhou S, Xu C, Gao Q (2019) Dense motion estimation of particle images via a convolutional neural network. Exp. Fluids 60:60–73
Morimoto M, Fukami K, Fukagata K (2021) Experimental velocity data estimation for imperfect particle images using machine learning. Phys Fluids 33:087121
Brunton SL, Hemanti MS, Taira K (2020) Special issue on machine learning and data-driven methods in fluid dynamics. Theor. Comput. Fluid Dyn. 34(4):333–337
Lee C, Kim J, Babcock D, Goodman R (1997) Application of neural networks to turbulence control for drag reduction. Phys. Fluids 9(6):1740–1747
Choi H, Moin P, Kim J (1994) Active turbulence control for drag reduction in wall-bounded flows. J. Fluid Mech. 262(3):75–110
Garnier P, Viquerat J, Rabault J, Larcher A, Kuhnle A, Hachem E (2021) A review on deep reinforcement learning for fluid mechanics. Comput Fluids 225:104973
Rabault J, Kuchta M, Jensen A, Réglade U, Cerardi N (2019) Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control. J. Fluid Mech. 865:281–302
Tang H, Rabault J, Kuhnle A, Wang Y, Wang T (2020) Robust active flow control over a range of reynolds numbers using an artificial neural network trained through deep reinforcement learning. Phys. Fluids 32(5):053605
Maulik R, Fukami K, Ramachandra N, Fukagata K, Taira K (2020) Probabilistic neural networks for fluid flow surrogate modeling and data recovery. Phys. Rev. Fluids 5:104401
Jagodinski E, Zhu X, Verma S (2020) Uncovering dynamically critical regions in near-wall turbulence 3D convolutional neural networks. arXiv:2004.06187
Selvaraju R. R., Das A, Vedantam R, Cogswell M, Parikh D, Batra D (2016) Grad-CAM: Why did you say that? arXiv:1611.07450
Selvaraju R. R., Cogswell M, Das A, Vedantam R, Parikh D, Batra D (2017) Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proc. IEEE Int. Conf. Comput. Vis., pages 618–626
Kim J, Lee C (2020) Prediction of turbulent heat transfer using convolutional neural networks. J. Fluid Mech. 882:A18
Kutz JN (2017) Deep learning in fluid dynamics. J. Fluid Mech. 814:1–4
Hasegawa K, Fukami K, Murata T, Fukagata K (2020) CNN-LSTM based reduced order modeling of two-dimensional unsteady flows around a circular cylinder at different Reynolds numbers. Fluid Dyn. Res. 52(6):065501
Hasegawa K, Fukami K, Murata T, Fukagata K (2020) Machine-learning-based reduced-order modeling for unsteady flows around bluff bodies of various shapes. Theor. Comput. Fluid Dyn. 34(4):367–388
Erichson NB, Mathelin L, Yao Z, Brunton SL, Mahoney MW, Kutz JN (2020) Shallow learning for fluid flow reconstruction with limited sensors. Proc. Royal Soc. A 476(2238):20200097
Kor H, Ghomizad M. Badri, Fukagata K (2017) A unified interpolation stencil for ghost-cell immersed boundary method for flow around complex geometries. J. Fluid Sci. Technol., 12(1):JFST0011
Franke R, Rodi W, Schonung B (1990) Numerical calculation of laminar vortex shedding flow past cylinders. J. Wind Eng. Ind. Aerodyn. 35:237–257
Robichaux J, Balachandar S, Vanka SP (1999) Three-dimensional floquet instability of the wake of square cylinder. Phys. Fluids 11:560
Caltagirone JP (1994) Sur l’interaction fluide-milieu poreux: application au calcul des efforts excerses sur un obstacle par un fluide visqueux. C. R. Acad. Sci. Paris 318:571–577
Bai H, Alam MdM (2018) Dependence of square cylinder wake on Reynolds number. Phys. Fluids 30:015102
Available on https://www.esrl.noaa.gov/psd/
Weller HG, Tabor G, Jasak H, Fureby C (1998) A tensorial approach to computational continuum mechanics using object-oriented techniques. Comput. Phys. 12(6):620–631
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagation errors. Nature 322:533–536
Domingos P (2012) A few useful things to know about machine learning. Communications of the ACM 55(10):78–87
Lui HFS, Wolf WR (2019) Construction of reduced-order models for fluid flows using deep feedforward neural networks. J. Fluid Mech. 872:963–994
Yu J, Hesthaven JS (2019) Flowfield reconstruction method using artificial neural network. AIAA J. 57(2):482–498
Kingma D. P., Ba J (2014) Adam: A method for stochastic optimization. arXiv:1412.6980
Nair V, Hinton G. E. (2010) Rectified linear units improve restricted boltzmann machines. Proc. Int. Conf. Mach. Learn., pages 807–814
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc. IEEE 86(11):2278–2324
Matsuo M, Nakamura T, Morimoto M, Fukami K, Fukagata K (2021) Supervised convolutional network for three-dimensional fluid data reconstruction from sectional flow fields with adaptive super-resolution assistance. arXiv:2103.09020
Moriya N, Fukami K, Nabae Y, Morimoto M, Nakamura T, Fukagata K (2021) Inserting machine-learned virtual wall velocity for large-eddy simulation of turbulent channel flows. arXiv:2106.09271
Nakamura T, Fukami K, Fukagata K (2021) Comparison of linear regressions and neural networks for fluid flow problems assisted with error-curve analysis. arXiv:2105.00913
Du X, Qu X, He Y, Guo D (2018) Single image super-resolution based on multi-scale competitive convolutional neural network. Sensors 18(789):1–17
Zhang Y, Sung W, Marvis D (2018) Application of convolutional neural network to predict airfoil lift coefficient. AIAA paper, 2018–1903
Miyanawala T.P., Jaiman R.K. (2018) A novel deep learning method for the predictions of current forces on bluff bodies. In: Proceedings of the ASME 2018 37th International Conference on Ocean, Offshore and Arctic Engineering OMAE2018, pages 1–10
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations
Guastoni L, Güemes A, Ianiro A, Discetti S, Schlatter P, Azizpour H, Vinuesa R (2020) Convolutional-network models to predict wall-bounded turbulence from wall quantities. J Fluid Mech 928:A27
Shorten C, Khoshgoftaar TM (2019) A survey on image data augmentation for deep learning. J. Big Data 6(1):60
Huang J, Liu H, Wang Q, Cai W (2020) Limited-projection volumetric tomography for time-resolved turbulent combustion diagnostics via deep learning. Aerosp. Sci. Technol., 106(106123)
Mikołajczyk A, Grochowski M (2018) Data augmentation for improving deep learning in image classification problem. In: 2018 international interdisciplinary PhD workshop (IIPhDW), pages 117–122. IEEE
Maulik R, San O (2017) Resolution and energy dissipation characteristics of implicit LES and explicit filtering models for compressible turbulence. Fluids 2(2):14
Duraisamy K (2021) Perspectives on machine learning-augmented reynolds-averaged and large eddy simulation models of turbulence. Phys. Rev. Fluids 6:050504
Fukami K, Maulik R, Ramachandra N, Fukagata K, Taira K (2021) Global field reconstruction from sparse sensors with Voronoi tessellation-assisted deep learning. Nat Mach Intell. https://doi.org/10.1038/s42256-021-00402-2
Stengel K, Glaws A, Hettinger D, King RN (2020) Adversarial super-resolution of climatological wind and solar data. Proc. Natl. Acad. Sci. USA 117(29):16805–16815
Nakamura T, Fukami K, Hasegawa K, Nabae Y, Fukagata K (2021) Convolutional neural network and long short-term memory based reduced order surrogate for minimal turbulent channel flow. Phys. Fluids 33:025116
Brunton SL, Proctor JL, Kutz JN (2016) Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. USA 113(15):3932–3937
Fukami K, Murata T, Fukagata K (2021) Sparse identification of nonlinear dynamics with low-dimensionalized flow representations. J Fluid Mech 926:A10
Saku Y, Aizawa M, Ooi T, Ishigami G (2021) Spatio-temporal prediction of soil deformation in bucket excavation using machine learning. Adv Robot. https://doi.org/10.1080/01691864.2021.1943521
Morimoto M, Fukami K, Zhang K, Nair AG, Fukagata K (2021) Convolutional neural networks for fluid flow analysis: toward effective metamodeling and low-dimensionalization. Theor Comput Fluid Dyn 35:633–658
Raissi M, Yazdani A, Karniadakis GE (2020) Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 367(6481):1026–1030
Wu Z, Pan S, Chen F, Long G, Zhang C, Philip SY (2021) A comprehensive survey on graph neural networks. IEEE Trans Neural Netw Learn Syst 32(1):4–24
Inubushi M, Goto S (2019) Transferring reservoir computing: Formulation and application to fluid physics. In: International Conference on Artificial Neural Networks, pages 193–199. Springer
Manohar K, Brunton BW, Kutz JN, Brunton SL (2018) Data-driven sparse sensor placement for reconstruction: Demonstrating the benefits of exploiting known patterns. IEEE Control Syst. 38(3):63–86
Nakai K, Yamada K, Nagata T, Saito Y, Nonomura T (2020) Effect of objective function on data-driven sparse sensor optimization. IEEE Access 9:46731–46743
Saito Y, Nonomura T, Nankai K, Yamada K, Asai K, Tsubakino Y, Tsubakino D () Data-driven vector-measurement-sensor selection based on greedy algorithm. IEEE Sensors Letters, 2020
Acknowledgments
This work was supported from Japan Society for the Promotion of Science (KAKENHI grant number: 18H03758, 21H05007).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Morimoto, M., Fukami, K., Zhang, K. et al. Generalization techniques of neural networks for fluid flow estimation. Neural Comput & Applic 34, 3647–3669 (2022). https://doi.org/10.1007/s00521-021-06633-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-021-06633-z