
Abstract
The extreme learning machine (ELM) is a new, non-tuned and fast training algorithm for feedforward neural networks (FFNN). It is highly precise and randomly produces the input weights of single-layer FFNN. In the current study, the scour depth around bridge piers is predicted by ELM as a powerful method of nonlinear system modeling. To predict scour depth, the effective dimensionless parameters are determined through dimensional analysis. Due to the complexity of scour mechanisms around bridges, different models with diverse input numbers are presented. In 5 categories, 31 different models were obtained for modeling and ELM analysis. Following the training and validation of each model presented, the optimum model was selected from each of the 5 categories and its relationship to the respective category was identified to help determine scour depth in practical engineering. For the best models presented in the different input modes, new explicit expressions were deduced. The results show that the most important parameters affecting relative scour depth (ds/y) include ratio of pier width to flow depth (D/y) and ratio of pier length to flow depth (L/y) (RMSE = 0.08; MARE = 0.0.35). The ELM performance was compared for a range of pier geometries with regression-based equations. The results confirm that ELM outperforms other methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
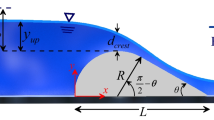
One of the most significant problems in bridge design regards the prediction of local scour depth around bridge abutments and piers. This is an intricate 3D problem challenging civil engineers around the world. Scour is a natural occurrence that suddenly alters river flow velocity and generates vorticities that spin at the pier nose and produce churning close to, or on the channel bed.
The precise forecasting of scour depth around bridge piers (SDABP) is essential for secure and economic plans. It is troublesome to formulate and define numerical methods of predicting scour influenced by the pier, bed materials and flow. On account of these factors, expanding a procedure to predict SDABP is problematic. Although numerous studies addressing scour depth prediction have been accomplished, the literature indicates the need for credible mathematical models in this field for different hydraulic conditions.
The results of each existing technique significantly differ from each other, therefore leading to controversies regarding the cost and design of protection approaches against scour as well as pier foundations [1, 2]. Subsequently, there has been continuous noteworthy research enthusiasm to evolve new approaches of approximating SDABP with precision. The majority of scour depth prediction formulas accessible in the literature have been established based on dimensional analyses and small-scale experimental tests under various assumptions, such as constant depth, uniform and non-cohesive bed materials and stable flow [3,4,5,6]. To gain full understanding of scour depth prediction and owing to the importance of ameliorating forecasting potency, numerous researchers have probed and refined techniques of increasing classical physical-based analyses.
Artificial intelligence (AI)-based approaches have been recently recognized as a puissant alternative for modeling complex nonlinear problems and are widely employed in prediction problems [7,8,9,10,11,12,13]. AI methods yield more precise results than classical regression-based methods. Previous scour surveys have shown that with the expected flexibility and complexity, intelligence methods can make up for the lack of validation by existing regression-based methods [14].
In past decades, different AI techniques have been developed to predict scour, including genetic programming [15,16,17,18], support vector regression [19, 20], artificial neural networks (ANN) [21], model trees (MT) [22] and group method of data handling (GMDH) [23,24,25,26,27]. Recently, extreme learning machine (ELM), a new machine learning technique, has become greatly popular. Olatunji et al. [28] investigated ELM accuracy, performance and feasibility in predicting the permeability of wells. The authors surveyed the performance of their proposed model in comparison with a general neural network and support vector machines. The results indicated that ELM outperforms other techniques in terms of accuracy. To overcome convergence to local minima and time consumption, Li and Cheng [29] utilized ELM to forecast monthly discharge. Deo and Şahin [30] confirmed ELM is a simple and fast nonlinear method of forecasting the Effective Drought Index (EDI) in eastern Australia. To examine the performance of ELM in terms of learning speed and forecasting ability, a comparison was conducted between ELM and a basic ANN trained with the Levenberg–Marquardt algorithm. The results demonstrated the higher accuracy and speed of ELM compared to ANN. Cao et al. [31] utilized ELM to estimate reservoir parameters, such as porosity and permeability.
The main objective of the current study is to develop the extreme learning machine (ELM) technique to predict SDABP using field datasets. For this purpose, the main parameters affecting local scour depth are determined, after which dimensionless parameters are proposed using the Buckingham theorem. To survey the effectiveness of each parameter on scour depth, 5 different categories with diverse input combinations are proposed. Therefore, for all categories 31 models are presented for ELM modeling. After selecting the best model in each category, the best input combination is selected and compared with existing regression-based models.
2 Methodology
In order to estimate SDABP, the effective factors should be determined first. To predict the factors influencing this phenomenon due to the complex scour mechanisms around the pier, the pier geometry, bed sediment properties and flow conditions should be considered. According to Khan et al. [32], the parameters affecting scour depth can be estimated as follows:
where ds is the local scour depth, y is the flow depth, U is the average velocity of approaching flow, d50 is the median diameter of particles, g is the gravity acceleration, D is the pier width, L is the pier length, and σ is the standard deviation related to bed grain size.
Applying dimensionless parameters leads to superior scour depth prediction [33,34,35]. Thus, according to the Buckingham theory, a functional equation for estimating scour depth is:
where Fr denotes the Froude number.
Subsequent to determining the dimensionless parameters for scour depth estimation, it is necessary to formulate a relationship with as few parameters as possible and with the best result among the parameters that can be used in different conditions. Therefore, 5 categories with 31 various models are suggested. The number of input parameters for the network is fixed in each category but differs among categories. All models proposed are presented in Table 1. Here, categories 1, 2, 3, 4 and 5 have, respectively, 1, 5, 10, 10 and 5 models. After establishing the models, the relative scour depth parameter value (ds/y) is estimated using ELM. In this study, a total of 476 field data are employed. The data were initially obtained by Mohammed et al. [36] and Landers and Mueller [37] who utilized ELM to predict SDABP at fourteen bridge sites that experience scour in three countries (Canada, India and Pakistan). The data are for four pier geometries, including round (231 data), square (107 data), sharp (95 data) and cylindrical (43 data). All experimental data samples are divided into training and testing datasets. The “random sampling without replacement” method is employed, and 20% of the data (96 data) are selected to comprise the testing dataset. The remaining data samples (i.e., 80% of samples = 380 data) comprise the training dataset. The parameter ranges applied in this study are presented in Table 2. Following training and model validation, the models in each category are evaluated, and finally, the best model is selected with a specific relationship determined for its category. The flowchart of the proposed methodology to develop ELM for predicting SDABP is presented in Fig. 1, while the classical regression-based models are provided in Table 3.

Flowchart of the proposed methodology to develop ELM for estimating SDABP
3 Extreme learning machines (ELM)
The ELM method for predicting SDABP is presented in this section. Owing to the superior performance in solving complex problems, simplicity and training algorithm speed, ELM is used extensively for a wide range of engineering problems. ELM is a simple and fast learning procedure that involves the least-squares techniques for generalizing single-layer feedforward neural networks (SLFFNN). The ELM utilized in this study for scour depth sensitivity analysis is shown in Fig. 2.

ELM structure
ELM contains three layers: input, hidden and output layers. The input layer introduces the knowledge to the ELM model. The core of ELM calculations is the hidden layers, which transfer the input layer information to the output layer. The information from the hidden layers is gathered in the output layer to prepare the ELM results. The ELM hidden layer weights (wij) and biases (b) are determined randomly, and only the output layer’s weights (βjk) are tuned in the training procedure [41]. Thus, the training load of an ELM model is much lower compared with other neural networks, which is why such model performs very fast in many cases.
In the ELM structure (Fig. 2), all hidden and input layers are linked to all output and hidden layers, respectively. If m and n are, respectively, the numbers of output and input variables for the problem considered, the ELM model has m and n neurons in the output and input layers, respectively. Thus, by considering the number of neurons in the hidden layer is equal to l, the weight matrices to connect the input layer to the hidden layer (w) and the hidden layer to the output layer (β) are defined as follows:
where wij is the weight matrix connecting the jth hidden neuron with the ith input neuron, and βjk is the weight matrix connecting the kth output neuron with the jth hidden neuron.
The matrices of the output (Y) and input (X) variables for the estimation problem are as follows:
The final ELM model results are obtained as T = (t1, t2, …, tQ)m×Q, where tj is defined as:
where Q and g(x) denote the input samples and activation function, respectively. Therefore, the ELM result takes the following form:
where H is:
If the numbers of input samples (Q) and hidden neurons (l) are the same, the ELM estimation error with the training dataset becomes zero. However, to obtain a simple model as well as to avoid overtraining that occurs when the difference between the training and testing estimation errors is high, l is lower than Q. Therefore, the modeling error is obtained as follows [42]:
ELM generates the w and b matrices randomly [42] and determines β using the following objective function:
Therefore, if H+ is the Moore–Penrose generalized inverse (MPGI) matrix of H, the results of Eq. (9) are:
With the present ELM method, trial and error is used to determine the number of neurons in the hidden layer. Moreover, the sigmoid function serves as activation function d in the training algorithm.
4 Results and discussion
This section investigates the modeling results of predicting scour depth around bridge piers using ELM and traditional regression-based equations. For this purpose, two statistical indices are employed, namely mean absolute relative error (MARE) and root mean squared error (RMSE). MARE and RMSE are defined as follows:
The results of estimating scour depth around a pier (ds/y) using the ELM algorithm for categories 2–5 that include more than one model (Table 1) are given in Fig. 3. Among 4-input parameter models, model 4 that contains L/y, d50/y, σ and Fr as the input parameter combination for scour depth estimation (ds/y) performs the best (RMSE = 0.09; MARE = 0.42). The model results indicate that among five parameters proposed to estimate ds/y (Eq. 2), D/y has the least impact and its deficiency leads to better results for the models from category 2 with 2 input combinations.

Appraisal of ds/y predictions by ELM according to statistical indices related to all input combinations with 1–4 input variables
It is also observed that model 3, which uses parameter D/y compared with model 4 which uses parameter L/y, has good results (RMSE = 0.08; MARE = 0.5). Therefore, using one of D/y or L/y in estimating scour depth with the models from category 2 does not lead to a significant increase or decrease in model performance. If each of the three parameters Fr, d50/y and σ were considered as input parameters in the models proposed in category 2, the models would exhibit significant performance reduction. Among the models in category 2, σ is deemed the most important parameter.
Among category 3 models, in which all defined input combinations contain 3 input parameters (Table 1), model 12 performs the best (RMSE = 0.096, MARE = 0.42). This model’s input combination is σ, L/y and Fr. In addition, model 14 performs well among category 3 models. The only parameter common in both models 12 and 14 is σ. Similar to category 2, this parameter is very important in category 3. Not using this parameter in category 3 models that include three input parameters (models 7, 8, 10 and 13) causes a 5 to 10% increase in relative error. Besides σ model 14 includes d50/L and D/y. Models 7, 13 and 14 contain two parameters d50/L and D/y of the three input parameters. It is observed that the models’ performance is not the same. Therefore, using these two parameters in category 3 models is not always associated with good performance, whereas selecting the third parameter displays a significant impact on model performance.
Category 4 entails different combinations of 2 input parameters to predict scour depth. Figure 3 indicates that model 24 performs the best in this category (RMSE = 0.08; MARE = 0.36) and estimates scour depth (ds/y) using two parameters: D/y and L/y. Furthermore, model 25 (σ, L/y) performs relatively better than model 24 (D/y, L/y). Models 18 and 21 employ parameter D/y to estimate scour depth along with σ and Fr as the second parameter, respectively. Unlike models 24 and 25, the higher statistical index values of models 18 and 21 indicate significant ELM ds/y prediction reduction. Models 19, 22 and 24 contain L/y as one of two parameters to estimate scour depth. The results of these three models have about 12% difference. Therefore, using one of these two parameters in model 24 (the best model in category 4) to estimate ds/y does not always lead to good results, but the simultaneous use of parameters L/y and D/y to estimate ds/y as a two-parameter model results in high-accuracy estimation. Model 17 [ds/y = f (Fr, d50/y)] performs the weakest in this category. According to models 17, 21, 23 and 23, none of which performs well, d50/y is one of the two most effective parameters.
Category 5 includes 5 models that all use 1 input parameter to estimate scour depth. Single-equation models are normally regarded as unreliable. Figure 3 indicates that the highest RMSE and MARE statistical index values for category 5 are for one input parameter. Model 30 (ds/y = f (L/y)) performs the best (RMSE = 0.10; MARE = 0.46) in category 5. This parameter in the best models with 2, 3 and 4 parameters is recognized as an effective parameter. The equations of the optimal models from each category with different numbers of inputs are as follows:
where BHI is the matrix of hidden neuron bias, InV is the matrix of input variables, and InW and OutW are the matrices of input and output weights (respectively). The values of BHI, InV, InW and OutW differ for each model based on the numbers of input variables and hidden layer neurons. Each matrix for the best model in each category is presented as follows:
for Model 1 (5 inputs)
for Model 4 (4 inputs)
for Model 12 (3 inputs)
for Model 24 (2 inputs)
for Model 30 (1 input)
According to the above explanation, the best models selected from all categories with different numbers of input parameters are compared, and the most capable model is selected for estimating SDABP. Since category 1 includes only 1 model, model 1 is the best in this category. Accordingly, in categories 2, 3, 4 and 5, models 4, 12, 24 and 30 are selected as the optimal models, respectively. It can be seen in Table 1 that parameter L/y is present in each superior model with one to five inputs, indicating the importance of this parameter in scour depth estimation. The best models selected in each category are compared in Fig. 4. The statistical index results for five models selected are presented in this figure. Evidently, the RMSE index is almost equal for the selected models. The highest RMSE value is for Model 30 (RMSE = 0.104), which only contains L/y as an input variable. Employing both of L/y and D/y simultaneously as input variables in the ELM network (Model 24) results in the lowest RMSE value (RMSE = 0.08) among all 31 models proposed in this study. Similar to the RMSE index, the lowest and highest MARE values are for Model 24 (MARE = 0.357) and 30 (MARE = 0.464), respectively. The MARE index for models with 5, 4 and 3 inputs (models 1, 4 and 12, respectively) is relatively equal, but model 24 displays the best performance according to this index. In fact, it is observed that the absence of parameter D/y from 4-parameter models does not cause a significant change in performance.

RMSE and MARE error histogram for ds/y predictions by ELM with the best model in each category
Figure 5 compares the ds/y estimation results using ELM with the regression-based equation results. The greatest estimation error according to this figure is produced by Shen’s et al. [40] equation, which overestimates most of the time. The relative error for Laursen and Touch [3] and Shen’s et al. [40] equations is very high. However, according to the statistical indices for ELM and the regression-based equations in Table 3, the mean relative error for Laursen and Touch’s [3] equation is about 30% higher than Shen’s et al. [40]. Richardson and Davis’ [38] equation also does not perform well in predicting SDABP, as it produces a high relative error and makes overestimations. According to Table 4, the relative error is about 5 times higher than ELM. Johnson’s [39] equation makes overestimated predictions much like other models (RMSE = 0.15; MARE = 0.37). Therefore, it can be said that none of the regressions provide good results, and using them would lead to uneconomical plans—something that can be alleviated by applying ELM. According to Table 4, ELM significantly increases estimation accuracy and solves problems caused by overestimation. Each statistical index value presented for ELM is superior to all regression-based equations. An advantage of ELM is the need for fewer parameters (D/y and L/y) than Johnson’s [39] (Fr, D/y and σ) equation.

Comparison of ELM and traditional equations in predicting SDABP
5 Conclusion
Since scour can significantly influence the flow around bridge foundations, it is necessary to analyze and evaluate scour in bridge design and maintenance. Therefore, in the current study, SDABP was predicted using ELM, which is known as a swift and highly accurate prediction method. The parameters affecting scour were determined, and dimensionless parameters were presented. To evaluate the different input combinations using sensitivity analysis, 31 models with different input combinations were presented. The best models with all input combinations did not significantly differ from each other. The best model presented in this study contains two inputs: L/y and D/y (RMSE = 0.08; MARE = 0.36). From the best models selected according to various input combinations, different relationships were derived for practical engineering. A comparison of ELM with regression-based equation results demonstrates a significant increase in scour depth estimation accuracy using the explicit expressions presented in this study. Existing regression relationships often make overestimated predictions with high relative error. In future studies, the methodology presented in this study can be extended using other artificial intelligence methods, such as group method of data handling, gene expressing programming, etc.
Abbreviations
- D :
-
Pier width
- d s :
-
Local scour depth
- d 50 :
-
Median diameter of particles
- Fr :
-
Froude number
- g :
-
Gravitational acceleration
- g(x):
-
Activation function (Eq. 5)
- L :
-
Pier length
- l :
-
Neurons in the hidden layer
- Q :
-
Number of input samples (Eq. 5)
- U :
-
Average velocity of approaching flow
- w :
-
Input-hidden layer
- w ij :
-
Connecting weight between the ith input neuron and the jth hidden neuron (Eq. 3)
- Y :
-
Flow depth
- Β :
-
Hidden-output layer weight
- β jk :
-
Connecting weight between the jth hidden neuron and the kth output neuron (Eq. 3)
- σ :
-
Standard deviation related to bed grain size
References
Lyn DA, Neseem E, Ramachandra Rao A, Altschaeffl AG (2000) A laboratory sensitivity study of hydraulic parameters important in the deployment of fixed-in-place scour-monitoring devices. Joint Transportation Research Program. Report No. FHWA/IN/JTRP-2000/12. Purdue University, Indiana, USA
Firat M, Gungor M (2009) Generalized regression neural networks and feed forward neural networks for prediction of scour depth around bridge piers. Adv Eng Softw 40:731–737. https://doi.org/10.1016/j.advengsoft.2008.12.001
Laursen EM, Toch A (1956) Scour around bridge piers and abutments. Iowa Highway Research Board, Washington
Breusers HNC, Nicollet G, Shen HW (1977) Local scour around cylindrical piers. J Hydraul Res 15:211–252
Richardson EV, Harrison LJ, Richardson JR, Davis SR (1993) Evaluating scour at bridges, 2nd edn. Federal Highway Administration, US Department of Transportation, McLean
Melville B, Chiew Y (1999) Time scale for local scour at bridge piers. J Hydraul Eng 125:59–65. https://doi.org/10.1061/(ASCE)0733-9429(1999)125:1(59)
Azamathulla HM, Yusoff MAM (2013) Soft computing for prediction of river pipeline scour depth. Neural Comput Appl 23(7–8):2465–2469. https://doi.org/10.1007/s00521-012-1205-x
Samadi M, Jabbari E, Azamathulla HM (2014) Assessment of M5′ model tree and classification and regression trees for prediction of scour depth below free overfall spillways. Neural Comput Appl 24(2):357–366. https://doi.org/10.1007/s00521-012-1230-9
Azimi H, Bonakdari H, Ebtehaj I, Michelson DG (2016) A combined adaptive neuro-fuzzy inference system–firefly algorithm model for predicting the roller length of a hydraulic jump on a rough channel bed. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2560-9
Ebtehaj I, Bonakdari H, Shamshirband S, Mohammadi K (2015) A combined support vector machine-wavelet transform model for prediction of sediment transport in sewer. Flow Meas Instrum 47:19–27. https://doi.org/10.1016/j.flowmeasinst.2015.11.002
Sattar AM (2014) Gene Expression models for the prediction of longitudinal dispersion coefficients in transitional and turbulent pipe flow. J Pipeline Syst Eng Pract 5:04013011. https://doi.org/10.1061/(ASCE)PS.1949-1204.0000153
Khoshbin F, Bonakdari H, Ashraf Talesh SH, Ebtehaj I, Zaji AH, Azimi H (2016) Adaptive neuro-fuzzy inference system multi-objective optimization using the genetic algorithm/singular value decomposition method for modelling the discharge coefficient in rectangular sharp-crested side weirs. Eng Optim 48(6):933–948. https://doi.org/10.1080/0305215X.2015.1071807
Sattar AM, Gharabaghi B (2015) Gene expression models for prediction of longitudinal dispersion coefficient in streams. J Hydrol 524:587–596. https://doi.org/10.1016/j.jhydrol.2015.03.016
Najafzadeh M, Barani GA, Azamathulla HM (2014) Prediction of pipeline scour depth in clear-water and live-bed conditions using group method of data handling. Neural Comput Appl 24:629–635. https://doi.org/10.1007/s00521-012-1258-x
Guven A, Gunal M (2008) Genetic programming approach for prediction of local scour downstream of hydraulic structures. J Irrig Drain Eng 134:241–249. https://doi.org/10.1061/(ASCE)0733-9437(2008)134:2(241)
Guven A, Azamathulla HM, Zakaria NA (2009) Linear genetic programming for prediction of circular pile scour. Ocean Eng 36:985–991. https://doi.org/10.1016/j.oceaneng.2009.05.010
Azamathulla HM, Ab Ghani A, Zakaria NA, Guven A (2009) Genetic programming to predict bridge pier scour. J Hydraul Eng 136:165–169. https://doi.org/10.1061/(ASCE)HY.1943-7900.0000133
Khan M, Azamathulla HM, Tufail M (2012) Gene-expression programming to predict pier scour depth using laboratory data. J Hydroinform 1:628–645. https://doi.org/10.2166/hydro.2011.008
Pal M, Singh NK, Tiwari NK (2011) Support vector regression based modeling of pier scour using field data. Eng Appl Artif Intell 24:911–916. https://doi.org/10.1016/j.engappai.2010.11.002
Hong J, Goyal M, Chiew Y, Chua L (2012) Predicting time-dependent pier scour depth with support vector regression. J Hydrol 468:241–248. https://doi.org/10.1016/j.jhydrol.2012.08.038
Kaya A (2010) Artificial neural network study of observed pattern of scour depth around bridge piers. Comput Geotech 37:413–418. https://doi.org/10.1016/j.compgeo.2009.10.003
Balouchi B, Nikoo MR, Adamowski J (2015) Development of expert systems for the prediction of scour depth under live-bed conditions at river confluences: application of ANNs and the M5P model tree. Appl Soft Comput 34:51–59. https://doi.org/10.1016/j.asoc.2015.04.040
Najafzadeh M, Barani GA, Hessami-Kermani MR (2013) GMDH based back propagation algorithm to predict abutment scour in cohesive soils. Ocean Eng 59:100–106. https://doi.org/10.1016/j.oceaneng.2012.12.006
Najafzadeh M, Barani GA, Hessami-Kermani MR (2013) Group method of data handling to predict scour depth around vertical piles under regular waves. Sci Iran 20:406–413. https://doi.org/10.1016/j.scient.2013.04.005
Najafzadeh M, Lim SY (2014) Application of improved neuro-fuzzy GMDH to predict scour depth at sluice gates. Earth Sci Inform 8:187–196. https://doi.org/10.1007/s12145-014-0144-8
Najafzadeh M (2015) Neuro-fuzzy GMDH systems based evolutionary algorithms to predict scour pile groups in clear water conditions. Ocean Eng 99:85–94. https://doi.org/10.1016/j.oceaneng.2015.01.014
Najafzadeh M (2015) Neuro-fuzzy GMDH based particle swarm optimization for prediction of scour depth at downstream of grade control structures. Eng Sci Technol Int J 18:42–51. https://doi.org/10.1016/j.jestch.2014.09.002
Olatunji SO, Selamat A, Raheem A, Azeez A (2013) Extreme learning machines based model for predicting permeability of carbonate reservoir. Int J Digit Content Technol Appl 7:450–459
Li B, Cheng C (2014) Monthly discharge forecasting using wavelet neural networks with extreme learning machine. Sci China Technol Sci 57:2441–2452. https://doi.org/10.1007/s11431-014-5712-0
Deo R, Şahin M (2015) Application of the extreme learning machine algorithm for the prediction of monthly Effective Drought Index in eastern Australia. Atmos Res 153(512):525. https://doi.org/10.1016/j.atmosres.2014.10.016
Cao J, Yang J, Wang Y (2015) Extreme learning machine for reservoir parameter estimation in heterogeneous reservoir. In: Proceedings of the ELM-2014. Springer, vol 2, pp 199–208
Khan M, Azamathulla HM, Tufail M, Ab Ghani A (2012) Bridge pier scour prediction by gene expression programming. Proc ICE Water Manag 165:481–493. https://doi.org/10.1680/wama.11.00008
Azamathulla HM, Deo MC, Deolalikar PB (2005) Neural networks for estimation of scour downstream of a ski-jump bucket. J Hydraul Eng 131:898–908. https://doi.org/10.1061/(ASCE)0733-9429(2005)131:10(898)
Guven A, Gunal M (2008) Prediction of scour downstream of grade-control structures using neural networks. J Hydraul Eng 134:1656–1660. https://doi.org/10.1061/(ASCE)0733-9429(2008)134:11(1656)
Najafzadeh M, Barani GA (2011) Comparison of group method of data handling based genetic programming and back propagation systems to predict scour depth around bridge piers. Sci Iran 18:1207–1213. https://doi.org/10.1016/j.scient.2011.11.017
Mohammed TH, Noor MJMM, Ghazali AH, Huat BBK (2005) Validation of some bridge pier scour formulate using field and laboratory data. Am J Environ Sci 1:119–125. https://doi.org/10.3844/ajessp.2005.119.125
Landers MN, Mueller DS (1999) U.S. Geological survey field measurements of pier scour. In: Proceedings of the compendium of papers on ASCE water resources engineering conference 1991 to 1998, pp 585–607
Richardson EV, Davis SR (2001) Evaluating scour at bridge, hydraulic engineering circular No. 18 (HEC-18). US Department of Transportation, Federal Highway
Johnson PA (1992) Reliability-basd pier scour engineering. J Hydraul Eng 118:1344–1357. https://doi.org/10.1061/(ASCE)0733-9429(1992)118:10(1344)
Shen HW, Schneider VR, Karaki S (1969) Local scour around bridge piers. J Hydraul Div 95:1919–1940
Huang GB, Zhou H, Ding X, Zhang R (2012) Extreme learning machine for regression and multiclass classification. IEEE Trans Syst Man Cybern Part B 42:513–529. https://doi.org/10.1109/TSMCB.2011.2168604
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70:489–501. https://doi.org/10.1016/j.neucom.2005.12.126
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare there is no conflict of interest.
Rights and permissions
About this article

Cite this article
Ebtehaj, I., Bonakdari, H., Zaji, A.H. et al. Sensitivity analysis of parameters affecting scour depth around bridge piers based on the non-tuned, rapid extreme learning machine method. Neural Comput & Applic 31, 9145–9156 (2019). https://doi.org/10.1007/s00521-018-3696-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-018-3696-6