
Abstract
Welding processes are considered as an essential component in most of industrial manufacturing and for structural applications. Among the most widely used welding processes is the shielded metal arc welding (SMAW) due to its versatility and simplicity. In fact, the welding process is predominant procedure in the maintenance and repair industry, construction of steel structures and also industrial fabrication. The most important physical characteristics of the weldment are the bead geometry which includes bead height and width and the penetration. Different methods and approaches have been developed to achieve the acceptable values of bead geometry parameters. This study presents artificial intelligence techniques (AIT): For example, radial basis function neural network (RBF-NN) and multilayer perceptron neural network (MLP-NN) models were developed to predict the weld bead geometry. A number of 33 plates of mild steel specimens that have undergone SMAW process are analyzed for their weld bead geometry. The input parameters of the SMAW consist of welding current (A), arc length (mm), welding speed (mm/min), diameter of electrode (mm) and welding gap (mm). The outputs of the AIT models include property parameters, namely penetration, bead width and reinforcement. The results showed outstanding level of accuracy utilizing RBF-NN in simulating the weld geometry and very satisfactorily to predict all parameters in comparison with the MLP-NN model.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
1.1 Background
In fact, the welding process is an essential process in the majority of the manufacturing procedures in industrial and structural practices [15, 20]. According to Kumar et al. [19], the welding process is to join two different or similar metals under heating by way of pressurized procedure and through using filler rod; however, in some cases, it does not necessary to use filler rod. In several branches of industries mainly mechanical and structural industries, the welding process is utilized. The sources of energy are an essential parameter in the welding process. Such sources are selected based on the type of application and environment surrounding. Regarding the energy sources, it could be gas flame, gas flame, an electric arc, a laser, ultrasound or an electron beam. On the other hand, with respect to the environment, it could be applied in open air, under water and in outer space. It can also be done in vacuum as well. With the help of welding technology, we can get strength up to 100 %. It is very easy to weld most of the material at any direction, and welding equipment can be transported to the work place easily.
The most known method for welding process is shielded metal arc welding (SMAW). According to Yousif et al. [32], SMAW is considered as the most prevalent welding process that is used in several activities. Actually, in several countries SMAW methods are used in more than 50 % of welding process activities. For its adaptability and straightforwardness, the SMAW is the most suitable method utilized for particularly in the maintenance and repair industry and considered as dominant method for construction of steel structures and also industrial fabrication. In recent years, once a new method, namely flux-cored arc welding (FCAW) had been initiated, SMAW has been relatively degenerated and become widespread used in industrial environments [28]. However, due to the low-cost equipment and extensive applicability, the SMAW is still considered as widespread method and more suitable for amateurs and small businesses.
1.2 Problem statement
In fact, the welding process is influenced by the bead geometry which consists of bead height and bead width which are essential physical properties of a weldment. Bradstreet [6] reported that weld cross-sectional area and the arc travel rate are vital parameters on the welding process and could be utilized to predict the cooling rate of a weld. The total shrinkage while cooling is prejudiced by the dimensional properties of the bead cross-sectional area, which determines largely the residual stresses and thus the distortion. Cary [7] refers to two types of penetration which is weld penetration (fusion) and heat penetration. In fusion welding, the depth of weld penetration or fusion is generally recognized as the distance below the original surface of the work to which the molten metal progresses. According to Singh et al. [29], there are different input parameters before starting the welding process which is generally selected by the professional welders and professional engineers due to their expertise and working experience. However, the selection procedure is still performed by trial and error technique. After performing particular trial, the welds should be investigated in order to examine the welding performance to figure out whether it fulfils the joint requirement or there is a need to change the input again. This kind of way is taking time, money, and effort [21].
By developing a mathematical model, a prediction can be made to produce the desired response factor. The successfulness of the SMAW is measured by detecting the value of weld bead. Indeed, with the expertise of the professional welders, the most significant input parameters that have a vital influence on the performance of SMAW process are welding current, welding voltage and welding speed. The operative range of input parameters should be decided according to the exterior appearance of weld bead by visual inspection such as smooth-continuous bead, nonappearance of faults and undercut. Actually, it is essential to reflect and utilize all the welding process parameters while reviewing and understanding the characteristics of the welding performance. It should be noticed that different welding conditions would result in difference significant characteristics of welding. Modeling such interrelationship between the inputs and the outputs is very difficult and time-consuming to be developed numerically.
Radial basis function neural network (RBF-NN)-based approaches could be used to figure out the interrelationship between several input–output variables and to model and predict any patterns that extracted and obtained from different conditions of the experiments. RBF-NN is a type of artificial neural network ANN’s methods. In the recent years, the applications of RBF-NN model have been widely used in several engineering pattern recognition problems and its ability has been proved for most of these applications. There are several advantages of the RBF-NN that make it as one of the first choice for researchers to use for any further prediction applications in engineering. The fact that RBF-NN model is simply to structure and its capability to mimic the input–output pattern and time consumption for training and avoiding the local minimum lead the researchers to utilize it in several applications, Singh et al. [29].
1.3 Objective
The main objective of this study is to investigate the potential of utilizing artificial intelligence techniques (AIT), namely RBF-NN and multilayer perceptron neural network (MLP-NN) to predict the welding features. In more details, this study proposed two different AIT models with supervised learning which have been utilized to predict the bead geometry and depth of penetration affected zone for different welding conditions. In the top of that, the study has been extended to examine and evaluate how sensitive each input parameter on the accuracy level of the targeted output.
2 Methods and materials
2.1 Experimental work
In order to investigate the weld characteristics, weld bead was obtained by welding two ABS marine grade-A mild steel plates of (190 × 80 × 6) mm dimensions. A square butt edge joint and flat position (1G) welder technique was selected. Mild steel plate was chosen as a sample to be welded because it is the most common form of steel as its price is relatively low while it provides material properties which are acceptable for many applications.
Weld bead geometry which includes bead height and bead width is important physical property of weldment. Since the weld bead quality depends more on the input process parameters, it is essential to study the effects of input process parameters on weld quality. Among the input process parameters are welding speed, welding current, arc length, joint gap and electrode diameter which were considered as significant parameters in SMAW process [17, 26], while output parameters were bead width, bead height and depth of penetrations shown in Fig. 1. Different combinations of input parameters were used to observe the effect on desired response. The working range was decided by inspecting the bead for smooth appearance and the absences of any visible defects. The upper limit of a factor was coded as (+1) and lower limit as (−1). Meanwhile, the normal limit (which is the working limit used by the welders in shipyard) was coded as (0). The selected process parameters with their limits and units are given in Table 1.

Weld bead geometry
The two-level full factorial design method was followed to create design matrix for this experiment. With two levels and five parameters, a total of 32 experiments were conducted. An addition set of experiment using level (0) was also carried out as a reference. A total of 33 combinations of input process parameters were considered in this study. In order to study the bead geometry, each welded sample was sectioned transversely. To get the macrostructure image, these sectioned beads were ground with emery papers and then polished with disk polishing machine. Etching was done with a mixture of 2 % nitric acid and 98 % ethyl alcohol solution. The average values of weld bead characteristic (as Fig. 2) were measured under optical microscope. The measurement of weld penetration, width and reinforcement was taken by using digital Vernier caliper. The image of weld bead is shown in Fig. 1.

Geometry of weld bead
2.2 Multilayer perceptron neural network (MLP-ANN)
Multilayer perceptron neural network (MLP-NN) is a feed-forward network that consists of a number of layers of neurons, with the output from each neuron propagating to the input of each neuron of the next layer. A MLP-NN is shown in Fig. 3. In MLP-NN, the nodes of the input layer just propagate the input values to the nodes of the first hidden layer [13, 14, 23]. The input–output relationship of each node of the hidden layers can be defined as follows:
where x j is the output from j node of the previous layer, w j is the weight of the connection between j node and the current node, b is the bias of the current node, and f is a nonlinear transfer function typically of the sigmoid form as presented in Eq. (2):
where z represents the weighted sum of the input to the neuron and f(z) is the neuron output. The input–output relationship of the output nodes is similar to that defined by Eq. (2), except that in case the network is utilized for function approximation, the function f can be a different type (e.g., linear function).

Multilayer perceptron neural network architecture
A MLP-NN architecture is based on units, which compute a nonlinear function of the scalar product of the input vector and weight vector. In general, the performance of MLP-NN models depends on the inherent architecture of the network. This does not only include the number of hidden layers and the number of neurons in each layer, but also the type of computation performed at each neuron.
2.3 Radial basis function neural network (RBF-NN)
The network model of the multilayer perceptron architecture is based on units, which compute a nonlinear function of the scalar product of the input vector and the weight vector. An alternative architecture of ANN is one in which the distance between the input vector and a certain prototype vector determines the activation of a hidden unit. This architecture is known as RBF-NN. RBF-NN is composed of receptive units (neurons) that act as the operator providing the information about the class to which the input signal belongs [1, 10, 11, 31].
RBF-NN gives an approximation of any input/output relationship as a linear combination of the radial basis functions (RBF). RBFs are a special class of functions with their characteristic feature that their response decreases (or increases) monotonically with distance from a central point. Although the architectural view of a RBF-NN is very similar to that of a multilayer perceptron network, the hidden neurons possess basis functions to characterize the partitions of the input space. Each neuron in the hidden layer provides a degree of membership value for the input pattern with respect to the basis vector of the respective hidden unit itself. The output layer is comprised of linear neurons [8].
The structure of a RBF-NN consists of an input layer, one hidden layer and an output layer, see Fig. 4. The input layer connects the inputs to the network. The hidden layer applies a nonlinear transformation from the input space to the hidden space. The output layer applies a linear transformation from the hidden space to the output space. The radial basis functions φ 1, φ 2, …, φ N are known as hidden functions while \(\{ \varphi_{i} (X)\}_{i}^{N}\) is called the hidden space. The number of basis functions (N) is typically less than the number of data points available for the input data set. Among several radial basis functions, the most commonly used is the Gaussian, which in its one-dimensional representation takes the following form:
where μ is the center of the Gaussian function (mean value of x) and d is the distance (radius) from the center of φ(x, μ), which gives a measure of the spread of the Gaussian curve. The hidden units use the radial basis function. If a Gaussian function is used, the output of each hidden unit depends on the distance of the input x from the center μ.

Architecture of radial basis function neural network
During the training procedure, the center μ and the spread d are the parameters to be determined. It can be deduced from the Gaussian radial function that a hidden unit is more sensitive to data points near the center. This sensitivity can be tuned (adjusted) by controlling the spread d. Figure 5 shows an example of a Gaussian radial function. It can be observed that the larger the spread, the less the sensitivity of the radial basis function to the input data. The number of radial basis functions inside the hidden layer depends on the complexity of the mapping to be modeled and not on the size of the data set, which is the case when utilizing multilayer perceptron ANN. The unique architecture of RBF-NNs makes their training procedure substantially faster than the methods used to train multilayer perceptron ANN. The interpretation given to the hidden units of RBF-NN leads to a two-stage training procedure. In the first stage, the parameters governing the basis functions (μ and d) are determined using fast un-supervised training methods that utilize only the input data. The second stage involves the determination of the output layer weight vector w j . Since these weights are defined in a linear problem, the second stage of training is also fast. It should be highlighted that the basis functions are kept fixed while the weights of the output layer are computed. Several learning algorithms have been proposed for training RBF-NN, and they can be reviewed in [9].

Radial basis function with different levels of spread. a Normal spread, b small spread, c large spread
The advantages of Using RBF-NN are:
-
1.
MLP-NN can have many layers of weights with a relatively complex pattern of connectivity. Several activation functions can be used within the same network. However, RBF-NN has a more simple architecture that consists of two layers of weights in which the first layer contains the parameters of the basis functions and the second layer forms linear combinations of these basis functions to generate water quality parameter in the output. The unique architecture of the RBF-NN has the advantage of a fast training procedure when compared to multilayer perceptron ANN.
-
2.
The parameters of the multilayer perceptron ANN (biases and weights) are determined simultaneously during the training procedure with supervised training techniques. On the other hand, RBF-NN is typically trained in two stages with the parameters of the basis functions being first determined by unsupervised learning techniques using the input data alone. The weights at the second layer are found by fast linear supervised methods.
-
3.
The interference and cross-coupling between the different hidden units of a multilayer perceptron ANN may result in a highly nonlinear training process in addition to problems of local minima. This can lead to very slow convergence even with advanced optimization strategies. By contrast, RBF-NN would not face this problem due to their localized basis functions, which are local with respect to the input space. Thus, for a given input vector, only a few hidden units will have significant activation.
2.3.1 Select appropriate inputs
One of the major steps in developing AIT model for any engineering application is to select the appropriate input variables. In fact, the effective and efficient structure of the AIT model basically depends on how strong the interrelationship between the input variable and pattern on the desired output variable is [2, 4, 12, 18, 24]. The most widely procedure for betterment selection of the input variable is based pre-statistical analysis for input–output patterns [22], whereas the close values of correlation between particular input variable and the output to 1 are chosen for the best accuracy level to predict the output. The drawback of cross-correlation is its weakness to detect the nonlinearity interrelationship between the input variable and the targeted output. The fact that cross-correction could distinguish the linear component of the input–output relation. Consequently, relying only on the cross-correlation analysis could lead to neglect important input parameters that have highly nonlinear relation with output parameter and then has a vital influence on the performance of the model. Two different preprocessing methods have been used to examine the effect of input parameters on the model performance. First, a priori knowledge [3, 27, 29] is supported by statistical correlation analysis [9]. On the other hand, the second method is the assessment process based on the level of prediction accuracy of the desired output variables.
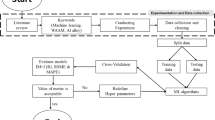
In the light of previous research, the available monitored values and pre-statistical analyses, the following five input variables have been selected for the AIT modeling in this study, namely current, arc length, speed, diameter and gap. Table 2 shows the input parameters used in this study. On the other hand, the study focused on important three output variables on the welding process, namely penetration, width and reinforcement. Table 3 shows the output parameter of this study. The optimal AIT model and a model general procedure (flowchart) including the position of the input variable, the algorithm-based selection for the model performance for the output variables accuracy are illustrated in Fig. 5.
There are two different approaches which have been acclaimed by many researches in order to determine the optimal parameters for learning process. The first approach by Benyounis and Olabi [5] utilized particular optimization algorithm such as Genetic algorithm, while [16] suggested trial and error procedure to tackle such process. Actually, it was reported that utilizing the optimization algorithm with AIT methods has the drawback of being computationally extension [9], especially in case the application experienced high nonlinearity behavior. Therefore, in this study it was preferable to use trial and error approach due to its advantage of yielding the desired accuracy of the model in low time consumption while training. In addition, the trial and error procedure outperformed the optimization approach due to its potential of having lower probability of over fitting the training data set.
2.3.2 Data preprocessing
Inputs data are generally on widely different scale. Therefore, all the data must be normalized to get an equivalent data. All data need to divide with the highest value of every part of input parameter. The range is between −1 and 1.
2.3.3 Model performance indicators
In general, one of the important steps in developing prediction model is to evaluate its performance throughout examining model performance indicators. The proposed prediction model for welding process would be examined utilizing three different statistical indexes. The first index is coefficient of efficiency (CE) which is usually used to examine the trend performance of the model. This index first has been introduced by Nash and Sutcliffe [25] as presented in Eq. (4).
where n is the number of (data set) observations, p and m are the predicted and monitored data, respectively, and \(\bar{m}\) is the average of monitored data (Fig. 6).

Optimal architecture of AIT and flowchart of algorithm procedure
The second index is the mean square error (MSE) which is used to determine how the proposed model output fits with the desired (actual output). Generally, the smaller the values of MSE mean, the model achieved well performance. It is defined as follows:
Finally, the third index is the coefficient of correlation (CC) which is often used to evaluate the linear relationship between the predicted and measured of data. It is defined as follows:
It is common practice to divide the available data into subsets which is a training set and testing set. For this, researcher suggested that the length of data can be divided into 80 % for the training set and 20 % for the test set. Lastly, the stopping criteria of this study suggested that stopping after a certain number of runs through all of the training data. The training data should be stopped when the target error reaches some low level. Then, the values between actual and predicted were compared. The percentage of error was calculated. The model was accepted to be adequate if the percentage of error was still in the range of acceptance. In general, an error range of (5–35 %) was acceptable, (0–5 %) being exceptionally good and (over 35 %) means that the data were unreliable or chaotic. The scatter diagram between actual and predicted values was plotted. The pattern of their intersecting points could graphically show relationship patterns. The scatter diagram was used to prove or disprove cause and affect relationships. Using scatter diagram, we could observe the correlation between actual and predicted values. This further supported the validity of the model. Scatter diagram generally showed one of six possible correlations between the variables.
3 Result and discussion
3.1 Multilayer perceptron neural network (MLP-NN)
In this study, we use different transfer functions and different numbers of neurons. Other than that, we use the different input to compare the correlation between input parameter and output parameter.
This is the result that we get when we do for the different transfer functions on three output parameters. For penetration, the purelin transfer function shows the best performance between actual and predicted simulations. For reinforcement, the log-sigmoid transfer function shows the best performance between actual and predicted simulations. Lastly, again for the bead width, the best performance falls to purelin transfer function. That means the purelin transfer function is the best for prediction of weld bead geometry in shielded arc welding using artificial neural network.
First, we select the proper input parameter that we should use for this project. To gain the lowest MSE and the best performance, we should normalize the value of the input welding parameter. The range value between each parameter is 0 and 1. According to Table 4, for the depth of penetration, the best R value is 0.96967 and the MSE is 0.008786 while for bead width, the best R is 0.96478 and the MSE is 0.0006262. Lastly, for the reinforcement, the best R is 0.96884 and the MSE is 0.006792.
Table 5 shows the best number of neurons for penetration is 10, while the best number of neurons for reinforcement is 6 and lastly the best number of neurons for bead width is 2. Other than that, we compare the best performance of different input parameters with the three output parameters. So, the result that we get for the 5 input produces the best performance among three outputs which have depth of penetration (0.96967), bead width (0.96884) and reinforcement (0.96478) (Tables 6, 7; Figs. 7, 8).

Value for three outputs with the different numbers of neurons

Mean square error of the different input for three outputs
3.2 Radial basis function neural network (RBF-NN)
In this study, the predictions use five different internal parameters of spread constant as shown in Table 8. These spread constants are suggested by many researchers. For each output parameter which is penetration, width and reinforcement will be train at every spread constant.
Reaching the optimized solution was achieved by applying several trial and error processes in which the internal parameters of RBF-NN were adjusted to attain the optimal values to reach the near optimal result that provides the lowest error. Then, the relationship between spread constant and MSE is compared between five different spread constants. Table 9 shows the result of comparison between MSE and spread constant (Fig. 9).

Scatter diagram of MLP-NN
From the Table 9, it shown that the best result for the penetration (P) is 1.0 of spread constant. Next for the width (W), the best result has shown from the 1.0 of spread constant too. Lastly, the best result for reinforcement is 2.0 of spread constant. The best results indicated the lowest MSE of the prediction result which is close to zero. A scatter diagrams are the visual presentation of two different variables (in our study, the model output vs. the actual data) in order to examine the trend and interrelationships between two variables. In this study, the variable on x-axis was the actual value. Meanwhile, the variable on y-axis was the predicted value. In this way, visualizing the pattern of their intersecting points might graphically provide information about how strong or weak relationship between both patterns is. The scatter diagram was used to prove or disprove cause and effect relationship. On the top of that, using scatter diagram, we could observe the correlation between actual and predicted values. This further supported the validity of the model. The scatter diagram between predicted and actual values of penetration, width and reinforcement is shown in Fig. 10. Based on the graph, we could categorize the correlation between actual and predicted values of penetration model as strong positive correlation. The value of CC, R for penetration is close to 1 which is 0.95, for width is 0.96 and for reinforcement 0.97. The percentage of error for this graph shown is within 10 %.

Scatter diagram of RBF-N
Sensitivity analysis is the study of how the uncertainty in the output of a mathematical model can be apportioned to different sources of uncertainty in its inputs. Therefore, in this study, the five different variables of four input parameters are tested for the sensitivity of the model as shown in Fig. 11. Firstly, ASDG which is used arc length parameter, speed parameter, diameter parameter and gap parameters. The correlation of ASDG is below than 0.9. Secondly, CADG model is developed based on four input parameters, namely; current parameter, arc length parameter, diameter parameter and gap parameter. The correlation of CADG is below than 0.9. Next, CASD is used current parameter, arc length parameter, speed parameter and diameter parameter. The correlation of CASD is below than 0.9. Then, CASG is used current parameter, arc length parameter, speed parameter and gap parameter. The correlation of CASG is below than 0.8. Lastly, CSDG is used current parameter, speed parameter, diameter parameter and gap parameter. The correlation of CSDG is below than 0.9. The best value of correlation is used for five input parameter which is among all the parameters. The correlation is close to 1 (Table 10).

Sensitivity analysis of the model
4 Conclusion
The procedure proposed in this research was implemented in order to optimize the prediction model for weld bead geometry in SMAW process. Since, the interrelationships between features of the weld bead geometry and welding output variables are nonlinear and complicated; an artificial intelligent technique (AIT)-based model has been employed to model such process. Two different AIT models have been developed, namely MLP-NN and RBF-NN. RBF-NN used for modeling the weld bead geometry and penetration and the analysis carried out for this confirm that RBF-NN is powerful tool for analysis and modeling. Comparisons were made between actual and prediction values, in term of accuracy in prediction of the outputs for the test cases. The best prediction of penetration and width is from spread constant 1.0; meanwhile, the best of prediction for the reinforcement is 2.0. Scatter diagram between actual and predicted values was plotted. The percentage of error for each model was 10 % for penetration, width and reinforcement. The results indicate that RBF-NN was able to achieve a high level of accuracy in simulating the weld geometry and very satisfactorily to predict all parameters in comparison with the MLP-NN model.
References
Acosta FMA (1995) Radial basis function and related models: an overview. Signal Process 45:37–58
Akrami SA et al (2014) Rainfall data analyzing using moving average (MA) model and wavelet multi-resolution intelligent model for noise evaluation to improve the forecasting accuracy. Neural Comput Appl 25(7–8):1853–1861
Al-Faruk A, Hasib MDA, Ahmed N, Kumar Das U (2014) Prediction of weld bead geometry and penetration on electric arc welding using artificial neural networks. Int J Mech Mech Eng IJMME-IJENS 10(4):19–23
Baymani M, Effati S, Niazmand H, Kerayechian A (2015) Artificial neural network method for solving the Navier–Stokes equations. Neural Comput Appl 26(4):765–773
Benyounis KY, Olabi AG (2008) Optimization of different processes using statistical and numerical approaches—a reference guide. Adv Eng Softw 39:483–496
Bradstreet BJ (1969) Effect of welding conditions on cooling rate and hardness in the heat affected zone. Weld J Am Weld Soc 48(11):499-S–504-S
Cary H (1988) Welding technology, 2nd edn. Prentice Hall, Upper Saddle River
Cowper MR, Mulgrew B, Unsworth CP (2002) Nonlinear prediction of chaotic signals using a normalized radial basis function network. Signal Process 82:775–789
El-Shafie A, Abdelazim T, Noureldin A (2010) Neural network modeling of time-dependent creep deformations in masonry structures. Neural Comput Appl 19(4):583–594
El-Shafie A, Najah A, Karim OA (2014) Amplified wavelet-ANFIS-based model for GPS/INS integration to enhance vehicular navigation system. Neural Comput Appl 24(7–8):1905–1916
Elzwayie A et al (2016) RBFNN-based model for heavy metal prediction for different climatic and pollution conditions. Neural Comput Appl 1–13. doi:10.1007/s00521-015-2174-7
Fayaed SS, El-Shafie A, Jaafar O (2013) Adaptive neuro-fuzzy inference system-based model for elevation–surface area–storage interrelationships. Neural Comput Appl 22(5):987–998
Hossain MS, El-Shafie A (2014) Evolutionary techniques versus swarm intelligences: application in reservoir release optimization. Neural Comput Appl 24(7–8):1583–1594
Hossain MS, El-shafie A (2014) Performance analysis of artificial bee colony (ABC) algorithm in optimizing release policy of Aswan High Dam. Neural Comput Appl 24(5):1199–1206
Khanna OP (2006) A text book of welding technology. Dhanpat Rai Publications Ltd., Delhi
Kim DW, Kim KH, Jang W, Frank Chen F (2002) Unrelated parallel machines scheduling with setup times using simulated annealing. Robot Comput Integr Manuf 18(3–4):223–231
Kolahan F, Heidari M (2010) A new approach for predicting and optimizing weld bead geometry in GMAW. Int J Mech Syst Sci Eng 2(2):138–142
Kostić S, Vasović D (2015) Prediction model for compressive strength of basic concrete mixture using artificial neural networks. Neural Comput Appl 26(5):1005–1024
Kumar A, Chauhan V, Bist AS (2013) Role of artificial neural network in welding technology: a survey. Int J Comput Appl 67(1):32–37
Mollah AA, Pratihar DK (2007) Modeling of TIG welding and abrasive flow machining processes using radial basis function networks. Int J Adv Manuf Technol (2008) 37:937–952
Nagesh DS, Datta GL (2002) Prediction of weld geometry and penetration in shielded metal-arc welding using artificial neural networks. J Mater Process Technol 123:303–312
Najah A, El-Shafie A, Karim OA, Jaafar O (2011) Integrated versus isolated scenario for prediction dissolved oxygen at progression of water quality monitoring stations. Hydrol Earth Syst Sci 15:2693–2708
Najah AA, El-Shafie A, Karim OA, Jaafar O (2012) Water quality prediction model utilizing integrated wavelet-ANFIS model with cross-validation. Neural Comput Appl 21(5):833–841
Najah A et al (2013) Application of artificial neural networks for water quality prediction. Neural Comput Appl 22(SUPPL.1):187–201
Nash JE, Sutcliffe JV (1970) River flow forecasting through conceptual model. Part 1—A discussion of principles. J Hydrol 10:282–290
Pal S, Pal SK, Samantaray AK (2008) Artificial neural network modeling of weld joint strength prediction of a pulsed metal inert gas welding process using arc signals. J Mater Process Technol 202:464–474
Palani PK, Murugan N (2007) Optimization of weld bead geometry for stainless steel claddings deposited by FCAW. J Mater Process Technol 190:291–299
Shi Y, Zheng Z, Huang J (2013) Sensitivity model for prediction of bead geometry in underwater wet flux cored arc welding. Trans Nonferr Met Soc China 23:1977–1984
Singh RP, Gupta RC, Sarkar SC (2012) Prediction of weld bead geometry in shielded metal arc welding under external magnetic field using artificial neural networks. Int J Manuf Technol Res 8(1):9–15
Talib F, Rahman Z (2010) Critical success factors of total quality management in service organization: a proposed model. Serv Mark Q 31(3):363–380
Yaseen ZM et al (2015) RBFNN versus FFNN for daily river flow forecasting at Johor River. Malaysia, Neural Comput Appl
Yousif YK, Daws DM, Kazem BI (2008) Prediction of friction stir welding characteristic using neural network. Jordan J Mater Ind Eng 2(3):151–155
Acknowledgments
This research was supported by the research Grant for the four authors from University Kebangsaan Malaysia DLP-2015-012.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ahmed, A.N., Noor, C.W.M., Allawi, M.F. et al. RBF-NN-based model for prediction of weld bead geometry in Shielded Metal Arc Welding (SMAW). Neural Comput & Applic 29, 889–899 (2018). https://doi.org/10.1007/s00521-016-2496-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2496-0