
Abstract
The Decision-making Trial and Evaluation Laboratory (DEMATEL) has widespread application in many fields as a system analysis method to explain the relationship between the risk factors in a system. By analyzing the influence relationship and degree of influence among risk factors, DEMATEL can determine their importance and priority. One characteristic of DEMATEL is that expert experience and knowledge should be fully considered. However, in practical applications, there are great uncertainties in the evaluation process because of the differences in experts’ historical experiences and subjective opinions. To address this issue, an improved fuzzy evidential DEMATEL method based on the two-dimensional correlation coefficient (2-DCC) and negation of basic probability assignment (BPA) is proposed in this paper. The new method uses 2-DCC to calculate the correlation between different expert evaluations in horizontal and vertical directions to get an overall correlation r and converts it into the macro-credibility and weight of experts. Then, to construct BPA according to the fuzzy evaluations, the total uncertainty (TU) measure and negation of BPA under the framework of evidence theory are used to deal with the uncertainty of evaluation, and then, the evaluations will be weighted and fused. Finally, the DEMATEL method is used to calculate the comprehensive influence matrix, and the importance of each risk factor is calculated. Two applications well verified the effectiveness of our method.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Risk management and control is always a problem that must be valued by managers (Abeysekara 2020). In order to minimize the impact of an accident, managers should evaluate the risks that exist in the system in advance, identify their priorities, and manage them effectively with limited resources so as to prevent accidents or reduce the harm caused by accidents. The issue of risk evaluation covers many fields. For example, in software programs, managers need to consider factors such as project schedules and the technical capabilities of employees (Tavares etal. 2019). In the medical field, the incidence of disease and mortality need to be considered (Altuntas and Gok 2021; Chauhan etal. 2021). In terms of food safety, technical and institutional risks should be considered (Choirun etal. 2020). In addition, when some major natural disasters occur, such as earthquakes (Trivedi 2018) and floods (Zheng et al. 2022), the causes and distribution areas need to be considered and analyzed, so as to reduce losses.
The existing risk evaluation methods mainly list the potential risks according to historical experience in the initial stage, and then, experts give their evaluations, analyzing the importance of these factors from multiple perspectives. For example, failure mode and effect analysis (FMEA) considers the probability, severity, and detection of risk factors (Zhongyi et al. 2021). Fault tree analysis (FTA) considers the causal relationship between factors (Yazdi et al. 2019). The analytic hierarchy process (AHP) identifies the levels of factors and determines the relationship between these levels (Kokangül et al. 2017). Some studies also use Bayesian networks (George and Renjith 2021) and petri nets (Zhang etal. 2020) to evaluate the risk. However, these methods do not consider the influencing relationship between risk factors. In practical applications, it is necessary to consider the internal relationship between factors; the ability to influence other factors and be affected by other factors can represent the importance of factors in the system to a certain extent. In terms of this issue, the DEMATEL method can analyze the importance of factors with their relationship to each other. The DEMATEL method has been used in many fields, such as the economy (Gang et al. 2021; Abraham et al. 2019), blockchain technology (Yadav and Singh 2020; Kouhizadeh et al. 2021; Kamble et al. 2020), and especially in the last 2 years in the control of coronavirus disease 2019 (COVID-19) (Tanvir et al. 2021; Ocampo and Yamagishi 2020), where it has played a huge role. In addition to making up for the defects of other methods, the DEMATEL method also has the advantage that it can be well combined with other theories and methods, such as gray theory (Raj etal. 2020; Kumar et al. 2021; Amirghodsi etal. 2020), evidence theory (Li et al. 2014; Yuan-Wei and Zhou 2019; Shang et al. 2020), and fuzzy theory (Chuanbo et al. 2020; Asan et al. 2018; Feng and Ma 2020). In order to better represent the fuzziness of expert evaluation language, more and more research has combined fuzzy set theory with DEMATEL. Among them, (Asan et al. 2018) proposed a DEMATEL method based on interval-valued hesitant fuzzy sets, which considers artificial uncertainty in the evaluation process and retains the differences among experts. Pandey et al. (2019) proposed a DEMATEL method that combines interval 2-type fuzzy numbers (IT2FS-DEMATEL), which combines triangular fuzzy numbers and trapezoidal fuzzy numbers. In this way, imprecise and ambiguous evaluations can be significantly avoided. These methods based on fuzzy sets need to defuzzify the expert evaluation, and this process tends to average the differences among the evaluations, which cannot effectively deal with the uncertainty generated in the evaluation process. To solve this problem, there are more and more studies on the improvement of DEMATEL based on evidence theory (Evidential-DEMATEL). Evidential-DEMATEL (Li et al. 2014) method converts the fuzzy evaluations to basic probability assignment(BPA), thus avoiding defuzzification. At the same time, the Dempster–Shafer combination rule is used to integrate group decision-making. On this basis, Yuan-Wei and Zhou (2019) used evidence theory to extract the subjectivity of experts in evaluation and proposed a DEMATEL method based on subjective experience and objective data. Shang et al. (2020) used belief entropy to calculate the reliability of evaluations. A reliability coefficient is added to each fused BPA to make the fused results more reasonable. In addition, Lin et al. (2018) extended DEMATEL to D-number theory to overcome the limitation that language evaluation by experts must be mutually exclusive. Since D-number allows information to be missing and incomplete, the improved D-DEMATEL is more suitable for language evaluation. But this method is less effective when there is too much missing information. Jiang et al. (2020) used Z numbers to represent expert evaluation information more flexibly and accurately and used a similarity measure-based method to cluster experts, which effectively dealt with uncertainty in the evaluation process. However, in practical application, the scale of expert groups would not be too large, and the application of this method would be limited. Another trend in the DEMATEL method is the hybrid application of multiple methods. For example, Mohammed et al. (2021) proposed a hybrid method of DEMATEL and TOPSIS that used DEMATEL to quantify the weight of evaluation criteria and the TOPSIS method to provide optimal decisions for decision-makers. Das et al. (2022) used AHP and DEMATEL to analyze the key factors affecting the global supply chain during the outbreak of COVID-19, aiming to help decision-makers develop a risk mitigation framework. There is no doubt that this hybrid multi-method technique can combine the advantages of each method and make the results closer to reality.
In the real world, in order to get more accurate evaluation information, an expert evaluation team is often set up to develop a joint evaluation plan. Due to the differences in historical experience and subjective opinions, their evaluations are not exactly the same, sometimes even contradictory. Therefore, it is necessary to consider the credibility of each expert when accepting their programs. Yazdi et al. (2020) improved DEMATEL by using the Best-Worst method (BWM) to obtain the evaluation criteria and the weight of experts. However, they ignore the impact of expert opinion differences. Chen et al. (2020) introduced belief entropy to measure the amount of information in evaluations and calculated the weight of experts. In order to improve the existing DEMATEL method more effectively, this paper mainly makes improvements to the following two issues:
-
1.
How to effectively measure the credibility and weight of experts?
-
2.
How to deal with uncertainty arising from the evaluation process?
In response to the two issues, we introduce the two-dimensional correlation coefficient (2-DCC) and the negation of BPA on the basis of fuzzy evidential DEMATEL. As for the first issue, the new method uses 2-DCC and the total uncertainty measure (TU) to calculate expert weights from macroscopic and microscopic perspectives, respectively. The 2-DCC has been able to measure the correlation of two matrices (Dikbaş 2017), and some research about the 2-DCC has been applied in environmental monitoring in recent years (Li et al. 2019; DİKBAŞ and BACANLI 2020; Yasar and Dikbas 2022). Compared with other DEMATEL methods, the new method not only considers the differences between the overall evaluations of experts but also the differences between each piece of evaluation, which can better express the credibility of each expert through the differences and is more in line with the actual situation. As for the second issue, the new method uses negation of BPA for weighted fusion to deal with the uncertainty of evaluation. Negation of BPA describes things from the negative perspective (Yager 2014), which can provide more valuable information. In recent years, many studies have focused on the properties and applications of negation of BPA. Mao and Deng (2022) proposed a calculated method of negation of BPA based on the belief interval and applied it in pattern recognition. Yin et al. (2018) proposed a new negation of BPA calculating method and, on this basis, a new uncertainty of BPA measuring method. Dongdong et al. (2020) proposed a new weighted average evidence calculation method using the negation of BPA and applied it to classification problems. Tang et al. (2022) proposed a method of measuring and managing the uncertainty in the negation information of evidence. In general, negation of BPA is becoming a useful tool to deal with conflicts between evidence. The main contribution of this paper is that we first propose to combine macro and total uncertainty to determine the credibility of expert evaluations. This provides a new idea and method to deal with the uncertainty of expert evaluation in DEMATEL.
The rest of this paper is organized as follows: Sect. 2 reviews the theoretical basis of this paper. In Sect. 3, on the basis of the existing fuzzy evidential DEMATEL method, a DEMATEL method based on 2-DCC and negation of BPA is proposed. Then, in Sect. 4, two case studies are used to verify the application of the proposed method. Finally, Sect. 5 is a summary of the content of this paper.
2 Preliminaries
2.1 Evidence theory
Evidence theory is a generalization of the Bayesian theory proposed by Professor Dempster in 1976 and improved by Shafer. Compared with traditional probability theory, evidence theory can effectively represent uncertain information. The relevant definitions are as follows:
Definition 1
Supposing \(\Omega =\lbrace \theta _1,\theta _2,\ldots ,\theta _n\rbrace \) is a set of mutually exclusive events, the elements of \(\Omega \) correspond to all possible events in a fixed scenario, and their probabilities of occurrence do not affect each other, so \(\Omega \) is called the frame of discernment (FOD). The set of all subsets of \(\Omega \) is called the power set of \(\Omega \), be denoted as \(2^\Omega \).
where \(\varnothing \) is empty set, The elements in \(2^\Omega \) are called propositions, and every proposition has a meaning.
Definition 2
Mass function represents the mapping relationship between the elements of \(2^\Omega \) and the interval \(\left[ 0,1\right] \), defined as follows:
This mapping is usually defined as a probability and satisfies the following conditions:
if m(A)>0, then A is called the focal element, and it indicates the extent to which the evidence supports A.
Definition 3
A set of mass function of the elements in \(2^\Omega \) is called as body of evidence(BOE), also called as the basic probability assignment (BPA), and BPA is defined as follows:
where \(\Re \) is a subset of \(2^\Omega \).
Definition 4
Belief function represents the lower limit of a proposition, For proposition A, the belief function is defined as follows:
Plausibility function represents the upper limit of a proposition, defined as follows:
Definition 5
Under the frame of evidence theory, two BPAs can be combined by Dempster–Shafer combination rule to obtain a new BPA. Supposing \(m_1\) and \(m_2\) are two BPAs in FOD, B and C are focal elements of \(m_1\) and \(m_2\), respectively. The combination rule is defined as follows:
where k is called as conflict coefficient and represents the degree of conflict between two BPAs, defined as follows:
2.2 Total uncertainty measure
There is always uncertainty in the real world (Zhang et al. 2018, 2017). There are many methods for measuring uncertainty under evidence theory (Wang and Song 2018; Deng 2020; Tang et al. 2023). The total uncertainty measure combines discord and non-specificity and gives rise to many uncertainty measures, such as entropy (Gao et al. 2019; Deng 2016), ambiguity measure (Jousselme et al. 2006), and Hartley measure (Pan et al. 2019). Among them, the most widely used method of measuring total uncertainty by Pal et al. (1992) is defined as follows:
Definition 6
where \(|x |\) represents the element’s cardinality. H(m) can be seen as the extension of Shannon entropy, which considers the cardinality of each element on the basis of Shannon entropy, and allocates the uncertainty contained in multi-element propositions. It also satisfies the properties of subadditivity, additivity, and continuity (Pal et al. 1993).
2.3 Negation of basic probability assignment
Yager proposed the negation of the probability distribution, redistributing the probabilities on the basis of the original probability distribution from the standpoint of negation (Yager 2014).
Definition 7
Supposing \(m=\lbrace m(A_1),m(A_2),\ldots ,m(A_n)\rbrace \) is a BPA, the negation of m is defined as follows:
where n represents the number of focal elements in m, \(m(A_j)\) is the original probability, and \(m({\bar{A}}_i)\) satisfy the following conditions:
2.4 Two-Dimensional correlation coefficient (2-DCC)
Definition 8
Similar to the Pearson correlation coefficient, 2-DCC is capable of evaluating the correlation of two matrices. By measuring the differences between matrices in the horizontal and vertical directions, it determines the horizontal correlation coefficient rh and the vertical correlation coefficient rv. In the horizontal direction, rh is assessed by computing the differences between the matrix elements and the row average, as in Eq. 12. In the vertical direction, rv is assessed by computing the differences between the matrix elements and the column average, as in Eq. 13 (Dikbaş 2017):
where m and n represent the row and column of matrices, respectively. \({\bar{A}}_m\) and \({\bar{B}}_m\) represent the mth row average of A and B, respectively. \({\bar{A}}_n\) and \({\bar{B}}_n\) represent the nth column average of A and B, respectively. rh and rv are in the range of \([-1,1]\). If rh or rv is closer to -1, it indicates a poorer correlation between the two matrices in either the horizontal or vertical direction, and if rh or rv is closer to 1, it indicates a stronger correlation between the two matrices in either direction. In this paper, in order to use the correlation between matrices to computing the support of matrices, to computing the weight of matrices, we average the rh and rv to get the overall correlation r, as in Eq. 14. It is simple to demonstrate that r is in the interval \([-1,1]\), which may affect the calculation of weights when \(r<0\). We have two explanations for this issue:
-
1.
In the DEMATEL method, the expert evaluation matrices, while varied, are not generally the opposite. So the correlation between them is greater than 0 in the vast majority.
-
2.
If we force the range of r to [0, 1], the difference between the correlations of matrices will be changed, and this will make the result inaccurate.
2.5 Intuitionistic fuzzy set
Definition 9
For a given domain of discourse X, the Intuitionistic fuzzy set on X is denoted as A (Atanassov 2016).
where \(\mu _A(x)\) and \(\nu _A(x)\) are all a mapping to \(\left[ 0,1\right] \), which satisfy \(0\le \mu _A(x)+\nu _A(x)\le 1\), \(\mu _A(x)\) represents the degree of membership that x with respect to A, and \(\nu _A(x)\) represents the degree of non-membership that x with respect to A. For convenience, \(m=(\mu _A(x),\nu _A(x))\) is called as intuitionistic fuzzy number (IFN).
Definition 10
The score function can convert IFN into a real number and be used to evaluate the merits and demerits of IFNs (Zeshui 2007). The score function is defined as follows:
where \(S_A\in \left[ -1,1\right] \); if \(S_A\le S_B\), then IFN B is better than IFN A.
2.6 Decision-making trial and evaluation laboratory (DEMATEL)
The Decision Laboratory Analysis (DEMATEL) method was first proposed by A. Gabus and E. Fontela at a conference in Geneva in 1971. This method uses graph theory and matrix theory to analyze the influence relationships of each factor in the system. According to the analysis results, the key factors in the system are defined so as to implement effective risk management and control. The steps of the traditional DEMATEL method are as follows:
Step 1: The direct relation matrix (DRM) is defined according to the influence relationship among the factors.
The influence relationship of each factor in the system can be represented by a directed graph, as shown in Fig. 1. Each vertex in the digraph represents a potential risk factor, directed edge represents the influence relationship between two factors, and the weight of directed edge represents the degree of influence. This digraph is converted into an adjacent matrix, which is called the direct relation matrix (Eq. 17). Due to the fuzziness of the influence relationship between factors, such as \(\lbrace \) no influence, weak influence, general influence, and great influence\(\rbrace \), the weight of edges can usually be expressed by different grades (from 0 to 4). It should be noted that if two vertices are not connected by a directed edge, the corresponding element in the adjacent matrix is 0, which is in contradiction with graph theory.

A weighted digraph representing the relationship of influence between factors
Step 2: Normalized DRM
The elements \(d_{ij}\) in DRM are converted into a mapping from \(d_{ij}\) to [0, 1]. There are many ways to normalize, but all of them are based on a maximum value. The common normalize method is defined as follows:
Step 3: Calculate the total relation matrix (TRM)
The elements \(N_{ij} \in [0,1]\), so as N multiplies itself, and the result goes to 0 indefinitely.
Each self-multiplication of N represents to increase the indirect influence of factors. The total relation matrix is the sum of the results of continuous self-multiplication of N, indicating the sum of all indirect effects.
where I represents identity matrix, N represents normalized matrix, and T represents total relation matrix.
Step 4: Analyze the importance of factors
Definition 11
Calculate the sum of the ith row of T, which represents the comprehensive influence value of the ith factor on other factors, denoted as \(R_i\), which is defined as follows:
Calculate the sum of the ith column of T, which represents the comprehensive influence value of other factors on the ith factor, denoted as Ci, which is defined as follows:
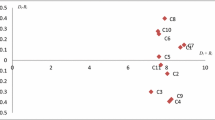
The value of \(R+C\) indicates the importance of the factor in the system, which is called centrality. The higher the value of \(R+C\), the stronger the correlation between the factor and other factors, which should be paid more attention to. The value of \(R-C\) is called causality, and it shows how much one factor affects another. If the \(R-C\) value of a factor is less than 0, it indicates that the factor is more affected by other factors, that is, the effect factor. If the value of \(R-C\) is greater than 0, it indicates that this factor will affect other factors, that is, cause factors. Risk factors can be defined by the relationship between \(R+C\) and \(R-C\), as in Fig. 2

The mapping between \(R+C\) and \(R-C\)
3 The improved fuzzy evidential DEMATEL based on 2-DCC and negation of BPA
This section will describe the flow of the new method in detail. The new method combines 2-DCC and total uncertainty to measure the weight, and the uncertainty and conflict will be dealt with by the weight average evidence that is obtained by negation of BPA. The general flow of this method is shown in Fig. 3. The detailed steps are as follows:

The flow of the improved DEMATEL method
Step 1: Determine the risk factors in the system and get evaluations from experts.
Step 1-1: The risk factors will be listed by managers and decision-makers according to historical experience.
Step 1-2: Construct a group of experts to evaluate the risk factors. In practice, the evaluations of experts tend to be fuzzy and cannot be represented by an exact number. The expert evaluations are denoted by IFNs in this paper. The common IFNs are shown in Table 1.
Step 2: Obtain the macro-weight of experts. The result of this step can be regarded as the macro-weights of the experts because it takes the differences between their overall evaluations as its basis.
Step 2-1: The IFNs matrix of experts is converted into a score matrix according to the score function.
Step 2-2: Calculate the correlation between each score matrix and the other score matrices by Eqs. 12–14, and the correlation coefficient matrix (CCM) is constructed as follows:
Step 2-3: The support of each expert is calculated based on CCM. The formula is as follows:
Step 2-4: Calculate the macro-weight.
Step 3: Calculate the micro-weight of evaluations according to the total uncertainty.
Step 3-1: Convert IFNs into BPAs.
Step 3-2: Calculate the negation of BPA with Eq. 10.
Step 3-3: Calculate the total uncertainty with Eq. 9.
Step 4: Weighted fuse evaluations
Step 4-1: Adjust the total credibility of evaluations on the basis of macro-weight and total uncertainty by Eq. 26. \(Wm_i\) is obtained by the differences of the overall evaluations, so \(Wm_i\) is the base number of Eq. 26.
Step 4-2: The evaluation credibility is normalized to obtain the comprehensive weight of the evaluation, as shown in Eq. 27.
Step 4-3: Calculate and fuse the weight average evidence (WAE).
Fuse WAE according to Eq. 7. If there are k experts, then perform \(k-1\) times fusion. The fused evaluation result is obtained.
Step 5: The DRM is constructed according to the fusion results, and the TRM is calculated by using the traditional DEMATEL method.
Step 5-1: Only a pair of comprehensive fusion evaluations among risk factors can be obtained by performing Step 4 once. So it is necessary to repeat Step 3 and Step 4 to calculate the comprehensive fusion evaluations among all factors and construct the DRM.
Step 5-2: Normalize the DRM.
Step 5-3: Calculate the TRM.
Step 5-4: Analyze the importance of risk factors. It should be noted that this method uses the negation of BPA to describe the evaluation from the negative perspective, so take the opposite number of the value of \(R-C\) as the result to determine risk factors.
4 Applications and discussion
4.1 Application in emergency management
In this section, an application in emergency management is used to verify the usability and effectiveness of the proposed method. The experiment defined some influencing factors in the emergency management system (Li et al. 2014), such as the “Well-planned emergency relief supply system” and “Reasonable organizational structure and clear awareness of responsibilities.” These factors have a mutual influence relationship. For example, “Well-planned emergency relief supply system” can promote “Applicable emergency response plan and regulations.” Through the new DEMATEL method to define the key factors in the system, the performance of the emergency management system can be effectively improved. The specific description is as follows:
Step 1: Based on the historical experience, the 10 existing risk factors in the system are listed, as shown in Table 2. And three experts were invited to evaluate the 10 risk factors and construct the IFN matrices such as Table 3. (The rest of the evaluation data could be found in Li et al. 2014.) Take the IFN (0.1, 0.9) from F1 to F3 in Table 3 as an example. This IFN under DEMATEL can be interpreted as the degree of membership of F1 directly related to F3 is 0.1 and the degree of non-membership of F1 directly related to F3 is 0.9.
Step 2: Turn the IFN matrices into the score matrices according to the score function of IFN. The result is shown in Table 4. According to the 2-DCC and overall correlation coefficient r, the correlation coefficient matrix between expert evaluations is constructed. And calculate the macro-weight of expert evaluations.
Correlation coefficient matrix:
Support degree of experts:
The macro-weight of experts:
Step 3: Convert the IFNs into BPAs. For example, the BPA construct by IFN (0.1,0.8) is: m(Y) = 0.1, m(N) = 0.8, m(Y, N) = 0.1, where m(Y) represents the probability that there is a direct relationship between factors, m(N) represents the probability that there is no direct relationship between factors, and m(Y, N) represents the uncertainty between m(Y) and m(N), and then weighted fuse the BPAs by total uncertainty and negation of BPA. Take the evaluations from F1 to F2 of the three experts as an example to demonstrate the calculation process.
The BPAs are construct as follows:
The negation of BPA:
The total uncertainty:
Step 4: Adjust the comprehensive weight by macro- and micro-weight, and construct WAE and fuse.
The comprehensive weight of BPA:
The weighted average evidence:
Fuse the WAE twice:
So far, we have obtained the fusion evaluation from F1 to F2 of three experts. Next, repeat Step 3 and Step 4 to obtain the fusion evaluation of all other factors, and construct the DRM. We can construct the DRM from positive (m(Y)) and negative (m(N)) (Tables 5 and 6)
Step 5: Calculate the TRM on the positive and negative sides, respectively (Tables 7 and 8), and analyze the importance of factors from the two perspectives. Tables 9 and 10 list the related indicators. Due to the negation of BPA, the value of \(R-C\) is negative.
“Positive” means that there is a direct relationship between two factors, so the value of \(R-C\) is higher when the risk is higher. As seen from Table 9, \(F9>F2>F6>F10>F5>F4>0\), which means that they affect other factors more than others, and define them as cause factors on the positive side. On the contrary, “negative” means that there is no direct relationship between two factors, so the value of \(R-C\) is smaller, the risk is higher. As seen from Table 10, \(F9<F2<F6<F10<F5<F4<0\), so they will be defined as cause factors on the side of negative. The results indicate that the causal factors defined by the two sides are the same.
4.2 Application in online shopping platform
In order to verify the usability of this method in the context of greater uncertainty and fuzzyness, we tested it with the application in online shopping platform. In online shopping, the customer may have some criteria when purchasing merchandise. These criteria are defined as influence factors that have an impact on the customer’s decision. And these criteria will be changed over time. We can determine which criteria have the greatest influence on customers’ decisions by analyzing the criteria of customers’ purchases in different periods through the new DEMATE. In this experiment, we suppose a customer has 12 criteria (factors) when he purchases a food item, they are calories (F1), fat (F2), sugar content (F3), packaging (F4),taste (F5), volume (F6), brand (F7), positioning (F8), advertising (F9), eating methods (F10), easy to cook or not (F11), nutrition or not (F12). And the relationships among the 12 influence factors were evaluated at three different periods in a day. The new DEMATEL was used to determine which factors had the most influence on the customer’s decision-making. Table 11 shows a portion of the detailed evaluations (Gao et al. 2021). The data are the fuzzy evaluation language in Table 1. It is clear that these data have more fuzzyness than the application in Sect. 4.1 because they are only divided into five levels. In addition, the conflict between the evaluations in application2 is even greater.
Due to space constraints, we will not demonstrate the specific calculation process. The results are shown below:
Figure 4 shows the result of the three periods and the fused result of this method. An analysis of the results of the three periods shows that the evaluations of three periods are conflicted (especially for F5, F6, and F10). According to the 2-DCC, the macro-weight of experts is \(Wm_1=0.3690\,Wm_2=0.3280\,Wm_3=0.3030\). So the fused result should be closer to the first expert. It follows that our results are reasonable.

The results of different periods and the fused result
4.3 Discussion
In order to better verify the ability of our method to identify risk factors, this part will discuss the effectiveness and accuracy of this method from several aspects by comparing it with other methods (E-DEMATEL Li et al. 2014, D-DEMATEL Zhou et al. 2017, and EFE-DEMATEL Han and Deng 2018). In order to be able to have a more intuitive comparison with other methods, we take the value of \(-(R-C)\) as the criterion in the positive side, and in negative side, we take the value of \(R-C\) as the criterion.
Figures 5 and 6 show the comparison of the value of \(R-C\) with other methods in its application to emergency management. It is obvious that the values of these methods are very close, which verifies the feasibility of our method. The ordered results are shown in Tables 12 and 13, which are roughly the same as with other methods. The highest risk factor in our method is F9, which is not the same as with other methods. As can be seen from Table 17, this is due to the consideration of macro-weights. However, the difference value between F2 and F9 is much smaller than the other methods, which are 0.0902 in the positive side and 0.216 in the negative side. In practice, managers tend to pay equal attention to factors with very similar \(R-C\) values, so our results are also reasonable. Regarding the determination of key risk factors, F9, F2, F6, F10, F5, and F4 were defined as key factors (causal factors) on both the positive and negative sides. Similar to the other methods, it shows the effectiveness of our method.

The comparison of \(R-C\) with other methods on the positive side

The comparison of \(R-C\) with other methods on the negative side
The comparison of the application in Sect. 4.2 is shown in Fig. 7. Among them, the classic DEMATEL fused the result by average values. The negation of BPA is a process of redistributing probabilities, which will make the probabilities average while preserving the differences between the BPAs and reducing the conflict between the BPAs. Furthermore, in cases of high conflict, the macro-weight is an important factor to consider. It is precisely because we take this factor into account and because the weight of the first period is the highest that our result curve is close to the result curve of the first period, which indicates the credibility of our result. Other methods ignore the differences in overall evaluations, and their results do not closely follow the curve of any period of time. So their results are not credible.

The comparison with other methods
Table 14 displays the ranking results for application 2. Due to the greater fuzzyness and conflict in the experimental data, the sorting results obtained by various methods are not the same. However, the F5 is defined as the highest risk factor, which is the same as other methods. And because we consider the expert macro-weight, several key factors (F1, F4, and F10) in the ranking will be different from other methods, which explains that our methodology further considers potential uncertainties and redefines new risk factors.
Han and Deng (2018) also proposed MAE to evaluate the processing ability of different methods under uncertainty and fuzzyness. MAE is defined as follows:
where N represents the number of risk factors, \(V_Y^i\) represents the value of \(R-C\) of factor i on the positive side, and \(V_N^i\) represents the value of \(R-C\) of factor i on the negative side. The MAE comparison with other methods is shown in Tables 15 and 16. That shows that the MAE of our proposed method is the largest in the two applications, indicating that our method can effectively deal with the uncertainty and fuzzyness in the evaluation process.
The biggest difference between our method and other methods is that we consider the differences between the overall evaluations of experts, and then, the macro-weight of the evaluation is determined. In order to better illustrate the impact of the difference in the overall evaluations of experts on the ordered results, we compared the results of this method with those of the method excluding macro-weight on the basis of Sect. 4.1. The ordered results are shown in Tables 17 and 18. Both the size of the \(R-C\) value and the order of factors are affected by the macro-weight, indicating that the difference between the overall evaluations of experts will have an impact on the result and should be taken into account in practice.
5 Conclusion
The DEMATEL method is widely used in practice in order to effectively control the potential risk factors in the system under the premise of limited resources so as to reduce the damage caused by accidents. But in practice, the evaluation is often inaccurate because of the fuzzyness and uncertainty of expert evaluation. Based on the existing fuzzy evidential DEMATEL method, this paper proposed an improved fuzzy evidential DEMATEL method based on 2-DCC and negation of BPA. The method evaluates the factors in the system with IFN and converts them into a score matrix using the score function of IFN, and the difference between the overall evaluations of experts will be measured by 2-DCC, which is introduced into the subsequent calculation. Then, BPA was modeled for the IFN, and the weighted average evidence was constructed and fused by combining the negation of BPA and total uncertainty. The DRM is constructed according to the fusion results, and risk factors with an \(R-C\) value greater than 0 are considered key factors in the system. This method can effectively identify the key factors in the system and improve the performance of the system.
Compared with other existing methods, the biggest contribution of this paper is to consider the differences between the overall evaluations of experts. Among them, the IFN score function can effectively measure the superiority and inferiority of IFN, and the 2-DCC can effectively measure the horizontal correlation and vertical correlation between matrices. Taking into account the differences in the overall evaluations of the experts will balance the impact of the differences in the evaluations and make the results more reliable. Secondly, the negation of BPA and total uncertainty are used to deal with the uncertainty of the expert evaluation, in which the total uncertainty can effectively quantify the uncertainty of the evaluation and the weighted average evidence obtained by negation of BPA is effectively applied to deal with the conflict between evaluations. Finally, the feasibility and superiority of this method are verified by two applications.
In future research, this method can also be applied to other uncertain fields, such as cost estimation and fault diagnosis. Considering differences in overall information and balancing their effects can make the results more accurate and realistic. In addition, due to the wide application of fuzzy sets, the two-dimensional correlation coefficient can be considered for the measurement of fuzzy numbers (Li and Wei 2020). In this way, the difference between fuzzy numbers can be measured on the premise of retaining the ambiguity of information, which is more consistent with its authenticity.
Data availability
All data generated or analyzed during this study are included in the article.
References
Abeysekara B (2020) Application of fuzzy set theory to evaluate large scale transport infrastructure risk assessment and application of best practices for risk management. In: 2020 IEEE international conference on industrial engineering and engineering management (IEEM). IEEE, pp 385–389
Abraham Z, Venkatesh Venkataswamy G, Yang L, Wan Ming Q, Ting HD (2019) Barriers to smart waste management for a circular economy in china. J Clean Product 240:118198
Altuntas F, Gok MS (2021) The effect of COVID-19 pandemic on domestic tourism: A DEMATEL method analysis on quarantine decisions. Int J Hosp Manag 92:102719
Amirghodsi S, Naeini AB, Makui A (2020) An integrated Delphi-DEMATEL-ELECTRE method on gray numbers to rank technology providers. IEEE Trans Eng Manag
Asan U, Kadaifci C, Bozdag E, Soyer A, Serdarasan S (2018) A new approach to DEMATEL based on interval-valued hesitant fuzzy sets. Appl Soft Comput 66:34–49
Atanassov K (2016) Intuitionistic fuzzy sets. Int J Bioautom 20:1
Chauhan A, Jakhar SK, Chauhan C (2021) The interplay of circular economy with industry 4.0 enabled smart city drivers of healthcare waste disposal. J Clean Product 279:123854
Chen L, Li Z, Deng X (2020) Emergency alternative evaluation under group decision makers: a new method based on entropy weight and DEMATEL. Int J Syst Sci 51(3):570–583
Choirun A, Santoso I, Astuti R (2020) Sustainability risk management in the agri-food supply chain: literature review. In: IOP conference series: earth and environmental science, vol 475. IOP Publishing, p 012050
Chuanbo X, Yunna W, Dai S (2020) What are the critical barriers to the development of hydrogen refueling stations in china? A modified fuzzy DEMATEL approach. Energy Policy 142:111495
Das D, Datta A, Kumar P, Kazancoglu Y, Ram M (2022) Building supply chain resilience in the era of COVID-19: An AHP-DEMATEL approach. Oper Manag Res 15(1):249–267
Deng Y (2016) Deng entropy. Chaos Solit Fractals 91:549–553
Deng Y (2020) Uncertainty measure in evidence theory. Sci China Inf Sci 63(11):1–19
Dikbaş F (2017) A novel two-dimensional correlation coefficient for assessing associations in time series data. Int J Climatol 37(11):4065–4076
DİKBAŞ F, BACANLIÜG (2020) Detecting drought variability by using two-dimensional correlation analysis. Teknik Dergi 32(4):10947–10965
Dongdong W, Liu Z, Tang Y (2020) A new classification method based on the negation of a basic probability assignment in the evidence theory. Eng Appl Artif Intell 96:103985
Feng C, Ma R (2020) Identification of the factors that influence service innovation in manufacturing enterprises by using the fuzzy DEMATEL method. J Clean Product 253:120002
Gang K, Özlem OA, Hasan D, Serhat Y (2021) Fintech investments in European banks: a hybrid IT2 fuzzy multidimensional decision-making approach. Financ Innov 7(1):1–28
Gao X, Liu F, Pan L, Deng Y, Tsai S-B (2019) Uncertainty measure based on Tsallis entropy in evidence theory. Int J Intell Syst 34(11):3105–3120
Gao Y, Liang H, Sun B (2021) Dynamic network intelligent hybrid recommendation algorithm and its application in online shopping platform. J Intell Fuzzy Syst 40(5):9173–9185
George PG, Renjith VR (2021) Evolution of safety and security risk assessment methodologies towards the use of Bayesian networks in process industries. Process Saf Environ Protect 149:758–775
Han Y, Deng Y (2018) An enhanced fuzzy evidential DEMATEL method with its application to identify critical success factors. Soft Comput 22(15):5073–5090
Jiang S, Shi H, Lin W, Liu H-C (2020) A large group linguistic Z-DEMATEL approach for identifying key performance indicators in hospital performance management. Appl Soft Comput 86:105900
Jousselme A-L, Chunsheng L, Dominic G, Éloi B (2006) Measuring ambiguity in the evidence theory. IEEE Trans Syst Man Cybernet Part A Syst Humans 36(5):890–903
Kamble SS, Angappa G, Rohit S (2020) Modeling the blockchain enabled traceability in agriculture supply chain. Int J Inf Manag 52:101967
Kokangül A, Polat U, Dağsuyu C (2017) A new approximation for risk assessment using the AHP and fine Kinney methodologies. Saf Sci 91:24–32
Kouhizadeh M, Saberi S, Sarkis J (2021) Blockchain technology and the sustainable supply chain: theoretically exploring adoption barriers. Int J Product Econ 231:107831
Kumar PS, Priyabrata C, Abdul MM, Hung LK (2021) Supply chain recovery challenges in the wake of COVID-19 pandemic. J Bus Res 136:316–329
Li S, Wei C (2020) Hesitant fuzzy linguistic correlation coefficient and its applications in group decision making. Int J Fuzzy Syst 22(6):1748–1759
Li Y, Yong H, Zhang X, Deng Y, Mahadevan S (2014) An evidential DEMATEL method to identify critical success factors in emergency management. Appl Soft Comput 22:504–510
Li Z, Dongmei F, Li Y, Wang G, Meng J, Zhang D, Yang Z, Ding G, Zhao J (2019) Application of an electrical resistance sensor-based automated corrosion monitor in the study of atmospheric corrosion. Materials 12(7):1065
Lin S, Li C, Fangqiu X, Liu D, Liu J (2018) Risk identification and analysis for new energy power system in china based on d numbers and decision-making trial and evaluation laboratory (DEMATEL). J Clean Product 180:81–96
Mao H, Deng Y (2022) Negation of BPA: a belief interval approach and its application in medical pattern recognition. Appl Intell 52(4):4226–4243
Mohammed A, Naghshineh B, Spiegler V, Carvalho H (2021) Conceptualising a supply and demand resilience methodology: A hybrid DEMATEL-TOPSIS-possibilistic multi-objective optimization approach. Comput Ind Eng 160:107589
Ocampo L, Yamagishi K (2020) Modeling the lockdown relaxation protocols of the Philippine government in response to the COVID-19 pandemic: an intuitionistic fuzzy DEMATEL analysis. Socio-Econ Plann Sci 72:100911
Pal NR, Bezdek JC, Rohan H (1992) Uncertainty measures for evidential reasoning I: a review. Int J Approx Reason 7(3–4):165–183
Pal NR, Bezdek JC, Hemasinha R (1993) Uncertainty measures for evidential reasoning II: a new measure of total uncertainty. Int J Approx Reason 8(1):1–16
Pan Q, Zhou D, Tang Y, Li X, Huang J (2019) A novel belief entropy for measuring uncertainty in dempster-shafer evidence theory framework based on plausibility transformation and weighted hartley entropy. Entropy 21(2):163
Pandey M, Litoriya R, Pandey P (2019) Identifying causal relationships in mobile app issues: an interval type-2 fuzzy DEMATEL approach. Wirel Pers Commun 108(2):683–710
Raj A, Dwivedi G, Sharma A, de Sousa Jabbour ABL, Rajak S (2020) Barriers to the adoption of industry 4.0 technologies in the manufacturing sector: an inter-country comparative perspective. Int J Product Econ 224:107546
Shang X, Song M, Huang K, Jiang W (2020) An improved evidential DEMATEL identify critical success factors under uncertain environment. J Ambient Intell Humaniz Comput 11(9):3659–3669
Tang Y, Chen Y, Zhou D (2022) Measuring uncertainty in the negation evidence for multi-source information fusion. Entropy 24(11):1596
Tang Y, Tan S, Zhou D (2023) An improved failure mode and effects analysis method using belief Jensen–Shannon divergence and entropy measure in the evidence theory. Arab J Sci Eng 48:7163–7176
Tanvir AS, Sayem A, Mithun AS, Sudipa S, Golam K et al (2021) Challenges to COVID-19 vaccine supply chain: implications for sustainable development goals. Int J Product Econ 239:108193
Tavares BG, da Silva CES, de Souza AD (2019) Risk management analysis in scrum software projects. Int Trans Oper Res 26(5):1884–1905
Trivedi A (2018) A multi-criteria decision approach based on DEMATEL to assess determinants of shelter site selection in disaster response. Int J Disaster Risk Reduct 31:722–728
Wang X, Song Y (2018) Uncertainty measure in evidence theory with its applications. Appl Intell 48(7):1672–1688
Yadav S, Singh SP (2020) Blockchain critical success factors for sustainable supply chain. Resour Conserv Recycl 152:104505
Yager RR (2014) On the maximum entropy negation of a probability distribution. IEEE Trans Fuzzy Syst 23(5):1899–1902
Yasar M, Dikbas F (2022) Multivariate outlier detection in a precipitation series using two-dimensional correlation. Fresenius Environ Bull 31(3):2451–2465
Yazdi M, Kabir S, Walker M (2019) Uncertainty handling in fault tree based risk assessment: state of the art and future perspectives. Process Saf Environ Protect 131:89–104
Yazdi M, Khan F, Abbassi R, Rusli R (2020) Improved DEMATEL methodology for effective safety management decision-making. Saf Sci 127:104705
Yin L, Deng X, Deng Y (2018) The negation of a basic probability assignment. IEEE Trans Fuzzy Syst 27(1):135–143
Yuan-Wei D, Zhou W (2019) New improved DEMATEL method based on both subjective experience and objective data. Eng Appl Artif Intell 83:57–71
Zeshui X (2007) Intuitionistic fuzzy aggregation operators. IEEE Trans Fuzzy Syst 15(6):1179–1187
Zhang R, Ashuri B, Deng Y (2017) A novel method for forecasting time series based on fuzzy logic and visibility graph. Adv Data Anal Classif 11(4):759–783
Zhang Q, Li M, Deng Y (2018) Measure the structure similarity of nodes in complex networks based on relative entropy. Physica A: Stat Mech Appl 491:749–763
Zhang C, Tian G, Fathollahi-Fard AM, Wang W, Wu P, Li Z (2020) Interval-valued intuitionistic uncertain linguistic cloud petri net and its application to risk assessment for subway fire accident. IEEE Trans Autom Sci Eng
Zheng Q, Shen S-L, Zhou A, Lyu H-M (2022) Inundation risk assessment based on G-DEMATEL-AHP and its application to Zhengzhou flooding disaster. Sustain Cities Soc 86:104138
Zhongyi W, Liu W, Nie W (2021) Literature review and prospect of the development and application of FMEA in manufacturing industry. Int J Adv Manuf Technol 112(5):1409–1436
Zhou X, Shi Y, Deng X, Deng Y (2017) D-DEMATEL: a new method to identify critical success factors in emergency management. Saf Sci 91:93–104
Funding
The work was supported by the Natural Science Basic Research Program of Shaanxi (Program No. 2023-JC-QN-0689) and NWPU Research Fund for Young Scholars (Grant No. G2022WD01010).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, Y., Tang, Y., Yang, Z. et al. Improved fuzzy evidential DEMATEL method based on two-dimensional correlation coefficient and negation evidence. Soft Comput 27, 11177–11192 (2023). https://doi.org/10.1007/s00500-023-08748-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08748-y