
Abstract
The prediction of river sediment load is an essential issue in water resource engineering problems. In this study, artificial neural network employed in order to estimate the daily sediment load on rivers. Two different algorithms, multi-layer perceptron (MLP) and hybrid MLP-FFA (MLP integrated with the FFA) were used for this purpose in the Lake Mahabad, Iran. For this purpose, nine different scenarios are considered as inputs of the models. Performance of selected models was evaluated on basis of performance criterion namely root mean square error (RMSE), mean absolute error (MAE), coefficient of determination (R2) for choosing best fit model. The results indicated that the new hybrid model MLP-FFA is successful in estimating sediment load with high accuracy as compared with its alternatives with RMSE = 2018 ton/day, MAE = 1698 and R2 = 0.95, which were much lower than those of MLP-based model with RMSE = 3044 ton/day, MAE = 2481 and R2 = 0.90. The results of the present study confirmed the suitability of proposed methodology for precise modeling of suspended sediment load.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Sediment load information is useful for problems in the design of reservoirs and dams, transport of sediment and pollutants in rivers, lakes and estuaries, design of stable channels and dams, protection of fish and wildlife habitats, determination of the effects of watershed management and environmental impact assessment (Cigizoglu 2004). Water quality and sediment modeling have been a challenging task in the field of computational hydrology (Kişi 2009). Traditionally used methods (e.g., Ahmad et al. 2009, 2010) to determine runoff often do not take into account sediment load. Estimation of sediment load has been approached through empirical relationships, numerical simulations, physically-based models and using remote sensing and Geographic Information Systems (GIS) techniques.
Precise simulation of sediment load is important for sustainable water supplies and environmental systems, because it plays a major role in any decision-making process on water availability. In recent years (Lohani et al. 2007; Boukhrissa et al. 2013; Yadav et al. 2018; Ampomah et al. 2010), the use of data-driven modeling techniques to produce improved sediment yield rating curves has attracted substantial attention. Previously, multiple sediment prediction models were developed by hydrology researchers, ranging from empirical, i.e., USLE/RUSLE (Wischmeier and Smith 1978; Fu et al. 2006; Arekhi et al. 2012; Borrelli et al. 2017) and mathematical, i.e., kinematic/ diffusion wave theory (Liu et al. 2004; Singh and Tayfur 2008; Schneider 2018) or linear/nonlinear programming optimization (Nicklow and Mays 2000; Dutta 2015; Wang et al. 2020) to physically dependent. Physically process-based models such as SWAT (Asres and Awulachew 2010; Chandra et al. 2014; Dutta and Sen 2018; Liu and Jiang 2019), WEPP (Yuksel et al. 2008; Saghafian et al. 2014; Singh et al. 2017; Ahmadi et al. 2020), and many others have shown better understanding of sediment yield modeling, yet their data hunger is often very large, and even watersheds intensively monitored lack adequate input data for these models. Therefore, alternative methods for forecasting runoff and yield of sediments need to be searched for. Soft computing methodology is one of the solutions to solving such problems.
Soft computing (SC) techniques such as the artificial neural network (ANN) model have successfully been used extensively for the prediction of suspended sediment load. The major advantage of such SC techniques is that these models are fully nonparametric and do not require a priori concept of the relations between the input variables and the output data (Gocić et al. 2015; Fahimi et al. 2017). Various researchers have used ANNs for hydrologic studies including time series predictions of runoff or streamflow (Hsu et al. 1995; Govindaraju 2000; Rajaee et al. 2009, 2010; Melesse et al. 2011; Lafdani et al. 2013; Khan et al. 2018; Meshram et al. 2019a, 2019b, 2020, 2021a, 2021b, 2021c; Iraji et al. 2020). Sudheer et al. (2003) used radial-based neural networks for partial weather data; Trajkovic (2005) used radial-based neural networks using temperature-based models; Kisi (2007) applied a neural computing technique using climatic data; and Aytek (2008) applied a co-active neuro-fuzzy interpretation system. Cobaner et al. (2009) used neural networks and adaptive neuro-fuzzy interference system techniques.
The rainfall–runoff correlation is positively modeled using ANNs (Raid and Mania 2004; Maier et al. 2010; Patel and Joshi 2017). ANNs were also measured as a dominant instrument to use in monthly river flow prediction and various groundwater problems (Coulibaly et al. 2001; Singh et al. 2013). Other applications of ANNs comprise unit hydrograph (Bhunya et al. 2011), regional drought analysis/flood frequency analysis (Adamowski et al. 2012; Adamowski et al. 2012; Belayneh et al. 2016), estimation of sanitary flows (Donovan et al. 2016), river basins classification (Fang et al. 2017), assessment of agricultural vulnerability (Ettinger et al. 2016), modeling hydraulic characteristics of severe contraction (Qiwei et al. 2016). Inside the entire work, the term MLPs (multi-layer perceptron) is favored over the common ANN explanation in light of the fact that there are different ANN algorithms, and MLPs are only one of them.
In the various water resource data, the MLPs establish the popular algorithm in the ANN application. Other algorithm such as RBFs (radial basis functions) (Heddam 2016; Nourani et al. 2017), Conjugate gradient algorithms (Yu-hong and Cai-xia 2013) cascade correlation algorithm (Schetinin 2003; Kaladhar et al. 2011) and recurrent neural networks (Graves et al. 2006) have also been active in some studies. However, these algorithms suffer from the capability of finding optimal parameters. Therefore, different optimization algorithms incorporate into the arrangement to improve the prediction accuracy. One of the popular optimization algorithms is Firefly Algorithm (FFA) (Kayarvizhy et al. 2014). FFA is a multimodal nature inspired metaheuristic optimization algorithm based on flashing behavior of fireflies (Yang 2009). A model that integrates the MLP with firefly algorithm (FFA) is developed to predict sediment load (Yang 2010). In another study by Ghorbani et al. (2017), a hybrid SVM-FFA arrangement has been developed to forecast the field capacity and permanent wilting point of soils in East Azerbaijan province, North-west Iran.
In this study, a hybrid model incorporating the firefly algorithm (FFA) into MLP is advanced to forecast sediment load. An ANN-based method developed to forecast the daily sediment load for Mahabad River in Iran. To find the optimal values for MLP parameters, the FFA algorithm incorporated to the model architecture. The model feasibility investigated further by making a comparison between the hybrid MLP-FFA approach and isolated MLP technique. The purpose of this study is, for the first time, to examine the application of MLP-FFA algorithm to predict sediment load data sets in Mahabad River, Iran.
2 Material and methods
2.1 Study area
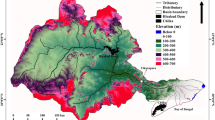
Mahabad River passes through the city and is composed of three branches. The river after passing through various villages and farmland irrigation and channel their way through the swamps South of the lake sheds. Mahabad river basin is located South of Lake Urmia in West Azarbaijan province. The basin covered 1524.53 km2 area about 3% of the total area is included the catchment basin of the lake. The locations of Mahabad river of its recording station used in this study are East Longitude 45°25′9″ to 46°45′51″ and North Latitude 36°23′51″ to 37°03′11″ (Fig. 1). The basin is roughly oval that the large diameter is the North–South, and the small diameter is East–West. This watershed is shared the Little Zab watershed basins in the South West, Gadr in West and Siminehroodin Southeast also in North borders the Lake Urmia.

Location map of the study area (Mahabad River)
2.2 Statistical specifications of data
In this study, the daily suspended sediment load (SSL) and streamflow data in Mahabad River were used. For this study, the observed streamflow and sediment data are 5 years (60 months) from 2011 to 2016 (Fig. 2). The statistical properties of the streamflow and sediment load data are given in Table 1. The maximum, mean and minimum values (Xmax, Xmean and Xmin), standard deviation (σx) and variation of coefficient (Cv) of the data are provided in Table 1. It is seen that the sediment load has a high standard deviation (3895.65). The statistics results evidence the highly stochastic between the streamflow and the sediment load. For both analysis (MLP and MLP-FFA), the first 70% of the whole data set is used for training, and the remaining 30% is used for testing. In the current study, it is aimed to model the daily SSL using the streamflow data based on the scenarios illustrated in Table 2. One-day, two-day, three-day and four-day streamflow and SSL delays are considered in this study. In fact, it evaluates the dynamic memory of streamflow for estimation of the SSL, and also, it is a way for identifying the best input variables to achieve the best results.

Observed streamflow and sediment load in Mahabad River
2.3 Model descriptions
2.3.1 Multi-layer perceptron neural networks (MLP)
Multi-layer feed-forward perceptron (MLP) is a multi-layered architecture of Neural Network including hidden layer besides input and output layer with Levenberg–Marquardt back propagation learning algorithm (Fig. 3). In each layer, the neurons are linked via a weight to the neurons in the following layer throughout training. The activation functions determined to be sigmoid and linear function for hidden layer and output layer, respectively. More details description about MLP structure is accessed in (Ghorbani et al. 2013).

Typical arrangement of multi-layer perceptron neural network
2.3.2 Firefly algorithm (FFA)
The FFA algorithm is a bio-inspired, swarm intelligence optimization technique motivated by flashing behavior of fireflies, introduced by Yang (2010) for the first time. In this technique, the arrangement of an optimization subject is established as operator i.e., firefly which beams in extent to its value. Therefore for every sunnier firefly pulls in its accomplices, paying little mind to their gender, makes the search for the pursuit space more operative (Lukasik and Zak 2009; Hemalatha et al. 2016; Al-shammari et al. 2016).
Fire flies are paying attention in to the brightness. The whole swarm transfers toward the sunniest firefly. Thus, the fireflies are attracted by the amount of their brilliance (Kayarvizhy et al. 2014; Fateen et al. 2012; Sudheer et al. 2014). Moreover, the brilliance lean on the concentration of the agent. For the development of FFA, the major issues are the objective function formulation and the light intensity variation. The light intensity I(L), the attraction (α) and the Cartesian distance among every two fireflies j and k can be represented as:
where I(L) and Io are the light concentration at distance L and the initial light concentration from a firefly, respectively. γ is the coefficient for the light absorption; α(L) and αo are the attraction at a distance L and L = 0, respectively. The subsequent movement of firefly j is exemplified as:
The initial part in the Eq. (5) corresponds to the attraction between fireflies, and the second part is related to the randomization parameters, wherein µ is the randomization coefficient varies from 0 to 1, and \(\epsilon\_i\) represents the random number vector resulted from Gaussian distribution.
In this research, optimum values of γ, ε and C for the weights of the MLP architecture were computed. Firstly, we divided data: 70% of data for training and 30% of data for testing in FFA, ANN. Then, the data for ANN model should be normalized, and the range of input data within 0–1 has been used. Figure 4 indicates the structure of the MLP-FFA (Lukasik and Zak 2009).

Structure of the MLP-FFA
2.4 Performance criteria
In this study, three statistically criteria namely, coefficient of efficiency (R2), root mean square error (RMSE) and mean absolute error (MAE) were applied in order to evaluate the models performances. The criteria are defined as follows:
where N is the total of observed data, xi and yi are the experimental and expected suspended sediment, individually. \(\overline{x}\) and \(\overline{y}\) are the averaged experimental and expected suspended sediment, respectively.
3 Results and discussion
In order to model a river's suspended sediment load, historical streamflow and suspended sediment load data are essential. The seasonality of rainfall has an impact on discharge and suspended sediment load. In this study, multi-layer perceptron (MLP) model was employed to calculate suspended sediment load. In order to enhance the robustness of the MLP model, a hybrid algorithm was developed by combining the MLP with FFA optimization technique. The performance of the two developed models was compared in terms of accurate suspended sediment load prediction.
In current study, the daily streamflow and sediment load data of current and prior days are used as inputs to the multi-layer perceptron (MLP) models and MLP-FFA models to estimate current sediment load value. These models evaluated by the RMSE, MAE and R2 criteria. The two different steps are employed here. In the first step, various input combination consisting of different number of antecedent and current sediment and streamflow data are tried using an MLP and MLP-FFA models. The best input combination is selected according to the performance criteria. In the second step, the MLP model compared with the MLP-FFA model.
The various input combinations used in the MLP and MLP-FFA model to estimate suspended sediment load for the Mahabad River are (i) St−1 (ii) Qt, St−1 (iii) St−1, St−2 (iv) Qt, St−1, St−2 (v) Qt, Qt−1, St−1 (vi) Qt, Qt−1, St−1, St−2 (vii) Qt, Qt−1, Qt−3, St−1, St−2 (viii) Qt, Qt−1, Qt−3, St−1, St−2, St−3 (ix) Qt, Qt−1, Qt−3, Qt−4, St−1, St−2, St−3, St−4 where Qt is the streamflow at day t, and St is the sediment load at day t. In all cases, the output layer had only one neuron, i.e., the sediment loads (St).
A program code was written in MATLAB for the MLP and MLP-FFA model simulations. Different architectures were tried using this code, and the appropriate model structures were determined for each input combination. Then, the MLP and MLP-FFA models were tested, and the results were compared by means of RMSE, MAE and R2 statistics (Table 2).
The number of neurons in the hidden layer was determined using the trial and error procedure and for each scenario the best network architecture was selected based on the three performance criteria (RMSE, MAE, R2). Table 2 shows the best architecture and their related performance criteria for each scenario. It is also showed that adding streamflow and sediment load of the previous day have a significant effect on the results. Hence, the MLP-9 and MLP-FFA-9 model with 8 inputs, 20 hidden and 1 output was selected as the most optimum model.
The results of MLP modeling at training and testing stages in Table 2 show that according to the results of the test period in all scenarios, it is pointed out that the MLP provides the best results in the 9th scenario where Qt, Qt−1, Qt−3, Qt−4, St−1, St−2, St−3, St−4 are used as input of the model to estimate SSL. It is found that the model error is lower, with 8 input where value of RMSE, MAE and R2 are found as 3044 (ton/day), 2481 (ton/day) and 0.901, respectively. The model error is also lower for the training data set where value of RMSE, MAE and R2 are found as 440 (ton/day), 102 (ton/day) and 0.987, respectively. The most accurate estimation is related to the 9th scenario called MLP9. Figure 5 shown observed and predicted daily sediment load for training and testing period.

Observed and predicted daily sediment load by MLP and MLP-FFA models for training period
The performances of proposed models of MLP-FFA in the current study are examined in terms of RMSE, MAE and R2 in Table 2. It is seen that the hybrid models (MLP-FFA) have a better performance than the MLP models. The MLP-FFA model has been able to estimate SSL with better accuracy than that of MLP models. The MLP-FFA hybrid model has the best performance with inputs combination of Qt, Qt−1, Qt−3, Qt−4, St−1, St−2, St−3, St−4 in terms of different evaluation criteria of RMSE, MAE and R2 with 72 ton/day, 25 ton/day and 0.989 respectively for training period. The most accurate estimation with the least error is related to the 9th scenario called MLP-FFA9. This scenario has the best correlation between observed values and estimated SSL value. This is a sign of the proper functioning of the FFA algorithm in optimizing the MLP to estimate SSL values.
Figure 5 and 6 depicts the observed and predicted sediment load values for the training and testing phase. The estimation of the hybrid model MLP-FFA9 is more closer to the observed data in contrast to the MLP9 model. Finally, it is concluded that the MLP-FFA model (hybrid) provides a very accurate simulation compared with MLP model (standalone). These outcomes are in consistent with the findings of Olatomiwa et al. (2015); Ghorbani et al. (2017); Moazenzadeh et al. (2018); Mohammadi et al. (2021); Darabi et al. (2021).

Observed and predicted daily sediment load by MLP and MLP-FFA models for testing period
4 Conclusion
The prime aim of this research was to predict the sediment load for Mahabad River, by employing the two soft computing techniques i.e., MLP and MLP-FFA. The prediction accuracy of these models was estimated using statistical measures (RMSE, MAE and R2) and graphical examination. Daily streamflow and sediment load data of one-four antecedent historical records are used for the modeling. Different input combinations were examined on all studied models to select the best scenario for further analysis. According to the result, MLP9 and MLP-FFA9 models which consist of four antecedent values of streamflow and sediment load have been selected as the best fit forecasting model. Comparison of the developed models based on the variety of statistical error measurement indices showed that the MLP-FFA9 model provide better performance than the MLP9 models for estimating the daily sediment load. In order to implement appropriate measures of soil conservation in the watershed to reduce the sediment load in the river, predicting the sediment yield is very necessary to maximize the life of the structure.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Adamowski J, Chan H, Prasher S, Sharda VN (2012) Comparison of multivariate adaptive regression splines with coupled wavelet transform artificial neural networks for runoff forecasting in Himalayan micro-watersheds with limited data. J Hydroinf 3:731–744
Ahmad MM, Ghumman AR, Ahmad S (2009) Estimation of Clark’s instantaneous unit hydrograph parameters and development of direct surface runoff hydrograph. Water Resour Manag 23:2417–2435. https://doi.org/10.1007/s11269-008-9388-8
Ahmad S, Kalra A, Stephen H (2010) Estimating soil moisture using remote sensing data: a machine learning approach. Adv Water Resour 33(1):69–80
Ahmadi M, Minaei M, Ebrahimi O (2020) Evaluation of WEPP and EPM for improved predictions of soil erosion in mountainous watersheds: a case study of Kangir River basin. Iran Model Earth Syst Environ 6:2303–2315. https://doi.org/10.1007/s40808-020-00814-w
Al-Shammari E, Mohammadi K, Keivani A, SitiHafizahAb Hamid, Akib S, Shamshirband S, Dalibor P (2016) Prediction of daily dew point temperature using a model combining the support vector machine with firefly algorithm, vol 5(no 142)
Ampomah R, Hosseiny H, Zhang L, Smith V, Sample-Lord K (2010) A regression-based prediction model of suspended sediment yield in the Cuyahoga River in Ohio using historical satellite images and precipitation data. Water 12:881
Arekhi S, Niazi Y, Kalteh AM (2012) Soil erosion and sediment yield modeling using RS and GIS techniques: a case study. Iran Arab J Geosci 5:285–296. https://doi.org/10.1007/s12517-010-0220-4
Asres MT, Awulachew SB (2010) SWAT based runoff and sediment yield modelling: a case study of the Gumera watershed in the Blue Nile basin. Ecohydrol Hydrobiol 10(2–4):191–199
Aytek A (2008) Genetic programming approach to suspended sediment modelling. J Hydrol 351:288–298
Belayneh A, Adamowski J, Khalil B, Quilty J (2016) Coupling machine learning methods with wavelet transforms and the bootstrap and boosting ensemble approaches for drought prediction. Atmos Res 172–173:37–47
Borrelli P, Robinson DA, Fleischer LR (2017) An assessment of the global impact of 21st century land use change on soil erosion. Nat Commun 8:2013. https://doi.org/10.1038/s41467-017-02142-7
Boukhrissa ZA, Khanchoul K, Bissonnais YL, Tourki M (2013) Prediction of sediment load by sediment rating curve and neural network (ANN) in El Kebir catchment, Algeria. J Earth Syst Sci 122(5):1303–1312
Chandra P, Patel PL, Porey PD, Gupta ID (2014) Estimation of sediment yield using SWAT model for Upper Tapi basin for Upper Tapi basin. ISH J Hydraul Eng 20(3):1–11
Cigizoglu HK (2004) Estimation and forecasting of daily suspended sediment data by multi-layer perceptron’s. Adv Water Resour 27:185–195
Cobaner M, Unal B, Kisi O (2009) Suspended sediment concentration estimation by an adaptive neuro-fuzzy and neural network approaches using hydro-meteorological data. J Hydrol 367(1–2):52–61
Coulibaly P, Anctil F, Aravena R, Bobee B (2001) Artificial neural network modeling of water table depth fluctuations. Water Resour Res 37(4):885–896
Darabi H, Mohamadi S, Karimidastenaei Z, Kisi O, Ehteram M, ELShafie A, Haghighi AT (2021) Prediction of daily suspended sediment load (SSL) using new optimization algorithms and soft computing models. Soft Comput 25:7609–7626. https://doi.org/10.1007/s00500-021-05721-5
Donovan G, Butry D, Mao M (2016) Statistical Analysis of Vegetation and Storm water Runoff in an Urban Watershed during summer and Winter Storms in Portland, Oregon U.S. Arboric Urban For 42(5):318–328
Dutta S (2015) Determination of reservoir capacity using linear programming. Int J Innov Res Sci Eng Technol 4(10):9549–9556
Dutta S, Sen D (2018) Application of SWAT model for predicting soil erosion and sediment yield. Sustain Water Resour Manag 4:447–468. https://doi.org/10.1007/s40899-017-0127-2
Ettinger E, Mounaud L, Magill C, Yao-Lafourcade A-F, Thouret J, Manville V, Negulescu C, Zuccaro G, Gregorio D, Nardone S, Uchuchoque JAL, Arguedas A, Macedo L, Nélida ML (2016) Building vulnerability to hydro-geomorphic hazards: estimating damage probability from qualitative vulnerability assessment using logistic regression. J Hydrol 541:563–581
Fahimi F, Yaseen ZM, El-shafie A (2017) Application of soft computing based hybrid models in hydrological variables modeling: a comprehensive review. Theor Appl Climatol 128:875–903. https://doi.org/10.1007/s00704-016-1735-8
Fang K, Siva Kumar B, Woldemeskel F (2017) Complex networks, community structure, and catchment classification in a large-scale river basin. J Hydrol 545:478–493
Fateen S, Bonilla-Petriciolet A, Pandu Rangaiah G (2012) Evaluation of covariance matrix adaptation evolution strategy, shuffled complex evolution and firefly algorithms for phase stability. Phase Equilib Chem Equilib Probl 90(12):2051–2071
Fu G, Chen S, McCool DK (2006) Modeling the impacts of no-till practice on soil erosion and sediment yield with RUSLE, SEDD, and ArcView GIS. Soil Till Res 85(1–2):38–49
Ghorbani MA, Khatibi R, Hosseini B, Bilgili M (2013) Relative importance of parameters affecting wind speed prediction using artificial neural networks. Theor Appl Climatology 114(1):107–111
Ghorbani MA, Shamshirband S, ZareHaghie D, Azania A, Bonakdarif H, Ebtehajf I (2017) Application of firefly algorithm-based support vector machines for prediction of field capacity and permanent wilting point. Soil Till Res 172:32–38
Gocić M, Motamedi SH, Shamshirband SH, Petković D, Ch S, Hashim R, Arif M (2015) Soft computing approaches for forecasting reference evapotranspiration. Comput Electron Agric 113:164–173
Govindaraju RS (2000) Artificial neural networks in hydrology. I: preliminary concepts. J Hydrol Eng 5(2):115–123
Graves A, Ferńandez S, Gomez F, Schmidhuber J (2006) Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks, in ICML, Pittsburgh, USA
Heddam S (2016) Simultaneous modelling and forecasting of hourly dissolved oxygen concentration (DO) using radial basis function neural network (RBFNN) based approach: a case study from the Klamath River, Oregon, USA, and Model. Earth Syst Environ 2:135
Hemalatha C, ValanRajkumar M, Vidhya Krishnan G (2016) Simulation and analysis of MPPT control with modified firefly algorithm for photovoltaic system. Int J Innov Stud Sci Eng Technol 2(11):48–52
Hsu KL, Gupta HV, Sorooshian S (1995) Artificial neural network modeling of the rainfall-runoff process. Water Resour Res 31(10):2517–2530
Iraji H, Mohammadi M, Shakouri B, Meshram SG (2020) Predicting Reservoirs Volume Reduction using Artificial Neural Network. Arab J Geosci 13:835. https://doi.org/10.1007/s12517-020-05772-2
Kayarvizhy N, Kanmani S, Uthariaraj RV (2014) ANN Models optimized using swarm intelligence algorithms. WSEAS Trans Comput 13:501–519
Khan MYA, Tian F, Hasan F, Chakrapani GJ (2018) Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga, Ganges Basin, India. Int J Sedim Res. https://doi.org/10.1016/j.ijsrc.2018.09.001
Kisi O (2007) Streamflow forecasting using different artificial neural network algorithms. J Hydrol Eng 12:532–539
Kişi O (2009) Wavelet regression model as an alternative to neural networks for monthly streamflow forecasting. Hydrol Process 23(24):3583–3597
Lafdani EK, Nia AM, Ahmadi A (2013) Daily suspended sediment load prediction using artificial neural networks and support vector machines. J Hydrol 478:50–62. https://doi.org/10.1016/j.jhydrol.2012.11.048
Liu Y, Jiang H (2019) Sediment yield modeling using SWAT model: case of Changjiang River Basin. IOP Conf Ser Earth Environ Sci 234:012031
Liu QQ, Chen L, Li JC, Singh VP (2004) Two-dimensional kinematic wave model of overland-flow. J Hydrol 291(1–2):28–41
Lohani AK, Goel NK, Bhatia KKS (2007) Deriving stage–discharge–sediment concentration relationships using fuzzy logic. Hydrol Sci J 52(4):793–807
Lukasik S, Zak S (2009) Firefly algorithm for continuous constrained optimization tasks. ICCCI 2009, LNAI 5796. Springer, Berlin, pp 97–106s
Maier H, Jain A, Dandy G, Sudheer KP (2010) Methods used for the development of neural networks for the prediction of water resource variables in river systems: current status and future directions. Environ Model Soft 25:891–909
Melesse AM, Ahmad S, McClain ME, Wang X, Lim YH (2011) Suspended sediment load prediction of river systems: an artificial neural network approach. Agric Water Manag 98(5):855–866. https://doi.org/10.1016/j.agwat.2010.12.012
Meshram SG, Ghorbani MA, Shamshirband S, Karimi V, Meshram C (2019a) River flow prediction using hybrid PSOGSA algorithm based on feed-forward neural network. Soft Comput 23(20):10429–10438
Meshram SG, Ghorbani MA, Deo RC, Kashani MH, Meshram C, Karimi V (2019b) New Approach for Sediment Yield Forecasting with a Two-Phase Feed forward Neuron Network-Particle Swarm Optimization Model Integrated with the Gravitational Search Algorithm. Water Resour Manag 33(7):2335–2356
Meshram SG, Singh VP, Kisi O, Karimi V, Meshram C (2020) Application of Artificial Neural Networks, Support Vector Machine and Multiple Model- ANN to Sediment Yield Prediction. Water Resour Manag. https://doi.org/10.1007/s11269-020-02672-8
Meshram SG, Safari MJS, Khosravi K, Meshram C (2021a) Iterative classifier optimizer-based pace regression and random forest hybrid models for suspended sediment load prediction. Environ Sci Pollut Res 28(1):11637–11649
Meshram SG, Pourghasemi HR, Abba SI, Alvandi E, Meshram C, Khedher KM (2021b) A comparative study between dynamic and soft computing models for sediment forecasting. Soft comput. https://doi.org/10.1007/s00500-021-05834-x
Meshram SG, Meshram C, Santos CAG, Benzougagh B, Khedher KM (2021c) Stream Flow Prediction Based on Artificial Intelligence Techniques. Iranian J Sci Technol, Trans Civil Eng. https://doi.org/10.1007/s40996-021-00696-7
Moazenzadeh R, Mohammadi B, Shamshirband S, Chau KW (2018) Coupling a firefly algorithm with support vector regression to predict evaporation in northern Iran. Eng Appl Comput Fluid Mech 12(1):584–597
Mohammadi B, Guan Y, Moazenzadeh R, Safari MJS (2021) Implementation of hybrid particle swarm optimization-differential evolution algorithms coupled with multi-layer perceptron for suspended sediment load estimation. Catena 198:105024
Nicklow JW, Mays LW (2000) Optimization of multiple reservoir networks for sedimentation control. J Hydraul Eng 126(4):232–242
Nourani V, Mousavi SH, Dabrowska D, Sadikoglu F (2017) Conjunction of radial basis function interpolator and artificial intelligence models for time-space modeling of contaminant transport in porous media. J Hydrol 548:569–587
Olatomiwa L, Mekhilef S, Shamshirband S, Mohammadi K, Petković D, Sudheer Ch (2015) A support vector machine–firefly algorithm-based model for global solar radiation prediction. Solar Energy 115:632–644
Patel A, Joshi G (2017) Modeling of rainfall-runoff correlations using artificial neural network—a case study of Dharoi Watershed of a Sabarmati River Basin, India. Civ Eng J 3(2):78–87
Qiwei L, Liang L, Li J, Wu SH, Liu J (2016) Modeling and analysis on cushion characteristics of fast and high-flow-rate hydraulic cylinder. Math Probl Eng 17:66
Raid S, Mania J (2004) Rainfall-runoff model using an artificial neural network approach. Math Comput Model 40:839–846
Rajaee T, Mirbagheri SA, Zounemat-Kermani M, Nourani V (2009) Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci Total Environ 407(17):4916–4927
Rajaee T, Nourani V, Zounemat-Kermani M, Kisi O (2010) River suspended sediment load prediction: application of ANN and wavelet conjunction model. J Hydrol Eng 16(8):613–627
Saghafian B, Meghdadi AR, Sima S (2014) Application of the WEPP model to determine sources of run-off and sediment in a forested watershed. Hydrol Process 29(4):481–497. https://doi.org/10.1002/hyp.10168
Schetinin V (2003) A learning algorithm for evolving cascade neural networks. Neural Process Lett 17:21–31
Schneider W (2018) On basic equations and kinematic-wave theory of separation processes in suspensions with gravity, centrifugal and Coriolis forces. Acta Mech 229:779–794. https://doi.org/10.1007/s00707-017-1998-x
Singh VP, Tayfur G (2008) Kinematic wave theory for transient bed sediment waves in Alluvial Rivers. J Hydrol Eng 13(5):297–304. https://doi.org/10.1061/(asce)1084-0699(2008)13:5(297)
Singh HV, Panuska J, Thompson AM (2017) Estimating sediment delivery ratios for grassed waterways using WEPP. Land Degrad Dev 28(7):2051–2061. https://doi.org/10.1002/ldr.2727
Sudheer KP, Gosain AK, Ramasastri KS (2003) Estimating actual evapotranspiration from limited climatic data using neural computing technique. J Irrig Drain Eng 129(3):214–218
Sudheer Ch, Sohani SK, Kumar D, Malik A, Chahar BR, Nema AK, Panigrahi BK, Dhiman RC (2014) A support vector machine-firefly algorithm based forecasting model to determine malaria transmission. Neurocomputing 129:279–288
Trajkovic S (2005) Temperature-based approaches for estimating reference evapotranspiration. J Irrig Drain Eng 131(4):316–323
Wang X, Feng Y, Ning Z, Hu X, Kong X, Hu B, Guo Y (2020) A collective filtering based content transmission scheme in edge of vehicles. Inf Sci 506:161–173. https://doi.org/10.1016/j.ins.2019.07.083
Wischmeier WH, Smith DD (1978) Predicting rainfall erosion losses—a guide to conservation planning. USDA Ag Handb 537:58p
Yadav A, Chatterjee S, Equeenuddin SM (2018) Prediction of suspended sediment yield by artificial neural network and traditional mathematical model in Mahanadi river basin, India. Sustain Water Resour Manag 4:745–759. https://doi.org/10.1007/s40899-017-0160-1
Yang XS (2009) Firefly algorithms for multimodal optimization. stochastic algorithms: foundations and applications, SAGA 2009. Lect Notes Comput Sci 5792:169–178
Yang XS (2010) Firefly algorithm, stochastic test functions and design optimization. Int J Bio-Inspired Comput 2(2):78–84
Yu-hong D, Cai-xia K (2013) A nonlinear conjugate gradient algorithm with an optimal property and an improved Wolfe line search. Soc Ind Appl Math 23(1):296–320
Yuksel A, Gundogan R, Akay AE (2008) Using the remote sensing and GIS technology for erosion risk mapping of Kartalkaya Dam Watershed in Kahramanmaras, Turkey. Sensors 8(8):4851–4865. https://doi.org/10.3390/s8084851
Acknowledgements
The authors thankfully acknowledge the Deanship of Scientific Research, King Khalid University, Abha, Kingdom of Saudi Arabia, for funding the research grant number RGP. 1/174/42.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Meshram, S.G., Meshram, C., Pourhosseini, F.A. et al. A Multi-Layer Perceptron (MLP)-Fire Fly Algorithm (FFA)-based model for sediment prediction. Soft Comput 26, 911–920 (2022). https://doi.org/10.1007/s00500-021-06281-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06281-4