
Abstract
Weight determination is a popular research issue in the field of multicriteria analysis. Well-known approaches include the analytic hierarchical/network process (AHP/ANP), ratio method, Delphi method, etc., and other modifications and extensions have been proposed to address situations that are more complicated, e.g., fuzzy, grey, etc. Generally speaking, the ANP is the most popular method and derives the weights of criteria by considering interdependent and feedback effects. However, a problem with ANP is the cumbersome process of calculating the weights of the network relationships between criteria. More critical problem with ANP is the issue of divergence when absorbing criteria exist. Although several methods, such as the DEMATEL-based ANP and diminishing utility decision model, have been proposed to address these issues, these approaches have several limitations. In this paper, we propose a novel way to overcome the limitations of the above approaches and provide a possible solution for determining the weights of criteria via network influence maps (NetIM) with pseudonodes. The results of the numerical examples show NetIM is more rational, flexible, and useful than other methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Problem-solving and decision-making are critical skills for a better life. Problem-solving and decision-making are interdependent, and one essential issue of decision-making is determining the weights of criteria. This issue has received much attention for several decades, since the weights of criteria have an important influence on decision-making. Tzeng et al. (1998) divided the approaches to determine weights into objective and subjective. Objective approaches include the entropy method (Hwang and Yoon 1981), standard deviation method (Diakoulaki et al. 1995), and maximizing deviation method (Wu and Chen 2007), which determine the weights of criteria based on information from decision tables but lack information from subjective judgments by decision-makers. Subjective approaches include the trade-off method, pricing-out method (Keeney and Raiffa 1976), ratio method (Edwards 1977), swing method (Kirkwood 1997), analytic hierarchy process (AHP) (Saaty 1980), point allocation method (Doyle et al. 1997), and Delphi method (Hwang and Yoon 1981).
Among the previous approaches, the AHP, proposed by Satty (1980), is clearly the most popular one and has been widely applied in various applications. However, the independent weights between criteria prevent the application of the AHP to solving realistic network problems. Hence, Saaty (1996) proposed the analytic network process (ANP) to release the independence assumption between criteria and derive the relative weights of criteria under a network structure. Recently, the ANP has been successfully used in solving various applications of multicriteria decision-making (MCDM), such as decision-making for solar thermal power plants (Aragonés-Beltrán et al. 2014), green supplier selection (Hashemi et al. 2015), asset maintenance (Chemweno et al. 2015), renewable energy investment risk assessment (Wu et al. 2019), and readiness assessment of vendor-managed inventory in health care (Sumrit 2019).
However, not every network structure can be handled by the ANP-based approaches. The major problem is that the steady-state distribution of a Markov chain usually requires all criteria to be connected to each other, i.e., a regular stochastic matrix. However, real-life problems are usually complicated and varied. The limitation of this assumption for the ANP restricts its possible applications in practice. For example, the steady-state distribution is unavailable when an absorbing criterion exists. Note that an absorbing criterion is a criterion which is influenced by others and does not influence others. In addition, a criterion gets higher weight if its inflows are larger than its outflows. This is arguably another problem since the influence of a criterion might account for the inflows and/or outflows in practice. Generally, the outflows might play a more important role than the inflows, and this is opposite to what the ANP does. We will discuss this issue in detail later.
Besides this, another major problem of the ANP is its pairwise comparisons between criteria. Usually, it takes a long time to collect the needed data, which is cumbersome when large sets of criteria are considered. Several approaches have been proposed, including the DEMATEL-based ANP (DANP) (Chen et al. 2011; Liou and Tzeng 2012) and diminishing utility decision model (DUDM) (Huang 2015), to simplify or modify the problem in the ANP. For example, the DEMATEL-based ANP was proposed to use the full direct and indirect influence matrix of the DEMATEL approach as the input of the supermatrix, instead of performing the pairwise comparisons. However, these approaches have other problems, such as problems with divergence and flexibility. For example, the result of the DEMATEL will be divergent if the input matrix is singular.
In this paper, we aim to solve the problems above and propose a novel approach for determining the weights of criteria from the perspective of network influence maps (NetIM). The network influence of a criterion is measured as a trade-off of the inflows, outflows, and feedback flows. These flows can be calculated using the network influence map, which contains the information of the interdependencies and feedback effects between criteria. Hence, we can consider the network influence flows to determine the weights of the criteria. Furthermore, we demonstrate the proposed method by three numerical examples and compare the results with the ANP, DANP, and DUDM. The experimental results indicate that NetIM is more rational and flexible than others and should be considered for more practical applications of decision-making.
1 Problem description
Let us first consider an absorbing criterion in the network structure, presented by Huang and Inuiguchi (2015) and shown in Fig. 1, to illustrate the problem here. An absorbing criterion indicates that a criterion is only influenced by others and it never influences others. The problem here is to derive the weights of the 4Ps of marketing (i.e., Product, Price, Promotion, and Place) under the given network structure.

The influence map of the 4P’s (Product, Price, Promotion, and Place) of marketing
As we know, a successful marketing mix, i.e., 4Ps, is the key point to providing a satisfactory product or service. However, the limited marketing budget should be rationally allocated to each component of the marketing mix. Hence, we should first derive the weights of the marketing mix before we start the marking project.
However, if we simply use the ANP-based approach to consider the above problem, the result will produce the irrational conclusion that only the criterion Place should be considered in the marketing mix, because Place is an absorbing criterion. This result violates the beginning assumption that all of the 4Ps are important and affect the success of the marketing strategy.
Next, we give another example to illustrate the problems with the ANP, as shown in Fig. 2. We assume that five criteria/clusters, C1–C5, are the criteria of a problem and that the criterion C1 influences others while others are only influenced by C1.

Criteria with a star structure
If the network structure is as shown in Fig. 2, the result of the ANP will conclude that C1 is of no importance and that the others share importance equally. The reason for this is that the weight of a criterion in the ANP equals the sum of the inflows from others minus the outflows to others. The greater a criterion’s net inflow, the more important it becomes. Note that since C1 and the other criteria are not in a hierarchical structure, we cannot simply use the AHP or other independent methods to derive their weights.
We should highlight that in Markov chain theory (the method that the ANP uses to calculate the global weights of criteria), the network structure describes the probability of transition from one state to another. Hence, greater inflows to a state indicate a higher probability that the state will happen. However, if we shift this concept to consider weights of criteria, sometimes we might think that the criteria which influence others are more important than the criteria which are influenced by others. The ANP only considers the power of the inflows and ignores the importance of the outflows.
1.1 Deriving weights by the ANP
The ANP was proposed by Saaty (1996) to generalize the AHP to consider interdependencies and feedback effects between criteria. First, we determine the network structure of the problems. Then, we calculate the local weights derived from the AHP several times and form the supermatrix based on the network structure. Finally, we can calculate the limiting power of the supermatrix to obtain the weights of criteria.
The mathematical view of the ANP is presented as follows. Let the normalized supermatrix \({\varvec{W}}\) represent the influence degree between criteria, from column headers to row headers, and ensure that the sum of each column equals unity exactly, where \({\varvec{W}}\) is irreducible and nonnegative. That is, each criterion of a matrix is strongly connected such that \(({\varvec{I}} + {\varvec{W}})^{n - 1} > 0,\) for an \(n \times n\) nonnegative matrix. Therefore, an irreducible matrix cannot have source or sink criteria. The detailed properties of calculating \(\mathop {\lim }\limits_{k \to \infty } {\varvec{W}}^{{{(}k{)}}}\) can refer to Appendix. Then, we raise the supermatrix to the limiting power to obtain the global weight matrix as follows:
where (k) denotes the power operator. Then, any column of \({{\varvec{\Phi}}}\) is the global weight vector. Instead of solving Eq. (1), we also can solve the following equation to obtain the global weight vector:
where \({\varvec{\phi}}\) is the global vector and named the steady-state vector for \({\varvec{W}}\); the condition for the steady state is that \({\varvec{W}}\) is a regular stochastic matrix.
It can be seen that the way to calculate the global weight vector in the ANP is via Markov chain theory. The major difference is that the transition probabilities of the ANP are derived from the AHP to reflect the influence from column headers to row headers. The advantages of the ANP are that it is appropriate for both quantitative and qualitative data types, and it can handle the problems of interdependencies and feedback effects between criteria (Saaty 1996).
However, the ANP may result in irrational results when absorbing criteria are presented, as shown in Fig. 3.

Absorbing situation of the analytic network process (ANP)
In Fig. 3, C2 is an absorbing criterion, which means that C3 is only affected by others. In this situation, the weight of C3 will be 1, and those of the others will be 0, whatever the elements of the supermatrix are. However, the result above is irrational because we think that the three criteria all have some influence on the decision problem.
To determine the result of an absorbing state, we first consider the following problem: to determine the weights of the five criteria depicted in Fig. 4. Note that C2, C3, and C4 are interdependent and C1 and C5 have the feedback effect. Among the criteria, C5 is an absorbing criterion, which means that this criterion is only influenced by others and has no influence on others. In addition, we should highlight that since all five criteria are indicated as influencing factors of the problem, their weights should be larger than zero, or they should not be considered in the network structure.

Demonstrating the Problem with the ANP
Here, we assume that all influences are equal for simplicity. Then, we can formulate the supermatrix based on Fig. 4 as follows:
Then, we raise the supermatrix to the limiting power to obtain the following result:
Finally, we can conclude that the weights of C1 to C5 via this method are 0, 0, 0, 0, and 1, respectively.
The concept of the ANP can be viewed as the process of determining the nodes’ inflows from others. Hence, the node that receives greater net inflow will get the higher weight. Clearly, since C5 is the only absorbing criterion, all flows will eventually go to C5 until the flows of other criteria become zero. Hence, we do not need to consider the concrete values of the elements in the supermatrix wij, and the conclusion can easily be inferred. However, the result of the ANP is not satisfactory because the result indicates that C5 is the only consideration and other weights should be cast aside.
1.2 Deriving weights by the DANP
Given the previously mentioned problems with the ANP, several papers have proposed ways to overcome the huge number of questionnaire problems in the ANP, e.g., DEMATEL-based ANP (Chen et al. 2011; Liou and Tzeng 2012). The original concept of DEMATEL comes from Leontief’s input and output model (Leontief 1949), which describes the processes of how one sector distributes its output to the other sectors of the economy. The process of DEMATEL can be described as follows. First, a respondent gives the influence degree from row headers to column headers in the range of 0 to 4, where 0 means no influence and 4 is the most influence. Then, the initial direct influence matrix D can be obtained by normalizing the direct influence matrix \({\varvec{X}} = [x_{ij} ]\) such that
where.
Then, the full (direct and indirect) influence matrix F can be calculated by.
The full influence matrix describes the influence degree from one factor (row-header) to another (column-header). Furthermore, we can depict the interrelationships among factors contained in the problematique. We omit the complete concept of DEMATEL because the purpose here is to discuss its extension to the DEMATEL-based ANP. Readers can refer to Tzeng and Huang (2011) for a more detailed description of the processes and results of DEMATEL.
The DEMATEL-based ANP is described as follows. First, the supermatrix of the ANP is derived by normalizing the transpose of DEMATEL, i.e., FT. Then, we raise the supermatrix to the limiting power for the result. Recently, the DANP approach has been used in reliability-based product optimization (Feng et al. 2018), renewable energy resources selection (Büyüközkan and Güleryüz 2016), and project risk management (Chen et al. 2019). However, the DEMATEL approach will produce an infinite matrix if the direct influence matrix is singular. Let us consider the following direct influence matrix:
The matrix seems to be normal in describing the direct influence between three elements in practice. However, if we derive the full influence matrix, it will be as follows:
Hence, the major problem of the DEMATEL is that if D is a singular matrix, the inverse of D is unavailable.
We return to our problem in Fig. 4 and construct the direct relation matrix, D, as the following matrix, where the degrees of all influencing relationships between criteria are set to 1 for simplicity:
Then, we can normalize the direct relation matrix and calculate the full influence matrix by Eq. (3) as follows:
Next, we can transpose \({\varvec{F}}\) and then normalize \({\varvec{F}}^{T}\) to the stochastic matrix as follows:
Similar to the ANP, we can calculate the limiting power of W to obtain the weight vector of the criteria as [C1, C2, C3, C4, C5]T = [0, 0, 0, 0, 1]T. The result is the same as that from the ANP and shows the method’s uselessness in handling the demonstrated problem, since it also considers the inflows of criteria to be the weights.
2 Weight determination by DUDM
DUDM was proposed by Huang and Inuiguchi (2015) to derive the weights of criteria by the integration of the AHP and modified DEMATEL. The procedure of the DUDM can be described as follows:
Step 1 Deriving the main weight vector, \({\varvec{v}}\), by the AHP.
Step 2 Formulating the interaction matrix, \({{\varvec{\Pi}}}\). The interaction matrix is given by the following:
where each \(\pi_{ij}\) is derived by conditional pairwise comparison as follows. Let \(a_{ij} = {{w_{i} } \mathord{\left/ {\vphantom {{w_{i} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }}\) and \(a_{kj} = {{w_{k} } \mathord{\left/ {\vphantom {{w_{k} } {w_{j} }}} \right. \kern-\nulldelimiterspace} {w_{j} }}\). The conditional pairwise comparison of \({{w_{i} } \mathord{\left/ {\vphantom {{w_{i} } {w_{k} }}} \right. \kern-\nulldelimiterspace} {w_{k} }}\) given by \(C_{j}\) can be derived as follows:
Then, we can derive the column vectors of \({{\varvec{\Pi}}}\) by using the AHP, and each column vector will be derived by a run of the AHP.
Step 3 Calculating the interaction weights of criteria. The sum of the interaction matrix of criteria can be calculated as follows:
where \(\alpha \in (0,1)\) denotes the psychological coefficient, which determines the level of decreasing psychological utility. Then, we can calculate the sum of the row of \({\varvec{S}}_{IM}\) as the interaction impact power of criteria and normalize it as the interaction weight.
Step 4 Synthesizing the weights of criteria. By setting the main and interaction weights, we can use a simple weighted method to calculate the final weights of criteria as follows:
where \(\beta\) denotes the weights of the main weight and \({\varvec{v}}\) is the main weight.
To conclude, DUDM used the simple weighted sum of the main and interaction weights to synthesize the finally weights of criteria. The main weights are derived by the AHP, and the interaction weights are modified by the DEMATEL approach by incorporating the psychological coefficient. In addition, it also suggested to use the AHP to determine the importance between the main and interaction weights.
It can be seen that the DUDM method modifies the DEMATEL approach to avoid possible divergence by adding the psychological coefficient \(\alpha\). However, the procedures of the DUDM still need to process the AHP many times to form the interaction matrix. In addition, the psychological coefficient may significantly affect the weights of criteria and still needs to be carefully chosen. Furthermore, like the ANP, it cannot reflect the importance of outflows of criteria. Next, we describe how the above issues are handled by developing the concept of network influence maps in this project.
3 Network influence Maps
Assume that a network structure is as shown in Fig. 5, where the circles denote different nodes (criteria), and q values denote the flows between nodes. We consider the importance of a criterion in terms of three factors: the amounts of inflows, outflows, and feedback flow. The weight of a criterion should consider a trade-off between the three factors. In addition, we also define the reference, R, of criterion i as the criteria which link to criterion i (e.g., criteria r and s). For example, in the link from r to i, denoted by \(r \to i\), the criterion r is the reference of criterion i.

An example network to illustrate the concept of the weight of a node
Let the status quo of criterion i be \(v_{i}\). The weight of the ith criterion at time t can be represented as a function:
where \(q_{ij}\) denotes the flow from the ith node to the jth node, \(f( \cdot )\) is a specific function which transfers the parameters to the weight, and \(w_{j} (t)\) is the weight of the jth node at time t. The network importance of the ith criterion is then calculated by.
where \(\pi_{i}\) denotes the steady state of the criterion and will be viewed as the weight of the criterion.
The inflow weight from criterion r to criterion i at time t in this paper can be defined as follows:
where \(w_{t}^{\rm in} (i,r) \in (0,1]\) and \(I_{i}\) indicates the input degree (number of inflows) of criterion i. \(\Upsilon = \{ 0,1\}\) denotes an indicator variable where \(\Upsilon = 1\) if criterion i has the feedback effect, and the feedback flow of criterion i is measured by.
Then, the outflow weight from criterion i to criterion j at time t here can be calculated as
where \(w_{t}^{\rm out} (i,j) \in (0,1]\) and \(O_{i}\) indicates the output degree (number of outflows) of criterion i. \(\Upsilon = \{ 0,1\}\) denotes an indicator variable where \(\Upsilon = 1\) if criterion i has the feedback effect, and the feedback flow of criterion i is measured by.
After obtaining the above indices, we can construct the inflow and outflow matrices, respectively, as follows:
where we reflect the influence of the feedback flows in the inflow and outflow matrices. Hence, we can rewrite Eqs. (9) and (10) as
where \({{\varvec{\uppi}}}\) denotes the weight vector in the steady state, and \({\varvec{v}}\) denotes the status quo vector of criteria, which is calculated by the AHP here.
We use the following example to demonstrate the indices defined here. This example has six criteria that contain interdependency and feedback effects between criteria, as shown in Fig. 6.

A network structure
The initial inflow and outflow matrices can be derived, respectively, as.
By using the information in \({\varvec{W}}^{\rm in} (t)\) and \({\varvec{W}}^{\rm out} (t)\), we can account for both the inflow and outflow influences of criteria and reflect these influences in the weight vector.
However, the above method cannot overcome the problem in Fig. 2. Before explaining the reason for this, we should introduce the definition of a regular stochastic matrix.
Definition 1
A stochastic matrix is called a regular stochastic matrix if there is a power of the matrix that contains only positive entries.
In other words, a stochastic matrix is regular if the nodes are connectable (irreducible) and at least one entry of the main diagonal is nonzero. Then, we can calculate the inflow and outflow matrices, respectively, for Fig. 2 as follows:
Clearly, the above two matrices are not regular. Next, we describe how to handle this situation by adding pseudonodes. We can reconsider Fig. 2 and add two pseudonodes, P1 and P2, as shown in Fig. 7.

Star structure with pseudonodes
The function of pseudonodes is to provide unlimited inflows or an unlimited container to receive outflows. The setting of pseudonodes is done to avoid the flow of a node being exhausted or a node becoming an absorbing criterion. The use of pseudonodes avoids the weight of a criterion becoming zero or one and ensures \({\varvec{W}}^{\rm in} (0)\) and \({\varvec{W}}^{\rm out} (0)\) are stochastic and regular. Hence, the flow information of the pseudonodes should be added into the inflow and outflow matrices, but they should not be considered in the result.
Before introducing the proposed method, we first explain the properties of a Markov chain as follows. Let \({\varvec{W}}\) be a column stochastic matrix and \({{\varvec{\uppi}}}\), where \({\varvec{e}}^{T} {{\varvec{\uppi}}} = 1\), be the steady-state vector of a Markov chain. To find \({{\varvec{\uppi}}}\), we solve the following equation:
Definition 2
Any linear combination of two stochastic matrices is a stochastic matrix.
Proof. Let \({\varvec{P}}_{1}\) and \({\varvec{P}}_{2}\) be two column stochastic matrices. Any linear combination of the two matrices can be presented as.
where \(\alpha \in [0,1]\). Then, we multiply both sides by \({\varvec{e}}^{T}\), where \({\varvec{e}}\) is the column vector of all ones:
Since \({\varvec{W}}^{\rm in} (t)\), \({\varvec{W}}^{\rm out} (t)\), and \({\varvec{ve}}^{T}\) are stochastic matrices, any linear combination of them is also a stochastic matrix. Hence, we can present the problem of finding \({{\varvec{\uppi}}}\) here as equivalent to solving the following equation:
where \(\alpha\) denotes the importance of the inflow matrix, \(\theta\) is the importance of the network influence, and \((1 - \theta )\) is the importance of the status quo of criteria.
Let \({\varvec{W}}(t)\user2{ = }\alpha {\varvec{W}}^{\rm in} (t) + (1 - \alpha ){\varvec{W}}^{\rm out} (t)\); we can rewrite Eq. (17) as
where \(\theta \in [0,1]\) denotes the importance of the network influence, \({\varvec{v}}\) is a column stochastic vector, and \({\varvec{e}}^{T} {\varvec{v}} = 1\).
We can rewrite Eq. (18) as
and if \(\theta \in (0,1)\), we can derive the weight vector of the criteria by.
It is well known that \(({\varvec{I}} - \theta {\varvec{W}}(t){)}^{ - 1}\) is invertible (Seneta 2006) and ensures the existence and convergence of \({{\varvec{\uppi}}}\). In addition, the NetIM method reduces to the ANP if \(\alpha = 1\) and \(\theta \to 1\), with the same stochastic matrix, and reduces to the AHP if \(\theta \to 0\).
4 Numerical examples
Here, we give three numerical examples to demonstrate the NetIM and compare the results with those from the ANP, DANP, and DUDM.
Example 1.
In this example, we reconsider Fig. 6 to derive the weights of the criteria via the NetIM and compare the result with those from the ANP and DUDM. Note that we assume that all criteria of the status quo are equal to simplify the comparisons between the methods. In addition, we set all influence levels in the ANP, DANP, and DUDM to be equal for simplicity.
Hence, the supermatrix of the ANP and the \({{\varvec{\Pi}}}\) of the DUDM can be represented as:
and the direct relation matrix of the DANP is given as:
On the other hand, we can use NetIM to derive the weights of the criteria. Note that the NetIM considers both the inflow and outflow matrices (Fig. 6), unlike the other methods which use only the inflow matrix. The comparison results are presented in Table 1.
Example 2.
Let us again reconsider Fig. 1. The weights given by the ANP and DANP have been explained, and in them, the criterion Place takes all the importance. However, these results are useless. Hence, we compare the NetIM method with DUDM as follows.
First, we assume that the pairwise comparison weights between the criteria are as follows:
Then, we can use the AHP to obtain the result as follows:
\(\user2{v = }\left[ {\begin{array}{*{20}c} {\text{Product}} \\ {\text{Price}} \\ {\text{Promotion}} \\ {\text{Place}} \\ \end{array} } \right] = \left[ {\begin{array}{*{20}c} {0.1336} \\ {0.3102} \\ {0.4948} \\ {0.0614} \\ \end{array} } \right],\) where \(\lambda_{\max }\) = 4.0788, and consistency ratio (CR) = 0.029.
By setting the different parameters of \(\alpha\) and \(\beta\), we can derive the weight vectors of the criteria by DUDM as shown in Table 2.
On the other hand, we can calculate the inflow and outflow matrices based on the network structure of Fig. 1, respectively, as follows:
Then, we can calculate the weight vectors via the NetIM method by setting different parameters, as shown in Table 2.
From Table 2, it can be seen that the proposed approach can obtain a more reasonable result than the ANP and DANP if an absorbing criterion exists. Although the DUDM approach produced results that also seem reasonable, it loses the information of the outflow matrix and results in the criterion Product being less important in any situation. By contrast, the NetIM approach can consider the information of the inflow and outflow matrices and displays different results across the weight vectors.
Example 3.
Here, we complete the problem in Fig. 2. We added two pseudonodes as shown in Fig. 7 to obtain inflow and outflow matrices, respectively, as follows:
Next, we calculate the status quo vector of criteria via the AHP. Assume that the comparison matrix is given as.
Then, we can use the eigenvalue method (EM) to obtain the eigenvector as.
The result of the CR (< 0.1) indicates that the status quo vector is rational and can be processed further. Note that since the pseudonodes should not be considered in the final result, we set the status quo values of the pseudonodes to be equal to zero. Assume that \(\alpha = 0.5\) and \(\theta = 0.5\). We can calculate the weight vector here as
Finally, we ignore the weights of the pseudonodes and normalize the other weights to 1 to obtain the final weight vector as.
Figure 2 is a simple and common network structure in practice. For example, Yilmaz and O’Connor (2012) suggested the social capital can affect helpfulness, communication transparency, social relations, and regular meetings. Labonte et al. (2016) proposed the switching behavior model which indicates demography and economy will affect service use, health status, and satisfaction. These examples showed social capital or demography and economy should play the major role in their model rather than the minor role as shown in the ANP. To our knowledge, this is the first MCDM method able to handle the problem; hence, we present only our result without other methods for comparison.
5 Discussions
Weight determination is an important issue in MCDM for correct decision-making. However, this problem is very hard due to the often-complex relationships between criteria. Although many methods, e.g., AHP, ANP, and DANP, have been proposed to capture the complex structure of criteria, these methods have different limitations in different applications.
Here, we propose a new method to deal with the problem of weight determination in a more complete and flexible way. First, we divide the influence of criteria into their inflow and outflow influences, which account for the importance of the in-degree and out-degree of a criterion. Next, we incorporate the status quo of criteria to reflect the initial weights of criteria without considering the network influence. Furthermore, we add the concept of pseudonodes to avoid situations of divergence in the method. Finally, we can derive our weight formulation and ensure the solution’s existence and uniqueness.
In addition, we demonstrated the proposed method using three numerical examples and compared the results with those from the ANP, DANP, and DUMD. The results of the examples indicate that the ANP and DANP cannot handle the absorbing criterion situation, like in Example 2, as they derived useless weights of the criteria. Although the DUMD approach can deal with the problem in Example 2, it cannot reflect the influence of the outflow matrix and loses flexibility for practical problems. Furthermore, the convergence condition of DUMD requires the interaction matrix,\({{\varvec{\Pi}}}\), to be regular. This condition also restricts the applications of DUMD to exclude possible applications like Example 3.
Hence, the advantages of NetIM can be described as follows. First, it is a complete method able to consider all available information from the network structure, including inflow and outflow matrices. Second, our method adds pseudonodes to handle the problem of a nonregular stochastic matrix, which cannot be handled by the existing methods. Third, NetIM provides the flexibility for decision-makers to adjust the parameters, i.e., \(\alpha\) and \(\theta\), to derive a satisfactory result. Fourth, the two most popular MCDM methods, i.e., AHP and ANP, are special forms of NetIM. Finally, our model ensures weight vector existence and uniqueness.
Since \(\alpha\) and \(\theta\) play important roles in determining the final result of criteria, we should provide some possible methods to determine the appropriate values of these parameters in practice. First, if the decision problem is uncertain or ambiguous, and the decision-maker’s preference is unsure, \(\alpha ,\theta = 0.5\) are rational guesses without loss any possible information. Second, if expert’s opinions are available, we can use the AHP to derive the values of \(\alpha\) and \(\theta\). Then, an expert should answer the question like “factors which affect others are __ important than affected factors“ and “network influence is __ important than the initial status.” Third, if the rank or scores of alternatives are available, e.g., collected by sample data or expert’s opinions, we can estimate the value of \(\alpha\) and \(\theta\) such that the rank/scores of criteria are most consistent with the suggested rank/scores.
In further research, NetIM can be applied to the handling of more practical problems to check its rationality and usefulness. In addition, more complicated situations, e.g., fuzzy, can be considered in the model. Finally, more MCDM methods can be compared with NetIM to verify the advantages of the model.
6 Conclusion
In this paper, we propose a novel approach, called NetIM, to determine the weights of criteria using the information of the inflow and outflow matrices with pseudonodes. We divide our model into two parts. The first part measures the network influence by considering the inflow and outflow weights. The second part considers the status quo of criteria, which is determined using the AHP. Then, we integrate the two parts to form the NetIM approach. Note that the results obtained using the proposed method may be very sensitive to values of two parameters of the method. Therefore, the choice of the parameters should be very careful. The proposed approach can overcome the problems of the (DEMATEL-based) ANP and shows more flexibility than the DUDM approach based on the results of the numerical examples.
References
Aragonés-Beltrán P, Chaparro-González F, Pastor-Ferrando JP, Pla-Rubio A (2014) An AHP (analytic hierarchy process)/ANP (analytic network process)-based multi-criteria decision approach for the selection of solar-thermal power plant investment projects. Energy 66:222–238
Büyüközkan G, Güleryüz S (2016) An integrated DEMATEL-ANP approach for renewable energy resources selection in Turkey. Int J Prod Econ 182:435–448
Chemweno P, Pintelon L, Van Horenbeek A, Muchiri P (2015) Development of a risk assessment selection methodology for asset maintenance decision making: an analytic network process (ANP) approach. Int J Prod Econ 170:663–676
Chen FH, Hsu TS, Tzeng GH (2011) A balanced scorecard approach to establish a performance evaluation and relationship model for hot spring hotels based on a hybrid MCDM model combining DEMATEL and ANP. Int J Hosp Manag 30(4):908–932
Chen YS, Chuang HM, Sangaiah AK, Lin CK, Huang WB (2019) A study for project risk management using an advanced MCDM-based DEMATEL-ANP approach. Journal of Ambient Intelligence and Humanized Computing 10(7):2669–2681
Diakoulaki D, Mavrotas G, Papayannakis L (1995) Determining objective weights in multiple criteria problems: The critic method. Comput Oper Res 22(7):763–770
Doyle JR, Green RH, Bottomley PA (1997) Judging relative importance: direct rating and point allocation are not equivalent. Organ Behav Hum Decis Process 70(1):65–72
Edwards, W. (1977), How to use multiattribute utility analysis for social decision-making. IEEE Transactions on System Man Cybernetics, SMC-7, 326–340.
Feng Y, Hong Z, Tian G, Li Z, Tan J, Hu H (2018) Environmentally friendly MCDM of reliability-based product optimisation combining DEMATEL-based ANP, interval uncertainty and Vlse Kriterijumska Optimizacija Kompromisno Resenje (VIKOR). Inf Sci 442:128–144
Hashemi SH, Karimi A, Tavana M (2015) An integrated green supplier selection approach with analytic network process and improved Grey relational analysis. Int J Prod Econ 159:178–191
Huang JJ, Inuiguchi M (2015) Diminishing utility decision model for weighting criteria. Int J Inf Technol Decis Mak 14(06):1263–1284
Hwang CL, Yoon K (1981) Multiple attribute decision-making: Methods and applications. Springer, Berlin
Keeney RL, Raiffa H (1976) Decisions with multiple objectives: preferences and value tradeoffs. Wiley, New York
Kirkwood CW (1997) Strategic decision-making: multiobjective decision analysis with spreadsheets. Duxbury Press, Belmont, CA
Labonte AJ, Benzer JK, Burgess JF, Cramer IE, Meterko M, Pogoda TK, Charns MP (2016) The effects of organization design and patient perceptions of care on switching behavior and reliance on a health care system across time. Med Care Res Rev 73(2):182–204
Leontief W (1949) Recent developments in the study of interindustrial relationships. Am Econ Rev 39(3):211–225
Liou JJ, Tzeng GH (2012) Comments on “Multiple criteria decision making (MCDM) methods in economics: an overview.” Technol Econ Dev Econ 18(4):672–695
Saaty TL (1980) The analytical hierarchy process. McGraw-Hill, New York
Saaty TL (1996) Decision making with dependence and feedback: the analytic network process. RWS Publications, Pittsburgh, PA
Seneta E (2006) Non-negative matrices and Markov chains. Springer, Berlin
Sumrit D (2019) A multi-criteria decision making model for readiness assessment of vendor managed inventory in healthcare. Int J Manag Decis Mak 18(4):376–406
Tzeng GH, Huang JJ (2011) Multiple attribute decision making: methods and applications. CRC Press, Boca Raton
Tzeng GH, Chen TY, Wang JC (1998) A weight assessing method with habitual domains. Eur J Oper Res 110(2):342–367
Wu Z, Chen Y (2007) The maximizing deviation method for group multiple attribute decision making under linguistic environment. Fuzzy Sets Syst 158(14):1608–1617
Wu Y, Wang J, Ji S, Song Z (2019) Renewable energy investment risk assessment for nations along China’s Belt & Road initiative: an ANP-cloud model method. Energy, in Press, 116381
Yilmaz M, O’Connor R (2012) Social capital as a determinant factor of software development productivity: an empirical study using structural equation modeling. Int J Hum Cap Inf Technol Prof 3(2):40–62
Funding
This study was not funded by any organizations.
Author information
Authors and Affiliations
Ethics declarations
Conflict of interest
I declare no conflict of interest.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
In Saaty’s suggestion (Saaty 1996), three conditions should be considered to obtain the limit of Wk as: 1) \(\lambda_{\max } = 1\) is a simple root and no other roots of unity exist, or, 2) there are other roots of unity that cause cycling, whether \(\lambda_{\max } = 1\) simple or multiple, and 3) \(\lambda_{\max } = 1\) is a multiple root.
In the first situation, the limiting priorities can be derived according to Sylvester’s formula as:
where \(f(\lambda ) = \lambda^{k}\) and the only root to the power k that does not tend to zero as \(k \to \infty\) in Sylvester’s formula is \(1^{k} \to 1\).
The above formula can be transformed as the following description that if the nonnegative matrix W is primitive, we can derive \(\mathop {\lim }\limits_{k \to \infty } {\varvec{W}}^{k} = {\varvec{we}}^{T}\), where \({\varvec{w}}\) is the normalized right principal eigenvector of W, i.e., \({\varvec{1^{\prime}w}} = 1\), and \({\varvec{e}}^{T}\) is the left eigenvector of W which will be the one vector, i.e., \({\varvec{e}}^{T} = {\varvec{1}}^{\prime}\).
For example, let
we can calculate the normalized right and left eigenvectors with \(\lambda_{\max } = 1\) as:
Then, we can derive the limiting priorities of the criteria as:
Situation 2) involves the cycling case of a stochastic matrix which can be handled by the Cesaro sum to obtain the limiting priorities. Surely, the proposed method can avoid the cycling problem, since we transform our problem from calculating the limiting priorities of W into deriving the inverse matrix of \(({\varvec{I}} - \theta {\varvec{W}}(t){)}\).
For situation 3), if \(\lambda_{\max } = 1\) is a multiple root, we can use Sylvester’s formula with \(\lambda_{\max } = 1\) a multiple root of multiplicity n1 to obtain the limiting priorities as follows:
where.
However, in practical way, we can derive the limiting priorities by directly calculating \(\mathop {\lim }\limits_{k \to \infty } {\varvec{W}}^{k}\) or \(({\varvec{I}} - {\varvec{W}})^{ - 1}\). However, the situation is only suitable for handling the hierarchical goal–criteria–alternative structure, i.e., a AHP problem, which is not the focus in this paper.
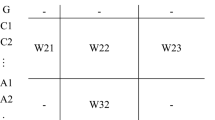
For example, we can consider a goal–criteria–alternative structure example as follows (Fig. 8 ):

A goal–criteria–alternative structure
If the stochastic matrix can be represented as:
we can derive the limiting priorities as:
where 0.4625 and 0.5375 denote the priorities of A1 and A2, respectively. Or, we can let
and calculate
to conclude the same result.
Rights and permissions
About this article

Cite this article
Huang, JJ. Determining weights of criteria via network influence maps with pseudonodes. Soft Comput 25, 9625–9637 (2021). https://doi.org/10.1007/s00500-021-05703-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-05703-7