
Abstract
Few research studies have investigated temporal kinematic swallow events in healthy adults to establish normative reference values. Determining cutoffs for normal and disordered swallowing is vital for differentially diagnosing presbyphagia, variants of normal swallowing, and dysphagia; and for ensuring that different swallowing research laboratories produce consistent results in common measurements from different samples within the same population. High-resolution cervical auscultation (HRCA), a sensor-based dysphagia screening method, has accurately annotated temporal kinematic swallow events in patients with dysphagia, but hasn’t been used to annotate temporal kinematic swallow events in healthy adults to establish dysphagia screening cutoffs. This study aimed to determine: (1) Reference values for temporal kinematic swallow events, (2) Whether HRCA can annotate temporal kinematic swallow events in healthy adults. We hypothesized (1) Our reference values would align with a prior study; (2) HRCA would detect temporal kinematic swallow events as accurately as human judges. Trained judges completed temporal kinematic measurements on 659 swallows (N = 70 adults). Swallow reaction time and LVC duration weren’t different (p > 0.05) from a previously published historical cohort (114 swallows, N = 38 adults), while other temporal kinematic measurements were different (p < 0.05), suggesting a need for further standardization to feasibly pool data analyses across laboratories. HRCA signal features were used as input to machine learning algorithms and annotated UES opening (69.96% accuracy), UES closure (64.52% accuracy), LVC (52.56% accuracy), and LV re-opening (69.97% accuracy); providing preliminary evidence that HRCA can noninvasively and accurately annotate temporal kinematic measurements in healthy adults to determine dysphagia screening cutoffs.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Establishing normative reference values for swallowing physiology across the lifespan is vital for understanding normal variation in swallowing, differentially diagnosing variants of normal swallowing such as presbyphagia vs. dysphagia, and characterizing swallowing impairments based on the underlying disease process that results in dysphagia [1, 2]. Reference values established on large sets of comparable data provide more robust assessments of performance in the population of interest against which patient data can be compared to estimate impairment severity. The variability of multiple exemplars of durational swallowing measures within subjects has been explored in middle-aged and older healthy adults [3] revealing nonsignificant but measurable differences in durational swallowing measures from swallow to swallow, highlighting the importance of obtaining multiple trials for each swallow condition during videofluoroscopic swallow studies (VFSSs) to gain a more holistic understanding of swallow function [3]. Changes in durational swallowing measures due to aging (i.e., presbyphagia) have been examined and revealed that older healthy adults have longer stage-transition duration (also referred to in the literature as “pharyngeal delay time” and “swallow reaction time”), pharyngeal transit duration, duration of upper esophageal sphincter (UES) opening, duration of laryngeal vestibule closure (LVC), and total swallowing duration compared to younger adults, all of which are recognized as typical for that population [4,5,6].
Current normative reference values have been established for temporal kinematic swallow measurements by having trained researchers/clinicians rate gold standard VFSSs using frame-by-frame analyses, or using clinical ratings tools (e.g., Modified Barium Swallow Impairment Profile [MBSImP], Penetration–Aspiration Scale [PAS]) [3, 4, 7,8,9,10,11,12]. While imaging methods are necessary to verify that specific impairments in temporal and spatial swallow kinematics are contributing to dysphagia, noninvasive dysphagia screening and assessment methods that provide some level of insight into a patient’s swallowing physiology may be useful when VFSSs are delayed, are not available/feasible within certain clinical settings, and/or are undesired by the patient. VFSSs are not always feasible or readily available when they are considered necessary, leaving clinicians to resort to management based solely on clinical assessments and their inherent limitations. Therefore, a noninvasive dysphagia screening and diagnostic adjunct that offers information about swallowing physiology could assist clinicians in managing patients who are awaiting VFSSs, patients who do not have access to VFSSs, and/or determining patients that should be referred for an instrumental swallow evaluation. Likewise, VFSSs are somewhat invasive requiring patient exposure to radiation which constrains the duration of observation of swallow function. In addition to this, few clinicians are trained in accurately performing temporal swallow kinematic measurements or have access to imaging software to perform these measurements, leading to more subjectivity in judgments of temporal measures and in some cases, over- or under-identification of patients most in need of dysphagia services to mitigate adverse events. In fact, based on a survey from speech-language pathologists (SLPs), one-third of SLP respondents conducting VFSSs reported performing frame-by-frame analysis of VFSSs “never” with another one-third indicating they used this method less than half of the time [13]. Likewise, clinical rating tools such as the MBSImP have shortcomings including time-consuming online training (20–25 h per the website) and an element of subjective judgment that is prone to drift in rater’s internal decision-making rules [8]. Although efforts are being made to establish cutoffs and severity classes using the MBSImP [14], a challenge of this rating scale is its categorical nature which introduces a degree of judgment subjectivity, and its limited ability to capture subtle changes or impairments due to broad rating categories (e.g., no movement, partial movement, or complete movement for anterior hyoid excursion).
Therefore, there is a need for a noninvasive, portable and feasible adjunct or needs-based surrogate to VFSSs that can also provide insight into physiological aspects of swallowing independent of a trained human rater. High-resolution cervical auscultation (HRCA) is a noninvasive dysphagia screening method that has been under investigation for several years that has demonstrated promise as a diagnostic adjunct to VFSSs. HRCA combines acoustic and vibratory signals from a contact microphone and a tri-axial accelerometer with advanced signal processing and machine learning techniques to measure swallow function. Although HRCA does require the use of intricate machine learning methods, one distinct advantage of HRCA is that clinicians are not needed to perform or interpret the complex signal feature analysis and machine learning algorithms. In fact, the visual representation of the raw HRCA signals provides no valuable information for clinicians to interpret about swallowing. While the signal waveforms reflect signal amplitudes and durations that are familiar to clinicians using other sensor-based modalities such as sEMG and manometry, they also contain additional information beyond their appearances such as the characteristics of the vibratory and acoustic energy generated during a swallow to that are used as inputs to the machine learning process and cannot be displayed visually because they are mathematical/statistical features of the raw signals without visual value. This line of research work represents the unique intersection of two disciplines (e.g., speech-language pathology and computer/electrical engineering) to characterize swallow function. Since HRCA is still being validated as a dysphagia screening and diagnostic adjunct to VFSSs, all swallow evaluations involve concurrent collection of VFSS images and HRCA signals, so that all HRCA signal features interpretations can be compared to the “ground truth” (e.g., expert human rater judgments of swallow function based on VFSS images). To date, studies examining HRCA’s capabilities have found that HRCA can differentiate between safe and unsafe swallows based on the PAS [15,16,17,18,19,20,21], accurately track hyoid bone movement [22, 23], identify specific temporal kinematic swallow events (e.g., UES opening, UES closure, LVC, LV re-opening) [24,25,26,27], classify swallows between healthy adults and patients post-stroke or with neurodegenerative diseases[28, 29], and classify swallows based on several MBSImP component scores [23, 26] with a high degree of accuracy in patients with suspected dysphagia using advanced signal processing and machine learning techniques. While previous studies have tested established machine learning algorithms that were trained on patients with suspected dysphagia on a small subset of healthy swallows (n = 45–50) to assess generalization to an outside dataset [23,24,25,26], no one has specifically trained and tested on healthy data alone to establish dysphagia screening cutoffs.
Few studies have established normative reference values for temporal swallow kinematic events in healthy adults across the lifespan or compared similar measurements in analogous samples of a population across research laboratories to determine consistency of measurements for pooled analyses. In addition to this, while previous research studies have examined HRCA’s ability to annotate specific temporal swallow kinematic events (e.g., LVC, UES opening duration) [24,25,26,27] in patients with suspected dysphagia, we have not previously examined HRCA’s ability to annotate temporal swallow kinematic events in healthy adults across the lifespan. Therefore, this research study aimed to determine (1) Reference values for VFSS temporal swallow kinematic events based on human judgments of VFSS images and compare these results to previously published reference values for the same measurements; (2) Whether HRCA can accurately and autonomously annotate temporal swallow kinematic events in healthy community dwelling adults across the lifespan with similar accuracy as VFSS analyses. We hypothesized that our reference values for VFSS measurements of temporal swallow kinematic events would closely align with a prior study and that HRCA signals combined with machine learning techniques would accurately and independently identify the timing of UES opening, UES closure, LVC, and LV re-opening in healthy community dwelling adults across the lifespan.
Methods
Participants, Study Procedures, and Equipment
This prospective observational study was approved by our institution’s Institutional Review Board. Seventy healthy community dwelling adults (31 males, 39 females) enrolled in this study, provided written informed consent, and generated 659 thin liquid swallows (700 swallows accrued, 41 excluded due to missing/corrupt data) that were entered into the analyses. Participant ages ranged between 21 and 87 years old (mean age 62.66 ± 14.80) with an even distribution across age ranges. Participants were eligible to participate based on the following inclusionary criteria (per participant report): no history of swallowing difficulties, no history of a neurological disorder, no prior surgery to the head or neck region, no chance of being pregnant (if female).
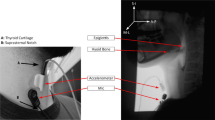
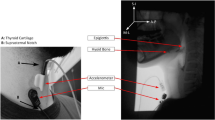
Data were prospectively collected using simultaneous accrual of VFSS data from a standard fluoroscopy system (Precision 500D system, GE Healthcare, LLC, Waukesha, WI), and from both a tri-axial accelerometer (ADXL 327, Analog Devices, Norwood, Massachusetts) that was powered by a 3 V output (model 1504, BK Precision, Yorba Linda, California), and a contact microphone. Signals from the accelerometer and the microphone were bandpass-filtered, amplified (model P55, Grass Technologies, Warwick, Rhode Island), digitized via a data acquisition device (National Instruments 6210 DAQ) through the Signal Express program in LabView (National Instruments, Austin, Texas), and then down sampled from 20 kHz to 4 kHz to smooth the transient (high frequency) noise components. All participants underwent standardized VFSSs to minimize radiation exposure (average fluoro time 0.77 s. to accrue 10 swallows). VFSSs were performed with concurrent HRCA and images were obtained in the lateral plane. VFSSs were conducted at a pulse rate of 30 pulses per second (PPS). Video signals and HRCA signals were captured at a higher sampling rate (73 frames per second) per Shannon’s sampling theorem [30] (AccuStream Express HD, Foresight Imaging, Chelmsford, MA) and then later down sampled to 30 FPS. The noninvasive HRCA sensors were placed on the anterior laryngeal framework and can be viewed in Fig. 1 [15, 31]. VFSS procedures consisted of 10 thin liquid boluses of Varibar barium (Bracco Diagnostics, Inc., < 5 cPs viscosity; International Dysphagia Diet Standardization Initiative level 0). Five boluses were 3 mL by spoon and 5 boluses were self-selected comfortable cup sips in a randomized order. When presented thin liquid boluses by spoon, participants were instructed to “Hold the liquid in your mouth and wait until I tell you to swallow it.” When presented thin liquid boluses by cup, participants were given a graduated cylinder containing 60 mL and were instructed to “Take a comfortable sip of liquid and swallow it whenever you’re ready.” VFSS recording durations spanned from the onset of oral transit through bolus clearance through the UES and the return to rest of the hyolaryngeal complex, while HRCA continuously recorded signals during and between swallows to ensure that all components of all swallow segments were accrued. Bolus characteristics for all swallows included in the data analyses for this study can be viewed in Table 1. Average cup sip volume for comfortable cup sips was 16.05 mL (± 9.21).

Placement of HRCA sensors during data collection
Historical Cohort Comparison Data
We used a subset of data from a recent publication examining temporal swallow kinematic events in healthy community dwelling adults using thin to extremely thick liquids as comparison data [12].Since the dataset from our lab included only thin liquid swallows, we included only the thin liquid swallows from this historical cohort (38 participants—19 each females and males, 114 swallows). The age of participants in this study ranged from 21 to 58 years of age (mean 34). Participants swallowed three thin liquid boluses by comfortable cup sip from a cup containing 40 mL with an average sip volume of 12.13 mL (± 6.68). Cup weight was taken before and after sips and was used to calculate sip volume in milliliters.
Temporal Swallow Kinematic Analyses
Trained raters underwent standardized training and subsequent inter and intra-rater reliability tests returning intra-class coefficients (ICCs)[32] of at least 0.9 before conducting temporal swallow kinematic analyses. Temporal swallow kinematic measurements for this study included recording the digital timer values for the following events: bolus passes the mandible, onset of maximal hyoid excursion (labeled in other studies as “hyoid burst”), hyoid return to rest, onset of UES opening, onset of UES closure, LVC onset, and LV re-opening onset. The definition for all temporal swallow kinematic events coded can be viewed in Table 2. Two trained raters conducted temporal swallow kinematic measurements on all swallows included for data analyses with ongoing testing of intra-rater reliability within a three-frame tolerance (0.1 s). Intra-rater reliability was maintained throughout analyses of this large dataset by randomly selecting one swallow to re-code every ten swallows. A third trained rater performed inter-rater reliability on 10% of swallows with ICCs of 0.992.
Data Analyses
A biostatistician (SP) fit a linear mixed model to determine statistical significance, and calculated effect sizes to determine clinical significance using a variation of Cohen’s d to compare the average magnitude of the temporal swallow kinematic measures to the historical cohort’s temporal swallow kinematic measures.
HRCA Signal Features Analysis and Machine Learning Algorithms
While our lab always obtains both acoustic and vibratory signals from the contact microphone and tri-axial accelerometer during data collection because they have been shown to contribute different and complementary information, we do not always use both acoustic and vibratory signals for analyses [33]. For example, in the present study we developed the machine learning algorithm for UES opening and UES closure using only the accelerometer HRCA signal features, while for the LVC machine learning algorithm we used HRCA signal features from the contact microphone and the accelerometer because they produced superior alignment with the human judgments.
To determine when UES opening and UES closure occurred during the swallow using HRCA, we built a convolutional recurrent neural network (CRNN) with two convolutional layers, two max pooling layers, three recurrent neural network layers, and 4 fully connected layers. The CRNN used the accelerometer signals as input. A summary of the HRCA signal features extracted can be viewed in Table 3. The specific details of this network are described in our previous publications [25,26,27]. The dataset was randomly divided into 10 equal groups to evaluate the CRNN using a tenfold cross-validation scheme. Therefore, the data was divided into 10 groups of ~ 66 swallows each. Nine groups were used to train the CRNN (~ 593 swallows) and one group was used to test the CRNN (66 swallows). This process was repeated until each group of swallows was used for testing at least once. The accuracy, sensitivity, and specificity of the CRNN was determined by calculating the difference between the CRNN’s predicted measurements and the “ground truth” (human measurements of UES opening and closing using VFSS images) (See Fig. 2).

Evaluation procedure for comparing the accuracy of (a) human measurements of UES opening and closure and (b) the CRNN measurements of UES opening and closure by (c) calculating the difference between human measurements and the CRNN measurements. TN true negative, FP false positive, TP true positive
To determine when LVC and LV re-opening occurred during the swallow, a CRNN model was built with two convolutional neural network layers, two max pooling layers, two recurrent neural network layers, 3 fully connected layers for decision making, using the HRCA signals as input. The specific details of this CRNN are described in our previous publication [24]. Similar to the UES opening and closing CRNN, the LVC and LV re-opening CRNN used tenfold cross-validation for training and testing the performance of the CRNN. The accuracy, sensitivity, and specificity of the CRNN was determined by calculating the difference between the CRNN’s predicted measurements and the “ground truth” (human measurements of LVC and LV re-opening using VFSS images) (See Fig. 3).

Evaluation procedure for comparing the accuracy of (a) human measurements of LVC and LV re-opening and (b) the CRNN measurements of LVC and LV re-opening by (c) calculating the difference between human measurements and the CRNN measurements. TN true negative, FP false positive, TP true positive
Results
Comparison to previously published historical healthy cohort:
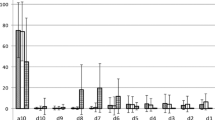
Results revealed that measurements of swallow reaction time and LVC duration from our lab were not significantly different (p > 0.05) from the previously published historical cohort. There were statistically significant differences between measurements from our lab and the historical cohort for hyoid onset to UES opening, duration of UES opening, and LVC reaction time (p < 0.05). Small effect sizes were found for hyoid onset to UES opening and LVC duration (d = 0.290 and 0.103 respectively), a moderate effect size (d = 0.495) was found for swallow reaction time, a moderate-large effect size for duration of UES opening (d = 0.702), and a large effect size (d = 2.40) for LVC reaction time. A summary of the descriptive statistics for the temporal swallow kinematic measures for our lab and the historical cohort and the complete results of the linear mixed model and effect size results can be viewed in Tables 4 and 5.
HRCA and Machine Learning Algorithm Results
Across the entire healthy community dwelling adult dataset, the CRNN for UES opening and closure performed with 88.53% accuracy, 88.37% sensitivity, and 89.44% specificity. When comparing the performance of the CRNN to human measurements of VFSS images, the CRNN identified UES opening within a 3-frame tolerance for 69.96% of swallows and UES closure for 64.52% of swallows (See Figs. 4 and 5). When examining the CRNN for LVC and LV re-opening across the entire healthy community dwelling adult dataset, the CRNN performed with 81.14% accuracy, 76.83% sensitivity, and 85.45% specificity. Compared to human measurements of LVC and LV re-opening based on VFSS images, the CRNN identified LVC within a 3-frame tolerance for 52.56% of swallows and LV re-opening for 69.97% of swallows (See Figs. 6 and 7).

Accuracy of the CRNN for detecting UES opening within a 3-frame (0.1 s tolerance) compared to human measurements of UES opening for the healthy community dweller dataset

Accuracy of the CRNN for detecting UES closure within a 3-frame (0.1 s tolerance) compared to human measurements of UES closure for the healthy community dweller dataset

Accuracy of the CRNN for detecting LVC within a 3-frame (0.1 s tolerance) compared to human measurements of LVC for the healthy community dweller dataset

Accuracy of the CRNN for detecting LV re-opening within a 3-frame (0.1 s tolerance) compared to human measurements of LV re-opening for the healthy community dweller dataset
Discussion
This research study found that some of our lab’s temporal swallow kinematic reference values closely matched the reference values of a historical cohort [12] and that our machine learning algorithms that used only HRCA signal features as input could autonomously identify the onsets of UES opening, UES closure, LVC, and LV re-opening with similar accuracy as human VFSS judgments of these temporal kinematic events in a group of healthy community dwelling adults across the lifespan. The accuracy of HRCA analyses combined with machine learning algorithms is made more attractive as a potential surrogate to VFSS due to its efficiency compared to traditional judgment by human judges, particularly when VFSS or other imaging-based gold standard testing is unavailable. For example, the CRNN for UES opening and closure can analyze 150 swallows in approximately 42 s compared to a human judge that would take approximately 2 min per swallow for a total of 5 h. While we found differences in hyoid onset to UES opening, duration of UES opening, and LVC reaction time (p < 0.05) between our lab’s dataset and the historical cohort’s dataset, it is likely these differences may have occurred due to age differences between the two groups or due to differences in methods (i.e., starting cup volume of 60 mL vs. 40 mL). This is in line with previous studies that have found that older adults exhibit longer durations for temporal swallow kinematic events and greater variability for swallowing [4,5,6,7]. Alternatively, these differences may exist due to differences in coding temporal kinematic measurements between research labs. This highlights a need for increased transparency between research labs in order to standardize measurements and terminology to allow for equivalent comparisons across research studies for pooled data analyses in similar samples.
In addition to this, the high accuracy of the machine learning algorithms we deployed using HRCA signals alone as input, add to a growing body of literature demonstrating HRCA’s promise as a dysphagia screening method and diagnostic adjunct to VFSSs [15,16,17,18,19,20,21,22,23,24,25,26, 28, 29]. Despite nonsignificantly but better performance of the HRCA algorithms that were trained and tested in previous studies of patients with dysphagia [24,25,26] compared to our current results derived from the healthy community dwelling adult dataset, both machine learning algorithms correctly identified temporal kinematic events (e.g., UES opening, UES closure, LVC, LV re-opening) with remarkably high accuracy given that they identified these events using HRCA signals alone and without any human supervision. In fact, we anticipated better performance accuracy on the patient dataset compared to the healthy community dweller dataset, because machine learning algorithms perform more robustly with large sets of variable data in which more impairments are present throughout the dataset. In addition to this, the CRNN for UES opening and closure had better accuracy than the CRNN for LVC and LV re-opening. These findings are in line with previous results from our lab that trained and tested these machine learning algorithms on patients with dysphagia [24,25,26,27, 34]. There are several potential reasons for this discrepancy in performance accuracy. Human ratings of LVC and LV re-opening within our lab tend to have greater inter and intra-rater variability than ratings of UES opening and closure, which may impact the accuracy of the CRNNs since machine learning algorithms are dependent on the training data provided and are compared to the “ground truth” for accuracy (in this case, human ratings of VFSS images). On the other hand, machine learning algorithms tend to perform more accurately with more chaos and increased variability in the data. As such, it’s possible that there was greater variability in measurements of UES opening and closure than in measurements of LVC and LV re-opening for this group of healthy adults, leading to improved performance of the machine learning algorithm of UES opening and closure. Additionally, the durations of these two events (e.g., duration of UES opening, LVC duration) are both quite short, which leaves little room for error when humans (or machines) judge temporal kinematic swallow events. Further, LVC duration is briefer than the duration of UES opening, introducing greater opportunity for error.
Despite some of these limitations, the results of this research study expand upon previous findings in our lab by demonstrating that HRCA combined with signal processing and machine learning techniques can not only accurately annotate specific temporal swallow kinematic events in healthy community dwelling adults and patients with suspected dysphagia, but it can do so with greater efficiency than traditional analysis methods without compromising accuracy. The current results from healthy participants adds to the ability of HRCA to classify typical vs. atypical swallow physiology in people with dysphagia when deploying HRCA within clinical settings in the future. While our research lab is eager to deploy HRCA as a dysphagia screening and diagnostic adjunct to VFSSs within clinical settings, it is important to note that we are still in the process of miniaturizing our HRCA system and finalizing all machine learning algorithms so that HRCA is an easily transportable evaluation tool that efficiently provides results to clinicians via everyday devices such as tablets and smart phones. Additionally, while HRCA does involve the collection of raw acoustic and vibratory signals from a contact microphone and a tri-axial accelerometer, the visual inspection of these raw waveforms does not have any clinical utility. Our HRCA system does not depend on the interpretation of swallowing sounds by human judges. In fact, we do not use the raw acoustic and vibratory signals for interpreting swallowing events at all. As described in the methods section of our paper, we filter and amplify aspects of the raw HRCA signals before extracting statistical features from the signals that are used for analyses (see Table 3). After feature analyses are performed, we use the HRCA signal features as input to machine learning algorithms to detect swallowing events. Therefore, in the future when HRCA is deployed within clinical settings, clinicians will not be responsible for visual inspection and interpretation of HRCA signals like they are when they perform VFSSs. Instead, clinicians will place the sensors on patients and receive the HRCA results of the autonomous machine learning algorithms on their smart phone or tablet.
Future work should expand upon the findings from this research study by establishing normative reference values for temporal swallow kinematic events in healthy community dwelling adults using additional bolus viscosities (e.g., thick liquids, puree, regular texture solids). In addition to this, future studies may aim to determine normative reference values for spatial swallow kinematic events in healthy community dwelling adults (e.g., hyoid bone and laryngeal displacement, UES diameter). Future studies should include a larger sample of swallows accrued from multiple sites using identical methods to assist in enhancing the performance of the machine learning algorithms and should investigate the efficacy of utilizing HRCA contemporaneously in clinical settings that require immediate dysphagia screening and diagnostic output.
Limitations
We prospectively collected and compared the temporal swallow kinematic measures from our lab to a historical cohort of data, which is an imperfect comparison since using historical data can introduce bias or confounding variables. While we attempted to control for confounding variables that could result in differences between our dataset and the historical cohort dataset (e.g., bolus viscosity), the methods of these two studies were not exactly the same (i.e., starting cup volume of 60 mL vs. 40 mL for comfortable cup sips, command swallows and comfortable cup sips in our dataset). In addition to this, the healthy community dwelling adults enrolled in our study were older on average (62.66 ± 14.80) than the historical cohort (34). These methodological and individual participant differences may have contributed to the differences and large effect sizes we observed in some temporal kinematic swallow measurements since healthy older adults have been shown to have longer durations and greater variability in swallowing than healthy younger adults [4,5,6,7]. In addition to this, we conducted standardized VFSSs with only thin liquid boluses to minimize radiation exposure for healthy community dwelling adults. This limits the generalizability of our findings to other bolus conditions and clinical settings since our normative reference values were established using a set protocol of only thin liquid swallows. Likewise, the machine learning algorithms for UES opening, UES closure, LVC, and LV re-opening were established on a dataset of only thin liquid swallows. While we included a relatively large dataset of swallows for this preliminary research study, it will be important to replicate this work with various bolus viscosities to establish normative reference values and to ascertain that the machine learning algorithms remain consistent across bolus conditions. Furthermore, while the CRNNs we developed identified temporal swallow kinematic events with an overall high degree of accuracy, machine learning performance improves with greater variability/chaos and more data. Therefore, it is vital to continue to improve the algorithms we have developed by adding swallows to our database from healthy community dwelling adults and patients across the lifespan. This will assist us as we explore the ability to deploy these machine learning algorithms in clinical settings in real-time to differentiate between patients with normal or disordered swallowing.
Conclusion
This study found that some of the temporal swallow kinematic reference values from our lab closely matched the reference values from a historical cohort. It also expanded upon previous research studies in our lab by providing preliminary evidence that HRCA signals combined with advanced machine learning techniques can accurately identify specific temporal swallow kinematic events (e.g., UES opening, UES closure, LVC, LV re-opening) in healthy community dwelling adults across the lifespan. Developing CRNNs that can accurately differentiate between swallows from healthy community dwelling adults vs. swallows from patients with dysphagia using cutoffs for specific temporal swallow kinematic events will be a useful enhancement to current dysphagia screening methods within clinical settings. Future studies should replicate and expand upon this work to generate a large database of healthy swallows across the lifespan to assist in differentially diagnosing presbyphagia and dysphagia. In addition to this, future studies should aim to improve the accuracy of the machine learning algorithms for detecting temporal swallow kinematic events and should investigate the ability to provide dysphagia screening results in real-time at the bedside within a variety of clinical settings.
References
Humbert IA, Robbins J. Dysphagia in the elderly. Phys Med Rehabil Clin N Am. 2008;19(4):853–66. https://doi.org/10.1016/j.pmr.2008.06.002.
Namasivayam-MacDonald AM, Riquelme LF. Presbyphagia to dysphagia: multiple perspectives and strategies for quality care of older adults. Semin Speech Lang. 2019;40:227–42. https://doi.org/10.1055/s-0039-1688837.
Lof GL, Robbins J. Test-retest variability in normal swallowing. Dysphagia. 1990;4:236–42. https://doi.org/10.1007/BF02407271.
Robbins J, Hamilton JW, Lof GL, Kempster GB. Oropharyngeal swallowing in normal adults of different ages. Gastroenterology. 1992;103:823–9.
Mancopes R, Gandhi P, Smaoui S, Steele CM. Which physiological swallowing parameters change with healthy aging? OBM Geriat. 2021. https://doi.org/10.21926/obm.geriatr.2101153.
Jardine M, Miles A, Allen J. A systematic review of physiological changes in swallowing in the oldest old. Dysphagia. 2020;35:509–32. https://doi.org/10.1007/s00455-019-10056-3.
Humbert IA, Sunday KL, Karagiorgos E, Vose AK, Gould F, Greene L, et al. Swallowing kinematic differences across frozen, mixed, and ultrathin liquid boluses in healthy adults: age, sex, and normal variability. J Speech Lang Hear Res. 2018;61:1544–59. https://doi.org/10.1044/2018_JSLHR-S-17-0417.
Martin-Harris B, Brodsky MB, Michel Y, Castell DO, Schleicher M, Sandidge J, et al. MBS measurement tool for swallow impairment–MBSImp: establishing a standard. Dysphagia. 2008;23:392–405. https://doi.org/10.1007/s00455-008-9185-9.
Mulheren RW, Azola AM, Kwiatkowski S, Karagiorgos E, Humbert I, Palmer JB, et al. Swallowing changes in community-dwelling older adults. Dysphagia. 2018;33:848–56. https://doi.org/10.1007/s00455-018-9911-x.
Robbins J, Coyle J, Rosenbek J, Roecker E, Wood J. Differentiation of normal and abnormal airway protection during swallowing using the penetration-aspiration scale. Dysphagia. 1999;14:228–32. https://doi.org/10.1007/PL00009610.
Garand KLF, Hill EG, Amella E, Armeson K, Brown A, Martin-Harris B. Bolus airway invasion observed during videofluoroscopy in healthy, non-dysphagic community-dwelling adults. Ann Otol Rhinol Laryngol. 2019;128:426–32. https://doi.org/10.1177/0003489419826141.
Steele CM, Peladeau-Pigeon M, Barbon CAE, Guida BT, Namasivayam-MacDonald AM, Nascimento WV, et al. Reference values for healthy swallowing across the range from thin to extremely thick liquids. J Speech Lang Hear Res. 2019;62:1338–63. https://doi.org/10.1044/2019_JSLHR-S-18-0448.
Vose AK, Kesneck S, Sunday K, Plowman EK, Humbert I. A survey of clinician decision making when identifying swallowing impairments and determining treatment. J Speech Lang Hear Res. 2018;61:2735–56. https://doi.org/10.1044/2018_JSLHR-S-17-0212.
Beall J, Hill EG, Armeson K, Garand KLF, Davidson KH, Martin-Harris B. Classification of physiologic swallowing impairment severity: a latent class analysis of modified barium swallow impairment profile scores. Am J Speech Lang Pathol. 2020;29:1001–11. https://doi.org/10.1044/2020_AJSLP-19-00080.
Dudik JM, Coyle JL, Sejdić E. Dysphagia screening: contributions of cervical auscultation signals and modern signal-processing techniques. IEEE Trans Hum Mach Syst. 2015;45:465–77. https://doi.org/10.1109/THMS.2015.2408615.
Sejdić E, Steele CM, Chau T. Classification of penetration–aspiration versus healthy swallows using dual-axis swallowing accelerometry signals in dysphagic subjects. IEEE Trans Biomed Eng. 2013;60:1859–66. https://doi.org/10.1109/TBME.2013.2243730.
Dudik JM, Jestrovic I, Luan B, Coyle JL, Sejdic E. A comparative analysis of swallowing accelerometry and sounds during saliva swallows. Biomed Eng Online. 2015;14(1):3.
Dudik JM, Kurosu A, Coyle JL, Sejdić E. A comparative analysis of DBSCAN, K-means, and quadratic variation algorithms for automatic identification of swallows from swallowing accelerometry signals. Comput Biol Med. 2015;59:10–8. https://doi.org/10.1016/j.compbiomed.2015.01.007.
Jestrović I, Dudik JM, Luan B, Coyle JL, Sejdić E. Baseline characteristics of cervical auscultation signals during various head maneuvers. Comput Biol Med. 2013;43:2014–20. https://doi.org/10.1016/j.compbiomed.2013.10.005.
Dudik JM, Coyle JL, El-Jaroudi A, Mao Z-H, Sun M, Sejdić E. Deep learning for classification of normal swallows in adults. Neurocomputing. 2018;285:1–9. https://doi.org/10.1016/j.neucom.2017.12.059.
Yu C, Khalifa Y, Sejdic E. Silent aspiration detection in high resolution cervical auscultations. IEEE EMBS Int Conf Biomed Health Inform (BHI). 2019;1–4.
Mao S, Zhang Z, Khalifa Y, Donohue C, Coyle JL, Sejdic E. Neck sensor-supported hyoid bone movement tracking during swallowing. R Soc Open Sci. 2019;6:181982. https://doi.org/10.1098/rsos.181982.
Donohue C, Mao S, Sejdić E, Coyle JL. Tracking hyoid bone displacement during swallowing without videofluoroscopy using machine learning of vibratory signals. Dysphagia. 2020. https://doi.org/10.1007/s00455-020-10124-z.
Mao S, Sabry A, Khalifa Y, Coyle JL, Sejdic E. Estimation of laryngeal closure duration during swallowing without invasive X-rays. Future Gener Comput Syst. 2021;115:610–8. https://doi.org/10.1016/j.future.2020.09.040.
Khalifa Y, Donohue C, Coyle JL, Sejdic E. Upper esophageal sphincter opening segmentation with convolutional recurrent neural networks in high resolution cervical auscultation. IEEE J Biomed Health Inform. 2020. https://doi.org/10.1109/JBHI.2020.3000057.
Donohue C, Khalifa Y, Perera S, Sejdić E, Coyle JL. How closely do machine ratings of duration of UES opening during videofluoroscopy approximate clinician ratings using temporal kinematic analyses and the mbsimp? Dysphagia. 2020. https://doi.org/10.1007/s00455-020-10191-2.
Khalifa Y, Donohue C, Coyle J, Sejdic E. On the robustness of high-resolution cervical auscultation-based detection of upper esophageal sphincter opening duration in diverse populations. Proc. SPIE 11730, Big Data III: Learning, Analytics, and Applications. 2021;117300M.
Kurosu A, Coyle JL, Dudik JM, Sejdic E. Detection of swallow kinematic events from acoustic high-resolution cervical auscultation signals in patients with stroke. Arch Phys Med Rehabil. 2019;100:501–8. https://doi.org/10.1016/j.apmr.2018.05.038.
Donohue C, Khalifa Y, Perera S, Sejdić E, Coyle JL. A preliminary investigation of whether HRCA signals can differentiate between swallows from healthy people and swallows from people with neurodegenerative diseases. Dysphagia. 2020. https://doi.org/10.1007/s00455-020-10177-0.
Oppenheim AV, Schafer RW, Buck JR. Discrete-Time Signal Processing. 2nd ed. Upper Saddle River, New Jersey: Prentice Hall Inc; 1999.
Takahashi K, Groher ME, Michi K. Methodology for detecting swallowing sounds. Dysphagia. 1994;9:54–62. https://doi.org/10.1007/BF00262760.
Shrout PE, Fleiss JL. Intraclass correlations: Uses in assessing rater reliability. Psychol Bull. 2005;86(2):420–28.
Dudik JM, Jestrović I, Luan B, Coyle JL, Sejdić E. A comparative analysis of swallowing accelerometry and sounds during saliva swallows. Biomed Eng Online. 2015;14:3. https://doi.org/10.1186/1475-925X-14-3.
Sabry A, Mahoney AS, Mao S, Khalifa Y, Sejdić E, Coyle JL. Automatic estimation of laryngeal vestibule closure duration using high-resolution cervical auscultation signals. Perspect ASHA Spec. 2020;5:1647–56. https://doi.org/10.1044/2020_PERSP-20-00073 (Interest Groups).
Acknowledgements
People: Thanks are due to Tara Smyth, M.A., Dan Kachnycz, B.A., and Erin Lucatorto, M.A. for assistance with data collection and coding.
Funding
Research reported in this publication was supported by the Eunice Kennedy Shriver National Institute of Child Health & Human Development of the National Institutes of Health under Award Number R01HD092239, while the data was collected under Award Number R01HD074819. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We have no conflicts of interest to declare.
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Donohue, C., Khalifa, Y., Mao, S. et al. Establishing Reference Values for Temporal Kinematic Swallow Events Across the Lifespan in Healthy Community Dwelling Adults Using High-Resolution Cervical Auscultation. Dysphagia 37, 664–675 (2022). https://doi.org/10.1007/s00455-021-10317-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00455-021-10317-0