
Abstract
The geometric problem of estimating an unknown compact convex set from evaluations of its support function arises in a range of scientific and engineering applications. Traditional approaches typically rely on estimators that minimize the error over all possible compact convex sets; in particular, these methods allow for limited incorporation of prior structural information about the underlying set and the resulting estimates become increasingly more complicated to describe as the number of measurements available grows. We address both of these shortcomings by describing a framework for estimating tractably specified convex sets from support function evaluations. Building on the literature in convex optimization, our approach is based on estimators that minimize the error over structured families of convex sets that are specified as linear images of concisely described sets—such as the simplex or the spectraplex—in a higher-dimensional space that is not much larger than the ambient space. Convex sets parametrized in this manner are significant from a computational perspective as one can optimize linear functionals over such sets efficiently; they serve a different purpose in the inferential context of the present paper, namely, that of incorporating regularization in the reconstruction while still offering considerable expressive power. We provide a geometric characterization of the asymptotic behavior of our estimators, and our analysis relies on the property that certain sets which admit semialgebraic descriptions are Vapnik–Chervonenkis classes. Our numerical experiments highlight the utility of our framework over previous approaches in settings in which the measurements available are noisy or small in number as well as those in which the underlying set to be reconstructed is non-polyhedral.
Similar content being viewed by others
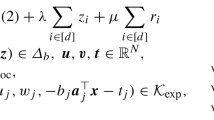


Avoid common mistakes on your manuscript.
1 Introduction
We consider the problem of estimating a compact convex set given (possibly noisy) evaluations of its support function. Formally, let \(K^{\star } \subset {\mathbb {R}}^d\) be a set that is compact and convex. The support function \(h_{K^{\star }}(u)\) of the set \(K^{\star }\) evaluated in the direction \(u\in S^{d-1}\) is defined as
Here \(S^{d-1} := \{ x\mid \Vert x\Vert _2 = 1 \} \subset {\mathbb {R}}^d\) denotes the \((d-1)\)-dimensional unit sphere. In words, the quantity \(h_{K^{\star }} (u)\) measures the maximum displacement in the direction \(u\) intersecting \(K^{\star }\). Given noisy support function evaluations \(\{ (u^{(i)}, y^{(i)} )\mid y^{(i)} = h_{K^{\star }} (u^{(i)}) + \varepsilon ^{(i)},\, 1 \le i \le n \}\), where each \(\varepsilon ^{(i)}\) denotes additive noise, our goal is to reconstruct a convex set \({\hat{K}}\) that is close to \(K^{\star }\).
The problem of estimating a convex set from support function evaluations arises in a wide range of problems such as computed tomography [24], target reconstruction from laser-radar measurements [18], and projection magnetic resonance imaging [13]. For example, in tomography the extent of the absorption of parallel rays projected onto an object provides support information [24, 30], while in robotics applications support information can be obtained from an arm clamping onto an object in different orientations [24]. A natural approach to fit a compact convex set to support function data is the following least-squares estimator (LSE):
An LSE always exists and it is not defined uniquely, although it is always possible to select a polytope that is an LSE; this is the choice that is most commonly employed and analyzed in prior work. For example, the algorithm proposed by Prince and Willsky [24] for planar convex sets reconstructs a polygonal LSE described in terms of its facets, while the algorithm proposed by Gardner and Kiderlen [10] for convex sets in any dimension provides a polytopal LSE reconstruction described in terms of extreme points. The least-squares estimator \({\hat{K}}^{\mathrm {LSE}}_n\) is a consistent estimator of \(K^\star \), but it has a number of significant drawbacks. In particular, as the formulation (1) does not incorporate any additional structural information about \(K^\star \) beyond convexity, the estimator \({\hat{K}}^{\mathrm {LSE}}_n\) can provide poor reconstructions when the measurements available are noisy or small in number. The situation is problematic even when the number of measurements available is large, as the complexity of the resulting estimate grows with the number of measurements in the absence of any regularization due to the regression problem (1) being non-parametric (the collection of all compact convex sets in \({\mathbb {R}}^d\) is not finitely parametrized); consequently, the facial structure of the reconstruction provides little information about the geometry of the underlying set.Footnote 1 Finally, if the underlying set \(K^\star \) is not polyhedral, a polyhedral choice for the solution \({\hat{K}}^{\mathrm {LSE}}_n\) (as is the case with much of the literature on this topic) can provide poor reconstructions. Indeed, even for intrinsically “simple” convex bodies such as the Euclidean ball, one necessarily requires many vertices or facets to obtain accurate polyhedral approximations. Figure 1 provides an illustration of these points.
1.1 Our Contributions
To address the drawbacks underlying the least-squares estimator, we seek a framework that regularizes the complexity of the reconstruction in the formulation (1). A natural approach to developing such a framework is to design an estimator with the same objective as in (1) but in which the decision variable \(K\) is constrained to lie in a subclass \({\mathcal {F}}\) of the collection of all compact, convex sets. For such a method to be useful, the subclass \({\mathcal {F}}\) must balance several considerations. First, \({\mathcal {F}}\) should be sufficiently expressive in order to faithfully model various attributes of convex sets that arise in applications (for example, sets consisting of both smooth and singular features in their boundary). Second, the elements of \({\mathcal {F}}\) should be suitably structured so that incorporating the constraint \(K\in {\mathcal {F}}\) leads to estimates that are more robust to noise; further, the type of structure underlying the sets in \({\mathcal {F}}\) also informs the analysis of the statistical properties of the constrained analog of (1) as well as the development of efficient algorithms for computing the associated estimate. Building on the literature on lift-and-project methods in convex optimization [12, 34], we consider families \({\mathcal {F}}\) in which the elements are specified as images under linear maps of a fixed ‘concisely specified’ compact convex set; the choice of this set governs the expressivity of the family \({\mathcal {F}}\) and we discuss this in greater detail in the sequel. Due to the availability of computationally tractable procedures for optimization over linear images of concisely described convex sets [21], the study of such descriptions constitutes a significant topic in optimization. We employ these ideas in a conceptually different context in the setting of the present paper, namely that of incorporating regularization in the reconstruction, which addresses many of the drawbacks with the LSE outlined previously. Formally, we consider the following regularized convex set regression problem:
Here \(C\subset {\mathbb {R}}^q\) is a user-specified compact convex set and \(L({\mathbb {R}}^{q},{\mathbb {R}}^d)\) denotes the set of linear maps from \({\mathbb {R}}^q\) to \({\mathbb {R}}^d\). The set \(C\) governs the expressive power of the family \(\{A(C)\mid A \in L({\mathbb {R}}^{q},{\mathbb {R}}^d)\}\). In addition to this consideration, our choices for \(C\) are also driven by statistical and computational aspects of the estimator (2). Our analysis of the statistical properties of the estimator (2) relies in part on the observation that sets \({\mathcal {F}}\) that admit certain semialgebraic descriptions form VC classes; this fact serves as the foundation for our characterization based on stochastic equicontinuity of the asymptotic properties of the estimator \({\hat{K}}_n^{C}\) as \(n \rightarrow \infty \). On the computational front, the algorithms we propose for (2) require that the support function associated to \(C\) as well as its derivatives (when they exist) can be computed efficiently. Motivated by these issues, the choices of \(C\) that we primarily discuss in our examples and numerical illustrations are the simplex and the spectraplex:
Example
The simplex in \({\mathbb {R}}^q\) is the set
where \(1= (1,\ldots ,1)^{T}\). Convex sets expressed as projections of \(\Delta ^{q}\) are precisely polytopes with at most q extreme points.
Example
Let \({\mathbb {S}}^p \cong {\mathbb {R}}^{p+1 \atopwithdelims ()2}\) denote the space of \(p \times p\) real symmetric matrices. The spectraplex \({\mathcal {O}}^{p} \subset {\mathbb {S}}^p\) (also called the free spectrahedron) is the set
where \(I \in {\mathbb {S}}^p\) is the identity matrix. The spectraplex is a semidefinite analog of the simplex, and it is especially useful if we seek non-polyhedral reconstructions, as can be seen in Fig. 1 and in Sect. 5; in particular, linear images of the spectraplex exhibit both smooth and singular features in their boundaries.
The specific selection of \(C\) from the families \(\{\Delta ^{q}\}_{q=1}^\infty \) and \(\{{\mathcal {O}}^p\}_{p=1}^\infty \) is governed by the complexity of the reconstruction one seeks, which is typically based on prior information about \(K^\star \). Our analysis in Sect. 3 of the statistical properties of the estimator (2) relies on the availability of such additional knowledge about the complexity of \(K^\star \). In practice in the absence of such information, cross-validation may be employed to obtain a suitable reconstruction; see Sect. 6.
In Sect. 2 we discuss preliminary aspects of our technical setup such as properties of the set of minimizers of the problem (2) as well as a stylized probabilistic model for noisy support function evaluations. These serve as a basis for the subsequent development in the paper. In Sect. 3 we provide the main theoretical guarantees of our approach. In our first result, we show that the sequence of estimates \(\{{\hat{K}}_n^{C}\}_{n=1}^{\infty }\) converges almost surely (as \(n \rightarrow \infty \)) in the Hausdorff metric to that linear image of \(C\) which is closest to the underlying set \(K^{\star }\) (see Theorem 3.1). Under additional conditions, we also characterize certain asymptotic distributional aspects of the sequence \(\{{\hat{K}}_n^{C}\}_{n=1}^{\infty }\) (see Theorem 3.4); this result is based on a functional central limit theorem, which requires the computation of appropriate entropy bounds for Vapnik–Chervonenkis (VC) classes of sets that admit semialgebraic descriptions, and it is here that our choice of \(C\) as either a simplex or a spectraplex plays a prominent role. Our third result describes the facial structure of \(\{{\hat{K}}_n^{C}\}_{n=1}^{\infty }\) in relation to the underlying set \(K^\star \). We prove under appropriate conditions that if \(K^\star \) is a polytope, our approach provides a reconstruction that recovers all the simplicial faces (for sufficiently large n); if \(K^\star \) is a simplicial polytope, we recover a polytope that is combinatorially equivalent to \(K^\star \). This result also applies more generally to ‘rigid’ faces for non-polyhedral \(K^{\star }\) (see Theorem 3.9).
In the sequel, we relate our formulation (2) (when \(C\) is a simplex) to the task of fitting piecewise affine convex functions to data (known as max-affine regression) as well as K-means clustering. Accordingly, the algorithm we propose in Sect. 4 for computing \({\hat{K}}_n^{C}\) bears significant similarities with methods for max-affine regression [20] as well as Lloyd’s algorithm for clustering problems.
A restriction in the development in this paper is that the simplex and the spectraplex represent particular affine slices of the non-negative orthant and the cone of positive semidefinite matrices. In principle, one can further optimize these slices (both their orientation and their dimension) in (2) to obtain improved reconstructions. However, this additional degree of flexibility in (2) leads to technical complications in establishing asymptotic normality in Sect. 3.2 as well as to challenges in developing algorithms for solving (2) (even to obtain a local optimum). The root of these difficulties lies in the fact that it is hard to characterize the variation in the support function with respect to small changes in the slice. We remark on these challenges in greater detail in Sect. 6, and for the remainder of the paper we proceed with investigating the estimator (2).

Comparison between our approach and the LSE
1.2 Related Work
1.2.1 Consistency of Convex Set Regression
There is a well-developed body of prior work on the consistency of convex set regression (1). Gardner et al. [11] prove that the (polyhedral) estimates \({\hat{K}}^{\mathrm {LSE}}_n\) converge almost surely to the underlying set \(K^\star \) in the Hausdorff metric as \(n \rightarrow \infty \) provided the directions \(\{u^{(i)}\}_{i=1}^{n}\) cover the sphere in a suitably uniform manner. Guntuboyina [14] analyzes rates of convergence in minimax settings, and also notes that constraining the growth of the number of vertices in the reconstruction as the number of measurements increases provides a form of robustness. Cai et al. [6] study the impact of choosing the directions \(\{u^{(i)}\}_{i=1}^{n}\) adaptively in estimating planar convex sets. In contrast, the consistency result in the present paper corresponding to the constrained estimator (2) is qualitatively different. On the one hand, for a given compact convex set \(C\subset {\mathbb {R}}^q\), we prove that the sequence of estimates \(\{{\hat{K}}_n^{C}\}_{n=1}^{\infty }\) converges to that linear image of \(C\) which is closest to the underlying set \(K^{\star }\); in particular, \(\{{\hat{K}}_n^{C}\}_{n=1}^{\infty }\) only converges to \(K^\star \) if \(K^\star \) can be represented as a linear image of \(C\). On the other hand, there are several advantages to the framework presented in this paper in comparison with prior work. First, the constrained estimator (2) lends itself to a precise asymptotic distributional characterization which is unavailable in the unconstrained case (1). Second, under appropriate conditions, the constrained estimator (2) recovers the facial structure of the underlying set \(K^\star \) unlike \({\hat{K}}_{\mathrm {LSE}}\). More significantly, beyond these technical distinctions, the constrained estimator (2) also yields concisely described non-polyhedral reconstructions (as well as associated consistency and asymptotic distributional characterizations) based on linear images of the spectraplex, in contrast to the usual choice of a polyhedral LSE in the previous literature.
1.2.2 Incorporating Prior Information and Fitting Smooth Boundaries
The problem of integrating prior information about the underlying convex set has been considered in [25], where the authors propose a method of incorporating certain structural or shape priors for fitting convex sets in two dimensions, with a particular focus on settings in which the underlying set is a disc or an ellipsoid. However, the reconstructions produced by the method in [25] are still polyhedral, and the method assumes that the support function evaluations are available at angles that are equally spaced. We are also aware of a line of work [8, 15] on fitting convex sets in two dimensions with smooth boundaries to support function measurements. The first of these papers estimates a convex set with a smooth boundary without any vertices, while the second proposes a two-step method in which one initially estimates a set of vertices followed by a second step that connects these vertices via smooth boundaries. In both cases, splines are used to interpolate between the support function evaluations with a subsequent smoothing procedure using the von Mises kernel. The smoothing is done in a local fashion and the resulting reconstruction is increasingly complex to describe as the number of measurements available grows. In contrast, our approach to producing non-polyhedral estimates based on fitting linear images of spectraplices is more global in nature, and we explicitly regularize the complexity of our reconstruction based on the dimension of the spectraplex. Further, the approaches proposed in [8, 15] estimate the singular and the smooth parts of the boundary separately, whereas our framework based on linear images of spectraplices estimates these features in a unified manner (for example, see the illustration in Fig. 12). Finally, the methods described in [8, 15, 25] are only applicable to two-dimensional reconstruction problems, while problems of a three-dimensional nature arise in many contexts (see Sect. 5.4 for an example that involves the reconstruction of a human lung).
1.2.3 Piecewise Affine Convex Regression
The formulation (2) when \(C= \Delta ^q\) may be viewed as a fitting a piecewise linear function (with at most q pieces) to the given data. This is a special case of the max-affine regression problem in which one is interested in fitting a piecewise affine function (typically with a bound on the number of pieces) to data, which is a topic that has been studied previously [2, 16, 20]. In particular, our algorithm in Sect. 4 when specialized to the setting \(C= \Delta ^q\) is analogous to the methods described in [20]. However, our framework and the algorithm in Sect. 4 may also be employed to fit more general convex functions that are not piecewise linear, but that can still be specified in a tractable manner via linear images of the spectraplex.
1.3 Outline
In Sect. 2 we discuss the geometric, algebraic, and analytic aspects of the optimization problem (2); this section serves as the foundation for the subsequent statistical analysis in Sect. 3. Throughout both of these sections, we give several examples that provide additional insight into our mathematical development. We describe algorithms for solving (2) in Sect. 4, and we demonstrate the application of these methods in a range of numerical experiments in Sect. 5. We conclude with a discussion of future directions in Sect. 6.
Notation: Given a convex set \(C\subset {\mathbb {R}}^q\), we denote the associated induced norm by \(\Vert A \Vert _{C,2} := \sup _{x\in C} \Vert A x\Vert _2\). We denote the unit \(\Vert \,{\cdot }\,\Vert \)-ball centered at \(x\) by \(B_{\Vert \cdot \Vert }(x) := \{ y\mid \Vert y-x\Vert \le 1 \}\), and we denote the Frobenius norm by \(\Vert \,{\cdot }\,\Vert _\mathrm{F}\). Given a point \(a\in {\mathbb {R}}^q\) and a subset \(U \subseteq {\mathbb {R}}^q\), we define \({{\,\mathrm{dist}\,}}(a,U) := \inf _{b\in U} \Vert a- b\Vert \), where the norm \(\Vert \,{\cdot }\,\Vert \) is the Euclidean norm. Last, given any two subsets \(U,V \subset {\mathbb {R}}^q\), the Hausdorff distance between U and V is denoted by
2 Problem Setup and Other Preliminaries
In this section, we begin with a preliminary discussion of the geometric, algebraic, and analytical aspects of our procedure (2); these underpin our subsequent development in this paper. We make the following assumptions about our problem setup for the remainder of the paper:
-
(A1)
The set \(K^{\star }\subset {\mathbb {R}}^d\) is compact and convex.
-
(A2)
The set \(C\subset {\mathbb {R}}^q\) is compact and convex.
-
(A3)
Probabilistic Model for Support Function Measurements: We assume that we are given n independent and identically distributed support function evaluations \(\{(u^{(i)},y^{(i)})\}_{i=1}^n \subset S^{d-1} \times {\mathbb {R}}\) from the following probabilistic model:
$$\begin{aligned} P_{K^{\star }}:\quad y = h_{K^{\star }} (u) + \varepsilon . \end{aligned}$$(3)Here \(u\in S^{d-1}\) is a vector distributed uniformly at random (u.a.r.) over the unit sphere, \(\varepsilon \) is a centered random variable with variance \(\sigma ^2\) (i.e., \({\mathbb {E}}[\varepsilon ]=0\) and \({\mathbb {E}}[\varepsilon ^2]=\sigma ^2\)), and \(u\) and \(\varepsilon \) are independent.
In our analysis, we quantify dissimilarity between convex sets in terms of a metric applied to their respective support functions. Let \(K_1,K_2\) be compact convex sets in \({\mathbb {R}}^d\), and let \(h_{K_1}(\,{\cdot }\,), h_{K_2}(\,{\cdot }\,)\) be the corresponding support functions. We define the \(L_p\) metric to be
where the integral is with respect to the Lebesgue measure over \(S^{d-1}\); as usual, we denote \(\rho _{\infty } (K_1, K_2) = \max _{u} | h_{K_1}(u) - h_{K_2}(u)|\). We prove our convergence guarantees in Sect. 3.1 in terms of the \(\rho _p\)-metric. This metric represents an important class of distance measures over convex sets. For instance, it features prominently in the literature on approximating convex sets as polytopes [5]. In addition, the specific case of \(p=\infty \) coincides with the Hausdorff distance [27, p. 66].
Due to the form of the estimator (2), one may reparametrize the optimization problem in terms of the linear map A. In particular, by noting that \(h_{A(C)}(u) = h_{C}(A^Tu)\), the problem (2) can be reformulated as follows:
Based on this observation, we analyze some properties of the set of minimizers of (2) via an analysis of (5). (The reformulation (5) is also more conducive to the development of numerical algorithms for solving (2).) In turn, a basic strategy for investigating the asymptotic properties of the estimator (5) is to analyze the minimizers of the loss function at the population level. Concretely, for any probability measure P over pairs \((u,y) \in S^{d-1} \times {\mathbb {R}}\), the loss function with respect to P is defined as
Thus, the focus of our analysis is on studying the set of minimizers of the population loss function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\):
2.1 Geometric Aspects
In this subsection, we focus on the convex sets defined by the elements of the set of minimizers \(M_{K^{\star },C}\). In the next subsection, we consider the elements of \(M_{K^{\star },C}\) as linear maps. To begin with, we state a simple lemma on the continuity of \(\Phi _{C}(\,{\cdot }\,,P)\):
Proposition 2.1
Let P be any probability distribution over measurement pairs \((u,y) \in S^{d-1} \times {\mathbb {R}}\) satisfying \({\mathbb {E}}_{P}[|y|]<\infty \). Then the function \(\Phi _{C}(\,{\cdot }\,,P)\) defined in (6) is continuous.
The proof uses a simple bound. We state the result formally as we require it at a later part.
Lemma 2.2
Given any pair of linear maps \(A_1, A_2 \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\), any unit-norm vector \(u\), and any scalar y, we have
Proof
First note that \(h_{C}(A_1^{T}u) \le h_{C}(A_2^{T}u) + h_{C}((A_1-A_2)^{T}u)\). Since u is unit-norm, we have \(h_{C}(A_1^{T}u) - h_{C}(A_2^{T}u) \le h_{C}((A_1-A_2)^{T}u) \le \Vert A_1 - A_2 \Vert _{C,2}\). Similarly we have \(h_{C}(A_2^{T}u) - h_{C}(A_1^{T}u) \le \Vert A_1 - A_2 \Vert _{C,2}\). Hence (8) follows. \(\square \)
Proof of Proposition 2.1
Let \(\epsilon >0\) be arbitrary. Let \(r = 1+\Vert A \Vert _{C,2}\) and pick \(\delta =\min {\{ \epsilon /(3{\mathbb {E}}[r+|y|]), r\}}\). Then for any \(A_0 \) satisfying \(\Vert A - A_0 \Vert _{C,2} < \delta \), we have
We apply Lemma 2.2 to obtain the bound
Combining this bound with our earlier expression, it follows that \(|\Phi (A,P) - \Phi (A_0,P)| < {\mathbb {E}}_{P} [\delta (2r+\delta +2|y|)] \le \epsilon \). \(\square \)
The following result gives a series of properties about the set \(M_{K^{\star },C}\). Crucially, it shows that \(M_{K^{\star },C}\) characterizes the optimal approximations of \(K^{\star }\) as linear images of \(C\):
Proposition 2.3
Suppose that the assumptions (A1), (A2), (A3) hold. Then the set of minimizers \(M_{K^{\star },C}\) defined in (7) is compact and non-empty. Moreover, we have
Proof
Define the event \(G_{r,v}:= \{ (u,y) \mid \langle v,u\rangle \ge 1/2, \,|y| \le r/4 \}\) over \(v\in S^{d-1}\). In addition, define the function \(s(v) := {\mathbb {P}}[ (u,y) \mid \langle v,u\rangle \ge 1/2 ]\). For every \(r \ge 0\), consider the function \(g_{r}(v) :={\mathbb {P}}[G_{r,v}]\). By noting that \( g_{r} \le g_{r^{\prime }}\) whenever \(r \le r^{\prime }\) (i.e., the sequence \(\{g_{r}\}_{r\ge 0}\) is monotone increasing), \(g_{r}(\,{\cdot }\,) \uparrow s(\,{\cdot }\,)\), and that \(g_{r}(\,{\cdot }\,)\) is a continuous function over the compact domain \(S^{d-1}\), we conclude that \(g_{r}(\,{\cdot }\,)\) converges to \(s(\,{\cdot }\,)\) uniformly. Thus there exists \({\hat{r}}\) sufficiently large so that \({\hat{r}}^2{\mathbb {P}}[G_{{\hat{r}},v}]/16>\Phi _{C}(0,P_{K^{\star }})\) for all \(v\in S^{d-1}\).
Next, we show that \(M_{K^{\star },C}\subseteq {\hat{r}} B_{\Vert \cdot \Vert _{C,2}} (0)\). Let \(A \notin {\hat{r}} B_{\Vert \cdot \Vert _{C,2}} (0)\). Then, for such an A, there exists \({\hat{x}}\in C\) such that \(\Vert A{\hat{x}}\Vert _{2} > {\hat{r}}\). Define \({\hat{v}} = A {\hat{x}}/\Vert A{\hat{x}}\Vert _{2}\). We have
Here, \(\mathbf{1 }(G_{{\hat{r}},{\hat{v}}})\) denotes the indicator function for the event \(G_{{\hat{r}},{\hat{v}}}\). As such, the above inequality implies that \(A \notin M_{K^{\star },C}\). Therefore \(M_{K^{\star },C}\subseteq {\hat{r}} B_{\Vert \cdot \Vert _{C,2}} (0)\), and hence \(M_{K^{\star },C}\) is bounded.
By Proposition 2.1, the function \(A \mapsto \Phi _{C}(A,P_{K^{\star }})\) is continuous. As the minimizers of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\), if they exist, must be contained in \( {\hat{r}} B_{\Vert \cdot \Vert _{C,2}} (0)\), we can view \(M_{K^{\star },C}\) as the set of minimizers of a continuous function restricted to the compact set \( {\hat{r}} B_{\Vert \cdot \Vert _{C,2}} (0)\), and hence it is non-empty. Moreover, since \(M_{K^{\star },C}\) is the pre-image of a closed set under a continuous function, it is also closed and thus compact.
By Fubini’s theorem, we have \({\mathbb {E}}[ \varepsilon (h_{C}(K^{\star }) - h_{C}(A^{T}u) )] = {\mathbb {E}}_{u} [ {\mathbb {E}}_{\varepsilon } [ \varepsilon (h_{C}(K^{\star }) - h_{C}(A^{T}u) ) ]] = 0\). Hence \(\Phi _{C}(A,P_{K^{\star }}) = {\mathbb {E}}\bigl [ (h_{C}(K^{\star }) + \varepsilon - h_{C}(A^{T}u) )^2\bigr ]= {\mathbb {E}}\bigl [(h_{C}(K^{\star }) - h_{C}(A^{T}u) )^2 \bigr ] + {\mathbb {E}}[ \varepsilon ^2 ]\), from which the last assertion follows. \(\square \)
It follows from Proposition 2.3 that an optimal approximation of \(K^{\star }\) as the projection of \(C\) always exists. In Sect. 3.1, we show that the estimators obtained using our method converge to an optimal approximation of \(K^{\star }\) as a linear image of \(C\) if such an approximation is unique. While this is often the case in applications one encounters in practice, the following examples demonstrate that the uniqueness condition need not always hold:
Example
Suppose \(K^{\star }\) is the regular q-gon in \({\mathbb {R}}^2\), and \(C\) is the spectraplex \({\mathcal {O}}^{2}\). Then \(M_{K^{\star },C}\) uniquely specifies an \(\ell _2\)-ball.
Example
Suppose \(K^{\star }\) is the unit \(\ell _2\)-ball in \({\mathbb {R}}^2\), and \(C\) is the simplex \(\Delta ^{q}\). Then the sets specified by the elements \(M_{K^{\star },C}\) are not unique; they all correspond to a centered regular q-gon, but with an unspecified rotation.
A natural question then is to identify settings in which \(M_{K^{\star },C}\) defines a unique set. Unfortunately, obtaining a complete characterization of this uniqueness property appears to be difficult due to the interplay between the invariances underlying the sets \(K^{\star }\) and \(C\). However, based on Proposition 2.3, we can provide a simple sufficient condition under which \(M_{K^{\star },C}\) defines a unique set:
Corollary 2.4
Assume that the conditions of Proposition 2.3 hold. Suppose further that we have \(K^{\star }= A^{\star } (C)\) for some \(A^{\star }\in L({\mathbb {R}}^q,{\mathbb {R}}^d)\). Then the set of minimizers \(M_{K^{\star },C}\) described in (7) uniquely defines \(K^{\star }\); i.e., \(K^{\star }= A (C)\) for all \(A \in M_{K^{\star },C}\).
Proof
It is clear that \(A^{\star }\in M_{K^{\star },C}\). Note that \(h_{C}(A^{T}u)\) is a continuous function of \(u\) over a compact domain for every \(A\in L({\mathbb {R}}^q,{\mathbb {R}}^d)\). Hence it follows that \({\hat{A}}\in M_{K^{\star },C}\) if and only if \(h_{C}(A^{\star T}u)=h_{C}({\hat{A}}^{T}u)\) everywhere. By applying Proposition 2.3 and using the fact that a pair of compact convex sets that have the same support function must be equal, it follows that \(K^{\star }={\hat{A}}(C)\) for all \({\hat{A}} \in M_{K^{\star },C}\).
\(\square \)
2.2 Algebraic Aspects of Our Method
While the preceding subsection focused on conditions under which the set of minimizers \(M_{K^{\star },C}\) specifies a unique convex set, the aim of the present section is to obtain a more refined picture of the collection of linear maps in \(M_{K^{\star },C}\). We begin by discussing the identifiability issues that arise in reconstructing a convex set by estimating a linear map via (5). Given a compact convex set \(C\), let g be a linear transformation that preserves \(C\); i.e., \(g(C)= C\). Then the linear map defined by Ag specifies the same convex set as A because \(Ag (C) = A (g(C)) = A (C)\). As such, every linear map \(A\in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) is a member of the equivalence class defined by
Here \({{\,\mathrm{Aut}\,}}C\) denotes the subset of linear transformations that preserve \(C\). When \(C\) is non-degenerate, the elements of \({{\,\mathrm{Aut}\,}}C\) are invertible matrices and form a subgroup of \(\mathrm {GL}(q,{\mathbb {R}})\). As a result, the equivalence class \(A \cdot {{\,\mathrm{Aut}\,}}C:= \{ Ag \mid g \in {{\,\mathrm{Aut}\,}}C\}\) specified by (9) can be viewed as the orbit of \(A \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) under (right) action of the group \({{\,\mathrm{Aut}\,}}C\). In the sequel, we focus our attention on convex sets \(C\) for which the associated automorphism group \({{\,\mathrm{Aut}\,}}C\) consists of isometries:
-
(A4)
The automorphism group of \(C\) is a subgroup of the orthogonal group, i.e., \({{\,\mathrm{Aut}\,}}C\lhd O (q,{\mathbb {R}})\).
This assumption leads to structural consequences that are useful in our analysis. In particular, as \({{\,\mathrm{Aut}\,}}C\) can be viewed as a compact matrix Lie group, the orbit \(A\cdot {{\,\mathrm{Aut}\,}}C\) inherits structure as a smooth manifold of the ambient space \(L({\mathbb {R}}^q,{\mathbb {R}}^d)\). The assumption (A4) is satisfied for the choices of \(C\) that are primarily considered in this paper—the automorphism group of the simplex is the set of permutation matrices, and the automorphism group of the spectraplex is the set of linear operators specified as conjugation by an orthogonal matrix.
Based on this discussion, it follows that the space of linear maps \(L({\mathbb {R}}^q,{\mathbb {R}}^d)\) can be partitioned into orbits \(A \cdot {{\,\mathrm{Aut}\,}}C\). Further, the population loss \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) is also invariant over orbits of A: for every \(g \in {{\,\mathrm{Aut}\,}}C\) we have that \(h_{C}(A^{T}u) = h_{C}((Ag)^{T}u)\). Thus, the set of minimizers \(M_{K^{\star },C}\) can also be partitioned into a union of orbits. Consequently, in our analysis in Sect. 3 we view the problem (5) as one of recovering an orbit rather than a particular linear map. The convergence results we obtain in Sect. 3 depend on the number of orbits in \(M_{K^{\star },C}\), with sharper asymptotic distributional characterizations available when \(M_{K^{\star },C}\) consists of a single orbit.
When \(M_{K^{\star },C}\) specifies multiple convex sets, then \(M_{K^{\star },C}\) clearly consists of multiple orbits; as an illustration, in the example in the previous subsection in which \(K^{\star }\) is the unit \(\ell _2\)-ball in \({\mathbb {R}}^2\) and \(C= \Delta ^{q}\), the corresponding set \(M_{K^{\star },C}\) is a union of multiple orbits in which each orbit specifies a unique rotation of the centered regular q-gon. However, even when \(M_{K^{\star },C}\) specifies a unique convex set, it may still be the case that it consists of more than one orbit:
Example
Suppose \(K^{\star }\) is the interval \([-1,1] \subset {\mathbb {R}}\) and \(C= \Delta ^{3}\). Then \(M_{K^{\star },C}\) is a union of orbits, with an orbit specified as the set of all permutations of the vector \((-1,1,\epsilon )\) for each \(\epsilon \in [-1, 1]\). Nonetheless, \(M_{K^{\star },C}\) specifies a unique convex set, namely, \(K^{\star }\).
More generally, it is straightforward to check that \(M_{K^{\star },C}\) consists of a single orbit if \(K^{\star }\) is a polytope with q extreme points and \(C= \Delta ^{q}\). The situation for linear images of non-polyhedral sets such as the spectraplices is much more delicate. One simple instance in which \(M_{K^{\star },C}\) consists of a single orbit is when \(K^{\star }\) is the image under a bijective linear map A of \({\mathcal {O}}^q\). Our next result states an extension to convex sets that are representable as linear images of an appropriate slice of the outer product of cones of positive semidefinite matrices.
Proposition 2.5
Let \(C=\bigl \{ X_1 \times \cdots \times X_k\mid X_i \in {\mathbb {S}}^{q_i}, \,X_i \succeq 0,\, \sum _{i=1}^{k} {{\,\mathrm{trace}\,}}X_i=1\bigr \}\), and let \(K^{\star }= A^{\star }(C) \subset {\mathbb {R}}^d\). Suppose that there is a collection of disjoint exposed faces \(F_i \subseteq K^{\star }\) such that: (i) \((A^{\star })^{-1}(F_i) \cap C\) is the i-th block \(\{ 0 \times \cdots \times 0 \times X_i \times 0 \times \cdots \times 0 \mid X_i \in {\mathbb {S}}^{q_i},\, X_i \succeq 0,\, {{\,\mathrm{trace}\,}}X_i=1\} \subset C\), and (ii) \(\dim F_i=\dim {\mathcal {O}}^{q_i}\). Then \(M_{K^{\star },C}\) consists of a single orbit.
Example
By expressing \(C= \Delta ^{q} = \bigl \{ X_1 \times \cdots \times X_q \mid X_i \in {\mathbb {S}}^{1},\, X_i \succeq 0, \sum _{i=1}^{q} {{\,\mathrm{trace}\,}}X_i=1\bigr \}\) and by considering \(K^{\star }\) to be a polytope with q extreme points, Proposition 2.5 simplifies to our earlier remark noting that \(M_{K^{\star },C}\) consists of a single orbit.
Example
The nuclear norm ball \(B_{\text {nuc}}:=\{X \in {\mathbb {S}}^2\mid \Vert X\Vert _{\text {nuc}}\le 1 \} \) is expressible as the linear image of \({\mathcal {O}}^{2} \times {\mathcal {O}}^{2}\). The extreme points of \(B_{\text {nuc}}\) comprise two connected components of unit-norm rank-one matrices specified by \(\{ U^{T} E_{11} U \mid U \in {{\,\mathrm{SO}\,}}(2,{\mathbb {R}}) \} \) and \(\{ - U^{T} E_{11} U \mid U \in {{\,\mathrm{SO}\,}}(2,{\mathbb {R}})\}\), where \(E_{11}\) is the \(2\times 2\) matrix with (1, 1)-entry equal to one and other entries equal to zero. Furthermore, each connected component is isomorphic to \({\mathcal {O}}^{2}\). It is straightforward to verify that the conditions of Proposition 2.5 hold for this instance, and thus \(M_{B_{\text {nuc}},{\mathcal {O}}^{2} \times {\mathcal {O}}^{2} }\) consists of a single orbit.
The proof of Proposition 2.5 requires an impossibility result showing that a spectraplex cannot be expressed as the linear image of the outer product of finitely many smaller-sized spectraplices. The result follows as a consequence of a related result stated in terms of the cone of positive semidefinite matrices [1, 26]. In the following, \({\mathbb {S}}^{q}_{+}\) denotes the cone of \(q\times q\) dimensional positive semidefinite matrices.
Proposition 2.6
Suppose that \({\mathbb {S}}^{q}_{+} = A( {\mathbb {S}}^{q_1}_{+} \times \cdots \times {\mathbb {S}}^{q_k}_{+} \cap L)\) for some linear map A and some affine subspace L. Then \(q \le \max q_i\).
Proposition 2.7
Let \(C= \bigl \{ X_1 \times \cdots \times X_k \mid X_i \in {\mathbb {S}}^{q_i}_{+},\, \sum _{i=1}^k{{\,\mathrm{trace}\,}}X_i=1\bigr \}\). Suppose \({\mathcal {O}}^{q} = A( C)\) for some A. Then \(q \le \max q_i\).
Proof
Express \({\mathbb {S}}^{q}_{+}\) as
where \(\Pi \) projects out the coordinate t. The result follows from Proposition 2.6. \(\square \)
Lemma 2.8
Let \(K= A(C) \subset {\mathbb {R}}^d\) where \(C\subset {\mathbb {R}}^q\) is compact convex, and suppose that \(\dim K=\dim C\). If \(K= {\tilde{A}}(C)\) for some \({\tilde{A}} \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\), then \({\tilde{A}} = A g\) for some \(g\in {{\,\mathrm{Aut}\,}}C\).
Proof
Suppose that \(0\notin {{\,\mathrm{aff}\,}}K\). By applying a suitable rotation, we may assume that \(K\) is contained in the first \(\dim K\) dimensions. Then the maps A and \({\tilde{A}}\) are of the form
Since \(\dim K=\dim C\), the map \(A_1\) is invertible. Subsequently \(A_1^{-1} A_1 \in {{\,\mathrm{Aut}\,}}C\), and thus \({\tilde{A}}_1 = A_1 g\) for some \(g \in {{\,\mathrm{Aut}\,}}C\).
The proof is similar for the case where \(0\in {{\,\mathrm{aff}\,}}K\). The only necessary modification is that we embed \(K\) into \({\mathbb {R}}^{d+1}\) via the set \({\tilde{K}}:=\{ (x,1) \mid x\in K\}\), and we repeat the same sequence of steps with \({\tilde{K}}\) in place of \(K\). We omit the necessary details as they follow in a straightforward fashion from the previous case. \(\square \)
Proof of Proposition 2.5
Let \({\tilde{A}} \in M_{K^{\star },C}\). We show that \({\tilde{A}}\) defines a one-to-one correspondence between the collection of faces \(\{F_i\}_{i=1}^{k}\) and the collection of blocks \(\{\{ 0 \times \cdots \times X_j \times \cdots \times 0\mid X_j \in {\mathcal {O}}^{q_j} \} \}_{j=1}^{k}\) subject to the condition \(\dim F_i=\dim {\mathcal {O}}^{q_j}\). We prove such a correspondence via an inductive argument beginning with the faces of largest dimensions.
We assume (without loss of generality) that \(\dim F_1=\ldots =\dim F_{k^{\prime }}>\ldots \) and that \(\dim {\mathcal {O}}^{q_1}=\ldots =\dim {\mathcal {O}}^{q_{k^{\prime }}}> \ldots \) We further denote \(q = q_1 = \ldots =q_{k^{\prime }}\). As \(F_i\) is an exposed face, the pre-image \({\tilde{A}}^{-1}(F_i) \cap C\) must be an exposed face of \(C\), and thus is of the form \(U_{i,1} X_{i,1} U_{i,1}^{\prime } \times \cdots \times U_{i,k} X_{i,k} U_{i,k}^{\prime }\), where \(X_{i,j} \in {\mathcal {O}}^{q_{i,j}}\) for some \(q_{i,j} \le q_j\), and where \(U_{i,j} \in {\mathbb {R}}^{q_{i,j} \times q_j}\) are partial orthogonal matrices. By Proposition 2.7, we have \(\max _j q_{i,j} \ge q_i = q\). Subsequently, by noting that there are \(k^{\prime }\) blocks with dimensions \(q \times q\), that there are also \(k^{\prime }\) faces \(F_i\) with \(\dim F_i = q\), and that the faces \(F_i\) are disjoint, we conclude that each block in the collection \(\{\{ 0 \times \cdots \times X_j \times \cdots \times 0 \mid X_j \in {\mathcal {O}}^{q_j} \} \}_{j=1}^{k}\) lies in the pre-image of a unique face \(F_i\), \(1\le i \le k^{\prime }\). By repeating the same sequence of arguments for the remaining faces of smaller dimensions, we establish a one-to-one correspondence between faces and blocks. Finally, we apply Lemma 2.8 to each face-block pair to conclude that, after accounting for permutations among blocks of the same size, the maps \(A_{i}^{\star }\) and \({\tilde{A}}_{i}\) are equivalent up to conjugation by an orthogonal matrix. The final assertion that \(M_{K^{\star },C}\) consists of a single orbit is straightforward to establish. \(\square \)
2.3 Analytical Aspects of Our Method
In this third subsection, we describe some of the derivative computations that repeatedly play a role in our paper in our analysis, examples, and numerical experiments. Given a compact convex set \(C\), the support function \(h_{C}(\,{\cdot }\,)\) is differentiable at \(u\) if and only if
is a singleton; the derivative in these cases is given by (10) (see [27, p. 47]). We denote the derivative of \(h_{C}\) at a differentiable \(u\) by \(e_{C}(u) := \nabla _{u} (h_{C}(u))\).
Example
Suppose \(C= \Delta ^{q} \subset {\mathbb {R}}^q\) is the simplex. The function \(h_{C}(\,{\cdot }\,)\) is the maximum entry of the input vector, and it is differentiable at this point if and only if the maximum is unique with the derivative \(e_{C}(\,{\cdot }\,)\) equal to the corresponding standard basis vector.
Example
Suppose \(C= {\mathcal {O}}^{p} \subset {\mathbb {S}}^p\) is the spectraplex. The function \(h_{C}(\,{\cdot }\,)\) is the largest eigenvalue of the input matrix, and it is differentiable at this point if and only if the largest eigenvalue has multiplicity one with the derivative \(e_{C}(\,{\cdot }\,)\) equal to the projector onto the corresponding one-dimensional eigenspace.
The following result gives a formula for the derivative of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\).
Proposition 2.9
Let P be a probability distribution over the measurement pairs \((u,y)\), and suppose that \({\mathbb {E}}_{P}[y^2] < \infty \). Let \(A \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) be a linear map such that \(h_{C}(\,{\cdot }\,)\) is differentiable at \(A^{T}u\) for P-a.e. \(u\). Then the function \(\Phi _{C}(\,{\cdot }\,,P)\) is differentiable with derivative
Proof
Let \(\lambda _{C}(\,{\cdot }\,,A,D)\) denote the remainder term satisfying
Since the function \(h_{C}(\,{\cdot }\,)\) is differentiable at \(A^{T}u\) for P-a.e. \(u\), we have \(\lambda _{C}(\,{\cdot }\,,A,D) \rightarrow 0\) as \(\Vert D\Vert _{C,2} \rightarrow 0\), P-a.e. Suppose D is in a bounded set. First, we can bound \(|h_{C}((A+D)^{T}u) + h_{C}(A^{T}u) -2y | \le c_1 (1 + |y|)\) for some constant \(c_1\). Second, by Lemma 2.2, we have the inequality \(| h_{C}((A+D)^{T}u) - h_{C}(A^{T}u)| \le \Vert D\Vert _{C,2}\). Third, by noting that \(|h_{C}(A^{T}u) - y|\) can be bounded by \(c_2 (1 + |y|)\) for some constant \(c_2\), and by noting that the entries of the linear map \( u\otimes e_{C}(A^{T}u)\) are uniformly bounded, we may bound \(\Vert (h_{C}(A^{T}u) - y) u\otimes e_{C}(A^{T}u)\Vert _{C,2}\) by a function of the form \(c_3 (1 + |y|)\) for some constant \(c_3\). Subsequently we may bound
for some constant c. Since \({\mathbb {E}}_{P} [y^2]<\infty \), we have \(\lambda _{C}(\,{\cdot }\,,A,D) \in {\mathcal {L}}^2(P)\), and hence \(\lambda _{C}(\,{\cdot }\,,A,D) \in {\mathcal {L}}^1(P)\). The result follows from an application of the Dominated Convergence Theorem. \(\square \)
It turns out to be considerably more difficult to compute an explicit expression of the second derivative of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\). For this reason, our next result applies in a much more restrictive setting in comparison to Proposition 2.9.
Proposition 2.10
Suppose that the underlying set \(K^{\star }= A^{\star }(C)\) for some \(A^{\star } \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\). In addition, suppose that the function \(h_{C}(\,{\cdot }\,)\) is continuously differentiable at \(A^{\star T}u\) for \(P_{K^{\star }}\)-a.e. \(u\). Then the map \(A \mapsto \Phi _{C}(A,P_{K^{\star }})\) is twice differentiable at \(A^{\star }\) and its second derivative is the operator \(\Gamma \in L(L({\mathbb {R}}^q,{\mathbb {R}}^d),L^*({\mathbb {R}}^q,{\mathbb {R}}^d))\) defined by
Proof
To simplify notation, we denote the operator norm \(\Vert \,{\cdot }\,\Vert _{C,2}\) by \(\Vert \,{\cdot }\,\Vert \) in the remainder of the proof. By Proposition 2.9, the map \(A\mapsto \Phi (A,P)\) is differentiable in an open neighborhood around \(A^{\star }\) with derivative \(2(h_{C}(A^{T}u) - y) u\otimes e_{C}(A^{T}u)\). Hence to show that the map is twice differentiable with second derivative \(\Gamma \), it suffices to show that
First we note that every component of \(\varepsilon (u) u\otimes e_{C}((A^{\star }+D)^{T}u)\) is integrable because \({\mathbb {E}}[\varepsilon (u)^2] < \infty \), and \(u\otimes e_{C}((A^{\star }+D)^{T}u)\) is uniformly bounded. Hence by Fubini’s Theorem we have
Similarly,
Second, by differentiability of the map \(A\mapsto \Phi (A,P)\) at \(A^{\star }\) the limit
is 0. By noting that every component of \(u\otimes e_{C}((A^{\star }+D)^{T}u)\) is uniformly bounded, and an application of the Dominated Convergence Theorem, we have
Third, since \(h_{C}(\,{\cdot }\,)\) is continuously differentiable at \(A^{\star T}u\) for P-a.e. \(u\), we have \(e_{C}((A^{\star }+D)^{T}u) \rightarrow e_{C}(A^{\star T}u)\) as \(\Vert D\Vert \rightarrow 0\), for P-a.e. \(u\). By the Dominated Convergence Theorem we have \({\mathbb {E}}[e_{C}((A^{\star }+D)^{T}u)] \rightarrow {\mathbb {E}}[ e_{C}(A^{\star T}u)] \) as \(\Vert D\Vert \rightarrow 0\). It follows that
The result follows by summing the contributions from (14) and (15), as well as noting that the expressions in (12) and (13) vanish. \(\square \)
3 Main Results
In this section, we investigate the statistical aspects of minimizers of the optimization problem (5). Our objective in this section is to relate a sequence of minimizers \(\{{\hat{A}}_n\}_{n=1}^\infty \) of \(\Phi _{C}(\,{\cdot }\,,P_{n,K^{\star }})\) to minimizers of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\). Based on this analysis, we draw conclusions about properties of sequences of minimizers \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) of the problem (2). In establishing various convergence results, we rely on an important property of the Hausdorff distance, namely that it defines a metric over collections of non-empty compact sets; therefore, the collection of all orbits \(\{A \cdot {{\,\mathrm{Aut}\,}}C\mid A \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\}\) endowed with the Hausdorff distance defines a metric space.
Our results provide progressively sharper recovery guarantees based on increasingly stronger assumptions. Specifically, Sect. 3.1 focuses on conditions under which a sequence of minimizers \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) of (2) converges to \(K^{\star }\); this result relies only on the fact that the optimal approximation of \(K^{\star }\) by a convex set specified by an element of \(M_{K^{\star },C}\) is unique (see Sect. 2.1 for the relevant discussion). Next, Sect. 3.2 gives a limiting distributional characterization of the sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) based on an asymptotic normality analysis of the sequence \(\{{\hat{A}}_n\}_{n=1}^\infty \); among other assumptions, this analysis relies on the stronger requirement that \(M_{K^{\star },C}\) consists of a single orbit. Finally, based on additional conditions on the facial structure of \(K^{\star }\), we describe in Sect. 3.3 how the sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) preserves various attributes of the face structure of \(K^{\star }\).
3.1 Strong Consistency
We describe conditions for convergence of a sequence of minimizers \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) of (2). Our main result essentially states that such a sequence converges to an optimal \(\rho _2\) approximation of \(K^{\star }\) as a linear image of \(C\), provided that such an approximation is unique:
Theorem 3.1
Suppose that the assumptions (A1)–(A4) hold. Let \(\{ {\hat{A}}_n \}_{n=1}^{\infty }\) be a sequence of minimizers of the empirical loss function \(\Phi _{C}(\,{\cdot }\,,P_{n,K^{\star }})\) with the corresponding reconstructions given by \({\hat{K}}_{n}^{C}= {\hat{A}}_n(C)\). We have that \({{\,\mathrm{dist}\,}}({\hat{A}}_n,M_{K^{\star },C})\rightarrow 0\) a.s. and
As a consequence, if \(M_{K^{\star },C}\) specifies a unique set—there exists \({\hat{K}}\subset {\mathbb {R}}^d\) such that \({\hat{K}}= A(C)\) for all \(A \in M_{K^{\star },C}\)—then \(\rho _{p} ( {\hat{K}}_{n}^{C}, {\hat{K}}) \rightarrow 0\) a.s. for \(1 \le p \le \infty \). Further, if \(K^{\star }= A^{\star }(C)\) for some linear map \(A^{\star } \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\), then \(\rho _{p} ({\hat{K}}_{n}^{C},K^{\star }) \rightarrow 0\) a.s. for \(1 \le p \le \infty \).
When \(M_{K^{\star },C}\) defines multiple sets, our result does not imply convergence of the sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\). Rather, we obtain the weaker consequence that the sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) eventually becomes arbitrarily close to the collection \(\{A(C)\mid A \in M_{K^{\star },C}\}\).
Example
Suppose \(K^{\star }\) is the unit \(\ell _2\)-ball in \({\mathbb {R}}^2\), and \(C= \Delta ^{q}\). The optimal \(\rho _2\) approximation is the regular q-gon with an unspecified rotation. The sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) does not have a limit; rather, there is a sequence \(\{g_n\}_{n=1}^{\infty } \subset {{\,\mathrm{SO}\,}}(2,{\mathbb {R}})\) such that \(g_n {\hat{K}}_{n}^{C}\) converges to a centered regular q-gon (with fixed orientation) a.s.
The proof of Theorem 3.1 comprises two parts. First, we show that there exists a ball in \(L({\mathbb {R}}^q,{\mathbb {R}}^d)\) such that \({\hat{A}}_n\) belongs to this ball for all sufficiently large n a.s. Second, we appeal to the following uniform convergence result. The structure of our proof is similar to that of a corresponding result for K-means clustering (see the main theorem in [22]).
Lemma 3.2
Let \(U \subset L({\mathbb {R}}^q,{\mathbb {R}}^d)\) be bounded and suppose the set \(C\subset {\mathbb {R}}^q\) satisfies assumption (A3). Let P be a probability distribution over the measurement pairs \((u,y) \subset S^{d-1} \times {\mathbb {R}}\) satisfying \({\mathbb {E}}_{P}[y^2] < \infty \), and let \(P_n\) be the empirical measure corresponding to drawing n i.i.d. observations from the distribution P. Consider the collection of functions \({\mathcal {G}} := \{ (h_{C}(A^{T}u) - y)^2\mid A \in U \}\) in the variables \((u,y)\). Then \(\sup _{g \in {\mathcal {G}}}|{\mathbb {E}}_{P_n}[g] - {\mathbb {E}}_{P}[g]| \rightarrow 0\) as \(n \rightarrow \infty \) a.s.
The proof of Lemma 3.2 follows from an application of the following uniform strong law of large numbers (SLLN) [23, Thm. 3, p. 8].
Theorem 3.3
(Uniform SLLN) Let Q be a probability measure and let \(Q_n\) be the corresponding empirical measure. Let \({\mathcal {G}}\) be a collection of Q-integrable functions. Suppose that for every \(\epsilon >0\) there exists a finite collection of functions \({\mathcal {G}}_{\epsilon }\) such that for every \(g\in {\mathcal {G}}\) there exist \({\overline{g}},{\underline{g}}\in {\mathcal {G}}_{\epsilon }\) satisfying
-
(i)
\({\underline{g}} \le {\overline{g}}\), and
-
(ii)
\({\mathbb {E}}_{Q}[ {\overline{g}} - {\underline{g}} ] < \epsilon \).
Then \(\sup _{g \in {\mathcal {G}}} | {\mathbb {E}}_{Q_n}[g] - {\mathbb {E}}[g] | \rightarrow 0 \) a.s.
Proof of Lemma 3.2
Based on Theorem 3.3, it suffices to construct the finite collection of functions \({\mathcal {G}}_{\epsilon }\). Pick r sufficiently large so that \(U \subset r B_{\Vert \cdot \Vert _{C,2}} (0)\). Let \({\mathcal {D}}_{\delta }\) be a \(\delta \)-cover for U in the \(\Vert \,{\cdot }\,\Vert _{C,2}\)-norm, where \(\delta \) is chosen so that \(4 \delta {\mathbb {E}}_{P}[ r + |y| ] \le \epsilon \). We define \({\mathcal {G}}_{\epsilon }:=\{ ((|h_{C}(A^{T}u)-y| - \delta )_{+})^2 \}_{A \in {\mathcal {D}}_{\delta }} \cup \{ (|h_{C}(A^{T}u)-y| + \delta )^2 \}_{A \in {\mathcal {D}}_{\delta }} \).
We proceed to verify (i) and (ii). Let \(g=(h_{C}(A^{T}u)-y)^2 \in {\mathcal {G}}\) be arbitrary. Let \(A_0 \in {\mathcal {D}}_{\delta }\) be such that \(\Vert A - A_0 \Vert _{C,2} \le \delta \). Define \({\underline{g}} = ((|h_{C}(A^{T}_0 u)-y| - \delta )_{+})^2\) and \({\overline{g}} = (|h_{C}(A^{T}_0 u)-y| + \delta )^2\). It follows that \({\underline{g}} \le g \le {\overline{g}}\), which verifies (i). Next, we have \({\mathbb {E}}[{\overline{g}} - {\underline{g}} ] \le 4 \delta {\mathbb {E}}[ | h_{C}(A_0^{T}u) - y| ] \le 4 \delta {\mathbb {E}}[ r + |y| ] \le \epsilon \), which verifies (ii). \(\square \)
Proof of Theorem 3.1
To simplify notation in the following proof, we denote \(B := B_{\Vert \cdot \Vert _{C,2}}(0)\). First, we recall the definition of the event \(G_{r,v}\) and the function \(s(v)\) from the proof of Proposition 2.3. Using a sequence of arguments identical as in the proof of Proposition 2.3, it follows that there exists \({\hat{r}}\) sufficiently large so that \({\hat{r}}^2{\mathbb {P}}[G_{{\hat{r}},v}]/16 > \Phi _{C}(0,P_{K^{\star }})\) for all \(v\in S^{d-1}\). We claim that \({\hat{A}}_{n} \in {\hat{r}} B\) eventually a.s. We prove this assertion via contradiction. Suppose on the contrary that \({\hat{A}}_{n} \notin {\hat{r}} B\) i.o. For every \({\hat{A}}_n \notin {\hat{r}} B\), there exists \({\hat{x}}_{n} \in C\) such that \(\Vert {\hat{A}}_n{\hat{x}}_{n} \Vert >{\hat{r}}\). The sequence of unit-norm vectors \({\hat{A}}_n {\hat{x}}_{n} / \Vert {\hat{A}}_n {\hat{x}}_{n} \Vert _{2}\), defined over the subset of indices n such that \({\hat{A}}_n \notin {\hat{r}} B\), contains a convergent subsequence whose limit point is \({\hat{v}}\in S^{d-1}\). Then
Here, the last equality follows from the SLLN. This implies \(\Phi _{C}({\hat{A}}_n, P_{n,K^{\star }}) > \Phi _{C}(0, P_{n,K^{\star }})\) i.o., which contradicts the minimality of \({\hat{A}}_n\). Hence \({\hat{A}}_{n} \in {\hat{r}} B\) eventually a.s.
Second, we show that \({{\,\mathrm{dist}\,}}({\hat{A}}_n,M_{K^{\star },C}) \rightarrow 0\) a.s. It suffices to show that \({\hat{A}}_n \in U\) eventually a.s., where U is any open set containing \(M_{K^{\star },C}\). Let \({\hat{A}} \in M_{K^{\star },C}\) be arbitrary. By Proposition 2.1, the function \(A \mapsto \Phi _{C}(A,P_{K^{\star }})\) is continuous. By noting that the set of minimizers of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) is compact from Proposition 2.3, we can pick \(\epsilon >0\) sufficiently small so that \(\{ A\mid \Phi _{C}(A,P_{K^{\star }}) <\Phi _{C}({\hat{A}},P_{K^{\star }}) + \epsilon \} \subset U\). Next, since \({\hat{A}}_n\) is defined as the minimizer of an empirical sum, we have \(\Phi _{C}({\hat{A}}_n,P_{n,K^{\star }}) \le \Phi _{C}({\hat{A}},P_{n,K^{\star }})\) for all n. By applying Lemma 3.2 with the choice of \(P=P_{K^{\star }}\), we have \(\Phi _{C}({\hat{A}}_n,P_{n,K^{\star }}) \rightarrow \Phi _{C}({\hat{A}}_n,P_{K^{\star }})\), and \(\Phi _{C}({\hat{A}},P_{n,K^{\star }}) \rightarrow \Phi _{C}({\hat{A}},P_{K^{\star }})\), both uniformly and in the a.s. sense. Subsequently, by combining the previous two conclusions, we have \(\Phi _{C}({\hat{A}}_n,P_{K^{\star }}) < \Phi _{C}({\hat{A}},P_{K^{\star }}) + \epsilon \) eventually, for any \(\epsilon >0\). This proves that \({{\,\mathrm{dist}\,}}({\hat{A}}_n,M_{K^{\star },C}) \rightarrow 0\) a.s.
Third, we conclude that
Fix an integer n, and let \(t_n ={{\,\mathrm{dist}\,}}({\hat{A}}_n,M_{K^{\star },C})\). Since \(M_{K^{\star },C}\) is compact, we may pick \({\bar{A}} \in M_{K^{\star },C}\) such that \(\Vert {\hat{A}}_{n} - {\bar{A}} \Vert _\mathrm{F} = t_n\). Given \(A \in {\hat{A}}_n \cdot {{\,\mathrm{Aut}\,}}C\), we have \(A = {\hat{A}}_n g\) for some \(g \in {{\,\mathrm{Aut}\,}}C\). Then \({\bar{A}} g \in {\bar{A}} \cdot {{\,\mathrm{Aut}\,}}C\), and since g is an isometry by assumption (A4), we have \(\Vert {\hat{A}}_{n} g - {\bar{A}} g \Vert _\mathrm{F} = \Vert {\hat{A}}_{n} - {\bar{A}} \Vert _\mathrm{F} = t_n\). This implies that \(d_{\text {H}}({\hat{A}}_n \cdot {{\,\mathrm{Aut}\,}}C,{\bar{A}} \cdot {{\,\mathrm{Aut}\,}}C) \le t_n\). Since \(t_n \rightarrow 0\) as \(n \rightarrow 0\), (16) follows. \(\square \)
3.2 Asymptotic Normality
In our second main result, we characterize the limiting distribution of a sequence of estimates \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) corresponding to minimizers of (2) by analyzing an associated sequence of minimizers of (5). Specifically, we show under suitable conditions that the estimation error in the sequence of minimizers of the empirical loss (5) is asymptotically normal. After developing this theory, we illustrate in Sect. 3.2.1 through a series of examples the asymptotic behavior of the set \({\hat{K}}_{n}^{C}\), highlighting settings in which \({\hat{K}}_{n}^{C}\) converges, as well as situations in which our asymptotic normality characterization fails due to the requisite assumptions not being satisfied. Our result relies on two key ingredients, which we describe next.
The first set of requirements pertains to non-degeneracy of the function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\). First, we require that the minimizers of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) constitute a unique orbit under the action of the automorphism group of the set \(C\); this guarantees the existence of a convergent sequence of minimizers of the empirical losses \(\Phi _{C}(\,{\cdot }\,,P_{n,K^{\star }})\), which is necessary to provide a Central Limit Theorem (CLT) type of characterization. Second, we require the function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) to be twice differentiable at a minimizer with a positive definite Hessian (modulo invariances due to \({{\,\mathrm{Aut}\,}}C\)); such a condition allows us to obtain a quadratic approximation of \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) around a minimizer \({\hat{A}}\), and to subsequently compute first-order approximations of minimizers of the empirical losses \(\Phi (\,{\cdot }\,,P_{n,K^{\star }})\). These conditions lead to a geometric characterization of confidence regions of the extreme points of the limit of the sequence \(\{{\hat{K}}_{n}^{C}\}_{n=1}^\infty \).
Our second main assumption centers around the collection of sets that serves as the constraint in the optimization problem (2). Informally, we require that this collection is not “overly complex,” so that we can appeal to a suitable CLT. The field of empirical processes provides the tools necessary to formalize matters. Concretely, as our estimates are obtained via minimization of an empirical process, we require that the following divided differences of the loss function are well controlled:
In particular, a natural assumption is that the graph associated to these divided differences, indexed over a collection centered at \({\hat{A}}\), is of suitably “bounded complexity”:
A powerful framework to quantify the ‘richness’ of such collections is based on the notion of a Vapnik–Chervonenkis (VC) class [33]. VC classes describe collections of subsets with bounded complexity, and they feature prominently in the field of statistical learning theory, most notably in conditions under which generalization of a learning algorithm is possible.
Definition
(Vapnik–Chervonenkis class) Let \({\mathcal {F}}\) be a collection of subsets of a set F. A finite set D is said to be shattered by F if for every \(A \subset D\) there exists \(G \in {\mathcal {F}}\) such that \(A = G \cap D\). The collection \({\mathcal {F}}\) is said to be a VC class if there is a finite k such that all sets with cardinality greater than k cannot be shattered by \({\mathcal {F}}\).
Whether or not the collection (17) is VC depends on the particular choice of \(C\). If \(C\) is chosen to be either a simplex or a spectraplex then such a property is indeed satisfied—see Sect. 3.2.2 for further details. Our analysis relies on a result by Stengle and Yukich showing that certain collections of sets admitting semialgebraic representations are VC [31]. We are now in a position to state our main result of this section:
Theorem 3.4
Suppose that the assumptions (A1)–(A4) hold. Suppose that there exists \({\hat{A}} \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) such that the set of minimizers \(M_{K^{\star },C}={\hat{A}} \cdot {{\,\mathrm{Aut}\,}}C\) (i.e., \(M_{K^{\star },C}\) consists of a single orbit), the function \(h_{C}(\,{\cdot }\,)\) is differentiable at \({\hat{A}}^{T}u\) for \(P_{K^{\star }}\)-a.e. \(u\), the function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) is twice differentiable at \({\hat{A}}\), and the associated Hessian \(\Gamma \) at \({\hat{A}}\) is positive definite restricted to the subspace \(T^{\perp }\), i.e., \(\Gamma |_{T^{\perp }} \succ 0\); here \(T:=T_{{\hat{A}}} M_{K^{\star },C}\) denotes the tangent space of \(M_{K^{\star },C}\) at \({\hat{A}}\). In addition, suppose that the collection of sets specified by (17) forms a VC class. Let \({\tilde{A}}_n \in {{\,\mathrm{arg\,min}\,}}_{A} \Phi _{C}(A,P_{n,K^{\star }})\), \(n \in {\mathbb {N}}\), be a sequence of minimizers of the empirical loss function, and let \({\tilde{A}}_n \in {{\,\mathrm{arg\,min}\,}}_{A \in {\hat{A}}_n \cdot {{\,\mathrm{Aut}\,}}C} \Vert {\hat{A}} - A \Vert _\mathrm{{F}}\), \(n \in {\mathbb {N}}\), specify an equivalent sequence defined with respect to the minimizer \({\hat{A}}\) of the population loss. Setting \(\nabla = \nabla _{A} ((h_{C}(A^{T}u)-y)^2)\), we have that
The proof of this theorem relies on ideas from the literature of empirical processes, which we describe next in a general setting.
Proposition 3.5
Suppose P is a probability measure over \({\mathbb {R}}^{q}\) and \(P_n\) is the empirical measure corresponding to n i.i.d. draws from P. Suppose \(f(\,{\cdot }\,,\,{\cdot }\,):{\mathbb {R}}^{q} \times {\mathbb {R}}^{p} \rightarrow {\mathbb {R}}\) is a Lebesgue-measurable function such that \(f(\,{\cdot }\,,t):{\mathbb {R}}^{q} \rightarrow {\mathbb {R}}\) is P-integrable for all \(t\in {\mathbb {R}}^{p}\). Denote the expectations \(F(t) = {\mathbb {E}}_{P}[ f(\,{\cdot }\,,t)]\) and \(F_n(t) = {\mathbb {E}}_{P_n}[f(\,{\cdot }\,,t)]\). Let \({\hat{t}} \in {{\,\mathrm{arg\,min}\,}}_{t}F(t)\) be a minimizer of the population loss, let \(\{ {\hat{t}}_n \}_{n=1}^{\infty }\), \({\hat{t}}_n \in {{\,\mathrm{arg\,min}\,}}_{t}F_n(t)\), be a sequence of empirical minimizers, and let \(f(\,{\cdot }\,,t) = f(\,{\cdot }\,,{\hat{t}}) + \langle t- {\hat{t}}, \Delta (\,{\cdot }\,) \rangle + \Vert t- {\hat{t}} \Vert _{2}r(\,{\cdot }\,,t)\) denote the linearization of \(f(\,{\cdot }\,,t)\) about \({\hat{t}}\) (we assume that \(f(\,{\cdot }\,,t)\) is differentiable with respect to \(t\) at \({\hat{t}}\) P-a.e., with derivative denoted by \(\Delta (\,{\cdot }\,)\)). Let \({\mathcal {D}}=\{d_{t, {\hat{t}}}(\,{\cdot }\,)\mid t\in B_{\Vert \cdot \Vert _{2}} ({\hat{t}}) \setminus \{{\hat{t}}\} \}\), where \(d_{t_1,t_2}(\,{\cdot }\,) = (f(\,{\cdot }\,,t_1)-f(\,{\cdot }\,,t_2)) / \Vert t_1 - t_2 \Vert _{2}\), denote the collection of divided differences. Suppose
-
(i)
\({\hat{t}}_n \rightarrow {\hat{t}}\) a.s.,
-
(ii)
the Hessian \(\nabla ^{2}:=\nabla ^{2}F(t)|_{t= {\hat{t}}}\) about \({\hat{t}}\) is positive definite,
-
(iii)
the collection of sets \(\bigl \{\{ (\,{\cdot }\,, s) \mid d_{t,{\hat{t}}}(\,{\cdot }\,) \ge s \ge 0\, \text { or } \,d_{t,{\hat{t}}}(\,{\cdot }\,) \le s \le 0 \}\, \mid \, t\in B_{\Vert \cdot \Vert _{2}} ({\hat{t}}) \setminus \{ {\hat{t}} \} \bigr \}\) form a VC class, and
-
(iv)
there is a function \({\bar{d}}(\,{\cdot }\,):{\mathbb {R}}^q \rightarrow {\mathbb {R}}\) such that \(|d(\,{\cdot }\,)|\le {\bar{d}}(\,{\cdot }\,)\) for all \(d \in {\mathcal {D}}\), \(|\langle \Delta (\,{\cdot }\,), e\rangle | \le {\bar{d}}(\,{\cdot }\,)\) for all unit-norm vectors \(e\), \({\bar{d}}(\,{\cdot }\,)>0\), and \({\bar{d}}(\,{\cdot }\,)\in {\mathcal {L}}^{2}(P)\).
Then \(\sqrt{n}({\hat{t}}_n - {\hat{t}}) \overset{D}{\rightarrow } {\mathcal {N}}\bigl (0, (\nabla ^{2})^{-1} [ ({\mathbb {E}}_{P}[\Delta \Delta ^{T}]) - ({\mathbb {E}}_{P}[\Delta ])({\mathbb {E}}_{P}[\Delta ])^{T} ] (\nabla ^{2})^{-1}\bigr )\).
The proof of Proposition 3.5 is based on a series of ideas developed in [23, Ch. VII] (see in particular Example 19). These rely on computing entropy numbers for certain function classes. More formally, given a probability measure P and a collection of functions \({\mathcal {F}}\) with each member being a mapping from \({\mathbb {R}}^q\) to \({\mathbb {R}}\), we define \(\eta (\epsilon , P, {\mathcal {F}})\) to be the size of the smallest \(\epsilon \)-cover of \({\mathcal {F}}\) in the \({\mathcal {L}}^{2}(P)\)-distance. As these steps are built on substantial background material from [23], we state the key conceptual arguments in the following proof and refer the reader to specific pointers in the literature for further details.
Proof of Proposition 3.5
To simplify notation we denote \(B_{{\hat{t}}}:=B_{\Vert \cdot \Vert _{2}}({\hat{t}}) \setminus \{ {\hat{t}} \}\). The graphs of \({\mathcal {D}}:=\{d_{t,{\hat{t}}}(\,{\cdot }\,) \mid t\in B_{{\hat{t}}} \}\) form a VC class by assumption. By [23, Cor. 17, p. 20], these graphs have polynomial discrimination (see [23, Ch. II]). In addition, the collection \({\mathcal {D}}\) have an enveloping function \({\bar{d}}\) by assumption. Hence by [23, Lem. 36, p. 34], there exist constants \(\alpha _{{\mathcal {D}}},\beta _{{\mathcal {D}}}\) such that \(\eta (\delta ( {\mathbb {E}}_{P_n} [{\bar{d}}^2])^{1/2}, P_n, {\mathcal {D}}) \le \alpha _{{\mathcal {D}}} (1/\delta )^{\beta _{{\mathcal {D}}}}\), for all \(0<\delta \le 1\) and all n.
We obtain a similar bound for graphs of \({\mathcal {E}} := \{ \langle \Delta (\,{\cdot }\,) ,(t-{\hat{t}})/\Vert t-{\hat{t}}\Vert _2 \rangle \mid t\in B_{{\hat{t}}} \}\). First, we note that \({\mathcal {E}}\) is a subset of a finite dimensional vector space. By [17, Lem. 9.6, p. 159], the collection of subgraphs \(\{ \{ (t,s)\mid f(t) \le s \} \mid f \in {\mathcal {E}} \}\) forms a VC class. Then, by noting that the singletons \(\{ \{ (t,s)\mid s \le 0 \} \}\) form a VC class, and that the collection of sets formed by taking intersections of members of two VC classes is also a VC class (see [17, Lem. 9.7, p. 159]), we conclude that the collection of sets \(\{ \{ (t,s)\mid f(t) \le s \le 0 \} \mid f \in {\mathcal {E}} \}\) is a VC class. A similar sequence of steps shows that the collection of sets \(\{ \{ (t,s)\mid f(t) \ge s \ge 0 \} \mid f \in {\mathcal {E}} \}\) also forms a VC class. The collection of graphs of \({\mathcal {E}}\) is the union of the previous two collections. Hence by [17, Lem. 9.7, p. 159] it is also a VC class. Subsequently, by applying the same sequence of steps as we did for \({\mathcal {D}}\), there exists constants \(\alpha _{{\mathcal {E}}},\beta _{{\mathcal {E}}}\) such that \(\eta (\delta ({\mathbb {E}}_{P_n}[{\bar{d}}^2])^{1/2}, P_n, {\mathcal {E}}) \le \alpha _{{\mathcal {E}}} (1/\delta )^{\beta _{{\mathcal {E}}}}\), for all \(0<\delta \le 1\) and all n.
Next, consider the collection of functions \({\mathcal {F}} := \{ r(\,{\cdot }\,,t)\mid t\in B_{{\hat{t}}} \}\). We have \(r(\,{\cdot }\,,t) = d_{t,{\hat{t}}}(\,{\cdot }\,)+\langle \Delta (\,{\cdot }\,), ( t- {\hat{t}} ) / \Vert t- {\hat{t}}\Vert _2 \rangle \), and hence every element in \({\mathcal {F}}\) is expressible as a sum of functions in \({\mathcal {D}}\) and \({\mathcal {E}}\) respectively. Given \((\delta /\sqrt{2})\)-covers for \({\mathcal {D}}\) and \({\mathcal {E}}\) in any \({\mathcal {L}}^{2}\)-distance, one can show via the AM-GM inequality that the union of these covers forms a \(\delta \)-cover for \({\mathcal {F}}\). Subsequently, we conclude that there exists constants \(\alpha \) and \(\beta \) such that \(\eta (\delta ({\mathbb {E}}_{P_n}[{\bar{d}}^2])^{1/2},P_n,{\mathcal {F}}) \le \alpha (1/\delta )^{\beta }\).
The remaining sequence of arguments is identical to those in [23, Ch. VII]. Our bound on the quantity \(\eta (\delta ({\mathbb {E}}_{P_n}[{\bar{d}}^2])^{1/2},P_n,{\mathcal {F}})\) implies that there exists \(\theta \) such that \(\int _{0}^{\theta } ( \eta (t,P_n,{\mathcal {F}}) / t)^{1/2} dt < \epsilon \) for all n and all \(\epsilon >0\). We apply [23, Lem. 15, p. 150] to obtain the following stochastic equicontinuity property: given \(\gamma >0\) and \(\epsilon >0\), there exists \(\theta \) such that
Here, \(E_n\) denotes the signed measure \(\sqrt{n}(P_n-P)\). One can check measurability of the inner supremum using the notion of permissibility—see [23, App. C] (in essence, we simply require f to be measurable and the index \(t\) to reside in an Euclidean space). Finally we apply [23, Thm. 5, p. 141] to conclude the result. \(\square \)
Proof of Theorem 3.4
The first step is to verify that the sequence \(\{ {\tilde{A}}_n \}_{n=1}^{\infty }\) quotients out the appropriate equivalences. Since \({\tilde{A}}_n \in {\hat{A}}_n \cdot {{\,\mathrm{Aut}\,}}C\), we have \({\tilde{A}}_n = {\hat{A}}_n g_n\) for an isometry \(g_n\). Subsequently we have \(\Vert {\tilde{A}}_n - {\hat{A}} \Vert _\mathrm{F} = \Vert {\hat{A}}_n g_n - {\hat{A}} \Vert _\mathrm{F} = \Vert {\hat{A}}_n - {\hat{A}} g_n^{-1} \Vert _\mathrm{F} \le d_{\text {H}} ({\hat{A}}_n,M_{K^{\star },C})\). Following the conclusions of Theorem 3.1, we have \({\tilde{A}}_n \rightarrow {\hat{A}}\) a.s. Furthermore, as a consequence of the optimality conditions in the definition of \({\tilde{A}}_n\), we also have \({\tilde{A}}_n - {\hat{A}} \in T^{\perp }\).
The second step is to apply Proposition 3.5 to the sequence \(\{{\tilde{A}}_n\}_{n=1}^{\infty }\) with \((h_{C} (A^{T}u) - y)^2\) as the choice of loss function \(f(\,{\cdot }\,,t)\), \(P_{K^{\star }}\) as the probability measure P, \((u,y)\) as the argument, and A as the index \(t\). First, the measurability of the loss as a function in A and \((u,y)\) is straightforward to establish. Second, the differentiability of the loss function at \({\hat{A}}\) for \(P_{K^{\star }}\)-a.e. \((u,y)\) follows from the assumption that \(h_{C}(\,{\cdot }\,)\) is differentiable at \({\hat{A}}^{T}u\) for \(P_{K^{\star }}\)-a.e. \(u\). Third, we have shown that \({\tilde{A}}_n \rightarrow {\hat{A}}\) a.s. in the above. Fourth, the Hessian \(\Gamma |_{T^{\perp }}\) is positive definite by assumption. Fifth, the graphs of \(\{ d_{C,A,{\hat{A}}}(u,y)\mid A \in B_{\Vert \cdot \Vert _\mathrm{F}}({\hat{A}}) \setminus \{ {\hat{A}} \} \}\) form a VC class by assumption. Sixth, we need to show the existence of an appropriate function \(d(\,{\cdot }\,)\) to bound the divided differences \(d_{C,A,{\hat{A}}}(\,{\cdot }\,)\) and the inner products \(\langle \nabla (\,{\cdot }\,) |_{A={\hat{A}}}, E \rangle \), where \(\Vert E\Vert _\mathrm{F} = 1\). In the former case, we note that \(|(h_{C} (A_1^{T}u)-y) + (h_{C} (A_2^{T}u) - y)| \le \Vert A_1 - A_2 \Vert _{C,2} \le c_1\Vert A_1-A_2\Vert _\mathrm{F}\) for some \(c_1>0\); here, the first inequality follows from Lemma 2.2 and the second inequality follows from the equivalence of norms. Then, by noting that \(A \in B_{\Vert \cdot \Vert _\mathrm{F}}({\hat{A}}) \setminus {{\hat{A}}}\) is bounded, the expression \(| (h_{C} (A^{T}u)-y)+(h_{C} ({\hat{A}}^{T}u) - y) |\) is bounded above by a function of the form \(c_2(1+|y|)\). By expanding the divided difference expression and by combining the previous two bounds, one can show that \(|d_{C,A,{\hat{A}}}(\,{\cdot }\,)| \le c_3(1+|y|)\) for some \(c_3 > 0\). In the latter case, the derivative is given by \(2(h_{C} ({\hat{A}}^{T}u) - y) u\otimes e_{C}({\hat{A}}^{T}u)\). By noting that \(h_{C}({\hat{A}}^{T}u)\), \(u\), and \(e_{C}({\hat{A}}^{T}u)\) are uniformly bounded over \(u\in S^{d-1}\), and by performing a sequence of elementary bounds, one can show that \(\langle \nabla , E \rangle \) is bounded above by \(c_4(1+|y|)\) uniformly over all unit-norm E. We pick \({\bar{d}}(\,{\cdot }\,)\) to be \(c(1+|y|)\), where \(c = \max {\{1,c_3,c_4\}}\). Then \({\bar{d}}(\,{\cdot }\,) > 0\) by construction and furthermore, \({\bar{d}} \in {\mathcal {L}}^2(P_{K^{\star }})\) as \({\mathbb {E}}_{P_{K^{\star }}}[ \varepsilon ^2 ]<\infty \).
Finally, the result follows from an application of Proposition 3.5. \(\square \)
This result gives an asymptotic normality characterization corresponding to a sequence of minimizers \(\{{\hat{A}}_n\}_{n=1}^\infty \) of the empirical losses \(\Phi _{C}(\,{\cdot }\,,P_{n,K^{\star }})\). In the next result, we specialize this result to the setting in which the underlying set \(K^{\star }\) is in fact expressible as a projection of \(C\), i.e., \(K^{\star }= A^{\star }(C)\) for some \(A^\star \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\). This specialization leads to a particularly simple formula for the asymptotic error covariance, and we demonstrate its utility in the examples in Sect. 3.2.1.
Corollary 3.6
Suppose that the conditions of Theorem 3.4 and of Proposition 2.10 hold. Using the notation of Theorem 3.4, we have that \({\mathbb {E}}[ \nabla \otimes \nabla |_{A=A^{\star }} ] = 2\sigma ^2 \Gamma \) with \(\Gamma \) given by (11). In particular, the conclusion of Theorem 3.4 simplifies to \(\sqrt{n}({\tilde{A}}_n - {\hat{A}}) \overset{D}{\rightarrow } {\mathcal {N}}\bigl (0, 2\sigma ^2 (\Gamma |_{T^{\perp }})^{-1}\bigr )\).
Proof
One can check that \(\nabla _{A} ((h_{C}(A^{T}u) - y)^2) |_{A=A^{\star }} = - 2\varepsilon u\otimes e_{C}(A^{\star T}u) \), from which we have that \({\mathbb {E}}[\nabla \otimes \nabla |_{A=A^{\star }} ] = 2\sigma ^2 \Gamma \). This concludes the result. \(\square \)
3.2.1 Examples
Here we give examples that highlight various aspects of the theoretical results described previously. In all of our examples, the noise \(\{\varepsilon ^{(i)}\}_{i=1}^{n}\) is given by i.i.d. centered Gaussian random variables with variance \(\sigma ^2\). We begin with an illustration in which the assumptions of Theorem 3.4 are not satisfied and the asymptotic normality characterization fails to hold:
Example
Let \(K^{\star }:=\{0\} \subset {\mathbb {R}}\) be a singleton. As \(S^{0} \cong \{ -1,1\}\), the random variables \(u^{(i)}\) are \(\pm 1\) u.a.r. Further, \(h_{K^{\star }}(u)=0\) for all \(u\) and the support function measurements are simply \(y^{(i)} = \varepsilon ^{(i)}\) for all \(i=1,\dots ,n\). For \(C\) being either a simplex or a spectraplex, the set \(M_{K^{\star },C}=\{ 0 \} \subset L({\mathbb {R}}^q,{\mathbb {R}})\) is a singleton consisting only of the zero map. First, we consider fitting \(K^{\star }\) with the choice of \(C= \Delta ^{1} \subset {\mathbb {R}}^1\). Then we have \({\hat{A}}_n =({1}/{n}) \sum _{i=1}^{n} \varepsilon ^{(i)} u^{(i)}\), from which it follows that \(\sqrt{n}({\hat{A}}_n - 0)\) is normally distributed with mean zero and variance \(\sigma ^2\)—this is in agreement with Theorem 3.4. Second, we consider fitting \(K^{\star }\) with the choice \(C= \Delta ^{2} \subset {\mathbb {R}}^2\). Define \(U_{-} = \{ i \mid u_i = -1 \}\) and \(U_{+} = \{ i \mid u_i = 1 \}\), and
Then \({\hat{K}}_{n}^{C}= \{ x \mid \alpha _{-} \le x \le \alpha _{+} \}\) if \(\alpha _{-} \le \alpha _{+}\) and \({\hat{K}}_{n}^{C}= \bigl \{ ({1}/{n}) \sum _{i=1}^{n} \varepsilon ^{(i)} u^{(i)} \bigr \}\) otherwise. Notice that \(\alpha _{-}\) and \(\alpha _{+}\) have the same distribution, and hence \({\hat{K}}_{n}^{C}\) is a closed interval with non-empty interior w.p. 1/2, and is a singleton w.p. 1/2. Thus, one can see that the linear map \({\hat{A}}_n\) does not satisfy an asymptotic normality characterization. The reason for this failure is that the function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) is twice differentiable everywhere excluding the line \(\{ (c,c) \mid c \in {\mathbb {R}}\}\); in particular, it is not differentiable at the minimizer (0, 0).
The above example is an instance where the function \(\Phi _{C}(\,{\cdot }\,,P_{K^{\star }})\) is not twice differentiable at \({\hat{A}}\). The manner in which an asymptotic characterization of \(\{{\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\) fails in instances where \(M_{K^{\star },C}\) contains multiple orbits is also qualitatively similar. Next, we consider a series of examples in which the conditions of Theorem 3.4 hold, thus enabling an asymptotic normality characterization behavior of \({\hat{K}}_{n}^{C}\). To simplify our discussion, we describe settings in which the choices of \(C\) and \(A^{\star }\) satisfy the conditions of Corollary 3.6, which leads to simple formulas for the second derivative \(\Gamma \) of the map \(A\mapsto \Phi _{C}(A,P_{K^{\star }})\) at \(A^{\star }\).
3.2.2 Polyhedral Examples
We present two examples in which \(K^{\star }\) is polyhedral, and we choose \(C= \Delta ^{q}\) where q is the number of vertices of \(K^{\star }\). With this choice, the set \(M_{K^{\star },C}\) comprises linear maps \(A \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) whose columns are the extreme points of \(K^{\star }\).
Proposition 3.7
Let \(K^{\star }\) be a polytope with q extreme points and let \(A^{\star }\) be the linear map whose columns are the extreme points of \(K^{\star }\) (in any order). The second derivative of \(\Phi _{C}(\,{\cdot }\,,P)\) at \(A^{\star }\) is given by \(\Gamma (D) = \sum _{j=1}^{q} \int _{u\in H_{A^{\star },j} } \langle u\otimes e_j , D \rangle u\otimes e_j ~ d u\), where \(H_{A,j} := \{ u\in S^{d-1}\mid u^{T} A e_j > u^{T} A e_k \text { for all } k \ne j \}\).
Proof
Let \(A\in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) be a linear map whose columns are pairwise distinct. Then the set \(V_{A} := \{ u\mid u^{T} A e_i = u^{T} A e_j ,\, 1 \le i < j \le d \} \) is a subset of \(S^{d-1}\) with measure zero. We note that the function \(h_{C}(\,{\cdot }\,)\) is differentiable at \(A^{T}u\) whenever \(u\in S^{d-1} \setminus \{V_{A}\}\), and hence the function \(h_{C}(A^{T}u)\) is differentiable with respect to \(u\) P-a.e. By Proposition 2.9, the derivative of \(\Phi _{C}(\,{\cdot }\,,P)\) at A is \(2{\mathbb {E}}_{P} [(h_{C}(A^{T}u) - y) u\otimes e_{C}(A^{T}u) ]\).
The subset of linear maps whose columns are pairwise distinct is open. Hence the derivative of \(\Phi _{C}(\,{\cdot }\,,P)\) exists in a neighborhood of \(A^{\star }\). It is clear that the derivative is also continuous at \(A^{\star }\). Finally, we note that the collection \(\{H_{A^{\star },j}\}_{j=1}^{q}\) forms a disjoint cover of \(S^{d-1}\) up to a subset of measure zero, and apply Proposition 2.10 to conclude the expression for \(\Gamma \). \(\square \)
We note that the operator \(\Gamma \) has block diagonal structure since each integral \(\int _{u\in H_{A^{\star },j} } \langle u\otimes e_j , D \rangle u\otimes e_j ~ d u\) is supported on a \(d\times d\) dimensional sub-block. Subsequently, by combining the conclusions of Theorem 3.1 and Proposition 3.7, we can conclude the following about \({\hat{K}}_{n}^{C}\): (i) it is a polytope with q extreme points, (ii) each vertex of \({\hat{K}}_{n}^{C}\) is close to a distinct vertex of \(K^{\star }\), (iii) the deviations (after scaling by a factor of \(\sqrt{n}\)) between every vertex-vertex pair are asymptotically normal with inverse covariance specified by a \(d\times d\) block of \(\Gamma \), and further these deviations are pairwise independent.
Example
Let \(K^{\star }\) be the regular q-gon in \({\mathbb {R}}^2\) with vertices \(v_{k} : = ({{\,\mathrm{cos}\,}}(2k\pi /q), {{\,\mathrm{sin}\,}}(2k\pi /q) )^{T}\), \(k=0,\dots ,q-1\). Let \({\hat{v}}_{n,k}\) be the vertex of \({\hat{K}}_{n}^{C}\) closest to \(v_{k}\). The deviation \(\sqrt{n}({\hat{v}}_{n,k} - v_{k})\) is asymptotically normal with covariance \(2\sigma ^2 M_{k,k}^{-1}\), where
The eigenvalues of \(M_{k,k}\) are \(1/q + (1/2\pi ){{\,\mathrm{sin}\,}}(2\pi /q)\) and \(1/q - (1/2\pi ){{\,\mathrm{sin}\,}}(2\pi /q)\), and the corresponding eigenvectors are \(({{\,\mathrm{cos}\,}}(2k\pi /q), {{\,\mathrm{sin}\,}}(2k\pi /q) )^{T}\) and \(({{\,\mathrm{sin}\,}}(2k\pi /q), - {{\,\mathrm{cos}\,}}(2k\pi /q) )^{T}\) respectively. Consequently, the deviation \({\hat{v}}_{n,k} - v_{k}\) has magnitude \(\approx \sigma \sqrt{q/n}\) in the direction \(v_{k}\), and has magnitude \(\approx \sigma \sqrt{3q^3/\pi ^2 n}\) in the direction \(v_{k}^{\perp }\). Figure 2 shows \(K^{\star }\) as well as the confidence intervals (ellipses) of the vertices of \({\hat{K}}_{n}^{C}\) for large n and \(q=5\).

Estimating a regular pentagon as the projection of \(\Delta ^{5}\). In the limit (large n), the estimator \({\hat{K}}_{n}^{C}\) is a pentagon. The typical deviation of the vertices of \({\hat{K}}_{n}^{C}\) from that of the pentagon (scaled by a factor of \(\sqrt{n}\)) is represented by the surrounding ellipses
Example
Let \(K^{\star }\) be the \(\ell _{\infty }\)-ball in \({\mathbb {R}}^d\). For any vertex \(v\) of \(K^{\star }\), let \({\hat{w}}_{n,v}\) denote the vertex of \({\hat{K}}_{n}^{C}\) closest to \(v\). The deviation \(\sqrt{n}({\hat{w}}_{n,v} - v)\) is asymptotically normal with covariance \(2\sigma ^2 M_{v, v}^{-1}\), where
Hence the deviation \({\hat{w}}_{n,v} - v\) has magnitude \(\approx \sigma 2^{(d+1)/2}(2/\pi + (1-2/\pi )/d)^{-1/2} n^{-1/2}\) in the span of \(v\) and magnitude \(\approx \sigma 2^{(d+1)/2}(1-2/\pi )^{-1/2} \sqrt{d/n} \) in the orthogonal complement \(v^\perp \).
3.2.3 Non-Polyhedral Examples
Next we present two examples in which \(K^{\star }\) is non-polyhedral. Unlike the previous polyhedral examples in which columns of the linear map \({\tilde{A}}_n\) map directly to vertices, our description of \({\hat{K}}_{n}^{C}\) requires a different interpretation of Corollary 3.6 that is suitable for sets with infinitely many extreme points. Specifically, we characterize the deviation \(\sqrt{n} ({\tilde{A}}_n - A^\star )\) in terms of a perturbation to the set \(K^{\star }= A^{\star }(C)\) by considering the image of \(C\) under the map \(\sqrt{n}({\tilde{A}}_n - A^\star )\).
Example
Suppose \(K^{\star }= B_{\Vert \cdot \Vert _2} (c)\) is the unit \(\ell _2\)-ball in \({\mathbb {R}}^d\) with center \(c\). We consider \(C:= \{ (1,v)^{T} \mid \Vert v\Vert _2 \le 1 \} \subset {\mathbb {R}}^{d+1}\), and \(A^{\star }\) is any linear map of the form \([c~Q] \in L({\mathbb {R}}^{d+1},{\mathbb {R}}^d)\), where \(Q \in O(d,{\mathbb {R}})\) is any orthogonal matrix. Then the restricted Hessian \(\Gamma |_{T^{\perp }}\) is a self-adjoint operator with rank \(d + {d+1 \atopwithdelims ()2}\). The eigenvectors of \(\Gamma |_{T^{\perp }}\) represent ‘modes of oscillations’, which we describe in greater detail. We begin with the case \(d=2\), \(c=0\). The set resulting from the deviation \(\sqrt{n} ({\tilde{A}}_n - A^\star )\) applied to \(C\) can be decomposed into five different modes of perturbation (these exactly correspond to the eigenvectors of the operator \(\Gamma |_{T^{\perp }}\)). Parametrizing the extreme points of \(A^{\star }(C)\) by \(\{(\cos \theta \ \sin \theta )^{T} \mid \theta \in [0,2\pi )\}\), the contribution of each mode at the point \((\cos \theta \ \sin \theta )^{T}\) is a small perturbation in the directions \((1\ 0)^{T}\), \((0\ 1)^{T}\), \((\cos \theta \ \sin \theta )^{T}\), \(( \cos \theta \ \, {-}\sin \theta )^{T}\), and \((\sin \theta \ \cos \theta )^{T}\) respectively—Fig. 3 provides an illustration. The first and second modes represent oscillations of \({\hat{K}}_{n}^{C}\) about \(c\), the third mode represents dilation, and the fourth and fifth modes represent flattening. The analysis for a general d is similar, with d modes representing oscillations about \(c\) and \({d+1\atopwithdelims ()2}\) modes whose contributions represent higher-dimensional analogs of flattening (of which dilation is a special case).

Modes of oscillations for an estimate of the \(\ell _2\)-ball in \({\mathbb {R}}^2\)
Example
Let \(K^{\star }\) be the spectral norm ball in \({\mathbb {S}}^2\). The extreme points of \(K^{\star }\) consist of three connected components: \(\{I\}\), \(\{-I\}\), and \(\{ U D U^{T} \mid U \in {{\,\mathrm{SO}\,}}(2,{\mathbb {R}}) \}\) where D is a diagonal matrix with entries \((1,-1)\). To simplify our discussion, we apply a scaled isometry to \(K^{\star }\) so that \(\{I\}\), \(\{-I\}\), and \(\{ U D U^{T}\mid U \in {{\,\mathrm{SO}\,}}(2,{\mathbb {R}}) \}\) are mapped to the points \(\{(0,0,1)^{T}\}\), \(\{(0,0,-1)^{T}\}\), and \(\{(\cos \theta ,\sin \theta ,0)^{T}\mid \theta \in [0,2\pi ) \}\) in \({\mathbb {R}}^3\), respectively. We choose
and \(A^{\star }\) to be the map defined by \(A^{\star }(X) = ( \langle A_1,X \rangle , \langle A_2, X \rangle , \langle A_3, X \rangle )^{T}\) where
For large n, \({\hat{K}}_{n}^{C}\) is a convex set with extreme points \(P_1\) and \(P_2\) near \((0,0,1)^{T}\) and \((0,0,-1)^{T}\) respectively, and a set of extreme points specified by an ellipse \(P_3\) near \(\{(\cos \theta ,\sin \theta ,0)^{T} \mid \theta \in [0,2\pi ) \}\). The operator \(\Gamma |_T^{\perp }\) is block diagonal with rank 14—it comprises two 3-dimensional blocks \(\Gamma _1\) and \(\Gamma _2\) associated with \(P_1\) and \(P_2\), and an 8-dimensional block \(\Gamma _3\) associated with \(P_3\). One conclusion is that the distributions of \(P_1\), \(P_2\), and \(P_3\) are asymptotically independent. Moreover, the deviations of \(P_1\) and \(P_2\) about \(\{(0,0,1)^{T}\}\) and \(\{(0,0,-1)^{T}\}\) are asymptotically normal with inverse covariance specified by \(\Gamma _1\) and \(\Gamma _2\), respectively. We consider the behavior of \(P_3\) in further detail. The operator \(\Gamma _3\) is the sum of an operator \(\Gamma _{3,xy}\) with rank 5 describing the variation of \(P_3\) in the xy-plane, and another operator \(\Gamma _{3,z}\) with rank 3 describing the variation of \(P_3\) in the direction of the z-axis. The operator \(\Gamma _{3,xy}\), when restricted to the appropriate subspace and suitably scaled, is equal to the operator we encountered in the previous example in the setting in which \(K^{\star }\) is the \(\ell _2\)-ball in \({\mathbb {R}}^2\). The operator \(\Gamma _{3,z}\) comprises a single mode representing oscillations of \(P_{3}\) in the z direction (see subfigure (b) in Fig. 4), and two modes representing “wobbling” of \(P_3\) with respect to the xy-plane (see subfigures (c) and (d) in Fig. 4). The set \(C\) we consider in this example is the intersection of the spectraplex \({\mathcal {O}}^{4}\) with an appropriate subspace specified by (18). A natural question is if the same analysis holds for \(C= {\mathcal {O}}^{4}\). Unfortunately, the introduction of additional dimensions introduces degeneracies (in the form of zero eigenvalues into \(\Gamma |_{T^{\perp }}\)) which violates the requirements of Theorem 3.4.

Estimating \(K^{\star }\), the spectral norm ball in \({\mathbb {S}}^2\), as the projection of the set \(C\) (18). The above figure describes the modes of oscillation corresponding to the set of extreme points of \({\hat{K}}_{n}^{C}\) given by an ellipse (see the above accompanying discussion). There are eight modes altogether—five occur in the xy-plane described in Fig. 3 and the remaining three are shown in (b), (c), and (d)
3.2.4 Specialization of Theorem 3.4 to Linear Images of Spectraplices
Proposition 3.8
Let \(C\) be the spectraplex. Then the collection specified by (17) forms a VC class.
Proof
Define the polynomial
where \(e_{1}, e_{2}, e_{4} \in {\mathbb {R}}^q\) and \(e_{3} \in {\mathbb {R}}^d\). By [31, Thm. 1], the following collection of sets forms a VC class:
Similarly, by [31, Thm. 1], the collection \(\{\{ (u,y,s)\,|\,s \ge 0 \}\mid D \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\}\) also forms a VC class. By [17, Lem. 9.7, p. 159], the collection of sets formed by taking intersections of members of two VC classes is a VC class. Hence it follows that the collection \(\{ (u,y,s)\mid (h_{C}(({\hat{A}}+D)^{T}u)-y)^2 - (h_{C}({\hat{A}}^{T}u)-y)^2\ge s \Vert D\Vert _\mathrm{F} \ge 0 \}\) is a VC class. Subsequently, by setting \(D = A - {\hat{A}}\) and by noting that a sub-collection of a VC class is still a VC class, the collection \(\{\{ (u,y,s) \,|\, d_{C,A,{\hat{A}}} (u,y) \ge s \ge 0 \} \mid A \in B_{\Vert \cdot \Vert _\mathrm{F}}({\hat{A}}) \setminus \{ {\hat{A}} \} \}\) forms a VC class. A similar sequence of arguments shows that the collection \(\{\{ (u,y,s)\,|\,d_{C,A,{\hat{A}}} (u,y) \le s \le 0 \} \mid A \in B_{\Vert \cdot \Vert _\mathrm{F}}({\hat{A}}) \setminus \{ {\hat{A}} \} \}\) also forms a VC class. Last, by [17, Lem. 9.7, p. 159], a union of VC classes is a VC class, and so our result follows. \(\square \)
3.3 Preservation of Facial Structure
Our third result describes conditions under which the constrained estimator (2) preserves the facial structure of the underlying set \(K^{\star }\). We begin our discussion with some stylized numerical experiments that illustrate various aspects that inform our subsequent theoretical development. First, we consider reconstruction of the \(\ell _1\)-ball in \({\mathbb {R}}^3\) from 200 noisy support function evaluations with the choices \(C= \Delta ^6\) and \(C= \Delta ^{12}\). Figure 5 shows these reconstructions along with the LSE. When \(C= \Delta ^6\), our results show a one-to-one correspondence between the faces of the reconstruction obtained using our method (second subfigure from the left) with those of the \(\ell _1\)-ball (leftmost subfigure); in contrast, we do not observe an analogous correspondence in the other two cases.

Reconstructions of the unit \(\ell _1\)-ball (left) in \({\mathbb {R}}^3\) from 200 noisy support function measurements using our method with \(C= \Delta ^6\) (second from left), and with \(C= \Delta ^{12}\) (third from left). The LSE is the rightmost figure

Two reconstructions of the unit \(\ell _{\infty }\)-ball in \({\mathbb {R}}^3\) from 75 noisy support function measurements using our method. The choice of lifting set is \(C= \Delta ^8\). The \(\ell _{\infty }\)-ball is the leftmost figure, and the reconstructions are the second and third figures from the left
Second, we consider reconstruction of the \(\ell _\infty \)-ball in \({\mathbb {R}}^3\) from 75 noisy support function measurements with \(C= \Delta ^8\). From Fig. 6 we see that both reconstructions (obtained from two different sets of 75 measurements) break most of the faces of the \(\ell _\infty \)-ball. In these examples the association between the faces of the underlying set and those of the reconstruction is somewhat transparent as the sets are polyhedral. The situation becomes more delicate with non-polyhedral sets. We describe next a numerical experiment in which we estimate the Race Track in \({\mathbb {R}}^2\) from 200 noisy support function measurements with \(C= {\mathcal {O}}^4\):
From this experiment, it appears that the exposed extreme points of the Race Track are recovered, although the two one-dimensional edges are not recovered and seem to be distorted into curves. However, the exact correspondence between faces of the Race Track and those of the reconstruction seems less clear (Fig. 7).

Reconstructions of the Race Track from 200 noisy support function measurements using (2) with \(C= {\mathcal {O}}^4\)
Our first technical contribution in this subsection is a formal notion of ‘preservation of face structure’. Motivated by the preceding example, the precise manner in which we do so is via the existence of an invertible affine transformation between the faces of the underlying set and the faces of the reconstruction. For analytical tractability, our result focuses on exposed faces (faces that are expressible as the intersection of the underlying set with a hyperplane).
Definition
Let \(\{K_n \}_{n=1}^{\infty } \subset {\mathbb {R}}^d\) be a sequence of compact convex sets converging to some \(K\subset {\mathbb {R}}^d\). Let \(F \subset K\) be an exposed face. We say that F is preserved by the sequence \(\{K_n \}_{n=1}^{\infty }\) if there is a sequence \(\{ F_n \}_{n=n_0}^{\infty }\), \(F_n \subseteq K_n\), such that:
-
(i)
\(F_n \rightarrow F\).
-
(ii)
\(F_n\) are exposed faces of \(K_n\).
-
(iii)
There is an invertible affine transformation \(b_n\) such that \(F = b_n F_n \) and \(F_n = b_n^{-1} F\).
As our next contribution, we consider conditions under which exposed faces of \(K^{\star }\) are preserved. To gain intuition for the types of assumptions that may be required, we review the results of the numerical experiments presented above. In the setting with \(K^{\star }\) being the \(\ell _1\)-ball in \({\mathbb {R}}^3\), all the faces are simplicial and the reconstruction with \(C= \Delta ^6\) preserves all the faces. In contrast, in the experiment with \(K^{\star }\) being the \(\ell _\infty \)-ball in \({\mathbb {R}}^3\) and \(C= \Delta ^8\), some of the faces of the \(\ell _\infty \)-ball are broken into smaller simplicial faces in the reconstruction. These observations suggest that we should only expect preservation of simplicial faces, at least in the polyhedral context. However, in attempting to reconstruct the \(\ell _1\)-ball with \(C= \Delta ^{12}\), some of the simplicial faces of the \(\ell _1\)-ball are broken into smaller simplicial faces in the reconstruction. This is due to the overparametrization of the class of polytopes over which the regression (2) is performed (polytopes with at most twelve vertices) relative to the complexity of the \(\ell _1\)-ball (a polytope with six vertices). We address this point in our theorem via the single-orbit condition discussed in Sect. 2.2, which also plays a role in Theorem 3.4. Finally, in the non-polyhedral setting with \(K^{\star }\) being the Race Track and \(C={\mathcal {O}}^4\), the two one-dimensional faces deform to curves in the reconstruction. This is due to the fact that (generic) small perturbations to the linear image of \({\mathcal {O}}^4\) that gives \(K^{\star }\) lead to a deformation of the edges of \(K^{\star }\) to curves. To ensure that faces remain robust to perturbations of the linear images, we require that the normal cones associated to faces that are to be preserved must be sufficiently large.
Theorem 3.9
Suppose that \(K^{\star }\subseteq {\mathbb {R}}^d\) is a compact convex set with non-empty interior. Let \(C\subset {\mathbb {R}}^q\) be a compact convex set such that \({{\,\mathrm{{Span}}\,}}C\cong {\mathbb {R}}^q\). Suppose that there is a linear map \(A^{\star } \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\) such that \(K^{\star }= A^{\star }(C)\), and \(M_{K^{\star },C}= A^{\star } \cdot {{\,\mathrm{Aut}\,}}C\). Let \(\{ {\hat{A}}_n \}_{n=1}^{\infty }\), \({\hat{A}}_n \in {{\,\mathrm{arg\,min}\,}}_{A} \Phi _{C}(A,P_{n,K^{\star }})\), be a sequence of minimizers of the empirical loss function, and let \(\{ {\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\), \({\hat{K}}_{n}^{C}= {\hat{A}}_n(C)\), be the corresponding sequence of estimators of \(K^{\star }\). Given an exposed face \(F^{\star } \subset K^{\star }\), let \(G = \{ x\mid A^{\star } x\in F^{\star }\} \cap C\) be its pre-image, and let \(N_{C} (G) := \{ v\mid \langle v, x \rangle \ge \langle v,y \rangle \ \text {for all}\ x \in G,\,y \in C\}\) be the normal cone of G w.r.t. \(C\). If
-
(i)
the linear map \(A^{\star }\) is injective when restricted to \({{\,\mathrm{aff}\,}}G\), and
-
(ii)
\(\dim {{\,\mathrm{{Span}}\,}}N_{C} (G) > q - {{\,\mathrm{rank}\,}}A^{\star }\),
then \(F^{\star }\) is preserved by the sequence \(\{ {\hat{K}}_{n}^{C}\}_{n=1}^{\infty }\).
Before giving a proof of this result, we remark next on some of the consequences.
Remark
Suppose \(K^{\star }\) is a full-dimensional polytope with q extreme points and we choose \(C= \Delta ^{q}\). It is easy to see that there is a linear map \(A^{\star }\) such that \(K^{\star }= A^{\star }(\Delta ^{q})\) and that \(M_{K^{\star },\Delta ^{q}} = A^{\star } \cdot {{\,\mathrm{Aut}\,}}\Delta ^{q}\). Let \(F^{\star } \subseteq K^{\star }\) be any face (note that all faces of a polytope are exposed), and let G be its pre-image in \(\Delta ^{q}\). Note that G is an exposed face, and hence G is of the form \(\{ \Pi x\mid x\ge 0, \,\langle x, 1 \rangle = 1,\, x_{s+1} = \ldots =x_{q} = 0 \}\) for some \(\Pi \in {{\,\mathrm{Aut}\,}}\Delta ^{q}\) and some \(s \le q\). The map \(A^{\star }\) being injective on \({{\,\mathrm{aff}\,}}G\) implies that the image of G under \(A^{\star }\) is isomorphic to G; i.e., \(F^{\star }\) is simplicial. The normal cone \(N_{\Delta ^q}(G)\) is given by \( \{ \Pi z\mid z\le 0, \,z_{1} = \ldots =z_{s} = 0 \}\), and the requirement \(\dim {{\,\mathrm{aff}\,}}N_{\Delta ^q}(G)> q - {{\,\mathrm{rank}\,}}A^{\star }\) holds precisely when \(s<d\); i.e., the face \(F^{\star }\) is proper. Thus, Theorem 3.9 implies that all proper simplicial faces of \(K^{\star }\) are preserved in the reconstruction.
Remark
Suppose \(K^{\star }\) is the image under \(A^\star \) of the spectraplex \(C= {\mathcal {O}}^{p}\) and that \(M_{K^{\star },C}= A^{\star } \cdot {{\,\mathrm{Aut}\,}}C\). Let \(F^{\star }\) be an exposed face and let G be its pre-image in \({\mathcal {O}}^{p}\). Then G is a face of \({\mathcal {O}}^{p}\), and is of the form
for some \(U\in O(p,{\mathbb {R}})\) and some \(r \le p\). Note that
Thus, the requirement that \(\dim {{\,\mathrm{aff}\,}}N_{{\mathcal {O}}^p}(G) >{p + 1 \atopwithdelims ()2} - {{\,\mathrm{rank}\,}}A^{\star }\) holds precisely when \(d > pr - {r-1 \atopwithdelims ()2}\). We consider this result in the context of our earlier example involving the Race Track. Specifically, one can represent the Race Track as a linear image of \({\mathcal {O}}^4\) given by the following linear map:
It is clear that \({{\,\mathrm{rank}\,}}A^{\star }= 2\). Let \(F^{\star }\) be the face connecting \((-1,0)^{T}\) and \((1,0)^{T}\), and let \(G_{{\mathcal {O}}^4}\) be the pre-image of \(F^{\star }\) in \({\mathcal {O}}^4\). One can check that
It follows that \(\dim {{\,\mathrm{aff}\,}}N_{{\mathcal {O}}^4}(G_{{\mathcal {O}}^4})=3\). As the dimension of \({\mathcal {O}}^4\) is 10, our requirement on \(\dim {{\,\mathrm{aff}\,}}N_{{\mathcal {O}}^4}(G_{{\mathcal {O}}^4})\) is not satisfied.
Proof of Theorem 3.9
As we noted in the above, let \({\tilde{A}}_n \in {{\,\mathrm{arg\,min}\,}}_{A \in {\hat{A}}_n \cdot {{\,\mathrm{Aut}\,}}C} \Vert {\hat{A}}_n - A \Vert _\mathrm{F}\), and denote \({F}_n = {\tilde{A}}_n (G)\).
[\(F_n \rightarrow {F}\)]: Since \(M_{K^{\star },C}= A^{\star } \cdot {{\,\mathrm{Aut}\,}}C\), it follows from Theorem 3.1 that \({\tilde{A}}_n \rightarrow A^{\star }\), from which we have \(F_n \rightarrow F^{\star }\).
[\(F_n\) are faces of \(K_n\)]: Since \(F^{\star }\) is an exposed face of \(K^{\star }\), there exists \(y\in {\mathbb {R}}^d\) and \(c \in {\mathbb {R}}\) such that \(\langle y,x\rangle = c\) for all \(x\in F^{\star }\), and \(\langle y,x\rangle > c\) for all \(x\in K^{\star }\setminus F^{\star }\). This implies that \(\langle A^{\star T} y,{\tilde{x}} \rangle = c\) for all \({\tilde{x}} \in G\), and \(\langle A^{\star T} y,{\tilde{x}} \rangle > c\) for all \({\tilde{x}} \in C\setminus G\). In particular, it implies that the row space of \(A^{\star }\) intersects the relative interior of \(N_{C}(G)\) in the direction \(A^{\star }y\).
By combining the earlier conclusion that \({\tilde{A}}_n \rightarrow A^{\star }\) a.s., and that \(\dim {{\,\mathrm{{Span}}\,}}N_{C}(G)) + {{\,\mathrm{rank}\,}}A^{\star }> q\), we conclude that the row spaces of the maps \({\tilde{A}}_n\) eventually intersect the relative interior of \(N_{C}(G)\) a.s. That is to say, there are an integer \(n_0\) and sequences \(\{ y_n \}_{n=n_0}^{\infty } \subset {\mathbb {R}}^d\), \(\{c_n\}_{n=n_0}^{\infty } \subset {\mathbb {R}}\) such that \(\langle y_n, x\rangle = c_n\) for all \(x\in F_n\), and \(\langle y_n, x\rangle > c_n\) for all \(x\in {\hat{K}}_{n}^{C}\setminus F_n\), \(n \ge n_0\), a.s. In other words, the sets \(F_n\) are exposed faces of \({\hat{K}}_{n}^{C}\) eventually a.s.
[One-to-one affine correspondence]: To establish a one-to-one affine correspondence between \(F_n\) and F we need to treat the case where \(0 \in {{\,\mathrm{aff}\,}}G\) and the case where \(0 \notin {{\,\mathrm{aff}\,}}G\) separately.
First suppose that \(0 \in {{\,\mathrm{aff}\,}}G\). Let \(H_{F} = {{\,\mathrm{aff}\,}}F\) and \(H_{G} = {{\,\mathrm{aff}\,}}G\). Since \(0 \in H_{G}\), it follows that \(H_{F}\) and \(H_{G}\) are subspaces. Moreover given that \(A^{\star }\) is injective restricted to \(H_{G} = {{\,\mathrm{aff}\,}}G\), it follows that \(H_{F}\) and \(H_{G}\) have equal dimensions. Hence the map t defined as the restriction of \(A^{\star }\) onto \(L(H_{G},H_{F})\) is square and invertible. Next let \(H_{F_n} ={{\,\mathrm{aff}\,}}F_n\), and let \(t_n\) denote the restriction of \({\tilde{A}}_n\) to \(L(H_{G},H_{F_n})\). Given that \({\tilde{A}}_n \rightarrow A^{\star }\), the maps \(\{t_n\}_{n=1}^{\infty }\) are also square and invertible eventually a.s. It follows that one can define a linear map \(b_n \in L({\mathbb {R}}^d,{\mathbb {R}}^d)\) that coincides with \(t \circ t_n^{-1}\) restricted to \(L(H_{F_n},H_{F})\), is permitted to be any square invertible map on \(L(H_{F_n}^{\perp },H_{F}^{\perp })\), and is zero everywhere else. Notice that \(b_n\) is invertible by construction. It straightforward to check that \(F = b_n F_n\) and \(F_n = b_n^{-1} F\).
Next suppose that \(0 \notin {{\,\mathrm{aff}\,}}G\). The treatment in this case is largely similar as in the previous case. Let \(H_{F}\) be the smallest subspace containing \(\{ (x, 1)\mid x\in F \} \subseteq {\mathbb {R}}^{d+1}\), where the set F is embedded in the first d coordinates. Let \(H_{F_n}\) be similarly defined. Let \(H_{G} = {{\,\mathrm{aff}\,}}(G \cup \{0\})\)—note that this defines a subspace. Since \(0 \notin {{\,\mathrm{aff}\,}}G\), there is a non-zero \(z\in {\mathbb {R}}^q\) such that \(\langle z, x\rangle = 1\) for all \(x\in G\) (i.e., there exists a hyperplane containing G). Define the linear map \(t \in L(H_{G},H_{F})\) as
where \(\Pi _{H_{F}}\) is the projection map onto the subspace \(H_{F}\). Since \(A^{\star }\) is injective on G, it follows that \(H_{F}\) and \(H_{G}\) have the same dimensions, and that t is square and invertible. One can define a square invertible map \(t_n\) analogously. The remainder of the proof proceeds in a similar fashion to the previous case, and we omit the details. Here, note that a linear invertible map operating on the lifted space \({\mathbb {R}}^{d+1}\) defines an affine linear invertible map in the embedded space \({\mathbb {R}}^d\). \(\square \)
4 Algorithm
We describe a procedure based on alternating updates for solving the optimization problem (2). In terms of the linear map A, the task of solving (2) can be reformulated as follows:
As described previously, the problem (19) is non-convex as formulated; consequently, our approach is not guaranteed to return a globally optimal solution. However, we demonstrate the effectiveness of these methods with random initialization in numerical experiments in Sect. 5.
We describe our method as follows. For a fixed A, we compute \(e^{(i)} \in C\), \(i=1,\dots ,n\), so that \(\langle e^{(i)}, A^{T}u^{(i)} \rangle = h_{C}(A^{T}u^{(i)})\), i.e., \(e^{(i)} = e_{C}(A^{T}u^{(i)})\). With these \(e^{(i)}\)’s fixed, we update A by solving the following least squares problem:
This least squares problem can sometimes be ill-conditioned, in which case we employ Tikhonov regularization (with debiasing); see Algorithm 1.
When specialized to the choice \(C= \Delta ^{q}\), our procedure reduces to the algorithm proposed by Magnani and Boyd [20] for max-affine regression. More broadly, as noted in [20], for \(C= \Delta ^{q}\) our method is akin to Lloyd’s algorithm for K-means clustering [19]. Specifically, Lloyd’s algorithm begins with an initialization of q centers, and it alternates between (i) assigning data-points to centers based on proximity (keeping the centers fixed), and (ii) updating the location of cluster centers to minimize the squared-loss error. In our context, suppose we express the linear map \(A = [a_1|\ldots |a_q] \in {\mathbb {R}}^{d \times q}\) in terms of its columns. The algorithm begins with an initialization of the q columns, and it alternates between (i) assigning measurement pairs \((u^{(i)},y^{(i)})\), \(1\le i \le n\), to the respective columns \(\{a_j\}_{1\le j \le q}\) so that the inner product \(\langle u^{(i)}, a_j \rangle \) is maximized (keeping the columns fixed), and (ii) updating the columns \(\{a_j\}_{1\le j \le q}\) to minimize the squared-loss error.

5 Numerical Experiments
In this section we describe the results of numerical experiments on fitting convex sets to support function evaluations in which we contrast our framework based on solving (2) to previous methods based on solving (1). The first few experiments are on synthetically generated data, while the final experiment is on a reconstruction problem with real data obtained from the Computed Tomography (CT) scan of a human lung. For each experiment, we apply Algorithm 1 described in Sect. 4 with multiple random initializations, and we select the solution that minimizes the least squared error. The (polyhedral) LSE reconstructions in our experiments are based on the algorithm proposed in [10, Sect. 4].
5.1 Reconstructing the \(\ell _1\)-ball and the \(\ell _2\)-ball
We consider reconstructing the \(\ell _1\)-ball \(\{ g\mid \Vert g\Vert _1 \le 1 \} \subset {\mathbb {R}}^3\) and the \(\ell _2\)-ball \(\{ g\mid \Vert g\Vert _2 \le 1 \} \subset {\mathbb {R}}^3\) from noiseless and noisy support function evaluations based on the model (3). In particular, we evaluate the performance of our framework relative to the reconstructions provided by the LSE for \(n=20,50,200\) measurements. For both the \(\ell _1\)-ball and the \(\ell _2\)-ball in the respective noisy cases, the measurements are corrupted with additive Gaussian noise of variance \(\sigma ^2 = 0.1\). The reconstructions based on our framework (2) of the \(\ell _1\)-ball employ the choice \(C= \Delta ^6\), while those of the \(\ell _2\)-ball use \(C= {\mathcal {O}}^3\). Figures 8 and 9 give the results corresponding to the \(\ell _1\)-ball and the \(\ell _2\)-ball, respectively.
Considering first a setting with noiseless measurements, we observe that our approach gives an exact reconstruction for both the \(\ell _1\)-ball and the \(\ell _2\)-ball. For the \(\ell _1\)-ball this occurs when we have \(n=200\) measurements, while the LSE provides a reconstruction with substantially more complicated facial structure that does not reflect that of the \(\ell _1\)-ball. Indeed, the LSE only approaches the \(\ell _1\)-ball with respect to the Hausdorff metric, but despite being the best solution in terms of minimizing the least-squares criterion, the reconstruction offered by this method provides little information about the facial geometry of the \(\ell _1\)-ball. Further, even with \(n=20,50\) measurements, our reconstructions bear far closer resemblance to the \(\ell _1\)-ball, while the LSE in these cases looks very different from the \(\ell _1\)-ball. For the \(\ell _2\)-ball, our approach provides an exact reconstruction with just \(n=20\) measurements, while the LSE only begins to resemble the \(\ell _2\)-ball with \(n=200\) measurements (and even then, the reconstruction is a polyhedral approximation).
Turning our attention next to the noisy case, the contrast between the results obtained using our framework and those of the LSE approach is even more stark. For both the \(\ell _1\)-ball and the \(\ell _2\)-ball, the LSE reconstructions bear little resemblance to the underlying convex set, unlike the estimates produced using our method. Notice that the reconstructions of the \(\ell _2\)-ball using our algorithm are not even ellipsoidal when the number of measurements is small (e.g., when \(n=20\)), as linear images of the spectraplex \({\mathcal {O}}^3\) may be non-ellipsoidal in general and need not even consist of smooth boundaries. Nonetheless, as the number of measurements available to our algorithm increases, the estimates improve in quality and offer improved reconstructions—with smooth boundaries—of the \(\ell _2\)-ball.
In summary, these synthetic examples demonstrate that our framework is much more effective than the LSE in terms of robustness to noise, accuracy of reconstruction given a small number of measurements, and in settings in which the underlying set is non-polyhedral.

Reconstruction of the unit \(\ell _1\)-ball in \({\mathbb {R}}^3\) from noiseless (first row) and noisy (second row) support function measurements. The reconstructions obtained using our method (with \(C= \Delta ^6\) in (2)) are on the left of every subfigure, while the LSE reconstructions are on the right of every subfigure

Reconstruction of the unit \(\ell _2\)-ball in \({\mathbb {R}}^3\) from noiseless (first row) and noisy (second row) support function measurements. The reconstructions obtained using our method (with \(C= {\mathcal {O}}^3\) in (2)) are on the left of every subfigure, while the LSE reconstructions are on the right of every subfigure
5.2 Reconstruction via Linear Images of the Spectraplex
In the next series of synthetic experiments, we consider reconstructions of convex sets with both smooth and non-smooth features on the boundary via linear images of the spectraplex. In these illustrations, we consider sets in \({\mathbb {R}}^2\) and in \({\mathbb {R}}^3\) for which noiseless support function evaluations are obtained and supplied as input to the problem (2), with \(C\) equal to a spectraplex \({\mathcal {O}}^p\) for different choices of p. For the examples in \({\mathbb {R}}^2\), the support function evaluations are obtained at 1000 equally spaced points on the unit circle \(S^1\). For the examples in \({\mathbb {R}}^3\), the support function evaluations are obtained at 2562 regularly spaced points on the unit sphere \(S^2\) based on an icosphere discretization.
We consider reconstruction of the \(\ell _1\)-ball in \({\mathbb {R}}^2\) and in \({\mathbb {R}}^3\). Figure 10 shows the output from our algorithm when \(d=2\) for \(p \in \{ 2,3,4 \}\), and the reconstruction is exact for \(p=4\). Figure 11 shows the output from our algorithm when \(d=3\) for \(p \in \{ 3,4,5,6 \}\). Interestingly, when \(d=3\) the computed solution for \(p=5\) does not contain any isolated extreme points (i.e., vertices) even though such features are expressible as projections of the spectraplex \({\mathcal {O}}^5\).

Approximating the \(\ell _1\)-ball in \({\mathbb {R}}^2\) as a projection of the spectraplices \({\mathcal {O}}^2\) (left), \({\mathcal {O}}^3\) (center), and \({\mathcal {O}}^4\) (right)

Approximating the \(\ell _1\)-ball in \({\mathbb {R}}^3\) as a projection of the spectraplices \({\mathcal {O}}^3\), \({\mathcal {O}}^4\), \({\mathcal {O}}^5\), and \({\mathcal {O}}^6\) (from left to right)
As our next illustration, we consider the following projection of \({\mathcal {O}}^4\):
We term this convex set the ‘uncomfortable pillow’ and it contains both smooth and non-smooth features on its boundary. Figure 12 shows the reconstruction of UPillow as linear images of \({\mathcal {O}}^3\) and \({\mathcal {O}}^4\) computed using our algorithm. The reconstruction based on \({\mathcal {O}}^4\) is exact, while the reconstruction based on \({\mathcal {O}}^3\) smoothens out some of the ‘pointy’ features of UPillow; see for example the reconstructions based on \({\mathcal {O}}^3\) and on \({\mathcal {O}}^4\) viewed in the (0, 1, 0) direction in Fig. 12).

Reconstructions of \(K^{\star }\) (defined in (21)) as the projection of \({\mathcal {O}}^3\) (top row) and \({\mathcal {O}}^4\) (bottom row). The figures in each row are different views of a single reconstruction, and are orientated in the (0, 0, 1), (0, 1, 0), (1, 0, 1), and (1, 1, 0) directions (from left to right) respectively
5.3 Polyhedral Approximations of the \(\ell _2\)-Ball and the Tammes Problem
In the third set of synthetic experiments, we consider polyhedral approximations of the \(\ell _2\)-ball in \({\mathbb {R}}^3\). This problem has been studied in many contexts under different guises. For instance, the Tammes problem seeks the optimal placement of q points on \(S^2\) so as to maximize the minimum pairwise distance, and it is inspired by pattern formation in pollens [32].Footnote 2 Another body of work studies the asymptotics of polyhedral approximations of general compact convex bodies (see, for example [5]). In the optimization literature, polyhedral approximations of the second-order cone have been investigated in [4]—in particular, the approach in [4] leads to an approximation that is based on expressing the \(\ell _2\)-ball via a nested hierarchy of planar spherical constraints, and to subsequently approximate these constraints with regular polygons.
Our focus in the present series of experiments is to investigate polyhedral approximations of the Euclidean sphere from a computational perspective by employing the algorithmic tools developed in this paper. The experimental setup is similar to that of the previous subsection: we supply 2562 regularly-spaced points in \(S^2\) (with corresponding support function values equal to one) based on an icosphere discretization as input to (2), and we select \(C\) to be the simplex \(\Delta ^{q}\) for a range of values of q. Figure 13 shows the optimal solutions computed using our method for \(q \in \{ 4,5,\ldots ,12\}\). It turns out that the results obtained using our approach are closely related for certain values of q to optimal configurations of the Tammes problem [7, 28]:
Specifically, the face lattice of our solutions is isomorphic to that of the Tammes problem for \(q \in \{ 4,5,6,7,12\}\), which suggests that these configurations are stable and optimal for a broader class of objectives. We are currently not aware if the distinction between the solutions to the two sets of problems for \(q\in \{8,9,10,11 \}\) is a result of our method recovering a locally optimal solution (in generating these results, we apply 500 initializations for each instance of q), or if it is inherently due to the different objectives that the two problems seek to optimize. For the case of \(q=8\), the difference appears to be due to the latter reason as an initialization supplied to our algorithm based on a configuration that is isomorphic to the Tammes solution led to a suboptimal local minimum.

Approximating the \(\ell _2\)-ball in \({\mathbb {R}}^3\) as the projection of \(\Delta ^{q}\) for \(q\in \{4,5,\ldots ,12\}\) (from left to right)
5.4 Reconstruction of a Human Lung
In the final set of experiments we apply our algorithm to reconstruct a convex mesh of a human lung. The purpose of this experiment is to demonstrate the utility of our algorithm in a setting in which the underlying object is not convex. Indeed, in many applications in practice of reconstruction from support function evaluations, the underlying set of interest is not convex; however, due to the nature of the measurements available, one seeks a reconstruction of the convex hull of the underlying set. In the present example, the set of interest is obtained from the CT scan of the left lung of a healthy individual [9]. We note that a priori it is unclear whether the convex hull of the lung is well approximated as a linear image of either a low-dimensional simplex or a low-dimensional spectraplex.
We first obtain \(n=50\) noiseless support function evaluations of the lung (note that this object lies in \({\mathbb {R}}^3\)) in directions that are generated uniformly at random over the sphere \(S^2\). In the top row of Fig. 14 we show the reconstructions as projections of \({\mathcal {O}}^{q}\) for \(q\in \{3,4,5,6\}\), and we contrast these with the LSE. We repeat the same experiment with \(n=300\) measurements, with the reconstructions shown in the bottom row of Fig. 14.
To concretely compare the results obtained using our framework and those based on the LSE, we contrast the description complexity—the number of parameters used to specify the reconstruction—of the estimates obtained from both frameworks. An estimator computed using our approach is specified by a projection map \(A \in L({\mathbb {R}}^q,{\mathbb {R}}^d)\), and hence it requires dq parameters, while the LSE proposed by the algorithm in [10] assigns a vertex to every measurement, and hence it requires dn parameters. The LSE using \(n=300\) measurements requires \(3 \times 300\) parameters to specify whereas the estimates obtained using our framework that are specified as projections of \({\mathcal {O}}^{5}\) and \({\mathcal {O}}^{6}\)—these estimates offer comparable quality to those of the LSE—require \(3 \times 15\) and \(3 \times 21\) parameters, respectively. This substantial discrepancy highlights the drawback of using polyhedral sets of growing complexity to approximate non-polyhedral objects in higher dimensions.

Reconstructions of the left lung from 50 support function measurements (top row) and 300 support function measurements (bottom row). Subfigures (a)–(d) and (f)–(i) are projections of spectraplices with dimensions as indicated, and subfigures (e) and (j) are LSEs
6 Conclusions and Future Directions
In this paper we describe a framework for fitting tractable convex sets to noisy support function evaluations. Our approach provides many advantages in comparison to the previous LSE-based methods, most notably in settings in which the measurements available are noisy or small in number as well as those in which the underlying set to be reconstructed is non-polyhedral. We discuss here some potential future directions.
Informed selection of model complexity In practice, a suitable choice of the dimension of the simplex or the spectraplex to employ in (2) may not be available in advance. Lower-dimensional choices for \(C\) provide more concisely-described reconstructions but may not fit the data well, while higher-dimensional choices provide better fidelity to the data at the risk of overfitting. Consequently, it is of practical relevance to develop methods to select \(C\) in a data-driven manner. We describe next a stylized experiment to choose \(C\) via cross-validation.
In the first illustration, we are given 100 support function measurements of the \(\ell _1\)-ball in \({\mathbb {R}}^3\) corrupted by Gaussian noise with standard deviation \(\sigma = 0.1\). We obtain 50 random partitions of this data into two subsets of equal size. For each partition, we solve (2) with \(C= \Delta ^q\) (with different choices of q) on the first subset and evaluate the mean-squared error on the second subset. The left subplot of Fig. 15 shows the average mean-squared error over the 50 partitions. We observe that initially the error decreases as q increases as a more expressive model allows us to better fit the data, and subsequently, the error plateaus out. Consequently, in this experiment an appropriate choice of \(C\) would be \(\Delta ^6\). In our second illustration, we are given 200 support function measurements corrupted by Gaussian noise with standard deviation \(\sigma = 0.05\) of a set \(K_{S3} = {{\,\mathrm{conv}\,}}(S_1 \cup S_2 \cup S_3) \subset {\mathbb {R}}^3\), where \(S_1,S_2,S_3\) are defined as follows. For \(j=1,2,3\):
In words, the sets \(S_1,S_2,S_3\) are disjoint planar discs. One can check that \(K_{S3}\) is representable as a linear image of \({\mathcal {O}}^6\). The other aspects remain the same as in the first illustration, and as we observe from the right subplot of Fig. 15, an appropriate choice for \(C\) would be \({\mathcal {O}}^6\).

Choosing the lifting dimension in a data-driven manner. The left sub-plot shows the cross-validation error of reconstructing the \(\ell _1\)-ball in \({\mathbb {R}}^3\) as the projection of \(\Delta ^{q}\) over different choices of q, and the right sub-plot shows the same quantity for \(K_{S3} \subset {\mathbb {R}}^3\) (see accompanying text) as the projection of \({\mathcal {O}}^{p}\) over different choices of p
Approximation power of semidefinite descriptions Theorem 3.1 demonstrates that our estimator converges almost surely to the linear image of \(C\) that best approximates the underlying set \(K^\star \). Consequently, a natural question is to understand the quality of the approximation of general convex bodies provided by linear images of the simplex (i.e., polytopes) or the spectraplex. There is a substantial body of prior work that studies approximations of convex bodies via polytopes (see, for instance [5]), but an analogous theory for approximations that are specified as linear images of the spectraplex as well as the more general collection of feasible regions of semidefinite programs is far more limited—the closest piece of work of which we are aware is a result by Barvinok [3]. Progress on these fronts would be useful for understanding the full expressive power of our framework. More generally, and as noted in [3], obtaining even a basic understanding about the approximation power of such descriptions has broad algorithmic implications concerning the use of semidefinite programs to approximate general convex programs.
Richer families of tractable convex sets A restriction in the development in this paper is that we only consider reconstructions specified as linear images of a fixed convex set \(C\); we typically choose \(C\) to be a simplex or a spectraplex, which are given by particular slices of the non-negative orthant or the cone of positive semidefinite matrices. As described in the introduction, optimizing over more general affine sections of these cones is likely to be intractable due to the lack of a compact description of the sensitivity of the optimal value of conic optimization problems with respect to perturbations of the affine section. Consequently, it would be useful to identify broader yet structured families of sets than the ones we have considered in this paper for which such a sensitivity analysis is efficiently characterized.
Notes
We note that this is the case even though the estimator \({\hat{K}}^{\mathrm {LSE}}_n\) is consistent; in particular, consistency simply refers to the convergence as \(n \rightarrow \infty \) of \({\hat{K}}^{\mathrm {LSE}}_n\) to \(K^\star \) in a topological sense (e.g., in Hausdorff distance) and it does not provide any information about the facial structure of \({\hat{K}}^{\mathrm {LSE}}_n\) relative to that of \(K^\star \).
The Tammes problem is a special case of Thompson’s problem as well as Smale’s 7th problem [29].
References
Averkov, G.: Optimal size of linear matrix inequalities in semidefinite approaches to polynomial optimization. SIAM J. Appl. Algebra Geom. 3(1), 128–151 (2019)
Balázs, G.: Convex Regression: Theory, Practice, and Applications. PhD thesis, University of Alberta (2016)
Barvinok, A.: Approximations of convex bodies by polytopes and by projections of spectrahedra (2012). arXiv:1204.0471
Ben-Tal, A., Nemirovski, A.: On polyhedral approximations of the second-order cone. Math. Oper. Res. 26(2), 193–205 (2001)
Bronstein, E.M.: Approximation of convex sets by polytopes. J. Math. Sci. (N.Y.) 153(6), 727–762 (2008)
Cai, T.T., Guntuboyina, A., Wei, Y.: Adaptive estimation of planar convex sets. Ann. Stat. 46(3), 1018–1049 (2018)
Danzer, L.: Finite point-sets on \(S^2\) with minimum distance as large as possible. Discrete Math. 60, 3–66 (1986)
Fisher, N.I., Hall, P., Turlach, B.A., Watson, G.S.: On the estimation of a convex set from noisy data on its support function. J. Am. Stat. Assoc. 92(437), 84–91 (1997)
Gaillard, F.: Normal chest CT-lung window. Radiopaedia. https://radiopaedia.org/cases/normal-chest-ct-lung-window
Gardner, R.J., Kiderlen, M.: A new algorithm for 3D reconstruction from support functions. IEEE Trans. Pattern Anal. Mach. Intell. 31(3), 556–562 (2009)
Gardner, R.J., Kiderlen, M., Milanfar, P.: Convergence of algorithms for reconstructing convex bodies and directional measures. Ann. Stat. 34(3), 1331–1374 (2006)
Gouveia, J., Parrilo, P.A., Thomas, R.R.: Lifts of convex sets and cone factorizations. Math. Oper. Res. 38(2), 248–264 (2013)
Gregor, J., Rannou, F.R.: Three-dimensional support function estimation and application for projection magnetic resonance imaging. Int. J. Imaging Syst. Technol. 12(1), 43–50 (2002)
Guntuboyina, A.: Optimal rates of convergence for convex set estimation from support functions. Ann. Stat. 40(1), 385–411 (2012)
Hall, P., Turlach, B.A.: On the estimation of a convex set with corners. IEEE Trans. Pattern Anal. Mach. Intell. 21(3), 225–234 (1999)
Hannah, L.A., Dunson, D.B.: Multivariate convex regression with adaptive partitioning. J. Mach. Learn. Res. 14, 3261–3294 (2013)
Kosorok, M.R.: Introduction to Empirical Processes and Semiparametric Inference. Springer Series in Statistics. Springer, New York (2008)
Lele, A.S., Kulkarni, S.R., Willsky, A.S.: Convex-polygon estimation from support-line measurements and applications to target reconstruction from laser-radar data. J. Optical Soc. Amer. A 9(10), 1693–1714 (1992)
Lloyd, S.P.: Least squares quantization in PCM. IEEE Trans. Inf. Theory 28(2), 129–137 (1982)
Magnani, A., Boyd, S.P.: Convex piecewise-linear fitting. Optim. Eng. 10(1), 1–17 (2009)
Nesterov, Yu., Nemirovskii, A.: Interior-Point Polynomial Algorithms in Convex Programming. SIAM Studies in Applied Mathematics, vol. 13. Society for Industrial and Applied Mathematics, Philadelphia (1994)
Pollard, D.: Strong consistency of \(k\)-means clustering. Ann. Stat. 9(1), 135–140 (1981)
Pollard, D.: Convergence of Stochastic Processes. Springer Series in Statistics. Springer, New York (1984)
Prince, J.L., Willsky, A.S.: Reconstructing convex sets from support line measurements. IEEE Trans. Pattern Anal. Mach. Intell. 12(4), 377–389 (1990)
Prince, J.L., Willsky, A.S.: Convex set reconstruction using prior shape information. CVGIP: Graph. Models Image Process. 53(5), 413–427 (1991)
Saunderson, J.: Limitations on the expressive power of convex cones without long chains of faces. SIAM J. Optim. 30(1), 1033–1047 (2020)
Schneider, R.: Convex Bodies: The Brunn–Minkowski Theory. Encyclopedia of Mathematics and Its Applications, vol. 151. Cambridge University Press, Cambridge (2014)
Schütte, K., van der Waerden, B.L.: Auf welcher Kugel haben \(5\), \(6\), \(7\), \(8\) oder \(9\) Punkte mit Mindestabstand Eins Platz? Math. Ann. 123, 96–124 (1951)
Smale, S.: Mathematical problems for the next century. Math. Intell. 20(2), 7–15 (1998)
Stark, H., Peng, H.: Shape estimation in computer tomography from minimal data. J. Opt. Soc. Am. A 5(3), 331–343 (1988)
Stengle, G., Yukich, J.E.: Some new Vapnik–Chervonenkis classes. Ann. Stat. 17(4), 1441–1446 (1989)
Tammes, P.M.L.: On the Origin of Number and Arrangement of the Places of Exit on the Surface of Pollen-Grains. Recueil des Travaux Botaniques Néerlandais, vol. 27. Koninklijke Nederlandse Botanische Vereniging (1930)
Vapnik, V.N., Chervonenkis, A.Ya.: On the uniform convergence of relative frequencies of events to their probabilities. Proc. USSR Acad. Sci. 181(4), 781–783 (1968). (in Russian)
Yannakakis, M.: Expressing combinatorial optimization problems by linear programs. J. Comput. Syst. Sci. 43(3), 441–466 (1991)
Author information
Authors and Affiliations
Corresponding author
Additional information
Editor in Charge: Kenneth Clarkson
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors were supported in part by NSF grants CCF-1350590 and CCF-1637598, by Air Force Office of Scientific Research Grant FA9550-16-1-0210, by a Sloan research fellowship, and an A*STAR (Agency for Science, Technology and Research, Singapore) fellowship.
Rights and permissions
About this article

Cite this article
Soh, Y.S., Chandrasekaran, V. Fitting Tractable Convex Sets to Support Function Evaluations. Discrete Comput Geom 66, 510–551 (2021). https://doi.org/10.1007/s00454-020-00258-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00454-020-00258-0