
Abstract
We study a random matching problem on closed compact 2-dimensional Riemannian manifolds (with respect to the squared Riemannian distance), with samples of random points whose common law is absolutely continuous with respect to the volume measure with strictly positive and bounded density. We show that given two sequences of numbers n and \(m=m(n)\) of points, asymptotically equivalent as n goes to infinity, the optimal transport plan between the two empirical measures \(\mu ^n\) and \(\nu ^{m}\) is quantitatively well-approximated by \(\big (\text {Id},\exp (\nabla h^{n})\big )_\#\mu ^n\) where \(h^{n}\) solves a linear elliptic PDE obtained by a regularized first-order linearization of the Monge–Ampère equation. This is obtained in the case of samples of correlated random points for which a stretched exponential decay of the \(\alpha \)-mixing coefficient holds and for a class of discrete-time sub-geometrically ergodic Markov chains having a unique absolutely continuous invariant measure with respect to the volume measure.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction and statement of the main results
1.1 The random matching problem and its asymptotic
The random matching problem is a popular optimization problem at the interface between analysis and probability with applications in many different fields such as statistical physics [16, 47], computer science [43] and economics [21, 25]. Within the mathematical literature, it has been subject of intense studies due to its interactions with many areas, including for instance graph theory [41] and geometric probability [55]. In this paper we focus on one of its simple versions. Let \(\{X_k\}_{1\le k\le n}\) and \(\{Y_k\}_{1\le k\le m}\) (with possibly \(m>n\)) be two families of random points on a compact Riemannian manifold \({\mathcal {M}}\) (endowed with the Riemannian distance \(\text {d}\)). We are interested in the quadratic matching problem

where

Classically, (1.1) can be phrased in terms of a transport problem. Indeed, letting
be the empirical measures associated with the two point clouds, the linear programming problem (1.1) amounts to determine the quadratic Wasserstein distance \(\ W_2^2(\mu ^n,\nu ^m)\).
In the special case \(n=m\) the Birkhoff–von Neumann Theorem provides a correspondence between (1.1) and the usual bipartite matching

where \({\mathcal {S}}_{n}\) denotes the set of injective maps \(\sigma : \{1, \dots , n\} \rightarrow \{1, \dots , n\}\). Indeed, since \(\Pi _{nn}\) is a convex polytope, minimizers in (1.1) have to be searched among extremal points. By the Birkhoff–von Neumann Theorem [8, Lemma 2.1.3], the latter are nothing but permutation matrices (up to a factor \(\tfrac{1}{n}\)).
A first natural question is to understand the asymptotics of (1.1) as \(n,m\uparrow \infty \). For the same number of samples \(n=m\) and independently and identically distributed (i.i.d.) on the unit square \([0,1]^d\), the scaling of the cost (1.1) has been well understood in the mathematical and statistical physics literature. A simple heuristic argument, see for instance [47], suggests that given a point \(X_i\), we can find a point \(Y_j\) within a volume of order \(O(n^{-1})\) with high probability. For this reason, the typical inter-point distance is of order \(O(n^{-\frac{1}{d}})\) suggesting that the scaling of (1.1) is of order \(O(n^{-\frac{2}{d}})\). Although attractive, this heuristic turns out to be unfortunately false in low dimension showing a critical behavior when \(d=2\). This critical case is the one on which we focus on in this paper. Ajtai et al. [1] were the first to show that, for i.i.d. uniform samples, a logarithmic correction is needed, derivingFootnote 1

extended later by Talagrand [58] for clouds of i.i.d. points which are distributed accordingly to more general common law. A recent breakthrough was obtained within the physics community by Caracciolo et al. [16], and further developed by Caracciolo and Sicuro [17] and by Sicuro in [54], where the asymptotics of the cost are formally derived thanks to a novel PDE approach and optimal transport theory rather than combinatorics. A couple of years later, in general 2-dimensional compact Riemannian manifolds without boundary, the first-order asymptotic has been rigorously justified by Ambrosio et al. [6] for i.i.d. uniform samples and recently extended by Ambrosio et al. [5] for samples distributed accordingly to more general laws which are absolutely continuous (with Hölder continuous density) w.r.t. the volume measure \(\text {d}\text {m}\), leading to

where \(|{\mathcal {M}}|\) denotes the Lebesgue measure of \({\mathcal {M}}\). The case \(n\ne m\) with \(n,m\uparrow \infty \) with similar rates is also covered, see [5, Theorem 1.2].
The novel approach introduced in [16], later revised in [11], consists in a linearization of the Monge–Ampère equation that allows for an explicit description of the cost thanks to the linearized proxies (see Sect. 1.2 for more details). The aim of this work is to quantitatively justify the linearization ansatz in terms of convergence of the approximating minimizers of (1.1) towards the optimal ones. In particular, we are interested in the case where the points are identically distributed with a common law \(\rho \,\text {d}\text {m}\) (where we recall that \(\text {d}\text {m}\) denotes the volume measure) and \(\rho \) satisfies for some \(\lambda ,\Lambda >0\)

To the best of our knowledge, there are only few results on the asymptotic behavior of the transport map and they are so far limited to the case of i.i.d. uniform samples in the study of the semi-discrete matching problem (that is couplings between \(\mu ^n\) and \(\text {d}\text {m}\)), see the work of Ambrosio et al. [4]. In connection with this work, quantitative estimates on the optimal map for the matching between the Lebesgue measure and Poisson clouds have been obtained by Goldman et al. [31] and Goldman and Huesmann [30].
Our extension in this paper is fourfold: First, we look at more general distribution of points and we consider the case of general densities \(\rho \) satisfying (1.6). Second, we do not assume independence and we consider samples which may possess correlations. Third, we do not restrict the analysis to the semi-discrete matching problem and we also investigate the ansatz for the full matching problem (1.1). Finally, we investigate the case where the points are not identically distributed and we extend our result to a class of sub-geometrically ergodic Markov chains.
We finally mention that the effectiveness of the linearization ansatz introduced in [16] is not only limited to the case of i.i.d. distributed points on bounded domains, but it can be employed in many different settings. See for instance [15] for an interesting application to the matching on unbounded domains, [37,38,39] for an application to Gaussian matching, [35] for an application in random matrix theory, [34, 64,65,66] for an application to a continuous instance of the matching problem, i.e. when the empirical measure is replaced by the occupation measure of a stochastic process. It is worth to further mention that these techniques can also be employed when considering the matching problem with p-costs in higher dimension, see [32] and when considering a larger class of optimization problems, see [33].
1.2 Linearization ansatz
We now briefly reproduce the linearization ansatz introduced in [16]. For simplicity, we consider the case \({\mathcal {M}} = {\mathbb {T}}^2\), \(n=m\) and i.i.d. samples with common distribution \(\rho \, \text {d}\text {m}\). Let \(T^n\) be an optimal transport map (whose existence is ensured by Brenier’s Theorem [14]) between \(\mu ^n\) and \(\nu ^n\). Based on the transport relation \(T^n_{\#}\mu ^n=\nu ^n\) and a change of variables, \(T^n\) solves (formally) the Monge–Ampère equation
Since the cost is quadratic, by [52, Theorem 1.25], there exists a function \(h^n\) such that \(T^n= \text {Id}+\nabla h^n\). Applying the law of large numbers, we further have the weak convergences \(\mu ^n,\nu ^n {\rightharpoonup }\rho \, \text {d}\text {m}\) as \(n\uparrow \infty \) so that we expect \(T^n\approx \text {Id}\) as \(n\uparrow \infty \). Thus, this suggests that the correction \(\nabla h^n\) is small as \(n\uparrow \infty \), allowing to perform (formally) the Taylor expansions

Plugging (1.8) into (1.7), neglecting the higher order terms and replacing \(\mu ^n\) by \(\rho \) yields
This formal linearization suggests the following two conjectures

Unfortunately, (1.10) cannot hold as it is, since the solution of (1.9) does not belong to \(\text {H}^1\) due to the roughness of the source term. To overcome this, following the strategy in [6], a regularization using the heat-semigroup at time \(\sim \frac{1}{n}\) (up to logarithmic corrections) is made. Doing so, the first item of (1.10) turns out to be true, leading to the result (1.5) (see for instance [3] for a convergence rate).
1.3 Formulation of the main results
For the remainder of the paper \({\mathcal {M}}\) denotes a 2-dimensional connected and compact Riemannian manifold without boundary (or the square \([0,1]^2\)) endowed with the Riemannian distance \(\text {d}\). For \(t>0\) we denote by \(p_t\) the fundamental solution of the heat operator \(\partial _t-\Delta \) on \({\mathcal {M}}\), where \(\Delta \) denotes the Beltrami-Laplace operator. We define the heat semigroup \((\text {P}_t)_{t>0}\) via its action on probability measures \(\mu \in {\mathcal {P}}({\mathcal {M}})\) and square integrable functions \(f\in \text {L}^2({\mathcal {M}})\)

We first introduce the class of correlated point clouds that we consider for studying the matching problem (1.1). This class concerns point clouds \(\{X_i\}_i\) for which the correlations between points decay at an exponential rate, where the correlations are measured in terms of the \(\alpha \)-mixing coefficient given by, for any \(\ell \ge 1\)

and the \(\beta \)-mixing coefficient given byFootnote 2

Assumption 1.1
(Correlated point clouds) We consider point clouds \(\{X_i\}_{i}\subset {\mathcal {M}}\) which are identically distributed according to \(\rho \,\text {d}\text {m}\) where \(\rho \) satisfies (1.6). We further assume decay of the correlations in the form of

and there exist \(a,b>0\) and \(\eta \in (0,\infty ]\) such that

Assumption 1.1 is made to ensure good concentration properties of the point clouds. On the one hand, under (1.13), the cost \(W^2_2(\mu ^n,\nu ^n)\) behaves as in the i.i.d. case (1.4) (cf. [12, Theorem 2] and Appendix B). On the other hand, the sub-exponential decay (1.14) of the \(\alpha \)-mixing coefficient ensures sub-exponential concentration properties (cf. [45, Theorem 1] and Proposition A.1), which is necessary to run our argument. We refer the reader to Sect. 2 for further technical details.
Our first main result concerns the approximation of transport plans coupling \(\{\mu ^n\}_n\) and \(\{\nu ^m\}_m\) defined in (1.2). We justify the formal linearization of the Monge–Ampère equation achieved in Sect. 1.2 in an annealed quantitative way (i.e. in expectation): We show that, a suitable regularization of, the plan \(\big (\text {Id},\exp (\nabla h^n)\big )_\#\mu ^n\), with \(h^n\) defined in (1.9), provides a good approximation when measuring the error with respect to the \(W_2\)-Wasserstein distance in the product space \({\mathcal {M}}\times {\mathcal {M}}\) endowed with the metric
The density \(\rho \) will need further regularity in form of fractional Sobolev spaces defined as, for some \(\varepsilon >0\)

where \(\{\lambda _k,\phi _k\}_{k}\) denote the eigenvalues and eigenvectors of \(-\Delta \) on \({\mathcal {M}}\) and \({\hat{f}}(k)=\int _{{\mathcal {M}}}f\,\phi _k\) denotes the Fourier modes of f. Finally, we denote by \(\dot{\text {H}}^1\) the \(\text {L}^2\)-based Sobolev space

Theorem 1.2
(Approximation of the transport plan) Let \(\rho \in \text {H}^{\varepsilon }\) for some \(\varepsilon >0\) satisfying (1.6) and \(\{\mu ^n\}_n\) and \(\{\nu ^{m}\}_m\) be defined in (1.2) (for \(m=m(n)\) with some given increasing map \(m:{\mathbb {N}}\rightarrow {\mathbb {N}}\)) with point clouds satisfying Assumption 1.1 and such that there exists \(q\in [1,\infty )\) for which \(\frac{m(n)}{n}\underset{n\uparrow \infty }{\rightarrow }\ q\). We considerFootnote 3\(h^{n,t}\in \dot{\text {H}}^1\) the weak solution of

for any \(t\in (0,1)\) with \(\mu ^{n,t}:=\text {P}_t\mu ^n\) and \(\nu ^{m,t}:=\text {P}_t\nu ^m\).
There exist an exponent \(\kappa >0\), a deterministic constant C and a random variable \({\mathcal {C}}_n\) both depending on \(\lambda , \Lambda \) and \({\mathcal {M}}\) for which given \(t=\frac{\log ^{\kappa }(n)}{n}\) and

it holds

where the \(\inf \) runs over all optimal transport plans \(\pi \) between \(\mu ^n\) and \(\nu ^m\).
Furthermore, if (1.14) holds with \(\eta >2\), the assumption (1.13) can be dropped and it holds

where the \(\inf \) runs over all optimal transport plans \(\pi \) between \(\mu ^n\) and \(\nu ^m\).
Our second main result concerns the particular case of the semi-discrete matching problem, i.e. optimal coupling between the common law \(\rho \,\text {d}\text {m}\) and \(\{\mu ^n\}_n\). We know from McCann’s theorem [42] that there exists a unique optimal transport map \(T^n\), that is the optimal transport plan \(\pi ^n\) can be written as

We show that \(T^n\) can be approximated in an annealed quantitative way in \(\text {L}^2\) by (a suitable regularized version of) the solution of (1.9) with \(\nu ^m\) replaced by \(\rho \).
Theorem 1.3
Let \(\rho \in \text {H}^{\varepsilon }\) for some \(\varepsilon >0\) satisfying (1.6) and \(\{\mu ^{n}\}_n\) be defined in (1.2) with a point cloud satisfying Assumption 1.1. We consider \(f^{n,t}\in \dot{\textrm{H}}^1\) the weak solution of

where, for all \(t\in (0,1)\), we recall that \(\mu ^{n,t}=\text {P}_t\mu ^n\) and \(\rho _t=\text {P}_t\rho \). Finally, we denote by \(T^n\) the optimal transport map from \(\rho \,\text {d}\text {m}\) to \(\mu ^n\).
There exist an exponent \(\kappa >0\), a deterministic constant C and a random variable \({\mathcal {C}}_n\) both depending on \(\lambda ,\Lambda \) and \({\mathcal {M}}\) for which given \(t=\frac{\log ^{\kappa }(n)}{n}\), it holds

Furthermore, if (1.14) holds with \(\eta >2\), the assumption (1.13) can be dropped and it holds

We finally mention that in the case where the eigenfunctions \(\{\phi _k\}_{k}\) admit a uniform bound, the conclusions (1.21) and (1.24) can be improved. We comment on the proof at the end of Sect. 3.5.
Remark 1.4
Let \(\{\mu ^n\}_n\) and \(\{\nu ^m\}_m\) be as in Theorem 1.2. We assume that the family of eigenfunctions \(\{\phi _k\}_k\) satisfies the uniform bound

Then, (1.21) and (1.24) hold true for \(\eta >1\) with a convergence rate \(\frac{\log (n)}{n}\sqrt{\frac{\log \log (n)}{\log ^{1-\frac{1}{\eta }}(n)}}\) and the same stochastic integrability. Note that (1.25) typically holds when the geometry of \({\mathcal {M}}\) is flat, see [60].
Theorems 1.2 and 1.3 are not restricted to the case of identically distributed point clouds and we present in the next section and in Appendix C a possible extension, using the same techniques, to a class of sub-geometrically ergodic discrete-time Markov chains.
1.4 Extension to a class of sub-geometrically ergodic Markov chains
We first recall some basic facts on discrete-time Markov chains on \({\mathcal {M}}\). Such a Markov process is described by its initial distribution \(\mu _0 \in {\mathcal {P}}({\mathcal {M}})\) and its transition kernel K, that is a measurable map from \({\mathcal {M}}\) to the space of probability measures \({\mathcal {P}}({\mathcal {M}})\). We recall that K acts on \({\mathcal {P}}({\mathcal {M}})\) in form of

and likewise on bounded measurable function \(\psi \) in form of

Given an initial distribution \(\mu _0\in {\mathcal {P}}({\mathcal {M}})\), we recall that the law of a Markov chain \(\{X_n\}_{n\ge 0}\) can be expressed with the help of the transition kernel, namely
where \(K^n\) stands for the \(n^{\text {th}}\)-iteration of the kernel K.
We now introduce the class of discrete-time Markov chains we consider.
Assumption 1.5
Let  be a 2-dimensional compact Riemannian manifold. Let
be a 2-dimensional compact Riemannian manifold. Let  and
and  be a Markov chain with initial law \(\mu _0\). We assume that the chain satisfies the two following conditions:
be a Markov chain with initial law \(\mu _0\). We assume that the chain satisfies the two following conditions:
-
(i)
We assume that there exists a measurable function
 and \(\lambda ,\Lambda >0\) such that for any Borel set \(A\subset {\mathcal {M}}\)$$\begin{aligned} K(x,A)=\int _{A}k(x,\cdot )\text {d}\text {m}\quad \text {with } \lambda \le k\le \Lambda . \end{aligned}$$(1.29)
and \(\lambda ,\Lambda >0\) such that for any Borel set \(A\subset {\mathcal {M}}\)$$\begin{aligned} K(x,A)=\int _{A}k(x,\cdot )\text {d}\text {m}\quad \text {with } \lambda \le k\le \Lambda . \end{aligned}$$(1.29) -
(ii)
We assume that there exist an unique invariant measure \(\mu _\infty \), i.e. \(K\mu _\infty =\mu _\infty \), constants \(a,b>0\) and \(\eta \in (0,1]\) as well as a map
 such that
such that  , for which for any \(\ell \ge 1\) and any \(\phi \in \text {L}^\infty ({\mathcal {M}})\)
, for which for any \(\ell \ge 1\) and any \(\phi \in \text {L}^\infty ({\mathcal {M}})\) (1.30)
(1.30)where

 and
and  such that
such that  , for which for any
, for which for any 

We now comment on the consequences of the above assumptions. First, the condition (1.29) ensures that the invariant measure \(\mu _\infty \) is absolutely continuous with respect to the volume measure with bounded density, namely
We briefly give the argument for (1.31). Using the second item of (1.29), we have that the operator

Furthermore, we note that the closed convex set  is invariant under the action of
is invariant under the action of  . Therefore Schauder’s fixed point theorem implies that
. Therefore Schauder’s fixed point theorem implies that  admits a fixed point in
admits a fixed point in  . Given such a fixed point \(\rho \), it is clear that \(\mu _\infty \) defined in (1.31) is an invariant measure according to (1.29).
. Given such a fixed point \(\rho \), it is clear that \(\mu _\infty \) defined in (1.31) is an invariant measure according to (1.29).
Second, for irreducible and aperiodic Markov chains, the condition (1.30) is satisfied when the kernel satisfies the following geometric drift condition: There exist a function  , a petite set
, a petite set  and a constant \(C>0\) such that
and a constant \(C>0\) such that  and
and

with for large \(x\ge 1\), \(\phi (x)=c\frac{x}{\log ^\alpha (x)}\) for some \(\alpha \ge 0\) and \(c>0\) ((1.30) is then satisfied with \(\eta =\frac{1}{1+\alpha }\)), see [22, Theorem 2.8 & Section 2.3] and the references therein. Moreover, the assumption (1.30) implies the sub-exponential decay of the \(\beta \)-mixing coefficient (1.12), namely there exists a constant C depending on \(\lambda \), \(\Lambda \) and  such that
such that

which ensures that (1.13) and (1.14) hold and ensures good concentration property of the Markov chain, see Proposition A.1. The estimate (1.32) can be seen as a direct consequence of the combination of the estimate on the \(\beta \)-mixing coefficient in [40, Proposition 3] and the assumptions (1.29) and (1.30).
Finally, the condition (1.30) quantifies the weak convergence of the law of the Markov chain to its stationary distribution, namely there exists a constant \(C>0\) such that for any 

We shortly give the argument. We first notice that a direct inductive argument together with the semigroup property \(K^{n_1+n_2} = K^{n_1}K^{n_2}\) for every \(n_1,n_2>0\) and Fubini’s theorem gives

The combination of (1.28), (1.34) and (1.30) gives
A classical example of a Markov chain satisfying Assumption 1.5 is given by iterated function systems with additive noise. For simplicity, let  . Let \(\{\theta _n\}_{n\ge 1}\) be i.i.d. random variables with common law \(h\,\text {d}\text {m}\) for some h satisfying \(\lambda \le h\le \Lambda \). Let \(F:{\mathbb {T}}^2\rightarrow {\mathbb {T}}^2\) be a contraction, i.e. there exists a constant \(L<1\) such that
. Let \(\{\theta _n\}_{n\ge 1}\) be i.i.d. random variables with common law \(h\,\text {d}\text {m}\) for some h satisfying \(\lambda \le h\le \Lambda \). Let \(F:{\mathbb {T}}^2\rightarrow {\mathbb {T}}^2\) be a contraction, i.e. there exists a constant \(L<1\) such that
We define the iterated function system \(\{X_n\}_{n\ge 1}\) according to the induction
The kernel is given by
so that K satisfies (1.29) with
Moreover, the condition (1.35) ensures the validity of (1.30), see for instance [2, Theorem 3.2]. Thus the Markov process \(\{X_n\}_{n\ge 1}\) satisfies Assumption 1.5.
We show in Appendix C that the conclusions of Theorem 1.3 and Theorem 1.2 hold true for Markov chains satisfying Assumption 1.5.
1.5 Open problems
We conclude this section with open questions that arise in view of our results. Those concern optimality of our convergence rates, extensions to more general costs and different type of correlated point clouds. For the latter, we mention two possible directions concerning the Ginibre ensemble and Coulomb gases that we think are worth investigating.
-
(1)
Sharpness of the rates. The convergence rate in (1.20) and (1.23) match with the one obtained for the case of uniformly distributed samples in [4]. However, even in the latter case, it has not been shown whether the rate is optimal and we suspect the opposite. A possible way to track the optimal rate could be to perform a second-order linearization of the Monge–Ampère equation (1.7). Following the same type of computations leading to (1.9) in the case \(\rho =1\), a second-order linearization \(q^n\) should solve
$$\begin{aligned} -\Delta q^n=\text {det}(\nabla ^2 h^n), \end{aligned}$$where we recall that \(h^n\) solves (1.9), providing the conjecture
$$\begin{aligned} \lim _{n\uparrow \infty }\bigg \vert \int _{{\mathbb {T}}^2}\vert T^n-(\text {Id}+\nabla h^n)\vert ^2-\int _{{\mathbb {T}}^2}\vert \nabla q^n\vert ^2\bigg \vert =0. \end{aligned}$$ -
(2)
Extension to p-costs. A natural question is to investigate if our results hold for different cost functions as p-cost functions for \(p>1\). The behavior of the cost has been optimally quantified in [1, 9, 13, 24]. However, to the best of our knowledge, quantitative estimates on the transport plan in the setting of general p-costs are not known, even for uniformly distributed samples. A possible approach would be to revise the linearization ansatz of [16] for general p-costs. Indeed, if the transport cost between two points x, y is given by \(\frac{1}{p}|x-y|^p\) on the torus, Gangbo-McCann’s theorem [26, Theorem 1.2] ensures that there exists a map \(h^n\) such that the optimal transport map \(T^n\) takes the form \(T^n= \text {Id} + |\nabla h^n|^{p'-2}\nabla h^n\), where \(p'\) denotes the conjugate exponent. Therefore, following the same type of computations leading to (1.9), a first-order linearization should solve the following degenerate \(p'\)-Laplace equation
$$\begin{aligned} -\nabla \cdot \rho |\nabla h^n|^{p'-2}\nabla h^n=\mu ^n- \nu ^m, \end{aligned}$$and we may expect
$$\begin{aligned} \lim _{n\uparrow \infty }\int _{{\mathbb {T}}^2}\vert T^n-(\text {Id}+|\nabla h^n|^{p'-2}\nabla h^n)\vert ^{p}=0. \end{aligned}$$See also [36] for a justification of this linearisation ansatz down to mesoscopic scales based on a large-scale regularity theory for the Monge–Ampère equation.
-
(3)
Ginibre ensemble. A (complex) Ginibre ensemble is a non-Hermitian random matrix with independent complex Gaussian entries. Given a \(n\times n\) Ginibre ensemble X, we define its empirical spectral distribution as
$$\begin{aligned} \mu ^n = \frac{1}{n} \sum _{i=1}^n \delta _{\lambda _i }, \end{aligned}$$where \(\{\lambda _i\}_{i=1}^n\) are the eigenvalues of the matrix \(\frac{X}{\sqrt{n}}\). The so called Circular Law states that, almost-surely, \(\mu ^n\) weakly converges to the uniform distribution on the complex unit disk \(\mu ^\infty \) having Lebesgue density \(\frac{1}{\pi }\mathbb {1}_{\text {B}_1}\), see for instance [59, Theorem 1.10]. An interesting question is to quantitatively understand the weak convergence of \(\mu ^n\) towards \(\mu ^\infty \) measured in Wasserstein distance. A possible approach to this problem would be to employ the linearization argument discussed in Sect. 1.2. Note that the Ginibre ensemble is not covered by our setting as it is posed on the whole space \({\mathbb {R}}^2\) and, in general, the eigenvalues \(\{\lambda _i\}_{i=1}^n\) possess long-range correlations and therefore do not satisfy our Assumption 1.1. However, in [50, Théorème 3.1.1], the linearization argument has been shown to be robust enough to derive an upper bound on \({\mathbb {E}}[W_2(\mu ^n, \mu ^\infty )]\) (see also [35, Theorem 1.3] for similar results for \({\mathbb {E}}[W_1(\mu ^n, \mu ^\infty )]\)). The techniques used in [35, 50] avoid a quantification of the correlations between the eigenvalues: This is done in [50] by a decomposition argument together with concentration estimates of the Wasserstein distance around the Moser’s coupling and in [35] by using classical tools from non-Hermitian random matrix theory. A challenging question would be to investigate the exact asymptotics of the transport cost \({\mathbb {E}}[W_2(\mu ^n, \mu ^\infty )]\) in the case of the Ginibre ensemble complementing, [50, Théorème 3.1.1] and [35, Theorem 1.3] with a lower bound and consequently quantify the convergence of the linearized proxies to the optimal transport map.
-
(4)
Planar Coulomb gases. Planar Coulomb gases are many particles systems, in which the particles \(\{X_i\}_{i=1}^n\) have repulsively Coulomb interactions and are confined by a potential \(V: {\mathbb {T}}^2 \rightarrow {\mathbb {R}}\). These are modelled by the Hamiltonian
 (1.36)
(1.36)and the Gibbs measure
 (1.37)
(1.37)where \(Z_{n,\beta }\) is the normalizing constant and \(\beta \) denotes the inverse temperature. In analogy with (1.2), we can define the empirical measure of a Coulomb gas by \(\mu ^n = \frac{1}{n} \sum _{i=1}^n \delta _{X_i}\). In this setting the convergence of the empirical measure exhibits a twofold behavior. On the one hand, for small temperature \(\beta \gg \frac{1}{n}\), the empirical measure \(\mu ^n\) weakly converges to the equilibrium measure \(\mu ^\infty _{\text {low}}\) defined as the minimizer
$$\begin{aligned} \mu ^\infty _{\text {low}}:= \mathop {\textrm{argmin}}\limits _{\mu \in {\mathcal {P}}({\mathbb {T}}^2)} \bigg \{ - \int _{{\mathbb {T}}^2\times {\mathbb {T}}^2} \log (x-y) \,\text {d}\mu \otimes \mu (x,y) + \int _{{\mathbb {T}}^2} V \,\text {d}\mu \bigg \}. \end{aligned}$$On the other hand, for large temperature \(\beta \ll \frac{1}{n}\), a correction term is required and the empirical measure \(\mu ^n\) weakly converges to the thermal equilibrium measure \(\mu ^\infty _{\text {high}}\), that is the minimizer
$$\begin{aligned} \mu ^\infty _{\text {high}}:=\mathop {\textrm{argmin}}\limits _{\mu \in {\mathcal {P}}({\mathbb {T}}^2)} \bigg \{- \int _{{\mathbb {T}}^2\times {\mathbb {T}}^2} \log (x-y) \,\text {d}\mu \otimes \mu (x,y) + \int _{{\mathbb {T}}^2} V \,\text {d}\mu + \frac{1}{n \beta } \int _{{\mathbb {T}}^2} \mu \log \mu \bigg \}. \end{aligned}$$We refer the reader to [53] for a complete exposition on 2D-Coulomb gases. This setting can be seen as an extension of the previous Ginibre ensemble on the torus. Indeed the law of the spectrum of the Ginibre ensemble is given by the Gibbs measure (1.37) choosing \(\beta =2\) and \(V(x)=|x|^2\) in (1.36). Motivated by this observation and the works [35, 50] on the Ginibre ensemble, we expect that the linearization approach could be employed also in this setting. First, we could justify the linearization Ansatz in the spirit of Theorem 1.2 in both temperature regimes, using available results in the literature. Indeed, concentration inequalities around the equilibrium measure have been derived in [27] (see also [18]), that would replace the Bernstein’s type inequality of Proposition A.1 and the matching cost estimates in Proposition B.1. Second, a more ambitious question would be to use the linearization argument to derive optimal rates of the convergence to the equilibrium measure in both temperature regimes.


2 Structure of the proof
This section is devoted to describe the main ideas and how are organized the proofs of Theorems 1.2 and 1.3. We mainly focus on the proof of Theorem 1.2 since the proof of Theorem 1.3 follows by the same strategy.
General strategy The proof of Theorem 1.2 follows the strategy employed in [4] to deal with independent and uniformly distributed random points. The main idea is to use the quantitative stability result for transport maps in [4, Theorem 3.2], stating that two transport maps are close in the \(\text {L}^2\)-topology if the target measures are close in the \(W_2\)-topology. We restate below the result for reader’s convenience.
Theorem 2.1
(Stability of transport maps) Let \(\nu ,\mu _1,\mu _2\in {\mathcal {P}}({\mathcal {M}})\) such that \(\nu \ll \text {m}\) and let \(T,S: {\mathcal {M}}\rightarrow {\mathcal {M}}\) be the optimal transport maps respectively for the pairs of measures \((\nu ,\mu _1)\) and \((\nu ,\mu _2)\). We assume that \(S=\exp (\nabla f)\) for some \(f:{\mathcal {M}}\rightarrow {\mathbb {R}}\) with \(\text {C}^{1,1}\)-regularity.
There exists a constant \(c>0\) depending on \({\mathcal {M}}\) such that, provided
we have

The first step consists of using Theorem 2.1 to deduce a stability estimate (in terms of the quadratic Wasserstein distance) of transport plans in the special case where \(\mu _1=\nu ^m\), \(\mu _2=\exp (\nabla h^{n,t})_\#\mu ^n\) and \(\nu =\mu ^n\). In this step, we immediately face the issue of the lack of regularity of \(h^{n,t}\) necessary to ensure the condition (2.1): Indeed, recalling that \(h^{n,t}\) solves (1.18), it does not have the \(\text {C}^{1,1}\)-regularity condition for non-smooth densities \(\rho \) that we consider here. We overcome this issue introducing an additional regularization step: We smooth the operator \(-\nabla \cdot \rho \nabla \) and implicitly \(\gamma ^{n,t}\) in form of
for a regularization parameter \(\delta \) to be optimized and \(\rho _\delta :=\text {P}_\delta \rho \). Classical Schauder’s theory ensures that \(h^{n,t}_\delta \) owns \(\text {C}^\infty \)-regularity. Doing so, we can use Theorem 2.1 to deduce, provided that
a stability error estimate which reads

where we refer to (3.107) for further details. Our argument then differs from [4] by splitting the error in two parts
Our proof then proceeds in two steps, controlling separately the two terms in (2.5).
Control of the regularization error To deal with the regularization error, we look at the difference \(e^{n,t}_\delta :=h^{n,t}_\delta -h^{n,t}\) which solves, according to (1.18) and (2.2),
Using an energy estimate, we get

On the one hand, since \(\rho \in \text {L}^\infty \), we have \(\rho _\delta \rightarrow \rho \) as \(\delta \downarrow 0\) in every \(\text {L}^q\) with \(q<\infty \). On the other hand, we learn from Meyers’ estimate (recalled in Proposition A.3) that there exists \({{\bar{q}}}>2\) such that \(\nabla h^{n,t}\in \text {L}^{{{\bar{q}}}}\). Consequently, we can treat (2.7) using Hölder’s inequality which provides

The next step is to control the averaged Meyers’ norm \({\mathbb {E}}\big [\Vert \nabla h^{n,t}\Vert ^2_{\text {L}^{{\bar{q}}}}\big ]\), that we show in Proposition 3.3 to be of order of

where we recall that \(\eta \) denotes the correlation length, see Assumption 1.1.
The combination of (2.8), (2.9) and local Lipschitzianity of the exponential map yields

where we refer to (3.104) for further details. We emphasize here that the stretched exponential decay assumption (1.14) of the \(\alpha \)-mixing coefficient plays a crucial role in the estimate (2.9). Indeed, the additional contribution on the numerator of the r.h.s. of (2.9) is due to the correlations and is only of logarithmic type \(\log ^{\frac{1}{\eta }}(n)\) thanks to the stretched exponential decay (1.14). Finally, the latter appears in the estimate (2.10) and can be compensated with the choice of \(\delta \) in (2.11) and the regularity assumption on \(\rho \) in form of (2.16).
Control of the stability error For the stability error, we first need to ensure (2.3). Our strategy follows the idea in [3] which consists of showing that (2.3) is satisfied with very high probability. In our case, a new difficulty comes from our regularization of \(\rho \) and the regularization parameter \(\delta \) has to be carefully optimized. We show that if \(\delta \) is taken as an inverse power of \(\log (n)\), (2.3) becomes very likely as \(n\uparrow \infty \). More precisely, we show in Proposition 3.4 that given two exponents \(\kappa _1\) and \(\upsilon \gg \kappa _1\), there exists \(\kappa _2\) such that given the choices
we have
This result is in the spirit of [3, Theorem 3.3] but, in our setting, the proof relies on Schauder’s theory rather than an explicit formula for \(h^{n,t}_\delta \) as well as concentration inequalities in form of Proposition A.1 to treat the correlations. For further details on the strategy, we refer to Sect. 3.3. We emphasize here that, to obtain the super-polynomial behaviour (2.12), we crucially use the fact that the concentration inequalities in Proposition A.1 are of sub-exponential type which is itself ensured by the sub-exponential decay assumption on the \(\alpha \)-mixing coefficient (1.14). The reason lies in the choices of \(\delta \) and t in (2.11). Indeed, the only room we have when optimizing t is in the logarithmic growth \(\log ^{\kappa _2}(n)\) (as already mention in Sect. 1.2, the natural regularization time is \(t\sim \frac{1}{n}\) up to logarithmic corrections). Furthermore, the quantity \(\Vert (\nabla h^{n,t}_\delta ,\nabla ^2\,h^{n,t}_\delta )\Vert _{\text {L}^{\infty }}\) can be heuristically estimated by an inverse power of \(\delta \) and \(t^{-1}\) as it involves powers of \(\Vert (\nabla \rho _\delta ,\nabla ^2\rho _\delta )\Vert _{\text {L}^\infty }\) and the norm \(\Vert \mu ^{n,t}-1\Vert _{\text {L}^{\infty }}\) by Schauder’s theory. Hence, in the best case scenario where exponential concentration holds, we expect

for some \(\tilde{\upsilon }>0\), which gives a super-polynomial behavior for the choices \(\delta =\frac{1}{\log ^{\kappa _1}(n)}\) and \(\lambda =\frac{1}{\log ^{\upsilon }(n)}\) for large \(\kappa _2\). Weaker properties, as for instance polynomial concentration, would only lead to a decay given by an inverse power of \(\log (n)\) which is not enough for our purpose.
With (2.12) in hands, we can restrict the analysis to realizations satisfying \(\Vert \nabla h^{n,t}_\delta \Vert _{\text {L}^{\infty }}+\Vert \nabla ^2\,h^{n,t}_\delta \Vert _{\text {L}^\infty }\le \tfrac{1}{\log ^{\upsilon }(n)}\) where, for \(n\gg 1\), (2.3) is satisfied which puts us in the validity of (2.4). We then treat each terms appearing in (2.4) separately:
-
The optimal control of the cost \(W^2_2(\mu ^n,\nu ^m)\) has been already well studied and is optimally estimated by
 (2.13)
(2.13)We refer to Appendix B for a detailed statement, references and extensions to the cases of Assumption 1.1 and Assumption 1.5.
-
The smoothing errors \(W^2_2(\mu ^n,\mu ^{n,t})\) and \(W^2_2(\nu ^m,\nu ^{m,t})\). Classical contractivity estimates are known and are usually applied to deal with these errors, see for instance [23, Theorem 3], which bound the errors by t. However, due to the choice of t in (2.11), this result is of no use since t is much larger than the magnitude of the cost, namely \(t\gg \frac{\log (n)}{n}\). Instead, we follow the approach in [3], where the authors showed that in the particular case of empirical measures in dimension 2, we can improve the rate and obtain the bound \(\frac{\log \log (n)}{n}\ll \frac{\log (n)}{n}\). We extend this result to our setting of non-constant densities and correlated points. In Proposition 3.5, we derive
 (2.14)
(2.14)As opposed to [3], our approach uses Fourier analysis together with additional cares to handle the correlations and non-constant densities.
-
The error in the Moser coupling \(W^2_2\big (\nu ^{m,t},\exp (\nabla h^{n,t}_\delta )_\#\mu ^{n,t}\big )\). We follow the strategy in [3]. This error can be related to a Moser coupling between \(\mu ^{n,t}\) and \(\nu ^{m,t}\) (see for instance [62, Appendix p. 16]): The equation (1.18) gives a natural coupling between \(\mu ^{n,t}\) and \(\nu ^{m,t}\) which can be formulated using Benamou–Brenier’s theorem [10],
$$\begin{aligned} \nu ^{m,t}=\phi (1,\cdot )_\#\mu ^{n,t}\quad \text {with} \phi \text {being the flow induced by} s\mapsto \frac{\rho _\delta \nabla h^{n,t}_\delta }{s\mu ^{n,t}+(1-s)\nu ^{m,t}}. \end{aligned}$$Then, using the transport plan \(\big (\phi (1,\cdot ),\exp (\nabla h^{n,t}_\delta )\big )_\#\mu ^{n,t}\) as a competitor, we get
$$\begin{aligned} W^2_2\big (\nu ^{m,t},\exp (\nabla h^{n,t}_\delta )_\#\mu ^{n,t}\big )&=W^2_2\big (\phi (1,\cdot )_\#\mu ^{n,t},\exp (\nabla h^{n,t}_\delta )_\#\mu ^{n,t}\big )\\&\le \int _{{\mathcal {M}}}\text {d}^2\big (\phi (1,\cdot ),\exp (\nabla h^{n,t}_\delta )\big ), \end{aligned}$$that we combine with a quantitative stability result for flows of vector fields, proved in [3, Proposition A.1], leading to

where we recall that \({\bar{q}}\) denotes the Meyers’ exponent introduced in (2.7). For further details, we refer to (3.115). It then remains to appeal to Meyers’ estimate, see Proposition A.3, to (2.6) together with (2.9) in form of

which finally yields
 (2.15)
(2.15)





To conclude, we see that all bounds involve errors in terms of the approximation of \(\rho \) using the heat-semigroup, that we need to quantify. This is where the assumption \(\rho \in \text {H}^\varepsilon \) plays a role, in form of the quantitative estimate

see (3.94) for a proof. Combining (2.4), (2.5), (2.10), (2.13), (2.14), (2.15), (2.16) with the choices of \(\delta \) and t in (2.11), we obtain Theorem 1.2. The proof of Theorem 1.3 is obtained using the same strategy where the first step is simpler, since we apply directly Theorem 2.1 with \(\mu _1=\rho \), \(\nu =\mu ^n\) and \(\mu _2=\exp (\nabla f^{n,t}_\delta )_\#\mu ^n\) where \(f^{n,t}\) solves \(-\nabla \cdot \rho _\delta \nabla f^{n,t}=\mu ^{n,t}-\rho _t\).
3 Proofs
3.1 Notations and preliminary results
We provide in this section some notations and preliminary results needed in the proofs of Theorems 1.2 and 1.3. We recall that throughout the paper, we denote by \({\mathcal {M}}\) a 2-dimensional compact connected Riemannian manifold (or the square \([0,1]^2\)) endowed with the Riemannian distance \(\text {d}\).
Wasserstein distance Given \(\mu , \nu \in {\mathcal {P}}({\mathcal {M}})\), we define the quadratic Wasserstein distance as
where \(\Pi (\mu , \nu )\) is the set of couplings between \(\mu \) and \(\nu \), that is the set of \(\pi \in {\mathcal {P}}({\mathcal {M}}\times {\mathcal {M}})\) having \(\mu \) and \(\nu \) as first and second marginal, respectively. We refer the reader to the monographs [61, 62] for a detailed overview on the subject of optimal transport. We recall the following simple, but useful Lipschitz contraction property of the Wasserstein distance.
Lemma 3.1
(Lipschitz property of the Wasserstein metric) Let \((D, \text {d}_D)\) be a complete and separable metric space, let \(\mu , \nu \in {\mathcal {P}}({\mathcal {M}})\) and let \(T: {\mathcal {M}} \rightarrow D\) be a L-Lipschitz map. It holds
Proof
For any coupling \(\pi \in \Pi (\mu , \nu )\), the push-forward \((T,T)_\# \pi \) is a coupling between \(T_\# \mu \) and \(T_\# \nu \). Moreover, it holds
Taking the infimum among all possible couplings \(\pi \in \Pi (\mu ,\nu )\) leads to (3.2). \(\square \)
Heat semigroup and heat kernelWe recall some basic facts on the heat semigroup and its generator, we refer the reader to [19, Chapter VI] for a more detailed overview. For \(t>0\), we denote by \(p_t\) the fundamental solution of the heat operator \(\partial _t-\Delta \) on \({\mathcal {M}}\), where \(\Delta \) denotes the Beltrami-Laplace operator. Classical Schauder’s theory ensures that \(p_t\) is smooth and it is known, see for instance [57] and [3, Appendix B], that \(p_t\) and its derivatives satisfy for some \(C>0\) depending on \({\mathcal {M}}\)

The kernel \(p_t\) admits the spectral decomposition
converging in \(\text {L}^2({\mathcal {M}}\times {\mathcal {M}})\), where we recall that \(\{\lambda _k,\phi _k\}\) denotes the eigenvalues and eigenvectors of \(-\Delta \) on \({\mathcal {M}}\). Specifying (3.4) on the diagonal and using \(\Vert \phi _k\Vert _{\text {L}^2({\mathcal {M}})}=1\), we obtain the trace formula
We recall that \(\{\phi _k\}_{k\ge 1}\) can be estimated in terms of the eigenvalues,

We briefly recall the argument. Applying the Gagliardo-Nirenberg’s interpolation inequality [7, Theorem 3.70], it holds

In combination with \(-\Delta \phi _k=\lambda _k\phi _k\) and elliptic regularity, in form of

we obtain (3.6).
We recall that \((\text {P}_t)_{t>0}\) admits the spectral gap property, that is there exists a constant \(C_{\text {sg}}>0\) such that
Note that equivalently, (3.7) can be formulated in terms of the eigenvalues \(\{\lambda _k\}_{k\ge 1}\) in form of
simply by specifying (3.7) on \(\{\phi _k\}_{k\ge 1}\). Finally, we recall the Riesz-transform bound

where \((-\Delta )^{\frac{1}{2}}\) can be defined via its spectral representation
with \((\cdot ,\cdot )_{\text {L}^2}\) the inner product in \(\text {L}^2\). We refer to the monograph [63] for a discussion of the inequalities (3.7) and (3.9), see Chapter 1 for the case of a Riemannian manifold without boundary and Chapter 2 for the case of a Riemannian manifold with (convex) boundary. In connection with the Wasserstein metric, the heat semigroup satisfies the following classical contraction property.
Lemma 3.2
(Semigroup contraction for absolutely continuous measures) Let \(\rho \in \text {L}^\infty \) satisfying (1.6). Given \(\rho _t:=\text {P}_t\rho \), it holds

Proof
Using g defined via \(-\Delta g=\rho _t-\rho \) together with (1.6), [3, Corollary 4.4] yields

Writing \(g=\int _{0}^{\infty }\text {P}_\tau (\rho _t-\rho )\,\text {d}\tau =-\int _{0}^t \rho _\tau \,\text {d}\tau \) together with \(\vert \int _{0}^t \rho _\tau \,\text {d}\tau \vert \le \Vert \rho \Vert _{\text {L}^{\infty }} t\) gives (3.11). \(\square \)
3.2 \(\text {L}^q\)-type estimates
As we have seen in (2.8), we need a sharp control of the averaged Meyers’ norm  . This will be obtained as an immediate corollary of the following proposition, for more details see (3.101).
. This will be obtained as an immediate corollary of the following proposition, for more details see (3.101).
Proposition 3.3
(\(\text {L}^{q}\)-estimates) Let \(\{\mu ^n\}_n\) be defined in (1.2) with point clouds satisfying Assumption 1.1. Let \({{\bar{q}}}\) be the Meyers exponent given in Theorem A.3 for the operator \(-\nabla \cdot \rho \nabla \). The solutionFootnote 4\(f^{n,t}\in \dot{\textrm{H}}^1\) of
satisfies:
and a random variable \({\mathcal {C}}_{n,t}\) satisfying for some generic constant \(C_q\) depending on q,
Furthermore, if (1.14) holds with \(\eta \ge 1\) then the assumption (1.13) can be dropped and the stochastic integrability can be improved up to losing a \(\log (n)\) factor, namely
and a random variable \({\mathcal {D}}_{n,t}\) satisfying for some generic constant \(D_q\) depending on q,
Proof
We proceed in four steps. In the first step, we prove a representation formula for \((-\Delta )^{\frac{1}{2}}\) that we will use as the core tool in the next steps. In the second step, we compare the two operators \(-\nabla \cdot \rho \nabla \) and \(-\Delta \), with help of Meyers’ estimate recalled in Theorem A.3. Doing so, we then have to bound the \(\text {L}^{q}\)-norms ( ) of the gradient of the solutionFootnote 5 to the Poisson equation with r.h.s. \(\mu ^{n,t}-\rho _t\) and Neumann boundary conditions. We control all the norms by the \(\text {L}^{4}\)-norm that, in turn, we estimate using the Riesz-transform bound (3.9) and following some ideas from [6, Lemma 3.17]. In the third and fourth steps, we control the bound previously obtained in expectation where our main tool is Assumption 1.1 and the concentration inequalities in Proposition A.1.
) of the gradient of the solutionFootnote 5 to the Poisson equation with r.h.s. \(\mu ^{n,t}-\rho _t\) and Neumann boundary conditions. We control all the norms by the \(\text {L}^{4}\)-norm that, in turn, we estimate using the Riesz-transform bound (3.9) and following some ideas from [6, Lemma 3.17]. In the third and fourth steps, we control the bound previously obtained in expectation where our main tool is Assumption 1.1 and the concentration inequalities in Proposition A.1.
Step 1. A representation formula for \((-\Delta )^{\frac{1}{2}}\). We show that given \(f\in \text {C}^2\) such that \(n_{{\mathcal {M}}}\cdot \nabla f=0\) on \(\partial {\mathcal {M}}\) we have
Note that \((-\Delta )^{\frac{1}{2}}f\), defined in (3.10), is well defined in \(\text {L}^2\). Indeed, using the fact that \((\phi _k,f)_{\text {L}^2}=\frac{1}{\lambda _k}(\phi _k,\Delta f)_{\text {L}^2}\) and (3.8), we have for any \(N\le M<\infty \)
which vanishes as \(N\uparrow \infty \) uniformly in M.
We now justify (3.16). Observe that since \(n_{\mathcal {M}}\cdot \nabla f=0\) on \(\partial {\mathcal {M}}\),
which is a direct consequence of two integration by parts using the heat-kernel representation \(\text {P}_s f=\int _{{\mathcal {M}}}p_s(\cdot ,y)f(y)\,\text {d}\text {m}(y)\). Therefore
where the last integral is well-defined in \(\text {L}^2\) since from (3.7)
We then use the spectral decomposition of the heat semigroup (3.4) to get
The combination of (3.18) and (3.19) yields for any \(\eta \in \text {L}^2\)
Using (3.8), we have
so that we can exchange integration and summation in (3.20) to obtain
which gives (3.16) by arbitrariness of \(\eta \). Finally, note that the r. h. s. integral in (3.16) is absolutely convergent thanks to the integration by parts \(\Delta \text {P}_\tau f=\text {P}_{\tau }\Delta f\) and the bounds on the heat kernel (3.3), so that it defines a function in \(\text {C}^0\).
Step 2. Comparison with the solution of the Poisson equation. We claim that for any \(q\in [2,\min \{{{\bar{q}}},4\}]\) and \(p<\infty \)

Let \(g^{n,t}\in {\dot{\text {H}}^1}\) be the solution of the following Poisson equation
Re-expressing the right-hand side of (3.12) as \(\nabla \cdot \nabla g^{n,t}\), we apply Meyers’ estimate recalled in Theorem A.3 and Hölder’s inequality to obtain:

We now introduce the Paley–Littlewood functional
We recall that the inverse of \({\mathcal {L}}\) is continuous, see [56], namely

Combining the Riesz transform bound (3.9) with (3.24) yields

We now claim that
which requires a special care when \({\mathcal {M}}\) has a boundary. We use the definition of \(\text {P}_s\) in form of \(\partial _s\text {P}_s=\Delta \text {P}_s\) to get
Recalling that \(n_{{\mathcal {M}}}\cdot \nabla g^{n,t}=0\), (3.17) implies that \(\Delta \text {P}_{\tau }g^{n,t}=\text {P}_{\tau }\Delta g^{n,t}\) which, combined with (3.22) and (3.16), gives
In particular, it implies that \(n_{{\mathcal {M}}}\cdot \nabla (-\Delta )^{\frac{1}{2}}g^{n,t}=0\). Therefore, one can use once more (3.17) and, together with (3.28), (3.27) turns into
Using a last time (3.17) in form of \(\text {P}_s\Delta \text {P}_{\tau }(\mu ^{n,t}-\rho _t)=\Delta \text {P}_s\text {P}_{\tau }(\mu ^{n,t}-\rho _t)\) that we combine with the semigroup property \(\text {P}_{t}\text {P}_{t'}=\text {P}_{t+t'}\) yields
which, together with (3.29) and (3.16) leads to (3.26).
The combination of (3.23), (3.25) and (3.26) together with Minkowski’s inequality gives

which is (3.21).
Step 3. Proof of (3.13). The estimate (3.13) is a consequence of (3.21) applied with \(p=1\) and

with
Indeed, plugging (3.30) in (3.21) gives

Using that

and analogously

We now show (3.30). First, using the definition (1.2) of \(\mu ^n\), we have
such that expanding the square gives
The estimate (3.30) is then a consequence of

Indeed, the first item of (3.34) immediately implies

while, using the assumption (1.14) and that  ,
,

It remains to prove (3.34) and we start with the first item. Here, we use the fact that

This can be seen from (3.10): Using that \(\text {P}_{\frac{s}{2}}\) is an auto-adjoint operator in \(\text {L}^2\) and that from (3.19) we learn \(\text {P}_{\frac{s}{2}}\phi _n =e^{-\lambda _n \frac{s}{2}}\phi _n\), we have

Hence, using the semi-group property \(\text {P}_{s+t}=\text {P}_{\frac{s}{2}}\text {P}_{\frac{s}{2}+t}\), we deduce

We now bound \(\Vert \text {P}_{\frac{s}{2}+t}(\delta _y-\rho )\Vert ^2_{\text {L}^{2}}\) in two different ways. First, using the bounds (3.3) of the heat-kernel, we have by the triangle inequality

yielding to the first alternative in the first item of (3.34). Second, applying Poincaré’s inequality yields

yielding to the second alternative in the first item of (3.34).
We now turn to the second item of (3.34). Here, we make use of the representation formula (3.16) applied to \(f=\text {P}_{s+t}(\delta _y-\rho )\). Using the semi-group property \(\text {P}_{\tau }\text {P}_{s+t}=\text {P}_{\tau +s+t}\), this takes the form
A direct application of the heat-kernel bounds (3.3) leads to

which is the first alternative in the second item of (3.34). For the second alternative, we write
so that, using (3.3),

Step 4. Proof of (3.15). Following the same computations done in the previous step, the estimate (3.15) is a consequence of (3.21) and the moment bounds

together with the second item of (3.34) and Lemma A.2, where we recall that \(\zeta \) is defined in (3.31).
We now show (3.37). Using (3.33) and the assumption \(\eta \ge 1\), we apply the concentration inequality in Proposition A.1 to the effect of: for any \(\lambda \ge 0\)

with
We then obtain (3.37) combining (3.38) with (3.34) and (3.35), together with an application of the Layer-cake formula. \(\square \)
3.3 Fluctuation estimates
This section is devoted to justify (2.12) needed to ensure the condition (2.3) with very high probability. Our result is in the spirit of [3, Theorem 3.3]. However, our strategy differs from [3, Theorem 3.3] and is based on Schauder’s theory, with an additional special care on the dependences on \(\delta \). We briefly sketch the main ingredients of the fluctuation estimates (2.12). By linearity, it is enough to show (2.12) for \(f^{n,t}_\delta \in \dot{\text {H}}^1\) being the solution of
We then make use of the chain rule to expand the equation in
and we define the auxiliary problem
such that the difference \(v^{n,t}_\delta :=f^{n,t}_\delta -u^{n,t}_\delta \) solves \(-\Delta v^{n,t}_\delta =\tfrac{1}{\rho _\delta }\nabla \rho _\delta \cdot \nabla f^{n,t}_\delta \). Doing so, on the one hand, we can control \(u^{n,t}_\delta \) which can be handled using the explicit formula in terms of the heat-kernel, the explicit bounds on the latter, cf (3.3), and the regularity of \(\frac{1}{\rho _\delta }\). On the other hand, we use Schauder’s estimates to control \(v^{n,t}_\delta \) and \(f^{n,t}_\delta \). Using the fact that those estimates depend polynomially on \(\Vert \rho _\delta \Vert _{\text {C}^{0,\alpha }}\), we can keep track on the dependences on \(\delta \) that we can optimize later on. We finally mention that in the case where \({\mathcal {M}}\) has a boundary, \(u^{n,t}_\delta \) cannot be directly defined by (3.41) since the r. h. s. does not have zero mean. In order to also include this case, we add a zero order term in the equation, see (3.42).
Proposition 3.4
(Fluctuation estimates) Let \(\{\mu ^n\}_n\) be defined in (1.2) with point clouds satisfying Assumption 1.1. For any parameter \(\delta \in (0,1)\) and \(\upsilon >0\), we defineFootnote 6\(u^{n,t}_{\delta }\in \text {H}^1\) weak solution of
and the two events

There exists \(\kappa >0\) such that for any \(\kappa _1>0\) and the choice

the solution \(f^{n,t}_\delta \in \dot{\text {H}}^1\) of (3.39) satisfies

Furthermore, there exists \(\kappa _2>0\) depending on \(\upsilon \) such that for the choice \(t=t_n:=\frac{\log ^{\kappa _2}(n)}{n}\), we have
Proof
The proof of Proposition 3.4 is split into two steps. In the first step, we prove (3.45) where our main tool is Schauder’s theory and an explicit formula for \(u^{n,t}_{\delta }\) defined in (3.40). In the second step, we show (3.46), where our main tool is the concentration inequalities in Proposition A.1 and the explicit formula for \(u^{n,t}_{\delta }\) used in the first step.
Step 1. Proof of (3.45). We define the difference \(v^{n,t}_{\delta }:=f^{n,t}_\delta -\Big (u^{n,t}_{\delta }-\int _{{\mathcal {M}}} u^{n,t}_\delta \Big )\in \dot{\text {H}}^1\) and note that from (3.40) and (3.42), it solves
We claim that there exists \(\kappa >0\) such that with the choices of \(\delta \) in (3.44), we have

The estimate (3.45) then follows from (3.48) and the triangle inequality.
We now prove (3.48). We apply Schauder’s estimate (see for instance [29] and [48, Chapter 10]) to (3.47) to obtain

While the second r. h. s. term is directly of order of \(\frac{1}{\log ^{\upsilon }(n)}\) in \({\mathcal {B}}_{\delta ,n}\), the first r. h. s. term requires additional attention. Using (1.6) and (3.3), \(\rho _\delta \) satisfies

and together with the algebraic property of \(\Vert \cdot \Vert _{\text {C}^{0,\alpha }}\), we have

The latter is bounded using Schauder’s estimate applied this time on (3.39) (knowing that the dependence on \(\Vert \rho _{\delta }\Vert _{\text {C}^{0,\alpha }}\) is at most polynomial): there exists \(\kappa >0\) such that

which yields the following control of the first r. h. s. term of (3.49)

which is of order of \(\frac{1}{\log ^{\upsilon -(\kappa +2)\kappa _1}(n)}\) in \({\mathcal {A}}_n\).
Step 2. Proof of (3.46). We provide the arguments for (3.46) in case that (1.14) holds for \(\eta <1\) and the event \({\mathcal {B}}^c_{\delta ,n}\) that we reduce to \(\{\Vert \nabla ^2 u^{n,t}_\delta \Vert _{\text {L}^{\infty }}\le \tfrac{1}{\log ^{\upsilon }(n)}\}\), the other cases as well as the case of \(\nabla u^{n,t}_\delta \) follow by a straightforward adaptation. The estimate (3.46) is a consequence of
for some constants \(C_1,C_2,C_3,C_4>0\). To see this, let \(\eta _n\) be defined by
By compactness of \({\mathcal {M}}\), we can find a \(\eta _n\)-net \(\{x_k\}_{1\le k\le N}\subset {\mathcal {M}}\) with  . We note that
. We note that
Indeed, if for any \(k\in \{1,\cdots ,N\}\), \(\vert \partial ^2_{ij}u^{n,t}_{\delta }(x_k)\vert \le \tfrac{1}{2\log ^{\upsilon }(n)}\) then for any \(x\in {\mathcal {M}}\) there exists \(j\in \{1,\cdots ,N\}\) such that

Applying \({\mathbb {P}}\) on (3.54) yields

Using (3.52) and

which can be proven following the arguments leading to the second item of (3.59) below, this yields \({{\mathbb {P}}}(\{\Vert \nabla ^2 u^{n,t}_\delta \Vert _{\text {L}^{\infty }}\le \tfrac{1}{\log ^{\upsilon }(n)}\})=o(\tfrac{1}{n^m})\) for any \(m\in {\mathbb {N}}\) for the choice \(\kappa _2>4\kappa _1+\frac{1}{\eta }+2\upsilon \).
We now prove (3.52). We first exploit the following explicit representation formulaFootnote 7 for \(u^{n,t}_{\delta }\),
that we expand, using the definition (1.2) of \(\mu ^{n}\), in form of
Then applying the concentration inequalities in Proposition A.1, we get
where
The estimate (3.52) then follows from the three following estimates

that we prove separately in the next three sub-steps.
Sub–step 2.1. Proof of the first item of (3.59). Splitting the time integral into \(\int _{0}^t+\int _{t}^\infty \) and subtracting and adding back \(\tfrac{1}{\rho _\delta (x)}\) in the first integral as well as using the semigroup property of \(\{\text {P}_s\}_{s}\) in form of
we decompose \(\omega \) into a regular-part \({\mathcal {J}}_1\) and a singular-part \({\mathcal {J}}_2\):
For the regular-part \({\mathcal {J}}_1\), we apply directly the heat-kernel bounds (3.3) and the first item of (3.50), to obtain from the triangle inequality and Minkowski’s inequality

The first r. h. s. term \({\mathcal {R}}_1(x)\) is dominated using directly the heat-kernel bounds (3.3) and (3.50)

For the second r. h. s. side term \({\mathcal {R}}_2(x)\), we first simplify the y-integral. Using that

we have by Jensen’s inequality and the heat-kernel bounds (3.3)

Thus,

The combination of (3.61), (3.62) and (3.63) yields

We now turn to the singular-part \({\mathcal {J}}_2\). We first apply Minkowski’s inequality in form of

We then simplify the y-integral. To this aim, we bound the integrand in \(\text {L}^{\infty }\) using the heat-kernel bounds (3.3), (3.50) and

in form of

This yields together with (3.66)

To conclude, the combination of (3.60), (3.65) and (3.69) shows the first item of (3.59).
Sub–step 2.2. Proof of the second item of (3.59). We use the decomposition (3.60). For the regular-part \({\mathcal {J}}_1\), we argue as in (3.61) for the first term whereas the second-term is estimated using the heat-kernel bounds (3.3) in form of

so that

Hence,

For the singular-part \({\mathcal {J}}_2\), we use the bound (3.68) which directly yields

The combination of (3.60), (3.70) and (3.71) gives the second item of (3.59).
Sub-Step 2.3. Proof of the third item of (3.59). According to the first item of (3.59), it suffices to give the argument for the second term in the definition (3.58) of \(v^2\). We use the assumption (1.14) together with the two first items of (3.59) in form of

which concludes since  . \(\square \)
. \(\square \)
3.4 Contractivity estimates
This section is devoted to the control of the smoothing errors \(W^2_2(\mu ^{n,t},\mu ^{n})\) and \(W^2_2(\nu ^{m,t},\nu ^{m})\) for the particular choice of t given in Proposition 3.4. The first result is in the spirit of [3, Theorem 5.2] that we extend in the case of non-uniformly distributed and correlated points. This extension requires a finer analysis of the error and the proof relies on Berry–Esseen type inequalities in the spirit of [12, Theorem 5].
Proposition 3.5
(Semigroup contraction for empirical measures) Let \(\{\mu ^n\}_n\) be defined in (1.2) with point clouds satisfying Assumption 1.1. Given t such that Proposition 3.4 holds, we have
for some random variable \({\mathcal {C}}_n\) satisfying for \(C<\infty \)
Furthermore, if (1.14) holds with \(\eta \ge 1\) then the assumption (1.13) can be dropped and the stochastic integrability can be improved up to losing a \(\log (n)\) factor, namely
for some random variable \({\mathcal {D}}_n\) satisfying for \(D<\infty \)

Proof
According to the fluctuation estimates in Proposition 3.4 together with \(W^2_2(\mu ^{n,t},\mu ^n)\le (\text {diam}({\mathcal {M}}))^2\), we can restrict the analysis in \({\mathcal {A}}_n\) defined in (3.43). Note that for n large enough, (1.6) yields

We split the proof into three steps. In the first step, we prove a Berry–Esseen type smoothing inequality for \(W^2_2(\mu ^{n,t},\mu ^n)\) which decomposes the error in a deterministic part involving \(\rho \) and a random part involving the Fourier coefficients \(\{\widehat{\mu ^n}(k)\}_k\) of \(\mu ^n\). In the second step, we prove (3.72). In the third step, we control the fluctuations of \(\{\widehat{\mu ^n}(k)\}_k\) using the concentration inequalities in Proposition A.1 and deduce (3.73).
Step 1. Berry–Esseen type inequality. Recalling that we denote by \(\{\lambda _k,\phi _k\}_k\) the eigenvalues and eigenfunctions of \(-\Delta \) respectively, we prove that

where
We first apply the triangle inequality and use the classical contractivity estimate in [23, Theorem 3] to get

We then apply Peyre’s estimate [49] to the second r. h. s. , which takes the form
Now, given an arbitrary f such that
we split
For the first r. h. s. term of (3.79), we expand the integral using (3.4). Thus, together with the semigroup property of \(\{\text {P}_{t}\}_{t>0}\) and Cauchy-Schwarz’s inequality, we get
Using that from (3.74) we have \(\mu ^{n,t+\frac{1}{n}}\ge \frac{\lambda }{2}\) and recalling (3.78), we get
Furthermore, noticing that \(\text {P}_t\phi _k=e^{-t\lambda _k}\phi _k\) which implies that, since \(\text {P}_t\) is self-adjoint
we obtain
This leads to

For the second r. h. s. of (3.79), we introduce \(w\in \dot{\textrm{H}}^1\) satisfying
so that from an integration by parts, Cauchy-Schwarz’ inequality and the combination of (3.74) and (3.78), we obtain

Using then the explicit formula \(w=-\int _{\frac{1}{n}}^{t+\frac{1}{n}}\rho _{\tau }\,\text {d}\tau \) together with \(\vert \int _{\frac{1}{n}}^{t+\frac{1}{n}}\rho _{\tau }\,\text {d}\tau \vert {\mathop {\le }\limits ^{(1.6)}} \Lambda t\), we get

so that

The combination of (3.79), (3.80), (3.81) and (3.76) leads to (3.75).
Step 2. Proof of (3.72). According to (3.75), it remains to show that

Writing
we first expand the square in form of
For the first r. h. s. term of (3.84), we use the normalisation \(\Vert \phi _k\Vert _{\text {L}^2}=1\) together with (1.6) to the effect of
and get
For the second r. h. s. term of (3.84), we use the definition of the \(\beta \)-mixing coefficient (1.12) together with the assumption (1.13) in form of

The combination of (3.84), (3.86) and (3.87) yields

It remains to show that

We only treat the second l. h. s. term of (3.88), the first term is controlled the same way. For any \(x,y\in {\mathcal {M}}\), we expand
We then disintegrate using the spectral decomposition of the heat kernel (3.4) in form of
so that we obtain

Step 3. Proof of (3.73). It is a consequence of the following fluctuation estimates

together with Lemma A.2. Indeed, applying Minkowski’s inequality followed by (3.89) and  yield
yield

and (3.73) follows from

which is obtained the same way as in (3.88) using additionally the trace formula (3.5).
We now prove (3.89). It follows from the estimate on the probability tails

for some \(C>0\), together with a simple application of the layer-cake representation.
To see (3.91), we use (3.83) together with Proposition A.1 to obtain

with
The estimate (3.91) is then a consequence of

The first item of (3.93) has been treated in (3.6). For the second item of (3.93), we use (3.85) and, combined with (1.14), we obtain

\(\square \)
3.5 Proof of Theorem 1.2: Approximation of the transport plan
We only give the arguments for (1.20), (1.21) is proved the same way using the corresponding results (3.15), (3.73) and (B.2) in the case \(\eta >2\) (where some additional comments are given if necessary along the proof). We split the proof into four steps. In the first step, we display some preliminary estimates useful all along the proof. In the second step, we deal with the approximation error that occurs in the process of regularizing \(\rho \) into \(\rho _\delta \). In the third step, we estimate the \(W_2\)-distance for the regularized quantity using the quantitative stability result in [4, Theorem 3.2], splitting the estimates in small pieces that we control in the fourth step. We finally comment on the proof of Remark 1.4 and Theorem 1.3, which are obtained with similar techniques.
Step 1. Preliminary estimates.
Heat kernel regularization The assumption \(\rho \in \text {H}^{\varepsilon }\) provides

Indeed, using the definition of the heat-kernel, Minkowski’s inequality and the spectral decomposition (3.4), we have
Noticing that

we get that

\(\text {L}^\infty \)-estimates Let \(\kappa _1>0\) and \(\upsilon >\max \{(\kappa +2)\kappa _1,\frac{1}{\eta }\}\), where \(\kappa \) is given in Proposition 3.4. For the given choices
provided in Proposition 3.4, we define \(h^{n,t}_\delta \in \dot{\text {H}}^1\) the weak solution of
Note that by linearity, one can decompose \(h^{n,t}_\delta =h^{(1)n,t}_\delta -h^{(2)n,t}_\delta \) with
so that, considering \(u^{n,t}_\delta \) as in (3.42) and likewise \(v^{n,t}_\delta \) with \(\mu ^{n,t}\) replaced by \(\nu ^{m,t}\) and defining
as well as
we deduce from Proposition 3.4 and \(m=m(n)\underset{n\uparrow \infty }{\sim }\ qn\) that

\(\text {L}^q\)-estimates A similar decomposition as in (3.97) of (1.18) together with (3.13) and the choice of t in (3.95) yields
where \({\mathcal {C}}_n\) denotes, all along the proof, a random variable which satisfies (3.14) and may change from line to line.
\(\text {L}^2\)-regularization error Note that from (3.96) and (1.18)
so that from an energy estimate, Hölder’s inequality, (3.101) and (1.6), we obtain
where \({\bar{q}}\) denotes the Meyers’ exponent of the operator \(-\nabla \cdot \rho \nabla \), see Theorem A.3.
Finally, since \(\inf _\pi W^2_2(\pi ,\gamma ^{n,t})\le (\text {diam}({\mathcal {M}}))^2\) and (3.46) holds, we can restrict our analysis in \({\mathcal {A}}_n\cap {\mathcal {B}}_{\delta ,n}\) that we do for the rest of the proof.
Step 2. Regularization error. We show that (3.103) survives when measuring the \(W_2\)-distance, namely
Using the coupling \(\big ((\text {Id},\exp (\nabla h^{n,t}_\delta )),(\text {Id},\exp (\nabla h^{n,t})\big )_\#\mu ^{n,t}\) as a competitor in (3.1) and the fact that  , we have
, we have

We then claim that

which, combined with (3.105) and (3.103) yields (3.104).
We now justify (3.106). The difficulty arises from the fact that \(\exp \) is not globally Lipschitz. To overcome this, we define
for a given \(\varsigma \) fixed later, and we split
For the first right-hand side integral, note that from the choice of \(C_n\) and (3.103), we can choose \(\varsigma \ll 1\) uniformly in n such that in \(\text {E}_n\) the quantity \(\vert \nabla h^{n,t}_{\delta }-\nabla h^{n,t}\vert \) can be made arbitrary small. Since \(\exp \) is Lipschitz-continuous in a neighborhood of the null vector, we deduce

For the second right-hand side term, we simply apply Markov’s inequality in form of
The combination of the two previous estimates gives (3.106).
To prove (1.21), we need to control arbitrary p-moments, according to Lemma A.2. The argument above can be easily adapted in this case by considering
We then follow the same argument, choosing \(\varsigma ^{-1}=O(\sqrt{p})\).
Step 3. Quantitative stability. We show that

where we recall that \(\gamma ^{n,t}_\delta \) is defined in (3.104).
Let \(\pi \) be a coupling between \(\mu ^n\) and \(\nu ^m\). We introduce a regularization parameter \(s<1\) and, smoothing the measure \(\mu ^n\) into \(\mu ^{n,s}:=\text {P}_s\mu ^n\), the optimal transport plan \(\pi ^{n,s}\) from \(\mu ^{n,s}\) to \(\nu ^m\) is represented by a transport map \(T^{n,s}\), according to McCann’s theorem [42], that is
We then apply the triangle inequality in form of
First, using (3.100), \(\nabla h^{n,t}_\delta \) is Lipschitz-continuous and \(\Vert \nabla h^{n,t}_\delta \Vert _{\text {L}^{\infty }}\) can be made as small as possible for n large. Since \(\exp \) is Lipschitz-continuous in a neighborhood of the null vector, we learn from Lemma 3.1 that

Second, we build a competitor for the second right-hand side term of (3.108): Defining
we have
Using again (3.100) we can apply, for large n, the quantitative stability result of transport maps, Theorem 2.1, to \(\mu _1=\nu ^m\), \(\mu _2=\exp (\nabla h^{n,t}_\delta )_\#\mu ^{n,s}\) and \(\nu =\mu ^{n,s}\) to the effect of

which turns into, using the triangle inequality,

The combination of (3.108), (3.109) and (3.110) yields

Since \(\mu ^{n,s}\underset{s\downarrow 0}{\rightharpoonup }\mu ^{n}\), and consequently (up to extracting a subsequence) \(\pi ^{n,s}\underset{s\downarrow 0}{\rightharpoonup }\pi \), for some optimal transport plan \(\pi \), according to the qualitative stability result [62, Theorem 5.20], we can pass to the limit as \(s\downarrow 0\) in (3.111) which leads to (3.107).
Step 4. Proof of (1.20). We now fix \(\kappa _1=\frac{1}{\eta }(\tfrac{\bar{q}}{2})\frac{1}{2\varepsilon }+1\) such that, applying (3.94), the regularization error (3.104) turns into, recalling that \(\delta \) is given by (3.95),
It remains to show that
which together with (3.94) and (3.112) leads to (1.20). To show (3.113), we control each terms of (3.107) separately.
The three last terms are controlled using the contractivity estimate (3.72) and (B.1) which gives
For the first two terms, we argue that
which combined with (B.1) leads to (3.113).
Let us define the curve \(\eta : s\in [0,1]\mapsto \eta _s:=s\mu ^{n,t}+(1-s)\nu ^{m,t}\) and note that from (1.18) we have
Applying Benamou–Brenier’ theorem [10], we learn that
Next, using that

and applying [3, Proposition A.1] together with Hölder’s inequality yields

Using Meyers’ estimate of Proposition A.3 to (3.102) together with (1.6) and (3.101) provides

which, combined with (3.115), yields (3.114).
We finally point out that, in the case \(\eta >2\), we use (3.73) and (B.2) and the same computations lead to (1.21).
Step 5. Proof of Theorem 1.3and Remark1.4. The proof of Theorem 1.3 follows the same strategy with the main difference that Step 3 is now dropped and Theorem 2.1 is directly applied with \(\mu _1=\rho \), \(\nu =\mu ^n\) and \(\mu _2=\exp (\nabla f^{n,t}_\delta )_\#\mu ^n\) where \(f^{n,t}_\delta \) solves
The improvement of Remark 1.4 follows from the improved contractivity estimate (3.73): Under the assumption 1.25, we have (keeping the notations as in Proposition 3.5)
i.e. we do not have the loss \(\log ^\frac{1}{\eta }(n)\) in (3.73). Inspecting the proof of (3.73), the loss \(\log ^{\frac{1}{\eta }}(n)\) comes from estimating \(v^2\) defined in (3.92). We obtain (3.116) by simply using (1.25) and (1.11) to upgrade the second item of (3.93) into

Notes
We use the notation
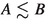 if there exists a global constant \(C>0\), which may only depend on d, such that \(A\le CB\). We write \(A\sim B\) if both
if there exists a global constant \(C>0\), which may only depend on d, such that \(A\le CB\). We write \(A\sim B\) if both  and
and  hold.
hold.We denote by \({\mathbb {P}}_X\) the law of a random variable X.
Where we impose additional Neumann boundary conditions in the case \({\mathcal {M}}=[0,1]^2\).
With Neumann boundary conditions in case \({\mathcal {M}}\) has a boundary.
Which belongs to any \(\text {L}^{q}\) for any \(q<\infty \) from Calderón-Zygmund’ theory, see for instance [28].
With Neumann boundary conditions in case \({\mathcal {M}}\) has a boundary.
A simple change of variable gives that the kernel \({\tilde{p}}_s\) associated to \(1-\Delta \) is given by \({\tilde{p}}_s=e^{-s}p_s\).
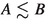 if there exists a global constant
if there exists a global constant  and
and  hold.
hold.References
Ajtai, M., Komlós, J., Tusnády, G.: On optimal matchings. Combinatorica 4, 259–264 (1984)
Alsmeyer, G.: On the Harris recurrence of iterated random Lipschitz functions and related convergence rate results. J. Theor. Probab. 16(1), 217–247 (2003)
Ambrosio, L., Glaudo, F.: Finer estimates on the \(2\)-dimensional matching problem. J. l’École Polytechnique-Mathématiques 6, 737–765 (2019)
Ambrosio, L., Glaudo, F., Trevisan, D.: On the optimal map in the \( 2 \)-dimensional random matching problem. Discrete Contin. Dyn. Syst. 39(12), 7291–7308 (2019)
Ambrosio, L., Goldman, M., Trevisan, D.: On the quadratic random matching problem in two-dimensional domains. Electron. J. Probab. 27, 1–35 (2022)
Ambrosio, L., Stra, F., Trevisan, D.: A PDE approach to a 2-dimensional matching problem. Probab. Theory Relat. Fields 173(1), 433–477 (2019)
Aubin, T.: Some Nonlinear Problems in Riemannian Geometry. Springer Science & Business Media, Berlin (1998)
Bapat, R.B., Raghavan, T.E.S.: Doubly Stochastic Matrices. Encyclopedia of Mathematics and its Applications, pp. 59–114. Cambridge University Press (1997)
Barthe, F., Bordenave, C.: Combinatorial Optimization Over Two Random Point Sets, pp. 483–535. Springer International Publishing, Heidelberg (2013)
Benamou, J.-D., Brenier, Y.: A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem. Numer. Math. 84(3), 375–393 (2000)
Benedetto, D., Caglioti, E.: Euclidean random matching in 2D for non-constant densities. J. Stat. Phys. 181(3), 854–869 (2020)
Borda, B.: Empirical measures and random walks on compact spaces in the quadratic Wasserstein metric. Ann. l’Institut Henri Poincare (B) Probab. stat. 59(4), 2017–2035 (2023)
Boutet de Monvel, J.H., Martin, O.C.: Almost sure convergence of the minimum bipartite matching functional in Euclidean space. Combinatorica 22(4), 523–530 (2002)
Brenier, Y.: Polar factorization and monotone rearrangement of vector-valued functions. Commun. Pure Appl. Math. 44, 375–417 (1991)
Caglioti, E., Pieroni, F.: Random matching in 2d with exponent 2 for densities defined on unbounded sets. arXiv preprint arXiv:2302.02602 (2023)
Caracciolo, S., Lucibello, C., Parisi, G., Sicuro, G.: Scaling hypothesis for the Euclidean bipartite matching problem. Phys. Rev. E 90(1), 012118 (2014)
Caracciolo, S., Sicuro, G.: Scaling hypothesis for the Euclidean bipartite matching problem. II. correlation functions. Phys. Rev. E 91(6), 062125 (2015)
Chafaï, D., Hardy, A., Maïda, M.: Concentration for Coulomb gases and Coulomb transport inequalities. J. Funct. Anal. 275(6), 1447–1483 (2018)
Chavel, I.: Eigenvalues in Riemannian Geometry. Academic press, Cambridge (1984)
Chung, F., Lu, L.: Concentration inequalities and martingale inequalities: a survey. Internet Math. 3(1), 79–127 (2006)
Crawford, V.P., Knoer, E.M.: Job matching with heterogeneous firms and workers. Econometrica 49(2), 437–450 (1981)
Douc, Randal, Fort, Gersende, Moulines, Eric, Soulier, Philippe: Practical drift conditions for subgeometric rates of convergence. Ann. Appl. Probab. 14(3), 1353–1377 (2004)
Erbar, M., Kuwada, K., Sturm, K.-T.: On the equivalence of the entropic curvature-dimension condition and Bochner’s inequality on metric measure spaces. Invent. Math. 201(3), 993–1071 (2015)
Fournier, N., Guillin, A.: On the rate of convergence in Wasserstein distance of the empirical measure. Probab. Theory Relat. Fields 162(3), 707–738 (2015)
Gale, D., Shapley, L.S.: College admissions and the stability of marriage. Am. Math. Mon. 69(1), 9–15 (1962)
Gangbo, W., McCann, R.J.: The geometry of optimal transportation. Acta Math. 177(2), 113–161 (1996)
García-Zelada, D.: Concentration for Coulomb gases on compact manifolds. Electron. Commun. Probab. 24, 1–18 (2019)
Giaquinta, M., Martinazzi, L.: An Introduction to the Regularity Theory for Elliptic Systems, Harmonic Maps and Minimal Graphs. Springer Science & Business Media, Berlin (2013)
Gilbarg, D., Trudinger, N.S.: Elliptic Partial Differential Equations of Second Order, vol. 224. Springer, Berlin (2015)
Goldman, M., Huesmann, M.: A fluctuation result for the displacement in the optimal matching problem. Ann. Probab. 50(4), 1446–1477 (2022)
Goldman, M., Huesmann, M., Otto, F.: A large-scale regularity theory for the Monge-Ampere equation with rough data and application to the optimal matching problem. arXiv:1808.09250 (2018)
Goldman, M., Trevisan, D.: Convergence of asymptotic costs for random Euclidean matching problems. Probab. Math. Phys. 2, 121–142 (2021)
Goldman, M., Trevisan, D.: Optimal transport methods for combinatorial optimization over two random point sets. Probab. Theory Relat. Fields (2023). https://doi.org/10.1007/s00440-023-01245-1
Huesmann, M., Mattesini, F., Trevisan, D.: Wasserstein asymptotics for the empirical measure of fractional Brownian motion on a flat torus. Stoch. Process. Appl. 155, 1–26 (2023)
Jalowy, J.: The Wasserstein distance to the circular law. Ann. Inst. Henri Poincaré Probab. Stat. 59(4), 2285–2307 (2023)
Koch, L.: Geometric linearisation for optimal transport with strongly p-convex cost. arXiv preprint arXiv:2303.10760 (2023)
Ledoux, M.: On optimal matching of Gaussian samples. J. Math. Sci. 238(4), 495–522 (2019)
Ledoux, M.: On optimal matching of Gaussian samples II (2019)
Ledoux, M., Zhu, J.-X.: On optimal matching of gaussian samples. Probab. Math. Stat. 41, 237–265 (2021)
Liebscher, E.: Towards a unified approach for proving geometric ergodicity and mixing properties of nonlinear autoregressive processes. J. Time Ser. Anal. 26(5), 669–689 (2005)
Lovász, L., Plummer, M.D.: Matching Theory, vol. 367. American Mathematical Society, Providence (2009)
McCann, R.J.: Polar factorization of maps on Riemannian manifolds. Geom. Funct. Anal. GAFA 11(3), 589–608 (2001)
Mehta, A.: Online matching and Ad allocation. Found. Trends® Theor. Comput. Sci. 8(4), 265–368 (2013)
Merlevède, F., Peligrad, M., Rio, E.: Bernstein inequality and moderate deviations under strong mixing conditions. In: High Dimensional Probability V: the Luminy Volume. Institute of Mathematical Statistics, pp. 273–292 (2009)
Merlevède, F., Peligrad, M., Rio, E.: A Bernstein type inequality and moderate deviations for weakly dependent sequences. Probab. Theory Relat. Fields 151(3), 435–474 (2011)
Meyers, N.G.: An \(\rm L ^p\)-estimate for the gradient of solutions of second order elliptic divergence equations. Annali della Scuola Normale Superiore di Pisa-Classe di Scienze 17(3), 189–206 (1963)
Mézard, M., Parisi, G.: The Euclidean matching problem. J. Phys. France 49(12), 2019–2025 (1988)
Nicolaescu, L.I.: Lectures on the Geometry of Manifolds. World Scientific, Singapore (2020)
Peyre, R.: Comparison between W2 distance and \(\dot{H}\)-1 norm, and localization of Wasserstein distance. ESAIM Control Optim. Calc. Var. 24(4), 1489–1501 (2018)
Prod’Homme, M.: Contributions to the optimal transport problem and its regularity. Université Paul Sabatier—Toulouse III, Theses (2021)
Riekert, A.: Convergence rates for empirical measures of Markov chains in dual and Wasserstein distances. Stat. Probab. Lett. 189, 109605 (2022)
Santambrogio, F.: Optimal Transport for Applied Mathematicians: Calculus of Variations, PDEs, and Modeling. Progress in Nonlinear Differential Equations and Their Applications, Springer International Publishing, New York (2015)
Serfaty, S.: Coulomb gases and Ginzburg–Landau vortices. arXiv preprint arXiv:1403.6860 (2014)
Sicuro, G.: Euclidean Matching Problems, pp. 59–118. Springer, Cham (2017)
Steele, J.M.: Probability Theory and Combinatorial Optimization. SIAM, New Delhi (1997)
Stein, E.M.: Topics in Harmonic Analysis Related to the Littlewood-Paley Theory. (AM-63). Princeton University Press, Princeton (2016)
Stroock, D.W., Turetsky, J.: Upper bounds on derivatives of the logarithm of the heat kernel. Commun. Anal. Geom. 6(4), 669–685 (1998)
Talagrand, M.: The Ajtai-Komlós-Tusnády matching theorem for general measures. In: Probability in Banach Spaces, 8: Proceedings of the Eighth International Conference. Springer, pp. 39–54 (1992)
Tao, T., Vu, V., Krishnapur, M.: Random matrices: Universality of ESDs and the circular law. Ann. Probab. 38(5), 2023–2065 (2010)
Toth, J.A., Zelditch, S.: Riemannian manifolds with uniformly bounded eigenfunctions. Duke Math. J. 111(1), 97–132 (2002)
Villani, C.: Topics in Optimal Transportation. Graduate Studies in Mathematics, vol. 58. American Mathematical Society, Providence (2003)
Villani, C.: Optimal Transport: Old and New. Grundlehren der mathematischen Wissenschaften, Springer, Berlin Heidelberg (2008)
Wang, F.-Y.: Analysis for Diffusion Processes on Riemannian Manifolds, vol. 18. World Scientific, Singapore (2014)
Wang, F.-Y.: Convergence in Wasserstein distance for empirical measures of semilinear SPDEs. Ann. Appl. Probab. 33(1), 70–84 (2023)
Wang, F.-Y., Wu, B.: Wasserstein convergence for empirical measures of subordinated diffusions on Riemannian manifolds. Potential Anal. 59(3), 933–954 (2023)
Wang, F.-Y., Zhu, J.-X.: Limit theorems in Wasserstein distance for empirical measures of diffusion processes on Riemannian manifolds. Ann. Inst. Henri Poincaré Probab. Stat. 59(1), 437–475 (2023)
Acknowledgements
The authors warmly thank Lorenzo Dello Schiavo, Antonio Agresti and Martin Huesmann for useful discussions and fruitful comments.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
NC has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant agreement No 948819). FM is supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) through the SPP 2265 Random Geometric Systems. FM has been funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy EXC 2044 -390685587, Mathematics Münster: Dynamics–Geometry–Structure. FM has been funded by the Max Planck Institute for Mathematics in the Sciences.
Appendices
Appendix A: Probabilistic and PDE tools
This section is devoted to recall some probabilistic and analytical tools needed in the proofs. We first recall some concentration inequalities for sequences of random variable satisfying Assumption 1.1. Originally proved for i.i.d. samples, see for instance [20, Theorem 3.6 & 3.7], the proofs in the correlated case can be found in [45, Theorem 1] and [44, Theorem 2].
Proposition A.1
Let \(n\in {\mathbb {N}}\), \(M>0\), \(\{X_i\}_{i}\) be a family of centred random variables such that \(\sup _{i\ge 1}\vert X_i\vert \le M\) for which (1.14) holds.
For any \(\lambda >0\), it holds for some constants \((C_i)_{i\in \{1,\cdot ,5\}}\) depending on a, b:
-
(i)
If \(\eta <1\),
$$\begin{aligned} {\mathbb {P}}\bigg (\Big \vert \frac{1}{n}\sum _{i=1}^n X_i\Big \vert >\lambda \bigg )\le \,&\, n\exp \bigg (-\frac{1}{C_1}\Big (\frac{n\lambda }{M}\Big )^{\eta }\bigg )+\exp \bigg (-\frac{1}{C_2}\frac{n^2\lambda ^2}{M^2+n v^2}\bigg )\\&+\exp \bigg (-\frac{1}{C_3}\frac{n\lambda }{M^2}\exp \Big (\frac{1}{C_4}\Big (\frac{n\lambda }{M}\Big )^{\eta (1-\eta )}\log ^{-1}(\tfrac{n\lambda }{M})\Big )\bigg ), \end{aligned}$$with
$$\begin{aligned} v^2:=\sup _{i\ge 1}\Big ({\mathbb {E}}[X^2_i]+2\sum _{j> i}\vert {\mathbb {E}}[X_iX_j]\vert \Big ). \end{aligned}$$ -
(ii)
If \(\eta =1\),
$$\begin{aligned} {\mathbb {P}}\bigg (\Big \vert \frac{1}{n}\sum _{i=1}^n X_i\Big \vert >\lambda \bigg )\le \exp \bigg (-\frac{1}{C_5}\frac{n^2\lambda ^2}{nv^2+M^2+n\lambda M(\log (n))^2}\Bigg ). \end{aligned}$$
We then recall the link between algebraic moments and exponential moments. The proof is a direct consequence of the Taylor expansion of the exponential function.
Lemma A.2
Let X be a non-negative random variable. The following two statements are equivalent:
-
(i)
There exists \(C_1>0\) such that
$$\begin{aligned} {\mathbb {E}}\big [\exp (\tfrac{1}{C_1}X)\big ]\le 2. \end{aligned}$$ -
(ii)
There exists \(C_2>0\) such that
$$\begin{aligned} {\mathbb {E}}[X^p]^{\frac{1}{p}}\le p\,C_2\quad \text { for any}\ p<\infty . \end{aligned}$$
We conclude this section by recalling the standard Meyers’ estimate for elliptic equations in divergence form, see for instance the original paper [46].
Theorem A.3
(Meyers estimate) Let \(a: {\mathcal {M}}\rightarrow {\mathbb {R}}^{2\times 2}\) be measurable and uniformly elliptic. Consider \(u\in \text {H}^1\) the solution of the Neumann boundary problem
for some \(g\in \text {L}^q\) with \(q>2\). There exists  such that
such that

Appendix B: Matching cost for point clouds
This section is devoted to recall the upper bounds on the matching cost, results which can be found in [12, Theorem 2] under mild \(\beta \)-mixing conditions. The case of Markov chains have been studied in [24, 51] where sharp upper bounds are obtained. We include a short proof for convenience.
Proposition B.1
(Matching cost) Let \(\rho \) satisfying (1.6) and \(\{\mu ^n\}_n\) be defined in (1.2) with point clouds satisfying the Assumption 1.1 or in the class of Markov chains satisfying the Assumption 1.5. There exists a constant \(C>0\) such that
Furthermore, if (1.14) holds with \(\eta \ge 1\) then the assumption (1.13) can be dropped and the stochastic integrability can be improved up to losing a \(\log (n)\) factor, namely
Proof
Note that the proof of (B.1) can be found in [12, Theorem 2] when the point cloud satisfies the Assumption 1.1. We first show how (B.1) can be extended to point clouds which are sampled from a Markov chain satisfying the Assumption 1.5. Second, we show how the stochastic integrability can be improved to (B.2) when (1.14) holds with \(\eta \ge 1\).
Step 1. Markov chains case. Recall that a Markov chain satisfying the Assumption 1.5 admits an absolutely continuous invariant measure of the form \(\mu _\infty = \rho \, \text {d}\text {m}\) with \(\rho \) satisfying (1.6), that is \(\lambda \le \rho \le \Lambda \). Recalling that we denote by \(\{\lambda _n,\phi _n\}_n\) the set of eigenvalues and normalized eigenfunctions of the Laplace-Beltrami operator \(-\Delta \) on \({\mathcal {M}}\), we have by definition (1.2) of \(\mu ^n\), for any \(k\ge 1\)
where we use interchangeably the notation \({\widehat{\rho }}(k) = \int \phi _k \rho \,\text {d}\text {m}= \mu _\infty (\phi _k)\). Using the Berry–Esseen smoothing inequality [12, Theorem 5] together with (B.3), we get

We now estimate the last two terms of (B.4) separately and we start with the third one. Using (1.33) and (3.93), we have

Thus, using in addition (3.5), we get

We now turn to the second term of (B.4). Expanding the square provides
We now estimate the two terms on the right hand side of (B.6). For the first term, an easy induction argument combining (1.29) and (1.28) show that for any \(n\ge 1\), \({\mathbb {P}}_{X_n}\ll \text {m}\) with \(\lambda \le \frac{\text {d}{\mathbb {P}}_{X_n}}{\text {d}\text {m}}\le \Lambda \). Therefore, we have
and we deduce

For the second term, we use (1.32) to obtain

Combining the latter with (B.4), (B.5), (B.6) and (B.7) yields

We finally conclude similarly as for (3.88).
Step 2. Higher stochastic integrability. We now prove (B.2). We argue using the moment estimate (3.89) which, together with Minkowski’s inequality and \(\lambda _k^\frac{1}{\log (n)} e^{-\frac{1}{n} \lambda _k} {\mathop {\sim }\limits ^{<}}e^{-\frac{1}{2n}\lambda _k}\) implies

Finally, combining the latter with the Berry–Esseen smoothing inequality [12, Theorem 5] and arguing similarly as for (3.88) yields (B.2) thanks to Proposition A.2. \(\square \)
Appendix C. Proof for the class of Markov chains
We provide in this Section the arguments for extending Theorems 1.2 and 1.3 to the class of Markov chains introduced in Sect. 1.4. The proof follows the lines of the proof of Theorem 1.2, where the main difference is that we drop the assumption that the point clouds is identically distributed. That affects the proofs of the main ingredients (we recall that the scaling of the cost has already be proven in Proposition B.1), namely the \(\text {L}^q\) estimates in Proposition 3.3, the fluctuation estimates in Proposition 3.4 and the contractivity estimates in Proposition 3.5. We show in the following how to adapt the proofs for a given Markov chain \(\{X_n\}_{n\ge 1}\) satisfying Assumption 1.5. In the following, we recall that \(\mu _\infty =\rho \,\text {d}\text {m}\) denotes the unique invariant measure of the chain. We split the proof into three steps.
Step 1. \(\text {L}^q\) estimates. We have to understand the extra error term coming from the deviation of \({\mathbb {E}}[\mu ^n]\) from \(\mu _\infty \). In view of (3.21), it is
Using the definition (1.2) of \(\mu ^n\), the convergence to equilibrium (1.33) applied to \(f=(-s\Delta )^{\frac{1}{2}}p_{s+t}(x,\cdot )\) and the heat-kernel estimates (3.3), we have for any \(s\ge 0\) and \(x\in {\mathcal {M}}\)

so that, recalling \(t=\frac{\log ^{\kappa }(n)}{n}\),

Step 2. Fluctuation estimates. Here, the distribution of the Markov chain affects the concentration estimate (3.52). We show that, defining
we have
where the r.h.s can be estimated following the lines of the proof of (3.52). As before, we investigate the extra term coming from the deviation of \({\mathbb {E}}[\mu ^n]\) from \(\mu _\infty \). The estimate (C.3) follows from
We argue as in (3.60), decomposing \(u^{n,t}_\delta -{\bar{u}}^{n,t}_\delta \) into a regular-part and a singular part: for any \(x\in {\mathcal {M}}\)
To estimate the second r.h.s integral of (C.5), we use (3.68). For the first r.h.s integral, that we denote by \({\mathcal {J}}\), we use the definition (1.2) of \(\mu ^n\), the convergence to equilibrium (1.33) and the heat-kernel bounds (3.3) to obtain

Step 3. Contractivity estimate. Here, the law of the Markov chain affects the estimate (3.82). The extra error term coming from the deviation of \({\mathbb {E}}[\mu ^n]\) from \(\mu _\infty \) reads
Using the definition (1.2) of \(\mu ^n\) and the convergence to equilibrium (1.33) applied with \(f=\phi _k\) and the bound on the eigenfunctions (3.6), we have for any \(k\le n\)

so that, using the trace formula (3.5) and the heat-kernel estimates (3.3), we deduce

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Clozeau, N., Mattesini, F. Annealed quantitative estimates for the quadratic 2D-discrete random matching problem. Probab. Theory Relat. Fields 190, 485–541 (2024). https://doi.org/10.1007/s00440-023-01254-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-023-01254-0