
Abstract
In this paper, we compare the solutions of the Dyson Brownian motion for general \(\beta \) and potential V and the associated McKean–Vlasov equation near the edge. Under suitable conditions on the initial data and the potential V, we obtain optimal rigidity estimates of particle locations near the edge after a short time \(t={{\,\mathrm{o}\,}}(1)\). Our argument uses the method of characteristics along with a careful estimate involving an equation of the edge. With the rigidity estimates as an input, we prove a central limit theorem for mesoscopic statistics near the edge, which, as far as we know, has been done for the first time in this paper. Additionally, combining our results with Landon and Yau (Edge statistics of Dyson Brownian motion. arXiv:1712.03881, 2017), we give a proof of the local ergodicity of the Dyson Brownian motion for general \(\beta \) and potential at the edge, i.e., we show the distribution of extreme particles converges to the Tracy–Widom \(\beta \) distribution in a short time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Random matrix models were originally proposed by Wigner [54, 55] as models for the nuclei of heavy atoms. The models he originally studied, the Gaussian orthogonal/unitary ensembles, were successful in describing the spacing distribution between energy levels. Wigner conjectured that the spacing distribution of a random matrix ensemble depends only on the symmetry class of the ensemble.
Later, in 1962 [17], Dyson interpreted the Gaussian orthogonal/unitary ensembles as dynamical limits of a matrix-valued stochastic differential equation. The equation is given by
where B(t) is the Brownian motion on real symmetric/complex Hermitian matrices, respectively. It turns out that the eigenvalues of the above process satisfy a system of self-consistent stochastic differential equations. These equations have later been generalized to other stochastic differential equations called the \(\beta \)-Dyson Brownian motion with potential“ V,
where the initial data \(\{\lambda _1(0),\lambda _2(0),\ldots ,\lambda _N(0)\}\) is in the closure of the Weyl chamber
When \(\beta =1\) and \(V = x^2/2\), the Eq. (1.2) correspond to the eigenvalue process of Eq. (1.1) for real symmetric matrices; when \(\beta =2\), they correspond to the eigenvalue process for complex Hermitian matrices.
Dyson speculated that, under this stochastic eigenvalue process, the bulk local statistics reach an equilibrium after a time of order slightly larger than 1/N. In other words, the distributions of the eigenvalue gaps would asymptotically match those of the corresponding \(\beta \)-symmetry class. In fact, one has three time scales.
-
1.
For time \(t \gg 1\), one should get the global equilibrium. Namely, the global spectral density should approach that of the corresponding \(\beta \) ensemble. For the Dyson Brownian motion with general \(\beta \) and potential V, this was studied in [44].
-
2.
For scales of order \(1/N\ll \eta ^* \ll 1 \), the spectral statistics on the scale \(\eta ^*\) should reach the equilibrium after running Dyson Brownian motion for time \(t \gg \eta ^*\). More precisely, mesoscopic quantities of the form \( \sum _{i=1}^{N} f((\lambda _i -E)/ \eta ^*)\) for appropriate test functions should be distributed according to a universal distribution.
-
3.
On the microscopic scale, i.e., the scale of order \({{\,\mathrm{O}\,}}(1/N)\), the microscopic eigenvalue distribution matches that of the Gaussian ensembles in the same symmetry class. For example, when \(\beta =2\), the microscopic eigenvalue distribution should be given by the determinantal point process with the Sine kernel \(K(x,y) =\sin (x-y)/(x-y)\) provided one runs the Dyson Brownian motion for \(t\gg 1/N\).
The fact that the local statistics of the Dyson Brownian motion reach an equilibrium in a short time plays an important role in the proof of Wigner’s original universality conjecture by Erdős, Schlein, and Yau [28]. The first step of their method is to prove a rigidity estimate of the eigenvalues, i.e., they show that the eigenvalues are close to their classical locations up to an optimal scale. This can be understood as an initial data estimate for the dynamic (1.2). The second step is to show that the Dyson Brownian motion reaches an equilibrium for local statistics in a short amount of time. Since one needs only to run the Dyson Brownian motion for a short time, the initial and final models can be compared. The last step is to compare the original random matrix ensemble with one that has a small Gaussian component. For a good review of the general framework regarding this type of analysis, we refer to the book [21] by Erdős and Yau.
Of the three steps described in the previous paragraph, the step that is the least robust is the proof of the rigidity estimates. This part depends very strongly on the model in consideration and requires significant effort to obtain an optimal estimate. Even in the basic case of Wigner matrices, the proof of the optimal rigidity estimates requires the so-called fluctuation averaging lemma [31]. The proof of such lemmas requires very delicate combinatorial expansions involving iterated applications of the resolvent entries. For models even more complicated than the Wigner matrices, proving such lemmas is an intricate effort. A more general method that does not depend on the details of the models is preferred. This will allow one to treat general classes of models uniformly. We remark here that in contrast to [31] we do not establish an entrywise or isotropic local law.
A dynamical approach to proving eigenvalue rigidity using the Dyson Brownian motion allows us to avoid technical issues involving the details of a matrix model. We do not need to perform complicated combinatorial analysis. In addition, it will allow us to treat models that do not occur naturally with an associated matrix structure, such as the \(\beta \)-ensembles. In an earlier paper by B. Landon and the second author [36], the rigidity estimates of the bulk eigenvalues arising dynamically from the Dyson Brownian motion were established. As a result, the optimal rigidity estimates in the bulk are purely a consequence of the dynamics. The proof of rigidity is based on a comparison between the empirical eigenvalue process of the Dyson Brownian motion and the deterministic measure-valued process obtained as the solution of the associated McKean–Vlasov equation by using the method of characteristics. The difference in the corresponding Stieltjes transforms can be analyzed by a Gronwall-type estimate. The method of characteristics was also applied in [6] to study the extreme eigenvalue gaps of Wigner matrices.
There are substantial difficulties involved in performing a comparison between the solutions of the Dyson Brownian motion and the associated McKean–Vlasov equation near the edge. In the bulk, one can derive sufficiently strong estimates by looking at the distance between the characteristics and the real line; this is thanks to the fact that we have strong bounds on the imaginary part of the Stieltjes transform in the bulk. Near the spectral edge, the power of these bounds decays and becomes too weak to prove optimal rigidity. In our case, we have to establish an equation determining the relative movement of our characteristics with respect to the edge. The estimates of the Stieltjes transform of the empirical particle density near the edge heavily depend on this relative movement. Informally, our main rigidity theorem is as follows; it summarizes Theorem 4.8 in the text.
Theorem 1.1
(Informal Eigenvalue Rigidity Theorem) Consider a probability measure \(\mu _0 = (1/N) \sum _{i=1}^N \delta _{\lambda _i}\) that satisfies the rigidity estimates on the scale \(\eta ^*\) near the edge. The empirical particle density \(\mu _t\) at any time \(t\gg \sqrt{\eta ^*}\) of the Dyson-Brownian motion with general \(\beta \) and potential starting from \(\mu _0\) satisfies an optimal rigidity estimate.
In addition to the rigidity estimates, another main innovation in this paper is the computation of the correlation kernel for the Stieltjes transform of the empirical particle density of the Dyson Brownian motion on mesoscopic scales near the edge. It allows us to prove a mesoscopic central limit theorem near the edge. The mesoscopic central limit in the bulk is proven for Wigner matrices in [10, 11, 33, 34, 46], for \(\beta \)-ensembles in [46] and for the Dyson Brownian motion in [16, 36, 39]. Applications for mesoscopic central limit theorems are given in [38]. Two-point correlation functions for all mesoscopic scales are considered in [35]. As far as we know, the mesoscopic central limit theorem near the edge is new even for Wigner matrices and \(\beta \)-ensembles. The dynamical method provides a unified approach to see how it emerges naturally, and allows us to see the universality of this correlation kernel. Informally, our main result on the mesoscopic central limit theorem can be stated as follows; it summarizes Theorem 4.8 and Corollary 5.4 in the text.
Theorem 1.2
(Informal Mesoscopic CLT) Consider a probability measure \(\mu _0 = (1/N) \sum _{i=1}^N \delta _{\lambda _i}\) which satisfies the rigidity estimates on the scale \(\eta ^*\) near the edge. The empirical particle density \(\mu _t\) at any time \(t\gg \max \{\sqrt{\eta ^*},\sqrt{\eta }\}\) of the Dyson-Brownian motion with general \(\beta \) and potential starting from \(\mu _0\) satisfies a mesoscopic central limit theorem on the scale \(\eta \).
Combining our result with [41], we can give a proof of the local ergodicity of the Dyson Brownian motion for general \(\beta \) and potential at the edge. In other words, we show that the distribution of extreme particles converges to the Tracy–Widom \(\beta \) distribution in a short time. Our proof uses only the dynamics and is independent of the matrix model (if it exists). This is in alignment with Dyson’s original vision on the nature of the universality of the local eigenvalue statistics. A consequence of our edge universality result is a purely dynamical proof of the edge universality for \(\beta \)-ensembles with general potential.
1.1 Related results in the literature
Results for the McKean–Vlasov equation were first established by Chan [12] and Rogers and Shi [49], who showed the existence of a solution for quadratic potentials V. The McKean–Vlasov equation for general potentials V was studied in detail in the works of Li, Li, and Xie. In their works [44] and [45], it was shown that, under very weak conditions on V, the solution of the McKean–Vlasov equation would converge to an equilibrium distribution for times \(t \gg 1\). The authors were able to interpret the time evolution under the McKean–Vlasov equation as a type of gradient descent on the space of measures. This gives the complete description of the Dyson Brownian motion on the macroscopic scale.
On the microscopic scale, the Dyson Brownian motion was studied in detail by Erdős, Yau and various coauthors across a multitude of papers [8, 22,23,24,25,26,27,28,29, 31]. Specifically, for the classical ensembles (\(\beta =1,2, 4\)) with quadratic potential and initial data given by the eigenvalues of a Wigner matrix, it is known that, after \(t \gg N^{-1}\), the bulk local statistics of the particles are asymptotically the same as those of the corresponding classical Gaussian ensemble. After this, the two works [20, 40] established gap universality for the classical (\(\beta =1,2,4\)) Dyson Brownian motion with general initial data by using estimates established in a discrete De Giorgi–Nash–Moser theorem in [29]. Fixed energy universality required a sophisticated homogenization argument that allowed for the comparison between the discrete equation and a continuous version; the results have been established in recent papers [7, 39]. An extension of this interpolation at the edge was proven in [41]. These results were a key step in the proof of edge and bulk universality in various models. An alternative approach to universality was established, independently, in the works of Tao and Vu [52] and for the edge in [51].
In the three-step strategy for proving universality, as developed by Erdős, Yau, and their collaborators, the first step is to derive a local law for the eigenvalue density. This is a very technical and highly model dependent procedure. In the case of Wigner matrices, the proofs have been established in [26, 27, 30, 31, 53]. Local laws can be established for other matrix models in the bulk, such as the case of sparse random matrices [22] or deformed Wigner matrices [43]. Establishing local laws near the edge is generally more involved; the case of correlated matrices was shown in [1, 4, 18]; the deformed Wigner matrices were considered in [42]; the sparse random graphs were studied in [5, 37]. Local laws for \(\beta \)-ensembles near the edge were considered in [9] with the discrete analog in [32].
1.2 Notations
For the rest of this paper, we will use C to represent a large universal constant and c to represent a small positive universal constant which may depend on other universal constants and may differ from line to line. We write that \(X={{\,\mathrm{O}\,}}(Y)\) if there exists some universal constant such that \(|X|\leqslant CY\). We write \(X={{\,\mathrm{o}\,}}(Y)\), or \(X\ll Y\) if the ratio \(|X|/Y\rightarrow 0\) as N goes to infinity. We write \(X\asymp Y\) if there exist universal constants such that \(cY\leqslant |X|\leqslant CY\). We denote the set \(\{1, 2,\ldots , N\}\) by \([\![{N}]\!]\). We say an event \(\Omega \) holds with overwhelming probability, if for any \(D>0\), and \(N\geqslant N_0(D)\) large enough, \({\mathbb {P}}(\Omega )\geqslant 1-N^{-D}\).
2 Background
In this section, we will provide the basic definitions and assumptions in our study of the \(\beta \)-Dyson Brownian motion and the associated McKean–Vlasov equation. This section collects some properties of solutions of the McKean–Vlasov equation, the proof of various important inequalities on the growth of the solution in time t, and the behavior of its characteristics \(z_t(u)\). These bounds provide the basis for our later estimates on the edge rigidity of the \(\beta \)-Dyson Brownian motion. To make the argument clean, we make the following assumption on the potential V. This assumption allows us to rewrite certain errors for the regions far away from the spectrum in Sect. 4 as a contour integral and simplifies the proof. Moreover, this assumption also makes the analysis of the McKean–Vlasov equation (2.2) easier. We believe the main results in this paper hold for V in \(C^4\) as in [36].
Assumption 2.1
We assume that the potential V is an analytic function.
We denote the space of probability measures on \({\mathbb {R}}\) by \(M_1({\mathbb {R}})\) and equip this space with the weak topology. We fix a sufficiently small time \(T>0\) and denote by \(C([0,T], M_1({\mathbb {R}}))\) the space of continuous processes on [0, T] taking values in \(M_1({\mathbb {R}})\). It follows from [44] that for all \(\beta \geqslant 1\) and initial data \(\varvec{\lambda }(0)\in \overline{\Delta _N}\), there exists a strong solution \((\varvec{\lambda }(t))_{0\leqslant t\leqslant T}\in C([0,T],\overline{\Delta _N})\) to the stochastic differential equation (1.2).
We recall the following estimates on the locations of extreme particles of the \(\beta \)-Dyson Brownian motion from [36, Proposition 2.5].
Proposition 2.2
Suppose V satisfies Assumption 2.1. Let \(\beta \geqslant 1\), and \(\varvec{\lambda }(0)\in \overline{\Delta _N}\). Let \({\mathfrak {a}}\) be a constant such that the initial data \(\Vert \varvec{\lambda }(0)\Vert _\infty \leqslant {\mathfrak {a}}\). Then for a sufficiently small time \(T>0\), there exists a finite constant \({\mathfrak {b}}={\mathfrak {b}}({\mathfrak {a}}, T )\), such that for any \(0\leqslant t\leqslant T\), the unique strong solution of (1.2) satisfies:
Assume that the empirical density of \(\varvec{\lambda }(0)\) converges to a probability measure \(\hat{\mu }_0\). Then, thanks to [44, Theorem 1.1 and 1.3], the empirical density of \(\varvec{\lambda }(t)\) converges to a probability measure \(\hat{\mu }_t\). We let \(\hat{m}_t(z)\) be the Stieltjes transform of \(\hat{\mu }_t\). The measure-valued process \(\{\hat{\mu }_t\}_{t\geqslant 0}\) satisfies the following equation
where
It is easy to see that for any fixed z, g(z, x) is analytic in \({\mathbb {C}}\) as a function of x, and for any fixed x, g(z, x) is analytic in \({\mathbb {C}}\) as a function of z.
We analyze (2.2) by the method of characteristics. Denote the upper half-plane by \({\mathbb {C}}_+\). Let
If the context is clear, we omit the parameter u, i.e., we simply write \(z_t\) instead of \(z_t(u)\). Plugging (2.4) into (2.2) and applying the chain rule, we obtain
The behaviors of \(z_s\) and \(\hat{m}_s(z_s)\) are governed by the system of Eqs. (2.4) and (2.5).
As a consequence of Proposition 2.2, if the probability measure \(\hat{\mu }_0\) is supported on \([-{\mathfrak {a}}, {\mathfrak {a}}]\), then there exists a finite constant \({\mathfrak {b}}={\mathfrak {b}}({\mathfrak {a}}, T)\), such that the \(\hat{\mu }_t\) are supported on \([-{\mathfrak {b}}, {\mathfrak {b}}]\) for \(0\leqslant t\leqslant T\). We fix a large constant \({\mathfrak {R}}\). If \(z_t(u)\in {\mathbb {B}}_{2{\mathfrak {R}}}(0)\) and \({{\,\mathrm{dist}\,}}(z_t(u),[-{\mathfrak {b}},{\mathfrak {b}}])\geqslant 1\), then
Therefore, for any \(u\in {\mathbb {B}}_{\mathfrak {R}}(0)\), we have \(z_t(u)\in {\mathbb {B}}_{2{\mathfrak {R}}}(0)\) for any \(0\leqslant t\leqslant T\), provided T is small enough.
We also frequently use the following estimates studying the imaginary part of the characteristics. They were proved in [36, Proposition 2.7].
Proposition 2.3
Suppose V satisfies Assumption 2.1. Let \(\beta \geqslant 1\), \(\varvec{\lambda }(0)\in \overline{\Delta _N}\), and \({\mathfrak {a}}\) be a constant satisfying \(\Vert \varvec{\lambda }(0)\Vert _\infty \leqslant {\mathfrak {a}}\). Fix a large constant \({\mathfrak {R}}>0\). Then for a sufficiently small time \(T>0\), there exist constants depending on the potential V and the constant \({\mathfrak {a}}\) such that the following holds. Fix any \(0\leqslant s\leqslant t\leqslant T\) with \(u\in {\mathbb {B}}_{{\mathfrak {R}}}(0)\) and \(\mathrm{Im}[z_t(u)]>0\). Then,
3 Square root behavior measures
In the earlier work [36], the bulk rigidity of the \(\beta \)-Dyson Brownian motion was proved via a comparison of the empirical density \(\mu _t\) with \(\tilde{\mu }_t\), the solution of the associated McKean–Vlasov equation with \(\mu _0\) as initial data. This is not a good choice for studying the spectral edge. In most applications, \(\mu _0\) is the empirical eigenvalue density of a random matrix and is a random measure. As a consequence, the solution \(\tilde{\mu }_t\) of the associated McKean–Vlasov equation with \(\mu _0\) as initial data is again a random measure. Even if we have good control of the difference between \(\mu _t\) and \(\tilde{\mu }_t\), it does not tell us the locations of the extreme eigenvalues unless we have very precise control of \(\tilde{\mu }_t\). Unfortunately, proving edge universality requires that we know exactly the locations of the extreme eigenvalues.
In order to circumvent this problem, we compare the empirical density \(\mu _t\) with \(\hat{\mu }_t\), the solution of the associated McKean–Vlasov equation with deterministic initial data \(\hat{\mu }_0\) close to \(\mu _0\). In most applications, e.g., [5, 37], we take \(\hat{\mu }_0\) to be either the semi-circle distribution,
or the Kesten–McKay distribution,
As one can see from the expressions of the semi-circle distribution (3.1), and the Kesten–McKay distribution (3.2), they both have square root behavior at the spectral edge. In fact, in the work of [3], it is observed that square root behavior at the edge is a general phenomenon of many random matrix ensembles. We remark here that it is believed that square root behavior is necessary for the Tracy–Widom fluctuation. Higher-order singularities lead to new kernels, see [2, 13,14,15, 19] For the remainder of the paper, we assume that the initial measure \(\hat{\mu }_0\) has square root behavior in the following sense.
Definition 3.1
We say a probability measure \(\hat{\mu }_0\) has square root behavior at \(E_0\) if the measure is supported in \((-\infty , E_0]\) and, in addition, there is some neighborhood around \(E_0\) such that its Stieltjes transform satisfies
with \(A_0(z)\) and \(B_0(z)\) analytic in a neighborhood around \(E_0\). \(z=E_0\) is a simple root of \(B_0(z)\). All throughout the paper, the complex square root is the branch with nonnegative real part, i.e., \(\sqrt{|z|e^{i\theta }}= \sqrt{|z|} e^{i \theta /2}\) for \(-\pi <\theta \leqslant \pi \).
Remark 3.2
If \(\hat{\mu }_0\) has square root behavior at the right edge \(E_0\), then, for any \(z=E_0+\kappa +\mathrm{i}\eta \) with \(\eta >0\), it is easy to check that
The Stieltjes transforms of the semi-circle distribution and the Kesten–McKay distribution are given by
They both have square root behavior in the sense of Definition 3.1. More generally, we have the following proposition.
Proposition 3.3
If \(\hat{\mu }_0\) has an analytic density \(\hat{\rho }_0\) in a small neighborhood of \(E_0\), given by
where \(S(x)>0\) is analytic on \([E_0-{\mathfrak {r}},E_0+{\mathfrak {r}}]\), then \(\hat{\mu }_0\) has square root behavior in the sense of Definition 3.1.
One important consequence of our definition of a measure with square root behavior is the following proposition, which shows how square root behavior is a property that propagates in time when solving the McKean–Vlasov equation (2.2). We postpone its proof to Appendix A.
Proposition 3.4
Let \(\hat{\mu }_0\) be a probability measure that has square root behavior at the right edge \(E_0\) in the sense of Definition 3.1. Fix a small time \(T>0\). Let \((\hat{\mu }_t)_{t\in [0,T]}\) be the solution of the McKean–Vlasov equation (2.2) with initial data \(\hat{\mu }_0\). Then, for \(0\leqslant t\leqslant T\), the measures \(\hat{\mu }_t\) have square root behavior at the right edge \(E_t\). The edge \(E_t\) satisfies
and it is Lipschitz in time, \(|E_t - E_s| = {{\,\mathrm{O}\,}}(|t-s|)\) for \(0\leqslant s\leqslant t\leqslant T\). As a consequence, \(\hat{\mu }_t\) has a density in the neighborhood of \(E_t\), given by
The constants \({\mathfrak {C}}_t\) are Lipschitz in time, \(|{\mathfrak {C}}_t - {\mathfrak {C}}_s| ={{\,\mathrm{O}\,}}(|t-s|)\), for \(0\leqslant s\leqslant t\leqslant T\). The Lipschitz constants of \(E_t\) and \({\mathfrak {C}}_t\) depend only on the initial measure \(\hat{\mu }_0\) and the potential V.
The following proposition studies the growth of the distance from the real part of the characteristics \(z_t(u)\) to the edge \(E_t\). This is the main proposition we use to give strong bounds on \(|m_t(z) - \hat{m}_t(z)|\) close to the edge, and it serves as one of our fundamental inequalities in the next section. The square root behavior of the measures \(\hat{\mu }_t\) will be used to describe an equation for the growth of \(E_t\) and to provide estimates for the Stieltjes transform.
Proposition 3.5
Let \(\hat{\mu }_0\) be a probability measure with square root behavior in the sense of Definition 3.1, let T be as in Proposition 3.4, and let \((\hat{\mu }_t)_{t\in [0,T]}\) be the solution of the McKean–Vlasov equation (2.2) with initial data \(\hat{\mu }_0\). Choose a small parameter \({\mathfrak {r}}>0\) such that \(\hat{\mu }_0\) has an analytic density in the neighborhood \([E_0 - {\mathfrak {r}}, E_0+{\mathfrak {r}}]\). If at some time \(t \ll 1\), we know that \(z_t(u) =E_t + \kappa _t(u) + \mathrm{i}\eta _t(u)\) with \(z_t(u) \in {\mathbb {B}}_{{\mathfrak {r}}}(E_t)\) and \(\kappa _t>0\), then, for times \(0 \leqslant s \leqslant t\), there exists a constant C such that \(\kappa _s \ge 0\). Moreover, the following inequality holds,
Proof
In the proof, we will write \(\kappa _s(u), \eta _s(u)\) as \(\kappa _s, \eta _s\). In the following, we prove that if \(\kappa _s\geqslant 0\), then \(\partial _s\kappa _s\leqslant -C\sqrt{\kappa _s}\) for some universal constant C. Then the claim (3.6) follows by integrating from s to t, and we have \(\kappa _s\geqslant 0\) for all \(0\leqslant s\leqslant t\).
We recall the differential equation (3.4) for the edge \(E_s\),
We take the real part of (2.4), and then compute its difference with (3.7)
For the first term in (3.8)
The purpose of the above decomposition is to write the expressions for the Stieltjes transform in a way that we can easily compare the corresponding integral expressions. From the integral expression, we can compute the leading order behavior in terms of \(\kappa _s\) and \(\eta _s\) in order to get an equation. Thanks to Proposition 3.4, \(\hat{\mu }_s\) has square root behavior. From Remark 3.2, we have \(\mathrm{d}\hat{\mu }_s(x)/\mathrm{d}x\asymp \sqrt{[E_s-x]_+}\) in a neighborhood of \(E_s\), and we can estimate (3.9)
where \(C>0\) is some universal constant. For the second term in (3.8)
where we used that \(V'\) is real on the real line,
Uniformly for \(0\leqslant s\leqslant t\), we have \(\kappa _s,\eta _s\leqslant 2{\mathfrak {r}}\). By taking \({\mathfrak {r}}\) sufficiently small, it follows by combining (3.9) and (3.10) that there exists some constant \(C>0\) such that
and the claim (3.6) follows. \(\square \)
4 Rigidity estimates
We prove our edge rigidity estimates in this section. In this section, we fix a deterministic measure \(\hat{\mu }_0\) which has square root behavior as defined in Definition 3.1, and a scale parameter \(\eta ^*\) which depends on N. Roughly speaking, if the initial data of the Dyson Brownian motion is close to \(\hat{\mu }_0\) on the scale \(\eta ^*\), then optimal rigidity holds for time \(t\gg \sqrt{\eta ^*}\). Throughout this section, we denote the solution of the McKean–Vlasov equation (2.2) with initial data \(\hat{\mu }_0\) by \(\hat{\mu }_t\). Thanks to Proposition 3.4, \(\hat{\mu }_t\) has square root behavior in the sense of Definition 3.1 around the right spectral edge \(E_t\). We also fix a small number \({\mathfrak {r}}>0\) and mainly study the behaviors of the Stieltjes transform \(m_t(z)\) in the radius \({\mathfrak {r}}\) neighborhood of the right spectral edge \(E_t\). We denote the characteristic flow as in (2.4) starting at \(z_0(u)=u\) by \(z_t(u)\). We decompose it according to its distance to the right spectral edge: \(z_t(u)=E_t+\kappa _t(u)+\mathrm{i}\eta _t(u)\), where \(\kappa _t(u)=\mathrm{Re}[z_t(u)]-E_t\). If the context is clear, we omit the parameter u, i.e., we simply write \(z_t, \kappa _t, \eta _t\) instead of \(z_t(u), \kappa _t(u), \eta _t(u)\).
Assumption 4.1
Let \(\varvec{\lambda }(0)=(\lambda _1(0),\lambda _2(0),\ldots ,\lambda _N(0))\in \overline{\Delta _N}\) where \(\Vert \varvec{\lambda }(0)\Vert _\infty \leqslant {\mathfrak {a}}\) for some constant \({\mathfrak {a}}\). Fix a scale parameter \(\eta ^*\) that depends on N. We assume that the initial empirical density
satisfies the following estimates.
-
1.
\(\lambda _1(0)\leqslant E_0+{\eta ^*/2}\).
-
2.
There exists a deterministic measure \(\hat{\mu }_0\), with square root behavior as defined in Definition 3.1 around the spectral edge \(E_0\), such that we have the estimate
$$\begin{aligned} |m_0(z) - \hat{m}_0(z)|\leqslant \frac{M}{N \mathrm{Im}[z]}, \quad { z\in \mathcal {D}_0^\mathrm{in}\cup {\mathcal {D}}_0^\mathrm{out}}, \end{aligned}$$(4.1)and
$$\begin{aligned} |m_0(z) - \hat{m}_0(z)|\leqslant \frac{M}{N }, \quad z\in \mathcal {D}_0^\mathrm{far}, \end{aligned}$$(4.2)where \(m_0(z)\) and \(\hat{m}_0(z)\) are the Stieltjes transforms of \(\mu _0\) and \(\hat{\mu }_0\) respectively, M is a control parameter \(M\gtrsim (\log N)^{12}\), and the domains \(\mathcal {D}_0^\mathrm{in}\), \(\mathcal {D}_0^\mathrm{out}\) and \(\mathcal {D}_0^\mathrm{far}\) are given by
$$\begin{aligned}&\mathcal {D}_0^\mathrm{in}:=\left\{ z\in {\mathbb {C}}^+\cap {\mathbb {B}}_{{\mathfrak {r}}}(E_0): \mathrm{Im}[z]\mathrm{Im}[\hat{m}_0(z)] \geqslant (\eta ^*)^{3/2} \right\} ,\\&\mathcal {D}_0^\mathrm{out}:=\{z\in {\mathbb {C}}^+\cap {\mathbb {B}}_{{\mathfrak {r}}}(E_0): \mathrm{Re}[z]\geqslant E_0+\eta ^* \},\\&\mathcal {D}_0^\mathrm{far}:=\{z\in {\mathbb {C}}^+: {\mathfrak {R}}-1\leqslant {{\,\mathrm{dist}\,}}(z,{{\,\mathrm{supp}\,}}\hat{\mu }_0)\leqslant {\mathfrak {R}}+1\}, \end{aligned}$$where \({\mathfrak {R}}\) is a large constant as defined in (2.6), and \({\mathbb {B}}_{{\mathfrak {r}}}(E_0)\) is the radius \({\mathfrak {r}}\) disk centered at \(E_0\).
Remark 4.2
We remark that, in Assumption 4.1, we can take any \(M \gtrsim (\log N)^{12}\). Concretely, one can take M to be some large power \((\log N)^C\) or small power \(N^{\mathfrak {d}}\) and get a slightly weaker rigidity result.
Remark 4.3
It is important to notice that it is essential to control the difference of \(m_0\) and \(\hat{m}_0\) far away from the support of \(\hat{\mu }_0\), i.e., in \(\mathcal {D}_0^\mathrm{far}\). The estimate for the Stieltjes transform far away from the spectrum is the key input in Claim 4.13. The effect of the potential V is to cause a long range interaction that will cause \(m_t\) and \(\hat{m}_t\) to diverge if we have no control in this region. To see this effect, one should notice that if we were to compare the linear statistics of the Dyson Brownian Motion from two different initial measures, then the difference of these linear statistics will not change too much on time scales \(t={{\,\mathrm{o}\,}}(1)\).
Remark 4.4
The Assumption 4.1 implies a stronger estimate of the Stieltjes transform \(m_0(z)\) on the domain \({\mathcal {D}}_0^\mathrm{out}\) outside the spectrum: For any \(z=E_0+\kappa +\mathrm{i}\eta \in {\mathcal {D}}_0^\mathrm{out}\),
If \(\eta \geqslant \kappa \), this directly follows from (4.1). If \(\kappa \geqslant \eta \), we can rewrite the difference \(m_0(z)-\hat{m}_0(z)\) as a contour integral
where the contour \({\mathcal {C}}\) is the rectangle centered at \(E_0+\kappa \), with height \(4\kappa \) and width \(2\kappa -\eta ^*\). Then, we have \({\mathcal {C}}\in {\mathcal {D}}_0^\mathrm{out}\), and, for any \(w\in {\mathcal {C}}\), it holds that \(|w-z|\gtrsim \kappa \). Therefore,
We define the following function
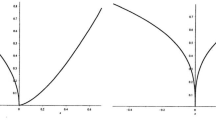
where the small constant \({\mathfrak {c}}>0\) will be chosen later. We observe that \(f(0)=\eta ^*\), and f(t) satisfies an inequality similar to (3.6). Namely, it satisfies \(\sqrt{f(s)}\leqslant \sqrt{f(t)}+{\mathfrak {c}}(t-s)\) for any \(0\leqslant s\leqslant t\). We use this function in interpolating from weak eigenvalue rigidity at the edge at time 0 to better eigenvalue rigidity at time t, where rigidity refers to estimates on the difference of the Stieltjes transforms \(|m_t -\hat{m}_t|\) (Fig. 1).
Theorem 4.5
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1. For time \(T={{\,\mathrm{o}\,}}(1)\), with high probability under the Dyson Brownian motion (1.2), we have \(\lambda _1(t) \leqslant E_t + f(t)\) for \(t\in [0,T]\).

The left pane is an illustration of the domains \(\mathcal {D}_0^\mathrm{far}, \mathcal {D}_0^\mathrm{in},\mathcal {D}_0^\mathrm{out},\overline{\mathcal {D}}_0^\mathrm{out}\). The right pane is an illustration of the domains \(\mathcal {D}_t^\mathrm{far}, \mathcal {D}_t^\mathrm{in},\mathcal {D}_t^\mathrm{out},\overline{\mathcal {D}}_t^\mathrm{out}\) for \(t>0\)
We define the spectral domains \(\mathcal {D}_t\). Roughly speaking, the information of the Stieltjes transform \(m_t(z)\) on \(\mathcal {D}_t\) reflects the regularity of the empirical particle density \(\mu _t\) on the scale f(t).
Definition 4.6
For any \(t\geqslant 0\), we define the region \({\mathcal {D}}_t= \mathcal {D}_t^\mathrm{in}\cup \mathcal {D}_t^\mathrm{out}\cup {\overline{{\mathcal {D}}}_t^\mathrm{out}} \cup \mathcal {D}_t^\mathrm{far}\), where
where we recall the small constant \({\mathfrak {c}}>0\) from (4.4), and \(\mathcal {D}_0^\mathrm{out}\) is defined in Assumption 4.1. We remark here that we do not use the notation \(\overline{{\mathcal {D}}}_t\) to denote the completion of the domain \({\mathcal {D}}_t\).
For any \(0\leqslant s\leqslant t\), the spectral domain \(\mathcal {D}_t\) is a subset of the domain \(\mathcal {D}_s\) under the characteristic flow. Our definition of \(\mathcal {D}_t^\mathrm{out}\) for \(t>0\) in (4.5) is not consistent with \(\mathcal {D}_0^\mathrm{out}\) in Assumption 4.1. We have taken \(\mathcal {D}_0^\mathrm{out}\) slightly larger for the following Claim.
Claim 4.7
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1. For any \(0\leqslant s\leqslant t\ll {\mathfrak {c}}\), we have
Proof
In the following, we prove that
The general statement follows from the same argument by only considering the characteristic flow from time s to time t. Let \(z_s=E_s+\kappa _s+\mathrm{i}\eta _s\) for \(0\leqslant s\leqslant t\). By integrating (2.6), we get that \(|z_t-z_0|={{\,\mathrm{O}\,}}(t)\) for any \(z_t\in \mathcal {D}_t^\mathrm{far}\). It follows that \(z_t^{-1}(\mathcal {D}_t^\mathrm{far})\subset \mathcal {D}_0^\mathrm{far}\), and \(z_t^{-1}({\mathbb {C}}^+\cap {\mathbb {B}}_{{\mathfrak {r}}-t/{\mathfrak {c}}}(E_t))) \subset {\mathbb {C}}^+\cap {\mathbb {B}}_{\mathfrak {r}}(E_0)\), provided that \({\mathfrak {c}}\) is small enough.
For any \(z_t\in {\overline{\mathcal {D}}}_t^\mathrm{out}\), it holds that \(\kappa _t\geqslant f(t)\). By the definition of f(t) in (4.4), we have
provided that \({\mathfrak {c}}\leqslant C/2\), where C is the constant in (3.6). We can rearrange (4.7) to get
As a consequence, we have \(E_0+\kappa _0\geqslant E_0+f(0)=E_0+\eta ^*\). Thus, \(\kappa _0\geqslant \eta ^*\). Moreover, thanks to Proposition 2.3, we have \(\eta _0\geqslant e^{{{\,\mathrm{O}\,}}(t)}\eta _t\geqslant e^{({{\,\mathrm{O}\,}}(1)+1/{\mathfrak {c}})t}M/N^{2/3} \geqslant M/N^{2/3}\), provided \({\mathfrak {c}}\) is small enough. Therefore, we have \(z_t^{-1}(\overline{\mathcal {D}}_t^\mathrm{out})\subset \overline{\mathcal {D}}_0^\mathrm{out}\). The same argument implies that \(z_t^{-1}(\mathcal {D}_t^\mathrm{out})\subset \mathcal {D}_0^\mathrm{out}\).
Thanks to Proposition 2.3, we have \(e^{-{{\,\mathrm{O}\,}}(t)}\mathrm{Im}[\hat{m}_0(z_0)]\leqslant \mathrm{Im}[\hat{m}_t(z_t)]\leqslant e^{{{\,\mathrm{O}\,}}(t)}\mathrm{Im}[\hat{m}_0(z_0)]\) and \(\eta _0\geqslant e^{-{{\,\mathrm{O}\,}}(t)}(\eta _t+t\mathrm{Im}[\hat{m}_t(z_t)])\). Therefore, it follows that
If \(z_t\in \mathcal {D}_t^\mathrm{in} \setminus \overline{\mathcal {D}}_t^\mathrm{out}\), then \(E_t+\kappa _t\leqslant E_t+f(t)\). Since \(\hat{\mu }_t\) has square root behavior in the sense of 3.1, \(\mathrm{Im}[\hat{m}_t(z_t)]\geqslant f(t)^{1/2}/C \) for some universal constant C. If \(t\leqslant \sqrt{\eta ^*}/(3{\mathfrak {c}})\), we have
provided \({\mathfrak {c}}\) is small enough. If \(t\geqslant \sqrt{\eta ^*}/(3{\mathfrak {c}})\), \(\kappa _t\leqslant \eta ^*\), and \(\eta _t \ge \eta ^*\), then \(\mathrm{Im}[\hat{m}_t(z_t)]\geqslant \sqrt{\eta ^*}/C\), and we have
provided that \({\mathfrak {c}}\) is small enough. Therefore, in both cases, we have that \(z_0\in \mathcal {D}_0^\mathrm{in}\). Finally, for the remaining case that \(t\geqslant \sqrt{\eta ^*}/(3{\mathfrak {c}})\) and \(z_t \in {\mathbb {C}}^+ \cap {\mathbb {B}}_{\eta ^*}(E_t)\), we will show that \(z_0 \in \mathcal {D}_0^\mathrm{out}\). We prove it by contradiction. Assume, for contradiction, that there exists some \(z_t\in {\mathbb {C}}^+\cap {\mathbb {B}}_{\eta ^*}(E_t)\) such that \(\kappa _0\leqslant \eta ^*\). By our assumption that \(\hat{\mu }_t\) has square root behavior, we have \(\mathrm{Im}[\hat{m}_t(z_t)]\leqslant C\sqrt{\eta ^*}\). In addition, we have the following inequality,
Let us explain how we derived the last inequality. Using Proposition 2.3, we have \(\eta _0\geqslant e^{-{{\,\mathrm{O}\,}}(t)}(\eta _t+t\mathrm{Im}[\hat{m}_t(z_t)])\geqslant e^{-{{\,\mathrm{O}\,}}(t)}t\mathrm{Im}[\hat{m}_t(z_t)]\). We notice that \(\eta _0/\sqrt{\eta ^*+\eta _0}\) is monotone in \(\eta _0\). The last inequality follows by replacing \(\eta _0\) with \(e^{-{{\,\mathrm{O}\,}}(t)}t\mathrm{Im}[\hat{m}_t(z_t)]\). The inequality (4.12) is impossible if \(t\geqslant \sqrt{\eta ^*}/(3{\mathfrak {c}})\), and \({\mathfrak {c}}\) is sufficiently small. This finishes the proof of (4.6) and Claim 4.7. \(\square \)
The following theorem gives optimal estimates for \(m_t\) both inside the spectrum and outside the spectrum, i.e., on the spectral domain \(\mathcal {D}_t^\mathrm{in}\cup \mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out}\cup \mathcal {D}_t^\mathrm{far}\).
Theorem 4.8
Suppose V satisfies Assumption 2.1. Fix time \(T={{\,\mathrm{o}\,}}(1)\). Consider any initial data \(\varvec{\lambda }(0)\) satisfying Assumption 4.1. Uniformly for any time \(0\leqslant t\leqslant T\) and \(w\in {\mathcal {D}}_t\), the following holds with overwhelming probability: if \(w\in \mathcal {D}_t^\mathrm{in}\),then
If \(w\in \mathcal {D}_t^\mathrm{far}\),then
If \(w\in \mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out}\),then
As a consequence of Theorems 4.5 and 4.8, by the same argument as [36, Corollary 3.2], we have the following corollary on the locations of the extreme eigenvalues.
Corollary 4.9
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1. Fix some time \(T={{\,\mathrm{o}\,}}(1)\). There exists a constant \({\mathfrak {e}}>0\) such that with high probability under the Dyson Brownian motion (1.2), for time \( 0\leqslant t\leqslant T\), and, uniformly for indices \(1\leqslant j\leqslant {\mathfrak {e}}N\), we have
where \(\gamma _j(t)\) are the classical particle locations of the measure \(\hat{\mu }_t\), i.e.,
The proof of Theorem 4.8 follows the argument in [36, Theorem 3.1] with several modifications. Firstly, when we use the Gronwall inequality, we need to take care of the error from the initial data, i.e., \(m_0(z)-\hat{m}_0(z)\ne 0\). This is where our Assumption 4.1 comes into play. Secondly, we estimate the error term involving the potential V using a contour integral. Finally, to get the estimates outside the spectrum, i.e., on \(\overline{\mathcal {D}}_t^\mathrm{out}\cup \mathcal {D}_t^\mathrm{out}\), we need to improve several estimates from [36, Theorem 3.1]. More precisely, in [36, Theorem 3.1], the error estimates at some \(w\in \mathcal {D}_t\) depend only on its imaginary part \(\mathrm{Im}[w]\). We improve all such estimates to depend on both \(\mathrm{Im}[w]\) and its distance to the spectral edge \(E_t\).
Remark 4.10
Similar to Remark 4.4, by performing a contour integral, we have the improved estimates of the Stieltjes transform outside the spectrum: if \(w\in \mathcal {D}_t^\mathrm{out}\), then
Thanks to the sharp estimates (4.15) of the Stieltjes transform on the domain \(\overline{\mathcal {D}}_t^\mathrm{out}\), Theorem 4.5 follows easily from Theorem 4.8.
Proof of Theorem 4.5
We prove the statement that with high probability, uniformly for any \(0\leqslant t\leqslant T\), and for \(w\in \overline{\mathcal {D}}_t^\mathrm{out}\) that
implies that, with high probability, there is no eigenvalue in the interval \([E_t+f(t)-e^{t/{\mathfrak {c}}}M/N^{2/3}, E_t+f(t) +e^{t/{\mathfrak {c}}}M/N^{2/3}]\). At time \(t=0\), by our Assumption 4.1, we have \(\lambda _1(0)\leqslant E_0+\eta ^*/2\leqslant E_0+f(0)\). Since \(\lambda _1(t)\) is continuous, we can conclude that \(\lambda _1(t)\leqslant E_t+f(t)\) for \(0\leqslant t\leqslant T\) with high probability.
We take \(w=E_t+f(t)+\mathrm{i}e^{t/{\mathfrak {c}}}M/N^{2/3}\); then, \(w\in \overline{\mathcal {D}}_t^\mathrm{out}\). Thanks to (4.15), with high probability, we have
provided that \(M\gg (\log N)^2\). Moreover, thanks to our Assumption 4.1 that \(\hat{\mu }_t\) has square root behavior and the fact that \(\mathrm{Im}[\hat{m}_t(w)]\asymp \mathrm{Im}[w]/\sqrt{|w-E_t|}\ll 1/N\mathrm{Im}[w]\), it follows that
If there exists some \(\lambda _i(t)\) such that \(\lambda _i(t)\in [E_t+f(t)-e^{t/{\mathfrak {c}}}M/N^{2/3}, E_t+f(t)+e^{t/{\mathfrak {c}}}M/N^{2/3}]\), then the right-hand side of (4.21) is at least \(1/(2N\mathrm{Im}[w])\). This leads to a contradiction. \(\square \)
Proof of Theorem 4.8
By Ito’s formula, \( m_s(z)\) satisfies the stochastic differential equation
We can rewrite (4.22) as
where g(z, x) is defined in (2.3). Plugging (2.4) into (4.23) and using the chain rule, we have
It follows from taking the difference between (2.5) and (4.24) that
We can integrate both sides of (4.25) from 0 to t and obtain
where the error terms are
We remark that \({\mathcal {E}}_1\) and \({\mathcal {E}}_2\) implicitly depend on u, the initial value of the flow \(z_s(u)\). The optimal rigidity estimates will eventually follow from an application of the Gronwall inequality to (4.26).
We define the following lattice on the upper half-plane \({\mathbb {C}}_+\),
It follows from Claim 4.7 that \(z_t^{-1}(\mathcal {D}_t)\subset {\mathcal {D}}_0^\mathrm{in}\cup {\mathcal {D}}_0^\mathrm{out}\cup \overline{\mathcal {D}}_0^\mathrm{out}\cup {\mathcal {D}}_0^\mathrm{far}\). Moreover, [36, Propsition 3.6] implies that \(z_t(u)\) is Lipschitz in u with Lipschitz constant bounded by \({{\,\mathrm{O}\,}}(N)\). Thus for any \(w\in {\mathcal {D}}_t\), there exists some lattice point \(u\in {\mathcal {L}}\cap z_t^{-1}({\mathcal {D}}_t)\), such that \(|z_t(u)-w|={{\,\mathrm{O}\,}}(N^{-2})\).
We define the stopping time
where \({\mathfrak {C}}\) is a large constant that we will choose later. The second line in the above definition (4.30) was used earlier in [36] to ensure that, up to time \(\sigma \), we have rigidity estimates inside the spectrum. The third line ensures we have rigidity estimates up to time \(\sigma \) outside the spectrum, i.e., in \({\mathcal {D}}_s^\mathrm{out}\cup \overline{{\mathcal {D}}}_s^\mathrm{out}\). We notice that as time evolves, this region will contain points closer to the spectral edge. As a consequence, the scale on which we have rigidity is improving along time. The fourth line is the analog for the region far away from the spectrum.
By the same argument we used to prove Theorem 4.5, we can use the estimates in (4.30) to show that, for any \(0\leqslant t\leqslant T\), we have
For \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{in})\) or \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{far})\), by the argument in [36, Proposition 3.8], using the Burkholder–Davis–Gundy inequality, there exists a set \(\Omega \) of Brownian paths \(\{B_1(s), B_2(s), \ldots , B_N(s)\}_{0\leqslant s\leqslant t}\) such that for any \(0\leqslant s\leqslant t\) and \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{in})\)
and \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{far})\),
The case \(\mathcal {D}_t^\mathrm{far}\) was not exactly considered in the previous work [36]. Since \(\mathcal {D}_t^\mathrm{far}\) is far away from the spectrum, we can apply trivial bounds to control the error term in this region. Namely, we have that \(|\lambda _i(t) - z| \gtrsim 1\) when \(z_t\in \mathcal {D}_t^\mathrm{far}\), and the analysis will not be significantly altered.
For \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out})\), using the estimate of the largest eigenvalue (4.31), we can get better estimates than those in [36, Proposition 3.8]. In [36, Theorem 3.1], the error estimates at some \(z_t\in \mathcal {D}_t\) depend only on its imaginary part \(\eta _t\). We improve all such estimates at \(z_t(u)\) to depend on both \(\eta _t\) and its distance \(\kappa _t\) to the spectral edge \(E_t\). The following claims analyze the error term (4.28) for \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out})\).
Claim 4.11
Under the assumptions of Theorem 4.8, for any \(u \in z_t^{-1}(\mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out})\) and \(0\leqslant s\leqslant t\), we have
Proof
If \(u\in {\mathcal {L}}\cap z_t^{-1}(\overline{\mathcal {D}}_t^\mathrm{out})\), we have \(\eta _{s\wedge \sigma }\geqslant e^{t/{\mathfrak {c}}}MN^{-2/3}\). From the definition (4.30) of \(\sigma \), we have that
If \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{out})\), then our construction of the domain \(\mathcal {D}_t^\mathrm{out}\) implies \(\kappa _{s\wedge \sigma }\geqslant 2f({s\wedge \sigma })\). Combining this with (4.31), we have that \(|\lambda _i({s\wedge \sigma })-z_{s\wedge \sigma }|\geqslant (\kappa _{s\wedge \sigma }+\eta _{s\wedge \sigma })/2\). By the argument in Corollary 4.9, we have optimal rigidity estimates for the first \({\mathfrak {e}}N\) particles at time \(s\wedge \sigma \): for indices \(1\leqslant j\leqslant {\mathfrak {e}}N\), we have
where \(\gamma _j({s\wedge \sigma })\) are the classical particle locations of the measure \(\hat{\mu }_{s\wedge \sigma }\) as defined in (4.17). We can estimate the left-hand side of (4.34) as
This finishes the proof of Claim 4.11. \(\square \)
Claim 4.12
Under the assumptions of Theorem 4.8, for \(u\in z_t^{-1}(\mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out})\) and any \(0\leqslant s\leqslant t\), we have
and there exists a set \(\Omega \) of Brownian paths \(\{B_1(s), B_2(s), \ldots , B_N(s)\}_{0\leqslant s\leqslant t}\), which holds with overwhelming probability, such that, on \(\Omega \), the following inequality holds
Proof
For simplicity of notation, we simply write \(z_s(u), \kappa _s(u), \eta _s(u)\) as \(z_s, \kappa _s, \eta _s\). By the definition of \(\sigma \), for \(\tau \leqslant \sigma \), it holds that \(\lambda _1(\tau )\leqslant E_\tau +f(\tau )\). As a consequence, we have
where we used Claim 4.11 in the second inequality; in the last line, we use (4.8), (2.7), and the increasing gap inequality (3.6): for any \(0\leqslant \tau \leqslant s\wedge \sigma \),
We remark that when considering characteristics such that \(\kappa _{s\wedge \sigma }\) is greater than \(\eta _{s \wedge \sigma }\), we replace each appearance of \(\kappa _{\tau }\) and \(\eta _{\tau }\) in the last line with \(\kappa _{s \wedge \sigma }\) and \(\eta _{s \wedge \sigma }\) respectively. Then, we get \(\frac{{{\,\mathrm{O}\,}}(\log N)}{N(\sqrt{\kappa _{s\wedge \sigma }}(\eta _{s\wedge \sigma }+\kappa _{s\wedge \sigma })}\). The denominator can be compared to \(\kappa _{s \wedge \sigma } + \eta _{s \wedge \sigma }\).
In contrast, when \(\eta _{s \wedge \sigma } \ge \kappa _{s \wedge \sigma }\), the replacement \(\eta _\tau \gtrsim \eta _{s \wedge \sigma } + \frac{\eta _{s\wedge \sigma }}{\sqrt{\kappa _{s\wedge \sigma } +\eta _{s\wedge \sigma }}(s\wedge \sigma -\tau )}\) is crucial and integrating in time will give us \(\frac{{{\,\mathrm{O}\,}}(\log N)}{N \eta _{s \wedge \sigma }}\). This is then less than \( \frac{{{\,\mathrm{O}\,}}(\log N)}{N(\kappa _{s\wedge \sigma }+ \eta _{s \wedge \sigma })}\) when \(\eta _{s \wedge \sigma } \ge \kappa _{s \wedge \sigma }\).
This finishes the proof of (4.36).
To prove (4.37), we notice that thanks to Claim 4.7, if \(z_t(u)\in \mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out}\), then \(z_s(u)\in \mathcal {D}_s^\mathrm{out}\cup \overline{\mathcal {D}}_s^\mathrm{out}\) for any \(0\leqslant s\leqslant t\). We define a series of partial stopping times \(0=t^0< t^1<t^2<\cdots \), as follows:
Notice that since \(\kappa _t\) and \(\eta _t\) are finite and cannot be smaller than \(N^{-1/{\mathfrak {c}}}\), for a given t, we have \(t^k=t\) for \(k\gtrsim \log N\). We now apply the Burkholder–Davis–Gundy inequality to our stochastic integral. This allows us to bound the supremum of our stochastic integral over a time range by its quadratic variation with overwhelming probability. We refer to [48] for a detailed introduction to the Burkholder–Davis–Gundy inequality. The quadratic variation can be found as follows:
where we used Claim 4.11 in the second inequality; in the third inequality, we use (4.8), the square root behavior of \(\hat{\mu }_s\): \(\mathrm{Im}[\hat{m}_s(z_s)]\asymp \eta _s/(\sqrt{\kappa _s+\eta _s})\), and
The Burkholder–Davis–Gundy inequality implies that with overwhelming probability we have
We define \(\Omega \) to be the set of Brownian paths \(\{B_1(s), \ldots , B_N(s)\}_{0\leqslant s\leqslant T}\) on which (4.40) holds for all k. It follows from the discussion above that \(\Omega \) holds with overwhelming probability. Therefore, for any \(s\in [t^{k-1},t^k]\), the bounds (4.40) and our choice of \(t^k\) (4.38) yield that, on \(\Omega \),
This finishes the proof of (4.37). \(\square \)
Thanks to Claim 4.12, for any \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{out}\cup \overline{\mathcal {D}}_t^\mathrm{out} )\), with high probability, we have:
For the last term in (4.27), we rewrite it as a contour integral and bound it by its absolute value.
Claim 4.13
Under the assumptions of Theorem 4.8, for any \(u \in z_t^{-1}(\mathcal {D}_t)\) and for any s satisfying \(0\leqslant s\leqslant t\), we have
Proof
From our choice of the stopping time (4.30), we have both \(\mu _{s\wedge \sigma }\) and \(\hat{\mu }_{s\wedge \sigma }\) are supported on \([-{\mathfrak {b}}, {\mathfrak {b}}]\). Moreover, \(g(z_{s\wedge \sigma }(u), x)\) is analytic in x; we can rewrite the integral in (4.42) as a contour integral
where \({\mathcal {C}}_s\) is a contour of distance \({\mathfrak {R}}\) away from the support of \(\hat{\mu }_s\). Thanks to our definition of \(\mathcal {D}_s^\mathrm{far}\) in (4.5), we have \({\mathcal {C}}_s\subset \mathcal {D}_s^\mathrm{far}\). The above contour integral can be bounded by
where we use the fact that g is bounded on the contour \({\mathcal {C}}_s\), the length of \({\mathcal {C}}_s\) is bounded, and there is rigidity along the contour \({\mathcal {C}}_s\), i.e., \(|\hat{m}_{s\wedge \sigma }(w)-m_{s\wedge \sigma }(w)|\leqslant {{\mathfrak {C}}}M/N\) on \({\mathcal {C}}_s\). \(\square \)
Now, let us return to Eq. (4.26) for the difference between \(\hat{m}_t(z)\) and \(m_t(z)\). We plug (4.32), (4.33) and (4.42) into (4.26). On the event \(\Omega \) such that (4.32) and (4.33) hold, for \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{in})\), we have
Thanks to Assumption 4.1, \(|m_0(z_0)-\hat{m}_0(z_0)|\leqslant M/N\eta _0\leqslant {{\,\mathrm{O}\,}}(M)/N\eta _{t\wedge \sigma }\). It follows from the Gronwall inequality and the argument in [36, Proposition 3.8] that
for some universal constant C provided that \(t\leqslant T={{\,\mathrm{o}\,}}(1)\). And similarly, for \(u\in {\mathcal {L}}\cap z_t^{-1}(\mathcal {D}_t^\mathrm{far})\), we have \(|m_0(z_0)-\hat{m}_0(z_0)|\leqslant M/N\) and
provided that \(t\leqslant T={{\,\mathrm{o}\,}}(1)\).
For \(u\in {\mathcal {L}}\cap z_t^{-1}(\overline{\mathcal {D}}_t^\mathrm{out}\cup \mathcal {D}_t^\mathrm{out})\), we plug (4.41) and (4.42) into (4.26), on the event \(\Omega \) as defined in Claim 4.12, we have
For the last term in (4.45), we have
where we used Claim 4.11. We denote the quantity,
and rewrite (4.45) as
By the Gronwall inequality, this implies the following estimate for any \( 0\leqslant t\leqslant T\)
For the function \(\beta (\tau )\), we have the following estimates
and thus
where in the last inequality, we used the estimate \(\log (\eta _{s}/\eta _{t\wedge \sigma }) \lesssim \log N\). Combining the above inequality (4.49) with (4.47), we can bound the last term in (4.48) by
Thanks to Proposition 2.3 and the square root behavior of the measure \(\hat{\mu }_{t\wedge \sigma }\), \(\mathrm{Im}[\hat{m}_s(z_s)]\asymp \mathrm{Im}[\hat{m}_{t\wedge \sigma } (z_{t\wedge \sigma })]\asymp \eta _{t\wedge \sigma }/(\kappa _{t\wedge \sigma }+\eta _{t\wedge \sigma })^{1/2}\). We can bound the first term on the right-hand side of (4.50) by
For the second term in the right-hand side of (4.50), we have
where in the second line we used (2.7). For the last term in the right-hand side of (4.50), we have
where we used (2.7) and (3.6) to get \(\kappa _0+\eta _0\gtrsim (t\wedge \sigma )\sqrt{\kappa _{t\wedge \sigma }+\eta _{t\wedge \sigma }}\). Combining all the above estimates, we have that, on the event \(\Omega \),
Thus, if we take \({\mathfrak {C}}\) in (4.30) larger than the constants C in (4.43), (4.44) and (4.52), then, with high probability, we have \(\sigma =T\). Thus, (4.13), (4.14) and (4.15) in Theorem 4.8 follow. This finishes the proof of Theorem 4.8. \(\square \)
5 Mesoscopic central limit theorem
We assume that the initial data \(\mu _0\) satisfies Assumption 4.1. In this section, we will prove a mesoscopic central limit theorem for eigenvalue statistics after running the Dyson Brownian motion. We remark here that in order to prove the mesoscopic central limit theorem on scale \(\eta \), we would need to run the Dyson Brownian motion for times \(t \gg \sqrt{\eta }\) in order to get the appropriate Gaussian fluctuations for the eigenvalues.
Theorem 5.1
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1. Fix time \(T=(\log N)^{-4}\), an arbitrary small parameter \({\mathfrak {d}}>0\), and scale \(\eta \) satisfying \(N^{-2/3 + 20{\mathfrak {d}}} \leqslant \eta \leqslant N^{-20{\mathfrak {d}}} \). Consider complex numbers \(w_1, w_2, \ldots ,w_k\) and a time t satisfying \(N^{{\mathfrak {d}}} \max \{\sqrt{\eta },\sqrt{\eta ^*}\} \leqslant t \leqslant T\), where \(\eta ^*\) is from Assumption 4.1. Then the rescaled quantities \(\Gamma _{\eta ,t}(w_i) :=N \eta \left[ m_{t}(E_{t} + w_i \eta ) - \hat{m}_{t}(E_t + w_i \eta )\right] - (2-\beta )/(4 \beta w_i)\) (where \(\hat{m}_t\) is as defined in (2.2)) asymptotically form a Gaussian field with limiting covariance kernel
for \(1\leqslant i,j\leqslant k\).
Proof of Theorem 5.1
We take a time s(t) depending on t (if the context is clear, we will omit the dependence), such that
In this section, we will consider the behavior of the fluctuation \(m_q(z_q) - \hat{m}_q(z_q)\) along characteristics \(z_q=E_q +\kappa _q + \mathrm{i}\eta _q\) such that, at the terminal time t, the characteristic satisfies \( \eta _t \asymp \eta \) and \(-N^{{\mathfrak {d}}} \eta _t \leqslant \kappa _t \lesssim \eta _t \). From Lemma B.1, we have, for any q satisfying \(s\leqslant q\leqslant t\), that there exists some universal C such that
Along these characteristics, we will use the improved rigidity estimates
from (4.18) when \(\kappa _q \gg N^{-2/3}\) or else
from (4.13) for times q with \(s(t)\leqslant q\leqslant t\). To apply the results of Theorem 4.8, we will use the analysis of characteristics in Lemma B.1 to argue that the points \(z_q\) along our characteristics are in the appropriate regions of applicability. For the rest of this section, we postpone some tedious but straightforward computations to Appendix B in order to keep the proof concise.
We rewrite (4.25) as
We will define \({\mathcal {S}}\) to be the set on which all the estimates from Theorem 4.8 hold with overwhelming probability. Thanks to the estimates (5.3) or (5.4) and Eq. (B.2) of the computational Lemma B.3, we can bound the second term on the right-hand side of (5.5) by first splitting it into a main term and an error term:
The main term coming from this contribution is \(\left( m_q(z_q) -\hat{m}_q(z_q)\right) \partial _z \hat{m}_q(z_q).\) For the third term on the right-hand side of (5.5), using Claim 4.13, we have that, on \({\mathcal {S}}\),
We can rewrite the last term on the right-hand side of (5.5) as
By standard computations using eigenvalue rigidity (Lemma B.3), on \({\mathcal {S}}\), we have
By plugging (5.6), (5.7), (5.8) and (5.9) into (5.5), we obtain the following simplified differential equation of the difference \(m_q(z_q) -\hat{m}_q(z_q)\)
where the error term \({\mathcal {E}}_q={{\,\mathrm{O}\,}}\left( \frac{N^{4{\mathfrak {d}}}}{N^2(|\kappa _q| +\eta _q)\eta _q^2}\right) \) holds uniformly over \({\mathcal {S}}\). We can explicitly solve the above equation by using
as an integrating factor. We have the following lemma that allows us to evaluate this quantity. We postpone its proof to Sect. 5.1.
Lemma 5.2
Recall the times s and t from (5.1). Under the assumptions of Theorem 5.1, we consider a characteristic \(\{z_\tau \}_{0\leqslant \tau \leqslant t}= E_\tau + \kappa _\tau + \mathrm{i}\eta _\tau \) terminating at \(z_t\) such that \( \eta _t\asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \leqslant \kappa _t \lesssim \eta \). Letting q be a time such that \(s \leqslant q \leqslant t\), we have
where \({\mathcal {I}}_t, {\mathcal {I}}_q\) are as defined in (5.11), and \(z_\tau =E_\tau +\kappa _\tau +\mathrm{i}\eta _\tau \) for any \(q\leqslant \tau \leqslant t\).
By using (5.11), the solution to the differential equation (5.10) can be expressed as
The deterministic integral in the above line is a correction term for the mean value. The stochastic integral is the cause of the Gaussian fluctuation. We replace every instance of \({\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}\) with the right-hand side of (5.12). Once this replacement is made, the remaining computations are standard.
We recall our choice of s in (5.1): \(N^{4{\mathfrak {d}}} \eta ^{1/2}\ll t-s\ll {\eta ^{1/4+{\mathfrak {d}}/6}}\). Due to the rigidity estimates (5.3) and (5.4) as well as the estimate of \(\kappa _q\) in (5.2), we can bound the first term on the right-hand side of (5.13) by
where we used (2.7) and \((t-s)\gg {N^{3{\mathfrak {d}}}}(|\kappa _t|+\eta _t)^{1/2}\). The first term in the integral on the right-hand side of (5.13) can be evaluated using the results of Lemma B.7.
We now combine the above estimates (5.14) and (5.15). After this, we integrate the rigidity bounds on the error term \({\mathcal {E}}_q\) in time using the computations detailed in Lemma B.4. Putting these estimates all together, on \({\mathcal {S}}\), it holds that
We remark that since we have that \(\eta _t \gg N^{-2/3+20{\mathfrak {d}}}\), the last error term in (5.16) will be less than the previous two terms and can essentially be absorbed into the \({{\,\mathrm{O}\,}}(N^{-{\mathfrak {d}}^2})\) factor appearing above.
In what follows, we will show that the Brownian motion integrals are asymptotically jointly Gaussian. Consider the points \(z_1,z_2,\ldots ,z_k \in {\mathbb {C}}_+\) such that, uniformly for all \(1\leqslant j\leqslant k\), \( |\mathrm{Re}[z_j]-E_t|, \mathrm{Im}[z_j]\asymp \eta \), and let \(u_1,u_2,\ldots , u_k\) be points such that \(z_t(u_j) = z_j\) for \(j=1,2,\ldots ,k\), respectively. We denote for any \(1\leqslant j\leqslant k\), \(z_t(u_j)=E_t+\kappa _t(u_j)+\mathrm{i}\eta _t(u_j)\). For \(1\leqslant j\leqslant k\), let
where the time s is chosen as in (5.1). We compute their joint characteristic function,
Since \(\sum _{j=1}^k a_j\mathrm{Re}[X_j(t)]+b_j\mathrm{Im}[X_j(t)]\) is a martingale, the following is also a martingale, where we use the notation \(\langle \cdot \rangle \) to denote the quadratic variation of the martingale term inside,
In particular, its expectation is one,
Using the following proposition, we can compute the quadratic variation in (5.19). Recalling (5.17), we see that \(X_j\) can be obtained via an algebraic manipulation of the Stieltjes transform \(m_t(z_t) - \hat{m}_t(z_t)\). The next proposition computes the quadratic variation of the Stieltjes transform. It will be proved at the end of this section.
Proposition 5.3
Recall the times s and t from (5.1). Under the assumptions of Theorem 5.1, we consider a pair of points \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) and \(z_t'=E_t+\kappa _t'+\mathrm{i}\eta _t'\) such that \(\eta _t, \eta _t'\asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \leqslant \kappa _t,\kappa _t'\lesssim \eta \). We have the following expressions for the quadratic variances:
After rescaling and other algebraic manipulations, we see that the expression of the full quadratic variation of \(X_j(t)\) is given as follows. It is a consequence of Proposition 5.3 and Lemma B.6.
Recall that, from (5.19), we know that the expectation (5.18) is equal to the value of the quadratic variation (5.23). This implies that the random variables \(X_j(t)\) are asymptotically joint Gaussian.
Using the Eq. (5.16), we see that, with high probability, we have the following relation.
If we take \(w_j=(z_t(u_j)-E_t)/\eta \) for \(j=1,2,\ldots , k\), we see that the left-hand side of the above equation represents the quantities \(\Gamma _{\eta ,t}(w_j)\) for \(j=1,2,\ldots ,k\) from Theorem 5.1. We have shown earlier that the \(X_j(t)\) are asymptotically joint Gaussian; the equality above implies that the \(\Gamma _{\eta , t}(w_j)\) are also asymptotically joint Gaussian with the covariance kernel given by
This completes the proof of Theorem 5.1. \(\square \)
We recall that the kernel in the bulk is given by
provided \(w\in {\mathbb {C}}_+, w'\in {\mathbb {C}}_-\), or \(w\in {\mathbb {C}}_-,w'\in {\mathbb {C}}_+\); otherwise, \(K_\mathrm{bulk}(w,w')=0\) (see [36]). We can, in fact, recover the kernel in the bulk from the kernel at the edge. We take \(w=\kappa +\mathrm{i}\eta \) and \(w=\kappa '+\mathrm{i}\eta '\), and let \(\kappa ,\kappa '\) tend to \(-\infty \). Then,
Corollary 5.4
Under the assumptions of Theorem 5.1, for any compactly supported test function \(\psi \) in the Sobolev space \(H^{s}\) with \(s>1\), we define
Recall that \(\eta \) is an N dependant value satisfying \(N^{-2/3 +20 {\mathfrak {d}}} \leqslant \eta \leqslant N^{-20 {\mathfrak {d}}}\) for some fixed parameter \({\mathfrak {d}}\) and t is a time satisfying \(N^{{\mathfrak {d}}} \max \{\sqrt{\eta },\sqrt{\eta ^*}\} \leqslant t \leqslant T \) where \(T= (\log N)^{-4}\). The normalized linear statistics converge to a Gaussian
in distribution, as \(N\rightarrow \infty \), where
Proof
The proof of this corollary follows the proof of the central limit theorem in [50, Theorem 4]. The idea is to combine a Littlewood–Paley decomposition in momentum space with covariance estimates on the Stieltjes transform. The estimates that we have established on the asymptotic normality of the Stieltjes transform in a radius \({{\,\mathrm{O}\,}}(\eta )\) sized neighborhood of the edge can be used with their Littlewood–Paley analysis. \(\square \)
5.1 Proofs of Lemmas used in Theorem 5.1
In the following lemma, we compute the leading order behavior of the function \(\sqrt{\kappa _t + \mathrm{i}\eta _t}\). This allows us to compute integrals in time involving the quantity \(\sqrt{\kappa _t + \mathrm{i}\eta _t}\), e.g., (5.15).
Lemma 5.5
We recall \({\mathfrak {C}}_q\) from (3.5) as well as the times s and t from (5.1). Under the assumptions of Theorem 5.1, consider any characteristic flow \(\{z_\tau \}_{0\leqslant \tau \leqslant t}\) with \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) such that \( \eta _t\asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \lesssim \kappa _t\lesssim \eta \). For any time q satisfying \(s \leqslant q \leqslant t\), we have
Proof
To derive a differential equation for \(\kappa _\tau + \mathrm{i}\eta _\tau \), we take the difference of (2.4) and (3.4),
At this stage, using Proposition 3.4, we can replace the integral appearing above with an expression that can be computed explicitly. As is detailed in Lemma B.5, the main contribution is from the part close to the edge, and we can consider the integral from \(-\infty \) to \(E_\tau -(\log N)^{-1}\) as an error term. A Taylor expansion indicates that the leading order contribution will be from the integral of \({\mathfrak {C}}_\tau \sqrt{[E_\tau -x]_+}\).
We can rewrite (5.28) as
We notice that the right-hand side is \({{\,\mathrm{O}\,}}(1)\). By integrating both sides of the above equation, we get
We can plug (5.30) into (5.29) and integrate both sides from q to t, again, to get
This finishes the proof of Lemma 5.5. \(\square \)
With Lemma 5.5 in hand, we can now perform the proposed time integral in Lemma 5.2 via an appropriate change of variables.
Proof of Lemma 5.2
Through straightforward calculations, we can compute the value of \({\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}\) for any q satisfying \(s \leqslant q\leqslant t\). Following the computations of Lemma B.5, we have
By the assumption in the condition of Lemma 5.2, we have \(t-s\ll {\eta ^{1/4+{\mathfrak {d}}/6}}\). Thanks to Lemma 5.5, we have
It gives the following comparison estimate
We combine the estimates in (5.31) and (5.32), and notice that \(|\kappa _s|, |\eta _s|\leqslant N^{-4{\mathfrak {d}}}\). This gives us
This finishes the proof of Lemma 5.2. \(\square \)
Our estimates of the characteristics from Lemma 5.5 will allow us to perform many of the time integrals that appear in the computation of the quadratic variances. The proof of Proposition 5.3 consists of bounding the error terms and performing other computations detailed in the appendix.
Proof of Proposition 5.3
When simplifying the expressions in (5.20), (5.21) and (5.22), one should first evaluate the Stieltjes transform for a fixed time; when this is done, we can deal with the time integral. We restrict ourselves to the event \({\mathcal {S}}\) defined earlier near the beginning of Theorem 5.1. On \({\mathcal {S}}\), we can apply the rigidity estimates (5.3) and (5.4) along the characteristic curve.
We denote \(\Delta m_q(w):=(m_q(w) - \hat{m}_q(w))\). Regarding (5.20), the left-hand side can be written as the derivative of the Stieltjes transform \(m_q\) at \(z_q\), and so
where we used Lemma B.3 to bound \(\partial _z^3\Delta m_q(z_q)\). To prove (5.20), we multiply both sides of (5.33) by \([{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}] ^2\) and integrate. The error term is given by \((6N^{-2})\int _s^t[{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}] ^2 \partial _z^3 \Delta m_q(z_q) . \) We can use Lemma 5.2 to bound \([{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}]^2\) from above by \({{\,\mathrm{O}\,}}\left( |\kappa _q + \mathrm{i}\eta _q|/|\kappa _t + \mathrm{i}\eta _t|\right) \). This leads to the upper bound
where we used Lemma B.4 for the last integral. Our choice of \(\eta _t \geqslant N^{-2/3+20{\mathfrak {d}}}\) will ensure that this error term is smaller than the main term, which is of order \(|\kappa _t +\mathrm{i}\eta _t|^{-2}\). For the leading order term, \((6N^{-2}) \int _s^t[{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}] ^2 \partial _z^3 m_q(z_q) \text {d}q\), we use Lemma 5.2 to derive
where the last step is a straightforward computation (Lemma B.6 with \(z_t= z_t'\)). (5.34) and (5.35) together finish the proof of Eq. (5.20).
Now we turn to our proof of the second Eq. (5.21). We write the left-hand side of (5.21) as a contour integral of \(\hat{m}_s\):
In the case that \(\max \{\eta _q/3, \eta _q'/3\} \geqslant |z_q-z'_q|\) (without loss of generality, we assume that the maximum is \(\eta _q/3\)), we set \({\mathcal {C}}\) to be a contour centered at \(z_q\) with radius \(\eta _q/2\). In this case, we have \({{\,\mathrm{dist}\,}}({\mathcal {C}}, \{z_q, z_q'\})\geqslant \eta _q/6\). In the case that \(|z_q-z'_q|\geqslant \max \{\eta _q/3, \eta _q'/3\}\), we let \({\mathcal {C}}={\mathcal {C}}_1\cup {\mathcal {C}}_2\) consist of two contours, where \({\mathcal {C}}_1\) is centered at \(z_q\) with radius \(\eta _q/6\), and \({\mathcal {C}}_2\) is centered at \(z_q'\) with radius \(\eta _q'/6\). Then, in this case, we have \({{\,\mathrm{dist}\,}}({\mathcal {C}}_1, z_q')\geqslant \eta _q/6\) and \({{\,\mathrm{dist}\,}}({\mathcal {C}}_2, z_q)\geqslant \eta _q'/6\).
We first estimate the error term in (5.36). If \({\mathcal {C}}\) consists of a single contour, we have
We used the estimates \(\Delta m_q(w) \leqslant \frac{N^{2{\mathfrak {d}}}}{N(|\kappa _q| + \eta _q)}\) and \(\eta _q \lesssim |w-z_q|,|w-z_q'| \) on the contour \({\mathcal {C}}\). Finally, we used that \(|{\mathcal {C}}|\asymp \eta _q\).
If \({\mathcal {C}}\) consists of two contours \({\mathcal {C}}_1 \cup {\mathcal {C}}_2\), we apply the estimates \(\Delta m_q(w) \leqslant \frac{N^{2{\mathfrak {d}}}}{N(|\kappa _q| + \eta _q)}\) and \(\eta _q \lesssim |w-z_q|, |w-z_q'|\) on \({\mathcal {C}}_1\) and the corresponding estimates with \(\eta _q'\) and \(\kappa _q'\) on \({\mathcal {C}}_2\). We can bound our error term by
where we used \(|{\mathcal {C}}_1| = {{\,\mathrm{O}\,}}(\eta _q)\) and \(|{\mathcal {C}}_2|={{\,\mathrm{O}\,}}(\eta _q')\). To prove (5.21), we multiply both sides of (5.37) or (5.38) by \([{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}][{\mathcal {I}}'_t ({\mathcal {I}}'_q)^{-1}]\). We can use Lemma 5.2 to bound \([{\mathcal {I}}_t ({\mathcal {I}}_q)^{-1}][{\mathcal {I}}'_t ({\mathcal {I}}'_q)^{-1}]\) from above by
This leads to the upper bound of the error term
where, in the first inequality, we used Lemma B.2 to get \(N^{-{\mathfrak {d}}} \leqslant |\kappa _q' + \mathrm{i}\eta '_q|/|\kappa _q +\mathrm{i}\eta _q| \leqslant N^{{\mathfrak {d}}}\), and the last inequality is a straightforward computation (see Lemma B.4). For the leading order term in (5.21), we have
where, in the first equality, we used Lemma 5.2, and the last step is a straightforward computation (see Lemma B.6). (5.39) and (5.40), together, finish the proof of Eq. (5.21).
For (5.22), we can first write the left-hand side in terms of the Stieltjes transform \(m_q\) as
We note that \(|\bar{z}_q-z_q'|\geqslant \eta _q+\eta _q'\). As before, we will separate \(m_q\) as \(m_q=\Delta m_q+\hat{m}_q\) and analyze the corresponding term with \(\Delta m_q\). For the terms in (5.41), we have by Lemma B.3 that
Using the estimate (5.42) as an input, the same analysis used to establish (5.21) can be used to give (5.22). \(\square \)
6 Edge universality
We recall the \(\beta \)-Dyson Brownian motion from (1.2)
where the initial data \(\varvec{\lambda }(0)=(\lambda _1,\lambda _2,\ldots ,\lambda _N)\) satisfies Assumption 4.1 and the potential V satisfies Assumption 2.1.
In Sect. 4, we showed that a measure with rigidity on the scale \(\eta ^*\) would have optimal edge rigidity after running a \(\beta \)-Dyson Brownian motion with potential V for time \(\sqrt{\eta ^*}\). Upon further applying the \(\beta \)-Dyson Brownian motion with potential V, we can compare the local eigenvalue fluctuations to that of the \(\beta \)-ensemble with an appropriate quadratic potential. The main strategy is to perform a coupling between the \(\beta \)-Dyson Brownian motion with potential V and the \(\beta \)-Dyson Brownian motion with an appropriate quadratic potential started from its equilibrium measure. We will, as in previous works, estimate the differences of the coupled processes via a continuous interpolation. A similar analysis has been performed for the bulk in [40] and at the edge in [41]. Our result on edge universality can be considered to be an extension of the result in [9] in that we can dynamically prove universality for more general point processes, i.e., the Airy \(\beta \)-point process for any \(\beta \geqslant 1\).
Without loss of generality, in the rest of this section, we assume that the initial data \(\varvec{\lambda }(0)\) has eigenvalue rigidity near the edge to an optimal scale, i.e., Assumption 4.1 holds with \(\eta ^*=(\log N)^C N^{-2/3}\). Otherwise, we can first apply the \(\beta \)-Dyson Brownian motion until we have rigidity near the edge to an optimal scale. We now define \(\mu _i\) to be the unique strong solution to the SDE
where the Brownian motion appearing here is the same Brownian motion appearing in the equation of \(\lambda _i(t)\) and the initial data \(\mu _i (0)\) has the same law as the \(\beta \)-ensemble with quadratic potential W,
The quadratic potential W is chosen so that its corresponding equilibrium measure behaves like \(\hat{\mu }_0\) from Assumption 4.1. More specifically, the equilibrium measure behaves like \({\mathfrak {C}}_0 \sqrt{[E_0-x]_+}\) to leading order as x approaches \(E_0\) from the right. It was proved in [47] that for any fixed integer \(K\geqslant 0\), the rescaled vector,
converges to the Airy \(\beta \)-point process, which is characterized by the stochastic Airy operator.
The main result of this section is the following, which states that the extreme particles of the Dyson Brownian motion for general \(\beta \) and potential V converge to the Airy-\(\beta \) point process in a short time.
Theorem 6.1
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1 with \(\eta ^*=(\log N)^C N^{-2/3}\). Let \(t \asymp N^{-1/3+\omega }\) where \(\omega >0\) is an arbitrarily small parameter and fix some large integer \(K>0\). With overwhelming probability, we have
for a small \({\mathfrak {c}}>0\) and for any index \(1\leqslant i\leqslant K\), where the \(\mu _i\)’s have the law of a \(\beta \)-ensemble as given in (6.1).
6.1 Interpolation
Let us start with a brief discussion of the main strategy in [41]. As was described earlier, one wants to find a coupling of the Dyson Brownian motions applied to the \(\lambda _i\)’s and \(\mu _i\)’s. It is easier to get estimates on this coupling if one uses the interpolation \(\alpha \lambda _i + (1-\alpha ) \mu _i\) with \(0\leqslant \alpha \leqslant 1\) between the eigenvalue processes for \(\lambda _i\) and those for \(\mu _i\), and studies a Dyson Brownian motion on these interpolated eigenvalues.
Just as we have used \(\hat{\mu }_0\) earlier as a deterministic measure which could be compared to the initial eigenvalue density \((1/N) \sum _{i=1}^N \delta _{\lambda _i(0)}\), we need to find a deterministic measure \(\hat{\mu }_0(x,\alpha )\) that can be compared to the interpolated eigenvalue density \((1/N) \sum _{i=1}^N \delta _{\alpha \lambda _i(0) +(1-\alpha )\mu _i(0)}\). The measure \(\hat{\mu }(x,\alpha )\) that we will construct has a continuous density \(\hat{\rho }(x,\alpha )\), and we will use \(\hat{\rho }(x,\alpha )\) to refer to this measure; similarly, we will refer to the initial measure \(\hat{\mu }_0\) as \(\hat{\rho }_0\) for the rest of this section.
It was observed in [41] that the eigenvalue fluctuations are due to short-range effects. In order to derive edge universality, it is only necessary to have control of the eigenvalues that lie within an \({{\,\mathrm{O}\,}}(1)\) neighborhood of the edge. The main difficulty in the construction of \(\hat{\rho }_0(x,\alpha )\) is to ensure we have a reasonable deterministic approximation in an \({{\,\mathrm{O}\,}}(1)\) neighborhood of the edge; one can directly use the random point process \((1/N) \sum _{i \not \in [1,cN]} \delta _{\alpha \lambda _i(0) +(1-\alpha )\mu _i(0)}\) for eigenvalues far away from the edge. To simplify the notation in the proof, we will assume that we have control of the eigenvalues \(\lambda _i(0)\) on the entire spectrum rather than just in an \({{\,\mathrm{O}\,}}(1)\) neighborhood of the edge. Our construction of \(\hat{\rho }_0(x,\alpha )\) will be less cumbersome, but will still illustrate how to approximate the eigenvalues near the edge.
We define the following interpolating processes for \(0 \leqslant \alpha \leqslant 1\).
The potential is
where W is the quadratic potential from (6.1), and the initial data is
for \(i=1,2,\ldots ,N\).
We define the Stieltjes transform of the empirical particle process \(z_i(t,\alpha )\) from (6.2) as
We recall that by our Assumption 4.1, we have
where \(f_0(x,1)\) is analytic in a neighborhood of \(x=E_0\) and satisfies \(\lim _{x \rightarrow E_0}f_0(x,1) = {\mathfrak {C}}_0 \). The equilibrium measure of the \(\beta \)-ensemble (6.1) with the quadratic potential W has the same form
with \(f_0(x,0)\) analytic in a neighborhood of \(E_0\) and \(\lim _{x \rightarrow E_0} f_0(x,0) = {\mathfrak {C}}_0\). It turns out that for any \(0\leqslant \alpha \leqslant 1\), there exists an analytic function \(f_0(x,\alpha )\) in a neighborhood of \(E_0\), such that the empirical distribution of the interpolated initial data \(z_i(0,\alpha )\) is close to the profile
The profile \(\hat{\rho }_0(x,\alpha )\) is characterized by the following relation
where \(\hat{F}^{-1}(y,\alpha )\) is the inverse function of \(\hat{F}(y,\alpha )\).
The next proposition establishes the previously claimed analyticity properties regarding the functions \(f_0(x,\alpha ),\alpha \in [0,1]\) in a more general setting. The proof follows from a direct power series expansion.
Proposition 6.2
Consider the two measures \(\rho _0(x)= f_0(x) \sqrt{[E_0-x]_+}\) and \(\rho _1(x) =f_1(x)\sqrt{[E_0-x]_+}\) where \(f_0(x)\) and \(f_1(x)\) are analytic functions around the spectral edge \(E_0\). The measure \(\rho _{\alpha }\) whose cumulative distribution function \(F(y,\alpha )=\int _y^\infty \rho _\alpha (x)\mathrm{d}x\) is determined by the relation
where F(y, 1) and F(y, 0) are the cumulative distribution functions of \(\rho _1(x)\) and \(\rho _0(x)\) respectively, is of the following form
where \(f_{\alpha }(x)\) is analytic around the spectral edge \(E_0\).
In our specific construction, we can establish eigenvalue rigidity estimates for the interpolated processes.
Proposition 6.3
Suppose V satisfies Assumption 2.1, and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1 with \(\eta ^*=(\log N)^C N^{-2/3}\). Then \(\hat{\rho }_0(x,\alpha )\) as constructed in (6.3) satisfies \(\hat{\rho }_0(x,\alpha )=({\mathfrak {C}}_0+{{\,\mathrm{o}\,}}(1)) \sqrt{[E_0-x]_+}\), as \(x\rightarrow E_0\) from the right, and, for \(1\leqslant i\leqslant {\mathfrak {e}}N\),
where the \(\hat{\gamma }_i(0,\alpha )\)s are the classical eigenvalue locations of \(\hat{\rho }_0(x,\alpha )\), i.e., \(\hat{\gamma }_i(0,\alpha )=\hat{F}^{-1}(i/n, \alpha )\). This rigidity of the eigenvalues would imply that the point process \((1/N)\sum _{i=1}^N \delta _{{ z_i}(0,\alpha )} \) is close to the measure \(\hat{\rho }_0(x,\alpha )\), which has square root behavior, in the sense of Assumption 4.1 up to the optimal scale \(\eta ^*=(\log N)^C N^{-2/3}\).
One should note that the above prop is simply a consequence of the definition (6.3). The value of \(\hat{\gamma }_i(0,\alpha )\) is the linearly interpolated value between the endpoints at \(\alpha =0\) and 1; in other words, \(\hat{\gamma }_i(0,\alpha ) = (1-\alpha ) \hat{\gamma }_i(0,0) + \alpha \hat{\gamma }_i(0,1)\). Since optimal rigidity holds at the endpoints, we have it for all \(0\leqslant \alpha \leqslant 1\).
We let \(\hat{\rho }_t (x, \alpha )\) be the solution of the McKean–Vlasov equation (2.2) with potential \(V_\alpha \) and initial data \(\hat{\rho }_0(x,\alpha )\), and denote its Stieltjes transform by \(\hat{m}_t (z, \alpha )\). It follows from Proposition 6.2 and Proposition 3.4 that \(\hat{\rho }_t(x,\alpha )\) has a square root density with a right edge, which we denote by \(E_t(\alpha )\). Let \(\hat{\gamma }_i (t, \alpha )\) be the classical eigenvalue locations with respect to \(\hat{\rho }_t (x, \alpha )\). To be more precise, they are defined by
As a consequence of Proposition 3.4, we have the following proposition for the densities \(\rho _t(x,\alpha )\).
Proposition 6.4
Suppose V satisfies Assumption 2.1 and the initial data \(\varvec{\lambda }(0)\) satisfies Assumption 4.1 with \(\eta ^*=(\log N)^C N^{-2/3}\). Fix small constants \({\mathfrak {e}},\omega >0\) and time \(t\asymp N^{-1/3+\omega }\). We have
-
1)
The solution \(\hat{\rho }_t(x,\alpha )\) of the McKean–Vlasov equation (2.2) with initial data \(\hat{\rho }_0(x,\alpha )\) satisfies \(\hat{\rho }_t(x,\alpha )=({\mathfrak {C}}_t(\alpha )+{{\,\mathrm{o}\,}}(1)) \sqrt{[E_t(\alpha )-x]_{+}}\), as \(x\rightarrow E_t(\alpha )\) from the right. The changes in the measure and edge locations in \(\alpha \) and time t satisfy:
$$\begin{aligned} |{\mathfrak {C}}_t(\alpha )-{\mathfrak {C}}_t(0)|={{\,\mathrm{O}\,}}(t),\quad |E_t(\alpha )-E_t(0)|={{\,\mathrm{O}\,}}(t). \end{aligned}$$The changes in the differences of the Stieltjes transforms for different \(\alpha \) are small: Fix any small \({\mathfrak {d}}>0\); for \( -N^{-2 {\mathfrak {d}}} N^{-2/3} \lesssim \kappa \leqslant 0\), we have
$$\begin{aligned} |\mathrm{Re}[\hat{m}_t(\kappa + E_t(\alpha ),\alpha )- \hat{m}_t(E_t(\alpha ), \alpha )] -\mathrm{Re}[\hat{m}_t(\kappa + E_t(0),0)- \hat{m}_t(E_t(0), 0)]| \lesssim |\kappa |N^{1/3+ {\mathfrak {d}}}. \end{aligned}$$(6.5)For \(0 \leqslant \kappa \lesssim { N^{-2 {\mathfrak {d}}}} N^{-2/3}\), we have
$$\begin{aligned} |\mathrm{Re}[\hat{m}_t(\kappa + E_t(\alpha ),\alpha )- \hat{m}_t(E_t(\alpha ), \alpha )] - \mathrm{Re}[\hat{m}_t(\kappa + E_t(0),0)- \hat{m}_t(E_t(0), 0)]| \lesssim |\kappa |^{1/2}N^{{\mathfrak {d}}}. \end{aligned}$$(6.6)We have the following estimates on the classical eigenvalue locations (as defined in (6.4)),
$$\begin{aligned} |\hat{\gamma }_i(t,\alpha ) -\hat{\gamma }_i(t,0)| \lesssim N^{-{\mathfrak {d}}}\frac{i^{2/3}t}{N^{2/3}}, \end{aligned}$$(6.7)for any \(1\leqslant i\leqslant {\mathfrak {e}}N\).
-
2)
The optimal rigidity estimates hold:
$$\begin{aligned} |m_t(z,\alpha ) - \hat{m}_t(z,\alpha )| \leqslant \frac{(\log N)^C}{N \eta }, \end{aligned}$$(6.8)where \(\eta = \mathrm{Im}[z] \gg N^{-2/3}\) and \(\kappa = \mathrm{Re}[z]-E_t(\alpha )\) satisfy \(|\kappa |, \eta \leqslant {\mathfrak {e}}\). We also have the rigidity estimates for each particle close to the right spectral edge,
$$\begin{aligned} \sup _{ 0 \leqslant \alpha \leqslant 1 } \sup _{ 0 \leqslant t \leqslant T } |z_i (t, \alpha ) - \hat{\gamma }_i (t, \alpha ) | \leqslant \frac{ (\log N)^C}{N^{2/3} i^{1/3}}, \end{aligned}$$(6.9)for \(1 \leqslant i \leqslant {\mathfrak {e}}N\) with overwhelming probability.
Part 1 in Proposition 6.4 consists of deterministic estimates regarding the solution \(\hat{\rho }_t(x,\alpha )\) of the McKean–Vlasov equation (2.2) and its Stieltjes transform. The proof is the same as in [41, Lemma 3.4], except that we assume that the initial data \(\varvec{\lambda }(0)\) satisfies optimal rigidity estimates. Thus, we do not need to run the Dyson Brownian motion first up to time \(t_0\) as in [41, Lemma 3.4]. The proof only involves knowing that the measures \(\hat{\rho }_t(x,\alpha )\) are close near the edge up to a small multiplicative factor along with the square root behavior of \(\hat{\rho }_t(x,\alpha )\) around the edge. For part 2 of Proposition 6.4, the rigidity estimates follow from Proposition 6.3 and Sect. 4.
6.2 Short-range approximation
We recall from (3.4) that the edge \(E_t(\alpha )\) satisfies the differential equation:
Combining this with the SDE of \(z_i (t, \alpha )\), we can derive an equation for \(\tilde{z}_i(t,\alpha ):= z_i(t,\alpha ) -E_t(\alpha )\).
The highest order contribution to the fluctuation around the edge comes from the short-range interactions, i.e., the particles close to \(\tilde{z}_i(t,\alpha )\). Following [41], to quantify this, we need to define a symmetric set of indices \({\mathcal {A}} \subseteq [\![{N}]\!] \times [\![{N}]\!]\), i.e., \((i, j) \in {\mathcal {A}}\) iff \((j, i) \in {\mathcal {A}}\). The definition of \({\mathcal {A}}\) requires the choice of a short-range scale parameter
We do not want to consider the effects on the dynamics from eigenvalues that are far away. The parameter \(\ell \) is introduced to quantify the scale of the short-range dynamics. We see that we will have to choose \({\omega }_\ell \geqslant \omega \) where \(\omega \) is from Theorem 6.1. As in [41], we choose \({\omega }_\ell = 10 \omega \) for concreteness. We let
We denote the interval
where \(j-=\min _j\{(i,j)\in {\mathcal {A}}\}\) and \(j+=\max _j\{(i,j)\in {\mathcal {A}}\}\).
We construct a new process \(\hat{z}_i(t,\alpha )\) that makes two simplifications to the dynamics. The first is to only consider the short-range interaction on the scale \(\ell \). The second is, on a scale \(N^{\omega _A}\) with \(\omega _A \geqslant \omega _\ell \), to replace \(E_t(\alpha )\) and \(m_t(E_t(\alpha ),\alpha )\) with \(E_t(0)\) and \(m_t(E_t(0),0)\). For concreteness, we will choose \(\omega _A = 10 \omega _\ell \). We will show that \(\tilde{z}_i(t,\alpha ) -\hat{z}_i(t,\alpha )\) is small. Moreover, the new dynamics \(\hat{z}_i(t,\alpha )\) are much easier to study.
For \(1 \leqslant i \leqslant N^{{\omega }_A}\), the dynamics of \(\hat{z}_i(t,\alpha )\) are given by
For \(N^{{\omega }_A} \leqslant i \), the dynamics of \(\hat{z}_i(t,\alpha )\) is
As we have mentioned before, the first advantage of the new process \(\hat{z}_i(t,\alpha )\) is that it only takes into account the short-range interaction. The second benefit is that the derivatives \(\partial _\alpha \hat{z}_i(t,\alpha )\) are vastly simplified when i is close to the edge since we have replaced many of the terms involving \(E_t(\alpha )\) by \(E_t(0)\).
We can show that the parabolic kernel associated with our system of equations is a contraction in \(\ell ^p\) space. Thus, if our initial error \(\hat{z}_i(0,\alpha ) - \tilde{z}_i(0,\alpha )\) is small, then it will be small for all later times t. Our initial rigidity estimates imply our initial errors are small. The details of the proof are similar to those of [41, Lemma 3.7]; we have the same rigidity estimates (6.9) as well as the measure comparison estimates (6.5)–(6.7).
Proposition 6.5
Under the assumptions of Proposition 6.4, with the construction (6.10) and (6.11), we have
for some \({\mathfrak {c}}>0\). For any fixed large integer \(K\geqslant 1\), we have
In the following, we show that for time \(t\gg N^{-1/3}\), \(\max _{1\leqslant i\leqslant K} |\partial _\alpha \hat{z}_i(t,\alpha )|\) is negligible. Let \(u_i (t, \alpha ) :=\partial _\alpha \hat{z}_i (t, \alpha )\). We see that \(u(t,\alpha )=(u_1(t,\alpha ), u_2(t,\alpha ),\ldots , u_N(t,\alpha ))\) satisfies the equation,
where the operator \({\mathcal {L}}\) and the force term \({\mathcal {E}}\) are given as follows. The operator \({\mathcal {L}}\) is
where
\({\mathcal {V}}\) is a diagonal operator, \(({\mathcal {V}} u) ={\mathcal {V}}_i u_i\), such that for \(1 \leqslant i \leqslant N^{{\omega }_A}\),
and, for \( N^{{\omega }_A} \leqslant i\),
In the definition of \({\mathcal {V}}\), we use the measure \(\hat{\rho }_t\) instead of one explicitly defined by the free convolution with the semicircle as in [41, Section 3.1.1].However, we can still derive similar energy estimates as well as finite speed estimates. This is due to the fact that the estimates in [41] involving the analog of the operator \({\mathcal {V}}\), such as Lemma 3.11, only really require the square root behavior of the comparison measure. Since we know our \(\hat{\rho }_t\) has square root behavior and we have the estimates in Proposition 6.4, we can derive the same estimates on the kernel \({\mathcal {L}}\).
As in [41, Section 4], the propagator of the operator \({\mathcal {L}}\) satisfies a finite speed estimate. We can replace it with a short-range operator. Afterward, an energy estimate as in [41, Section 3.5] implies that \(|u_i(t,\alpha )|=|\partial _\alpha \hat{z}_i(t, \alpha )|\leqslant N^{{\mathfrak {c}}}/(N^{1/3}t)\) for arbitrarily small \({\mathfrak {c}}\). As a consequence, we get
provided \(t\gg N^{-1/3}\), and Theorem 6.1 follows.
References
Adhikari, A., Che, Z.: Edge universality of correlated Gaussians. Electron. J. Probab. 24(44), 25 (2019)
Akemann, G., Atkin, M.R.: Higher order analogues of Tracy–Widom distributions via the Lax method. J. Phys. A 46(1), 015202 (2013). 19
Alt, J., Erdős, L., Krüger, T.: The Dyson equation with linear self-energy: spectral bands, edges and cusps. preprint, arXiv:1804.07752 (2018)
Alt, J., Erdős, L., Krüger, T., Schroder, D.: Correlated random matrices: band rigidity and edge universality. preprint, arXiv:1804.07744 (2018)
Bauerschmidt, R., Huang, J., Knowles, A., Yau, H.-T.: Edge rigidity and universality of random regular graphs of intermediate degree. preprint, arXiv:1910.10121 (2019)
Bourgade, P.: Extreme gaps between eigenvalues of Wigner matrices. preprint, arXiv:1812.10376 (2018)
Bourgade, P., Erdős, L., Yau, H.-T., Yin, J.: Fixed energy universality for generalized Wigner matrices. Commun. Pure Appl. Math. 69(10), 1815–1881 (2016)
Bourgade, P., Erdős, L., Yau, H.-T.: Bulk universality of general \(\beta \)-ensembles with non-convex potential. J. Math. Phys. 53(9), 095221 (2012). 19
Bourgade, P., Erdős, L., Yau, H.-T.: Edge universality of beta ensembles. Commun. Math. Phys. 332(1), 261–353 (2014)
de Monvel, A.B., Khorunzhy, A.: Asymptotic distribution of smoothed eigenvalue density. I. Gaussian random matrices. Random Oper. Stoch. Equ. 7(1), 1–22 (1999)
de Monvel, A.B., Khorunzhy, A.: Asymptotic distribution of smoothed eigenvalue density. II. Wigner random matrices. Random Oper. Stoch. Equ. 7(2), 149–168 (1999)
Chan, T.: The Wigner semi-circle law and eigenvalues of matrix-valued diffusions. Probab. Theory Relat. Fields 93(2), 249–272 (1992)
Cipolloni, G., Erdős, L., Krüger, T., Schröder, D.: Cusp universality for random matrices, II: the real symmetric case. Pure Appl. Anal. 7, 615–707 (2019)
Claeys, T., Its, A., Krasovsky, I.: Higher-order analogues of the Tracy–Widom distribution and the Painlevé II hierarchy. Commun. Pure Appl. Math. 63(3), 362–412 (2010)
Claeys, T., Neuschel, T., Venker, M.: Critical behavior of non-intersection Brownian motions. preprint, arXiv:1912.02142 (2019)
Duits, M., Johansson, K.: On mesoscopic equilibrium for linear statistics in Dyson’s Brownian motion. Mem. Am. Math. Soc. 255(1222), v+118 (2018)
Dyson, F.J.: A Brownian-motion model for the eigenvalues of a random matrix. J. Math. Phys. 3, 1191–1198 (1962)
Erdős, L., Krüger, T., Schröder, D.: Random matrices with slow correlation decay. Forum Math. Sigma 7(e8), 89 (2019)
Erdős, L., Krüger, T., Schröder, D.: Cusp universality for random matrices, I: local law and the complex Hermitian case. preprint, arXiv:1809.03971 (2018)
Erdős, L., Schnelli, K.: Universality for random matrix flows with time-dependent density. Ann. Inst. Henri Poincaré Probab. Stat. 53(4), 1606–1656 (2017)
Erdős, L., Yau, H.-T.: A dynamical approach to random matrix theory, volume 28 of Courant Lecture Notes in Mathematics. Courant Institute of Mathematical Sciences, New York; American Mathematical Society, Providence, RI (2017)
Erdős, L., Knowles, A., Yau, H.-T., Yin, J.: Spectral statistics of Erdős-Rényi graphs I: local semicircle law. Ann. Probab. 41(3B), 2279–2375 (2013)
Erdős, L., Péché, S., Ramírez, J.A., Schlein, B., Yau, H.-T.: Bulk universality for Wigner matrices. Commun. Pure Appl. Math. 63(7), 895–925 (2010)
Erdős, L., Ramírez, J., Schlein, B., Tao, T., Van, V., Yau, H.-T.: Bulk universality for Wigner Hermitian matrices with subexponential decay. Math. Res. Lett. 17(4), 667–674 (2010)
Erdős, L., Ramírez, J.A., Schlein, B., Yau, H.-T.: Universality of sine-kernel for Wigner matrices with a small Gaussian perturbation. Electron. J. Probab. 15(18), 526–603 (2010)
Erdős, L., Schlein, B., Yau, H.-T.: Local semicircle law and complete delocalization for Wigner random matrices. Commun. Math. Phys. 287(2), 641–655 (2009)
Erdős, L., Schlein, B., Yau, H.-T.: Semicircle law on short scales and delocalization of eigenvectors for Wigner random matrices. Ann. Probab. 37(3), 815–852 (2009)
Erdős, L., Schlein, B., Yau, H.-T.: Universality of random matrices and local relaxation flow. Invent. Math. 185(1), 75–119 (2011)
Erdős, L., Yau, H.-T.: Gap universality of generalized Wigner and \(\beta \)-ensembles. J. Eur. Math. Soc. JEMS 17(8), 1927–2036 (2015)
Erdős, L., Yau, H.-T., Yin, J.: Bulk universality for generalized Wigner matrices. Probab. Theory Relat. Fields 154(1–2), 341–407 (2012)
Erdős, L., Yau, H.-T., Yin, J.: Rigidity of eigenvalues of generalized Wigner matrices. Adv. Math. 229(3), 1435–1515 (2012)
Guionnet, A., Huang, J.: Rigidity and edge universality of discrete \(\beta \)-ensembles. Commun. Pure Appl. Math. 72(9), 1875–1982 (2019)
He, Y.: Mesoscopic linear statistics of Wigner matrices of mixed symmetry class. J. Stat. Phys. 175, 932–959 (2019)
He, Y., Knowles, A.: Mesoscopic eigenvalue statistics of Wigner matrices. Ann. Appl. Probab. 27(3), 1510–1550 (2017)
He, Y., Knowles, A.: Mesoscopic eigenvalue density correlations of Wigner matrices. Probab. Theory Relat. Fields (2019)
Huang, J., Landon, B.: Rigidity and a mesoscopic central limit theorem for Dyson Brownian motion for general \(\beta \) and potentials. Probab. Theory Relat. Fields 175(1–2), 209–253 (2019)
Huang, J., Landon, B., Yau, H.-T.: Transition from Tracy-Widom to Gaussian fluctuations of extremal eigenvalues of sparse Erdős-Rényi graphs. preprint, arXiv:1712.03936 (2017)
Landon, B., Sosoe, P.: Applications of mesoscopic CLTs in random matrix theory. preprint, arXiv:1811.05915 (2018)
Landon, B., Sosoe, P., Yau, H.-T.: Fixed energy universality of Dyson Brownian motion. Adv. Math. 346, 1137–1332 (2019)
Landon, B., Yau, H.-T.: Convergence of local statistics of Dyson Brownian motion. Commun. Math. Phys. 355(3), 949–1000 (2017)
Landon, B., Yau, H.-T.: Edge statistics of Dyson Brownian motion. preprint, arXiv:1712.03881 (2017)
Lee, J.O.: Edge universality for deformed Wigner matrices. Rev. Math. Phys. 27(8), 1550018 (2015). 94
Lee, J.O., Schnelli, K., Stetler, B., Yau, H.-T.: Bulk universality for deformed Wigner matrices. Ann. Probab. 44(3), 2349–2425 (2016)
Li, S., Li, X.-D., Xie, Y.-X.: Generalized Dyson Brownian motion, McKean-Vlasov equation and eigenvalues of random matrices. preprint, arXiv:1303.1240 (2013)
Li, S., Li, X.-D., Xie, Y.-X.: On the law of large numbers for the empirical measure process of generalized Dyson Brownian motion. preprint, arXiv:1407.7234 (2015)
Lodhia, A., Simm, N.J.: Mesoscopic linear statistics of Wigner matrices. preprint, arXiv: 1503.03533 (2015)
Ramírez, J.A., Rider, B., Virág, B.: Beta ensembles, stochastic Airy spectrum, and a diffusion. J. Am. Math. Soc. 24(4), 919–944 (2011)
Revuz, D., Yor, M.: Continuous martingales and Brownian motion, volume 293 of Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences], 3rd edn. Springer, Berlin (1999)
Rogers, L., Shi, Z.: Interacting Brownian particles and the Wigner law. Probab. Theory Relat. Fields 95(4), 555–570 (1993)
Sosoe, P., Wong, P.: Regularity conditions in the CLT for linear eigenvalue statistics of Wigner matrices. Adv. Math. 249, 37–87 (2013)
Tao, T., Van, V.: Random matrices: universality of local eigenvalue statistics up to the edge. Commun. Math. Phys. 298(2), 549–572 (2010)
Tao, T., Van, V.: Random matrices: universality of local eigenvalue statistics. Acta Math. 206(1), 127–204 (2011)
Tao, T., Van, V.: Random matrices: sharp concentration of eigenvalues. Random Matrices Theory Appl. 2(3), 1350007 (2013). 31
Wigner, E.P.: Characteristic vectors of bordered matrices with infinite dimensions. Ann. Math. 2(62), 548–564 (1955)
Wigner, E.P.: Characteristic vectors of bordered matrices with infinite dimensions. II. Ann. Math. 2(65), 203–207 (1957)
Acknowledgements
We want to thank the anonymous reviewers for their comments and suggestions, which significantly improved the readability of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Proof of Proposition 3.4
The proof of Proposition 3.4 is based on performing a power series expansion of the analytic functions \(A_0\) and \(B_0\) in a neighborhood around \(E_0\) and solving the McKean–Vlasov equation (2.2) term by term. \(A_0(z)\) and \(B_0(z)\) have power series representations
such that
The following proposition states that the Stieltjes transform of \(\hat{\mu }_t\) has the form \(A_t+\sqrt{B_t}\), and \(A_t, B_t\) have power series representations in a neighborhood of \(E_0\). Proposition 3.4 is a natural consequence of the proceeding proposition.
Proposition A.1
We assume (3.3) holds. We fix a sufficiently small \(T>0\) and let \(L= 1/T\). Then for \(t\in [0,T]\), the solution of (2.2) is given by
with \(A_t(z)\) and \(B_t(z)\) analytic functions in a small neighborhood of \(E_0\). In this neighborhood, \(A_t(z)\) and \(B_t(z)\) have power series representations,
where the coefficients satisfy
Moreover, in a small neighborhood of \(E_0\), \(B_t(z)\) has a unique simple root at \(z=E_t\), which satisfies the differential equation
Proof
We suppose that the solution of (2.2) is given by (A.1), and \(A_t(z)\), \(B_t(z)\) have power series representations given by (A.2). We plug (A.1) into (2.2) to get
where
are analytic in a neighborhood of \(E_0\). One should note here that our goal in this section is not to show the existence of solutions to the original McKean–Vlasov equation, but only that said solution is analytic in a small neighborhood of \(E_0\). Thus, the fact that we use \(\hat{\mu }_t\) in our expression of \(R_t(z)\) is not an issue.
For (A.5) to hold, it is sufficient that
We solve (A.7) using the power series representations. Let
Then, (A.7) is equivalent to the following infinite system of ordinary differential equations. For \(i=0,1,2,\ldots \),
Although (A.8) is not Lipschitz, we can still solve this system by the Picard iteration. Let
and define recursively
As we have noted before, the existence of the measure \(\hat{\mu }_t\) is not in question and, thus, we do not need to perform an iteration of the \(r_i(t)\) terms in n.
We take large constants \(C>0\), \(L>0\) and a small constant \(T=1/L\). We first prove by induction that uniformly for \(t\in [0,T]\),
Since \(R_t(z)\) is analytic in a neighborhood of \(E_0\), we can take \(C_0, M>0\) large enough such that
We assume that (A.10) holds for n. Using (A.9), we have
provided \(C>4C_0\) and \(L>24eCM\). Similarly, for \(b_i^{(n+1)}(t)\),
provided \(C>2C_0\) and \(L>36eCM\). This finishes the proof of claim (A.10).
In the following, we prove that \(d_i^{(n)}(t), b_i^{(n)}(t)\) converge uniformly as n goes to infinity. This follows from
We prove (A.12) by induction. We assume that (A.12) holds for n. By using (A.9), the difference \(|d_i^{(n+1)}(t)-d_i^{(n)}(t)|\) is bounded by
provided that \(L\geqslant 24eCM\). Similarly, the difference \(|b_i^{(n+1)}(t)-b_i^{(n)}(t)|\) is bounded by
provided \(L\geqslant 72eCM\).
We denote for \(i=0,1,2,\ldots \),
They satisfy the system of differential equations (A.9), and (A.3) holds.
Using the same argument we used for (A.11) gives us
And, thus, for \(T>0\) small enough, times \(0\leqslant t\leqslant T\), and z on a small circle centered at \(E_0\),
Thus, by Rouché’s theorem, \(B_t(z)\) has a unique simple root at \(z=E_t\) inside a small neighborhood of \(E_0\). Moreover, from our construction, \(\bar{B}_t(z)=B_t(\bar{z})\). Thus, \(E_t\) is real. By taking the derivative of \(B_t(E_t)=0\) with respect to t and using (A.7), we get
This finishes the proof of Proposition A.1. \(\square \)
Proof of Proposition 3.4
It follows from Proposition A.1 that \(\hat{\mu }_t\) has square root behavior. In addition, \(\hat{m}_t(E_t) = A_t(E_t) +\sqrt{B_t(E_t)}\) is uniformly bounded for \(0\leqslant t\leqslant T\). The claim that \(E_t\) is Lipschitz in time simply follows from integrating (A.4).
Next, we prove that \({\mathfrak {C}}_t\) is Lipschitz in time. We notice that \({\mathfrak {C}}_t^2=\partial _z B_t(E_t)\). To prove \(|{\mathfrak {C}}_t-{\mathfrak {C}}_s|={{\,\mathrm{O}\,}}(t-s)\), it suffices to prove this for \(s=0\). Using the series expansion, as in the notation of (A.2), we see that
Using the differential equation (A.8), we see that \(b_1(t) -b_1(0)={{\,\mathrm{O}\,}}(t)\). Earlier, we showed that \((E_t - E_0)\) is of \({{\,\mathrm{O}\,}}(t)\). The infinite sum converges provided we take T sufficiently small. Therefore, it follows that \({\mathfrak {C}}_t^2 - {\mathfrak {C}}_0^2 ={{\,\mathrm{O}\,}}(t)\). Since \({\mathfrak {C}}_0\) is bounded away from 0, this would imply that \({\mathfrak {C}}_t -{\mathfrak {C}}_0 = {{\,\mathrm{O}\,}}(t)\) as desired. \(\square \)
B Rigidity bounds in the Proof of the Mesoscopic Central Limit Theorem
We start this section by collecting some lemmas that analyze the movement of characteristic flows that terminate in a radius \(\eta \) (\(N^{-2/3} \ll \eta \ll 1\)) neighborhood of the edge \(E_t\). Knowing the precise values of \(\kappa _s\) and \(\eta _s\) along a characteristic of the form \(z_s = E_s + \kappa _s + \mathrm{i}\eta _s\) will allow us to apply many of the improved rigidity bounds from Theorem 4.8 and the following remarks.
Lemma B.1
Suppose V satisfies Assumption 2.1 and let \({\mathfrak {d}}\) be a small parameter. Consider a characteristic \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) as in (2.4) with terminal time \(t=o(1)\). If \(z_t\) satisfies
then for any \(0\leqslant s\leqslant t\), we have:
Proof
From the equation determining the motion of the characteristics (2.4), we know that each characteristic moves at a rate \({{\,\mathrm{O}\,}}(1)\) in time. Thus, if \(\eta _t \leqslant N^{-20{\mathfrak {d}}}\), we have \(\eta _s \leqslant N^{-20{\mathfrak {d}}}+C(t-s)\). Thanks to the estimates (2.7), if \(\eta _t \geqslant N^{-2/3+ 20{\mathfrak {d}}}\), we have \(\eta _s \geqslant N^{-2/3+ 20{\mathfrak {d}}}(1-C(t-s))\).
In the following, we estimate the ratio \( \kappa _s/\eta _s\). Let \(z_t - E_t =\kappa _t+\mathrm{i}\eta _t=(R_t+\mathrm{i}a_t)^2\), and \(z_s-E_s= \kappa _s+\mathrm{i}\eta _s=(R_s+\mathrm{i}a_s)^2\), where \(R_t, a_t, R_s\), and \(a_s>0\). By our assumption on \(z_t\), we have
and it follows that \(N^{-{\mathfrak {d}}}/C\leqslant \frac{R_t}{a_t}\leqslant C\). Thanks to (2.7) and the assumption of square root behavior, we have \(a_t\asymp \mathrm{Im}[\hat{m}_t(z_t)]\asymp \mathrm{Im}[\hat{m}_s(z_s)]\asymp a_s\). Moreover, using (2.7) again, we have \(2a_sR_s=\eta _s\asymp (\eta _t+(t-s)a_t)\asymp (a_s R_t+(t-s)a_s)\). We conclude that \(R_s\asymp R_t+(t-s)\), and
It follows, by rearranging, that
This finishes the proof of Lemma B.1. \(\square \)
Lemma B.2
Suppose V satisfies Assumption 2.1. Consider a characteristic \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) as in (2.4) with terminal time \(t={{\,\mathrm{o}\,}}(1)\). If its terminal point \(z_t = E_t +\kappa _t + \mathrm{i}\eta _t\) satisfies \(-\eta _t \leqslant \kappa _t \leqslant C \eta _t \), then we have, for \(t-q \geqslant \sqrt{\eta _t}\), that \(\sqrt{|\kappa _q| +\eta _q} \asymp (t-q)\), and, for \(t-q \leqslant \sqrt{\eta _t}\), it holds that \(\sqrt{|\kappa _q|+ \eta _q} \asymp \sqrt{\eta _t}\). We always have \(\eta _q \asymp \eta _t + (t-q) \sqrt{\eta _t}\).
If we consider a characteristic whose terminal point instead satisfies \(-N^{{\mathfrak {d}}} \eta _t \leqslant \kappa _t \leqslant -\eta _t \), we instead find that \(\sqrt{\kappa _q + \eta _q} \asymp (t-q)\) for \(t-q \geqslant \sqrt{|\kappa _t| + \eta _t}\). For \(t-q \leqslant \sqrt{|\kappa _t| +\eta _t}\), we have \(\sqrt{|\kappa _q| + \eta _q} \asymp \sqrt{|\kappa _t| + \eta _t}\). We always have \(\eta _q \asymp \eta _t +(t-q) \sqrt{|\kappa _t| +\eta _t}\).
Proof
Consider a characteristic whose terminal point \(z_t\) satisfies \(-\eta _t\leqslant \kappa _t \leqslant C \eta _t\). By square root behavior, this will imply \(\mathrm{Im}[\hat{m}_t(z_t)] \asymp \sqrt{\eta _t}\). Finally, by the final line of (2.7), we have that \(\eta _q \asymp \eta _t + (t-q) \sqrt{\eta _t}\). We see that, for \(t-q \leqslant \sqrt{\eta _t}\), we have that \(\eta _q \asymp \eta _t\), while, for \((t-q) \geqslant \sqrt{\eta _t}\), we have that \(\eta _q \asymp (t-q) \sqrt{\eta _t}\).
We additionally have the relation \(\mathrm{Im}[\hat{m}_q(z_q)] \asymp \mathrm{Im}[\hat{m}_t(z_t)]\) by the second line of (2.7). This will certainly imply that \(z_q\) cannot move far inside the spectrum, and, instead, we must have
This will imply
Thus, when \(t-q \geqslant \sqrt{\eta _t}\), we have that \(\sqrt{|\kappa _q|}\asymp (t-q)\).
Now let us consider, instead, the case that \(- N^{{\mathfrak {d}}} \eta _t \leqslant \kappa _t \leqslant - \eta _t\). We will have the relation \(\eta _q \asymp \eta _t + (t-q) \sqrt{|\kappa _t|}\). For \(t-q \geqslant \eta _t/\sqrt{\kappa _t}\), this will be comparable to \((t-q)\sqrt{|\kappa _t|}\). To maintain \(\mathrm{Im}[m_q(z_q)]\asymp \mathrm{Im}[m_t(z_t)]\), when \(t-q \leqslant \sqrt{\kappa _t}\), would necessitate \(|\kappa _q| + \eta _q \asymp |\kappa _t| + \eta _t\). When \((t-q) \geqslant \sqrt{\kappa _t}\), we would instead have the relation
This would then imply that \(\sqrt{\kappa _q + \eta _q}\asymp (t-q)\). \(\square \)
The improved rigidity bounds in Theorem 4.8 allow us to get sharp estimates on the derivatives of the Stieltjes transform as in the following lemma.
Lemma B.3
Recall the times s and t from Eq. (5.1) as well as the event \({\mathcal {S}}\) from Sect. 5. Under the assumptions of Theorem 5.1, consider a characteristic \(z_t\) such that \(\eta _t\asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \leqslant \kappa _t \lesssim \eta \). On \({\mathcal {S}}\), we have the following estimate uniformly for times q satisfying \(s\leqslant q\leqslant t\).
where \(\tilde{{\mathfrak {d}}}\) is any parameter strictly greater than \({\mathfrak {d}}\).
Proof
Since both \(m_q\) and \(\hat{m}_q\) are analytic on the upper half-plane, by Cauchy’s integral formula,
where \({\mathcal {C}}\) is a small contour in the upper half-plane centered at \(z_q\) with radius \(\eta _q/2\). We take the absolute value of both sides to get
If we have that \(\kappa _q \geqslant \eta _q \gg N^{-2/3}\), we will be in a region in which we can apply the improved error estimates (4.18) to argue that \(|m_q(w) - \hat{m}_q(w)| \leqslant \frac{M(\log N)^2}{N (\kappa _q + \eta _q)}\). Otherwise, we have, instead, that \(\eta _q \geqslant \kappa _q \geqslant - N^{{\mathfrak {d}}} \eta _q\) by applying Lemma B.1. At this point, we can apply the error estimate from (4.13) to conclude that \(|m_q(w) -\hat{m}_q(w)| \leqslant \frac{N^{{\mathfrak {d}}} (\log N) M}{N(|\kappa _q|+\eta _q)}\).
We can regard the M and \(\log N\) factors as unimportant relative to the \(N^{{\mathfrak {d}}}\) factor in the numerator for sufficiently large N. We can additionally bound \(|w-z_q|\) in the denominator from below by \(\eta _q\). Applying these considerations to the contour integral (B.3), we derive the bound
where \(\tilde{{\mathfrak {d}}}\) is any parameter greater than \({\mathfrak {d}}\). \(\square \)
We will often have to perform the time integral of the error term coming from our rigidity estimates. This lemma explicitly performs the time integrals that frequently appear in our analysis.
Lemma B.4
Recall the times s and t from Eq. (5.1). Under the assumptions of Theorem 5.1, consider a characteristic \(z_\tau = E_\tau + \kappa _\tau + \mathrm{i}\eta _\tau \) that, at time t, satisfies the conditions \(\eta _t \asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \lesssim \kappa _t \lesssim \eta \). We have
where the implicit constant is universal.
Proof
We can perform explicit calculations thanks to (2.7)
The claim follows from our assumption of square root behavior. We chose the time difference \(t -s\) large enough so that the quantity \(\eta _t + (t-s) \mathrm{Im}[\hat{m}_t(z_t)]\) is much larger than \(\eta _t\). Finally, we used the fact that, at \(z_t\), we have \(\mathrm{Im}[\hat{m}_t(z_t)] \leqslant C \sqrt{\eta _t}\) for some large constant C. \(\square \)
The following lemma computes the main contribution of the quadratic variance terms from Proposition 5.3.
Lemma B.5
We recall \({\mathfrak {C}}_q\) from (3.5) and the times s and t from Eq. (5.1). Under the assumptions of Theorem 5.1 and for any time q satisfying \(s\leqslant q\leqslant t\), we have the following integral evaluation,
where the characteristics \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t,z_t'=E_t+\kappa _t'+\mathrm{i}\eta _t'\) satisfy \(\eta _t, \eta _t'\asymp \eta \), \(-N^{{\mathfrak {d}}}\eta \leqslant \kappa _t,\kappa _t'\leqslant \eta \).
Proof
We recall from Proposition 3.4 that the measure \(\hat{\mu }_q\) is supported on \((-\infty , E_q]\), and has a density in a small neighborhood of \(E_q\) of the form
Now, we try to explicitly identify the main term found in (B.4). We have
The second term of the above equation can clearly be bounded by \({{\,\mathrm{O}\,}}((\log N)^4)\) if one takes into account the fact that \(z_q\) and \(z_q'\) are far away from \(E_q-(\log N)^{-1}\). This can easily be seen to be an \({{\,\mathrm{O}\,}}(N^{-{\mathfrak {d}}^2})\) factor of the main term in (B.4).
To estimate the other quantity, we do a Taylor expansion of \(\hat{\rho }_q(x)\) around the point 0 as \(|\hat{\rho }_q(x) -{\mathfrak {C}}_q\sqrt{x}| = {{\,\mathrm{O}\,}}(x^{3/2})\). Without loss of generality, we will assume that \(|\kappa _q| \geqslant |\kappa _q'|\). To illustrate the computation, we will only consider the case that \(-\kappa _q \geqslant \eta _q\), and \(-\kappa _q' \geqslant \eta _q'\). Similar techniques can be used in all other cases and are generally simpler. The above computation can be divided into two cases; the first case is when \(|\kappa _q - \kappa _q'| \geqslant |\kappa _q|/2\). We will perform a decomposition of the integral as follows:
We need to show that the above quantity will be less than \(N^{-{\mathfrak {d}}^2} |\kappa _q|^{-2} |\kappa _q'|^{-1/2}\). This is implied by the two inequalities \(\eta _q \leqslant N^{-20{\mathfrak {d}}}\) and \(|\kappa _q| \leqslant N^{{\mathfrak {d}}} \eta _q \) from Lemma B.1.
Next, we consider the case in which \(|\kappa _q - \kappa _q'| \leqslant |\kappa _q|/2\). We can divide the integral as
To show that the above error is smaller than \(N^{-{\mathfrak {d}}^2} |\kappa _q|^{-2} |\kappa _q'|^{-1/2}\), we would only need to show that \(|\kappa _q|^{5} \leqslant N^{-{\mathfrak {d}}^2} \eta _q^2 \eta _q'^2\). Applying \(\eta _q \asymp \eta _q'\) and the fact that \(|\kappa _q| \leqslant N^{{\mathfrak {d}}} \eta _q \), we see that we would only need to prove that \(\eta _q \leqslant N^{- {\mathfrak {d}}^2 - 5 {\mathfrak {d}}}\). This is due to the fact that \(\eta _q \leqslant N^{-20{\mathfrak {d}}}\).
We now only need to compute the following integral
where the square roots come from the branch with positive real part, and the error term \((\log N)^{5/2}\) can be absorbed into the \(N^{-{\mathfrak {d}}^2}\) factor of the main term. This finishes the proof of Lemma B.5. \(\square \)
We now compute the time integrals of the main terms in Proposition 5.3 weighted by the factors \({\mathcal {I}}_t ({\mathcal {I}}_s)^{-1}\). By using the equation of the characteristics, we can integrate this by a simple change of variables formula.
Lemma B.6
We recall \({\mathfrak {C}}_q\) from (3.5) and times s and t from Eq. (5.1). Under the assumptions of Theorem 5.1, take two characteristics \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) and \(z_t'=E_t+\kappa _t'+\mathrm{i}\eta _t'\) such that \(\eta _t, \eta _t'\asymp \eta \), \(-N^{{\mathfrak {d}}}\eta \lesssim \kappa _t,\kappa _t'\lesssim \eta \). We have that
Proof
Using the results of Lemma B.5, we have
Let \(A= \sqrt{\kappa _s + \mathrm{i}\eta _s}\) , \(A' = \sqrt{\kappa _s' + \mathrm{i}\eta _s'}\) and \(B_q = \pi /2 \int _{q}^{t} {\mathfrak {C}}_\tau \mathrm{d}\tau \). By using our characteristic estimates from (5.27), we would like to replace \(\sqrt{\kappa _q + \mathrm{i}\eta _q}\) with the sum \(\sqrt{\kappa _t + \mathrm{i}\eta _t} + \pi /2 \int _q^t {\mathfrak {C}}_\tau \mathrm{d}\tau \) up to some small error. For times \((t-q) \ll (|\kappa _t| + \eta _t)^{1/4}\), this replacement is valid up to a multiplicative factor of \((1+ {{\,\mathrm{O}\,}}(N^{-{\mathfrak {d}}^2}))\).
We will change the integration variable from \(q \rightarrow B_q\); the Jacobian of this transform will be \(\pi /2 {\mathfrak {C}}_q\). Upon this transformation, we see that we would have to integrate \(\int _{B_s=0}^{B_t} \frac{1}{(A+A' -2 x)^3} \mathrm{d}x\). This can be evaluated explicitly and will give us the last line of (B.7) up to a multiplicative factor of the form \(1+{{\,\mathrm{O}\,}}(N^{-{\mathfrak {d}}^2})\), due to the fact that we have to invert the substitution \(\sqrt{\kappa _t + \mathrm{i}\eta _t} + \pi /2 \int _q^t {\mathfrak {C}}_\tau \mathrm{d}\tau \rightarrow \sqrt{\kappa _q + \mathrm{i}\eta _q}\). We remark here that if we have that \(t-s\gg \sqrt{\eta }\), the last line of (B.7) can be subsumed as an \({{\,\mathrm{O}\,}}(N^{- {\mathfrak {d}}^2})\) error of the second term. \(\square \)
The following lemma collects the last computation appearing in Sect. 5. It follows from the arguments of Lemma B.5 and Lemma B.6. We will only mention the result here for reference.
Lemma B.7
We recall \({\mathfrak {C}}_q\) from (3.5) and times s and t from Eq. (5.1). Under the assumptions of Theorem 5.1, consider a characteristic \(z_t=E_t+\kappa _t+\mathrm{i}\eta _t\) such that \( \eta _t\asymp \eta \) and \(-N^{{\mathfrak {d}}}\eta \lesssim \kappa _t\lesssim \eta \). We have
and
Rights and permissions
About this article

Cite this article
Adhikari, A., Huang, J. Dyson Brownian motion for general \(\beta \) and potential at the edge. Probab. Theory Relat. Fields 178, 893–950 (2020). https://doi.org/10.1007/s00440-020-00992-9
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-020-00992-9