
Abstract
Image dehazing is an important direction of low-level visual tasks, and its quality and efficiency directly affect the quality of high-level visual tasks. Therefore, how to quickly and efficiently process hazy images with different thicknesses of fog has become the focus of research. This paper presents a multi-feature fusion embedded image dehazing network based on transmission guidance. Firstly, we propose a transmission graph-guided feature fusion enhanced coding network, which can combine different weight information and show better flexibility for different dehazing information. At the same time, in order to keep more detailed information in the reconstructed image, we propose a decoder network embedded with Mix module, which can not only keep shallow information, but also allow the network to learn the weights of different depth information spontaneously and re-fit the dehazing features. The comparative experiments on RESIDE and Haze4K datasets verify the efficiency and high quality of our algorithm. A series of ablation experiments show that Multi-weight attention feature fusion module (WA) module and Mix module can effectively improve the model performance. The code is released in https://doi.org/10.5281/zenodo.10836919.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image dehazing has always been a hot topic in bottom(low-level) visual tasks, because haze is closely related to our life and travel. Obtaining a clearer view in foggy days is the main task of image dehazing. In addition, image dehazing, a basic visual task, has always been a prerequisite for effective display in advanced visual tasks, and it is often used as a preprocessing step to obtain clear images. For example, object detection [1,2,3], semantic segmentation [4,5,6] and stereo matching [7,8,9] are implicitly influenced by haze images. Therefore, how to obtain dehazing images has aroused widespread concern from industry and academia.
The main task of image defogging is to restore blurred images to clear images for subsequent advanced visual tasks or observations. The atmospheric scattering model [10,11,12] explains the formation process of foggy images, and researchers often apply the inverse process to defog images.
where \(x\) represents the image pixel position, and \(I\left( x \right)\) represents the foggy image, \(J\left( x \right)\) represents the clear image after defogging, \(A\) represents the global atmospheric light value, and \(t\left( x \right)\) represents the transmittance of different positions in the atmosphere and can be further expressed as:
where \(\beta\) is the atmospheric scattering coefficient, and \( d \left( x \right)\) is the distance from the object to the imaging plane of the camera.
Researchers have proposed a series of methods to solve the image dehazing by Formula (1). These methods can be divided into two categories: physical methods based on apriori [13,14,15,16] and deep learning methods based on neural networks [17,18,19,20]. In the early literature, the ambiguity was eliminated mainly by constructing a physical model. On the premise of a priori assumption, the transmission map \(t\left( x \right)\) and the global atmospheric light value \(A\) were characterized, and then the defogged image was obtained [13, 14]. A dark channel prior algorithm for image dehazing is proposed through statistical analysis of a large number of hazy images [15]. \(A\) prior condition of color attenuation is proposed, which estimates the transmission rate and restores the scene radiance through the atmospheric scattering model to effectively remove the fog from a single image [16]. However, these methods can only be performed well under the prior assumption, and image distortion will occur when the scene features do not satisfy the prior conditions.
With the development of deep learning in the field of computer vision, researchers use convolutional neural networks to defog images. An end-to-end feature fusion attention network is proposed to directly restore fog-free images [22]. A multi-scale estimation module based on attention is proposed, which can efficiently exchange information of different scales, thus effectively alleviating the bottleneck problem of multi-scale estimation [19]. [23] set gating mechanism to capture finer image differences. [22] demonstrated that the channel attention mechanism can better encode the global atmospheric light value \(A\), and the pixel attention related to the image pixel position can effectively encode the transmission value \(t\left( x \right)\). Residual can potentially express the relationship between foggy images and fog-free images. Although the above model has achieved good results, the unevenness of fog distribution and some noise lead to color imbalance and artifacts in the defogging image, and considering the efficiency of image de-fogging, we propose a transmission map guided multi-feature fusion network. From formula (1), we can see that the encoding of the transmission map is the key factor affecting the model results, and the coding learning of \(t\left( x \right)\) is very difficult due to the uneven fog distribution. As we all know, fog is related to the depth of the image, and the deeper the depth value, the thicker the fog concentration. According to Formula (2), the transmission map contains atmospheric light scattering coefficient and depth information, and the depth corresponding to different image contents is different, so different image contents also correspond to different fog concentrations. We use the transmission diagram as a guide, which can better get the fog information of different thickness areas in the image. At the same time, considering the problem of dehaze efficiency, we did not construct a very complex network structure. Specifically, we first adopt U-Net network [21] as our infrastructure and combine local residual [24] with global residual [25] to realize the fusion of local and global multi-scale information. The hazy and transmission images used as the network inputs. In the coding stage, we propose a new multi-weight fusion module and use the transmission map as the guide to enhance the information of different dehazing image. In the decoding stage, We also used the transmission map guidance mechanism to guide the reconstruction of the fog removal image. We believe that the transmission map contains the fog concentration information corresponding to different image contents. Moreover, the residual and adaptive decoding modules are adopted. Different from adding the parameter α to ACER [26], we can spontaneously select appropriate weights for the characteristics of different channels to better integrate the characteristics of different depths and scales. The method proposed in this paper can significantly improve the image defogging effect, and a large number of experiments prove that the model can show better performance on datasets.
Our main contributions can be summarized as follows:
-
a)
We design a WA module is embedded in the encoding network. It can fuse multiple feature weight information, which can better encode transmission value \(t\left( x \right)\) and global atmospheric light value \(A\). And the dehazing features can be fused and re-fitted.
-
b)
Our proposed Mix module can dynamically combine the feature maps of different scales for up-sampling, and combine with the local residual module to allow the network to skip the foggy area and pay more attention to the thick foggy area. The spatial attention module SA and the pixel enhancement module guided by the transmission map can reconstruct the defogged image more finely.
-
c)
Our proposed dehaze network can effectively dehaze and has good performance on OTS and Haze4K datasets.
The rest of this paper is as follows: The second section introduces the relevant contents, the third section mainly introduces the proposed dehazing network, the fourth section carries out comparative and ablation experiments, and the fifth section draws conclusion.
2 Related work
Image dehazing methods can be roughly divided into two categories: physical methods based on manual prior and deep learning methods based on neural network. When the image satisfies the prior conditions, the method based on manual prior can show good results, but distortion will occur when the prior conditions do not match the image. The neural network-based method has occupied a dominant position with the development of artificial intelligence.
2.1 Image dehazing based on prior conditions
Through statistical method, it is found that there is at least one color channel with a lower brightness value in the pixels of the sky-free area of most fog-free images. The transmission map is further estimated, and a clear fog-free image is obtained by combining the global atmospheric light value A. Fattal et al. [27] inferred the color information of the original image by assuming that the surface shadow in the scene is unrelated to the transmission map in local statistics. Tan et al. [28] constructed a Markov random field with an energy function. Salazar-Colores et al. [28] combined DCP with morphological operations such as corrosion and expansion to calculate the transmission diagram. Meng et al. [29] added boundary constraints and context regularization to DCP to obtain a better transmission graph. Liu et al. [30] refined the transmission map by regularization to obtain a more refined transmission map. Zhu et al. [16] obtained the projection map by analyzing the relationship between the depth of the scene and the difference of blurred images in different channels. Sheng et al. [48] proposed a depth-aware motion blur model to enhance image. However, the image defogging will distort when the prior conditions are not satisfied.
2.2 Image dehazing based on deep learning
Owing to the rapid development of deep learning, convolutional neural networks have been applied to image defogging. DehazeNet [17] and MSCNN [32], as pioneers in the field of image defogging, applied neural network to estimate transmission value t(x) and artificial prior to estimate atmospheric light value \(A\). Their effects did not show higher performance than prior manual operation. Then DCPDN [33] used two networks to estimate the transmission value \(t\left( x \right)\) and the atmospheric light value a respectively. AOD-Net [18] uses a lightweight backbone network to predict the variable \(k\), and finally uses a physical defogging model variant to get a defogging image. Ren et al. [19] adopted a gated fusion idea, and took the fusion results generated by white balance, contrast enhancement and gamma correction as the final defogged image. Liu et al. [20] used attention and multi-scale methods to directly predict defogging images. Qin et al. [22] proposed an end-to-end defogging network based on channel attention and pixel attention, which can effectively encode transmission value t(x) and atmospheric light value \(A\). Lu et al. [35] proposed that multi-scale large convolution module and parallel attention module can better eliminate uneven smog. Zhao et al. [36] proposed a two-stage defogging network combining the advantages of prior and learning. Fan et al. [37] combined scene depth with multi-scale residual connection, which has a good performance in real scenes. Wen et al. [49] enhanced image by modifying the Cyclegan network. Zhou et al. [50] proposed a feedback spatial attention dehazing network, which has a good performance in SOTS dataset. C2Pnet [51] proposed a deep learning network that enhances image dehazing performance by utilizing cascaded channel and spatial attention mechanisms.The RIDCP [52] (Revitalizing Real Image Dehazing via High-Quality Codebook Priors) aims to address the challenges faced by existing methods when dealing with hazy images in the real world. This paper focuses on the coding of transmission value \(t\left( x \right)\) by multi-scale information and attention mechanism. These dehazing models achieve good results by learning the mapping from the fog map to the defog image from end to end, but they do not consider the relationship between the content of the image and the fog density. The transmission map can directly express the relationship between the content of the image and the concentration of fog. Therefore, we propose a transmission guided multi-feature fusion image dehaze network.
3 Proposed methods
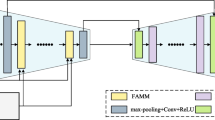
The proposed Transmission-Guided Multi-Feature fusion network (TGMF) does not adopt a complex structure, and is only based on a simple U-Net architecture. The model architecture shown in Fig. 1, it has four down-sampling stages and four up-sampling stages. In each down-sampling stage, it is composed of WA mmodule. Different from the up-sampling stage of U-Net, an adaptive weight adjustment method is applied to connect the down-sampling and up-sampling stages, so that the network can independently allocate the weights of different path feature maps. Given \(\left\{ {I\left( x \right),T\left( x \right),J\left( x \right)} \right\}\) as the input of the network, \(I\left( x \right)\) is a foggy image, \(T\left( x \right)\) is a transmission image, and \(J\left( x \right)\) is a clear image, we use SSIM, perceptual and \(L_{1}\) loss to train the network model.

TGMF-Net network structure. TGMF-Net consists of four up-sampling structures and four down-sampling structures
3.1 Multi-layer attention feature fusion module
Our design of WA mldule is inspired by FFA-Net [22], and we think that channel attention and pixel attention can effectively encode global variable A and local variable t(x). Therefore, two pixel attention modules are connected in parallel after Channel Attention module, and different features are fused through MLP module. Assuming that the feature and transmission maps are \(\left\{ {x,T_{r} } \right\} \) respectively, we add the them in the channel dimension as inputs, and then use Channel Attention module to code the global variable \(A\). Channel Attention module can effectively extract the global information and change the channel dimension of the feature, and can assign different weights to different channels to make our network pay more attention to the dense fog area, high-frequency texture information and color fidelity.
Channel Attention can be expressed as:
where \({\text{AvgPool}}2d\) is a global average pooling, \(x\) represents the feature map after global average pooling, \({\text{Conv}}2d\) is a convolution module, \({\text{Relu}}\) is an activation function, and \({\text{Sigmoid}}\) assigns different weights to each channel. The structure of Channel Attention network is shown in Fig. 2.

The structure of WA module. MLP means Multilayer Perceptron. Conv2d means Convolution Network. \(\oplus\) means Point-wise Addition, \(\otimes\) means Hadamard Product
Then, for the local variable \(t\left( x \right)\), we use trans map as a pixel-level weight coding local variable \(t\left( x \right)\), and trans map as a weight guided feature map to enhance the features of foggy areas. We think that the spatial attention module can improve the feature expression of key areas and code the local variable \(t\left( x \right) \) effectively.
WA module can be formulated as:
where \(x_{T}\) represents the feature map guided by trans map, \(x_{sp}\) represents the feature map after spatial attention, and the network structure of Spatial Attention module is shown in Fig. 2.
The transmission map contains the scattering coefficient and depth information of atmospheric light at different locations. We use it as a weight information to guide the network to learn fog information in different regions of the image features, and add more weights to the regions with larger concentrations.
We add \(x_{T}\) and \(x_{sp}\) in the feature dimension, and then send them into a multilayer perceptron, which can transform the number of feature channels into the initial number of feature channels. The multilayer perceptron contains two Conv convolutions, and Relu is used as the activation function. We believe that the multilayer perceptron can not only fuse different features, but also fit the defogging features.
MLP can be expressed as:
where \(x_{{{\text{out}}}}\) is the output of MLP module, and the overall structure of WA module is shown in Fig. 2.
3.2 Mix module
Different from the upsampling module of Unet network, our upsampling structure adopts an adaptive method to let the network spontaneously select appropriate weights and assign them to the feature maps of different paths, so as to effectively realize the fusion of shallow and deep features. Channel attention can effectively extract global information, change the channel dimension of features, and assign different weights to different channels to make our network pay more attention to dense fog areas, high-frequency texture information and color fidelity. Assuming that \(\left\{ {x_{a} ,x_{b} } \right\}\) are two input characteristic graphs, our upsampling adaptive weight allocation module can be expressed as:
After the adaptive weight assignment module, trans map and spatial attention are used to highlight the importance of different spatial positions of feature maps, which can make the network pay more attention to haze pixels and high-frequency image areas, thus highlighting the output features. The local residual structure is used to combine the output with the input feature map of Mix module, which can make the network bypass less important information such as mist area and low frequency area and make the network pay more attention to effective information. Moreover, the combination of local residual and global residual can not only avoid training difficulties, but also transmit shallow information to the depths of the network, so that the network can obtain more detailed spatial characteristics and semantic information. In Mix module, we still use trans map as the guide and fuse the spatial feature map, so that our network can encode \(t\left( x \right)\) to the maximum extent, and the network can reconstruct relatively clear images from fog regions with different concentrations. Finally, MLP can integrate defogging features by adjusting the number of network channels (Fig. 3).

Mix module structure diagram. The mix structure combines adaptive upsampling with attention module and MLP structure
Mix module can be formulated as:
3.3 Train loss
Given a pair of images \(\left\{ {I,J} \right\}\), \(I\) represents the foggy image and \(J\) represents the corresponding clear image. Let TGMF-Net predict the dehaze image to get \(\hat{J}\). L_1, perceptual and ssim losses are used to train our model.
In order to restore a more real de-fog image, to prevent the loss of details and texture information. We adopted \(L_{1}\) loss.
\(L_{1}\) loss can be expressed as:
where the \(J\) represents a clear image, \(\widehat{J }\) represents a predict image, \(H\) and \(W\) represent the height and width of the image. \(\left| \right| \ {\rm represents}\) an absolute value.
In order to obtain a defogging image that is close to the true value, we should not only focus on the differences between pixels, but on the characteristics and style differences between the predicted defogging image and the true value. We adopted perceptual loss.
perceptual loss can be expressed as:
where the \(\phi_{j}\), \(H\), and \(W\) represent the feature map, the height and width, respectively The \(m\), \(n\) represent positions.
Compared with L1 loss, it pays more attention to structural similarity, and is more consistent with the human visual system's judgment on the similarity of two images.
ssim loss can be expressed as:
where \(\mu_{{Y_{m} }}\) is the average of \(Y_{m}\), \(\mu_{{Y_{m}{\prime} }}\) is the average of \(Y_{m}{\prime}\), \(\sigma_{{Y_{m} }}\) is the variance of \(Y_{m}\), \(\sigma_{{Y_{m}{\prime} }}^{2}\) is the variance of \(Y_{m}\), \(\sigma_{{Y_{m}{\prime} }}^{2}\) is the variance of \(Y_{m}\), \(\sigma_{{Y_{m} Y_{m}{\prime} }}\) is the covariance of \(Y_{m}\), and \(Y_{m}{\prime}\), and \(\theta_{1}\) and \(\theta_{2}\) are constants. \(\theta_{1}\) and \(\theta_{2}\) are used to prevent the system instabilities produced by a zero denominator. The value range of \(L\) is [− 1,0].
The total loss function can be expressed as:
where the \(\lambda\) is a hyperparameter, \(\lambda = 0.1\).
4 Experiments
In this section, we will describe the experimental details from the dataset preparation, evaluation indicators and experimental settings, and comparative experiments and ablation experiments to evaluate our model performance.
4.1 Experimental settings
4.1.1 Datasets
To better demonstrate the performance of the model, Haze4K [38] and RESIDE [39] datasets are applied for comparative experiments. And in order to better demonstrate the performance of the model, we compared it with the real world data set.
RESIDE data set is a new large-scale benchmark that includes both synthetic and real hazy images, Such as resistance-in (indoor training set), resistance-out (outdoor training set) and synthetic objective testing set (SOTS). Following the setting of FFANet [21], we adopt RESIDE-OUT(Outdoor Training Set) as our training dataset, which contains 313,950 pairs of pictures. In addition, we take 500 paired images from Synthetic Objective Testing Set (SOTS) as our test set.
Haze4k is a synthetic data set containing 4000 hazy images, in which each hazy image contains a potential clean image and a transmission image. We follow the setting of PMNet [40], in which 3000 images are used to train 1000 images for testing. Compared with RESIDE dataset, Haze4K dataset mixes the images of indoor and outdoor scenes, and the synthetic pipeline is more realistic.
4.1.2 Training details
We trained TGMF-Net on Nvidia RTX 4090 GPU. We use AdamW optimizer to set the learning rate to 0.0003, the exponential decay rate to \({\beta }_{1}\)=0.5, \({\beta }_{2}\)=0.99, and combine with cosine annealing strategy to gradually decrease. The batch size of training is set to 8. The total training epoch is 800.
Because our network uses hazy images and transmission maps as inputs, the transmission maps of foggy images need to be generated. We do not use the method of optimizing hazy images before generating depth maps in MSCDN [37], but directly use GDCP [41] to generate transmission maps of hazy images. Although we believe that the transmission map generated by optimizing the hazy image will be better, this does not directly reflect the role of our network. Figure 4 shows the partially generated transmission map.

Hazy image and corresponding transmission map
4.1.3 Evalute system
To better evaluate the effectiveness and superiority of the algorithm, we use structural similarity index (SSIM) and Peak Signal to Noise Ratio (PSNR) as our objective evaluation indicators. The skimage library is applied to calculate SSIM and PSNR to avoid significant differences in calculation results caused by different calculation methods.
4.2 Comparison with state-of-the-art methods
To verify the validity of TGMF-Net model, we compared TGMF-Net with several other advanced methods, including DCP [15], MSCNN [32], AOD-Net [18], Dehaze-Net [17], GFN [20], MSBDN [31], DMT-Net [34] and PGCGA [43], KMAN [44], Transweather [45], PSPAN [46], C2Pnet [51]. In this section, the first, second and third items in Table 1 are represented in bold, single and dashed underlines respectively.
The comparison of TGMF-Net and other baseline performance demonstrates that our proposed TGMF-Net network is a better and more efficient dehazing network. In the RESIDE-OUT dataset, our TGMF-Net ranks second in PSNR. On the Haze4K dataset, our TGMF-Net ranks first in both PSNR and SSIM, and the second is DMT-Net, with a difference of 7.1 dB compared with TGMF-Net. Compared with C2PNet, our TGMF-net does not have a big gap between the two datasets, and the results of the two datasets are still better than other algorithms. In terms of model parameters, our model is only 17.307 M. Although it has larger model parameters than C2PNet, it is still easy for edge devices. In the reasoning test stage, the image processing speed is only 5.969 ms, which is 3 times as fast as MSBDN and 5 times as fast as DMT-Net. Although MSCNN, AOD-Net, Dehaze-Net, and GFN can achieve higher speed, they are not competitive due to their insufficient image dehazing ability. Therefore, our TGMF-Net network can undertake timely image dehazing tasks.
In Fig. 5, we selected four pictures from the SOTS test set for comparison. Both DCP and AOD-Net have sky overexposure, and MSBDN has weak defogging ability on the last picture, which is not perfect for restoring.

Visual comparison of different dehazing algorithms on RESIDE-OTS dataset. The red areas represent local details
image details and colors. The defogging effect of FFA-Net is the closest to our TGMF-Net, but FFA-Net is still insufficient for image details. Compared with the real fog-free image, it is obvious to find that TGMF-Ne has the best defogging effect and can effectively restore the image details and color information.
Figure 6 shows the visual comparison of different algorithms on Haze4K dataset, which confirms that our proposed TGMF-Net network has a more obvious image dehazing effect. DCP is prone to overexposure in the sky area, the color recovery effect of AOD-Net image is insufficient, and the dehazing effect of MSBDN and FFA-Net on Haze4K is poor. Our proposed TGMF-Net is more effective in defogging. And compared with other algorithms, our TGMF-Net pays more attention to image details and color restoration, such as color restoration in the sky area, and the image processed by TGMF-Net is closest to the GT image.

Visual comparison of different dehazing algorithms on Haze4K dataset. The red boxes indicate the significant differences
Figure 7 shows our de-fogging effect in the real world. The first column shows the image containing fog, and the second column shows the effect after image de-fogging by using DCP algorithm. It can be seen that there are artifacts and color deviation. The second column uses AOD-Net to de-fog the image, the de-fog effect is not obvious, and the image becomes dim. Compared with TGMF, FFA-Net has poor defogging effect, and the defogging effect at short distance is not obvious. MSBDN is close to our de-fog effect, but the effect is not good at different scene depths.

Visual comparison of different dehazing algorithms on real-word
4.3 Ablation study
To better show the performance of the model and the effectiveness of each part, we conducted ablation experiments. All models in the ablation experiment are identical to the final model, and the objective evaluation index and visual comparison are displayed.
Firstly, we conducted ablation experiments on the functions of each module: (1) The basic architecture adopte, and the number of up-sampling and down-sampling was the same as that of our TGMF-Net. (2) added WA module to the basic U-Net architecture. (3) Added Mix module to the basic U-Net architecture. The experiment is carried out on Haze4K data sets and the results are shown in Table 2.
Secondly, we conducted ablation experiments on whether the input image contains transmission map. (1) inputed hazy image; (2) inputed hazy and transmission images. The experimental results are shown in Table 3.
Thirdly, We conducted ablation tests on different loss functions to verify the validity of the three loss functions we used. (1) Only used \(L1 loss\). (2) Used \(L1 loss\) and \(Perceptual loss\). (3) Used \(L1 loss\), \(perceptual loss\) and \(ssim loss\).
Table 2 presents that the SSIM of the basic TGMF-Net-Base network is 0.949, and the PSNR is 28.101. Compared with TGMF-Net-Base, PSNRand SSIM increased by about 3 dB and 0.019 respectively after adding Mix module in the decoding stage, which reflect the effectiveness of our proposed network adaptive upsampling module. Compared with TGMF-Net-Base, PSNR and SSIM increased by about 4 dB and 0.022 respectively after adding WA module in the coding stage, which shows that our proposed WA module can encode the global atmospheric light value A and transmission value t(x) more effectively. Finally, our model reached SSIM and PSNR of 0.975 and 35.64 in Haze4K dataset after adding two modules.
Table 3 presents that the SSIM is 0.972 and the PSNR is 34.862 when the input image does not contain the transmission image. When the input image is a fusion of transmitted and blurred images, SSIM and PSNR increase by approximately 0.03 and 0.784, respectively. It can be seen that choosing transmission and hazy images as our input images will positively gain the dehazing network.
Table 4 shows that only used \(L1 loss\) as loss function, SSIM is 0.965 and PSNR is 32.72, \(L1 loss\) and \(perceptual loss\) were used as loss functions, with SSIM of 0.968 and PSNR of 33.67. \(L1 loss\), \(perceptual loss\) and \(ssim loss\) are used as loss functions. SSIM is 0.975 and PSNR is 35.646. It can be seen in Table 4 that only L1 loss is used as a loss function, with an SSIM of 0.965 and a PSNR of 32.72. L1 loss and perceptual loss were used as loss functions, with SSIM of 0.968 and PSNR of 33.67. L1 loss, perceptual loss and ssim loss are used as loss functions. SSIM is 0.975 and PSNR is 35.646. We can see that the three loss functions, which we adopted have a better effect on our network.
5 Conclusion
In order to further improve the quality of image defogging and improve the performance of upstream visual tasks, a trans map guided multi-feature fusio defogging network TGMF-Net is proposed in this study. It includes a transmission-guided module, a down-sampling coding module, an adaptive multi-scale up-sampling module and a residual structure. The subsampling coding module can better encode t(x) by combining strings, and at the same time, the transmission map is used as the weight to guide the network to learn fog information of different depth scenes. The adaptive multi-scale upper sampling module can enable the network to spontaneously combine information of different depths, so as to better fit the de-fog features. The combination of local residuals and global residuals not only enables the network to target dense and semantically rich regions more specifically, but also predicts the underlying information between fog-free and hazy images. At the same time, we embed the projection map guide module in the up-sampling process, so that the predicted fog-free image can perform better under different depth content. A large number of experiments show that our proposed TGMF-Net is superior to other algorithms in data sets and real scenarios.
References
Redmon J, Farhadi A (2018) YOLOv3: An Incremental Improvement
He, K., Gkioxari, G., Dollar, P., Girshick, R.: Mask R-CNN. In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, Venice, pp. 2980–2988 (2017)
Ghiasi, G., Lin, T.-Y., Le, Q.V.: NAS-FPN: learning scalable feature pyramid architecture for object detection. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Long Beach, CA, USA, pp. 7029–7038 (2019)
Shelhamer, E., Long, J., Darrell, T.: Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 640–651 (2017). https://doi.org/10.1109/TPAMI.2016.2572683
Chen, L.-C., Papandreou, G., Kokkinos, I., et al.: DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 40, 834–848 (2018). https://doi.org/10.1109/TPAMI.2017.2699184
Zhao, H., Shi, J., Qi, X., et al.: Pyramid scene parsing network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Honolulu, HI, pp. 6230–6239 (2017)
Kendall, A., Martirosyan, H., Dasgupta, S., et al.: End-to-end learning of geometry and context for deep stereo regression. In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, Venice, pp. 66–75 (2017)
Chang, J.-R., Chen, Y.-S.: Pyramid stereo matching network. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Salt Lake City, UT, pp. 5410–5418 (2018)
Guo, X., Yang, K., Yang, W., et al.: Group-wise correlation stereo network. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Long Beach, CA, USA, pp. 3268–3277 (2019)
Cantor, A.: Optics of the atmosphere–Scattering by molecules and particles. IEEE J. Quantum Electron. 14, 698–699 (1978). https://doi.org/10.1109/JQE.1978.1069864
Narasimhan, S.G., Nayar, S.K.: Vision and the atmosphere. In: ACM SIGGRAPH ASIA 2008 courses on-SIGGRAPH Asia ’08, pp. 1–22. ACM Press, Singapore (2008)
Nayar, S.K., Narasimhan, S.G.: Vision in bad weather. In: Proceedings of the Seventh IEEE International Conference on Computer Vision. IEEE, Kerkyra, Greece, vol. 2D, pp. 820–827 (1999)
Berman, D., Treibitz, T., Avidan, S.: Non-local Image Dehazing. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Las Vegas, NV, USA, pp. 1674–1682 (2016)
Fattal, R.: Dehazing using color-lines. ACM Trans. Gr. 34, 1–14 (2014). https://doi.org/10.1145/2651362
Kaiming, H., Jian, S., Xiaoou, T.: Single image haze removal using dark channel prior. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, Miami, FL, pp. 1956–1963 (2009)
Zhu, Q., Mai, J., Shao, L.: A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 24, 3522–3533 (2015). https://doi.org/10.1109/TIP.2015.2446191
Cai, B., Xu, X., Jia, K., et al.: DehazeNet: an end-to-end system for single image haze removal. IEEE Trans. Image Process. 25, 5187–5198 (2016). https://doi.org/10.1109/TIP.2016.2598681
Li, B., Peng, X., Wang, Z., et al.: AOD-Net: all-in-one Dehazing network. In: 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, Venice, pp. 4780–4788 (2017)
Liu, X., Ma, Y., Shi, Z., Chen, J.: GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Seoul, Korea (South), pp. 7313–7322 (2019)
Ren, W., Ma, L., Zhang, J., et al.: Gated fusion network for single image Dehazing. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Salt Lake City, UT, pp. 3253–3261 (2018)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation (2015)
Qin, X., Wang, Z., Bai, Y., et al.: FFA-net: feature fusion attention network for single image Dehazing. AAAI 34, 11908–11915 (2020). https://doi.org/10.1609/aaai.v34i07.6865
Chen, D., He, M., Fan, Q., et al.: Gated context aggregation network for image Dehazing and Deraining. In: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, Waikoloa Village, HI, USA, pp. 1375–1383 (2019)
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Honolulu, HI, pp. 2790–2798 (2017)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Las Vegas, NV, USA, pp. 770–778 (2016)
Wu, H., Qu, Y., Lin, S., et al.: Contrastive learning for compact single image Dehazing. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Nashville, TN, USA, pp. 10546–10555 (2021)
Fattal, R.: Single image dehazing. ACM Trans. Gr. 27, 1–9 (2008). https://doi.org/10.1145/1360612.1360671
Salazar-Colores, S., Cabal-Yepez, E., Ramos-Arreguin, J.M., et al.: A fast image Dehazing algorithm using morphological reconstruction. IEEE Trans. Image Process. 28, 2357–2366 (2019). https://doi.org/10.1109/TIP.2018.2885490
Meng, G., Wang, Y., Duan, J., et al.: Efficient image Dehazing with boundary constraint and contextual regularization. In: 2013 IEEE International Conference on Computer Vision. IEEE, Sydney, Australia, pp. 617–624 (2013)
Liu, Q., Gao, X., He, L., Lu, W.: Single image Dehazing with depth-aware non-local total variation regularization. IEEE Trans. Image Process. 27, 5178–5191 (2018). https://doi.org/10.1109/TIP.2018.2849928
Dong, H., Pan, J., Xiang, L., et al.: Multi-scale boosted Dehazing network with dense feature fusion. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Seattle, WA, USA, pp. 2154–2164 (2020)
Ren, W., Pan, J., Zhang, H., et al.: Single image Dehazing via multi-scale convolutional neural networks with holistic edges. Int. J. Comput. Vis. 128, 240–259 (2020). https://doi.org/10.1007/s11263-019-01235-8
Zhang, H., Patel, V.M.: Densely connected pyramid Dehazing network. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, Salt Lake City, UT, USA, pp. 3194–3203 (2018)
Zhang, D., Wang, X.: Dynamic multi-scale network for dual-pixel images defocus deblurring with transformer. In: 2022 IEEE International Conference on Multimedia and Expo (ICME). IEEE, Taipei, Taiwan, pp. 1–6 (2022)
Lu, L., Xiong, Q., Chu, D., Xu, B.: MixDehazeNet: Mix Structure Block for Image Dehazing Network (2023)
Zhao, S., Zhang, L., Shen, Y., Zhou, Y.: RefineDNet: a weakly supervised refinement framework for single image Dehazing. IEEE Trans. Image Process. 30, 3391–3404 (2021). https://doi.org/10.1109/TIP.2021.3060873
Fan, G., Gan, M., Fan, B., Chen, C.L.P.: Multiscale cross-connected Dehazing network with scene depth fusion. IEEE Trans. Neural Netw. Learn. Syst. 5, 1–15 (2022). https://doi.org/10.1109/TNNLS.2022.3184164
Liu, Y., Zhu, L., Pei, S., et al.: From synthetic to real: image Dehazing collaborating with unlabeled real data. In: Proceedings of the 29th ACM International Conference on Multimedia. ACM, Virtual Event China, pp. 50–58 (2021)
Li, B., Ren, W., Fu, D., et al.: Benchmarking single-image Dehazing and beyond. IEEE Trans. Image Process. 28, 492–505 (2019). https://doi.org/10.1109/TIP.2018.2867951
Ye, T., Jiang, M., Zhang, Y., et al.: Perceiving and Modeling Density is All You Need for Image Dehazing (2021)
Peng, Y.-T., Cao, K., Cosman, P.C.: Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 27, 2856–2868 (2018). https://doi.org/10.1109/TIP.2018.2813092
Su, Y.Z., Cui, Z.G., He, C., et al.: Prior guided conditional generative adversarial network for single image dehazing. Neurocomputing 423, 620–638 (2021). https://doi.org/10.1016/j.neucom.2020.10.061
Guo, F., Zhao, X., Tang, J., et al.: Single image dehazing based on fusion strategy. Neurocomputing 378, 9–23 (2020). https://doi.org/10.1016/j.neucom.2019.09.094
Liu, P., Liu, J.: Knowledge-guided multi-perception attention network for image dehazing. Vis. Comput. (2023). https://doi.org/10.1007/s00371-023-03177-2
Jose, V.J.M., Yasarla. R., Patel, V.M.: TransWeather: transformer-based restoration of images degraded by adverse weather conditions. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, New Orleans, LA, USA, pp. 2343–2353 (2022)
Zhang, Y., Xu, T., Tian, K.: PSPAN:pyramid spatially weighted pixel attention network for image dehazing. Multimed. Tools Appl. 83, 11367–11385 (2024). https://doi.org/10.1007/s11042-023-15844-6
Qu, Y., Chen, Y., Huang, J., Xie, Y.: Enhanced Pix2pix Dehazing network. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Long Beach, CA, USA, pp. 8152–8160 (2019)
Sheng, B., Li, P., Fang, X., et al.: Depth-aware motion deblurring using loopy belief propagation. IEEE Trans. Circuits Syst. Video Technol. 30, 955–969 (2020). https://doi.org/10.1109/TCSVT.2019.2901629
Wen, Y., Chen, J., Sheng, B., et al.: Structure-aware motion Deblurring using multi-adversarial optimized CycleGAN. IEEE Trans. Image Process. 30, 6142–6155 (2021). https://doi.org/10.1109/TIP.2021.3092814
Zhou, Y., Chen, Z., Li, P., et al.: FSAD-net: feedback spatial attention Dehazing network. IEEE Trans. Neural Netw. Learn. Syst. 34, 7719–7733 (2023). https://doi.org/10.1109/TNNLS.2022.3146004
Zheng, Y., Zhan, J., He, S., et al.: Curricular contrastive regularization for physics-aware single image Dehazing. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, pp. 5785–5794 (2023)
Wu, R.-Q., Duan, Z.-P., Guo, C.-L., et al.: RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Vancouver, BC, Canada, pp. 22282–22291 (2023)
Acknowledgements
This work was funded by the National Natural Science Foundation of China under Grants 52025111.
Author information
Authors and Affiliations
Contributions
XZ: Conceptualization, Methodology, Software, Writing – Original Draft. ZD, ZZ: Validation, Funding acquisition. Writing – Review & Editing. ZW: Investigation, Data Curation, Visualization, Formal analysis. HQ: Supervision, Funding acquisition.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing fnancial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethical approval
The data collected come from a publicrepository. They are permitted and don't violate any ethical rules.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhao, X., Wang, Z., Deng, Z. et al. Transmission-guided multi-feature fusion Dehaze network. Vis Comput (2024). https://doi.org/10.1007/s00371-024-03533-w
Accepted:
Published:
DOI: https://doi.org/10.1007/s00371-024-03533-w