
Abstract
For the partially linear errors-in-variables panel data models with fixed effects, we, in this paper, study asymptotic distributions of a corrected empirical log-likelihood ratio and maximum empirical likelihood estimator of the regression parameter. In addition, we propose penalized empirical likelihood (PEL) and variable selection procedure for the parameter with diverging numbers of parameters. By using an appropriate penalty function, we show that PEL estimators have the oracle property. Also, the PEL ratio for the vector of regression coefficients is defined and its limiting distribution is asymptotically chi-square under the null hypothesis. Moreover, empirical log-likelihood ratio for the nonparametric part is also investigated. Monte Carlo simulations are conducted to illustrate the finite sample performance of the proposed estimators.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The analysis of panel data is the subject of one of the most active and innovative bodies of literature in econometrics. Panel data sets have various advantages over that of pure time-series or cross-sectional data sets, among which the most important one is perhaps that the panel data provide researchers a flexible way to model both heterogeneity among cross-sectional units and possible structural changes over time. Arellano (2003), Baltagi (2005) and Hsiao (2003) provided excellent overviews of statistical inference and econometric analysis of parametric panel data models. However, a misspecified parametric panel data model may result in misleading inference. Therefore, econometricians and statisticians have developed some flexible nonparametric and semi-parametric panel data models. For example, Su and Ullah (2007) proposed a class of two-step estimators for nonparametric panel data with random effects. Cai and Li (2008) studied dynamic nonparametric panel data models. Henderson et al. (2008) considered nonparametric panel data model with fixed effects. Rodriguez-Poo and Soberon (2014) considered varying coefficient fixed effects panel data models, established direct semiparametric estimations. Chen et al. (2013) studied partially linear single-index panel data models with fixed effects, proposed a dummy variable method to remove fixed effects and established a semi-parametric minimum average variance estimation procedure. Baltagi and Li (2002) discussed partially linear panel data models with fixed effects, developed the series estimation procedure and the profile likelihood estimation technique. Hu (2014) proposed the profile likelihood procedure to estimate semi-varying coefficient model for panel data with fixed effects. The partially linear panel data models with fixed effects are widely used in econometric analysis; see, e.g., Henderson et al. (2008), Horowitz and Lee (2004), Hu (2017) and Li et al. (2011).
In this paper, we consider the following partially linear panel data models with fixed effects (e.g. Su and Ullah 2006):
where \(Y_{it}\) is the response, \((X_{it},Z_{it})\in R^p\times R\) are strictly exogenous variables, \({\beta }=(\beta _1,\ldots ,\beta _p)^\tau \) is a vector of p-dimensional unknown parameters, and the superscript \(\tau \) denotes the transpose of a vector or matrix. \(g(Z_{it})\) is a unknown functions and \(\mu _{i}\) is the unobserved individual effects, \(\varepsilon _{it}\) is the random model error. Here, we assume \(\varepsilon _{it}\) to be i.i.d. with zero mean and finite variance \(\sigma ^2>0\). We allow \(\mu _i\) to be correlated with \(X_{it}\), and \(Z_{it}\) with an unknown correlation structure. Hence, model (1.1) is a fixed effects model.
It is well known that in many fields, such as engineering, economics, biology, biomedical sciences and epidemiology, observations are measured with error. For example, urinary sodium chloride level (Wang et al. 1996) and serum cholesterol level (Carroll et al. 1995) are often subjects to measurement errors. Simply ignoring measurement errors (errors-in-variables), known as the naive method, would result in biased estimators. Handing the measurement errors in covariates is generally a challenge for statistical analysis. For the past two decades, errors-in-variables can be handled by means of corrected score function (Nakamura 1990), corrected likelihood method (Hanfelt and Liang 1997), the instrumental variables estimation approach (Schennach 2007) and so on.
Specifically, we consider the following partially linear errors-in-variables panel data models with fixed effects
where the covariate variables \(X_{it}\) are measured with additive error and are not directly observable. Instead, \(X_{it}\) are observed \(W_{it}=X_{it}+\nu _{it}\), where the measurement errors \(\nu _{it}\) are independent and identically distributed, independent of \((X_{it},Z_{it},\varepsilon _{it})\), with mean zero and covariance matrix \(\Sigma _{\nu }\). We will assume that \(\Sigma _{\nu }\) is known, as in the papers of Zhu and Cui (2003) and You and Chen (2006) and other. When \(\Sigma _{\nu }\) is unknown, we can estimate it by repeatedly measuring \(W_{it}\); see Liang et al. (1999) and Fan et al. (2013) for details.
It is well-known that high-dimensional data analysis arises frequently in many contemporary statistical studies. The emergence of high-dimensional data, such as the gene expression values in microarray, brings challenges to many traditional statistical methods and theory. One important aspect of the high-dimensional data under the regression setting is that the number of covariates is diverging. When dimensionality diverges, variable selection through regularization has proven to be effective. As argued in Hastie et al. (2009) and Fan and Lv (2008), penalized likelihood can properly adjust the bias-variance trade-off so that the performance improvement can be achieved; Various powerful penalization methods have been developed for variable selection. Fan and Li (2001) proposed a unified approach via nonconcave penalized least squares to automatically and simultaneously select variables. Li and Liang (2008) developed the nonconcave penalized quasilikelihood method for variable selection in semiparametric regression model. Recently, a new and efficient variable selection approach, PEL introduced for the first time by Tang and Leng (2010), was applied to analyze mean vector in multivariate analysis and regression coefficients in linear models with diverging number of parameters. As demonstrated in Tang and Leng (2010), the PEL has merits in both efficiency and adaptivity stemming from a nonparametric likelihood method. Also, the PEL method possesses the same merit of the empirical likelihood (EL) which only uses the data to determine the shape and orientation of confidence regions and without estimating the complex covariance. As far as we know, there are a few papers related to the PEL approach, such as Ren and Zhang (2011) proposed the PEL approach for variable selection in moment restriction models; Leng and Tang (2012) applied the PEL approach to parametric estimation and variable selection for general estimating equations; Wang and Xiang (2017) studied PEL inference for sparse additive hazards regression with a diverging number of covariates.
It is worth pointing out that there is no result available in the literature when the number of covariates is diverging in partially linear errors-in-variables panel data models with fixed effects. In this paper, our aim is to extend the results in Fan et al. (2016) for high-dimensional partially linear varying coefficient model with measurement errors to partially linear error-in-variables panel data models with fixed effects. Our contribution can be summarized as follows. Following the estimation procedure proposed by Fan et al. (2005), we first adapt a local linear dummy variable approach to remove the unknown fixed effects. Moreover, we utilize the EL method to construct confidence regions of unknown parameter and establish asymptotic normality of maximum empirical likelihood (MEL) estimator of the parameter. At last, for building sparse models, we propose an estimating equation-based PEL, a unified framework for variable selection in optimally combining estimating equations. More specifically, this method has the oracle property. Moreover, PEL ratio statistic shows the Wilks’ phenomenon, facilitating hypothesis testing and constructing confidence regions.
The layout of the remainder of this paper is as follows. In Sect. 2, we construct corrected-attenuation EL ratio and test statistic as well as define the MEL and PEL estimators of the parameter and give their asymptotic properties. Moreover, empirical log-likelihood ratio for the nonparametric part is also investigated. Finally, we briefly introduce computational algorithm. The simulated example is provided in Sect. 3. Section 4 summarizes some conclusions and discusses future research. Assumption conditions and the proofs of the asymptotic results are given in Appendix.
2 Methodology and main results
2.1 Modified empirical likelihood
We give vector and matrix notations in the following. Let \(Y=(Y_1^{\tau },\ldots ,Y_n^{\tau })^{\tau }\), \(X=(X_1^{\tau },\ldots , X_n^{\tau })^{\tau }\), \(Z=(Z_1^{\tau }, \ldots ,Z_n^{\tau })^{\tau }\), \(\mu _0=(\mu _1^{\tau },\ldots ,\mu _n^{\tau })^{\tau }\) and \(\varepsilon =(\varepsilon _1^{\tau },\ldots ,\varepsilon _n^{\tau })^{\tau }\) be \(nT\times 1\) vectors, where \(Y_i=(Y_{i1},\ldots ,Y_{iT})^{\tau }\), \(X_i=(X_{i1},\ldots ,X_{iT})^{\tau }\), \(Z_i=(Z_{i1},\ldots ,Z_{iT})^{\tau }\), \(\varepsilon _i=(\varepsilon _{i1},\ldots ,\varepsilon _{iT})^{\tau }\), and \(D_0=I_{n}\otimes i_T \) with \(\otimes \) the Kronecker product, \(I_n\) denotes the \(n\times n\) identity matrix, and \(i_n\) denotes the \(n\times 1\) vector of ones. We rewrite model (1.1) in a matrix format which yields
For the identification purpose, we impose the restriction \(\sum ^n_{i=1}\mu _i=0\). Letting \(D=[-i_{n-1}\quad I_{n-1}]\otimes i_T \) and \(\mu =(\mu _2,\ldots ,\mu _n)^\tau \), model (2.1) can then be rewritten as
Let \(G_{it}(z,h)=(1, (Z_{it}-z)/h)^{\tau }\), \(K_h(z)=K(\cdot /h)/h\) with a kernel function \(K(\cdot )\) and a bandwidth h. The diagonal matrices
and \(\zeta =(\mu ^\tau ,\beta ^\tau )^\tau \). Given \(\zeta \), we can estimate the functions \(g(\cdot )=(g(z),\{hg'(z)\}^{\tau })^{\tau }\) by
Let \(G(z,h)=[G_1^{\tau }(z,h),\ldots , G_n^{\tau }(z,H)]^{\tau }\), \(G_i(z,h)=(G_{i1}(z,h),\ldots , G_{iT}(z,h))^{\tau },\) \(g'(z)=\partial g(z)/\partial z\) and \(z=z_{it}\) is in a neighborhood of \(Z_{it}\). Then the solution of problem (2.3) is given by
In particular, the estimator for g(z) is given by
where \(s(z,h)=(1~~0)S(z,h)\).
Now we consider a way of removing the unknown fixed effects motivated by a least squares dummy variable model in parametric panel data analysis, for which we solve the following optimization problem:
where the smoothing matrix S is
Supposing that \(\widetilde{X}=(I_{nT}-S)X\), \(\widetilde{Y}=(I_{nT}-S)Y\), \(\widetilde{D}=(I_{nT}-S)D\), we have \(\widetilde{\mu }=(\widetilde{D}^{\tau }\widetilde{D})^{-1}\widetilde{D}^{\tau }(\widetilde{Y}-\widetilde{X}\beta )\). Let \(H=I_{nT}-\widetilde{D}(\widetilde{D}^{\tau }\widetilde{D})^{-1}\widetilde{D}^{\tau },\) we can obtain \(H\widetilde{D}\mu =0\). Hence, the fixed effects term \(D\mu \) is eliminated in (2.3). Let \(e_{it}\) be the \(nT\times 1\) vector with its \(\{(i-1)T+t\}\)th element being 1 and others 0. We state the approximate residuals as the following:
However, \(X_{it}\)’s can not be observed in our case and we just have \(W_{it}\). If we ignore the measurement error and replace \(X_{it}\) with \(W_{it}\) in (2.4) directly, (2.4) can be used to show that the resulting estimate is inconsistent. It is well known that in linear regression or partially linear regression, inconsistency caused by the measurement error can be overcome by applying the so-called “correction for attenuation”, see Liang et al. (1999) and Hu et al. (2009) for more details.
Note that \(E(\Gamma _i(\beta ))=0\), if \(\beta \) is the true parameter. Therefore, similar to Owen (1990), we define a corrected-attenuation empirical likelihood (CAEL) ratio of \(\beta \) as.
With the assumption that 0 is inside the convex hull of the point \((\Gamma _1(\beta ),\ldots ,\Gamma _n(\beta ))\), a unique value for \(R_{n}(\beta )\) exists. By the Lagrange multiplier method, one can obtain that
where \(\gamma \) is determined by
Theorem 2.1
Suppose that the conditions of (B1)–(B7) in the Appendix hold. Further assume that \(E(\varepsilon ^3|X,Z)=0\) almost surely or \(k\ge 8\). If \(\beta _0\) is the true value of the parameter vector and \({\mathop {\rightarrow }\limits ^{d}}\) stands for convergence in distribution, \(p^{3+2/(k-2)}/n\rightarrow 0\) as \(n\rightarrow \infty \), then \((2p)^{-1/2}(2R_{n}(\beta _0)-p){\mathop {\rightarrow }\limits ^{d}}N(0,1)\).
Define \(\hat{\beta }_{ME}=\arg \min _{\beta }R_{n}(\beta )\), which is the MEL estimator of the parameter \(\beta \).
Theorem 2.2
Under the conditions of Theorem 2.1, we have
\(A_n\) represents a projection of the diverging dimensional vector to a fixed dimension s, and \(A_n\) is a \(s\times p\) matrix such that \(A_nA_n^{\tau }\rightarrow \Delta \),\(\Delta \) is a \(s\times s\) nonnegative symmetric matrix with fixed s, and \(\Omega =\Sigma _0^{-1}\Sigma _1\Sigma _0^{-1}\), \(\Sigma _1=(T-1)\big \{E(\varepsilon _{11}-\nu _{11}\beta _0)^2\Sigma _2 +\sigma ^2\Sigma _{\nu }+ E[(\nu _{11}\nu _{11}^{\tau }-\Sigma _{\nu })\beta _0]^2\big \}\), \(\Sigma _2=E\{[{X_{11}}-E({X_{11}}|Z_{11})]^{\tau }[{X_{11}}-E({X_{11}}|Z_{11})]\}\) and \(\Sigma _0=(T-1)\Sigma _2\).
Further, \(\widehat{\Sigma }_2^{-1}\widehat{\Sigma }_1\widehat{\Sigma }_2^{-1}\) is a consistent estimator of \(\Sigma _2^{-1}\Sigma _1\Sigma _2^{-1}\) where \(\widehat{\Sigma }_2=\frac{1}{n}\widetilde{W}^{\tau }H\widetilde{W}-(T-1)\Sigma _{\nu }\) and \(\widehat{\Sigma }_1=\{\frac{1}{n}\sum _{i=1}^n\sum _{t=1}^T[\widetilde{W}_{it}^{\tau }H(\widetilde{Y}_{it}-\widetilde{W}_{it}\widehat{\beta })]+(T-1)(\Sigma _{\nu }\widehat{\beta })\}^{\oplus 2}\) and \(\mathbf {A}^{\oplus 2}\) means \(\mathbf {A}\mathbf {A}^{\tau }\). By Theorem 2.2, we obtain that
2.2 Penalized empirical likelihood for variable selection
We use the PEL by combining the profile likelihood method and the smoothly clipped absolute deviation (SCAD) penalized approach. The SCAD penalty is defined in terms of its first derivative.
We define the penalized empirical likelihood (PEL) as follows,
where \(p_{\lambda }(\cdot )\) is a penalty function with tuning parameter \(\lambda \). See Fan and Li (2001) for example of this function. In this paper, we use the smoothly clipped absolute deviation penalty, whose first derivative satisfies
for some \(a>2\) and \(p_{\lambda }'(0)=0\). Following Fan and Li (2001), we set \(a=3.7\) in our work.
Maximizing the PEL function (2.8) is equivalent to minimizing
Let \(\mathcal {B}=\{j:\beta _{0j}\}\) be the set of nonzero components of the true parameter vector \(\beta _0\) and its cardinality \(|\mathcal {B}|=d\) where d is allowed grow as \(n\rightarrow \infty \). Without loss of generality, one can partition the parameter vector as \(\beta =(\beta _1^{\tau },\beta _2^{\tau })^{\tau }\) where \(\beta _1\in \mathbb {R}^d\) and \(\beta _2\in \mathbb {R}^{p-d}\). Hence, the true parameter \(\beta _0=(\beta _{10}^{\tau },0^{\tau })^{\tau }\) and we write \(\widehat{\beta }=(\widehat{\beta }_1^{\tau },\widehat{\beta }_2^{\tau })^{\tau }\) called PEL estimator which is the minimizer of (2.13). The matrix \(\Omega \) can be decomposed as a block matrix according to the arrangement of \(\beta _0\) as \(\Omega =\left( \begin{array}{cc} \Omega _{11}&{} \Omega _{12}\\ \Omega _{21} &{} \Omega _{22} \end{array}\right) .\)
Theorem 2.3
Suppose that Assumptions (B1)–(B9) hold. If \(p^5/n\rightarrow 0\), then with probability tending to 1, the PEL estimator \(\widehat{\beta }\) satisfies
-
(a)
(Sparity): \(\widehat{\beta }_2=0\);
-
(b)
(Asymptotic normality): \(n^{1/2}W_n\Omega _p^{-1/2}(\widehat{\beta }_1-\beta _{10}){\mathop {\rightarrow }\limits ^{d}}N(0,G)\), where \(W_n\in R^{q \times d}\) such that \( W_n W_n^{\tau }\rightarrow G\) for \(G\in R^{q\times q}\) with fixed q and \(\Omega _p=\Omega _{11}-\Omega _{12}\Omega _{22}^{-1}\Omega _{21}\).
A remarkable advantage of PEL lies in testing hypotheses and constructing confidence regions for \(\beta \). To understand this more clearly, we consider the problem of testing linear hypothesis:
where \(L_n\) is \(q\times s\) matrix such that \(L_nL_n^{\tau }=I_q\) for a fixed and finite q. A nonparametric profile likelihood ratio statistic is constructed as
We summarize the property of the test statistic in the following theorem.
Theorem 2.4
Under the conditions of Theorem 2.3. Then under the null hypothesis \(H_0\), we have
As a consequence of the theorem, confidence regions for the parameter \(\beta \) can be constructed. More precisely, for any \( 0\le \alpha <1\), let \(c_{\alpha }\) be such that \(P(\chi _q^2>c_{\alpha })\le 1-\alpha \). Then \(\ell _{PEL}(\alpha )=\{\beta \in R^p:\widetilde{\mathcal {L}}_{n}({\beta })\le c_{\alpha }\}\) constitutes a confidence region for \(\beta \) with asymptotic coverage \(\alpha \) because the event that \(\beta \) belongs to \(\ell _{PEL}(\alpha )\) is equivalent to the event that \(\widetilde{\mathcal {L}}_{n}({\beta })\le c_{\alpha }\).
2.3 Empirical likelihood for the nonparametric part
For model (2.2), we solve the the following optimization problem:
we have \(\mu =({D}^{\tau }{D})^{-1}{D}^{\tau }[Y-X\beta -g(Z)]\). For given \(\beta \) and z, an auxiliary random vector for nonparametric part can be stated as
where \(Q=D({D}^{\tau }{D})^{-1}{D}^{\tau }\). Note that \(E[\Xi _{i}\{g(z)\}]=0\) if g(z) is the true parameter. Thus we can define an empirical log-likelihood ratio statistic for g(z) by using the methodology in Owen (1988). We introduce an adjusted auxiliary random vector for g(z) as follows.
By the adjustment in \(\hat{\Xi }_{i}\{g(z)\}\), we not only correct the bias, but also avoid undersmoothing the function g(z), as proved in the Appendix. The adjusted empirical log-likelihood ratio for g(z) can be defined as
By the Lagrange multiplier method, one can obtain that
where \(\phi \) is determined by
Theorem 2.5
Suppose that the conditions of (B1)–(B9) in the Appendix hold. For a given \(z\in \mathcal {Z}\), if g(z) is the true value of the parameter, then
2.4 Computational algorithm
This section employs the local quadratic approximation algorithm to obtain the minimizer of PEL ratio defined by (2.13). Specifically, for each \(j=1,\ldots , p, [p_{\lambda }(|\beta _j|)]'\) can be locally approximated by the quadratic function defined as \([p_{\lambda }(|\beta _j|)]'=p'_{\lambda }(|\beta _j|)sgn(\beta _j)\approx \{p'_{\lambda }(|\beta _{j0}|/|\beta _{j0}|)\}\beta _j\) at an initial value \(\beta _{j0}\) of \(\beta _j\) is not close to 0; otherwise, we set \(\hat{\beta }_j=0\). In other words, in a neighborhood of a given nonzero \(\beta _{j0}\), we assume that \(p_{\lambda }(|\beta _{j}|)\approx p_{\lambda }(|\beta _{j0}|)+\frac{1}{2}\{p'_{\lambda }(|\beta _{j0}|/|\beta _{j0}|\}(\beta _j^2-\beta _{j0}^2)\). We then make use of algorithm (see Owen, 2001) to obtain the minimum through nonlinear optimization. The procedure is repeated until convergence.
We apply the following Bayesian information criterion (BIC) to select the tuning parameter \(\lambda \), which is defined by
where \(df_{\lambda }\) is the number of nonzero estimated parameters. Then the optimal tuning parameter is the minimizer of the BIC.
3 Simulation studies
In this section, we carry out some simulation to study the finite sample performance of our proposed method. Throughout this section, we choose the Epanechnikov kernel \(K(u)=\frac{3}{4}(1-u^2)I\{|u|\le 1\}\) and use the “leave-one-subject-out” cross-validation bandwidth method to select the optimal handwidth \(h_{opt}\).
Firstly, we consider the following partially linear errors-in-variables panel data models with fixed effects:
where \(\beta =(3,1.5,0,0,2,0,\ldots ,0)^{\tau }\), \(g(Z_{it})=\cos (2\pi Z_{it})\), \(Z_{it}{\sim }U(0,1)\), \(\mu _i=\frac{1}{2}\bar{Z_i}+w_i\) and \(w_i{\sim }N(0,0.1^2)\) for \(i=1,2,\ldots ,n\), and \( \bar{Z_i}=\frac{1}{T}\sum _{t=1}^{T}Z_{it}.\) The measurement error \(\nu _{it}{\sim }N(0,\Sigma _{\nu })\) where we take \(\Sigma _{\nu }=0.2^2I_{10}\) and \(0.4^2I_{10}\) to represent different levels of measurement error. The covariate \(X_{it}\) is a p-dimensional normal distribution random vector with mean zero and covariance matrix cov\((X_{it},X_{jt})=0.5^{|i-j|}\).
In our simulations, we take p as the integer part of \(10(6n)^{1/5.1}-20\) and the sample sizes \((n,T)=(50,4), (50,6)\) and (100, 6), respectively. In order to show the performance of the proposed methods, we compare MEL and PEL estimators with the native maximum empirical likelihood (NMEL) and native penalized empirical likelihood (NPEL) estimators that the neglecting the measurement errors with a direct replacement of X by W in our proposed estimators. In each case the number of simulated realizations is 500.
Seen from Table 1, when the nominal level is 0.9 and 0.95, shows the coverage probability of confidence region for the whole \(\beta \) constructed by MEL and PEL method, respectively. From the results, we can see that the PEL confidence region has slightly higher coverage probability than the NEL confidence region, and the coverage probability tends to the nominal level as the sample size increases.
From Table 2, we can see the average model errors (ME) and the standard deviations (SD) of the \(\beta _1\) that is nonzero components of \(\beta \). based on PEL and MEL estimators decreases as the sample size increases and the PEL estimator gives the smallest ME and SD among the estimators based on PEL, MEL, NPEL and NMEL methods for all settings. The ME is defined as \(ME(\hat{\beta _1})=(\hat{\beta _1}-\beta _1)^{\tau }E(X^{\tau }X)(\hat{\beta _1}-\beta _1).\)
Table 3 summaries the variable selection results, where important variable have large effects. The column labeled “C” gives average number of correct zeros and column labeled “I” gives the average number of incorrect zeros. From Table 3, it can be seen that variable selection method based on the PEL select all three true predictors and the average number of correct zeros are close to \(p-5\) in all settings. Further the smaller measurement errors lead to better performance. It can also be seen that the PEL approach perform better than the NPEL method for all settings. These findings imply that the model selection result based on the PEL approach effectively reduces model complexity and the selected model is very close to the true model in terms of nonzero coefficients.
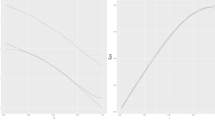
From Fig. 1, We see that the method based on the EL performs slighter better than the NA method since the EL method gives shorter confidence intervals than the NA method which is shown in Theorem 4 in Xue and Zhu (2008). Besides, interestingly, seen from Fig. 1, \(\Sigma _v=0.2\) gives shorter confidence intervals and narrower confidence bands than \(\Sigma _v=0.4\) for g(z). This shows the empirical likelihood ratio generally works well.

95% confidence intervals for g(z) for \(\Sigma _v=0.2\) (left panel) and \(\Sigma _v=0.4\) (right panel) based on EL (dotted curve) and NA (dot-dashed curve). The solid curve is the estimated cure of g(z)
4 Conclusion remarks
The partially linear panel data models with fixed effects has received a lot of attention. But there have been few studies about partially linear errors-in-variables panel data models with fixed effects. We apply empirical likelihood both for parameter and nonparametric parts. Moreover, we propose PEL and variable selection procedure for the parameter with diverging numbers of parameters. By using an appropriate penalty function, we show that PEL estimators has the oracle property. Also, we introduce the PEL ratio statistic to test a linear hypothesis of the parameter and prove it follows an asymptotically chi-square distribution under the null hypothesis. We conduct simulation studies to demonstrate the finite sample performance of our proposed method. Still, more work is needed to extend the method to more complex settings, including errors-in-function, cross-sectional dependence and spatial panel data model. The results presented in this paper provide the foundation for additional work in these directions.
References
Arellano M (2003) Panel data econometrics. Oxford University Press, New York
Baltagi BH (2005) Econometric analysis of panel data, 2nd edn. Wiley, New York
Baltagi BH, Li D (2002) Series estimation of partially linear panel data models with fixed effects. Ann Econ Fin 3(1):103–116
Cai Z, Li Q (2008) Nonparametric estimation and varying coefficient dynamic panel data models. Econom Theory 24:1321–1342
Carroll RJ, Ruppert D, Stefanski LA (1995) Measurement error in nonlinear models. Chapman & Hall, London
Chen J, Gao J, Li D (2013) Estimation in partially linear single-index panel data models with fixed effects. J Bus Econ Stat 31(3):315–330
Fan J, Huang T (2005) Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli 11(6):1031–1057
Fan J, Li R (2001) Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc 96:1348–1360
Fan J, Lv J (2008) Sure independence screening for ultrahigh dimensional feature space. J R Stat Soc Ser B 70(5):849–911
Fan J, Peng H, Huang T (2005) Semilinear high-dimensional model for normalization of microarrays data: a theoretical analysis and partial consistency. J Am Stat Assoc 100:781–796
Fan GL, Liang HY, Wang JF (2013) Statistical inference for partially time-varying coefficient errors-in-variables models. J Stat Plan Inference 143:505–519
Fan GL, Liang HY, Shen Y (2016) Penalized empirical likelihood for high-dimensional partially linear varying coefficient model with measurement errors. J Multivar Anal 147:183–201
Hall P, Heyde CC (1980) Martingale limit theory and its application. Academic Press, New York
Hanfelt JJ, Liang KY (1997) Approximate likelihood for generalized linear errors-in-variables models. J R Stat Soc Ser B 59(3):627–637
Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer, New York
He BQ, Hong XJ, Fan GL (2017) Block empirical likelihood for partially linear panel data models with fixed effects. Stat Probab Lett 123(4):128–138
Henderson DJ, Carroll RJ, Li Q (2008) Nonparametric estimation and testing of fixed effects panel data models. J Econom 144:257–275
Horowitz JL, Lee S (2004) Semiparametric estimation of a panel data proportional hazards model with fixed effects. J Econom 119:155–198
Hsiao C (2003) Analysis of panel data, 2nd edn. Cambridge University Press, New York
Hu XM (2014) Estimation in a semi-varying coefficient model for panel data with fixed effects. J Syst Sci Complex 27:594–604
Hu XM (2017) Semi-parametric inference for semi-varying coefficient panel data model with individual effects. J Multivar Anal 154:262–281
Hu XM, Wang Z, Zhao Z (2009) Empirical likelihood for semiparametric varying-coefficient partially linear errors-in-variables models. Stat Probab Lett 79(8):1044–1052
Leng C, Tang CY (2012) Penalized empirical likelihood and growing dimensional general estimating equations. Biometrika 99(3):703–716
Li R, Liang H (2008) Variable selection in semiparametric regression modeling. Ann Stat 36(1):261–286
Li DG, Chen J, Gao JT (2011) Non-parametric time-varying coefficient panel data models with fixed effects. Econometrics 14:387–408
Li G, Lin L, Zhu L (2012) Empirical likelihood for a varying coefficient partially linear model with diverging number of parameters. J Multiva Anal 105:85–111
Liang H, Härdle W, Carroll RJ (1999) Estimation in a semiparametric partially linear errors-in-variables model. Ann Stat 27:1519–1535
Nakamura T (1990) Corrected score function for errors-in-variables model: methodoology and application to generalized linear models. Biometrika 77(1):127–137
Owen AB (1988) Empirical likelihood ratio confidence intervals for a single functional. Biometrika 75:237–249
Owen AB (1990) Empirical likelihood ratio confidence regions. Ann Stat 18:90–120
Ren Y, Zhang X (2011) Variable selection using penalized empirical likelihood. Sci China Math 54(9):1829–1845
Rodriguez-Poo JM, Soberon A (2014) Direct semi-parametric estimation of fixed effects panel data varying coefficient models. Econom J 17(1):107–138
Schennach SM (2007) Instrumental variable estimation of nonlinear errors-in-variables models. Econometrics 75:201–239
Su LJ, Ullah A (2006) Profile likelihood estimation of partially linear panel data models with models with fixed effects. Econom Lett 92:75–81
Su L, Ullah A (2007) More efficient estimation of nonparametric panel data models with random effects. Econom Lett 96(3):375–380
Tang CY, Leng C (2010) Penalized high-dimensional empirical likelihood. Biometrika 97(4):905–920
Wang S, Xiang L (2017) Penalized empirical likelihood inference for sparse additive hazards regression with a diverging number of covariates. Stat Comput 27(5):1347–1364
Wang N, Carroll RJ, Liang KY (1996) Quasi-likelihood and variance functions in measurement error models with replicates. Biometrics 52:423–432
Xue LG, Zhu LX (2008) Empirical likelihood-based inference in a partially linear model for longitudinal data. Sci China Ser A 51(1):115–130
You JH, Chen GM (2006) Estimation in a statistical inference in a semiparametric varying-coefficient partially linear errors-in-variables model. J Multivar Anal 97:324–341
Zhou HB, You JH, Zhou B (2010) Statistical inference for fixed-effects partially linear regression models with errors in variables. Stat Papers 51:629–650
Zhu LX, Cui HJ (2003) A semiparametric regression model with errors in variables. Scand J Stat 30:429–442
Acknowledgements
The authors are grateful to two anonymous referees for providing detailed lists of comments and suggestions which greatly improved the presentation of the paper. This research is supported by the National Social Science Fund of China (18BTJ034).
Author information
Authors and Affiliations
Corresponding author
Appendix: Proofs of the main results
Appendix: Proofs of the main results
We use Frobenius norm of a matrix A, defined as \(||A||=\{tr(A^{\tau }A)\}^{1/2}\). Before we give the details of the proofs, we present some regularity conditions.
-
(B1)
The random vector \(Z_{it}\) has a continuous density function \(f(\cdot )\) with a bounded support \(\mathcal {Z}\). \( 0<inf_{z\in \mathcal {Z}}f(\cdot )\le sup_{z\in \mathcal {Z}}f(\cdot )<\infty \).
-
(B2)
The functions \(E(X_{it}|Z_{it}=z)\) and \(g(\cdot )\) have two bounded and continuous derivatives on \(\mathcal {Z}\).
-
(B3)
The kernel K(v) is a symmetric probability density function with a continuous derivative on its compact support \(\mathcal {Z}\).
-
(B4)
\((\mu _i,W_{it}, Z_{it}, \varepsilon _{it}),~ i=1,\ldots ,n,~t=1,\ldots ,T\) are i.i.d. \(E(\varepsilon |W,Z,\mu )=0\) almost surely. Furthermore, for some integer \(k\ge 4,\) \(E(||W\varepsilon ||^k)\le \infty ,\) \(E(||W||^k)\le \infty ,\) \(E(|\varepsilon |^k)\le \infty .\)
-
(B5)
\(E|\breve{X}_{it}|^{2+\delta }<\infty \), \(\Sigma =E[\breve{X}_{it}\breve{X}_{it}^{\tau }]\) is non-singular, where \(\breve{X}_{it}=X_{it}-E(X_{it}|Z_{it}).\)
-
(B6)
The bandwidth h satisfies \(h\rightarrow 0\), \(Nh^8\rightarrow 0\) and \(Nh^2/(logN)^2\rightarrow \infty \) as \(n\rightarrow \infty \).
-
(B7)
\(\Sigma _1\) and \(\Sigma _2\) are positive definite matrices with all eigenvalues being uniformly bounded away from zero and infinity.
-
(B8)
Let \(\varpi _1=\sum _{t=1}^T\frac{T-1}{T}(X_{it}-E(X_{it}|U_{it}))(\varepsilon _{it}-\nu _{it}\beta _0)\), \(\varpi _2=\sum _{t=1}^T\frac{T-1}{T}\nu _{it}\varepsilon _{it}\), \(\varpi _3=\sum _{t=1}^T\frac{T-1}{T}(\nu _{it}\nu _{it}^{\tau }-\Sigma _{\nu })\beta _0\) and \(\varpi _{sj}, j=1,\ldots ,p\) be the j-th component of \(\varpi _{s}.\) For k of condition (B4), there is a positive constant c such that as \(n\rightarrow \infty \), \(E(||\varpi _{s}/\sqrt{p}||^k)\le c, s=1,2,3\).
-
(B9)
The \(p_{\lambda }(\cdot )\) satisfy \(\mathop {max}\limits _{j\in \mathcal {B}}p_{\lambda }'(|\beta _{j0}|)=o((np)^{-1/2})\) and \( \mathop {max}\limits _{j\in \mathcal {B}}p_{\lambda }''(|\beta _{j0}|)=o(p^{-1/2}) \).
Note that the obove conditions are assumed to hold uniformly in \(z\in \mathcal {Z}\). Conditions (B1)–(B9) while look a bit lengthy, are actually quite mild and can be easily satisfied. (B1)–(B2) are standard in the literature on local linear/polynomial estimation. B5 implies \(E(\varepsilon _{it}|X_i,Z_i,\mu _i)=E(\varepsilon _{it}|X_{it},Z_{it},\mu _{it})=0.\) (B1)–(B5) can be founded in Su and Ullah 2006. (B6) and (B7) have been used in Zhou et al. (2010).
For the convenience and simplicity, let \(\vartheta _k=\int z^kK(z)dz\), \(c_N=\{log(1/h)/(Nh)\}^{1/2}+h^2\) and \(\widetilde{M}_{\widetilde{D}}=\widetilde{D}(\widetilde{D}^{\tau }\widetilde{D})^{-1}\widetilde{D}^{\tau }\)
Lemma A.1
Suppose that Assumptions (B1)–(B6) hold. Then
Proof
Note that
Each element of the above matrix is in the form of a kernel regression. Similar to the proof of Lemma A.2 in Fan and Huang (2005), we can derive the desired result. \(\square \)
Lemma A.2
Suppose that Assumptions (B1)–(B6) hold, we have
Proof
Similar to the proof of Lemma 5.1 in He et al. (2017). \(\square \)
Lemma A.3
Suppose that Assumptions (B1)–(B6) hold, we have
where \(\Sigma _2=E\{[{X_{11}}-E({X_{11}}|Z_{11})]^{\tau }[{X_{11}}-E({X_{11}}|Z_{11})]\}.\)
Proof
By Lemma A.1, we can obtain
Then we have
and
By the law of large numbers, we have
Hence, to prove the lemma, we consider the limit of \(N^{-1}\widetilde{{W}}^{\tau }\widetilde{M}_{\widetilde{D}}\widetilde{{W}}\). It is easy to show that \(N^{-1}\widetilde{{W}}^{\tau }\widetilde{M}_{\widetilde{D}}\widetilde{{W}}=N^{-1}A^{\tau }\widetilde{M}_{\widetilde{D}}A+O_p(c_N)\). Let \((\widetilde{M}_{\widetilde{D}})_{e_{kl}e_{it}}\triangleq m_{e_{kl}e_{it}}\) and \((A)_{it}\triangleq a_{it}=\widetilde{{W}}_{it}\), where \(e_{kl}=(k-1)T+l\). Then
For the term \(I_2\), we have
Note that \((X_{11},Z_{11}),\ldots ,(X_{nT},Z_{nT})\) are i.i.d. and \(E(a_{it}|Z_{it})=0\), when \(e_{kl}\ne e_{rs}\) and \(e_{it}\ne e_{uv}\), we have
Using the same argument and \(m_{e_{kl}e_{it}}=m_{e_{it}e_{kl}}\), we have
By Conditions (B3), we obtain
where c is a constant. Hence
Note that \(I_1\) can be decomposed as
By the definition of S, it is easy to show that
where
Let \(D_1\) is the first column vector of D, thus we have
Because
and
we have
Consider the projection matrix, for \(i=1,\ldots ,T\), we obtain
Because \({\widetilde{D}}_1\) is the first column vector of \({\widetilde{D}}\). It is easy to show that \(\widetilde{M}_{\widetilde{D}}\widetilde{M}_{{\widetilde{D}}_1}=\widetilde{M}_{{\widetilde{D}}_1}\widetilde{M}_{\widetilde{D}}=\widetilde{M}_{{\widetilde{D}}_1}\). Hence, \(\widetilde{M}_{\widetilde{D}}-\widetilde{M}_{{\widetilde{D}}_1}\) is also a projection matrix. Thus \(\widetilde{M}_{\widetilde{D}}-\widetilde{M}_{\widetilde{D}_1}=(\widetilde{M}_{\widetilde{D}}-\widetilde{M}_{{\widetilde{D}}_1})^2\ge 0 \). We obtain \((\widetilde{M}_{\widetilde{D}})_{ii}\ge (\widetilde{M}_{{\widetilde{D}}_1})_{ii}=\frac{1}{T}+O_p(\frac{1}{Nh}),~i=1,\ldots ,T\). By a similar argument, we can show that \((\widetilde{M}_{\widetilde{D}})_{ii}\ge \frac{1}{T}+O_p(\frac{1}{Nh}),i=T+1,\ldots ,N\). Thus, we have
then, it is easy to show that
Hence, we have
By (A.2), it is easy to show that
By the law of large numbers, \(\Pi _1\) is bounded as
By (A.2), (A.3) and (A.6), the lemma holds. \(\square \)
Lemma A.4
Under the conditions of Theorem 2.1, if \(\beta \) is the true value of the parameter, we have
Proof
Since the proof of (A.8) is similar of (A.7), we prove only (A.7)here. Let \(\zeta _N=N^{1/2}/log(N)\),
The second term is \(o_p(1)\) by Lemma A.2. For the first term, let \(R_{it}\) be the event that \(|\widetilde{g}_{it}|\le ch^4\). Then
Since \(\widetilde{g}_{it}\{I(R_{it})=1\}\le ch^4\) is independent of \(\nu _{it}\), the first term is \(O\{N\zeta _N^{-2}c^2h^8\}=o(1)\). The second term is easily seen to equal zero. \(\square \)
Lemma A.5
Under the conditions of Theorem 2.1, if \(\beta _0\) is the true value of the parameter, we have
Proof
From the definition of \(\Gamma _{i}(\beta )\) by (2.7), and a simple calculation, yields
By Lemma A.1, we have \(S\varepsilon =O_p(c_N)\). Similar to the proof of Lemma A.3 and under Assumption (B7), we have \(\frac{1}{\sqrt{N}}\widetilde{{X}}^{\tau }HS\varepsilon =O(\sqrt{N}c_N^2)=o_p(1)\). Therefore
Similar to the proofs of (A.12), we can derive that
which combining with Lemma A.4, it is easy to obtain
Therefore, we have
Let \(\varpi _s^{*}=\mathop {max}\limits _{1\le i\le n}||\varpi _{si}||,~s=1,2,3\), and \(\{\varpi _{si}, i=1,\ldots , n \}\) is a sequence of independent random variables with common distribution. for any \(\varepsilon \ge 0\), then
From conditions (B4) and (B7) and Cauchy-Schwarz inequality yields that \(\varpi _1^{*}=o_p(\sqrt{p}n^{1/k}).\) By the condition \(p=o(n^{(k-2)/(2k)}\) in Theorem 2.1, it is easy to check that \(\varpi _1^{*}=o_p(\sqrt{n/p}n^{2-k/(2k)}p)=o_p(\sqrt{n/p})\). Similar to the proof, we obtain \(\varpi _2^{*}=o_p(\sqrt{n/p})\) and \(\varpi _3^{*}=o_p(\sqrt{n/p})\). Then \(\mathop {max}\nolimits _{1\le i\le n}||\Gamma _i(\beta _0)||=o_p(\sqrt{n/p}).\)
By applying the martingale central limit theorem as give in Hall and Heyde (1980) and (A.13), it is easy to obtain (A.11). The proof of Lemma A.5 is thus completed. \(\square \)
Lemma A.6
Under the conditions of Theorem 2.1. Denote\(D_n=\{\beta :||\beta -\beta _0||\le ca_n\}\) Then \(||\gamma (\beta )||=O_p(a_n)\), for \(\beta \in D_n\).
Proof
For \(\beta \in D_n\), let\(\gamma (\beta )=\rho \theta \), where\(\rho \ge 0, \theta \in R^p\), and \(||\theta ||=1\). Set
From (2.7), we can obtain
Then
Observe that
Let \(\mathcal {X}_{it}=\widetilde{W}_{it}H\widetilde{W}_{it}\) According to Condition (B.7) and Minkowski inequality, we have
Then we obtain that
which combining with (A.11)
For \(\bar{\Gamma }(\beta )\), it is easy to see that
Similar to the proofs of (A.10) in Fan et al. (2016), we obtain
Therefore, it follows from (A.15) and (A.16), we have \(\mathop {max}\nolimits _{1\le i\le n}||\Gamma _i(\beta )||=n^{-1}|\sum _{i=1}^n\).
From (2.7), similar to the proof (A.11) in Fan et al. (2016) and Lemma B.4 in Li et al. (2012), we can derive \(tr[(J(\beta _0)-\Sigma _1)^2]=O_p(p^2(c_n^4+1/n))\) which means that all the eigenvalues of \(J(\beta _0)\) converge to those of \(\Sigma _1\) at the rate of \(O_p(p^2(c_n^4+1/n))\). Therefore, by Lemma A.2, (2.7), (A.16), together with Condition (B7), we have
we can obtain \(\theta ^{\tau }J(\beta )\theta =\theta ^{\tau }\Sigma _1\theta {\mathop {\rightarrow }\limits ^{P}}c.\) Therefore, we obtain \(\rho \le c|\theta ^{\tau }\bar{\Gamma }(\beta )|=O_p(a_n),\) then \(||\gamma (\beta )||=O_p(a_n)\). \(\square \)
Lemma A.7
Under the conditions of Theorem 2.1. as \(n\rightarrow \infty \), with probability tending to 1, \(R_{n}(\beta )\) has a minimum in \(D_n\).
Proof
For \(\beta \in D_n\),
According to Lemma A.6, we have \(\gamma ^\tau \Gamma _i(\beta )=o_p(1)\). Apply Taylor expansion to \(H_{1n}(\beta ,\gamma )\), we obtain \( \bar{\Gamma }(\beta )-J(\beta )\gamma +\delta _n=0,\) where \(\bar{\Gamma }(\beta )=\frac{1}{n}\sum _{i=1}^n\Gamma _i(\beta )\), \(\delta _n=\frac{1}{n}\sum _{i=1}^n\Gamma _i(\beta )(\gamma ^\tau \Gamma _i(\beta ))^2/[1+\zeta _i]^3\) for some \(|\zeta _i|\le |\gamma ^\tau \Gamma _i(\beta )|\). We have \(\gamma =J(\beta )^{-1}\bar{\Gamma }(\beta )+J(\beta )^{-1}\delta _n\). Substituting \(\gamma \) into (2.6), it is easy to see that
For \(\beta \in \partial D_n\), where \(\partial D_n\) denotes the boundary of \(D_n\), we write \(\beta =\beta _0+ca_n\phi \) where \(\phi \) is a unit vector, we have a decomposition as \(2R_{n}(\beta )=\Pi _0+\Pi _1+\Pi _2\), where \(\Pi _0=n\bar{\Gamma }(\beta _0)^{\tau }\Sigma _1^{-1}\bar{\Gamma }(\beta _0)\), \(\Pi _1=n(\bar{\Gamma }(\beta )-\bar{\Gamma }(\beta _0))^{\tau }J(\beta )^{-1}(\bar{\Gamma }(\beta )-\bar{\Gamma }(\beta _0))\), \(\Pi _2=n[\bar{\Gamma }(\beta _0)^{\tau }(J(\beta )^{-1}-\Sigma _1^{-1})\bar{\Gamma }(\beta _0)+2\bar{\Gamma }(\beta _0)^{\tau }J(\beta )^{-1}(\bar{\Gamma }(\beta )-\bar{\Gamma }(\beta _0)]-n\delta _n^{\tau }J(\beta )^{-1}\delta _n+\frac{2}{3}\sum _{i=1}^n(\gamma ^\tau \Gamma _i(\beta ))^3(1+\zeta _i)^{-4}\) As \(n\rightarrow \infty \), we see that
\(\Pi _2/\Pi _1{\mathop {\rightarrow }\limits ^{P}}0\) and \(2R_{n}(\beta _0)-\Pi _0=o_p(1)\). This implies that for any c given, as \(n\rightarrow \infty \), \(Pr\{2[R_{n}(\beta )- R_{n}(\beta _0)]\ge c\}\rightarrow 1\). In addition, note that for n large,
where the last inequality holds due to Conditions (B9) and the unbiased property of the SCAD penalty so that \(j\in \mathcal {B}\), \(p_{\lambda }(|\beta _j|)=p_{\lambda }(|\beta _{j0}|)\) when n is large. Hence, \(Pr\{\mathcal {L}_{n}(\beta )\ge \mathcal {L}_{n}(\beta _0)\}\rightarrow 1\) for \(\beta \in \partial D_n\), which establishes Lemma A.7. \(\square \)
Proof of Theorem 2.1
Let \(U_i=\gamma ^\tau \Gamma _i(\beta _0)\). Apply Taylor expansion to (2.10), we have
where \(\delta _n=\frac{1}{n}\sum _{i=1}^n\Gamma _i(\beta _0)U_i^2-\frac{1}{n}\sum _{i=1}^n\Gamma _i(\beta _0)\frac{U_i^3}{1+U_i}\).
From (A.11) and Lemma A.6, we have
Similar to the proof of (A.19) in Li et al. (2012), we can get \(||\delta _n ||=o_p(p^{5/2}n^{-1}(n^{-1/2}+c_n^2))+o_p(p^2n^{-1}c_n).\) From (A.19), we obtain that \(\gamma =J(\beta _0)^{-1}\bar{\Gamma }(\beta _0)+J(\beta _0)^{-1}\delta _n\). Taylor expansion implies \(\ln (1+U_i)=U_i-U_i^2/2+U_i^3/3(1+\varsigma _i)^4,\) for some \(\varsigma _i\) such that \(|\varsigma _i|\le |U_i|\). Therefore, combining (A.16) and some elementary calculation, we have
where \(\mathcal {R}_n=\sum _{i=1}^n[\gamma ^\tau \Gamma _i(\beta _0)]^3\), By using the proving method of (A.22) and Lemma B.6 in Li et al. (2012), we can easily derive \(n\delta _n^{\tau }J(\beta _0)^{-1}\delta _n=o_p(\sqrt{p})\) and \(n\bar{\Gamma }^{\tau }(\beta _0)(J(\beta _0)^{-1}-\Sigma _1^{-1})\bar{\Gamma }(\beta _0)=o_p(\sqrt{p})\). The proof of Theorem 2.1 is concluded from the above results together with (A.11). \(\square \)
Proof of Theorem 2.2
Let \(H_{1n}(\beta ,\gamma )=\frac{1}{n}\sum _{i=1}^n\frac{\Gamma _i(\beta )}{1+\gamma ^\tau \Gamma _i(\beta )}\) and \(H_{2n}(\beta ,\gamma )=\frac{1}{n}\sum _{i=1}^n\frac{\Gamma _i(\beta )}{1+\gamma ^\tau \Gamma _i(\beta )}(\frac{\partial \Gamma _i(\beta )}{\partial \beta }^{\tau })^{\tau }\gamma \). Note that \(\hat{\beta }\) and \(\hat{\gamma }\) satisfy \(H_{1n}(\hat{\beta },\hat{\gamma })=0\) and \(H_{2n}(\hat{\beta },\hat{\gamma })=0\) Let \(\varphi =(\beta ^{\tau },\gamma ^{\tau })^{\tau }\), \(\varphi _0=(\beta _0^{\tau },0)^{\tau }\) and \(\hat{\varphi }_0=(\hat{\beta }_0^{\tau },\hat{\gamma }^{\tau }_0)^{\tau }\). Then by
where \(\delta _{jn}\) with \(\delta _{jn}=\frac{1}{2}(\hat{\varphi }_0-\varphi _0)^{\tau }H_{jn}^{\prime \prime }(\varphi )(\hat{\varphi }_0-\varphi _0)\) for \(j=1,2\). Here \(H_{jn}^{\prime \prime }(\varphi )\) denotes the Hessian matric of \(H_{jn}(\varphi )\). Then
from Lemma A.3, we have
Note that \(||\hat{\gamma }(\beta )||=O_p(a_n)\) by Lemma A.6 and \(||\hat{\beta }-\beta _0||=O_p(a_n)\) by Lemma A.7. Then using the Cauchy-Schwarz inequality, we find
and Condition (B9) yields that
and combining with \(H_{1n}(\beta _0,0)=n^{-1}\sum _{i=1}^n\Gamma _i(\beta _0)\) , we have
Note that
Therefore,
Invoking the Slutsky theorem and the central limit theorem, we can prove Theorem 2.2. \(\square \)
Proof of Theorem 2.3
From the Lemma A.7, we note that the minimizer of \(\mathcal {L}_{n}(\beta )\) is in \(\mathcal {D}_n\). Considering \(\beta \in \mathcal {D}_n\), we have that for each of its components
First, \(\mathop {max}\nolimits _{j\in \mathcal {B}}|I_j|\le \gamma \Sigma _j(1+o_p(1))=O_p(a_n)\), because \(\gamma ^\tau \Gamma _i(\beta )=o_p(1)\),where \(\Sigma _j\) denotes the jth column of \(\Sigma \). as \(\tau (n/p)^{1/2}\rightarrow \infty \). \(Pr(\mathop {max}\nolimits _{j\in \mathcal {B}}|I_j|>\tau /2)\rightarrow 0\). it can be seen that \(p_{\lambda }'(|\beta _j|)sign(\beta _j)\) dominates the sign of \(\frac{\partial \mathcal {L}_{n}(\beta )}{\partial \beta _i}\) asymptotically for all \(j\notin \mathcal {B}\), as \(n\rightarrow \infty \), for any \(j\notin \mathcal {B}\), with probability tending to 1,
which implies that \(\hat{\beta }_j=0\) for all \(j\notin \mathcal {B}^c\), with probability tending to 1. Thus part (a) of Theorem 2.3 follows.
Next, we establish part (b), Let \(\Psi _1\) and \(\Psi _2\) be matrices such that \(\Psi _1\beta =\beta _1\) and \(\Psi _2\beta =\beta _2\). As we have shown that as \(n\rightarrow \infty \), \(Pr(\hat{\beta }_2=0)\rightarrow 1\), thus by the Lagange multiplier method, finding the minimizer of \(\mathcal {L}_{n}(\beta )\) is asymptotic equivalent to solve the minimization of the following objective function
where v is \(p-s\) dimensional column vector of an other Lagrange multiplier. Define
and \(\tilde{Q}_{3n}(\beta ,\gamma ,v)=\Psi _2\beta \). where
The minimizer \((\beta ,\gamma ,v)\) of (A.24) satisfies \(\tilde{Q}_{in}(\beta ,\gamma ,v)=0, (i=1,2,3)\). Since \(||\gamma ||=O_p(a_n)\) for \(\beta \in \mathcal {B}\), we can obtain that \(||v||=O_p(a_n)\) from \(\tilde{Q}_{2n}(\beta ,\gamma ,v)=0\), In order to expand \(\tilde{Q}_{in}(\beta ,\gamma ,v)(i=1,2,3)\) around the value \((\beta _0,0,0)\), we first give the following partial derivatives,
Then by Taylor expansion, we immediately derive that
where \(\Sigma (\beta _0)=n^{-1}\sum _{i=1}^n\partial \Gamma _i(\beta _0)/\partial \beta \), \(R_n=\sum _{l=1}^5R_n^{(l)}\), \(R_n^{(1)}=(R_{1n}^{\tau 1},R_{2n}^{\tau 1},0)^{\tau }\), \(R_{jn}^{\tau 1}\in R^p\) and the kth component of \(R_{jn}^{\tau 1}\) for \(j=1,2\) is given by
\(\vartheta =(\beta ,\gamma )^{\tau }, \tilde{\vartheta }=(\tilde{\beta },\tilde{\gamma })^{\tau }\) satisfying \(||\tilde{\vartheta }-\vartheta _0||\le ||\hat{\vartheta }-\vartheta _0||\). \(R_n^{(2)}=(0,b^{\tau }(\beta _0),0)^{\tau }\), \(R_n^{(3)}=[0,\{b'(\tilde{\vartheta })(\hat{\vartheta }-\vartheta _0)\},0]^{\tau }\), \(R_n^{(4)}=[\{(J(\beta _0)-\Sigma _1))\hat{\gamma }\}^{\tau }+(\Sigma (\beta _0)-\Sigma _0)(\hat{\beta }-\beta )\}^{\tau },0,0]^{\tau }\) and \(R_n^{(5)}=[0,\{(\Sigma (\beta _0)-\Sigma _0)\hat{\gamma }\}^{\tau },0]^{\tau }\). Similar to the proof of (A.22), we can get \(R_n^{(1)}=o_p(n^{-1/2})\). Given Condition (B8) and (B9), we see that \(R_n^{(2)}=o_p(n^{-1/2})\) and \(R_n^{(3)}=o_p(n^{-1/2})\). By (A.21) and (A.17) which together with Lemma A.6 yields that \(R_n^{(4)}=o_p(n^{-1/2})\) and \(R_n^{(5)}=o_p(n^{-1/2})\). Hence, we can get \(R_n^{(k)}=o_p(n^{-1/2}),k=1,\ldots ,5\).
Define \(K_{11}=-\Sigma _1, K_{12}=[\Sigma _0,~~0]\) and \(K_{21}=K_{12}^{\tau }\),
and let \(\kappa =(\beta ^{\tau },v^{\tau })^{\tau }\). Then by inverted (A.25), we find
As matrix K is partitioned into four blocks, it can be inverted blockwise as follows
where \(A=K_{22}-K_{21}K_{11}^{-1}K_{12}=\left[ \begin{array}{ccc} \Omega ^{-1} &{}\quad \Psi _2^{\tau }\\ \Psi _2&{}\quad 0\\ \end{array}\right] \) and \(\Sigma \) is defined in Theorem 2.2. Thus, we get
Matric A can also be inverted blockwise by using the analytic inversion formula,ie.,
Further, we have
It follows by an expansion of \(\hat{\beta }_1\) that
Then similar to the proof of Theorem 2.3 in Fan et al. (2016), we have \(n^{1/2}W_n\Omega _p^{-1/2}(\widehat{\beta }_1-\beta _{10}){\mathop {\rightarrow }\limits ^{d}}N(0,G)\), which completes the proof of Theorem 2.3. \(\square \)
Proof of Theorem 2.4
Let \(\hat{\beta }\) be the minimizer (2.13) and \(U_i=\hat{\gamma }^{\tau }\Gamma _i(\beta )\). Taylor expansion gives
where \(|\xi _i|\rightarrow |U_i|\) and \(o_p(1)\) is due to the penalty function. From (A.26), we have \(\hat{\gamma }=[\Sigma _1^{-1}+\Sigma _1^{-1}\Sigma _0\{\Omega -\Omega \Psi _2^{\tau }(\Psi _2\Omega \Psi _2^{\tau })^{-1}\Psi _2\Omega \}\Sigma _0^{\tau }\Sigma _1^{-1}][\bar{\Gamma }(\beta _0)+o_p(n^{-1/2})].\)
Similar to Tang and Leng (2010), Substituting the expansion of \(\hat{\gamma }\) and \(\hat{\beta }\) given by (A.24) into \(U_i\), we show that
Under the null hypothesis, because \(L_nL_n^{\tau }=I_q\), there exists \(\tilde{\Psi }_2\) such that \(\tilde{\Psi }_2\beta =0\) and \(\tilde{\Psi }_2\tilde{\Psi }_2^{\tau }=I_{p-d+q}.\) Now by repeating the proof of Theorem 2.3, we establish that under the null hypothesis, the estimation of \(\beta \) can be obtained by minimizing (A.27), where \(\Psi _2\) is replaced by \(\tilde{\Psi }_2\), we can easily obtain that
Combining Eqs. (A.28), we have
where
and
are two idempotent matrices. As the rank of \(P_1-P_2\) is q, \(P_1-P_2\) can be written as \(\Upsilon ^{\tau }\Upsilon \), where \(\Upsilon \) is \(q\times p\) matrix such that \(\Upsilon ^{\tau }\Upsilon =I_q\), further, we see that
Then
and the proof of Theorem 2.4 is finished. \(\square \)
Lemma A.8
Under the conditions of Theorem 2.5. For a given z, if g(z) is the true value of the parameter, then
where \(b(z)=\left( \frac{N}{h}\right) ^{1/2}\frac{T-1}{T}E[g(Z_{it})-g(z)]f(z)\int K(z)dz\) and \(R=\sigma ^2f(z)\int K^2(z)dz\).
Proof
Observe that
where
It is not difficult to prove \(E[S_1(z)]=0\) and \(Var[S_1(z)]=R+o(1)\). \(S_1(z)\) satisfies the conditions of the Cramer–Wold theorem and the Lindeberg condition. Therefore, we get
We can also prove that
Theorems 2.2 and condition (B8) imply that \(\beta -\hat{\beta }=O_p(N^{-1/2})\). Therefore, we get \(S_3(z)=O_p(h^{1/2})\). This together with (A.32) and (A.33) proves (A.29).
Analogously to the proof of (A.30). We can verify (A.30) easily. As to (A.31), we find
From Markov inequality and conditions (B3) and (B4), one can obtain
which implies that \(J_1=o_p(\sqrt{Nh})\). Using some arguments similar to those used in the proof of Lemma A.6, we can prove \(J_2=o_p(\sqrt{Nh})\) and \(J_3=o_p(\sqrt{Nh})\). Therefore we obtain that \(\mathop {max}\nolimits _{1\le i\le n}||\hat{\Xi }_{i}\{g(z)\}||=o_p(\sqrt{Nh}).\)
Applying (A.30) and the proof in Owen (1990), one can derive that \(\phi =O_p(N^{-1/2})\), which completes the proof of Lemma A.8. \(\square \)
Proof of Theorem 2.5
Invoking some arguments similar to those used in the proof of can be proved Theorems 2.4, we can proof
From Lemma A.8, we can prove that \(2\mathcal {Q}_{n}(g(z)){\mathop {\rightarrow }\limits ^{d}}\chi _1^2.\) \(\square \)
Rights and permissions
About this article

Cite this article
He, BQ., Hong, XJ. & Fan, GL. Penalized empirical likelihood for partially linear errors-in-variables panel data models with fixed effects. Stat Papers 61, 2351–2381 (2020). https://doi.org/10.1007/s00362-018-1049-2
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-018-1049-2