
Abstract
We consider minimax-optimal designs for the prediction of individual parameters in random coefficient regression models. We focus on the minimax-criterion, which minimizes the “worst case” for the basic criterion with respect to the covariance matrix of random effects. We discuss particular models: linear and quadratic regression, in detail.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The subject of this paper is random coefficients regression (RCR) models. These models have been initially defined in biosciences (see e. g. Henderson 1975) and are now popular in many other fields of statistical applications. Besides the estimation of population (fixed) parameters, the prediction of individual random effects in RCR models are often of prior interest. Locally optimal designs for the prediction have been discussed in Prus and Schwabe (2016a, b). However, these designs depend on the covariance matrix of random effects. Therefore, some robust criteria like minimax (or maximin), which minimize the largest value of the criterion or maximize the smallest efficiency with respect to the unknown variance parameters, are to be considered. For fixed effects models, such robust design criteria have been well discussed in the literature (see e. g. Müller and Pázman 1998; Dette et al. 1995; Schwabe 1997). For optimal designs in nonlinear models see e. g. by Pázman and Pronzato (2007), Pronzato and Walter (1988) and Fackle-Fornius et al. (2015).
Here we focus on the minimax-criterion for the prediction in RCR models, which minimizes the “worst case” for the basic criterion with respect to the variance parameters. We choose the integrated mean squared error (IMSE) as the basic criterion. We consider particular linear and quadratic regression models in detail.
The structure of this paper is the following: The second part specifies the RCR models and presents the best linear unbiased prediction of the individual random parameters. The third part provides the minimax-optimal designs for the prediction. The paper will be concluded by a short discussion in the last part.
2 RCR model
We consider the RCR models, in which observation j of individual i is given by the following formula:
where m is the number of observations per individual, n is the number of individuals,\(\mathbf {f} =(f_1, \dots ,f_p)^\top \) is a vector of known regression functions. The experimental settings \(x_j\) come from an experimental region \(\mathcal {X}\). The observational errors \(\varepsilon _{ij}\) are assumed to have zero mean and common variance \(\sigma ^2>0\). The individual parameters \({\varvec{\beta }}_i=( \beta _{i1}, \dots , \beta _{ip})^\top \) have unknown expected value (population mean) \(\mathrm {E}\,({\varvec{\beta }}_i)={{\varvec{\beta }}}\) and known covariance matrix \(\mathrm {Cov}\,({\varvec{\beta }}_i)=\sigma ^2\mathbf {D}\). All individual parameters \({\varvec{\beta }}_{i}\) and all observational errors \(\varepsilon _{ij}\) are assumed to be uncorrelated.
The best linear unbiased predictor for the individual parameter \({\varvec{\beta }}_i\) is given by
where \(\hat{{\varvec{\beta }}}_{i;{\mathrm {ind}}}=(\mathbf {F}^\top \mathbf {F})^{-1}\mathbf {F}^\top \mathbf {Y}_i\) is the individualized estimator based only on observations at individual i, \(\hat{{\varvec{\beta }}}=(\mathbf {F}^\top \mathbf {F})^{-1}\mathbf {F}^\top \bar{\mathbf {Y}} \) is the best linear unbiased estimator for the population mean parameter, \(\mathbf {Y}_i=(Y_{i1}, \dots ,Y_{im})^\top \) is the individual vector of observations, \(\bar{\mathbf {Y}} =\frac{1}{n}\sum _{i=1}^n{\mathbf {Y}_i}\) is the mean observational vector and \(\mathbf {F}=(\mathbf {f}(x_1), \dots , \mathbf {f}(x_m))^\top \) is the design matrix, which is assumed to be of full column rank. If the dispersion matrix \(\mathbf {D}\) of individual random effects is non-singular, the best linear unbiased predictor (2) simplifies to
and may be recognized as a weighted average of the individualized estimator \(\hat{{\varvec{\beta }}}_{i;{\mathrm {ind}}}\) and the estimator \(\hat{{\varvec{\beta }}}\) for the population parameter.
The mean squared error matrix of the vector \(\hat{\mathbf {B}}=(\hat{{\varvec{\beta }}}_1^\top , \dots ,\hat{{\varvec{\beta }}}_n^\top )^\top \) of all predictors of all individual parameters is given by the following formula (see e. g. Prus and Schwabe 2016b):
where \(\mathbf {I}_n\) denotes the identity matrix, \(\mathbf {J}_n\) is the square matrix of order n with all entries equal to 1 and \(\otimes \) denotes the Kronecker product. For non-singular covariance matrix of random effects the mean squared error matrix (4) simplifies to
3 Optimal designs
For this paper we define the exact designs as follows:
where \(x_1, \dots , x_k\) are the distinct experimental settings (support points), \(k\le m\), and \(m_1, \dots , m_k\) are the corresponding numbers of replications. For analytical purposes we will focus on the approximate designs, which we define as
where \(w_j=m_j/m\) and only the conditions \(w_j\ge 0\) and \(\sum _{j=1}^{k}w_j=1\) have to be satisfied (integer numbers of replications are not required). Further we will use the notation
for the standardized information matrix from the fixed effects model and \(\varvec{\varDelta }=m\, \mathbf {D}\) for the adjusted dispersion matrix of the random effects. We assume the matrix \(\mathbf {M}(\xi )\) to be non-singular. With this notation the definition of the mean squared error matrix of the prediction [formulas (4) and (5)] can be extended for approximate designs to
for general dispersion matrix \(\mathbf {D}\), and
for non-singular \(\mathbf {D}\), when we neglect the constant term \(\frac{\sigma ^2}{m}\).
3.1 IMSE-criterion
In this work our main interest is in the prediction of the individual response curves \(\mu _i=\mathbf {f}^\top {\varvec{\beta }}_i\). Therefore, we focus on the integrated mean squared error (IMSE-) criterion. The IMSE-criterion for the prediction can be defined (see also Prus and Schwabe 2016b) as the sum over all individuals
of the expected integrated squared distances of the predicted and the real response, \(\hat{\mu }_i=\mathbf {f}^\top \hat{{\varvec{\beta }}}_i\) and \(\mu _i\), with respect to a suitable measure \(\nu \) on the experimental region \(\mathcal {X}\), which is typically chosen to be uniform on \(\mathcal {X}\) with \(\nu (\mathcal {X})=1\). This criterion may also be presented as the following function of the mean squared error matrix \(\mathrm {MSE}\):
where \(\mathbf {V}=\int _{\mathcal {X}} \mathbf {f}(x)\mathbf {f}(x)^\top \nu (\mathrm {d}x)\), which may be recognized as the information matrix for the weight distribution \(\nu \) in the fixed effects model. For an approximate design \(\xi \) the IMSE-criterion has the form
which simplifies for non-singular covariance matrix of individual random parameters to a weighted sum of the IMSE-criterion for fixed effects models and the Bayesian IMSE-criterion:
3.2 Minimax-criteria
In this section we consider optimal designs for the prediction in particular RCR models: straight line and quadratic regression. We define the minimax-criterion as the worst case of the IMSE-criterion with respect to the unknown variance parameters.
We additionally assume the diagonal covariance structure of random effects. Then the IMSE-criterion [(13) and (14)] will increase with increasing values of variance parameters. However, if all these parameters will be large, the criterion function will tend to the IMSE-criterion in the fixed effects model (multiplied by the number of individuals n). Therefore, we fix some of the variances and consider the behavior of minimax-optimal designs in the resulting particular cases.
Note that for special RCR, where only the intercept is random, optimal designs for fixed effects models retain their optimality (see Prus and Schwabe 2016b).
3.2.1 Straight line regression
We consider the linear regression model
on the experimental regions \(\mathcal {X}=[0,1]\) with the diagonal covariance structure of random effects: \(\mathbf {D}=\text {diag} (d_1, d_2)\). For the IMSE-criterion we choose the uniform weighting \(\nu =\lambda _{[0,1]}\), which leads to
As proved in Prus (2015, ch. 5), IMSE-optimal designs for the prediction in model (15) are of the form
where w denotes the optimal weight of observations at the support point \(x=1\). Consequently, standardized information matrix (8) is given by:
Using formula (14), we obtain the following form of the IMSE-criterion:
where
which is independent of the variance parameters and coincides (neglecting the constant term) with the IMSE-criterion for the linear regression model without random effects, and
which depends on both the weight w of the observations at the support point \(x=1\) and the variance parameters \(d_1\) and \(d_2\).
Further we focus on the situation with small values of the intercept dispersion \(d_1\) or equivalently small intercept variance \(\sigma ^2d_1\). In this case, the IMSE-criterion may be computed as limiting criterion (19) for \(d_1\rightarrow 0\):
Note that for very large values of the observational errors variance \(\sigma ^2\) the assumption, \(d_1\rightarrow 0\) and \(d_2>0\), may be interpreted in the following way: the intercept variance \(\sigma ^2d_1\) has a positive value and the slope variance \(\sigma ^2d_2\) tends to infinity.
Note also that for fixed intercept (\(d_1= 0\)) the IMSE-criterion may be determined using formula (13). In this case we would obtain the same result (22).
It is easy to see that criterion (22) increases with increasing values of the slope dispersion \(d_2\). The latter property allows us to define the minimax-criterion as follows:
which results in
and leads to the following optimal weight:
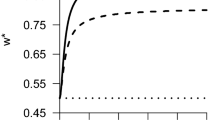
Figure 1 illustrates the behavior of the optimal design with respect to the number of individuals n for all integer values in the interval [2, 500]. As we can see in Fig. 1, the optimal weight increases with increasing number of individuals. Figure 2 presents the efficiency of the minimax-optimal design \(w^*_{max}\) with respect to the locally optimal designs in dependence of the rescaled slope variance \(\rho ={d_2}/{(1+d_2)}\) for fixed numbers of individuals \(n=10\), \(n=50\) and \(n=500\). For all numbers of individuals the efficiency is high and increases with increasing slope variance.

Minimax-optimal weight \(w^*_{max}\) in dependence of number of individuals n for linear regression

Efficiency of minimax-optimal designs for linear regression for \(n=10\) (solid line), \(n=50\) (dashed line), \(n=500\) (dotted line)
3.2.2 Quadratic regression
We investigate the quadratic regression model
on the standard symmetric design region \(\mathcal {X}=[-1,1]\) with a diagonal covariance matrix of random effects: \(\mathbf {D}=\text {diag} (d_1, d_2, d_3)\). For the IMSE-criterion we apply the uniform weighting \(\nu =\frac{1}{2}\lambda _{[-1,1]}\), which results in
In Prus (2015, ch. 5), it has been established that in model (26) optimal designs are of the form
where w denotes the optimal weight of observations at the support points \(x=-1\) and \(x=1\), and standardized information matrix (8) is of the form
Then using formula (14) we obtain the IMSE-criterion
where
which is independent of the variance parameters and coincides with the IMSE-criterion for the fixed effects model (neglecting the constant),
which depends on the variance parameters \(d_1\) and \(d_3\) and is independent of \(d_2\), and
which depends on the dispersion \(d_2\) of the slope and is independent of other variance parameters.
Further we fix some of the variance parameters and consider minimax-criteria for the resulting particular cases.
Case 1\(d_1\rightarrow 0\) and \(d_2\rightarrow 0\)
If both the intercept and the slope dispersions \(d_1\) and \(d_2\) are very small, IMSE-criterion (30) simplifies to
where
Note that for fixed intercept and fixed slope (\(d_1 = 0\) and \(d_2 = 0\)) the IMSE-criterion may be computed using formula (13), which leads to the same result (34).
IMSE-criterion (34) increases with increasing variance parameter \(d_3\). Therefore, we define the minimax-criterion as
which results in
We minimize criterion (37) directly and obtain the following optimal weight:
Figure 3 illustrates the behavior of the optimal design with respect to the number of individuals n.
Note that for given observational errors variance \(\sigma ^2\), the assumption of very small intercept and slope dispersions (\(d_1\rightarrow 0\) and \(d_2\rightarrow 0\)) is equivalent to the assumption of very small variances (\(\sigma ^2d_1\rightarrow 0\) and \(\sigma ^2d_2\rightarrow 0\)). However, if \(\sigma ^2\) becomes very large, the assumption may be interpreted as follows: the intercept and slope variances \(\sigma ^2d_1\) and \(\sigma ^2d_2\) are positive and the variance \(\sigma ^2d_3\) of the coefficient of the quadratic term tends to infinity. The next assumptions (in cases 2–5) may also be interpreted in a similar way.
Case 2\(d_1\rightarrow 0\) and \(d_3\rightarrow 0\)
For small dispersions of the intercept and of the coefficient of the quadratic term \(d_1\) and \(d_3\), IMSE-criterion (30) simplifies to
which is increasing in \(d_2\). Hence, we define the minimax-criterion as limiting criterion (39) for \(d_2\rightarrow \infty \):
and obtain
which leads to the following optimal design:
The behavior of the design is described by Fig. 4.

Minimax-optimal weight \(w^*_{max}\) in dependence of number of individuals n for quadratic regression, case 1

Minimax-optimal weight \(w^*_{max}\) in dependence of number of individuals n for quadratic regression, cases 2 and 3
Note that for fixed intercept and fixed coefficient of the quadratic term (\(d_1 = 0\) and \(d_3 = 0\)), using formula (13) we would also obtain criterion (39).
Case 3 \(d_3\rightarrow 0\)
If only the dispersion \(d_3\) of the coefficient of the quadratic term is small, the IMSE-criterion is given by
where
which is independent of w and \(d_2\), increasing in \(d_1\) and converges to 30 for \(d_1 \rightarrow \infty \). \(\varPhi _3(\xi ,d_2)\) increases with increasing values of \(d_2\). Then we define the minimax-criterion as
which equals to
and coincides with minimax-criterion (41) for case 2 (neglecting the constant term \(2(n-1)\)).
Case 4 \(d_2\rightarrow 0\)
If only the slope dispersion is small, the IMSE-criterion has the form
which is increasing in \(d_1\) and \(d_3\). Then we define the minimax-criterion as
and obtain
which results in
Case 5\(d_1\rightarrow 0\)
For small intercept dispersion \(d_1\), the IMSE-criterion simplifies to
The criterion increases with both variance parameters \(d_2\) and \(d_3\). Therefore, we define the minimax-criterion as the limiting IMSE-criterion (51):
which results in
and leads to the minimax-optimal weight
The behaviors of the optimal designs in cases 4 and 5 are illustrated by Figs. 5 and 6.

Minimax-optimal weight \(w^*_{max}\) in dependence of number of individuals n for quadratic regression, case 4

Minimax-optimal weight \(w^*_{max}\) in dependence of number of individuals n for quadratic regression, case 5
Note that for \(d_3 = 0\), \(d_2 = 0\) or \(d_1 = 0\) we would obtain the same results, (43), (47) or (51), respectively, using formula (13).
As we can see on the graphics, the optimal weights increase with increasing number of individuals n in cases 1, 2, 3 and 5 and decrease in case 4. The specific behavior in case 4 is caused by the joint influence of the intercept dispersion \(d_1\) and the dispersion of the coefficient of the quadratic term \(d_3\), which are included in part \(\varPhi _2(\xi ,d_1,d_3)\) of the IMSE-criterion. If at least one of these variance parameters is zero (cases 1, 2, 3 and 5), \(\varPhi _2(\xi ,d_1,d_3)\) simplifies much and the co-action of \(d_1\) and \(d_3\) is getting lost, which leads to completely different behaviors of the optimal designs.
For cases 1 and 2 we consider the efficiency of the minimax-optimal designs with respect to the locally optimal designs in dependence of the rescaled variances \(\rho ={d_3}/{(1+d_3)}\) and \(\rho ={d_2}/{(1+d_2)}\), respectively, for fixed numbers of individuals (Figs. 7 and 8). The efficiency turns out to be high and increasing with increasing variance parameters for both cases 1 and 2 and all values of the number of individuals (\(n=10\), \(n=50\), \(n=500\)).

Efficiency of minimax-optimal designs for quadratic regression, case 1, for \(n=10\) (solid line), \(n=50\) (dashed line), \(n=500\) (dotted line)

Efficiency of minimax-optimal designs for quadratic regression, case 2, for \(n=10\) (solid line), \(n=50\) (dashed line), \(n=500\) (dotted line)
4 Discussion
In this paper we have considered minimax-optimal designs for the IMSE-criterion for the prediction in particular RCR models: linear and quadratic regression. We have assumed the diagonal structure of the covariance matrix of random effects. In this case the IMSE-criterion is increasing with increasing values of all variance parameters. If all variances converge to infinity, the limiting criterion coincides with the IMSE-criterion in fixed effects models and, consequently, the optimal designs in fixed effects models retain their optimality for the prediction. If some of variance parameters are small, the minimax-optimal designs in RCR depend on the number of individuals and differ from the optimal designs in fixed effects models. For some particular cases we have considered the efficiency of the minimax-optimal designs with respect to the locally optimal designs. The efficiency turns out to be high and increase with increasing variance parameters.
Change history
12 September 2019
Unfortunately, due to a technical error, the articles published in issues 60:2 and 60:3 received incorrect pagination. Please find here the corrected Tables of Contents. We apologize to the authors of the articles and the readers.
References
Dette H, Heiligers B, Studden WJ (1995) Minimax designs in linear regression models. Ann Stat 23:30–40
Fackle-Fornius E, Miller F, Nyquist H (2015) Implementation of maximin efficient designs in dose-finding studies. Pharm Stat 14:63–73
Henderson CR (1975) Best linear unbiased estimation and prediction under a selection model. Biometrics 31:423–477
Müller CH, Pázman A (1998) Applications of necessary and sufficient conditions for maximin efficient designs. Metrika 48:1–19
Pázman A, Pronzato L (2007) Quantile and probability-level criteria for nonlinear experimental design. In: Fidalgo JL, Rodríguez-Díaz JM, Torsney B (eds) mODa 8–advances in model-oriented design and analysis. Heidelberg, Germany, pp 157–164
Pronzato L, Walter E (1988) Robust experimental design via maximin optimality. Math Biosci 89:161–176
Prus M (2015) Optimal designs for the prediction in hierarchical random coefficient regression models. Ph.D. thesis, Otto-von-Guericke University, Magdeburg
Prus M, Schwabe R (2016) Interpolation and extrapolation in random coefficient regression models: optimal design for prediction. In: Müller CH, Kunert J, Atkinson AC (eds) mODa 11–advances in model-oriented design and analysis. Springer, Berlin, pp 209–216
Prus M, Schwabe R (2016) Optimal designs for the prediction of individual parameters in hierarchical models. J R Stat Soc 78:175–191
Schwabe R (1997) Maximin efficient designs. Another view at D-optimality. Stat Probab Lett 35:109–114
Acknowledgements
The author is grateful to two anonymous referees and the guest editor for helpful comments which improved the presentation of the results.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research has been supported by Grant SCHW 531/16-1 of the German Research Foundation (DFG).
Rights and permissions
About this article

Cite this article
Prus, M. Optimal designs for minimax-criteria in random coefficient regression models. Stat Papers 60, 465–478 (2019). https://doi.org/10.1007/s00362-018-01072-w
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-018-01072-w