
Abstract
This paper proposes an algorithm named Reverse Engineering Recursive Rule Extraction (RE-Re-RX) for symbolic rule extraction from neural network with mixed attributes. RE-Re-RX algorithm is an extension of the existing Recursive Rule Extraction (Re-RX) algorithm. Re-RX algorithm generates disjoint rules for continuous and discrete attributes. The algorithm first generates rules for discrete attributes. A rule for discrete attributes is further refined recursively if it does not produce satisfactory result. A rule is refined by generating rules with the discrete attributes (if present) that are not covered by the rule or else the process is terminated by generating rules with the continuous attributes (if present). The novelty of the proposed RE-Re-RX algorithm lies in generating rules for continuous attributes. Re-RX generates linear hyper plane for continuous attributes which may not be able to deal with the non-linearity present in data. To overcome this limitation RE-Re-RX algorithm generates simple rules for continuous attributes in the form of input data ranges and target. RE-Re-RX uses the concept of Rule Extraction by Reverse Engineering the NN (RxREN) algorithm in slightly different way to generate rules. RxREN only uses misclassified patterns, whereas RE-Re-RX uses both classified and misclassified patterns of each continuous attribute to calculate input data ranges for constructing rules. The proposed algorithm is validated with six benchmark datasets. The experimental results clearly show the superiority of the proposed algorithm to Re-RX.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Data mining is an analytic process designed to explore data in search of consistent patterns and/or systematic relationships between data components, and to validate the findings by applying the detected patterns to new subsets of data. The interest of researchers in data mining is growing as huge amount of data are collected day-by-day and hence, various issues related to handling large volume data are arising. Database researchers are more concerned about efficient retrieval of hidden information (patterns) from large database using available database technology.
Data mining is the most commonly used knowledge acquisition technique for knowledge discovery. There are many data mining tasks for knowledge discovery. Recently, there has been a trend of using neural networks (NNs) for data mining tasks [1] and classification is one of them. Many algorithms for classification have been designed, which enable the researchers to solve their problem in various domains. NNs are commonly used technique for the classification of data with mixed mode attributes [2], as they achieve high classification accuracy on huge volume of data with low computational cost [3]. It is accepted that NNs provides an effective means of nonlinear data processing of real-world classification problems.
Despite of many advantages of NNs, they lack in explanation capability while making a decision, i.e., it is difficult to understand their internal processing about how a decision is made. This makes NN unfit for many applications which requires transparent decision. For example, in a disease diagnosis problem it is important to know why the disease is caused so that correct medicine can be provided or correct preventive measures can be taken in future. To counteract this limitation of NNs many studies have been performed, which convert black box nature of NNs to a white box by extracting rules from NNs [4]. Rule extraction from NNs represents the internal knowledge in the form of symbolic rules. For example, a rule extracted for the disease diagnosis problem will contain presence or the absence of symptoms as the antecedents of the rule and presence or absence of the disease as the consequent of the rule. Symbolic rule extraction makes NNs preferable over other machine learning methods for handling various classification problems which require transparent decision [5].
NNs are one of the best tools to produce higher classification accuracy for data sets with mixed attributes. Various rule extraction algorithms also exist which generates rules from NNs with mixed attributes and Re-RX [6] is one of the popular algorithms among them. The algorithm is recursive in nature and generates hierarchical rules where rule conditions for discrete attributes are disjoint from continuous attributes. However, when the class labels of the data are described as a nonlinear function of the continuous inputs, the extracted rules do not adequately preserve the accuracy of the neural network (NN) because Re-RX generates only linear hyperplane involving the continuous attributes. Therefore, this paper proposes a Reverse Engineering Recursive Rule Extraction (RE-Re-RX) algorithm which overcomes the limitation of Re-RX involving continuous attributes. RE-Re-RX replaces the linear hyperplane for continuous attributes with simple classification rule in the form of input data ranges and target. It uses reverse engineering process to analyze each continuous attributes to find the technological details hidden in them in the form of data ranges. The data range for a continuous attribute is calculated based on the classified patterns by the attribute and misclassified patterns due to the attribute. For example, suppose a network contains three continuous attributes {c1, c2, c3}. The algorithm analyzes attribute c1 based on the misclassified patterns calculated in absence of c1 from the network and the classified patterns only in presence of c1 in the network.
The paper is organized as follows: “Types of Rule Extraction Algorithms and Re-RX Algorithm” section shows some rule extraction algorithms according to their types and describes Re-RX algorithm along with its variants in brief, “Reverse Engineering Recursive Rule Extraction (RE-Re-RX) Algorithm” section describes the proposed methodology in details, “Illustration with Credit Approval Dataset” section illustrates the method with an example, “Experimental Results and Discussion” section shows some important experimental results and provides discussion on the results, and finally “Conclusions” section draws conclusion.
Types of Rule Extraction Algorithms and Re-RX Algorithm
This section is divided in two parts: first subsection shows different works based on different categories of rule extraction and second subsection provides a brief introduction to Re-RX and its different variants.
Types of Rule Extraction Algorithms
Rule extraction can be categorized into three approaches: decompositional, pedagogical and eclectic. Decompositional approaches (‘looks inside’ the network) involve analyzing the weights between the units and activation output to extract rules. Pedagogical approaches treat the network as a ‘black box’ and extract rules by examining the relationship between the inputs and outputs. Eclectic approaches incorporate both decompositional and pedagogical approaches together [7]. Many rule extraction algorithms using NN have been designed for classification based on these three approaches.
(a) Decompositional Approach
Fu [8] has proposed KT algorithm that can handle NNs with smooth activation function such as back propagation with sigmoidal where the activation function is bounded in the region [0, 1]. Towell et al. [9] have proposed SUBSET and MofN algorithms. SUBSET algorithm specifies a NN where the output of each neuron in the network is either close to zero or close to one and explicitly searches for subsets of incoming weights that exceed the bias on a unit. The MofN algorithm is an extension of SUBSET algorithm, which clusters the weights of a trained network into equivalent classes and extracts m-of-n style rules. Setiono et al. [10] have proposed NeuroRule which extracts rule from pruned network with discretized hidden unit activation values. NeuroRule extract rules from NNs (NNs) that have been pruned because removing irreverent connections simplifies the rule extraction process, however, requires discretization of continuous attributes of a data set before training the NN. Setiono et al. [11] have proposed NeuroLinear which is able to extract oblique classification rules from data set with continuous attributes. Taha et al. [12] have proposed full-RE method which extracts accurate rules without normalizing the continuous attributes of the data (dataset) prior to network training. Anbananthen et al. [13] have proposed Artificial NN Tree (ANNT) algorithm which extracts rules based on decision tree and generates less number of rules with more accuracy. Khan et al. [14] have shown how to extract knowledge from survey data using ANNTalgorithm. Odajima et al. [15] have proposed a Greedy rule generation (GRG) method for generating classification rules from datasets with discrete attributes. Wang et al. [16] have proposed a rule extraction method from NN using optimized activation function to generate simpler rules easily. Setiono et al. [6] have proposed a Recursive Rule Extraction algorithm (Re-RX) that generates hierarchical rules from datasets having both discrete and continuous attributes. Re-RX generates separate rules for continuous and discrete attributes. Hara et al. [17] have proposed an Ensemble-Recursive-Rule Extraction (E-Re-RX) algorithm which is based on Re-RX algorithm [6] and uses two NNs to achieve high recognition rates. Hayashi et al. [18] have proposed three ensemble NN rule extraction using Recursive-Rule Extraction algorithm which uses three NNs to generate symbolic rules. Hruschka et al. [19] have proposed a rule extraction method from NN which employs CGA (clustering genetic algorithm) to find clusters of hidden unit activation values and generates logical rules from these clusters. Kahramanli et al. [20] have proposed a hybrid NN based rule extraction method using Artificial Immune Systems. Setiono et al. [21] have shown how to train NN using augmented discretized inputs and extract MofN rules.
(b) Pedagogical Approach
Sestilo et al. [22] have proposed a pedagogical technique of rule extraction called BRAINNE, which extracts rule from NN using back propagation and does not require discretization of continuous data. Craven et al. [23] have proposed Trepan algorithm which extracts a decision tree from a trained network. The trained network is used as an “oracle” which is able to answer queries during the learning process and determines the class of each pattern that is presented as a query. Setiono [24] has proposed rule extraction (RX) algorithm that works on discrete data. RX recursively generates rules by analyzing the discretized hidden unit activations of a pruned network with one hidden layer. When the number of input connections to a hidden unit is larger than a certain threshold, a new NN is created and trained with the discretized activation values as the target outputs. Otherwise, the rule generation method X2R [25] is applied to obtain rules that explain the hidden unit activation values in terms of the inputs. Taha et al. [12] have proposed Binarized Input–Output Rule extraction (BIO-RE) that extracts binary rules from any NN. Etchells et al. [26] have proposed an Orthogonal Search based Rule Extraction algorithm (OSRE) which is applied on both support vector machines (SVM) and NNs. This algorithm converts given input to 1 from N form and then performs rule extraction based on activation responses. Augasta et al. [3] have proposed a rule extraction algorithm called Rule Extraction by Reverse Engineering the NN (RxREN) which relies on the reverse engineering technique to prune the insignificant input neurons and to discover the technological principles of each significant input neuron of NN. It extracts classification rules from a pruned NN in the form of data ranges of inputs. Biswas et al. [27] have proposed Rule Extraction from Neural Network using Classified and Misclassified data (RxNCM) which is an extension to RxREN algorithm. RxREN uses only misclassified data whereas RxNCM uses both classified and misclassified data to find the data ranges of significant attributes. Fortuny et al. [28] have proposed Active Learning-Based Pedagogical Rule Extraction technique which is able to extract rules from any black box. It generates rule by generating new artificial data points around training vectors with low confidence score.
(c) Eclectic Approach
Setiono et al. [29] have proposed an eclectic rule extraction algorithm, Fast Extraction of Rules from NNs (FERNN) to extract rules without network retraining which makes the process faster. Iqbal [30] has proposed an algorithm called [Hierarchical and Eclectic Rule Extraction via Tree Induction and Combination (HERETIC)] that uses a symbolic learning algorithm (decision tree) on each unit of the NN to extract rules.
Re-RX Algorithm and its Variants
Re-RX [6] algorithm is the main focus of this paper. As mentioned above Re-RX algorithm generates hierarchical rules comprising of disjoint rules for discrete and continuous attributes recursively. It uses decision tree to generate rules with discrete attributes and it generates linear hyperplane with continuous attributes. It starts with generating rules with discrete attribute(s) if present or else generates rules with the continuous attribute(s) and stops. The subspace of a rule with discrete attribute(s) is further subdivided by calling the whole algorithm recursively if the rule satisfies certain criterion and the process continues with those attribute(s) not covered by the subspace of the rule. Though Re-RX algorithm is one of the good rule extraction algorithms but the accuracy of Re-RX algorithm drops in cases where the continuous attributes are best described by nonlinear function. So, to improve the accuracy various variants of Re-RX are proposed. Some of them are mentioned in the previous subsection [17, 18]. Variants such as E-Re-RX [17] performed ensembling to improve the accuracy. Hayashi et al. [31] used J48graft technique with Re-RX to achieve highly accurate and concise rules from a large breast cancer dataset. Hayashi et al. [32] have shown the use of sampling Re-RX with J48graft on Pima Indian Diabetes dataset to achieve highly accurate, concise, and interpretable classification rules. Though accuracy improved in few cases but the problem related to rules with continuous attributes still exists. So, Hayashi et al. [33] have proposed continuous Re-RX with the objective to assess the effectiveness of Re-RX algorithm with continuous attributes in extracting highly accurate, concise, and interpretable classification rules for the diagnosis of thyroid disease. It uses C4.5 decision tree to extract rules for both discrete and continuous attributes. It removed the drawback but at the same time it lost the main novelty of the Re-RX algorithm which is to generate disjoint rules for discrete and continuous attributes. Hayashi [34] has shown the application of some rule extraction algorithms from Re-RX family on credit risk assessment from a Pareto optimal perspective.
Though various variants have been proposed to improve the accuracy of Re-RX but no one of them is able to deal with the limitation of Re-RX along with preserving the novelty of the algorithm. This paper proposes an algorithm RE-Re-RX to overcome this limitation without losing the novelty of the Re-RX algorithm.
Reverse Engineering Recursive Rule Extraction (RE-Re-RX) Algorithm
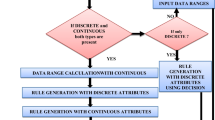
The full potential of NNs may not be realized without some form of explanation capability. The rapid applications of NNs in many fields, such as commerce, science, industry, medicine, etc., offer a clear authentication to the capability of NN paradigm. This section aims to introduce a symbolic rules extraction algorithm, termed as RE-Re-RX from trained NN which generates rules recursively. The proposed algorithm consists of two parts. NN pruning is done in the first part by removing insignificant input neurons. The second part generates a set of classification rules separately for discrete and continuous attributes. C4.5 algorithm is used for generating rules with discrete attributes and concept of RxREN [3] algorithm is used in a slightly different way for generating rules with continuous attributes. The whole algorithm is called recursively again and again to generate rules separately for discrete and continuous attributes. The flowchart for the algorithm RE-Re-RX is given in Fig. 1. The outline of the proposed algorithm is as follows:

Flowchart of RE-Re-RX algorithm
Algorithm RE-Re-RX (S, D, CN)

The details of the algorithm are described below:
Network Training and Pruning
The proposed algorithm uses a feed forward NN (FFNN) with one hidden layer and uses back propagation algorithm for training. For pruning, the algorithm [35] developed by Setiono is used. The algorithm uses a penalty function for pruning the NN. The penalty function consists of two terms. The first term is to discourage the use of unnecessary connections, and the second term is to prevent the weights of the connections from taking excessively large values. The properly classified patterns by the pruned network are used in the next step. The algorithm for pruning is as follows:
Step1: Let η1 and η2 be two positive scalars such that \(\eta_{1} \; + \;\eta_{2} < 0. 5\). Let (w, v) be a set of weights of a NN. Train the network using back propagation algorithm to minimize the function Ө (w, v) = F (w, v) + P (w, v) until each properly classified pattern satisfies the following condition (1):
where η1 = [0, 0.5], F (w, v) is the cross entropy function and P (w, v) is the penalty function.\(N_{p}\) is the network output and T P is the target.
Step2: Remove connections between input nodes and hidden nodes and between hidden nodes and output nodes. This task is accomplished in two phases. In the first phase, connections between input nodes and hidden nodes are removed. For each \(w _{\text{ml}}\) (weight between input and hidden) in the network if the condition (2) holds then remove \(w _{\text{ml}}\) from the network. \(v _{\text{pm}}\) is the weight between hidden and output layers.
In the second phase, connections between hidden nodes and output nodes are removed. For each \(v _{\text{pm}}\) in the network if the condition (3) holds then remove \(v _{\text{pm}}\) from the network.
Step3: If no weights satisfy conditions (2) and (3), Compute \(w _{\text{ml}} \; = \;\mathop {\hbox{max} }\limits_{p} \left| {v _{\text{pm}} w _{\text{ml}} } \right|\) and remove \(w _{\text{ml}}\) with smallest value.
Step4: Retrain the network and calculate the classification accuracy of the network.
Step5: If classification accuracy of the network falls below an acceptable level, then stop and use the previous setting of the network weights. Otherwise, go to Step2.
Rule Extraction
This step extracts rule(s) separately for continuous and discrete attributes. If the pruned network contains any discrete attribute(s), the algorithm extracts rule(s) in a way similar to Re-RX algorithm [6] using only discrete attribute(s) of the pruned network. It uses C4.5 decision tree algorithm to extract rules with discrete attributes. If all the discrete attributes are pruned in step1, the algorithm extracts rule(s) with the continuous attributes using the concept of RxREN algorithm [3] in a modified way. RxREN algorithm [3] uses only misclassified patterns whereas the proposed algorithm uses both classified and misclassified patterns for finding data ranges to extract rules. The algorithm evaluates the rules generated with discrete attributes in terms of error and support. The support of a rule is the percentage of patterns classified by that rule and error is the number of misclassification by that rule. If the error exceeds a specified threshold and the support meets the minimum threshold, then the algorithm further divides the subspace of the rule by either calling the whole algorithm recursively, when some discrete attributes are still present, which are not there in the conditions of the rule or by generating rules involving only the continuous attributes. Details of rule extraction using only continuous attributes are explained below.
For generating rules with continuous attributes the proposed algorithm RE-Re-RX uses the following steps:
(a) Data Range Computation
The RxREN [3] uses only misclassified patterns to find the data range, but both classified and misclassified patterns are essential for proper classification of a pattern. The proposed algorithm RE-Re-RX first finds the properly classified patterns \(\varvec{ P}_{\varvec{i}}\) from S′ and misclassified patterns \(\varvec{ E}_{\varvec{i}} \varvec{ }\) from S′ for each continuous input neuron \(\varvec{ CN^{\prime}}_{\varvec{i}}\) of the NN. Then for each input \(\varvec{ CN^{\prime}}_{\varvec{i}}\), it finds \(\varvec{ UCM}_{{\varvec{i }}}\) shown in (4), which is union of misclassified patterns \(\varvec{ E}_{\varvec{i}}\) and properly classified patterns \(\varvec{ P}_{\varvec{i}}\).
\(\varvec{mp}_{\varvec{i}}\) holds the total number of patterns in \(\varvec{UCM}_{\varvec{i}}\). RE-Re-RX creates a data length matrix, as shown in Fig. 2, for finding the data range of ith. continuous attribute of the network, by placing patterns belonging to \(\varvec{ UCM}_{\varvec{i}}\). within proper ranges with respect to respective classes. The number of patterns in each class for an attribute, i is denoted by \(\varvec{mc}_{{\varvec{ik}}}\). It should be noted that range of k lies from \({\mathbf{1}} \ldots \varvec{n}\). Finally, the algorithm generates a data range matrix as shown in Fig. 3 by finding the low range \(\varvec{ L}_{{\varvec{ik}}}\) and upper range \(\varvec{ U}_{{\varvec{ik}}}\) of properly classified and misclassified patterns from \(\varvec{ UCM}_{\varvec{i}}\) for each continuous attribute \(\varvec{ CN^{\prime}}_{\varvec{i}}\) in respective class \(\varvec{ C}_{\varvec{k}}\) of the network.

Data length matrix

Data range matrix
An attribute may not be significant for classifying patterns in all classes, i.e., a particular attribute may not be necessary to classify patterns in all the n classes of a dataset, but can be required to classify any one target class or some k target classes, where k ≤ n. Figure 4 shows that attribute 1 and attribute 2 are important for classifying patterns in class1 whereas attribute 2 and attribute 3 are important for classifying patterns in class2.

Significance of three attributes in classifying patterns into two classes
Therefore, the algorithm selects data ranges of those attributes for each class, which satisfy the following condition (5).
α is a fraction value which specifies the minimum percentage of classified and misclassified patterns that should be required for knowledge discovery. The condition for finding significant data ranges of the data range matrix is shown below in (6).
(b) Rule Construction
The RE-Re-RX algorithm uses derived data range of each continuous input attribute \(\varvec{ CN^{\prime}}_{\varvec{i}}\) to construct rules for classifying patterns. The algorithm constructs rules for each target class \(\varvec{ C}_{\varvec{k}}\) using the data ranges available in the corresponding column k of the data range matrix. The algorithm writes the rules in descending order of number of attributes required for rule, i.e., the first rule is written for a class which requires more number of attributes. In general, rules can be written as,
-
If ((data(\(\varvec{ CN^{\prime}}_{1}\)) ≥ \(\varvec{ L}_{11}\) ∧ data(\(\varvec{ CN^{\prime}}_{1}\)) ≤ \(\varvec{ U}_{11}\)) ∧ (data(\(\varvec{ CN^{\prime}}_{2}\)) ≥ \(\varvec{ L}_{21}\) ∧ data(\(\varvec{ CN^{\prime}}_{2}\)) ≤ \(\varvec{ U}_{21}\))∧\(\cdots\)∧ (data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\)) ≥ \(\varvec{ L}_{{\varvec{m}1}}\) ∧ data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\)) ≤ \(\varvec{ U}_{{\varvec{m}1}}\))) then class = \(\varvec{ C}_{1}\)
-
Else
-
If ((data(\(\varvec{ CN^{\prime}}_{1}\)) ≥ \(\varvec{ L}_{12}\) ∧ data(\(\varvec{ CN^{\prime}}_{1}\)) ≤ \(\varvec{ U}_{12}\)) ∧ (data(\(\varvec{ CN^{\prime}}_{2}\))) ≥ \(\varvec{ L}_{22}\) ∧ data(\(\varvec{ CN^{\prime}}_{2}\))) ≤ \(\varvec{ U}_{22}\))∧\(\cdots\)∧(data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\))) ≥ \(\varvec{ L}_{{\varvec{m}2}}\) ∧ data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\))) ≤ \(\varvec{ U}_{{\varvec{m}2}}\))) then class = \(\varvec{ C}_{2}\)
-
Else
-
\(\cdots\)
-
If ((data(\(\varvec{ CN^{\prime}}_{1}\)) ≥ \(\varvec{ L}_{{1\varvec{n} - 1}}\) ∧ data(\(\varvec{ CN^{\prime}}_{1}\)) ≤ \(\varvec{ U}_{{1\varvec{n} - 1}}\)) ∧ (data(\(\varvec{ CN^{\prime}}_{2}\)) ≥ \(\varvec{ L}_{{2\varvec{n} - 1}}\) ∧ data(\(\varvec{ CN^{\prime}}_{2}\)) ≤ \(\varvec{ U}_{{2\varvec{n} - 1}}\))∧\(\cdots\) ∧ (data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\))) ≥ \(\varvec{ L}_{{\varvec{mn} - 1}}\) ∧ data(\(\varvec{ CN^{\prime}}_{\varvec{m}}\))) ≤ \(\varvec{ U}_{{\varvec{mn} - 1}}\))) then class = \(\varvec{ C}_{{\varvec{n} - 1}}\)
-
Else
-
Class = \(\varvec{C}_{\varvec{n}}\)
(c) Rule Pruning
The rule pruning step removes the irrelevant conditions from the initial rules if the accuracy increases after pruning. The algorithm first tests the accuracy, \(\varvec{R}_{{\text{acc}}}\) of the initial rule, \(\varvec{R}_{\varvec{k}}\) with the validation dataset. It then calculates accuracy, \(\varvec{R}_{{\text{newacc}}}\) with the validation dataset by removing each condition from \(\varvec{R}_{\varvec{k}}\). The algorithm removes the condition \(\varvec{cn}_{\varvec{j}}\) from \(\varvec{R}_{\varvec{k}}\) if \(\varvec{R}_{{\text{newacc}}} \ge \varvec{R}_{{\text{acc}}}\). The condition for rule pruning is shown in condition (7) below.
(d) Rule Update
Unlike RxREN [3] the proposed algorithm considers the classified as well as misclassified patterns for finding the data range matrix, and thus rules obtained from the data range matrix after pruning will classify maximum patterns correctly. However, there may be some misclassifications due to the overlapping of data ranges of an attribute in different classes as shown in Fig. 5. The area between the solid line and dotted line shows the overlapping data ranges between two classes.

Class1 data overlapped with class 2 data
Some values may be very frequent for one class and less frequent for others within a range of data. Therefore, the rule update step improves the accuracy by shifting the upper or lower or both ranges of data. Consequently, it updates the data ranges involved in the rules that are based on the ranges of classified and misclassified patterns.
Each condition, \(\varvec{cn}_{\varvec{j}}\) in a rule consists of one lower limit value (L) or one upper limit value (U) or both. Let \(\text{min}_{{\varvec{ik}}}\) and \(\text{max}_{{\varvec{ik}}}\) be the minimum and maximum values of the attribute \(\varvec{ CN^{\prime}}_{\varvec{i}}\) for class \(\varvec{ C}_{\varvec{k}}\), respectively, on the newly classified and misclassified patterns by the rule set R on validation dataset. The algorithm modifies the condition \(\varvec{cn}_{\varvec{j}}\) if \(\varvec{R}_{{\text{newacc}}} \ge {\mathbf{R}}_{{\text{acc}}}\) where \(\varvec{R}_{{\text{acc}}}\) is the classification accuracy of the rule set R on validation dataset and \(\varvec{R}_{{\text{newacc}}}\) is the accuracy of the newly modified rule set, i.e., accuracy of the rule set R after modifying the condition \(\varvec{cn}_{\varvec{j}}\) by the new limits \(\text{min}_{{\varvec{ik}}}\) and \(\text{max}_{{\varvec{ik}}}\) on validation dataset. The rule update continues if accuracy increases. This step generalizes the rules by eliminating less frequent values and selects the optimal range of an attribute for a class, which covers more patterns of that class.
Algorithm for generating rules using continuous attribute:

Illustration with Credit Approval Dataset
The credit approval dataset is collected from UCI repository which consists of 690 patterns among which 37 patterns consist of missing values. After removing the patterns with missing values and after binarization, the dataset contains 654 patterns and 47 attributes respectively. Training set contains 523 patterns (80%) and testing set contains 131 patterns (20%). The dataset contains 6 continuous attributes and 41 binary attributes. The continuous attributes are labeled as C3, C4, C35, C40, C46, C47 and the discrete attributes are labeled as \({\text{D1}},{\text{ D2}},{\text{ D5}}, \ldots ,{\text{D34}},{\text{D36}}, \ldots ,{\text{D39}},{\text{D41}}, \ldots ,{\text{D45}}\). Initially, a NN with single hidden layer is trained. After initial pruning the pruned network contains 10 attributes and set S′ contains 348 properly classified patterns. Attributes of the pruned network are C′ = {C40, C46, C47} and D′ = {D1, D7, D11, D31, D38, D39, D42}. The algorithm generates rules for the binary attributes using C4.5 decision tree algorithm.

Thresholds δ1 and δ2 are set to 0.02. From Table 1 it can be seen that Rules 3, 5 and 6 have support and error greater then threshold 0.02. So, the sub-spaces for Rule 3, 5, and 6 are divided recursively. For Rule 5a, NN is trained with 96 patterns classified by the Rule 5. The attributes for this network are D1, D7, D38, C40, C46 and C47. The pruning algorithm did not remove any attribute, i.e., all the attributes, D1, D7, D38, C40, C46, C47 remained in the network and 93 patterns are properly classified by this network. As the network contains binary attributes, rules are generated for the binary attributes using C4.5 decision tree algorithm.

65 patterns are classified by rule 5a. Again the support and error for rule 5a are greater than threshold 0.02. So, the subspace of rule 5a is again divided. The input attributes are D7, D38, C40, C46, and C47. After pruning C40, C46 and C47 remained in the network and 59 patterns are properly classified by the network. So rules are generated for the continuous attributes using the properly classified 59 patterns by reverse engineering. Data range matrix for the continuous attributes is created as shown in Table 2 using the method described before in the previous section.
Initial rules generated for the continuous attributes are as follow:

Next for rule pruning and rule update steps a validation set is used. Here training set is used as the validation set. After rule pruning, the rule generated is shown below:

Accuracy does not increase further on rule update. So the rule generated after pruning is considered as the final rule for continuous attribute. Similarly for rule 3 and rule 6, rules are generated recursively. Final set of rules generated by the proposed algorithm RE-Re-RX for the credit approval dataset is given below.

Experimental Results and Discussion
Six datasets are collected from UCI repository for validating the algorithm. Among which five datasets (Credit Approval, Staglog (Heart), Australian Credit Approval, Thyroid and Echocardiogram) are having mixed attributes and one (Pima Indians Diabetes) is having continuous attributes. The descriptions of the datasets are given below in Table 3. Experiment on all the datasets is done by MATLAB in windows environment. The algorithm is validated with experimental results of fivefold cross validation and 10 independent runs of tenfold cross validation.
Rules Generated
A single hidden layer NN is trained and used for rule extraction. For each architecture, MSE (mean square error) is measured and the architecture which finds minimum MSE is selected for further experimentation and is called optimal architecture of the network [36, 37]. Rules generated for the credit approval dataset are shown in the previous section. Rules generated for rest of the datasets for an 80- to 20-fold are shown below.
(a) Staglog (Heart) Data Set
It contains 270 patterns and 13 attributes among which 6 are real, 3 are binary, 3 are nominal and 1 is ordered. After binarisation of all the discrete attributes the dataset contains 25 attributes. Continuous attributes are labeled as C1, C8, C9, C15, C18, C22 and discrete attributes are labeled as \({\text{D2}}, \ldots ,{\text{D7}},{\text{ D1}}0, \ldots ,{\text{D14}},{\text{ D16}},{\text{ D17}},{\text{ D19}}, \ldots ,{\text{D21}},{\text{ D23}}, \ldots ,{\text{D25}}\). Rules generated by the RE-Re-RX algorithm are given below.

(b) Australian Credit Approval Data Set
This dataset contains mixture of continuous, nominal with small number of values, and nominal with larger number of values. There are 690 patterns and 39 attributes after binarization of discrete attributes. Continuous attributes are labeled as C2, C3, C30, C33, C38, C39 and discrete attributes are labeled as \({\text{D1}},{\text{ D4}},{\text{ D5}}, \ldots ,{\text{D29}},{\text{ D31}},{\text{ D32}},{\text{ D34}}, \ldots ,{\text{D37}}\). Rules generated by the RE-Re-RX algorithm are given below.

(c) Thyroid
This dataset determines whether a patient referred to the clinic is Hypothyroid. It is a highly imbalanced dataset with three classes: normally functioning (class 3), under-functioning (primary hypothyroidism, class 2), or overactive (hyperthyroidism, class 1). Class 1 and class 2 represent 2.3% (166 patterns) and 5.1% (367 patterns) of the dataset, respectively, and the remaining 92.6% (6667 patterns) are classified as class 3. It contains 6 continuous and 15 binary attributes. Binary attributes are labeled as \({\text{D2}},{\text{ D3}}, \ldots ,{\text{D16}}\) and continuous attributes are labeled as \({\text{C1}},{\text{ C17}},{\text{ C18}}, \ldots ,{\text{C21}}\). Rules generated by the RE-Re-RX algorithm are given below.

(d) Echocardiogram
The dataset is used for predicting whether a patient will survive after 1 year of heart attack or not. It contains 12 attributes among which attribute numbers 11 and 12 are removed. From the remaining 10 attributes, 2 are binary and 8 are continuous. Binary attributes are labeled as D2, D4 and continuous attributes are labeled as \({\text{C1}},{\text{ C3}},{\text{ C5}}, \ldots ,{\text{C1}}0\). There are total 132 patterns among which 71 patterns are removed as they contain missing values. Rules generated by the RE-Re-RX algorithm are given below.

(e) Pima Indians Diabetes
The dataset contains 768 patterns and 8 continuous attributes. Rules generated by the proposed algorithm are given below.

Classification accuracies of the above rules for all the datasets are shown in Table 4.
Comparison with Re-RX [6]
The algorithm is compared with Re-RX algorithm as it is a modification of the Re-RX algorithm. Comparison with other existing algorithms is not shown as Re-RX is already compared with other methods such as NeuroRule [10], Trepan [25], etc. The comparison of mean and MAPE (mean absolute percentage error) of classification accuracies for fivefolds and 10 independent runs of tenfolds by RE-Re-RX and Re-RX is shown in Table 5. Graphical comparison of the mean accuracies between RE-Re-RX and Re-RX algorithms is shown in Fig. 6. All the results show that the accuracy of generated rules by the proposed RE-Re-RX is better than Re-RX algorithm.

Graphical comparisons between Re-RX and RE-Re-RX with mean of—a fivefold cross-validation results, and b 10 independent runs of tenfold cross-validation results
RE-Re-RX and Re-RX [6] is also compared based on different well known performance measures such as recall, FP-rate, precision, f-measure, Matthews correlation coefficient (MCC), Area Under the Curve (AUC). A good algorithm desires higher accuracy, precision, MCC, recall, f-measure, AUC, and lower FP-rate. Table 6 shows the comparison of RE-Re-RX with Re-RX based on the above mentioned measures for an 80- to 20-fold of the datasets. All the performance measures for RE-Re-RX algorithm are better in all the datasets except recall for credit approval dataset. Staglog (heart), Echocardiogram, and Pima Indian Diabetes datasets have shown equal recall, equal precision and equal FP-rate, respectively, for both RE-Re-RX and Re-RX algorithm. But as maximum of the measures are better for RE-Re-RX, it can be said that the performance of RE-Re-RX is better than Re-RX. Table 7 shows the comparison of RE-Re-RX with Re-RX based on the average performances of 10 independent runs of tenfold cross-validation results. For all of the datasets, RE-Re-RX algorithm has shown better average performances compared to Re-RX algorithm except average FP-rate of Australian credit approval and Staglog (heart) datasets, and average recall of Echocardiogram dataset.
Hypothesis Testing
Results of RE-Re-RX and Re-RX [6] are validated using two well-known hypothesis tests: t test (parametric statistical test) and Wilcoxon rank-sum test (non-parametric statistical test). The aim for both the test is to check the significance level (alpha) at which the respective null hypothesis is rejected and if the significance level is small, then the experimental results in favour of the alternative hypothesis are statistically significant.
Here, the null hypothesis is set as: There is no difference between the performance of RE-Re-RX and Re-RX algorithms. The tests are performed for the possible rejection of the null hypothesis and acceptance of the alternative: Performance of RE-Re-RX is better than Re-RX. Tables 8 and 9 shows the results of t test and Wilcoxon rank-sum test, respectively, for fivefold cross-validation results of both the algorithms. Table 8 shows that for Staglog (heart), Thyroid, and Pima Indian Diabetes datasets the null hypothesis is rejected at significance level = 0.05 and for rest of the datasets null hypothesis is rejected at significance level = 0.1. Table 9 shows that for all datasets the null hypothesis is rejected at significance level = 0.1. So, according to t test all the results of RE-Re-RX are statistically significant at 95 or 90% confidence level and according to Wilcoxon rank-sum test all the results of RE-Re-RX are statistically significant at 90% confidence level.
Similarly, RE-Re-RX has shown better performance than Re-RX algorithm when 10 independent runs of 10 cross-validation results is taken into consideration. For some datasets, null hypothesis is rejected at α = 0.05 and for some at 0.1.
Discussion
RE-Re-RX is an extension to Re-RX [6] algorithm. Re-RX is not able to preserve the accuracy of NN when the outputs are best described as a non-linear function of the continuous attributes because Re-RX creates linear hyperplane for continuous attributes. RE-Re-RX overcomes this limitation using attribute data ranges for creating rules with continuous attributes. This makes the rules simple and understandable as well as the rules can handle the non-linearity present in a dataset better. All the results presented in the preceding subsection show that the proposed model RE-Re-RX is able to generate more accurate rules than Re-RX. Comparison results for six datasets are shown. Mean and MAPE (mean absolute percentage error) of fivefolds and 10 independent runs of tenfolds for each dataset are calculated and RE-Re-RX produced higher mean and lower MAPE. Lower MAPE means that approximation to solution by RE-Re-RX algorithm is more close to the actual solution. The performance of the algorithm is also validated based on different performance measures and hypothesis testing.
The numbers of generated rules by both the algorithms are same as the proposed innovation lies only in the continuous part but RE-Re-RX is able to generate more accurate rule set and the rules for continuous attributes are simpler compared to Re-RX.
Conclusions
Real world datasets consist of data in mixed format. Robust data mining algorithms are required to handle data with mixed mode attributes. So, in this paper, a data mining algorithm called RE-Re-RX is presented which works with mixed mode attributes. It generates rules separately for discrete and continuous attributes. RE-Re-RX algorithm is a modification of Re-RX algorithm [6]. Re-RX uses linear hyper-plane to separate patterns with continuous attributes but RE-Re-RX uses input data ranges of continuous attributes to create rules to classify patterns with continuous attributes. RE-Re-RX uses the concept of RxREN algorithm [3] to create rules with continuous attributes but in a slightly different way. RxREN algorithm used only misclassified patterns to compute data ranges of attributes but the proposed RE-Re-RX uses both classified and misclassified patterns to compute data ranges of continuous attributes. Comparison of the proposed algorithm with Re-RX is shown with five mixed datasets and one continuous dataset taken from UCI repository. RE-Re-RX produces rules with higher accuracy for all the datasets. The performance of the proposed algorithm is also validated based on different performance measures (precision, MCC, AUC, recall, f-measure and FP-rate) and hypothesis testing (t test and Wilcoxon rank-sum test) which proved the superiority of the proposed algorithm compared to Re-RX.
It can be concluded that RE-Re-RX is a better algorithm for data mining using NN compared to Re-RX. The proposed algorithm can be used in any classification tasks such as diagnosis, prediction and many others.
References
Malone, J., McGarry, K., Wermter, S., Bowerman, C.: Data mining using rule extraction from Kohonen self-organising maps. Neural Comput. Appl. 15(1), 9–17 (2006)
Han, J., Kamber, M., Pei, J.: Data mining: concepts and techniques, 3rd edn. Morgan Kaufmann Publishers, San Francisco (2011)
Augasta, M.G., Kathirvalavakumar, T.: Reverse engineering the NNs for rule extraction in classification problems. Neural Process. Lett. 35(2), 131–150 (2012)
Setiono, R.: Extracting M-of-N rules from trained NNs. IEEE Trans. Neural Netw. 11(2), 512–519 (2000)
Jivani, K., Ambasana, J., Kanani, S.: A survey on rule extraction approaches based techniques for data classification using NN. Int. J. Futuristic Trends Eng. Technol. 1(1), 4–7 (2014)
Setiono, R., Baesens, B., Mues, C.: Recursive NN rule extraction for data with mixed attributes. IEEE Trans. Neural Netw. 19(2), 299–307 (2008)
Craven, M.W., Shavlik, J.W.: Using NNs for data mining. Future Gen. Comput. Syst. 13(2–3), 21l–229 (1997)
Fu, L.M.: Rule generation from neural networks. IEEE Trans. Syst. Man Cybern. 28(8), 1114–1124 (1994)
Towell, G., Shavlik, J.: The extraction of refined rules from knowledge based NNs. Mach. Learn. 13(1), 71–101 (1993)
Setiono, R., Liu, H.: Symbolic representation of NNs. IEEE Comput. 29(3), 71–77 (1996)
Setiono, R., Liu, H.: NeuroLinear: from NNs to oblique decision rules. Neurocomputing 17, 1–24 (1997)
Taha, I.A., Ghosh, J.: Symbolic interpretation of artificial NNs. IEEE Trans. Knowl. Data Eng. 11(3), 448–463 (1999)
Anbananthen, S.K., Sainarayanan, G., Chekima, A., Teo, J.: Data mining using pruned artificial NN tree (ANNT). Inf. Commun. Technol. 1, 1350–1356 (2006)
Khan, I., Kulkarni, A.: Knowledge extraction from survey data using neural networks. Procedia Comput. Sci. 20, 433–438 (2013)
Odajimaa, K., Hayashi, Y., Tianxia, G., Setiono, R.: Greedy rule generation from discrete data and its use in NN rule extraction. NNs 21(7), 1020–1028 (2008)
Wang, J.G., Yang, J.H., Zhang, W.X., Xu, J.W.: Rule extraction from artificial NN with optimized activation functions. In: IEEE 3rd International Conference on Intelligent System and Knowledge Engineering, pp. 873–879. (2008)
Hara, A., Hayashi, Y.: Ensemble NN rule extraction using Re-RX algorithm. NNs (IJCNN) 1–6 (2012)
Hayashi, Y., Sato, R., Mitra, S.: A new approach to three ensemble NN rule extraction using Recursive-Rule Extraction algorithm. NNs (IJCNN) 1–7 (2013)
Hruschka, E.R., Ebecken, N.F.F.: Extracting rules from multilayer perceptrons in classification problems: a clustering-based approach. Neurocomputing 70(1–3), 384–397 (2006)
Kahramanli, H., Allahverdi, N.: Rule extraction from trained adaptive NNs using artificial immune systems. Expert Syst. Appl. 36(2), 1513–1522 (2009)
Setiono, R., Azcarraga, A., Hayashi, Y.: MofN rule extraction from neural networks trained with augmented discretized input. In: International Joint Conference on Neural Networks (IJCNN) 6–11 July, Beijing, China, pp. 1079–1086. (2014). https://doi.org/10.1109/ijcnn.2014.6889691
Sestito, S., Dillon, T.: Automated knowledge acquisition of rules with continuously valued attributes. In: Proceedings of 12th International Conference on Expert Systems and their Applications, pp. 645–656. (1992)
Craven, M., Shavlik, J.: Extracting tree-structured representations of trained network. Adv. Neural Inf. Process. Syst. (NIPS) 8, 24–30 (1996)
Setiono, R.: Extracting rules from NNs by pruning and hidden-unit splitting. Neural Comput. 9(1), 205–225 (1997)
Liu, H., Tan, S.T.: X2R: A fast rule generator. In: Proceedings of the 7th IEEE International Conference on Systems, Man and Cybernetics, vol. 2, pp. 631–635. (1995)
Etchells, T.A., Lisboa, P.J.G.: Orthogonal search-based rule extraction (OSRE) for trained NNs: a practical and efficient approach. IEEE Trans. NNs 17(2), 374–384 (2006)
Biswas, S.K., Chakraborty, M., Purkayastha, B., Thounaojam, D.M., Roy, P.: Rule extraction from training data using neural network. Int. J. Artif. Intell. Tool 26, 3 (2017)
de Fortuny, E.J., Martens, D.: Active learning-based pedagogical rule extraction. IEEE Trans. NNs Learn. Syst. 26(11), 2664–2677 (2015)
Rudy, S., Kheng, W.: FERNN: an algorithm for fast extraction of rules from NNs. Appl. Intell. 12(1), 15–25 (2000)
Iqbal, R.A.: Eclectic rule extraction from NNs using aggregated decision trees. In: IEEE, 7th International Conference on Electrical & Computer Engineering (ICECE), pp. 129–132 (2012)
Hayashi, Y., Nakano, S.: Use of a recursive-rule extraction algorithm with j48graft to archive highly accurate and concise rule extraction from a large breast cancer dataset. Inform. Med. Unlocked 1, 9–16 (2016)
Hayashi, Y., Yukita, S.: Rule extraction using recursive-rule extraction algorithm with J48graft combined with sampling selection techniques for the diagnosis of type 2 diabetes mellitus in the Pima Indian dataset. Inform. Med. Unlocked 2, 92–104 (2016)
Hayashi, Y., Nakano, S., Fujisawa, S.: Use of the recursive-rule extraction algorithm with continuous attributes to improve diagnostic accuracy in thyroid disease. Inform. Med. Unlocked. 1, 1–8 (2015)
Hayashi, Y.: Application of a rule extraction algorithm family based on the Re-RX algorithm to financial credit risk assessment from a Pareto optimal perspective. Oper. Res. Perspect. 3, 32–42 (2016)
Setiono, R.: A penalty-function approach for pruning feedforward NNs. Neural Comput. 9(1), 185–204 (1997)
Permanasari, A.E., Rambli, D.R.A., Dominic, P.D.D.: Forecasting of salmonellosis incidence in human using artificial NN (ANN). In: Computer and Automation Engineering (ICCAE), the 2nd International Conference, vol. 1, pp. 136–139. (2010)
Mondal, S.C., Mandal, P.: Application of artificial NN for modeling surface roughness in centerless grinding operation. In: 5th International & 26th All India Manufacturing Technology, Design and Research Conference, IIT Guwahati, Assam, India, 12–14 December 2014
Author information
Authors and Affiliations
Corresponding author
About this article

Cite this article
Chakraborty, M., Biswas, S.K. & Purkayastha, B. Recursive Rule Extraction from NN using Reverse Engineering Technique. New Gener. Comput. 36, 119–142 (2018). https://doi.org/10.1007/s00354-018-0031-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00354-018-0031-9