
Abstract
Objective
We demonstrate the feasibility of direct generation of attenuation and scatter-corrected images from uncorrected images (PET-nonASC) using deep residual networks in whole-body 18F-FDG PET imaging.
Methods
Two- and three-dimensional deep residual networks using 2D successive slices (DL-2DS), 3D slices (DL-3DS) and 3D patches (DL-3DP) as input were constructed to perform joint attenuation and scatter correction on uncorrected whole-body images in an end-to-end fashion. We included 1150 clinical whole-body 18F-FDG PET/CT studies, among which 900, 100 and 150 patients were randomly partitioned into training, validation and independent validation sets, respectively. The images generated by the proposed approach were assessed using various evaluation metrics, including the root-mean-squared-error (RMSE) and absolute relative error (ARE %) using CT-based attenuation and scatter-corrected (CTAC) PET images as reference. PET image quantification variability was also assessed through voxel-wise standardized uptake value (SUV) bias calculation in different regions of the body (head, neck, chest, liver-lung, abdomen and pelvis).
Results
Our proposed attenuation and scatter correction (Deep-JASC) algorithm provided good image quality, comparable with those produced by CTAC. Across the 150 patients of the independent external validation set, the voxel-wise REs (%) were − 1.72 ± 4.22%, 3.75 ± 6.91% and − 3.08 ± 5.64 for DL-2DS, DL-3DS and DL-3DP, respectively. Overall, the DL-2DS approach led to superior performance compared with the other two 3D approaches. The brain and neck regions had the highest and lowest RMSE values between Deep-JASC and CTAC images, respectively. However, the largest ARE was observed in the chest (15.16 ± 3.96%) and liver/lung (11.18 ± 3.23%) regions for DL-2DS. DL-3DS and DL-3DP performed slightly better in the chest region, leading to AREs of 11.16 ± 3.42% and 11.69 ± 2.71%, respectively (p value < 0.05). The joint histogram analysis resulted in correlation coefficients of 0.985, 0.980 and 0.981 for DL-2DS, DL-3DS and DL-3DP approaches, respectively.
Conclusion
This work demonstrated the feasibility of direct attenuation and scatter correction of whole-body 18F-FDG PET images using emission-only data via a deep residual network. The proposed approach achieved accurate attenuation and scatter correction without the need for anatomical images, such as CT and MRI. The technique is applicable in a clinical setting on standalone PET or PET/MRI systems. Nevertheless, Deep-JASC showing promising quantitative accuracy, vulnerability to noise was observed, leading to pseudo hot/cold spots and/or poor organ boundary definition in the resulting PET images.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
18F-FDG PET imaging is commonly used for clinical diagnosis, staging, restaging and monitoring of response to treatment in clinical oncology [1]. Quantitative and semi-quantitative image–derived PET metrics, such as the standardized uptake value (SUV), are used for non-invasive quantification of physiological processes, providing valuable information for diagnosis and therapy monitoring of malignant diseases [2].
Good image quality is essential for pertinent qualitative visual interpretation and accurate quantitative analysis of 18F-FDG PET images [3]. Compton scatter of one or both annihilation photons, which undergoes interaction within dense materials in the gantry (patient body, instrument bed, detector and electronic components), results in a scatter fraction of 30–35% and 50–60% of all recorded events in 3D brain and whole-body PET data collection, respectively. Scattered photons can be rejected by falling outside the predetermined acceptance energy window (e.g. [435–650 keV] on the considered PET scanner). These photons are no longer relevant for scatter correction but still contribute to attenuation events [4]. However, the wrong lines of response (LORs) assigned following path change of scattered photons (even LORs recorded outside the patient’s body) within the acceptance energy window require scatter correction. Attenuation and scatter events result in local decrease and increase in the number of detected counts, which lead to underestimation and overestimation of the tracer uptake, respectively, resulting in loss of image contrast and quantification errors. The distribution and magnitude of scattered photons in non-attenuation and scatter corrected (PET-nonSAC) images are to some extent dependent on the energy resolution, sensitivity and time-of-flight capability of PET scanners. Correction of physical degrading factors, such as Compton scatter (SC) [4] and photon attenuation correction (AC) [5], which can result in mislocation of loss of detected events, is crucial. On commercial hybrid PET/CT scanners, SC can be performed by modelling the scatter component based on attenuation and uncorrected emission PET images. AC is also performed by converting Hounsfield units in CT images to linear attenuation coefficients at 511 keV. AC in PET/MRI is still an open area of research since MRI provides information about proton density which cannot be directly converted to electron density [6]. To address this, various strategies have been devised, including bulk segmentation of tissues from different MR sequences into a predefined number of classes [7, 8], atlas-based methods [9] and emission-based methods that are capable of direct estimation of attenuation maps from emission data [10, 11]. While some of these methods proved promising for AC in PET/MRI, segmentation and atlas-based techniques are limited by tissue misclassification, intra-subject co-registration between CT and MR images, truncation or metal-induced artefacts and by the presence of anatomical abnormalities. As such, AC remains a significant and nontrivial challenge in PET/MRI [6].
Deep learning algorithms have been developed for various medical image analysis applications [12]. Pioneering efforts have successfully applied deep convolutional networks to various tasks, including image denoising [13], resolution recovery [14] and image reconstruction [15]. Multiple studies explored the suitability of deep learning approaches for cross-modality transformation from MRI to CT images [16] and vice-versa [17], as well as in AC of PET data [18,19,20]. Recent works focused on the generation of pseudo-CT images from T1-weighted [16, 21, 22], ultra-short echo time (UTE) [23], zero echo time (ZTE) [24] and Dixon [25] MR sequences for AC of 18F-FDG PET images in the brain and pelvic regions. Two closely related but independent works reported on the direct conversion of non-attenuation corrected brain 18F-FDG PET images to the attenuation corrected image using convolutional encoder-decoder neural networks [20, 26].
Interest in simultaneous maximum likelihood reconstruction of attenuation and activity (MLAA) based on emission data was revived with the introduction of time-of-flight (TOF) PET [10, 27]. However, these algorithms are limited by insufficient coincidence time resolution, which leads to positional uncertainty [28], ill-posedness of the problem and high noise levels, which result in slow convergence and inaccurate estimations. Recent studies proposed to generate pseudo-CT AC maps through the application of deep learning to the output of joint activity and attenuation estimation in brain and whole-body PET imaging in an attempt to address the limitation of the MLAA [29, 30]. In addition, recently proposed methods that generate pseudo-CT images from MRI are limited by the need for co-registered pairs of CT and MRI images for the training phase. Such methods also require cross-modality conversion in the image space (e.g. from a proton density (MRI) to an electron density (CT)) [6]. However, more recently MRI to CT transformation using unpaired data was also reported [31].
Previous works aiming at direct attenuation and scatter correction in image space focused mostly on brain imaging resulting in a promising performance with clinically tolerable errors owing to the rigidity of structures within the head and minor inter-patient variability [20, 26]. More recent independent work focused on application of this approach in whole-body imaging demonstrated promising reliability and quantitative accuracy using a limited number of training/test datasets [32]. However, the application of this approach in whole-body imaging warranted a thorough investigation of potential outliers owing to large inter-patient anatomical and posture variability and physiological motion. As such, this study sets out to investigate the potential of this approach using a large sample size through the assessment of outliers and to provide some insight into its potential to handle respiratory motion artefacts. The objective of this work is to demonstrate the feasibility of the direct generation of attenuation and scatter corrected images from non-attenuation and scatter corrected (PET-nonASC) images in whole-body 18F-FDG PET imaging without the use of anatomical information using an unprecedently large sample size for training, test and validation. This is achieved using a framework involving the use of a deep residual convolutional neural network for joint attenuation and scatter correction (Deep-JASC).
Materials and methods
PET/CT data acquisition
This retrospective study was approved by our institutional review board and informed consent was obtained from all patients (ethic number REC.1397.095, Tehran University of Medical Sciences). Clinical whole-body 18F-FDG PET/CT studies of 1388 patients acquired between 2016 and 2018 on a Siemens Biograph 6 True point scanner. Two hundred thirty-eight patients were excluded from this study owing to technical or logistic issues (artefacts, missing CT and/or PET-nonASC images). The patients were injected with an activity of 370 ± 49 MBq of 18F-FDG and scanned 60 ± 13 min post-injection. Detailed patient demographics are given in Table 1 for training, validation and external validation datasets. A low-dose CT scan (110 kVp, 145 mAs) was performed prior to PET data acquisition for attenuation correction. Scatter correction was performed only on PET-CTAC images using the single-scatter simulation (SSS) algorithm with two iterations [33]. In Siemens Biograph 6 True Point, the energy resolution is ~ 12% at 511 keV and the energy window set to 425–650 keV. The SSS algorithm estimates the scatter component for each LOR only for single Compton scattering [33]. Analytical calculations using the Klein-Nishina equation provide an estimation of the contribution of scattered photons to each LOR where the total amount (distribution) of single scattering is determined from the superposition of the estimations. The total scatter fraction is determined though tail fitting of the estimated scatter distribution to scattered photons outside the body contour. Random, dead-time, decay, normalization corrections were applied prior to point-spread function (PSF)–based image reconstruction for both PET-nonASC and CTAC images. PET images were reconstructed using the ordinary Poisson ordered subsets-expectation maximization (OP-OSEM) algorithm with 2 iterations and 21 subsets followed by with 5-mm FWHM Gaussian post-reconstruction smoothing. All images were reconstructed into a 168 × 168 matrix and cropped to 154 × 154 matrix (excluding empty regions on both sides) with a voxel size of 4.073 × 4.073 × 3 mm2. Both reference CT, CT-based attenuation/scatter-corrected (PET-CTAC) and PET-nonASC images were archived for all patients.
Data preparation
The 1150 whole-body 18F-FDG PET studies included in this work were randomly divided into training (900), validation (100) and independent validation (150) datasets. Evaluation of the proposed algorithm was performed using the unseen external validation set. These images were not used within the training or evaluation of the network. In the first step, the voxel intensities in the whole dataset consisting of 1150 PET-CTAC and PET-nonASC images were converted to standardized uptake values (SUVs) to reduce the dynamic range of the intensity of PET images. Moreover, to further reduce the dynamic range of the voxel intensities for the sake of effective training of the network, PET-CTAC images were normalized with an empiric factor equal to 9 determined from the images. Likewise, PET-nonASC images were normalized with a factor equal to 3.
Deep-JASC network architecture
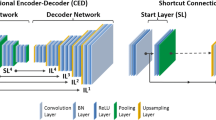
The residual network (ResNet) [34] proposed in the Python library of Niftynet pipeline [35], built upon TensorFlow (version 1.12.) [36], was used to implement Deep-JASC algorithm. ResNet is composed of 20 convolutional layers where a 3 × 3 × 3-voxel convolution kernel is used in the first seven layers. These layers extract low-level features, for instance edges, from the input data. The next seven layers employ the dilated convolution kernel by a factor of two to encode the medium-level features from the input. The last six layers also increase the dilation of the convolution kernel by 4, in addition to the previous layers, to enable capturing high-level features (Fig. 1A). A residual connection links every two convolutional layers. A batch normalization and element-wise rectified linear unit (ReLU) is connected to the convolutional layers located in the residual blocks.

(A) Architecture of the deep residual network (Deep-JASC) and implementation framework employed in the present study. (B) The training of the network was repeated three times: (left) in 2D slice-by-slice mode (DL-2DS), (middle) anisotropic 3D mode extended across several slices (DL-3DS) and (right) isotropic 3D mode using a fixed patch size of 64 × 64 × 64 (DL-3DP)
Implementation details
The training of the Deep-JASC was performed using 900 pairs of PET-nonASC and PET-CTAC images as input and output, respectively. To this end, the Deep-JASC model training repeated three times in 2D mode using successive slices (DL-2DS), anisotropic 3D mode extended across several slices (DL-3DS) and isotropic 3D mode using a fixed patch size of 64 × 64 × 64 (DL-3DP) (Fig. 1B). For DL-2DS training, a 2-dimensional (2D) spatial window equal to 154 × 154 voxels and batch size of 30 were set. For the DL-3DS mode, a spatial window of 154 × 154 × 32 voxels and a batch size of 2 were selected. For the DL-3DP mode, a spatial window equal to 64 × 64 × 64 voxels and a batch size of 4 were set. The same settings were used for the three training modes as follows: learning rate = 0.001, sample per volume = 1, optimizer = Adam, loss function = L2norm and decay = 0.0001. During the training process, 10% of the training dataset was devoted to evaluation within the training of the model to verify the possibility of overfitting. Insignificant differences between the evaluation and training losses (errors) were observed for the three modes of training, which indicates no risk of overfitting. Decay factor refers to the regularization imposed on the trainable parameters. To this end, a ridge regression scheme using the following formula was utilized to prevent overfitting.
where λ is the decay factor (λ = 0.0001) and w is an array containing the entire trainable parameters. In addition, the training was started with a learning rate equal to 0.005 and for the last 2 epochs, the learning rate was reduced to 0.
Evaluation strategy
Qualitative and quantitative evaluation of the proposed framework was performed using an independent external validation set consisted of 150 patients. The image quality of the generated images was assessed using the following metrics using PET-CTAC images as a reference for evaluation.
Voxel-wise mean error (ME), mean absolute error (MAE), relative error (RE%) and absolute relative error (ARE%) were calculated between reference PET-CTAC and predicted PET images for the three training modes, namely DL-2DS, DL-3DS and DL-3DP.
Here, PETpredicted stands for PET images corrected for attenuation/scatter using Deep-JASC whereas PETref stands for the reference PET-CTAC images. Vxl and v denote the total number of voxels and voxel index, respectively.
Moreover, the root mean square error (RMSE), structural similarity index (SSIM) [37] and peak signal-to-noise ratio (PSNR) were calculated to assess the quality of the predicted PET images using Eqs. 6–8.
In Eq. (7), peak denotes the maximum intensity of either PETref or PETpredicted whereas MSE indicates the mean squared error. In Eq. (8), Averef and Avepredicted stand for the mean value of PETref and PETpredicted, respectively. δref and δpredicted denote the variances and δref,predicted the covariances of PETref and PETpredicted images, respectively. The constants (C1 = 0.01 and C2 = 0.02) were set to avoid division by very small values. The quantitative assessment of the proposed techniques was performed separately for the whole-body and for different regions of the body, namely the head, neck, chest, lung/liver, abdomen and pelvis as (Supplemental Figure 1). The lung/liver region contains slices from the liver dome until the end of the lungs. This region was reported separately since most respiratory motion errors/artefacts occur in this region.
Moreover, the performance of Deep-JASC was further investigated through the analysis of different types of malignant lesions delineated manually on 150 patients in the test dataset. To this end, volumes of interests (VOIs) were manually defined on lesions depicted on PET-CTAC images and copied on the corresponding predicted PET images. Conventional PET quantitative parameters, including SUVmax and SUVmean as well as histogram-based, second- and high-order texture features were extracted from the VOIs defined on the lesions. For patients lacking metabolic abnormalities, a 3 cm2 VOI was defined on the liver to extract the abovementioned features. Overall, 171 VOIs form 150 patients (external validation) were extracted for further analysis. A detailed description of the radiomics features is provided in Supplemental Table 1. The relative errors (REs%) were calculated between features extracted from reference PET-CTAC and Deep-JASC images using Eq. 9.
Paired-sample t test was used for statistical analysis to compare the image-derived metrics between the different training modes. The significance level of p values was set to 0.05 for all comparisons. Moreover, a joint histogram analysis (with Pearson correlation) was performed to display the distribution of voxel-wise PET SUV correlation between the Deep-JASC approaches and reference PET-CTAC for a SUV range of 0.1 to 18 in 200 bins.
Results
Figure 2 provides head-to-head comparison of a representative clinical example of PET-nonASC, PET-CTAC, PET-DL-2DS, PET-DL-3DS and PET-DL-3DP images as well as difference SUV maps with respect to reference PET-CTAC image. As shown in Fig. 2, Deep-JASC provides image quality comparable with PET-CTAC. Quantification errors can be observed in the chest region and in regions with high heterogeneity and complexity, such as the liver, bones, soft tissues and air. The DL-2DS method provided overly better image quality and quantitative accuracy compared with the two 3D methods. A comparison of horizontal profiles drawn through a lesion in the lung between PET-CTAC (reference) and the three synthesized PET images is also shown. The profiles of the PET-CTAC and Deep-JASC images match each other in both high and low activity areas of the chest region of lung cancer patients. Supplemental Figure 2 shows maximum intensity projections of PET-CTAC and the three different Deep-JASC algorithms of ten randomly selected patients.

Comparison of coronal views of the PET images corrected for attenuation/scatter using Deep-JASC approach. (A) CT, (B) PET-CTAC, (C) PET-nonASC, (D) PET-DL-2DS, (E) PET-DL-3DS, (F) PET-DL-3DP and the difference bias maps (G) PET-DL-2DS – PET-CTAC, (H) PET-DL-3DS – PET-CTAC, (I) PET-DL-3DP – PET-CTAC. The plot shows SUV profiles drawn through a lung lesion on the four PET images
The comparisons of image quality metrics computed on SUV images (mean ± SD) including ME, MAE, voxel-wise RE (%), voxel-wise ARE (%), SSIM, PSNR, and RMSE between the different methods (DL-2DS, DL-3DS and DL-3DP) for different regions in the body are summarized in Table 2. Supplemental Tables 2–4 provide the p values for comparisons of the three Deep-JASC techniques in different body regions. Across the 150 patients of the independent external validation set, the voxel-wise REs (%) were − 1.72 ± 4.22%, 3.75 ± 6.91% and − 3.08 ± 5.64 for DL-2DS, DL-3DS and DL-3DP, respectively.
The DL-2DS method led to lower RE (%) compared with both DL-3DS and DL-3DP approaches (p values = 0.01 and 0.03, respectively). In the DL-2DS technique, the lowest and highest REs (%) were 0.5 ± 5.04% in the neck region and − 4.7 ± 4.02% in the lung region, respectively. For DL-3DS, the lowest and highest REs (%) were 0.41 ± 6.86 in the lung-liver and 5.81 ± 4.85 in the pelvic region, respectively. The RE (%) decreased significantly for DL-2DS (1.25 ± 2.51%) in the pelvis region (p value < 0.05).
The average ME and ARE (%) for DL-2DS attenuation/scatter corrected images were − 0.02 ± 0.06 and 11.61 ± 4.25%, respectively. The DL-3DP, DL-3DS, and DL-2DS techniques ranked from the highest to lowest in terms of ARE (%) and MAE metrics. The DL-2DS, DL-3DS and DL-3DP approaches led to PSNR of 34.59 ± 3.28, 34.24 ± 3.44 and 34.09 ± 3.32 and SSIM of 0.96 ± 0.03, 0.95 ± 0.03, and 0.95 ± 0.03, respectively. However, the differences between these results were not statistically significant (Table 2).
The quantitative evaluation of PET images was conducted by voxel-wise comparisons of tracer uptake (SUV) within the body contour. Figure 3 compares the box plots of ARE, RE, MAE and RMSE, SSIM, PSRN, respectively, of the various methods within different regions of the body (box plot of ME is provided in Supplemental Figure 3). The lowest RMSE (0.22 ± 0.08) and MAE (0.22 ± 0.09) were achieved by DL-2DS.

Comparison of (A) absolute relative errors (ARE), (B) relative errors (RE%), (C) mean absolute errors (MAE), (D) root mean-square errors (RMSE), (E) peak signal to noise ratio (PSNR) and (F) structural similarity index (SSIM) obtained in different body regions when using DL-2DS, DL-3DS and DL-3DP SC/AC approaches. The box plots display the intraquartile range (IQR), minimum (Q1–1.5 × IQR), first quartile (Q1), median, third quartile (Q3), maximum (Q3 + 1.5 × IQR) and outliers
Figure 4 depicts the heat map of REs (%) calculated on 17 radiomics features for different types of cancer in Deep-JASC PET images. Table 3 summarizes the mean ± SD of radiomics features for different Deep-JASC approaches, wherein REs of SUVmean of − 2.54 ± 2.36%, − 1.75 ± 4.02% and − 5.03 ± 3.05% were obtained for 2DS, 3DS and 3DP approaches, respectively. 2DS and 3DS approaches resulted in mean REs of less than 5% for all radiomics features, while 3DP led to REs of − 5.03 ± 3.05%, − 5.27 ± 3.22% and − 5.24 ± 2.98% for SUVmean, Q1 and Q2 from histogram features, respectively. Supplemental Tables 5–7 present details of RE% (mean ± SD) calculated for different radiomics features and different cancer types in Deep-JASC PET images.

Heat map depicting relative errors of 17 radiomics features extracted from 171 VOIs of 150 patients (external validation) across different cancer types for PET-DL-2DS, PET-DL-3DS and PET-DL-3DP images versus reference PET-CT images
The joint histogram analysis exhibited voxel-wise similarity between reference CTAC and Deep-JASC attenuation and scatter correction techniques with slopes of 0.98, 1.05 and 1.02 for DL-2DS, DL-3DS and DL-3DP, respectively (Fig. 5). Moreover, the DL-2DS approach showed higher correlation (R2 = 0.985) compared with DL-3DS and DL-3DP (R2 = 0.980 and R2 = 0.981, respectively). Overall, DL-2DS exhibited smaller variation across the whole range of SUVs compared to the two 3D methods. However, for lower uptake voxels, DL-3DP showed comparable performance (variation) to the DL-2DS approach.

Joint histogram analysis displaying the correlation between activity concentration in PET- DL-2DS, PET- DL-3DS and PET- DL-3DP images and versus reference PET-CT image. Note that a logarithmic scale was used to display the SUV levels
Figure 6 shows an example of PET-CTAC affected by noticeable respiratory motion owing to the local mismatch between PET-nonASC and CT images in the liver dome region. This mismatch led to large discrepancies between PET-CTAC and PET-nonASC that was reasonably well recovered by the Deep-JASC approach. Overall, despite the promising results achieved by the Deep-JASC approach, pseudo hot and cold spots were observed in Deep-JASC PET images in some of the cases in the independent validation dataset (150 patients). One such example is illustrated in Fig. 7 showing CT, PET-nonASC, PET-CTAC, PET-DL-2DS, PET-DL-3DS and PET-DL-3DP images as well as different SUV maps relative to PET-CTAC. A similar pseudo hot uptake appeared in the abdomen for the three Deep-JASC images where the line profiles drawn on the hot spot show the level of local SUV overestimation in Deep-JASC images compared with the reference PET-CTAC. Supplemental Figures 4–6 show representative examples wherein Deep-JASC failed to identify underlying structures (Supplemental Figure 4), to pinpoint lesions (Supplemental Figure 5) due to high levels of noise in PET-nonASC images, or cause artefact-like pseudo structures (Supplemental Figure 6).

Case report of a clinical PET/CT study suffering from mismatch between PET and CT images owing to respiratory motion reflected in the PET-CTAC images that was partially compensated by PET images corrected using deep learning-based SC/AC approach. (A) CT, (B) PET-CTAC, (C) PET-nonASC, (D) PET-DL-2DS, (E) PET-DL-3DS, (F) PET-DL-3DP and the difference bias maps (G) PET-DL-2DS – PET-CTAC, (H) PET-DL-3DS – PET-CTAC and (I) PET-DL-3DP – PET-CTAC. The plot shows SUV profiles drawn through the pseudo hot spot

Case report of an outlier showing: A pseudo hot spot appeared in the PET images corrected for attenuation/scatter using the different deep learning-based approaches. (A) CT, (B) PET-CTAC, (C) PET-nonASC, (D) PET-DL-2DS, (E) PET-DL-3DS, (F) PET-DL-3DP and the difference bias maps (G) PET-DL-2DS – PET-CTAC, (H) PET-DL-3DS – PET-CTAC and (I) PET-DL-3DP – PET-CTAC. The plot shows SUV profiles drawn through the pseudo hot spot
Among the different Deep-JASC approaches, DL-2DS resulted in the lowest SUV error metrics (RMSE = 0.22 ± 0.08, RE = − 1.72 ± 4.22%and SSIM = 0.96 ± 0.03). The highest error metrics (ARE = 15.16 ± 3.96%, lowest PSNR = 31.7 ± 2.52 and SSIM = 0.93 ± 0.03) were observed in the chest region. Regarding 3D implementations of Deep-JASC, ARE decreased significantly for DL-3DS (11.16 ± 3.42%, p value < 0.05) and DL-3DP (11.69 ± 2.71, p value < 0.05) approaches, respectively.
Discussion
The aim of the present work was to demonstrate the feasibility of the direct generation of attenuation/scatter-corrected whole-body 18F-FDG PET images from uncorrected images without using anatomical information. The evaluation of the proposed methods was performed on an independent validation set consisting of 150 patients using established quantitative imaging metrics. SUV quantification in the generated SC/AC images was highly reproducible.
Attenuation patterns in the chest region are different from other regions in PET-nonASC images. Lung tissue appears brighter in contrast to other regions of the body, whereas areas closer to the skin appear brighter and areas closer to the center appear darker in PET-nonASC images. The bias maps showed the highest error in the chest and liver regions owing to their higher heterogeneity (soft tissue, lung, air, bone and ribs). In addition, slight respiratory motion, causing local miss-match between PET and CT images, added to the complexity of this region which led to a higher relative error compared with other regions, including the brain, pelvis and abdomen. Prior to training, pairs of PET images suffering from low quality were removed from the training/test datasets. The causes of poor image quality were mostly gross patient motion within PET images (blurring) and miss-match between CT and PET images. In some cases, belonging to the external validation set (Fig. 6), one can observe a large difference between PET images generated using Deep-JASC and CTAC in the lung region and the liver dome. The mismatch between PET and CT images induced by respiratory motion in the lung and upper abdomen cause artefacts in PET-CTAC images. In Deep-JASC, attenuation and scatter corrections are performed using only emission data without the use of anatomical images, such as CT and MRI. Therefore, Deep-JASC is less vulnerable to mismatch artefacts in the chest and upper abdomen, which partly explains the difference between Deep-JASC and CTAC PET images in these regions. Even though large ARE (%) and RE (%) were observed in the chest region, partly due to the division by very small SUV values, the absolute SUV differences between the predicted PET images and reference PET-CTAC images are comparable with those obtained in other regions. Previous whole-body PET AC studies showed SUV bias in lung lesions up to 15% when using atlas-based methods and over 20% when using segmentation-based [7, 38].
Despite the large anatomical intra- and inter-patient variability, the spatial distribution of the scatter component in PET images follows commonly a smooth variation across slices and/or regions. As such, the scatter patterns are not much affected in the chest region. Moreover, the scatter fraction, estimated via the tail fitting approach, is commonly regularized over the axial coverage to ensure smooth scatter pattern changes. Therefore, although large anatomical variations exist in this region, the scatter patterns do not change drastically across the patients and through the different regions.
The results demonstrated that training in 2D mode led to superior (or at least slightly better) performance compared with the two 3D training modes. Three different methods, namely 2D slices (low computation burden, large data size with high variability, AC/SC performed in 2D), 3D slices (considering the 3D volume and include different information from sagittal and coronal planes, which allows a better continuity of image intensity in the axial direction) and 3D patches (seeing the different structures in different FOVs), were considered for implementation of Deep-JASC. Nevertheless, the 3D approaches provided better results in highly heterogeneous regions, such as the lung region owing to the inclusion of information from neighbouring slices. The training dataset in 2D mode is markedly larger that in 3D mode, which might partly explain its better performance. In addition, 3D training mode may also complicate the learning/convergence process of regression and consequently results in sub-optimal performance. 3D training dramatically increases the number of trainable parameters, subsequently complicating the optimization process to converge to a global minima loss. It should be noted that the training of datasets for a specific body region may improve the quality of the outcome. Dividing the body into a number of sub-regions for training is an option to consider to enhance the performance of the Deep-JASC approach. In addition, hybrid 3D and 2D training might result in overall enhanced performance, for instance in the lung region where 3D implementations outperformed the 2D one.
Deep learning techniques were previously reported for cross-modality transformation from MRI to CT for MRI-only guided radiation therapy and AC in PET/MRI. Dedicated (UTE/ZTE) MR sequences require long acquisition time to generate an appropriate attenuation map, rendering these methods impractical for whole-body imaging. Hwang et al. [30] proposed a deep learning–based synthetic CT generation which the input to this network is the attenuation map estimated from MLAA reconstruction in brain imaging. They reported the average voxel-wise RE 12.82% ± 2.45%, 5.61% ± 0.68% and 2.05% ± 1.51% for MLAA based AC, four segment-based AC and deep learning–based AC, respectively. Shi et al. [39] proposed a line-integral projection loss (LIP-loss) function that incorporates the physics of PET attenuation into attenuation map generation. They reported a MAE of 21.4%, 7.8%, 9.4%, 9.2% and 11.26% for MLAA; 3.5%, 4.2%, 4.8%, 4.4% and 4.1% for the deep learning method; and 3.2%, 3.7%, 4.1%, 3.6% and 3.6% for Deep-LIP in the head, neck/chest, abdomen, pelvis and whole-body regions, respectively. Despite the promising results, pseudo-CT synthesis from MRI for AC faces a number of challenges [24, 40, 41], including mismatch between MRI and PET images, internal organ displacements and the lack of direct relationship between proton density and electron density [6]. To address these challenges, our proposed method performs direct AC from emission data only. This approach is less vulnerable to the challenges of pseudo-CT synthesis and is applicable to standalone PET scanners and PET/MRI systems.
Van Hemmen et al. [42] applied a deep convolutional encoder-decoder (CED) network using a U-Net architecture for whole-body PET attenuation correction and reported an ARE of ~ 30% for 10 subjects. Yang et al. [43] applied 3D generative adversarial networks for attenuation and scatter correction of whole-body PET images reporting an average ME and MAE in whole-body imaging of 2.49% ± 7.98% and 16.55% ± 4.43%, respectively, in a population of 30 patients. More recently, Dong et al. [32] proposed a deep learning approach for whole-body PET AC in the absence of structural information. They reported an average ME of 13.84% ± 10.11%, 13.42% ± 10.13% and − 17.02% ± 11.98% in the lung and 2.05% ± 2.21%, 2.25% ± 1.93% and 0.62% ± 1.26% in whole-body imaging for U-Net, GAN and cycle-GAN, respectively. Reliable assessment of deep learning algorithms requires a large dataset for training and validation, allowing for proper interpretation of the results and robustness to outliers. In the present study, we used an unprecedently large sample size of training, test and validation dataset for reliable assessment of Deep-JASC, which enabled the reporting of potential outliers and deficiencies of the proposed approach.
In an MRI-guided AC in whole-body PET imaging study, Arabi et al. [44] reported REs (%) of 15.8 ± 10.1, − 1.0 ± 6.8 and 3.9 ± 11.7 in the lung and − 9.6 ± 8.2, − 3.4 ± 5.2 and − 4.9 ± 6.7 in soft-tissue when using segmentation-based, atlas-based and Hofmann’s pseudo CT generation approaches, respectively. Mehranian et al. [45] performed a clinical assessment of MLAA-guided MRI-constrained Gaussian mixture model (GMM) algorithm and 4-class MRI segmentation-based (MRAC) attenuation correction in whole-body time TOF PET/MR imaging. They reported an average SUV RE % (and RMSE) of − 5.4 ± 12.0 (13.1) and − 3.5 ± 6.6 (7.5) in the lung, − 7.4 ± 1.8 (7.6) and − 5.4 ± 3.2 (6.3) in the liver, and − 9.2 ± 6.0 (11.0) and − 3.1 ± 6.8 (7.5) in the myocardium for MRAC and MLAA-GMM methods, respectively. Hofmann et al. [46] evaluated segmentation and atlas-pattern recognition (AT&PR)–based whole-body AC in PET/MRI and reported REs (%) of 14.1 ± 10.2 and 7.7 ± 8.4 for the segmentation and the AT&PR approaches, respectively. Segmentation-based techniques require substantial pre-processing steps and have limited performance in the lung and bone regions because of weak signals produced by both tissues. Different MR sequences address the signal generation problem in conventional MR sequences. However, they are limited by image artefacts, high levels of noise, limited diagnostic value and long acquisition time. Atlas-based AC methods are affected by registration accuracy, which is limited by inter/intra-patients variability.
Chang et al. [47] developed a PET-nonASC-based segmentation using an active contour algorithm for PET AC and reported SUV bias of 6% ± 7% in whole-body imaging. More recently, Rezaei et al. [11] applied joint reconstruction of activity and attenuation in TOF PET imaging, achieving a RE (%) of − 7.5 ± 4.6 in the whole-body. Likewise, Salomon et al. [48] exploited a different framework for implementation of the joint activity and attenuation correction and reported averaged REs of − 10.3, − 2.9, − 2.0 and − 5.7 for bone, soft-tissue, fat and lung regions, respectively. In an investigation of the impact of TOF reconstruction on PET quantification, Mehranian et al. [49] reported REs of − 3.4 ± 11.5 for the lung and − 21.8 ± 2.9 for bone using a non-TOF MRI-guided AC method. In this study, the voxel-wise REs across the 150 patients of the independent external validation set were − 1.72 ± 4.22%, 3.75 ± 6.91% and − 3.08 ± 5.64% for DL-2DS, DL-3DS and DL-3DP methods, respectively. The DL-2DS method led to lower RE compared with both DL-3DS (p value < 0.02) and DL-3DP (p value < 0.05) approaches. In the DL-2DS technique, the lowest and highest REs were 0.5 ± 5.04% in the neck region and − 4.7 ± 4.02% in the lung region. For DL-3DS, the lowest and highest REs were 0.41 ± 6.86 in the lung-liver and 5.81 ± 4.85 in the pelvic region. The REs in the lung region were − 4.7 ± 4.02%, 2.54 ± 5.61% and − 1.01 ± 3.03% for DL-2DS, DL-3DS and DL-3DP, respectively. Among the different Deep-JASC approaches, DL-2DS resulted in the lowest SUV error metrics (RMSE = 0.22 ± 0.08, RE = − 1.72 ± 4.22% and SSIM = 0.96 ± 0.03). The highest error metrics (ARE = 15.16 ± 3.96%, lowest PSNR = 31.7 ± 2.52 and SSIM = 0.93 ± 0.03) were observed in the chest region.
Overall, the 2DS approach exhibited superior performance over the different body regions, except the chest region (Fig. 3). Smaller ARE% and MAE were observed in the brain, neck, lung/liver, abdomen and pelvis regions when using the 2DS approach compared with 3D modes. This trend was reversed in the chest region where 3D approaches led to significantly smaller ARE% and MAE compared with the 2DS approach. This observation could be partly attributed to the complexity and irregularity of attenuation correction in this region wherein insufficient structural/underlying uptake information in 2D slices led to the inferior performance of the 2DS approach. Despite the higher ARE% and MAE, 2DS exhibited better performance with respect to PSNR and SSIM metrics, which may be due to the patchy appearance of the images in the 3D approaches.
The average errors calculated over either whole-body or regional body regions reflected mostly the technical performance of Deep-JASC approaches. However, a detailed analysis of tracer uptake in malignant lesions clarified the relevant clinical performance of these approaches. Both 2DS and 3DS approaches resulted in less than 4% errors in SUVmean and SUVmax estimation (outperforming the 3DP approach with more than 5% REs). Moreover, the significantly lower standard deviations achieved by 2DS confirmed the better performance of this approach. The high tracer uptake, signal-to-noise ratio and contrast of malignant lesions make them easy to resolve in PET-nonASC images. As such, Deep-JASC performed relatively better on malignant lesions in terms of tracer uptake quantification compared with other body regions containing mixtures of tissues/activity concentration levels.
A major limitation of this approach is its vulnerability to noise beyond the normal/average levels of noise or signal-to-noise ratio (SNR) in PET-nonASC images existing in the training dataset. In such a situation, the deep learning–based technique would fail to discriminate noise from the underlying structures or distinguish genuine organ/lesion boundaries (supplemental Figures 4 and 5), thus potentially leading to noise-induced pseudo structures and/or loss of signal pertinent to underlying structures (Supplemental Figure 6). The PET-nonASC image shown in Supplemental figure 4C suffers from low SNR reflected by poor organ boundaries particularly in the lung and shoulders regions where the deep learning–based approach failed to recover the actual activity distribution, leading to gross errors in the chest region. However, in other patients (e.g. Fig. 2), where PET-nonASC images bear relatively good SNR, the proposed approach succeeded to recover the actual activity distribution.
Although direct attenuation and scatter correction in the image domain is immune to mismatch between PET and CT images and potential respiratory motion-related errors, this approach warrants the implementation of thorough quality control measures of the resulting PET images to ensure accurate lesion conspicuity and quantitative accuracy. This is mainly due to the fact that this approach is still in an embryonic stage and requires further research and development efforts to shed light on the potential capabilities and pitfalls of this approach. Moreover, this approach performs the correction in an end-to-end fashion, and as such, failure of the deep learning approach would directly translate into errors in the resulting PET images.
We included disease-free and pathological patients with various indications, such as age, weight and disease type (for training and independent validation sets) resulting in a heterogeneous database. This study naturally bears a number of limitations. First, the training and independent validation processes were performed on only 18F-FDG as a tracer. For different radiotracer distributions, the network will need to be retrained on PET images using other radiotracers. However, the network trained on 18F-FDG PET images could be used to initialize networks trained on PET images acquired with other radiotracers via transfer learning [50]. This will also help to address the issue of having a limited training dataset. Second, all images were acquired on a PET/CT scanner. Hence, the network has not yet been validated for PET/MRI applications since this hybrid imaging uses rigid and surface MR coils (invisible in PET images) in the field-of-view. This will add challenges to the Deep-JASC approach, in particular for non-rigid surface coils as they may not impact PET-nonASC images similarly/repeatability across the subjects. The network should be validated for PET/MRI. Yet, PET/CT images included the CT couch, yet the network performed reasonably well.
Conclusion
This work demonstrated the feasibility of joint attenuation and scatter correction of whole-body 18F-FDG PET images in the image space using a residual convolutional neural network (Deep-JASC) using an unprecedently large sample size. The proposed algorithm does not require the use of anatomical images (CT or MRI), thus providing a sensible solution in a clinical setting for standalone PET scanners and PET/MRI systems. Nevertheless, despite the promising results obtained, the technique is vulnerable to and noise-induced artefacts, which resulted in pseudo hot/cold spots or noticeable quantification errors across the organ boundaries, in particular between the lung and liver. Further research is guaranteed to improve the algorithm’s performance.
References
Ben-Haim S, Ell P. 18F-FDG PET and PET/CT in the evaluation of cancer treatment response. J Nucl Med. 2009;50:88–99.
Zaidi H, Karakatsanis N. Towards enhanced PET quantification in clinical oncology. Br J Radiol. 2018;91:20170508.
Boellaard R. Standards for PET image acquisition and quantitative data analysis. J Nucl Med. 2009;50:11S–20.
Zaidi H, Koral KF. Scatter modelling and compensation in emission tomography. Eur J Nucl Med Mol Imaging. 2004;31:761–82.
Kinahan PE, Hasegawa BH, Beyer T. X-ray-based attenuation correction for positron emission tomography/computed tomography scanners. Semin Nucl Med. 2003;33:166–79.
Mehranian A, Arabi H, Zaidi H. Vision 20/20: magnetic resonance imaging-guided attenuation correction in PET/MRI: challenges, solutions, and opportunities. Med Phys. 2016;43:1130–55.
Arabi H, Rager O, Alem A, Varoquaux A, Becker M, Zaidi H. Clinical assessment of MR-guided 3-class and 4-class attenuation correction in PET/MR. Mol Imaging Biol. 2015;17:264–76.
Martinez-Moller A, Souvatzoglou M, Delso G, Bundschuh RA, Chefd'hotel C, Ziegler SI, et al. Tissue classification as a potential approach for attenuation correction in whole-body PET/MRI: evaluation with PET/CT data. J Nucl Med. 2009;50:520–6.
Arabi H, Koutsouvelis N, Rouzaud M, Miralbell R, Zaidi H. Atlas-guided generation of pseudo-CT images for MRI-only and hybrid PET–MRI-guided radiotherapy treatment planning. Phys Med Biol. 2016;61:6531–52.
Mehranian A, Zaidi H. Joint estimation of activity and attenuation in whole-body TOF PET/MRI using constrained Gaussian mixture models. IEEE Trans Med Imaging. 2015;34:1808–21.
Rezaei A, Deroose CM, Vahle T, Boada F, Nuyts J. Joint reconstruction of activity and attenuation in time-of-flight PET: a quantitative analysis. J Nucl Med. 2018;59:1630–5.
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88.
Sanaat A, Arabi H, Mainta I, Garibotto V, Zaidi H. Projection-space implementation of deep learning-guided low-dose brain PET imaging improves performance over implementation in image-space. J Nucl Med. 2020; in press.
Shiri I, Leung K, Geramifar P, Ghafarian P, Oveisi M, Ay MR, et al. PSFNET: ultrafast generation of PSF-modelled-like PET images using deep convolutional neural network [abstract]. J Nucl Med. 2019;60:1369.
Haggstrom I, Schmidtlein CR, Campanella G, Fuchs TJ. DeepPET: a deep encoder-decoder network for directly solving the PET image reconstruction inverse problem. Med Image Anal. 2019;54:253–62.
Han X. MR-based synthetic CT generation using a deep convolutional neural network method. Med Phys. 2017;44:1408–19.
Jin CB, Kim H, Liu M, Jung W, Joo S, Park E, et al. Deep CT to MR synthesis using paired and unpaired data. Sensors. 2019;19:2361.
Bortolin K, Arabi H, Zaidi H. Deep learning-guided attenuation and scatter correction in brain PET/MRI without using anatomical images. IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC). Manchester, UK; 2019.
Arabi H, Zeng G, Zheng G, Zaidi H. Novel adversarial semantic structure deep learning for MRI-guided attenuation correction in brain PET/MRI. Eur J Nucl Med Mol Imaging. 2019;46:2746–59.
Yang J, Park D, Gullberg GT, Seo Y. Joint correction of attenuation and scatter in image space using deep convolutional neural networks for dedicated brain (18)F-FDG PET. Phys Med Biol. 2019;64:075019.
Spuhler KD, Gardus J 3rd, Gao Y, DeLorenzo C, Parsey R, Huang C. Synthesis of patient-specific transmission image for PET attenuation correction for PET/MR imaging of the brain using a convolutional neural network. J Nucl Med. 2019;60:555–60.
Arabi H, Dowling JA, Burgos N, Han X, Greer PB, Koutsouvelis N, et al. Comparative study of algorithms for synthetic CT generation from MRI: consequences for MRI-guided radiation planning in the pelvic region. Med Phys. 2018;45:5218–33.
Jang H, Liu F, Zhao G, Bradshaw T, McMillan AB. Technical note: deep learning based MRAC using rapid ultra-short echo time imaging. Med Phys. 2018;45:3697–704.
Gong K, Yang J, Kim K, El Fakhri G, Seo Y, Li Q. Attenuation correction for brain PET imaging using deep neural network based on Dixon and ZTE MR images. Phys Med Biol. 2018;63:125011.
Leynes AP, Yang J, Wiesinger F, Kaushik SS, Shanbhag DD, Seo Y, et al. Zero-echo-time and Dixon deep pseudo-CT (ZeDD CT): direct generation of pseudo-CT images for pelvic PET/MRI attenuation correction using deep convolutional neural networks with multiparametric MRI. J Nucl Med. 2018;59:852–8.
Shiri I, Ghafarian P, Geramifar P, Leung KH, Ghelichoghli M, Oveisi M, et al. Direct attenuation correction of brain PET images using only emission data via a deep convolutional encoder-decoder (deep-DAC). Eur Radiol. 2019;29:6867–79.
Rezaei A, Defrise M, Bal G, Michel C, Conti M, Watson C, et al. Simultaneous reconstruction of activity and attenuation in time-of-flight PET. IEEE Trans Med Imaging. 2012;31:2224–33.
Mehranian A, Arabi H, Zaidi H. Quantitative analysis of MRI-guided attenuation correction techniques in time-of-flight brain PET/MRI. Neuroimage. 2016;130:123–33.
Hwang D, Kim KY, Kang SK, Seo S, Paeng JC, Lee DS, et al. Improving the accuracy of simultaneously reconstructed activity and attenuation maps using deep learning. J Nucl Med. 2018;59:1624–9.
Hwang D, Kang SK, Kim KY, Seo S, Paeng JC, Lee DS, et al. Generation of PET attenuation map for whole-body time-of-flight (18)F-FDG PET/MRI using a deep neural network trained with simultaneously reconstructed activity and attenuation maps. J Nucl Med. 2019;60:1183–9.
Wolterink JM, Dinkla AM, Savenije MHF, Seevinck PR, van den Berg CAT, Išgum I. Deep MR to CT synthesis using unpaired data. International Workshop on Simulation and Synthesis in Medical Imaging SASHIMI. Cham: Springer International Publishing; 2017. p. 14–23.
Dong X, Lei Y, Wang T, Higgins K, Liu T, Curran WJ, et al. Deep learning-based attenuation correction in the absence of structural information for whole-body PET imaging. Phys Med Biol. 2020;65(5):055011.
Watson CC. New, faster, image-based scatter correction for 3D PET. IEEE Trans Nucl Sci. 2000;47:1587–94.
Li W, Wang G, Fidon L, Ourselin S, Cardoso MJ, Vercauteren T. On the compactness, efficiency, and representation of 3D convolutional networks: brain parcellation as a pretext task. In: Niethammer M, Styner M, Aylward S, Zhu H, Oguz I, Yap P-T, et al., editors. Information Processing in Medical Imaging. Cham: Springer International Publishing; 2017. p. 348–60.
Gibson E, Li W, Sudre C, Fidon L, Shakir DI, Wang G, et al. NiftyNet: a deep-learning platform for medical imaging. Comput Methods Prog Biomed. 2018;158:113–22.
Abadi M, Barham P, Chen J, Chen Z, Davis A, Dean J, et al. TensorFlow: a system for large-scale machine learning. Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation. Savannah, GA, USA: USENIX Association; 2016. p. 265–83.
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Proc. 2004;13:600–12.
Arabi H, Zaidi H. One registration multi-atlas-based pseudo-CT generation for attenuation correction in PET/MRI. Eur J Nucl Med Mol Imaging. 2016;43:2021–35.
Shi L, Onofrey JA, Revilla EM, Toyonaga T, Menard D, Ankrah J, et al. A novel loss function incorporating imaging acquisition physics for PET attenuation map generation using deep learning. International Conference on Medical Image Computing and Computer-Assisted Intervention: Springer; 2019. p. 723–31.
Liu F, Jang H, Kijowski R, Bradshaw T, McMillan AB. Deep learning MR imaging–based attenuation correction for PET/MR imaging. Radiology. 2017;286:676–84.
Liu F, Jang H, Kijowski R, Zhao G, Bradshaw T, McMillan AB. A deep learning approach for (18)F-FDG PET attenuation correction. EJNMMI Phys. 2018;5:24.
Van Hemmen H, Massa H, Hurley S, Cho S, Bradshaw T, McMillan A. A deep learning-based approach for direct whole-body PET attenuation correction [abstract]. J Nucl Med. 2019;60:569.
Yang X, Lei Y, Dong X, Wang T, Higgins K, Liu T, et al. Attenuation and scatter correction for whole-body PET using 3D generative adversarial networks [abstract]. J Nucl Med. 2019;60:174.
Arabi H, Zaidi H. Magnetic resonance imaging-guided attenuation correction in whole-body PET/MRI using a sorted atlas approach. Med Image Anal. 2016;31:1–15.
Mehranian A, Zaidi H. Clinical assessment of emission-and segmentation-based MR-guided attenuation correction in whole-body time-of-flight PET/MR imaging. J Nucl Med. 2015;56:877–83.
Hofmann M, Bezrukov I, Mantlik F, Aschoff P, Steinke F, Beyer T, et al. MRI-based attenuation correction for whole-body PET/MRI: quantitative evaluation of segmentation-and atlas-based methods. J Nucl Med. 2011;52:1392–9.
Chang T, Diab RH, Clark JW Jr, Mawlawi OR. Investigating the use of nonattenuation corrected PET images for the attenuation correction of PET data. Med Phys. 2013;40:082508.
Salomon A, Goedicke A, Schweizer B, Aach T, Schulz V. Simultaneous reconstruction of activity and attenuation for PET/MR. IEEE Trans Med Imaging. 2011;30:804–13.
Mehranian A, Zaidi H. Impact of time-of-flight PET on quantification errors in MR imaging–based attenuation correction. J Nucl Med. 2015;56:635–41.
Mesnil G, Dauphin Y, Glorot X, Rifai S, Bengio Y, Goodfellow I, et al. Unsupervised and transfer learning challenge: a deep learning approach. Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning workshop-Volume 27: JMLR. org; 2011. p. 97–111.
Funding
This work was supported by the Swiss National Science Foundation under grant SNRF 320030_176052 and the Swiss Cancer Research Foundation under Grant KFS-3855-02-2016.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Research involving human participants
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection on Advanced Image Analyses (Radiomics and Artificial Intelligence)
Electronic supplementary material
ESM 1
(DOCX 6018 kb)
Rights and permissions
About this article

Cite this article
Shiri, I., Arabi, H., Geramifar, P. et al. Deep-JASC: joint attenuation and scatter correction in whole-body 18F-FDG PET using a deep residual network. Eur J Nucl Med Mol Imaging 47, 2533–2548 (2020). https://doi.org/10.1007/s00259-020-04852-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00259-020-04852-5