
Abstract
We describe two sets of experiments that examine the ability of vibrotactile encoding of simple position error and combined object states (calculated from an optimal controller) to enhance performance of reaching and manipulation tasks in healthy human adults. The goal of the first experiment (tracking) was to follow a moving target with a cursor on a computer screen. Visual and/or vibrotactile cues were provided in this experiment, and vibrotactile feedback was redundant with visual feedback in that it did not encode any information above and beyond what was already available via vision. After only 10 minutes of practice using vibrotactile feedback to guide performance, subjects tracked the moving target with response latency and movement accuracy values approaching those observed under visually guided reaching. Unlike previous reports on multisensory enhancement, combining vibrotactile and visual feedback of performance errors conferred neither positive nor negative effects on task performance. In the second experiment (balancing), vibrotactile feedback encoded a corrective motor command as a linear combination of object states (derived from a linear-quadratic regulator implementing a trade-off between kinematic and energetic performance) to teach subjects how to balance a simulated inverted pendulum. Here, the tactile feedback signal differed from visual feedback in that it provided information that was not readily available from visual feedback alone. Immediately after applying this novel “goal-aware” vibrotactile feedback, time to failure was improved by a factor of three. Additionally, the effect of vibrotactile training persisted after the feedback was removed. These results suggest that vibrotactile encoding of appropriate combinations of state information may be an effective form of augmented sensory feedback that can be applied, among other purposes, to compensate for lost or compromised proprioception as commonly observed, for example, in stroke survivors.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Reaching and manipulation behaviors are central to how people interact with the world. Learning and control of these dexterous behaviors require timely and reliable sensory feedback (Mussa-Ivaldi and Miller 2003). In certain pathological conditions, one or more sensory modalities are compromised (e.g., loss of visual feedback in blindness; loss of proprioceptive feedback of limb state that can occur, for example, after stroke). Sensory loss can compromise the ability to perform dexterous movements and thus negatively affect quality of life. A technique that has been proposed as a means to compensate for sensory loss is sensory substitution (Rauschecker 1995; Bach-y-Rita and Kercel 2003). Sensory substitution seeks to re-establish real-time feedback control by delivering lost sensory information to a different sensory modality for which the brain retains the ability to process feedback. However, the nervous system is normally limited in the quantity and quality of information conveyed by the various senses (Repperger et al. 1995). In order for one sensory channel to efficiently substitute another, both channels should have similar information capacities (Bach-y-Rita 1970; Novich and Eagleman 2015). A related technique, multimodal sensory augmentation (Sigrist et al. 2013), seeks to enhance sensorimotor performance by distributing task-relevant information across the different senses. Here, feedback encoding schemes can even encode information not readily available via the natural senses. For example, stabilization of dynamical systems such as an inverted pendulum requires estimation of current pendulum states [e.g., deflection from the vertical (the goal) and rate of change of deflection] and the integration of that information into ongoing motor commands. This is a challenging sensorimotor control problem because even though subjects may receive direct feedback of object state, it is unclear which combination of limb and object states need to be attended to in order to optimize performance. There are two ways to achieve sensory augmentation. First, one could provide sensory cues that encode redundant information, i.e., information already available to the brain through the inherent senses. A classic example is the orientation cues provided to pilots who must deal with spatial disorientation during conditions of low visibility (Sklar and Sarter 1999), providing cues for mission-critical performance variables, such as which direction is down, can enhance task performance by reducing demands on visual feedback and the division of visual attention. Alternatively, one could augment sensory feedback with new kinds of information not readily available to the brain (e.g., useful combinations of manipulated object states). This later approach creates new possibilities for “goal-aware” feedback that have the potential, for example, to optimize human-in-the-loop systems performing reaching and manipulation tasks.
To be effective, augmented feedback must be delivered in an inconspicuous way that does not require constant visual attention and does not interfere with other critical behaviors such as the production and perception of speech (Bach-y-Rita 1970). Auditory (Sun et al. 2010), electrotactile (Kaczmarek et al. 1991), force-based haptic feedback (Guo and Song 2009; Huang and Krakauer 2009; Sigrist et al. 2013) and vibrotactile interfaces (Sienko et al. 2008; Bark et al. 2015) have been proposed as potential supplements to visual feedback. Of these, vibrotactile feedback seems to have the most advantages. Comparison studies have shown that vibrotactile feedback outperforms auditory feedback in enhancing performance of a pursuit rotor task (Sun et al. 2010) and, in some cases, can be as effective as vision (Sklar and Sarter 1999). Acoustic stimulation can also interfere with perception of speech. Electrotactile stimulation has the potential to cause skin breakdown (Kaczmarek et al. 1991) or interfere with speech production (Danilov and Tyler 2005). Finally, haptic force feedback systems require specialized object interfaces that constrain motions of the user and therefore do not allow free exploration of the task space. Because motor learning is predominantly driven by the production and subsequent correction for performance errors (Scheidt et al. 2000; Thoroughman and Shadmehr 2000; Patton et al. 2006), it is not clear whether haptic feedback systems that constrain motion are truly effective in promoting sensorimotor learning of desired behaviors that transfer to unconstrained situations (Huang and Krakauer 2009; Sigrist et al. 2013). Previous proof-of-concept studies demonstrating the effective use of vibrotactile feedback to promote motor learning include the teaching of musical instruments (van der Linden et al. 2011), the teaching of sports (Spelmezan et al. 2009) and specific body motions (Lieberman and Breazeal 2007; Bark et al. 2015), controlling the motion of a prosthetic arm (Hasson and Manczurowsky 2015) and mitigating deficits of proprioceptive feedback after stroke (Tzorakoleftherakis et al. 2015).
The literature provides no strong theoretical or computational basis for designing augmented sensory feedback signals (Sigrist et al. 2013). The most popular approach encodes performance error information within the augmented feedback signal (Scheidt et al. 2000; Patton et al. 2006; Lieberman and Breazeal 2007; Patton et al. 2013). With error encoding, deviations from a desired state (the “goal”) are fed back to the user, who can drive performance back to that desired state. An alternate augmented feedback approach uses a computational model of the controlled object along with linear-quadratic regulator (LQR) techniques from control systems engineering to compute the best combination of object states to be fed back to the user, such that human-in-the-loop control is optimized (Tzorakoleftherakis et al. 2014). This form of supplemental vibrotactile feedback provides the user with explicit knowledge of how one specific combination of state variables—sensed via the natural feedback pathways—should be used to drive motor responses. In the studies we describe here, we examine the ability of each form of supplemental feedback to enhance performance of reaching or object manipulation tasks. Previous studies have reported that the addition of supplemental sensory feedback can lead to one of three possible outcomes: a) no change in performance as a result of ignoring the additional stimuli—see, e.g., the Colavita effect (Colavita 1974), b) performance degradation due to the division of attention (Bark et al. 2008; Hasson and Manczurowsky 2015) or c) performance improvement. In one recent study of simple reaction time (SRT) in response to single or combined visual and vibrotactile stimuli, subjects were to press a button as fast as possible after the presentation of single or double, unimodal or bimodal stimuli. Consistent with the phenomenon known as multisensory enhancement (Hershenson 1962; Nickerson 1973), Forster et al. (2002) found that normal observers respond faster to simultaneous visual and electrotactile stimuli than to either visual or tactile stimuli alone. We reasoned therefore that supplemental vibrotactile feedback may enhance performance in the production of reach and manipulation behaviors wherein response time was to be minimized.
In this paper, we tested the application of simple position error and combined state encoding for vibrotactile feedback during goal-directed, time-constrained reaching and manipulation tasks. In a first set of experiments, subjects performed two goal-directed reaching tasks (discrete and continuous target tracking) and we tested the hypothesis that vibrotactile encoding of hand position errors can suffice to guide performance of goal-directed movements. In these first experiments, the vibrotactile feedback was redundant with visual feedback in that it did not encode any information above and beyond what was already available via vision. In a second set of experiments, subjects were to balance an inverted pendulum for as long as possible. Unlike the first experiment wherein supplemental vibrotactile feedback encoded only position error, feedback in this second experiment encoded an optimized linear combination of object state information, thus always suggesting the optimal corrective motor command. In this condition, vibrotactile feedback provided information that was not readily available from visual feedback alone. We tested the hypothesis that vibrotactile encoding of an appropriate combination of object states can enhance performance and learning of this novel manipulation skill, above and beyond levels attained in the vision-only condition. The results of the first experiment demonstrate that vibrotactile encoding of hand position errors is indeed effective in driving goal-directed movements in the absence of visual feedback, while results of the second experiment suggest that training under the guidance of an optimal controller facilitates both the immediate closed-loop performance in the stabilization task as well as transfer to subsequent testing conditions without vibrotactile guidance. These last results demonstrate the potential power of this new, “goal-aware” training approach.

a System overview. Arrows indicate flow of information. b A schematic of the inverted pendulum/cart system; the rod and cart are considered massless. c A typical LQR control loop. d Extended LQR loop where the controller is used to “teach” the user how to balance the system. Symbol descriptions; r: reference state vector; u: system input; \(x_c\): cart position; x: full state vector \([x_c \, \dot{x}_c \, \theta \; \dot{\theta }]^T\) with \(\ddot{x}_c\) being kinematically controlled, i.e., \(\ddot{x}_c=h=u\); y: output angle \(\theta\); N: precompensator (a block that is used to make the steady state error of the system zero); \(u_{LQR}=Nr-Kx\) where K is the LQR Gain Matrix; V: voltage; v: vibrotactile feedback; h: hand position
Methods
Participants
Forty-three subjects participated in one of two experiments examining the utility of two different forms of “goal-aware” vibrotactile feedback in enhancing motor performance. Each experiment was conducted in a single session lasting no more than 30 min. Thirteen students (ten males, three females) participated in the first experiment (tracking), which examined how well visual and vibrotactile information about hand position error can drive performance of goal-directed movements during a target capture task. Thirty students (18 males, 12 females) took part in a second experiment (balancing), which examined the ability of vibrotactile feedback to enhance visuomotor performance during a task that required dynamic stabilization of an inverted pendulum. Here, the “goal-aware” vibrotactile feedback encoded an optimized linear combination of pendulum states, thus providing a “teacher” signal that instructed subjects how to manipulate the pendulum for optimal performance. In both experiments, participants were free to decide how they would utilize the feedback that was provided to them. All participants reported normal tactile perception, normal or corrected vision and no history of neurological disorders. All were unaware of the purpose of the study and were free to terminate the experiment at any time. All gave written informed consent prior to participating, using protocols approved by Northwestern University’s Institutional Review Board.
Apparatus and materials
A block diagram of the experimental setup used for the two experiments is shown in Fig. 1a. Both tasks required presentation of visual and/or vibrotactile feedback; visual information was provided using a computer monitor, while vibrotactile feedback was relayed using vibrating motors (tactors), based on the subjects response as captured by a Microsoft Kinect sensor. Specifically, we used eccentric rotating mass (ERM) vibrating motors (Precision Microdrives Inc., Model # 310-117) due to their compact size (5 mm radius) and low weight (1.2 g). The tactors were controlled using pulse-width modulation (PWM). Depending on the operating pulse width, the range of the vibration frequency and amplitude were 0–200 Hz and 0–0.8 G, respectively (\(G \approx 9.8\)m/s\(^2\)). The response time of the tactors upon generation of a new cue from the computer was measured to be <10 ms.
In the tracking task, subjects were provided with visual and vibrotactile cues that motivated them to move their right hand so that the position of a red, on-screen cursor overlaid a moving, green, screen target. In the simulated balancing task, subjects used their right hand to directly control the cart position of a planar inverted cart/pendulum system; the goal was to keep the pendulum from falling by relying on the provided visual and vibrotactile information. Cursor, target and cart motion were constrained to move in the horizontal direction on the screen.
Extended LQR loop: using an optimal controller as a “teacher”
The subject’s goal in the balancing task was to learn how to keep an inverted pendulum as close to the upright position as possible. We conjectured that an effective way to teach this task would be to first design an ideal optimal controller and then use a vibrotactile body–machine interface to train subjects to learn from the controller’s output. In contrast to existing approaches in sensorimotor learning that rely mainly on error-based synthesis of the training signal, this novel approach provides an optimized linear combination of object state information.
The nonlinear dynamics of the simulated cart pendulum shown in Fig. 1b are given by:
where the input \(x_c\) is the position of the cart, \(\theta\) is the angle of the pendulum, g is the acceleration due to gravity, b is a damping coefficient and l is the distance to the mass m at the end of the pendulum. The state vector is thus \(x=[x_c \, \dot{x}_c \, \theta \; \dot{\theta }]^T\), and the input to the system, u, is the lateral acceleration of the cart. Linearization about the vertically upright equilibrium position, \(\theta =0\), gives the following state-space equations:
The desired response can be achieved by designing a LQR loop (see Fig. 1c) that optimizes the following cost functional with respect to u,
according to the preselected weights Q and R. The parameters we used for simulating the system and calculating the controller are: \(m=4\), \(l=6\), \(g=9.81\), \(b=0.01\), \(Q={\mathbb {I}}_{4\times 4}\), \(R=1\), and finally for the reference input r (see Fig. 1b, c), we chose \(r=[x_c \, 0 \, 0 \,0]^T\). This choice of reference r “forces” the controller to stabilize the pendulum about the upright, anywhere along the horizontal axis (i.e., regardless of the position of the cart).
The derived controller observes all the state information needed to balance the pendulum at a reference cart position r. Whereas the LQR gain matrix in Fig. 1 was computed off-line, the output of the LQR (\(u_{LQR}\) in Fig. 1b, c) was converted into a vibrotactile signal in real time. We used two tactors to map the signed LQR output \(u_{LQR}\) to each tactor’s voltage input by passing \(u_{LQR}\) through a linear bounded saturation function (Fig. 1d). Thus, both the target position and direction of movement could be encoded by regulating the amplitude of vibration of the appropriate tactor. If subjects can “follow” the resulting vibrotactile feedback v accurately, they should be able to successfully complete the balancing task. Note that even though \(u_{LQR}\) was by itself capable of balancing the pendulum, it was only used to synthesize the goal-aware “teacher” signal; it was not itself used as an input to the simulated cart–pendulum system. Instead, the input to the cart–pendulum system was based on the subject’s right-hand position h (Fig. 1d) as captured by the Kinect imaging system. As a result, once the subject received the suggested feedback v, it was entirely up to them to decide how they should move their hand. Related to this observation, it is known that the LQR operates best when the system is close to the nominal operating point, i.e., the reference r in this case. The “LQR recommendations” conveyed by the vibrotactile signal essentially instructed the subject to stay close to that region. Failure to do so usually caused immediate task failure, since it was very hard for the user to steer the pendulum back to the upright without letting it fall. In all cases, the vibrotactile feedback was intuitive to the subjects and in agreement with what they should do (i.e., the appropriate tactor was vibrating given a clockwise or counterclockwise deviation from upright). Being part of the control loop, subjects were expected to learn the optimal, energy-minimizing behavior instructed by the LQR that would otherwise be unintuitive, and which would require considerable exploration to obtain.

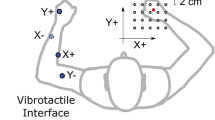
a Experimental setup with a participant standing in front of a Microsoft Kinect sensor. The tactors attached to the right thumb and little finger provide vibrotactile feedback related to task performance. b Desired and actual hand position signals from a discrete tracking trial with vibrotactile feedback. Only a portion of the trial is displayed. Reaction time measure used in the discrete tracking task is also shown. c Example of a vibrotactile signal. The percentage of activation indicates the amplitude of vibration fed back to the subject during the trial. This signal corresponds to the trial in the upper part of (b)
Procedure
Tracking task Each subject participated in a single experimental session wherein they performed goal-directed reaching movements. Subjects stood in front of a computer monitor and used right-hand motions to control the horizontal position of a cursor (2-cm-wide red block) on the screen. The task goal was to match the cursor’s position to that of a moving target (a 2-cm-wide green block) as quickly and as accurately as possible. The target could move according to one of two motion patterns (discrete, jumping motions and continuous, smoothly varying motions) in one of three different sensory feedback conditions (visual feedback only, V; tactor feedback only, T; combined tactor + visual feedback, TV). In discrete tracking, the target jumped every 5 seconds to a new location that was uniformly sampled from a 60-cm range of desired locations along the horizontal axis (see Fig. 2b). In continuous tracking, the desired horizontal position of the hand varied smoothly in time as determined by the following formula:
where t is time and x is the position of the target. The period of this pursuit tracking signal is approximately 31 seconds. In discrete tracking, the target trajectory was random, while in continuous tracking, it varied as a complex sum of sinusoids. In both cases, uncertainty in the target trajectory ensured that participants based their performance on sensory feedback rather than on some learned sequence of target positions. In two of the three tested feedback conditions, tactile feedback of performance errors was provided by two tactors attached to the thumb and little finger of the tracking hand (Fig. 2a). The vibrotactile stimulus encoded error direction (whether the desired hand position was to the left or right of the actual hand position) and error magnitude (how far was the desired hand position from the actual hand position). An example of a vibrotactile stimulus is shown in Fig. 2c; stronger vibration indicates large error. The third condition (pure visual tracking) involved visual cues only (i.e., the visual target and cursor). Thus, both tactile and visual cues encode similar types of information (i.e., hand position error with respect to the current position of the target).
To acquire experience with the augmented vibrotactile feedback (i.e., what the amplitude of the vibration means and how it should be used), participants practiced the tracking tasks for 5–10 min before the experiment began. In the continuous tracking case, subjects practiced on a different target trajectory than the one used in data collection sessions to ensure that they did not learn the sequence of target positions. Data collection consisted of 1-min trials for each combination of feedback and tracking condition (six trials in total per subject). We found 1-min trials to be adequate for performance comparisons without any noticeable fatigue effects (Welford 1980). The total duration of a session was approximately 20 min (including breaks), and the order of trials was counterbalanced across subjects.

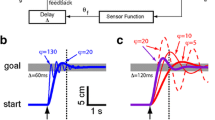
a Example from a single subject of discrete tracking in the vision-only (V) condition. The corresponding graph from the tactile + vision (TV) condition is very similar to this response. b Example of vibrotactile only (T) tracking in the discrete tracking task. The underdamped behavior may reflect the limited training subjects received in these experiments; additional exposure to the vibrotactile interface may facilitate performance with less overshoot errors (i.e., a more damped response). c An example of continuous tracking from a single subject in the V feedback condition. The corresponding visuo-tactile graph is very similar to this response. d An example of vibrotactile only performance in continuous tracking e–f sample response from a TV group subject in the balancing task. The hand response to the provided vibrotactile feedback is shown in (e), and the corresponding pendulum angle is in (f). In this trial, the angle remains near the upright position throughout the entire trial
Balancing task Subjects were divided into three groups of ten participants each and were asked to play a “video game” for approximately 30 min (including 5 min of practice, and breaks as needed between trials). The experimental setup was similar to that described for the tracking task; participants used their right hand to directly control the position of an on-screen cursor (the “cart”) so as to keep an inverted pendulum balanced for as long as possible. The experiment had two phases: a training phase and a testing phase (10 min each with a short break in-between). Within each phase of the experiment, trials continued until the end of the experiment. Whenever the pendulum fell, a new trial started immediately. We found that 10 min of training sufficed to learn the task. During the training phase, one group received both visual and vibrotactile feedback (the TV group) as in Fig. 2a. The second group received only visual feedback (the V group), and the third group received only vibrotactile feedback (the T group). Unlike the first experiment wherein supplemental vibrotactile feedback did not encode any information above and beyond what was already available via vision, vibrotactile feedback in this second experiment encoded an optimized linear combination of object state information, thus always suggesting the optimal corrective motion that the subject should follow. During the testing phase, all three groups received only visual feedback of the pendulum/cart system (i.e., no vibrotactile feedback). Defining the training and testing phases in this way allowed us to test the hypothesis that vibrotactile encoding of optimal “goal-aware” feedback can enhance performance and learning of a novel object manipulation skill.
Data analysis
In the tracking task, we quantified performance using measures of response latency and movement accuracy. In the discrete tracking task, we quantified response latency using reaction time: the time it took for the hand to reach a velocity threshold of 15 cm/s after a new target and/or vibrotactile cue was presented (Fig. 2b). In the continuous tracking condition, response latency was calculated using the phase lag (i.e., the time when the cross-correlation between the target trajectory and the subject’s hand response took its maximum value). To quantify the accuracy of tracking in both tasks, we computed the cross-correlation between the desired and actual hand positions to determine the peak correlation coefficient (i.e., \(R^2\)), thereby accounting for the confounding effect of variable phase lag between desired and actual movements across trials and tasks.
In the balancing task, we used time to failure (TTF) as our primary performance metric. For each trial, we computed TTF as the amount of time (in seconds) during which the subject was able to keep the pendulum from falling. As an experimental control, we tested system performance without active user intervention to estimate the “default” TTF obtained when the system was driven predominantly by sensor noise inherent to the Kinect motion tracking system. Pilot subjects, that took part only in this experimental control condition, stood with their right arm held as if participating in the main experiments described above. These individuals were instructed to stand as still as possible while the Kinect sampled the position of the right hand. Visual and vibrotactile displays were not activated during this “No Control Intervention” pilot testing. Ten of such trials yielded a default TTF of (3.9 ± 0.3 s); see middle bar in Fig. 5).

a Reaction time profiles for all three sensory feedback conditions (discrete tracking case). b Response latency results. Different techniques were used to compute response latency for the two tasks, and as such, a between-task comparison of response latency is not appropriate. c Accuracy results. Error bars indicate standard error
Results
Tracking task
Figure 3a through d shows sample responses from the two forms of tracking examined in this study. In the vision-only condition (Fig. 3a, c), the hand initially converged to the target without oscillations (i.e., it tracked the target in a critically or over-damped manner), although the hand started to overshoot the target later in the trial (i.e., tracking became underdamped). In the vibrotactile only feedback condition (Fig. 3b, d), the subject was able to successfully utilize the vibrotactile feedback. However, prolonged oscillatory behavior after each transition reflects a difference in how the subject processed tactile vs. visual information, and may reflect the limited training subjects received in these experiments; additional exposure to the vibrotactile interface may yield performance with less oscillations (i.e., a more damped response). As one might expect given a lifetime of experience using vision, target capture accuracy appeared to be somewhat better in the vision-only tracking condition. Performance in the TV feedback condition (data not shown) was indistinguishable from that in the vision-only condition.
Because we used different measures of response latency in the two tasks, we performed separate repeated-measures ANOVA to compare the influence of feedback condition on reaction time during discrete tracking and on phase lag during continuous tracking. In the discrete tracking task, we found no main effect of feedback condition on reaction time [\(F(1.23, 14.756) = 0.65\), \(p = 0.464\)]. The average reaction times and standard deviations were: \(\hbox {mean}=644\,\hbox {ms}\), \(\hbox {SD}=0.131\,\hbox {ms}\) for T feedback; \(\hbox {mean}=657\,\hbox {ms}\), \(\hbox {SD}=0.1\,\hbox {ms}\) for V feedback; and \(\hbox {mean}=690\,\hbox {ms}\), \(\hbox {SD}=0.12\,\hbox {ms}\) for TV feedback (Fig. 4a). By contrast, repeated-measures ANOVA of phase lag in the continuous tracking task revealed significant performance differences between the three sensory feedback conditions [\(F(1.061, 12.730) = 55.237\), \(p < 0.0005\)]. Bonferroni-corrected post hoc pairwise comparisons revealed that continuous tracking using only tactile feedback (\(\hbox {mean}=0.4\,\hbox {s}\), \(\hbox {SD}=0.17\,\hbox {s}\)) lagged the target to a considerably greater extent than the V (\(\hbox {mean}=0.032\,\hbox {s}\), \(\hbox {SD}=0.033\,\hbox {s}\), \(p < 0.0005\)) and TV groups (\(\hbox {mean}=0.043\,\hbox {s}\), \(\hbox {SD}=0.037\,\hbox {s}\), \(p < 0.0005\)), which did not differ from each other (\(p = 0.876\)).
We used mixed model, two-way, repeated-measures ANOVA to compare tracking accuracy \(R^2\) within and across experimental tasks. We found a significant main effect of feedback condition on tracking accuracy [\(F(2,24) = 31.378\), \(p < .0005\)] and a significant interaction between task type and feedback condition [\(F(2,24) = 6.41\), \(p = 0.006\)]. In discrete tracking, we found that feedback condition had a significant effect on accuracy [\(F(2, 24) = 5.535\), \(p < 0.011\)]. Post hoc pairwise comparisons using Bonferroni correction found \(R^2\) of T tracking (\(\hbox {mean} = 90.62,\) \(\hbox {SD} = 3.53\)) to differ from \(R^2\) of V tracking (\(\hbox {mean} = 95.52\), \(\hbox {SD} = 3.86\); \(p < 0.025\)), which did not differ from TV tracking (\(\hbox {mean} = 94.04\), \(\hbox {SD} = 4.53\), \(p = 1\)). No significant difference was found between T and TV tracking (\(p = 0.062\)). In continuous tracking, there were similar feedback-dependent variations in \(R^2\) [\(F(1.045, 12.534) = 26.444\), \(p < 0.0005\)], although feedback-dependent differences appeared to be exaggerated in this task. Post hoc pairwise comparisons using Bonferroni correction revealed that tactile tracking (\(\hbox {mean}=86.24\), \(\hbox {SD}=8.35\)) was less accurate than both V (\(\hbox {mean}=98.4\), \(\hbox {SD}=0.66\); \(p < 0.0005\)) and TV tracking (\(\hbox {mean}=97.67\), \(\hbox {SD}=1.34\); \(p < 0.005\)), which did not differ from each other (\(p = 0.261\)). As suggested by these relatively high \(R^2\) values in both tasks, tracking was reasonably accurate in all cases. So, while the availability of visual feedback leads to faster and more accurate tracking of a continuously moving target, sensory substitution via vibrotactile feedback of hand position error is nearly as effective as visual feedback in driving target capture performance, especially in the discrete tracking case. We found this to be true even after only 10 min of practice (Fig. 4b, c). However, supplementing visual feedback by the addition of vibrotactile position error feedback did not enhance target-tracking performance in either tracking task (continuous or discrete).
Balancing task
Figure 3e, f shows a sample trial performance from a TV group subject during the training phase of the balancing task. The output of the LQR “teacher” is shown in (e), and the desired and actual pendulum angle are shown in (f). For this trial, the subject clearly was able to use the vibrotactile feedback to follow the LQR teaching signal, which conveyed the optimal action at each moment during the trial. By doing so, the subject was able to balance the inverted pendulum for more than 60 seconds (more than three times the average V group performance).
We used a one-way Welch ANOVA to evaluate the effect of feedback condition on the average time-to-failure values from the last five training trials in the balancing task (where homogeneity of variances was violated). We found significant differences in performance between the three feedback groups V, T, TV [\(F(2, 15.537) = 40.902\), \(p < 0.0005\)]. Post hoc comparisons using the Games–Howell test revealed that the TV group \((\hbox {mean} = 37.64s\), \(\hbox {SD} = 23.19\,\hbox {s})\) performed better than both the T group \((\hbox {mean} = 9.18\,\hbox {s}\), \(\hbox {SD} = 1.23\,\hbox {s}, p< 0.01)\) and the V group \((\hbox {mean} = 13.3\,\hbox {s}\), \(\hbox {SD} = 0.9\,\hbox {s}, p < 0.05)\). The V group also performed better than the T group (\(p < 0.0005\)). Importantly, vibrotactile feedback was effective even in the absence of visual feedback; T group performance far exceeded the TTF for the control condition without active user input (\(t(17) = 12.458\), \(p < 0.0005\); see Fig. 5). These results suggest that vibrotactile encoding of the optimal corrective motor command yields an immediate performance enhancement in the manipulation (i.e., stabilization) of an unstable dynamic object. The increased variability observed in the TTF of the TV group suggests that people likely require more than 10 min of training to fully learn how to capitalize on the training signal.
One-way ANOVA evaluating the effect of feedback condition on the average time-to-failure values from the last ten trials of the testing phase indicated the presence of a persistent effect of feedback condition on TTF [\(F(2, 27) = 9.884\), \(p = 0.001\); Fig. 5]. Bonferroni-corrected post hoc analysis verified that TV participants \((\hbox {mean} = 16.42\,\hbox {s}\), \(\hbox {SD} = 2.28\,\hbox {s})\) outperformed the other two groups (\(p = 0.002\) for V and \(p = 0.001\) for T group). Performances from the vision-only group \((V: \hbox {mean} = 13.74\,\hbox {s}\), \(\hbox {SD} = 1.32\,\hbox {s})\) did not differ from those of the tactor-only group \((T: \hbox {mean} = 13.59\,\hbox {s}\), \(\hbox {SD} = 0.86\,\hbox {s}\); \(p = 0.976\)). Taken together, these results are consistent with our second hypothesis, namely that vibrotactile encoding of the optimal corrective motor command can enhance learning of a dexterous manipulation skill.

Summary of group results for the balancing study: Mean time to failure (MTTF) across feedback conditions and experimental phases. Error bars indicate standard error. The large standard error in the TV training case may reflect the limited training subjects received in these experiments; some subjects were able to learn how to integrate the vibrotactile feedback faster than others. We would expect additional exposure to the vibrotactile interface to yield a more consistent performance across subjects
Discussion
This paper described two sets of experiments that examined the ability of vibrotactile encoding of simple position error and combined object states to enhance performance of reaching and manipulation tasks. The first set tested the utility of error-based, vibrotactile feedback during discrete and continuous target-tracking tasks and found that brief practice with vibrotactile feedback yielded performances approaching those of visually guided reaching. However, the combined visual and vibrotactile testing condition did not yield performance enhancements in these tasks. The second set of experiments tested whether vibrotactile encoding of the optimal corrective motor command (a “teacher” signal) could enhance both the immediate online performance of a dynamic stabilization task as well as the learning and transfer of that skill to testing conditions without vibrotactile guidance. Remarkably, both hypothesized effects were observed after only minutes of training with the optimal state encoding scheme, thus demonstrating the potential power of this new, “goal-aware” training approach.
Vibrotactile and visual contributions to pursuit tracking performance
In the discrete tracking experiment, vibrotactile encoding of performance errors drove performances that were both timely and accurate. Reaction times were approximately equal across the three training conditions and movement accuracy (i.e., \(R^2\) values) exceeded 0.9 in all cases. By contrast, continuous tracking performances driven by the same vibrotactile encoding scheme did not quite achieve the levels of performance obtained when visual feedback was provided. Even though vibrotactile feedback of performance errors sufficed to yield continuous tracking accuracy values >85 %, hand positions driven by T feedback lagged desired target positions by approximately 0.4 s. By contrast, continuous tracking phase lag in the TV condition was less than 0.05 s and accuracy values jumped to >97 %.
There are at least three possible explanations for the pattern of response latency results in the continuous tracking task. First, in order for a sensory channel to efficiently substitute for another, both channels should have sufficient information processing capacity to perform all the neural computations required by the task at hand (Bach-y-Rita 1970; Novich and Eagleman 2015). Earlier studies have reported a progression of information capacities for the fingertip, ear and eye of, \(10^2:10^4:10^6\) bits/s, respectively (Kokjer 1987; Repperger et al. 1995). As the target changed location only once every 5 seconds and performance was similar under all feedback conditions in the discrete tracking task, the tactile feedback channel evidently had sufficient capacity to mediate effective control comparable to that driven by the visual channel in this task. By contrast, the target moved constantly in the continuous tracking trials, thus possibly requiring a channel with greater information capacity than provided via the tactile feedback channel.
Second, while the sum-of-sinusoids target trajectory in the continuous task was complex, it was not altogether unpredictable. It is possible that the very short latencies in the V and TV conditions result through the action of an established adaptive controller (Neilson et al. 1988a, b) that uses recent history of visual target motions to generate a short time horizon prediction of imminent target motions, which can then be used to improve the planning and execution of tracking motions in real time. Given the possibility of adaptive predictive control and the novelty of vibrotactile feedback of limb motion, it is reasonable to expect that learning how to combine recent memories of vibrotactile feedback to generate predictive control signals may require substantial practice, more than the 10 min of exposure we provided.
A third potential explanation for superior continuous tracking performances in the presence of vision emerges from the literature on interactions between eye and hand control. Gauthier et al. (1988) and Koken and Erkelens (1992) found that when the hand is used as a target or to track a visual target, the dynamic characteristics of the smooth pursuit system are markedly improved, i.e., they contain fewer catch-up saccades. Moreover, hand trajectory is more precise when accompanied by smooth pursuit eye motions (Miall and Reckess 2002). In an attempt to explain these findings, a mutual coupling between eye and hand motor control systems has been proposed, in which coordination signals issued from the cerebellum control the eye movements in oculo-manual tracking (Vercher and Gauthier 1988; Miall and Reckess 2002). Indeed, using fMRI, the cerebellum was found to be preferentially activated during coordinated eye and hand movements (Miall et al. 2000, 2001). Because we did not control for eye motions during our experiments, we cannot determine the extent to which continuous tracking performances in the presence of vision may have resulted from a mutual coupling between the eye and hand motor control systems. Future studies of augmented sensory feedback control should quantify and optimize control capacity through parametric evaluation of information content, stimulation site and careful experimental control of the interactions between visual and manual control actions.
Error-based encoding: sensorimotor control without multisensory enhancement
It has long been known that in simple reaction time (SRT) tasks, responses to stimuli are faster when cued by multiple- vs. single-modality sensory stimuli (Raab 1962) and that the difference in response latency is greater if the redundant stimuli are presented in different sensory modalities—a phenomenon known as multisensory enhancement (Hershenson 1962; Nickerson 1973). In a SRT task, subjects are to generate a single action (e.g., a button press) as fast as possible in response to a set of sensory cues. Hecht et al. (2008) and Girard et al. (2011) have extended this phenomenon to choice reaction time (CRT) tasks, which require an additional cognitive stage wherein one of several actions are selected based on a set of rules. Whereas Hecht et al. (2008) found that multisensory enhancement was larger in CRT than in SRT tasks, Girard et al. (2011) found no difference in the multisensory gain between SRT and CRT for spatially aligned stimulation (i.e., when all stimuli are presented from the same side of the body). The reasons for this discrepancy of the reported results remain unclear.
In experiment 1, addition of vibrotactile feedback to visual feedback in the TV condition did not seem to have either a positive or negative affect on performance in the tracking task (both continuous and discrete tracking are considered). Why does the addition of vibrotactile sensory input fail to yield performance enhancement? One possibility is that performance with vision alone may have reached a level limited only by execution variability, and as a result, there remains little or no room for improvement with the addition of vibrotactile stimulation (a ceiling effect). Another possibility is related to the Colavita effect (Colavita 1974), according to which, in speeded discrimination tasks involving redundant multimodal feedback, responses are dominated by the visual channel (Hecht and Reiner 2009), most likely due to its higher information processing capacity (Kokjer 1987; Repperger et al. 1995). As mentioned earlier, in our tracking experiments, both the visual and the tactile channel convey error information redundantly; thus, it is possible that the subjects exploit the information redundancy and simply ignore the coarser tactile cues to produce their responses. Finally, it is possible that the multisensory enhancements observed in the CRT experiments of Hecht et al. (2008) may in fact be limited to a small number of “choices.” By contrast, in our discrete tracking experiment, the target moved randomly across the screen, effectively yielding an infinite number of possible cue (and thus, hand) locations. Future studies should further explore the factors contributing to multisensory enhancement during pursuit tracking tasks driven by supplemental vibrotactile sensory feedback.
Optimal, “goal-aware” encoding: enhanced performance and control policy learning
In perceptual tasks requiring multisensory integration, cue integration has been shown to follow an optimization process (Ernst and Banks 2002; Reuschel et al. 2010; van Beers et al. 2002a) that is well modeled as a maximum likelihood estimation (MLE) process. More specifically, the maximum likelihood multisensory percept is optimal in that it has lower variance than any of the individual sensory percepts. Hence, the neural mechanisms responsible for integrating sensory signals for perception seem to use knowledge of the statistical properties of the cues to optimize the state estimate. Based on that idea, Ankarali et al. (2014) used a juggling task to show that visuo-haptic integration improved performance of a complex, rhythmic, sensorimotor task. In an attempt to explain those results, they relied on the “separation principle” found in the linear-quadratic-Gaussian (LQG) control problem. According to this principle, the state estimation and the controller are two independent processes that contribute to the stability of the overall system behavior.
The separation principle could explain our findings in the balancing task; the control action of the hand and the estimation of the states of the cart–pendulum system could be handled separately by the brain. In particular, the state estimation block in the training phase (supervised learning) should be more effective for the TV group where vibrotactile feedback provides information about how object state estimates obtained from visual feedback should be combined to yield optimal task performance. Indeed, we observed an immediate enhancement of performance in the TV condition (i.e., \(3\times\) longer TTFs) over those provided by training in the V and T conditions. This effect was evident within the first minute or so of training and persisted over the entire training period (10 min). By attempting to follow a “goal-aware” vibrotactile signal that combines states in an appropriate way, subjects were able to extract information that is not readily available via visual feedback and used it to excel at the task. The large variability in performance of the TV group observed in Fig. 5 may reflect the limited training subjects received in these experiments; some subjects learned to exploit the vibrotactile feedback faster than others. We would expect additional exposure to the vibrotactile interface to yield a more consistent performance across subjects.
Results from the testing phase of the balancing task (performed with V feedback only) revealed a persistent benefit of prior training under the guidance of the optimal corrective command provided via vibrotactile stimulation. The presence of the performance boost after TV training strongly indicates that subjects did in fact learn a more effective motor control strategy when allowed to train with the vibrotactile “teacher signal.” Although the magnitude of the TV testing phase performance boost was small relative to training with V or T feedback (approximately a 12 % benefit), we expect that additional benefits may accrue with longer training phase exposure to the optimal feedback.
A limitation of our study stems from the fact that we only provided supplemental goal-aware feedback via tactile stimulation and not, for example, via acoustic or other form of sensory stimulation. Thus, we cannot say whether another means of providing goal-aware feedback could have yielded better results than those presented here for vibrotactile stimulation. While our results demonstrate that goal-aware vibrotactile feedback suffices to induce improvements in the performance of an object manipulation task, future studies should explore how best to provide supplemental sensory feedback (e.g., in different sensory modalities) and in a broader range of tasks.
In summary, we have described two sets of experiments that examined the ability of vibrotactile feedback to enhance performance of reaching and manipulation tasks. The work is novel in that we have introduced a new sensory augmentation approach—vibrotactile encoding of an optimal combination of object state information—and have demonstrated its ability to enhance the immediate performance and learning of an effective sensorimotor control policy. Subjects were able to capitalize on this form of feedback within the first few minutes of exposure, thereby demonstrating the potential power of this training approach. Recent advances in wearable technologies have created considerable potential for the development of assistive technologies capable of sensing the dynamic state of the user’s arm and hand during interaction with objects in the physical environment (Lieberman and Breazeal 2007). We envision potential applications of the sensory feedback enhancement techniques we have described to include the mitigation of visual impairment in blindsighted individuals, athletic performance optimization in sports, skill optimization in the teleoperation of surgical tools and in the physical rehabilitation of limb movements following neuromotor injury, especially in cases where limb proprioception is compromised (Tzorakoleftherakis et al. 2015).
References
Ankarali MM, Şen HT, De A, Okamura AM, Cowan NJ (2014) Haptic feedback enhances rhythmic motor control by reducing variability, not improving convergence rate. J Neurophysiol 111(6):1286–1299
Bach-y-Rita P (1970) Neurophysiological basis of a tactile vision-substitution system. IEEE Trans Man-Mach Syst 11(1):108–110
Bach-y-Rita P, Kercel SW (2003) Sensory substitution and the human machine interface. Trends Cogn Sci 7(12):541–546
Bark K, Hyman E, Tan F, Cha E, Jax S, Buxbaum LJ, Kuchenbecker KJ et al (2015) Effects of vibrotactile feedback on human learning of arm motions. IEEE Trans Neural Syst Rehabil Eng 23(1):51–63
Bark K, Wheeler JW, Premakumar S, Cutkosky MR (2008) Comparison of skin stretch and vibrotactile stimulation for feedback of proprioceptive information. In: IEEE international symposium on haptic interfaces for virtual environment and teleoperator systems, pp 71–78
Colavita FB (1974) Human sensory dominance. Percept Psychophys 16(2):409–412
Danilov Y, Tyler M (2005) Brainport: an alternative input to the brain. J Integr Neurosci 4(04):537–550
Ernst MO, Banks MS (2002) Humans integrate visual and haptic information in a statistically optimal fashion. Nature 415:429–433
Forster B, Cavina-Pratesi C, Aglioti SM, Berlucchi G (2002) Redundant target effect and intersensory facilitation from visual-tactile interactions in simple reaction time. Exp Brain Res 143(4):480–487
Gauthier G, Vercher J, Ivaldi FM, Marchetti E (1988) Oculo-manual tracking of visual targets: control learning, coordination control and coordination model. Exp Brain Res 73(1):127–137
Girard S, Collignon O, Lepore F (2011) Multisensory gain within and across hemispaces in simple and choice reaction time paradigms. Exp Brain Res 214(1):1–8
Guo S, Song Z (2009) A novel motor function training assisted system for upper limbs rehabilitation. In: Proceedings of IEEE/RSJ international conference on intelligent robots and systems (IROS ’09), pp 1025–1030
Hasson CJ, Manczurowsky J (2015) Effects of kinematic vibrotactile feedback on learning to control a virtual prosthetic arm. J Neuroeng Rehabil 12(1):31
Hecht D, Reiner M, Karni A (2008) Multisensory enhancement: gains in choice and in simple response times. Exp Brain Res 189(2):133–143
Hecht D, Reiner M (2009) Sensory dominance in combinations of audio, visual and haptic stimuli. Exp Brain Res 193(2):307–314
Hershenson M (1962) Reaction time as a measure of intersensory facilitation. J Exp Psychol 63(3):289–293
Huang VS, Krakauer JW (2009) Robotic neurorehabilitation: a computational motor learning perspective. J Neuroeng Rehabil 6(1):5
Kaczmarek K, Webster JG, Bach-y-Rita P, Tompkins WJ et al (1991) Electrotactile and vibrotactile displays for sensory substitution systems. IEEE Trans Biomed Eng 38(1):1–16
Koken PW, Erkelens CJ (1992) Influences of hand movements on eye movements in tracking tasks in man. Exp Brain Res 88(3):657–664
Kokjer KJ (1987) The information capacity of the human fingertip. IEEE Trans Syst Man Cybern 17(1):100–102
Lieberman J, Breazeal C (2007) TIKL: Development of a wearable vibrotactile feedback suit for improved human motor learning. IEEE Trans Robot 23(5):919–926
Miall RC, Imamizu H, Miyauchi S (2000) Activation of the cerebellum in co-ordinated eye and hand tracking movements: an fMRI study. Exp Brain Res 135(1):22–33
Miall R, Reckess G, Imamizu H (2001) The cerebellum coordinates eye and hand tracking movements. Nat Neurosci 4(6):638–644
Miall R, Reckess G (2002) The cerebellum and the timing of coordinated eye and hand tracking. Brain Cogn 48(1):212–226
Mussa-Ivaldi FA, Miller LE (2003) Brain-machine interfaces: computational demands and clinical needs meet basic neuroscience. Trends Neurosci 26(6):329–334
Neilson P, Neilson M, O’dwyer N (1988a) Internal models and intermittency: a theoretical account of human tracking behavior. Biol Cybern 58(2):101–112
Neilson P, O’dwyer N, Neilson M (1988b) Stochastic prediction in pursuit tracking: an experimental test of adaptive model theory. Biol Cybern 58(2):113–122
Nickerson RS (1973) Intersensory facilitation of reaction time: energy summation or preparation enhancement? Psychol Rev 80(6):489–509
Novich SD, Eagleman DM (2015) Using space and time to encode vibrotactile information: toward an estimate of the skins achievable throughput. Exp Brain Res 233(10):2777–2788
Patton J, Stoykov M, Kovic M, Mussa-Ivaldi F (2006) Evaluation of robotic training forces that either enhance or reduce error in chronic hemiparetic stroke survivors. Exp Brain Res 168(3):368–383
Patton J, Wei YJ, Bajaj P, Scheidt RA (2013) Visuomotor learning enhanced by augmenting instantaneous trajectory error feedback during reaching. PLoS One 8:1–6
Raab DH (1962) Statistical facilitation of simple reaction time. Trans NY Acad Sci 24(5):574–590
Rauschecker JP (1995) Compensatory plasticity and sensory substitution in the cerebral cortex. Trends Neurosci 18(1):36–43
Repperger DW, Phillips CA, Chelette TL (1995) A study on spatially induced virtual force with an information theoretic investigation of human performance. IEEE Trans Syst Man Cybern 25(10):1392–1404
Reuschel J, Drewing K, Henriques DYP, Rosler F, Fiehler K (2010) Optimal integration of visual and proprioceptive movement information for the perception of trajectory geometry. Exp Brain Res 201(4):853–862
Scheidt RA, Reinkensmeyer DJ, Conditt MA, Rymer WZ, Mussa-Ivaldi FA (2000) Persistence of motor adaptation during constrained, multi-joint, arm movements. J Neurophysiol 84(2):853–862
Sienko KH, Balkwill MD, Oddsson L, Wall C (2008) Effects of multi-directional vibrotactile feedback on vestibular-deficient postural performance during continuous multi-directional support surface perturbations. J Vestib Res 18(5):273–285
Sigrist R, Rauter G, Riener R, Wolf P (2013) Augmented visual, auditory, haptic, and multimodal feedback in motor learning: a review. Psychon Bull Rev 20(1):21–53
Sklar AE, Sarter NB (1999) Good vibrations: Tactile feedback in support of attention allocation and human-automation coordination in event-driven domains. Hum Factors J Hum Factors Ergon Soc 41(4):543–552
Spelmezan D, Jacobs M, Hilgers A, Borchers J (2009) Tactile motion instructions for physical activities. In: Proceedings of SIGCHI conference on human factors in computing systems, pp 2243–2252
Sun M, Ren X, Cao X (2010) Effects of multimodal error feedback on human performance in steering tasks. J Inf Process 18:284–292
Thoroughman KA, Shadmehr R (2000) Learning of action through adaptive combination of motor primitives. Nature 407(6805):742–747
Tzorakoleftherakis E, Bengtson MC, Mussa-Ivaldi FA, Scheidt RA, Murphey TD (2015) Tactile proprioceptive input in robotic rehabilitation after stroke. In: Proceedings of IEEE international conference on robotics and automation (ICRA 2015), pp 6475–6481
Tzorakoleftherakis E, Mussa-Ivaldi FA, Scheidt RA, Murphey TD (2014) Effects of optimal tactile feedback in balancing tasks: a pilot study. In: Proceedings of American control conference (ACC 2014), pp 778–783
van Beers RJ, Baraduc P, Wolpert DM (2002a) Role of uncertainty in sensorimotor control. Philos Trans R Soc Lond B Biol Sci 357(1424):1137–1145
van der Linden J, Schoonderwaldt E, Bird J, Johnson R (2011) Musicjacket—combining motion capture and vibrotactile feedback to teach violin bowing. IEEE Trans Instrum Meas 60(1):104–113
Vercher J, Gauthier G (1988) Cerebellar involvement in the coordination control of the oculo-manual tracking system: effects of cerebellar dentate nucleus lesion. Exp Brain Res 73(1):155–166
Welford A (1980) Choice reaction time: basic concepts. In: Reaction times pp 73–128
Acknowledgments
This material is based upon work supported by the National Science Foundation under Grant CNS 1329891 and the National Institutes of Health under Grant R01HD053727. Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation or the National Institutes of Health. The authors would like to thank F. A. Mussa-Ivaldi of the Rehabilitation Institute of Chicago and Northwestern University for his thoughtful support and suggestions throughout the course of this study. We would also like to thank Jarvis Schultz of Northwestern University for his support in the software development.
Author information
Authors and Affiliations
Corresponding author
Additional information
T. D. Murphey and R. A. Scheidt contributed equally to this study.
Rights and permissions
About this article

Cite this article
Tzorakoleftherakis, E., Murphey, T.D. & Scheidt, R.A. Augmenting sensorimotor control using “goal-aware” vibrotactile stimulation during reaching and manipulation behaviors. Exp Brain Res 234, 2403–2414 (2016). https://doi.org/10.1007/s00221-016-4645-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-016-4645-1