
Abstract
In this paper, a partially linear varying-coefficient model with measurement errors in the nonparametric component as well as missing response variable is studied. Two estimators for the parameter vector and nonparametric function are proposed based on the locally corrected profile least squares method. The first estimator is constructed by using the complete-case data only, and another by using an imputation technique. Both proposed estimators of the parametric component are shown to be asymptotically normal, and the estimators of nonparametric function are proved to achieve the optimal strong convergence rate as the usual nonparametric regression. Some simulation studies are conducted to compare the behavior of these estimators and the results confirm that the estimators based on the imputation technique perform better than the complete-case data estimator in finite samples. Finally, an application to a real data set is illustrated.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The partially linear varying-coefficient model, as a very important semi-parametric model, takes the form as
where Y is the response variable, \(\mathbf{X} \in R^p,\mathbf{Z} \in R^q\) and U are the associated covariates, \(\varvec{\beta }=(\beta _1,\ldots ,\beta _p)^T\) is a p-dimensional vector of unknown parameter and \(\varvec{\alpha }(.)=(\alpha _1(.),\ldots ,\alpha _q(.))^T\) is a q-dimensional vector of unknown coefficient function, \(\varepsilon \) is the random error that is assumed to be independent of \((U,\mathbf{X} , \mathbf{Z} )\) with mean zero and finite variance \(\sigma ^2\). Since model (1) keeps both the interpretation power of parametric model and the flexibility of nonparametric model, it has been extensively studied by researches (Ahmad et al. 2005; Fan and Huang 2005; Kai et al. 2011; Long et al. 2013; You and Zhou 2006; Zhang et al. 2002; among others).
With the development of science and technology, the study of data with missing observations has been attracted more attention in various scientific fields, such as economics, engineering, biology and epidemiology. Dealing with missing data, several problems may arise when traditional statistical inference procedures for complete data sets are applied directly. There has been extensive research on statistical models with missing observations. In the partially linear model with the missing response data, Wang et al. (2004) proposed a class of semiparametric estimators for the regression coefficient and the response mean. Wang and Sun (2007) developed the imputation, semi-parametric surrogate regression and inverse marginal probability weighted methods to estimate unknown parameter. Xue and Xue (2011) proposed the bias-corrected method to calibrate the empirical likelihood ratios so that the estimator has asymptotically chi-squared distribution. Besides, with the missing response data in the partially linear varying-coefficient model (1), Wei (2012a) presented a profile least squares estimator for the parametric part based on the complete-case data.
Besides missing data, error-in-variables(EV) data, as another complex data can always be seen in real problems. It is well known that, if the measurement errors are ignored directly, the resulting estimators will not be unbiased. A great deal of researches on regression models with EV data have been studied. The simple specification of EV data is that the variables are measured with additive errors. Instead of observing certain covarites \(\mathbf{X} \), we observe \(\mathbf{W} =\mathbf{X} +\varvec{\xi }\), where the measurement error \(\varvec{\xi }\) is independent of other variables. Taking model (1) as an example, under the situation of \(\mathbf{X} \) is measured with additive error, You and Chen (2006) proposed a locally corrected profile least squares procedure to estimate the parameter and showed that the estimator is consistent and asymptotically normal. Zhang et al. (2011) and Wei (2012b) developed a restricted modified profile least squares estimator of the parameter under some additional linear restrictions. Hu et al. (2009) and Wang et al. (2011) constructed confidence regions for the unknown parameters with the empirical likelihood inference. On the other hand, when the nonparametric part \(\mathbf{Z} \) is measured with additive error in model (1), Feng and Xue (2014) conducted a locally bias-corrected restricted profile least squares estimators of both parameter and nonparametric functions. Fan et al. (2016a) used some auxiliary information to construct empirical log-likelihood ratios and Fan et al. (2016b) extended the penalized empirical likelihood to the high-dimensional model. Fan et al. (2018) suggested a bias-correction penalized profile least squares variable selection method in high dimensional models. Moreover, when \(\mathbf{X} \) is measured with additive errors as well as the response Y is missing in model (1), Wei and Mei (2012) applied the empirical likelihood method to construct confidence regions for parameters and Yang and Xia (2014) obtained restricted estimators under the linear constraint. However, the simultaneous existence of missing response and measurement error in the nonparametric part of model (1) has been seldom discussed. In addition, it should be noted that the assumption of additive measurement errors may be too simple in some applications. To analyze data from certain biomedical and health-related studies, one cannot directly observe some covariates and the response variable, but may obtain their distorted observations by certain functions of an observed confounding variable. Zhang et al. (2018) considered the nonlinear regression model under the assumption that both the response and predictors are unobservable and distorted by the multiplicative effects of some observable confounding variables. More interesting work for further study with model (1) will consider this situation.
In this paper, we study partially linear varying-coefficient models in which the response variable Y cannot be observed completely and the covariate \(\mathbf{Z} \) cannot be observed accurately. Throughout this paper, we introduce an indicator variable \(\delta \) such that \(\delta =1\) means that Y is observed and \(\delta =0\) indicates that Y is missing. We assume that data missing mechanism follows
Meanwhile, the variable \(\mathbf{Z} \) is measured with additive errors. That is
where \(\varvec{\xi }\) is the measurement error and independent of \((Y,\mathbf{X} , \mathbf{Z} ,U,\varvec{\varepsilon }, \delta )\) and has mean zero and known covariance \(\mathrm{Cov}(\varvec{\xi })=\Sigma _{\varvec{\xi }}\). Even if covariance \(\Sigma _{\varvec{\xi }}\) is unknown, a consistent and unbiased estimator can still be obtained by repeatedly observing \(\mathbf{W} _i\) (see Liang et al. (2007) for details). If \(\mathbf{Z} \) is observed exactly, then the probability of missingness is independent of missing responses and the resulting mechanism is called missing at random (MAR). However, considering model (1) under assumption (3), the covariate \(\mathbf{Z} \) is observed with measurement error and therefore Y is not missing at random which has been pointed out by Wei and Mei (2012) and Liang et al. (2007).
The rest of this paper is organized as follows. In Sect. 2, the locally corrected profile linear least squares estimation procedure with complete-case data is proposed, and then the asymptotic properties of the estimators are proved under some assumptions. In Sect. 3, an imputation technique is used to improve the accuracy of the estimator and corresponding asymptotic results are obtained. Some simulation studies are conducted in Sect. 4 to assess the performances of the proposed two estimators. In Sect. 5, the methodologies are illustrated by a real data example. Sect. 6 is conclusion and the proofs of the main Theorems are left in the “Appendix”.
2 Estimation method based on complete-case data
Firstly, we assume that measurement errors do not exist thus covariate \(\mathbf{Z} \) can be observed exactly. Suppose that the observation data \(\{{Y_i;\delta _i,\mathbf{X} _i,\mathbf{Z} _i,U_i}\}_{i=1}^n\) is generated from model (1) under assumption (2), then we have the following equation
We assume that \(\varvec{\beta }\) is known, then the model (4) can be rewritten as the following varying coefficient regression model,
where \(Z_{ij}\) is the jth element of \(\mathbf{Z} _{i}\) and \(\alpha _j(.)\) is the jth function of \(\varvec{\alpha }(.),j=1,\ldots ,q\). We can estimate the coefficient functions \({\alpha }_j(.),j=1\cdots ,q\) by the local linear fitting procedure. Specifically, for u in a small neighborhood of \(u_0\), \({\alpha }_j(u)\) can be locally approximated by a linear function as following:
where \(\alpha _j^{(1)}(u)={\partial \alpha _j(u)}/{\partial u} \) denotes the first order derivative of \(\alpha _j(u)\). Then, the estimators of \(\alpha _j(.)\) can be obtained by selecting \(\{(a_j,b_j),j=1,\ldots ,q\}\) to minimize:
where \(K_{h_1}(.)=K(./{h_1})/{h_1}\), K(.) is a kernel function and \({h_1}\) is the bandwidth. The solution to problem (6) is obtained by
where \(\mathbf{Y} =(Y_1,\ldots ,Y_n)^T\), \(\mathbf{X} =(\mathbf{X} _1,\ldots ,\mathbf{X} _n)^T\), \(\varvec{\omega }^\delta _u=\mathrm{diag}(K_{h_1}(U_1-u)\delta _1,\ldots ,K_{h_1}(U_n-u)\delta _n)\), and
Now consider \(\mathbf{Z} _i\)’s are not observed due to measurement error and \(\mathbf{W} _i\)’s are the observable surrogate data. Thus, \(\hat{\varvec{\alpha }}(u;\varvec{\beta })\) is not consistent and unbiased if \(\mathbf{W} _i\) is replaced by \(\mathbf{Z} _i\) directly in (7). Based on the idea of Feng and Xue (2014), a modified locally corrected linear estimators of \(\varvec{\alpha }(.)\) can be given by
where \(\mathbf{D} _u^\mathbf{W} \) has the same form as \(\mathbf{D} _u^\mathbf{Z} \) except that \(\mathbf{Z} _i\) is replaced by \(\mathbf{W} _i\) and
with \(\otimes \) is the Kronecker product.
Taking u to be \(U_1,\ldots ,U_n\) in (8), we can get that \(\hat{\varvec{\alpha }}(U_i;\varvec{\beta })=\mathbf{Q} _i(\mathbf{Y} -\mathbf{X} \varvec{\beta })\), where \(\mathbf{Q} _i=(\mathbf{I} _q,\mathbf 0 _{q})[(\mathbf{D} _{U_i}^\mathbf{W} )^T \varvec{\omega }_{U_i}^\delta \mathbf{D} _{U_i}^\mathbf{W} -\varvec{\Omega }^\delta _{U_i}]^{-1}(\mathbf{D} _{U_i}^\mathbf{W} )^T\varvec{\omega }_{U_i}^\delta .\) For the convenience of expression, let
and denote \(\tilde{Y}_i={Y}_i-\sum _{k=1}^n \mathbf{S} _{ik}^{c} Y_k\) and \(\tilde{\mathbf{X }}_i=\mathbf{X }_i-\sum _{k=1}^n \mathbf{S} _{ik}^{c}{} \mathbf{X} _k\), where \(\mathbf{S} _{ik}^{c}\) is the (i, k)th component of matrix \(\mathbf{S} _c\).
Then, the locally corrected profile least squares estimator \(\varvec{{\hat{\beta }}}_c\) of \(\varvec{{\beta }}\) based on complete-case data is obtained by minimizing
It is noted that the second term on the right hand side of (9) is included to avoid underestimating for \(\varvec{\beta }\) which is caused by measurement errors. By simple calculation, estimator \(\hat{\varvec{\beta }}_c\) can be obtained by
Then, substituting \(\varvec{\hat{\beta }}_c\) into \(\hat{\varvec{\alpha }}(u;\varvec{\beta })\) of (8) gives the estimator \(\hat{\varvec{\alpha }}(u;\varvec{\hat{\beta }}_c)\) of \({\varvec{\alpha }}(u)\),that is
The asymptotic properties of \(\varvec{{\hat{\beta }}}_c\) and \(\hat{\varvec{\alpha }}_c(u)\) are given in the following Theorems.
Theorem 1
Suppose that the Conditions in the Appendix C1–C5 hold. Then we have
where “\({\mathop {\longrightarrow }\limits ^{d}}\)” denotes convergence in distribution,
When we make statistical inference for \(\varvec{\beta }\) by Theorem 1, asymptotic variance of \(\varvec{\beta }\) is required to be estimated firstly. \(\varvec{\Sigma }_1^{-1}\varvec{\Omega }_1 \varvec{\Sigma }_1^{-1}\) is estimated by \(\varvec{\hat{\Sigma }}_1^{-1}\varvec{\hat{\Omega }}_1 \varvec{\hat{\Sigma }}_1^{-1}\) with plug-in method, where \(\varvec{\hat{\Sigma }}_1=\frac{1}{n}\sum _{i=1}^n \delta _i \{ \tilde{\mathbf{X }}_i\tilde{\mathbf{X }}_i^T-\mathbf{X} ^T\mathbf{Q} _i^T \varvec{\Sigma }_{\xi } \mathbf{Q} _i \mathbf{X} \},\) and \(\varvec{\hat{\Omega }}_1=\frac{1}{n}\sum _{i=1}^n \delta _i \big \{ \tilde{\mathbf{X }}_i(\tilde{\mathbf{Y }}_i-\tilde{\mathbf{X }}_i^T\hat{\varvec{\beta }}_c) -\mathbf{X} ^T \mathbf{Q} _i^T\varvec{\Sigma }_\xi \mathbf{Q} _i [\mathbf{Y} -\mathbf{X} \hat{\varvec{\beta }}_c]\big \}^{\otimes 2}.\)
Theorem 2
Suppose that the Conditions C1–C5 in the Appendix hold and \(h_1=c n^{-1/5}\), where c is a constant. Then we have
3 Estimation method based on imputation technique
It is noted that the estimator \(\hat{\varvec{\beta }}_c\) defined by (10) use complete-case data only and discard sample when \(Y_i\) is missing. This procedure may reduce the efficiency of the estimators of \(\varvec{\beta }\) which is caused without making full use of sample information.
When we are dealing with missing data, an imputation technique is prevalent which has been applied to various semi-parametric models, such examples can be found in Yang et al. (2011) and Xue and Xue (2011). The main idea of this method is to firstly impute a reasonable value for each missing data and then make statistical inference as if the data set is complete. Specifically, if covariate \(\mathbf{Z} \) can be observed directly, based on the estimator \(\hat{\varvec{\beta }}_c\) and \(\hat{\varvec{\alpha }}_c(u;\hat{\varvec{\beta }}_c)\), we have \((\hat{H}_i^0;\mathbf{X} _i,\mathbf{Z} _i,U_i)_{i=1}^n\), where
However, \(\hat{H}_i^0\) can not be obtained since \(\mathbf{Z} _i\) can not be observed in practice. Instead, \(\hat{H}_i=\delta _iY_i+(1-\delta _i)[\mathbf{X} _i^T\hat{\varvec{\beta }}_c+\mathbf{W} _i^T\hat{\varvec{\alpha }}_c(U_i;\hat{\varvec{\beta }}_c)]\) is available. Based on data \((\hat{H}_i;\mathbf{X} _i,\mathbf{W} _i,U_i)_{i=1}^n\), the following partially linear varying-coefficient model with measurement errors in both covariate and response can be written as
where \(e_i=\hat{H}_i^0-Y_i+\varepsilon _i\) is the model error.
Then, the estimator \(\hat{\varvec{\beta }}_I\) of parameter \(\varvec{\beta }\) based on model (12) can be obtained by minimizing
where \(\check{\varvec{\alpha }}(u;\varvec{\beta })\) has the same form as \(\hat{\varvec{\alpha }}(u;\varvec{\beta })\) defined in (8), except that \(\varvec{\omega }_u^\delta \) and \(\varvec{\Omega }_u^\delta \) are replaced by \(\varvec{\omega }_u\) and \(\varvec{\Omega }_u\), respectively. That is
with \(\varvec{\omega }_u=\mathrm{diag}(K_{h_2}(U_1-u),\ldots ,K_{h_2}(U_n-u))\), \(\hat{\mathbf{H }}=(\hat{H}_1,\hat{H}_2,\ldots ,\hat{H}_n)^T\), and
and \(K_{h_2}(.)=K(./{h_2})/{h_2}\) with a kernel function K(.) and a bandwidth \({h_2}\).
Besides the second term in (13), the third term is added to correct the bias which is induced by \(\mathbf{W} _i\) contained in \(\hat{H}_i\). Similarity, denote \(\mathbf{R} _i=(\mathbf{I} _q,\mathbf 0 _{q})[(\mathbf{D} _{U_i}^\mathbf{W} )^T \varvec{\omega }_{U_i} \mathbf{D} _{U_i}^\mathbf{W} -\varvec{\Omega }_{U_i}]^{-1}(\mathbf{D} _{U_i}^\mathbf{W} )^T\varvec{\omega }_{U_i},\) then \(\check{\varvec{\alpha }}(U_i;\varvec{\beta })=\mathbf{R} _i(\hat{\mathbf{H }}-\mathbf{X} \varvec{\beta })\). Let
Denote \(\bar{H}_i=\hat{H}_i-\sum _{k=1}^n \mathbf{S} _{ik}^{I} \hat{H}_k\) and \(\bar{\mathbf{X }}_i=\mathbf{X }_i-\sum _{k=1}^n \mathbf{S} _{ik}^{I}{} \mathbf{X} _k \), where \(\mathbf{S} _{ik}^{I}\) is the (i, k)th component of matrix \(\mathbf{S} _I\).
By simple calculation, the estimator \(\hat{\varvec{\beta }}_I\) based on the imputation method is obtained by
Then, the corresponding imputation estimator \(\hat{\varvec{\alpha }}_I(u)\) of \({\varvec{\alpha }}(u)\) is defined as
The asymptotic normality of \(\varvec{{\hat{\beta }}}_I\) and the convergence of \(\hat{\varvec{\alpha }}_I(u)\) are given in the following Theorems.
Theorem 3
Suppose that the Conditions C1–C5 in the Appendix hold. Then we have
where
where \(\varvec{\Sigma }_1\) and \(\varvec{\Omega }_1\) are defined in Theorem 1.
Theorem 4
Suppose that the Conditions C1–C5 in the Appendix hold and \(h_2=c n^{-1/5}\), where c is a constant. Then we have

4 Simulation study
In this section, we conduct some simulations to assess the performances of the proposed estimators in finite samples. The data are generated from the following partially linear varying-coefficient measurement error model with missing responses
where parameter vector \(\varvec{\beta }=(\beta _1,\beta _2,\beta _3,\beta _4,\beta _5)^T=(1,1.5,2,1.5,1)^T\), coefficient functions \(\alpha _1(u)=\mathrm{cos}(2\pi u)\) and \(\alpha _2(u)=\mathrm{sin}(2\pi u)\). The covariate variables \(X_1,X_2,\) \(X_3,X_4,X_5\) are independently generated from N(1, 1), \(Z_1,Z_2\) are independently generated from \(N(-1,1)\) and U is independently drawn from a uniform distribution on [0,1]. In addition, the model error \(\varepsilon \sim N(0,1)\) and the measurement error \({\varvec{\xi }}=(\xi _1,\xi _2)^T \sim N(\mathbf 0 ,\Sigma _{\xi })\) with \(\Sigma _{\xi }=0.2 I_2\) and \(\Sigma _{\xi }=0.4 I_2\), respectively. \(I_2\) is identity matrix with order 2. We consider the following two missing schemes as
Case (i). \(\mathrm{Pr}(\delta =1|X_1=x_1,X_2=x_2,X_3=x_3,X_4=x_4,X_5=x_5,Z_1=z_1,Z_2=z_2,U=u)=0.8\) for all \(x_1,x_2,x_3,x_4,x_5,z_1,z_2,u\).
Case (ii). \(\mathrm{Pr}(\delta =1|X_1=x_1,X_2=x_2,X_3=x_3,X_4=x_4,X_5=x_5,Z_1=z_1,Z_2=z_2,U=u)=0.8+0.6(|z_1|+|z_2|+|u-0.5|)\) if \(|z_1|+|z_2|+|u-0.5|<1\), and otherwise 0.8. In this case, the mean response rates is approximately 0.87.
Kernel function K(t) is chosen as Epanechnikov kernel \(K(t)=(3/4)(1-t^2)\) if \(|t|\le 1\), and 0 otherwise. In our simulation, we set the sample size n to be 100, 200 and 300. For each sample size, we generate 1000 random samples.
Some simulation results are reported in Tables 1, 2, 3, 4, 5, 6 and 7 to evaluate the performances of the proposed estimators \(\varvec{\hat{\beta }}_c\) and \(\varvec{\hat{\beta }}_I\). Firstly, to determine whether the choice of bandwidth has influences on the performance of the estimators, we choose three bandwidths with \(h_1=h_2=h_{opt}=2.34*\mathrm{{sd}}(U)*n^{-1/5}\), where \(\mathrm{{sd}}(U)\) is the standard deviation of the observations of \(U_1,U_2,\ldots ,U_n\). The average estimation errors \(||\varvec{\hat{\beta }}_c-\varvec{\beta }||\) and \(||\varvec{\hat{\beta }}_I-\varvec{\beta }||\) in \(L_2\)-norm are computed with three different bandwidths in Table 1. We can see that the choice of bandwidth shows a very slight impact on the estimators \(\varvec{\hat{\beta }}_c\) and \(\varvec{\hat{\beta }}_I\), especially when the sample size is large. Hence, we choose \(h_{opt}\) as the selected bandwidth for the later examples.
Secondly, in Tables 2, 3, 4, 5 and 6, “Bias” and “SD” denote the bias and the standard deviation of the 1000 estimators, respectively. For comparison, we not only report the proposed estimates \(\hat{\beta }_c\) and \(\hat{\beta }_I\), but also \(\hat{\beta }_T\) and \(\hat{\beta }_N\), which stand respectively for the true and naive estimates. The true estimate \(\hat{\beta }_T\) is obtained via the standard profile least squares approach by using the complete data \((Y_i;X_i,Z_i,U_i), i =1,\ldots , n\). However, \(\hat{\beta }_T\) is not applicable in practice since some observations of \(Y_i\) are not available due to missing and \(Z_i\) can not be obtained as a result of measurement errors. The naive estimate \(\hat{\beta }_N\) is calculated by ignoring the measurement errors, not performing the bias correction as in equations (8) and (9), and applying the complete-case data only.
From Tables 2, 3, 4, 5 and 6, it is observed that the bias and SD of both estimators \(\hat{\beta }_c\) and \(\hat{\beta }_I\) are relatively small, which show that the proposed estimation procedures in this paper can work well in finite samples. The estimators \(\hat{\beta }_c\) and \(\hat{\beta }_I\) are comparable to \(\hat{\beta }_T\), though it is impossible to obtain in practice. The bias and the SD of \(\hat{\beta }_N\) is much larger than other three estimators, which indicate that the measurement error should not be ignored directly. It is noted that the estimator \(\hat{\beta }_I\) based on the imputation technique outperform the complete-case estimator \(\hat{\beta }_c\) in terms that it gives smaller SD in most cases. This is due to the fact that \(\hat{\beta }_I\) can make full use of the sample information. Furthermore, the values of SD in the missing data case (i) are usually greater than those in case (ii). The reason for this is that the number of observed responses generated from the missing data case (i) is less than that from case (ii). In addition, the larger variance of measurement error \(\Sigma _\xi \) yields larger SD. It can also be observed that all methods perform better with smaller bias and SD as the sample size increases.
To illustrate the effect of the variance of model error \(\varepsilon \) on the proposed estimation methods, we compare the average mean square error(MSE) of vector \(\beta \) in Table 7. The smaller variance of model error \(\varepsilon \), the smaller MSE. It can be seen that all the proposed estimation procedures perform better with the small variance of model error.
In addition, we report the performances of the proposed estimation procedures for the nonparametric function. We plot the estimated curve of the nonparametric function when the measurement error covariance is \(\Sigma _\xi =0.2I_2\) and the missing scheme is case (i) with sample size 200 in Fig. 1. We also evaluate the performance of the estimator \(\varvec{\alpha }(.)\) by using the square root of mean-squared errors (RMSE) which is defined as
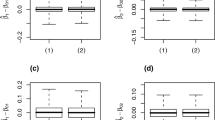
where \(U_k,k=1,\ldots ,N\) are the grid points at which the function is evaluated. In our simulation, we set \(N = 200\) and \(U_k\) is equally taken on interval (0,1). Figure 2 shows the box-plots for 1000 RMSE values for the nonparametric functions \(\varvec{\alpha }(.)\) with different methods.

The plot of the nonparametric estimator. The dotted, the dashed and the solid lines respectively denote \(\hat{\alpha }_c(.),\) \(\hat{\alpha }_I(.)\) and the true curve \(\alpha (.)\)

The boxplots of the 1000 RMSE values for the nonparametric functions based on the complete-case data (left panel) and imputation technique (right panel)
From Fig. 1, we can see that the estimators \(\hat{\alpha }_c(.)\) and \(\hat{\alpha }_I(.)\) are almost same, and they all approximate the real curve. It shows that both the proposed methods can perform well in terms of nonparametric functions. From Fig. 2, it is observed that the RMSE values, obtained by the complete-case data and imputation technique, both decrease as the sample size increases. In addition, \(\hat{\alpha }_I(.)\) performs better than \(\hat{\alpha }_c(.)\) since it has smaller RMSE values.
In this simulation, we assume that the dimension p of the parameter \(\beta \) is fixed. In a general setup, the dimension p can grow with the sample size n, and thus model (1) extends to a high-dimensional partially linear varyingcoefficient model. As there would be some spurious covariates in the parametric component, some penalized profile least squares estimation procedures should be developed. The assumption that there are simultaneous missing response observations and additive errors in the nonparametric component in high-dimensional partially linear varying-coefficient model (1), would be more practical, but more challenging, which is left for the future research.
5 A real example
In this section, we apply our proposed estimation procedures to the Boston housing data set, which has been analyzed by several researches, such as Fan and Huang (2005), Wang and Xue (2011) and Li and Mei (2013) via different regression models. The median value of houses and several associated variables which might explain the variation of housing values are our main interest. In this study, we take the median value of owner-occupied homes in $1000s(MEDV) as the response variable Y, per capita crime rate by town(CRIM), nitric oxide concentration parts per 10 million(NOX), average number of rooms per dwelling(RM), full-value property tax per $10,000(TAX), proportion of owner-occupied units built prior to 1940(AGE) and pupil-teacher ratio by town school district(PTRATIO) as covariates, denoted by \(Z_2,Z_3,Z_4,Z_5, X_1\) and \(X_2\),respectively. We take \(Z_1=1\) as the intercept term and  as the index variable, where LSTAT means lower status of the population. We employ the following partially linear varying-coefficient model
as the index variable, where LSTAT means lower status of the population. We employ the following partially linear varying-coefficient model
to fit the given data.
Before building the model, the response and covariate variables should be standardized for mean zero and unit sample standard deviation. In addition, the index variable U is transformed so that its marginal distribution is U[0,1]. To illustrate our method to this data set, as mentioned in Feng and Xue (2014), we consider the situation that covariate \(Z_5\) has measurement error and can not be observed directly. Instead of \(Z_5\), \(W_5\) can be observed and has the following form
where \(U_5\sim N(0,0.3^2)\). Firstly, we fit the data set by models (17) and (18) without response missing. The estimator of \(\varvec{\beta }\), denoted by \(\hat{\varvec{\beta }}_0=(0.0435,-0.1446)^T\) is obtained with all observation data. Secondly, we remove 10%,15% and 20% of the response Y values at random. Since \(\delta \) is randomly generated, we estimate \(\varvec{\beta }\) from 100 simulation runs and the average results can be found in Table 8.
From Table 8, we can obtain that two estimates of the parameter with complete-case data and imputation technique are almost same, and close to the case with no response missing. In addition, the missing rate is smaller, the estimator value is closer to the case of no missing.
The estimated coefficient functions when the missing rata is \(20\%\) are depicted in Fig. 3. From Fig. 3, we can observe that the shapes of the \(\hat{\alpha }_c(.)\) and \(\hat{\alpha }_I(.)\) are very similar in five different coefficient functions.

The estimated coefficient functions, where the solid line and the dotted line represent the estimated coefficient functions \(\hat{\alpha }_c(.)\) and \(\hat{\alpha }_I(.)\), respectively
6 Conclusions
In this paper, we study the partially linear varying-coefficient model when the nonparametric component is measured with additive error and the response variable is missing simultaneously. Firstly, we propose a locally corrected profile linear least squares estimation procedure based on the complete-case data only. Furthermore, a semiparametric imputation technique is applied to construct another estimator for improving the accuracy of the estimator. We establish the asymptotic normality property of the proposed two estimators of the parameters. As well, we show that the estimator of nonparametric component converge at an optimal rate. Theoretically, the estimator based on the imputation technique has advantages compared to the complete-case data method because it makes full use of information of the observation data. This conclusion is confirmed by the simulation studies and a real example.
However, we only consider the case in which there are a fixed number of predictors in this study. Currently highdimensional data analysis has attracted extensive attention. One important aspect of a regression model for highdimensional data is that the number of covariates is diverging. There has been some remarkable results on variable selection and parameter estimation in partially linear varying coefficient errors-invariables model with no missing data (Fan et al. 2016b, 2018). The simultaneous existence of missing response observations as well as measurement errors in the covariates would be extremely challenge in the highdimensional data modeling. We may apply some penalization methods for variable selection. Specifically, a penalty function could be added to Eqs. (9) or (13). The penalized estimator of \(\beta \) based on complete-case data can be obtained by minimizing the following bias-corrected penalized least square function
where \(p_\lambda (.)\) is a pre-specified penalty function, such as the SCAD penalty. The tuning parameter \(\lambda \) can be selected by some data-driven criteria, such as BIC, AIC, CV. Since the SCAD penalty function is irregular at the origin, the commonly used gradient method is not applicable. To solve this difficulty, an iterative algorithm is proposed by Fan and Li (2001). The penalty function is locally approximated by a quadratic function and then Newton–Raphson algorithm can be used to minimize problem (19). This method can significant reduce the computational burden and should be studied in the future work.
References
Ahmad I, Leelahanon S, Li Q (2005) Efficient estimation of a semiparametric partially linear varying coefficient model. Ann Stat 33:258–283
Fan JQ, Huang T (2005) Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli 11:1031–1057
Fan JQ, Li R (2001) Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc 9:1348–1360
Fan GL, Xu HX, Huang ZS (2016a) Empirical likelihood for semivarying coefficient model with measurement error in the nonparametric part. Adv Stat Anal 100:21–41
Fan GL, Liang HY, Shen Y (2016b) Penalized empirical likelihood for high-dimensional partially linear varying coefficient model with measurement errors. J Multivar Anal 147:183–201
Fan GL, Liang HY, Zhu LX (2018) Penalized profile least squares-based statistical inference for varying coefficient partially linear errors-in-variables models. Sci China Math 61:1677–1694
Feng SY, Xue LG (2014) Bias-corrected statistical inference for partially linear varying coefficient errors-in-variables models with restricted condition. Ann Inst Stat Math 66:121–140
Hu XM, Wang ZZ, Zhao ZW (2009) Empirical likelihood for semiparametric varying-coefficient partially linear errors-in-variables models. Stat Probab Lett 79:1044–1052
Kai B, Li R, Zou H (2011) New efficient estimation and variable selection methods for semiparametric varying-coefficient partially linear models. Ann Stat 39:305–332
Li TZ, Mei CL (2013) Estimation and inference for varying coefficient partially nonlinear models. J Stat Plann Infer 143:2023–2037
Liang H, Wang SJ, Carroll RJ (2007) Partially linear models with missing response variables and error-prone covariates. Biometrika 94:185–198
Long W, Ouyang M, Shang Y (2013) Efficient estimation of partially linear varying coefficient models. Econ Lett 121:79–81
Wang QH, Sun ZH (2007) Estimation in partially linear models with missing responses at random. J Multivar Anal 98:1470–1493
Wang QH, Xue LG (2011) Statistical inference in partially-varying-coefficient single-index model. J Multivar Anal 201:1–19
Wang QH, Linton O, Härdle W (2004) Semiparametric regression analysis with missing response at random. J Am Stat Assoc 99:334–345
Wang XL, Li GR, Lin L (2011) Empirical likelihood inference for semi-parametric varying-coefficient partially linear EV models. Metrika 73:171–185
Wei CH (2012a) Statistical inference in partially linear varying-coefficient models with missing responses at random. Commun Stat Theory Methods 41:1284–1298
Wei CH (2012b) Statistical inference for restricted partially linear varying coefficient errors-in-variables models. J Stat Plan Inference 142:2464–2472
Wei CH, Mei CL (2012) Empirical likelihood for partially linear varying-coefficient models with missing response variables and error-prone covariates. J Korean Stat Soc 41:97–103
Xia YC, Li WK (1999) On the estimation and testing of functional-coefficient linear models. Stat Sin 9:737–757
Xue LG, Xue D (2011) Empirical likelihood for semiparametric regression model with missing response data. J Multivar Anal 102:723–740
Yang H, Xia XC (2014) Equivalence of two tests in varying coefficient partially linear errors in variable model with missing responses. J Korean Stat Soc 43:79–90
Yang YP, Xue LG, Cheng WH (2011) Two-step estimators in partial linear models with missing response variables and error-prone covatiates. J Syst Sci Complex 24:1165–1182
You JH, Chen GM (2006) Estimation of a semiparametric varying-coefficient partially linear errors-in-variables model. J Multivar Anal 97:324–341
You JH, Zhou Y (2006) Empirical likelihood for semi-parametric varying coefficient partially linear model. Stat Probab Lett 76:412–422
Zhang WY, Lee SY, Song XY (2002) Local polynomial fitting in semivarying coefficient model. J Multivar Anal 82:166–188
Zhang WW, Li GR, Xue LG (2011) Profile inference on partially linear varying-coefficient errors-in-variables models under restricted condition. Comput Stat Data Anal 55:3027–3040
Zhang J, Zhou NG, Chen Q, Chu TY (2018) Nonlinear measurement errors models subject to partial linear additive distortion. Braz J Probab Stat 32:86–116
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 11601419, 11801438).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Proofs of the main results
Appendix: Proofs of the main results
We begin with the following assumption conditions required to derive the main results. These conditions are quite mild and can be easily satisfied.
C1: The random variable u has a bounded support \(\Pi \). Its probability density function f(.) is Lipschitz continuous and bounded away from 0 on its support.
C2: The \(q\times q\) matrix \(\mathrm{E}(\mathbf{ZZ} ^T|U)\) and \(\mathrm{E}(\delta \mathbf{ZZ} ^T|U)\) are nonsingular for each \(U\in \Pi \). The matrix \(\mathrm{E}(\mathbf{ZZ} ^T|U)\), \(\mathrm{E}(\mathbf{ZZ} ^T|U)^{-1}\), \(\mathrm{E}(\delta \mathbf{ZZ} ^T|U)\), \(\mathrm{E}(\delta \mathbf{ZZ} ^T|U)^{-1}\), \(\mathrm{E}(\mathbf{ZX} ^T|U)\) and \(\mathrm{E}(\delta \mathbf{ZX} ^T|U)\) are all Lipschitz continuous.
C3: There exists an \(s>0\) such that \(\mathrm{E}||\mathbf{X} ||^{2s}<\infty \),\(\mathrm{E}||\mathbf{Z} ||^{2s}<\infty \) and for some \(k<2-s^{-1}\) such that \(n^{2k-1}h\longrightarrow \infty .\)
C4: \(\alpha _j(u),j=1,\ldots ,q\) have continuous second derivative for \(u\in \Pi \).
C5: The Kernel K(.) is a symmetric probability density function with compact support and the bandwidth h satisfies \(nh^8\longrightarrow 0\) and \(nh^2/(\mathrm{log} n)^2\longrightarrow \infty \) when \(n\longrightarrow \infty \).
In order to prove the main results, we first give several Lemmas. The following notations will be used in the proof of the Lemmas and Theorems. Let \(c_n=(\mathrm{log}n/nh)^{1/2}\), \(\mu _i=\int _0^{\infty } t^i K(t)\mathrm{d}t\), \(\mathbf{M} =[\mathbf{Z} _1^T\varvec{\alpha }(U_1),\dots ,\mathbf{Z} _n^T\varvec{\alpha }(U_n)]^T\), \(\mathbf{M} ^\mathbf{W }=[\mathbf{W} _1^T\varvec{\alpha }(U_1),\ldots ,\mathbf{W} _n^T\varvec{\alpha }(U_n)]^T\), \(\tilde{\varepsilon }_i={\varepsilon }_i-\sum _{k=1}^n \mathbf{S} _{ik}^{c} \varepsilon _k\) and \(\tilde{\mathbf{Z }}_i=\mathbf{Z }_i-\sum _{k=1}^n \mathbf{S} _{ik}^{c} \mathbf{Z} _k.\)
Lemma 1
Suppose that conditions C1–C5 hold. Then the followings hold uniformly
Proof
Equations (20) and (21) are given in Lemma 2 in Feng and Xue (2014). Similarly, Eqs. (22) and (23) can also be obtained.
Lemma 2
Suppose that conditions C1–C5 hold. Then
where \(\varvec{\Sigma _1}\) is defined in Theorem 1, \(\varvec{\Sigma }\) and \(\varvec{\Sigma }_2\) are defined in Theorem 3.
Proof
The proof of this Lemma is similar to that of Lemma 7.2 in Fan and Huang (2005). Hence, the details are omitted.
Proof of Theorem 1
Let
and
Then,
For \(A_n\), by simple calculation and similar proof of Lemma 4 in Feng and Xue (2014), we have
It is easy to see that \(\mathbf{G} _i\) is independent and identical distributed with mean zero and \(\mathrm {Cov}(\mathbf{G} _i)=\varvec{\Omega }_1.\)
Thus, by the Slutsky theorem, Lemma 2 and the central limit theorem, we complete the Theorem.
Proof of Theorem 2
By the definition of \(\hat{\varvec{\alpha }}_c(u)\), we can obtain that
By Theorem 1, similar to the proof of Theorem 3.1 in Xia and Li (1999), it is easy to show that
Let \(h_1=cn^{-1/5}\), where c is a constant. Then it yields that
Proof of Theorem 3
Similar to Theorem 1, it can be shown that
where
and

For convenience, we denote \([\mathbf{S} _c(\mathbf{A} )]_i\) and \([\mathbf{S} _I(\mathbf{A} )]_i\) to respectively be the ith row of product of \(\mathbf{S} _c \mathbf{A} \) and \(\mathbf{S} _I\mathbf{A} \) for a given matrix \(\mathbf{A} \).
By simple calculation, it is obtained that

By Lemma 1, we have
In view of Theorem 1 and the law of large numbers, it follows that
where \(\mathbf{G} _i\) is defined in Theorem 1.
\(I_3\) can be written as
By Lemma 1, it can be shown that
In a similar way, we obtain that,
Therefor,
\(I_4\) can be expressed as
where \(\hat{\mathbf{M }}_c^\mathbf{W }=[\mathbf{W} _1^T\hat{\varvec{\alpha }}_c(U_1),\ldots ,\mathbf{W} _n^T\hat{\varvec{\alpha }}_c(U_n)]^T\). By Lemma 1, it can be shown that \(I_{41}=o_p(1)\) and \(I_{42}=o_p(1)\). By the fact that \(\hat{\varvec{\beta }}_c-\varvec{\beta }=O_p(n^{-1/2})\) from Theorem 1 and \(\frac{1}{{ n}}\sum _{i=1}^{n}\bar{\mathbf{X }}_i[\mathbf{S} _I(\mathbf{X} )]_i=o_p(1)\), \(I_{43}=o_p(1)\) is obtained. \(I_{44}=o_p(1)\) can also be proved similarly. Thus, we have
Similar to the calculation of \(I_4\), we can show that
Invoking (26)–(31), it can be obtained that
Thus, by the Slutsky theorem, Lemma 2 and the central limit theorem, we concludes the theorem.
Proof of Theorem 4
The proof of Theorem 4 is similar to Theorem 2, then, we omit it.
Rights and permissions
About this article

Cite this article
Xiao, YT., Li, FX. Estimation in partially linear varying-coefficient errors-in-variables models with missing response variables. Comput Stat 35, 1637–1658 (2020). https://doi.org/10.1007/s00180-020-00967-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-020-00967-3