
Abstract
In modern industrial processes, various types of soft sensors are used in process monitoring, control, and optimization, and the soft sensors designed to maintain or update these models are highly desirable in the industry. This paper proposes a novel technique for monitoring and control optimization of soft sensors in automation industry for fault detection. The fault detection has been carried out using probabilistic multi-layer Fourier transform perceptron (PMLFTP), and the input data has been pre-processed for removal of samples containing null values for fault detection and diagnosis process through Fourier transform–based detection and multi-layer perceptron–based diagnosis in the manufacturing process. The controlling of data in soft sensors has been optimized using auto-regression-based ant colony optimization (AR_ACO), and the experimental results have been reported in terms of computational rate of 40%, QoS of 78%, RMSE of 45%, fault detection rate of 90%, and control optimization of 93%.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
It is tough and time-consuming to design defect detection methods for complex real-world industrial operations [1]. Numerous manufacturing cells execute a variety of assembly activities as well as functional tests in modern computer-based manufacturing systems. Computer software supervises a specific production process, many of which are custom created, and the cells are controlled by it. One of the most significant duties for computers assigned to manufacturing plant supervision is to detect as well as diagnose product problems. Obtaining data required for process analysis is the initial stage in this task. Only a few data-generating mechanisms and sensing devices were used in first inspection systems. As a result, engineers could only analyze a limited amount of data for fault diagnosis method, and a more method based on structured data analysis was needed [2]. Limit checking is still the only method of fault detection utilized in numerous manufacturing plants today [3]. In this example, for a given characteristic in production process for a product, maximal and minimum values are known as thresholds. When value of a feature is within these defined boundaries, it is said to be in a normal functioning state. Although simple, resilient, and trustworthy, this technique is sluggish to respond to deviations in a particular data characteristic as well as fails to detect complicated failures, which are detected by examining feature correlations. Another issue with this method is difficulty in defining threshold values for each attribute.
In terms of data analysis, industrial applications with heavy machinery, in particular, might advantage from a deeper understanding of underlying methods as well as equipment state to modify their maintenance plans [4]. These components are used in the machine’s rotating mechanics. These bearing parts deteriorate over time as a result of friction as the machine rotates. Traditionally, condition of a rolling bearing element was estimated using breakdown data from the past. Nowadays, state of a bearing element is determined by installing vibration sensors on certain sections of machines or detecting the motor currents of electrical engine that drives these elements. Vibrations, in particular, have proven to be beneficial in revealing underlying status of bearings. Raw signals must be denoised as well as pre-processed before analysis, utilizing complicated and time-consuming signal processing methods to obtain useful data, which is a vital requirement for an effective analysis. As a result, the emphasis has switched to deep learning algorithms that can analyze raw data and create features automatically by recognizing patterns in input data. This automated approach saves time, is less prone to human error, and may need a specialized domain expert with less subject experience [5].
FDD (fault detection and diagnosis) is a vital control technique for achieving this task among numerous process supervision techniques because many industries seek to enhance their process performance by increasing their FDD capability. FDD’s primary functions are categorized into 2 sections: (1) monitoring process behavior and (2) disclosing presence, characteristics, and root causes of errors. To preserve high process output as well as throughput in industrial processes, rapid, significant detection tools for process or equipment failures that may affect whole system’s performance are needed [4,5,6]. The FDD for many different processes has gained a lot of attention from many industrial sectors and academia over the years due to the many significant benefits that may be obtained from lowering process or product-related costs, improving quality and productivity. FDD has played a key role in a variety of industrial engineering methods, including semiconductor production and chemical and software engineering to name a few. As a result, there is an enhancing requirement for effective detection as well as diagnosis of suspicious defects to avert process deterioration, which could ultimately result in a decrease in product yield or process throughput. In general, the FDD work is conducted based on multiple processes as well as equipment data measured by instruments as a key way for process supervision [6].
Research contribution is as follows:
-
To collect historical data from soft sensors in designing fault detection systems for monitoring and controlling with optimization
-
To pre-process the collected data in removing null values and missing data
-
To detect and diagnose the faults of processed data using probabilistic multi-layer Fourier transform perceptron (PMLFTP)
-
To optimize and control the data of soft sensors using auto-regression-based ant colony optimization (AR_ACO)
The experimental analysis has been carried out in terms of computational rate, quality of service (QoS), root mean square error (RMSE), fault detection rate, control optimization for various fault scenarios.
2 Related works
The value of foreign direct investment (FDI) was originally recognized in high-risk fields such as flight control, railways, medicine, nuclear power plants, and many others. Due to the growing use of computational intelligence for data analysis done by real-time methods, the necessity for problem detection has become even more pressing. This is particularly true in real-time energy-efficient management of distributed resources [7], real-time control as well as mobile crowd sensing [8], and protection of sensitive data collected by wearable sensors [9]. Regular inspections of sensor validation, measurement device calibration, software configuration, and preventative maintenance are required to ensure error-free operation. [10]. According to [11], maintenance costs might be anything from 15 to 60% of the entire cost of manufacturing items. Within these margins, almost 33% of maintenance costs are directly related to redundant as well as inappropriate equipment maintenance. As a result, enhancing equipment efficiency while lowering the costs of costly maintenance could result in a significant reduction in overall production costs [12]. According to [13], equipment maintenance can be divided into three categories: (1) modification maintenance entails upgrading components to boost machine productivity as well as performance, (2) preventive maintenance entails replacing a component just before it fails, and (3) breakdown corrective maintenance is when a part fails and needs to be replaced, resulting in machine downtime. Focus on preventive maintenance in this paper, which is divided into 2 types: UBM (usage-based maintenance) and condition-based maintenance (CBM) are two types of maintenance. Time-domain analysis and frequency-domain analysis are two traditional methods for identifying representative characteristics to categorize signals [14, 15]. The large number of features derived from various domains results in an HD dataset, as one could expect. As a result, features are chosen [16] and methods like PCA (principal component analysis) [17] or LDA (linear discriminant analysis) [18] are typically employed to reduce dimensionality of these features. In addition, [19], for example, used data entropy to preprocess raw time series data. RPCA (recursive PCA) [20], DPCA (dynamic PCA) [21], and KPCA (kernel PCA) [22] are used to monitor a variety of industrial processes, including adaptive, dynamic, and nonlinear processes [23]. Two RPCA algorithms were published in [24] to adapt for regular process changes in semiconductor production operations. They did this by iteratively updating the correlation matrix [25].
3 System model
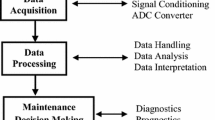
This section discusses the fault detection in automation industry based on soft sensors in monitoring and controlling with optimization. The data has been collected from soft sensors in which the fault has to be detected. This collected data has been pre-processed for removal of samples containing null values. For this processed data, the detection and diagnosis have been carried out using probabilistic multi-layer Fourier transform perceptron (PMLFTP). Then, controlling of data in soft sensors has been optimized using auto-regression-based ant colony optimization (AR_ACO) which has effect in increasing the production of industry automatically. The overall proposed architecture is shown in Fig. 1.

Overall proposed architecture
3.1 Fault detection and diagnosis using probabilistic multi-layer Fourier transform perceptron (PMLFTP)
Input variables of model under study are given by N-dimensional vector x = × 1, × 2,…,xN, and response variable is represented by g (x). As stated in Eq. (1), the answer g(x) is a hierarchical correlated function expansion of input variables:
where g0 denotes the 0th order component function or mean response of g(x). Function gi1i2 (xi1, xi2) is a 2nd-order that defines how variables xi1 and xi2 work together to produce output g(x). Last one g12,…, N (× 1, × 2,…, xN) comprises any residual dependency of all input variables linked together cooperatively to impact output g(x). For component functions in Eq. (2), this approach reduces to the following relationship.
Now consider the 1st order of g(x) given by Eqs. (3) and (4):
Fourier transform pairs formulation is given by Eqs. (5) and (6):
The marginal density and features function of Y are pY(y) and MY (θ) indicates imaginary number given as i = √ − 1 given by Eq. (7):
Since the function \({f}_{p}(t)\) in points \(t={t}^{(m)}\) and \(t={t}^{(m)}+{h}^{(m)}\) has discontinuities, for Fourier series following relations are valid by Eq. (8):
The following integral is local Fourier transform given by Eqs. (9) and (10):
where \(k=\frac{2\pi n}{{h}^{(m)}}={\omega }^{(m)}n;n=0,\pm 1,\pm 2,\dots ;\;m=\mathrm{1,2},\dots .\)
Steps in proposed technique for fault probability evaluation are as follows:
-
1.
If \(\mathrm{u}={\left\{{u}_{1},{u}_{2},\dots ,{u}_{N}\right\}}^{T}\in {\mathfrak{R}}^{N}\) is standard Gaussian variable, let \({\mathrm{u}}^{*}={\left\{{u}_{1}^{*},{u}_{2}^{*},\dots ,{u}_{N}^{*}\right\}}^{T}\) be MPP or design point. Create an orthogonal matrix \(\mathrm{R}\in {\mathfrak{R}}^{N\times N}\) whose N − th column is\({\alpha }^{*}={\mathrm{u}}^{*}/{\beta }_{HL}\), i.e., \(\mathrm{R}=\left[{\mathrm{R}}_{1}\mid {\alpha }^{*}\right]\) where \({\mathrm{R}}_{1}\in {\mathfrak{R}}^{N\times N-1}\) satisfies \({\alpha }^{*T}{\mathrm{R}}_{1}=0\in {\mathfrak{R}}^{1\times N-1}\). MPP has a distance βHL, which is commonly mentioned as Hasofer-Lind reliability index [1–3]. For an orthogonal transformation u = Rv. Let \(\mathrm{v}={\left\{{v}_{1},{v}_{2},\dots ,{v}_{N}\right\}}^{T}\in {\mathfrak{R}}^{N}\) indicates rotated Gaussian space with MPP \({\mathrm{v}}^{*}={\left\{{v}_{1}^{*},{v}_{2}^{*},\dots ,{v}_{N}^{*}\right\}}^{T}\). Gaussian space v with \(={\left\{{v}_{1}^{*},{v}_{2}^{*},\dots ,{v}_{N}^{*}\right\}}^{T}\) as reference point as Eq. (11):
$$\begin{array}{c}\grave{g}(\mathbf{v})\equiv g\left({v}_{1},{v}_{2},\dots ,{v}_{N}\right)\\ =\sum\nolimits_{i=1}^{N} g\left({v}_{1}^{*},\dots ,{v}_{i-1}^{*},{v}_{i},{v}_{i+1}^{*},\dots ,{v}_{N}^{*}\right)-(N-1)g\left({\mathbf{v}}^{*}\right)\\ \sum\nolimits_{n=-\infty }^{\infty } F(m,k)=-j\pi \sum\nolimits_{i=1}^{I} {A}_{i}(m){\sum }_{s=1}^{S} {b}_{si}\mathrm{ctg}\left(j\pi {a}_{si}\right)\end{array}$$(11)
Furthermore, MPP is selected as reference point. Terms \(g\left({v}_{1}^{*},\dots ,{v}_{i-1}^{*},{v}_{i},{v}_{i+1}^{*},\dots ,{v}_{N}^{*}\right)\) are individual component functions which are independent of each other as shown by Eq. (12).
The Park-Goreva equations for synchronous machine are stated utilizing the relative unit method given by Eq. (13).
New intermediate variables are given as Eq. (14)
These new variables are used to convert approximation function into the following form using Eq. (15).
In system of walking coordinates given by Eq. (16), the following equation is obtained in mth local interval of recurrence of converter within the duration of commutation of stages γ related to valve switching:
where \(\theta =\omega t,\theta \in [\alpha ;\;\alpha +\gamma ];\;{i}_{\gamma }^{(m)}-\) exciter current stage, ending switching and \({i}_{\gamma }^{(m)}(\alpha )={i}_{f}^{(m)}(\alpha ),{i}_{\gamma }^{(m)}(\alpha +\gamma )=0\).
The index l corresponds to value of variable at switching point, i.e., when controlling signal is submitted to next thyristor of converter, as demonstrated by following formula, Eq. (17):
Consider above-mentioned synchronous generator has outputs coupled to active and inductive loads \({r}_{W},{x}_{W}\), as given in Eq. (18):
After applying LFT to Eqs. (19), (20), and (21) in the field, obtain the synchronous generator’s equations as well as its activator.
In this context, it is generally known that the equation gives MLPNN state space formulation with one hidden layer (22).
where \(\mathbf{x}(n)={\left[\begin{array}{llll}x(n)& \cdots & x(n-K+1)& 1\end{array}\right]}^{T}\) is (K + 1) × 1 input vector, which is constituted by elements of perceptual feature vector and bias of MLPNN; z(n) = \({\left[\begin{array}{ccc}{z}_{0}(n)& \cdots & {z}_{l-1}(n)\end{array}\right]}^{T}\) is neuron output vector in hidden layer.
The desired output is yd(n), output error is e(n), and the error measure’s gradients concerning a(n) and b(n) are ∇Ea(n) and ∇Eb(n). From Eq. (24) concept of error measures, in the least-squares sense, it is observed that MLPNN seeks to make its output as near to subjective measure yd(n) as possible.
Let the differential operator be expressed by Eq. (25),
Then, H(w(n))d(n) is given by Eq. (26)
During training and tests were calculated based on correlation, ρ, and variance of error \({\sigma }_{e}^{2}\), given by Eqs. (27) and (28):
3.2 Data controlling and optimization using auto-regression-based ant colony optimization (AR_ACO)
The autoregressive model AR(p) uses a linear combination of the p last values by Eq. (29) to determine the value of a process at an arbitrary time step t.
The order of the AR model is denoted by the number p. The model parameters are the weights φi of the linear combination. They are thought to be constant. Furthermore, an AR model requires that this process is superimposed by white noise. εt are regarded uncorrelated in time and identically distributed, with a zero expected value and finite variance. AR(p) is the abbreviation for this model.
The AR(p) model is used to characterize a given time series, as shown in Eq. (30):
This calculation assumes a one-unit change over time. In general, the time step can be of any unit, and it can be substituted by ∆t by altering the unit of time, and the equation can be rewritten as Eq. (31):
The AR(p) model can be thought of as a linear operator that is applied to an initial vector of time series data. In this view, the definition’s equation is expressed as a matrix equation by Eqs. (32) and (33):
with a matrix
The attribute graph’s nodes are arranged in the same order as the composite vector’s boundary values. There are N edges eik, k1::N between two consecutive nodes vi and viz1 when N binary BCs are combined. Each edge, eik in E, shows a couple of conditional probabilities (i.e., \(p\left(\left[{v}_{i},{v}_{i+1}\right]\mid {c}_{1}\right),p\left(\left[{v}_{i},{v}_{i+1}\right]\mid \overline{{c }_{2}}\right)\) integrated with attribute interval \(\left[{v}_{i},{v}_{i+1}\right]\). Conditional probability distribution of original instance of attribute from kth BC is used to calculate these probabilities. Conditional probabilities labelling edge \({e}_{11}=\left[{v}_{1},{v}_{2}\right]\) are evaluated in the following way by Eq. (34):
The characteristic polynomial of Ap is \({\chi }_{p}(\lambda )=(-1{)}^{p}\cdot \left({\lambda }^{p}-{\phi }_{1}{\lambda }^{p-1}-\dots -{\phi }_{p-1}\lambda -{\phi }_{p}\right)\)
The case p = 1 with Eq. (35)
Induction step starts with Eq. (36):
As indicated in Eq. (37), the determinant of this matrix will be determined by utilizing the Laplace expansion along the last column.
The Laplace expansion reduces the p × p matrix (Ap − λI) into two matrices. The first matrix’s determinate is one since its structure has a lower triangular matrix of zeros, and the diagonal’s product is one. The induction hypothesis is met by the second matrix, which is given by Eq. (38):
characteristic polynomial of \({\mathbf{A}}_{p}\) is \({\chi }_{p}(\lambda )\)
k-fold application of linear operator Ap is represented by Eq. (39):
Using corresponding eigenvectors, matrix A2 is decomposed into \({\mathbf{A}}_{2}=\mathbf{T}\cdot \mathbf{D}\cdot {\mathbf{T}}^{-1}\) shown in Eq. (40):
closed form of this AR(2)-model is represented by Eq. (41):
The key principle behind understanding a differential equation as an AR model is that it is symmetric; not only can the difference equation be understood as an AR model, but it can also be reversed. Furthermore, higher-order AR models relate to differential equations of increasing degree. Aside from the following difference quotients, namely, forward difference by Eq. (42):
There are also difference quotients for the numerical calculation of higher derivatives to approach the first-order derivative. Equation (43) provides a recursive definition of higher-order central difference quotients:
for even degrees of n, and by Eq. (44):
by substituting k-th derivative by \({\lambda }^{k}\) in Eq. (45):
The roots are real or occur in conjugate pairs if all coefficients ai are real. The rules for solving higher-order differential equations with constant coefficients can then be used to find the required n linearly independent solutions: If r is a real root that appears k times, then Eq. (46) represents the solutions:
If r = α ± βi are complex conjugate roots appearing k times, then results are given by Eq. (47):
The proposed optimization algorithm is discussed below (Fig. 2).
-
Stage 1: Assign number of clusters to c = 2 and cmax, and use formula to obtain the right number of clusters (8). Set settings for ACO technique, initialize solution Si, I = 1,…, T, and replace Si with 2i = Si in fitness function (5).
-
Stage 2: Sort answers by fitness function and then organize them in ascending order. Probability value for renewing results as Si I = 1,…, T) using (9) and (10).
-
Stage 3: Evaluate mean µ utilizing probability value produced by Step 2 and roulette technique and set SD σ i v utilizing (11). If condition \(\left|{f}^{(l+1)}\left({\mu }^{i}\right)-{f}^{(l+1)}\left({S}_{i}\right)\right|<0\) is satisfied, then set Si = µ i; otherwise, keep original Si.
-
Stage 4: If condition \(\left|{f}^{(l+1)}\left({S}_{i}\right)-{f}^{(t)}\left({S}_{i}\right)\right|<\delta\) is satisfied, then define Si ≡ 2i; otherwise set l = l + 1 and return to Step 2.
-
Stage 5: Examine for less fitness value utilizing (5) until condition \(\Vert {\mathbf{U}}_{n-1}^{(d+1)}-{\mathbf{U}}^{(l)}\Vert <\varepsilon\) is satisfied, where \({\mathbf{U}}^{(t)}=\left[\begin{array}{ccc}{u}_{11}^{(l)}& \cdots & {u}_{1N}^{(l)}\\ \vdots & \ddots & \vdots \\ {u}_{c1}^{(l)}& \cdots & {u}_{eN}^{(l)}\end{array}\right]\)

Optimization algorithm
The center of bell-shaped MF α i q and SD of bell-shaped MF \({\beta }_{q}^{i}\) is given by following formulas given by Eqs. (48) and (49):
The grade of MF \({A}_{g}^{i}\left({x}_{q}(k)\right)\) is given by (3) weight wi(k) and output yˆ is given as \({w}_{i}(k)={\prod }_{q=1}^{n} {A}_{q}^{i}\left({x}_{q}(k)\right)\), and \(\grave{y}(k)=\frac{{\sum }_{i=1}^{\sum } {m}_{i}(k){y}^{\mathrm{^{\prime}}}(k)}{{\sum }_{i=1}^{\sum } {m}_{i}(k)}\)
-
Stage 6: Replace input–output data and yˆ(k) by Eq. (50).
where \(\mathbf{e}=\mathbf{y}-\grave{\mathbf{y}},\) real model \(\mathbf{y}={\left[\begin{array}{lll}y(1)& \dots & y(N)\end{array}\right]}^{T}\) the established model \(\grave{\mathbf{y}}={\left[\begin{array}{lll}\grave{y}(1)& \dots & \grave{y}(N)\end{array}\right]}^{T},\Phi\) is shown in Eq. (51)
-
Step 7: Convert set χi, where i = 1,...,r, produced from Step 6 as orthogonal basis vectors, utilizing subsequent process:
-
1.
\(\mathrm{Set}\;\overset\leftharpoonup m=1\)
-
2.
\({\Gamma }_{1}={\chi }_{1}\) and \({q}_{1}=\frac{\langle {\Gamma }_{1}\cdot {y}_{2}\rangle }{\langle {\Gamma }_{1}\cdot {\Gamma }_{1}\rangle }\).
-
3.
For \(\overset\leftharpoonup m=2\) to \(r\)
$$\gamma_{\mathrm{iin}}=\frac{\langle\Gamma_{1,xa\rangle}}{\langle\Gamma_{i,\Gamma}\rangle},1\leq i<\overset\leftharpoonup m$$
\({q}_{i}=\frac{\langle {\Gamma }_{i}y\rangle }{\langle {\Gamma }_{i},{\Gamma }_{i}\rangle }\) 3) Figure out \(\grave{\Theta }\) by subsequent equation:
where
4 Results and discussion
The Python programming language was used to implement the strategy. The proposed solution is implemented using the The ano library, which features dynamic C code generation, robust and rapid optimization techniques, and integration with mathematical NumPy library. A learning method plus a real-time module make up implementation. Learning method learns the parameters for both spatial pooling as well as temporal inference continuously and saves them in a database that is shared with real-time module. Real-time method uses parameters contained in shared database to execute real-time FDI. Module is simply concerned with execution of technique with already learned parameters and does not perform any learning. This operation of separating the learning and execution processes is required to provide real-time functioning, which would otherwise be impossible to achieve. The learning method is executed on a dedicated server, and deployed method is made available as a service. System begins by obtaining multiple data samples from an SPC database. Database stores a lot of signals created by manufacturing methods as they occur throughout time. This information is recorded in a database as textual data as well as imported into computer memory by learning method as a list of string objects.
Table 1 shows the parametric comparison for fault situation 1, fault situation 2, and fault situation 3. The parameters considered are computational rate, QoS, RMSE, fault detection rate, and control optimization. The techniques compared are PCA and LDA with proposed technique. The graph for above comparison table is given below.
Figures 3, 4, and 5 show parametric analysis in terms of computational rate, QoS, RMSE, fault detection rate, control optimization. The proposed technique has been compared with existing PCA and LDA. In terms of computational rate of 50%, QoS of 80%, RMSE of 57%, fault detection rate of 89%, and control optimization of 92% for fault situation 1 by proposed technique. Computational rate of 52%, QoS of 79.9%, RMSE of 50%, fault detection rate of 89.9%, and control optimization of 92% for fault situation 2 calculated based on fault detection. Based on this comparison, proposed technique obtained higher QoS and fault detection rate in fault location. In terms of computational rate of 40%, QoS of 78%, RMSE of 45%, fault detection rate of 90%, and control optimization of 93% for fault situation 3 by proposed technique.

Analysis of fault situation 1 in terms of a computational rate, b QoS, c RMSE, d fault detection rate, e control optimization

Analysis of fault situation 2 in terms of a computational rate, b QoS, c RMSE, d fault detection rate, e control optimization

Analysis of fault situation 3 in terms of a computational rate, b QoS, c RMSE, d fault detection rate, e control optimization
More crucially, an inferential model like this might be used to forecast paperboard qualities like flat crush strength and compression strength directly. Controlling the refining parameters directly based on feedback from the finished product (board or paper) quality could be a modern control method for refining. Overall, the findings of this study showed that machine learning–based solutions have a lot of promise in the pulp and paper industry, as long as the constraints of data-driven solutions are understood and significant process expertise is used when constructing predictive models.
5 Conclusion
This research proposed novel design in monitoring and control optimization of soft sensors in automation industry for fault detection. The aim is to collect the historical data from soft sensors in designing fault detection systems for monitoring and controlling with optimization. Then, to pre-process the collected data in removing null values and missing data. For detection and diagnosis of the faults of processed data using probabilistic multi-layer Fourier transform perceptron (PMLFTP). Then, optimization and control of the data of soft sensors have been done using auto-regression-based ant colony optimization (AR_ACO) which has effect in increasing the production of industry automatically. The experimental results have been carried out in terms of computational rate of 40%, QoS of 78%, RMSE of 45%, fault detection rate of 90%, and control optimization of 93% which been obtained for various historical data–based evaluations.
Data availability
N/A.
Code availability
N/A.
References
Iqbal R, Maniak T, Doctor F, Karyotis C (2019) Fault detection and isolation in industrial processes using deep learning approaches. IEEE Trans Industr Inf 15(5):3077–3084
Villalba-Diez J, Schmidt D, Gevers R, Ordieres-Meré J, Buchwitz M, Wellbrock W (2019) Deep learning for industrial computer vision quality control in the printing industry 4.0. Sensors 19(18):3987
Lyu Y, Chen J, Song Z (2019) Image-based process monitoring using deep learning framework. Chemom Intell Lab Syst 189:8–17
Sun Q, Ge Z (2021) A survey on deep learning for data-driven soft sensors. IEEE Trans Industr Inf 8:465–471
Lomov I, Lyubimov M, Makarov I, Zhukov LE (2021) Fault detection in Tennessee Eastman process with temporal deep learning models. J Ind Inf Integr 23:100216
Rai R, Tiwari MK, Ivanov D, Dolgui A (2021) Machine learning in manufacturing and industry 4.0 applications. Int J Prod Res 59(16):4773–4778
Zheng D, Zhou L, Song Z (2021) Kernel generalization of multi-rate probabilistic principal component analysis for fault detection in nonlinear process. IEEE/CAA Journal of AutomaticaSinica 8(8):1465–1476
Cecconi F, Rosso D (2021) Soft sensing for on-line fault detection of ammonium sensors in water resource recovery facilities. Environ Sci Technol 55(14):10067–10076
Ullrich T (2021) On the autoregressive time series model using real and complex analysis. Forecasting 3(4):716–728
Tsai SH, Chen YW (2016) A novel fuzzy identification method based on ant colony optimization algorithm. IEEE Access 4:3747–3756
Bouktif S, Hanna EM, Zaki N, Khousa EA (2014) Ant colony optimization algorithm for interpretable Bayesian classifiers combination: application to medical predictions. PLoS One 9(2):e86456
Rao BN, Chowdhury R (2008) Probabilistic analysis using high dimensional model representation and fast Fourier transform. Int J Comput Methods Eng Sci Mech 9(6):342–357
Ribeiro MV, Barbedo JGA, Romano JMT, Lopes A (2005) Fourier-lapped multilayer perceptron method for speech quality assessment. EURASIP J Adv Signal Process 2005(9):1–10
Fedotov A, Fedotov E, Bahteev K (2017) Application of local Fourier transform to mathematical simulation of synchronous machines with valve excitation systems. Latv J Phys Tech Sci 54(1):31
Cai Q, Zhang D, Zheng W, Leung SC (2015) A new fuzzy time series forecasting model combined with ant colony optimization and auto-regression. Knowl-Based Syst 74:61–68
Taqvi SAA, Zabiri H, Tufa LD, Uddin F, Fatima SA, Maulud AS (2021) A review on data‐driven learning approaches for fault detection and diagnosis in chemical processes. Chem Bio Eng Rev
Bernardi E, Adam EJ (2020) Observer-based fault detection and diagnosis strategy for industrial processes. J Frankl Inst
Liu B, Chai Y, Liu Y, Huang C, Wang Y, Tang Q (2021) Industrial process fault detection based on deep highly-sensitive feature capture. J Process Control 102:54–65
Huang K, Wu S, Li F, Yang C, Gui W (2021) Fault Diagnosis of Hydraulic Systems Based on Deep Learning Model With Multirate Data Samples. IEEE Transactions on Neural Networks and Learning Systems
Kazemi P, Bengoa C, Steyer JP, Giralt J (2021) Data-driven techniques for fault detection in anaerobic digestion process. Process Saf Environ Prot 146:905–915
Yella J, Zhang C, Petrov S, Huang Y, Qian X., Minai AA, Bom S (2021) Soft-sensing conformer: a curriculum learning-based convolutional transformer. In 2021 IEEE International Conference on Big Data (Big Data) (pp. 1990–1998). IEEE
Zhe L, Wang KS (2017) Intelligent predictive maintenance for fault diagnosis and prognosis in machine centers: Industry 4.0 scenario. Adv Manuf 5:377–387
Alom MZ, Taha TM, Yakopcic C, Westberg S, Sidike P, Nasrin MS, Hasan M, Van Essen BC, Awwal AAS, Asari VK (2019) A State-of-the-art survey on deep learning theory and architectures. Electronics
Neupane D, Seok J (2020) Bearing fault detection and diagnosis using case western reserve university dataset with deep learning approaches: a review. IEEE Access 8:93155–93178
Deutsch J, He D (2018) Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans Syst Man Cybern Syst 48:11–20
Acknowledgements
Funding: No
Author information
Authors and Affiliations
Contributions
Wongchai A: conceived and design the analysis. Mohammed A.S. Abourehab: editing and figure design, investigation. Mohammed Altaf Ahmed: methodology, writing—original draft preparation, collecting the data. Saibal Dutta: contributed data and analysis stools, performed and analysis, software, validation. Koduganti Venkatrao: visualization, conception and design of study, conceptualization, wrote the paper. Kashif Irshad: funding acquisition, investigation, project administration, supervision, writing—review and editing.
Corresponding author
Ethics declarations
We confirm that we have read, understand, and agreed to the submission guidelines, policies, and submission declaration of the journal.
Ethical approval
This article does not contain any studies with animals performed by any of the authors.
Consent to participate
Not applicable
Consent for publication
Not applicable
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wongchai A, Abourehab, M.A.S., Ahmed, M.A. et al. Application of soft sensors and ant colony optimiation for monitoring and managing defects in the automation industry. Int J Adv Manuf Technol (2023). https://doi.org/10.1007/s00170-022-10753-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00170-022-10753-8