
Abstract
Designing product families is an enabling strategy for mass customization. In general, there are four prevalent classes of problems when designing product families: (i) product family positioning; (ii) customer preferences modeling; (iii) product family modeling; and (iv) product family configuration. Although these classes are interwoven through design problems stemming from marketing, engineering, and economic areas, they are rarely handled together in product family design methods. The lack of a systemic, integrated design perspective may lead to locally optimal solutions and ultimately result in product families not making the economic benefits of customization worthwhile. Over the years, some methods have attempted to overcome this absence of holistic design view. However, because they are restricted to theoretical levels or lack detailed applications, their practical implementation is often not possible. To bridge the pathway between theory and practical implementation, this paper uses the market-driven modularity (MDM) method to design a family of autonomous mobile palletizers economically oriented to market requirements. The empirical application of the method points out the palletizers family as being economically feasible. Furthermore, it also indicates which modules should be developed in successive design phases, as well as reveal the definition of the product family structure as the MDM’s outcome that is more sensitive to the variation of parameters/variables composing the configuration model. The main contribution of this work lies in the presentation of practical implementation details of the MDM method, which, to the best of our knowledge, has not been reported since its proposition.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Increasing product variety without compromising the efficiency of production systems has been a challenge for many organizations [1]. This issue has been addressed in industry and academia primarily via product family design, which embraces a collection of products sharing a common platform yet having distinct characteristics to fulfill the heterogeneity of customer requirements [2]. Generally, there are four prevalent classes of problems when designing product families [3]: (i) product family positioning; (ii) customer preferences modeling; (iii) product family modeling; and (iv) product family configuration. Although these classes are interwoven through design problems stemming from marketing, engineering, and economic areas [4], they are rarely handled together in most product family design methods [5]. It may seem a natural research move to focus on the specifics of particular classes of design problems. However, from a systemic standpoint, the functioning of a system cannot be entirely understood from an independent evaluation of its parts, just as parts cannot be comprehended without knowing their contribution to the whole [6]. Consequently, the lack of a systemic, integrated design view of the product family may result in local solutions, not optimal global ones [7]. Furthermore, when moderated by certain design criteria, it may result in economically unfeasible families [8].
Few studies have systemically addressed the classes of design problems. As proof, Simpson et al. [3, 9] organized several methods for designing product families and platforms into collections of articles. However, while these works allow seeing the methods approaching particular classes of problems in the context of the product family design, they do not explore the interactions or interrelations among the methods within the design process, thus not addressing how the classes of design problems relate to each other. This fact may be restrictive since comprehension of the whole develops through interactions among its parts [10]. In turn, Ferguson et al. [4] proposed a product development framework for mass customization that partially fulfills the role of integrating the classes of design problems. This is because, given the level of granularity used, some design problems, such as product family planning and positioning and building of product family structure, are not addressed. For those design problems considered, their inputs and outputs are not made explicit. Furthermore, in terms of design criteria, the framework overlooks some important ones for assessing the economic viability of product family design, such as market share, demand, and profit [11]. Similarly, Otto et al. [12] organized many strands of research into a logical sequence for developing product platforms. The authors’ proposition presents the design problems and the respective inputs and outputs. The design logic is also demonstrated in an empirical application concerning the design of a family of uncrewed ground vehicles. The problem is that the extension of the proposed method is limited to the first three classes, thus not considering the product family configuration. Finally, Gauss et al. [5] connected multiple methods for designing modular product families into a comprehensive functional model. Although the model addresses the four classes of design problems, their inputs and outputs, and the criteria and techniques for their execution, it is essentially theoretical and does not provide an empirical application that attests to its proposition. The cited authors later proposed an integrated method for designing product families economically oriented to the marketplace [13]. As complete as the previous one, the method is evaluated through a series of expert assessments and practical applications. Nevertheless, the level of detail presented in the empirical applications does not favor the method’s replication in practical terms.
In summary, on the one hand, the methods that independently or partially address the classes of design problems present empirical applications that favor their adoption but lead to locally optimized solutions. On the other hand, the methods that systematically address the classes of design problems altogether and, consequently, lead to globally satisfactory or optimal solutions, are essentially theoretical or do not provide detailed applications allowing their use in practical terms. Given those above, this study poses the following research question: how to systemically and empirically design product families relying on economically feasible customization? Aiming to answer this question while bridging the gap between theory and practical implementation, this study uses the market-driven modularity (MDM) method [13] to conceptually design a family of autonomous mobile palletizers economically oriented to market requirements. The empirical application of the method pointed out the palletizers family as being economically feasible. Moreover, it also identified the optimal set of modules that should be developed in subsequent design phases, as well as revealed the definition of the product family structure as the MDM’s outcome that is more sensitive to the variation of parameters/variables (i.e., market size and variable cost) composing the configuration model. The main contribution of this work lies in developing practical implementation details of the MDM method, which have not been reported since its proposition. When evaluated in perspective to other works that have addressed palletizer design [e.g., 14–16], this paper brings an economic and market standpoint, complementary to the engineering point of view traditionally adopted by machine manufacturers.
The remainder of this article is organized as follows. Section 2 summarizes the related work on modular product family design, while Sect. 3 provides details of the MDM method. Section 4 describes the empirical application of the method, and Sect. 5 discusses the findings. Finally, Sect. 6 outlines the concluding remarks, limitations, and directions for future research.
2 Related research on modular product family design
Designing product families is an enabling strategy for mass customization [17]. In contrast to developing a single product at a time, the purpose of product family design is to create a modular architecture made up of platforms and modules, from which a multitude of family members are derived [12]. The instantiation of family members is carried out by mixing and matching modules from the platform or scaling the platform variables according to preset configuration rules [18]. There are four prevalent classes of problems when designing product families [3]. The first is product family positioning, where product offerings are optimized based on customer preferences. The second is customer preferences modeling, where the customer choices’ influence on product profiles is modeled. The third class is product family modeling, wherein modules and platforms are conceived. Finally, the last one is product family configuration, wherein product family variants are instantiated.
Many methods for designing product families have been developed in the past 20 years [5]. Besides the ones described in Sect. 1 [3, 5, 9, 13], the method by Jiang and Allada [19] also encompasses the four classes of design problems together. However, it presupposes that the modules’ set already exists, which makes the method sensitive to extant modules’ ability to meet the customer desired attributes. Other methods covering the first three classes of design problems are also found in the literature [12, 20,21,22,23,24,25,26,27]. However, their fundamental drawback is choosing the modules to make up the product family structure based on individual evaluations rather than combining modules into variants. The problem is that the combination of modules affects the performance of the configured variants [28, 29]. Therefore, there is no guarantee that a local selection will result in global optimized variants.
Further methods focus on modules identification within the product family modeling [30,31,32,33,34,35,36,37,38,39,40]. However, few, if any, methods in this group perform the functional and physical decomposition concurrently, which may result in modular architectures constrained by physical interactions. Furthermore, such methods only measure the quality of the clustering solution on occasion, thus not assuring that the solution found is the most suitable one. Still concerning the product family modeling, some methods combine this class with product family positioning [40,41,42,43], whereas others combine it with customer preferences modeling [14, 44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60]. In both cases, although few methods obtain the product desired attributes from the customers themselves, most only guide design decisions in criteria essentially linked to customer preferences. The disadvantage of this strategy is that it may end up in specifications that can barely be achieved in reality [61] or induce economically unfeasible product families [8].
Finally, other methods focus on the product family configuration [7, 29, 62,63,64,65,66,67]. In this group, most methods solve the optimization problem of combining and parametrizing modules into product family variants through meta-heuristics. Among the design criteria used for composing the objective function, cost appears most frequently [5]. Nonetheless, considering it alone, or even in conjunction with utility, may not be enough to justify the investments in a product family design/redesign project [62]. Therefore, some methods combine cost with demand and price to obtain profit. Although profit consists of an adequate criterion for assessing economic viability [11], it assumes the use of fixed costs. Nonetheless, rating fixed costs has shown to be counterproductive in selecting the product mix, as it favors more high-volume variants than those more profitable [68]. With further regard to this group, some methods contemplate the product family modeling and configuration being performed together [17, 28, 69,70,71,72,73]. Nevertheless, as well as the work by Jiang and Allada [19], the assumption that a collection of modules already exists hinders the use of configuration procedures to rationalize the product family structure, which ultimately may result in low-utility configuration spaces.
In summary, the missing integration among the classes of design problems precludes using a single method to conduct the entire design process and leads to local optima. Furthermore, when combined with profit-related design criteria, this situation may end up in product families that fail to reap the profitability expected from customization. These are gaps that the market-driven modularity method [13], outlined next, sets out to overcome without yet demonstrating detailed empirical applications that would enable its use in practical terms.
3 Market-driven modularity – MDM
MDM is a method for conceptually designing product family structures economically driven to the customers’ requirements [13]. Conceived for use in early design stages, the MDM consists of 23 steps organized into 4 classes of design problems that can be executed by an open architecture of techniques. The rationale of the method is to define the target market segments, model the customer preferences for each of them, and then create a modular architecture aiming at covering all segments. From the modular architecture, multiple instances of design parameters are devised and further arranged in a multitude of segment-related variants. Next, established the price and estimated the demand, each segment variant’s throughput (sale price minus variable costs) is computed. Finally, the throughputs of the most contributive variants are pooled into the product family throughput, and the design parameter instances comprising them are chosen to make up the final product family structure. The process ceases when the profit exceeds the investment or a pre-determined profit threshold is reached, as seen in Fig. 1. The two primary intended outcomes are (i) ensuring the product family’s economic viability and (ii) the product family structure that economically meets the market requirements.

MDM’s diagram (adapted from Gauss et al. [13])
3.1 Product family planning and positioning (Cp1)
In further depth, MDM begins with converting the company strategy into objective measurements for product family design. In step S1.1, the potential market size \(\left(Mk\right)\), the share of market segments \(\left(Sms\right)\), and investment parameters are estimated. Similarly, the target market segments, \(MS\equiv \left\{{ms}_{i}| i=1,\dots ,I\right\}\), technological trends, product family leveraging strategy, and complementary elements are defined. The market segmentation is then refined in step S1.2, and the resulting specifications trigger the identification of the customer desired attributes, \(A\equiv \left\{{a}_{l} | l=1,\dots ,L\right\}\), in step S2.1, or feedback on the strategic product family planning in step S1.1.
3.2 Customer preferences modeling (Cp2)
In Cp2, the method continues to model the influence of customer choices on product profiles. It starts in step S2.1 by determining the customers’ desired attributes. The attributes should be derived from existing or future needs, and, in some circumstances, they are also used to refine the market segments established in the preceding step. In step S2.2, it is undertaken the translation of customer attributes to engineering attributes, \(E\equiv \left\{{e}_{m} | m=1,\dots ,M\right\}\), followed by the mapping of their relationships in step S2.3, which entails that \({\left[A\right]}_{L}={\left[R\right]}_{LM}{\left[E\right]}_{M}\). The customer-related engineering attributes proceed to step S2.4, while the unrelated ones are discarded. Engineering attributes usually have different levels, i.e., \({E}_{m}^{*}\equiv \left\{{e}_{mn}^{*} | n=1,\dots ,{N}_{m}\right\}\), which are identified in step S2.4 from a set of competing alternatives, \(Z\equiv \left\{{\overrightarrow{z}}_{ik} | k=1,\dots ,{K}_{i}\right\}\), related to the target market segments previously defined \(\left(MS\right)\).
In other words, the competing alternative is a vector of engineering attribute values \(\left({\breve {e}}^{*}\right)\) and price \(\left(\breve {p}\right)\), \({\overrightarrow{z}}_{ik}=\left[{\breve e_{1_{ik}}^{*}}, {\breve e_{2_{ik}}^{*}},\dots ,{\breve e_{\Omega-M_{N\;ik}}^{*}},{\breve {p}}_{ik}\right]\), from which the levels are inductively defined. From a market-pull standpoint, the competing alternatives may often be obtained from definitions other players assumed or from the company’s actual products. In turn, from the technology-push perspective, the alternatives are derived from the company’s vision of the future. At this step (S2.4), new engineering attributes might arise; when it happens, they serve as feedback for step S2.2.
In the following step (S2.5), the set of product profiles via which the customers express their preferences is built. Given the possibility of exceptionally high combinations involving engineering attributes \(\left({e}_{m}\right)\) and levels \(\left({e}_{mn}^{*}\right)\), \(\prod_{m=1}^{N}{N}_{m}\), the goal of step S2.5 is to minimize the number of product profiles while maintaining their significance. The data on customer preferences are then gathered in step S2.6. When data is mainly available, the customers are asked to choose a profile from the set, simulating real-world purchase decisions. When data is scarcely known, the experts or the key customers are requested to perform pairwise comparisons involving the customer desired attributes \(\left(a\right)\), engineering attributes \(\left(e\right)\), and their respective levels \(\left({e}^{*}\right)\) hierarchically. Concluding, in step S2.7, the importance of engineering attribute levels and the price is computed for each segment, i.e., \({\overrightarrow{w}}_{i}=\left[{{w}_{1}}_{i}, {{w}_{2}}_{i},\dots ,{{w}_{\Omega -{M}_{N}}}_{i},{{w}_{\Omega +1}}_{i}\right]\). If some kind of deviation in market segmentation appears, the process should be repeated until achieving a final solution.
3.3 Product family modeling (Cp3)
Following the customer preferences model, in Cp3, the challenge is to define the product family architecture, break it down into modules, and then generate design parameter instances that might compose the product family structure. In step S3.1, the process begins with the formulation of logical entities capable of accomplishing one or more engineering attributes, referred to as design parameters, \(DP\equiv \left\{{dp}_{q} | q=1,\dots ,Q\right\}\). The formulation of design parameters stems from the available technology, existing product features, technological trends, and analogous systems, as shown in Fig. 1. Once defined, in step S3.2, the design parameters and engineering attributes are mapped into a product family architecture covering the target segments altogether, i.e., \({\left[DP\right]}_{Q}={\left[PFA\right]}_{QM}{\left[E\right]}_{M}\). Then, in step S3.3, the functional modules are derived from the decomposition of the product family architecture, \(FM\equiv \left\{{fm}_{s} | s=1,\dots ,S; {fm}_{s}=\left\{{e}_{m},{dp}_{q}\right\}\right\}\), followed by the evaluation of its clustering solution in step S3.4. If the clustering solution succeeds in producing a level of functional modularity higher than or equal to 0.5 (e.g., \({MI}_{f}\ge 0.5\)), the process continues; otherwise, it ends. After defining the functional modules, the next step (S3.5) is to specify the many constructive solutions that a design parameter can assume, referred to as design parameter instances (or building blocks), i.e., \({DP}_{q}^{*}\equiv \left\{{dp}_{qr}^{*} | r=1,\dots ,{R}_{q}\right\}\). A design parameter instance consists of a vector formed of engineering attribute values and variable cost, \(\overrightarrow{dp}_{qr}^{*}=\left[\widehat e_{1_{qr}}^{*},\;\widehat e_{2_{qr}}^{*},\dots,\widehat e_{\Omega-M_{N\;qr}}^{*},\widehat{cv}_{\omega\;qr}^{*}\right]\); therefore, these properties should also be specified in step S3.5. Subsequently, preliminary geometric layouts are undertaken in step S3.6 to reveal the physical interactions among modules’ constituents. At this point of the method, it is possible to delete incompatible design parameter instances, but new design parameters may arise, closing a feedback loop with steps S3.6 and S3.1. The physical interactions resulting from step S3.6 work as inputs for mapping the structural relationships among design parameters in step S3.7, i.e., \({\left[DP\right]}_{Q}={\left[DSM\right]}_{QQ}{\left[DP\right]}_{Q}\). In step S3.8, the functional modules are converted to physical modules, \(PM\equiv \left\{{pm}_{s} | s=1,\dots ,S; {pm}_{s}=\left\{{dp}_{q}\right\}\right\}\), and then evaluated in step S3.9. If physical interactions do not constraint the modular architecture, i.e., \(\left({MI}_{p}\ge {MI}_{f} | {MI}_{f}\ge 0.5\right)\), the process moves on. Otherwise, physical modularity is refined in successive iterations until achieving the desired threshold. Concluding, the solution space for product family configuration is set in step S3.10, \({\left[{DP}_{q}^{*}\right]}_{\Lambda =\sum_{q=1}^{Q}{R}_{q}}={{\left[{\widehat{PF}}^{*}\right]}_{\mathrm{\Lambda \Omega }}\left[{E}_{m}^{*}\right]}_{\Omega =\sum_{m=1}^{M}{N}_{m}}\). Eventually, any required modification may feedback step S3.2.
3.4 Product family configuration (Cp4)
Finally, in Cp4, the aim is to pool the market and investment parameters, customer preferences, competing alternatives, product family architecture, and candidate building blocks into a unique model intended to select and parameterize the design parameter instances to constitute the product family structure. This class starts in step S4.1 by building the configuration model, as further detailed by Gauss et al. [13]. Then, in step S4.2, the design parameter instances are combined and parameterized, yielding a finite group of variants for each target market segment, i.e., \(\breve {PF}\subseteq PF\) wherein \(PF\equiv \left\{{\overrightarrow{pf}}_{ij} | j=1,\dots ,{J}_{i}\right\}\). In step S4.3, the price \(\left({\breve {p}}_{ij}\right)\) for each variant is determined, \({\overrightarrow{pf}}_{ij}=\left[\breve e_{1_{ij}}^{*}, \breve e_{2_{ij}},\dots ,{\breve e_{\Omega-M_{N\;ij}}^{*}},{\breve {p}}_{ij}\right]\), and the product family throughput \(\left(Tp\right)\) is calculated in step S4.4. The steps from S4.1 to S4.4 are iteratively undertaken until reaching a satisfactory or optimal throughput. The less contributive variants are then eliminated, and the product family profit is discounted to present value \(\left(NPV\right)\). In step S4.5, if \(NPV\ge 0\), the most contributive variants are computed, and their design parameter instances become part of the product family structure. Otherwise, the process restarts until reaching the desired value or a final discard, as seen in Fig. 1.
Lastly, Table 1 complements the functional description of MDM by providing an open architecture of techniques. The left and the right-hand side techniques are respectively more suitable for scarce and abundant data availability. Techniques in the middle part of the table serve to be used for both situations.
4 Empirical application
The empirical execution of MDM in the conceptual design of a family of autonomous mobile palletizers is presented in this section. The application was carried out by the first author of this work with the assistance of two engineers from the Brazilian machine manufacturer (referred to here as to company) who provided data for this study. The data stem from 35 palletizing projects quoted by the company during 5 years and the websites of five leading players. Such a situation configures a scarce data availability scenario.
Palletizing consists of stacking products onto a pallet, whereas a palletizer is equipment that executes this operation [102]. In general, palletizers can be of two types [14]: (i) conventional or (ii) robotic. A traditional palletizer is preferred for long production runs handling non-variable stock-keeping units (SKU) and size packages. In turn, robotic palletizers are best suited in conditions that require palletizing of multiple SKU pallets with different package sizes and short production cycles [102]. In today’s economic scenario, retailers and distribution centers use fewer single SKU pallets and more mixed-load ones. Thus, the adoption of robotic palletizers is expected to overtake conventional ones shortly [103]. Following this direction and considering industrial robotics as an enabling technology for advanced manufacturing [104], the company defined collaborative and autonomous mobile robotics as technological trends for product family design in step S1.1. The roadmap in Fig. 2 aided this definition by depicting the relationships among technology, product, and market layers, as reasoned by Paul and Muller [74]. The technology layer shows the evolution of industrial robotics in terms of morphology, control, and payload capacity. In turn, the product layer indicates how technological progress might support the emergence of new intermediate goods (e.g., collaborative robots (COBOT), autonomous mobile robots (AMR), autonomous mobile cobots (AMC), and unmanned aerial vehicles (UAV)) to compose future production systems. Lastly, the market layer suggests upcoming opportunities from the two bottom ones.

Technology roadmap for autonomous mobile palletizers
Two potential product families were identified based on future opportunities, as illustrated in Figs. 2 and 3. The first refers to a family of autonomous mobile palletizers (PF1), whereas the other consists of a family of aerial palletizers (PF2). Given that PF2 can potentially be developed from the PF1 platform, the company chose first to develop product family PF1, which comprises the scope of this study.

Aggregate project (adapted from Wheelwright and Clark [75])
Estimate the potential market size \(\left(Mk\right)\) is another activity to be done in step S1.1. In this case, such action was assisted by the existing market data, in conjunction with experts’ knowledge [20]. According to Fortune Business Insights [105], the global palletizer market reached USD 1.6 billion in 2019 and possibly must surpass USD 2.2 billion by 2027. Regarding the Brazilian market, based on the experience of engineers who supported this work and the company’s historical sales data, Brazil accounts for less than 5% of the global demand, with an average price per stacking position equal to USD 120,000.00. Assuming the global palletizer market size as a uniform distributed variable \(U\left(1.63.{10}^{9},2.16.{10}^{9}\right)\), the Brazilian market size as a constant fraction (5%) of the global demand, and the price per stacking position as a normally distributed variable \(N\left(120.{10}^{3},20.{10}^{3}\right)\), the average market size was estimated as 814 stacking positions a year from 2021 to 2027.
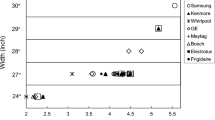
Coupled with this arose the necessity to determine the target market segments and the product family leveraging strategy. To this end, the market segmentation grid (MSG) was employed multidimensionally, as depicted in Fig. 4. The MSG axis represents the key customer desired attributes and their respective performance tiers. The markers, in turn, consist of palletizing projects quoted by the company for different markets and package types. The bars on the left and the upper left of Fig. 4a represent the competing alternatives, whereas their length suggests how they span the corresponding axis. In Fig. 4b, the red, green, and blue areas show the design frontiers of product family PF1, set based on cobots and AMC’s payload capacity and production rate. The markers dropping in these areas indirectly point out the target market segments of PF1, while the bars on the left and the upper left of Fig. 4b depict its working principle and leveraging strategy to reach the intended attribute levels.

Market segmentation grid: a market segmentation; b leveraging strategy
The last activity of step S1.1 was to estimate the investment parameters required to develop the product family. So, the company estimated an investment of USD 4,000,000.00 that would be possible to launch the product family PF1 in up to two years, i.e., \(I=\mathrm{4,000,000.00} \left[USD\right]\). In addition, the company argued that for the project to be viable, the payback period should not exceed 2 years, \(t\le 2 \left[\mathrm{years}\right]\), considering a discount rate of 12% a year, i.e., \(i=12 \left[\mathrm{\%}/\mathrm{year}\right]\).
With the product family strategically planned, the next step (S1.2) was to define the share of market niches \(\left(Sms\right)\). This task started with a change in segmentation perspective, which shifted from “sector” to “package type.” Then, based on the projects quoted, nine market niches and their respective shares were defined. Of these niches, six in line with the working principle and leverage strategy of PF1 were considered targets, as illustrated by Fig. 5. At the end of this first class of design problems (Cp1), the information generated was aggregated into a requirements list, as recommended elsewhere [82].

MSG (adapted from Meyer and Lehnerd [76])
Next, the issue was to model the customer preferences for each target market niche. It was undertaken in class Cp2 and began with the identification of customer-desired attributes \(\left(A\right)\) in step S2.1. In this case, 9 customers’ desired attributes were derived from a content analysis performed on the 35 projects quoted by the company, as reasoned by Bardin [84]. After identifying, the customer desired attributes were analyzed as to the possibility of still existing in 2027. There was a consensus among the company engineers that, regardless of their relative importance might change, they would nonetheless reflect the customer needs shortly. Finally, each attribute was linked to its respective niche, as illustrated in Table 2.
Subsequently, in step S2.2, 27 engineering attributes \(\left(E\right)\), including price, were formulated from five competitors’ product portfolios in the palletizing market. This task was undertaken through the analysis of existing technical systems combined with benchmarking, as proposed by Pahl et al. [82] and Thevenot and Simpson [86]. Then, in step S2.3, the customer desired attributes were mapped to engineering attributes, as depicted in the upper part of Table 2 and reasoned by Suh [87]. Table 2 also shows the preferred direction of engineering attributes, resembling quality function deployment [106].
The engineering attributes often have different levels \(\left({E}_{m}^{*}\right)\). In order to identify these levels, the competing alternatives \(\left({\overrightarrow{z}}_{ik}\right)\) covering all target niches and their respective engineering attribute values \(\left({\breve {e}}^{*}\right)\) and price \(\left(\breve {p}\right)\) were captured in step S2.4, i.e., \({\overrightarrow{z}}_{ik}=\left[\breve e_{1_{ik}}^{*}, \breve e_{2_{ik}}^{*},\dots ,{\breve e_{\Omega-M_{N\;ik}}^{*}},{\breve {p}}_{ik}\right]\). This activity used the same techniques and data sources of step S2.2 and resulted in the identification of 50 engineering attribute levels \(\left({e}^{*}\right)\) retrieved from 10 competing alternatives divided into six market niches, as presented in Tables 2 and 3.
Given the scenario of scarce data availability, in step S2.5, the customer-desired attributes, engineering attributes, and respective levels were organized in a three-level hierarchy. Then, in step S2.6, the two company engineers and the first author of this work independently performed a set of pairwise comparisons between elements of the same hierarchical level, for each target market niche. The technique employed was the analytical hierarchy process [88], with preference aggregation being performed through geometric mean [89]. The outcomes of steps S2.5 and S2.6 are summarized in Table 3, with all cases presenting consistency ratios lower than 0.1.
At the end of Cp2, it was found no deviation from the market niches established in step S2.1. Therefore, the next challenge was determining the modular product family architecture and creating the design parameter instances that might compose the product family structure. These activities happen in class Cp3 and began with the formulation of design parameters \(\left(DP\right)\) in step S3.1. The formulation of \(DP\) was assisted by the classification scheme by Pahl et al. [82], wherein the working principles \(\left(WP\right)\) related to engineering attributes were identified and cataloged, as illustrated in Table 4 and further detailed in Supplementary Material. Then, the logical entities underlying the working principles with the same physical effect were inductively derived. For instance, in Table 4, the working principles \({wp}_{15}\), \({wp}_{16}\), and \({wp}_{17}\), though differing morphologically, they share the same physical effect of gripping packages. Concerning the robotic palletizers, the logical entity executing that function is the end-effector; thus, it was defined as the design parameter number seven \(\left({dp}_{7}\right)\).
Following this reasoning and supported by the company engineers, 17 design parameters stem from the 37 working principles recorded in Table 4.
In step S3.2, the design parameters and engineering attributes were mapped into the product family architecture, i.e., \({\left[DP\right]}_{Q}={\left[PFA\right]}_{QM}{\left[E\right]}_{M}\). Then, through the ranking order clustering [91], the rows and columns of \({\left[PFA\right]}_{QM}\) were rearranged leading to the identification of functional modules \(\left(FM\right)\) in step S3.3. Lastly, in step S3.4, the clustering solution was evaluated via functional modularity index \(\left({MI}_{f}\right)\) [93]. In this application, steps from S3.1 to S3.4 were iteratively performed until the clustering solution, composed of seven functional modules, reached the \({MI}_{f}=0.63\), as shown in Table 5.
The next issue was to define the constructive solutions (i.e., building blocks) that a design parameter might take, which MDM refers to as design parameter instances, i.e., \({DP}_{q}^{*}\equiv \left\{{dp}_{qr}^{*} | r=1,\dots ,{R}_{q}\right\}\). Given that a design parameter instance is a vector of engineering attribute values and variable cost, \(\overrightarrow{dp}_{qr}^\ast=\left[\widehat e_{1_{qr}}^\ast,\;\widehat e_{2_{qr}}^\ast,\dots,\widehat e_{\Omega-M_{N\;qr}}^\ast,\widehat{cv}_{\omega\;qr}^\ast\right]\), these elements were also determined in step S3.5. In this context, the constructive solutions were derived from the classification scheme presented in Table 4, while the engineering attribute values were abductively defined based on Tables 2 and 3.
Finally, the variable cost was estimated through a linear arrangement of cost-related design features (CDF)Footnote 1, based on Gauss et al. [13]. In this sense, the mean coefficients were obtained through artificial neural networks, with no hidden layers, after 30 replications. The activation function used was linear, and the algorithm employed to calculate the coefficients was the resilient backpropagation [94]. This approach requires the existence of historical cost data, which, when not available, was bypassed by requesting quotes from suppliers [96]. In total, 134 design parameter instances were specified, as illustrated in Table 6. Besides the direction, this table also shows the case associated with each engineering attribute level, as recommended elsewhere [13]. Further details on CDFs are disposed of in Appendix (Fig. 10).
Next, in step S3.6, 12 geometric layouts were created to identify the physical interactions among the design parameters, as shown in Fig. 6. In the end, no incompatible design parameter instances were found, and the resulting interactions were mapped using a design structure matrix in step S3.7 (Table 7), as reasoned by Browning [98].

Example of the geometric layout
Then, in step S3.8, the physical modules \(\left(PM\right)\) were established by joining together the design parameters belonging to the corresponding functional modules, e.g., \({pm}_{1}\subset {fm}_{1}=\left\{{dp}_{7},{dp}_{6},{dp}_{15}\right\}\), as presented in Table 7. Afterward, the clustering solution was again evaluated, but at this time from a constructive perspective, by using the physical modularity index \(\left({MI}_{p}\right)\) in step S3.9. The result was \({MI}_{p}=0.94\), indicating that the product family PF1 had a modular architecture physically unconstrained. Finally, in step S3.10, the configuration space, composed of 7 modules (functional/physical), 17 design parameters, 134 design parameter instances, and able to generate billions of variants, was formalized in tabular (Table 6) and graphical form (Fig. 8a).
In product family configuration (Cp4), the goal is to pool the market and investment parameters, customer preferences (Table 3), competing alternatives (Table 2), product family architecture (Table 5), and candidate building blocks (Table 6) into a mathematical model intended to choose the design parameter instances to constitute the product family structure. This routine started in step S4.1 by formulating the configuration model, as detailed in Gauss et al. [13]. The design parameter instances were then instantiated in step S4.2, yielding one variant for each target market niche. In step S4.3, the price of variants was set, succeeded by the computing of the overall product family throughput \(\left(Tp\right)\) in step S4.4. In this work, steps from S4.2 to S4.4 were performed using a genetic algorithm (GA), as reasoned by Jiao and Zhang [107] and illustrated in Fig. 7.

Results of genetic algorithm for the market niche \({ms}_{4}\)
The GA hyperparameters were determined using sensitivity analysis, wherein four population sizes were considered to set up the experiments: 100, 300, 400, and 600. Likewise, four crossover rates (0.6, 0.7, 0.8, and 0.9) and five mutation rates (0.005, 0.01, 0.05, 0.1, and 0.2) were also used. These values were defined based on the rule-of-thumb from previous GA applications [108]. Then, 16 experiments were generated through fractional factorial design [80]. After 160 replications, ten for each experiment, the parameters were selected based on the highest average fitness value, as reasoned by Jiao et al. [109]. Considering a population size of 300 variants, a crossover rate equivalent to 0.8, and a mutation rate equal to 0.1, the GA found the results in Table 8 after 400 generations.
The bottom row of Table 8 shows the results of PF1 comprising all target niches, in which the maximum throughput reached was \(Tp=\mathrm{16,162,788.81 }\left[USD/\mathrm{year}\right]\). Considering a fixed cost \(\left(cf\right)\) around 2.106 [USD/year], a payback period \(\left(t\right)\) of 2 [years], a discount rate \(\left(i\right)\) equals 12 [%/year], and an investment \(\left(I\right)\) equivalent to 4.106 [USD], the net present value was calculated as \(NPV=\mathrm{7,290,488.53} [USD]\). The result indicated that it would be worth investing in PF1.
In step S4.5, with the family considered economically feasible, the design parameter instances making up the most profitable variants (second column of Table 8) were chosen to constitute the final structure of PF1. The solution comprises 7 physical modules, 17 design parameters, and 49 design parameter instances. It is able to generate 25,194,240 variants. Figure 8b shows it. Following the original proposal, it is the product family structure that economically meets the market requirements. Thus, it is the one that should proceed to the following developing stages, an issue not covered in this work.

Final configuration: a solution space; b product family structure
5 Discussion
The primary MDM outcomes are (i) the product family’s economic viability and (ii) the respective structure that economically meets the market requirements. In managerial terms, the first outcome supports the decision to invest or not in the product family. In the case of feasibility, the second outcome indicates which building blocks should be kept or removed from the product structure, or still, which ones should be further developed.
These outcomes stem from integrating the four prevalent classes of design problems, as shown in Fig. 9. The integration of classes is one of the contributions of MDM, and it naturally leads to globally satisfactory solutions. This is because the solution space is conceived based on customer preferences and the selection of alternatives considers the economic impact of the building blocks (local solution) on the configured variants (global solution), a different perspective if compared to the methods presented in Sect. 2. Another contribution of MDM that amplifies the ability to obtain globally satisfactory solutions is the use of throughput as a performance measure for configuring the product family variants. This strategy overcomes the profit limitation in favoring the configuration of higher volume variants rather than most contributive ones, which has to do with the fact that throughput does not consider the fixed costs and apportionment [68].

Conceptual framework of MDM
The MDM provides an open architecture of techniques, and depending on which one is used in the configuration process; it is possible to obtain optimal solutions. Besides the techniques, the MDM outcomes are also influenced by the parameters and variables making up the configuration model. Table 9 adds a sensitivity analysis in which parameters/variables were modified independently until one of the MDM outcomes changed. The variation of parameters/variables was accounted for in relative terms concerning the results obtained in the previous section, referred to as baseline in Table 9.
In a closer look, although the decision variable price \(\left({\breve {p}}_{ij}\right)\) has a negative influence on the choice probability \(\left({Pr}_{i\pi }\right)\), the model tended to increase it to maximize throughput \(\left(Tp\right)\). The unintended effect was that the model did this for variants of shallow utility \(\left({U}_{i\pi }\right)\) and variable cost \(\left({\breve {Cv}}_{ij}\right)\), a pattern incompatible with reality. This occurred for the reason that the marginal increase in throughput reached from the price increment was greater than the one retrieved from the raise in choice probability. To inhibit this behavior, a constraint between price and the variable cost was added to the model, i.e., \(\frac{{\breve {p}}_{ij}}{{\breve {Cv}}_{ij}}\le \xi\), as further detailed in Gauss et al. [13]. In practical terms, for the case presented in Sect. 4, the company indicated this relationship as being \(\xi \le 2\). Concerning the price variation, by exceeding the limits given in Table 9, the viability of the product family was maintained while the product family structure changed.
In terms of demand variation, it may be associated with errors in the estimation of market size \(\left(Mk\right)\) or the share of segments/niches \(\left({Sms}_{i}\right)\). Regardless of the source of error, given the relationship between these two parameters, the variation is perceived in the demand of each market segment/niche, i.e., \({Q}_{i}=Mk.{Sms}_{i}\). Thus, for parsimony, the sensitivity analysis only considered variations in market size \(\left(Mk\right)\), which, when outpacing the limits of Table 9, primarily induced changes in the product family structure. This slight variation in \(Mk\) (−1.5%) was noticed in the segment/niche \({ms}_{3}\) where the demand is the lowest, i.e., \({Q}_{3}\approx 24\), a pattern that did not occur in the others.
Two other parameters influence the outputs of the proposed method; the engineering attributes values \(\left({\breve {e}}^{*}\right)\) and the variable cost of design parameter instances \(\left({\widehat{cv}}_{qr}^{*}\right)\). Although these parameters stem from the same constructive solution \(\left({dp}_{qr}^{*}\right)\), they might be independently affected by errors arising from the techniques used to obtain them. For this reason, they were evaluated separately in the sensitivity analysis. As shown in Table 9, the engineering attribute values and the variable cost of design parameter instances induced changes in the product family structure before altering decisions related to its economic feasibility. In this context, the \({\widehat{cv}}_{qr}^{*}\) appeared to be the most influential product parameter. It is essential to mention that errors associated with the engineering attribute values of competing alternatives \(\left({\overrightarrow{z}}_{ik}\right)\) might also influence the MDM outcomes. However, since they are revealed parameters and not estimated by the proposed method, they were not evaluated in this work.
Whether in a configured variant \(\left({\overrightarrow{pf}}_{ij}\right)\) or a competing alternative \(\left({\overrightarrow{z}}_{ik}\right)\), a factor that moderates the effects of the resultant engineering attribute values \(\left(\breve e_{{\upomega ij}}^{*}\right)\) and price \(\left({\breve {p}}_{ij}\right)\) is the customer preference. In MDM, this preference is modeled using a weight vector for each market segment/niche, \(W\equiv \left\{{\overrightarrow{w}}_{i} |i=1,\dots ,I\right\}\), as depicted in Table 3. Of the nine customer desired attributes \(\left({a}_{l}\right)\) identified in this research, the three most influential ones (\({a}_{1}\), \({a}_{2}\), and \({a}_{9}\)), accounting for 68.4% of \(W\), were considered in the sensitivity analysis. In all three cases, variations exceeding the limits expressed in Table 9 induced changes in the product family structure and not in the decisions related to its economic viability.
In short, the economic viability of the product family is verified by all trials in Table 9 ,i.e., \(NPV\ge 0\). This means that the MDM outcome that is most sensitive to changes in the parameters/variables comprising the configuration model is the definition of the product family structure. Concerning the parameters/variables themselves, the market size \(\left(Mk\right)\) was the most relevant, as the relative fluctuations of −1.5% and +0.0% required the configuration of new structures.
Finally, although the MDM considers the rationale of platforming through the constructive solutions shared across different product family variants, this is done passively. In other words, no mutual exclusion constraints between cross-segment/niche compatible building blocks are considered in the model. This pattern was noticed after the engineers who supported this work critically analyzed the product family structure presented in Fig. 8b. On this occasion, they identified the possibility of communalizing instances belonging to design parameters \({DP}_{1}\), \({DP}_{2}\), \({DP}_{3}\), \({DP}_{4}\), and \({DP}_{9}\). However, despite reducing the quantity of design parameter instances \(\left({DP}_{q}^{*}\right)\) from 49 to 43, the proposed solution decreased the throughput from 16,162,788.81 [USD] to 13,895,896.61 [USD], which shows that communality is not always associated with obtaining better results. Having discussed the results, attention is now turned to the main concluding remarks of this work.
6 Concluding remarks
Aiming at systemically and empirically designing product families that economically meet the market requirements, this paper carried out an in-depth application of the MDM method in the conceptual design of a family of autonomous mobile palletizers. This work made it possible to understand how integrating classes of design problems, combined with the use of throughput in the configuration process, supported the investment decision in the product family design and defined which building blocks should be developed, maintained, or removed from the product structure. Furthermore, this work allows visualizing the method in use and assessing the sensitivity of its results regarding the uncertainty of the model’s parameters and variables.
In addition to the main contribution of this paper, which lies in a detailed empirical application of the MDM method, limitations prompting future research directions were also found. The first refers to not exploring the adequate number of variants per segment/niche, which, combined with a pricing strategy, could result in complementary positionings, thus influencing the throughput. The second is that the MDM did not consider the company’s resource capabilities in accomplishing the potential demand, which could be seen as a moderator of NPV and, consequently, project viability. The third has to do with the passive way the MDM considered platform identification, which could potentially be exploited by evaluating the impacts of cross-segment/niche commonality constraints on throughput. Finally, given the sensitivity to the parameters/variables composing the configuration model, the definition of product family structures in contexts of uncertainty could also be explored in future studies. Further studies should include the relationship of module-based design with the concept of open innovation, which represents a change in developing innovative solutions and doing business within companies [110]. Open innovation includes sharing intellectual property, joint search for innovative solutions, and creative potential outside the company aiming at providing a competitive edge not only by new products but also by new methods to support decision-making processes [111].
Notes
Design characteristics that determine the cost of a given product [95]
References
Piran FS, Lacerda DP, Sellitto MA, Morandi MIWM (2020) Influence of modularity on delivery dependability: analysis in a bus manufacturer. Prod Plan Control 1–11. https://doi.org/10.1080/09537287.2020.1776411
Park K, Gul E, Kremer O (2019) An investigation on the network topology of an evolving product family structure and its robustness and complexity. Res Eng Des 30:381–404. https://doi.org/10.1007/s00163-019-00310-y
Simpson TW, Jiao J, Siddique Z, Hölttä-Otto K (2014) Advances in product family and product platform design: methods & applications, Springer, New York. https://doi.org/10.1007/978-1-4614-7937-6
Ferguson SM, Olewnik AT, Cormier P (2014) A review of mass customization across marketing, engineering and distribution domains toward development of a process framework. Res Eng Des 25:11–30. https://doi.org/10.1007/s00163-013-0162-4
Gauss L, Lacerda DP, Cauchick Miguel PA (2021) Module-based product family design: systematic literature review and meta-synthesis. J Intell Manuf 32:265–312. https://doi.org/10.1007/s10845-020-01572-3
Shaked H, Schechter C (2017) Definitions and development of systems thinking. Syst Think Sch Leaders Holist Leadersh Excell Educ 9–22. https://doi.org/10.1007/978-3-319-53571-5
Ziaei M, Ketabi S, Ghandehari M (2021) Integrative design, production, and marketing policy for a configurable product family. Int J Manag Sci Eng Manag 1–15. https://doi.org/10.1080/17509653.2020.1852126
Hölttä-Otto K, De Weck O (2007) Degree of modularity in engineering systems and products with technical and business constraints. Concurr Eng Res Appl 15:113–126
Simpson TW, Siddique Z, Jiao J (2006) Product platform and product family design: methods and applications, Springer. https://doi.org/10.1007/0-387-29197-0
Senge PM (1990) The fifth discipline: the art and practice of the learning organization. Currency Doubleday, New York
Kumar D, Chen W, Simpson TW (2009) A market-driven approach to product family design. Int J Prod Res 47:71–104. https://doi.org/10.1080/00207540701393171
Otto K, Hölttä-Otto K, Simpson TW, Krause D, Ripperda S, Moon SK (2016) Global views on modular design research: linking alternative methods to support modular product family concept development. J Mech Des. https://doi.org/10.1115/1.4033654
Gauss L, Lacerda DP, Cauchick Miguel PA (2022) Market-driven modularity: design method develop under a design science paradigm. Int J Prod Econ 246:108412. https://doi.org/10.1016/j.ijpe.2022.108412
Gauss L, Lacerda DP, Sellitto MA (2019) Module-based machinery design: a method to support the design of modular machine families for reconfigurable manufacturing systems. Int J Adv Manuf Technol 102:3911–3936. https://doi.org/10.1007/s00170-019-03358-1
Lee JD, Chang CH, Cheng ES, Kuo CC, Hsieh CY (2021) Intelligent robotic palletizer system. Appl Sci. https://doi.org/10.3390/app112412159
Mendoza-Calderón KD, Jaimes JAM, Maradey-Lazaro JG, Rincón-Quintero AD, Cardenas-Arias CG (2022) Design of an automatic palletizer. J Phys Conf Ser. https://doi.org/10.1088/1742-6596/2224/1/012095
Baylis K, Zhang G, McAdams DA (2018) Product family platform selection using a Pareto front of maximum commonality and strategic modularity. Res Eng Des 29:547–563. https://doi.org/10.1007/s00163-018-0288-5
Simpson TW, Maier JR, Mistree F (2001) Product platform design: method and application. Res Eng Des Theory Appl Concurr Eng 13:2–22. https://doi.org/10.1007/s001630100002
Jiang L, Allada V (2005) Robust modular product family design using a modified Taguchi method. J Eng Des 16:443–458. https://doi.org/10.1080/09544820500287359
Jiao J, Tseng MM (1999) Methodology of developing product family architecture for mass customization. J Intell Manuf 10:3–20. https://doi.org/10.1023/A:1008926428533
Asan U, Polat S, Serdar S (2004) An integrated method for designing modular products. J Manuf Technol Manag 15:29–49. https://doi.org/10.1108/09576060410512257
Hsiao S-WS-W, Liu E (2005) A structural component-based approach for designing product family. Comput Ind 56:13–28. https://doi.org/10.1016/j.compind.2004.10.002
Kazemzadeh RB, Behzadian M, Aghdasi M, Albadvi A (2008) Integration of marketing research techniques into house of quality and product family design. Int J Adv Manuf Technol 41:1019–1033. https://doi.org/10.1007/s00170-008-1533-2
Hsiao S-W, Ko Y-C, Lo C-H, Chen S-H (2013) An ISM, DEI, and ANP based approach for product family development. Adv Eng Inform 27:131–148. https://doi.org/10.1016/j.aei.2012.10.008
Sahin-Sariisik AA, Terpenny J, Van Aken EM, Orfi N (2014) A structured approach to platform-driven product planning. Eng Manag J 26:10–23. https://doi.org/10.1080/10429247.2014.11432007
Pakkanen J, Juuti T, Lehtonen T (2016) Brownfield process: a method for modular product family development aiming for product configuration. Des Stud 45:210–241. https://doi.org/10.1016/j.destud.2016.04.004
Ma J, Kim HM (2016) Product family architecture design with predictive, data-driven product family design method. Res Eng Des 27:5–21. https://doi.org/10.1007/s00163-015-0201-4
Colombo EF, Shougarian N, Sinha K, Cascini G, de Weck OL (2020) Value analysis for customizable modular product platforms: theory and case study. Res Eng Des 31:123–140. https://doi.org/10.1007/s00163-019-00326-4
Song Q, Ni Y, Ralescu DA (2020) Product configuration using redundancy and standardisation in an uncertain environment. Int J Prod Res. https://doi.org/10.1080/00207543.2020.1815888
Thevenot HJ, Alizon F, Simpson TW, Shooter SB (2007) An index-based method to manage the tradeoff between diversity and commonality during product family design. Concurr Eng Res Appl 15:127–139. https://doi.org/10.1177/1063293X07079318
Arciniegas AJR, Kim HM (2011) Optimal component sharing in a product family by simultaneous consideration of minimum description length and impact metric. Eng Optim 43:175–192. https://doi.org/10.1080/0305215X.2010.486032
AlGeddawy T, ElMaraghy H (2013) Reactive design methodology for product family platforms, modularity and parts integration. CIRP J Manuf Sci Technol 6:34–43. https://doi.org/10.1016/j.cirpj.2012.08.001
Agard B, Bassetto S (2013) Modular design of product families for quality and cost. Int J Prod Res 51:1648–1667. https://doi.org/10.1080/00207543.2012.693963
Li Z, Cheng Z, Feng Y, Yang J (2013) An integrated method for flexible platform modular architecture design. J Eng Des 24:25–44. https://doi.org/10.1080/09544828.2012.668614
Aydin M, Ulutas BH (2016) A new methodology to cluster derivative product modules: an application. Int J Prod Res 54:7091–7099. https://doi.org/10.1080/00207543.2016.1143133
Ma S, Du G, Jiao J, Zhang R (2016) Hierarchical game joint optimization for product family-driven modular design ga. J Oper Res Soc 67:1496–1509. https://doi.org/10.1057/jors.2016.32
Hou W, Shan C, Yu Y, Hu P, Zhang H (2017) Modular platform optimization in conceptual vehicle body design via modified graph-based decomposition algorithm and cost-based priority method. Struct Multidiscip Optim 55:2087–2097. https://doi.org/10.1007/s00158-016-1629-5
Hou W, Shan C, Yu Y, Hu P, Zhang H (2018) Product-family shared-component selection based on the consistency constraint function. Proc Inst Mech Eng Part D J Automob Eng 232:838–849. https://doi.org/10.1177/0954407017707453
Borjesson F, Hölttä-Otto K (2014) A module generation algorithm for product architecture based on component interactions and strategic drivers. Res Eng Des 25:31–51. https://doi.org/10.1007/s00163-013-0164-2
Miao C, Du G, Jiao RJ, Zhang T (2017) Coordinated optimisation of platform-driven product line planning by bilevel programming. Int J Prod Res 55:3808–3831. https://doi.org/10.1080/00207543.2017.1294770
ElMaraghy H, AlGeddawy T (2012) New dependency model and biological analogy for integrating product design for variety with market requirements. J Eng Des 23:722–745. https://doi.org/10.1080/09544828.2012.709607
Simpson TW, Bobuk A, Slingerland LA, Brennan S, Logan D, Reichard K (2012) From user requirements to commonality specifications: an integrated approach to product family design. Res Eng Des 23:141–153. https://doi.org/10.1007/s00163-011-0119-4
Fan B, Qi G, Hu X, Yu T (2015) A network methodology for structure-oriented modular product platform planning. J Intell Manuf 26:553–570. https://doi.org/10.1007/s10845-013-0815-1
Dahmus JB, Gonzalez-Zugasti JP, Otto KN (2000) Modular product architecture. Proc DETC’00 ASME Des Eng Tech Conf Comput Inf Eng Conf 22:409–424. https://doi.org/10.1016/S0142-694X(01)00004-7
Zhang WY, Tor SY, Britton GA (2006) Managing modularity in product family design with functional modeling. Int J Adv Manuf Technol 30:579–588. https://doi.org/10.1007/s00170-005-0112-z
Meng X, Jiang Z, Huang GQ (2007) On the module identification for product family development. Int J Adv Manuf Technol 35:26–40. https://doi.org/10.1007/s00170-006-0712-2
Stone RB, Kurtadikar R, Villanueva N, Arnold CB (2008) A customer needs motivated conceptual design methodology for product portfolio planning. J Eng Des 19:489–514. https://doi.org/10.1080/09544820802286711
Park J, Shin D, Insun P, Hyemi H (2008) A product platform concept development method. J Eng Des 19:515–532. https://doi.org/10.1080/09544820802043583
Yan X-T, Stewart B (2010) Developing modular product family using GeMoCURE within an SME. Int J Manuf Res 5:449–463. https://doi.org/10.1504/IJMR.2010.035813
Emmatty FJ, Sarmah SP (2012) Modular product development through platform-based design and DFMA. J Eng Des 23:696–714. https://doi.org/10.1080/09544828.2011.653330
Yang Q, Yu S, Jiang D (2014) A modular method of developing an eco-product family considering the reusability and recyclability of customer products. J Clean Prod 64:254–265. https://doi.org/10.1016/j.jclepro.2013.07.030
Wei W, Liu A, Lu SCY, Wuest T (2015) A multi-principle module identification method for product platform design. J Zhejiang Univ A 16:1–10. https://doi.org/10.1631/jzus.A1400263
Jung S, Simpson TW (2016) An integrated approach to product family redesign using commonality and variety metrics. Res Eng Des 27:391–412. https://doi.org/10.1007/s00163-016-0224-5
Cheng Q, Li W, Xue D, Liu Z, Gu P, Li K (2017) Design of adaptable product platform for heavy-duty gantry milling machines based on sensitivity design structure matrix. Proc Inst Mech Eng Part C J Mech Eng Sci 23:4495–4511. https://doi.org/10.1177/0954406216670685
Wang Q, Tang D, Yin L, Ullah I, Tan L, Zhang T (2018) An optimization model for low carbon oriented modular product platform planning (MP3). Int J Precis Eng Manuf Green Technol 5:121–132. https://doi.org/10.1007/s40684-018-0013-x
Bonjour E, Deniaud S, Dulmet M, Harmel G (2009) A fuzzy method for propagating functional architecture constraints to physical architecture. J Mech Des 131:061002. https://doi.org/10.1115/1.3116253
Bejlegaard M, ElMaraghy W, Brunoe TD, Andersen AL, Nielsen K (2018) Methodology for reconfigurable fixture architecture design. CIRP J Manuf Sci Technol 23:172–186. https://doi.org/10.1016/j.cirpj.2018.05.001
Du X, Jiao J, Tseng MM (2006) Understanding customer satisfaction in product customization. Int J Adv Manuf Technol 31:396–406. https://doi.org/10.1007/s00170-005-0177-8
Krishnapillai R, Zeid A (2006) Mapping product design specification for mass customization. J Intell Manuf 17:29–43. https://doi.org/10.1007/s10845-005-5511-3
Tan C, Chung H, Barton K, Jack Hu S, Freiheit T (2020) Incorporating customer personalization preferences in open product architecture design. J Manuf Syst 56:72–83. https://doi.org/10.1016/j.jmsy.2020.05.006
Aungst S, Barton R, Wilson D (2003) The virtual integrated design method. Qual Eng 15:565–579. https://doi.org/10.1081/QEN-120018389
Jiao JR (2012) Product platform flexibility planning by hybrid real options analysis. IIE Trans (Inst Ind Eng) 44:431–445. https://doi.org/10.1080/0740817X.2011.609874
Pate DJ, Patterson MD, German BJ (2012) Optimizing families of reconfigurable aircraft for multiple missions. J Aircr 49:1988–2000. https://doi.org/10.2514/1.C031667
Hanafy M, Elmaraghy H (2015) A modular product multi-platform configuration model. Int J Comput Integr Manuf 28:999–1014. https://doi.org/10.1080/0951192X.2014.941407
Goswami M, Daultani Y, Tiwari MK (2017) An integrated framework for product line design for modular products: product attribute and functionality-driven perspective. Int J Prod Res 55:3862–3885. https://doi.org/10.1080/00207543.2017.1314039
Xiao W, Du G, Zhang Y, Liu X (2018) Coordinated optimization of low-carbon product family and its manufacturing process design by a bilevel game-theoretic model. J Clean Prod 184:754–773. https://doi.org/10.1016/j.jclepro.2018.02.240
Tucker CS, Kim HM (2008) Optimal product portfolio formulation by merging predictive data mining with multilevel optimization. J Mech Des 130:041103. https://doi.org/10.1115/1.2838336
Hilmola OP, Li W (2016) Throughput accounting heuristics is still adequate: response to criticism. Expert Syst Appl 58:221–228. https://doi.org/10.1016/j.eswa.2016.03.051
Rai R, Allada V (2003) Modular product family design: agent-based pareto-optimization and quality loss function-based post-optimal analysis. Int J Prod Res 41:4075–4098. https://doi.org/10.1080/0020754031000149248
Li L, Huang GQ, Newman ST (2008) A cooperative coevolutionary algorithm for design of platform-based mass customized products. J Intell Manuf 19:507–519. https://doi.org/10.1007/s10845-008-0137-x
Li L, Huang GQ (2009) Multiobjective evolutionary optimisation for adaptive product family design. Int J Comput Integr Manuf 22:299–314. https://doi.org/10.1080/09511920802014920
Dong M, Shao X, Xiong S (2011) Flexible optimization decision for product design agility with embedded real options. Proc Inst Mech Eng Part B J Eng Manuf 1431–1446. https://doi.org/10.1177/09544054JEM2216
Chowdhury S, Maldonado V, Tong W, Messac A (2016) New modular product-platform-planning approach to design macroscale reconfigurable unmanned aerial vehicles. J Aircr 53:309–322. https://doi.org/10.2514/1.C033262
Phaal R, Muller G (2009) An architectural framework for roadmapping: towards visual strategy. Technol Forecast Soc Change 76:39–49. https://doi.org/10.1016/j.techfore.2008.03.018
Wheelwright SC, Clark KB (1992) Creating project plans to focus product development. Harv Bus Rev 70:70–82. https://doi.org/10.1007/s00464-008-0110-y
Meyer MH, Lehnerd AP (1997) The power of product platforms: building value and cost leadership. Free Press
Dalkey N (1969) An experimental study of group opinion: the Delphi method. Futures 1:408–426. https://doi.org/10.1016/S0016-3287(69)80025-X
Premachandra IM (2001) An approximate of the activity duration distribution in PERT. Comput Oper Res 28:443–452. https://doi.org/10.1016/S0305-0548(99)00129-X
Forza C (2002) Survey research in operations management: a process-based perspective. Int J Oper Prod Manag 22:152–194. https://doi.org/10.1108/01443570210414310
Montgomery DC, Runger GC (2011) Applied statistics and probability for engineers, 5th ed., John Wiley & Sons, Ltd
Chen W, Hoyle C, Wassenaar HJ (2013) Decision-based design: integrating consumer preferences into engineering design, Springer. London. https://doi.org/10.1007/978-1-4471-4036-8
Pahl G, Beitz W, Feldhusen J, Grote K-H (2007) Engineering design: a systematic approach, Springer. 617. https://doi.org/10.1111/dsu.12130
Malhotra NK, Birks DF (2007) Marketing research: an applied approach, 3rd ed., Prentice Hall Inc
Bardin L (1993) L’analyse de contenu [Content Analysis]. Presses Universitaires de France Le Psychologue, Paris
Yearworth M, White L (2013) The uses of qualitative data in multimethodology: developing causal loop diagrams during the coding process. Eur J Oper Res 231:151–161. https://doi.org/10.1016/j.ejor.2013.05.002
Thevenot HJ, Simpson TW (2007) A comprehensive metric for evaluating component commonality in a product family. J Eng Des 18:577–598. https://doi.org/10.1080/09544820601020014
Suh NP (2001) Axiomatic design: advances and applications. Oxford University Press, New York
Saaty TL (2008) Decision making with the analytic hierarchy process. Int J Serv Sci 1:83. https://doi.org/10.1504/IJSSCI.2008.017590
Ossadnik W, Schinke S, Kaspar RH (2016) Group aggregation techniques for analytic hierarchy process and analytic network process : a comparative analysis. Gr Decis Negot 25:421–457. https://doi.org/10.1007/s10726-015-9448-4
Eskandari H, Rabelo L (2007) Handling uncertainty in the analytic hierarchy process: a stochastic approach. Int J Inf Technol Decis Mak 6:177–189. https://doi.org/10.1142/S0219622007002356
King JR (1980) Machine-component grouping in production flow analysis: an approach using a rank order clustering algorithm. Int J Prod Res 18:213–232. https://doi.org/10.1080/00207548008919662
Kusiak A, Chow WS (1987) Efficient solving of the group technology problem. J Manuf Syst 6:117–124. https://doi.org/10.1016/0278-6125(87)90035-5
Jung S, Simpson TW (2017) New modularity indices for modularity assessment and clustering of product architecture. J Eng Des 28:1–22. https://doi.org/10.1080/09544828.2016.1252835
Haykin S (2008) Neural networks and learning machines, 3rd edn. Prentice Hall, Ontario
Jiao J, Tseng MM (1999) A pragmatic approach to product costing based on standard time estimation. Int J Oper Prod Manag 19:738–755. https://doi.org/10.1108/01443579910271692
Gümüş M (2014) With or without forecast sharing: competition and credibility under information asymmetry. Prod Oper Manag 23:1732–1747. https://doi.org/10.1111/poms.12192
Eissen K, Steur R (2007) Sketching: drawing techniques for product designers, 13th ed., BIS Publishers
Browning TR (2001) Applying the design structure matrix to system decomposition and integration problems: a review and new directions. IEEE Trans Eng Manag 48:292–306. https://doi.org/10.1109/17.946528
Hilier F, Lieberman G (2015) Introduction to operational research, 10th ed., McGraw-Hill, New York. https://doi.org/10.2307/2077150
Daly SR, Yilmaz S, Christian JL, Seifert CM, Gonzalez R (2012) Design heuristics in engineering. J Eng Educ 101:601–629
Rui H, Cuervo-Cazurra A, Un CA (2016) Learning-by-doing in emerging market multinationals: integration, trial and error, repetition, and extension. J World Bus 51:686–699. https://doi.org/10.1016/j.jwb.2016.07.007
Popple RA (2009) The science of palletizing: how to choose the right system. Columbia Machine Inc, Vancouver
More A (2019) Palletizer Market 2019 Research by Business Opportunities, Top Manufactures, Industry Growth, Industry Share Report, Size, Regional Analysis and Global Forecast to 2024 | Market Reports World - MarketWatch. https://www.marketwatch.com/press-release/palletizer-market-2019-research-by-business-opportunities-top-manufactures-industry-growth-industry-share-report-size-regional-analysis-and-global-forecast-to-2024-market-reports-world-2019-05-31 (Accessed 7 Dec 2019)
Ghobakhloo M (2018) The future of manufacturing industry: a strategic roadmap toward Industry 4.0. J Manuf Technol Manag 29:910–936. https://doi.org/10.1108/JMTM-02-2018-0057
Insight FB (2021) Palletizer: global market analysis, Insights and Forecast (2016 - 2027). https://www.fortunebusinessinsights.com/palletizer-market-104445
Chan L-KL-K, Wu M-LM-L (2002) Quality function deployment: a literature review. Eur J Oper Res 143:463–497. https://doi.org/10.1016/S0377-2217(02)00178-9
Jiao J, Zhang Y (2005) Product portfolio planning with customer-engineering interaction. IIE Trans (Institute Ind Eng) 37:801–814. https://doi.org/10.1080/07408170590917011
Hassanat A, Almohammadi K, Alkafaween E, Abunawas E, Hammouri A, Prasath VBS (2019) Choosing mutation and crossover ratios for genetic algorithms-a review with a new dynamic approach. Information. https://doi.org/10.3390/info10120390
Jiao J, Zhang Y, Wang Y (2007) A heuristic genetic algorithm for product portfolio planning. Comput Oper Res 34:1777–1799. https://doi.org/10.1016/j.cor.2005.05.033
Baierle I, Benitez G, Nara JSE, Sellitto M (2020) Influence of open innovation variables on the competitive edge of small and medium enterprises. J Open Innov Technol Mark Complex 6:179–196
Nara EOB, Sordi DC, Schaefer JL, Schreiber JNC, Baierle IC, Sellitto MA, Furtado JC (2019) Prioritization of OHS key performance indicators that affecting business competitiveness – a demonstration based on MAUT and Neural Networks. Saf Sci 118:826–834. https://doi.org/10.1016/j.ssci.2019.06.017
Acknowledgements
The authors do appreciate the recommendations of the reviewers and editor who dedicated their time and provided remarkable suggestions that undoubtedly enhanced our manuscript. We also thank the Coordination of Superior Level Staff Improvement (CAPES) and the Brazilian Council for Scientific and Technological Development (CNPq) for funding this research.
Funding
This work was funded by the Coordination for the Improvement of Higher Education Personnel (CAPES) and the Brazilian National Council for Scientific and Technological Development (CNPq) for funding.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by Leandro Gauss and Daniel P. Lacerda. The first draft of the manuscript was written by Leandro Gauss and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix

Cost-related design features \(\left(CDF\right)\)
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gauss, L., Lacerda, D.P., Cauchick-Miguel, P.A. et al. Market-driven modularity: an empirical application in the design of a family of autonomous mobile palletizers. Int J Adv Manuf Technol 123, 1377–1400 (2022). https://doi.org/10.1007/s00170-022-10128-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-022-10128-z