
Abstract
Predicting chatter stability in a micro-milling operation is challenging since the experimental identification of the tool-tip dynamics is a complicated task. In micro-milling operations, in-process chatter monitoring strategies can use acoustic emission signals, which present an expressive rise during unstable cutting. Several authors propose different time and frequency domain metrics for chatter detection during micro-milling operations. Nevertheless, some of them cannot be exploited during cutting since they require long acquisition periods. This work proposes an in-process chatter detection method for micro-milling operation. A sliding window algorithm is responsible for extracting datasets from the acoustic emissions using optimal window and step packet sizes. Nine statistical-based features are derived from these datasets and used during training/testing phases of machine-learning classifiers. Once trained, machine learning classifiers can be used in-process chatter detection. The results assessed the trade-off between the number of features and the complexity of the classifier. On the one hand, a Perceptron-based classifier converged when trained and tested with the complete set of features. On the other hand, a support vector classifier achieved good accuracy values, false positive and negative rates, considering the two most relevant features. A classifier’s output is derived at every step; therefore, both proposals are suitable for in-process chatter detection.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
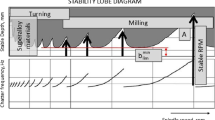
Micro-milling manufacturing operations exploit reduced-sized end mills (tool) at high rotational speeds for producing complex-shaped components. Consequently, the dynamics and the cutting coefficients vary due to the elastoplastic behavior of the workpiece’s material and the required high-speed values [1]. In addition, chip thickness variation can occur for a specific combination of process parameters due to the modulations left on the surface during the successive cuts (as illustrated in Fig 1). This complex interaction yields large forces and displacements that can promote chatter. This self-exciting vibration affects the surface finishing and reduces the tool life, affecting productivity.
Some authors have proposed modeling strategies aiming to monitor and predict this instability. For instance, Afazov et al. [2], and Jin and Altintas [3] proposed different chatter modeling approaches considering nonlinearities in the micro-milling cutting forces and damping process, respectively. Recently, Lu et al. [4] included the centrifugal forces and gyroscopic effects caused by the high-speed rotation of the micro-milling spindle in their modeling strategy, aiming for a more realistic representation of this phenomenon. Due to the variation of the dynamics, Graham et al. [5] presented two novel robust chatter stability models considering uncertain parameters. Recently, Mamedov [6] revised different modeling techniques related to the micro-milling process. One can conclude from the proposed models modeling the dynamics of a micro-milling process is a challenging task.
Therefore, model-free alternatives for monitoring and predicting the occurrence of chatter have also been investigated since a proper selection of cutting parameters can ensure a chatter-free cut [1]. These alternatives require the use of dedicated instrumentation as dynamometers, accelerometers, cameras, and microphones. Moreover, the monitoring and predicting strategies should adequately process the data acquired by these devices. For instance, Chen et al. [7] exploited Support Vector Machines (SVM) for detecting chatter using image features captured by a camera. This method is highly influenced by noise; therefore, it requires extensive data treatment, which might jeopardize its in-process applicability. The online chatter detection method proposed [8] involves the use of piezoelectric actuators to excite the system externally. Despite its accuracy, the use of external actuators is a significant drawback in this proposal. Li et al. [9], and Yuan et al. [10] used accelerometers for measuring the vibration signals during the machining process. A shift of the dominant frequency components and a sharp vibration amplitude can be perceived during chatter occurrence. Due to these phenomena, Li et al. [9] used a dimensionless chatter indicator based on revolution root-mean-square (RMS) values for evaluating the stability of the micro-milling process. Alternatively, Yuan et al. [10] proposed a novel chatter-detection method based on wavelet coherence functions for the same evaluation. The authors concluded that the wavelet coherence functions of two orthogonal acceleration signals are sensitive enough for chatter detection.
Acoustic emissions (AE), illustrated in Fig. 1, are the most common data during chatter detection in micro-milling operations. Inasaki [11] discussed the advantages of the AE sensor for tool condition monitoring highlighting its feasibility regarding sensor mounting and signal processing. These signals contain information about vibrations, tool-workpiece contact, surface integrity, and topography [12]. Other assets are that the required instrumentation is a non-invasive, low-cost alternative [13]. Due to these characteristics, it does not modify the system dynamics.

Illustration of successive cuts
In this way, time- and frequency-domain metrics using AE-signals aiming for chatter detection in micro-milling operations have been proposed. Filippov et al. [14] investigated AE and acceleration signals, concluding that the power spectrum signal is an appropriate metric for monitoring the fast-occurring changes in the cutting process stability. Ribeiro et al. [12] evaluated the time-domain metric proposed, namely chatter indicator, by Li et al. [9] using AE signals instead of acceleration data, concluding that this indicator is not directly applicable for this set of data. Therefore, Ribeiro et al. [12] proposed a metric based on the AE RMS values and evaluated it for two grain-sized materials during chatter-free and chatter cuts. Figure 2 shows the micro-milling experiments. Unfortunately, neither discussions nor evaluations of the required period for the data used to derive the metric are presented, jeopardizing any conclusion about the metric applicability for in-process chatter detection. Li et al. [15] claimed that fast Fourier transform and the time-domain RMS value of AE signals could be effectively used for detection of chatter in the robotic milling process. Still, no conclusions can be directly drawn for micro-milling operations.

Micro-milling machining experiments [12]
Due to the complexity of the dynamics involved in the micro-milling process, machine learning algorithms can be helpful for chatter detection since they have been successfully employed as classifiers. Inasaki [11] discusses the application of the artificial neural network (ANN) for identifying chatter in the machining processes using AE signals. Recently, Wang et al. [16] employed an unsupervised machine learning-based method for chatter detection in milling operations using time- and frequency-domain metrics based on AE, acceleration, and bending signals. The authors concluded that the signal fractal dimension is the best time-domain feature for training an accurate classifier. Regarding micro-milling operations, [17] used SVM for predicting the surface roughness, demonstrating the potential of these techniques. This work investigates the use of machine learning-based classifiers for chatter detection in micro-milling operations. We can indicate the most appropriate features and classifiers for in-process detection through this investigation. These classifiers require strategies with low computation effort; therefore, only time-domain features are investigated. Moreover, an optimizer exploits a sliding window strategy to acquire time-domain signals, maximize the classifier accuracy, and minimize false positive/negative rates.
This article is organized as follows. Section 2 presents some concepts regarding the machine learning-based classifiers exploited in this work: the Perceptron and the SVM. Both classifiers are supervised learning algorithms requiring data from the different classes during the training phase. Section 3 details the proposed in-process chatter detection technique. The authors investigated the performance of the proposed classifiers for two different materials: COSAR and UFG (workpiece in Fig. 2). Figure 2 shows the experimental setup, and details about this experimental campaign are given in Sect. 4. The results of this investigation are presented and discussed in Sect. 5. Finally, conclusions are drawn in Sect. 5.
2 Machine learning-based classifiers
Machine learning-based classifiers are capable of separating different data classes. For the sake of illustration, Fig. 3 shows the separability of two datasets characterized by two features, \(F_1\) and \(F_2\). While Fig. 3(a) illustrates linearly separable (LS) sets, Fig. 3(a) shows nonlinearly separable (NLS) ones. On the one hand, a straight line is capable of separating the datasets in Fig. 3(a), demonstrating that these are LS. LS can be classified by simple strategies which require fewer computation resources. There are several techniques for linear separation such as linear programming, artificial neural networks (ANN), Fisher’s linear discriminant method, among others [18]. On the other hand, the datasets illustrated in Fig. 3(b) cannot be separated by a straight line since they are NLS. Therefore, these NLS require other strategies, such as Multi-Layer Perceptron and SVM-based classifiers.

Class separability: a linearly separable and b nonlinearly separable sets
The chatter detection methodology proposed in this work employs two machine learning-based classifiers: the Perceptron, an ANN-based classifier often used to classify LS, and the SVM, which presents a satisfactory performance NLS.
In this work, nine features extracted from the datasets are used to compose input vector \(\mathbf {x}_i \in \mathbb {R}^N\) where N is the number of selected features used by the classifiers, \(i=1 \ldots n\), and n is the number of evaluated sets extracted by the sliding window algorithm. In other words, these vectors contain statistical features extracted from the AE signals acquired during the micro-milling of two workpieces with other sized-grain materials (COSAR and UFG).
2.1 ANN-based classifier: the perceptron
The use of less complex machine learning algorithms, such as Perceptron, is often possible to classify two classes of samples. The Perceptron is a supervised learning algorithm used in binary classifications. This learning algorithm converges in a finite number of iterations for LS. The user can explore this fact to verify the datasets’ linear separability since the Perceptron does not converge for NLS. Furthermore, the use of this supervised machine learning algorithm brings a computational advantage over the others because it is simple to be implemented [18].
The threshold function is used for classification to map the inputs \(\mathbf {x}_i \in \mathbb {R}^N\) to a single binary value, as illustrated in Fig. 4:
where \({}_P\mathbf {w} \in \mathbb {R}^N\) is the weighting vector, \({}_Pb\) is the bias.

Illustration of a Perceptron-based classifier
2.2 Support Vector Machine (SVM)
SVM consists of a supervised method of machine learning widely used in problems involving classification. This algorithm aims to find a hyperplane, also known as hard-margin, that differentiates the data classes. For example, Fig. 5 shows two classes illustrated by circles and stars separated by a hyperplane. These classes are allocated in the plot according to two features, \(F_1\) and \(F_2\). The points closest to the hyperplane are called support vectors. Mathematically, the hyperplane can be described as:
where \(\mathbf {w}\) and b are the coefficients to be found during the training phase aiming the maximization of the distances between the hyperplane and the support vectors [19]. This distance is illustrated as the total margin in Fig. 5. This optimization problem can be described as:
where the bias b and the scalar \(y_i\) defines if the set \(\mathbf {x}_i\) belong to a specific class.
Some scenarios in the described algorithm cannot achieve satisfactory results. In these scenarios, the datasets are not separable by a hyperplane, and some techniques can obtain better results, namely: Kernel functions soft-margin SVM.
Kernel functions exploit an adimensional transformation for the input sets. Due to this transformation, the classes became linearly separable. Several Kernel functions are proposed in the literature, for instance, linear, polynomial, RBF Kernel functions [20]. This work investigates the soft-margin SVM considering the RBF Kernel function. Considering two input vectors, \(\mathbf {x}_{a} \in \mathbb {R}^n\) and \(\mathbf {x}_{b} \in \mathbb {R}^n\), the RBF Kernel function is calculated by:
where the term \(\gamma\) controls the flexibility of the function.
On the other hand, the soft-margin SVM modifies the maximum penalty value imposed for margins violations. This can be posed as a multiobjective problem aiming the maximization of the distances between the hyperplane and the support vectors, and the minimization of the misclassification error. This error can be quantified by taking into account the distance between the misclassified points to the margins, \(d_i\) in Fig. 5(b). Using the weighted sum method, this multiobjective problem can be posed as:
where \(i = 1 \ldots n\) and the parameter C, denoted as the box constraint, controls the trade-off between maximizing the margin and minimizing the number of misclassified points. An optimization approach can be used for choosing an appropriate value of C. This work uses soft-margin SVM with RBF Kernel function.

Illustration of a soft-margins SVM-based classifier
3 Methodology
This section describes our proposal for classifying the occurrence of chatter, an in-process chatter detection technique. Based on the inputs, \(\mathbf {x}\), machine learning-based classifiers should present a binary classification: chatter-free and chatter cuts. In other words, there are only two possible outputs for these classifiers. Our proposal should be as simple as possible, enabling in-process classification; therefore, it uses only time-domain signals. Moreover, to keep the generality of the proposal, only statistical features are extracted from these signals. According to the literature, these features, described in Table 1, are usually correlated with the occurrence of chatter.
These features are derived for time intervals, denoted as windows, with w data points. The algorithm shifts this window by a step of s data points as illustrated in Fig. 6 (arbitrary values are used in this illustration). This sliding window algorithm extracts n windows. The statistical features are derived for each window yielding the input vectors, \(\mathbf {F}_j \in \mathbb {R}^n\), where \(j= 1 \ldots 9\), as Table 1.

Feature extraction using the sliding window algorithm and illustration of the input vectors \(\mathbf {F}_j\) where \(j = 1 \ldots 9\)
Figure 7 shows the matrix of data used for the training of the classifiers considering arbitrary values. For each window (as shown in Fig. 6), nine features are extracted (\(\mathbf {F}_j \in \mathbb {R}^n\), where \(j= 1 \ldots 9\) as described in Table 1). The output vector \(\mathbf {O_c}^M\) is associated with binary classification, i.e., the output values can be 0 or 1, depending on the event the occurrence of chatter. The value of \(\mathbf {O_c}^M(i) = 0\) for data acquired during a free-chatter cut and \(\mathbf {O_c}^M(i) = 1\) for data acquired during a chatter cut. The index M is related to the workpiece’s material. A classifier should be trained for each material.

Set of points used for training and testing classifiers
In this work, two sets of features are used as inputs: Features’ Set 1 and Features’ Set 2. Features’ Set 1 takes into account all the extracted features described in Table 1. Therefore, \(\mathbf {x}_i^{Set 1} = [\mathbf {F}_1(i) \ \mathbf {F}_2(i) \ \ldots \mathbf {F}_9(i)]\). Features’ Set 2 only considers two selected features, named \(\mathbf {F}^{*}_1\) and \(\mathbf {F}^{ *}_2\). Therefore, \(\mathbf {x}_i^{Set 2} = [\mathbf {F}^{*}_1(i) \ \mathbf {F}^{*}_2(i)]\). Batista et al. [21] proposed that the selected features should be strongly correlated with the desired output of the classifier (\(\mathbf {O_c^M}\)) and also weakly related to each other. They can be numerically evaluated by:
where M is the material, \(j = 1 \ldots 9\), \(\rho ^M_{j}\) is the Pearson correlation between the \(\mathbf {F}_j\) and expected classifier outputs \(\mathbf {O}_c^{M}\), and \(\rho _{j}=\sum _{k=1}^{9} \rho _{jk}\) where \(\rho _{jk}\) is the Pearson correlation between the features \(\mathbf {F}_j\) and \(\mathbf {F}_k\). The features with the two highest \(z^{M}_{j}\) values are selected to be used by the classifiers, the \(\mathbf {F}^{*}_1\) and \(\mathbf {F}^{*}_2\).
The performance of the classifiers can be improved by using optimal values for the window and step (see Fig. 6). The optimal values of the window (\(w^*\)) and step (\(s^*\)) are found by maximizing the function:
where lw and ls are the lower bounds and uw and us are the upper bounds of the decision variables. A Differential Evolution (DE) optimizer was applied to Eq. 7 and the results are discussed in the next section. Moreover, Accuracy (ACC), False Positive Rate (FPR), and False Negative Rate (FNR) are derived as:
where TP and TN are the true positive and true negative classifications, while FP and FN are the false positive and true negative ones, i.e., the misclassifications. These indicators are also used for evaluating the classifiers. If these performance indicators are satisfactory, we consider that the algorithms have converged.
The proposal considers the division of the data set, obtained by applying the sliding window algorithm, into a set that will be applied in the training phase and another that will be applied in the testing phase. For this purpose, the sets were randomly divided in the proportion 80-20%, respectively. In summary, Algorithm 1 shows the steps of the proposed technique considering both Features’ Sets.

4 Experimental data
Ribeiro et al. [12] carried out an experimental campaign for acquiring AE data from a micro-milling operation during chatter-free and chatter cuts. Therefore, the reader can find more details about this campaign in [12]. Hereafter, the most relevant aspects of this campaign are summarized regarding the proposal of ML-based classifiers.
Figure 2 depicts the experimental setup: a workpiece, an AE sensor, and the tool-holder. An adapted CNC milling machine Romi D800 with a position accuracy of 1 µm was responsible for the machining operations. These micro-milling operations exploited the sloth-cutting strategy. This cutting strategy removes material considering the entire tool diameter as the cutting width; therefore, the process can manufacture micro-channels with the tool diameter width.
The authors of this work manufactured four micro-channels (Ch1, Ch2, Ch3, and Ch4) using a 1-mm-diameter carbide endmill tool with two flutes. The channels are 26 mm long and 1 mm in width. The machining operator adjusted the cutting parameters to a 125 m/min cutting speed, 3µm/tooth feed, 100 µm depth of cut, and 1.0 mm width of cut. The tool’s flexibility and runout were not considered in the analysis, given that they did not influence the cutting dynamic. The feed marks measured by the 3D confocal OLS 4100 Olympus microscope on the slot floor reached 3 µm/tooth as programmed in the machining center. The endmill-workpiece engagement with low chip load and depth of cut decreased significantly such dynamic effect during the micro-milling.
The dimensions of the workpieces were 8\(\times\)26\(\times\)60 mm. We investigated two materials: (COSAR) biphasic low-carbon steel with a grain size of 11 µm, and (UFG) ultra-fined grain COSAR-60 with a grain size of 0.7 µm. Due to differences in their microstructure, the most relevant features for detecting chatter could be different, requiring the training of different classifiers for each material.
The AE signals were acquired during the machining processes by a piezoelectric acoustic emission (AE) commercial sensor with a dynamic response up to 1 MHz (see Fig. 2). A high-pass filter conditioned these signals with a 250 Hz cutoff and an amplification of 35 dB. A NI PCI-6251 board at the rate of 1.25 MHz was responsible for acquiring this data. These signals acquired during the micro-milling operations are depicted in Figs. 8 and 9. The occurrence of chatter is indicated in these figures. Chatter-free cuts are illustrated with the green color, while chatter cuts with the red color, as illustrated in Fig. 7.

Time domain AE signal from micro-milling of COSAR in a Ch1, b Ch2, c Ch3 and d Ch4

Time domain AE signal from micro-milling of UFG in a Ch1, b Ch2, c Ch3 and d Ch4
5 Results
Both Perceptron-based and SVM-based classifiers should detect the occurrence of chatter \(\mathbf {Oc}^{M}=1\), where M indicates the COSAR (\(M = COSAR\)) and UFG (\(M=UFG\)). These classifiers were trained and tested using Matlab. The output of these classifiers should be null otherwise (chatter-free cut). The data used during the training and testing phases are shown in Figs. 8 and 9. The number of data points for chatter or chatter-free cuts and the different materials is described in Table 2. These data are divided randomly between the training and the testing sets. 80% of this data is used in the training phase, while 20% in the testing phase.
Two features sets are investigated in this work. Features’ Set 2 only considers two features, \([\mathbf {F}^{*}_1\)\(\mathbf {F}^{ *}_2]\). These features, described in Table 3, obtained the highest \(z^{M}_{j}\) values given by Eq. 6. This proposal obtained different relevant features for each material. Feature 2, the RMS value of signal amplitude, is the most relevant feature for both materials. This relevance indicates that this might be an important feature for other materials as well. The second most relevant features are Feature 3, the highest absolute value, and Feature 7, the variance of signal amplitude, for COSAR and UFG, respectively.
We derived Perceptron and SVM-based classifies according to the proposal given by Algorithm 1. An important asset of this proposal is the use of optimal values for the sliding window algorithm. In this work, DE algorithm found the window (\(w^*\)) and step (\(s^*\)) values that maximize Eq. 7. Table 4 gives these optimal values regarding the exploited set of features and the classifier. Figure 10 shows objective function values for 400 randomly selected decision variables. This figure demonstrates that a proper choice for window and step values can yield better classifiers’ performance. These optimal values should be used during the data processing being an important assessment for the industrial viability of the proposal.

ACC-FNR-FPR (Eq. 7) values for randomly selected step and window values
The classifiers’ performance is summarized in Tables 5 and 6 for the COSAR and UFG, respectively.
Considering Features’ Set 2, \([\mathbf {F}^{*}_1 \ \mathbf {F}^{*}_2]\), Perceptron does not converge for both materials. This lack of convergence indicates that these sets are not linearly separable. One observes this fact in Figs. 11 and 12. The chatter and chatter-free cuts’ classes and the straight line derived by the Perceptron are depicted in both figures. However, this straight line cannot separate the classes as some points cross the straight line invading the other class area. However, perceptron converges for the Features’ Set 2, \([[\mathbf {F}_1 \ \mathbf {F}_2 \ \ldots \mathbf {F}_9]]\), achieving an accuracy of 100 %.

Nonlinearly Separable Classes—COSAR Material

Nonlinearly Separable Classes—UFG Material
SVM-based classifiers achieved good performance indexes for both Features’ Sets. For COSAR, the SVM parameters were C = 950.52 and \(\gamma\) = 2937.64, and UFG, C = 26.96 and \(\gamma\) = 8376.4.
These results are undoubtedly revealing since the two strategies performed adequately:
-
1.
One can spend some computational effort selecting relevant features and exploit a more complex classifier: the SVM-based classifier; or
-
2.
One can spend no computational effort selecting features and exploit a simpler classifier: the Perceptron-based classifier.
Figure 13 illustrates the in-process chatter detection strategy using a Perceptron-based classifier’s output for the data acquired during the cutting process of Ch4 of the COSAR workpiece. A classifier’s output is expected at every step; therefore, the proposal is suitable for in-process chatter detection. AE data have been acquired during this cutting process during chatter and chatter-free cuts. Two images of the surface topography considering both cutting conditions are also shown in Fig. 13, demonstrating the occurrence of chatter during the first part of the process.

Illustration of the in-process chatter detection strategy: Perceptron-based classifier’s output for the Ch4 of COSAR material
A significant drawback is a necessity of acquiring data for the training phase. However, it is important to highlight that the classifiers were trained with a small dataset, usually available in industrial environments.
6 Conclusions
In this work, we investigated the use of machine learning-based classifiers for chatter detection in micro-milling operations using acoustic emission signals. Data from chatter and chatter-free cuts were acquired during the micro-milling of two workpieces of COSAR and UFG using a sloth-cutting strategy.
These data are processed using a sliding window strategy that divides the complete set into several data packets. Statistical features are derived from these packets. Two case studies are investigated: (1) a features’ set composed of nine features and (2) a features’ set composed of the two most relevant features. The most relevant features should be strongly correlated with the desired output of the classifier. Moreover, optimal parameters for the sliding window strategy are found using a DE optimizer.
These data are used for training and testing two supervised machine learning classifiers: a Perceptron-based classifier and an SVM-based classifier. The former converges if the classes are linearly separable, while the latter considers misclassifications.
Through this investigation, one can conclude that the RMS value of the amplitude signal can be a relevant feature for detecting chatter. Nevertheless, this choice is dependent on the material under investigation. The time-domain signals should be acquired and processed according to the optimal window and step values for maximizing the classifiers’ performance. A classifier’s output is derived at every step; therefore, the proposal is suitable for in-process chatter detection.
A trade-off between the number of features and the complexity of the classifiers was identified. Perceptron-based classifiers converged for both materials using the nine proposed statistical features. While SVM-based classifiers can adequately detect chatter using only the two most relevant features or the larger set of features.
This work exploits supervised machine learning classifiers using time-domain data. However, the training phase of these classifiers requires AE data from chatter and chatter-free cuts, which might cause undesired disruption. Therefore, unsupervised methods should also be investigated since they only need AE data from chatter-free cuts. Thus, the use of unsupervised classifiers could enhance the usability of the proposal. Moreover, industrial data, described in time and frequency domain, should also be exploited, promoting other ways of detecting chatter.
References
Park SS, Rahnama R (2010) Robust chatter stability in micro-milling operations. CIRP Ann 59(1):391–394. https://doi.org/10.1016/j.cirp.2010.03.023
Afazov SM, Ratchev SM, Segal J, Popov AA (2012) Chatter modelling in micro-milling by considering process nonlinearities. Int J Mach Tools Manuf 56:28–38. https://doi.org/10.1016/j.ijmachtools.2011.12.010
Jin X, Altintas Y (2013) Chatter stability model of micro-milling with process damping. J Manuf Sci Eng 135(3). https://doi.org/10.1115/1.4024038
Lu X, Jia Z, Liu S, Yang K, Feng Y, Liang SY (2019) Chatter stability of micro-milling by considering the centrifugal force and gyroscopic effect of the spindle. J Manuf Sci Eng 141(11). https://doi.org/10.1115/1.4044520
Graham E, Mehrpouya M, Nagamune R, Park SS (2014) Robust prediction of chatter stability in micro milling comparing edge theorem and LMI. CIRP J Manuf Sci Technol 7(1):29–39. https://doi.org/10.1016/j.cirpj.2013.09.002
Mamedov A (2021) Micro milling process modeling: a review. Manag Rev 8:3. https://doi.org/10.1051/mfreview/2021003
Chen Y, Li H, Jing X, Hou L, Bu X (2019) Intelligent chatter detection using image features and support vector machine. Int J Adv Manuf Technol 102(5–8):1433–1442. https://doi.org/10.1007/s00170-018-3190-4
Shi Y, Mahr F, von Wagner U, Uhlmann E (2012) Chatter frequencies of micromilling processes: Influencing factors and online detection via piezoactuators. Int J Mach Tools Manuf 56:10–16. https://doi.org/10.1016/j.ijmachtools.2011.12.001
Li H, Jing X, Wang J (2014) Detection and analysis of chatter occurrence in micro-milling process. Proc Inst Mech Eng B J Eng Manuf 228(11):1359–1371. https://doi.org/10.1177/0954405414522216
Yuan Y, Jing X, Li H, Ehmann KF, Zhang D (2018) Chatter detection based on wavelet coherence functions in micro-end-milling processes. Proc Inst Mech Eng B J Eng Manuf 233(9):1934–1945. https://doi.org/10.1177/0954405418808214
Inasaki I (1998) Application of acoustic emission sensor for monitoring machining processes. Ultrasonics 36(1–5):273–281. https://doi.org/10.1016/s0041-624x(97)00052-8
Ribeiro KSB, Venter GS, Rodrigues AR (2020) Experimental correlation between acoustic emission and stability in micromilling of different grain-sized materials. Int J Adv Manuf Technol 109(7–8):2173–2187. https://doi.org/10.1007/s00170-020-05711-1
Sio-Sever A, Leal-Muñoz E, Lopez-Navarro JM, Alzugaray-Franz R, Vizan-Idoipe A, de Arcas-Castro G (2020) Non-invasive estimation of machining parameters during end-milling operations based on acoustic emission. Sensors 20(18):5326. https://doi.org/10.3390/s20185326
Filippov AV, Rubtsov VE, Tarasov SY, Podgornykh OA, Shamarin NN (2017) Detecting transition to chatter mode in peakless tool turning by monitoring vibration and acoustic emission signals. Int J Adv Manuf Technol 95(1–4):157–169. https://doi.org/10.1007/s00170-017-1188-y
Li M, Huang D, Yang X (2021) Chatter stability prediction and detection during high-speed robotic milling process based on acoustic emission technique. Int J Adv Manuf Technol 117(5–6):1589–1599. https://doi.org/10.1007/s00170-021-07844-3
Wang R, Song Q, Liu Z, Ma H, Gupta MK, Liu Z (2021) A novel unsupervised machine learning-based method for chatter detection in the milling of thin-walled parts. Sensors 21(17):5779. https://doi.org/10.3390/s21175779
Wang X, Lu X, Jia Z, Jia X, Li G, Wu W (2013) Research on the prediction model of micro-milling surface roughness. Int J Nanomanuf 9(5/6):457. https://doi.org/10.1504/ijnm.2013.057595
Elizondo D (2006) The linear separability problem: some testing methods. IEEE Trans Neural Networks 17(2):330–344. https://doi.org/10.1109/tnn.2005.860871
Wang L (2005) Support vector machines: theory and applications. Studies in fuzziness and soft computing. Springer, Berlin Heidelberg. https://books.google.com.br/books?id=UVd7CwAAQBAJ
Christmann A, Steinwart I (2008) Support vector machines. Springer, New York. https://doi.org/10.1007/978-0-387-77242-4
Batista OE, Flauzino RA, de Araujo MA, de Moraes LA, da Silva IN (2016) Methodology for information extraction from oscillograms and its application for high-impedance faults analysis. Int J Electr Power Energy Syst 76:23–34. https://doi.org/10.1016/j.ijepes.2015.09.019
Funding
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001. Also, the authors would like to thank the Brazilian funding agencies: CNPq 303884/2021-5, and FAPESP 2019/00343-1.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study’s conception and design. Kandice Ribeiro, Giuliana Venter, and Alessandro Roger Rodrigues performed material preparation and data collection. Guilherme Serpa Sestito performed conceptualization of this study, methodology, and software. Maíra Martins da Silva also worked on conceptualizing this study and data curation. The first draft of the manuscript was written by Guilherme Serpa Sestito and Maíra Martins da Silva, and all authors commented on previous versions of the manuscript. Finally, all authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sestito, G.S., Venter, G.S., Ribeiro, K.S.B. et al. In-process chatter detection in micro-milling using acoustic emission via machine learning classifiers. Int J Adv Manuf Technol 120, 7293–7303 (2022). https://doi.org/10.1007/s00170-022-09209-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-022-09209-w